In-place Switch: Reprogramming based SLC Cache Design for Hybrid 3D SSDs
Abstract
Recently, 3D SSDs have been widely adopted in PCs, data centers, and cloud storage systems. High-bit-density cells, such as Triple-Level Cell (TLC), are utilized within 3D SSDs to increase capacity. However, due to the inferior performance of TLC, a portion of TLCs is configured to operate as Single-Level Cells (SLC) to provide high performance, with host data initially directed to the SLCs. In SLC/TLC hybrid 3D SSDs, a portion of the TLC space is designated as an SLC cache to achieve high SSD performance by writing host data at the SLC speed. Given the limited size of the SLC cache, block reclamation is necessary to free up the SLC cache during idle periods. However, our preliminary studies indicate that the SLC cache can lead to a performance cliff if filled rapidly and cause significant write amplification when data migration occurs during idle times.
In this work, we propose leveraging a reprogram operation to address these challenges. Specifically, when the SLC cache is full or during idle periods, a reprogram operation is performed to switch used SLC pages to TLC pages in place (termed In-place Switch, IPS). Subsequently, other free TLC space is allocated as the new SLC cache. IPS can continuously provide sufficient SLC cache within SSDs, significantly improving write performance and reducing write amplification. Experimental results demonstrate that IPS can reduce write latency and write amplification by up to 0.75 times and 0.53 times, respectively, compared to state-of-the-art SLC cache technologies.
Index Terms:
Hybrid 3D SSDs, SLC Cache, TLC, Reprogram.
I Introduction
Recently, NAND flash memory-based SSDs have been widely adopted in personal computers, data centers, and cloud storage systems due to their high performance, large capacity, and low power consumption. To enhance the capacity of SSDs, high-bit-density cells, such as triple-level cells (TLC) or quad-level cells (QLC), are utilized to store more bits per cell. Additionally, various three-dimensional (3D) architectures of NAND flash memory, in conjunction with high bit-density cells (with TLC as the focus in this discussion), have been launched into the market to overcome the scaling limit of planar NAND flash arrays [8, 6, 16]. However, there is no such thing as a free lunch; while 3D TLC SSDs significantly increase storage density, they come with poorer performance. Compared to single-level cell (SLC) or multi-level cell (MLC) based SSDs, 3D TLC SSDs require more time to decode (read) or encode (write) data.
As an alternative solution, SLC caches are integrated into commercial 3D TLC SSDs to mitigate this performance issue [23, 9, 26]. During host writes, data is first written to a limited-capacity SLC cache, leveraging the higher performance of SLCs to deliver better overall SSD performance. SLC cache is cleared during idle time to sustainably provide enough space for following writes. However, two key challenges arise from the characteristics of SLC caches: 1) The limited SLC cache can quickly become saturated under sustained write workloads. Due to the low bit density of SLC, hybrid 3D SSDs typically allocate only a small portion of TLC space as an SLC cache, preserving the capacity advantage of hybrid 3D SSDs. Once saturated, sustained writes are redirected to the TLC space and are processed at TLC performance levels, leading to a performance cliff; 2) The reclamation process for the SLC cache results in a large amount of additional writes. The SLC cache is cleared by migrating data from used SLC pages to available TLC space and erasing used blocks during idle time. Since NAND flash memory is a wear-sensitive storage medium, this additional data migration leads to noticeable write amplification increase [30, 28, 11].
To overcome the above mentioned problems, we present In-place Switch (IPS), which adopts reprogram operations to reuse the SLC cache when it is full. Firstly, IPS continually attempts to allocate a new SLC cache to prevent performance cliffs and ensure sustained high write performance. Additionally, IPS reprograms used SLC pages into TLC pages for switching SLC pages to TLC pages in place, reducing the data migration associated with SLC cache reclamation. This process maintains the capacity advantage of hybrid SSDs. IPS adheres to the limitations of the reprogram operation in 3D TLC SSDs, and the feasibility of the reprogram operation in 3D TLC SSDs has been validated[7]. The results reveal that IPS can effectively improve the performance and reduce the write amplification of hybrid 3D SSDs. On average, write latency is reduced by 0.75 times, and write amplification is reduced by 0.53 times at most. We summarized our contributions as follows:
-
•
We analyze the performance and write amplification of SLC/TLC hybrid 3D SSDs, and then point out the potential pitfalls of hybrid 3D SSDs;
-
•
We propose an In-place Switch based SLC cache design for hybrid 3D SSDs to overcome the disadvantages of conventional hybrid 3D SSDs;
-
•
We evaluate IPS in a modified hybrid 3D SSDs-based simulator [12]. The experimental results show that IPS effectively improves performance and reduces the write amplification of hybrid 3D SSDs.
