Incremental Composition of Learned Control Barrier Functions in Unknown Environments
Abstract
We consider the problem of safely exploring a static and unknown environment while learning valid control barrier functions (CBFs) from sensor data. Existing works either assume known environments, target specific dynamics models, or use a-priori valid CBFs, and are thus limited in their safety guarantees for general systems during exploration. We present a method for safely exploring the unknown environment by incrementally composing a global CBF from locally-learned CBFs. The challenge here is that local CBFs may not have well-defined end behavior outside their training domain, i.e. local CBFs may be positive (indicating safety) in regions where no training data is available. We show that well-defined end behavior can be obtained when local CBFs are parameterized by compactly-supported radial basis functions. For learning local CBFs, we collect sensor data, e.g. LiDAR capturing obstacles in the environment, and augment it with simulated data from a safe oracle controller. Our work complements recent efforts to learn CBFs from safe demonstrations—where learned safe sets are limited to their training domains—by demonstrating how to grow the safe set over time as more data becomes available. We evaluate our approach on two simulated systems, where our method successfully explores an unknown environment while maintaining safety throughout the entire execution.
I Introduction
A key characteristic of a truly autonomous agent is the ability to safely explore an unknown environment by iteratively gathering data, in a safe manner, about its surroundings, and then replanning based on its new belief. Consider, as an example, a mobile search and rescue robot placed in an abandoned warehouse. Upon entering its environment, the robot has only an incomplete understanding of the obstacles in this previously unseen warehouse, and hence must explore the environment, using its onboard sensors to gather information about the surrounding obstacles. If this exploration is not done in a safe manner, the robot may accidentally enter situations where it becomes damaged and can no longer complete its mission. For real-world mission-critical deployments, handling this inherent tension between safety and liveliness in a mathematically rigorous way is of paramount importance.
In this work, we attack the safe exploration problem by incrementally composing locally-learned control barrier functions (CBFs). In particular, we extend prior work in offline CBF learning [1, 2, 3, 4] to the online setting by incrementally learning local CBFs that individually ensure that the system acts safely with respect its immediate surroundings. Learning local CBFs has considerable computational advantages, especially for long-running agents, since the complexity of each learning problem scales only with the amount of new data collected, and not with cumulative data. We compose these locally-valid CBFs into a single valid global CBF via a pointwise maximum, using recent progress on non-smooth CBFs [5]. In order to ensure that our CBFs can indeed be meaningfully composed in such a manner, we utilize compactly supported basis functions [6] which ensure negative behavior off the support of the training data. Together, these ingredients allow us to incrementally expand the number of safe states that an autonomous system is able to operate in, as more data becomes available, while provably remaining safe throughout the exploration process by inheriting the rigorous safety guarantees of CBFs.
Our approach improves on existing work in the area of safe exploration with CBFs [7, 8] by leveraging a learning framework to produce dynamics-aware CBFs, rather than CBFs which only encode obstacle information, a limitation that can lead to safety-filter infeasibility or the requirement of unbounded actuation to maintain safety.
Contributions: (1) We learn local CBFs that are globally well-defined by leveraging compactly supported basis functions to obtain negative end-behavior [6]. (2) We provide conditions on the basis function parameters and CBF-synthesis QP to certify that valid local CBFs compose, via pointwise maximum, to a valid, nonsmooth global CBF. (3) We provide simulations that illustrate the correctness and applicability of our method.
Related Work: For a known dynamical system and environment, there is a rich body of literature on safe control synthesis via both Hamilton-Jacobi (HJ) reachability [9] and control barrier functions (CBF) [10], which are closely related [11]. Furthermore, generalizations of both HJ reachability and CBFs that handle complex system types—including multi-agent and hybrid systems—through the framework of composition have been recently explored [5, 12, 13, 14].
In this work, we primarily focus on CBFs, motivated by their practical use in designing safe control laws via convex programming [10]. However, directly applying CBFs to the problem of safe exploration is difficult for a multitude of reasons. First, even when both the system and environment are known beforehand, deriving a valid CBF from first principles is a challenging problem. Recent work has focused instead on using safe expert-demonstration trajectories to learn a CBF directly from data [1, 3, 4]. While learning-based approaches significantly expand the applicability of CBFs, we cannot naïvely apply these techniques to safe exploration since we do not have a full description of the environment, nor a complete set of safe demonstration trajectories that covers the entire safe space.
