Improving Expressive Power of Spectral Graph Neural Networks
with Eigenvalue Correction
Abstract
In recent years, spectral graph neural networks, characterized by polynomial filters, have garnered increasing attention and have achieved remarkable performance in tasks such as node classification. These models typically assume that eigenvalues for the normalized Laplacian matrix are distinct from each other, thus expecting a polynomial filter to have a high fitting ability. However, this paper empirically observes that normalized Laplacian matrices frequently possess repeated eigenvalues. Moreover, we theoretically establish that the number of distinguishable eigenvalues plays a pivotal role in determining the expressive power of spectral graph neural networks. In light of this observation, we propose an eigenvalue correction strategy that can free polynomial filters from the constraints of repeated eigenvalue inputs. Concretely, the proposed eigenvalue correction strategy enhances the uniform distribution of eigenvalues, thus mitigating repeated eigenvalues, and improving the fitting capacity and expressive power of polynomial filters. Extensive experimental results on both synthetic and real-world datasets demonstrate the superiority of our method. The code is available at: https://github.com/Lukangkang123/EC-GNN
Introduction




Graph neural networks (GNNs) have recently achieved excellent performance in graph learning tasks such as abnormal detection (Gao et al. 2023a, b), molecular prediction (Fang et al. 2024, 2023; Gong, Zheng, and Feng 2025), and recommendation systems (Wu et al. 2022; Gong et al. 2025). Existing GNNs can be divided into two categories: spatial GNNs and spectral GNNs. Spatial GNNs often adopt a message-passing mechanism to learn node representations by aggregating neighbor node features. Spectral GNNs map node features to a new desired space by selectively attenuating or amplifying the Fourier coefficients induced by the normalized Laplacian matrix of the graph. This study primarily centers on the realm of spectral GNNs.
Existing spectral filters are commonly approximated using fixed-order (or truncated) polynomials. Specifically, these polynomial filters take the normalized Laplacian eigenvalues as input and map them to varying scalar values via a polynomial function. However, our empirical findings unveil that the eigenvalues of normalized Laplacian matrix in real-world graphs tend to exhibit high multiplicity. This phenomenon is visually demonstrated in Figure 1111Additional distribution histograms for more datasets are provided in Appendix B., where a substantial number of eigenvalues cluster around the value 1. Consequently, when two frequency components share the same eigenvalue , they will be scaled by the same amount (Wang and Zhang 2022). As a result, the coefficients of these frequency components will retain the same proportion in predictions as in the input. And an abundance of repeated eigenvalues inevitably curbs the expressive capacity of polynomial filters. To illustrate, Figure 2 highlights how a filter possessing seven distinct eigenvalues exhibits weaker fitting capabilities than the one endowed with eleven distinct eigenvalues.
Based on the insights gained thus far, it’s apparent that the eigenvalue multiplicity of the normalized Laplacian matrix significantly impedes the polynomial filter’s capacity to effectively fit. More severely, the challenge cannot be readily addressed by simply elevating the polynomial order, because even exceedingly high-order polynomials could fail to differentiate outputs for identical eigenvalues. To tackle this, we propose an eigenvalue correction strategy to generate more distinct eigenvalues, which reduces eigenvalue multiplicity and in return enhances the fitting prowess of polynomial filters across intricate and diverse scenarios. In essence, our strategy combines the original eigenvalues and the eigenvalues sampled at equal intervals from [0, 2]. This amalgamation ensures a more uniform eigenvalue distribution while still retaining the frequency information encapsulated within the eigenvalues. Furthermore, we manage to enhance training efficiency without excessively elongating precomputation time, which allows us to efficiently amplify the order of polynomial spectral GNNs, contributing to a refined and potent modeling capability.
To summarize, our contributions in this work are highlighted as follows:
-
•
We empirically discover that the normalized Laplacian matrix of a majority of real-world graphs exhibits elevated eigenvalue multiplicity. Furthermore, we provide theoretical evidence that the distinctiveness of eigenvalues within the normalized Laplacian matrix critically shapes the efficacy of polynomial filters. Consequently, a surplus of repeated eigenvalues obstructs the potential expressiveness of these filters.
-
•
We introduce an innovative eigenvalue correction strategy capable of substantially diminishing eigenvalue multiplicity. By ingeniously amalgamating original eigenvalues with equidistantly sampled counterparts, our method can seamlessly integrate with existing polynomial filters of GNNs.
-
•
Extensive experiments on synthetic and real-world datasets unequivocally demonstrate the superiority of our proposed approach over state-of-the-art polynomial filters. This substantiates the remarkable enhancement in the fitting prowess and expressive capacity of polynomial filters, achieved through the novel eigenvalue correction strategy we present.


Related Work
Spectral GNNs
According to whether the filter can be learned, the spectral GNNs can be divided into predefined filters (Kipf and Welling 2017; Gasteiger, Bojchevski, and Günnemann 2019; Zhu et al. 2021) and learnable filters (Defferrard, Bresson, and Vandergheynst 2016; Chien et al. 2021; He et al. 2021; Wang and Zhang 2022).
