Inference of dynamic systems from noisy and sparse data via manifold-constrained Gaussian processes
Abstract
Parameter estimation for nonlinear dynamic system models, represented by ordinary differential equations (ODEs), using noisy and sparse data is a vital task in many fields. We propose a fast and accurate method, MAGI (MAnifold-constrained Gaussian process Inference), for this task. MAGI uses a Gaussian process model over time-series data, explicitly conditioned on the manifold constraint that derivatives of the Gaussian process must satisfy the ODE system. By doing so, we completely bypass the need for numerical integration and achieve substantial savings in computational time. MAGI is also suitable for inference with unobserved system components, which often occur in real experiments. MAGI is distinct from existing approaches as we provide a principled statistical construction under a Bayesian framework, which incorporates the ODE system through the manifold constraint. We demonstrate the accuracy and speed of MAGI using realistic examples based on physical experiments.
Key Points
Ordinary differential equations are a ubiquitous tool for modeling behaviors in science, such as gene regulation, biological rhythms, epidemics and ecology. An important problem is to infer and characterize the uncertainty of parameters that govern the equations. Here we present an accurate and fast inference method using manifold-constrained Gaussian processes, such that the derivatives of the Gaussian process must satisfy the dynamics of the differential equations. Our method completely avoids the use of numerical integration and is thus fast to compute. Our construction is embedded in a principled statistical framework and is demonstrated to yield fast and reliable inference in a variety of practical problems. Our method works even when some system component(s) is/are unobserved, which is a significant challenge for previous methods.
Keywords Parameter estimation Ordinary differential equations Posterior sampling Inverse problem
Introduction
Dynamic systems, represented as a set of ordinary differential equations (ODEs), are commonly used to model behaviors in scientific domains, such as gene regulation [1], biological rhythms [2], spread of disease [3], ecology [4], etc. We focus on models specified by a set of ODEs
| (1) |
where the vector contains the system outputs that evolve over time , and is the vector of model parameters to be estimated from experimental/observational data. When f is nonlinear, solving given initial conditions and generally requires a numerical integration method, such as Runge-Kutta.
Historically, ODEs have mainly been used for conceptual or theoretical understanding rather than data fitting as experimental data were limited. Advances in experimental and data-collection techniques have increased the capacity to follow dynamic systems closer to real-time. Such data will generally be recorded at discrete times and subject to measurement error. Thus, we assume that we observe at a set of observation time points with error governed by noise level . Our focus here is inference of given , with emphasis on nonlinear f where specialized methods that exploit a linear structure, e.g. [5, 6], are not generally applicable. We shall present a coherent, statistically principled framework for dynamic system inference with the help of Gaussian processes (GPs). The key of our method is to restrict the GPs on a manifold that satisfies the ODE system: thus we name our method MAGI (MAnifold-constrained Gaussian process Inference). Placing a GP on facilitates inference of without numerical integration, and our explicit manifold constraint is the key novel idea that addresses the conceptual incompatibility between the GP and the specification of the ODE model, as we shall discuss shortly when overviewing our method. We show that the resulting parameter inference is computationally efficient, statistically principled, and effective in a variety of practical scenarios. MAGI particularly works in the cases when some system component(s) is/are unobserved. To the best of our knowledge, none of the current available software packages that do not use numerical integration can analyze systems with unobserved component(s).
Overview of our method
Following the Bayesian paradigm, we view the -dimensional system to be a realization of the stochastic process , and the model parameters a realization of the random variable . In Bayesian statistics, the basis of inference is the posterior distribution, obtained by combining the likelihood function with a chosen prior distribution on the unknown parameters and stochastic processes. Specifically, we impose a general prior distribution on and independent GP prior distributions on each component so that , where is a positive definite covariance kernel for the GP and is the mean function. Then for any finite set of time points , has a multivariate Gaussian distribution with mean vector and covariance matrix . Denote the observations by , where is the collection of all observation time points and each component can have its own set of observation times . If the -th component is not observed, then , and . is the total number of observations. We note that for the remainder of the paper, the notation shall refer to time generically, while shall refer specifically to the observation time points.
As an illustrative example, consider the dynamic system in [1] that governs the oscillation of Hes1 mRNA () and Hes1 protein () levels in cultured cells, where it is postulated that a Hes1-interacting () factor contributes to a stable oscillation, a manifestation of biological rhythm [2]. The ODEs of the three-component system are
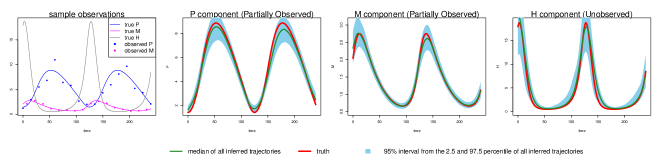
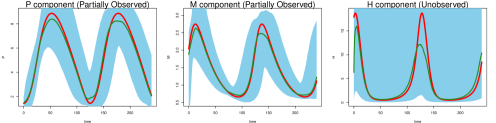
where are the associated parameters. In Fig 1 (left panel) we show noise-contaminated data generated from the system, which closely mimics the experimental setup described in [1]: and are observed at 15-minute intervals for 4 hours but is never observed. In addition, and observations are asynchronous: starting at time 0, every 15 minutes we observe ; starting at 7.5 minutes, every 15 minutes we observe ; and are never observed at the same time. It can be seen that the mRNA and protein levels exhibit the behavior of regulation via negative feedback.
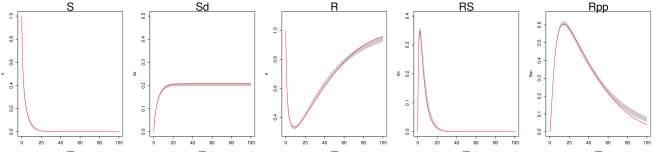
The goal here is to infer the seven parameters of the system: govern the rate of protein synthesis in the presence of the interacting factor; are the rates of decomposition; and are inhibition rates. The unobserved component poses a challenge for most existing methods that do not use numerical integration, but is capably handled by MAGI: the and panels of Fig 1 show that our inferred trajectories provide good fits to the observed data, and the panel shows that the dynamics of the entirely unobserved component are largely recovered as well. We emphasize that these trajectories are inferred without any use of numerical solvers. We shall return to the Hes1 example in detail in the Results section.
Intuitively, the GP prior on facilitates computation as GP provides closed analytical forms for and , which could bypass the need for numerical integration. In particular, with a GP prior on , the conditional distribution of given is also a GP with its mean function and covariance kernel completely specified. This GP specification for the derivatives , however, is inherently incompatible with the ODE model because (1) also completely specifies given (via the function ). As a key novel contribution of our method, MAGI addresses this conceptual incompatibility by constraining the GP to satisfy the ODE model in (1). To do so, we first define a random variable quantifying the difference between stochastic process and the ODE structure with a given value of the parameter :
| (2) |
if and only if ODEs with parameter are satisfied by . Therefore, ideally the posterior distribution for and given the observations and the ODE constraint, , is (informally)
| (3) |
While (3) is the ideal posterior, in reality is not generally computable. In practice we approximate by finite discretization on the set such that and similarly define as
| (4) |
Note that is the maximum of a finite set, and monotonically as becomes dense in . Therefore, the practically computable posterior distribution is
which is the joint conditional distribution of and together. Thus, effectively, we simultaneously infer both the parameters and the unobserved trajectory from the noisy observations .
Under Bayes’ rule, we have
where the right hand side can be decomposed as
The first term (1) can be simplified as due to the prior independence of and ; it corresponds to the GP prior on . The second term (2) corresponds to the noisy observations. The third term (3) can be simplified as
which is the conditional density of given evaluated at . All three terms are multivariate Gaussian: the third term is Gaussian because given has a multivariate Gaussian distribution as long as the kernel is twice differentiable.
