Improving Distinction between ASR Errors and Speech Disfluencies with Feature Space Interpolation
Abstract
Fine-tuning pretrained language models (LMs) is a popular approach to automatic speech recognition (ASR) error detection during post-processing. While error detection systems often take advantage of statistical language archetypes captured by LMs, at times the pretrained knowledge can hinder error detection performance. For instance, presence of speech disfluencies might confuse the post-processing system into tagging disfluent but accurate transcriptions as ASR errors. Such confusion occurs because both error detection and disfluency detection tasks attempt to identify tokens at statistically unlikely positions. This paper proposes a scheme to improve existing LM-based ASR error detection systems, both in terms of detection scores and resilience to such distracting auxiliary tasks. Our approach adopts the popular mixup method in text feature space and can be utilized with any black-box ASR output. To demonstrate the effectiveness of our method, we conduct post-processing experiments with both traditional and end-to-end ASR systems (both for English and Korean languages) with 5 different speech corpora. We find that our method improves both ASR error detection scores and reduces the number of correctly transcribed disfluencies wrongly detected as ASR errors. Finally, we suggest methods to utilize resulting LMs directly in semi-supervised ASR training.
Index Terms: disfluency detection, error detection, post-processing
1 Introduction
Post-processing is the final auditor of an automatic speech recognition (ASR) system before its output is presented to consumers or downstream tasks. Two notable tasks often entrusted to the post-processing step are ASR error detection [1, 2, 3] and speech disfluency detection [4, 5, 6].
A recent trend in post-processing is to fine-tune pretrained transformer-based language models (LMs) such as BERT [7] or GPT-2 [8] for designated tasks. Utilizing language patterns captured by huge neural networks during their unsupervised pretraining yields considerable advantages in downstream language tasks [9, 10, 11]. When using pretrained LMs, both ASR error correction and speech disfluency detection tasks employ a similar setup, where the LM is further fine-tuned with task-specific data and label, often in a sequence-labeling scheme [12, 13]. Disfluency in speech, by definition, consists of sequence of tokens unlikely to appear together. ASR errors are statistically likely to introduce tokens heavily out of context. Both descriptions resemble the pretraining objective of LMs, which is to learn a language's statistical landscape.
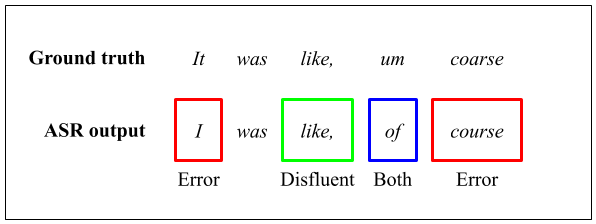
From such observation, a natural question follows: in a situation where objectives of two post-processing tasks are mutually exclusive (but both attune to the LM pretraining objective), will utilizing a pretrained LM benefit a single task? Such concerns arise especially in production settings, where customer orations tend to contain significantly more disfluencies than in audio found in academic benchmarks. This situation is illustrated in Figure 1. In the figure, ASR output of disfluent speech (ASR output) is compared with its reference transcript (Ground truth). Words like and um in the reference are annotated as disfluent. The post-processing system must only detect ASR errors (red and blue), while refraining from detecting merely disfluent speech (green) as ASR errors.
This paper proposes a regularization scheme that improves ASR error detection performance by weakening an LM’s propensity to tag accurate transcriptions of disfluent speech as ASR errors. Our method is applied during the LM fine-tuning stage. Resulting LMs have been applied as drop-in replacements in existing ASR error correction systems in production.
Furthermore, LM artifacts from our method can be utilized beyond post-prcessing. Recent advancements in semi-supervised ASR training take advantage of deep LMs to create pseudo-labels for unlabeled audio [14, 15]. To ensure the quality of synthetic labels, [14] uses an LM during beam-search decoding; [15] filters created labels by length-normalized language model scores. In both cases, an LM robust to speech disfluencies is essential in improving transcription accuracy.