Recent works have addressed the issue of safe exploration with CBFs for various special cases. The work [15] considers online tuning of parameterized CBFs specialized to single-integrator, multi-agent systems. In [16], the authors show how to ensure simultaneous safety and exploration when learning a general stochastic, discrete-time system, assuming that a ground truth CBF is available a-priori. Furthermore, the works [17, 8, 7, 18, 19, 20] consider the use of sensor data (particularly LiDAR data) to obtain CBFs online. However, these works either consider specialized dynamics models [18, 17], require retraining on the entire demonstration dataset whenever new measurements are gathered [8], or restrict CBFs to e.g. elliptical sub-level sets or signed distance functions [7, 20, 19]. The latter restriction is not guaranteed to satisfy dynamic feasibility—especially under input constraints or underactuation—and hence cannot guarantee safety in general; we illustrate this issue with a Dubins car example in Section IV.
II Background
Consider the control-affine system where and are states and control inputs, respectively. We wish to ensure that the system’s trajectory remains within a compact set for all times . To accomplish this, we use control barrier functions (CBFs) [10], which certify the existence of control inputs guaranteeing forward invariance of the set .
Definition 1 (Control Barrier Function)
Given a compact set , a set of control inputs , and a locally Lipschitz continuous extended class- function 111An extended class- function is strictly increasing and s.t. ., a continuously differentiable function is said to be a control barrier function on an open set if:
| (1a) | ||||
| (1b) | ||||
| (1c) | ||||
| (1d) | ||||
Given a reference control signal , i.e. an open-loop control signal that we would like to match, we can use the CBF as a safety filter to keep the trajectory within the set while closely following .
Lemma 1 (Safety Filter [10])
Given a CBF and a reference control signal , we compute a control signal that renders the set forward invariant by solving the convex quadratic program:
| (2) | ||||
In the remainder, we will refer to the quadratic program in Eq. 2 as the CBF-QP.

II-A Learning CBFs from Data
Constructing valid CBFs is generally challenging and has motivated learning-based approaches. We briefly review our prior work in [1, 2] on learning CBFs from demonstrations, which serves as a basis for this paper. Here, an expert dataset is given where state-action pairs demonstrate safe system behavior. From the dataset , a CBF of the form is learned by solving a quadratic program (QP) where are pre-defined basis functions and are the decision variables. This QP is formed by constructing three distinct datasets using information from . The buffer dataset contains the boundary points of the dataset , obtained via boundary point detection algorithms (see [2] for details), on which we enforce the dynamics constraint (1d). The safe dataset contains the remaining points in , on which we enforce the positivity and dynamics constraints (1a) and (1d), respectively. The unsafe dataset contains points that surround , e.g. obtained by sampling or again applying boundary point detection, on which we enforce the negativity constraint (1b).
Definition 2 (Learning-CBF QP [1])
Given the datasets , , and , the hyperparameters , a locally Lipschitz continuous extended class- function , and a basis function with bounded Lipschitz constant, we learn a candidate CBF by solving the convex quadratic program:
| (3a) | |||||
| (3b) | |||||
| (3c) | |||||
| (3d) | |||||
where denotes the Jacobian of .
We refer to (3) as the Learning-CBF QP, and remark that the candidate CBF obtained by solving the Learning-CBF QP is valid when conditions on the density of the datapoints in , , and and the Lipschitz constants of , , and are satisfied (we refer the reader to [1] for details). Specifically, we will use the Learning-CBF QP to learn local CBFs that are valid on a domain . For the experiments in [1], the basis functions are chosen to be random Fourier features [21]. Unfortunately, the oscillatory end-behavior of Random Fourier features prevents composition of multiple learned CBFs via the -operator (cf. Figure 1), since the locally learned CBFs may oscillate to positive outside of their domain . Obtaining negative end-behavior motivates our use of compactly supported RBFs.
II-B Compactly Supported Radial Basis Functions
Radial basis functions (RBFs) are scalar functions that exhibit radial symmetry about a center , i.e. for a scalar function . For a set of centers , we will combine RBFs linearly as , where . We consider a specific family of RBFs, referred to as compactly supported radial basis functions (CS-RBFs). CS-RBFs are zero outside of a pre-specified radius around , which ensures that can be guaranteed to be negative outside of its region of validity for . When using CS-RBFs to learn control barrier functions, we require continuous differentiability, and so we use Wendland’s functions, which are compactly supported, polynomial basis functions that are minimal in their polynomial degree [6]. Some examples of Wendland’s functions are for , and for .
