Improving the Estimation of Site-Specific Effects and their Distribution in Multisite Trials
Abstract
In multisite trials, researchers are often interested in several inferential goals: estimating treatment effects for each site, ranking these effects, and studying their distribution. This study seeks to identify optimal methods for estimating these targets. Through a comprehensive simulation study, we assess two strategies and their combined effects: semiparametric modeling of the prior distribution, and alternative posterior summary methods tailored to minimize specific loss functions. Our findings highlight that the success of different estimation strategies depends largely on the amount of within-site and between-site information available from the data. We discuss how our results can guide balancing the trade-offs associated with shrinkage in limited data environments.
Keywords: multisite trials, site-specific effects, finite-population estimand, Dirichlet process mixture; constrained Bayes; triple-goal estimator; heterogeneous treatment effects
1 Introduction
Multisite trials, which conduct (nearly) identical randomized experiments simultaneously at multiple sites, have become increasingly prevalent as an experimental design in education (Spybrook and Raudenbush,, 2009; Spybrook,, 2014; Raudenbush and Bloom,, 2015). Multisite trials can be viewed as a form of planned meta-analysis (Bloom et al.,, 2017). By synthesizing evidence from multiple contexts to estimate the average treatment effect, multisite trials can establish a more robust foundation for general policy recommendations (Meager,, 2019). Understanding the extent of treatment effect variation allows researchers to determine how an intervention may perform in diverse contexts (e.g., Sabol et al.,, 2022; Schochet and Padilla,, 2022).
Expanding on such meta-analytic objectives of multisite trials, researchers occasionally direct their attention to the sites in the sample itself. This approach pursues several inferential goals, including (a) estimating individual site-specific treatment effects, (b) ranking the sites, and (c) analyzing the distribution of site-specific effects. Institutional performance evaluation studies have pioneered the examination of such fine-grained, site-specific parameters. For instance, school or teacher effectiveness studies directly aim to estimate individual school- or teacher-specific “value-added” effect parameters (Angrist et al.,, 2017; Chetty et al.,, 2014; McCaffrey et al.,, 2004; Mountjoy and Hickman,, 2021). There has also been a sustained interest in generating rankings or league tables based on estimated effectiveness for schools or other service providers (Goldstein and Spiegelhalter,, 1996; Lockwood et al.,, 2002; Mogstad et al.,, 2020). Performance evaluation objectives also include estimating empirical distribution functions (EDFs) or histograms of site-specific parameters (Kline et al.,, 2022), identifying outliers or hot spots (Ohlssen et al.,, 2007), and determining the proportion of sites with effects surpassing a threshold (Gu and Koenker,, 2023). These practices can be effectively adapted to contexts that investigate site-specific treatment effects in multisite trial settings.
In this paper, we conduct a comprehensive simulation study to examine how different analytic strategies can enhance the estimation of site-specific effects under various conditions. As we cannot directly observe the true individual site-specific effects, we must model them using observed data. Standard modeling approaches depend on parametric distributional assumptions in random-effect multilevel models. Generally, random effects are assumed to follow a normal distribution, and empirical Bayes (EB) estimates are used for the random effects themselves (e.g., Raudenbush and Bloom,, 2015; Weiss et al.,, 2017). When adopting a fully Bayesian approach, empirical Bayes is replaced by the marginal posterior means (PM) of the random effects.
Assuming a normal distribution for random effects can be problematic when the true distribution is far from normal. For instance, McCulloch and Neuhaus, (2011) discovered that when the true distribution is multi-modal or long-tailed, the distribution of the EB predictions may reflect the assumed Gaussian distribution rather than the true distribution of effects. To address this issue and safeguard against model misspecification, researchers have proposed more flexible distributional assumptions for random effects. These alternatives encompass continuous parametric non-Gaussian distributions (Liu and Dey,, 2008); arbitrary discrete distributions obtained using nonparametric maximum likelihood estimation (Rabe-Hesketh et al.,, 2003); and mixture distributions (Ghidey et al.,, 2004; Paddock et al.,, 2006; Verbeke and Lesaffre,, 1996).
Instead of relaxing the normality assumption, some approaches replace EB or PM estimators with alternative posterior summaries, such as constrained Bayes (CB, Ghosh,, 1992) and triple-goal (GR111The abbreviation ”GR” denotes the dual inferential objectives: the EDF () and the rank () of site-specific parameters, commonly referenced as the triple-goal estimator in studies such as Paddock et al., (2006)., Shen and Louis,, 1998) estimators. These alternatives, designed to correct shrinkage-induced underdispersion in PM estimates, directly adjust the loss function minimized by the estimator in order to target specific inferential goals. Such strategies have received less attention compared to flexible modeling of the random-effects distribution.
In practice, the joint application of these two strategies has been relatively rare, with only a few notable exceptions (e.g., Paddock et al.,, 2006; Lockwood et al.,, 2018). The costs and benefits of these strategies have not been systematically compared in previous simulation studies exploring similar topics (e.g., Kontopantelis and Reeves,, 2012; Paddock et al.,, 2006; Rubio-Aparicio et al.,, 2018). For instance, if the true distribution is not Gaussian and the inferential goal is to estimate the empirical distribution of site-specific effects, a question arises about which approach performs better: (a) combining the misspecified Gaussian model for random effects with a targeted posterior summary method (CB or GR), or (b) utilizing the flexible semiparametric model for the prior in conjunction with the misselected posterior mean estimator that solely aims at the optimal estimation of individual site-specific effects. To our knowledge, no prior studies have compared these two strategies within the context of multisite trials, thereby revealing an unexplored area in the literature that warrants further investigation.
This paper offers four important contributions. First, our simulations focus on educational applications, which are often characterized by small sample sizes. Beyond the standard relative comparisons between methods, we offer practical guidelines for practitioners in these low-data settings, acknowledging that even the best method may deliver suboptimal results. Second, we bring attention to the frequently overlooked distinction between super population and finite-population estimands (e.g., the distribution of impacts across sites in the sample vs. the distribution of sites in the population where the sample came from), which serves to frame and motivate different estimators. Third, rather than solely focusing on one strategy, we examine the effects of combining flexible random-effects distributions with alternative posterior summaries. Finally, we apply insights gleaned from our simulation to real-world multisite trial data, illustrating how the selection of analytic strategies can considerably influence site-specific estimates.
This paper is structured as follows. First, we introduce standard approaches for modeling super population and finite-population effects. Next, we discuss inferential goals, identify potential threats to inferences for site-specific effects, and outline two strategies to improve these inferences. We then provide a comprehensive description of our simulation study’s design and results, and follow with a real-data example that demonstrates the application of these strategies. Finally, we summarize our findings and consider their practical implications.
2 Standard approaches to modeling site-specific effects
2.1 Basic setup: the Rubin (1981) model
Suppose a multisite trial consists of sites, indexed by , where identical treatments are administered within each site. The analytic setting considered in this paper is based on the Rubin (1981) model for parallel randomized experiments, also known as a random-effects meta-analysis (Raudenbush and Bryk,, 1985). For data inputs, this model requires only the observed or estimated effects from each of the sites, along with their corresponding squared standard errors . The are estimating , the true average impact in site ; under the potential outcomes framework, this would be the difference in the average outcomes of units if all were treated minus if all were control; we would make the usual assumptions about non-interference of treatment and a well-defined treatment (SUTVA) both within and across sites to make the estimand well defined (see, e.g., Imbens and Rubin, (2015) for further discussion). The and values are obtained through maximum likelihood (ML) estimation using data exclusively from site . Our meta-analytic approach closely aligns with the fixed intercept, random coefficient (FIRC) estimator (Raudenbush and Bloom,, 2015), as it focuses on modeling only the true, randomly varying treatment effect . This approach effectively circumvents some of the strong joint distributional assumptions typically made between and a randomly varying intercept or control group mean (Bloom et al.,, 2017).
The first stage of the hierarchical model describes the relationship between the observed statistics and the parameter :
where
| (1) |
When estimating average impacts, the central limit theorem applied to the individuals within the site provides the normality, or something close to it. For the standard error, denotes the sample size and represents the proportion of units treated in site . signifies the (assumed constant across treatment arms) variance in outcomes within treatment arms for a given site. The coefficient reflects the proportion of variance in the outcome explained by unit-level covariates. For example, if , e.g., due to having a reasonable pre-test score of an academic outcome, a improvement in the precision of due to covariate adjustment can be expected for a fixed .
The second stage assumes that the site average impacts are independent and identically distributed () with a specific prior distribution222We refer to as a ‘prior distribution’ to be consistent with standard practices in Bayesian hierarchical models (Gelman et al.,, 2013; Rabe-Hesketh and Skrondal,, 2022). In this framework, represents our prior knowledge or beliefs about the parameter before observing the data from site . In contrast, within the frequentist framework, is interpreted as a distributional assumption regarding . ,
| (2) |
The prior distribution is generally unknown but is classically specified as a Gaussian distribution with two hyperparameters: , the average treatment effect across the sites, and , the variance in true site-specific effects across sites, both defined at the super population level. Here represents the unadjusted intent-to-treat (ITT) effect within each site. Consequently, the variance encapsulates the aggregate variation in treatment effects across sites, stemming from two main sources: “compositional” differences in unit-level covariates across sites and “contextual” differences in site-level covariates or unobserved compositional differences (Lu et al.,, 2023; Rudolph et al.,, 2018). One could redefine to be the conditional or adjusted site-level average treatment effect, potentially estimated by including covariate by treatment interaction terms; this would typically results in a reduced . This reduction occurs because such an analysis would account for and removes the variation attributed to compositional differences across sites, though could also increase in certain scenarios as highlighted by Lu et al., (2023). In the work of this paper, this distinction is immaterial: we seek to estimate, with , the distribution defined by the .
