Improved Analysis and Rates for Variance Reduction under Without-replacement Sampling Orders
Abstract
When applying a stochastic algorithm, one must choose an order to draw samples. The practical choices are without-replacement sampling orders, which are empirically faster and more cache-friendly than uniform-iid-sampling but often have inferior theoretical guarantees. Without-replacement sampling is well understood only for SGD without variance reduction. In this paper, we will improve the convergence analysis and rates of variance reduction under without-replacement sampling orders for composite finite-sum minimization.
Our results are in two-folds. First, we develop a damped variant of Finito called Prox-DFinito and establish its convergence rates with random reshuffling, cyclic sampling, and shuffling-once, under both convex and strongly convex scenarios. These rates match full-batch gradient descent and are state-of-the-art compared to the existing results for without-replacement sampling with variance-reduction. Second, our analysis can gauge how the cyclic order will influence the rate of cyclic sampling and, thus, allows us to derive the optimal fixed ordering. In the highly data-heterogeneous scenario, Prox-DFinito with optimal cyclic sampling can attain a sample-size-independent convergence rate, which, to our knowledge, is the first result that can match with uniform-iid-sampling with variance reduction. We also propose a practical method to discover the optimal cyclic ordering numerically.
1 Introduction
We study the finite-sum composite optimization problem
| (1) |
where each is differentiable and convex, and the regularization function is convex but not necessarily differentiable. This formulation arises in many problems in machine learning [34, 39, 14], distributed optimization [20, 3, 19], and signal processing [4, 9].
| Algorithm | Supp. Prox | Sampling | Asmp⋄ | Convex | Strongly Convex |
| Prox-GD | Yes | Full-batch | |||
| SGD [22] | No | Cyclic | |||
| SGD [22] | No | RR | |||
| PSGD [21] | Yes | RR | |||
| PIAG [35] | Yes | Cyclic/RR | |||
| AVRG [37] | No | RR | |||
| SAGA [33] | Yes | Cyclic | |||
| SVRG [33] | Yes | Cyclic | |||
| DIAG [23] | No | Cyclic | |||
| Cyc. Cord. Upd [5] | Yes | Cyclic/RR | |||
| SVRG [18]♣ | No | Cyclic/RR | |||
| SVRG [18]♣ | No | RR | |||
| SVRG [18]♣ | No | RR | |||
| Prox-DFinito (Ours) | Yes | RR | |||
| Prox-DFinito (Ours) | Yes | worst cyc. order | |||
| Prox-DFinito (Ours) | Yes | best cyc. order | |||
| ⋄ The “Assumption” column indicates the scope of smoothness and strong convexity, where means | |||||
| smoothness and strong convexity in the average sense and assumes smoothness and strong convexity | |||||
| for each summand function. | |||||
| ♣[18] is an independent and concurrent work. | |||||
| † This complexity is attained under big data regime: . | |||||
| ‡ This complexity can be attained in a highly heterogeneous scenario, see details in Sec 4.2. | |||||
The leading methods to solve (1) are first-order algorithms such as stochastic gradient descent (SGD) [28, 2] and stochastic variance-reduced methods [14, 6, 7, 17, 10, 32]. In the implementation of these methods, each can be sampled either with or without replacement. Without-replacement sampling draws each exactly once during an epoch, which is numerically faster than with-replacement sampling and more cache-friendly; see the experiments in [1, 38, 11, 7, 37, 5]. This has triggered significant interests in understanding the theory behind without-replacement sampling.
Among the most popular without-replacement approaches are cyclic sampling, random reshuffling, and shuffling-once. Cyclic sampling draws the samples in a cyclic order. Random reshuffling reorders the samples at the beginning of each sample epoch. The third approach, however, shuffles data only once before the training begins. Without-replacement sampling have been extensively studied for SGD. It was established in [1, 38, 11, 22, 24] that without-replacement sampling enables SGD with faster convergence For example, it was proved that without-replacement sampling can speed up uniform-iid-sampling SGD from to (where is the iteration) for strongly-convex costs in [11, 12], and to for the convex costs in [24, 22]. [31] establishes a tight lower bound for random reshuffling SGD. Recent works [27, 22] close the gap between upper and lower bounds. Authors of [22] also analyzes without-replacement SGD with non-convex costs.
In contrast to the mature results in SGD, variance-reduction under without-replacement sampling are less understood. Variance reduction strategies construct stochastic gradient estimators with vanishing gradient variance, which allows for much larger learning rate and hence speed up training process. Variance reduction under without-replacement sampling is difficult to analyze. In the strongly convex scenario, [37, 33] provide linear convergence guarantees for SVRG/SAGA with random reshuffling, but the rates are worse than full-batch gradient descent (GD). Authors of [35, 23] improved the rate so that it can match with GD. In convex scenario, existing rates for without-replacement sampling with variance reduction, except for the rate established in an independent and concurrent work [18], are still far worse than GD [33, 5], see Table 1. Furthermore, no existing rates for variance reduction under without-replacement sampling orders, in either convex or strongly convex scenarios, can match those under uniform-iid-sampling which are essentially sample-size independent. There is a clear gap between the known convergence rates and superior practical performance for without-replacement sampling with variance reduction.
