Improving Dither Modulation based Robust Steganography by Overflow Suppression
Abstract
Nowadays, people are sharing their pictures on online social networks (OSNs), so OSN is a good platform for Steganography. But OSNs usually perform JPEG compression on the uploaded image, which will invalidate most of the existing steganography algorithms. Recently, some works try to design robust steganography which can resist JPEG compression, such as Dither Modulation-based robust Adaptive Steganography (DMAS) and Generalized dither Modulation-based robust Adaptive Steganography (GMAS). They relieve the problem that the receivers cannot extract the message correctly when the quality factor of channel JPEG compression is larger than that of cover images. However, they only can realize limited resistance to detection and compression due to robust domain selection. To overcome this problem, we meticulously explore three lossy operations in the JPEG recompression and discover that the key problem is spatial overflow. Then two preprocessing methods Overall Scaling (OS) and Specific Truncation (ST) are presented to remove overflow before message embedding as well as generate a reference image. The reference image is employed as the guidance to build asymmetric distortion for removing overflow during embedding. Experimental results show that the proposed methods significantly surpass GMAS in terms of security and achieve comparable robustness.
Index Terms:
OSNs, robust steganography, asymmetric distortion, dither modulation, overflow.1 Introduction
Steganography is a science and art of covert communication that transmits secret messages through digital media without attracting the attention of others [1, 2]. Many different mediums can be used in steganography, such as texts, audios, images and videos. Among them, JPEG images are now widely used in people’s lives because they can provide high-level visual quality with low storage costs [3]. At present, the most remarkable steganographic schemes at JPEG images are based on the framework of minimizing distortion [4, 5]. Within this framework, researchers define a modification cost to each cover element and use Syndrome-Trellis Codes (STCs) [6] to embed message, where STCs can asymptotically reach the payload-distortion bound for additive distortion.
With the practical steganographic code STCs, the latest researches focused on how to design effective distortion function. There are a lot of distortion functions about JPEG image, such as J-UNIWARD (JPEG UNIverlet WAvelet Relative Distortion) [7], UERD (Uniform Embedding Revisited Distortion) [8], RBV (Residual Block Value) [9], BET (Block Entropy Transformation) [10], GUED (Generalized Uniform Embedding Distortion) [11] and J-MiPOD (Minimizing the Power of Optimal Detector for JPEG domain) [12]. Their main purpose is to assign low costs to the coefficients in complex areas of an image and high costs to the coefficients in smooth areas according to the “Complexity-First Rule” [13]. Non-additive cost functions on JPEG images are defined to keep the continuity of adjacent blocks in the spatial domain [14, 15, 16].
The aforementioned works have been performed well on lossless channels. However, images transmitted over online social networks (OSNs), such as Facebook and Twitter, generally suffer from lossy processes. To ensure image quality while saving storage space, OSN usually performs JPEG compression on the uploaded images. JPEG recompression will invalidate the traditional steganography scheme because the stego changes during transmission [17]. Therefore, JPEG recompression resistance is the major concern due to the wide use of the JPEG recompression in OSNs [18]. In recent years, there has been a growing number of publications [19, 20, 21, 22, 23, 24] focusing on the steganography in this real-world communication and aiming to resist these lossy processes.
We summarize existing steganographic algorithms against JPEG compression into two categories according to their application scenarios. The first category performs well only if we know the quality factor (QF) for channel recompression or can use the channel at will, and is called “White-Box Robust”. The representative of this category is TCM (Transport Channel Matching) proposed by Zhao et al. [19], which repeatedly processes the image by applying channel manipulations until the image is nearly identical before and after processing. They additionally utilized the Error Correction Code (ECC) to reduce the Bit Error Rate (BER). However, this method requires repeatedly uploading and downloading cover images on OSNs, which is abnormal behaviour and will arouse the suspicion of the attacker.
The other category, which does not require a priori knowledge of the channel and cannot be used arbitrarily, is named “Black-Box Robust”. Zhang et al. [20] proposed Dither Modulation-based robust Adaptive Steganography (DMAS) based on “Robust Domain Selection + ECC-STCs Codes” [21] to achieve undetectability and robustness in this situation. This approach avoids behavioral insecurity. They chose middle frequency AC (Alternating Current) coefficients as the cover and utilized dither modulation for message embedding. Yu et al. [22] further upgraded dither modulation to generalized dither modulation by expanding robust domain and introducing asymmetric distortion in Generalized dither Modulation-based robust Adaptive Steganography (GMAS). However, they only perform well when the QF of the cover image is less than that of the channel recompression, which is called “Upward Robust”. Concerning the other case that the QF of channel JPEG compression is less than that of cover image, Tao et al. [23] proposed an enjoyable scheme. They deduce the JPEG compression process in mathematical to adjust the DCT coefficients so that the receiver can exactly extract the secret messages from the stego after compression. Nevertheless, this method does not consider the rounding and truncation in the spatial domain so is hardly used in practice. Thus, designing the algorithm available in this case is still an open problem.
In summary, black-box robust steganography, such as GMAS and DMAS, are the current practical algorithms with wide application scope, yet they can realize desirable resistance to detection and compression only at low capacity due to the limitations of robust domain selection. To overcome these problems, we first explore the reasons for the errors of previous upward robust steganography algorithms: lossy operations in the JPEG recompression. Then we investigate the impacts caused by spatial operations, a key issue that has not received much attention in previous studies, and find that spatial overflow is the severest operation. Based on this finding, we propose a novel robust steganographic method by cover-preprocessing and asymmetric cost definition. In detail, cover-preprocessing can effectively reduce spatial overflow to enhance the robustness of the coefficient as well as generate a reference image. The asymmetric distortion is designed according to the reference images to make steganography towards the direction which produces a more robust image. The security of the proposed scheme is verified with detailed experiments under different compression QFs and valid steganalysis with CCPEV (PEV features [25] enhanced by Cartesian Calibration) [26], DCTR (Discrete Cosine Transform Residual) [27] and SRNet [28]. Notably, we use the image before preprocessing as cover and image through steganography as stego for steganalysis when evaluating the security of the algorithm, which is more practical than the assessment method used in [19]. The experimental results show that the proposed scheme can reach higher robustness and security compared to previous algorithms.
