In-Network Accumulation: Extending the Role of NoC for DNN Acceleration
Abstract
Network-on-Chip (NoC) plays a significant role in the performance of a DNN accelerator. The scalability and modular design property of the NoC help in improving the performance of a DNN execution by providing flexibility in running different kinds of workloads. Data movement in a DNN workload is still a challenging task for DNN accelerators and hence a novel approach is required. In this paper, we propose the In-Network Accumulation (INA) method to further accelerate a DNN workload execution on a many-core spatial DNN accelerator for the Weight Stationary (WS) dataflow model. The INA method expands the router’s function to support partial sum accumulation. This method avoids the overhead of injecting and ejecting an incoming partial sum to the local processing element. The simulation results on AlexNet, ResNet-50, and VGG-16 workloads show that the proposed INA method achieves improvement in latency and improvement in power consumption on the WS dataflow model.
Index Terms:
Network-on-Chip (NoC), Convolutional Neural Network (CNN), Routing, In-Network Accumulation (INA), DNN Accelerator, Weight Stationary (WS)I INTRODUCTION
The increasing popularity of Deep Neural Networks (DNN) can be attributed to the availability of training data, advancements in semiconductor technology, and rapid evolution in DNN algorithms. However, there is also a disparity between the rate at which DNN architecture is evolving and the underlying hardware that executes DNN to satisfy the need of real-world applications. DNN execution demands high computing and power budget, however, many AI applications demand the execution on hardware with limited computation and power budget. Hence, traditional general-purpose processors are no longer able to cater to this need, which drives the research on domain-specific processors i.e., accelerators [1].
Spatial architecture [2] is a popular class of domain-specific architecture where a number of Processing Elements (PEs) are connected via a communication fabric to exploit the computing and communication parallelism. DNN accelerators typically consist of an array of PEs each configured with its own local memory, and control unit, as well as a global buffer that hides the DRAM access latency. These PEs are typically connected via the Network-on-Chip (NoC) [3] which serves a critical role in the overall performance of the DNN execution [4]. NoC enables parallelism in computation and communication by allowing multiple PE support and parallel data movement.
The dataflow model determines the processing order and where data is stored and reused, i.e., the way data (including inputs, weights, and partial sums) communication happens between the PEs and the global memory. DNN algorithms can be mapped onto the PEs using various dataflow models [5] like Output Stationary (OS), Weight Stationary (WS), Row Stationary (RS), etc. each of them has its own memory usage and energy advantage.
Authors in [6] demonstrated that more than of a certain class of DNN workload execution time on a single-threaded CPU was spent on a convolution layer. Similarly, in most commonly used DNNs the multiply and accumulate (MAC) operations in CONV and FC layers consume more than of the total operations involved. Due to the volume of MAC operations and data (weights, inputs) involved, the DNN execution bottleneck in hardware can be broadly categorized into communication and computation.
The computation bottleneck is fairly straightforward to resolve. This involves adding or increasing the number of PEs or computation nodes. However, it is also to note that increasing computation resources will increase a fair amount of complexity in the communication infrastructure. Additionally, DNN comes in a variety of shape and sizes which include the diversity in layers, kernels, etc. In order to handle these diverse workloads, the communication needs should be reconfigurable. In this paper, we propose the In-Network Accumulation (INA) method which focuses on reducing the network load and potentially memory transactions that will help in alleviating the communication bottleneck.
II Background and Motivation

Fig. 1 shows an example of the Weight Stationary (WS) dataflow model where each PE keeps the filter weight stationary in a PE while the input activations and partial sums move across the PE array. When these weights are no longer needed, they will be replaced with other weights. This setting reuses the weights and minimizes the energy consumption in reading the weights. Google’s TPU [2] is one example of a design that uses the WS dataflow model.
The dominant computing architecture today relies on memory to provide data to the PE when required. This approach of computing has hit the memory wall i.e., there is a big gap to fill in between the memory latency and CPU execution latency. To overcome this gap, near memory computing or in-memory computing [7] is considered a promising candidate. The main philosophy behind these architectures is to process the data close to where it is stored. Inspired by this philosophy, in this paper we present in-network accumulation to accelerate the DNN workload in accelerators. The fundamental principle of this architecture is to process the data in the network while routing the data.
