2022
These authors contributed equally to this work.
These authors contributed equally to this work.
[1]\fnmJun \surZhu
[2,3]\fnmYi \surZhong
1]Dept. of Comp. Sci. & Tech., Institute for AI, BNRist Center, Tsinghua-Bosch Joint ML Center, THBI Lab, Tsinghua University, Beijing, China
2]School of Life Sciences, IDG/McGovern Institute for Brain Research, Tsinghua University, Beijing, China
3]Tsinghua-Peking Center for Life Sciences, Beijing, China
4]Centre for Artificial Intelligence, UCL, London, UK
Incorporating neuro-inspired adaptability for continual learning in artificial intelligence
Abstract
Continual learning aims to empower artificial intelligence (AI) with strong adaptability to the real world. For this purpose, a desirable solution should properly balance memory stability with learning plasticity, and acquire sufficient compatibility to capture the observed distributions. Existing advances mainly focus on preserving memory stability to overcome catastrophic forgetting, but remain difficult to flexibly accommodate incremental changes as biological intelligence (BI) does. By modeling a robust Drosophila learning system that actively regulates forgetting with multiple learning modules, here we propose a generic approach that appropriately attenuates old memories in parameter distributions to improve learning plasticity, and accordingly coordinates a multi-learner architecture to ensure solution compatibility. Through extensive theoretical and empirical validation, our approach not only clearly enhances the performance of continual learning, especially over synaptic regularization methods in task-incremental settings, but also potentially advances the understanding of neurological adaptive mechanisms, serving as a novel paradigm to progress AI and BI together.
keywords:
Continual Learning, Lifelong Learning, Catastrophic Forgetting, Brain-Inspired AI1 Introduction
Continual learning, also known as lifelong learning, provides the foundation for artificial intelligence (AI) systems to accommodate real-world changes. Since the external environment tends to be highly dynamic and unpredictable, an intelligent agent needs to learn and remember throughout its lifetime chen2018lifelong ; parisi2019continual ; kudithipudi2022biological . Numerous efforts have been devoted to preserving memory stability to mitigate catastrophic forgetting in artificial neural networks, where parameter changes for learning each new task well typically result in a dramatic performance drop of the old tasks mccloskey1989catastrophic ; mcclelland1995there ; wang2023comprehensive . Representative strategies include selectively stabilizing parameters kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; chaudhry2018riemannian ; ritter2018online , recovering old data distributions rebuffi2017icarl ; shin2017continual ; wang2021memory and allocating dedicated parameter subspaces serra2018overcoming ; fernando2017pathnet , etc. However, they usually achieve only modest improvements in specific scenarios, with effectiveness varying widely across experimental settings (e.g., task type and similarity, input size, number of training samples, etc.) parisi2019continual ; delange2021continual ; kudithipudi2022biological . As a result, there is still a huge gap between existing advances and realistic applications.
To overcome this limitation, we theoretically analyze the key factors on which continual learning performance depends, suggesting a broader objective beyond the current focus. Specifically, in order to perform well on all tasks ever seen, a desirable solution should properly balance memory stability of old tasks with learning plasticity of new tasks, while being adequately compatible to capture their distributions (see Methods for details). For example, if you want to accommodate a sequence of cakes (i.e., incremental tasks) into a bag (i.e., a solution), you should optimize the efficiency of space allocation for each cake as well as the total space of the bag, rather than simply freezing the old cakes.
Since biological learning systems are natural continual learners that exhibit strong adaptability to real-world changes kudithipudi2022biological ; hadsell2020embracing ; parisi2019continual , we argue that they have been equipped with effective strategies to address the above challenges. In particular, the subset of the Drosophila mushroom body (MB) is a biological learning system that is essential for coping with different tasks in succession and enjoys relatively clear and in-depth understanding at both functional and anatomical levels shuai2010forgetting ; cohn2015coordinated ; waddell2016neural ; modi2020drosophila ; aso2014mushroom ; aso2016dopaminergic ; gao2019genetic ; zhao2023genetic (Fig. 1a), which emerges as an excellent source for inspiring continual learning in AI.
As a key functional advantage, the MB system can regulate memories in distinct ways to optimize memory-guided behaviors in changing environments richards2017persistence ; shuai2010forgetting ; dong2016inability ; zhang2018active ; davis2017biology ; gao2019genetic ; mo2022age . First, old memories are actively protected from new disruption by strengthening the previously-learned synaptic changes zhang2018active ; mo2022age . This idea of selectively stabilizing parameters has been widely used to alleviate catastrophic forgetting in continual learning kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; chaudhry2018riemannian . Besides, old memories can be actively forgotten for better adapting to a new memory shuai2010forgetting ; dong2016inability ; gao2019genetic ; cervantes2016scribble . There are specialized molecular signals to regulate the speed of memory decay davis2017biology ; noyes2021memory , whose activation reduces the persistence of outdated information, while inhibition exhibits the opposite effect shuai2010forgetting ; dong2016inability ; gao2019genetic ; cervantes2016scribble . However, the benefits of active forgetting for continual learning remain to be explored kudithipudi2022biological . Here, we propose a functional strategy that incorporates active forgetting together with stability protection for a better trade-off between new and old tasks, where the active forgetting part is formulated as appropriately attenuating old memories in parameter distributions and optimized by a synaptic expansion-renormalization process. Without compromising old tasks, our proposal can greatly enhance the performance of new tasks by eliminating the past conflicting information.
We further explore the organizing principles of the MB system that support its function, which employs five compartments (1-5) with dynamic modulations to perform continual learning in parallel cohn2015coordinated ; waddell2016neural ; modi2020drosophila ; aso2014mushroom ; aso2016dopaminergic . As shown in Fig. 1a, the sensory information is incrementally input from Kenyon cells (KCs), while the valence is conveyed by dopaminergic neurons (DANs) waddell2016neural ; cognigni2018right ; amin2019neuronal . The outputs of these compartments are carried by distinct MB output neurons (MBONs) and integrated in a weighted-sum fashion to guide adaptive behaviors cognigni2018right ; amin2019neuronal ; modi2020drosophila . In particular, the DANs allow for distinct learning rules and forgetting rates in each compartment, where the latter has been shown important for processing sequential conflicting experiences aso2016dopaminergic ; handler2019distinct ; mccurdy2021dopaminergic ; berry2012dopamine ; berry2018dopamine . Inspired by this, we design a specialized architecture of multiple parallel learning modules, which can ensure solution compatibility for incremental changes by coordinating the diversity of learners’ expertise. Interestingly, adaptive implementations of the proposed functional strategy can naturally serve this purpose through adjusting the target distribution of each learner, suggesting that the neurological adaptive mechanisms are highly synergistic rather than operating in isolation.