In the category of predefined filters, GCN (Kipf and Welling 2017) uses a simplified first-order Chebyshev polynomial, which is shown to be a low-pass filter. APPNP (Gasteiger, Bojchevski, and Günnemann 2019) utilizes Personalized Page Rank (PPR) to set the weight of the filter. GNN-LF/HF (Zhu et al. 2021) designs filter weights from the perspective of graph optimization functions, which can fit high-pass and low-pass filters.
Another category of spectral GNNs employs learnable filters. ChebNet (Defferrard, Bresson, and Vandergheynst 2016) uses Chebyshev polynomials with learnable coefficients. GPR-GNN (Chien et al. 2021) extends APPNP by directly parameterizing its weights and training them with gradient descent. ARMA (Bianchi et al. 2021) learns a reasonable filter through an autoregressive moving average filter family. BernNet (He et al. 2021) uses Bernstein polynomials to learn filters and forces all coefficients positive. JacobiConv (Wang and Zhang 2022) adopts an orthogonal and flexible Jacobi basis to accommodate a wide range of weight functions. FavardGNN (Guo and Wei 2023) learns an optimal polynomial basis from the space of all possible orthonormal basis.
However, the above filters typically use repeated eigenvalues as input, which hinders their expressiveness. In contrast, we propose a novel eigenvalue correction strategy that can generate more distinct eigenvalues and thus improve the expressive power of polynomial filters.
| datasets | Cora | Citeseer | Pubmed | Computers | Photo | Texas | Cornell | Squirrel | Chameleon | Actor |
|---|---|---|---|---|---|---|---|---|---|---|
| 2708 | 3327 | 19717 | 13752 | 7650 | 183 | 183 | 5201 | 2277 | 7600 | |
| 5278 | 4552 | 44324 | 245861 | 119081 | 279 | 277 | 198353 | 31371 | 26659 | |
| 2199 | 1886 | 7595 | 13344 | 7474 | 106 | 115 | 3272 | 1120 | 6419 | |
| 81.2% | 56.7% | 38.5% | 97.0% | 97.7% | 57.9% | 62.8% | 62.9% | 49.2% | 84.5% |
Expressive Power of Spectral GNNs
The Weisfeiler-Lehman test (Weisfeiler and Leman 1968) is considered as a classic algorithm for judging graph isomorphism. GIN (Xu et al. 2019) shows that the 1-WL test limits the expressive power of GNNs to distinguish non-isomorphic graphs. Balcilar et al. (2021) theoretically demonstrates some equivalence of graph convolution procedures by bridging the gap between spectral and spatial designs of graph convolutions. JacobiConv (Wang and Zhang 2022) points out that the condition for spectral GNN to generate arbitrary one-dimensional predictions is that the normalized Laplacian matrix has no repeated eigenvalues and no missing frequency components of node features.
Distribution of Eigenvalues of Normalized Laplacian Matrix
For random graphs, Jiang (2012) proves that the empirical distribution of the eigenvalues of the normalized Laplacian matrix of Erdős-Rényi random graphs converges to the semicircle law. Chung, Lu, and Vu (2003) also proves that the Laplacian spectrum of a random graph with expected degree obeys the semicircle law. Empirically, we observe that as the average degree of a random graph increases, its eigenvalue distribution becomes more concentrated around 1. Histograms of their distributions can be found in Appendix C.
For real-world graphs, we empirically find that almost all real-world graphs have many repeated eigenvalues, especially around the value 1, which is consistent with the findings of QPGCN (Wu et al. 2023) and SignNet (Lim et al. 2023). Furthermore, some works (Banerjee and Jost 2008; Mehatari and Banerjee 2015) attempt to explain the generation of the multiplicity of eigenvalue 1 by motif doubling and attachment. The number and proportion of distinct eigenvalues for real-world graphs are shown in Table 1. It’s evident that almost all datasets do not have enough distinct eigenvalues, and some are even lower than 50%, which will hinder the fitting ability and expressive power of polynomial filters.
Proposed Method
Preliminaries
Assume that we have a graph , where denotes the vertex set of nodes, is the edge set and is node feature matrix. The corresponding adjacency matrix is , where if there is an edge between nodes and , and otherwise. The degree matrix of is a diagonal matrix with its -th diagonal entry as . The normalized adjacency matrix is . Let denote the identity matrix. The normalized Laplacian matrix . Let denote the eigen-decomposition of , where is the matrix of eigenvectors and is the diagonal matrix of eigenvalues.
The Fourier transform of a graph signal is defined as , and its inverse is . Thus the graph propagation for signal with kernel can be defined as:
| (1) |
where denotes the spectral kernel coefficients. In Eq. (1), the signal is first transformed from the spatial domain to the spectral domain, then signals of different frequencies are enhanced or weakened by the filter , and finally transformed back to the spatial domain to obtain the filtered signal . To avoid eigen-decomposition, current works with spectral convolution usually use the polynomial functions to approximate different kernels, we call them polynomial spectral GNNs:
| (2) |
where is a learnable weight matrix for feature mapping and is the prediction matrix.