There exist enough operations in the DNN workload that can be offloaded to the memory as near-memory computing. Authors in [8] proposed an in-memory computing architecture for neural network applications, however, this method is not suitable for CNN workloads. This architecture does not offer flexibility in data reuse which leads to frequent reloading of input feature maps and weights during the DNN execution. Similarly, authors in [9] propose a Computing-On-the-Move (COM) architecture to address the shortcomings of [8]. COM [9] is implemented on a 2D Mesh NoC to enable the inter-memory computation like psum addition.
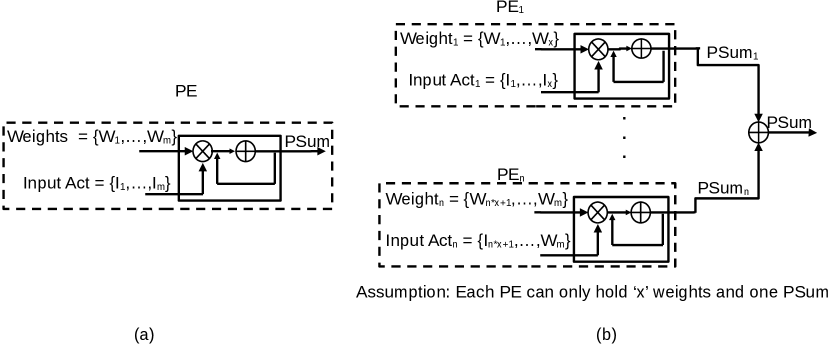
However, the aforementioned architectures cannot be easily integrated with existing accelerator designs adopting different dataflow models. Let us assume a WS dataflow model, where filter weights are stored at local PEs and kept there until all the MAC operations involving the weights are exhausted. The major bottleneck in this approach is to keep the filter weights in the local PE where we have limited scratch memory or a register file. To address this problem, only a portion of the weights are kept in a PE, and overall multiple PEs share and store the weights of one filter. This distribution of filter weights results in the distribution of the partial sum across multiple PEs which need accumulation. A similar distribution also occurs in the RS dataflow model.
Fig. 2 shows the partial sum (psum) generation method which is explained by showing the MAC operation in different dataflow models. A weight vector consisting of elements and an input vector consisting of elements are streamed from the streaming bus to the PE in the OS dataflow model where the psum accumulation is performed at a single PE as shown in Fig. 2 (a). However, due to the distributed nature of weights/inputs in the WS/RS dataflow model particularly due to the memory limitation, psum accumulation needs to happen across different PEs as shown in Fig. 2 (b). Assuming that each PE can hold only elements from the weights and input vector, only a part of the psum is generated at each PE. This provides an opportunity to optimize the way psum accumulation happens in the WS/RS dataflow model.
In this paper, INA is provided as a solution to perform the psum accumulation on memory constraint models like WS/RS where only a portion of calculation happens in a PE. INA eliminates the additional network traffic due to the limited memory of a PE. The proposed method helps in reducing unnecessary movement of the psum by allowing the psum accumulation perform at the router.
III Architectural Support
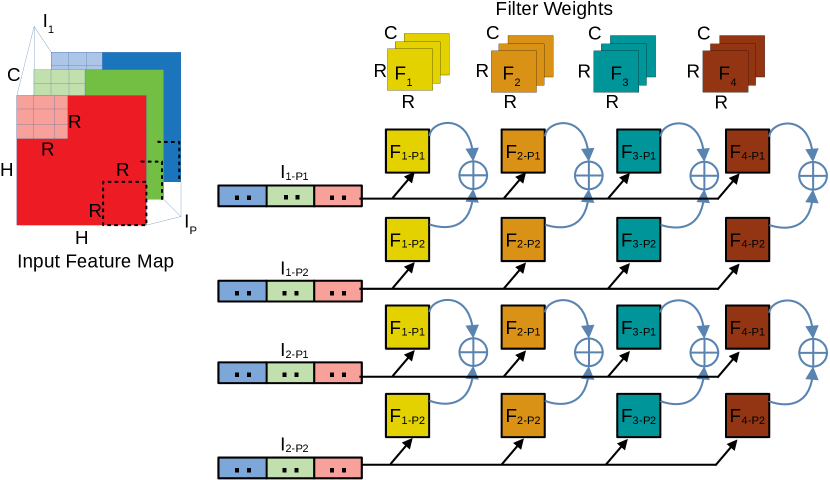
The INA design modifies the router to support psum accumulation which makes it easy to integrate with the existing accelerator design. The INA is controlled by a central controller, hence the accelerator can be optimized for individual DNN layers unlike in COM [9] where the dataflow control is distributed. Fig. 3 shows an example of the WS dataflow model on a mesh. Assume that a CONV operation with a filter in , input activation in each with a dimension of is implemented on a mesh where each PE can hold half the elements of a filter. In order to generate one output activation, two PEs are required as shown in Fig. 3 where the filter weights are divided into two parts and distributed among two adjacent PEs in the same column. After both PEs generate a psum, they can be accumulated across the PEs to get the final output activations.