1.1 Main results
This paper narrows such gap by providing convergence analysis and rates for proximal DFinito, a proximal damped variant of Finito/MISO [7, 17, 26], which is a well-known variance reduction algorithm, under without-replacement sampling orders. Our main achieved results are:
-
•
We develop a proximal damped variant of Finito/MISO called Prox-DFinito and establish its gradient complexities with random reshuffling, cyclic sampling, and shuffling-once, under both convex and strongly convex scenarios. All these rates match with gradient descent, and are state-of-the-art (up to logarithm factors) compared to existing results for without-replacement sampling with variance-reduction, see Table 1.
-
•
Our novel analysis can gauge how a cyclic order will influence the rate of Prox-DFinito with cyclic sampling. This allows us to identify the optimal cyclic sampling ordering. Prox-DFinito with optimal cyclic sampling, in the highly data-heterogeneous scenario, can attain a sample-size-independent convergence rate, which is the first result, to our knowledge, that can match with uniform-iid-sampling with variance reduction in certain scenarios. We also propose a numerical method to discover the optimal cyclic ordering cheaply.
1.2 Other related works
Our analysis on cyclic sampling is novel. Most existing analyses unify random reshuffling and cyclic sampling into the same framework; see the SGD analysis in [11], the variance-reduction analysis in [10, 36, 23, 37], and the coordinate-update analysis in [5]. These analyses are primarily based on the “sampled-once-per-epoch” property and do not analyze the orders within each epoch, so they do not distinguish cyclic sampling from random reshuffling in analysis. [16] finds that random reshuffling SGD is basically the average over all cyclic sampling trials. This implies cyclic sampling can outperform random reshuffling with a well-designed sampling order. However, [16] does not discuss how much better cyclic sampling can outperform random reshuffling and how to achieve such cyclic order. Different from existing literatures, our analysis introduces an order-specific norm to gauge how cyclic sampling performs with different fixed orders. With such norm, we are able to clarify the worst-case and best-case performance of variance reduction with cyclic sampling.
Simultaneously and independently, a recent work [18] also provided an improved rates for variance reduction under without-replacement sampling orders that can match with gradient descent. However, [18] does not discuss whether and when variance reduction with replacement sampling can match with uniform sampling. In addition, [18] studies SVRG while this paper studies Finito/MISO. The convergence analyses in these two works are very different. The detailed comparison between this work and [18] can be referred to Sec. 3.3.
1.3 Notations
Throughout the paper we let denote a column vector formed by stacking . We let and define the proximal operator as
| (2) |
which is single-valued when is convex, closed and proper. In general, we say is an operator and write if maps each point in space to another space . So for all . For simplicity, we write and for operator composition.
Cyclic sampling. We define as an arbitrary determined permutation of sample indexes. The order is fixed throughout the entire learning process under cyclic sampling.
Random reshuffling. When starting each epoch, a random permutation is generated to specify the order to take samples. Let denote the permutation of the -th epoch.
2 Proximal Finito/MISO with Damping
The proximal gradient method to solve problem (1) is
| (3a) | ||||
| (3b) | ||||
To avoid the global average that passes over all samples, we propose to update one per iteration:
| (4c) | ||||
| (4d) | ||||
When is invoked with uniform-iid-sampling and , algorithm (4c)–(4d) reduces to Finito/MISO [7, 17]. When is invoked with cyclic sampling and , algorithm (4c)–(4d) reduces to DIAG [23] and WPG [19]. We let . The update (4c) yields
| (5) |
This update can be finished with operations if are stored with memory. Furthermore, to increase robustness and simplify the convergence analysis, we impose a damping step to and when each epoch finishes. The proximal damped Finito/MISO method is listed in Algorithm 1. Note that the damping step does not incur additional memory requirements. A more practical implementation of Algorithm 1 is referred to Algorithm 3 in Appendix A.
2.1 Fixed-point recursion reformulation
Algorithm (4c)–(4d) can be reformulated into a fixed-point recursion in . Such a fixed-point recursion will be utilized throughout the paper. To proceed, we define and introduce the average operator as . We further define the -th block coordinate operator as
where denotes the identity mapping. When applying , it is noted that the -th block coordinate in is updated while the others remain unchanged.
Proposition 1.
Prox-DFinito with fixed cyclic sampling order is equivalent to the following fixed-point recursion (see proof in Appendix B.1.)
| (6) |
where . Furthermore, variable can be recovered by
| (7) |
Similar result also hold for random reshuffling scenario.