2 Related work
2.1 ASR post-processing
Post-processing is a task that complements ASR systems by analyzing their output. Compared to tasks involved in directly manipulating components within the ASR system, the black-box approach of ASR post-processing yields several advantages. It is often intractable for the LM inside an ASR system to account for and rank all hypothesis presented by the acoustic model [ogrodniczuk_proceedings_2020]. A post-processing system is free from such constraints within an ASR system [1]. ASR post-processing also helps improve performance in downstream tasks [16] as well as in domain adaptation flexibility [17].
2.1.1 ASR error detection
One common approach to ASR error detection is through machine translation. Machine translation approaches in error detection commonly interpret error detection as a sequence-to-sequence task, and construct a system to translate erroneous transcriptions to correct sentences [3, 11, 18]. [3] suggests a method applicable to off-the-shelf ASR systems. [11] and [18] translates acoustic model outputs directly to grammatical text.
In some domains, however, necessity of huge parallel training data can render translation-based error detection infeasible [19]. Another popular approach models ASR error detection as a sequence labeling problem. This approach requires much less training samples compared to sequence-to-sequence systems. Both [9] and [tanaka_neural_nodate] use a large, pretrained deep LM to gauge the likeliness of each output token from an ASR system.
2.1.2 Speech disfluency detection
The aim of a disfluency detection task is to separate well-formed sentences from its unnatural counterparts. Disfluencies in speech include deviant language, such as hesitation, repetition, correction, and false starts [5]. Speech disfluencies display regularities that can be detected with statistical systems [4]. While various suggestions such as semi-supervised [6] and self-supervised [20, 21] approaches were proposed, supervised training on pretrained LM remains state-of-the-art [10, 12]. Both [10] and [12] fine-tunes deep LMs for sequence tagging.
2.2 Data interpolation for regularization
Interpolating existing data for data augmentation is a popular method for regularization. The mixup method suggested in [22] has been particularly effective, especially in the computer vision domain [23, 24, 25]. Given dataset consisting of (data, label) pairs, mixup “mixes” two random training samples and to generate a new training sample :
| (1) |
| (2) |
where
is a hyperparameter for the mixup operation that characterizes the Beta distribution to randomly sample from.
[26] suggests manifold mixup to utilize mixup in the feature space after the data has been passed through a vectorizing layer, such as a deep neural network (DNN). Whereas mixup explicitly generates new data by interpolating existing samples in the data space, manifold mixup adds a regularization layer to an existing architecture that mixes data in its vectorized form. In essence, mixup and its variants discourage a model from making extreme decisions. A hidden space visualization in [26] shows that correct targets and non-correct targets are better separated within the mixup model because it learns to handle intermediate values instead of making wild guesses in face of uncertainty.
Because text is both ordered and discrete, mixup with text data is best applied at feature space. Magnitudes of each token id in a tokenized text sequence does not convey any relative meaning; whereas in an image, varying the degrees of continuous pixel values does gradually manipulate its properties.
While mixup is yet to be widely studied in speech-to-text or natural language processing domains, several studies have found success in applying the method to text data. [27] constructs a new token sequence by randomly selecting a token from two different sequences at each index. [28] suggests applying mixup in feature space, after an intermediary layer of a pretrained LM. New input data is then generated by reversing the synthetic feature to find the most similar token in the vocabulary. While these two works involve interpolating text inputs, our method differs significantly in that we do not directly generate augmented training samples; instead, we utilize mixup as a regularizing layer during the training process. Our method also does not require reversing word-embeddings or discriminative filtering using GPT-2 introduced in [28].
[29], a work most similar to ours, applies manifold mixup on text data to calibrate a model to work best on out-of-distribution data. However, the study focuses on sentence-level classification, which requires a substantially different feature extraction strategy from the work in this paper. Our paper suggests a token-level mixup method, and aims to gauge the impact of single task (ASR error detection) regularization on an auxiliary task (speech disfluency detection).