The Bayesian hierarchical framework plays a vital role in separating the genuine heterogeneity in true effects across different sites () from the sampling variation of each estimated effect around its true effect within sites (). A key focus in our analytic setting is to assess the relative magnitudes of and , aiming to understand how this signal-to-noise ratio influences the efficacy of various estimation strategies. Particularly when is relatively large, the values will generally be overdispersed compared to true values. This can lead to a misrepresentation of the rank order of effects across different sites; e.g., when the vary due to factors such as site size, the smaller sample sizes might produce more extreme estimates. When estimating conditional effects, incorporating unit-level covariates into our analysis could concurrently reduce both and , although these reductions might occur at different rates, or in some cases, might even increase. This introduces an additional layer of complexity to the comparative analysis of these two variances. Therefore, to ensure focused and clear exposition and formulas regarding the comparisons of and , our study deliberately defers the inclusion of conditional effects and covariates interacted with treatment to future research; covariates for precision gain will simply decrease the standard errors and increase the information of the estimates regarding the estimands and all our results carry.
2.2 Site-specific parameter estimation
In the special case of the normality assumption for the conditional posterior distribution of given the hyperparameters and is normal and the corresponding conditional posterior mean and variance of have simple closed-form expressions:
where
| (3) |
In other words, the posterior mean effect, , is the observed mean effect, , shrunk toward the prior mean effect, (Gelman et al.,, 2013). The weight , commonly referred to as the shrinkage factor, indicates the reliability of the ML estimator , and is defined as the proportion of the variance of the ML estimator attributable to genuine underlying heterogeneity across sites (Rabe-Hesketh and Skrondal,, 2022). If , the ML estimator is perfectly precise or reliable, and the posterior mean and the ML estimator are identical . A large indicates the data is less informative, relative to the variation in , resulting in the posterior mean effect, , being more significantly shrunk toward the prior mean effect, .
To assess the magnitude of relative to the sampling error for each site, we use the shrinkage factor as a direct measure for site . For a comprehensive evaluation across all sites, we calculate the geometric mean of , yielding an average measure of reliability for the ML estimator , which we call the informativeness ():
| (4) |
The value ranges between 0 and 1 . Higher values of indicate the ’s provide greater information about the ’s, on average, as compared to lower values.
2.3 Super population vs. finite-population estimands
The Rubin model highlights two estimands of interest: the super population distribution of site-specific effects, , and the finite-population distribution, , for the sites in the experiment. These two estimands correspond to distinct research objectives. Super population inference aims to recover , the effect distribution for the broader population of sites from which the experimental sites were sampled. This task is referred to as a Bayes deconvolution problem, wherein the observed, noisy sample estimates are used to compute an estimate of (Efron,, 2016). Performance evaluation studies typically focus on this research objective, as they often have sufficiently large (e.g., Gilraine et al.,, 2020). In contrast, finite-population inference examines the distribution of the true site-effect parameters for the specified sites, taking these sites as the entire finite population of interest.
In multisite trial settings, recovering the super population estimand can be challenging without assumptions about the form of . For a normal model of , only two hyperparameters, and , require estimation in the deconvolution process. However, when the prior is unknown, the performance of deconvolution estimators heavily relies on the shape of the underlying and the number of sites (McCulloch and Neuhaus,, 2011). Specifically, the mathematical guarantees of flexible estimators are typically asymptotic in nature, necessitating a large (Jiang and Zhang,, 2009). In the context of multisite trials in education, however, is often small to moderate (Weiss et al.,, 2017), rendering such asymptotics potentially less applicable. The core concern is that a random sample of 30 to 40 sites’ , even if obtained without measurement error, may not give a sharp picture of the target distribution. Furthermore, it may be unreasonable to assume that the experimental sites in many multisite trials are adequately representative of the super population (Stuart et al.,, 2011). For example, Tipton et al., (2021) found that schools involved in grants from the Institute of Education Science were predominantly located in large urban districts, geographically close to one another and to the study’s principal investigators.
In this paper, we focus on finite-population estimands, represented by . This approach helps us circumvent the risks associated with generalizing treatment effect estimates from a sample of sites to a super population when systematic discrepancies exist between them. Moreover, concentrating on a finite-population of sites typically results in more precise effect estimates compared to situations where researchers aim to generalize to a super population (Miratrix et al.,, 2021). This approach is statistically less demanding, allowing for more relevant recommendations in low-data settings for multisite trials.
3 Improving inferences for site-specific effects
3.1 Inferential goals and threats to inferences for
Shen and Louis, (1998) identify three common inferential goals regarding a set of site-specific parameters: (1) estimating the individual site-specific effect parameters, , (2) ranking the sites based on , and (3) estimating the empirical distribution function (EDF) of the ’s. Each of these three goals can be associated with a different loss function, which may be minimized by a distinct estimator. The loss function typically associated with the first goal is the mean-squared error loss (MSEL):
| (5) |
where is the estimate of generated by a candidate estimator. In practice, we measure the root-mean-squared error, , which is more interpretable because it preserves the scale of the values. The theoretical posterior means of for , minimize the expected MSEL and RMSE. For example, when the values are indeed normally distributed, setting from equation (3) minimizes the MSEL and RMSE.
For the second inferential goal, we can choose an estimator for the vector of ranks of that minimizes the mean squared error loss of the ranks (MSELR),
| (6) |
where, is the true rank of , is the indicator function, and is an estimated rank. In practice, we measure the mean squared error loss of the percentiles (MSELP),
| (7) |
where and correspond to the estimated and true percentiles, respectively. The MSELP is less sensitive to changes in , so it can be compared across settings with different numbers of sites. The theoretical expected posterior percentiles in decimal form minimize expected MSELP. These expected posterior percentiles may not correspond to the percentiles based on the posterior means, and indeed, Goldstein and Spiegelhalter, (1996) show that ranks based on posterior means can be suboptimal in general.
For the third inferential goal, Shen and Louis, (1998) suggest minimizing the integrated squared-error loss (ISEL):
| (8) |
where is the true EDF and is an estimated EDF, . They show that minimizes the expected ISEL. The third inferential goal is related to the deconvolution problem, where the goal is to use observed data to recover an unknown prior density (Efron,, 2016). We focus on finite-population inference in this paper, so our goal is to use the observed values to infer the EDF of the true values.
The three inferential goals, their associated loss functions, and their optimal estimators reveal two primary challenges in achieving valid finite-population estimation. The first challenge is model misspecification, which arises when we assume an incorrect parametric form for the super population distribution . If the true distribution is not Gaussian, assuming normality may result in insensitivity to skewness, long tails, multimodality, and other complexities in the EDF of the ’s (McCulloch and Neuhaus,, 2011). Consequently, estimators based on the standard Rubin model become unreliable, especially for the third inferential goal. The second challenge emerges when, for a given goal, an unsuitable estimator is chosen, even when the prior distribution is accurately specified in a model. The optimal estimator is contingent upon the chosen loss function or inferential goal. However, practitioners often use the same set of posterior mean effect estimates for all three goals, leading to suboptimal outcomes for at least some of them. For instance, the EDF of posterior mean effect estimates will tend to be underdispersed compared to the EDF of due to shrinkage towards the prior mean effect . Conversely, the EDF of raw observed ML effect estimates is overdispersed because of sampling error (Mislevy et al.,, 1992).
3.2 Strategies to improve inferences for the distribution of
To address the threats outlined in the previous section, two strategies can be employed. The first strategy entails adopting flexible semiparametric or nonparametric specifications for the prior distribution to protect against model misspecification (Paddock et al.,, 2006). One prominent Bayesian nonparametric specification is the Dirichlet process (DP) prior, which has gained widespread use in the literature (Paganin et al.,, 2022). The second strategy focuses on employing posterior summary methods, such as the constrained Bayes or the triple-goal estimators. These estimators are designed to directly target the loss functions associated with specific inferential goals. The following sections discuss these two strategies and their implications for addressing the challenges in finite-population estimation.
3.3 Posterior summary methods: Constrained Bayes and triple-goal estimators
Our primary target of interest is , representing the EDF of the ’s. Both CB and GR generate estimates of the that are not as overly shrunk as the simple posterior means. The CB estimator directly modifies the posterior mean estimates to avoid under-dispersion, rescaling them to ensure that the estimated variance of site-specific effect estimates aligns with the estimated marginal variance of the latent parameters . In equation (3), the posterior mean of is denoted as , and the posterior variance of as . We introduce to represent the finite-population mean of the posterior mean estimates and as the corresponding finite-population variance. The CB estimates are then:
| (9) |
Here, is an estimate of the shrinkage factor, defined in equation (3) as . The estimate of the cross-site impact standard deviation and the variance of the posterior means are:
| (10) |
Posterior mean estimates tend to be under-dispersed because their variance is always less than the estimated marginal variance , as demonstrated in equation (10). By rescaling the site-specific estimates by , the CB estimator in equation (9) attempts to ”reverse” overshrinkage towards the finite-population prior mean effect driven by . This adjustment expands the gap between and because is equal to . An empirical Bayes version of the CB estimator was also introduced by Bloom et al., (2017).
In contrast, the GR estimator employs evenly spaced percentiles of the estimated to generate its estimates. The GR estimator is constructed via a three-stage process. In the first stage, an estimate of the distribution function that minimizes ISEL is constructed as
| (11) |
The smooth function is then discretized to an EDF that places a mass of at evenly spaced discrete points for . In the second stage, a rank for each site is computed as
| (12) |
The generally non-integer-valued ranks are then discretized to integer-valued ranks as . In the final stage, the GR estimate for each site is computed as . Intuitively, the GR estimator first finds a good estimate of the full distribution of values and then produces estimates for the sites as evenly spaced quantiles of , in an appropriate order.