Through satisfying the identified criteria, our approach exhibits superior generality across various continual learning benchmarks and achieves significant performance gains. We further cross-validate the computational model with biological findings, so as to better understand the underpinnings of real-world adaptability for both AI and BI.
2 Result
2.1 Active Forgetting with Stability Protection
A central challenge of continual learning is to resolve the mutual interference between new and old tasks due to their distribution differences. The functional advantages of the MB system suggest that stability protection and active forgetting are both important richards2017persistence ; shuai2010forgetting ; dong2016inability ; zhang2018active ; davis2017biology ; gao2019genetic ; mo2022age (Fig. 1b), although current efforts mainly focus on the former to prevent catastrophic forgetting mccloskey1989catastrophic ; mcclelland1995there . Here we formulate this process with the framework of Bayesian learning, which has been hypothesized to well model biological synaptic plasticity by tracking the probability distribution of synaptic weights under dynamic sensory inputs aitchison2021synaptic ; schug2021presynaptic . We briefly describe a simple case of two tasks (Fig. 2a) and leave the full details to Methods.
Let’s consider a neural network with parameters continually learning tasks and from their training data and in order to perform well on their test data, which is called a “continual learner”. From a Bayesian perspective, the learner first places a prior distribution on . After learning task , the learner updates the belief of the parameters, resulting in a posterior distribution that incorporates the knowledge of task . Then, task can be performed successfully by finding a mode of the posterior: . For learning task , becomes the prior and the posterior will further incorporate the knowledge of task . Similarly, the learner needs to find , corresponding to maximizing both for learning task and for remembering task .
However, due to the differences in data distribution, remembering old tasks precisely can increase the difficulty of learning each new task well. Inspired by the biological active forgetting, we introduce a forgetting rate and replace with
| (1) |
where is a non-informative prior without incorporating old knowledge wang2021afec . is a -dependent normalizer that keeps a normalized probability distribution (Supplementary Section 1.1). tends to forget task when , while be dominated by with full old knowledge when . For the new target , we derive the loss function
| (2) |
is the loss function of learning task . and are hyperparameters that control the strengths of two regularizers responsible for stability protection and active forgetting, respectively. The stability protection part is to selectively penalize the deviance of each parameter from depending on its “importance” for old task(s), estimated by the Fisher information .
The optimization of active forgetting can be achieved in two equivalent ways, i.e., AF-1 and AF-2 (Fig. 2b). They both encourage the network parameters to renormalize with an “expanded” set of parameters when learning task . For AF-1, is “empty” with equal selectivity for renormalization, where the active forgetting term becomes the norm of . The hyperparameters and , indicating that the old memories are directly affected. For AF-2, is the optimal solution for task only, obtained from optimizing , and is the Fisher information. The forgetting rate is fully integrated into and is independent of . In the absence of active forgetting (), the loss function in Eq. (2) is left with only and the stability protection term, which is (approximately benzing2022unifying ) equivalent to regular synaptic regularization methods such as EWC kirkpatrick2017overcoming . In particular, since the loss functions of these methods kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; chaudhry2018riemannian typically have a similar form and differ only in the metric for estimating the parameter importance benzing2022unifying (Methods Eq. (11)), our proposal can be naturally combined with them by plugging in the active forgetting term.
For biological neural networks, active forgetting is able to remove outdated information and provide flexibility for adapting to a new memory shuai2010forgetting ; dong2016inability ; richards2017persistence . This strategy is essential for Drosophila to cope with the interference of previous tasks shuai2010forgetting ; dong2016inability ; bouton1993context ; zhang2018active . Here we theoretically analyze how this benefit is achieved in our computational model. First, an appropriate forgetting rate is able to improve the probability of learning new tasks well through attenuating old memories in (Methods Eq. (5)), which can be empirically determined by a grid search of and/or . Second, when moves to the neighborhood of an empirical optimal solution, the active forgetting term in Eq. (2) can minimize the upper bound of generalization errors for continual learning, especially for new tasks (Methods Proposition 2).
Now we evaluate the efficacy of active forgetting on three continual learning benchmarks for visual classification tasks. They are all constructed from the CIFAR-100 dataset krizhevsky2009learning of 100-class colored images but with different degrees of overall knowledge transfer wang2021afec . As shown in Fig. 2c, the proposed active forgetting can largely enhance the average accuracy of all tasks, using EWC kirkpatrick2017overcoming as a baseline for preserving memory stability. Then we analyze the benefits of active forgetting on learning plasticity and memory stability with the metrics of forward transfer and backward transfer, respectively, where the former is clearly dominant. Similar results are observed when plugging the active forgetting term in other synaptic regularization methods that only preserve memory stability (Supplementary Fig. 1). In contrast, active forgetting fails to improve the joint training performance (Supplementary Fig. 4a), suggesting that its benefits are specific to continual learning. From visual interpretation of the latest task predictions in Fig. 2d, active forgetting can indeed eliminate the past conflicting information, leading to better recognition of the object itself.
2.2 Coordination of Multiple Continual Learners
After demonstrating the benefits of active forgetting together with stability protection for a single continual learner (SCL), we turn to investigate the organizing principles of the MB system where new memory forms and active forgetting happens shuai2010forgetting ; cohn2015coordinated ; waddell2016neural ; modi2020drosophila ; gao2019genetic ; berry2012dopamine ; berry2018dopamine ; handler2019distinct ; shuai2015dissecting . Specifically, there are five compartments that process sequential experiences in parallel. The outputs of these compartments are integrated in a weighted sum fashion to guide adaptive behaviors. Inspired by this, we design a MB-like architecture consisting of multiple parallel continual learners (Fig. 3a). Each learner employs a parameter space to learn all tasks, but its dedicated output head is removed and the weighted sum of the previous layer’s output is fed into a shared output head, where the output weights of each learner are incrementally updated.
In such a MB-like architecture, the relationship between learners is critical to the performance of continual learning. When the diversity of their expertise is properly coordinated, the obtained solution can provide a high degree of compatibility with both new and old tasks. Here we present a conceptual illustration via performing tasks , and with different similarities (Fig. 3c). Since it is difficult to find a shared optimal solution for all tasks, the SCL has to converge to a high error region for tasks and . In contrast, the multiple continual learners (MCL) with appropriate diversity allow for division of labor to address task discrepancy and complement their functions as parameter changes. Then, the output weights can integrate respective expertise of each learner into the final prediction.
