[1]organization=Wyant College of Optical Sciences, University of Arizona, city=Tuscon, Arizona, country=USA \affiliation[2]organization=School of Electrical Engineering and Telecommunications, University of New South Wales, city=Sydney, country=Australia
Improving the Performance of Echo State Networks Through Feedback
Abstract
Reservoir computing, using nonlinear dynamical systems, offers a cost-effective alternative to neural networks for complex tasks involving processing of sequential data, time series modeling, and system identification. Echo state networks (ESNs), a type of reservoir computer, mirror neural networks but simplify training. They apply fixed, random linear transformations to the internal state, followed by nonlinear changes. This process, guided by input signals and linear regression, adapts the system to match target characteristics, reducing computational demands. A potential drawback of ESNs is that the fixed reservoir may not offer the complexity needed for specific problems. While directly altering (training) the internal ESN would reintroduce the computational burden, an indirect modification can be achieved by redirecting some output as input. This feedback can influence the internal reservoir state, yielding ESNs with enhanced complexity suitable for broader challenges. In this paper, we demonstrate that by feeding some component of the reservoir state back into the network through the input, we can drastically improve upon the performance of a given ESN. We rigorously prove that, for any given ESN, feedback will almost always improve the accuracy of the output. For a set of three tasks, each representing different problem classes, we find that with feedback the average error measures are reduced by . Remarkably, feedback provides at least an equivalent performance boost to doubling the initial number of computational nodes, a computationally expensive and technologically challenging alternative. These results demonstrate the broad applicability and substantial usefulness of this feedback scheme.
keywords:
Reservoir Computing, Echo State Network, Feedback Improvement1 Introduction
Compared to recurrent neural networks where excellent performance could only be obtained with very computationally expensive system adjustment procedures, the premise of reservoir computing is to use a fixed nonlinear dynamical system of the form (1)-(2) to perform signal processing tasks:
| (1) | ||||
| (2) |
where is the input signal at time [1, 2, 3]. The output of the dynamical system is then typically taken as a simple linear combination of the states (nodes) of the dynamical system as given in (2) plus some constant (as the output bias), where is a weight matrix and is its transpose. The nodes correspond to a basis map that is used to approximate an unknown map which maps input (discrete-time) sequences to output sequences that are to be learned by the dynamical system. Using the linear combination of states makes the training extremely straightforward and efficient as the weight matrix can be determined by a simple linear regression.
Reservoir computers (RCs) have been extensively used to predict deterministic sequences, in particular chaotic sequences, and data-based chaotic system modelling, see, e.g., [4, 5, 6]. In the deterministic setting it has found applications in channel equalization [4], chaos synchronisation and encryption [7], and model-free observers for chaotic systems [8]. RCs have also be studied for modelling of stochastic signals and systems with applications including time series modelling, forecasting, filtering and system identification [9, 10, 11, 12].
Physical reservoir computing employs a device with complex temporal evolution, tapping into the computational power of a nonlinear dynamical system without extensive parameter optimization needed in typical neural networks. Inputs are fed into a reservoir, a natural system with complex dynamics, influencing its state based on current and past inputs due to its (limited) memory. The reservoir, running automatically, is altered only by these inputs. This approach models complex, nonlinear functions with minimal requirements: problem-related inputs and a linear fitting algorithm. Various physical platforms have been experimentally demonstrated for reservoir computing include, for instance, photonics [13, 6], spintronics [14] and even quantum systems [15, 16, 17]. For a review of physical reservoir computing and quantum reservoir computing, see, e.g., [3, 18, 19, 20].
An echo state network (ESN) [4, 21, 22, 23] is a type of RC using an iterative structure for adding nonlinearity to inputs. It is similar to a recurrent neural network, except that the neural weights are fixed and optimization occurs only at the output layer. In an ESN, the reservoir state at time step is represented by vector , equivalent to the neural outputs at step . Each step involves applying a fixed linear transformation given by a matrix to , then adding to it a vector times the input value , forming a new vector . The matrix represents the fixed neural weights, while the vector represents the biases. A nonlinear transformation on each element of generates , akin to neuron outputs. The affine function of given in (2) is then fit to a target value sequence , giving an output that approximates the target system. We describe the ESN framework with further detail in Section 2.1.
The main drawback of this approach is that any specific ESN is only going to be effective for a certain subset of problems because the transformations that the reservoir applies are fixed, so a specific reservoir will tend to modify the inputs in the same way, leading to a limited range of potential outputs. It has been shown in [10] that ESNs as a whole are universal, meaning that for any target sequence and a given input sequence , there will be an ESN with specific choices of that can approximate it to any desired accuracy. However, it may not be practically feasible to find a sufficiently accurate ESN for a particular problem of interest as it may require choosing an excessively and unpractically large ESN, and one may have to settle for an ESN with a weaker performance instead.
There have been previous efforts related to the above issue. In the context of an autonomous ESN with no external driving input, the work [24] introduces a number of architectures. One architecture includes adding a second auxiliary ESN network besides the principal “generator” ESN. The auxiliary is fed by a tunable linear combination of some nodes of the generator ESN, while a fixed (non-tunable) linear combination of the nodes of the auxiliary ESN is fed back to the generator network. The same error signal at the output of the generator ESN is used to train both the output weight of the principal and the weights that connect the generator to the auxiliary. The weight update is done recursively through an algorithm called the First-Order, Reduced and Controlled Error (FORCE) learning algorithm, which is in turn based on the recursive least squares algorithm. A second architecture does not use feedback but allows modification of the some internal weights of the ESN besides the output weight, as in a conventional recurrent neural network. The internal and output weights are also updated using the FORCE algorithm. In [25], multiple ESNs with tunable output weights that are interconnected in a fixed feedforward architecture (with no feedback loops) are considered. A set of completely known but randomly generated “surrogate” ESNs are coupled according to some architecture and trained by simulation (“in silico”) using the backpropagation algorithm for artificial neural networks. The “intermediate” signals generated at the output of each component ESN are then used to train the output weights of another set of random ESNs, representing the “true” ESNs that will be deployed, in the same architecture. The output weights of the individual true ESNs can be trained by linear regression. In [26], in the continuous time setting, it was shown that an affine nonlinear system given by the nonlinear ODE:
for scalar real functions and is universal in the sense that it can exactly emulate any other -th order ODE of the form
that is driven by a signal , where is a scalar signal and denotes the -th derivative of with respect to time. The emulation is achieved by appropriately choosing scalar-valued real functions and and setting and , where is the column vector , where denotes the transpose of a matrix. Also, any system of higher order ODEs in of the form above can be emulated by using different feedback terms.
In this work, unlike [24], we are interested in ESNs that are driven by external input and are required to be convergent (forget their initial condition). Notably, the ESN in [24] could not be convergent because a limit cycle was used to generate a periodic output without any inputs in the ESN. When driven by an external input such networks may produce an output diverging in time. Also, while the study in [24] is motivated by biological networks, our work is motivated by the applications of physical reservoir computing. In particular, we are interested in enhancing the performance of a fixed physical RC by adding a simple but tunable structure external to the computer. Also, in contrast to [25], in this paper we do not consider multiple interconnected ESNs in a feedforward architecture and do not use surrogates, but train a single ESN augmented with a feedback loop directly with the data. While our work is related to [26] as discussed above, we do not seek universal emulation, but consider a linear feedback that only depends on the state , but not the input , to enhance the approximation ability of ESNs.
