Infinite-dimensional next-generation reservoir computing
Abstract
Next-generation reservoir computing (NG-RC) has attracted much attention due to its excellent performance in spatio-temporal forecasting of complex systems and its ease of implementation. This paper shows that NG-RC can be encoded as a kernel ridge regression that makes training efficient and feasible even when the space of chosen polynomial features is very large. Additionally, an extension to an infinite number of covariates is possible, which makes the methodology agnostic with respect to the lags into the past that are considered as explanatory factors, as well as with respect to the number of polynomial covariates, an important hyperparameter in traditional NG-RC. We show that this approach has solid theoretical backing and good behavior based on kernel universality properties previously established in the literature. Various numerical illustrations show that these generalizations of NG-RC outperform the traditional approach in several forecasting applications.
I Introduction
Reservoir computing (RC) [23, 32, 24, 31] has established itself as an important tool for learning and forecasting dynamical systems [20, 24, 41, 40, 30, 48, 2]. It is a methodology in which a recurrent neural network with a randomly generated state equation and a functionally simple readout layer (usually linear) is trained to proxy the data-generating process of a time series. One example is the echo state networks (ESNs) [36, 37, 24], which have demonstrated excellent empirical performance and have been shown to have universal approximation properties in several contexts [21, 16, 17, 15]. Another family with similar theoretical properties is the state-affine systems (SAS) introduced in [44, 22] and that is prevalent in engineering applications [9] and in quantum reservoir computing (QRC) [34, 35].
Despite the ease of training associated with the RC methodology, its implementation depends heavily on hyperparameters that are sometimes difficult to estimate robustly. This difficulty has motivated various authors to replace the standard RC approach with nonlinear vector autoregression in which the covariates are monomials constructed using the previous inputs. In these methods, the only hyperparameters to be chosen are the maximum order of the monomials and the number of lags of past signals. This approach has been called next-generation reservoir computing (NG-RC) [13, 5, 4, 26, 25, 42] and has displayed excellent performances in control and spatio-temporal forecasting tasks.
One downside of the NG-RC approach is that its performance and complexity depend strongly on the above-mentioned hyperparameters. Yet, as these hyperparameters grow, the computational effort associated with NG-RC increases exponentially. One goal of this paper is to place NG-RC in the context of kernel methods. Kernels are classical tools employed in static classification, regression, and pattern recognition tasks [43, 39, 7]. Due to the Representer Theorem, kernels provide a way of passing inputs into higher-dimensional feature spaces where learning takes place linearly without scaling with the dimension of the feature space. By kernelizing NG-RC, we show a more computationally tractable approach to carrying out the NG-RC methodology that does not increase complexity with the hyperparameter values. In particular, we shall see that NG-RC is a particular case of polynomial kernel regression.
The idea that we just explained can be pushed all the way to considering all past lags and polynomial orders of arbitrarily high order in the polynomial kernel regression. Even though this leads to an infinite-dimensional covariate space (hence the title of the paper), the kernel regression can be explicitly and efficiently implemented using the recurrence properties of the Volterra kernel introduced in [14]. Since the Volterra kernel regression method has as covariates the left-infinite sequence of inputs and all the monomials of all degrees constructed from these inputs, this implies that, unlike NG-RC or the polynomial kernel regression, this approach is agnostic with respect to the number of lags and the order of monomials. Moreover, the Volterra kernel has been shown in [14] to be universal in the space of fading memory input/output systems with uniformly bounded inputs and, moreover, has a computational complexity that outperforms the NG-RC whenever higher-order monomials and lags are required for modeling more functionally complex systems.
The last part of the paper contains various numerical simulations that illustrate that (i) using the more computationally tractable polynomial kernel regression, one has access to a broader feature space, which allows learning more complex systems than those typically presented when using the NG-RC methodology and (ii) the Volterra kernel is a useful tool that can produce more accurate forecasts because it allows one to take infinite lags and monomial orders into account, which is of relevance in the modeling of long-memory phenomena that exhibit functionally complex dependencies. All the codes and data necessary to reproduce the results in the paper are available at https://github.com/Learning-of-Dynamic-Processes/kernelngrcvolterra.
II Preliminary discussion
II.1 Notation
We often work with input or output sequence spaces. Let denote the set of integers and be the set of non-positive integers. Denote by the set of real numbers and the -dimensional Euclidean space by . Let the space of sequences of -dimensional real vectors indexed by be denoted . Denote generically the input space by and the output space by , which, in most cases, will be subsets of a finite-dimensional Euclidean space. Given , we shall denote by the space of -long sequences of -dimensional real inputs indexed by . Given the input space , we will denote the set of semi-infinite sequences with elements in by . The components of the sequences are given by , , that is, . Now, given , , and , we denote by and by .
II.2 Data generating processes
Throughout this paper, we are interested in the learning and forecasting of discrete-time, time-invariant, and causal dynamic processes that are generated by functionals of the form , that is, given , we have that , . In practice, the inputs can be just deterministic sequences or realizations of a stochastic process. A related data generating process that we shall be using are the causal chains with infinite memory (CCIM) [10, 11, 1]. These are infinite sequences , where for all , are such that for all and some functional . Takens’ Theorem [45] and its generalizations [27, 28, 18, 19] guarantee that the low-dimensional observations of dynamical systems follow, under certain conditions, a dynamical prescription of this type.
