Improving Factual Consistency Between a Response and Persona Facts
Appendix A Using Only the Persona-Consistency Sub-reward
By using the persona-consistency sub-reward as the only reward function, the policy learns only to generate responses that state information about the persona facts and ignores the topical coherence with its former utterance.
| Persona | ||||||
|---|---|---|---|---|---|---|
|
||||||
| Dialogue | ||||||
|
Table 1 illustrates an example dialogue that is conducted with an agent trained with only the persona consistency sub-reward (). The agent always repeats, “i fix airplanes. i fix them.”, no matter what the input message is about. This problem not only produces topically irrelevant responses but also makes the agent look nagging and self-centered in a conversation.
| Persona | ||||
|---|---|---|---|---|
|
||||
| Dialogue | ||||
|
Table 2 illustrates another example dialogue with the agent where it is trained only by persona-consistency sub-reward. The agent keeps repeating “hunting” from the persona to maximize its reward. The NLI model used for evaluates the inference relation between a response and a persona and does not capture the topical coherence of the response with its former utterance and language fluency of the response. It is therefore necessary to use in combination with topical coherence () and language fluency sub-rewards ( and ), as we propose in our reward function.
Appendix B Weight Optimization and Reward Ablation
We examine various weight sets to balance the contribution of sub-rewards in the complete reward function on the held out set (10% of the PersonaChat training set). Table 3 shows those weights.
| 0.00 | 0.00 | 0.00 | 0.00 | 02.04 |
| 1.00 | 0.00 | 0.00 | 0.00 | 16.34 |
| 0.00 | 1.00 | 0.00 | 0.00 | 16.12 |
| 0.00 | 0.00 | 1.00 | 0.00 | 12.77 |
| 0.00 | 0.00 | 0.00 | 1.00 | 17.91 |
| 0.70 | 0.00 | 0.30 | 0.00 | 16.37 |
| 0.65 | 0.00 | 0.35 | 0.00 | 19.90 |
| 0.60 | 0.00 | 0.40 | 0.00 | 16.98 |
| 0.50 | 0.00 | 0.50 | 0.00 | 16.07 |
| 0.25 | 0.25 | 0.25 | 0.25 | 18.27 |
| 0.60 | 0.20 | 0.00 | 0.20 | 15.54 |
| 0.40 | 0.20 | 0.20 | 0.20 | 20.57 |
| 0.40 | 0.16 | 0.22 | 0.22 | 20.75 |
| 0.45 | 0.13 | 0.17 | 0.20 | 19.98 |
| 0.47 | 0.12 | 0.17 | 0.20 | 19.95 |
| 0.47 | 0.10 | 0.17 | 0.21 | 20.33 |
| 0.47 | 0.10 | 0.19 | 0.19 | 19.73 |
| 0.50 | 0.10 | 0.16 | 0.20 | 19.10 |
| 0.40 | 0.20 | 0.15 | 0.20 | 19.34 |
| 0.43 | 0.20 | 0.12 | 0.20 | 20.22 |
| 0.45 | 0.20 | 0.12 | 0.20 | 20.13 |
| 0.45 | 0.25 | 0.00 | 0.25 | 17.40 |
| 0.40 | 0.10 | 0.25 | 0.25 | 18.93 |
| 0.40 | 0.15 | 0.20 | 0.20 | 19.80 |
| 0.40 | 0.20 | 0.20 | 0.15 | 20.44 |
| 0.45 | 0.17 | 0.21 | 0.17 | 18.85 |
| 0.50 | 0.15 | 0.15 | 0.15 | 20.25 |
| 0.47 | 0.13 | 0.20 | 0.15 | 19.97 |
| 0.50 | 0.15 | 0.20 | 0.15 | 17.64 |
| 0.55 | 0.15 | 0.15 | 0.10 | 19.15 |
The balanced weights give the highest F1 score, suggesting that a combination of sub-rewards leads to responses that are more similar to the human responses.
We also evaluate the use of each sub-reward in isolation, and show the results in Table 4, in comparison with our chosen balanced weights in the bottom line.
| Repetition(%) | Consistent (%) | Neutral (%) | Contradiction (%) | PC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1.00 | 0.00 | 0.00 | 0.00 | 16.34 | 25.35 | 36.20 | 34.02 | 64.62 | 01.36 | 66.33 |
| 0.00 | 1.00 | 0.00 | 0.00 | 16.12 | 21.44 | 13.36 | 12.24 | 86.34 | 01.42 | 55.50 |
| 0.00 | 0.00 | 1.00 | 0.00 | 12.77 | 04.76 | 12.21 | 00.46 | 99.35 | 00.20 | 51.49 |
| 0.00 | 0.00 | 0.00 | 1.00 | 17.91 | 21.35 | 01.62 | 03.53 | 95.90 | 00.57 | 50.13 |
| 0.40 | 0.16 | 0.22 | 0.22 | 20.75 | 12.36 | 09.61 | 14.14 | 84.54 | 01.32 | 56.50 |
For the other metrics, we can see that maximizes the number of entailments from the persona facts, minimizes perplexity, and gives lowest repetition. Besides F1 score, the balanced weights give good performance across perplexity, repetition, and persona consistency. The setups with fewer neutral responses also tend to have more responses that contradict the persona facts, e.g., for . Neutral responses are a trivial way to avoid contradictory responses and the setup with the least contradictions, , has almost no responses that are consistent with the persona facts. The better overall persona consistency is reflected in the highest PC score for and next highest for the balanced weights, which trades of PC for less repetition, lower perplexity and a higher F1 score.
