Impact of classification difficulty on the weight matrices spectra in Deep Learning and application to early-stopping
Abstract
Much research effort has been devoted to explaining the success of deep learning. Random Matrix Theory (RMT) provides an emerging way to this end: spectral analysis of large random matrices involved in a trained deep neural network (DNN) such as weight matrices or Hessian matrices with respect to the stochastic gradient descent algorithm. To have more comprehensive understanding of weight matrices spectra, we conduct extensive experiments on weight matrices in different modules, e.g., layers, networks and data sets. Following the previous work of Martin and Mahoney (2021), we classify the spectra in the terminal stage into three main types: Light Tail (LT), Bulk Transition period (BT) and Heavy Tail(HT). These different types, especially HT, implicitly indicate some regularization in the DNNs. A main contribution from the paper is that we identify the difficulty of the classification problem as a driving factor for the appearance of heavy tail in weight matrices spectra. Higher the classification difficulty, higher the chance for HT to appear. Moreover, the classification difficulty can be affected by the signal-to-noise ratio of the dataset, or by the complexity of the classification problem (complex features, large number of classes) as well. Leveraging on this finding, we further propose a spectral criterion to detect the appearance of heavy tails and use it to early stop the training process without testing data. Such early stopped DNNs have the merit of avoiding overfitting and unnecessary extra training while preserving a much comparable generalization ability. These findings from the paper are validated in several NNs, using Gaussian synthetic data and real data sets (MNIST and CIFAR10).
Keywords: Deep Learning, Weight matrices, Heavy tailed spectrum, Early stopping
1 Introduction
In the past decade, deep learning (LeCun et al., 2015) has achieved impressive success in numerous areas. Much research effort has since been concentrated on providing a rational explanation of the success. The task is difficult, particularly because the training of most successful deep neural networks (DNNs) relies on a collection of expert choices that determine the final structure of the DNNs. These expert choices include nonlinear activation, hidden layer architecture, loss function, back propagation algorithm and canonical datasets. Unfortunately, these empirical choices usually bring nonlinearity into the model, and nonconvexity of optimization into the training process. As a matter of consequence, practitioners of deep learning are facing certain lack of general guidelines about the “right choices” to design and train an effective DNN for their own machine learning problem.
To make progress on the understanding of existing trained and successful DNNs, it is important to explore their properties in some principled way. To this end, a popular way has recently emerged in the literature, namely spectral analysis of various large characteristic random matrices of the DNNs, such as the Hessian matrices of the back-propagation algorithm, weight matrices between different layers, and covariance matrices of output features. Actually, such spectral analysis helps to gain insights into the behavior of DNNs, and many researchers believe that these spectral properties, once better understood, will provide clues to improvements in deep learning training (Dauphin et al., 2014; Papyan, 2019b, a; Sagun et al., 2017; Yao et al., 2020; Granziol, 2020; Pennington and Worah, 2019; Ge et al., 2021). Recently, Martin and Mahoney (2021) studied the empirical spectra distributions (ESD) of weight matrices in different neural networks, and observed a “Phase Transition 5+1” phenomenon in these ESDs. Interestingly, the phenomenon highlights signatures of traditionally regularized statistical models even though there is no set-up of any traditional regularization in the DNNs. Here, traditional regularization refers to the minimization of an explicitly defined and penalized loss function of the form with some tuning parameter ( denotes all the parameters in the DNN). However, those well-known expert choices such as early stopping also produces a regularization effect in DNNs, and this is the reason why such expert choices are recommended for practitioners. Actually, Kukacka et al. (2017) presented about 50 different regularization techniques which may improve DNN’s generalization. Among them, batch normalization, early stopping, dropout, and weight decay are a few commonly used ones.