Fig. 4 shows the flow for psum accumulation with and without in-network support. Fig. 4 (a) shows the flow where - are the sequential steps that need to be performed in order to process the accumulation of the partial sum generated at each node on a WS dataflow model as shown in Fig. 1. In the absence of in-network accumulation, the incoming packet with partial sum is first ejected to the PE where accumulation happens locally and then the packet with the new accumulation result needs to be injected back to the network for the next hop .
Fig. 4 (b) shows the alternative approach of accumulation of the partial sum generated at each node on a WS dataflow model in the presence of an in-network accumulation unit. Steps - show the flow of partial sum accumulation in the presence of in-network accumulation support. This method of accumulation brings the computation close to the data source and helps in removing the redundant and obvious network transactions. The incoming packet can be directly accumulated in the router with the partial sum as generated by the local node before forwarding it to the next hop . One thing to notice here is ejection and injection of the packets are saved with the support of in-network accumulation which not only helps in improving the latency but also saves the network power consumption.
III-A INA Modeling
INA is beneficial for the WS and RS dataflow models where certain parameters are stored at the PE until reused. Consider a WS dataflow model on a mesh with 1 PE/router with a memory capacity of bits. For any CONV layer with kernel size, channels, filters, output feature map, -bit precision. We can model the INA of partial sums using a series of equations shown below:
Condition to perform INA, iff Equation (1) holds true.
| (1) |
Number of PEs () to distribute the filter weights is:
| (2) |
Rounds of INA () to complete one CONV layer on a given mesh:
| (3) |
Equation 1 shows that the condition to perform an INA during a CONV layer execution is dependent on the size of memory for PEs. With sufficient memory there is no need for the INA, however, this is not feasible practically. Hence, to keep in the practical range, certain dataflow models like WS, RS should distribute the weights, inputs, etc. among multiple PEs leading to the INA as an effective solution. Note that represents the total rounds of psum accumulation on a mesh for a given CONV layer. This means the total number of accumulations in each CONV layer is different. Tables I and II show the number of rounds of INA operation for and mesh, respectively. It is seen that there exist enough INA operations that can be optimized. Also, we can see that VGG-16 [10] has a lot of INA rounds compared to AlexNet [11] since VGG-16 has a lot of filters with larger channels which makes the parameter fit in one PE’s memory difficult. Hence, the weights are distributed among different PEs leading to an increase in INA rounds.
| Layer | R | C | F | O | , N=8 | , N=16 | |
|---|---|---|---|---|---|---|---|
| CONV1 | 11 | 3 | 64 | 55 | 1 | NA | NA |
| CONV2 | 5 | 64 | 192 | 27 | 2 | 4374 | 1094 |
| CONV3 | 3 | 192 | 384 | 13 | 2 | 2028 | 507 |
| CONV4 | 3 | 384 | 256 | 13 | 4 | 2704 | 676 |
| CONV5 | 3 | 256 | 256 | 13 | 3 | 2704 | 541 |
| *Note: q=32bit, M=32KB, 1 PE/Router | |||||||
| Layer | R | C | F | O | , N=8 | , N=16 | |
|---|---|---|---|---|---|---|---|
| CONV1 | 3 | 3 | 64 | 224 | 1 | NA | NA |
| CONV2 | 3 | 64 | 64 | 224 | 1 | NA | NA |
| CONV3 | 3 | 64 | 128 | 112 | 1 | 25088 | 6272 |
| CONV4 | 3 | 128 | 128 | 112 | 2 | 50176 | 12544 |
| CONV5 | 3 | 128 | 256 | 56 | 2 | 25088 | 6272 |
| CONV6 | 3 | 256 | 256 | 56 | 3 | 50176 | 10036 |
| CONV7 | 3 | 256 | 256 | 56 | 3 | 50176 | 10036 |
| CONV8 | 3 | 256 | 512 | 28 | 3 | 25088 | 5018 |
| CONV9 | 3 | 512 | 512 | 28 | 5 | 50176 | 8363 |
| CONV10 | 3 | 512 | 512 | 28 | 5 | 50176 | 8363 |
| CONV11 | 3 | 512 | 512 | 14 | 5 | 12544 | 2091 |
| CONV12 | 3 | 512 | 512 | 14 | 5 | 12544 | 2091 |
| CONV13 | 3 | 512 | 512 | 14 | 5 | 12544 | 2091 |
| *Note: q=32bit, M=32KB, 1 PE/Router | |||||||
Similarly, for multiple PEs/router Equation 3 can be written as:
| (4) |
It is also to note that, with the increase in computation capacity the performance does not scale linearly since the addition of PEs/router will increase the communication load in the network as well.
