Improving Online Algorithms via ML Predictions††thanks: The conference version [18] of this work appeared in NeurIPS 2018.
Abstract
In this work we study the problem of using machine-learned predictions to improve the performance of online algorithms. We consider two classical problems, ski rental and non-clairvoyant job scheduling, and obtain new online algorithms that use predictions to make their decisions. These algorithms are oblivious to the performance of the predictor, improve with better predictions, but do not degrade much if the predictions are poor.
1 Introduction
Dealing with uncertainty is one of the most challenging issues that real-world computational tasks, besides humans, face. Ranging from “will it snow next week?” to “should I rent an apartment or buy a house?”, there are questions that cannot be answered reliably without some knowledge of the future. Similarly, the question of “which job should I run next?” is hard for a CPU scheduler that does not know how long this job will run and what other jobs might arrive in the future.
There are two interesting and well-studied computational paradigms aimed at tackling uncertainty. The first is in the field of machine learning where uncertainty is addressed by making predictions about the future. This is typically achieved by examining the past and building robust models based on the data. These models are then used to make predictions about the future. Humans and real-world applications can use these predictions to adapt their behavior: knowing that it is likely to snow next week can be used to plan a ski trip. The second is in the field of algorithm design. Here, the effort has to been to develop a notion of competitive ratio111Informally, competitive ratio compares the worst-case performance of an online algorithm to the best offline algorithm that knows the future. for the goodness of an algorithm in the presence of an unknown future and develop online algorithms that make decisions heedless of the future but are provably good in the worst-case, i.e., even in the most pessimistic future scenario. Such online algorithms are popular and successful in real-world systems and have been used to model problems including paging, caching, job scheduling, and more (see the book by Borodin and El-Yaniv [5]).
Recently, there has been some interest in using machine-learned predictions to improve the quality of online algorithms [21, 19]. The main motivation for this line of research is two-fold. The first is to design new online algorithms that can avoid assuming a worst-case scenario and hence have better performance guarantees both in theory and practice. The second is to leverage the vast amount of modeling work in machine learning, which precisely deals with how to make predictions. Furthermore, as machine-learning models are often retrained on new data, these algorithms can naturally adapt to evolving data characteristics. When using the predictions, it is important that the online algorithm is unaware of the performance of the predictor and makes no assumptions on the types of prediction errors. Additionally, we desire two key properties of the algorithm: (i) if the predictor is good, then the online algorithm should perform close to the best offline algorithm (consistency) and (ii) if the predictor is bad, then the online algorithm should gracefully degrade, i.e., its performance should be close to that of the online algorithm without predictions (robustness).
Our problems. We consider two basic problems in online algorithms and show how to use machine-learned predictions to improve their performance in a provable manner. The first is ski rental, in which a skier is going to ski for an unknown number of days and on each day can either rent skis at unit price or buy them for a higher price and ski for free from then on. The uncertainty is in the number of skiing days, which a predictor can estimate. Such a prediction can be made reasonably well, for example, by building models based on weather forecasts and past behavior of other skiers. The ski rental problem is the canonical example of a large class of online rent-or-buy problems, which arise whenever one needs to decide between a cheap short-term solution (“renting”) and an expensive long-term one (“buying”). Several extensions and generalizations of the ski rental problem have been studied leading to numerous applications such as dynamic TCP acknowledgement [11], buying parking permits [22], renting cloud servers [14], snoopy caching [13], and others. The best known deterministic algorithm for ski rental is the break-even algorithm: rent for the first days and buy on day . It is easy to observe that the break-even algorithm has a competitive ratio of 2 and no deterministic algorithm can do better. On the other hand, Karlin et al. [12] designed a randomized algorithm that yields a competitive ratio of , which is also optimal.
The second problem we consider is non-clairvoyant job scheduling. In this problem a set of jobs, all of which are available immediately, have to be scheduled on one machine; any job can be preempted and resumed later. The objective is to minimize the sum of completion times of the jobs. The uncertainty in this problem is that the scheduler does not know the running time of a job until it actually finishes. Note that a predictor in this case can predict the running time of a job, once again, by building a model based on the characteristics of the job, resource requirements, and its past behavior. Non-clairvoyant job scheduling, introduced by Motwani et al. [24], is a basic problem in online algorithms with a rich history and, in addition to its obvious applications to real-world systems, many variants and extensions of it have been studied extensively in the literature [9, 3, 1, 10]. Motwani et al. [24] showed that the round-robin algorithm has a competitive ratio of 2, which is optimal.