Therefore, the practically computable posterior distribution simplifies to
| (5) | |||
where , is the cardinality of , is short for the -th component of , and the multivariate Gaussian covariance matrix and the matrix can be derived as follows for each component :
| (6) |
where , , and .
In practice we choose the Matern kernel where , is the Gamma function and is the modified Bessel function of the second kind, and the degree of freedom is set to be 2.01 to ensure that the kernel is twice differentiable. has two hyper-parameters and . Their meaning and specification are discussed in the Materials and Methods section.
With the posterior distribution specified in (5), we use Hamiltonian Monte Carlo (HMC) [7] to obtain samples of and the parameters together. At the completion of HMC sampling, we take the posterior mean of as the inferred trajectory, and the posterior means of the sampled parameters as the parameter estimates. Throughout the MAGI computation, no numerical integration is ever needed.
Review of related work
The problem of dynamic system inference has been studied in the literature, which we now briefly review. We first note that a simple approach to constructing the ‘ideal’ likelihood function is according to , where is the numerical solution of the ODE obtained by numerical integration given and the initial conditions. This approach suffers from a high computational burden: numerical integration is required for every sampled in an optimization or Markov chain Monte Carlo (MCMC) routine [8]. Smoothing methods have been useful for eliminating the dependence on numerical ODE solutions, and an innovative penalized likelihood approach [9] uses a B-spline basis for constructing estimated functions to simultaneously satisfy the ODE system and fit the observed data. While in principle the method in [9] can handle an unobserved system component, substantive manual input is required as we show in the Results, which contrasts with the ready-made solution that MAGI provides.
As an alternative to the penalized likelihood approach, GPs are a natural candidate for fulfilling the smoothing role in a Bayesian paradigm due to their flexibility and analytic tractability [10]. The use of GPs to approximate the dynamic system and facilitate computation has been previously studied by a number of authors [8, 11, 12, 13, 14, 15]. The basic idea is to specify a joint GP over with hyperparameters , and then provide a factorization of the joint density that is suitable for inference. The main challenge is to find a coherent way to combine information from two distinct sources: the approximation to the system by the GP governed by hyperparameters , and the actual dynamic system equations governed by parameters . In [8, 11], the factorization proposed is , where comes from the observation model and comes from the GP prior as in our approach. However, there are significant conceptual difficulties in specifying : on one hand, the distribution of is completely determined by the GP given , while on the other hand is completely specified by the ODE system ; these two are incompatible. Previous authors have attempted to circumvent this incompatibility of the GP and ODE system: [8, 11] use a product-of-experts heuristic by letting , where the two distributions in the product come from the GP and a noisy version of the ODE, respectively. In [15], the authors arrive at the same posterior as [8, 11] by assuming an alternative graphical model that bypasses the product of experts heuristic; nonetheless, the method requires working with an artificial noisy version of the ODE. In [12], the authors start with a different factorization: , where and are given by the GP and is a Dirac delta distribution given by the ODE. However, this factorization is incompatible with the observation model as discussed in detail in [16]. There is other related work that uses GPs in an ad hoc partial fashion to aid inference. In [13], GP regression is used to obtain the means of and for embedding within an Approximate Bayesian Computation estimation procedure. In [14], GP smoothing is used during an initial burn-in phase as a proxy for the likelihood, before switching to the ‘ideal’ likelihood to obtain final MCMC samples. While empirical results from the aforementioned studies are promising, a principled statistical framework for inference that addresses the previously noted conceptual incompatibility between the GP and ODE specifications is lacking. Our work presents one such principled statistical framework through the explicit manifold constraint. MAGI is therefore distinct from recent GP-based approaches [11, 15] or any other Bayesian analogs of [9].
In addition to the conceptual incompatibility, none of the existing methods that do not use numerical integration offer a practical solution for a system with unobserved component(s), which highlights another unique and important contribution of our approach.
Results
We apply MAGI to three systems. We begin with an illustration that demonstrates the effectiveness of MAGI in practical problems with unobserved system component(s). Then, we make comparisons with other current methods on two benchmark systems, which show that our proposed method provides more accurate inference while having much faster runtime.
Illustration: Hes1 model
The Hes1 model described in the Introduction demonstrates inference on a system with an unobserved component and asynchronous observation times. This section continues the inference of this model. Ref [1] studied the theoretical oscillation behavior using parameter values , , , ; , , , which leads to one oscillation cycle approximately every 2 hours. Ref [1] also set the initial condition at the lowest value of when the system is in oscillation equilibrium [1]: , , . The noise level in our simulation is derived from [1] where the standard error based on repeated measures are reported to be around 15% of the (protein) level and (mRNA) level, so we set the simulation noise to be multiplicative following a log-normal distribution with standard deviation 0.15, and throughout this example we assume the noise level is known to be 0.15 from repeated measures reported in [1]. The component is never observed. Owing to the multiplicative error on the strictly positive system, we apply our method to the log-transformed ODEs, so that the resulting error distributions are Gaussian. To the best of our knowledge, MAGI is the only one that provides a practical and complete solution for handling unobserved component cases like this example.
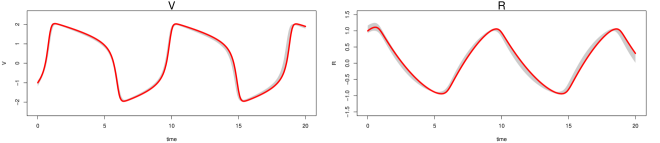
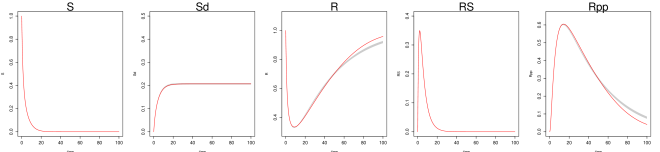
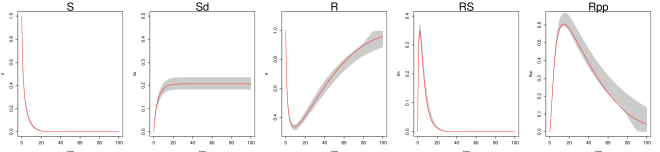
We generate 2000 simulated datasets based on the above setup for the Hes1 system. The left-most panel in Fig 1 shows one example dataset. For each dataset, we use MAGI to infer the trajectories and estimate the parameters. We use the posterior mean of as the inferred trajectories for the system components, which are generated by MAGI without using any numerical solver. Fig 1 summarizes the inferred trajectories across the 2000 simulated datasets, showing the median of the inferred trajectories of together with the 95% interval of the inferred trajectories represented by the 2.5% and 97.5% percentiles. The posterior mean of is our estimate of the parameters. Table 1 summarizes the parameter estimates across the 2000 simulated datasets, by showing their means and standard deviations. Fig 1 shows that MAGI recovers the system well, including the completely unobserved component. Table 1 shows that MAGI also recovers the system parameters well, except for the parameters that only appear in the equation for the unobserved component, which we will discuss shortly. Together, Fig 1 and Table 1 demonstrate that MAGI can recover the entire system without any usage of a numerical solver, even in the presence of unobserved component(s).
Metrics for assessing the quality of system recovery
To further assess the quality of the parameter estimates and the system recovery, we consider two metrics. First, as shown in Table 1, we examine the accuracy of the parameter estimates by directly calculating the root mean squared error (RMSE) of the parameter estimates to the true parameter value. We call this measure the parameter RMSE metric. Second, it is possible that a system might be insensitive to some of the parameters; in the extreme case, some parameters may not be fully identifiable given only the observed data and components. In these situations, it is possible that the system trajectories implied by quite distinct parameter values are similar to each other (or even close to the true trajectory). We thus consider an additional trajectory RMSE metric to account for possible parameter insensitivity, and measure how well the system components are recovered given the parameter and initial condition estimates. The trajectory RMSE is obtained by treating the numerical ODE solution based on the true parameter value as the ground truth: first, the numerical solver is used to reconstruct the trajectory based on the estimates of the parameter and initial condition (from a given method); then, we calculate the RMSE of this reconstructed trajectory to the true trajectory at the observation time points. We emphasize that the trajectory RMSE metric is only for evaluation purpose to assess (and compare across methods) how well a method recovers the trajectories of the system components, and that throughout MAGI no numerical solver is ever needed.