The contributions of this work are summarized as follows.
-
1)
This paper explores the lossy process of JPEG compression in detail and finds that the key problem in anti-compression steganography is spatial overflow. Reducing the impact of spatial truncation operations is a effective way to improve robust steganography.
-
2)
With the analysis of the JPEG compression, we first propose a preprocessing method that completely removes spatial overflow and theoretically proves its effectiveness. In the pursuit of greater security, a heuristic preprocessing method with fewer modifications is proposed. Both methods enhance the stability of the coefficients, allowing the entire image to be used as a robust region.
-
3)
Considering both security and robustness, a novel asymmetric distortion definition method is proposed, which combines the embedding process with the removal of the spatial overflow together.
The rest of this paper is organized as follows. We introduce the related work in Section 2. An investigation of the JPEG recompression on the dither modulation based algorithms is in Section 3. The exhaustive process of the proposed scheme are described in Section 4. The consequences of contrast experiments and tests on their performance are shown in Section 5. Finally, Section 6 concludes the paper.
2 Related Work
2.1 Notations and JPEG Recompression
Throughout the paper, matrices, vectors and sets are written in capital letters. Unless otherwise indicated, we use symbol to denote the matrices of quantized DCT coefficients, to denote the matrices of quantization table, to denote the matrices of spatial values derived from by IDCT and to denote the matrices of pixels. Elements in the matrix are denoted by corresponding lowercase letters, for example , , , , where the subscripts mean their position. Considering the way JPEG compression chunking operates we normally use block, namely, . Also considering the storage limitations in JPEG, , , and . The transformation functions are denoted by bold symbols, additionally, , and are denote rounding methods round, ceil and floor in mathematics. The aforesaid notations and the relationship among the above elements can be briefly explained through the JPEG compression process as follows.
The JPEG recompression process first converts the DCT coefficients to spatial values, then truncates and rounds them to obtain spatial image, finally converts spatial image into quantized DCT coefficients with the QF of channel. For detail, the process of recompressing an DCT block from quality factor to is as follows:
-
•
coefficients dequantization:
(1) -
•
inverse discrete cosine transformation:
(2) -
•
spatial truncation:
(3) -
•
spatial rounding:
(4) -
•
spatial shift:
(5) -
•
discrete cosine transformation:
(6) -
•
coefficients quantization:
(7)
We use to denote the matrices of unquantized DCT coefficients. The function TRU is truncation of the pixel which value is out of the spatial range thus called overflow:
| (8) |
Notably, DCT coefficient quantization referred to in this paper usually includes both quantization and rounding operations unless specified. Greek letters denote costs of the coefficients and parameters. Specific explanations of the notations, or elements not mentioned, will be elaborated on later.
2.2 Dither Modulation

Dither modulation is an extension of the original uniform quantized index modulation (QIM) algorithm [29]. Since dither modulation can be robust in embedding while maintaining high visual quality of the image, it is widely used in watermarking algorithms. In the below, we briefly introduce the embedding process of dither modification on DCT coefficients in [30].
The modification method of algorithm [30] is shown in Figure 1(a). We use and to represent the unquantized DCT coefficients and the quantization step associated with them is . The axes which represent the unquantized DCT coefficients can be divided into many segments by quantization step . As seen in the Figure 1(a), in the odd segment represents the message bit ‘1’, and in the even segment represents the message bit ‘0’. If we want to represent the message bit ‘0’, we will add to it and adjust it to the center of the nearest even segment. A similar modification will be performed if the message represented by is changed.
2.3 DMAS and GMAS
Dither Modulation-based robust Adaptive Steganography (DMAS) [20] is a recent robust steganographic algorithm under the “Robust Domain Selection + ECC-STCs Codes” framework. It constructs compression-resistant domain mainly by choosing middle frequency DCT coefficients as the embedding domain in conjunction with dither modulation. DMAS can be applied in either spatial or DCT domain.
Generalized dither Modulation-based robust Adaptive Steganography (GMAS) [22] improves resistance to detection and compression by generalized dither modulation and expanding the embedding domain of DMAS. The embedding scheme of generalized dither modulation is illustrated in the Figure 1(b). Unlike DMAS, which modifies the coefficients to the center of the nearest interval. GMAS considers the possibility of modifying to both sides as well as introduces ternary embedding and asymmetric distortion for hiding message. We will only describe GMAS in detail here:
-
i.
Select Cover Elements from Expended Robust Domain. The expended embedding domain are composed of coefficients satisfying the . These coefficients are selected as steganographic cover and embedded using generalized dither modulation.
-
ii.
Calculate Asymmetric Distortion. Calculate the spatial pixels that eliminate the JPEG compression block effect.
(9) (10) To improve the performance, use this as a reference and define asymmetric distortion to encourage modifications toward the reference image. In detail, a block DCT transformation of yields unquantized DCT coefficients , calculate symmetric costs with existing distortion functions then asymmetric costs of the quantized DCT coefficients can be defined as follows:
(11) (12) where denotes the quantized DCT coefficients and controls the intensity of the adjustment. The final asymmetric costs and for the unquantized DCT coefficients are calculated as follow:
(13) (14) where is an integer. and denote the unquantized DCT coefficients and the corresponding quantization step, respectively.
-
iii.
RS Encoding and Ternary STC Embedding. Utilizing RS codes to encode the messages. A modifiable ternary sequence can be obtained from the selected coefficients using generalized dither modulation so ternary STC is used to embed to attain a lower bit error rate and stronger security. Specifically, ternary STC can be implemented using double-layered STCs [31].