Proposition 2.
Prox-DFinito with random reshuffling is equivalent to
| (8) |
where . Furthermore, variable can be recovered by following (7).
2.2 Optimality condition
Assume there exists that minimizes , i.e., . Then the relation between the minimizer and the fixed-point of recursion (6) and (8) can be characterized as:
Proposition 3.
minimizes if and only if there is so that (proof in Appendix B.2)
| (9) | ||||
| (10) |
2.3 An order-specific norm
To gauge the influence of different sampling orders, we now introduce an order-specific norm.
Definition 1.
Given and a fixed cyclic order , we define
as the -specific norm.
For two different cyclic orders and , it generally holds that . Note that the coefficients in are delicately designed for technical reasons (see Lemma 1 and its proof in the appendix). The order-specific norm facilitates the performance comparison between two orderings.
3 Convergence Analysis
In this section we establish the convergence rate of Prox-DFinito with cyclic sampling and random reshuffling in convex and strongly convex scenarios, respectively.
3.1 The convex scenario
We first study the convex scenario under the following assumption:
Assumption 1 (Convex).
Each function is convex and -smooth.
It is worth noting that the convergence results on cyclic sampling and random reshuffling for the convex scenario are quite limited except for [22, 33, 5, 18].
Cyclic sampling and shuffling-once. We first introduce the following lemma showing that is non-expansive with respect to , which is fundamental to the convergence analysis.
Lemma 1.
Recall (6) that the sequence is generated through . Since and is non-expansive, we can prove the distance will converge to sublinearly:
Lemma 2.
Under Assumption 1, if step-size and the data is sampled with a fixed cyclic order , it holds for any that (see proof in Appendix
| (12) |
where is the damping parameter.
Theorem 1.
Remark 2.
Random reshuffling. We let denote the sampling order used in the -th epoch. Apparently, is a uniformly distributed random variable with realizations. With the similar analysis technique, we can also establish the convergence rate under random reshuffling in the expectation sense.
Theorem 2.
3.2 The strongly convex scenario
In this subsection, we study the convergence rate of Prox-DFinito under the following assumption:
Assumption 2 (Strongly Convex).
Each function is -strongly convex and -smooth.
Theorem 3.
Remark 3.
Note when , Prox-DFinito actually reaches the best performance, so damping is essentially not necessary in strongly convex scenario.
3.3 Comparison with the existing results
Recalling , it holds that
| (17) |
For a fair comparison with existing works, we consider the worst case performance of cyclic sampling by relaxing to its upper bound . Letting , and assuming , the convergence rates derived in Theorems 1–3 reduce to
| C-Cyclic | |||
| SC-Cyclic |
where “C” denotes “convex” and “SC” denotes “strongly convex”, , and hides the factor. Note that all rates are in the epoch-wise sense. These rates can be translated into the the gradient complexity (equivalent to sample complexity) of Prox-DFinito to reach an -accurate solution. The comparison with existing works are listed in Table 1.
Different metrics. Except for [5] and our Prox-DFinito algorithm whose convergence analyses are based on the gradient norm in the convex and smooth scenario, results in other references are based on function value metric (i.e., objective error ). The function value metric can imply the gradient norm metric, but not always vice versa. To comapre Prox-DFinito with other established results in the same metric, we have to transform the rates in other references into the gradient norm metric. The comparison is listed in Table 1. When the gradient norm metric is used, we observe that the rates of Prox-DFinito match that with gradient descent, and are state-of-the-art compared to the existing results. However, the rate of Prox-DFinito in terms of the function value is not known yet (this unknown rate may end up being worse than those of the other methods).
For the non-smooth scenario, our metric may not be bounded by the functional suboptimality , and hence Prox-DFinito results are not comparable with those in [21, 35, 37, 33, 18]. The results listed in Table 1 are all for the smooth scenario of [21, 35, 37, 33, 18], and we use “Support Prox” to indicate whether the results cover the non-smooth scenario or not.
Assumption scope. Except for references [18, 35] and Proximal GD algorithm whose convergence analyses are conducted by assuming the average of each function to be -smooth (and perhaps -strongly convex), results in other references are based on a stronger assumption that each summand function to be -smooth (and perhaps -strongly convex). Note that can be much smaller than sometimes. To compare [18, 35] and Proximal GD with other references under the same assumption, we let each in Table 1. However, it is worth noting that when each is drastically different from each other and can be evaluated precisely, the results relying on (e.g., [35] and [18]) can be much better than the results established in this work.
Comparison with GD. It is observed from Table 1 that Prox-DFinito with cyclic sampling or random reshuffling is no-worse than Proximal GD. It is the first no-worse-than-GD result, besides the independent and concurrent work [18], that covers both the non-smooth and the convex scenarios for variance-reduction methods under without-replacement sampling orders. The pioneering work DIAG [23] established a similar result only for smooth and strongly-convex problems111While DIAG is established to outperform gradient descent in [23], we find its convergence rate is still on the same order of GD. Its superiority to GD comes from the constant improvement, not order improvement..