3.4 Relaxing the distributional assumption for the prior : Dirichlet process mixture
Instead of presupposing a known parametric form for the prior distribution in equation (2), a Dirichlet process (DP) can be employed as the prior for to accommodate uncertainty regarding its shape. Conceptually, the DP model can be viewed as an infinite mixture model in which both the priors and the data contribute to determining the number of observed mixture components.
The DP prior is characterized by two hyperparameters: a base distribution and a precision parameter (Antoniak,, 1974). A two-stage hierarchical model, incorporating the DP prior, can be formulated as follows:
| (13) |
is a discrete distribution, with positive probability on a countably infinite number of points. It models the distribution of site impacts, therefore, as a set of clusters, where groups of sites will all have the same impact. In a given finite sample we would observe such clusters, with potentially being less than .
To finalize the model specification, we must define the base distribution and establish a hyperprior for the parameter . serves as the initial best guess for the shape of the prior distribution . Typically, we assume follows a Gaussian distribution with mean and variance . For computational convenience, the base distribution is typically constructed as the product of conjugate distributions, such as a normal distribution for the mean parameter and an inverse-gamma distribution for the variance parameter (Paganin et al.,, 2022).
The precision hyperparameter controls the degree to which converges toward (see the Supplemental Material). The larger the , the larger the number of unique observed site impact estimates . It is worth noting that does not always precisely correspond to the number of mixture components, , representing latent subpopulations with substantive meaning, as would be defined in a finite mixture modeling approach. However, can be reasonably regarded as an upper limit for (Ishwaran and Zarepour,, 2000).
The hyperprior for plays a pivotal role in determining , which in turn shapes the posterior distribution over clusters. Using a Gamma distribution - with as the shape parameter and as the rate parameter - as a hyperprior for is common practice, attributable to its computational advantages (Escobar and West,, 1995). While the choices of parameters and can significantly influence the posterior distribution of , thus impacting clustering behavior (Dorazio,, 2009; Murugiah and Sweeting,, 2012), other studies suggest that data are typically sufficient to produce a concentrated posterior, thereby reducing the influence of the hyperprior even when a high-variance prior for is used (Leslie et al.,, 2007; Gelman et al.,, 2013).
Our objective is to assess the sensitivity under two distinct hyperprior options for , particularly in the context of varying levels of data informativeness. The first hyperprior, explored by Antonelli et al., (2016), is relatively diffuse, allowing for numerous clusters. This strategy, which we refer to as the DP-diffuse model, is applicable when prior knowledge about is absent. The DP-diffuse model chooses values of and such that is centered between 1 and , with a large variance to assign a priori mass to a wide range of possible values. For instance, with , we might set the mean of the distribution to 25 and its variance to 250 , ten times the mean. With these initial values, we can use the moments of a Gamma distribution to derive the corresponding hyperparameters and , based on the formulas and .
This research proposes a novel approach, employing a distribution to formulate an informative hyperprior for . Assume we have , a prior that encapsulates our knowledge of the distribution of . Dorazio, (2009) provides an expression for , the probability mass function for the prior distribution induced by a Gamma prior for and . We can then obtain optimal values for and by minimizing the discrepancy between the encoded prior and the -induced prior using the Kullback-Leibler divergence measure.
We propose setting to more intuitively encapsulate our prior knowledge on and its inherent uncertainty. This strategy is primarily motivated by the fact that the distribution has a mean and variance of and , respectively. For instance, if we regard five clusters () among 50 sites as a reasonable approximation of the underlying distribution, we could assume that follows a distribution and specify a that closely matches . In this case, the appropriate Gamma distribution would have parameters (see the Supplemental Material). This approach, which we term the DP-inform model, is particularly effective for crafting an informative prior for , especially when aiming to impose near-zero probabilities beyond a certain threshold (e.g., as shown in Figure 1) and to clarify the prior mean and variance of .

In Figure 1, we observe that the two DPM models represent contrasting beliefs regarding . The DP-diffuse model favors a smoother with approximately 25-30 clusters for 50 sites, while the DP-inform model, based on , is more favorable to a more uneven , assuming that about five clusters are needed for 50 sites. Further details about the choices of hyperpriors and their implementations can be found in the Supplemental Material.
4 A simulation study
4.1 Simulation design
To compare the performance of different models and posterior summary methods, we conduct a comprehensive Monte Carlo simulation. We generate data by systematically varying five factors: (a) the number of sites (), (b) the average number of observations per site (), (c) the coefficient of variation in site sizes (), (d) the true cross-site population distribution of , and (e) the true cross-site population standard deviation of impacts (). We calibrate our simulated datasets to mirror typical data settings for multisite trials in education, as described by Weiss et al., (2017).
We consider five values for the number of sites in our study: , and . The number of random assignment blocks reported in the 16 studies from Weiss et al., (2017) ranged from 20 to 356, with a median of 78. Although multisite trials typically involve a small to moderate numbers of sites, we also wanted to investigate model performance for larger multisite trials, such as the Head Start Impact Study (e.g., Bloom and Weiland,, 2015).
We vary the average number of observations per site in our study as , and . Weiss et al., (2017) reported a range of mean site sizes, from 11 in the Head Start Impact Study to 1,176 in the Welfare-to-Work Program, with the 25th and 75th percentiles at 75 and 163, respectively. Larger site sizes also capture contexts where we are using baseline covariates to increase precision, as both size and directly impact site-level uncertainty, which is what drives our overall performance (see equation (1) and the definition of informativeness in equation (4)). We control the variation in site sizes by setting the coefficient of variation of the site sizes to be by sampling from a gamma distribution with a mean of and a standard deviation of . We then truncate at the lower limit of . Finally, we compute the within-site sampling variances as: (this is assuming we are in an effect size metric with a control-side standard deviation of 1 within site).
We vary the cross-site impact standard deviation as and in effect size units. Weiss et al., (2017) report that the cross-site standard deviation of program impact, in effect size units, ranges between 0.00 and 0.35, with most values falling between 0.10 and 0.25. They define 0.05, 0.15, and 0.25 as having a modest, moderate, and substantial impact variation, respectively. In conjunction with the range of determined by our selection of , determines the magnitude of the average reliability of the ML estimates, denoted by . Across our simulation conditions, varies between 0.01 and 0.71, with a mean of 0.25.
Finally, we consider three different population distributions for : Gaussian, a mixture of two Gaussians, and asymmetric Laplace (AL). The Gaussian mixture represents a scenario where the actual is multimodal, while the AL distribution exemplifies a situation where the true is skewed and exhibits a long tail. We rescale the simulated so that the variance of equals . Additional details on the data-generation process can be found in the Supplemental Material.
Using the five design factors (, , CV, , and ), we generate 1,500 simulation conditions, each with 100 replications. We fit each replication with three data-analytic models: Gaussian, DP-diffuse, and DP-inform, and, for each model, use Markov Chain Monte Carlo to obtain 4,000 posterior samples from the joint posterior distributions of the J site-specific effects. Finally, we apply all three posterior summary methods (PM, CB, and GR) to each model fit. This gives 9 estimators for each generated dataset.
4.2 Simulation analysis
To analyze the simulation results, we separate the three true population distributions into samples of 450,000 observations each, generated as a factorial combination of the four remaining design factors (, , CV, and ), two data-analytic factors (data-analytic model and posterior summary method), and 100 replications. We construct 50,000 cluster (i.e., dataset) identifiers based on the four design factors and 100 replications to account for the statistical dependence induced by analyzing the same simulated dataset.
We use meta-model regressions (Skrondal,, 2000) to examine the relationship between performance criteria and simulation factors. Unlike visual or descriptive methods, meta-models allow for a more precise detection of significant patterns while accounting for uncertainty from Monte Carlo error (Boomsma,, 2013). We focus on the three performance criteria outlined in Section 3.1 as our target outcome variables: RMSE, ISEL, and MSELP. To ease the interpretation of the meta-model regression coefficients, we apply a logarithmic transformation to the outcome variables. As for the explanatory variables, we create a set of dummy variables representing the six design and data-analytic factors, along with their two-way interaction terms. The reference groups are , , , , the Gaussian model, and the PM summary method. Lastly, since we include each dataset nine times in each meta-model regression (corresponding to every model/posterior summary method combination), we cluster our standard errors on datasets.
5 Results: Effects of data-generating factors
Our simulation produces nine (three performance criteria three true population distributions ) meta-model regressions, each summarizing a six-factor factorial experiment. Rather than exhaustively exploring these results, we divide our analyses into two simple, practical sections. We first explore how the four design factors (, , CV, and ) generally affect the performance of each model and posterior summary method. We then directly compare the model/method combinations, using hypothetical case studies to illustrate how they may perform relative to each other in real-world applications.
Figure 2 illustrates how the design factors affect the outcome metric for each model/method combination, under the Gaussian mixture data-generating distribution. Results for the Gaussian and AL data-generating distributions are qualitatively similar (see the Supplemental Material). The values within each cell indicate the predicted multiplicative change in average RMSE, ISEL, or MSELP by the meta-model regressions. This change corresponds to altering a single data-generating factor from the base condition (, , , ) to the value indicated by the row. These values are provided for each model, posterior summary method, and outcome metric, as indicated by the column, column panel, and row panel, respectively. Values less than 1 indicate improvement compared to the base condition. For example, the value 0.77 in the top-left cell indicates that for the Gaussian model using the PM estimator, increasing from 10 to 20 reduces the RMSE by approximately 23% on average, when all other design factors are held at their baseline levels.
While the metrics respond differently to changes in the data-generating factors, we highlight some overall patterns in Figure 2. First, increasing significantly improves all three metrics. The three metrics all measure how well some feature of the finite population distribution of site-level effects is estimated; increasing increases the average precision of the site-level effect estimates , so it naturally improves these finite population metrics. Second, changing CV has little effect on any of the metrics, indicating that the variation in site sizes matters much less than the average site size.