II.3 Kernel methods
Kernels and feature maps. A kernel on is a function that is symmetric and positive semi-definite. In this context, positive semi-definiteness means that for any , , ,
Given , define the Gram matrix or Gramian to be the matrix . The kernel function being symmetric and positive semi-definite is equivalent to the Gramian being positive semi-definite in a matrix sense. The next example is a family of kernel functions of importance in our discussion.
Example 1 (Polynomial kernels).
Let for some . For any constant , a polynomial kernel of degree is the function given by
Let be a Hilbert space of real-valued functions on endowed with pointwise sum and scalar multiplication. Denote the inner product on by . We say that is a reproducing kernel Hilbert space (RKHS) associated to the kernel if the following two conditions hold. First, for all , we have that the functions , and for all and all , the reproducing property, , , is satisfied. The maps of the form are called kernel sections. Second, the Dirac functionals defined by are continuous, for all .
In this setup one may define the map given by , . Then from the reproducing property of the RKHS, the kernel function can be written as the inner product of kernel sections. Indeed, given . we can write
We call the map the canonical feature map and the RKHS is referred to as its canonical feature space.
By the Moore-Aronszajn Theorem [3, 7], any kernel has a unique RKHS, and this RKHS can be written as
| (1) |
where the bar denotes the completion with respect to the metric induced by the inner product . This inner product obviously satisfies that for , . We use the symbol for the norm induced by .
The construction we just presented produces an RKHS and a feature map out of a kernel map. Conversely, given any Hilbert space and a map from the set into , we can construct a kernel map that has as a feature map and as a feature space, that is, define
| (2) |
Such a function is clearly symmetric and positive semi-definite; thus, it satisfies the conditions needed to be a kernel function. It can actually be proved (see [7, Theorem 4.16]) that a map is a kernel if and only if there exists a feature map that allows to be represented as in (2). Note that given a kernel function, the feature representation (2) is not unique in the sense that neither the feature space nor the feature map are unique. In particular, given , the canonical feature map and the RKHS are a choice of feature map and feature space for , respectively.
When a kernel function is defined as in (2) using a feature map , Theorem 4.21 in [7] proves that the corresponding RKHS is given by
| (3) |
equipped with the Hilbert norm
| (4) |
Using this fact, we prove the following lemma, which shows the equality of the RKHS spaces associated with kernels with feature maps related by a linear isomorphism.
Lemma 2.
Suppose and are kernels with feature spaces and and feature maps and , respectively. Denote the corresponding RKHSs by and . Suppose that there exists a bounded linear isomorphism such that , then .
Proof.
By the bounded inverse theorem, , which is linear, is bounded. By the Riesz representation theorem, the adjoints of and , denoted by and are well defined. By (3), for , there exists such that for any . Then it is easy to see that for any , so that . The reverse inclusion is similar. ∎
Kernel universality. An important feature of some kernels is their universal approximating properties [38, 7, 8] which we now define. Suppose we have a continuous kernel map . For any compact subset , define the space of kernel sections to be the subset of given by
| (5) |
This time around, the bar denotes the uniform closure. Note that the continuity of , the reproducing property, and the compactness of imply that the uniform closure that defines contains the completion of the vector space . The continuous kernel is called kernel universal when for any compact subset ,
Many kernels used in practice are universal, e.g., the Gaussian kernel on Euclidean space.
Note that in the framework discussed in Section II.2, where the behavior of outputs is determined by causal functionals or CCIMs, whenever the corresponding functional is continuous and the inputs are defined on a compact input space, kernel universality implies that the elements of the corresponding RKHS can be used to uniformly approximate the data generating functional.
Kernel and nonlinear regressions. The universal approximation properties of RKHSs that we just described make them good candidates to serve as concept spaces in nonlinear regressions. More explicitly, suppose that , , and that a function needs to be estimated using a finite sample of pairs of input and outputs where and , . If the estimation is carried out using a empirical risk with squared loss
and the hypothesis set is the RKHS corresponding to a kernel , the Representer Theorem states that the minimizer of the ridge regularized empirical risk on , that is,
| (6) |
for some lies on the span of the kernel sections generated by the sample. More explicitly, the solution of (6) has the form , where the vector can be determined by solving the regularized linear (Gramian) regression problem associated to the Gram matrix of the sample, that is,
| (7) |
where and denotes the Euclidean norm. The optimization problem (7) admits the closed form solution
| (8) |
The optimization problem formulated in (6) is usually referred to as a kernel ridge regression. When the kernel that is used to implement it has a feature map associated, the kernel ridge regression can be reformulated as a standard linear regression in which the covariates are the components of the feature map. More explicitly, due to (3) and (4), the following equality holds true:
| (9) |
Then if we set
we can conclude that
| (10) |
which proves our claim in relation to interpreting the kernel ridge regression as a standard linear regression with covariates given by the feature map. In particular, for new inputs , the estimator generates the out-of-sample outputs
| (11) |
II.4 The NG-RC methodology
Next-generation reservoir computing, as introduced in [13], proposes to estimate a causal polynomial functional link between an explained variable at time and the values of certain explanatory variables encoded in the components of at time and in all the -instants preceding it. Mathematically speaking, its estimation amounts to solving a linear regression problem that has as covariates polynomial functions of the explanatory variables in the past.