After receiving the compressed stego image, the receiver first converts JPEG images to spatial values, then obtains the unquantized DCT coefficients derived from spatial images, finally calculates the quantized DCT coefficients with the same quantization table as that used for embedding, and we call this entire operation “DCT Coefficients Restoration”. After that, the same middle frequency DCT coefficients are chosen to gain the message using STCs and RS decoding.
3 Anti-compression Analysis of Dither Modulation



State-of-the-art black-box robust steganography is based on dither modulation, which is the main reason why they do not require knowledge of channel to achieve robustness. In this section we will explore the advantages and disadvantages of this approach.
As displayed in Section 2.1, there are three lossy steps in the recompression process: spatial truncation, spatial rounding and coefficients quantization. These three operations have different effects on the DCT coefficients. Let’s start our detailed analysis by probing the principle of upward robust.
3.1 Explanation of Upward Robustness
Yu et al. [22] experimentally found that steganographic algorithms using dither modulation for embedding (such as DMAS and GMAS) generally behave excellently when the QF of channel compression is larger than that of the cover image and called this phenomenon “Upward Robust”. This part will provide a theoretical analysis of this phenomenon.
Generally, we denote the unquantized DCT coefficient of a stego JPEG image by . Then the relation among , the corresponding quantized coefficients , and quantization steps is as follows:
| (15) |
This means that the unquantized DCT coefficients of the JPEG image are exactly at the center of the region divided by the quantization step. If the quantization step used for this coefficient in channel compression is , the maximum modifications caused by channel compression is without considering the processing of the spatial pixels. So after channel compression we have:
| (16) |
where is unquantized DCT coefficient after channel compression. As described in the Section 2.3, it is necessary to perform DCT coefficients restoration. Denote the coefficient after restoration at this situation as . When the channel compression QF is larger than the cover QF (the corresponding quantization step of channel compression is less than that of the cover), it is obvious from the Figure 1(c) that
| (17) |
In this case, the coefficients after coefficients restoration are the same as the original ones, so the message can be extracted accurately. If the QF of channel compression is smaller than the QF of cover, the corresponding quantization steps will produce a contrary consequence. Also as shown in Figure 1(c):
| (18) |
where and are unquantized and quantized coefficients in this situation. Such cases usually involve extraction errors and error propagation due to the utilization of STCs. Here we consider the generalized dither modulation.The above analysis explained the fundamental principle of dither modulation to achieve upward robustness. So dither modulation based algorithms (DMAS and GMAS) require the selection of the image with a lower QF to meet the real-world application scenarios.
In summary, the embedding using dither modulation is theoretically error-free when the channel compression QF is larger than the cover QF (Upward Robust). But this method still has errors in a real-world implementation even if the QF meets the requirement of Upward Robust. The reason is that we have considered only one of the three lossy processes in the recompression (coefficients quantization). The influences of spatial truncation and rounding were not considered, which will be discussed in the next subsection.
3.2 Exploration of Spatial Operation
According to the inference of Section 3.1, dither modulation-based algorithms are unaffected by coefficients quantization. However, when considering the impact of spatial operations, Equation (16) will not necessarily be true. So we will explore this below.
To measure the effect of the spatial truncation and rounding, we summarize the JPEG recompression process in Section 2.1 as follows,
| (19) |
First we investigate the impact of spatial rounding. We ignore the truncation operations on the spatial domain. Then the recompression process is represented as follows,
| (20) | ||||
where is a rounding error block and all the elements of belong to . Here, we assume that in is an independent identically distributed (i.i.d.) random variable with uniform distribution in the range of . Then, based on the central limit theorem, for each element in , can be approximately regarded as a Gaussian distribution [33]. Consequently, we see that
| (21) | ||||
where is the quantization step corresponding to the recompression quality factor . Therefore, spatial rounding has almost no effect on the recompressed DCT coefficients with recompression , since each element of the quantization matrix is larger than 1. This way we can exclude the effect of the spatial rounding operation on the robust steganography algorithm. As a conclusion, in the case where the recompression QF is larger than the cover QF, spatial truncation operation is the primary cause of the error. Here is an experiment to verify the above conclusion. We characterize the magnitude to which the DCT coefficient is affected by spatial operations as the stability of the coefficient. From Figure 2, we can observe experimentally that truncation operations in the spatial values are the major contributor to the instability of the DCT coefficients, and that rounding operations in the spatial values contribute only relatively small effects.

The specific operation of spatial truncation is shown in Equation (8). Compared to spatial rounding, truncation operations usually cause larger variation, correspondingly also have a greater impact on DCT coefficients, as shown in Figure 2. Obviously, the exact extent of the impact caused by the truncation operation is related to the magnitude of the corresponding block overflow. And the cause of spatial overflow is that the DCT coefficient derived from the unoverflowed spatial value becomes a coefficient with a larger absolute value during quantization when the image is saved in JPEG format. From the cause of overflow, it is known that the magnitude of overflow depends on the size of the corresponding quantization step. Notably, this quantization step is a save-time one, which is in the quantization table of the cover for the steganographer. We counted the overflow extent of the images in BOSSbase 1.01 [32] with different QFs and the results are shown in Figure 3. The smaller the QF of the cover image, the larger the quantization step, the greater the degree of overflow, and the greater the impact suffered from the spatial truncation operation. For robustness, dither modulation based steganography need to choose the image with long quantization step as cover, but this makes them subject to the spatial truncation, even if GMAS chooses to embed in the middle frequency regions with large quantization steps, it is impossible to avoid errors. The reason why repeatedly processing the images through channels can improve the robustness is also that the spatial overflow of the images can be reduced in repeated compression, making the instability of the DCT coefficients diminished. But repeated uploads and downloads are behaviorally insecure. Through the above analysis, we can fundamentally improve the robustness and security by dealing with the image overflow.