We summarize the trajectory RMSEs of MAGI in Table 2 for the Hes1 system.
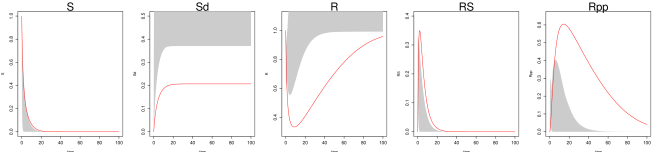
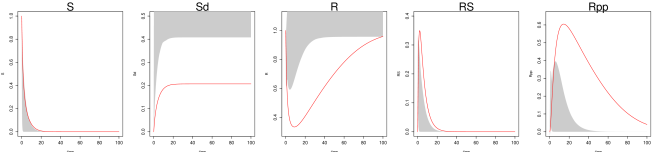
We compare MAGI with the benchmark provided by the B-spline-based penalization approach of Ref [9]. To the best of our knowledge, among all the existing methods that do not use numerical integration, Ref [9] is the only one with a software package that can be manually adapted to handle an unobserved component. We note, however, this package itself is not ready-made for this problem: it requires substantial manual input as it does not have default or built-in setup of its hyper-parameters for the unobserved component. None of the other benchmark methods, including Ref [11, 15], provide software that is equipped to handle an unobserved component. Table 1 compares our estimates against those given by Ref [9] based on the parameter RMSE, which shows that the parameter RMSEs for MAGI are substantially smaller than [9]. Fig 1 shows that the inferred trajectories from MAGI are very close to the truth. On the contrary, the method in [9] is not able to recover the unobserved component nor the associated parameter and ; see Fig S1 in the SI for the plots. Table 2 compares the trajectory RMSE of the two methods. It is seen that the trajectory RMSE of MAGI is substantially smaller than that of [9]. Further implementation details and comparison are provided in the SI.
Finally, we note that MAGI recovers the unobserved component almost as well as the observed components of and , as measured by the trajectory RMSEs. In comparison, for the result of [9] in Table 2, the trajectory RMSE of the unobserved component is orders of magnitude worse than those of and . The numerical results thus illustrate the effectiveness of MAGI in borrowing information from the observed components to infer the unobserved component, which is made possible by explicitly conditioning on the ODE structure. The self-regulating parameter and inhibition rate parameter for the unobserved component appear to have high inference variation across the simulated datasets despite the small trajectory RMSEs. This suggests that the system itself could be insensitive to and when the component is unobserved.
| MAGI | Ref [9] | ||||
|---|---|---|---|---|---|
| Truth | Estimate | RMSE | Estimate | RMSE | |
| a | 0.022 | 0.021 0.003 | 0.003 | 0.027 0.026 | 0.026 |
| b | 0.3 | 0.329 0.051 | 0.059 | 0.302 0.086 | 0.086 |
| c | 0.031 | 0.035 0.006 | 0.007 | 0.031 0.010 | 0.010 |
| d | 0.028 | 0.029 0.002 | 0.003 | 0.028 0.003 | 0.003 |
| e | 0.5 | 0.552 0.074 | 0.090 | 0.498 0.088 | 0.088 |
| f | 20 | 13.759 3.026 | 6.936 | 604.9 5084.8 | 5117.0 |
| g | 0.3 | 0.141 0.026 | 0.162 | 1.442 9.452 | 9.519 |
Comparison with previous methods based on GPs
To further assess MAGI, we compare with two methods: Adaptive Gradient Matching (AGM) of Ref [11] and Fast Gaussian process based Gradient Matching (FGPGM) of Ref [15], representing the state-of-the-art of inference methods based on GPs. For fair comparison, we use the same benchmark systems, scripts and software provided by the authors for performance assessment, and run the software using the settings recommended by the authors. The benchmark systems include the FitzHugh-Nagumo (FN) equations [17] and a protein transduction model [18].
FN model
The FitzHugh-Nagumo (FN) equations are a classic Ion channel model that describes spike potentials. The system consists of , where is the variable defining the voltage of the neuron membrane potential and is the recovery variable from neuron currents, satisfying the ODE
where are the associated parameters. As in [15, 11], the true parameters are set to , and we generate the true trajectories for this model using a numerical solver with initial conditions , .
| MAGI | FGPGM [15] | AGM [11] | ||||
|---|---|---|---|---|---|---|
| Estimate | RMSE | Estimate | RMSE | Estimate | RMSE | |
| a | 0.19 0.02 | 0.02 | 0.22 0.04 | 0.05 | 0.30 0.03 | 0.10 |
| b | 0.35 0.09 | 0.17 | 0.32 0.13 | 0.18 | 0.36 0.06 | 0.17 |
| c | 2.89 0.06 | 0.13 | 2.85 0.15 | 0.21 | 2.04 0.14 | 0.97 |
To compare MAGI with FGPGM of Ref [15] and AGM of Ref [11], we simulated 100 datasets under the noise setting of with 41 observations. The noise level is chosen to be on similar magnitude with that of [15], and the noise level is set to be the same across the two components as the implementation of [11] can only handle equal-variance noise. The number of repetitions (i.e., 100) is set to be the same as [15] due to the high computing time of these alternative methods.
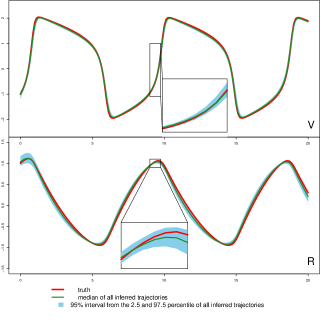
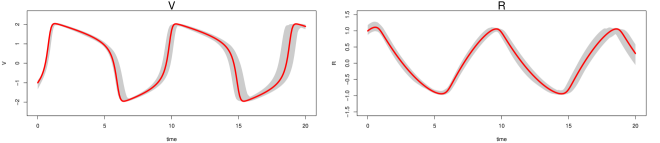
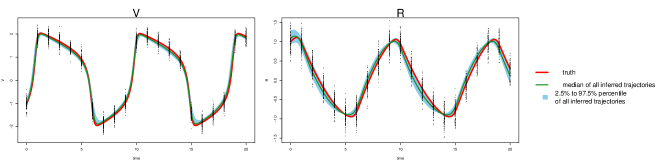
The parameter estimation results from the three methods are summarized in Table 3, where MAGI has the lowest parameter RMSEs among the three. Fig 2 shows the inferred trajectories obtained by our method: MAGI recovers the system well, and the 95% interval band is so narrow around the truth that we can only see the band clearly after magnification (as shown in the figure inset). The SI provides visual comparison of the inferred trajectories of different methods, where MAGI gives the most consistent results across the simulations. Furthermore, to assess how well the methods recover the system components, we calculated the trajectory RMSEs, and the results are summarized in Table 4, where MAGI significantly outperforms the others, reducing the trajectory RMSE over the best alternative method for 60% in and 25% in . We note that compared to the true parameter value, all three methods show some bias in the parameter estimates, which is partly due to the GP prior as discussed in [15], and MAGI appears to have the smallest bias.
For computing cost, the average runtime of MAGI for this system over the repetitions is 3 minutes, which is 145 times faster than FGPGM [15] and 90 times faster than AGM [11] on the same CPU (we follow the authors’ recommendation for running their methods, see SI for details).
| Method | ||
|---|---|---|
| MAGI | 0.103 | 0.070 |
| FGPGM [15] | 0.257 | 0.094 |
| AGM [11] | 1.177 | 0.662 |
Protein transduction model
This protein transduction example is based on systems biology where components and represent a signaling protein and its degraded form, respectively. In the biochemical reaction binds to protein to form the complex , which enables the activation of into . satisfies the ODE
where are the associated rate parameters.