3 Methodology
3.1 BERT for sequence tagging
To utilize BERT for a sequence labeling problem, a token classification head (TCH) must be added after BERT’s final layer. There is no restriction on what constitutes a TCH. In [12], for example, a combination of conditional random field and a fully connected network was attached to BERT’s output as a TCH. In our study, a simple fully-connected layer with the same number of inputs and outputs as the original input token sequence suffices as a TCH because our aim is to measure the effectiveness of regularization that takes place between BERT and the TCH. We modify a reference BERT implementation [30] with a TCH.
A single data sample during the supervised training stage consists of input token sequence , and a sequence of labels for each token, . Each corresponding label has a value of 1 if the token contains a character with erroneous ASR output, and 0 if the token contains no wrong character. All input sequences are tokenized into subword tokens [31] before entering BERT. For the rest of this paper, boldfaced letters denote vectors.
3.2 Feature space interpolation
Our proposed method adds a regularizing layer between BERT’s output and the token classification head. BERT produces a hidden state sequence , with length equal to that of input token sequence :
| (3) |
From we obtain , a randomly permuted version of . Each corresponding label in is also rearranged accordingly, creating a new label vector . The same index-wise shuffle applied to applies to , such that each label originally assigned to an input token follows the new index for that value during the shuffling process:
where
Next, we apply the mixup process element-wise to and , according to equation (1) and (2):
| (4) |
Similarly, we also mix the original label vector with its permuted counterpart :
| (5) |
Where . This process “softens” the originally binary labels into range .

For the mixup hyperparameter , we empirically chose value a of . Figure 3 shows the experimentally observed relationship between and the normalized counts of the fine-tuned system erroneously tagging disfluent speech as ASR errors.
is propagated to the token classification head, whose prediction loss is calculated using binary cross entropy against , instead of the original ground truth label .

4 Experiments
4.1 Experiment setup
To obtain ASR outputs on which to perform error detection, we process multiple speech corpora through black box ASR systems. Detailed descriptions of datasets used is provided in the next section. Within the decoded transcript, we tag subword token indices that contain ASR errors to be used as labels during the post-processing fine-tuning. We also tag indices in the transcription with speech disfluencies. To demonstrate the effectiveness of our method across various off-the-shelf ASR environments, we transcribe all available speech corpora with both a traditional ASR system and an end-to-end (E2E) ASR system. For English corpora, we utilize a pretrained LibriSpeech Kaldi [32] model (factorized time-delay neural networks-based chain model) for the traditional system, and a reference wav2letter++ (w2l++) [33] system for the E2E system. For Korean corpora, we use the same respective architectures trained from scratch on internal data.
To create error-labeled decoded transcripts, each decoded transcript is compared with corresponding ground truth reference transcription. We use the Wagner-Fischer algorithm [34] to build a shortest-distance edit matrix from the decoded transcript to its reference transcription. Traversing the edit matrix from the lowest, rightmost column to the highest, leftmost column yields a sequence of delete, replace, and insert instructions to convert the decoded transcript into the reference transcript. Each character instructed to be deleted and replaced in the decoded transcript is marked as ASR errors.
Disfluency labels in reference transcripts must be transferred over to corresponding positions within the decoded transcripts. Since the introduction of ASR errors causes the decoder transcripts to be mere approximations of its ground truth transcripts, mapping each character index from the reference transcript to the decoded transcript is not rigorously a defined process. Here we again utilize the Wagner-Fischer algorithm, mapping only the character indices in the decoded transcript without any edit instructions to their corresponding indices in the reference transcript.
We judge the effectiveness of our regularization method by two criteria: how much it helps in error detection (Error detection ), and how much it reduces the number of accurately transcribed disfluent speech tagged as errors (Disfluencies wrongly tagged).
4.2 Desciption of datasets
We tested our proposed methodology on five different speech datasets (4 English, 1 Korean). All speech corpora were provided with reference transcripts hand-annotated with speech disfluency positions.
4.2.1 SCOTUS
4.2.2 CallHome
4.2.3 AMI Meeting Corpus (AMI)
The AMI Meeting Corpus [37] contains recordings of multiple-speaker meetings on a wide range of subjects. Multiple types of crowd-sourced annotations are available, including speech disfluencies, body gestures, and named entities.