The RMSE metric is sensitive to changes in both and . When increases, the RMSE decreases. Adding sites increases the sample size used to estimate the cross-site variation. This improves the models’ estimates of the cross-site variation, which in turn improves their site-specific effect estimates. Conversely, increasing generally results in a higher RMSE. The models all apply shrinkage to the raw site-specific estimates, which biases the estimates but typically reduces their RMSE by significantly decreasing their variance. As the variation of the true site-specific effects increases, however, there is more room for bias as the sites are more spread out, and the benefits of variance reduction will no longer outweigh this bias cost. Given this, with larger , the models shrink less. For example, equation (3) illustrates how the estimates produced by the Gaussian/PM combination approach the initial raw site-specific estimates as increases, given a fixed average site size. Overall, RMSE tends to be larger when is larger, particularly for models and methods that exhibit the most shrinkage in the base case. As observed in Figure 2, this effect is strongest for the Gaussian/PM combination and weaker for the DP-diffuse model and the CB and GR summary methods.
In terms of the ISEL metric (for measuring how close our estimated distribution is to the truth), increasing improves results. Similar to the RMSE, a larger allows for better estimation of cross-site variation, thereby enhancing the estimates. Adding more sites is equivalent to drawing additional noisy samples from the true EDF, which provides information about the true EDF’s shape. The DP-inform model is particularly effective at incorporating this information, although the other models also show improvement.
In contrast to the RMSE, higher values result in better ISEL. Shrinkage causes systematic underestimation of large true effects and overestimation of small true effects. While this generally improves RMSE, which does not differentiate between overestimation and underestimation, excessive shrinkage can create significant discrepancies between the true and estimated EDFs, resulting in poor ISEL values. Consequently, ISEL rewards estimates that are not overly shrunken toward the overall mean. As increases, Figure 2 demonstrates how the CB/GR methods are better able to maintain correspondingly diffuse EDF estimates, while the PM method struggles in this regard.
Lastly, we observe that MSELP (measuring how well we rank the sites) improves as either or increases and remains largely unaffected by , CV , model, and summary method. Generally, the primary factor influencing order estimation is the average reliability of the ML estimates, , which quantifies the relative magnitude of between-site and within-site variations. When most variation occurs between sites, it is easier to distinguish and accurately rank them. Increasing raises the proportion of total variation in the data that is between sites (rather than within sites), thereby enhancing MSELP. Similarly, a higher reduces the impact of within-site variation, which also improves MSELP. Employing different models and summary methods seldom alters the ordering of site-specific effect estimates, and thus, does not affect MSELP.
6 Results: Case studies of best model-method choices
We now directly compare the models and posterior summary methods to assess the most effective combinations under various design settings. Figure 3 illustrates the best model-method combinations, as indicated by the average outcome metric predicted by the meta-model regressions, for the Gaussian mixture data-generating distribution across different values of , , and (with held constant). In the figure, both the shape and color at each design setting represent the model-method combination yielding the lowest average error metric value, while the numbers indicate the value of for each respective design setting.

Although Figure 3 may be subject to some simulation noise, it uncovers several intriguing patterns for the best posterior summary method. As anticipated, the posterior mean (PM) summary method consistently outperforms other methods in terms of RMSE. Since the PM method is designed to minimize RMSE, practitioners aiming to optimize RMSE should always employ the posterior mean summary method. Conversely, PM is seldom the best summary method for ISEL. The CB and GR summary methods typically exhibit less shrinkage than the PM method, leading to more accurate representations of the EDF of site-specific effects.
Figure 3 additionally highlights patterns for the best prior model for . We observe that these patterns are predominantly influenced by the average reliability of , represented as . As or increase, the value of also increases, ranging from 0.01 to 0.71, indicating that the data becomes more informative. The number of sites introduces an extra dimension of data informativeness; the patterns alter as increases, since a higher number of sites supply more information, even if the value of remains constant. Consequently, the model’s performance depends on three variables that determine the overall informativeness of the data: , , and .
The DP models typically outperform the Gaussian model in highly informative settings. We observe that the DP-inform model tends to yield the lowest RMSE when is approximately greater than 0.44. Meanwhile, the DP-diffuse model performs best in terms of ISEL. Notably, this relationship is influenced by the number of sites, . For example, when , the DP models significantly outperform the Gaussian model in terms of ISEL if the level is above roughly 0.20. For or , the DP models require an level exceeding approximately 0.40 to significantly outperform the Gaussian model. With a low of 25, the DP models’ performance on ISEL is never significantly better than the Gaussian model, even at the maximum level we explored (). The Supplemental Material displays the 95% prediction intervals around the meta-model predicted values, accounting for Monte Carlo error, to assess the statistical significance of the DP models’ superior performance.

In less informative settings, however, Figure 3 demonstrates that the Gaussian model often has better performance. We note that while the DP-inform model performs the best when and is approximately less than 0.05, it only marginally outperforms the Gaussian model in these situations (refer to the Supplemental Material). Despite the true data-generating distribution not being Gaussian in these simulations, the Gaussian model combined with a suitable posterior summary method outperforms the DP models in settings with low-to-moderate informativeness, which is frequently the case in educational applications.
It is important to highlight that the performance of DP models is sensitive to the extent of between-site information present in the data. Figure 4 demonstrates the substantial improvement in the ISEL of the DP models (all employing the GR estimator) as both and increase. Conversely, the Gaussian model’s imposed shape constraint on prevents it from effectively using the additional cross-site information, even when site sizes are substantially large (). In scenarios characterized by a considerable amount of between-site information, the DP models’ adaptive clustering facilitates the recovery of site-effect distributions with significantly higher accuracy compared to the Gaussian model.
6.1 Case 1: Large between-site information & Large within-site information
We now examine a series of case studies to assess the relative performance of different model-method combinations in various real-world situations. Figure 5 displays the performance of each combination in a simulation scenario characterized by high informativeness, encompassing considerable between-site information (, ) and significant within-site information (). We note that Weiss et al., (2017) do not provide directly comparable cases, highlighting the challenge of acquiring highly informative data at both the within- and between-site levels in real-world multisite trials.

Panel A of Figure 5 plots histograms of the estimates made by the different model-method combinations against the super population density of true site-specific effects. Panel A aggregates estimates across all simulations, so it does not show how well these approaches estimate the true finite-population distribution of site-specific effects for any given simulation sample; nonetheless, it illustrates the general behaviors of each of these approaches. We see that in this highly informative setting, the DP models can consistently adapt to the sampled sites, while the Gaussian estimator tends to shrink estimates toward the overall average. Similarly, even in this highly informative setting, the PM estimator tends to shrink estimates much more than the CB or GR estimators.
To summarize these results, we visualize the log-outcomes predicted by the meta-model regressions in Panels B and C of Figure 5. In this highly informative setting, the DP models outperform the Gaussian model in terms of both RMSE and ISEL. For example, using the DP-inform model with the GR estimator significantly improves ISEL compared to the Gaussian model with the same estimator. We see no significant differences in performance between the two DP models, suggesting that with sufficient information, the DP models are quite data-adaptive and insensitive to the choice of prior on .
6.2 Case 2: Large between-site information & Small within-site information
Figure 6 shows results in a scenario similar to the Head Start Impact Study (Puma et al.,, 2010), which has significant between-site information (, ) but limited within-site information (). In Panel A, we see how the lack of within-site information leads even the DP models to lean more heavily on the Gaussian base distribution, leading to roughly Gaussian histograms when aggregated across all simulations.

When there is significantly more between-site information than within-site information, shrinkage toward the overall mean effect can considerably influence model estimates. For instance, the DP-diffuse model is found to be unsuitable for both RMSE and ISEL due to undershrinkage, which can be attributed to the model’s assumption of a large number of clusters and the substantial between-site information. Consequently, this leads to excessive weight being placed on a broad spectrum of potential site-specific effects. Conversely, the Gaussian model exhibits excessive shrinkage as a result of its shape constraints. In this scenario, the DP-inform model demonstrates strong performance in terms of ISEL, as its flexible shape allows it to adapt appropriately to the considerable between-site information, while its limited number of assumed clusters prevents undershrinkage.
In general, the choice of posterior summary method has a more pronounced impact than model selection. Using the PM summary, RMSE improves by 16-42% compared to CB or GR methods. In contrast, only a 1% RMSE difference is observed between the Gaussian and DP-inform models with PM. For ISEL, CB or GR methods outperform PM by 1.85 to 2.14 times, a more significant gain than the 20-35% improvement when choosing the DP-inform over the Gaussian model with CB/GR methods.
6.3 Case 3: Small between-site information & Large within-site information
Figure 7 presents simulation results for a setting akin to the Performance-Based Scholarships study, characterized by limited between-site information (, ) but abundant within-site information (). In this scenario, the choice of model does not substantially influence performance once a suitable posterior summary method is employed (i.e., PM for RMSE, CB/GR for ISEL). The data-adaptive nature of the DP models is evident; they exhibit less shrinkage than the Gaussian model in Case 2, where is large,

but more shrinkage in the current scenario, where is small, even with the relatively significant within-site information. As demonstrated in Figure 4, the true cross-site impact variation, , tends to have a considerable impact on the DP models, particularly when is moderate to large. In situations where is estimated to be very small (i.e., ), Gaussian models may help protect results from excessive shrinkage. Similar patterns are evident in scenarios with or (see the Supplemental Material).
7 Results: Real data example
In this section, we apply the strategies from this paper to study site-specific effects in the Conditional Subsidies for School Attendance program in Bogota, Colombia (Barrera-Osorio et al.,, 2019). The program conducted two conditional cash transfer (CCT) experiments in San Cristobal and Suba, covering 13,491 participants across 99 sites. In San Cristobal, eligible students in grades 6 to 11 were randomly assigned to a “basic” treatment, “savings” treatment, or control group. In contrast, in Suba, eligible participants in grades 9 to 11 were randomly assigned to a tertiary treatment or control group. We focus on the primary outcomes of secondary school enrollment and graduation in San Cristobal, with results for the Suba district available in the Supplemental Material.