We follow the same simulation setup as [15, 11], by taking as the observation times, as the initial values, and as the true parameter values. Two scenarios for additive observation noise are considered: (low noise) and (high noise). Note that the observation times are unequally spaced, with only a sparse number of observations from to . Further, inference for this system has been noted to be challenging due to the non-identifiability of the parameters, in particular and [15]. Therefore, the parameter RMSE is not meaningful for this system, and we focus our comparison on the trajectory RMSE.
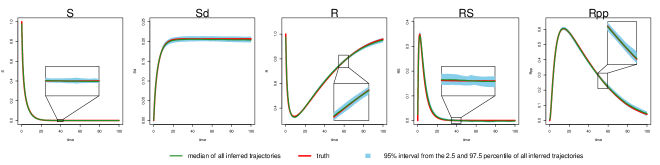
We compare MAGI with FGPGM of Ref [15] and AGM of Ref [11] on 100 simulated datasets for each noise setting (see the SI for method and implementation details). We plot the inferred trajectories of MAGI in the high noise setting in Fig 3, which closely recover the system. The 95% interval band from MAGI is quite narrow that for most of the inferred components we need magnifications (as shown in the figure insets) to clearly see the 95% band. We then calculated the trajectory RMSEs, and the results are summarized in Table 5 for each system component. In both noise settings, MAGI produces trajectory RMSEs that are uniformly smaller than both FGPGM [15] and AGM [11] for all system components. In the low noise setting, the advantage of MAGI is especially apparent for components , , , and , with trajectory RMSEs less than half of the closest comparison method. For the high noise setting, MAGI reduces trajectory RMSE the most for and (50%). AGM [11] struggles with this example at both noise settings. To visually compare the trajectory RMSEs in Table 5, plots of the corresponding reconstructed trajectories by different methods at both noise settings are given in the SI.
The runtime of MAGI for this system averaged over the repetitions is 18 minutes, which is 12 times faster than FGPGM [15] and 18 times faster than AGM [11] on the same CPU (we follow the authors’ recommendation for running their methods, see SI for details).
Discussion
We have presented a novel methodology for the inference of dynamic systems, using manifold-constrained Gaussian processes. A key feature that distinguishes our work from the previous approaches is that it provides a principled statistical framework, firmly grounded on the Bayesian paradigm. Our method also outperformed currently available GP-based approaches in the accuracy of inference on benchmark examples. Furthermore, the computation time for our method is much faster. Our method is robust and able to handle a variety of challenging systems, including unobserved components, asynchronous observations, and parameter non-identifiability.
A robust software implementation is provided, with user interfaces available for R, MATLAB, and Python, as described in the SI. The user may specify custom ODE systems in any of these languages for inference with our package, by following the syntax in the examples that accompany this article. In practice, inference with MAGI using our software can be carried out with relatively few user interventions. The setting of hyperparameters and initial values is fully automatic, though may be overridden by the user.
The main setting that requires some tuning is the number of discretization points in . In our examples, this was determined by gradually increasing the denseness of the points with short sampler runs, until the results become indistinguishable. Note that further increasing the denseness of has no ill effect, apart from increasing the computational time. To illustrate the effect of the denseness of on MAGI inference results, an empirical study is included in the SI “varying number of discretization” section, where we examined the results of the FN model with the discretization set taken to be 41, 81, 161, and 321 equally spaced points, respectively. The results confirm that our proposal of gradually increasing the denseness of works well. The inference results improve as we increase from 41 to 161 points, and at 161 points the results are stabilized. If we further increase the discretization to 321 points, that doubles the compute time with only a slight gain in accuracy compared to 161 points in terms of trajectory RMSEs. This empirical study also indicates that as becomes an increasingly dense approximation of , an inference limit would be expected. A theoretical study is a natural future direction of investigation.
We also investigated the stability of MAGI when the observation time points are farther apart. This empirical study, based on the FN model with 21 observations, is included in the SI “FN model with fewer observations” section. The inferred trajectories from the 21 observations are still close to the truth, while the interval bands become wider, which is expected as we have less information in this case. We also found that the denseness of the discretization needs to be increased (to 321 time points in this case) to compensate for the sparser 21 observations111This finding echos the classical understanding that stiff systems require denser discretization (observations farther apart make the system appear relatively more stiff)..
An inherent feature of the GP approximation is the tendency to favor smoother curves. This limitation has been previously acknowledged [15, 11]. As a consequence, two potential forms of bias can exist. First, estimates derived from the posterior distributions of the parameters may have some statistical bias. Second, the trajectories reconstructed by a numerical solver based on the estimated parameters may differ slightly from the inferred trajectories. MAGI, which is built on a GP framework, does not entirely eliminate these forms of bias. However, as seen in the benchmark systems, the magnitude of our bias in both respects is significantly smaller than the current state-of-the-art in [15, 11].
We considered the inference of dynamic systems specified by ODEs in this article. Such deterministic ODE models are often adequate to describe dynamics at the aggregate or population level [19]. However, when the goal is to describe the behavior of individuals (e.g., individual molecules [20, 21]), models such as stochastic differential equations (SDEs) and continuous-time Markov processes, which explicitly incorporate intrinsic (stochastic) noise, often become the model of choice. Extending our method to the inference of SDEs and continuous-time Markov models is a future direction we plan to investigate. Finally, recent developments in deep learning have shown connections between deep neural networks and GPs [22, 23]. It could thus also be interesting to explore the application of neural networks to model the ODE system outputs in conjunction with GPs.
Materials and Methods
For notational simplicity, we drop the dimension index in this section when the meaning is clear.
Algorithm overview
We begin by summarizing the computational scheme of MAGI. Overall, we use Hamiltonian Monte Carlo (HMC) [7] to obtain samples of and the parameters from their joint posterior distribution. Details of the HMC sampling are included in the SI section ‘Hamiltonian Monte Carlo’. At each iteration of HMC, and the parameters222The parameters here refer to and . If the noise level is known a priori, the parameters then refer to only. are updated together with a joint gradient, with leapfrog step sizes automatically tuned during the burn-in period to achieve an acceptance rate between 60-90%. At the completion of HMC sampling (and after discarding an appropriate burn-in period for convergence), we take the posterior means of as the inferred trajectories, and the posterior means of the sampled parameters as the parameter estimates. The techniques we use to temper the posterior and speed up the computations are discussed in the following ‘Prior tempering’ subsection and ‘Techniques for computational efficiency’ in the SI.
Several steps are taken to initialize the HMC sampler. First, we apply a GP fitting procedure to obtain values of and for the observed components; the computed values of the hyper-parameters are subsequently held fixed during the HMC sampling, while the computed value of is used as the starting value in the HMC sampler. (If is known, the GP fitting procedure is used to obtain values of only.) Second, starting values of for the observed components are obtained by linearly interpolating between the observation time points. Third, starting values for the remaining quantities – and for any unobserved component(s) – are obtained by optimization of the posterior as described below.
Setting hyper-parameters for observed components
The GP prior , is on each component separately. The Gaussian process Matern kernel has two hyper-parameters that are held fixed during sampling: controls overall variance level of the GP, while controls the bandwidth for how much neighboring points of the GP affect each other.
When the observation noise level is unknown, values of are obtained jointly by maximizing GP fitting without conditioning on any ODE information, namely:
| (7) |
where . The index set is the smallest evenly spaced set such that all observation time points in this component are in , i.e., . The priors and for the variance parameter and are set to be flat. The prior for the bandwidth parameter is set to be a Gaussian distribution: (a) the mean is set to be half of the period corresponding to the frequency that is the weighted average of all the frequencies in the Fourier transform of on (the values of on are linearly interpolated from the observations at ), where the weight on a given frequency is the squared modulus of the Fourier transform with that frequency, and (b) the standard deviation is set such that is three standard deviations away from . This Gaussian prior on serves to prevent it from being too extreme. In the subsequent sampling of , the hyper-parameters are fixed at while gives the starting value of in the HMC sampler.