In general, each learner’s expertise is directly modulated by its target distribution, where the proposed functional strategy can naturally serve this purpose. With the formulation of active forgetting, the target distribution tends to be different for learners with different forgetting rates , and vice versa (Fig. 3b). Therefore, we implement the forgetting rates adaptively for these learners to coordinate their relationship. Since the target distribution also depends on , we further propose a supplementary modulation that constrains explicitly the differences in predictions between learners, corresponding to adjusting the learning rules for each new task. We refer to the MB-like architecture with these two modulations as Collaborative continual learners with Active Forgetting (CAF), and provide a formal definition in Methods Eq. (12).
For multiple learners with identical network architectures and similar forms of learning objectives, the priority is to obtain adequate differentiation of their expertise. In this case, the forgetting rates serve to diversify these learners, similar to the neurological strategy of decaying old memories differentially in each compartment aso2016dopaminergic ; handler2019distinct ; mccurdy2021dopaminergic ; berry2012dopamine ; berry2018dopamine . In practice, the differences of learners can also arise from their innate randomness, such as the use of dropout and different random initializations, leading to sub-optimal solutions with moderate performance. This potentially corresponds to the anatomical randomness of KCs receiving olfactory signals in Drosophila chen2023ai ; caron2013random ; endo2020synthesis . At this point, the modulations of forgetting rates and learning rules can provide finer adjustments, e.g., by constraining excessive differences.
Given the same network width for each learner, using more learners (i.e., more parameters) generally results in better performance. However, there is an intuitive trade-off between learner number and width under a limited parameter budget. We verify that this trade-off is independent of training data distributions (Supplementary Section 1.3) and is relatively insensitive over a wide range (Supplementary Table 5). Therefore, we simply choose five learners () corresponding to the five biological compartments, which employs approximately 5 parameters, and then reduce the network width accordingly to keep the total amount of parameters similar to that of the SCL. To evaluate the effect of innate diversity, we construct a low-diversity background by removing the dropout and using the same random initialization for each learner, and a high-diversity background by maintaining these randomness factors, where the overall diversity of expertise is evaluated by the average cosine or Euclidean distance between learners’ predictions.
As shown in Fig. 3e,f, adaptive implementations of either active forgetting (AF-1) or its supplementary modulation (AF-S) can greatly enhance the performance of MCL, where the degree of improvement varies with the effectiveness of increasing inadequate diversity or reducing excessive diversity in the two backgrounds, respectively. In response to different degrees of innate diversity, the respective advantages of AF-1 and AF-S are combined to achieve consistently better performance. Such modulations enable the multiple learners to effectively divide and cooperate in continual learning (Fig. 3d, Supplementary Fig. 4b,c, Supplementary Fig. 5). They exhibit a clear diversity of task expertise with several experts collaborating on each task, validating the conceptual model in Fig. 3c. Accordingly, the performance of CAF is largely superior to that of the SCL, averaging the predictions of five independently-trained continual learners, or using a separate learner for each task (Supplementary Fig. 6a,b). In particular, CAF can improve the SCL by a similar magnitude under different parameter budgets, indicating its outstanding scalability (Supplementary Fig. 7a, Supplementary Fig. 6c).
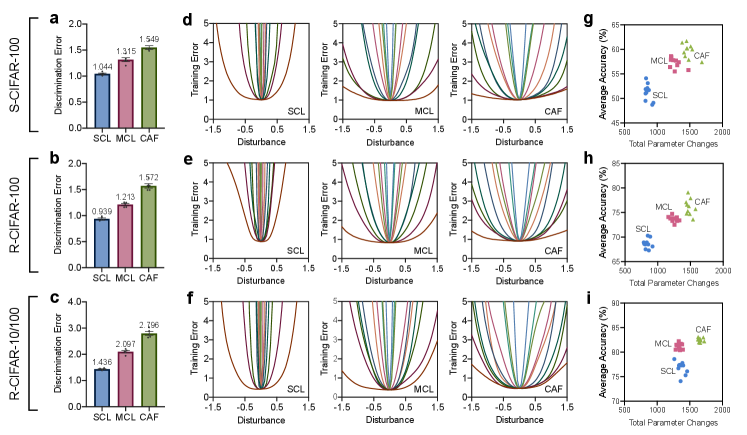
According to our theoretical analysis in Methods Proposition 1, the performance of a shared solution for new and old tasks depends on the discrepancy of task distributions and the flatness of loss landscape around it. With respect to these two aspects, we delve more deeply into the benefits of our approach. As for the former, we evaluate the discrepancy of task distributions in feature space via the difficulty of distinguishing them after continual learning long2015learning ; wang2022coscl (Fig. 4a-c). The large increase in discrimination error suggests that our approach can successfully reconcile this discrepancy. As for the latter, the solution obtained by ours enjoys a clearly flatter loss landscape (Fig. 4d-f), indicating that it is more robust to modest parameter changes in response to dynamic data distributions. Therefore, CAF can update parameters more flexibly than the SCL (Fig. 4g-i), with the performance of new and old tasks simultaneously improved (Supplementary Fig. 7b,c).
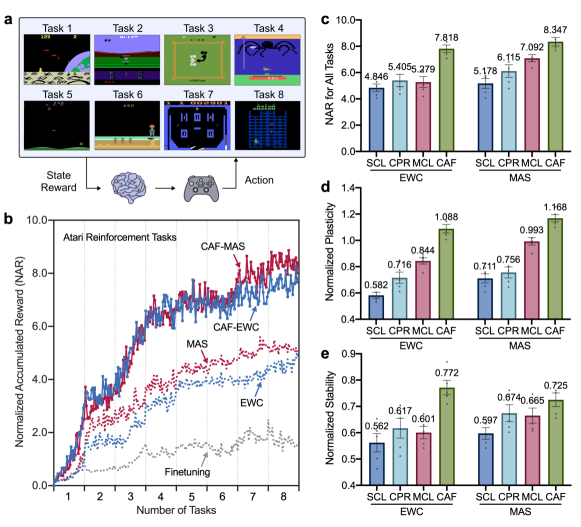
Finally, we evaluate CAF under the setting of task-incremental learning van2022three and compare it to a range of representative methods kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; riemer2018learning ; schwarz2018progress ; jung2020continual ; cha2020cpr . We first consider visual classification tasks with different particular challenges. Besides the overall knowledge transfer, we employ additionally four benchmark datasets such as Omniglot lake2015human for long task sequence with imbalanced class numbers, CUB-200-2011 wah2011caltech and Tiny-ImageNet delange2021continual for larger scale images, and CORe50 lomonaco2017core50 for smoothly-changed observations. As shown in Fig. 5, the performance of all baselines varies widely across experimental settings, while CAF achieves consistently the strongest performance in a plug-and-play manner. We further experiment with Atari reinforcement tasks, where an agent incrementally learns to play several Atari games (Fig. 6a). The overall performance is evaluated by the normalized accumulated reward (NAR) jung2020continual ; wang2021afec ; cha2020cpr , where the rewards obtained for all tasks ever seen are normalized with the maximum reward of fine-tuning on each task, and then accumulated. Likewise, CAF can greatly enhance the performance of baseline approaches (Fig. 6b,c) through improving both learning plasticity and memory stability (Fig. 6d,e).