II Background and Related Work
II-A 3D NAND Flash Memory based SSD
Figure 1 illustrates the architecture of a hybrid 3D SSD that integrates SLC and TLC spaces within a single storage device. The SSD architecture comprises two parts: 1) The front end consists of the control and communication units. The SSD controller handles read and write requests from the host interface and executes Flash Translation Layer (FTL) functions such as Address Mapping (AM), Garbage Collection (GC), and Wear Leveling (WL). The flash controller serves as the interface between the front end and the back end; 2) The back end consists of the data storage units that provide actual storage capacity. To boost SSD performance, the internal architecture employs four levels of parallelism: from channel to chip, die, and plane[12]. Each plane contains multiple blocks, which can only be written sequentially.
The primary distinction between 3D SSDs and 2D SSDs lies in the architecture of the flash block. As shown on the right of Figure 1, 3D SSDs employ a vertical block architecture. To transition from 2D to 3D, 3D SSDs introduce layers, with each layer consisting of multiple word lines on a horizontal plane, and each word line comprising multiple flash cells. TLC flash provides three types of bits for each cell, Least-Significant-Bit (LSB), Center-Significant-Bit (CSB), and Most-Significant-Bit (MSB). Traditionally, program operations shift the voltage state from ”erased” to a specific higher voltage level, representing three-bit values in TLC (LSB, CSB, MSB). Using three registers, one-shot programming enables the simultaneous writing of three pages to a single word line, a process known as ”one-shot programming” [10]. SSDs employ an out-of-place update strategy for program operations, where updates are written to free pages while the original pages are invalidated. A cell can only be reprogrammed after it has been erased.
II-B Reprogram Operation in 3D TLC SSDs
Previous works [22, 4, 2, 3, 7, 29] have developed reprogram operations for both 2D and 3D flash memory. Reprogram operation refers to the process of reprogram flash cells that are at a certain voltage state to a higher voltage state before they are erased, thereby achieving in-place updates to reduce cell wear or improving the reading process. As shown in Figure 2, this process can accelerate reads in TLC SSDs [4]. The x-axis represents the voltage threshold, and the y-axis indicates the probability of each state. By charging flash memory cells with different amounts of electrons, the entire voltage range can be divided into eight states (E, P1P7). If LSB bits are invalidated, the eight states of CSB and MSB bits can be grouped into four pairs (E-P7, P1-P6, P2-P5, P3-P4) due to identical data. Reprogramming the voltage thresholds in the first four states (EP3) to the latter four states (P4P7) can accelerate the read process [25].






However, two main challenges affect the reliability of reprogram operations: cell-to-cell interference [1] and background pattern dependency [17]. The former has a relatively minor impact, while the latter plays a more significant role in reducing reliability. Therefore, to maintain the reliability of flash memory, reprogram operations must be performed with caution. According to the verification of reprogram operation presented in [7], there are two restrictions for performing the technology: First, 3D TLC only can be randomly reprogrammed within two layers in 3D TLC SSDs without loss of reliability; Second, each TLC can be reprogrammed four times at most. In this work, these restrictions are strictly satisfied when reprogram operation is considered.
II-C SLC Cache in Hybrid 3D SSDs
Modern commodity hybrid 3D SSDs combine SLC and TLC [5, 28], where SLC is used as the cache to store user data for boosting the performance of hybrid SSDs. As shown in the left part of Figure 1, during host writes, data is first written to the limited-capacity SLC cache. This approach leverages the higher performance of SLCs, resulting in improved overall SSD performance. Meanwhile, the TLC space ensures that the 3D SSDs maintain their high-density advantage, providing ample storage capacity despite the lower performance and reduced reliability compared to the SLC cache. When the SLC cache is full, the SSD controller performs GC, which involves migrating valid data and erasing used blocks to reclaim the SLC cache. Note that GC operations occur whenever SSD physical space is insufficient, not just when the SLC cache is full.