Comparison with RR/CS methods. Prox-DFinito achieves the nearly state-of-the-art gradient complexity in both convex and strongly convex scenarios (except for the convex and smooth case due to the weaker metric adopted) among known without-replacement stochastic approaches to solving the finite-sum optimization problem (1), see Table 1. In addition, it is worth noting that in Table 1, algorithms of [33, 35, 23] and our Prox-DFinito have an memory requirement while others only need memory. In other words, Prox-DFinito is memory-costly in spite of its superior theoretical convergence rate and sample complexity.
Comparison with uniform-iid-sampling methods. It is known that uniform-sampling variance-reduction can achieve an sample complexity for strongly convex problems [14, 26, 6] and (when using metric ) for convex problems [26]. In other words, these uniform-sampling methods have sample complexities that are independent of sample size . Our achieved results (and other existing results listed in Table 1 and [18]) for random reshuffling or worst-case cyclic sampling cannot match with uniform-sampling yet. However, this paper establishes that Prox-DFinito with the optimal cyclic order, in the highly data-heterogeneous scenario, can achieve an sample complexity in the convex scenario, which matches with uniform-sampling up to a factor, see the detailed discussion in Sec. 4. To our best knowledge, it is the first result, at least in certain scenarios, that variance reduction under without-replacement sampling orders can match with its uniform-sampling counterpart in terms of their sample complexity upper bound. Nevertheless, it still remains unclear how to close the gap in sample complexity between variance reduction under without-replacement sampling and uniform sampling in the more general settings (i.e., settings other than highly data-heterogeneous scenario).
4 Optimal Cyclic Sampling Order
Sec.3.3 examines the worst case gradient complexity of Prox-DFinito with cyclic sampling, which is worse than random reshuffling by a factor of in both convex and strongly convex scenarios. In this section we examine how Prox-DFinito performs with optimal cyclic sampling.
4.1 Optimal cyclic sampling
Given sample size , step-size , epoch index , and constants , and , it is derived from Theorem 1 that the rate of -order cyclic sampling is determined by constant
| (18) |
We define the corresponding optimal cyclic order as follows.
Definition 2.
An optimal cyclic sampling order of Prox-DFinito is defined as
| (19) |
Such an optimal cyclic order can be identified as follows (see proof in Appendix F).
Proposition 4.
The optimal cyclic order for Prox-DFinito is the reverse order of .
Remark 4 (Importance indicator).
Proposition 4 implies that can be used as an importance indicator of sample . Recall from Remark 1. If is initialized as , the importance indicator of sample reduces to , which is determined by both and . If is initialized close to , we then have . In other words, the importance of sample can be measured by , which is consistent with the importance indicator in uniform-iid-sampling [41, 40].
4.2 Optimal cyclic sampling can achieve sample-size-independent complexity
Recall from Theorem 1 that the sample complexity of Prox-DFinito with cyclic sampling in the convex scenario is determined by . From (17) we have
| (20) |
In Sec. 3.3 we considered the worst case performance of cyclic sampling, i.e., we bound with its upper bound . In this section, we will examine the best case performance using the lower bound , and provide a scenario in which such best case performance is achievable. We assume as in previous sections.
Proposition 5.
Given fixed constants , , , , , and optimal cyclic order , if the condition
| (21) |
holds, then Prox-DFinito with optimal cyclic sampling achieves sample complexity .
The above proposition can be proved by directly substituting (21) into Theorem 1. In the following, we discuss a data-heterogeneous scenario in which relation (21) holds.
A data-heterogeneous scenario. To this end, we let and , it follows from Remark 1 that . If we set (which is common in the implementation) and (the theoretically suggested step-size), it then holds that . Next, we assume () holds. Under such assumption, the optimal cyclic order will be . Now we examine and :
when is large, which implies that since is a constant independent of . With Proposition 5, we know Prox-DFinito with optimal cyclic sampling can achieve , which is independent of sample size . Note that implies a data-heterogeneous scenario where can roughly gauge the variety of data samples.
4.3 Adaptive importance reshuffling
The optimal cyclic order decided by Proposition 4 is not practical since the importance indicator of each sample depends on the unknown . This problem can be overcome by replacing by its estimate , which leads to an adaptive importance reshuffling strategy.
We introduce as an importance indicating vector with each element indicating the importance of sample and initialized as In the -th epoch, we draw sample earlier if is larger. After the -th epoch, will be updated as
| (22) |
where and is a fixed damping parameter. Suppose , the above recursion will guarantee . In other words, the order decided by will gradually adapt to the optimal cyclic order as increases. Since the order decided by importance changes from epoch to epoch, we call this approach adaptive importance reshuffling and list it in Algorithm 2. We provide the convergence guarantees of the adaptive importance reshuffling method in Appendix G.