In conclusion, coefficient quantization results in the primary effect among the three lossy operations, but the application of dither modulation solves this problem. In the two remaining problems, spatial truncation plays a major role, while the effect of spatial rounding is almost negligible. Consequently, in the procedure of channel compressing, the DCT coefficients of the blocks with the overflow spatial values tend to change dramatically. Inspired by the above discoveries, we have designed a strategy called Removing Overflow based Adaptive robuSt sTeganography (ROAST) to effectively remove the spatial overflow of cover images, which strengthens the stability of the DCT coefficients, thus we do not need to select the robust domain as previous steganography algorithms and can embed on the entire image, which not only significantly enlarges the embedding capacity, but also improves the anti-detection performance remarkably. The proposed strategy ROAST can resist compression primarily because of the removal of spatial overflow, which can be accomplished in two methods: Overall Scale and Specific Truncation. We designed corresponding steganography schemes based on the respective properties of the two approaches. Each is described in detail later.
4 Proposed Methods

4.1 Overall Scale to Remove Overflow
The first method of removing spatial overflow is Overall Scale (OS). This method is primarily concerned with theoretical rigor and enabling greater removal of spatial overflow in particular. The concrete process can be outlined in Figure 4, and the subsequent part will describe the details and prove the feasibility of this approach.
-
i.
Inverse DCT and Inspection. The object of the algorithm is an DCT coefficient block of a JPEG image. Convert it to spatial block with inverse DCT. Denote the unquantized DCT coefficients of row column in the DCT block by and the spatial values of row column in the spatial block by . Note that the spatial value here is not a pixel, an shifting is required to convert it to a pixel. The relationship between the DCT coefficient and the spatial value can be obtained by the formula of DCT:
(22) where denotes the side length of the block. For a more intuitive description, we rewrite Equation (22) to the following form:
(23) where denotes the value of when , which is the variation caused by a single spatial value on this DCT coefficient. Once the conversion is complete, the overflow can be observed via the spatial value, namely, check if satisfies or . If there exists an overflow in a block, then this block will be processed to remove the overflow. If not, then the block will be skipped.
-
ii.
Scale of Spatial Values. Remove spatial overflow by scaling the whole block to a block without overflow:
(24) where denotes the spatial value after scaling and is the parameter. The amount of depends on the degree of spatial overflow of the block:
(25) where denotes the spatial value with the maximum absolute value. So that calculated in this way makes the scaled block without overflow.
-
iii.
DCT and Quantization. Convert the block which has been removed overflow into DCT coefficients. The DCT coefficients corresponding to the scaled block are :
(26) At this time, this block gets rid of overflow. Thereafter, the DCT coefficients will be quantized to integer. Generally, the round function “” is adopted which modifies a number to the nearest integer for quantization. However, the round operation will cause undesirable changes, e.g. the coefficient increases. The former scaling changes intend to reduce the amplitude of DCT coefficients, therefore FIX which modifies the number to the nearest integer with a smaller absolute value is utilized here for quantization.
(27) The final processed DCT coefficient is ,
(28) where is the corresponding quantization step.
Here gives the proof that the processed block is without the overflow. The unquantized DCT coefficient corresponding to the finally stored DCT coefficient is :
| (29) |
where is a parameter jointly determined by quantization and overall scale. It is obvious from the above process that . Similar to the way the DCT formula in Equation (23), rewrite the inverse DCT in the following format:
| (30) |
where denotes the value of when . The spatial value corresponding to the adjusted coefficients is :
| (31) |
Apparently, as a result of . Hence, the corresponding spatial values diminish spatial overflow after adjusting the DCT coefficients. Even though it may occasionally cause overflow after steganography, the effect will be minimal compared to before.
4.2 Overall Scale based Steganography: ROAST-OS
The stability of the coefficients can be significantly improved via the Overall Scale method introduced in the previous section, so we use this method and generalized dither modulation to design an upward robust steganography scheme named ROAST-OS. Figure 5 illustrates the procedure of the scheme. The process and details are described hereunder:
-
i.
Preprocessing of Cover Image. Removing the spatial overflow of cover image by the Overall Scale method. The cover after preprocessing is generally considered to be sufficiently robust that the whole image can be regarded as a robust region, which we called robust cover.
-
ii.
Define Distortion for Robust Cover. Define the asymmetric distortion of robust cover using the Equation (11) and Equation (12). Here the distortion of the quantized DCT coefficients instead of the unquantized DCT coefficients are calculated, that is, Equation (13) and Equation (14) are not required here. This is according to the Equation (15) which means the unquantized DCT coefficients of the JPEG image are exactly at the center of the region divided by the quantization step.
-
iii.
RS Encoding and Ternary STC Embedding. Utilizing RS codes to encode the messages and ternary STC to embed.
The receiver first performs the DCT coefficients restoration introduced in Section 2.3 on the compressed stego image. The message is then decoded with the RS code and STCs.
4.3 Specific Truncation to Remove Overflow

Although the aforesaid Overall Scale method can remove the overflow to produce a robust cover and is also outstanding in practical steganography schemes, we need to consider the anti-detection performance while pursuing robustness in robust steganography. The employment of the Overall Scale generates a large number of modifications, which greatly affects the anti-detection performance, so we devised a method named Specific Truncation (ST) for targeted tuning of the overflow location and parameterizing the processing intensity to remove spatial overflow with relatively fewer modifications. The concrete procedure of the method is shown in Figure 4, and the details are presented as follows.
-
i.
Inverse DCT and Inspection. Convert the DCT block to spatial values and detect whether the block is overflowing or not, namely, check if there is satisfying or . If there exists an overflow, then the block will be processed to remove the overflow. If not, then it will be ignored.
-
ii.
Specific Truncation of Overflow Values. For all out-of-range positions, denoted as ( or ), the truncation operation is performed as follows:
(32) is a parameter to control the intensity of the truncation operation and the magnitude of the modification, which pursues a better trade-off between robustness and resistance to detection. Denote the processed spatial block as .
-
iii.
DCT and Quantization. Convert the processed spatial block to coefficients using DCT:
(33) Following the setting in section Section 4.1, we apply FIX() in the quantization phase as well.
(34) is the robust block after the removal of the spatial overflow.