3 Discussion
Whether for animals, robots or other intelligent agents, the ability of continual learning is critical for successfully adapting to the real world. In this work, we draw inspirations from the adaptive mechanisms equipped in a robust biological learning system, and present a generic approach for continual learning in artificial neural networks. Our preliminary versions of some individual components have been presented at top conferences in artificial intelligence wang2021afec ; wang2022coscl , while the current version enjoys substantial extensions in terms of technical robustness, synergistic cooperation and biological plausibility (Supplementary Section 3). The superior performance and generality of our approach can facilitate realistic applications, such as smartphone, robotics and autonomous driving, to flexibly accommodate user needs and environmental changes. Meanwhile, the deployment of continual learning avoids retraining all previous data each time the model is updated, which provides an energy-efficient and eco-friendly path for developing AI systems.
To bridge the gap between AI and BI, we carefully avoid involving specific implementations or overly strong assumptions in both theoretical analysis and computational modeling. This consideration not only allows for an adequate exploitation of biological advantages, but also facilitates the emergence of interdisciplinary insights. Computationally, our approach is proven to satisfy the key factors on which continual learning performance depends, such as stability, plasticity and compatibility, with active forgetting playing an important role. This potentially extends the previous focus of preventing catastrophic forgetting in continual learning. Starting with this idea, below we discuss more broadly the connections between AI and BI in adaptability.
In a biological sense, active forgetting allows flexibility to accommodate external changes by removing outdated information richards2017persistence ; ryan2022forgetting ; davis2017biology . This perspective is well supported by extensive theoretical and empirical evidence in our computational model. Recent work in neurobiology is deeply dissecting its underlying mechanisms from molecular to synaptic structural levels, where activation of the molecular signaling that mediates active forgetting initially leads to rapid growth of synaptic structures, but prolonged activation instead leads to their shrinkage shuai2010forgetting ; davis2017biology ; ryan2022forgetting ; luo1996differential ; tashiro2000regulation ; hayashi2010disrupted ; hayashi2015labelling ; wang2021afec . In our computational model, active forgetting of old memories in parameter distributions can derive two equivalent synaptic expansion-renormalization processes. These two processes and their linear combinations cover a wide range of possible forms, including whether old memories are directly affected and whether expanded parameters encode new memories, which can serve as testable hypotheses for further research. As for the five compartments of the MB system, the modulated forgetting rates have been shown to be important for coping with conflicting memories in succession aso2016dopaminergic ; handler2019distinct ; mccurdy2021dopaminergic ; berry2012dopamine ; berry2018dopamine . Correspondingly, adaptive implementations of active forgetting help the MB-like architecture to better accommodate incremental changes. Besides, we identify the necessity of regularizing learners’ predictions of new tasks, suggesting that the adaptation of learning rules may also contribute to continual learning in a more general context.
AI and BI share the common goal of adaptation and survival in the real world. These two fields have great potential to inspire each other and progress together. This requires generalized theories and methodologies to integrate their advances, as suggested by our work in continual learning. Subsequent work could further explore the “natural algorithms” responsible for other advantages of the biological brain, thereby evolving progressively the current AI systems.
4 Methods
4.1 Synaptic Expansion-Renormalization
For the case of two tasks, the learner needs to find a mode of the posterior distribution that incorporates the knowledge of tasks and :
| (3) | ||||
where is the loss for task . Although is generally intractable, we can locally approximate it with a second-order Taylor expansion around , resulting in a Gaussian distribution whose mean is and precision matrix is the Hessian of the negative log posterior kirkpatrick2017overcoming ; ritter2018online ; martens2015optimizing . To simplify the computation, the Hessian is approximated by the diagonal of the Fisher information matrix:
| (4) |
To improve learning plasticity, we introduce a forgetting rate , and replace in Eq. (3) with as Eq. (1), where is deterministic and is a -dependent normalizer. Correspondingly, the target distribution becomes . has a nice property that it follows a Gaussian distribution if and are both Gaussian (Supplementary Section 1.1), so we can compute in a similar way as we compute . A certain value of can maximize the probability of learning each new task well through forgetting the old knowledge, validating the motivation of introducing the non-informative prior in Eq. (1):
| (5) |
With the implementation of active forgetting, the learner needs to find
| (6) | ||||
which can be optimized in two equivalent ways, i.e., AF-1 and AF-2. Correspondingly, we derive the loss function in Eq. (2).
For continual learning of more than two tasks, e.g., tasks for any , the learner needs to find
| (7) |
where denotes the training data of previous task(s) and denotes the previously-used forgetting rate(s). Similarly, we replace the posterior that absorbs all information of with
| (8) |
where is a -dependent normalizer that keeps a normalized probability distribution. To simplify the hyperparameter tuning, we adopt an identical forgetting rate in continual learning, i.e., for . Then we obtain the loss function:
| (9) |
is the obtained solution for previous tasks, i.e., the old network parameters. For AF-1, , , and . For AF-2, , , and . is recursively updated by
| (10) |
When , the loss function in Eq. (9) degenerates to a similar form as regular synaptic regularization methods that only preserve memory stability kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; chaudhry2018riemannian :
| (11) |
Since these methods differ mainly in the metric of estimating the importance of parameters for performing old tasks benzing2022unifying , the active forgetting term can be naturally combined with them. We discuss in more depth the motivation and implementation of active forgetting in Supplementary Section 1.2, including the choice of an appropriate , the connections of two equivalent versions, and the technical details of derivation.