Appendix C REINFORCE vs Actor-Critic
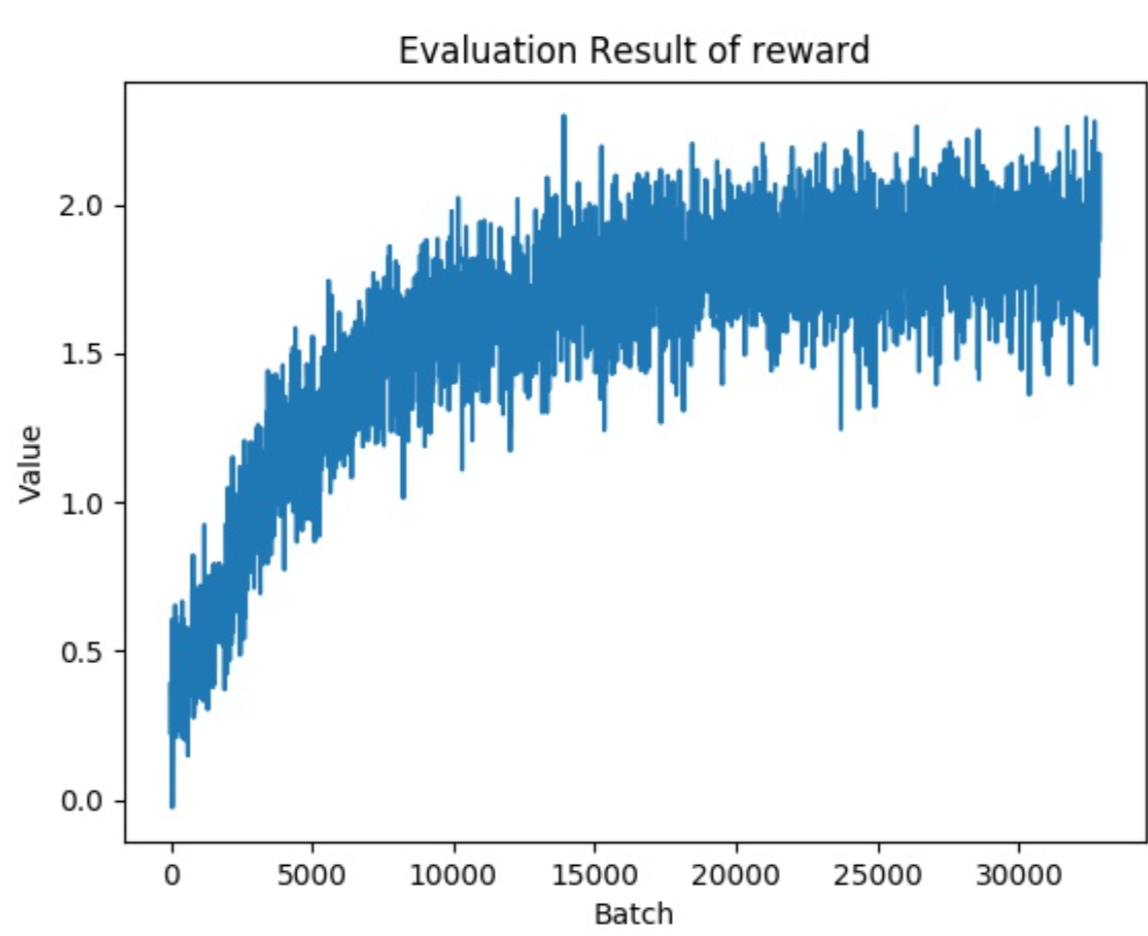
Figures 1 and 2 show the trend of changes in our reward function during training by REINFORCE and Actor-Critic, respectively. All parameters are the same for the two experiments. We observe that the actor-critic approach converges faster \MMF[as well as]and also is less noisy (has a lower variance) than REINFORCE.
 |
 |
Appendix D Human Evaluation
For each sample, we show to each participant a set of persona facts, a dialogue history, and the response generated by one of TransferTransfo-SL and TransferTransfo-RL. We instruct our participants to assess semantic plausibility according to the following objective definition: “grammatical correctness, lowest repetitiveness, and coherence”. The plausibility rates are integer values between 1 and 5, where 5 is most plausible.
To measure persona consistency, we instruct participants as follows:
An answer is considered consistent if:
-
•
It contradicts with neither the dialogue history nor the persona facts;
-
•
It is relevant to any of the given persona facts.
An answer is considered neutral if:
-
•
It contradicts with neither the dialogue history nor the persona facts;
-
•
It is not relevant to any of the given persona facts.
Appendix E Human Evaluation: Confusion Matrix
Table 5 presents the distributions of consistency labels for TransferTransfo-RL’s responses given the consistency labels for TransferTransfo-SL’s responses. For the majority of cases whose TransferTransfo-SL’s responses are contradictory or neutral, TransferTransfo-RL generates consistent responses, showing improved factual consistency with persona facts. However, TransferTransfo-RL generates contradictory responses for some cases whose TransferTransfo-SL responses are consistent with their personas. This may be due to errors in the NLI model’s predictions of entailment, hence a more accurate NLI model may improve the quality of the reward function and consequently the consistency of responses. Alternatively, these contradictory responses may receive high rewards from the topic consistency and fluency sub-rewards, which could override .
| TransferTransfo-RL label | ||||
|---|---|---|---|---|
| Consistent | Neutral | Contradicting | ||
| Transfer | Consistent | |||
| Transfo | Neutral | |||
| -SL | Contradicting | |||