If is known, then values of are obtained by maximizing
| (8) |
and held fixed at in the subsequent HMC sampling of . The priors for and are the same as previously defined.
Initialization of for the observed components
To provide starting values of for the HMC sampler, we use the values of at the observation time points and linearly interpolate the remaining points in .
Initialization of the parameter vector when all system components are observed
To provide starting values of for the HMC sampler, we optimize the posterior (5) as a function of alone, holding and unchanged at their starting values, when there is no unobserved component(s). The optimized is then used as the starting value for the HMC sampler in this case.
Settings in the presence of unobserved system components: setting , initializing for unobserved components, and initializing
Separate treatment is needed for the setting of and initialization of , for the unobserved component(s). We use an optimization procedure that seeks to maximize the full posterior in (5) as a function of together with and the whole curve of for unobserved components, while holding the , and for the observed components unchanged at their initial value discussed above. We thereby set for the unobserved component, and the starting values of and for unobserved components at the optimized value. In the subsequent sampling, the hyper-parameters are fixed at the optimized , while the HMC sampling starts at the and the obtained by this optimization.
Prior tempering
After is set, we use a tempering scheme to control the influence of the GP prior relative to the likelihood during HMC sampling. Note that (5) can be written as
| (9) | ||||
As the cardinality of increases with more discretization points, the prior part grows, while the likelihood part stays unchanged. Thus, to balance the influence of the prior, we introduce a tempering hyper-parameter with the corresponding posterior
A useful setting that we recommend is , where is the number of system components, is the number of discretization time points, and is the total number of observations. This setting aims to balance the likelihood contribution from the observations with the total number of discretization points.
Data availability
All of the data used in the article are simulation data. The details, including the models to generate the simulation data, are described in Results and the SI. Our software package also includes complete replication scripts for all the data and examples.
Acknowledgements
The research of S.W.K.W. is supported in part by Discovery Grant RGPIN-2019-04771 from the Natural Sciences and Engineering Research Council of Canada. The research of S.C.K. is supported in part by NSF Grant DMS-1810914.
References
- [1] Hirata H, et al. (2002) Oscillatory expression of the bHLH factor Hes1 regulated by a negative feedback loop. Science 298(5594):840–843.
- [2] Forger DB (2017) Biological clocks, rhythms, and oscillations: the theory of biological timekeeping. (MIT Press).
- [3] Miao H, Dykes C, Demeter LM, Wu H (2009) Differential equation modeling of HIV viral fitness experiments: model identification, model selection, and multimodel inference. Biometrics 65(1):292–300.
- [4] Busenberg S (2012) Differential Equations and Applications in Ecology, Epidemics, and Population Problems. (Elsevier).
- [5] Gorbach NS, Bauer S, Buhmann JM (2017) Scalable variational inference for dynamical systems in Advances in Neural Information Processing Systems. pp. 4806–4815.
- [6] Wu L, Qiu X, Yuan Yx, Wu H (2019) Parameter estimation and variable selection for big systems of linear ordinary differential equations: A matrix-based approach. Journal of the American Statistical Association 114(526):657–667.
- [7] Neal RM (2011) MCMC Using Hamiltonian Dynamics in Handbook of Markov Chain Monte Carlo, Chapman & Hall/CRC Handbooks of Modern Statistical Methods, eds. Brooks S, Gelman A, Jones G, Meng X. (CRC Press), pp. 113–162.
- [8] Calderhead B, Girolami M, Lawrence ND (2009) Accelerating Bayesian inference over nonlinear differential equations with Gaussian processes in Advances in neural information processing systems. pp. 217–224.
- [9] Ramsay JO, Hooker G, Campbell D, Cao J (2007) Parameter estimation for differential equations: a generalized smoothing approach. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 69(5):741–796.
- [10] Hennig P, Osborne MA, Girolami M (2015) Probabilistic numerics and uncertainty in computations. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 471(2179):20150142.
- [11] Dondelinger F, Husmeier D, Rogers S, Filippone M (2013) ODE parameter inference using adaptive gradient matching with gaussian processes in International Conference on Artificial Intelligence and Statistics. pp. 216–228.
- [12] Barber D, Wang Y (2014) Gaussian processes for Bayesian estimation in ordinary differential equations in International Conference on Machine Learning. pp. 1485–1493.
- [13] Ghosh S, Dasmahapatra S, Maharatna K (2017) Fast approximate Bayesian computation for estimating parameters in differential equations. Statistics and Computing 27(1):19–38.
- [14] Lazarus A, Husmeier D, Papamarkou T (2018) Multiphase MCMC sampling for parameter inference in nonlinear ordinary differential equations in International Conference on Artificial Intelligence and Statistics. pp. 1252–1260.
- [15] Wenk P, et al. (2019) Fast Gaussian process based gradient matching for parameter identification in systems of nonlinear ODEs in International Conference on Artificial Intelligence and Statistics. pp. 1351–1360.
- [16] Macdonald B, Higham C, Husmeier D (2015) Controversy in mechanistic modelling with Gaussian processes. Proceedings of Machine Learning Research 37:1539–1547.
- [17] FitzHugh R (1961) Impulses and physiological states in theoretical models of nerve membrane. Biophysical journal 1(6):445–466.
- [18] Vyshemirsky V, Girolami MA (2007) Bayesian ranking of biochemical system models. Bioinformatics 24(6):833–839.
- [19] Kurtz TG (1972) The relationship between stochastic and deterministic models for chemical reactions. The Journal of Chemical Physics 57(7):2976–2978.
- [20] Kou SC, Xie XS (2004) Generalized langevin equation with fractional gaussian noise: subdiffusion within a single protein molecule. Physical review letters 93(18):180603.
- [21] Kou SC, Cherayil B, Min W, English B, Xie X (2005) Single-molecule michaelis-menten equations. The Journal of Physical chemistry. B 109(41):19068–19081.
- [22] Jacot A, Gabriel F, Hongler C (2018) Neural tangent kernel: convergence and generalization in neural networks in Proceedings of the 32nd International Conference on Neural Information Processing Systems. pp. 8580–8589.
- [23] Lee J, et al. (2018) Deep neural networks as gaussian processes in International Conference on Learning Representations.
This supporting information file presents techniques for efficient computation, a description of Hamiltonian Monte Carlo, further details and discussion for each of the dynamic system examples in the main manuscript, and additional empirical studies on varying the number of discretization points and reducing the number of observations.
Techniques for computational efficiency
After setting , the matrix inverses , can be pre-computed and held fixed in the sampling of from the target posterior, Eq. (5) in the main text. Thus, the computation of Eq. (5) in the main text at sampled values of () only involves matrix multiplication, which has typical computation complexity of , where is the matrix dimension (i.e., number of discretization points). Due to the short-term memory and local structure of Gaussian processes (GPs), the partial correlation of two distant points diminishes quickly to zero, resulting in the off-diagonal part of precision matrices and being close to zero. Similarly, is the projection matrix of the Gaussian process to its derivative process, and since derivative is a local property, the effect from a far away point is small given one’s neighboring points, resulting in the off-diagonal part of projection matrix being close to zero as well. Therefore, an efficient band matrix approximation may be used on , , and to reduce computation into , when calculating Eq. (5) in the main text at each sampled () with a fixed band size. In our experience, a band size of 20 to 40 is sufficient, and we recommend using an evenly spaced for best results with the band matrix approximation and thus faster computation. In our implementation, a failure in the band approximation is automatically detected by checking for divergence in the quadratic form, and a warning is outputted to the user to increase the band size.
Hamiltonian Monte Carlo
Sampling procedure with HMC
We outline the HMC procedure for sampling from a target probability distribution. The interested reader may refer to Ref [7] for more thorough introduction to HMC.