Since the SLC cache is engineered by only storing one bit in the original TLC, the size of the SLC cache should be carefully dimensioned. Allocating more TLC space to the SLC cache enhances performance but reduces overall capacity. Conversely, allocating less TLC space to the SLC cache preserves capacity but limits performance gains from the SLC cache. Traditionally, the SLC cache is allocated from a fixed portion of TLC space, preventing excessive consumption of TLC capacity. Typically, the size of the SLC cache in commodity SSDs ranges from several gigabytes (GBs) to over a hundred GBs [23, 9, 26]. For example, Samsung’s Turbo Write technology suggests that a 3GB SLC cache is sufficient for most daily use scenarios [26]. Other manufacturers, such as Micron, allocate larger SLC caches to accommodate data-intensive applications [23].
II-D Related Work
Previous works on hybrid SSDs can be categorized into several types: First, the size of the SLC cache is adjusted by considering the amount of data stored in the SSD or SSD’s status, thus better performance is achieved without significantly losing the capacity [30, 26, 23, 27]; Second, the SLC cache can be used to accelerate time-consuming activities, such as GC, so that the performance of SSDs is boosted [20, 31]; Third, the SLC cache is leveraged to store hot data, thus most GCs are triggered in SLC cache as it has better endurance and lower read and write latencies [13, 21, 19]; Fourth, to balance the wear rates of SLC and TLC, Jimenez et al. [14] proposes to distribute writes to the SLC cache or TLC space according to flash cells’ wear rate.
However, above mentioned works still need block reclamation to empty the SLC cache, which does harm to performance and lifetime of SSDs from the perspective of write latency and write amplification. Therefore, in this work, we attempt to alleviate block reclamation’s impact via reprogram operation.
III Motivation and Problem Statement
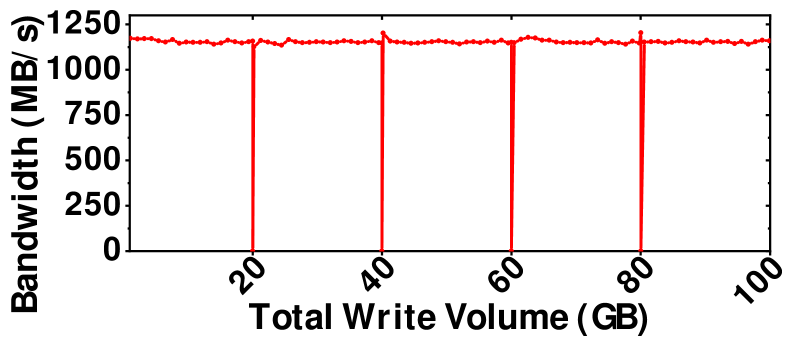
To analyze the characteristics of SLC cache in hybrid SSD, a real 3D hybrid SSD with 500GB [5] is evaluated with two scenarios: bursty access and daily use. For bursty access, the SSD is accessed by sustained sequential writes without idle time and its bandwidth is measured, as shown in Figure 3. For daily use, five distinct sequential write streams are executed in order, each of which writes 20GB data into the SSD. A free period of 10 minutes is introduced between consecutive write streams to allow the device to idle, which is large enough as Turbo Write technology adopted by Samsung sets the idle time to smaller than 1 minute [26]. The measured bandwidth for the daily use scenario is presented in Figure 4.
For bursty access, as denoted in Figure 3(a), a bandwidth cliff is evident when a total 65GB data is written. After this point, the bandwidth is significantly decreased. Thus, two conclusions can be drawn: First, the size of the SLC cache in this SSD is approximately 65GB. Second, when the SLC cache is filled and there is no idle time to reclaim the used SLC cache, the performance is markedly reduced as subsequent writes are performed at the TLC performance level. However, in the daily use scenario, as illustrated in Figure 4, the bandwidth remains steady at around 1090 MB/s throughout the process, even when the total write size exceeds 65GB. This is because the SLC cache is cleared during idle periods, allowing it to be reused for subsequent writes.