The goal of this paper is to study the use of feedback in the context of ESNs and show that it will improve the performance of ESNs in the overwhelming majority of cases. Our proposal is to feed a linear function of the reservoir state back into the network as input. That is, for some vector , we change the input from to . We then optimize with respect to the cost function to achieve a better fit to the target sequence . This has the effect of changing the linear transformation that the reservoir performs on at each time step, allowing us to partially control how the reservoir state evolves without modifying the reservoir itself. This will in essence provide us with a wider range of possible outputs for any given ESN, and can provide smaller ESNs an accuracy boost that makes them comparable to larger ones. Thus, our new paradigm of ESNs with feedback generates a significant performance boost with minimal perturbation of the system. We offer a thorough proof of a broad theorem, confidently ensuring that almost any ESN will experience a performance enhancement when a feedback mechanism is implemented, making this new scheme of ESNs with feedback universally applicable.
The structure of the paper is as follows. In Section 2, we provide some background on reservoir computers and echo state networks and introduce our feedback procedure. In Section 3, we provide a proof of the superiority of ESNs with feedback. In Section 4, we describe how the new parameters introduced by feedback are optimized. In Section 5, we provide numerical results that demonstrate the effectiveness of feedback for several different representative tasks. Finally, in Section 6 we give our concluding remarks.
In this paper, we denote the transpose of a matrix as , with the same notation used for vectors. The identity matrix is written as , while the zero matrix of any size (including any zero vector) is written as . We treat an -dimensional vector as an rectangular matrix in terms of notation, and in particular the outer product of two vectors and is written as . The vector norm denotes the standard 2-norm . For a sequence whose th element is given by , we denote the entire sequence as . When finite, a sum of the elements of such a sequence is often written notationally as if they were a sample of some stochastic process. We write weighted sums of these sequences as determinstic “expectation” values (averages), so that for a sequence with entries starting from we may write . We also define the mean of such a sequence as and its variance as . The expectation operator is denoted by , the expectation of a random variable is denoted by and the conditional expectation of a random variable given random variables is denoted by . We will denote the input and the output sequences of the training data as , respectively.
2 Theory of Reservoir Computing with Feedback
2.1 Reservoir Computing and Echo State Networks
A general RC is described by the following two equations:
| (3) | ||||
| (4) |
where is a vector representing the reservoir state at time step , is the th member of some input sequence, and is the predicted output. The function is defined by the reservoir and is fixed, but the output function is fit to the target sequence by minimizing a cost function . In practice we usually choose (for training data points)
| (5) | |||
| (6) |
where the scalar and vector are chosen to minimize , so that the problem of fitting the output function to data is just a linear regression problem. This setup is what enables the simulation and prediction of complex phenomena with a low computational overhead, because the reservoir dynamics encoded in are complex enough to get a nonlinear function of the inputs that can then be made to approximate using linear regression.
In order for a RC to work, it must obey what is known as the (uniform) convergence property, or echo state property [12, 27]. It states that, for a reservoir defined by the function and a given input sequence defined for all , there exists a unique sequence of reservoir states that satisfy for all . The consequence of this property is that the initial state of the reservoir in the infinite past does not have any bearing on what the current reservoir state is. This consequence combined with the continuity of leads to the fading memory property [28], which tells us that the dependence of on an input for must dwindle continuously to zero as tends to infinity. This means that any initial state dependence should become negligible after the RC runs for a certain amount of time, so that the RC is reusable and produces repeatable, deterministic results while also retaining some memory capacity for past inputs.
It has been shown [10, 29] that a given RC will have the uniform convergence property if the reservoir dynamics are contracting, or in other words if it satisfies
| (7) |
where is some real number . The norm in this inequality is arbitrary (as all norms on finite-dimensional metric spaces have equivalent effects), but it is usually chosen to be the standard vector norm . This ensures that all reservoir states will be driven toward the same sequence of states defined by the inputs .
An ESN is a specific type of RC described above, with
| (8) |
where and are a random but fixed matrix and vector, respectively, while is a nonlinear function that acts on each component of its input . Throughout the paper we will take the dimension of the state to be , and the dimensions of and to be and , respectively. For the output of the ESN we have that is a real scalar and is a real column vector of dimension . This design gives the ESN resemblance to a typical neural network, where the linear transformation defines the input into the array of neurons, with providing the weights and providing a bias. The element-wise nonlinear function gives the array of outputs of the neurons as a function of the weighted inputs. The choices of and define a specific ESN, though in practice is often chosen to be one of a specific set of preferred functions such as the sigmoid or functions. In this work, we choose the sigmoid function for our numerical results.
The convergence of the ESN can be guaranteed by subjecting the matrix to the constraint that for a constant . In other words, the singular values of must all be strictly less than some number which is determined by . For the sigmoid function, we can use , while for the function we use . This originates from proving that
| (9) |
for all , so that the convergence inequality will always be satisfied as long as
| (10) |
for some . Note that this is a sufficient but not necessary condition, as there could be combinations of and such that
| (11) |
for all and , but this singular value criterion is much easier to test and design for while still providing a large space of possible reservoirs to choose from.
We parameterize how well the output of the ESN matches the target data using the normalized mean-square error (NMSE). In a linear regression problem we can show that the mean-squared error is
| (12) |
where we are averaging over the time steps corresponding to the training interval. With , we can show that
| (13) | ||||
| (14) | ||||
| (15) |
where
| (16) | ||||
| (17) |
The values of and that minimize the mean-squared error are
| (18) | |||
| (19) |
Note that since is a covariance matrix, it must be positive semi-definite, but by inverting it to find the optimal value of we have further assumed that it is positive definite. This assumption is equivalent to saying that all of the vectors span the entire vector space , where is the dimension of and all ’s. This is reasonable because in practice we usually take the number of training steps , and since each is a nonlinear transformation of the previous one, it is unlikely that any vector will satisfy for all . Nevertheless, in the event that is not invertible, we can take the pseudoinverse of instead. This is because the components of parallel to the zero eigenvectors of are not fixed by the optimization (which is why the inversion fails in the first place), so we are free to choose those components to be zero, which makes Eq. (19) correct when using the pseudoinverse of as well.
Plugging the optimized values of and into the mean-squared error gives
| (20) |
From the original expression for the mean-squared error in Eq. (12), we can see that it is non-negative. Since is a covariance matrix, the quantity . Thus is bounded above by , so we may define a normalized mean-squared error, or NMSE, by
| (21) |
This quantity is guaranteed to be between 0 and 1 for the training data, though it may exceed 1 for an arbitrary test data set. We can also see by Eqs. (12) and (20), the task of minimizing as a function of and is equivalent to maximizing as a function of .
2.2 ESNs with Feedback
The main result of this work is the introduction of a feedback procedure to improve the performance of ESNs. We add an additional step to the process where the input is taken to be at each time step as opposed to just . The reservoir of the ESN is then described by
| (22) |
From this equation, we see that the feedback causes this ESN to behave like a different network that uses as a transformation matrix instead of . We achieve this without modifying the RC itself, using only the pre-existing input channel and the reservoir states that we are already measuring. This provides a practical way of changing the reservoir dynamics without any internal hardware modification. We then optimize for using batch gradient descent to further reduce the cost function .
Note, however, that in attempting to modify we run the risk of eliminating the uniform convergence of the ESN. Thus, there must be a constraint placed on in order to keep the network convergent. In accordance with the constraint in Eq. (10), we require that in addition to , which places some limitations on the value of . This constraint is generally quite complex to solve beyond this inequality, but it is possible to formulate this as a linear matrix inequality in ; see, e.g., [12, §IV]. In addition, this condition can be easily applied during the process of optimizing .