4.2 Multiple Parallel Continual Learners
The MB-like architecture of multiple continual learners (MCL) adopts identically structured neural networks , corresponding to continual learners with their own parameter spaces. We remove the dedicated output head of each learner, and feed the weighted sum of the previous layer’s output into a shared output head to make predictions, where the output weight of each learner is updated incrementally. Then, the final prediction becomes , where the optimizable MCL parameters include , and . The proposed MCL is applicable to a wide range of loss functions for continual learning. By default, here we focus on the synaptic regularization methods kirkpatrick2017overcoming ; aljundi2018memory ; zenke2017continual ; chaudhry2018riemannian as defined in Eq. (11). In order to coordinate the diversity of learners’ expertise, we implement the proposed active forgetting in each learner. We further regularize differences in their predictive distributions, quantified by the widely-used Kullback Leibler (KL) divergence. Therefore, the loss function for the full version of our approach is defined as:
| (12) |
where denotes the amount of parameters for learner . The current task has training samples, and is the prediction of learner for . We mainly consider AF-1 instead of AF-2 for computational efficiency, while keeping identical to each learner for ease of implementation. We then discuss the implementation of and . If we consider CAF as an overall continual learning model, active forgetting can be implemented similarly to Eq. (1) and Eq. (2), setting a uniform forgetting rate as well as a uniform learning rule to each learner. This implementation is indeed effective under strong innate randomness to reduce excessive diversity . In a more general context, the proposed MCL provides a spatial degree of freedom to modulate the diversity of learner’s expertise. This idea can be implemented by constraining the average of to be a deterministic hyperparameter , i.e., where and , but allowing their relative strength as well as to be optimized with gradients of the same loss function. Specifically, we perform softmax of a few optimizable parameters to ensure the constraint and obtain for each learning module. can be implemented in a similar way by constraining their average , so as to enjoy the spatial degree of freedom.
4.3 Theoretical Analysis of Generalization Ability
Continual learning aims to find a solution that can generalize well over a new distribution and a set of old distributions . Let and denote the generalization errors. The training set and test set of each task follow the same distribution (), where the training set includes data-label pairs. Then we define and , where can be generalized for any bounded loss function of task . To minimize and without the use of old training samples , a continual learning model can only minimize an empirical risk over the current training samples in a parameter space applicable to old tasks wang2022coscl ; knoblauch2020optimal , denoted as where . In practice, sequential learning of each task by can find multiple solutions with different generalizability for and , where a solution with flatter loss landscape typically acquires better generalizability and is therefore more robust to catastrophic forgetting deng2021flattening ; cha2020cpr ; mirzadeh2020understanding .
Accordingly, we define a robust empirical risk for the current task as by the worst case of parameter perturbations , where denotes the norm and is the radius of perturbations around . Likewise, a robust empirical risk for the old tasks is . Then, can find a flat minima over the current task. However, parameter changes that are much larger than the “radius” of the old minima can interfere with the performance of old tasks, while staying around the old minima can interfere with the performance of new tasks. Therefore, it is necessary to find a solution that can properly balance memory stability with learning plasticity, while being adequately compatible with the observed distributions. Formally, we analyze the generalization errors of a certain solution for continual learning with PAC-Bayes theory mcallester1999pac , so as to provide the objective for computational modeling of neurological adaptive mechanisms. We leave technical details to Supplementary Section 1.3 and present the main results below:
Proposition 1.
Let be a set of parameter spaces ( in general), be a VC dimension of , with VC dimension , and as a given parameter budget. Let denote the optimal solution of the continually learned tasks by robust empirical risk minimization over the current task, i.e., . Then for any , with probability at least :
| (13) | ||||
where and represent the cover of parameter space. is the -divergence of and , where is the characteristic function. is the total number of training samples over all old tasks, where is the number of training samples over task .
From Proposition 1, the generalization gaps over new and old tasks, corresponding to learning plasticity and memory stability, are uniformly constrained by the loss flatness and task discrepancy, which further depend on the cover of parameter space, i.e., and . In particular, we have and for . When , and due to for . This means that employing multiple continual learners (i.e., ) compared to a single continual learner (i.e., ) can tighten the generalization bounds and thus benefit the performance of continual learning. Likewise, the benefits of active forgetting can be explained from a similar perspective:
Proposition 2.
Let be a set of parameter spaces ( in general), be a VC dimension of , with VC dimension , and as a given parameter budget. Based on Proposition 1, for , the upper bound of generalization gap is further externalized with and , where and are two strictly increasing functions under some technical conditions on and , respectively.
Proposition 2 externalizes the two generalization bounds in Proposition 1 by defining the VC dimension with norm for parameters under some technical assumptions. Notably, the claim in Proposition 1 regarding the benefits of using multiple continual learning still holds in such a tightened version. In particular, optimization of the active forgetting term in Eq. (2) and Eq. (12), which takes the form of minimizing a weighted norm regarding all parameters, can contribute to tightening the two generalization bounds in Proposition 2, especially through optimizing and . Besides, becomes larger as increases, while remains constant in general. This means that will decrease more rapidly around the empirical optimal solution as more tasks are introduced, resulting in more pronounced improvements in learning plasticity.
4.4 Implementation
We mainly consider the setting of task-incremental learning van2022three to perform continual learning experiments, with task identities provided in both training and testing. We split representative benchmark datasets for visual classification tasks. The CIFAR-100 dataset (krizhevsky2009learning, ) includes 100-class colored images of size . We split it based on different principles to evaluate the effect of overall knowledge transfer. Specifically, R-CIFAR-100 and S-CIFAR-100 are constructed by splitting CIFAR-100 into 20 tasks, depending on random order or superclasses defined by semantic similarity, respectively. R-CIFAR-10/100 includes 2 tasks randomly split from the CIFAR-10 dataset (krizhevsky2009learning, ) of 10-class colored images, followed by the 20 tasks of R-CIFAR-100. The Omniglot dataset lake2015human includes 50 alphabets for a total of 1623 classes of characters, where each class contains 20 hand-written digits of size . We split each alphabet as a task consisting of a different number of classes. The CUB-200-2011 dataset wah2011caltech includes 200-class bird images of size , and the Tiny-ImageNet dataset delange2021continual includes 200-class natural images of size , both split randomly into 10 tasks. The CORe50 dataset lomonaco2017core50 includes 50 handheld objects with smoothly-changed observations of size , randomly split into 10 tasks pham2021contextual . We construct a sequence of Atari reinforcement tasks for continual learning, i.e., DemonAttack - Robotank - Boxing - NameThisGame - StarGunner - Gopher - VideoPinball - Crazyclimber, using the same PPO algorithm schulman2017proximal to learn each task. The network architecture and training regime are described in Supplementary Sections 2.1 and 2.2, respectively.