Expressive Power of Existing Polynomial Spectral GNNs
For the expressive power of polynomial spectral GNNs, The following lemma is given in JacobiConv:
Lemma 1
polynomial spectral GNNs can produce any one-dimensional prediction if has no repeated eigenvalues and contains all frequency components.
The proof of this lemma can be found in Appendix B.1 of JacobiConv (Wang and Zhang 2022). The lemma shows that the expressive power of polynomial spectral GNNs is related to the repeated eigenvalues.
To focus on exploring the fitting ability of the filter and avoid the influence of , we fix the weight matrix and assume that all elements of are non-zero. Thus, for the relationship between the expressive power of polynomial spectral GNNs and the distinct eigenvalues, we have the following theorem:
Theorem 1
When there are only distinct eigenvalues of the normalized Laplacian matrix, polynomial spectral GNNs can produce at most different filter coefficients, and thus can only generate one-dimensional predictions with a maximum of arbitrary elements.
We provide the proof of this theorem in Appendix A.1. Theorem 1 strictly shows that when the eigenvalues are more distinct, the polynomial spectral GNNs will be more expressive. In other words, the more repeated eigenvalues, the less expressive polynomial spectral GNNs are. Thus, the number of distinct eigenvalues is the key to the expressive power of polynomial spectral GNNs. Therefore, we need to reduce the repeated eigenvalues of the normalized Laplacian matrix as much as possible, given that real-world graphs often have many repeated eigenvalues.
Eigenvalue Correction
We now elaborate on the proposed eigenvalue correction strategy. In order to reduce repeated eigenvalues, a natural solution is that we can sample equally spaced from [0, 2] as new eigenvalues . Thus, the -th value of is defined as follows:
| (3) |
where is the number of nodes, which is also the number of eigenvalues. We serialize the vector into . Obviously, the sequence is a strictly monotonically increasing arithmetic sequence with 0 as the first item and as the common difference. We call equidistant eigenvalues.


However, the original eigenvalue of the normalized Laplacian matrix describes the frequency information and represents the speed of the signal change. Specifically, the magnitude of the eigenvalue represents the difference information of the signal between the neighbors of the node. Therefore, if we directly use the in Eq. (3) as the new eigenvalues, polynomial spectral GNNs will not be able to capture the frequency information represented by each frequency component. Hence, it is still necessary to include the original eigenvalues in the input. A simple way is to amalgamate them linearly to obtain the new eigenvalues :
| (4) |
where is a tunable hyperparameter, and is a sequence of original eigenvalues in ascending order. Thus, we have the following theorem:
Theorem 2
When , the sequence is strictly monotonically increasing, that is, all n elements of the sequence are different from each other.
The proof of this theorem is given in Appendix A.2. Theorem 2 indicates that the new eigenvalues have no repeated elements when , thus satisfying the condition of Lemma 1. It should be noted that if the spacing between two eigenvalues is very small, it is difficult for a polynomial spectral GNN to generate different filter coefficients for them. Therefore, the spacing between eigenvalues is crucial to guarantee the expressive power of polynomial spectral GNNs.
It is worth noting that is a key hyperparameter in Eq. (4), which can be used to trade off between and . The smaller , the closer is to , and the more uniform the spacing between the new eigenvalues , but the frequency information may not be captured. On the contrary, the larger , the closer is to , and the closer the new eigenvalue is to the frequency it represents, but the spacing between the eigenvalues may be uneven. When , degenerates into the original eigenvalues of the Laplacian matrix. When , degenerates to the equidistantly sampled in Eq. (3), whose spacing is absolutely uniform. In short, the hyperparameter needs to be set to an appropriate value so that the spacing between eigenvalues is relatively uniform and not too far away from the original eigenvalues.
For example, the Figure 3 shows the distribution histogram of the original eigenvalues and the corrected eigenvalues on Cora dataset when =0.5. We can see that, compared to Figure 3(a), Figure 3(b) has no sharp bumps, and the distribution of eigenvalues is more uniform. Hence, it is expected to fit more complex and diverse filters.
Combination of Corrected Eigenvalues with Existing Polynomial Filters
In order to fully take advantage of polynomial spectral GNNs, after getting the corrected eigenvalues, We are required to integrate them with a polynomial filter. First, we set , . Combined with Eq. (4) and , we have:
| (5) |
Then, a polynomial of order can be written as:
| (6) |
where . The difference between the proposed method and the existing polynomial filter is that is replaced by . Therefore, our method can be quite flexibly integrated into existing polynomial filters without excessive modifications. However, when the degree of the polynomial is high, the matrix multiplication will be computationally expensive, especially for dense graphs. Fortunately, we can compute by directly using polynomials of the eigenvalues instead of polynomials of the matrix:
| (7) |
We find that using Eq. (7) to calculate is much faster than Eq. (6), resulting in improved training efficiency. Moreover, we can increase the order to improve the fitting ability without increasing too much computational cost.