Main results. Before we present our main results we need a few formal notions. In online algorithms, the competitive ratio of an algorithm is defined as the worst-case ratio of the algorithm cost to the offline optimum. In our setting, this is a function of the error of the predictor222The definition of the prediction error is problem-specific. In both the problems considered in this paper, is defined to be the norm of the error.. We say that an algorithm is -robust if for all , and that it is -consistent if . So consistency is a measure of how well the algorithm does in the best case of perfect predictions, and robustness is a measure of how well it does in the worst-case of terrible predictions.
Let be a hyperparameter. For the ski rental problem with a predictor, we first obtain a deterministic online algorithm that is -robust and -consistent (Section 2.2). We next improve these bounds by obtaining a randomized algorithm that is -robust and -consistent, where is the cost of buying (Section 2.3). For the non-clairvoyant scheduling problem, we obtain a randomized algorithm that is -robust and -consistent. Note that the consistency bounds for all these algorithms circumvent the lower bounds, which is possible only because of the predictions.
It turns out that for these problems, one has to be careful how the predictions are used. We illustrate through an example that if the predictions are used naively, one cannot ensure robustness (Section 2.1). Our algorithms proceed by opening up the classical online algorithms for these problems and using the predictions in a judicious manner. We also conduct experiments to show that the algorithms we develop are practical and achieve good performance compared to ones that do not use any prediction.
Related work. The work closest to ours is that of Medina and Vassilvitskii [21] and Lykouris and Vassilvitskii [19]. The former used a prediction oracle to improve reserve price optimization, relating the gap beween the expected bid and revenue to the average predictor loss. In a sense, this paper initiated the study of online algorithms equipped with machine learned predictions. The latter developed this framework further, introduced the concepts of robustness and consistency, and considered the online caching problem with predictions. It modified the well-known Marker algorithm to use the predictions ensuring both robustness and consistency. While we operate in the same framework, none of their techniques are applicable to our setting. Another recent work is that of Kraska et al. [17] that empirically shows that better indexes can be built using machine learned models; it does not provide any provable guarantees for its methods.
There are other computational models that try to tackle uncertainty. The field of robust optimization [16] considers uncertain inputs and aims to design algorithms that yield good performance guarantees for any potential realization of the inputs. There has been some work on analyzing algorithms when the inputs are stochastic or come from a known distribution [20, 23, 6]. In the optimization community, the whole field of online stochastic optimization concerns online decision making under uncertainty by assuming a distribution on future inputs; see the book by Russell Bent and Pascal Van Hentenryck [4]. Our work differs from these in that we do not assume anything about the input; in fact, we do not assume anything about the predictor either!
2 Ski rental with prediction
In the ski rental problem, let rentals cost one unit per day, be the cost to buy, be the actual number of skiing days, which is unknown to the algorithm, and be the predicted number of days. Then is the prediction error. Note that we do not make any assumptions about its distribution. The optimum cost is .
2.1 Warmup: A simple consistent, non-robust algorithm
We first show that an algorithm that naively uses the predicted number of days to decide whether or not to buy is 1-consistent, i.e., its competitive ratio is 1 when . However, this algorithm is not robust, as the competitive ratio can be arbitrarily large in case of incorrect predictions.
Lemma 2.1.
Let denote the cost of the solution obtained by Algorithm 1 and let denote the optimal solution cost on the same instance. Then .
Proof.
We consider different cases based on the relative values of the prediction and the actual number of days of the instance. Recall that Algorithm 1 incurs a cost of whenever the prediction is at least and incurs a cost of otherwise.
-
•
.
-
•
-
•
-
•
∎
A major drawback of Algorithm 1 is its lack of robustness. In particular, its competitive ratio can be unbounded if the prediction is small but . Our goal next is to obtain an algorithm that is both consistent and robust.
2.2 A deterministic robust and consistent algorithm
In this section, we show that a small modification to Algorithm 1 yields an algorithm that is both consistent and robust. Let be a hyperparameter. As we see later, varying gives us a smooth trade-off between the robustness and consistency of the algorithm.
Theorem 2.2.
Proof.
We begin with the first bound. Suppose and the algorithm buys the skis at the start of day . Since the algorithm incurs a cost of whenever , the worst competitive ratio is obtained when , for which . In this case, we have . On the other hand, when , the algorithm buys skis at the start of day and rents until then. In this case, the worst competitive ratio is attained whenever as we have and .