However, in daily use scenarios, better performance is achieved at the penalty of frequent data migration. To further elaborate data migration in the SLC cache, a workload-driven SSD simulator [12] is adopted in this work, which can quantitatively analyze the number of pages migrated during idle time. We simulate a 500GB SSD configured with a 4GB SLC cache, as the total write size of the evaluated workloads is small. To ensure a comprehensive experiment, we evaluate the simulated SSD not only under daily use scenarios with various workloads[24] but also under bursty access scenarios. To simulate a bursty access scenario, incoming writes should be reconstructed to fill up the SLC cache without idle time. Thus, incoming writes of all workloads are configured as sequential writes with 32KB write size. And then, arriving time is accelerated so that there is no idle time. For the daily use scenario, regular workloads are executed. Additionally, at the end of each workload, all data in the SLC cache is migrated to the TLC space, and the used blocks are erased. The results are collected and presented in Figure 5, where all writes are categorized into three parts: writing to SLC cache (SLC Writes), data migration from SLC cache to TLC space (SLC2TLC) and directly writing to TLC space (TLC Writes).


For bursty access, as shown in Figure 5(a), TLC writes, which do not cause write amplification, dominate the majority of workloads (9 out of 11). As a result, write amplifications of most workloads only can be slightly reduced as SLC2TLC writes only account for only a small portion. On the contrary, for daily use, as shown in Figure 5(b), there is a lack of TLC Writes because the SLC cache is frequently reclaimed during idle time. Thus, write amplifications of all workloads are significantly increased, which exceeds 1.9 as the worst one reaches 1.997.
Based on the above evaluations, two potential pitfalls in hybrid SSDs arise: First, hybrid SSDs will lead to a performance cliff in bursty access; Second, hybrid SSDs leave a severe write amplification problem in daily use scenarios.
IV IPS: In-place Switch Design
To address these challenges, we introduce a reprogramming-based SLC cache design known as In-place Switch (IPS). Initially, the fundamental concept behind IPS is explained. Following this, advanced garbage collection techniques are utilized to enhance IPS’s efficiency. Additionally, we propose a design that combines advanced GC-assisted IPS with traditional SLC cache to expand the SLC cache size. Finally, we present a comprehensive discussion of the proposed approach.


IV-A Basic Idea of IPS
IPS seeks to allocate a new SLC cache rather than reclaim the used SLC cache. To prevent excessive allocation of free TLC space, a new SLC cache is only allocated when the used SLC cache is fully reprogrammed, ensuring no capacity is wasted. Thus, in this design, if the SLC cache is full, host writes are utilized to reprogram SLC pages, converting them into TLC pages in place. This process not only continuously provides free SLC pages but also avoids additional data migration. Figure 6(b) illustrates the changes in voltage thresholds as SLC pages are reprogrammed into TLC pages. To construct the SLC cache, only two states are encoded in each TLC cell, storing one bit per cell. IPS initially programs the flash cells into the two lower voltage thresholds (compared to traditional SLC) to represent the two SLC states. If reprogram operation is needed to convert SLC back to TLC in place, the original data is first read and then rewritten with new data. Reprogramming the lower two voltage thresholds used for the SLC cache into the higher eight voltage thresholds required for TLC involves two reprogram operations.
However, considering the restrictions of reprogram operation [7], the SLC cache is allocated at the granularity of two layers per block. Initially, the first two layers of all blocks are allocated as SLC cache to provide basic SLC cache capacity. As shown in Figure 6(a), the first two layers (termed SLC layer) of all blocks in different planes (denoted as Plane 0 and Plane 1) are allocated and grouped as SLC cache. At the beginning, within each plane, all blocks containing the SLC layer are programmed sequentially to store data in SLC pages (Step 1). After all SLC layers in a plane have been exhausted, reprogram operations are performed in Step 2, requiring four operations to convert two SLC pages back to TLC pages. Once an SLC layer has been fully reprogrammed, the next two layers in the same block are allocated as new SLC layers. Consequently, subsequent writes can be processed at the SLC performance level again (Step 3).
For bursty access, IPS enhances performance over traditional SLC caches, as host writes benefit from the new SLC cache. For daily use, write amplification is reduced by substituting traditional idle-time data migration with reprogram operations, avoiding additional writes to the SSDs. However, reprogram operations are performed at the TLC performance level, leading to a decrease in performance. To address this, we propose leveraging advanced garbage collection techniques [15] to regain the high-performance benefits of the SLC cache while preserving the reduction in write amplification achieved by IPS.