More explicitly, assume that we have a collection of inputs and outputs . For each , construct the -th -delay vector
Re-indexing so that
| (12) |
write the vector containing all -degree monomials of elements of as
For a chosen maximum monomial order , define the feature vector as
| (13) |
where denotes the dimension of the feature space, namely,
| (14) |
NG-RC proposes as link between inputs and outputs the solution of the nonlinear regression that uses the components of as covariates, that is, it requires solving the optimization problem:
| (15) |
This ridge-regularized problem obviously admits a unique solution that we now explicitly write. We first collect the feature vectors and outputs into a design matrix and an output vector , respectively:
The closed-form solution for the optimization problem (15) is
| (16) |
where denotes the identity matrix. Consequently, the output of an NG-RC system at each time step corresponding to an input is given by
| (17) |
III Kernelization of NG-RC
We now show that NG-RC can be kernelized using the polynomial kernel function introduced in Example 1. The term kernelization in this context means that, along the lines of what we saw in (10), the solution (17) of the NG-RC nonlinear regression problem can be written as the solution of the kernel ridge regression problem (6) associated to the polynomial kernel. More explicitly, we shall see that the solution function in (17) can be written as a linear combination of the kernel sections of generated by the data, with the coefficients obtained in (7) coming from the Representer Theorem. A similar result can be obtained for kernels based on Taylor polynomials as in [7].
Proposition 3.
Consider a sample of input/output observations where and . Let be a chosen delay and let be a maximum polynomial order, let
| (18) |
be the -lagged polynomial kernel on . Then, the kernel regression problem on the left-hand side of (9), corresponding to the input/output set and the kernel has the same solution as the NG-RC optimization problem given in (15), corresponding to . In particular, the corresponding solution functions coincide, that is,
| (19) |
for any and where is the NG-RC solution (16), as in (14), and is the solution of the Gramian regression in (8) for .
Proof.
For , recall the reindexing of the -delay vector in (12) and additionally let . By the multinomial theorem, for any ,
| (20) |
where is the NG-RC feature map introduced in (13), denotes component-wise (Hadamard) multiplication, and the constant vector is given by
| (21) |
Notice that the relation (20) implies that the map is a feature map for the kernel . Additionally, whenever , the component-wise product with the vector can be written as a bounded linear isomorphism which can be represented by the diagonal by matrix with the elements of on the diagonal.
Define the kernel function obtained out of the dot product of the NG-RC feature vector (13), that is,
which is obviously a kernel function because the dot product is symmetric and positive semi-definite.
By the Moore-Aronszajn Theorem, and each have unique RKHSs associated and , respectively. Since each of their feature maps and , respectively, are related by a bounded linear isomorphism, by Lemma 2 we have that,
| (22) |
This implies that the kernel regression problems (6) associated with and are identical and hence have the same solution. This observation, combined with the identity (9), proves the statement. ∎
Example 4.
In the setup of the previous proposition, consider the case , , and . In that situation, the two kernels in the previous discussion are given by:
and given that the NG-RC map is given by:
we have that
As we already pointed out in the proof of Proposition 3, the same monomials appear in and , which only differ by constants.
Another important observation that is visible in these expressions is the difference in computation complexity between NG-RC and its kernelized version introduced in Proposition 3. Recall that NG-RC produces the vector in (19) while the polynomial kernel regression yields . NG-RC is a nonlinear regression on the components of the (six-dimensional in this case) feature map , and to carry it out, all those components have to be evaluated at all the data points; on the contrary, the kernelized version only requires the evaluation of at the data points, which is computationally simpler. The kernelized version of NG-RC is, hence, computationally more efficient. This difference is even more visible as , , and increase since the dependence (14) of the number of covariates in the NG-RC regression on those parameters makes them grow rapidly, while the behavior of the computational complexity of the polynomial kernel is much more favorable. This difference in computational performance between the two approaches will be more rigorously analyzed later in Section V.2.
IV Infinite-dimensional NG-RC and Volterra kernels
Apart from the computational efficiency associated with the kernelized version of NG-RC, this approach allows for an extension of this methodology that would be impossible in its original feature map-based version. More explicitly, in this section, we will see that by pursuing the kernel approach, NG-RC can be extended to the limiting cases , , hence taking into account infinite lags into the past and infinite polynomial degrees in relation with the input series. This is a valuable feature in modeling situations in which one is obliged to remain agnostic with respect to and . The natural tool to carry this out is the Volterra kernel introduced in [14], which is, roughly speaking, an infinite lag and infinite monomial degree counterpart of the polynomial kernel and that we recall in the following paragraphs.
Let such that be the projection operator onto the -th term of a semi-infinite sequence. Given , define the -time-delay operator by for all . Given , define the space of -bounded inputs by . Choose such that and choose some such that . Define the Volterra kernel by the recursion
| (23) |
The rationale behind this recursion is the definition of the Volterra kernel proposed in [14] as the kernel associated with a feature map obtained as the unique solution of a certain state space equation in an infinite-dimensional tensor space. The recursion in that state space equation implies the defining recursion in (23). Alternatively, the Volterra kernel can be introduced by writing the unique solution of (23), namely:
| (24) |
It can be verified that the Volterra kernel is a kernel map on the space of semi-infinite sequences with real entries in the sense discussed in Section II.3.
The Volterra kernel as an infinite order and lag polynomial kernel. Observe that the -lagged polynomial kernel map (18) can be rewritten as
where we notice that the term marked with is the sum of all monomials of up to order on the variables that appear in the inner products . This expression yields the polynomial kernel as a polynomial of some finite degree on the components of the input terms up to some finite lag .