5 Numerical Experiments
5.1 Comparison with SVRG and SAGA under without-replacement sampling orders
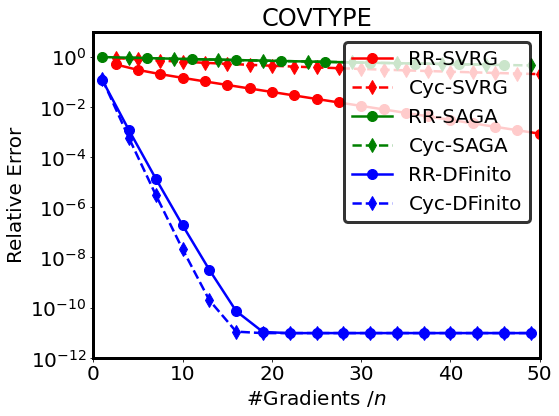
In this experiment, we compare DFinito with SVRG [14] and SAGA [7] under without-replacement sampling (RR, cyclic sampling). We consider a similar setting as in [18, Figure 2], where all step sizes are chosen as the theoretically optimal one, see Table 2 in Appendix H. We run experiments for the regularized logistic regression problem, i.e. problem (1) with with three widely-used datasets: CIFAR-10 [15], MNIST [8], and COVTYPE [29]. This problem is -smooth and -strongly convex with and . From Figure 1, it is observed that DFinito outperforms SVRG and SAGA in terms of gradient complexity under without-replacement sampling orders with their best-known theoretical rates. The comparison with SVRG and SAGA with the practically optimal step sizes is in Appendix J.


5.2 DFinito with cyclic sampling
Justification of the optimal cyclic sampling order. To justify the optimal cyclic sampling order suggested in Proposition 4, we test DFinito with eight arbitrarily-selected cyclic orders, and compare them with the optimal cyclic ordering as well as the adaptive importance reshuffling method (Algorithm 2). To make the comparison distinguishable, we construct a least square problem with heterogeneous data samples with , , , (see Appendix I for the constructed problem). The constructed problem is with when , , and , which is close to . In the left plot in Fig. 2, it is observed that the optimal cyclic sampling achieves the fastest convergence rate. Furthermore, the adaptive shuffling method can match with the optimal cyclic ordering. These observations are consistent with our theoretical results derived in Sec. 4.2 and 4.3.


Optimal cyclic sampling can achieve sample-size-independent complexity. It is established in [26] that Finito with uniform-iid-sampling can achieve -independent gradient complexity with . In this experiment, we compare DFinito () with Finito under uniform sampling (8 runs, ) in a convex and highly heterogeneous scenario (). The constructed problem is with , , , and , (see detailed initialization in Appendix J). We also depict DFinito with random-reshuffling (8 runs) as another baseline. In the right plot of Figure 2, it is observed that the convergence curve of DFinito with -cyclic sampling matches with Finito with uniform sampling. This implies DFinito can achieve the same -independent gradient complexity as Finito with uniform sampling.
5.3 More experiments
We conduct more experiments in Appendix J. First, we compare DFinito with GD/SGD to justify its empirical superiority to these methods. Second, we validate how different data heterogeneity will influence optimal cyclic sampling. Third, we examine the performance of SVRG, SAGA, and DFinito under without/with-replacement sampling using grid-search (not theoretical) step sizes.
6 Conclusion and Discussion
This paper develops Prox-DFinito and analyzes its convergence rate under without-replacement sampling in both convex and strongly convex scenarios. Our derived rates are state-of-the-art compared to existing results. In particular, this paper derives the best-case convergence rate for Prox-DFinito with cyclic sampling, which can be sample-size-independent in the highly data-heterogeneous scenario. A future direction is to close the gap in gradient complexity between variance reduction under without-replacement and uniform-iid-sampling in the more general setting.
References
- [1] L. Bottou. Curiously fast convergence of some stochastic gradient descent algorithms. In Proceedings of the symposium on learning and data science, Paris, volume 8, pages 2624–2633, 2009.
- [2] L. Bottou, F. E. Curtis, and J. Nocedal. Optimization methods for large-scale machine learning. Siam Review, 60(2):223–311, 2018.
- [3] S. Boyd, N. Parikh, and E. Chu. Distributed optimization and statistical learning via the alternating direction method of multipliers. Now Publishers Inc, 2011.
- [4] S. S. Chen, D. L. Donoho, and M. A. Saunders. Atomic decomposition by basis pursuit. SIAM review, 43(1):129–159, 2001.
- [5] Y. T. Chow, T. Wu, and W. Yin. Cyclic coordinate-update algorithms for fixed-point problems: Analysis and applications. SIAM Journal on Scientific Computing, 39(4):A1280–A1300, 2017.