We first extract the design characteristics of the multisite trials, presented in Table 1. In San Cristobal, a total of 6,506 participants were nested within 38 sites, with an average site size of 171.2. Site sizes varied considerably, ranging from 23 to 484, with a coefficient of variation (CV) of 0.67. We combine the basic and savings treatments for analysis, resulting in an average treatment rate of 67% within each site.
| Basic/Savings experiment | ||
| On-time secondary | Secondary | |
| enrollment | graduation | |
| Average treatment effect | 0.07 | 0.05 |
| Cross-site effect SD | 0.04 | 0.06 |
| Geometric mean of | 0.21 | 0.24 |
| Average reliability of | 0.04 | 0.06 |
| Total sample size | 6,506 | |
| Number of | 38 | |
| Average site size | 171.2 | |
| Coefficient of variation of site sizes (CV) | 0.67 | |
| Range of site sizes | ||
| Average proportion of units treated | 0.67 | |
-
•
Note: We excluded sites with extreme probabilities, that is, necessitating both and to be at least 8, where represents the site size and denotes the proportion of participants treated in site . Detailed distributions of and and comparisons of outcome means by experimental group are available in the Supplemental Material.
We then apply the basic Rubin model (equations (1) and (2)) to estimate the cross-site impact variation () and the sampling variation within sites. The average reliability of () for each outcome is crucial for assessing data informativeness within and between sites, guiding the choice of the optimal model/method combination. Since all four outcomes are binary, we summarize the observed site-specific effects using the log odds ratio (logOR), yielding and estimates on the logOR scale. To facilitate interpretation, we transformed these estimates to the standard mean difference scale, known as Cohen’s . Specifically, we converted using for the average treatment effect, and for the cross-site effect standard deviation (Borenstein et al.,, 2009).
San Cristobal’s multisite CCT experiment exhibited small between-site information (, or ) and large within-site information (). The estimated average reliability of for this experiment were 0.04 and 0.06 for secondary on-time enrollment and graduation, respectively. As in Section 6.3, this led to significant shrinkage toward the prior mean effect , emphasizing the importance of choosing the appropriate model-method combination for controlling shrinkage and achieving the desired inferential goals.

Figure 8 highlights the considerable differences in the distributions of site-specific effects estimated by the model/method combinations. The posterior mean summary method and the DP-inform model notably shrink estimates more strongly than the other methods and models. Interestingly, the DP-diffuse model preserves the extreme estimates around -0.25 and 0.40 by assigning greater weight to a broad range of possible values, unlike the other two models. We also observe that the GR summary method generates smoother site-effect histograms due to its use of quantile estimates.
From the third case study, discussed in Section 6.3, we may be more inclined to trust the EDF estimates produced by the model-method combination least prone to excessive shrinkage. A simulated case study based on the San Cristobal experiment scenario, detailed in the Supplemental Material, indicates that the Gaussian model with the PM and GR summary methods demonstrates the best performance for RMSE and ISEL, respectively. If extreme effects were expected or of particular interest, we might choose to use the DP-diffuse model instead.
8 Discussion
This study primarily aimed to identify optimal approaches for enhancing inferences about site-specific effect estimates to address various inferential goals. We conducted a systematic simulation study evaluating the performance of combinations of two strategies: flexible prior modeling for and posterior summary methods designed to minimize specific loss functions. We focused on the low-data environments commonly encountered in multisite trials. Below we discuss the key insights derived from this study.
The most influential factor for all inferential goals was the average reliability, or informativeness , of raw site-specific effect estimates. In the data analysis stage, researchers should initially estimate the average reliability of (), as it dictates data informativeness and guides the best model-method combination. Increasing , which enhances the average precision of the estimates, significantly improved the results for all three loss functions: RMSE, ISEL, and MSELP. Thus, when confronted with budgetary or logistical constraints during the design phase of multisite trials, it is important to prioritize increasing the average number of subjects per site (irrespective of the variation in site sizes) when the focus is on estimating site-specific effects. This holds especially true if the goal is to rank the values, given that MSELP was only affected by and .
In scenarios characterized by high data informativeness or a large average reliability of (), semiparametric Dirichlet Process models typically outperform Gaussian models. Nonetheless, we also found that certain requirements must be satisfied to use DP priors with a reasonable degree of confidence in practical applications. First, the performance of DP models is particularly sensitive to the amount of between-site information in the data. For a fixed average site size, the ability of DP models to recover the EDF of ’s is greatly enhanced by a large and a large number of sites, . Specifically, the level of cross-site impact variation, , dramatically alters the DP model’s relative performance on ISEL compared to the Gaussian model. The case studies also demonstrated that when the value of is low (around ), the estimates of obtained using the DP models exhibited shrinkage behavior that was sensitive to the value of , shrinking less when was large and more when was small. These results indicate the necessity of assessing whether sufficient cross-site information ( and ) is available to effectively apply semiparametric estimation in practice. Flexible models such as DP models and recent NPMLE-based deconvolution methods (Armstrong et al.,, 2022; Gu and Koenker,, 2023) are designed to adapt to cluster-level data, and their mathematical guarantees are asymptotic in nature. Consequently, their suitability for analyzing real-world multisite trial data — where obtaining highly informative data both within and between sites is extremely challenging — must be carefully considered.
Second, even in highly informative settings with abundant between-site information, DP priors must be used jointly with targeted posterior summary methods to achieve specific inferential goals. Our simulations demonstrate that, even in highly informative settings, the posterior mean method combined with DP priors consistently outperforms both CB and GR in terms of RMSE, while it is rarely the best estimator for ISEL. We emphasize the joint use of flexible distributions for and targeted posterior summary methods because estimators that produce optimal estimates of the collection of individual site-specific effects may produce poor estimates of the shape of their distribution, and vice versa.
In scenarios with low-to-moderate data informativeness, often observed in multisite trials with an average reliability below 0.20, it is much more important to target the posterior summary to the metric of interest than it is to choose a flexible prior model for . In simulations with these conditions, the Gaussian model, paired with an appropriate posterior summary method, performed on par with or better than the DP models, even when the true was non-Gaussian. Practically, researchers might lean towards Gaussian models when data is limited. While the performance of DP models is data-adaptive and insensitive to the choice of prior on when sufficient information is available, the choice can substantially affect the degree of shrinkage in uninformative settings. As a result, the Gaussian model offers a somewhat less assumption-heavy approach for estimation, which may be preferable in such cases.
A key limitation of this study is the assumption that site size is independent of site-specific treatment effects, i.e., zero correlation between and in our data-generation and analytic methods. In general, smaller school sites may be less (or more) efficient than larger school sites in implementing efficacious interventions and thus tend to have smaller (or larger) values (Angrist et al.,, 2022). One advantage of the Bayesian model-based approach is the ability to estimate models with and without restrictions on the bivariate distribution of and , and to assess the sensitivity of site-specific effect estimates to this assumption. Alternatively, we can treat as a covariate in the conditional distribution of , or apply Brown, (2008)’s variance-stabilizing transform to to achieve approximately constant sampling variance.
In conclusion, no single estimation strategy universally excels across varied data scenarios and inferential goals. Flexible semiparametric models are not a panacea, given the complex interplay between study design characteristics and modeling choices. Researchers should carefully select methods tailored to their specific inferential goals, taking into account the amount of within-site and between-site information. Ideally, multisite trials should be prospectively designed to address inferential goals related to site-specific treatment effects.
References
- Angrist et al., (2022) Angrist, J., Hull, P., and Walters, C. R. (2022). Methods for measuring school effectiveness. Technical Report Working Paper No. 30803, National Bureau of Economic Research.
- Angrist et al., (2017) Angrist, J. D., Hull, P. D., Pathak, P. A., and Walters, C. R. (2017). Leveraging lotteries for school value-added: Testing and estimation. The Quarterly Journal of Economics, 132(2):871–919.
- Antonelli et al., (2016) Antonelli, J., Trippa, L., and Haneuse, S. (2016). Mitigating bias in generalized linear mixed models: The case for bayesian nonparametrics. Statistical science: a review journal of the Institute of Mathematical Statistics, 31(1):80.
- Antoniak, (1974) Antoniak, C. E. (1974). Mixtures of dirichlet processes with applications to bayesian nonparametric problems. The Annals of Statistics, 2(6):1152–1174.
- Armstrong et al., (2022) Armstrong, T. B., Kolesár, M., and Plagborg-Møller, M. (2022). Robust empirical bayes confidence intervals. Econometrica, 90(6):2567–2602.
- Barrera-Osorio et al., (2019) Barrera-Osorio, F., Linden, L. L., and Saavedra, J. E. (2019). Medium-and long-term educational consequences of alternative conditional cash transfer designs: Experimental evidence from colombia. American Economic Journal: Applied Economics, 11(3):54–91.
- Bloom et al., (2017) Bloom, H. S., Raudenbush, S. W., Weiss, M. J., and Porter, K. (2017). Using multisite experiments to study cross-site variation in treatment effects: A hybrid approach with fixed intercepts and a random treatment coefficient. Journal of Research on Educational Effectiveness, 10(4):817–842.
- Bloom and Weiland, (2015) Bloom, H. S. and Weiland, C. (2015). Quantifying variation in head start effects on young children’s cognitive and socio-emotional skills using data from the national head start impact study. Technical report, MDRC, New York, NY.
- Boomsma, (2013) Boomsma, A. (2013). Reporting monte carlo studies in structural equation modeling. Structural Equation Modeling: A Multidisciplinary Journal, 20(3):518–540.