4.2.4 ICSI Meeting Corpus (ICSI)
The ICSI Meeting Corpus [38] is a collection of multi-person meeting recordings. The ICSI Meeting corpus provides the highest count of disfluency-annotated transcripts out of the five corpora used in this paper.
4.2.5 KsponSpeech (Kspon)
KsponSpeech [39] is a collection of spontaneous Korean speech. The corpora is a recording of sub-10 seconds of spontaneous Korean speech. Each recording is labeled with disfluencies and mispronunciations.
| Corpus | Training samples | Token level error rate | ||
|---|---|---|---|---|
| E2E | Traditional | E2E | Traditional | |
| SCOTUS | ||||
| CallHome | ||||
| AMI | ||||
| ICSI | ||||
| Kspon | ||||
ASR output for each corpus was randomly split into 8:1:1 train:validation:test splits. Table 1 describes the characteristics of ASR outputs with which we fine-tune BERT. Training samples denote the number of sub-word tokenized sequences obtained from each ASR output. Token level error rate shows the rate at which subword tokens contain errors in transcription. This latter statistic is purely concerned with processing ASR outputs, and thus conveys a slightly different meaning than conventional ASR error metrics, such as character error rates. Most importantly, words missing in ASR outputs (compared to ground-truth transcriptions) is not tallied in Table 1’s token level error rate. This omission was introduced on purpose, because at inference time our model is not expected to introduce new edits but merely tag each subword token as correct or incorrect.
Number of training examples obtained from a single corpus transcribed with English E2E ASR differs from the number of training examples obtained from the same corpus transcribed with English traditional ASR. This discrepancy stems from the utilized E2E system’s tendency to refrain from transcribing words with low confidence. Since the purpose of this study is to demonstrate the effectiveness of our proposed regularization method in various ASR post-processing setups, the discrepancy in the number of training examples from different ASR systems was generated on purpose.
4.3 Results
Results of applying our proposed method is presented Table 2. Corpus names in the first column are each marked with the name of ASR system used for transcription. The second and third columns of table 3 show error detection scores with and without applying proposed regularization, respectively. The fourth and fifth columns report the number of correctly transcribed disfluencies wrongly tagged as ASR errors.
The proposed regularization in this paper shows greater influence as the number of training data increases (AMI and ICSI). One surprising outcome is the unchanging scores on the CallHome corpus. Analysis of the corpus and high scores in error detection indicate the uniform scores are a result of distinct patterns in ASR errors during transcription; the fine-tuned LM in every setting learns to confidently and consistently pick out only certain tokens as ASR errors.
| Corpus | Error detection | Disf. wrongly tagged | ||
|---|---|---|---|---|
| Mixup | No mixup | Mixup | No mixup | |
| SCOTUS (w2l++) | ||||
| SCOTUS (Kaldi) | ||||
| CallHome (w2l++) | ||||
| CallHome (Kaldi) | ||||
| AMI (w2l++) | ||||
| AMI (Kaldi) | ||||
| ICSI (w2l++) | ||||
| ICSI (Kaldi) | ||||
| Kspon (w2l++) | ||||
| Kspon (Kaldi) | ||||
5 Conclusion
The discrete nature of textual data has stifled adaptation of mixup in natural language processing and speech-to-text domains. In this study we propose a way to effectively apply mixup to improve post-processing error detection.
We extensively demonstrate the effect of our proposed approach on various speech corpora. Impact of feature-space mixup is especially pronounced in high resource settings. The proposed regularization layer is also computationally inexpensive and can be easily retrofitted to existing systems as a simple module. While we chose the popular BERT LM for our experiments, our method can be applied to fine-tuning any deep LM in a sequence tagging setting. We also highlighted potential uses of resulting LMs in semi-supervised ASR training as pseudo-label filters. Testing the effectiveness of this approach in other sequence-level tasks is left to further research.