III-B Router Support
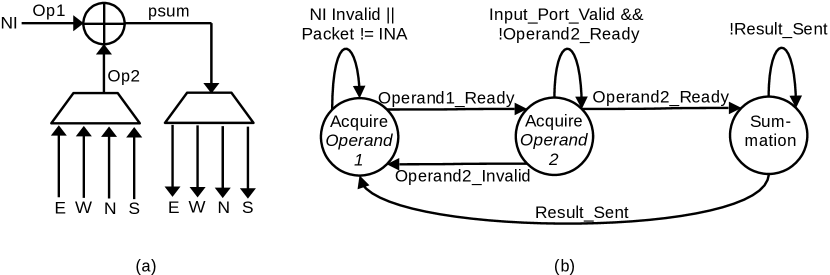
Fig. 5 shows the changes required to make in the existing router architecture from [12] to support the INA. The INA block (Fig. 6(a)) is added along with the required control (Fig. 6(b)) and signals to support the INA as shown in Fig. 6. The INA block is responsible for monitoring the operands from the incoming local port i.e., NI, and from the neighboring node i.e., N, S, E, W port. The INA performs the psum addition without letting the incoming psum exit the router. INA fully utilizes the existing router pipeline and does not affect the existing pipeline stage. The four-stage router pipelines [3] are sufficient to perform the psum accumulation similar to [12] while implementing the gather router.
Steps - from Fig. 4(b) can be equivalently mapped to the states , and states respectively from Fig. 6 (b). The source of is the incoming packet from the neighboring node which contains a portion of the partial sum. The source of is the NI of the local PE which calculates the other portion of the partial sum based on the set of weights and input activations distributed to this node and intends to forward it to the next node to complete the partial sum addition.

During the DNN execution, weights are distributed to different nodes in part. The number of parts depends on the memory size of the node and the size of weights for a CONV layer. The scheduler or the top level controller will assign at the runtime i.e., during streaming which node should initiate the INA packet. This is usually the first node that holds the first part of the weight during the distribution.
The purpose of this work is to show the effectiveness of INA in DNN execution by evaluating the network efficiency. There are multiple ways of implementing the adder unit in the router to achieve INA. Various analog adders have been proposed based on ReRAM technology one such example is [13]. To adopt the ReRAM based structure, we need some additional structures like the digital to analog converter and vice versa. There are other fast digital adders [14]-[16] as an alternative to analog adders. For the multiple PEs/router scenario we can further extend the adders into a simple SIMD/Vector adder unit, some of the alternative choices are presented in [17]-[19]. In this work, our primary goal is to show the efficiency of the INA, hence we prefer to use a digital adder from [14] to validate our concept.
| Topology | 8x8 Mesh | |
|---|---|---|
| Virtual Channels | 2 | |
| Latency | router: 4 cycles, link: 1 cycle | |
| Buffer Depth | 4 flits | |
| Flit Size | 128 bits/flit | |
| Gather Payload | 32 bits | |
| Number of PE per router | 1,2,4,8 | |
| Gather Packet Size |
|
|
| Unicast Packet Size |
|
IV Performance Evaluation
We assume that there is a higher level entity or a mapping framework similar to [2], [20] that does the task of mapping neurons to the PEs, streaming the inputs and weights in parts, controlling timing for better synchronization without stalls, so that our focus is on evaluating the performance of the on-chip network.
To evaluate the performance of INA for the WS dataflow model, we ran simulations for different CNN workloads on 8x8 mesh-based NoCs modified with a two-way streaming architecture [12]. For the WS dataflow model, all the weights are streamed in full or in parts as needed depending on the memory availability, these weights are stored in the local memory of the PE and used for multiple rounds of MAC operation for all the input activations. Hence, input activation will not be streamed, and the PE should not start the MAC operation until all the weights are streamed to the local memory of the PE. In this section, we describe the experiment settings, followed by presenting the results.