- Borenstein et al., (2009) Borenstein, M., Hedges, L. V., Higgins, J. P., and Rothstein, H. R. (2009). Converting among effect sizes. In Introduction to Meta-Analysis, chapter 7, pages 45–49. John Wiley & Sons, Ltd. DOI: https://doi.org/10.1002/9780470743386.ch7.
- Brown, (2008) Brown, L. D. (2008). In-season prediction of batting averages: A field test of empirical bayes and bayes methodologies. Annals of Applied Statistics, 2(1):113–152.
- Chetty et al., (2014) Chetty, R., Friedman, J. N., and Rockoff, J. E. (2014). Measuring the impacts of teachers i: Evaluating bias in teacher value-added estimates. American economic review, 104(9):2593–2632.
- Dorazio, (2009) Dorazio, R. M. (2009). On selecting a prior for the precision parameter of dirichlet process mixture models. Journal of Statistical Planning and Inference, 139(9):3384–3390.
- Dunson et al., (2007) Dunson, D. B., Pillai, N., and Park, J.-H. (2007). Bayesian density regression. Journal of the Royal Statistical Society Series B: Statistical Methodology, 69(2):163–183.
- Efron, (2016) Efron, B. (2016). Empirical bayes deconvolution estimates. Biometrika, 103(1):1–20.
- Escobar and West, (1995) Escobar, M. D. and West, M. (1995). Bayesian density estimation and inference using mixtures. Journal of the American Statistical Association, 90(430):577–588.
- Gelman, (2006) Gelman, A. (2006). Prior distributions for variance parameters in hierarchical models. Bayesian Analysis, 1(3):515–533.
- Gelman et al., (2013) Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2013). Bayesian Data Analysis. Chapman and Hall/CRC, 3rd edition.
- Ghidey et al., (2004) Ghidey, W., Lesaffre, E., and Eilers, P. (2004). Smooth random effects distribution in a linear mixed model. Biometrics, 60(4):945–953.
- Ghosh, (1992) Ghosh, M. (1992). Constrained bayes estimation with applications. Journal of the American Statistical Association, 87(418):533–540.
- Gilraine et al., (2020) Gilraine, M., Gu, J., and McMillan, R. (2020). A new method for estimating teacher value-added. Technical report, National Bureau of Economic Research.
- Goldstein and Spiegelhalter, (1996) Goldstein, H. and Spiegelhalter, D. J. (1996). League tables and their limitations: statistical issues in comparisons of institutional performance. Journal of the Royal Statistical Society: Series A (Statistics in Society), 159(3):385–409.
- Gu and Koenker, (2023) Gu, J. and Koenker, R. (2023). Invidious comparisons: Ranking and selection as compound decisions. Econometrica, 91(1):1–41.
- Imbens and Rubin, (2015) Imbens, G. W. and Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge University Press.
- Ishwaran and Zarepour, (2000) Ishwaran, H. and Zarepour, M. (2000). Markov chain monte carlo in approximate dirichlet and beta two-parameter process hierarchical models. Biometrika, 87(2):371–390.
- Jiang and Zhang, (2009) Jiang, W. and Zhang, C.-H. (2009). General maximum likelihood empirical bayes estimation of normal means. The Annals of Statistics, 37(4):1647–1684.
- Kline et al., (2022) Kline, P., Rose, E. K., and Walters, C. R. (2022). Systemic discrimination among large us employers. The Quarterly Journal of Economics, 137(4):1963–2036.
- Kontopantelis and Reeves, (2012) Kontopantelis, E. and Reeves, D. (2012). Performance of statistical methods for meta-analysis when true study effects are non-normally distributed: A comparison between dersimonian–laird and restricted maximum likelihood. Statistical Methods in Medical Research, 21(6):657–659.
- Leslie et al., (2007) Leslie, D. S., Kohn, R., and Nott, D. J. (2007). A general approach to heteroscedastic linear regression. Statistics and Computing, 17:131–146.
- Liu and Dey, (2008) Liu, J. and Dey, D. K. (2008). Skew random effects in multilevel binomial models: an alternative to nonparametric approach. Statistical modelling, 8(3):221–241.
- Lockwood et al., (2018) Lockwood, J., Castellano, K. E., and Shear, B. R. (2018). Flexible bayesian models for inferences from coarsened, group-level achievement data. Journal of Educational and Behavioral Statistics, 43(6):663–692.
- Lockwood et al., (2002) Lockwood, J., Louis, T. A., and McCaffrey, D. F. (2002). Uncertainty in rank estimation: Implications for value-added modeling accountability systems. Journal of educational and behavioral statistics, 27(3):255–270.
- Lu et al., (2023) Lu, B., Ben-Michael, E., Feller, A., and Miratrix, L. (2023). Is it who you are or where you are? accounting for compositional differences in cross-site treatment effect variation. Journal of Educational and Behavioral Statistics, 48(4):420–453.
- McCaffrey et al., (2004) McCaffrey, D. F., Lockwood, J., Koretz, D., Louis, T. A., and Hamilton, L. (2004). Models for value-added modeling of teacher effects. Journal of Educational and Behavioral Statistics, 29(1):67–101.
- McCulloch and Neuhaus, (2011) McCulloch, C. E. and Neuhaus, J. M. (2011). Misspecifying the shape of a random effects distribution: Why getting it wrong may not matter. Statistical Science, pages 388–402.
- Meager, (2019) Meager, R. (2019). Understanding the average impact of microcredit expansions: A bayesian hierarchical analysis of seven randomized experiments. American Economic Journal: Applied Economics, 11(1):57–91.
- Miratrix et al., (2021) Miratrix, L. W., Weiss, M. J., and Henderson, B. (2021). An applied researcher’s guide to estimating effects from multisite individually randomized trials: Estimands, estimators, and estimates. Journal of Research on Educational Effectiveness, 14(1):270–308.
- Mislevy et al., (1992) Mislevy, R. J., Beaton, A. E., Kaplan, B., and Sheehan, K. M. (1992). Estimating population characteristics from sparse matrix samples of item responses. Journal of Educational Measurement, 29(2):133–161.
- Mogstad et al., (2020) Mogstad, M., Romano, J. P., Shaikh, A., and Wilhelm, D. (2020). Inference for ranks with applications to mobility across neighborhoods and academic achievement across countries. Technical report, National Bureau of Economic Research.
- Mountjoy and Hickman, (2021) Mountjoy, J. and Hickman, B. R. (2021). The returns to college (s): Relative value-added and match effects in higher education. Technical report, National Bureau of Economic Research.
- Murugiah and Sweeting, (2012) Murugiah, S. and Sweeting, T. (2012). Selecting the precision parameter prior in dirichlet process mixture models. Journal of Statistical Planning and Inference, 142(7):1947–1959.
- Ohlssen et al., (2007) Ohlssen, D. I., Sharples, L. D., and Spiegelhalter, D. J. (2007). A hierarchical modelling framework for identifying unusual performance in health care providers. Journal of the Royal Statistical Society: Series A (Statistics in Society), 170(4):865–890.
- Paddock et al., (2006) Paddock, S. M., Ridgeway, G., Lin, R., and Louis, T. A. (2006). Flexible distributions for triple-goal estimates in two-stage hierarchical models. Computational statistics & data analysis, 50(11):3243–3262.
- Paganin et al., (2022) Paganin, S., Paciorek, C. J., Wehrhahn, C., Rodríguez, A., Rabe-Hesketh, S., and de Valpine, P. (2022). Computational strategies and estimation performance with bayesian semiparametric item response theory models. Journal of Educational and Behavioral Statistics, page 10769986221136105.
- Paxton et al., (2001) Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., and Chen, F. (2001). Monte carlo experiments: Design and implementation. Structural Equation Modeling, 8(2):287–312.
- Puma et al., (2010) Puma, M., Bell, S., Cook, R., Heid, C., Shapiro, G., Broene, P., Jenkins, F., et al. (2010). Head start impact study. final report. Technical report, Administration for Children & Families.
- Rabe-Hesketh et al., (2003) Rabe-Hesketh, S., Pickles, A., and Skrondal, A. (2003). Correcting for covariate measurement error in logistic regression using nonparametric maximum likelihood estimation. Statistical Modelling, 3(3):215–232.
- Rabe-Hesketh and Skrondal, (2022) Rabe-Hesketh, S. and Skrondal, A. (2022). Multilevel and Longitudinal Modeling Using Stata, Volume I: Continuous Responses. Stata Press, College Station, TX, 4 edition.
- Raudenbush and Bloom, (2015) Raudenbush, S. W. and Bloom, H. S. (2015). Learning about and from a distribution of program impacts using multisite trials. American Journal of Evaluation, 36(4):475–499.
- Raudenbush and Bryk, (1985) Raudenbush, S. W. and Bryk, A. S. (1985). Empirical bayes meta-analysis. Journal of educational statistics, 10(2):75–98.
- Rosenbaum and Rubin, (1983) Rosenbaum, P. R. and Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1):41–55.
- Rubin, (1981) Rubin, D. B. (1981). Estimation in parallel randomized experiments. Journal of Educational Statistics, 6(4):377–401.
- Rubio-Aparicio et al., (2018) Rubio-Aparicio, M., Marin-Martinez, F., Sanchez-Meca, J., and Lopez-Lopez, J. A. (2018). A methodological review of meta-analyses of the effectiveness of clinical psychology treatments. Behavior Research Methods, 50:2057–2073.
- Rudolph et al., (2018) Rudolph, K. E., Schmidt, N. M., Glymour, M. M., Crowder, R., Galin, J., Ahern, J., and Osypuk, T. L. (2018). Composition or context: Using transportability to understand drivers of site differences in a large-scale housing experiment. Epidemiology, 29(2):199–206.