References
- [1] M. Feld, S. Momtazi, F. Freigang, D. Klakow, and C. Müller, “Mobile texting: can post-asr correction solve the issues? an experimental study on gain vs. costs,” in Proceedings of the 2012 ACM international conference on Intelligent User Interfaces, 2012, pp. 37–40.
- [2] M. Ogrodniczuk, Ł. Kobyliński, and P. A. N. I. P. Informatyki, Proceedings of the PolEval 2020 Workshop. Institute of Computer Science. Polish Academy of Sciences, 2020. [Online]. Available: https://books.google.co.kkjkkr/books?id=grRSzgEACAAJ
- [3] A. Mani, S. Palaskar, N. V. Meripo, S. Konam, and F. Metze, “ASR Error Correction and Domain Adaptation Using Machine Translation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6344–6348.
- [4] E. E. Shriberg, “Preliminaries to a theory of speech disfluencies,” PhD Thesis, Citeseer, 1994.
- [5] E. Salesky, S. Burger, J. Niehues, and A. Waibel, “Towards fluent translations from disfluent speech,” in 2018 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2018, pp. 921–926.
- [6] F. Wang, W. Chen, Z. Yang, Q. Dong, S. Xu, and B. Xu, “Semi-supervised disfluency detection,” in Proceedings of the 27th International Conference on Computational Linguistics, 2018, pp. 3529–3538.
- [7] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019, pp. 4171–4186.
- [8] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- [9] Y. Weng, S. S. Miryala, C. Khatri, R. Wang, H. Zheng, P. Molino, M. Namazifar, A. Papangelis, H. Williams, F. Bell, and others, “Joint Contextual Modeling for ASR Correction and Language Understanding,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6349–6353.
- [10] N. Bach and F. Huang, “Noisy BiLSTM-Based Models for Disfluency Detection.” in INTERSPEECH, 2019, pp. 4230–4234.
- [11] O. Hrinchuk, M. Popova, and B. Ginsburg, “Correction of Automatic Speech Recognition with Transformer Sequence-To-Sequence Model,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7074–7078.
- [12] D. Lee, B. Ko, M. C. Shin, T. Whang, D. Lee, E. H. Kim, E. Kim, and J. Jo, “Auxiliary Sequence Labeling Tasks for Disfluency Detection,” arXiv preprint arXiv:2011.04512, 2020.
- [13] T. Tanaka, R. Masumura, H. Masataki, and Y. Aono, “Neural error corrective language models for automatic speech recognition,” in INTERSPEECH, 2018.
- [14] D. S. Park, Y. Zhang, Y. Jia, W. Han, C.-C. Chiu, B. Li, Y. Wu, and Q. V. Le, “Improved noisy student training for automatic speech recognition,” arXiv preprint arXiv:2005.09629, 2020.
- [15] W.-N. Hsu, A. Lee, G. Synnaeve, and A. Hannun, “Semi-supervised speech recognition via local prior matching,” arXiv preprint arXiv:2002.10336, 2020.
- [16] L. Wang, M. Fazel-Zarandi, A. Tiwari, S. Matsoukas, and L. Polymenakos, “Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors,” arXiv preprint arXiv:2006.05635, 2020.
- [17] C. Anantaram and S. K. Kopparapu, “Adapting general-purpose speech recognition engine output for domain-specific natural language question answering,” arXiv preprint arXiv:1710.06923, 2017.
- [18] A. Mani, S. Palaskar, and S. Konam, “Towards Understanding ASR Error Correction for Medical Conversations,” ACL 2020, p. 7, 2020.
- [19] M. Popel and O. Bojar, “Training tips for the transformer model,” The Prague Bulletin of Mathematical Linguistics, vol. 110, no. 1, pp. 43–70, 2018, publisher: Sciendo.
- [20] S. Wang, W. Che, Q. Liu, P. Qin, T. Liu, and W. Y. Wang, “Multi-task self-supervised learning for disfluency detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, 2020, pp. 9193–9200, issue: 05.
- [21] S. Wang, Z. Wang, W. Che, and T. Liu, “Combining Self-Training and Self-Supervised Learning for Unsupervised Disfluency Detection,” arXiv preprint arXiv:2010.15360, 2020.