Rewriting (24) using the geometric series, we have for ,
where is again a sum of all monomials of order on variables similar to the expression for . However, in contrast to the polynomial kernel, note that in this case, we are taking monomial combinations of arbitrarily high degree and lags with respect to and . This implies that the Volterra kernel considers additional functional and temporal information about the input, which allows us to use it in situations where we have to remain agnostic about the number of lags and the degree of monomials that need to be used.
Infinite-dimensionality and universality. The discussion above hints that the Volterra kernel can be understood as the kernel induced by the feature map (20) associated with the polynomial kernel, but extended to an infinite-dimensional codomain capable of accommodating all powers and lags of the input variables. This statement has been made rigorous in [14], where the Volterra kernel was constructed out of an infinite-dimensional tensor feature space, which, in particular, makes it universal in the space of continuous functions defined on uniformly bounded semi-infinite sequences. This implies that any continuous data-generating functional with uniformly bounded inputs can be uniformly approximated by elements in the RKHS generated by the Volterra kernel. This is detailed in the following theorem proved in [14]. The statement uses the notation introduced in (5).
Theorem 5.
Let be the Volterra kernel given by (24) and let be the associated space of kernel sections. Then
In contrast, the polynomial kernel (equivalently NG-RC) is not universal (see [46]). These arguments suggest that the Volterra kernel should outperform polynomial kernel regressions and the NG-RC in its ability to, for example, learn complex systems. This will indeed be illustrated in numerical simulations in Section V.
Computation of Volterra Gramians. Even though the Volterra kernel is defined in the space of semi-infinite sequences, in applications, only finite samples of size of the form are available. In that situation, it is customary to construct semi-infinite inputs of the form , for each , and we then define for that sample the Volterra Gram matrix as
Due to the recursive nature of the kernel map introduced in (23), the entries of the Gram matrix can be computed also recursively by
| (25) |
where for all .
We recall now that, due to the Representer Theorem, the learning problem (6) associated with the squared loss can be solved using the Gramian that we just constructed by computing (7). Moreover, the solution has the form , with given by (8).
For a newly available set of inputs , the estimator can be used to forecast outputs . Extend the Gram matrix to a rectangular matrix by using the recursion
that can be initialized by for all . Then the forecasted outputs are
V Numerics
V.1 Data generating processes and experimental setup
Simulations were performed, using each of the three estimators discussed in the paper, on three dynamic processes: the Lorenz autonomous dynamical system, the Mackey-Glass delay differential equation, and the Baba-Engle-Kraft-Kroner (BEKK) input/output system.
For the Lorenz and Mackey-Glass dynamical systems, the task consisted of performing the usual path-continuation. During training, inputs are the spatial coordinates at time and outputs are the -th spatial coordinate, and estimators are trained on a collection of input/outputs . To test their performance, the estimators are run autonomously. That is, after seeing initial input ,the outputs , for some forecasting horizon , are fedback into the estimator as inputs. These outputs for are compared against the reserved set of testing values for , unseen by the estimators.
For the BEKK input/output system, the goal is to perform input/output forecasting. That is, during training, each estimator is given a set of inputs and fitted against a set of outputs . Then, during testing, given a new set of unseen inputs , the outputs of the estimator are compared against the actual outputs , unseen by the estimator.
The Lorenz system is a three-dimensional system of ordinary differential equations used to model atmospheric convection [29]. The following Lorenz system
with the initial conditions
was chosen. A discrete-time dynamical system was derived using Runge-Kutta45 (RK45) numerical integration with time-step 0.005 to simulate a trajectory with 15001 points. The first 5000 points were reserved for training. The remaining points were reserved for testing. By the celebrated Takens’ embedding theorem [45], the Lorenz dynamical system admits a functional that expresses each observation as a function of seven of its past observations. Thus, the Lorenz dynamical system lies within the premise discussed in Section II.2.
The Mackey-Glass equation is a first-order nonlinear delay differential equation (DDE) describing physiological control systems given by [33]. We chose the following instance of the Mackey-Glass equation
with the initial condition function being the constant function . To numerically solve this DDE, the delay interval was discretized with time step of 0.02, then the usual RK45 procedure was performed on the discretized version of the system. The resulting dataset was flattened back into a one-dimensional dataset, and to reduce the size of the dataset, the dataset was further spliced to take every 50-th data point. The final dataset consisted of 7650 points, and the first 3000 points were reserved for training. The remaining points were reserved to compare against the path-continued outputs of each estimator. Due to the discretization process, the differential equation becomes a system of equations where each is a function of past observations, as is assumed by our premise in Section II.2.
The BEKK model is an input/output parametric time series model that is used in financial econometrics in the forecasting of the conditional covariances of returns of stocks traded in the financial markets [12]. We consider assets and the BEKK(1, 0, 1) model for their log-returns and associated conditional covariances given by
where the input innovations are Gaussian IID, and the output observations are the conditional covariances . The diagonal BEKK specification is chosen where is an upper-triangular matrix, and and are diagonal matrices of dimension . It is known that there exists a unique stationary and ergodic solution whenever for , which expresses as a highly nonlinear function of its past inputs [6] (as per our premise in Section II.2). Since the covariance matrices are symmetric, we only need to learn the outputs , , where the vech operator stacks the columns of a given square matrix from the principal diagonal downwards. An existing dataset from [14] was used with input dimensions of 15 and output dimensions of 120. The dataset consisted of 3760 input and output points, the first 3007 were reserved for training, and the remaining 753 were reserved for testing. Since the output points were very small, to minimize loss of accuracy due to computational truncation errors, the output values were scaled by 1000. The training output data was further normalized so that each dimension would have 0 mean and variance of 1.