4.4 Specific Truncation based Steganography: ROAST-ST
Specific Truncation is a de-overflow method with relatively smaller modifications compared to Overall Scale, but it also unavoidably weakens the performance of overflow removing. The steganographic scheme called ROAST-ST is designed to enhance the robustness by using robust asymmetric distortion. As shown in Figure 6, it consists of three parts: preprocessing, calculate robust asymmetric distortion, and STCs embedding. Each step of the scheme is described in detail below:
-
i.
Preprocessing. The preprocess is designed to enhance the stability of the DCT coefficients by removing the spatial overflow with Specific Truncation operations. When determining whether a block is overflowed or not, it is not as straightforward as before, but instead first calculates the extent of the overflow. Because the preprocessing always has a more significant impact on the image compared to the embedding process and an intuitive way to improve security is to make fewer changes. The overflow of a block is measured by , which is calculated as follow:
(35) Actually, it is the de-overflow operation rather than steganographic modification impacts on the security of the block. We therefore introduce to control whether or not the block is considered overflow. The block will be considered as overflow block if or not if . This way we can divide the blocks of cover into two groups: with overflow and without overflow. A de-overflow operation on yields and doesn’t do the processing, thus obtain a robust cover for steganography. While reducing the magnitude of the modification in the Specific Truncation, it also leads to the consequence that it is difficult to completely remove all spatial overflow with this method used only once. So we expect to remove spatial overflow further during embedding. A de-overflow operation on again yields and twice de-overflow operations on yields , thus obtain a reference cover with less overflow than robust cover. Making close to in the process of embedding modifications can enhance coefficient stability.
-
ii.
Define Robust Asymmetric Distortion. In the aforementioned preprocessing, not only a robust cover is prepared, but also a reference image is given for designing asymmetric distortion. Therefore we can combine the de-overflow into the process of message embedding. In detail, we employ the distortions and calculated by the Equation (11) and Equation (12) on the robust cover as the basic distortions. Denote the quantized DCT coefficient of the robust cover and the reference image as and , respectively. Robust asymmetric distortion is calculated as follows:
(36) (37) and are asymmetric distortion after performing robustness adjustment. is a parameter for adjusting distortion. This defines a smaller “+1” cost for locations where the coefficient of the reference image is larger than that of the robust cover and a smaller “-1” cost for locations where the coefficient of the reference image is less than that of the robust cover.
-
iii.
RS Encoding and Ternary STC Embedding. This part is the same as mentioned before.
The receiver extracts the message in the same way as Section 4.2, which is not repeated here.
5 Experiment
5.1 Setups
All experiments in this paper are conducted on BOSSbase 1.01 [32] containing 10,000 grayscale images. We randomly selected 2000 of them and the original images are JPEG compressed using quality factor 65 as the cover image. From Section 3 we know that the dither modulation based algorithm needs to choose a cover with a relatively low QF to achieve robustness. Therefore, we use 65 as an example in our experiments. The relative payload is , where is the length of the original embedded messages rather than the encoded messages by RS codes and is the number of non-zero AC DCT coefficients of the original cover image rather than the robust cover after de-overflow processing. Previous steganographic algorithms typically set the range of the relative payloads of robust adaptive steganography from to bits per non-zero AC DCT coefficients (bpnzac) due to their limited performance. We refer to such payloads as low payloads and perform experiments with high payload from to (bpnzac) in this paper. The extraction error rate , where is the number of wrong message bits. The QF of the cover image and channel JPEG compression is denoted as and , respectively. Two effective feature sets (CCPEV [26], DCTR [27]) and SRNet [28] are selected for steganalysis of JPEG image. We will set the secure parameter of STCs, and RS (31,15) will be adopted in the following experiments. As for (, ) RS codes, and denote the code length and message length respectively, and the greater the ratio of to , the stronger the error correction ability of RS codes.
The detectors are trained as binary classifiers implemented using the FLD ensemble with default settings [34]. The ensemble by default minimizes the total classification error probability under equal priors , where and are the false-alarm probability and the missed-detection probability respectively. SRNet is fed the cover and stego images. The training first runs for 300 epocks with an initial learning rate of and then for an additional 100 epochs with a learning rate of . A separate classifier and a deep network are trained for each embedding algorithm and payload. The ultimate security is qualified by average error rate , and larger means stronger security.
5.2 Investigation of the Preprocessing
The preprocessing improves the stability of the DCT coefficients by removing the spatial overflow of the cover image. It is an operation that has a relatively high impact on security and robustness therefore we use parameters to find a trade-off between them. Subsequently, we will explore these in detail through experiments.
5.2.1 Security of Preprocessing
Both methods of removing overflow in the preprocessing modify the original images. Although the final steganography process is performed on the modified images, the attacker is likely to use the original image for training in steganalysis. It generally seems to us that the original image should be more readily available. In contrast to [19], this paper proposes that the practical security of robust steganography should be evaluated by the original image before processing and the image after steganography.
The effect of the preprocessing process on steganography security is shown in Figure 7. The error detection rate in the figure is detected on the preprocessed image when the payload is 0. The horizontal coordinates are about the parameter in Specific Truncation which has no influence on the Overall Scale. From the experimental results, it can be seen that the preprocessing operation has a sharp decrease in anti-detection performance. The Specific Truncation has less decrease on the anti-detection ability than the Overall Scale method. Additionally, the change in the parameter has little influence on the anti-detection performance of ROAST-ST. The above consequences are consistent with expectations because of a large number of coefficients modified during preprocessing and there are relatively slight number of points modified as changes.
5.2.2 Effect of Preprocessing on Robustness

To demonstrate the improvement in the anti-compression capability of the preprocessing operation, we have compared the robustness of employing GMAS on images preprocessed by the Specific Truncation method () with that of employing GMAS directly on the original images. The experimental results presented in Figure 8 show that the preprocessing operation has a significant effect on improving the stability of the coefficient and the robustness of the algorithm. It can also be noted that combining the preprocessing with the GMAS algorithm can virtually make at low payloads, indicating that the preprocessing does make sense for improving robustness. It is clear from Figure 7 and Figure 8 that preprocessing can dramatically improve robustness at the sacrifice to security through extensive modifications. So we use and to make a trade-off. The effect of each parameter on the robustness is shown below.