- [22] H. Zhang, M. Cisse, Y. N. Dauphin, and D. Lopez-Paz, “mixup: Beyond Empirical Risk Minimization,” in International Conference on Learning Representations, 2018.
- [23] T. He, Z. Zhang, H. Zhang, Z. Zhang, J. Xie, and M. Li, “Bag of tricks for image classification with convolutional neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 558–567.
- [24] D. Berthelot, N. Carlini, I. Goodfellow, N. Papernot, A. Oliver, and C. Raffel, “Mixmatch: A holistic approach to semi-supervised learning,” arXiv preprint arXiv:1905.02249, 2019.
- [25] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint arXiv:2004.10934, 2020.
- [26] V. Verma, A. Lamb, C. Beckham, A. Najafi, I. Mitliagkas, D. Lopez-Paz, and Y. Bengio, “Manifold mixup: Better representations by interpolating hidden states,” in International Conference on Machine Learning. PMLR, 2019, pp. 6438–6447.
- [27] D. Guo, Y. Kim, and A. M. Rush, “Sequence-level Mixed Sample Data Augmentation,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 5547–5552.
- [28] R. Zhang, Y. Yu, and C. Zhang, “SeqMix: Augmenting Active Sequence Labeling via Sequence Mixup,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 8566–8579.
- [29] L. Kong, H. Jiang, Y. Zhuang, J. Lyu, T. Zhao, and C. Zhang, “Calibrated Language Model Fine-Tuning for In- and Out-of-Distribution Data,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Online: Association for Computational Linguistics, Nov. 2020, pp. 1326–1340. [Online]. Available: https://www.aclweb.org/anthology/2020.emnlp-main.102
- [30] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, and others, “HuggingFace’s Transformers: State-of-the-art Natural Language Processing,” ArXiv, pp. arXiv–1910, 2019.
- [31] R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words with subword units,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pp. 1715–1725.
- [32] D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y. Qian, P. Schwarz, J. Silovsky, G. Stemmer, and K. Vesely, “The Kaldi Speech Recognition Toolkit,” in IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. IEEE Signal Processing Society, Dec. 2011, event-place: Hilton Waikoloa Village, Big Island, Hawaii, US.
- [33] V. Pratap, A. Hannun, Q. Xu, J. Cai, J. Kahn, G. Synnaeve, V. Liptchinsky, and R. Collobert, “wav2letter++: The fastest open-source speech recognition system. arxiv 2018,” arXiv preprint arXiv:1812.07625.
- [34] G. Navarro, “A guided tour to approximate string matching,” ACM computing surveys (CSUR), vol. 33, no. 1, pp. 31–88, 2001, publisher: ACM New York, NY, USA.
- [35] V. Zayats, M. Ostendorf, and H. Hajishirzi, “Multi-domain disfluency and repair detection,” in Fifteenth Annual Conference of the International Speech Communication Association, 2014.
- [36] Linguistic Data Consortium, CABank CallHome English Corpus. TalkBank, 2013. [Online]. Available: http://ca.talkbank.org/access/CallHome/eng.html
- [37] I. McCowan, J. Carletta, W. Kraaij, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V. Karaiskos et al., “The ami meeting corpus,” in Proceedings of Measuring Behavior 2005, 5th International Conference on Methods and Techniques in Behavioral Research. Noldus Information Technology, 2005, pp. 137–140.
- [38] A. Janin, D. Baron, J. Edwards, D. Ellis, D. Gelbart, N. Morgan, B. Peskin, T. Pfau, E. Shriberg, A. Stolcke, and C. Wooters, “The ICSI meeting corpus,” 2003, pp. I–364.
- [39] J.-U. Bang, S. Yun, S.-H. Kim, M.-Y. Choi, M.-K. Lee, Y.-J. Kim, D.-H. Kim, J. Park, Y.-J. Lee, and S.-H. Kim, “KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition,” Applied Sciences, vol. 10, no. 19, 2020. [Online]. Available: https://www.mdpi.com/2076-3417/10/19/6936