The complete filtering process can be expressed as:
| (8) |
Next, we present the details of the proposed eigenvalue correction strategy integrated into existing polynomial filters.
Insertion into GPR-GNN.
GPR-GNN (Chien et al. 2021) directly assigns a learnable coefficient to each order of the normalized adjacency matrix , and its polynomial filter is defined as:
| (9) |
where is an element-wise operation, and . It is worth noting that GPR-GNN uses a polynomial of the normalized adjacency matrix instead of the Laplacian matrix. Fortunately, they are constrained via : . Therefore, we integrate the corrected eigenvalues into GPR-GNN to obtain a new polynomial filter:
| (10) |
Insertion into BernNet.
BernNet (He et al. 2021) expresses the filtering operation with Bernstein polynomials and forces all coefficients to be positive, and its filter is defined as:
| (11) |
Similarly, we have:
| (12) |
Insertion into JacobiConv.
JacobiConv (Wang and Zhang 2022) proposes a Jacobi basis to adapt a wide range of weight functions due to its orthogonality and flexibility. The iterative process of Jacobi basis can be defined as:
| (13) | ||||
where and are tunable hyperparameters. Unlike GPR-GNN and BernNet, JacobiConv adopts an individual filter function for each output dimension :
| (14) |
Then, we integrate the corrected eigenvalues into the JacobiConv:
| (15) |
Experiment
In this section, we conduct a series of comprehensive experiments to demonstrate the effectiveness of the proposed method. First, we integrate the eigenvalue correction strategy into the three methods of GPR-GNN, BernNet, and JacobiConv to complete the learning of filter functions on synthetic datasets and node classification tasks on real-world datasets. Then, we report experiments on ablation analysis and sensitivity analysis of the hyperparameter . Finally, we show the evaluation of the time cost. All experiments are conducted on a machine with 3 NVIDIA A5000 24GB GPUs and Intel(R) Xeon(R) Silver 4310 2.10GHz CPU.
Evaluation on Learning Filters
Following previous works (He et al. 2021; Wang and Zhang 2022), we transform 50 real images to 2D regular 4-neighbor grid graphs. The nodes are pixels, and every two neighboring pixels have an edge between the corresponding nodes. Five predefined graph filters, i.e., low (), high (), band (), reject (), and comb () are used to generate ground truth graph signals. We use the mean squared error of 50 images as the evaluation metric.
To verify the effectiveness of the proposed Eigenvalue Correction (EC) strategy, we integrate it into three representative spectral GNNs with trainable polynomial filters, i.e., GPR-GNN (Chien et al. 2021), BernNet (He et al. 2021), and JacobiConv (Wang and Zhang 2022). Thus, we have three variants: EC-GPR, EC-Bern, and EC-Jacobi. For fairness, all experimental settings are the same as the base model, including dataset partition, hyperparameters, random seeds, etc. We just tune the hyperparameter to select the best model. In addition, for a more comprehensive comparison, we also consider four other baseline methods, including GCN (Kipf and Welling 2017), GAT (Veličković et al. 2019), ARMA (Bianchi et al. 2021), and ChebNet (Defferrard, Bresson, and Vandergheynst 2016).
The quantitative experiment results are shown in Table 2, revealing that our methods all achieve the best performance compared to the base models. For example, on low-pass and high-pass filters, our method outperforms the base model by an average of 12.9%, while on band-pass, comb-pass, and reject-pass filters, our method outperforms the base model by an average of 77.9%. Since complex filters require more frequency components to fit, our method improves more on band-pass, comb-pass, and reject-pass filters. Moreover, GCN and GAT only perform better on low-pass filters applied to homophilic graphs, illustrating the limited fitting ability of fixed filters. In contrast, polynomial-based GNNs perform better due to the ability to learn arbitrary filters. Nevertheless, they all take a large number of repeated eigenvalues as input, therefore, their expressive power is still weaker than our methods.
| Low | High | Band | Reject | Comb | |
| GCN | |||||
| GAT | |||||
| ARMA | |||||
| ChebyNet | |||||
| GPR-GNN | |||||
| EC-GPR | |||||
| BernNet | |||||
| EC-Bern | |||||
| JacobiConv | |||||
| EC-Jacobi |
| Datasets | GCN | APPNP | Chebynet | GPR-GNN | EC-GPR | BernNet | EC-Bern | JacobiConv | EC-Jacobi |
|---|---|---|---|---|---|---|---|---|---|
| Cora | |||||||||
| Citeseer | |||||||||
| Pubmed | |||||||||
| Computers | |||||||||
| Photo | |||||||||
| Chameleon | |||||||||
| Actor | |||||||||
| Squirrel | |||||||||
| Texas | |||||||||
| Cornell |
Evaluation on Real-World Datasets
We also evaluate the proposed method on the node classification task on real-world datasets. Following JacobiConv (Wang and Zhang 2022), for the homophilic graphs, we employ three citation datasets Cora, CiteSeer and PubMed (Yang, Cohen, and Salakhudinov 2016), and two co-purchase datasets Computers and Photo (Shchur et al. 2018). For heterophilic graphs, we use Wikipedia graphs Chameleon and Squirrel (Rozemberczki, Allen, and Sarkar 2021), the Actor co-occurrence graph, and the webpage graph Texas and Cornell from WebKB3 (Pei et al. 2020). Their statistics are listed in Table 1.