Since NG-RC methodology does not typically require normalization, the NG-RC datasets were not normalized. For the polynomial kernel, kernel values could become too large and result in truncation inaccuracies, so the training inputs were normalized to have a maximum of 1 and a minimum of 0. Due to the construction of the Volterra kernel, the input sequence space into the kernel for a finite sample is truncated with zeros. We thus demean the training input data. Moreover, to avoid incurring truncation errors for and values, the maximum Euclidean norm of the inputs is set to 1, by scaling the training input values. Note that for all estimators, normalization is always performed based only on information from the training values, then the testing data is shifted and scaled based on what was used for the training data. This prevents leakage of information such as the mean, standard deviation, maximum, minimum, etc., to the testing datasets.
V.2 Time complexities
Following [39, page 280], we compute the time complexities for the NG-RC, polynomial kernel regression and Volterra kernel regression. We assume for both kernel regressions, as per the procedure used in the numerical simulations, that the usual Euclidean dot product was used.
In each forecasting scheme, training involves computing the closed-form solutions (16) for the NG-RC and (8) for the polynomial and Volterra kernel regressions. For the NG-RC, to compute takes steps, recalling the definition of given in (14). To compute matrix inversion in (16), is . The remaining matrix multiplications have complexities dominated by . Thus, the final complexity for training weights in NG-RC is . On the other hand, for polynomial or Volterra kernel regressions, one needs to compute the kernel map for each entry of the Gram matrix. For the polynomial kernel, in view of (18), this is , and for the Volterra kernel map, in view of (25), this is . Then, to compute the Gram matrix is and for polynomial and Volterra kernel regression, respectively. Forecasting involves computing (17) for the NG-RC and (11) for the polynomial and Volterra kernel regressions. For each time step, the complexity is for the NG-RC, for the polynomial kernel regression, and for the Volterra kernel regression.
The combinatorial term for the NG-RC can be bounded above by where . Thus, in big-O notation, the term can be replaced by . It can then be seen that when the sample size is small, and when and need not be large, the NG-RC will be faster than the polynomial and Volterra kernels. However, as and grow, as is needed to learn more complex dynamical systems, the complexity for NG-RC grows exponentially, and the polynomial and Volterra kernel regressions will outperform the NG-RC significantly. For each of the forecasting schemes, the complexities associated with the training and generation of a single prediction are given in Table 1.
| Training | Prediction | |
|---|---|---|
| NG-RC | ||
| Polynomial | ||
| Volterra |
V.3 Cross-validation
For each estimator, hyperparameters have to be selected. The hyperparameters that were cross-validated and the chosen values are given in Table 2.
| System | Estimator | Washout | Hyperparameters |
|---|---|---|---|
| Lorenz | NG-RC | 3 | |
| Polynomial | 6 | ||
| Volterra | 100 | ||
| Mackey-Glass | NG-RC | 4 | |
| Polynomial | 17 | ( | |
| Volterra | 100 | ||
| BEKK | NG-RC | 1 | |
| Polynomial | 1 | ||
| Volterra | 100 |
Note that the washout was not cross-validated for. For both NG-RC and polynomial kernel regression, washout is the number of delays taken. For the Volterra kernel, a longer washout is needed to wash the effect of truncating input samples with zeros. A washout of 100 was sufficient to generate meaningful results both for the full training set and when the training sets were restricted during cross-validation.
For the path-continuation tasks (Lorenz and Mackey-Glass), to select hyperparameters, cross-validation was performed by splitting each training set into training-validation folds that overlapped. During validation, path-continuation was performed and compared with the validation set. That is, the outputs of each estimator were fed back as inputs, and these autonomously generated outputs were compared with the validation set. With overlapping datasets, a smaller training set would be sufficient to create multiple training folds starting from different initial points, such that in each training fold, the estimator has sufficient time to capture dynamics during training. Then during the validation phase for each fold, for a good estimator, there would be dynamical evolution in the outputs generated by the estimator. For example, the estimator did not just fit the average. This leads to meaningful validation set errors which improves the selection process for optimal hyperparameters.
For the BEKK input/output forecasting task, the usual time-series training-validation folds were used. That is, the training dataset was split into equally sized sets where the -th training fold was the concatenation of the first sets and the -th validation fold was -set. For input/output forecasting, where estimator sees, during forecasting, a new set of inputs, this method of cross-validating turned out to be sufficient for estimators to capture the dynamics of input and output variables. Note that cross-validation training and testing were made to mimic as closely as possible the actual task to be performed on the full training set, so normalization in each fold was also performed as would have been done on the full training dataset.
The range of parameters cross-validated were chosen so that the regularization was performed over the same set of values. As detailed in the previous section, time complexity for NG-RC grows exponentially for larger lag and degree hyperparameters. It was thus impractical to cross-validate over a large range of parameters as with each increase in number of lag or maximum degree of monomials, the computational time would grow exponentially. Thus, only a smaller range of parameters could be cross-validated over. The polynomial kernel was cross-validated over a larger space of the same delay and degree hyperparameters. When cross-validating for the Lorenz system, since Takens’ embedding says only seven lags are needed, a smaller set of lags (up to 10) were cross-validated over. For the rest of the datasets, up to 101 lags were cross-validated over. Such a large range of hyperparameters was possible because by Proposition 3 and Example 4 the polynomial kernel regression uses the same covariates but is faster when more covariates are considered. Finally, mean square error was chosen to be the metric over which the best hyperparameters were chosen.