3 Universal Superiority of ESN with Feedback over ESN without Feedback
In this section, we prove our central theorem stating that the ESN with feedback accomplishes smaller overall errors than the ESN without feedback. For this, we start with a theorem for an individual ESN:
Theorem 1 (Superiority of feedback for a given ESN and training data).
For any given matrix and vector in Eq. (8), and given sets of training inputs and outputs of finite length, define an optimized cost function with appropriate optimal and . Then, for almost any given except for vanishingly small number of , the feedback always reduces the cost function further:
| (23) |
Moreover, if is such that , where is a constant that guarantees that the ESN is convergent, then the feedback gain can alawys be chosen such that the ESN with feedback is also convergent and satisfy the above.
3.1 Preliminary Definitions and Relations
To prove Theorem 1, we will set up a number of lemmas and definitions prior to starting the main proof. This preliminary work will primarily concern the cases in which Eq. (23) does not hold, and the lemmas will show that the number of such cases is vanishingly small. The main proof of Theorem 1 will then prove the strict inequality for all other cases. The following rigorously proves that the number of cases for that satisfies the above is vanishingly small.
We will need a number of new symbols and definitions to facilitate the proofs of Theorem 1 and the following lemmas. For a given RC and training data set , there are several cases where the change in the vector may be zero. Consider an ESN with a specific choice of the matrix , vector , and nonlinear function . Also consider a fixed input sequence , and to train our network we will use the time steps ranging from 0 to . To see how the derivative of the minimized cost function with respect to the feedback parameters can be zero, define the matrix for time steps in the training data set. This is similar to the procedure used in [30] to optimize for . In other words, with computational nodes ( coming from the vector and 1 from ) and training data points, the matrix is an rectangular matrix whose columns are proportional to the mean-adjusted reservoir state at each time step in the training set. Further, define the vector . With these definitions, we can rewrite the quantities previously defined in the context of Eq. (16) as
| (24) | ||||
| (25) |
Here, the second equality of Eq. (24) used the fact that .
Denote the pseudoinverse of as . Note that while is the identity matrix, is not the identity matrix in the vector space of time steps denoted by . Instead, it is a projection operator we will call . The singular value decomposition of is given by , where is an orthogonal matrix, is taken to be an rectangular diagonal matrix with non-negative values, and is an orthogonal matrix. The pseudoinverse of is defined to be , where the pseudoinverse of is defined so that with we have . This also implies that since .
The product of and is given by , where the elements of are defined by
| (26) |
where is the step function with . Note that this is a projection operator since it satisfies . Thus the product of and is given by
| (27) |
must also be a projection operator since . We also see that is symmetric since is symmetric, so as well. This method of defining a singular value decomposition of the matrix and obtaining the corresponding projection matrix is similar to the methods used to obtain theoretical results in [31, 32]. Note that the inversion of assumes that all singular values are nonzero, but we already make this assumption when optimize for . By the expression for in Eq. (19) and the discussion following that equation, this assumption to reasonable.
To get an expression for (short for ) in this formalism, define the -dimensional vector such that its elements are given by . It can then be shown that . Then the variance of can be written as , where is the identity matrix of dimension . From this expression and the expression for twice the optimal cost given in Eq. (20), is then
| (28) | ||||
| (29) |
With the projection operator , we can rewrite this expression for optimal cost function as
| (30) |
Thus the effect of indirectly modifying the RC with feedback is to shift the basis of the projection operator to have as large of an overlap with the target sequence as possible. The derivative of with respect to some general parameter of the RC is then given simply by
| (31) |
The target is independent of the RC and thus independent of , so any changes to as a result of changing must come from a change in . The fact that is a projection operator of rank tells us some properties of any of its derivatives. First, from the property we get
| (32) |
Note that this implies . The only matrix that is equal to 2 times itself is the zero matrix, so must be the zero matrix.
3.2 Lemmas for Proving the Lower Dimensionality of Cases where
Now that we have established that the dependence of the cost function on the reservoir is entirely determined by a projection matrix , we are ready to begin discussing cases where .
Lemma 1 (Categorization of cases where a derivative of w.r.t. a general reservoir parameter vanishes).
Given and any parameter that the reservoir is dependent on, the cases where fall into one of two categories, one where only for specific target sequences and one where . Furthermore, the former category is divided into 3 more categories in which , , or neither.
Proof.
For the discussion that follows, define the vector subspace to be the space of -dimensional vectors with real coefficients such that . Define also the vector subspace such that . Note that it is always possible to construct an orthonormal basis of vectors in where the first basis vectors are in and the remaining basis vectors are in . This makes it useful to define
| (33) | ||||
| (34) | ||||
| (35) |
where in the last line we used to simplify the first term and to eliminate the second term. This definition is useful because , so from the definition above , and therefore from Eq. (32) we have
| (36) |
This also implies that
| (37) |
so the change in depends entirely upon with respect to .
From the definition of in Eq. (33), because there is a on the left side of the matrix, we then have that for all . Since has dimension , there must be at least zero singular values of . Let be the matrix rank of (number of nonzero singular values), which by the previous argument cannot be larger than . Then the singular value decomposition of can be written as
| (38) |
where is a strictly positive singular value of , is one of orthonormal basis vectors in , and one of orthonormal basis vectors in . The reason the right basis vectors are in is because of the on the right side of Eq. (33), which makes to so that for all .
With this decomposition of , we can use Eq. (37) to rewrite as
| (39) |
where and . There are 3 broad categories of for which vanishes for a given :
-
1.
is orthogonal to every , or equivalently .
-
2.
is orthogonal to every , or equivalently .
-
3.
Neither of the above statements are true, but the coefficients and are such that the sum vanishes.
There is also the possibility that is zero, meaning that every singular value of is zero, so that for any . ∎
In what follows, while we cannot rule out any of these possibilities for the feedback vector , we can show that the space of ’s that fit into the above three criterion are of lower dimension than the general space of -dimensional vectors that encompasses all ’s, and give criterion for numerically testing whether any of these cases hold for a given reservoir computation. Also, in the event that the gradient of with respect to vanishes for any , we will show that the number of solutions in the space of possible matrices , vectors , and input sequences is of lower dimension as well with testable criterion for a given ESN.
Lemma 2 (Lower dimensionality of cases where while ).
Given a specific ESN defined by a matrix , vector , and input sequence such that the projection operator satisfies , the space of training vectors that then leads to is of lower dimension than the space of all training vectors, whose dimension is .
Proof.
Define to be the same as in Eq. (33) with replaced with for each . In order for the gradient to be zero, we require that be zero for all ’s. This means that for a given set of ’s, there are three cases in which because of the particular form of :
-
Case 1:
Let be the span of the set of vectors that contains for every and , and let its dimension be . Then if is such that for all , then because for all . This includes the case where is at its maximum possible value of , in which the RC has utterly failed to capture any properties of . The dimension of the space of ’s that fall under this case is . This is because is spanned by basis vectors, so the space of ’s that are orthogonal to all of them is spanned by the remaining basis vectors. We can calculate from the matrix defined as
(40) is given by the rank of because each is a positive semi-definite matrix, so the only way that is if for all . The dimension of the space of vectors that satisfy this relation is as mentioned previously, so if has zero eigenvalues, then that leaves nonzero eigenvalues.