5.2.3 Effect of Parameter on Robustness

In Section 5.2.1, we discovered that changes of in the preprocessing have an ignorable effect on the anti-detection performance because the additional modifications due to parameter variations are marginal. However, changes in can have a tangible effect on the robustness of the ROAST-ST as shown in Figure 9. As increases, the robustness of the ROAST-ST algorithm improves considerably, and when , it becomes more robust than the ROAST-OS algorithm. Utilization of can enhance robustness with little impact on security. This phenomenon suggests that the preprocessing of the algorithm is effective in conjunction with the robust asymmetric distortion design.
5.2.4 Effect of Parameter


The parameter is the threshold for determining whether preprocessing is performed. See Section 4.4 for details and Figure 10 for experimental results. Obviously, as increases, the number of modified blocks decreases, the robustness of the ROAST-ST algorithm decreases and the security increases. This confirms the previous statement and makes the algorithm more flexible to adjust security and robustness to achieve practical requirements.
5.3 Investigation of Robust Asymmetric Distortion
5.3.1 Effect of Robust Asymmetric Distortion on Robustness

In this section, we examine the effect of robust asymmetric distortion on robustness. This asymmetric distortion concept is analogous to the side information steganography [35], in which the side information is used to improve security, while this asymmetric distortion is used to improve robustness. Therefore, we adopt the image after the second de-overflow operation as the reference image. The exact calculation of distortion is described in detail by Section 4.4. The robustness of the ROAST-ST, which employs asymmetric distortion, varies with as shown in Figure 11. As the effect of asymmetric distortion increases with decreasing , the robustness of the ROAST-ST is considerably improved. The robustness of the ROAST-ST is comparable to that of the ROAST-OS at , and stronger robustness is obtained at a smaller . This means that the definition of robust asymmetric distortion indeed contributes to the robustness. Notably, the robust distortion adjustment only adjusts a relatively small amount of the distortion, so even if is chosen to be very small, the impact on security is also acceptable. This will be discussed in the next section.
5.3.2 Security of Robust Asymmetric Distortion

The above experiments demonstrate that the proposed asymmetric distortion can effectively improve robustness. To investigate the role of robust adjustment on security, we compare the security between the asymmetric distortion in GMAS and the robust asymmetric distortion proposed in this paper. The covers utilized here are all images processed by the Specific Truncation method (). The experimental results and concrete parameters are shown in Figure 12. Only images before and after steganography are used here for steganalysis experiments to avoid interference of preprocessing. As can be seen, robustness adjustments do cause a decrease in anti-detection performance. However, the difference of security is a trivially visible difference when using feature CCPEV for steganalysis, and even more trivial when using feature DCTR. An essential observation from previous experiments is that security and robustness cannot always be achieved perfectly at the same time. There will always be some sacrifices to security involved in improving robustness. Overall, the impact on security is still acceptable when applying parameters and asymmetric distortion to enhance robustness. This is the reason ROAST-ST has an advantage over ROAST-OS in terms of both security and robustness at lower payloads. The following is a detailed demonstration.
5.4 Comparison with the State-of-the-art Algorithms





In this section, we compare the proposed algorithms with state-of-the-art algorithms. First of all, in terms of applicability, the algorithm proposed by Tao et al. [23] only works in the scenario that the QF of channel compression is less than that of cover images (Downward Robust). TCM [19] works well only if the channel parameters are known or if the channel can be used at will. Therefore, we compare the proposed algorithms to GMAS [22] and DMAS [20] that have the same application environment. After that, we choose parameters for ROAST-ST that make it perform comparable to ROAST-OS according to the results of the previous experiment. The specific values are , , .
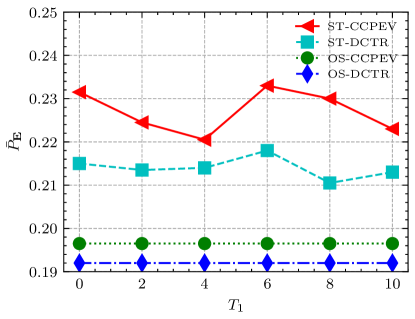
The comparison of robustness is shown in Figure 13 and the security is shown in Figure 14. In terms of robustness, except for with payloads near bpnzac, both algorithms proposed in this paper have significant advantages over the previous algorithms. Comparing robustness at and , we can obtain that as the recompression QF decreases, the robustness performance of the algorithm decreases. This is consistent with the inference in Section 3.1 regarding the recompression QF. In terms of security, it is also the proposed algorithms that have significant advantages, except when using CCPEV feature and the payload is near bpnzac. Representatively, average detection error rate is increased by +18% when utilizing DCTR features with bpnzac and +14% when utilizing CCPEV features with bpnzac. It is worth mentioning that both DMAS and GMAS almost fail to resist detection at when utilizing more powerful DCTR features, and the proposed algorithms are even more outstanding in this situation. We also compare the security when using the popular CNN-based steganalysis in Figure 15. The security of the proposed method is enhanced at low embedding rate compared with DMAS and GMAS. Average detection error rate is increased by +5% when utilizing SRNet with bpnzac. Overall ROAST-ST and ROAST-OS achieve notable robustness and security.
The two algorithms proposed in this paper have their strengths and weaknesses, due to the use of de-overflow operations and corresponding steganographic strategies. From Figure 14, roughly divided by , ROAST-ST has superiority in both robustness and security when the payload is small, and ROAST-OS has superiority in both when the payload is large. With smaller payloads, the security of the algorithm is substantially determined by the method of preprocessing, so this case can demonstrate the benefits of fewer preprocessing modifications and robust asymmetric distortions in ROAST-ST. When the payload is large, the modifications caused by embedding also progressively take effect, and therefore the strengths of fewer modifications in preprocessing operations are not so much, instead, the stable robustness of more preprocessing modifications and the security of distortion without robust adjustment will be exhibited. Consequently, both of these two algorithms are characterized by their properties.