III Safe Exploration via Incremental Composition of CBFs
In this section, we describe our approach to safe exploration via incrementally composing local CBFs in an unknown environment. Let denote the a-priori unknown geometric safe region, e.g. the obstacle-free space for a robot, along with those states from which obstacles can be avoided via an appropriate control signal. Denote for as the observable coordinates from a subset of the full coordinates for which safety can be determined by a measurement map that takes the state to a subset of the geometric safe region, projected222 onto the coordinates . represents local information obtainable about from state ; for example, spatial measurements collected from onboard sensors, e.g. LiDAR. For a sensor that detects all obstacles in a radius around , , where is a ball of radius centered at and is the complement of .
Our goal is to safely guide the system to collect new measurements in order to compose a CBF that defines a safe set which covers as much of as possible, while respecting for all times. We solve this safe exploration problem by combining local CBFs as follows. At time , we take a measurement and, using the Learning-CBF QP (cf. Definition 2), learn an initial CBF which is valid on some set , and renders a subset forward invariant.333Here, is the set on which the constraints in Definition 2 are satisfied. In addition, we require that agrees with the measurement, i.e. . Let denote the number of measurements taken so far (starting at ). We proceed iteratively as follows:
-
1.
Let denote the CBF that renders forward invariant.
-
2.
Use to approach the boundary of the current invariant set (cf. Remark 1).
-
3.
Take a new measurement , and learn a CBF which is valid on some set , renders a subset forward invariant, and satisfies .
-
4.
Increment .
Remark 1
In order to approach the boundary of the current invariant set , one can choose a point such that , and construct a model predictive controller (MPC) that steers towards . The control signal generated by this MPC can then be filtered by the CBF-QP in Eq. 2 to obtain a signal that safely approaches the boundary of .
Our procedure works by learning CBFs in an incremental manner when new measurements become available. This yields an efficient algorithm where one does not need to recompute CBFs for regions of the state space where no new information about the set is obtained. However, this incremental CBF construction raises two important questions. The first question, which we address in Section III-A, is how one obtains the necessary expert dataset in Step 3) in order to apply the Learning-CBF QP while satisfying . The second question, addressed in Section III-B, is what conditions are needed to ensure that the composition in Step 1) yields a valid global CBF.
III-A Obtaining Expert Demonstrations Online
The Learning-CBF QP described in Section II-A provides us with a powerful framework to learn valid CBFs from demonstrations. In order to apply the framework, we need access to a dataset of expert demonstrations containing safe state-action pairs (cf. Definition 2). However, this may not be the case as we freely explore the state space. For example, suppose our measurement map is implemented via a LiDAR sensor. While this sensor provides us with a point cloud of obstacles, it does not provide us with expert control inputs that safely avoid said obstacles.
We provide two remedies for the lack of safe inputs. Our first solution is based on the dual norm. Suppose that the input set is a norm ball of the form . Then, the CBF derivative constraint and hence the constraint Eq. 3 in the Learning-CBF QP can be rewritten in terms of the dual norm as follows [22]:
Observe that the above expression does not require any input demonstrations . However, there are two limitations to this approach. Firstly, the resulting Learning-CBF QP is nonconvex. Secondly, sensors may not fully characterize the safe states (i.e. ), e.g., consider a car with a LiDAR sensor. The LiDAR provides safe and unsafe positions, but not the safe steering angles and velocities which are needed to avoid system states that inevitably lead to a collision.
To address the limitations of the dual norm, our second approach is based on the notion of a safety oracle. Given a safe set returned by a sensor, we define a safety oracle to be a function that takes this safe set as input and returns safe state-action pairs for which there exists a control signal that keeps the system in the aforementioned safe set for all time.
Definition 3 (Safety Oracle)
Recall that denotes the observed subset of the full coordinates . For some state at which a measurement is obtained, assume that the measurement map returns a local safe subset contained in a local scan region around , i.e. for all and . A safety oracle takes the observed safe set and returns some safe state-action pairs for which there exists a control signal that ensures for all times and for all initial conditions .