V.4 Results
Pointwise and climate metrics were used to evaluate the performance of the estimators. Pointwise metrics are distance functions that evaluate the error committed by estimators from time step to time step. Climate metrics, see also [47], are performance metrics that evaluate whether the statistical or physical properties are similar to the true system. We also consider the valid prediction time for each estimator in Lyapunov time for the two chaotic attractors (Lorenz and Mackey-Glass).
Denoting the true value , the estimated value , and the testing set size , the following pointwise error metrics were chosen: the usual mean square error, the normalized mean square error (NMSE) given by
the mean absolute error (MAE) given by
where is the 1-norm, the median absolute error (MdAE) given by
where is the -th dimension of the -th vector , the mean absolute percentage error (MAPE),
for some very small , and lastly the -score given by
where denotes the average of the -th dimension of the vector over time steps .
Whether the estimator replicated the climate of the true time series was measured by considering the difference in the true and estimated power spectral density (PSD) and the difference in distributions using the Wasserstein-1 distance. Welch’s method with the Hann window was used to compute the PSD. The number of points per segment was chosen by visual inspection for a balance between frequency resolution and error variance. When the PSD tapers off to zero after some frequency , the remaining frequencies are not considered in the final difference. Finally, the PSD error (PSDE) is computed by taking
where PSD is the periodogram of the actual data and is the periodogram of the estimated data. The subscript denotes the -th term in the PSD sequence in the -th dimension.
The Wasserstein-1 distance was computed to compare the distributions of the true and estimated systems. For one-dimensional systems, the Wasserstein-1 distance can be computed using scipy.stats.wasserstein_distance which uses the equivalent Cramer-1 distance, that is,
where are the probability distributions of and respectively while CDF, denote the cumulative distributive functions. For time series in -dimensions, using scipy.stats.wasserstein_distance_nd, corresponds to solving the linear programming problem
where is the set of probability distributions whose marginals are and on the first and second factors respectively. and are the joint distributions of and respectively. It is noted that computing the Wasserstein distance for the multidimensional case is significantly more computationally expensive than in the one-dimensional case. In the case of the Lorenz dynamical system, sampling had to be performed to make using scipy.stats.wasserstein_distance_nd tractable.
Finally, we note that for the dynamical systems Lorenz and Mackey-Glass, the Lyapunov time, defined to be the inverse of the top Lyapunov exponent, is a timescale for which a chaotic dynamical system is predictable. In deterministic path-continuing tasks, which were carried out for the Lorenz and Mackey-Glass dynamical systems, we measure the valid prediction time percent, , which is the Lyapunov time taken for the predicted dynamics to differ from the true dynamics by 20%. A similar metric was used in [47].
The performance of the estimators was measured in the following manner for the dynamical systems. First, the valid prediction time was computed. Then, the ceiling of the best-performing valid prediction time is taken. The point-to-point error metrics MSE, NMSE, MAE, MdAE, MAPE, and are measured only up to . Beyond the characteristic predictable timescale given by the Lyapunov time, it is not meaningful to measure the step-to-step error as the trajectories diverge exponentially according to the Lyapunov exponent. To determine if the climate is well replicated over the full testing dataset, the climate metrics PSDE and are computed for the full testing dataset, with the Lorenz needing to be sampled to compute . The errors are reported in Table 3.
| System | Estimator | MSE | NMSE | MAE | MdAE | MAPE | PSDE | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Lorenz | NG-RC | 7.178 | 25.910 | 0.252 | 1.827 | 0.0897 | 1.598 | 0.621 | 7.606 | 2.114 |
| Polynomial | 9.126 | 13.383 | 0.0960 | 1.155 | 0.0377 | 1.230 | 0.812 | 7.169 | 1.683 | |
| Volterra | 10.566 | 6.840 | 0.0427 | 0.428 | 0.00385 | 0.222 | 0.907 | 8.325 | 1.982 | |
| Mackey-Glass | NG-RC | 0.3 | 0.0502 | 0.0548 | 0.188 | 0.174 | 0.235 | 0.0202 | 28.815 | 0.155 |
| Polynomial | 7.035 | 0.00358 | 0.00390 | 0.0274 | 0.00751 | 0.0329 | 0.930 | 6.831 | 0.00147 | |
| Volterra | 8.305 | 0.00171 | 0.00186 | 0.0162 | 0.00202 | 0.0190 | 0.967 | 5.059 | 0.00138 | |
| BEKK | NG-RC | — | 0.00125 | 0.150 | 0.0204 | 0.0166 | 0.644 | 0.125 | 1.565 | 0.332 |
| Polynomial | — | 0.00124 | 0.150 | 0.0204 | 0.0166 | 0.642 | 0.123 | 1.140 | 0.337 | |