We see from Eq. (35) that computing will involve calculating , but since we are only interested in the rank of the matrix we can find an alternative. Recall that is an matrix whose singular values are strictly positive, so therefore the rank of is . Furthermore, , so the span of the right eigenvectors of must be . Since the span of the left eigenvectors of is a subspace of for all , the span of is also a subspace of , and we can multiply by on both sides without changing the rank and use Eq. (35) to get a simpler matrix
(41) Since this has the same number of nonzero eigenvalues as , is also given by the number of nonzero eigenvalues of . This allow us to compute without the need to calculate directly like we would have if we calculated using Eq. (35) for .
-
Case 2:
Let be the span of the set of vectors that contains for every and , and let its dimension be . Then if is such that for all , then because for all . This includes the minimal case where , in which the RC perfectly describes and no further improvement is possible. The dimension of the space of ’s that fall under this case is . This is because is spanned by basis vectors, so the space of ’s that are orthogonal to all of them is spanned by the remaining basis vectors. We can calculate from the matrix defined as
(42) is given by the rank of because each is a positive semi-definite matrix, so the only way that is if for all . The dimension of the space of vectors that satisfy this relation is as mentioned previously, so if has zero eigenvalues, then that leaves nonzero eigenvalues.
-
Case 3:
Neither of the above cases holds, but every nonetheless. Since there are different ’s, then we have equations of constraint on which ’s of this type set to zero. However, it may be possible that some of these equations are not independent, which would imply that there is at least one linear combination of ’s such that . Define to be the number of independent constraints of this form. Then the dimension of the space of ’s for which is given by , the number of free parameters left after applying the constraints. We can calculate using the matrix whose components are defined to be
(43) is given by the rank of , since if the linear combination then the -dimensional vector defined by is an eigenvector of with eigenvalue .
As long as dimensions of the spaces of ’s that satisfy the three cases above are all smaller than the total dimension of all ’s, then it is very unlikely that any given will fall into any of these categories. The total dimension of the space of vectors is , and the dimension of the spaces for each of the three cases are and , respectively, so as long as and are all positive, than this argument holds. We can check whether or not they are zero by taking the traces of their respective matrices and since they are all positive semi-definite matrices, so the only way that the sums of their eigenvalues are zero is if every eigenvalue is zero. It turns out that all three traces are equal, since
| (44) |
so therefore if any one of or are found to be zero, then all three are guaranteed to be zero. This is because a matrix whose eigenvalues are all zero must be the zero matrix, so this implies that for all , which is the subject of our second proof below. Conversely, Eq. (44) also implies that if any one of them is positive, then they all must be positive as well, so we need only check that one of them is nonzero for this proof to hold. The easiest one to check is likely as we can use in place of and avoid directly calculating the . ∎
Lemma 3 (Lower dimensionality of cases where ).
The space of ESNs defined by matrices, vectors, and input sequences that satisfies is of lower dimension than the space of all possible ESNs.
Proof.
Our second part of this proof will show that in the space of all matrices , vectors , and input sequences that lead to a convergent RC, the subspace of these where for all (or equivalently that for all ) must be of lower dimension as well. If it was not of lower dimension, then that would imply that holds over a finite region of the possible values of and . If the function representing the reservoir dynamics is analytic, then all reservoir states must be analytic functions of and as well. In this paper, we are considering ESNs with , where is the element-wise sigmoid function, which is analytic. So if all reservoir states are analytic in and , then is an analytic function of these variables as well, so if holds over a finite region of the possible values of these variables, then must be constant with respect to for all and , which is a direct consequence of the identity theorem of an analytical function [33]. However, the ESN will become unstable for a with a sufficiently large norm, in which case the fit to will be poor and would have to be larger than if we had no feedback. Thus must not be constant with respect to for all and , and therefore the space of matrices , vectors and training inputs that satisfy is of lower dimension than the space of all possible . ∎
Lemma 4 (Lower dimensionality of the subdomain of for which ).
The dimension of the space of matrices, vectors, input sequences, and target sequences that satisfy is strictly less than the dimension of the space of all possible , which implies that the number of cases in which has a null gradient w.r.t. is vanishingly small compared to all cases.
Proof.
Lemma 2 proves that when , the number of cases where is vanishingly small in the space of all training sequences , and therefore also in the space of all possible . Lemma 3 proves that when , the number of cases where is vanishingly small in the space of all matrices , vectors , and training inputs , and therefore for all training sequences as well. Therefore, the number of cases of where is vanishingly small over all possible , regardless of . ∎
Finally, we note that all of this work dedicated to finding where is a necessary but not sufficient condition for proving that feedback will not improve the result. That is, the points where correspond to the extrema of with respect to , but these extrema could be minima, maxima, or saddle points. However, only minima will prevent feedback from improving the output of an ESN, and if we use a non-local method to find the global minimum of with respect to , then local minima do not mitigate improvement, either.
It is possible to compute without much extra overhead for any given run of a RC to see if it is zero. The derivatives can be calculated iteratively using the relation
| (45) | ||||
| (46) |
where . This uses , , and the reservoir states that have already been obtained from running of the RC. We can also avoid computing matrices like directly by noting that from previous results we have . was already computed when optimizing for , so there is no additional matrix inversion needed to find . It is also feasible to check whether this due to the specific or a symptom of the RC by checking if using defined in Eq. (41). has the same form as , but with replaced with the matrix , so by replacing with for every and in the definition of we can check if is zero without much extra work.
3.3 Proving the Universal Superiority of ESNs with Feedback
We are now ready to finally present the proof of Theorem 1 since we know that is nonzero except on a lower dimensional subspace.
Proof of Theorem 1.
Note that is a real analytic functional with respect to matrix (see the definition of in Eq. (6)), having the Taylor series
| (47) |
where the last term consolidates the second and the higher order of . A reasonable ansatz for that reduces the second term most is
| (48) |
where is a constant to be determined. We now calculate the second term as
| (49) |
where
| (50) |
If , one can always choose an arbitrarily small such that
| (51) |
This is because the left side is linear with respect to whereas the right side is higher-order polynomial of , and therefore, such (arbitrarily small) satisfying the above always exists.
The only case where such cannot be found is the case where :
| (52) |
However, we have proved in Lemma 4 that the number of cases in which this occurs is vanishingly small. Then, the strict inequality in Eq. (23) is proved in almost every case.
Now, we prove that with will make the ESN convergent. The set is an open convex set in for any . As has been shown earlier, for the overwhelming majority of there is always a choice of that decreases . Since , by the continuity of the maximum singular value of with respect to (for any choice of matrix norm) and by the particular choice of , there always exists a small number such that (guaranteeing that the ESN with feedback remains convergent) while still decreasing the cost, ). This concludes the proof of Theorem 1.
∎
3.4 Superiority of ESNs with Feedback for the Whole Class of ESNs
According to Theorem 1, the cost of the ESN with feedback is guaranteed to be smaller than the cost of the ESN without feedback for almost all fixed . Next, the following corollary states that ESN with feedback exceeds the performance of ESN without feedback in the whole class of ESNs.
Corollary 1 (Universal superiority of ESN with feedback over the whole class).
For given and fixed finite input and output sequences and , let and be drawn randomly according to some probability measure on . Let and be such that . Let and choose such that . Let , where the expectation (average) is taken with respect to the probability measure , for a fixed training dataset . Then, for the given training data set, ESN with feedback on average has a smaller cost function values than ESN without feedback for various on average. That is, the following holds on average over all possible :
| (53) |
Proof.