Following previous work (Wang and Zhang 2022), we use the full-supervised split, i.e., 60% for training, 20% for validation, and 20% for testing. Mean accuracy and 95% confidence intervals over 10 runs are reported. We integrate the eigenvalue correction strategy into GPR-GNN (Chien et al. 2021), BernNet (He et al. 2021), and JacobiConv (Wang and Zhang 2022). Moreover, we also add the results of GCN (Kipf and Welling 2017), APPNP (Gasteiger, Bojchevski, and Günnemann 2019), and ChebyNet (Defferrard, Bresson, and Vandergheynst 2016). For a fair comparison, we only tune the hyperparameter , and the other experimental settings remain the same as the base model. All hyperparameter settings can be found in Appendix D.
| Datasets | GPR-GNN | EC-GPR | BernNet | EC-Bern | JacobiConv | EC-Jacobi | Decomposition |
|---|---|---|---|---|---|---|---|
| Cora | 6.73/1.40 | 4.09/0.84 | 22.25/6.06 | 4.73/1.28 | 9.50/5.02 | 9.29/3.74 | 0.62 |
| Citeseer | 6.90/1.46 | 4.09/0.93 | 22.12/6.46 | 4.39/1.29 | 9.39/4.71 | 9.45/3.07 | 0.82 |
| Pubmed | 7.18/1.46 | 9.15/1.86 | 20.45/8.70 | 9.73/4.15 | 9.90/7.63 | 13.79/11.26 | 58.59 |
| Computers | 8.20/1.88 | 7.83/1.09 | 29.40/8.32 | 8.49/2.31 | 9.81/5.58 | 11.91/7.92 | 27.53 |
| Photo | 7.09/1.56 | 4.54/1.23 | 21.04/8.74 | 5.26/2.21 | 9.23/6.66 | 9.97/8.18 | 3.86 |
| Chameleon | 7.31/1.65 | 4.12/1.00 | 22.61/5.12 | 5.01/1.18 | 9.32/7.47 | 9.62/7.10 | 0.27 |
| Actor | 7.17/2.54 | 4.53/1.49 | 18.74/6.68 | 5.44/2.02 | 9.37/4.25 | 9.97/3.86 | 3.56 |
| Squirrel | 7.23/3.65 | 3.96/1.75 | 22.66/7.54 | 2.42/0.63 | 9.44/8.16 | 9.60/7.86 | 1.61 |
| Texas | 6.83/1.41 | 3.80/0.79 | 22.42/4.76 | 4.50/0.95 | 9.58/6.47 | 9.33/6.48 | 0.03 |
| Cornell | 7.17/1.48 | 3.89/0.80 | 22.34/4.66 | 4.49/0.93 | 9.10/5.30 | 9.53/3.18 | 0.02 |
Table 3 presents the experimental results on real-world datasets, from which we have the following observations. 1) GNNs with learnable filters tend to perform better than GNNs with fixed filters since fixed filters, such as GCN and APPNP, cannot learn complex filter responses. In contrast, GPR-GNN, BernNet, and JacobiConv can learn different types of filters from both homophilic graphs and heterophilic graphs. 2) The proposed method outperforms the base models in at least eight of the ten datasets, especially on the Squirrel dataset, with an average improvement of 17% over the three base models. This is because heterophilic graphs require more frequency components than homophilic graphs to fit the patterns. In general, we achieve a 4.2% improvement in GPR-GNN, 3.7% improvement in BernNet, and 0.68% improvement in JacobiConv, demonstrating that our proposed eigenvalue correction strategy can improve the expressive power of polynomial spectral GNNs. 3) With our eigenvalue correction strategy, GPR-GNN and BernNet achieve competitive performance with JacobiConv, which shows that the expressive power of different polynomial filters with the same order is the same.
Ablation Analysis

This subsection aims to validate our design through ablation studies. Previously, we believe that neither the original eigenvalues nor the equally spaced eigenvalues are optimal, while only combining them in a certain proportion can achieve the optimal performance. Therefore, we design two variants EC--A and EC--B to verify our conjecture, where {GPR, Bern, Jacobi}. EC--A directly uses the equidistant eigenvalues as input, that is, in Eq. (4) equals to 0. In contrast, EC--B directly uses the original eigenvalues as input, that is, in Eq. (4) equals to 1.
Figure 4 shows the results of the ablation experiments on two homophilic graphs, Cora and Photo, and two heterophilic graphs, Chameleon and Squirrel. From Figure 4, we have the following findings: 1) The utilization of solely the original eigenvalues and equidistant eigenvalues as input demonstrates a decrease in performance, corroborating our hypothesis necessitating their amalgamation. 2) EC--B of the heterophilic graphs drops more than the homophilic graphs, which indicates that the heterophilic graphs need more frequency component information to fit various responses.