IV-B Advanced GC assisted IPS
Advanced GC (AGC) aims to divide GC into several atomic processes including multiple valid page migrations and erase operations. By moving these processes from runtime to idle time, AGC can hide its time cost and improve the performance of SSDs. In this work, IPS is designed with considering AGC (termed IPS/agc). IPS/agc leverages valid page migration of AGC to reprogram used SLC pages during idle time. In detail, instead of migrating data from the SLC cache to free TLC space, valid pages of AGC are read and reprogrammed to used SLC pages so that a new SLC layer can be allocated during idle time. IPS/agc can outperform traditional SLC cache due to three main reasons: First, no additional data migration occurs so that the write amplification IPS achieves can be maintained; Second, used SLC pages can be reprogrammed more frequently during idle time so that more new SLC cache can be allocated to store host writes in runtime; Third, valid page migration from AGC blocks can be flexibly interrupted to barely delay host writes.

Take Figure 7 as an example. Assume that the SLC cache is composed of two SLC pages. For a traditional SLC cache, if a host write arrives suddenly when block reclamation is being performed, it has to be delayed until the reclamation process is finished. Therefore, the conflict between host write and block reclamation can cause a large delay time. But for IPS/agc based SLC cache, to deal with the arriving write, valid page migration of AGC is interrupted in time, thus the arriving write can be directed to other SLC pages in the same plane with less delay time. Note that, reprogram latency is conservatively set to TLC program latency in this work.
IV-C Cooperating IPS/agc and Traditional SLC Cache
To meet the demand for a large SLC cache capacity, we propose to cooperate IPS/agc cache with a traditional SLC cache. Due to the limitations of the reprogram operation, IPS/agc can only allocate a small portion of TLC space as an SLC cache. In the proposed cooperative design, the first two layers of the majority of blocks are designated as SLC layers within the IPS/agc cache. Subsequently, the remaining smaller portion of flash blocks is allocated as the traditional SLC cache.

In order to relieve performance cliffs and significant write amplification, the IPS/agc cache is prioritized for handling host writes, as shown in Figure 8. First, host writes are directed to the IPS/agc cache (Step 1). If no additional host writes arrive, valid page migration is performed within the AGC to reprogram the used SLC pages to TLC pages in the IPS/agc cache (Step 2.1). After which a new SLC layer is allocated within the IPS/agc. This cooperative design only activates the traditional SLC cache when sustained host writes require additional space, redirecting subsequent host writes to the traditional SLC cache (Step 2.2).
To ensure that subsequent writes can continuously benefit from the cooperative design, idle time is utilized not only to reprogram used SLC pages in the IPS/agc cache but also to reclaim the traditional SLC cache if it has been consumed. Since the data migration directions for the IPS/agc cache and the traditional SLC cache are opposite, data from the traditional SLC cache can be read and reprogrammed into the IPS/agc cache. This allows blocks in the traditional SLC cache to be reclaimed while used SLC pages in the IPS/agc cache are reprogrammed (Step 3.1). During this process, if all SLC pages in the IPS/agc cache have been reprogrammed but there are still blocks in the traditional SLC cache that have not yet been reclaimed, the data in these blocks are redirected to free TLC space (Step 3.2). After completing the data migration, the traditional SLC cache undergoes erase operations (step 4) to reclaim space. Conversely, if all data in the traditional SLC cache has been migrated but the IPS/agc cache still contains used SLC pages that have not been fully reprogrammed, valid page migration from the AGC will fill these gaps.
IV-D Discussion
IV-D1 Reliability Issue
To ensure reliability, IPS strictly adheres to the reprogram restrictions outlined in [7]: First, each TLC cell is programmed as SLC, which offers better error tolerance. This means data in the SLC cache can be read and corrected with a lower bit error rate before reprogram operation. Second, used SLC cells require only two reprogram operations to revert to TLC. Third, SLC pages are reprogrammed sequentially, minimizing the impact of cell-to-cell interference [1]. Quantitatively, each cell in the IPS cache experiences twice the cell-to-cell interference from neighboring cells, while the reliable reprogram method proposed in [7] can tolerate up to twelve times the interference.
IV-D2 Wear Leveling
SLC has better endurance than TLC, and wear leveling between them can be achieved by correlating their wear rates. Although Jimenez et al. [14] identified a wear factor between SLC and TLC, it introduces a margin of error that grows with program and erase cycles. This work presents IPS, which achieves wear leveling without depending on a wear factor. Since all flash cells undergo the same wear from program and reprogram operations, IPS uses erase operations as the wear leveling metric. In the cooperative design, wear leveling for the traditional SLC cache is achieved by evenly using TLC space as traditional SLC, while the IPS/agc cache follows the above method.