- [6] A. Defazio, F. Bach, and S. Lacoste-Julien. SAGA: A fast incremental gradient method with support for non-strongly convex composite objectives. arXiv preprint arXiv:1407.0202, 2014.
- [7] A. Defazio, J. Domke, et al. Finito: A faster, permutable incremental gradient method for big data problems. In International Conference on Machine Learning, pages 1125–1133. PMLR, 2014.
- [8] L. Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- [9] D. L. Donoho. Compressed sensing. IEEE Transactions on information theory, 52(4):1289–1306, 2006.
- [10] M. Gurbuzbalaban, A. Ozdaglar, and P. A. Parrilo. On the convergence rate of incremental aggregated gradient algorithms. SIAM Journal on Optimization, 27(2):1035–1048, 2017.
- [11] M. Gurbuzbalaban, A. Ozdaglar, and P. A. Parrilo. Why random reshuffling beats stochastic gradient descent. Mathematical Programming, pages 1–36, 2019.
- [12] J. Haochen and S. Sra. Random shuffling beats sgd after finite epochs. In International Conference on Machine Learning, pages 2624–2633. PMLR, 2019.
- [13] X. Huang, E. K. Ryu, and W. Yin. Tight coefficients of averaged operators via scaled relative graph. Journal of Mathematical Analysis and Applications, 490(1):124211, 2020.
- [14] R. Johnson and T. Zhang. Accelerating stochastic gradient descent using predictive variance reduction. Advances in neural information processing systems, 26:315–323, 2013.
- [15] A. Krizhevsky. Learning multiple layers of features from tiny images. 2009.
- [16] S. Ma and Y. Zhou. Understanding the impact of model incoherence on convergence of incremental sgd with random reshuffle. In International Conference on Machine Learning, pages 6565–6574. PMLR, 2020.
- [17] J. Mairal. Incremental majorization-minimization optimization with application to large-scale machine learning. SIAM Journal on Optimization, 25(2):829–855, 2015.
- [18] G. Malinovsky, A. Sailanbayev, and P. Richtárik. Random reshuffling with variance reduction: New analysis and better rates. arXiv preprint arXiv:2104.09342, 2021.
- [19] X. Mao, Y. Gu, and W. Yin. Walk proximal gradient: An energy-efficient algorithm for consensus optimization. IEEE Internet of Things Journal, 6(2):2048–2060, 2018.
- [20] G. Mateos, J. A. Bazerque, and G. B. Giannakis. Distributed sparse linear regression. IEEE Transactions on Signal Processing, 58(10):5262–5276, 2010.
- [21] K. Mishchenko, A. Khaled, and P. Richtárik. Proximal and federated random reshuffling. arXiv preprint arXiv:2102.06704, 2021.
- [22] K. Mishchenko, A. Khaled Ragab Bayoumi, and P. Richtárik. Random reshuffling: Simple analysis with vast improvements. Advances in Neural Information Processing Systems, 33, 2020.
- [23] A. Mokhtari, M. Gurbuzbalaban, and A. Ribeiro. Surpassing gradient descent provably: A cyclic incremental method with linear convergence rate. SIAM Journal on Optimization, 28(2):1420–1447, 2018.
- [24] D. Nagaraj, P. Jain, and P. Netrapalli. Sgd without replacement: Sharper rates for general smooth convex functions. In International Conference on Machine Learning, pages 4703–4711. PMLR, 2019.
- [25] Y. Park and E. K. Ryu. Linear convergence of cyclic saga. Optimization Letters, 14(6):1583–1598, 2020.
- [26] X. Qian, A. Sailanbayev, K. Mishchenko, and P. Richtárik. Miso is making a comeback with better proofs and rates. arXiv preprint arXiv:1906.01474, 2019.
- [27] S. Rajput, A. Gupta, and D. Papailiopoulos. Closing the convergence gap of sgd without replacement. In International Conference on Machine Learning, pages 7964–7973. PMLR, 2020.
- [28] H. Robbins and S. Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400–407, 1951.
- [29] R. A. Rossi and N. K. Ahmed. The network data repository with interactive graph analytics and visualization. In AAAI, 2015.
- [30] E. K. Ryu, R. Hannah, and W. Yin. Scaled relative graph: Nonexpansive operators via 2d euclidean geometry. arXiv: Optimization and Control, 2019.
- [31] I. Safran and O. Shamir. How good is sgd with random shuffling? In Conference on Learning Theory, pages 3250–3284. PMLR, 2020.
- [32] M. Schmidt, N. Le Roux, and F. Bach. Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 162(1-2):83–112, 2017.
- [33] T. Sun, Y. Sun, D. Li, and Q. Liao. General proximal incremental aggregated gradient algorithms: Better and novel results under general scheme. Advances in Neural Information Processing Systems, 32:996–1006, 2019.