6 Conclusions
Robust steganography is a research dedicated to the practical application of steganography. JPEG compression is the current primary processing operation for user-uploaded images in social networks, which is also the major focus of robust steganography research.
This paper explores the effect of JPEG recompression on the dither modulation algorithms by theoretical derivation based on DMAS and GMAS. Then we propose the critical steps required to implement effective upward robust steganography: the removal of spatial overflow. The advanced robust steganography algorithms are designed accordingly. The proposed algorithm enhances the stability of coefficients by eliminating overflow thus does not require the selection of a robust domain when embedding message and greatly improves robustness and security. This also enables a much higher embedding capacity than previous algorithms. Besides the concise steganography scheme ROAST-OS, we design a more practical scheme ROAST-ST by utilizing asymmetric distortion. ROAST-ST can improve the detection resistance by reasonably reducing the modification magnitude while ensuring robustness. Based on this, we discuss the dichotomy between robustness and security as well as how to make a trade-off or find a reasonable balance. Even though the algorithm in this paper has been significantly improved in performance compared to the previous algorithm, it is still necessary to reasonably adjust the performance for the practical scenario under the defined performance limits, which is why we have designed multiple parameters. In the future, we will improve the method to more realistic and complex scenarios.
Acknowledgment
The authors would like to thank DDE Laboratory of SUNY Binghamton for sharing the source code of steganography, steganalysis and ensemble classifier on the webpage (http://dde.binghamton.edu/download/).
References
- [1] L. Y. Zhang, Y. Zheng, J. Weng, C. Wang, Z. Shan, K. Ren, You can access but you cannot leak: defending against illegal content redistribution in encrypted cloud media center, IEEE Transactions on Dependable and Secure Computing (2018).
- [2] A. El-Atawy, Q. Duan, E. Al-Shaer, A novel class of robust covert channels using out-of-order packets, IEEE Transactions on Dependable and Secure Computing 14 (2) (2015) 116–129.
- [3] G. K. Wallace, The JPEG still picture compression standard, IEEE transactions on consumer electronics 38 (1) (1992) xviii–xxxiv.
- [4] W. Lu, Y. Xue, Y. Yeung, H. Liu, J. Huang, Y. Shi, Secure halftone image steganography based on pixel density transition, IEEE Transactions on Dependable and Secure Computing (2019).
- [5] Z. Qian, H. Zhou, X. Zhang, W. Zhang, Separable reversible data hiding in encrypted jpeg bitstreams, IEEE Transactions on Dependable and Secure Computing 15 (6) (2016) 1055–1067.
- [6] T. Filler, J. Judas, J. Fridrich, Minimizing additive distortion in steganography using syndrome-trellis codes, IEEE Transactions on Information Forensics and Security. 6 (3-2) (2011) 920–935.
- [7] V. Holub, J. J. Fridrich, T. Denemark, Universal distortion function for steganography in an arbitrary domain, EURASIP Journal of Information Security. 2014 (2014) 1.
- [8] L. Guo, J. Ni, W. Su, C. Tang, Y. Shi, Using statistical image model for JPEG steganography: Uniform embedding revisited, IEEE Transactions on Information Forensics and Security. 10 (12) (2015) 2669–2680.
- [9] Q. Wei, Z. Yin, Z. Wang, X. Zhang, Distortion function based on residual blocks for JPEG steganography, Multimedia Tools and Applications. 77 (14) (2018) 17875–17888.
- [10] X. Hu, J. Ni, Y. Shi, Efficient JPEG steganography using domain transformation of embedding entropy, IEEE Signal Processing Letters. 25 (6) (2018) 773–777.
- [11] W. Su, J. Ni, X. Li, Y. Shi, A new distortion function design for JPEG steganography using the generalized uniform embedding strategy, IEEE Transactions on Circuits Systems and Video Technology. 28 (12) (2018) 3545–3549.
- [12] R. Cogranne, Q. Giboulot, P. Bas, Steganography by minimizing statistical detectability: The cases of JPEG and color images., in: ACM Information Hiding and MultiMedia Security (IH&MMSec), 2020.
- [13] B. Li, S. Tan, M. Wang, J. Huang, Investigation on cost assignment in spatial image steganography, IEEE Transactions on Information Forensics and Security. 9 (8) (2014) 1264–1277.
- [14] W. Li, W. Zhang, K. Chen, W. Zhou, N. Yu, Defining joint distortion for JPEG steganography, in: R. Böhme, C. Pasquini, G. Boato, P. Schöttle (Eds.), Proceedings of the 6th ACM Workshop on Information Hiding and Multimedia Security, Innsbruck, Austria, June 20-22, 2018, ACM, 2018, pp. 5–16.
- [15] Y. Wang, W. Li, W. Zhang, X. Yu, K. Liu, N. Yu, BBC++: Enhanced block boundary continuity on defining non-additive distortion for jpeg steganography, IEEE Transactions on Circuits and Systems for Video Technology. (2020) 1–1.
- [16] Y. Wang, W. Zhang, W. Li, N. Yu, Non-additive cost functions for jpeg steganography based on block boundary maintenance, IEEE Transactions on Information Forensics and Security. (2020) 1–1.
- [17] C. Kin-Cleaves, A. D. Ker, Adaptive steganography in the noisy channel with dual-syndrome trellis codes, in: 2018 IEEE International Workshop on Information Forensics and Security (WIFS), IEEE, 2018, pp. 1–7.
- [18] W. Sun, J. Zhou, Y. Li, M. Cheung, J. She, Robust high-capacity watermarking over online social network shared images, IEEE Transactions on Circuits and Systems for Video Technology. (2020).