First, suppose the target distribution has density , where is the normalizing constant, and is the negation of the log target density. has the physical interpretation of the “potential energy” at “position” . In MAGI, is the collection of and the parameters. When the noise level is known a priori, the parameters refer to only; when is unknown, the parameters refer to and . In MAGI the function is the negation of the log posterior density in Eq. (5) of the main text.
Second, momentum variables, , of the same dimension as , are introduced. A “kinetic energy” is defined to be .
Third, define the “Hamiltonian” to be , and consider the joint density of and , which is proportional to . Under this construction, and are independent, where the marginal probability density of is the target , and the marginal probability density of is Gaussian. We will then sample from this augmented distribution for .
We repeat the following three steps, that together compose one HMC iteration: (1) Sample from the normal distribution since corresponds to a Gaussian kernel; (2) construct a proposal for by simulating the Hamiltonian dynamics using the leapfrog method (detailed in the next subsection), and (3) accept or reject as the next state of according to the usual Metropolis acceptance probability, .
After repeating the HMC iteration for the desired number of iterations, the sampled are taken to be the samples from . Recall is the collection of and the parameters in MAGI, so at the completion of HMC sampling, we have samples of and the parameters. We finally take the posterior mean of as the inferred trajectory, and the posterior means of the sampled parameters as the parameter estimates.
Leapfrog method for Hamiltonian dynamics
The generating of proposals in HMC is inspired by Hamiltonian dynamics. The leapfrog method is used to approximate the Hamiltonian dynamics.
One step of the leapfrog method with step size from an initial point consists of three parts. First, we make a half step for the momentum, . Second, we make a full step for the position, . Third, we make a full step for the momentum using the gradient evaluated at the new position, .
The step size and the number of leapfrog steps can be tuned. In our MAGI implementation, we recommend fixing the number of leapfrog steps, and tuning the leapfrog step size automatically during the burn-in period to achieve an acceptance rate between 60% and 90%.
More details of the examples
Hes1 model
As stated in the main text, this system has three components, , following the ODE
where are the associated parameters.
The true parameter values in the simulation are set as , , , ; , , , which leads to one oscillation cycle approximately every 2 hours. The initial condition is set to be , , . Recall that these settings, along with the simulated noise level, are derived from Ref [1], where the standard error based on repeated measures are reported to be around 15% of the (protein) level and (mRNA) level. Thus the simulation noise is set to be multiplicative following a log-normal distribution with standard deviation 0.15, since all components in the system are strictly positive. The number of observations is also set based on Ref [1], where and are observed at 15-minute intervals for 4 hours but the component is entirely unobserved. In addition, the observations for and are asynchronous: starting at time 0, every 15 minutes we observe ; starting at the 7.5 minutes, every 15 minutes we observe . Following our notation in the main text, , , and . In total we have observations for , observations for , and observations for ; and are never observed at the same time. See Fig 1 (leftmost panel) of the main text for a visual illustration.
We provide additional details on how to set up MAGI, as applied to this system. Since the components are strictly positive, we first apply a log-transformation to the system so that the resulting noise is additive Gaussian. Define
so that the transformed system is:
We conduct all the inference on the log-transformed system, and transform back to the original scale only at the final step to obtain inferred trajectories on the original scale.
As described in “Setting hyper-parameters for observed components” in the Materials and Methods, we consider the observed component and the observed component separately when setting their respective hyper-parameters . For , since the observation time points are already equally spaced, we have ; is obtained by optimization of Eq (8) in the main text given , and fixing the noise level at the true value of 0.15. For , since the observation time points are also equally spaced, we have ; for is obtained by optimization of Eq (8) in the main text, given , and fixing the noise level at the true value of 0.15 as well.
Next, we consider the discretization set . In this example we use all observation time points as the discretization set, i.e., . To initialize for the observed component and , we follow the approach as described in Materials and Methods, using the values of at the observation time points and linear interpolation for the remaining points in .
We set the hyper-parameter and the initial values for the unobserved component by maximizing the full likelihood function, Eq. (5) of the main text, as described in the Materials and Methods Section (“Settings in the presence of unobserved system components: setting , initializing for unobserved components, and initializing ”).
To balance the contribution from the GP prior and that from the observed data, we use prior tempering (as described in the “Prior tempering” subsection of Materials of Methods of the main text). We set , since we have a total of 33 observations (17 observations for , 16 observations for , and 0 observations for ) and total of 33 discretization points (at times 0, 7.5, 15, …, 240) for each of the 3 dimensions. Finally, priors for each parameter in are set to be flat on the interval .
Having initialized the sampler for this system, we next provide details on HMC sampling to obtain our estimates of the trajectory and parameters. A total of 20000 HMC iterations were run, with the first 10000 discarded as burn-in. Each HMC iteration uses 500 leapfrog steps, where the leapfrog step size is drawn randomly from a uniform distribution on for each iteration. During the burn-in period, is adaptively tuned: at each HMC iteration is multiplied by 1.005 if the acceptance rate in the previous 100 iterations is above 90%, and is multiplied by 0.995 if the acceptance rate in the previous 100 iterations is below 60%. To speed up computations, we use a band matrix approximation (see ‘Techniques for computational efficiency’ in this SI document) with band size 20. Using the draws from the 10000 HMC iterations after burn-in, the posterior mean of is our inferred trajectory for the system components at time points in , which are generated by MAGI without using any numerical solver; the posterior mean of provides our parameter estimates.
We make comparisons with the B-spline-based penalization method of Ref [9], which provides the estimated parameters for a given dataset and ODE, but does not provide estimates for the system components (i.e., the trajectories) of the ODE. Thus, to infer the trajectories of system components implied by the method of Ref [9], we run the numerical solver for each parameter estimate (and initial values) produced by the method of Ref [9] to obtain the inferred trajectories for the system components. The method of Ref [9] also has hyper-parameters, in particular, the spline basis functions. The authors’ R package CollocInfer does not provide the capability to fit spline basis functions if there are unobserved system components. Thus, to obtain results with unobserved components, we fit these spline basis functions using the true value of all system components at the observation time points in this study, which in fact gives the method of Ref [9] an additional advantage than in practice: in the analysis of real data, the true value of the system components is certainly unavailable. Specifically, we used the routines in the R package CollocInfer by Ref [9] twice: the first time, we supply the package with the fully-observed noiseless true values of all system components at the observation time points, and thus obtain the estimated B-spline basis functions as part of the package output; the second time, we supply the package with noisy data, together with the B-spline basis functions we obtained in the first run for the unobserved component, to get the final inference results. All other settings are kept at the default values in the package.
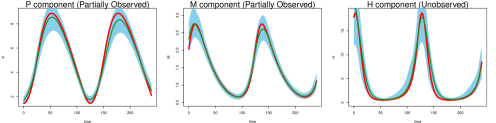
Even under this setting, the method of Ref [9] had difficulty recovering the system trajectories and parameters (Figure S1, Table 1 of the main text). Figure S1 plots the inferred trajectories across the 2000 datasets, comparing the two methods side by side, where the method of Ref [9] is seen to have difficulty to recover the unobserved component . Table 1 of the main text shows the parameter RMSE, where the method of Ref [9] has difficulty to recover the parameters and , which are associated with the unobserved component . Even for the observed components and , the inferred trajectory of Ref [9] has much larger RMSE compared to MAGI (see Figure S1 and Table 2 of the main text).
Finally, we want to highlight that none of the other benchmark methods, for example, [11, 15], provides software that is equipped to handle an unobserved component.



FitzHugh-Nagumo (FN) Model
As stated in the main text, the FitzHugh-Nagumo (FN) model has two components, , following the ODE
where are the associated parameters.
Following the same simulation setup as Refs [15, 11], the initial conditions of the system are set at , the true parameter values are set at , and the system is observed at the equally spaced time points from 0 to 20 with 0.5 interval, i.e, . Simulated observations have Gaussian additive noise with on both components.