To prove the theorem over the whole class, we adopt a slightly different approach. The cost function after minimizing for and can be written as a function of the ESN parameters (short for ). With feedback using a vector , the new minimum is given by . Let us separate the matrix into two components given by
| (54) | ||||
| (55) | ||||
| (56) |
This is essentially pulling the degrees of freedom of in the direction apart from all other degree of freedom, so that and are independent. This is best shown by calculating the inner product:
| (57) |
Thus we can write the minimized cost function as a function of these independent variables so that we can define . With feedback, these quantities become and , and therefore . This all means that when we use feedback and optimize with respect to we are equivalently choosing , the minimum value of as a function of , subject to the convergence constraint. We note that, therefore,
| (58) |
since the cost function can further be reduced by optimizing an additional degree of freedom (equivalently, ). The equality occurs when is the optimal solution, making the feedback unnecessary. One can verify that the derivative of the cost function with respect to is not zero except for vanishingly small cases of . To show this, let us take the derivative of at :
| (59) |
The condition for this to become zero is exactly the same condition appearing in Eq. (52), for which we proved that only vanishingly small number of satisfy the above equation. Therefore, the strict inequality holds for most of .
The average cost without feedback is given by , averaging over all three variables. But with feedback, as stated above this is equivalent to minimizing the cost with respect to , so the average cost with feedback is given by . The average over does nothing in this case because all of the different initial will get shifted to the minimizing value. Because for each individual choice of and , and and are measurable functions of and by construction, we must have that for all . Furthermore, equality only holds if every choice of yields the same value of . By the definition of and and the hypothesis that , and since the number of that makes completely independent from is vanishingly small (c.f. the proof of Theorem 1), one can always choose under which and are sampled to be such that . Therefore, we have the strict inequality when averaged over :
| (60) | ||||
Thus an ESN with feedback will always do better than an ESN without feedback over the whole ESN class on average, given the same number of computational nodes. ∎
We note that this corollary could be proven more succinctly using Theorem 1 under the same hypothesis on the probability measure under which and are sampled by arguing that the average over ESNs will always include cases where the strict inequality (23) holds, and therefore the average also obeys a strict inequality. However, the proof given here adopted a different path from the proof of Theorem 1, providing an alternative explanation of the corollary.
4 Optimization of ESN with Feedback
One of the main advantages to using an ESN is that the training procedure is a linear regression problem that can be solved exactly without much computational effort. To use the ESN to match a target sequence for a given input sequence , we first run the ESN driven by the input for a number of steps until the initial state of the network is forgotten. This ensures that the states of the network is close to the unique sequence solely determined by the input that is guaranteed to exist by the uniform convergence property. In most of our simulations, we let the ESN run for steps before beginning training, which appears to be significantly more than necessary for our examples. We were able to use as few as steps of startup for some of our tests without any issue.
After this initial set of steps that insure that the system has converged to the input dependent state sequence, we then record the values of the state for the entire range of training steps, which we define to be a total of steps staring from . We then define the network’s output to be , where the parameters and are optimized using the cost function given in Eq. (6), and whose exact solutions are given in Eqs. (18,19). Then, any future step in is estimated using for some .
With feedback, we also must optimize with respect to the feedback vector to determine the modified input sequence . Since the network states will have a highly complex and nonlinear dependence on , we cannot solve it exactly as we do with and . It also turns out that, unfortunately, the cost function is not a convex function with respect to (see Fig. 1). Therefore, a simple gradient descent or a linear regression for optimizing (training) is not guaranteed to converge to the global minimum of the cost function. In this case, optimizing to minimize the cost function is tricky.

In fact, a good candidate for (which is at least locally optimal) is obtained by choosing such that the difference between the left and the right hand side of the inequality (51) becomes maximum:
| (61) |
Then, a good should be given by . Therefore, a strategy to optimize is, first, to perform the optimization for assuming there is no feedback, which will result in . Then, one calculates , which will require additional optimization of for given perturbed for each entry of . Such perturbation requires number of optimizations of ’s for different ’s. This will allow to calculate , which will lead to a good . We, however, note that obtaining requires the calculations of , , , etc., which are computationally demanding. Thus, in practice, we use different method that is more practical.
In our numerical examples, we used a standard batch gradient descent method to optimize , with a forced condition that ensures that the ESN will remain convergent during every step. We cannot use stochastic gradient descent because of the causal nature of the ESN, meaning that the order and size of the training set influences the optimal value of . The proofs in Section 3 guarantee that gradient descent will almost always provide an improvement to the fit. The mathematical details of the gradient descent method that we used is explained in A.
To begin our gradient descent routine, we start at . First, we run the ESN without feedback and optimize for and as usual. Then, we calculate , which as we will demonstrate below can be done using only quantities already obtained from running the ESN. We then choose to be our new feedback vector for the next step, where is a learning rate that must be chosen beforehand. We repeat this process many times, running the ESN with as the input sequence, optimizing for and under the new inputs, and then recalculating to update the feedback vector for the next step using . This is performed for a set number of iterations. In the event that the gradient descent converges to an ESN that is unstable, we will also detail a procedure we use to keep every within a certain convex region for which the ESN is guaranteed to be stable.
Here, we present the method to enforce the ESN’s stability while updating . For this, we need to make sure that the ESN remains convergent at every step of gradient descent. The constraint on is given by the constraint for convergence on the ESN following from Eq. (10) with in place of . Formally, the constraint is , where is a constant value that depends on the nonlinear function of the ESN. We use the sigmoid function, so we take . We ensure that the gradient descent algorithm obeys this constraint by applying a correction to any gradient descent step that causes the new value of to violate the constraint inequality. This correction is designed to only change the component of perpendicular to the surface defined by as a function of , so that gradient descent can still freely adjust in any direction parallel to this surface.
For some small shift in given by , the change in is given by
| (62) | ||||
| (63) | ||||
| (64) |
If gradient descent ends up causing the largest singular value of to reach or exceed , it would cause our ESN to cease being uniformly convergent. We can use the associated normalized eigenvector associated with to get
| (65) | ||||
| (66) | ||||
| (67) | ||||
| (68) |
We can ignore the dependence of on in this equation because the derivative of a normalized vector is always orthogonal to the original vector, so the first-order shift in each above gets eliminated by the other . We can solve this in terms of to get
| (69) |
This formula tells us that we can adjust the singular values of by using for our gradient descent step instead of just for some small positive value . We take to be for some small positive number . This ensures that the new step will keep the singular values of strictly less than with a minimal change to the original step , so that the convergence of the gradient descent procedure is minimally impacted. is guaranteed to be of the same order of magnitude as the norm of because we assume that leads to convergent dynamics, but does not, so but , and since is of the same order as the difference must be as well, where the last inequality is because . If multiple singular values exceed due to a single step, we can apply this procedure for each singular value independently since the eigenvectors associated with these singular values are orthogonal, so each adjustment to has no overlap with any of the other adjustments. We calculate and directly from , while is chosen to be . To the order of approximation used in Eq. (69), we can take and use their eigenvectors interchangeably for our calculation of the adjustment to aside from the value of .
5 Benchmark Test Results
We conducted numerical demonstrations of ESNs with feedback by focusing on three distinct tasks: the Mackey-Glass task, the Nonlinear Channel Equalization task, and the Coupled Electric Drives task. These tasks are elaborated in the supplementary material of the reference [34] for the first two and in [35] for the latter. Each task represents a unique class of problems. The Mackey-Glass task exemplifies a highly nonlinear chaotic system, challenging the ESN’s ability to handle complex dynamics. The Nonlinear Channel Equalization task involves the recovery of a discrete signal from a nonlinear channel, testing the ESN’s proficiency in signal processing. Finally, the Coupled Electric Drives task is focused on system identification for a nonlinear stochastic system, evaluating the ESN’s performance in modeling and memory retention. Together, these three tasks provide a comprehensive evaluation of ESNs, covering aspects like nonlinear modeling, system memory, and advanced signal processing. This multifaceted approach ensures a thorough assessment of ESN capabilities across various complex systems.