- Sabol et al., (2022) Sabol, T. J., McCoy, D., Gonzalez, K., Miratrix, L., Hedges, L., Spybrook, J. K., and Weiland, C. (2022). Exploring treatment impact heterogeneity across sites: Challenges and opportunities for early childhood researchers. Early Childhood Research Quarterly, 58:14–26.
- Schochet and Padilla, (2022) Schochet, O. N. and Padilla, C. M. (2022). Children learning and parents earning: Exploring the average and heterogeneous effects of head start on parental earnings. Journal of Research on Educational Effectiveness, 15(3):413–444.
- Shen and Louis, (1998) Shen, W. and Louis, T. A. (1998). Triple-goal estimates in two-stage hierarchical models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 60(2):455–471.
- Skrondal, (2000) Skrondal, A. (2000). Design and analysis of monte carlo experiments: Attacking the conventional wisdom. Multivariate Behavioral Research, 35(2):137–167.
- Spybrook, (2014) Spybrook, J. (2014). Detecting intervention effects across context: An examination of the precision of cluster randomized trials. The Journal of Experimental Education, 82(3):334–357.
- Spybrook and Raudenbush, (2009) Spybrook, J. and Raudenbush, S. W. (2009). An examination of the precision and technical accuracy of the first wave of group-randomized trials funded by the institute of education sciences. Educational Evaluation and Policy Analysis, 31(3):298–318.
- Stuart et al., (2011) Stuart, E. A., Cole, S. R., Bradshaw, C. P., and Leaf, P. J. (2011). The use of propensity scores to assess the generalizability of results from randomized trials. Journal of the Royal Statistical Society: Series A (Statistics in Society), 174(2):369–386.
- Tipton et al., (2021) Tipton, E., Spybrook, J., Fitzgerald, K. G., Wang, Q., and Davidson, C. (2021). Toward a system of evidence for all: Current practices and future opportunities in 37 randomized trials. Educational Researcher, 50(3):145–156.
- Verbeke and Lesaffre, (1996) Verbeke, G. and Lesaffre, E. (1996). A linear mixed-effects model with heterogeneity in the random-effects population. Journal of the American Statistical Association, 91(433):217–221.
- Weiss et al., (2017) Weiss, M. J., Bloom, H. S., Verbitsky-Savitz, N., Gupta, H., Vigil, A. E., and Cullinan, D. N. (2017). How much do the effects of education and training programs vary across sites? evidence from past multisite randomized trials. Journal of Research on Educational Effectiveness, 10(4):843–876.
Supplemental Material for
‘Improving the Estimation of Site-Specific Effects and their Distribution in Multisite Trials’
Appendix A Simulation details
A.1 Connecting sampling errors to site sizes
For a simple design-based estimator for site-specific effects , the sampling variation of each around its true effect within sites will be approximately
| (A.1) |
where is sample size at site and is the proportion of units treated in site , which Rosenbaum and Rubin, (1983) refer to as the propensity score. represents the assumed constant variation in outcome for a given treatment arm in a given site. is the explanatory power of level-1 covariates. This expression is Neyman’s classic formula under the assumption of homoskedasticity (Miratrix et al.,, 2021).
In effect size units, . If we further assume constant proportion treated, for convenience, we have
| (A.2) |
for some constant . If and with a reasonable pre-test score, . Without level-1 covariates, equals 4. Now we can obtain a vector of simulated ’s, denoted as , by directly controlling two constants, and , and one variable, . Our data-generating function for follows this relationship assuming and . Consequently, the magnitude of the sampling errors were set to be .
A.2 The average reliability under the simulation conditions of this study
The average reliability determines how informative the first-stage ML estimates ’s are on average. is calculated as where is the geometric mean of , . Consequently, a large average reliability value indicates less noisy and more informative observed ML estimates ’s relative to the degree of cross-site impact heterogeneity.

Figure A.1 illustrates the magnitudes of assumed by the simulation conditions we chose for and . The assumed level is equal to 0.714 if the average size of sites is 160 and the cross-site impact standard deviation is 0.25. In this situation, the cross-site impact variance is approximately 2.5 times the average within-site sampling variance (). In contrast, if , the average is roughly four times as large as (), resulting in noisy ’s. Since is the median of the possible levels shown in Figure A.1, half of our simulation conditions assume quite noisy and low informative data environments, which are often encountered in practical applications with small site sizes.
A.3 Data-generating models for
Figure A.2 illustrates three different population distribution for : Gaussian, a mixture of two Gaussians, and asymmetric Laplace (AL).
Note that the Gaussian distribution in Figure A.2 has a mean of zero and a variance of one (). For comparability with the Gaussian model, the Gaussian mixture and AL models were also normalized to have zero means and unit variances. Then, we rescaled the by multiplying the sampled distributions by .
Suppose that the Gaussian mixture data-generating model has two mixture components, and , with a mixture weight for the first component, . To force this mixture distribution to have mean 0 and variance 1, we define a normalizing factor denoted as :
| (A.3) |
where and . Then, with probability , is simulated from the first normalized component , otherwise from the second normalized component with probability of .

To simulate from the AL distribution with zero mean and unit variance, the location and scale parameters, and , are adjusted as follows as function of the skewness parameter :
where
| (A.4) |
The skewness parameter is set to 0.1 so that the resulting can have a right-skewed distribution with a long tail. This AL data-generating model is useful to evaluate whether the two strategies for the improved inferences help to recover large but rare site-level effects.
A.4 Data-analytic models
We fit three models to each of the simulated datasets: (a) is standard Gaussian model, (b) is a Dirichlet process mixture (DPM) model with a diffuse prior (DP-diffuse), and (c) is a DPM model with an informative prior (DP-inform). These three models share the same first stage model specifications: . The models differ based on the second stage specifications for modeling , where represents a vector of hyperparameters for .
The Gaussian model assumes that where hyperpriors are set to be vague: and . We avoid using the inverse-gamma prior for because it does not have any proper limiting posterior distribution particularly for the simulation settings we have, where the number of sites is small or the site-level variation is small by design (Gelman,, 2006). The two DPM models assume that where is a Gaussian base distribution and is a precision parameter, and differ in their priors for the precision parameter. Both DPM models, DP-diffuse and DP-inform, share the same base distribution with non-informative hyperpriors as in the Gaussian model: and .
The two DPM models differ in their specification of the priors for . In the DP-diffuse models, and are chosen such that the mean and variance of are and , respectively. For the five choices of and , the pairs of for the DP-diffuse model are , and , respectively. Conversely, for the DP-inform models, and are chosen as the solution that minimizes the KL distance of the distribution of the number of clusters to the distribution with . This means that the DP-inform models assume the expected number of clusters is . The obtained solutions were , and for the five choices of and , respectively. Section B.1 outlines the detailed procedure for selecting and in the DP-inform models.
A.5 Meta-model regressions
Meta-model regressions offer a comprehensive summary of results by regressing performance metrics on the experimental factors. In contrast to visual or descriptive analyses, meta-models deliver a model-based inferential analysis, guided by experimental design, that enables the accurate identification of significant patterns and precise estimation of their magnitudes (Boomsma,, 2013; Paxton et al.,, 2001).
Our meta-model regressions follow the form: . We focus on the three performance criteria as our target outcome variables: RMSE, ISEL, and MSELP. To ease the interpretation of the meta-model regression coefficients, we apply a logarithmic transformation to the outcome variables. As for the explanatory variables , we create a set of dummy variables representing the six design and data-analytic factors, along with their two-way interaction terms. The reference groups are , the Gaussian model, and the PM summary method.
Figure 2 visualizes the difference in predicted log-outcome between the given condition and the baseline condition, i.e., , where corresponds to the given design factor values and corresponds to the average log-outcome in the baseline condition. Recall that for and close to each other, , i.e., the difference in log-outcomes approximates the percent change. In Figure 2, the estimated differences in log outcomes were exponentiated to yield the multiplicative factor of change in average performance metrics.
Lastly, since we include each dataset nine times in each meta-model regression (corresponding to every model/posterior summary method combination), we cluster our standard errors on datasets. This approach results in a model akin to a repeated-measures ANOVA, with data-analytic model and summary method serving as within-subject factors, and the remaining design variables acting as between-subject factors.
Appendix B Estimator and model details
B.1 Dirichlet process priors
provides an initial best guess of the shape of the prior distribution , which is commonly taken to be a Gaussian distribution in practice. The precision parameter then controls the degree of shrinkage of to . In other words, determines the extent to which distributions in the sample space partitioned into measurable subsets are divergent from . To understand the role of and more intuitively, it is helpful to refer to a form of the induced prior distribution on the site-specific parameter , so-called the Polya urn scheme (Dunson et al.,, 2007):
| (B.1) |
where denotes a point mass at . This conditional prior distribution for is a weighted mixture of the base distribution and probability masses at the previous site’s parameter values, that is, the EDF of . In this scheme, the first site’s treatment effect is drawn from . Then the second site’s treatment effect is drawn from with probability of or a new empirical distribution with probability of . This sampling rule continues, and for the th site, is drawn from with probability proportional to , the number of previous sites which already have realized site-specific parameters, or is sampled from the new empirical distribution of with probability proportional to (Gelman et al.,, 2013).
can be viewed as a prior sample size in some sense (Gelman et al.,, 2013), as opposed to the sample size of empirical data . Thus, a huge value implies an extreme weight on the (prior) base distribution . In that case, the joint distribution of ’s tends to be the product of independent draws from (Antonelli et al.,, 2016) and the second-stage model in equation (13) converges to the Rubin, (1981) model with a Gaussian prior. On the other hand, a zero value imposes a null weight on , which leads to the distribution of being a point mass of . Then, the second-stage model in equation (13) collapses to a model with all sites sharing the common value of .