- [34] R. Tibshirani. Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological), 58(1):267–288, 1996.
- [35] N. D. Vanli, M. Gürbüzbalaban, and A. Ozdaglar. A stronger convergence result on the proximal incremental aggregated gradient method. arXiv: Optimization and Control, 2016.
- [36] N. D. Vanli, M. Gurbuzbalaban, and A. Ozdaglar. Global convergence rate of proximal incremental aggregated gradient methods. SIAM Journal on Optimization, 28(2):1282–1300, 2018.
- [37] B. Ying, K. Yuan, and A. H. Sayed. Variance-reduced stochastic learning under random reshuffling. IEEE Transactions on Signal Processing, 68:1390–1408, 2020.
- [38] B. Ying, K. Yuan, S. Vlaski, and A. H. Sayed. Stochastic learning under random reshuffling with constant step-sizes. IEEE Transactions on Signal Processing, 67(2):474–489, 2018.
- [39] H.-F. Yu, F.-L. Huang, and C.-J. Lin. Dual coordinate descent methods for logistic regression and maximum entropy models. Machine Learning, 85(1-2):41–75, 2011.
- [40] K. Yuan, B. Ying, S. Vlaski, and A. Sayed. Stochastic gradient descent with finite samples sizes. 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), pages 1–6, 2016.
- [41] P. Zhao and T. Zhang. Stochastic optimization with importance sampling for regularized loss minimization. In international conference on machine learning, pages 1–9. PMLR, 2015.
Appendix
Appendix A Efficient Implementation of Prox-Finito
Appendix B Operator’s Form
B.1 Proof of Proposition 1
B.2 Proof of Proposition 3
Appendix C Cyclic–Convex
C.1 Proof of Lemma 1
Proof.
Without loss of generality, we only prove the case in which where .
To ease the notation, for , we define -norm as
| (28) |
Note when .
C.2 Proof of Lemma 2
Proof.
We define to ease the notation. Then by Proposition 1. To prove Lemma 2, notice that
| (33) |
The above relation implies that is non-increasing. Next,
| (34) |
where equality (c) holds because Proposition 3 implies .
Summing the above inequality from to we have
| (35) |
Since is non-increasing, we reach the conclusion. ∎
C.3 Proof of Theorem 1
Proof.
Since for , it holds that
| (36) |
which further implies that
| (37) |
Next we bound the two terms on the right hand side of (40) by . For the second term, it is easy to see
| (41) |
where inequality (d) is due to Cauchy’s inequality with , and inequality (e) holds because .
For the first term, we first note for ,
| (42) |
By (29), we have
| (43) |
In the last inequality, we used the algebraic inequality that . Therefore we have
| (44) |
Appendix D RR–Convex
D.1 Non-expansiveness Lemma for RR
While replacing order-specific norm with standard norm. the following lemma establishes that is non-expansive in expectation.
Lemma 3.
Under Assumption 1, if step-size and data is sampled with random reshuffling, it holds that
| (46) |
It is worth noting that inequality (46) holds for -norm rather than the order-specific norm due to the randomness brought by random reshuffling.
Proof.
Given any vector with positive elements where denotes the -th element of , define -norm as follows
| (47) |
for any . Following arguments in (30), it holds that
| (48) |
where and is the -th unit vector. Define
| (49) |
where , then we can summarize the above conclusion as follows.
Lemma 4.
Given with positive elements and its corresponding -norm, under Assumption 1, if step-size , it holds that
| (50) |
Therefore, with Lemma 4, we have that
| (51) |
With the above relation, if we can prove
| (52) |
then we can complete the proof by
| (53) |
D.2 Proof of Theorem 2
Proof.
In fact, with similar arguments of Appendix C.2 and noting for any realization of , we can achieve
Lemma 5.
Under Assumption 1, if step-size and the data is sampled with random reshuffling, it holds for any that
| (56) |
Based on Lemma (5), we are now able to prove Theorem 2. By arguments similar to Appendix C.3, such that
| (57) |
The second term on the right-hand-side of (57) can be bounded as
| (58) |
Therefore we have
| (61) |
In the last inequality, we use the algebraic inequality that .
Appendix E Proof of Theorem 3
Proof.
Before proving Theorem 3, we establish the epoch operator and are contractive in the following sense:
Lemma 6.
Proof of Lemma 6.
For -order cyclic sampling, without loss of generality, it suffices to show the case of . To begin with, we first check the operator . Suppose ,
| (65) |
where -norm in the first equality is defined as (28) with and inequality (f) holds because
| (66) |
where the last inequality holds when . Furthermore, the inequality (E) also implies that
| (67) |
where denotes the -th block coordinate.
Combining (E) and (E), we reach
| (68) |
where . With (68) and the following fact
| (69) |
we have
| (70) |
where the last inequality holds because .