IV-D3 IPS work with QLC-SLC SSDs
Currently, our proposed IPS only operates with TLC-SLC SSDs. Since the voltage margin between the two states of QLC is smaller than that of TLC, the reliability of reprogramming QLC is lower compared to TLC [18]. Therefore, it is crucial to first study the limitations of reprogramming SLC to QLC. Based on these findings, the SLC cache allocation scheme can be redesigned to minimize the impact of the reprogram operation. In the worst-case scenario, to minimize cell-to-cell interference, reprogram operations may be restricted to within a single layer, thereby reducing the available SLC cache size. However, with the assistance of the proposed cooperating design, IPS can still enhance performance and extend lifespan when host data is prioritized for writing into the SLC cache.
V Evaluation
V-A Evaluation Setup
V-A1 Simulated SSDs and Workloads
In this work, a workload-driven SSD simulator [12] is used, which is configured to match the characteristics of 3D SLC/TLC hybrid SSDs. The evaluation involves a 384GB hybrid SSD, with parameters detailed in Table I. Note that, SLC cache is evenly allocated in all planes to exploit the parallelism of SSDs. The SLC cache size is set to 4GB, which is similar to that of Samsung Turbo Write SSDs [26]. For the proposed cooperative design, the total SLC cache size is increased to 64GB (3.125GB for IPS/agc cache and 60.875GB for traditional SLC cache), roughly matching the size of the real SSD evaluated in Section III. The workloads studied in this work include a subset of MSR Cambridge Workloads from servers [24, 7].
|
|
||||||||
|
|
V-A2 Evaluated Schemes
The baseline in this work adopts Turbo Write technology [26]. First, the SLC cache size is set to 4GB for baseline, IPS (without AGC assistance), and IPS/agc (with AGC assistance). Then, the cooperating design is implemented with a 64GB SLC cache size. Although dynamic SLC cache allocation is supported in most modern hybrid SSDs, it is realized before processing host writes. Therefore, the size of the SLC cache is fixed in this evaluation for simplicity.
V-B Results and Analysis
V-B1 Results of IPS
First, for bursty access, Figure 9(a) shows the write latencies of baseline and IPS during runtime. Take HM_0 as an example. For the first 100,000 writes, we can have three observations: First, in the left blue box, IPS achieves the same write latency with baseline because all writes are programmed at the SLC performance level; Second, when the SLC cache is filled up, the latencies of both schemes are significantly increased to the TLC performance level; Third, in the right blue box, compared with the baseline, IPS can achieve lower write latency as the new SLC cache is intermittently allocated.


In Figure 10(a), the average write latency of IPS is collected and normalized to baseline. On average, IPS reduces write latency by 0.77 times compared to the baseline. However, for HM_1 and PROJ_4, IPS achieves similar write latency to the baseline because most data is programmed at SLC performance levels. In terms of write amplification, IPS reduces it by nearly half for these workloads, as all SLC cache data must be migrated to TLC space. For other workloads, where the SLC cache is quickly depleted and most data is written directly to TLC space, the reduction in write amplification is modest. Overall, IPS reduces write amplification by 0.83 times compared to the baseline.


For daily use, evaluated results of baseline and IPS are collected and presented in Figure 10(b). Similarly, for the first 100,000 writes of HM_0, we have two observations: First, the write latency is gradually increased due to the conflict between block reclamation and host writes. Second, compared with the baseline, the write latency of IPS is larger, which is increased by 1.3 times, as shown in Figure 10(b). However, there also are several workloads that achieve lower write latency over baseline, such as PROJ_4. Due to its small total write size, no reprogram operations are operated for PROJ_4. But for baseline, host writes still suffer from the conflict between time-consuming block reclamation and host writes, causing write latency to increase. For write amplification, on average, IPS reduces it by 0.53 times compared to the baseline. This is because only a small amount of data is updated before data migration. Therefore, IPS which does not cause write amplification can almost reduce write amplification to half.
V-B2 Results of IPS/agc
In this section, write latency and write amplification of IPS and IPS/agc are normalized to baseline and presented in Figure 11.