The Mackey-Glass task requires the ESN to approximate a chaotic dynamical system described by in the Mackey-Glass equation:
| (70) |
where we choose the standard values and . We numerically approximate the solution to this equation using with and . We also run the solution for steps before using it for the task, or in other words the target sequence we use actually starts with . The task for the ESN is to predict what the sequence will be 10 time steps into the future. In other words, using the input sequence , we want the ESN to successfully predict .
The second task is the Nonlinear Channel Equalization task. In this task, there is some sequence of digits , each of which can take one of 4 values so that , that is put through a nonlinear propagation channel. This channel is a polynomial in another linear channel , which is in turn a linear combination of 10 different values. The linear channel is given by
| (71) |
The nonlinear transformation of this channel is given by
| (72) |
where is a Gaussian white noise term with a signal-to-noise ratio of . That is, each noise term is a random number generated from a Gaussian distribution with a mean of 0 and a standard deviation given by , so that the signal-to-noise ratio is . The task for the ESN is to recover the original digit sequence from the nonlinear channel , which is used as input. In other words, using the input sequence described by Eq. (72), we want the ESN to produce the digit sequence as output. Since the ESN produces a continuous output while the target sequence takes discrete values, we round the output of the ESN to the nearest value in for the final error analysis. However, we still use the continuous outputs during training using the standard cost function described in Eq. (6).
The third test is fitting the Coupled Electric Drives data set, which is derived from a real physical process and is intended as a benchmark data set for nonlinear system identification [36, 37]. In system identification, the ESN is used to approximately model an unknown stochastic dynamical system. This is achieved by tuning the free parameters of the ESN so that it approximates the nonlinear input/output (I/O) map generated by the unknown system through I/O data generated by the latter. This I/O map sends input sequences to output sequences for all . To this end, the ESN is configured as a nonlinear stochastic autoregressive model following [12], which is briefly explained in B.
We fit to the output signal labeled in [35], which uses a PRBS input with amplitude . We model the data using a combination of the input and the previous state of the system such that for each time step , the next time step is obtained using an input given by for some parameter . This parameter is chosen by optimizing the cost function of the training data using gradient descent, in much the same way that we optimize the feedback vector . However, this procedure is used to provide information about both and the past values of to the ESN through a single input channel, and is in no way related to our feedback procedure. In the context of the discussion in B, the function that is defined in that appendix is in this case given by , where if no state feedback is used, otherwise with feedback the value of is determined though the I/O data. Through our empirical analysis, we find that the global minimum of the cost function with respect to is always located near , such that the cost function is locally convex in an interval that always contains . Thus using gradient descent starting from to find the optimal value of will always converge to the global minimum of this parameter. In our numerical work below, we choose a learning rate of without feedback and a learning rate of when using feedback.


Fig. 2 shows histograms of the NMSE values obtained during the Mackey-Glass task for many different ESNs. We see that for 10 computational nodes without feedback, the distribution of NMSE values roughly takes the shape of a skewed Gaussian, with an average of about and a standard deviation of about , and a longer tail on the right side than the left. With feedback, the distribution shifts significantly toward lower NMSE values, with an average of about and a standard deviation of about . This is a roughly reduction of the average NMSE. For 100 computational nodes without feedback, the average is about with a standard deviation of about , with a slight skew toward larger NMSE values this time. Note that the 10-node histogram with feedback appears to have two primary peaks, one centered around the lower edge of the 10-node distribution without feedback and one centered much closer to the 100-node average. With a better method of optimizing , it may be possible to get more cases toward the left peak in this distribution and demonstrate results comparable to a 100-node calculation using only 10 nodes with feedback. Such an analysis is beyond the scope of this article, however.


In Fig. 3, we show histograms of the number of errors obtained in the Channel Equalization task for many different ESNs. We count the number of errors based on how far off the ESN prediction is from the actual signal, using the expression . For example, if the true signal value was but the ESN gave us , this counts as 1 error, but if and we count it as 2 errors. We see that for 10 computational nodes without feedback, the distribution of total error values also takes the shape of a skewed Gaussian, with an average of about errors and a standard deviation of about , and a longer tail on the right side than the left. With feedback, the distribution again shifts significantly toward a lower number of errors, with an average of about errors and a standard deviation of about , a nearly reduction to the average error count. For 100 computational nodes without feedback, the average is about errors with a standard deviation of about .
In this task, all of the distributions roughly adhere to the shape of a Gaussian with a long tail on the right. This is in contrast to the Mackey-Glass task, where each distribution had a slightly different skew. The feedback procedure has definitely improved the average performance of 10-node ESNs, but unlike the Mackey-Glass task there is no secondary peak, so it may be the case that in most of the cases the gradient descent algorithm has settled near a minimum and will not improve the results further. Still, the 10-node average with feedback is much closer to the 100-node result on average than the 10-node result.


Fig. 4 shows the average dependence of the error of the ESN without feedback as a function of the number of nodes, using the NMSE for the Mackey-Glass task and the total number of errors in the Channel Equalization task. We also include the average value of the 10-node results with feedback for comparison. The error bars in each plot represent the standard deviation associated with each specific number of nodes. We see that, on average, using feedback on a 10-node ESN with 100 steps of gradient descent for optimizing is roughly equivalent to a little more than a node calculation for the Mackey-Glass task, while it is closer to a or node calculation for Channel Equalization.
The main reason for this discrepancy is because the Mackey-Glass task is significantly more difficult for the ESN than the Channel Equalization task. In Mackey-Glass, we are asking the network to predict time steps into the future, but not all ESNs have a memory capacity going back steps, especially with only computational nodes. In contrast, the Channel Equalization task is much easier because the ESN does not have to reproduce the exact digits , it only has to achieve a difference of less than 1 to be considered correct, so there is more room for error on with the continuous output of the ESN. This is evidenced by the fact that the nodal dependence in the Mackey-Glass task seems to continue decreasing almost linearly near 100 nodes, while for Channel Equalization the dependence is close to zero as the ESN is almost perfectly reproducing the signal with 100 nodes. This also suggests that the results for the Mackey-Glass task could see further improvement with feedback using a better method for optimizing , since even the addition of computational nodes seems to converge slowly.
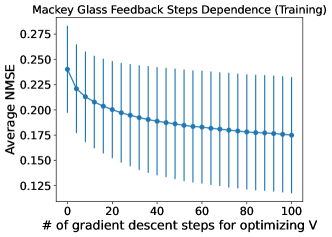

In Fig. 5, we show the average dependence of the error of 10-node ESNs with feedback as a function of the number of gradient descent steps for optimizing , using the NMSE for the Mackey-Glass task and the total number of errors in the Channel Equalization task. Note that these plots show the NMSE and total errors for the training data set of steps, as opposed to all of the previous plots which use the times immediate after training. This is why we have rescaled the average number of errors by a factor of in the plot for the Channel Equalization task: we are checking the errors of 1000 steps for each ESN in these plots instead of 500 like all the others, so the total number of errors is doubled as a result, hence the rescaling. The error bars in each plot represent the standard deviation associated with each specific number of gradient descent steps.