Some examples of safety oracles are Hamilton-Jacobi reachability analysis [9], safe MPC [23], and obstacle-aware shooting methods [24]. Our proposed approach allows us to efficiently use local oracle computations in two ways. Firstly, while oracle computations may only provide safe state-action pairs for a finite set of states, the learned locally-valid CBF interpolates between the given datapoints (cf. Definition 2), yielding safety guarantees over the entire local domain. Secondly, oracle computatations may be costly. By synthesizing local safety computations into a composable CBF, we can store and combine them in a principled way, circumventing the need to recalculate the safety of already-certified trajectories. The following example illustrates how our approach leverages a safety oracle.

Dubins car: Consider dynamics , with position and a fixed velocity . The system operates in an unknown environment with access to a LiDAR sensor that returns a dataset of safe positions , and a dataset of unsafe positions . Critically, the LiDAR does not provide safe or unsafe values, nor does it provide control inputs . By joining the unsafe dataset with unsafe positions sampled from beyond the convex hull of , we can perform Hamilton-Jacobi reachability analysis [9] to obtain a value function that, for each , is positive for safe ’s for which there exists a control signal that avoids . For each the safe angles are . For a discretized range of ’s, the result is a dataset of safe states and control inputs, where the gradient of the value function, , is used to obtain safe control inputs according to . Note that synthesizing into a locally-valid CBF effectively allows us to interpolate the gridded solution to the HJB-PDE, and to combine information from multiple PDE solutions by composing their learned CBFs.
III-B Composing Locally-Valid CBFs
In the previous subsection, we generated datasets of safe state-action pairs, which can be used to obtain locally-valid CBFs via the Learning-CBF QP. Consider the task of composing locally-valid CBFs . Clearly, since is only constrained to be valid on some region where its dataset was sampled from, should be negative for . Thus, if each CBF is valid on , and , then is a valid nonsmooth CBF on all .
Let denote a vector of compactly supported radial basis functions that decay to zero in radius . Specifically, each component of is a Wendland’s function of the form for , where and is polynomial in with order less than [6]. Note that .
Assume that is a compact and contains all centers of . We show that as long as all centers whose corresponding weight is positive are at least a distance of away from , which can be guaranteed by sampling unsafe points to increase the size of in Eq. 3c, then on all . It follows that is forward invariant under control inputs generated by . Let denote the smallest Euclidean distance from point to set .
Theorem 1 (Forward Invariance for )
Consider continuously differentiable CBFs parameterized as with weights , centers , and . Let each be locally valid on a corresponding region from . For all , assume that and that if . If for all with there exists such that the following (modified) CBF-QP has a bounded solution
then is a valid non-smooth CBF that guarantees forward invariance of the set .
Proof: If for all s.t. , then (strict ineq.) by the compact support property of . By Theorem 3 of [5], it immediately follows that is a non-smooth CBF that guarantees forward invariance of the set . ∎
The set is called the “almost-active” set in [5]. The CBF-QP in Theorem 1 hence imposes a derivative constraint for each with to obtain forward invariant control inputs.

IV Case Studies
To illustrate the validity of our approach, we incrementally learn global CBFs for two systems: a planar, feedback-linearizable system and a fixed-velocity Dubins car. For both case studies, we choose and obtain CS-RBFs . For simplicity, we pick the centers to fall on a grid on their domains; more sophisticated arrangements of centers could be chosen, e.g. along safe trajectories provided by the oracle. The code for our case studies can be found at https://github.com/paullutkus/learning-cbfs-online.
IV-A Dubins Car
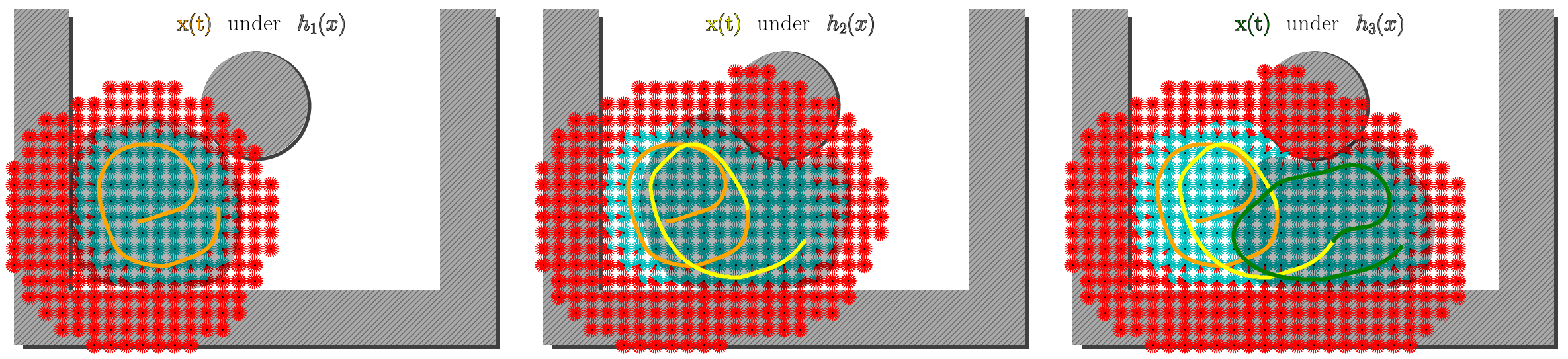
The dynamics of the Dubins car are with fixed velocity and initial condition . We also consider the input constraints . The environment consists of a central circular obstacle and four walls (Fig. 2).