IV-A Experiment Setup
Table III shows the NoC setting used for performance analysis. To accommodate the gather payload after INA, we have used various gather flit sizes. After the INA, the gather packet can have 1 flit to 9 flits depending upon the number of nodes used to get the accumulation result. For the 1 PE/router case, if the INA is performed on 2 nodes, then the gather packet needs to collect the result of 4 nodes on 8x8 mesh. This information is identified at the compile time by the higher level entity or a mapping framework.
We compare the WS dataflow model with and without INA both using gather packets in terms of the runtime latency and power consumption, we further extended the result to compare the INA-enabled WS dataflow model with the OS dataflow model with gather support from [12]. We assume that the INA is using a similar digital adder proposed in [14] which is fast and has various bit widths suitable for our analysis, we also assume that the accumulation latency in both cases, with INA and without INA are comparable. We use the parameters obtained from Pytorch framework [21] to model the traces for the NoC. Accumulation happens using INA in the router as explained in Fig. 4. We have used a cycle-accurate C++ based NoC simulator [22] to simulate the generated traces for AlexNet [11], ResNet-50 [23], and VGG-16 [10]. Orion 3.0 [24] is used to estimate the power consumption for NoC.
IV-B Results
Fig. 7 (a), (b) shows the improvement in the total runtime latency and power consumption of the WS dataflow model with INA against the one without INA case for all convolution layers in AlexNet [11] on 8x8 mesh-based NoCs. We can see that INA can improve the latency up to and power consumption up to compared to without INA case. A similar improvement is seen across other DNN workloads as shown in Fig. 8 and Fig. 9 for ResNet [23] and VGG-16 [10], respectively.



For all the workloads, the improvement in latency is almost similar in 1, 2, and 4 PEs/router, and the improvement increases for 8 PEs/router. The latency improvement in this comparison is determined by the packet size used for both INA and without INA. For 1, 2, 4 PEs/router, both the cases will use a similar number of flits per packet, and hence we can also see a similar improvement in latency. However, for 8 PEs/router packet size should increase, and without INA case larger packet size adds up to more latency. We can also see that VGG-16 on average has a larger improvement than other workloads due to the multiple rounds of INA () needed in VGG-16. Even though ResNet-50 is bigger in terms of the number of CONV layers than VGG-16, most of the ResNet-50 does not need to split the weights among multiple PEs () and hence ResNet-50 is not showing the highest improvement even with a larger network model.
As for the power improvement, a smaller number of PEs shows the highest improvement. As the number of PEs increases, the number of flits per gather packet should also increase to accommodate all the payloads which contribute to the additional power in the case of INA. Dynamic flit would have made an impact here but in this experiment, we have assumed a static packet size. However, without INA, packets do not need to increase the flit size since the addition is happening between two nodes and a smaller flit can be used to move the partial sum for accumulation. A similar trend for performance is seen across different workloads where VGG-16 is the highest performing due to the similar reasons as explained for the latency improvement.
Fig. 10 - Fig. 12 shows the comparison between the WS dataflow model with INA and gather supported and OS dataflow model with gather supported. The latency result of WS is degrading with the number of PEs increasing because, for the WS dataflow model, weights need to be distributed before the psum accumulation begins. As the number of PEs increases the distribution of weights also takes longer due to the larger packet size. However, on the OS dataflow model both the weight and input distribution happen together and hence the psum accumulation can begin earlier. As for the power improvement, the WS dataflow model outperforms the OS dataflow model in all the cases. This improvement is mainly due to the better reuse of weights leading to less streaming than the OS dataflow model. We see fluctuations in power improvement going from 1 PE/router to 2 PEs/router and from 4 PEs/router to 8 PEs/router because this is the boundary where a change in the flit size happens due to the increase in the number of PEs in the router.



V Conclusion
DNN workloads can be executed with a variety of dataflow models. Supporting different dataflow models is important to ensure effective data reuse during the DNN execution. In this paper, we present the In-Network Accumulation (INA) architecture to support partial sum accumulation without ejecting the packet from the network on a WS dataflow model. To support the psum accumulation, an INA block enclosing a digital adder will be added to each router. We performed the simulation on different DNN workloads and showed improvement in the runtime latency and improvement in the power consumption. Further comparison with the OS dataflow model with gather support, the WS dataflow model with INA achieves up to latency improvement and improvement in the power consumption across different DNN workloads. In our future work, this method will be explored further with other dataflow models and NoC topologies.
Acknowledgment
This work is supported in part by the National Science Foundation under grant no. 1949585.