Hence, we can infer that determines the number of distinct values of , often referred to as the unique number of clusters generated by the DP. The is not necessarily an exact representation of the number of mixture components (latent subpopulation with substantive meaning) as specified in finite mixture models, but can be considered as an upper bound of the (Ishwaran and Zarepour,, 2000). The expected number of is a function of and , given by the sum of the weights of in equation (B.1) over all sites:
| (B.2) |
The hyper prior for plays an essential role in determining the expected number of clusters and therefore in controlling the posterior distribution over clusters. In practice, it is a standard approach to use a distribution with fixed hyperparameters, the shape parameter and the rate parameter , to capture the uncertainty in (Escobar and West,, 1995). A key issue is whether the choice of and may have a substantial impact on the posterior distribution of , and in turn on the clustering behavior. There exist a group of studies arguing that the choice of hyperparameters is a less of concern because the data tend to be quite informative, resulting in a concentrated posterior even with a high variance prior for (Leslie et al.,, 2007; Gelman et al.,, 2013). On the other hand, another group of studies report that estimation or inference can be sensitive to the specific choice of the hyperparameters and in general to the strategies for selecting (Dorazio,, 2009; Paddock et al.,, 2006; Murugiah and Sweeting,, 2012). Our interest is to evaluate the sensitivity under two different options, diffuse and informative DP priors, particularly in the context of recovering the EDF of ’s.
The first option is to specify a diffuse Gamma distribution when a priori knowledge on or is absent. Antonelli et al., (2016) chose values of and such that is centered between 1 and with a large variance to assign a priori mass to a wide range of values. If , for example, we can assign 25 as the mean of the distribution and 250 as a variance which is ten times the magnitude of the mean. Given these a priori values for the mean and variance of , we can obtain the corresponding values of and based on the moments of a Gamma distribution: and .
This study suggests the second option, using distribution to construct an informative prior for . This strategy is based on the probability mass function for the prior distribution of induced by a prior for and the number of sites (Dorazio,, 2009; Antonelli et al.,, 2016):
| (B.3) |
where is the unsigned Stirling number of the first kind and . Suppose that encodes our prior information for the distribution of the expected number of clusters . We can obtain a solution for and by minimizing the discrepancy between the encoded prior and the -induced prior , defined by the following Kullback-Leibler (KL) divergence measure:
| (B.4) |
Dorazio, (2009) proposed specifying and to be the values for which most closely matches the discrete uniform distribution to reflect the absence of explicit prior information. This method attempts to mimic a noninformative prior for .
Our proposal is to take to more intuitively encode our prior knowledge on the expected number of clusters and its uncertainty. The distribution has only one parameter: a positive integer that specifies the number of degrees of freedom. Our framework is mainly motivated by the feature of the distribution that its mean and variance are and , respectively. If it is expected that there are approximately five clusters () and , then one can simply assume that follows distribution and specify a that closely matches using equation (B.3) and (B.4). Panel A of Figure B.1 shows the result of the numerical analysis based on a grid search algorithm designed to identify the global minimum of the KL divergence measure defined in equation (B.4). The Gamma distribution with obtained as the solution that minimizes the KL closely matches the distribution as shown in Panel B of Figure B.1. This strategy is useful for constructing an informative prior for , particularly when one wants to impose near-zero probabilities beyond a certain threshold ( in the example shown in Figure B.1) and to be clear about the prior mean and variance of .

B.2 Constrained Bayes (CB) estimator
The choice of rescaling for the CB estimator is derived as follows. Shen and Louis, (1998) showed that the optimal EDF estimator that minimizes the ISEL in equation (8) is
| (B.5) |
where . Let the posterior mean of , , be and the posterior variance of , , be . Then, the marginal mean of and the finite population version of the marginal variance of can be written as follows (Shen and Louis,, 1998):
| (B.6) |
| (B.7) |
The finite population variance of posterior means appears in the second term of equation (B.7). PMs tend to be under-dispersed because their variance lacks the first term in the estimated marginal variance of , . The goal of the CB estimator is to adjust the posterior means to have a variance equal to the estimated marginal variance specified in equation (B.7). As a result, the CB estimate is defined as follows (Ghosh,, 1992):
| (B.8) |
B.3 Triple-goal (GR) estimator
The triple-goal estimator aims to obtain a single set of estimates that simultaneously targets all three inferential goals. In practice, however, the triple-goal estimator is designed to minimize the losses for two of the goals: estimating the EDF of values, , and estimating the rank of , . The abbreviation “GR” reflects the two direct inferential targets and is often used to denote the triple-goal estimator in the literature (e.g., Paddock et al.,, 2006).
Shen and Louis, (1998) show that minimizes the expected ISEL, which is the loss function that targets the EDF of values. The GR estimator therefore uses the sample estimate of to minimize ISEL. To parallel the EDF estimates made using PMs or the CB estimator, the sample estimate of is then discretized to contain only mass points.
Similarly, some basic calculus shows us that the posterior expected ranks minimize MSELR. The GR estimator therefore ranks sites using the sample estimated ranks to minimize MSELR. Again, to parallel the EDF estimates made using PMs or the CB estimator, the sample estimated ranks are discretized to discrete rank values.
As a result, the GR estimator intuitively minimizes both ISEL and MSELR, since it makes use of optimal estimators for both metrics. The GR estimator pays no explicit attention to reducing the MSEL of the individual site-specific parameters . However, Shen and Louis, (1998) argued that the GR estimator tends to produce small MSEL for the individual ’s because assigning the values by a permutation vector to minimize results in the same assignments as assigning them to minimize . Regardless, the focus of the GR estimator is on estimating the EDF and ranks of ’s.
Appendix C Detailed simulation results







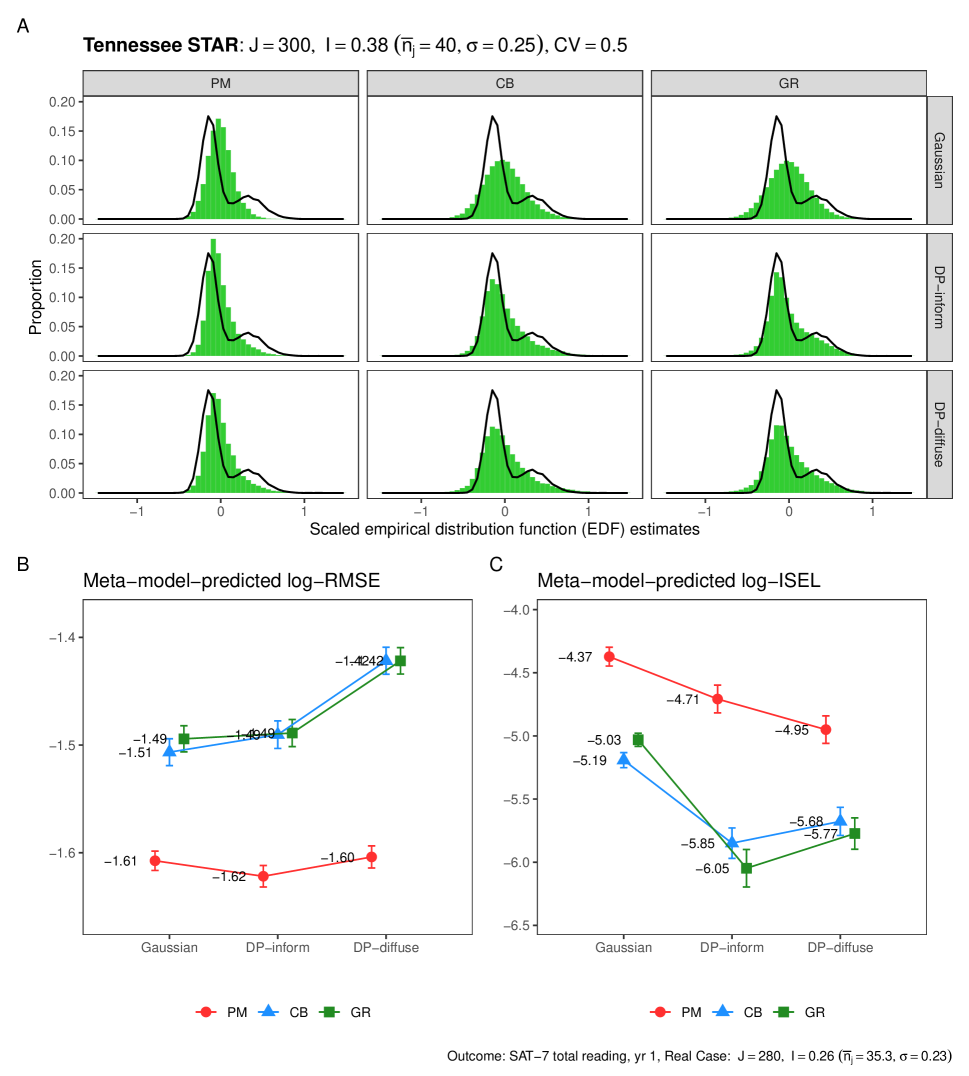






Appendix D Detailed analysis results of real-world data

| Tertiary experiment | ||
| Tertiary enrollment, | Tertiary enrollment, | |
| any time | University | |
| Average treatment effect | 0.08 | -0.06 |
| Cross-site effect SD | 0.08 | 0.10 |
| Geometric mean of | 0.35 | 0.45 |
| Average reliability of | 0.05 | 0.05 |
| Total sample size | 1,496 | |
| Number of | 27 | |
| Average site size | 55.4 | |
| Coefficient of variation of site sizes (CV) | 0.63 | |
| Range of site sizes | ||
| Average proportion of units treated | 0.46 | |
-
•
Note: We excluded sites with extreme probabilities, that is, we required both and to be at least 8, where represents the site size and denotes the proportion of participants treated in site .