We provide additional details on how to set up MAGI, as applied to this system. As described in “Setting hyper-parameters for observed components” in the Materials and Methods, the smallest index set that includes the observation time points is ; then given , values of are obtained by optimizing Eq (7) in the main text. Next, we consider the discretization set . In this example we insert 3 additional equally spaced discretization time points between two adjacent observation time points, i.e., , time points. As noted in the Discussion section of the main text, we successively increased the denseness of points in and found that a further increase in the number of discretization points yielded only slightly better results as . Next, to initialize for the sampler, we follow the approach as described in Materials and Methods, using the values of at the observation time points and linear interpolation for the remaining points in . Then, we obtain a starting value of for the HMC sampler according to the “Initialization of the parameter vector when all system components are observed” subsection in the main text. We apply tempering to the posterior distribution following our guideline in the “Prior tempering” subsection in the main text, where . Finally, the prior distributions for each parameter in are set to be flat on .
Having initialized the sampler for this system, we run HMC sampling to obtain our estimates of the trajectory and parameters. A total of 20000 HMC iterations were run, with the first 10000 discarded as burn-in. Each HMC iteration uses 100 leapfrog steps, where the leapfrog step size is drawn randomly from a uniform distribution on for each iteration. During the burn-in period, is adaptively tuned: at each HMC iteration is multiplied by 1.005 if the acceptance rate in the previous 100 iterations is above 90%, and is multiplied by 0.995 if the acceptance rate in the previous 100 iterations is below 60%. To speed up computations, we use a band matrix approximation (see ‘Techniques for computational efficiency’ in this SI document) with band size 20. Using the draws from the 10000 HMC iterations after burn-in, the posterior mean of is our inferred trajectory for the system components at time points in , which are generated by MAGI without using any numerical solver; the posterior mean of provides our parameter estimates.
For the two benchmark methods, we strictly follow the authors’ recommendation. Specifically, for FGPGM of Ref [15], we run their provided software with all settings as recommended by the authors: the standard deviation parameter there for handling potential mismatch between GP derivatives and the system is set to , a Matern52 kernel is used, and 300000 MCMC iterations are run. We treat the first half of the iterations as burn-in, and use the posterior mean as the estimate of the parameters and initial conditions. For AGM of Ref [11], the observation noise level is assumed to be known and fixed at their true values (as this method cannot handle unknown noise level), and 300000 MCMC iterations are run. We treat the first half of the iterations as burn-in, and use the posterior mean of the sampled values of the parameters and initial conditions as their respective estimates.
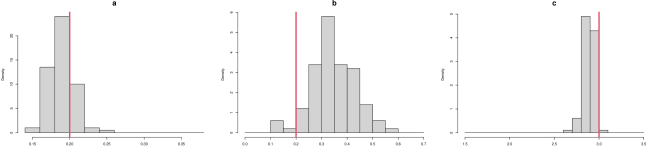
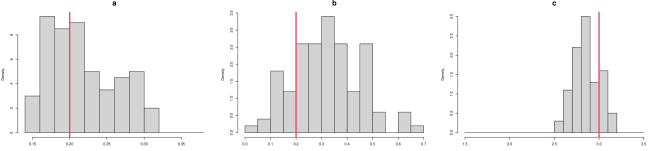
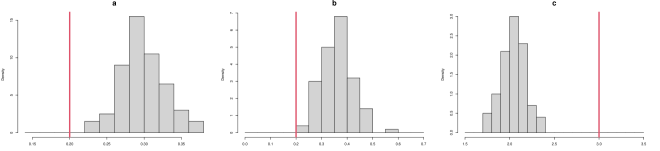
As described in “Metrics for assessing the quality of system recovery” in the main text, the parameter RMSE is the root mean squared error (RMSE) of the parameter estimates to the true parameter value. To visualize the parameter estimates of different methods, we plot the histogram of estimated parameters for each of the methods in Figure S2. The red line indicates the true value of each parameter , and the histograms show the distributions of the corresponding parameter estimates over the 100 simulated datasets. For MAGI (upper panel), the red lines lie close to the histogram values for each parameter, indicating that statistical bias is small; the spreads of the histogram values illustrate the variances of the estimates. For FGPGM [15] (middle panel), the red lines lie close to the histogram values for each parameter, indicating that statistical bias is small; the spreads of the histogram values are visibly wider compared to the upper panel, showing larger variances of the estimates. For AGM [11] (lower panel), the relatively narrow spreads of the histogram values indicate that the variances of the parameter estimates are small; however, for parameters and the histogram values are much further from the true values, indicating a larger statistical bias than the other two methods.
As described in “Metrics for assessing the quality of system recovery” in the main text, the trajectory RMSE is computed for each method based on its estimate of the parameters and initial conditions. Recall that the trajectory RMSE treats the numerical ODE solution based on the true parameter values as the ground truth, and is obtained as follows: first, the numerical solver is used to reconstruct the trajectory based on the estimates of the parameter and initial condition from a given method; then, the RMSE of this reconstructed trajectory to the true trajectory at the observation time points is calculated. To visualize the trajectory RMSEs shown in Table 4 of the main text for each method, Figure S3 plots the true trajectory (red lines) and the 95% interval of the reconstructed trajectories (gray bands) over the 100 simulated datasets for MAGI, FGPGM of Ref [15], and AGM of Ref [11]. For MAGI (upper panel), the gray bands closely follow the true trajectories for both components, showing that the statistical bias of the reconstructed trajectories is small; the bands are also quite narrow, showing that the variance in the reconstructed trajectories is low. For FGPGM [15] (middle panel), the gray bands largely follow the true trajectories for both components, showing that the statistical bias of the reconstructed trajectories is small; however, the bands are visibly wider compared to the upper panel for both components, indicating larger variances in the reconstructed trajectories. For AGM [11] (lower panel), the gray bands do not capture the true trajectory for either component, which indicates there is clear statistical bias in the reconstructed trajectories, and the bands are also much wider than the other two methods indicating a higher variance; this is probably due to the underlying statistical bias in the parameter estimates as seen in the lower panel of Figure S2.








Protein transduction model
As stated in the main text, the protein transduction model has five components, , following the ODE
where are the associated rate parameters.
Following the same simulation setup as in [15, 11], the initial conditions of the system are , the true parameter values are , and the system is observed at the time points
In the low noise scenario, simulated observations have Gaussian additive noise with , while in the high noise scenario . As noted in the main text, inference for this system is challenging due to the non-identifiability of the parameters, so the comparison of different method focuses on the trajectory recovery rather than the parameter RMSE.
We provide additional details on how to set up MAGI, as applied to this system. Recall that the observation times are unequally spaced. Thus, as described in “Setting hyper-parameters for observed components” in the Materials and Methods, we take , which is the smallest index set with equally spaced time points that includes the observation times, and use linear interpolation between the observations to obtain ; given , values of are obtained by optimization. Next, we consider the discretization set . In this example we insert 1 additional equally spaced discretization time point between two adjacent time points in , i.e., , time points. As noted in the Discussion, we successively increased the denseness of points in and found that a further increase in the number of discretization points did not continue to offer improved results compared to this setting of . Next, to initialize for the sampler, we follow the approach as described in Materials and Methods, using the values of at the observation time points and linear interpolation for the remaining points in . Then, we obtain a starting value of for the HMC sampler according to “Initialization of the parameter vector when all system components are observed”. We apply tempering to the posterior following our guideline in “Prior tempering”, so that . Finally, priors for each parameter in are set to be uniform on the interval as in Ref [15].
Having initialized the sampler for this system, we run HMC sampling to obtain samples of the trajectory and parameters. A total of 20000 HMC iterations were run, with the first 10000 discarded as burn-in. Each HMC iteration uses 100 leapfrog steps, where the leapfrog step size is drawn randomly from a uniform distribution on for each iteration. During the burn-in period, is adaptively tuned: at each HMC iteration is multiplied by 1.005 if the acceptance rate in the previous 100 iterations is above 90%, and is multiplied by 0.995 if the acceptance rate in the previous 100 iterations is below 60%. To speed up computations, we use a band matrix approximation (see ‘Techniques for computational efficiency’ in this SI document) with band size 40. Using the draws from the 10000 HMC iterations after burn-in, the posterior mean of is our inferred trajectory for the system components, which are generated by MAGI without using any numerical solver; the posterior mean of provides our parameter estimates.