- [19] Z. Zhao, Q. Guan, H. Zhang, X. Zhao, Improving the robustness of adaptive steganographic algorithms based on transport channel matching, IEEE Transactions on Information Forensics and Security. 14 (7) (2019) 1843–1856.
- [20] Y. Zhang, X. Zhu, C. Qin, C. Yang, X. Luo, Dither modulation based adaptive steganography resisting jpeg compression and statistic detection, Multimedia Tools and Applications. 77 (14) (2018) 17913–17935.
- [21] Y. Zhang, X. Luo, C. Yang, D. Ye, F. Liu, A framework of adaptive steganography resisting JPEG compression and detection, Security and Communication Networks 9 (15) (2016) 2957–2971.
- [22] X. Yu, K. Chen, Y. Wang, W. Li, W. Zhang, N. Yu, Robust adaptive steganography based on generalized dither modulation and expanded embedding domain, Signal Processing. 168 (2020).
- [23] J. Tao, S. Li, X. Zhang, Z. Wang, Towards robust image steganography, IEEE Transaction on Circuits and Systems for Video Technology. 29 (2) (2019) 594–600.
- [24] W. Lu, J. Zhang, X. Zhao, W. Zhang, J. Huang, Secure robust jpeg steganography based on autoencoder with adaptive bch encoding, IEEE Transactions on Circuits and Systems for Video Technology (2020).
- [25] T. Pevný, J. J. Fridrich, Merging markov and DCT features for multi-class JPEG steganalysis, in: E. J. D. III, P. W. Wong (Eds.), Security, Steganography, and Watermarking of Multimedia Contents IX, San Jose, CA, USA, January 28, 2007, Vol. 6505 of SPIE Proceedings, SPIE, 2007, p. 650503.
- [26] J. Kodovský, J. J. Fridrich, Calibration revisited, in: E. W. Felten, J. Dittmann, J. J. Fridrich, S. Craver (Eds.), Multimedia and Security Workshop, MM&Sec 2009, Princeton, NJ, USA, September 07 - 08, 2009, ACM, 2009, pp. 63–74.
- [27] V. Holub, J. J. Fridrich, Low-complexity features for JPEG steganalysis using undecimated DCT, IEEE Transactions on Information Forensics and Security. 10 (2) (2015) 219–228.
- [28] M. Boroumand, M. Chen, J. Fridrich, Deep residual network for steganalysis of digital images, IEEE Transactions on Information Forensics and Security 14 (5) (2018) 1181–1193.
- [29] B. Chen, G. W. Wornell, Quantization index modulation: A class of provably good methods for digital watermarking and information embedding, IEEE Transactions on Information theory 47 (4) (2001) 1423–1443.
- [30] A. Miyazaki, A. Okamoto, Analysis of watermarking systems in the frequency domain and its application to design of robust watermarking systems, in: IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2001, 7-11 May, 2001, Salt Palace Convention Center, Salt Lake City, Utah, USA, Proceedings, IEEE, 2001, pp. 1969–1972.
- [31] W. Zhang, X. Zhang, S. Wang, A double layered ”plus-minus one” data embedding scheme, IEEE Signal Processing Letters. 14 (11) (2007) 848–851.
- [32] P. Bas, T. Filler, T. Pevný, ”break our steganographic system”: The ins and outs of organizing BOSS, in: T. Filler, T. Pevný, S. Craver, A. D. Ker (Eds.), Information Hiding - 13th International Conference, IH 2011, Prague, Czech Republic, May 18-20, 2011, Revised Selected Papers, Vol. 6958 of Lecture Notes in Computer Science, Springer, 2011, pp. 59–70.
- [33] W. Luo, J. Huang, G. Qiu, JPEG error analysis and its applications to digital image forensics, IEEE Transactions on Information Forensics and Security 5 (3) (2010) 480–491.
- [34] J. Kodovský, J. J. Fridrich, V. Holub, Ensemble classifiers for steganalysis of digital media, IEEE Transactions on Information Forensics and Security. 7 (2) (2012) 432–444.
- [35] W. Li, K. Chen, W. Zhang, H. Zhou, Y. Wang, N. Yu, JPEG steganography with estimated side-information, IEEE Transactions on Circuits and Systems for Video Technology (2019).
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76160438-3db2-403d-81d4-5f8972adf595/x21.png) |
Kai Zeng received his B.S. degree in 2019 from the University of Science and Technology of China (USTC). Currently, he is pursuing the M.S. degree with Key Laboratory of Electromagnetic Space Information, School of Information Science and Technology, University of Science and Technology of China, Hefei. His research interests include information hiding and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76160438-3db2-403d-81d4-5f8972adf595/x22.png) |
Kejiang Chen received his B.S. degree in 2015 from Shanghai University (SHU) and a Ph.D. degree in 2020 from the University of Science and Technology of China (USTC). Currently, he is a postdoctoral researcher at the University of Science and Technology of China. His research interests include information hiding, image processing and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76160438-3db2-403d-81d4-5f8972adf595/x23.png) |
Weiming Zhang received his M.S. degree and Ph.D. degree in 2002 and 2005, respectively, from the Zhengzhou Information Science and Technology Institute, P.R. China. Currently, he is a professor with the School of Information Science and Technology, University of Science and Technology of China. His research interests include information hiding and multimedia security. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76160438-3db2-403d-81d4-5f8972adf595/x24.png) |
Yaofei Wang received the B.S. degree from the School of Physical Science and Technology, Southwest Jiaotong University, in 2017. He is currently pursuing the Ph.D. degree in information security with the University of Science and Technology of China. His research interests include information hiding, image processing, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/76160438-3db2-403d-81d4-5f8972adf595/x25.png) |
Nenghai Yu received his B.S. degree in 1987 from Nanjing University of Posts and Telecommunications, an M.E. degree in 1992 from Tsinghua University and a Ph.D. degree in 2004 from the University of Science and Technology of China, where he is currently a professor. His research interests include multimedia security, multimedia information retrieval, video processing and information hiding. |