Parameter Sensitivity Analysis
As discussed above, we add a key hyperparameter to adjust the ratio of the original eigenvalue and the equidistant eigenvalue . Now we analyze the impact of this hyperparameter on the performance of homophilic graphs and heterophilic graphs. Similar to the ablation experiments, we select two homophilic datasets Cora and Photo, and two heterophilic datasets Chameleon and Squirrel. Figure 5 shows the effect of the hyperparameter on the performance of the three methods EC-GPR, EC-Bern, and EC-Jacobi.
Figure 5 indicates that on the Cora dataset, the general trend of model performance is to decrease with the increase of , and then increase, which shows that both the equidistant eigenvalues and original eigenvalues are useful. The trend on the Photo dataset is not prominent, possibly due to its limited occurrence of repeated eigenvalues. In comparison, for heterophilic graphs, the model performance is maintained at a high level when is less than 0.6, and when is greater than 0.6, the model performance drops significantly. This suggests that equidistant eigenvalues contribute more to heterophilic graphs, which is consistent with our previous analysis.

Evaluation on Time Cost
Table 4 shows our time cost compared with the base models GPR-GNN, BernNet and JacobiConv. We can conclude that our time spent with the JacobiConv model is similar, 30.9% less than GPR-GNN and 75.5% less than BernNet. In particular, we significantly improve the training efficiency of BernNet, which is a quadratic time complexity related to the order of its polynomial. This is because we change the time-consuming polynomial of the matrix to the polynomial of the eigenvalues, thus reducing the calculation time.
Since obtaining eigenvalues and eigenvectors requires eigen-decomposition, we also add the time overhead of eigen-decomposition in Table 4. We can see from Table 4, the eigen-decomposition time for most datasets is less than 5 seconds, even for a large graph with nearly 20,000 nodes like Pubmed, the time for eigen-decomposition is less than one minute. For larger graphs, we can follow previous works (Lim et al. 2023; Bo et al. 2023; Lin, Chen, and Wang 2023; Yao, Yu, and Jiao 2021) and only take the largest and smallest eigenvalues and eigenvectors without a full eigen-decomposition. Moreover, the eigen-decomposition only needs to be precomputed once and can be reused in training afterward. In summary, the cost of eigen-decomposition is acceptable and negligible.
Conclusions
In this paper, we point out that the current polynomial spectral GNNs have insufficient expressive power due to a large number of repeated eigenvalues, so we propose a novel eigenvalue correction strategy that amalgamates the original eigenvalues with equidistant eigenvalues counterparts to make the distribution of eigenvalues more uniform, and not to deviate too far from the original frequency information. Moreover, we improve the training efficiency without increasing the precomputation time too much, which allows us to efficiently increase the order of polynomial spectral GNNs. Extensive experiments on synthetic and real-world datasets demonstrate that the proposed eigenvalue correction strategy outperforms the base model.
Acknowledgments
The work was supported by the National Natural Science Foundation of China (Grant No. U22B2019), National key research and development plan (Grant No. 2020YFB2104503), BUPT Excellent Ph.D. Students Foundation(CX2023128) and CCF-Baidu Open Fund.
References
- Balcilar et al. (2021) Balcilar, M.; Guillaume, R.; Héroux, P.; Gaüzère, B.; Adam, S.; and Honeine, P. 2021. Analyzing the expressive power of graph neural networks in a spectral perspective. In Proceedings of the International Conference on Learning Representations (ICLR).
- Banerjee and Jost (2008) Banerjee, A.; and Jost, J. 2008. On the spectrum of the normalized graph Laplacian. Linear algebra and its applications, 428(11-12): 3015–3022.
- Bianchi et al. (2021) Bianchi, F. M.; Grattarola, D.; Livi, L.; and Alippi, C. 2021. Graph neural networks with convolutional arma filters. IEEE transactions on pattern analysis and machine intelligence, 44(7): 3496–3507.
- Bo et al. (2023) Bo, D.; Shi, C.; Wang, L.; and Liao, R. 2023. Specformer: Spectral Graph Neural Networks Meet Transformers. In The Eleventh International Conference on Learning Representations.
- Chien et al. (2021) Chien, E.; Peng, J.; Li, P.; and Milenkovic, O. 2021. Adaptive Universal Generalized PageRank Graph Neural Network. In International Conference on Learning Representations.
- Chung, Lu, and Vu (2003) Chung, F.; Lu, L.; and Vu, V. 2003. Spectra of random graphs with given expected degrees. Proceedings of the National Academy of Sciences, 100(11): 6313–6318.
- Defferrard, Bresson, and Vandergheynst (2016) Defferrard, M.; Bresson, X.; and Vandergheynst, P. 2016. Convolutional neural networks on graphs with fast localized spectral filtering. Advances in neural information processing systems, 29.
- Fang et al. (2023) Fang, J.; Liu, W.; Gao, Y.; Liu, Z.; Zhang, A.; Wang, X.; and He, X. 2023. Evaluating Post-hoc Explanations for Graph Neural Networks via Robustness Analysis. In Thirty-seventh Conference on Neural Information Processing Systems.