4.5 Baseline Approach
To ensure generality in realistic applications, we restrict the old training samples to be unavailable in continual learning, and compare with representative methods that follow this restriction. Specifically, EWC kirkpatrick2017overcoming , MAS aljundi2018memory and SI zenke2017continual are synaptic regularization methods that selectively penalized parameter changes to preserve memory stability. AGS-CL jung2020continual took advantages of parameter isolation and synaptic regularization to prevent catastrophic forgetting. P&C schwarz2018progress adopted an additional active column on the basis of EWC kirkpatrick2017overcoming to improve learning plasticity. CPR cha2020cpr encouraged convergence to a flat loss landscape, which can be combined with other baseline approaches. The hyperparameters for continual learning are determined with a comprehensive grid search. We construct a different task sequence (e.g., different class splits, data shuffling, task orders and random seeds) from the actual experiments and run it for once. Then we use the best combinations of hyperparameters to perform the actual experiments for multiple runs, as described in Supplementary Section 2.3.
4.6 Evaluation Metric
We consider three evaluation metrics for visual classification tasks, i.e., average accuracy (AAC), forward transfer (FWT) and backward transfer (BWT) lopez2017gradient ; wang2023comprehensive :
| (14) |
| (15) |
| (16) |
where is the test accuracy of task after continual learning of task , and is the test accuracy of each task learned from random initialization. ACC is the average performance of all tasks ever seen, which evaluates the overall performance of continual learning. FWT evaluates the average influence of remembering old tasks to new tasks for learning plasticity. BWT evaluates the average influence of learning new tasks to old tasks for memory stability.
The diversity of learners’ predictions is quantified by the average cosine (Cos) or Euclidean (Euc) distance:
| (17) |
| (18) |
where and denote the predictions of learners and , respectively.
The discrepancy of task distributions in feature space is evaluated by the difficulty of distinguishing them, which is an empirical approximation of the -divergence long2015learning ; wang2022coscl in Proposition 1. We train a simple discriminator consisting of a fully-connected layer and use binary cross-entropy to measure the average discrimination error on test sets.
The performance of Atari reinforcement tasks is evaluated by the normalized accumulated reward (NAR), normalized plasticity (NP) and normalized stability (NS), corresponding to the overall performance, learning plasticity and memory stability, respectively:
| (19) |
| (20) |
| (21) |
where is the reward for task obtained in the test step after learning task , and is the maximum reward for task obtained in each test step of fine-tuning on the task sequence.
Data Availability
All benchmark datasets used in this paper are publicly available, including CIFAR-10/100 (krizhevsky2009learning, ) (https://www.cs.toronto.edu/ kriz/cifar.html), Omniglot lake2015human (https://www.omniglot.com), CUB-200-2011 wah2011caltech (https://www.vision.caltech.edu/datasets/cub_200_2011/), Tiny-ImageNet delange2021continual (https://www.image-net.org/download.php), CORe50 lomonaco2017core50 (https://vlomonaco.github.io/core50/) and Atari games mnih2013playing (https://github.com/openai/baselines).
Code Availability
The implementation code is available at the GitHub repository https://github.com/lywang3081/CAFwang2023caf_code .
Acknowledgments
This work was supported by the National Key Research and Development Program of China (2020AAA0106302, to J.Z.), the STI2030-Major Projects (2022ZD0204900, to Y.Z.), the National Natural Science Foundation of China (Nos. 62061136001 and 92248303, to J.Z., 32021002, to Y.Z., U19A2081, to H.S.), the Tsinghua-Peking Center for Life Sciences, the Tsinghua Institute for Guo Qiang, and the High Performance Computing Center, Tsinghua University. J.Z. was also supported by the New Cornerstone Science Foundation through the XPLORER PRIZE. L.W. was also supported by Shuimu Tsinghua Scholar.
Author Contributions Statement
L.W., X.Z., J.Z. and Y.Z. conceived the project. L.W., X.Z., Q.L. and M.Z. designed the computational model. X.Z. performed the theoretical analysis, assisted by L.W. L.W. performed all experiments and analyzed the data. L.W., X.Z. and Q.L. wrote the paper. L.W., X.Z., Q.L., M.Z., H.S., J.Z. and Y.Z. revised the paper. J.Z. and Y.Z. supervised the project.
Competing Interests Statement
The authors declare no competing interests.




References
- \bibcommenthead
- (1) Chen, Z., Liu, B.: Lifelong machine learning. Synthesis Lectures on Artificial Intelligence and Machine Learning 12(3), 1–207 (2018)
- (2) Parisi, G.I., Kemker, R., Part, J.L., Kanan, C., Wermter, S.: Continual lifelong learning with neural networks: A review. Neural Networks (2019)
- (3) Kudithipudi, D., Aguilar-Simon, M., Babb, J., Bazhenov, M., Blackiston, D., Bongard, J., Brna, A.P., Chakravarthi Raja, S., Cheney, N., Clune, J., et al.: Biological underpinnings for lifelong learning machines. Nature Machine Intelligence 4(3), 196–210 (2022)
- (4) McCloskey, M., Cohen, N.J.: Catastrophic interference in connectionist networks: The sequential learning problem. Psychology of Learning and Motivation 24, 109–165 (1989)
- (5) McClelland, J.L., McNaughton, B.L., O’Reilly, R.C.: Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological Review 102(3), 419 (1995)
- (6) Wang, L., Zhang, X., Su, H., Zhu, J.: A comprehensive survey of continual learning: Theory, method and application. arXiv preprint arXiv:2302.00487 (2023)
- (7) Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al.: Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences 114(13), 3521–3526 (2017)
- (8) Aljundi, R., Babiloni, F., Elhoseiny, M., Rohrbach, M., Tuytelaars, T.: Memory aware synapses: Learning what (not) to forget. In: Proceedings of the European Conference on Computer Vision, pp. 139–154 (2018)