To prove the second bound, we need to consider the following two cases. Suppose . Then, for all , we have . On the other hand, for , we have . The second inequality follows since either (if ) or (if ). Suppose . Then, for all , we have . Similarly, for all , we have . Finally for all , noting that , we have . Thus we obtain , completing the proof. ∎
Thus, Algorithm 2 gives an option to trade-off consistency and robustness. In particular, greater trust in the predictor suggests setting close to zero as this leads to a better competitive ratio when is small. On the other hand, setting close to one is conservative and yields a more robust algorithm.
2.3 A randomized robust and consistent algorithm
In this section we consider a family of randomized algorithms and compare their performance against an oblivious adversary. In particular, we design robust and consistent algorithms that yield a better trade-off than the above deterministic algorithms. Let be a hyperparameter. For a given , Algorithm 3 samples the day when skis are bought based on two different probability distributions, depending on the prediction received, and rents until that day.
Theorem 2.3.
Proof.
We consider different cases depending on the relative values of and .
(i) . Here, we have . Since the algorithm incurs a cost of when we buy at the beginning of day , we have
(ii) . Here, we have . On the other hand, the algorithm incurs a cost of only if it buys at the beginning of day . In particular, we have
which establishes robustness. In order to prove consistency, we can rewrite the RHS as follows
since and .
(iii) . Here, we have . On the other hand, the expected cost of the algorithm can be computed similar to (ii)
(iv) . Here, we have . The expected cost incurred by the algorithm is as in (i).
| where the last inequality is proven in Lemma A.2 in the Appendix. This completes the proof of robustness. To prove consistency, we rewrite the RHS as follows. | ||||
Algorithms 2 and 3 both yield a smooth trade-off between the robustness and consistency guarantees for the ski rental problem. As shown in Figure 1, the randomized algorithm offers a much better trade-off by always guaranteeing smaller consistency for a given robustness guarantee. We remark that setting in Algorithms 2 and 3 allows us to recover the best deterministic and randomized algorithms for the classical ski rental problem without using predictions.

2.4 Extensions
Consider a generalization of the ski rental problem where we have a varying demand for computing resources on each day . Such a situation models the problem faced while designing small enterprise data centers. System designers have the choice of buying machines at a high setup cost or renting machines from a cloud service provider to handle the computing needs of the enterprise. One can satisfy the demand in two ways: either pay to rent one machine and satisfy one unit of demand for one day, or pay to buy a machine and use it to satisfy one unit of demand for all future days. It is easy to cast the classical ski rental problem in this framework by setting for the first days and to 0 later. Kodialam [15] considers this generalization and gives a deterministic algorithm with a competitive ratio of 2 as well as a randomized algorithm with competitive ratio of .
Now suppose we have predictions for the demand on day . We define to be the total error of the predictions. Both Algorithms 2 and 3 extend naturally to this setting to yield the same robustness and consistency guarantees as in Theorems 2.2 and 2.3. Our results follow from viewing an instance of ski rental with varying demand problem as disjoint instances of the classical ski rental problem, where is an upper bound on the maximum demand on any day. The proofs are similar to those in Sections 2.2 and 2.3; we omit them for brevity.
3 Non-clairvoyant job scheduling with prediction
We consider the simplest variant of non-clairvoyant job scheduling, i.e., scheduling jobs on a single machine with no release dates. The processing requirement of a job is unknown to the algorithm and only becomes known once the job has finished processing. Any job can be preempted at any time and resumed at a later time without any cost. The objective function is to minimize the sum of completion times of the jobs. Note that no algorithm can yield any non-trivial guarantees if preemptions are not allowed.
Let denote the actual processing times of the jobs, which are unknown to the non-clairvoyant algorithm. In the clairvoyant case, when processing times are known up front, the optimal algorithm is to simply schedule the jobs in non-decreasing order of job lengths, i.e., shortest job first. A deterministic non-clairvoyant algorithm called round-robin (RR) yields a competitive ratio of 2 [24], which is known to be best possible.
Now, suppose that instead of being truly non-clairvoyant, the algorithm has an oracle that predicts the processing time of each job. Let be the predicted processing times of the jobs. Then is the prediction error for job , and is the total error. We assume that there are no zero-length jobs and that units are normalized such that the actual processing time of the shortest job is at least one. Our goal in this section is to design algorithms that are both robust and consistent, i.e., can use good predictions to beat the lower bound of 2, while at the same time guaranteeing a worst-case constant competitive ratio.