- Fang et al. (2024) Fang, J.; Zhang, S.; Wu, C.; Yang, Z.; Liu, Z.; Li, S.; Wang, K.; Du, W.; and Wang, X. 2024. MolTC: Towards Molecular Relational Modeling In Language Models. In ACL (Findings). Association for Computational Linguistics.
- Gao et al. (2023a) Gao, Y.; Wang, X.; He, X.; Liu, Z.; Feng, H.; and Zhang, Y. 2023a. Addressing Heterophily in Graph Anomaly Detection: A Perspective of Graph Spectrum. In WWW, 1528–1538. ACM.
- Gao et al. (2023b) Gao, Y.; Wang, X.; He, X.; Liu, Z.; Feng, H.; and Zhang, Y. 2023b. Alleviating Structural Distribution Shift in Graph Anomaly Detection. In WSDM, 357–365. ACM.
- Gasteiger, Bojchevski, and Günnemann (2019) Gasteiger, J.; Bojchevski, A.; and Günnemann, S. 2019. Predict then Propagate: Graph Neural Networks meet Personalized PageRank. In International Conference on Learning Representations.
- Gong et al. (2025) Gong, C.; Yang, B.; Zheng, W.; Huang, X.; Huang, W.; Wen, J.; Sun, S.; and Yang, B. 2025. Scalable GNN Training via Parameter Freeze and Layer Detachment. In Database Systems for Advanced Applications(DASFAA).
- Gong, Zheng, and Feng (2025) Gong, C.; Zheng, W.; and Feng, H. 2025. Accelerating DeepWalk via Context-Level Parameter Update and Huffman Tree Pruning. In Database Systems for Advanced Applications(DASFAA).
- Guo and Wei (2023) Guo, Y.; and Wei, Z. 2023. Graph Neural Networks with Learnable and Optimal Polynomial Bases. arXiv preprint arXiv:2302.12432.
- He et al. (2021) He, M.; Wei, Z.; Xu, H.; et al. 2021. Bernnet: Learning arbitrary graph spectral filters via bernstein approximation. Advances in Neural Information Processing Systems, 34: 14239–14251.
- Jiang (2012) Jiang, T. 2012. Empirical distributions of Laplacian matrices of large dilute random graphs. Random Matrices: Theory and Applications, 1(03): 1250004.
- Kipf and Welling (2017) Kipf, T. N.; and Welling, M. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In International Conference on Learning Representations.
- Lim et al. (2023) Lim, D.; Robinson, J. D.; Zhao, L.; Smidt, T.; Sra, S.; Maron, H.; and Jegelka, S. 2023. Sign and Basis Invariant Networks for Spectral Graph Representation Learning. In The Eleventh International Conference on Learning Representations.
- Lin, Chen, and Wang (2023) Lin, L.; Chen, J.; and Wang, H. 2023. Spectral Augmentation for Self-Supervised Learning on Graphs. In The Eleventh International Conference on Learning Representations.
- Mehatari and Banerjee (2015) Mehatari, R.; and Banerjee, A. 2015. Effect on normalized graph Laplacian spectrum by motif attachment and duplication. Applied Mathematics and Computation, 261: 382–387.
- Pei et al. (2020) Pei, H.; Wei, B.; Chang, K. C.-C.; Lei, Y.; and Yang, B. 2020. Geom-GCN: Geometric Graph Convolutional Networks. In International Conference on Learning Representations.
- Rozemberczki, Allen, and Sarkar (2021) Rozemberczki, B.; Allen, C.; and Sarkar, R. 2021. Multi-scale attributed node embedding. Journal of Complex Networks, 9(2): cnab014.
- Shchur et al. (2018) Shchur, O.; Mumme, M.; Bojchevski, A.; and Günnemann, S. 2018. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868.
- Veličković et al. (2019) Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; and Bengio, Y. 2019. Graph Attention Networks. In International Conference on Learning Representations.
- Wang and Zhang (2022) Wang, X.; and Zhang, M. 2022. How powerful are spectral graph neural networks. In International Conference on Machine Learning, 23341–23362. PMLR.
- Weisfeiler and Leman (1968) Weisfeiler, B.; and Leman, A. 1968. The reduction of a graph to canonical form and the algebra which appears therein. nti, Series, 2(9): 12–16.
- Wu et al. (2023) Wu, G.; Lin, S.; Shao, X.; Zhang, P.; and Qiao, J. 2023. QPGCN: Graph convolutional network with a quadratic polynomial filter for overcoming over-smoothing. Applied Intelligence, 53(6): 7216–7231.
- Wu et al. (2022) Wu, S.; Sun, F.; Zhang, W.; Xie, X.; and Cui, B. 2022. Graph neural networks in recommender systems: a survey. ACM Computing Surveys, 55(5): 1–37.
- Xu et al. (2019) Xu, K.; Hu, W.; Leskovec, J.; and Jegelka, S. 2019. How Powerful are Graph Neural Networks? In International Conference on Learning Representations.