For write latency, compared with baseline, IPS/agc can averagely reduce it by 0.75 times while IPS increases write latency by 1.3 times. But there are two exceptions for IPS/agc (STG_0 and WDEV_0), of which write latencies still are larger than that of baseline. The main reason is that IPS/agc still can suffer from reprogram operations as used SLC pages have not been fully reprogrammed when host writes arrive.
For write amplification, AGC may increase it when valid pages that will be invalidated soon are migrated in advance. During the evaluation, write amplification resulting from AGC is counted into IPS/agc. Thus, IPS/agc averagely increases write amplification by 0.07 times compared to IPS. Compared with baseline, IPS/agc can reduce write amplification by 0.59 times, on average.

V-B3 Results of cooperating Design
In this section, write latency and write amplification of cooperating design are evaluated and normalized to baseline. For bursty access, take HM_0 as an example. Total write size is varied from 64GB to 136GB by running workload repeatedly. As shown in Figure 12(a), when the total write size is 64GB, all data can be written into the SLC cache, and the cooperating design has the same write latency as that of the baseline. Similarly, cooperating design only can achieve a slight write amplification decrease as only less data is written into the IPS/agc cache. However, with the increase in total write size, more writes can benefit from new allocated IPS/agc cache so that the write latency of the cooperating design is reduced. When the total write size is 136GB, the cooperating design can averagely reduce write latency by 0.79 times compared to baseline. On the contrary, normalized write amplification is gradually approaching 1 with the increase of total write size. This is because baseline programs more writes into TLC space without causing write amplification. Therefore, the contribution from IPS/agc gradually dwindles. When the total write size is 136GB, the cooperating design only can reduce write amplification by 0.98 times compared to the baseline.


For daily use, workloads are executed repeatedly to increase the total write size. In this evaluation, we set the total write size to 64GB as results with larger write sizes are similar. Results of cooperating design are normalized to baseline and presented in Figure 12(b). The cooperating design achieves similar results to the baseline for some workloads, such as STG_0, due to sufficient idle time for data migration, which allows most data to be written to the SLC cache. In contrast, for workloads like PROJ_4, the cooperating design significantly reduces write latency compared to the baseline. This improvement is attributed to the higher priority given to IPS/agc writes, which allows host writes to be delayed with reduced time costs. On average, the cooperating design decreases write latency by 0.78 times and reduces write amplification by 0.67 times compared to the baseline.
VI Conclusion
In this work, firstly, we evaluate emerging hybrid 3D SSDs and deliver the potential pitfalls that cause performance decreases and significant write amplification. Then, reprogram operation is used to conduct a new SLC cache without generating additional writes, thus data migration of the traditional SLC cache is removed from the critical path. As a result, evaluated results show that the proposed IPS can effectively improve write performance and reduce write amplification.
References
- [1] Yu Cai, Saugata Ghose, Yixin Luo, and et al. Vulnerabilities in mlc nand flash memory programming: Experimental analysis, exploits, and mitigation techniques. In HPCA. IEEE, 2017.
- [2] Yu-Ming Chang, Yung-Chun Li, Ping-Hsien Lin, and et al. Realizing erase-free slc flash memory with rewritable programming design. In CODES. ACM, 2016.
- [3] Wonil Choi, Mohammad Arjomand, Myoungsoo Jung, and et al. Exploiting data longevity for enhancing the lifetime of flash-based storage class memory. In POMACS. ACM, 2017.
- [4] Wonil Choi, Myoungsoo Jung, and Mahmut Kandemir. Invalid data-aware coding to enhance the read performance of high-density flash memories. In MICRO. IEEE, 2018.
- [5] Crucial. Crucial p1 nvme ssd. https://www.crucial.com/products/ssd/p1-ssd.
- [6] Pei-Ying Du, Hang-Ting Lue, Yen-Hao Shih, and et al. Overview of 3d nand flash and progress of split-page 3d vertical gate (3dvg) nand architecture. In ICSICT. IEEE, 2014.
- [7] Congming Gao, Min Ye, Qiao Li, and et al. Constructing large, durable and fast ssd system via reprogramming 3d tlc flash memory. In MICRO. ACM, 2019.
- [8] Akira Goda. Recent progress on 3d nand flash technologies. Electronics, 2021.
- [9] Jonmichael Hands. Benefits of nvme ssds in client implementations. https://nvmexpress.org/.