Here, we observe that for the Mackey-Glass task the gradient descent algorithm still has not fully converged even after 100 steps, and the variance in the performance is very large. In contrast, the gradient descent algorithm for the Channel Equalization task appears to have converged on average after about to steps to a value of about , with a moderately large standard deviation. This corroborates the discussion of Fig. 4, where we see that the ESN has trouble with the Mackey-Glass task, and so the convergence is slow and highly dependent on the specific ESN. Meanwhile, the Channel Equalization task is easier, and so the convergence occurs faster and more consistently. This further motivates using a better optimization method for to get the most we can out of an ESN for task like Mackey-Glass. For easier tasks like Channel Equalization we have likely already done the best we can with batch gradient descent, which seems to indicate that feedback can be more useful that adding an equal number of parameters as new computational nodes, at least for small ESNs.


In Fig. 6, we show plots of one ESN’s fit to the Coupled Electric Drive data given in [35]. We specifically use , the PRBS signal with an amplitude of . Note that since this data set contains only 500 data points, we use significantly less training data and test data than before, with only and steps, respectively. We are also only using 2 computational nodes here as opposed to or more in the previous tasks. This is in accordance with [12], where it was shown that ESNs with 2 computational nodes perform well on the Coupled Electric Drives data set. The first plot shows the fit to test data for a specific choice of of ESN with and without feedback. We see that in this specific instance the original ESN has some trouble fitting to the data, but with feedback the fit becomes much better, nearly matching the target data. The NMSE value without feedback was about , but with feedback it is reduced by a full order of magnitude to about .
The right plot shows the average correlations between the residuals of the test data for a fixed time difference. This is calculated using the formula
| (73) |
where and are the sample mean and variance of the residuals. This measures the correlation between the residuals at different time steps. If the residuals correspond to white noise, then of the correlations would fit into the confidence interval shown in the plot. We see that in the original ESN, there is a strong correlation between residuals that are one and two time steps apart, along with anti-correlations when they are 5 to 10 steps apart as well as from 25 to 30 step apart. With feedback, the one step correlation is significantly reduced, and all but one of the other correlations are found within the confidence interval. This suggests that the ESN without feedback was not completely capturing part of the correlations in the test data, but with feedback the accuracy is improved to the point that most of the statistically significant correlations have been eliminated. We also checked that the residuals are consistent with Gaussian noise using the Lilliefors test [38, 39] and checking a Q-Q plot [40] against the CDF of a normal distribution. We found that both with and without feedback, the residuals pass the Lilliefors test and follow a roughly linear trend on the Q-Q plot. Finally, we checked the correlation between the residuals and the input to see whether the residual noise is uncorrelated with the input and, therefore, unrelated to the system dynamics. We found that for this ESN, the residuals without feedback show a statistically significant anti-correlation of about , below the confidence threshold of . With feedback, the correlation becomes about , a significant reduction in magnitude that now puts it within the confidence interval.
The average behavior of feedback for this task also shows good improvement. Taking an average over 9600 different ESNs (including the one in Fig. 6), we find that the average NMSE without feedback using 2 computational nodes is about with a standard deviation of about , but with feedback this average goes down to with a standard deviation of about . This is a roughly reduction of the average NMSE. We also find that the average correlation with the input is about without feedback, below the confidence threshold of , but with feedback it is on average above the threshold with a value of about . Additionally, the average one time step difference correlation between residuals is about without feedback, but with feedback it reduces to about . However, this does not reduce it into the confidence interval for Gaussian white noise, suggesting that there is still room for improvement with feedback. We note that batch gradient descent may not be the most effective choice for optimizing for this task, especially considering the use of a large learning rate of to get these results. If we were able to reach the true global minimum of , we may be able to much more consistently reach a scenario like the one shown in Fig. 6.
6 Discussions and Conclusion
In this work, we have introduced a new method for improving the performance of an ESN using a feedback scheme. This scheme uses a combination of the existing input channel of the ESN and the previously measured values of the network state as a new input, so that no direct modification of the ESN is necessary. We proved rigorously that using feedback is almost always guaranteed to provide an improvement to the performance, and that the number of cases in which such an improvement is not possible using batch gradient descent is vanishingly small compared to all possible ESNs. In addition, we proved rigorously that such a feedback scheme provides a superior performance over the whole class of ESN on average. We laid out the procedure for optimizing the ESN as a function of the fitting parameters and , exactly solving for and while using batch gradient descent on for a fixed number of steps. We then demonstrated the performance improvements for the Mackey-Glass, Channel Equalization, and Coupled Electric Drives tasks, and commented on how the relative difficulty of the tasks affected the results. The ESNs with feedback exhibited outstanding performance improvement in the Channel Equalization and Coupled Electric Drives tasks, and we observed a roughly and improvement in their respective error measures. For the more difficult Mackey-Glass task, we still saw a roughly improvement in the averaged NMSE, showing that feedback produces a significant boost in performance for a variety of tasks. These ESNs with feedback were shown to perform just as well on average, if not better than, the ESNs that have double the number of computational nodes without feedback.
Although there will be an additional hardware modification required to implement feedback, such a modification will only be external to the reservoir computer and, therefore, the burden will be minimal. This feedback scheme is designed to avoid any direct modification of the ESN’s main body (i.e., the computing bulk) since we only need to take the readout of the network and send some component of that readout back into the network with the usual input. Thus, we will only need an apparatus that connects to the readout and the input of the ESN, but does not require modifying the internal reservoir. Given that our results suggest that ESNs with feedback will perform just as well as, if not better than, ESNs of double the number of nodes without feedback, the cost-benefit analysis of adding feedback hardware is very likely to be more favorable than increasing the size of the ESN to achieve similar performance.
Because of the highly complex and nonlinear dependence of the network states on , we used batch gradient descent for the optimization of , but better methods may very well exist. The question of how to best optimize is indeed closely related to how to choose the best for a given training data set and . This is an open question for which any progress would be monumental in the general theoretical development of reservoir computing and neural networks. Even providing just a measure of the computing power of a given or outside of the cost function itself could provide some classification of tasks that will save us significant computational time and resources in the future.
Appendix A Batch Gradient Descent Method for Optimizing
At the beginning of each step, we train the ESN using as the input sequence for the current feedback vector , with as the initial step. To get the change in , we use the gradient of given by
| (74) | ||||
| (75) | ||||
| (76) |
where . The derivatives can be calculated by iteration starting from the initial condition . Then we simply shift for some learning rate at each step of the descent, using the optimal solutions for and for the current value of .
Appendix B Nonlinear Stochastic Autoregressive Model
The basic model is
where is some function of , and taking values in and are I/O pairs generated at time by the stochastic dynamical system of interest. The quantity is the output of the ESN and functions as an approximation of . Assuming convergence, after washout can be expressed as [12]:
for some nonlinear functional of past input and output values, and , respectively. Letting be the approximation error of by , , the ESN then generates a nonlinear infinite-order autoregressive model with exogenous input:
To complete the model, it is stipulated that is Gaussian white noise sequence that is uncorrelated with the input sequence . By making the substitution , the system identification procedure identifies an approximate state-space model of the unknown stochastic dynamical system given by:
where
where and free inputs to the model. The stochasticity in the model comes from the free noise sequence and possibly also the input (typically the case in system identification). This model can then be used, for instance, to design stochastic control laws for the unknown stochastic dynamical system or to simulate it on a digital computer. The hypothesis of the model, that is a Gaussian white noise sequence that is uncorrelated with the input sequence is tested after the model is fitted using a separate validation data set (different from the fitting data set) by residual analysis; see, e.g., [36, 37].
References
- [1] M. Lukoševičius, H. Jaeger, Reservoir computing approaches to recurrent neural network training, Computer science review 3 (3) (2009) 127–149.