3.1 A preferential round-robin algorithm
In scheduling problems with preemption, we can simplify exposition by talking about several jobs running concurrently on the machine, with rates that sum to at most 1. For example, in the round-robin algorithm, at any point of time, all unfinished jobs run on the machine at equal rates of . This is just a shorthand terminology for saying that in any infinitesimal time interval, fraction of that interval is dedicated to running each of the jobs.
We call a non-clairvoyant scheduling algorithm monotonic if it has the following property: given two instances with identical inputs and actual job processing times and such that for all , the objective function value found by the algorithm for the first instance is no higher than that for the second. It is easy to see that the round-robin algorithm is monotonic.
We consider the Shortest Predicted Job First (SPJF) algorithm, which sorts the jobs in the increasing order of their predicted processing times and executes them to completion in that order. Note that SPJF is monotonic, because if processing times became smaller (with predictions staying the same), all jobs would finish only sooner, thus decreasing the total completion time objective. SPJF produces the optimal schedule in the case that the predictions are perfect, but for bad predictions, its worst-case performance is not bounded by a constant. To get the best of both worlds, i.e. good performance for good predictions as well as a constant-factor approximation in the worst-case, we combine SPJF with RR using the following, calling the algorithm Preferential Round-Robin (PRR).
Lemma 3.1.
Given two monotonic algorithms with competitive ratios and for the minimum total completion time problem with preemptions, and a parameter , one can obtain an algorithm with competitive ratio .
Proof.
The combined algorithm runs the two given algorithms in parallel. The -approximation (call it ) is run at a rate of , and the -approximation () at a rate of . Compared to running at rate 1, if algorithm runs at a slower rate of , all completion times increase by a factor of , so it becomes a -approximation. Now, the fact that some of the jobs are concurrently being executed by algorithm only decreases their processing times from the point of view of , so by monotonicity, this does not make the objective of any worse. Similarly, when algorithm runs at a lower rate of , it becomes a -approximation, and by monotonicity can only get better from concurrency with . Thus, both bounds hold simultaneously, and the overall guarantee is their minimum. ∎
We next analyze the performance of SPJF.
Lemma 3.2.
The SPJF algorithm has competitive ratio at most .
Proof.
Assume w.l.o.g. that jobs are numbered in non-decreasing order of their actual processing times, i.e. . For any pair of jobs , define as the amount of job that has been executed before the completion time of job . In other words, is the amount of time by which delays . Let denote the output of SPJF. Then
For such that , the shorter job is scheduled first and hence , but for job pairs that are wrongly predicted, the longer job is scheduled first, so . This yields
which yields . Now, using our assumption that all jobs have length at least 1, we have . This yields an upper bound of on the competitive ratio of SPJF. ∎
We give an example showing that this bound is asymptotically tight. Suppose that there are jobs with processing times and one job with processing time and suppose the predicted lengths are for all jobs. Then , , and, if SPJF happens to schedule the longest job first, increasing the completion time of jobs by each, . This gives the ratio of , which approaches the bound in Lemma 3.2 as increases and decreases.
Finally, we bound the performance of the preferential round-robin algorithm.
Theorem 3.3.
The preferential round-robin algorithm with parameter has competitive ratio at most . In particular, it is -robust and -consistent.
Proof.
Setting gives an algorithm that beats the round-robin ratio of in the case of sufficiently good predictions. For the special case of zero prediction errors (or, more generally, if the order of jobs sorted by is the same as that sorted by ), we can obtain an improved competitive ratio of via a more sophisticated analysis.
Theorem 3.4.
The preferential round-robin algorithm with parameter has competitive ratio at most when .
Proof.
Suppose w.l.o.g. that the jobs are sorted in non-decreasing job lengths (both actual and predicted), i.e. and . Since the optimal solution schedules the jobs sequentially, we have
| (1) |
We call a job active if it has not completed yet. When there are active jobs, the preferential round-robin algorithm executes all active jobs at a rate of , and the active job with the shortest predicted processing time (we call this job current) at an additional rate of . Note that each job finishes while being the current job. This can be shown inductively: suppose job finishes at time . Then by time , job has received strictly less processing than , but its size is at least as big. So it has some processing remaining, which means that it becomes current at time and stays current until completion. Let phase of the algorithm denote the interval of time when job is current.