- [10] Chien-Chung Ho, Yung-Chun Li, Yuan-Hao Chang, and et al. Achieving defect-free multilevel 3d flash memories with one-shot program design. In DAC. ACM, 2018.
- [11] Xiao-Yu Hu, Evangelos Eleftheriou, Robert Haas, and et al. Write amplification analysis in flash-based solid state drives. In SYSTOR. ACM, 2009.
- [12] Yang Hu, Hong Jiang, Dan Feng, and et al. Exploring and exploiting the multilevel parallelism inside ssds for improved performance and endurance. In TC. IEEE, 2012.
- [13] Soojun Im and Dongkun Shin. Comboftl: Improving performance and lifespan of mlc flash memory using slc flash buffer. In JSA. Elsevier, 2010.
- [14] Xavier Jimenez, David Novo, and Paolo Ienne. Libra: Software-controlled cell bit-density to balance wear in nand flash. In TECS. ACM, 2015.
- [15] Myoungsoo Jung, Ramya Prabhakar, and Mahmut Taylan Kandemir. Taking garbage collection overheads off the critical path in ssds. In Middleware. Springer, 2012.
- [16] Geun Ho Lee, Sungmin Hwang, Junsu Yu, and et al. Architecture and process integration overview of 3d nand flash technologies. Applied Sciences, 2021.
- [17] Seungjae Lee, Jin-yub Lee, Il-han Park, and et al. 7.5 a 128gb 2b/cell nand flash memory in 14nm technology with tprog= 640s and 800mb/s i/o rate. In ISSCC. IEEE, 2016.
- [18] Qiao Li, Hongyang Dang, Zheng Wan, and et al. Midas touch: Invalid-data assisted reliability and performance boost for 3d high-density flash. In HPCA, pages 657–670. IEEE, 2024.
- [19] Shicheng Li, Longfei Luo, Yina Lv, and et al. Latency aware page migration for read performance optimization on hybrid ssds. In NVMSA. IEEE, 2022.
- [20] Shuai Li, Wei Tong, Jingning Liu, and et al. Accelerating garbage collection for 3d mlc flash memory with slc blocks. In ICCAD. IEEE, 2019.
- [21] Duo Liu, Lei Yao, Linbo Long, and et al. A workload-aware flash translation layer enhancing performance and lifespan of tlc/slc dual-mode flash memory in embedded systems. In MICPRO. Elsevier, 2017.
- [22] Linbo Long, Jinpeng Huang, Congming Gao, and et al. Adar: Application-specific data allocation and reprogramming optimization for 3-d tlc flash memory. TCAD, 2022.
- [23] Micron. Optimized client computing with dynamic write acceleration. https://www.micron.com/.
- [24] Dushyanth Narayanan, Eno Thereska, Austin Donnelly, and et al. Migrating server storage to ssds: Analysis of tradeoffs. In EuroSys. ACM, 2009.
- [25] Yangyang Pan, Guiqiang Dong, Qi Wu, and et al. Quasi-nonvolatile ssd: Trading flash memory nonvolatility to improve storage system performance for enterprise applications. In HPCA. IEEE, 2012.
- [26] Samsung. Samsung solid state drive turbo write technology write paper. https://www.samsung.com/.
- [27] Liang Shi, Longfei Luo, Yina Lv, and et al. Understanding and optimizing hybrid ssd with high-density and low-cost flash memory. In ICCD. IEEE, 2021.
- [28] Seung-Hwan Shin, Dong-Kyo Shim, Jae-Yong Jeong, and et al. A new 3-bit programming algorithm using slc-to-tlc migration for 8mb/s high performance tlc nand flash memory. In VLSIC. IEEE, 2012.
- [29] Tai-Chou Wu, Yu-Ping Ma, and Li-Pin Chang. Flash read disturb management using adaptive cell bit-density with in-place reprogramming. In DATE. IEEE, 2018.
- [30] Sangjin Yoo and Dongkun Shin. Reinforcement learning-based slc cache technique for enhancing ssd write performance. In HotStorage. USENIX, 2020.
- [31] Wenhui Zhang, Qiang Cao, Hong Jiang, and et al. Spa-ssd: Exploit heterogeneity and parallelism of 3d slc-tlc hybrid ssd to improve write performance. In ICCD. IEEE, 2019.