- Yang, Cohen, and Salakhudinov (2016) Yang, Z.; Cohen, W.; and Salakhudinov, R. 2016. Revisiting semi-supervised learning with graph embeddings. In International conference on machine learning, 40–48. PMLR.
- Yao, Yu, and Jiao (2021) Yao, S.; Yu, D.; and Jiao, X. 2021. Perturbing eigenvalues with residual learning in graph convolutional neural networks. In Asian Conference on Machine Learning, 1569–1584. PMLR.
- Zhu et al. (2021) Zhu, M.; Wang, X.; Shi, C.; Ji, H.; and Cui, P. 2021. Interpreting and unifying graph neural networks with an optimization framework. In Proceedings of the Web Conference 2021, 1215–1226.
Appendix A Proofs of Theorems
Below we show proofs of several theorems in the main text of the paper.
A.1 Proof of Theorem 1
Proof. We first prove the first part of Theorem 1. We know from Eq. 2 in the paper that the filter coefficients of polynomial spectral GNNs are generated by . We assume that the polynomial is of sufficiently high order so that it can produce different outputs for different inputs . However, when , = . That is, can only produce the same output for the same input. Therefore, when the normalized Laplacian matrix has only different eigenvalues, polynomial spectral GNNs can only produce at most different filter coefficients.
Next, we prove the second part of Theorem 1. For the filtering process . We first assume all elements of are non-zero. And we set vector and . Thus we have where .
It can be seen that if , then . Given that we have distinct eigenvalues, only elements of the vector are arbitrary. Therefore, we can always represent Z by a vector of elements and a matrix of rows and columns. Thus, we have :
| (16) |
where is the number of distinct eigenvalues. We can conclude that if Eq. (1) has a solution, it has at least redundant equations. Without loss of generality, we assume that the last equations are redundant, so we have: , where is a constant. Therefore, given ,,, we can uniquely determine ,,, thus polynomial spectral GNNs can only generate one-dimensional predictions with a maximum of arbitrary elements.
A.2 Proof of Theorem 2
We formalize Theorem 2 in the paper as follows:
Theorem 3
When , , .
Proof. When , given , we have where .
Similarly, when , given , we have where .
Combining the above two conclusions, we can get the following inequality:
| (17) |
Therefore, when , , .
Appendix B Eigenvalue distribution of normalized Laplacian matrix
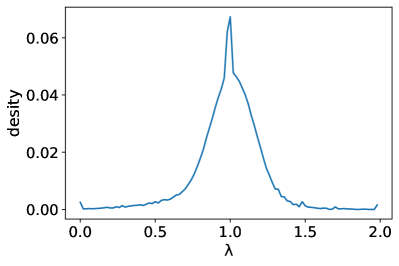
Figure 6 shows the distribution of the eigenvalues of the normalized Laplacian matrix in different datasets, from which we can see that the eigenvalues of all datasets are clustered around 1, so there will be many repeated eigenvalues.









Appendix C Eigenvalue distribution of random graphs
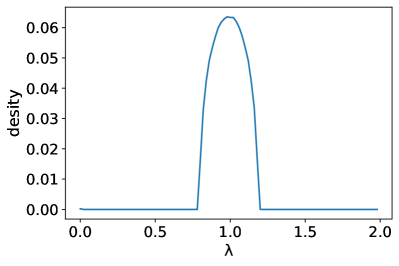
Figure 7 shows the variation of eigenvalues with the average degree for a random graph with four thousand nodes. We find that the higher the average degree of the node, the more concentrated the distribution of eigenvalues is at the value 1, which is consistent with the distribution trend in Figure 1. Therefore, we speculate that the tendency that the eigenvalues of real-world graphs to be concentrated around 1 is also related to their average degree.









Appendix D The setting of hyperparameter
| datasets | Low | High | Band | Reject | Comb |
|---|---|---|---|---|---|
| EC-GPR | 0.80 | 0.70 | 0.00 | 0.00 | 0.00 |
| EC-Bern | 0.60 | 0.90 | 0.70 | 0.00 | 0.00 |
| EC-Jacobi | 0.90 | 0.90 | 0.70 | 0.70 | 0.00 |
Tables 5 and 6 present the hyperparameter settings of EC-GPR, EC-Bern, and EC-Jacobi on synthetic datasets and real-world datasets.
| datasets | Cora | Citeseer | Pubmed | Computers | Photo | Chameleon | Actor | Squirrel | Texas | Cornell |
|---|---|---|---|---|---|---|---|---|---|---|
| EC-GPR | 0.90 | 0.25 | 0.75 | 0.15 | 0.05 | 0.09 | 0.90 | 0.23 | 0.91 | 0.77 |
| EC-Bern | 0.63 | 0.78 | 0.05 | 0.12 | 0.05 | 0.33 | 0.86 | 0.44 | 0.86 | 0.18 |
| EC-Jacobi | 0.50 | 0.32 | 0.50 | 0.39 | 0.47 | 0.29 | 0.26 | 0.76 | 0.40 | 0.70 |