For our idealized LiDAR sensor, we define a circular scan radius of (depicted in red in Fig. 4) around the position of the system. Because all states outside of the scan radius could potentially be obstacles, the incrementally learned CBF must keep the system within the scan radius while avoiding detected obstacles. Our local CBFs and thus also the incremental CBF accomplish this requirement, while satisfying input constraints, see Figs. 2, LABEL:, and 3.
In contrast, candidate CBFs constructed from sensor scans without incorporating dynamics may not be valid and fail to satisfy safety constraints. To illustrate this point, we consider signed distance functions (SDFs), which have been used as candidate CBFs in the past, see e.g. [7]. Fig. 4 shows that an SDF cannot provide safety for this system, even with unbounded actuation (, because the gradient of an SDF to obstacles is always orthogonal to the vector field of the Dubins car (since ). Though high-order CBFs can be used to resolve this incompatibility, we are able to control the system with a simpler, first-order CBF.

IV-B Planar System
The dynamics of the planar system are:
with and initial condition . We consider the input constraints . The environment consists of two vertically-aligned circular obstacles and four walls (Fig. 5). The scan radius of the LiDAR sensor is .
Here, we compare our incremental CBF with a CBF that is trained in a single-shot on all the data that was used to incrementally train . We find that not only do we match the performance of such a single-shot CBF, but our incremental CBF also performs better in this case (Fig. 5). Specifically, the zero-level set is closer to the obstacle, and larger gradients allow the system to approach a target more quickly. This is not surprising, as the maximum of continuously-differentiable CBFs is a more expressive function class than a single continuously differentiable CBF. Furthermore, incrementally learning a CBF is almost three times faster (s total for four local CBFs vs. s).
V Conclusion
We presented an online approach for incremental composition of a non-smooth CBF via locally learned CBFs. As a result, our approach allows for the safe exploration of unknown and static environments. We rely on a class of compactly-supported radial basis functions, called Wendland’s functions, whose end behavior guarantee the valid composition of local CBFs. We validated our approach on a feedback-linearizable planar system and a fixed-velocity Dubins car, and compared our approach to existing works.
Though we observe good performance from using Wendland’s functions, we find that their Lipschitz constants can sometimes be too large to certify validity of local CBFs following the conditions in [1], which are sufficient but not necessary. This suggests that we may benefit from a richer class of basis functions, perhaps compactly-supported neural networks [25], or less-conservative conditions for validity. Another avenue of future work is to generalize our approach to handle non-static and stochastic environments.
References
- [1] A. Robey, H. Hu, L. Lindemann, H. Zhang, D. V. Dimarogonas, S. Tu, and N. Matni, “Learning control barrier functions from expert demonstrations,” 2020.
- [2] L. Lindemann, A. Robey, L. Jiang, S. Das, S. Tu, and N. Matni, “Learning robust output control barrier functions from safe expert demonstrations,” IEEE Open Journal of Control Systems, 2024.
- [3] H. Zhao, X. Zeng, T. Chen, Z. Liu, and J. Woodcock, “Learning safe neural network controllers with barrier certificates,” Formal Aspects of Computing, vol. 33, pp. 437–455, 2021.
- [4] D. Sun, S. Jha, and C. Fan, “Learning certified control using contraction metric,” in Conference on Robot Learning. PMLR, 2021, pp. 1519–1539.