| Volterra | — | 0.00102 | 0.136 | 0.0170 | 0.0139 | 0.634 | 0.382 | 0.963 | 0.319 |
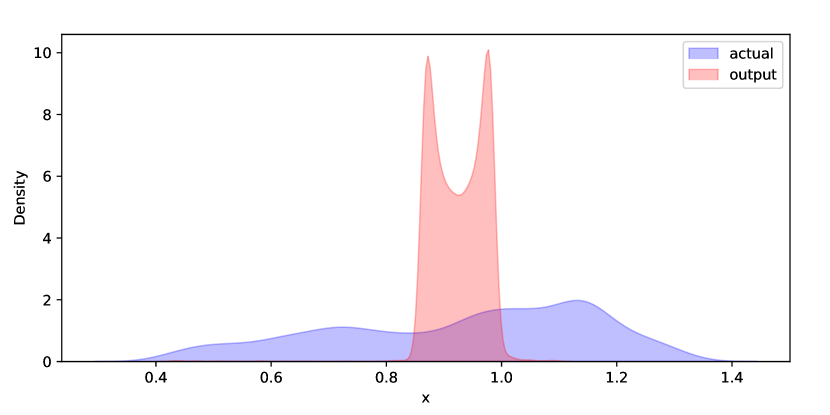
In more complex systems such as Mackey-Glass and BEKK, the Volterra reservoir and polynomial kernel regressions easily outperform the NG-RC because they have access to much richer feature spaces. In second-order systems such as the Lorenz system, even though pointwise errors perform better than in the polynomial and Volterra kernel regressions, the climate metrics indicate that the NG-RC better captured the climate of the true Lorenz dynamical system. It could be that a lower-order system offered by the NG-RC acts as a better proxy for lower-order true dynamical systems, which accounts for the difference in climate performance. This difference in climate replication performance, however, is only slight. Observe that in Figure 1(f), all estimators capture the power spectral density of the original system well, even if the Volterra kernel is slightly outperformed by the polynomial kernel. For even more complex systems, both the kernel regression methods can capture the climate of the true dynamical system but the same cannot be said for NG-RC. A similar story holds when one considers the Wasserstein-1 distance. The distributions are in Figure 2(f). Even though the Wasserstein-1 distance for Volterra performs the poorest, the difference in distribution performance is still small, and the bulk of the distribution is still replicated. On the other hand, for complex systems such as the BEKK, the polynomial kernel and the NG-RC fail to replicate the climate of the original system completely.
Lorenz
ct-.005inVolterra

ct-.005inPolynomial

ct-.005inNG-RC

Mackey-Glass



BEKK



Lorenz
ct-.1inVolterra

ct-.1inPolynomial

ct-.1inNG-RC

Mackey-Glass


BEKK



We also observe that, especially in the case of BEKK, when significantly complex dynamical systems are being learned, considering large but finite lags or monomial degrees may be insufficient. Even if finite lags are sufficient, the Gram or feature matrix values may, anyway, be too large to be handled with finite precision. In such cases, the Volterra kernel regression significantly outperforms the other two methods because it is agnostic to the lags and monomial powers, and so its Gram values do not grow with the feature choice. Moreover, as we saw in Section IV, taking infinite lag and monomial powers into consideration, offers a rich feature space and makes the associated RKHS universal, meaning that it can approximate complex systems to any desired accuracy.
Acknowledgments: The authors thank Daniel Gauthier for insightful discussions about the relation between NG-RC and the results in this paper. LG and JPO thank the hospitality of the Nanyang Technological University and the University of St. Gallen, respectively; it is during respective visits to these two institutions that some of the results in this paper were obtained. HLJT is funded by a Nanyang President’s Graduate Scholarship of Nanyang Technological University. JPO acknowledges partial financial support from the School of Physical and Mathematical Sciences of the Nanyang Technological University.
References
- Alquier and Wintenberger [2012] Alquier, P., and O. Wintenberger (2012), Bernoulli 18 (3), 883, arXiv:arXiv:0902.2924v4 .
- Arcomano et al. [2022] Arcomano, T., I. Szunyogh, A. Wikner, J. Pathak, B. R. Hunt, and E. Ott (2022), Journal of Advances in Modeling Earth Systems 14 (3), e2021MS002712.
- Aronszajn [1950] Aronszajn, N. (1950), Transactions of the American Mathematical Society 68 (3), 337.
- Barbosa and Gauthier [2022] Barbosa, W. A. S., and D. J. Gauthier (2022), Chaos: An Interdisciplinary Journal of Nonlinear Science 32 (9).
- Bollt [2021] Bollt, E. (2021), Chaos: An Interdisciplinary Journal of Nonlinear Science 31 (1), 13108.
- Boussama et al. [2011] Boussama, F., F. Fuchs, and R. Stelzer (2011), Stochastic Processes and their Applications 121 (10), 2331.
- Christmann and Steinwart [2008] Christmann, A., and I. Steinwart (2008), Support Vector Machines (Springer).
- Christmann and Steinwart [2010] Christmann, A., and I. Steinwart (2010), in Advances in Neural Information Processing Systems, Vol. 23, edited by J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta (Curran Associates, Inc.).
- Dang Van Mien and Normand-Cyrot [1984] Dang Van Mien, H., and D. Normand-Cyrot (1984), Automatica 20 (2), 175.
- Dedecker et al. [2007] Dedecker, J., P. Doukhan, G. Lang, J. R. León, S. Louhichi, and C. Prieur (2007), Weak Dependence: With Examples and Applications (Springer Science+Business Media).
- Doukhan and Wintenberger [2008] Doukhan, P., and O. Wintenberger (2008), Stochastic Processes and their Applications 118 (11), 1997.
- Engle and Kroner [1995] Engle, R. F., and F. K. Kroner (1995), Econometric Theory 11, 122.
- Gauthier et al. [2021] Gauthier, D. J., E. Bollt, A. Griffith, and W. A. S. Barbosa (2021), Nature Communications 12 (1), 5564.