For any pair of jobs , define as the amount of job that has been executed before the completion time of . In other words, is the amount of time by which delays . We can now express the cost of our algorithm as
| (2) |
If , as job completes before job , we have . To compute the last term in (2), consider any phase , and let denote its length. In this phase, the current job executes at a rate of at least , which implies that . During phase , jobs receive amount of processing each. Such a job delays jobs with smaller indices, namely . Let denote the delay in phase :
Substituting back into Equation (2),
using Equation (1) for the last line. ∎
4 Experimental results
4.1 Ski rental
We test the performance of our algorithms for the ski rental problem via simulations. For all experiments, we set the cost of buying to and the actual number of skiing days is a uniformly drawn integer from . The predicted number of days is simulated as where is drawn from a normal distribution with mean 0 and standard deviation . We consider both randomized and deterministic algorithms for two different values of the trade-off parameter . Recall that by setting , our algorithms ignore the predictions and reduce to the known optimal algorithms (deterministic and randomized, respectively) [12]. We set for the deterministic algorithm that guarantees a worst-case competitive ratio of 3. In order to obtain the same worst-case competitive ratio, we set for the randomized algorithm. For each , we plot the average competitive ratio obtained by each algorithm over 10000 independent trials in Figure 2(a). We observe that even for rather large prediction errors, our algorithms perform significantly better than their classical counterparts. In particular, even our deterministic algorithm that uses the predictions performs better than the classical randomized algorithm for errors up to a standard deviation of .
4.2 Non-clairvoyant scheduling
N min max mean 50 1 22352 2168 5475.42
We generate a synthetic dataset with 50 jobs where the processing time of each job is sampled independently from a Pareto distribution with an exponent of . (As observed in prior work [7, 8, 2], job size distributions in a number of settings are well-modeled by a Pareto distribution with close to 1.) Pertinent characteristics of the generated dataset are presented in Table 1. In order to simulate predicted job lengths and compare the performance of the different algorithms with respect to the errors in the prediction, we set the predicted job length , where is drawn from a normal distribution with mean zero and standard deviation .
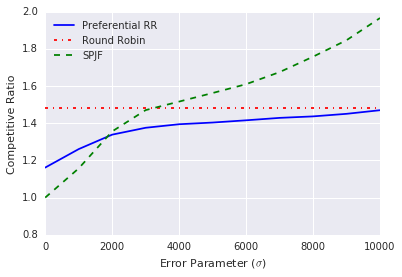
Figure 2(b) shows the competitive ratio of the three algorithms versus varying prediction errors. For a parameter , we plot the average competitive ratio over 1000 independent trials where the prediction error has the specified standard deviation. As expected, the naïve strategy of scheduling jobs in non-decreasing order of their predicted job lengths (SPJF) performs very well when the errors are low, but quickly deteriorates as the errors increase. In contrast, our preferential round-robin algorithm (with ) performs no worse than round-robin even when the predictions have very large error.

5 Conclusions
In this paper we furthered the study of using ML predictions to provably improve the worst-case performance of online algorithms. There are many other important online algorithms including -server, portfolio optimization, etc, and it will be interesting to see if predictions can be useful for them as well. Another research direction would be to use the error distribution of the ML predictor to further improve the bounds.
Acknowledgements
We thank Chenyang Xu for pointing out a bug in the conference version [18] and thank Erik Vee for his help in fixing the bug.
References
- [1] Nikhil Bansal, Kedar Dhamdhere, Jochen Könemann, and Amitabh Sinha. Non-clairvoyant scheduling for minimizing mean slowdown. Algorithmica, 40(4):305–318, 2004.
- [2] Nikhil Bansal and Mor Harchol-Balter. Analysis of SRPT scheduling: Investigating unfairness. In SIGMETRICS, pages 279–290, 2001.
- [3] Luca Becchetti and Stefano Leonardi. Non-clairvoyant scheduling to minimize the average flow time on single and parallel machines. In STOC, pages 94–103, 2001.
- [4] Russell Bent and Pascal Van Hentenryck. Online Stochastic Combinatorial Optimization. MIT Press, 2009.
- [5] A. Borodin and R. El-Yaniv. Online Computation and Competitive Analysis. Cambridge University Press, 1998.
- [6] Sebastien Bubeck and Aleksandrs Slivkins. The best of both worlds: Stochastic and adversarial bandits. In COLT, pages 42.1–42.23, 2012.