- [5] P. Glotfelter, J. Cortés, and M. Egerstedt, “Boolean composability of constraints and control synthesis for multi-robot systems via nonsmooth control barrier functions,” in 2018 IEEE Conference on Control Technology and Applications (CCTA). IEEE, 2018, pp. 897–902.
- [6] H. Wendland, “Piecewise polynomial, positive definite and compactly supported radial functions of minimal degree,” Advances in computational Mathematics, vol. 4, pp. 389–396, 1995.
- [7] K. Long, C. Qian, J. Cortés, and N. Atanasov, “Learning barrier functions with memory for robust safe navigation,” IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4931–4938, 2021.
- [8] M. Srinivasan, A. Dabholkar, S. Coogan, and P. A. Vela, “Synthesis of control barrier functions using a supervised machine learning approach,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 7139–7145.
- [9] S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” in 2017 IEEE 56th Annual Conference on Decision and Control (CDC). IEEE, 2017, pp. 2242–2253.
- [10] A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” 2019.
- [11] J. J. Choi, D. Lee, K. Sreenath, C. J. Tomlin, and S. L. Herbert, “Robust control barrier–value functions for safety-critical control,” in 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021, pp. 6814–6821.
- [12] L. Lindemann and D. V. Dimarogonas, “Control barrier functions for signal temporal logic tasks,” IEEE control systems letters, vol. 3, no. 1, pp. 96–101, 2018.
- [13] M. Black and D. Panagou, “Consolidated control barrier functions: Synthesis and online verification via adaptation under input constraints,” arXiv preprint arXiv:2304.01815, 2023.
- [14] S. Yang, M. Black, G. Fainekos, B. Hoxha, H. Okamoto, and R. Mangharam, “Safe control synthesis for hybrid systems through local control barrier functions,” arXiv preprint arXiv:2311.17201, 2023.
- [15] Z. Gao, G. Yang, and A. Prorok, “Online control barrier functions for decentralized multi-agent navigation,” in 2023 International Symposium on Multi-Robot and Multi-Agent Systems (MRS). IEEE, 2023, pp. 107–113.
- [16] W. Luo, W. Sun, and A. Kapoor, “Sample-efficient safe learning for online nonlinear control with control barrier functions,” in International Workshop on the Algorithmic Foundations of Robotics. Springer, 2022, pp. 419–435.
- [17] C. Li, Z. Zhang, A. Nesrin, Q. Liu, F. Liu, and M. Buss, “Instantaneous local control barrier function: An online learning approach for collision avoidance,” arXiv preprint arXiv:2106.05341, 2021.
- [18] A. S. Lafmejani, S. Berman, and G. Fainekos, “Nmpc-lbf: Nonlinear mpc with learned barrier function for decentralized safe navigation of multiple robots in unknown environments,” in 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 10 297–10 303.
- [19] Y. Zhang, G. Tian, L. Wen, X. Yao, L. Zhang, Z. Bing, W. He, and A. Knoll, “Online efficient safety-critical control for mobile robots in unknown dynamic multi-obstacle environments,” arXiv preprint arXiv:2402.16449, 2024.
- [20] A. Safari and J. B. Hoagg, “Time-varying soft-maximum control barrier functions for safety in an a priori unknown environment,” arXiv preprint arXiv:2310.05261, 2023.
- [21] A. Rahimi and B. Recht, “Random features for large-scale kernel machines,” Advances in neural information processing systems, vol. 20, 2007.
- [22] L. Lindemann, H. Hu, A. Robey, H. Zhang, D. Dimarogonas, S. Tu, and N. Matni, “Learning hybrid control barrier functions from data,” in Conference on Robot Learning. PMLR, 2021, pp. 1351–1370.
- [23] J. V. Frasch, A. Gray, M. Zanon, H. J. Ferreau, S. Sager, F. Borrelli, and M. Diehl, “An auto-generated nonlinear mpc algorithm for real-time obstacle avoidance of ground vehicles,” in 2013 European Control Conference (ECC). IEEE, 2013, pp. 4136–4141.
- [24] P. T. An and N. T. Le, “Multiple shooting approach for finding approximately shortest paths for autonomous robots in unknown environments in 2d,” Journal of Combinatorial Optimization, vol. 47, no. 5, pp. 1–32, 2024.
- [25] A. Barbu and H. Mou, “The compact support neural network,” Sensors, vol. 21, no. 24, p. 8494, 2021.