We compare MAGI with FGPGM of Ref [15] and AGM of Ref [11] on 100 simulated datasets for each of the two noise settings. All methods use the same priors for , namely uniform on as used previously in Ref [15]. We strictly follow the authors’ recommendation for running their methods. Specifically, for FGPGM of Ref [15], we run their provided software with all settings as recommended by the authors: the standard deviation parameter there for handling potential mismatch between GP derivatives and the system is set to , a sigmoid kernel is used, and 300000 MCMC iterations are run. We treat the first half of the iterations as burn-in, and use the posterior mean as the estimate of the parameters and initial conditions. For AGM of Ref [11], the observation noise level is assumed to be known and fixed at their true values (as this method cannot handle unknown noise level), and 300000 MCMC iterations are run. We treat the first half of the iterations as burn-in, and use the posterior mean as the estimate of the parameters and initial conditions.
As described in “Metrics for assessing the quality of system recovery” in the main text, the trajectory RMSE is computed for each method based on its estimate of the parameters and initial conditions. Recall that the trajectory RMSE treats the numerical ODE solution based on the true parameter values as the ground truth, and is obtained as follows: first, the numerical solver is used to reconstruct the trajectory based on the estimates of the parameter and initial condition from a given method; then, the RMSE of this reconstructed trajectory to the true trajectory at the observation time points is calculated. To visualize the trajectory RMSEs shown in Table 4 of the main text for each method, Figures S4 and S5 (for the low and high noise cases, respectively) plot the true trajectory (red lines) and the 95% interval of the reconstructed trajectories (gray bands) over the 100 simulated datasets for MAGI, FGPGM of Ref [15], and AGM of Ref [11].
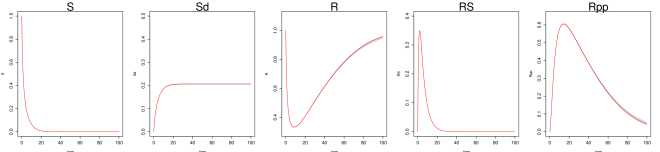
In the low noise case (Figure S4), the gray bands for MAGI (top panel) closely follow the true trajectories for all five system components, showing that the statistical bias of the reconstructed trajectories is small overall. The interval bands are also very narrow, indicating that the variance in the reconstructed trajectories is low. For FGPGM [15] (middle panel), the gray bands largely follow the true trajectories for most of the system components, indicating that the statistical bias of the reconstructed trajectories is small for most of the time range; however, there is clearly visible bias for the second half of the time period ( to ) for and . The interval bands are also narrow, indicating that the variance in the reconstructed trajectories is low. For AGM [11] (lower panel), the gray bands are unable to capture the true trajectories, indicating there is significant statistical bias in the reconstructed trajectories. The wide interval bands indicate a high variance in the reconstructed trajectories as well; note that the 97.5 percentile of AGM also exceeds the visible upper limit of the plots for and .
Inference is more challenging in the high noise case (Figure S5). For MAGI (upper panel), the gray bands still closely follow the true trajectories for all five system components, showing that the statistical bias of the reconstructed trajectories is small overall, with some slight bias for . The interval bands are wider than the corresponding low noise case but still relatively narrow for all the components, indicating that the variance in the reconstructed trajectories is low. For FGPGM [15] (middle panel), the gray bands largely follow the true trajectories for all the system components, showing that the statistical bias of the reconstructed trajectories is small overall. The interval bands are, however, significantly wider than the upper panel; the variance in the reconstructed trajectories of FGPGM is thus much increased compared to that of MAGI. For AGM [11] (lower panel), the gray bands are again unable to capture the true trajectories, which indicates there is significant statistical bias in the reconstructed trajectories. The wide interval bands indicate a high variance in the reconstructed trajectories; note that the 97.5 percentile of AGM also exceeds the visible upper limit of the plots for and .






Varying number of discretization
In this section we empirically study the effect of replacing by . Specifically, we examine the results from varying the number of discretization points in in the context of the FN model example.
As discussed in the main text, the number of discretization points in is the main setting that requires some tuning. In our examples, this was determined by gradually increasing the denseness of the points with short sampler runs, until the results become stabilized. Note that further increasing the denseness of has no ill effect, apart from increasing the computational time.
Here we illustrate the effect of by varying the number of discretization points, using the same dataset of the FN system presented in the main text. The result is summarized in Table S1. The results in the main text Tables 3 and 4 are based on 161 discretization points. As can be seen, the inference results improve as we increase from 41 to 161 points, and at 161 points the results are stabilized. If we further increase the discretization to 321 points, that doubles the compute time with only a slight gain in accuracy compared to 161 points in terms of the RMSEs.
| number of | parameter a | parameter b | parameter c | trajectory RMSE | run time | ||||
|---|---|---|---|---|---|---|---|---|---|
| discretizations | Estimate | RMSE | Estimate | RMSE | Estimate | RMSE | V | R | (minutes) |
| 41 | 0.20 0.03 | 0.026 | 0.24 0.08 | 0.091 | 2.83 0.12 | 0.211 | 0.358 | 0.146 | 0.84 |
| 81 | 0.19 0.02 | 0.020 | 0.34 0.09 | 0.165 | 2.82 0.07 | 0.199 | 0.270 | 0.142 | 1.67 |
| 161 | 0.19 0.02 | 0.020 | 0.35 0.09 | 0.172 | 2.89 0.06 | 0.128 | 0.103 | 0.070 | 3.13 |
| 321 | 0.19 0.02 | 0.020 | 0.33 0.09 | 0.162 | 2.92 0.06 | 0.097 | 0.072 | 0.051 | 5.94 |
FN model with fewer observations
In this section we study the FN system with 21 observations, which is fewer than the 41 observations presented in the main text. This investigation aims to answer two questions: (1) how does MAGI perform when the number of observations is more sparse, and (2) how does MAGI perform if the observation time points are spaced farther apart?
Following the same setup as the FN system in the main text, we now consider the scenario where 21 observations are made at equally spaced time points from 0 to 20, i.e, . When applying MAGI, the discretization set was determined by successively increasing its denseness (with short sampler runs), until the results become stabilized. The numerical results show that in this scenario with sparser observations that are also farther apart, a higher number of discretization points is needed for the results to be stabilized. Specifically for this example with 21 observations, 321 points in the discretization set , i.e., are needed to obtain stable inference results. The required increase in discretization seen here echos the classical understanding that stiff systems require denser discretization (observations farther apart make the system appear relatively more stiff).
The inference results are presented in Table S2. The trajectory RMSE is 0.128 for V component and 0.107 for R component, which is roughly times the trajectory RMSE for that of 41 observations as reported in the main text. The factor is expected, as we halved the number of observations. Further visualization in Figure S6 suggests that the inferred trajectory is quite close to the true system, while the interval bands become wider, which is expected as we have less information in this case.
| number of | number of | parameter a | parameter b | parameter c | trajectory RMSE | run time | ||||
| observations | discretizations | Estimate | RMSE | Estimate | RMSE | Estimate | RMSE | V | R | (minutes) |
| 21 | 321 | 0.19 0.03 | 0.029 | 0.44 0.15 | 0.280 | 2.79 0.16 | 0.261 | 0.128 | 0.107 | 5.81 |
Software implementation
User interfaces for MAGI are available for R, MATLAB, and Python at the Github repository https://github.com/wongswk/magi. Detailed instructions are provided therein for using our package with custom ODE systems specified in any of these languages. Detailed instructions are also provided for replicating all of our results and figures provided in the paper.