- [7] Mark E Crovella and Azer Bestavros. Self-similarity in world wide web traffic: Evidence and possible causes. Transactions on Networking, 5(6):835–846, 1997.
- [8] Mor Harchol-Balter and Allen B Downey. Exploiting process lifetime distributions for dynamic load balancing. ACM TOCS, 15(3):253–285, 1997.
- [9] Sungjin Im, Janardhan Kulkarni, and Kamesh Munagala. Competitive algorithms from competitive equilibria: Non-clairvoyant scheduling under polyhedral constraints. J. ACM, 65(1):3:1–3:33, 2017.
- [10] Sungjin Im, Janardhan Kulkarni, Kamesh Munagala, and Kirk Pruhs. Selfishmigrate: A scalable algorithm for non-clairvoyantly scheduling heterogeneous processors. In FOCS, pages 531–540, 2014.
- [11] Anna R Karlin, Claire Kenyon, and Dana Randall. Dynamic TCP acknowledgement and other stories about . Algorithmica, 36(3):209–224, 2003.
- [12] Anna R. Karlin, Mark S. Manasse, Lyle A. McGeoch, and Susan Owicki. Competitive randomized algorithms for nonuniform problems. Algorithmica, 11(6):542–571, 1994.
- [13] Anna R. Karlin, Mark S. Manasse, Larry Rudolph, and Daniel Dominic Sleator. Competitive snoopy caching. Algorithmica, 3:77–119, 1988.
- [14] Ali Khanafer, Murali Kodialam, and Krishna P.N. Puttaswamy. The constrained ski-rental problem and its application to online cloud cost optimization. In INFOCOM, pages 1492–1500, 2013.
- [15] Rohan Kodialam. Competitive algorithms for an online rent or buy problem with variable demand. In SIAM Undergraduate Research Online, volume 7, pages 233–245, 2014.
- [16] Panos Kouvelis and Gang Yu. Robust Discrete Optimization and its Applications, volume 14. Springer Science & Business Media, 2013.
- [17] Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. The case for learned index structures. In SIGMOD, pages 489–504, 2018.
- [18] Ravi Kumar, Manish Purohit, and Zoya Svitkina. Improving online algorithms via ML predictions. In NeurIPS, pages 9684–9693, 2018.
- [19] Thodoris Lykouris and Sergei Vassilvitskii. Competitive caching with machine learned advice. In ICML, pages 3302–3311, 2018.
- [20] Mohammad Mahdian, Hamid Nazerzadeh, and Amin Saberi. Online optimization with uncertain information. ACM TALG, 8(1):2:1–2:29, 2012.
- [21] Andres Muñoz Medina and Sergei Vassilvitskii. Revenue optimization with approximate bid predictions. In NIPS, pages 1856–1864, 2017.
- [22] Adam Meyerson. The parking permit problem. In FOCS, pages 274–282, 2005.
- [23] Vahab S. Mirrokni, Shayan Oveis Gharan, and Morteza Zadimoghaddam. Simultaneous approximations for adversarial and stochastic online budgeted allocation. In SODA, pages 1690–1701, 2012.
- [24] Rajeev Motwani, Steven Phillips, and Eric Torng. Nonclairvoyant scheduling. Theoretical Computer Science, 130(1):17–47, 1994.
Appendix A Deferred Proofs
We first state a few simple observations that will be useful.
Lemma A.1.
For ,
-
(i)
.
-
(ii)
.
-
(iii)
.
Proof.
(i) For , we have and hence .
(ii) For any , we have . Showing (ii) is equivalent to showing . But since , we can substitute to get
(iii) We first show that is concave for (since , we define to make it continuous at ). Indeed, consider . Note that for all , we have , and hence we have . Thus is concave in the range . By concavity, we get that for all , as desired. ∎
Lemma A.2.
Let be an integer and let be a real number. Then,
Proof.
For convenience, let and rearrange the terms so that the lemma statement is equivalent to showing the following, subject to .
Note that we used here while rearranging the terms. Using , it instead suffices to show the following inequality.
| (3) |
The LHS of (3) is a quadratic in , written as:
| (4) |
The goal is to show (4) is non-negative when . To do this, we minimize subject to .
The minimum of is attained at
yielding
Consequently, subject to the constraint that , the minimum of is attained at . Plugging in in (4), we get
This completes the proof. ∎