References
- [1] N. P. Jouppi, et.al., “A domain-specific architecture for deep neural networks,” in Commun. ACM, Sept. 2018, pg.50–59.
- [2] N. P. Jouppi, et al., “In-datacenter performance analysis of a tensor processing unit,” in Proc. 44th ISCA, 2017.
- [3] W. Dally, B. Towles, “Principles and practices of interconnection networks,” Morgan Kaufmann Publishers Inc., San Francisco, USA, 2003.
- [4] S. M. Nabavinejad, et al., “An overview of efficient interconnection networks for deep neural network accelerators,” IEEE J. Emerg. Sel. Topics Circuits Syst., vol. 10, no. 3, 2020.
- [5] V. Sze, Y. Chen, J. Emer, A. Suleiman and Z. Zhang, “Hardware for machine learning: challenges and opportunities,” in Proc. CICC, 2017.
- [6] J. Cong and B. Xiao, “Minimizing computation in convolutional neural networks,” in Proc. ICANN, 2014, pp. 281-290.
- [7] G. Singh, et al., “A review of near-memory computing architectures: opportunities and challenges,” in Proc. DSD, 2018, pp. 608-617.
- [8] H. Jia, et al., “A programmable neural-network inference accelerator based on scalable in-memory computing,” in Proc. ISSCC, 2021.
- [9] K. Zhou, Y. He, R. Xiao, J. Liu and K. Huang, “A customized NoC architecture to enable highly localized computing-on-the-move DNN dataflow,” IEEE Trans. Circuits Syst., II, Exp. Briefs, vol. 69, no. 3, Mar. 2022.
- [10] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. ICLR, 2015.
- [11] A. Krizhevsky, “One weird trick for parallelizing convolutional neural networks,” CoRR, vol. abs/1404.5997, 2014. [Online]. Available: http://arxiv.org/abs/1404.5997.
- [12] B. Tiwari, M. Yang, X. Wang, Y. Jiang, “Data streaming and traffic gathering in mesh-based NoC for deep neural network acceleration,” J. Syst. Archit., vol. 126, 2022.
- [13] L. Song, X. Qian, H. Li and Y. Chen, “PipeLayer: a pipelined ReRAM-based accelerator for deep learning,” in Proc. HPCA, 2017, pp. 541-552.
- [14] M. A. Akbar, B. Wang, and A. Bermak, “Self-repairing carry-lookahead adder with hot-standby topology using fault-localization and partial reconfiguration,” IEEE Open J. Circuits Syst., vol. 3, Mar. 2022.
- [15] L. Pilato, S. Saponara and L. Fanucci, “Performance of digital adder architectures in 180nm CMOS standard-cell technology,” in Proc. AE, 2016, pp. 211-214.
- [16] S. Shriram, J. Ajayan, K. Vivek, D. Nirmal and V. Rajesh, “A high speed 256-bit carry look ahead adder design using 22nm strained silicon technology,” in Proc. ICECS, 2015, pp. 174-179.
- [17] R. Rogenmoser, L. O’Donnell and S. Nishimoto, “A dual-issue floating-point coprocessor with SIMD architecture and fast 3D functions,” in Proc. ISSCC, 2002, vol.1, pp. 414-415.
- [18] S. Payer, et al., “SIMD multi format floating-point unit on the IBM z15(TM),” in Proc. ARITH, 2020, pp. 125-128.
- [19] L. Crespo, P. Tomás, N. Roma and N. Neves, “Unified posit/IEEE-754 vector MAC unit for transprecision computing,” IEEE Trans. Circuits Syst., II, Exp. Briefs, vol. 69, no. 5, May 2022.
- [20] Z. Du, et al., “ShiDianNao: shifting vision processing closer to the sensor,” in Proc. 42nd ISCA, 2015, pp. 92-104.
- [21] A. Paszke, et al., “PyTorch: an imperative style, high-performance deep learning library,” in Proc. NIPS, 2019, pp. 8024-8035.
- [22] X. Wang, et al., “On self-tuning networks-on-chip for dynamic network-flow dominance adaptation,” in Proc. 7th IEEE/ACM NOCS, 2013.
- [23] k. He, X. Zhang, et al., “Deep residual learning for image recognition,” in Proc. CVPR, 2016.
- [24] A. B. Kahng, B. Lin, and S. Nath, “ORION3.0: a comprehensive NoC router estimation tool,” IEEE Embedded Syst. Lett., vol. 7, no. 2, pp. 41–45, Jun. 2015.