With (E), we finally reach
| (71) |
In other words, the operator is a contraction with respect to the -norm. Recall that , we have
| (72) |
As to random reshuffling, we use a similar arguments while replacing by . With similar arguments to (68), we reach that
| (73) |
for any with positive elements, where -norm follows (47) and follows (49). Furthermore, it follows direct induction that , and we have
| (74) |
Therefore, with the fact that
| (75) |
it holds that
| (76) | ||||
Remark 5.
One can taking expectation over cyclic order in 16 to obtain the convergence rate of Prox-DFinito shuffled once before training begins
where .
Appendix F Optimal Cyclic Order
Proof.
We sort all and denote the index of the -th largest term as . The optimal cyclic order can be represented by Indeed, due to sorting inequality, it holds for any arbitrary fixed order that ∎
Appendix G Adaptive importance reshuffling
Proposition 6.
Suppose converges to and are distinct, then there exists such that
where and .
Proof.
Since converges to , we have converges to . Let , then there exists such that , it holds that and hence the order of are the same as for all . Further more by the same argument as Appendix D.2, we reach the conclusion. ∎
Appendix H Best known guaranteed step sizes of variance reduction methods under without-replacement sampling
Appendix I Existence of highly heterogeneous instance
Proposition 7.
Given sample size , strong convexity , smoothness parameter , step size and initialization , there exist such that is -strongly convex and -smooth with fixed-point satisfying .
Proof.
Let , we show that one can obtain a desired instance by letting and choosing proper , .
First we generate a positive number and vectors . Let . Then we generate such that , , which assures are -strongly convex and -smooth.
After that we solve , . Note these exist as long as we choose . Therefore we have by our definition of .
Since , then by letting , it holds that
| (82) |
and hence we know , i.e., is a global minimizer.
Appendix J More experiments
DFinito vs SGD vs GD. In this experiment, we compare DFinito with full-bath gradient descent (GD) and SGD under RR and cyclic sampling (which is analyzed in [22]). We consider the regularized logistic regression task with MNIST dataset (see Sec. 5.1). In addition, we manipulate the regularized term to achieve cost functions with different condition numbers. Each algorithm under RR is averaged across 8 independent runs. We choose optimal constant step sizes for each algorithm using the grid search.



In Fig. 3, it is observed that SGD under without-replacement sampling works, but it will get trapped to a neighborhood around the solution and cannot converge exactly. In contrast, DFinito will converge to the optimum. It is also observed that DFinito can outperform GD in all three scenarios, and the superiority can be significant for certain condition numbers. While this paper establishes that the DFinito under without-replacement sampling shares the same theoretical gradient complexity as GD (see Table 1), the empirical results in Fig. 3 imply that DFinito under without-replacement sampling may be endowed with a better (though unknown) theoretical gradient complexity than GD. We will leave it as a future work.
Influence of various data heterogeneity on optimal cyclic sampling. According to Proposition 5, the performance of DFinito with optimal cyclic sampling is highly influenced by the data heterogeneity. In a highly data-heterogeneous scenario, the ratio . In a data-homogeneous scenario, however, it holds that . In this experiment, we examine how DFinito with optimal cyclic sampling converges with varying data heterogeneity. To this end, we construct an example in which the data heterogeneity can be manipulated artificially and quantitatively. Consider a problem in which each and . Moreover, we generate according to the uniform Gaussian distribution. We choose and in the experiment, generate with each element following distribution , and initialize , otherwise . Since and , we have . It then holds that is unchanged across different . On the other hand, since , we have . Apparently, ratio ranges from to as increases from to . For this reason, we can manipulate the data heterogeneity by simply adjusting . We also depict DFinito with random-reshuffling (8 runs’ average) as a baseline. Figure 4 illustrates that the superiority of optimal cyclic sampling vanishes gradually as the data heterogeneity decreases.



Comparison with empirically optimal step sizes. Complementary to Sec. 5.1, we also run experiments to compare variance reduction methods under uniform sampling (US) and random reshuffling (RR) with empirically optimal step sizes by grid search, in which full gradient is computed once per two epochs for SVRG. We run experiments for regularized logistic regression task with CIFAR-10 (), MNIST () and COVTYPE (), where is the condition number. All algorithms are averaged through 8 independent runs.



From Figure 5, it is observed that all three variance reduced algorithms achieve better performance under RR, and DFinito outperforms SAGA and SVRG under both random reshuffling and uniform sampling. While this paper and all other existing results listed in Table 1 (including [18]) establish that the variance reduced methods with random reshuffling have worse theoretical gradient complexities than uniform-iid-sampling, the empirical results in Fig. 5 imply that variance reduced methods with random reshuffling may be endowed with a better (though unknown) theoretical gradient complexity than uniform-sampling. We will leave it as a future work.