- (9) Zenke, F., Poole, B., Ganguli, S.: Continual learning through synaptic intelligence. In: Proceedings of the International Conference on Machine Learning, pp. 3987–3995 (2017)
- (10) Chaudhry, A., Dokania, P.K., Ajanthan, T., Torr, P.H.: Riemannian walk for incremental learning: Understanding forgetting and intransigence. In: Proceedings of the European Conference on Computer Vision, pp. 532–547 (2018)
- (11) Ritter, H., Botev, A., Barber, D.: Online structured laplace approximations for overcoming catastrophic forgetting. In: Advances in Neural Information Processing Systems, vol. 31 (2018)
- (12) Rebuffi, S.-A., Kolesnikov, A., Sperl, G., Lampert, C.H.: Icarl: Incremental classifier and representation learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2001–2010 (2017)
- (13) Shin, H., Lee, J.K., Kim, J., Kim, J.: Continual learning with deep generative replay. In: Advances in Neural Information Processing Systems, pp. 2990–2999 (2017)
- (14) Wang, L., Zhang, X., Yang, K., Yu, L., Li, C., Hong, L., Zhang, S., Li, Z., Zhong, Y., Zhu, J.: Memory replay with data compression for continual learning. In: Proceedings of the International Conference on Learning Representations (2021)
- (15) Serra, J., Suris, D., Miron, M., Karatzoglou, A.: Overcoming catastrophic forgetting with hard attention to the task. In: Proceedings of the International Conference on Machine Learning, pp. 4548–4557 (2018)
- (16) Fernando, C., Banarse, D., Blundell, C., Zwols, Y., Ha, D., Rusu, A.A., Pritzel, A., Wierstra, D.: Pathnet: Evolution channels gradient descent in super neural networks. arXiv preprint arXiv:1701.08734 (2017)
- (17) Delange, M., Aljundi, R., Masana, M., Parisot, S., Jia, X., Leonardis, A., Slabaugh, G., Tuytelaars, T.: A continual learning survey: Defying forgetting in classification tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
- (18) Hadsell, R., Rao, D., Rusu, A.A., Pascanu, R.: Embracing change: Continual learning in deep neural networks. Trends in Cognitive Sciences 24(12), 1028–1040 (2020)
- (19) Shuai, Y., Lu, B., Hu, Y., Wang, L., Sun, K., Zhong, Y.: Forgetting is regulated through rac activity in drosophila. Cell 140(4), 579–589 (2010)
- (20) Cohn, R., Morantte, I., Ruta, V.: Coordinated and compartmentalized neuromodulation shapes sensory processing in drosophila. Cell 163(7), 1742–1755 (2015)
- (21) Waddell, S.: Neural plasticity: Dopamine tunes the mushroom body output network. Current Biology 26(3), 109–112 (2016)
- (22) Modi, M.N., Shuai, Y., Turner, G.C.: The drosophila mushroom body: From architecture to algorithm in a learning circuit. Annual Review of Neuroscience 43, 465–484 (2020)
- (23) Aso, Y., Sitaraman, D., Ichinose, T., Kaun, K.R., Vogt, K., Belliart-Guérin, G., Plaçais, P.-Y., Robie, A.A., Yamagata, N., Schnaitmann, C., et al.: Mushroom body output neurons encode valence and guide memory-based action selection in drosophila. Elife 3, 04580 (2014)
- (24) Aso, Y., Rubin, G.M.: Dopaminergic neurons write and update memories with cell-type-specific rules. Elife 5, 16135 (2016)
- (25) Gao, Y., Shuai, Y., Zhang, X., Peng, Y., Wang, L., He, J., Zhong, Y., Li, Q.: Genetic dissection of active forgetting in labile and consolidated memories in drosophila. Proceedings of the National Academy of Sciences 116(42), 21191–21197 (2019)
- (26) Zhao, J., Zhang, X., Zhao, B., Hu, W., Diao, T., Wang, L., Zhong, Y., Li, Q.: Genetic dissection of mutual interference between two consecutive learning tasks in drosophila. Elife 12, 83516 (2023)
- (27) Richards, B.A., Frankland, P.W.: The persistence and transience of memory. Neuron 94(6), 1071–1084 (2017)
- (28) Dong, T., He, J., Wang, S., Wang, L., Cheng, Y., Zhong, Y.: Inability to activate rac1-dependent forgetting contributes to behavioral inflexibility in mutants of multiple autism-risk genes. Proceedings of the National Academy of Sciences 113(27), 7644–7649 (2016)
- (29) Zhang, X., Li, Q., Wang, L., Liu, Z.-J., Zhong, Y.: Active protection: Learning-activated raf/mapk activity protects labile memory from rac1-independent forgetting. Neuron 98(1), 142–155 (2018)
- (30) Davis, R.L., Zhong, Y.: The biology of forgetting—a perspective. Neuron 95(3), 490–503 (2017)
- (31) Mo, H., Wang, L., Chen, Y., Zhang, X., Huang, N., Liu, T., Hu, W., Zhong, Y., Li, Q.: Age-related memory vulnerability to interfering stimuli is caused by gradual loss of mapk-dependent protection in drosophila. Aging Cell, 13628 (2022)
- (32) Cervantes-Sandoval, I., Chakraborty, M., MacMullen, C., Davis, R.L.: Scribble scaffolds a signalosome for active forgetting. Neuron 90(6), 1230–1242 (2016)
- (33) Noyes, N.C., Phan, A., Davis, R.L.: Memory suppressor genes: Modulating acquisition, consolidation, and forgetting. Neuron 109(20), 3211–3227 (2021)
- (34) Cognigni, P., Felsenberg, J., Waddell, S.: Do the right thing: Neural network mechanisms of memory formation, expression and update in drosophila. Current Opinion in Neurobiology 49, 51–58 (2018)
- (35) Amin, H., Lin, A.C.: Neuronal mechanisms underlying innate and learned olfactory processing in drosophila. Current Opinion in Insect Science 36, 9–17 (2019)
- (36) Handler, A., Graham, T.G., Cohn, R., Morantte, I., Siliciano, A.F., Zeng, J., Li, Y., Ruta, V.: Distinct dopamine receptor pathways underlie the temporal sensitivity of associative learning. Cell 178(1), 60–75 (2019)
- (37) McCurdy, L.Y., Sareen, P., Davoudian, P.A., Nitabach, M.N.: Dopaminergic mechanism underlying reward-encoding of punishment omission during reversal learning in drosophila. Nature Communications 12(1), 1–17 (2021)
- (38) Berry, J.A., Cervantes-Sandoval, I., Nicholas, E.P., Davis, R.L.: Dopamine is required for learning and forgetting in drosophila. Neuron 74(3), 530–542 (2012)
- (39) Berry, J.A., Phan, A., Davis, R.L.: Dopamine neurons mediate learning and forgetting through bidirectional modulation of a memory trace. Cell Reports 25(3), 651–662 (2018)
- (40) Aitchison, L., Jegminat, J., Menendez, J.A., Pfister, J.-P., Pouget, A., Latham, P.E.: Synaptic plasticity as bayesian inference. Nature Neuroscience 24(4), 565–571 (2021)
- (41) Schug, S., Benzing, F., Steger, A.: Presynaptic stochasticity improves energy efficiency and helps alleviate the stability-plasticity dilemma. Elife 10, 69884 (2021)