- [2] B. Schrauwen, D. Verstraeten, J. Van Campenhout, An overview of reservoir computing: theory, applications and implementations, in: Proceedings of the 15th european symposium on artificial neural networks. p. 471-482 2007, 2007, pp. 471–482.
- [3] G. Tanaka, T. Yamane, J. B. Héroux, R. Nakane, N. Kanazawa, S. Takeda, H. Numata, D. Nakano, A. Hirose, Recent advances in physical reservoir computing: A review, Neural Networks 115 (2019) 100–123.
- [4] H. Jaeger, H. Haas, Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communications, Science 304 (2004) 5667.
- [5] J. Pathak, et al., Model-free prediction of large spatiotemporally chaotic systems from data: A reservoir computing approach, Physical review letters 120 (2) (2018) 024102.
- [6] M. Rafayelyan, et al., Large-scale optical reservoir computing for spatiotemporal chaotic systems prediction, Phys. Rev. X 10 (2020) 041037.
- [7] P. Antonik, M. Gulina, J. Pauwels, S. Massar, Using a reservoir computer to learn chaotic attractors, with applications to chaos synchronization and cryptography, Physical Review E 98 (1) (2018) 012215.
- [8] Z. Lu, et al., Reservoir observers: Model-free inference of unmeasured variables in chaotic systems, Chaos 27 (2017) 041102.
- [9] L. Grigoryeva, J. Henriques, J.-P. Ortega, Reservoir computing: information processing of stationary signals, in: Joint 2016 CSE, EUC and DCABES, IEEE, 2016, pp. 496–503.
- [10] L. Grigoryeva, J.-P. Ortega, Echo state networks are universal, Neural Networks 108 (2018) 495–508. doi:https://doi.org/10.1016/j.neunet.2018.08.025.
- [11] L. Gonon, J.-P. Ortega, Reservoir computing universality with stochastic inputs, IEEE transactions on neural networks and learning systems 31 (1) (2019) 100–112.
- [12] J. Chen, H. I. Nurdin, Nonlinear autoregression with convergent dynamics on novel computational platforms, IEEE Transactions on Control Systems Technology 30 (5) (2022) 2228–2234. doi:10.1109/TCST.2021.3136227.
- [13] L. Larger, et al., High-speed photonic reservoir computing using a time-delay-based architecture: Million words per second classification, Physical Review X 7 (1) (2017) 011015.
- [14] J. Torrejon, et al., Neuromorphic computing with nanoscale spintronic oscillators, Nature 547 (7664) (2017) 428–431.
- [15] J. Chen, H. I. Nurdin, N. Yamamoto, Temporal information processing on noisy quantum computers, Phys. Rev. Applied 14 (2020) 024065. doi:10.1103/PhysRevApplied.14.024065.
- [16] Y. Suzuki, et al., Natural quantum reservoir computing for temporal information processing, Sci. Reports 12 (1) (2022) 1353.
- [17] T. Yasuda, et al., Quantum reservoir computing with repeated measurements on superconducting devices, arXiv preprint arXiv:2310.06706 (October 2023).
- [18] K. Nakajima, I. Fischer, Reservoir Computing: Theory, Physical Implementations, and Applications, Springer Singapore, 2021.
- [19] P. Mujal, et al., Opportunities in quantum reservoir computing and extreme learning machines, Adv. Quantum Technol. 4 (2021) 2100027.
- [20] D. Marković, J. Grollier, Quantum neuromorphic computing, Applied Physics Letters 117 (15) (2020) 150501.
- [21] H. Jaeger, The “echo state” approach to analysing and training recurrent neural networks-with an erratum note, Bonn, Germany: German National Research Center for Information Technology GMD Technical Report 148 (34) (2001) 13.
- [22] H. Jaeger, Echo state network, scholarpedia 2 (9) (2007) 2330.
- [23] M. Lukoševičius, A practical guide to applying echo state networks, in: Neural Networks: Tricks of the Trade: Second Edition, Springer, 2012, pp. 659–686.
- [24] D. Sussillo, L. F. Abbott, Generating coherent patterns of activity from chaotic neural networks, Neuron 63 (4) (2009) 544–557.
- [25] M. Freiberger, P. Bienstman, J. Dambre, A training algorithm for networks of high-variability reservoirs, Scientific Reports 10 (2020) 14451.
- [26] W. Maass, P. Joshi, E. D. Sontag, Computational aspects of feedback in neural circuits, PLoS Comp. Bio. 3 (2007) article no. e165.
- [27] G. Manjunath, H. Jaeger, Echo state property linked to an input: Exploring a fundamental characteristic of recurrent neural networks, Neural Computation 25 (3) (2013) 671–696. doi:10.1162/NECO_a_00411.
- [28] S. Boyd, L. Chua, Fading memory and the problem of approximating nonlinear operators with volterra series, IEEE Transactions on Circuits and Systems 32 (11) (1985) 1150–1161. doi:10.1109/TCS.1985.1085649.
- [29] D. N. Tran, B. S. Rüffer, C. M. Kellett, Convergence properties for discrete-time nonlinear systems, IEEE Transactions on Automatic Control 64 (8) (2019) 3415–3422. doi:10.1109/TAC.2018.2879951.
- [30] K. Fujii, K. Nakajima, Harnessing disordered-ensemble quantum dynamics for machine learning, Phys. Rev. Appl. 8 (2017) 024030. doi:10.1103/PhysRevApplied.8.024030.
- [31] T. Kubota, H. Takahashi, K. Nakajima, Unifying framework for information processing in stochastically driven dynamical systems, Phys. Rev. Res. 3 (2021) 043135. doi:10.1103/PhysRevResearch.3.043135.
- [32] K. Nakajima, K. Fujii, M. Negoro, K. Mitarai, M. Kitagawa, Boosting computational power through spatial multiplexing in quantum reservoir computing, Phys. Rev. Appl. 11 (2019) 034021. doi:10.1103/PhysRevApplied.11.034021.
- [33] W. Rudin, Principles of Mathematical Analysis, New York: McGraw-Hill, 1976.
- [34] T. Hülser, F. Köster, K. Lüdge, L. Jaurigue, Deriving task specific performance from the information processing capacity of a reservoir computer, Nanophotonics 12 (5) (2023) 937–947. doi:doi:10.1515/nanoph-2022-0415.
- [35] T. Wigren, M. Schoukens, Coupled electric drives data set and reference models, Tech. rep., Department of Information Technology, Uppsala University, Uppsala, Sweden (2017).
- [36] L. Ljung, System Identification: Theory for the User, 2nd Edition, Prentice-Hall, 1999.
- [37] S. A. Billings, Nonlinear System Identification: NARMAX Methods in the Time, Frequency, and Spatio-Temporal Domains, Wiley, 2013.
- [38] H. W. Lilliefors, On the Kolmogorov-Smirnov test for normality with mean and variance unknown, Journal of the American Statistical Association 62 (318) (1967) 399–402.
- [39] H. Abdi, P. Molin, Lilliefors/Van Soest’s test of normality, Encyclopedia Meas. Stat. (01 2007).
-
[40]
M. B. Wilk, R. Gnanadesikan, Probability plotting methods for the analysis for the analysis of data, Biometrika 55 (1) (1968) 1–17.
arXiv:https://academic.oup.com/biomet/article-pdf/55/1/1/730568/55-1-1.pdf, doi:10.1093/biomet/55.1.1.
URL https://doi.org/10.1093/biomet/55.1.1