- Gonon et al. [2022] Gonon, L., L. Grigoryeva, and J.-P. Ortega (2022), arXiv:2212.14641 .
- Gonon et al. [2023] Gonon, L., L. Grigoryeva, and J.-P. Ortega (2023), The Annals of Applied Probability 33 (1), 28.
- Gonon and Ortega [2020] Gonon, L., and J.-P. Ortega (2020), IEEE Transactions on Neural Networks and Learning Systems 31 (1), 100, arXiv:1807.02621 .
- Gonon and Ortega [2021] Gonon, L., and J.-P. Ortega (2021), Neural Networks 138, 10.
- Grigoryeva et al. [2021] Grigoryeva, L., A. G. Hart, and J.-P. Ortega (2021), Physical Review E - Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics 103, 062204.
- Grigoryeva et al. [2023] Grigoryeva, L., A. G. Hart, and J.-P. Ortega (2023), Nonlinearity 36, 4674.
- Grigoryeva et al. [2014] Grigoryeva, L., J. Henriques, L. Larger, and J.-P. Ortega (2014), Neural Networks 55, 59.
- Grigoryeva and Ortega [2018a] Grigoryeva, L., and J.-P. Ortega (2018a), Neural Networks 108, 495, arXiv:/arxiv.org/abs/1806.00797 [http:] .
- Grigoryeva and Ortega [2018b] Grigoryeva, L., and J.-P. Ortega (2018b), Journal of Machine Learning Research 19 (24), 1, arXiv:1712.00754 .
- Jaeger [2010] Jaeger, H. (2010), German National Research Center for Information Technology, Tech. Rep. (German National Research Center for Information Technology).
- Jaeger and Haas [2004] Jaeger, H., and H. Haas (2004), Science 304 (5667), 78.
- Kent et al. [2024] Kent, R., W. Barbosa, and D. Gauthier (2024), Nature Communications 15, 10.1038/s41467-024-48133-3.
- Kent et al. [2023] Kent, R. M., W. A. S. Barbosa, and D. J. Gauthier (2023), arXiv preprint arXiv:2307.03813 .
- Kocarev and Parlitz [1995] Kocarev, L., and U. Parlitz (1995), Physical Review Letters 74 (25), 5028.
- Kocarev and Parlitz [1996] Kocarev, L., and U. Parlitz (1996), Physical Review Letters 76 (11), 1816.
- Lorenz [1963] Lorenz, E. N. (1963), “Deterministic nonperiodic flow,” .
- Lu et al. [2018] Lu, Z., B. R. Hunt, and E. Ott (2018), Chaos 28 (6), 10.1063/1.5039508, arXiv:1805.03362 .
- Maass [2011] Maass, W. (2011), in Computability In Context: Computation and Logic in the Real World, edited by S. S. Barry Cooper and A. Sorbi, Chap. 8 (World Scientific) pp. 275–296.
- Maass et al. [2002] Maass, W., T. Natschläger, and H. Markram (2002), Neural Computation 14, 2531.
- Mackey and Glass [1977] Mackey, M. C., and L. Glass (1977), Science 197, 287.
- Martínez-Peña and Ortega [2023] Martínez-Peña, R., and J.-P. Ortega (2023), Physical Review E - Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics 107 (3), 035306.
- Martínez-Peña and Ortega [2024] Martínez-Peña, R., and J.-P. Ortega (2024), “Input-dependence in quantum reservoir computing,” .
- Matthews [1992] Matthews, M. B. (1992), On the Uniform Approximation of Nonlinear Discrete-Time Fading-Memory Systems Using Neural Network Models, Ph.D. thesis (ETH Zürich).
- Matthews [1993] Matthews, M. B. (1993), Circuits, Systems, and Signal Processing 12 (2), 279.
- Micchelli et al. [2006] Micchelli, C. A., Y. Xu, and H. Zhang (2006), Journal of Machine Learning Research 7 (12), 2651.
- Mohri et al. [2018] Mohri, M., A. Rostamizadeh, and A. Tawalkar (2018), Foundations of Machine Learning, 2nd ed. (The MIT Press).
- Pathak et al. [2018] Pathak, J., B. Hunt, M. Girvan, Z. Lu, and E. Ott (2018), Physical Review Letters 120 (2), 24102.
- Pathak et al. [2017] Pathak, J., Z. Lu, B. R. Hunt, M. Girvan, and E. Ott (2017), Chaos 27 (12), 10.1063/1.5010300, arXiv:1710.07313 .
- Ratas and Pyragas [2024] Ratas, I., and K. Pyragas (2024), Physical Review E 109 (6), 64215.
- Schölkopf and Smola [2002] Schölkopf, B., and A. J. Smola (2002), Learning with Kernels (MIT Press).
- Sontag [1979] Sontag, E. D. (1979), IEEE Transactions on Circuits and Systems 26 (5), 342.
- Takens [1981] Takens, F. (1981) (Springer Berlin Heidelberg) pp. 366–381.
- Wang and Zhang [2013] Wang, B., and H. Zhang (2013), arXiv:1310.5543 [stat.ML] .
- Wikner et al. [2024] Wikner, A., J. Harvey, M. Girvan, B. R. Hunt, A. Pomerance, T. Antonsen, and E. Ott (2024), Neural Networks 170, 94.
- Wikner et al. [2021] Wikner, A., J. Pathak, B. R. Hunt, I. Szunyogh, M. Girvan, and E. Ott (2021), Chaos: An Interdisciplinary Journal of Nonlinear Science 31 (5), 53114.