- (42) Wang, L., Zhang, M., Jia, Z., Li, Q., Bao, C., Ma, K., Zhu, J., Zhong, Y.: Afec: Active forgetting of negative transfer in continual learning. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
- (43) Benzing, F.: Unifying importance based regularisation methods for continual learning. In: Proceedings of the International Conference on Artificial Intelligence and Statistics, pp. 2372–2396 (2022)
- (44) Bouton, M.E.: Context, time, and memory retrieval in the interference paradigms of pavlovian learning. Psychological Bulletin 114(1), 80 (1993)
- (45) Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images. Technical report, Citeseer (2009)
- (46) Shuai, Y., Hirokawa, A., Ai, Y., Zhang, M., Li, W., Zhong, Y.: Dissecting neural pathways for forgetting in drosophila olfactory aversive memory. Proceedings of the National Academy of Sciences 112(48), 6663–6672 (2015)
- (47) Chen, L., Chen, Z., Jiang, L., Liu, X., Xu, L., Zhang, B., Zou, X., Gao, J., Zhu, Y., Gong, X., et al.: Ai of brain and cognitive sciences: From the perspective of first principles. arXiv preprint arXiv:2301.08382 (2023)
- (48) Caron, S.J., Ruta, V., Abbott, L.F., Axel, R.: Random convergence of olfactory inputs in the drosophila mushroom body. Nature 497(7447), 113–117 (2013)
- (49) Endo, K., Tsuchimoto, Y., Kazama, H.: Synthesis of conserved odor object representations in a random, divergent-convergent network. Neuron 108(2), 367–381 (2020)
- (50) Long, M., Cao, Y., Wang, J., Jordan, M.: Learning transferable features with deep adaptation networks. In: Proceedings of the International Conference on Machine Learning, pp. 97–105 (2015)
- (51) Wang, L., Zhang, X., Li, Q., Zhu, J., Zhong, Y.: Coscl: Cooperation of small continual learners is stronger than a big one. In: Proceedings of the European Conference on Computer Vision, pp. 254–271 (2022)
- (52) van de Ven, G.M., Tuytelaars, T., Tolias, A.S.: Three types of incremental learning. Nature Machine Intelligence, 1–13 (2022)
- (53) Riemer, M., Cases, I., Ajemian, R., Liu, M., Rish, I., Tu, Y., Tesauro, G.: Learning to learn without forgetting by maximizing transfer and minimizing interference. In: Proceedings of the International Conference on Learning Representations (2018)
- (54) Schwarz, J., Czarnecki, W., Luketina, J., Grabska-Barwinska, A., Teh, Y.W., Pascanu, R., Hadsell, R.: Progress & compress: A scalable framework for continual learning. In: Proceedings of the International Conference on Machine Learning, pp. 4528–4537 (2018)
- (55) Jung, S., Ahn, H., Cha, S., Moon, T.: Continual learning with node-importance based adaptive group sparse regularization. In: Advances in Neural Information Processing Systems, vol. 33, pp. 3647–3658 (2020)
- (56) Cha, S., Hsu, H., Hwang, T., Calmon, F., Moon, T.: Cpr: Classifier-projection regularization for continual learning. In: Proceedings of the International Conference on Learning Representations (2020)
- (57) Lake, B.M., Salakhutdinov, R., Tenenbaum, J.B.: Human-level concept learning through probabilistic program induction. Science 350(6266), 1332–1338 (2015)
- (58) Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The caltech-ucsd birds-200-2011 dataset (2011)
- (59) Lomonaco, V., Maltoni, D.: Core50: a new dataset and benchmark for continuous object recognition. In: Conference on Robot Learning, pp. 17–26 (2017). PMLR
- (60) Ryan, T.J., Frankland, P.W.: Forgetting as a form of adaptive engram cell plasticity. Nature Reviews Neuroscience 23(3), 173–186 (2022)
- (61) Luo, L., Hensch, T.K., Ackerman, L., Barbel, S., Jan, L.Y., Nung Jan, Y.: Differential effects of the rac gtpase on purkinje cell axons and dendritic trunks and spines. Nature 379(6568), 837–840 (1996)
- (62) Tashiro, A., Minden, A., Yuste, R.: Regulation of dendritic spine morphology by the rho family of small gtpases: Antagonistic roles of rac and rho. Cerebral Cortex 10(10), 927–938 (2000)
- (63) Hayashi-Takagi, A., Takaki, M., Graziane, N., Seshadri, S., Murdoch, H., Dunlop, A.J., Makino, Y., Seshadri, A.J., Ishizuka, K., Srivastava, D.P., et al.: Disrupted-in-schizophrenia 1 (disc1) regulates spines of the glutamate synapse via rac1. Nature Neuroscience 13(3), 327–332 (2010)
- (64) Hayashi-Takagi, A., Yagishita, S., Nakamura, M., Shirai, F., Wu, Y.I., Loshbaugh, A.L., Kuhlman, B., Hahn, K.M., Kasai, H.: Labelling and optical erasure of synaptic memory traces in the motor cortex. Nature 525(7569), 333–338 (2015)
- (65) Martens, J., Grosse, R.: Optimizing neural networks with kronecker-factored approximate curvature. In: Proceedings of the International Conference on Machine Learning, pp. 2408–2417 (2015)
- (66) Knoblauch, J., Husain, H., Diethe, T.: Optimal continual learning has perfect memory and is np-hard. In: Proceedings of the International Conference on Machine Learning, pp. 5327–5337 (2020). PMLR
- (67) Deng, D., Chen, G., Hao, J., Wang, Q., Heng, P.-A.: Flattening sharpness for dynamic gradient projection memory benefits continual learning. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
- (68) Mirzadeh, S.I., Farajtabar, M., Pascanu, R., Ghasemzadeh, H.: Understanding the role of training regimes in continual learning. Advances in Neural Information Processing Systems 33, 7308–7320 (2020)
- (69) McAllester, D.A.: Pac-bayesian model averaging. In: Proceedings of the Twelfth Annual Conference on Computational Learning Theory, pp. 164–170 (1999)
- (70) Pham, Q., Liu, C., Sahoo, D., Steven, H.: Contextual transformation networks for online continual learning. In: Proceedings of the International Conference on Learning Representations (2021)
- (71) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 (2017)
- (72) Lopez-Paz, D., et al.: Gradient episodic memory for continual learning. In: Advances in Neural Information Processing Systems, pp. 6467–6476 (2017)
- (73) Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., Riedmiller, M.: Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602 (2013)
- (74) Wang, L., Zhang, X.: lywang3081/caf: Caf paper. https://doi.org/10.5281/zenodo.8293564 (2023)
- (75) Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 618–626 (2017)
Supplementary_Information.pdf, 1-25