A main finding from Martin and Mahoney (2021) is that the effects of these regularization practices can be identified through the spectra of different weight matrices of a DNN. Moreover, the forms of these spectra in the “5+1 phase transition” help assess the existence of some regularization in the DNN. For instance, if these spectra are far away from the Marčenko-Pastur (MP) law, or the largest eigenvalue departs from the Tracy-Widom (TW) Law (see in AppendixA), there is strong evidence for the onset of more regular structures in the weight matrices. A connection between implicit regularization in a DNN and the forms of the spectra of its weight matrices is thus established. Particularly, they considered the evolution of weight matrices spectra during the training process of a DNN from its start to its final stage (usually 200-400 epochs), and pointed out that in the late stage of the training, the deviation between the spectra and MP Law (namely the emergence of Heavy Tail) indicates some regularization technique which will improve the generalization error in some way. Indeed, the emergence of Heavy Tail is due to the complex correlations which are generated from such regularization technique. Some theoretical analysis of Heavy Tail is proposed to illustrate such correlations. Recently, Gurbuzbalaban et al. (2021) pointed out that SGD can bring out heavy tails in linear regression settings, Hodgkinson and Mahoney (2021) prove the phenomenon under a more generalized case.
A generally accepted definition of the concept of Regularization in a DNN refers to any supplementary mechanism that aims at making the model generalize better (see in Kukacka et al. (2017)). In the next work from Martin et al. (2021), they claimed that the “Heavy Tail based metrics can do much better—quantitatively better at discriminating among series of well-trained models with a given architecture; and qualitatively better at discriminating well-trained versus poorly trained models.” An important issue we notice from spectral analysis is HT plays a more significant role for guiding the practice of Deep Learning . In our synthetic data experiments, an interesting phenomenon is that HT emerges when the training data quality is low. Unlike the factors proposed by Hodgkinson and Mahoney (2021) such as increasing the step size/decreasing the batch size or increasing regularization to achieve Heavy Tail, we emphasize a special factor that affect the emergence of Heavy Tail–classification difficulty in data sets. More difficult to classify, higher possibility HT appears. We say the factor is specical in the reason that it includes two different cases when HT appears. One case is the poor data quality, the emergence of HT indicates an attempt for DNNs to extract more features and increase testing accuracy. Another case is modern data sets with complex features and hard for the information extraction, the emergence of HT indicates an attempt for DNNs to identify data information and improve generalization error. Both cases are in high classification difficulty, but the training results could be entirely different. In the second case, the emergence of HT indicates the feature extraction and some regularization for improving the test accuracy. However, in the first case, HT indicates some excessive information extraction and thus overfitting happens.
The paper is aim to give a more comprehensive understanding of HT phenomenon. Intuitively, the classification difficulty is a metric for how difficult the data sets will get classification or get prediction under certain model architectures. Nevertheless the classification difficulty is vague and hard for a clear definition, there are a lot of indicators that give a significant impact. For example, the decrease of signal-to-noise ratio (SNR), the increment of class numbers or the complex features in the data sets would all increase the difficult level for the data sets to get classification. The factor we find is indeed consistent with the statement in Martin and Mahoney (2021). In line with Martin et al. (2021), the weight matrix spectrum could be regarded as information encoder during training procedure. Leveraging on this findings, a spectral criterion is proposed in section 4 to guide the early stopping in practice. To our best knowledge, it is the first quantitative criterion based on the spectra to guide early stopping in practice. Without prior information, HT indicates some regularization at play or some problematic issues such as overfitting in the training procedure. The spectral criterion depends on the detection of appearance of HT. We summarize our contributions below:
-
1.
We identify that the classification difficulty is a driving factor for the appearance of heavy tail in weight matrices spectra. Experiments are conducted on both synthetic and real data sets. Decrease of SNR or increment of class numbers in Gaussian data experiments, which both bring in higher classification difficulty, will generate heavy tail at the end of training. In real data experiments, heavy tails appears more in experiments with CIFAR10 than with MNIST due to the complex features in CIFAR10.
-
2.
Following the previous work in Martin and Mahoney (2021), the terminal spectrum bulk type in our paper are divided into three parts: Light Tail (LT), Bulk Transition period (BT) and Heavy Tail (HT). With decrease of classification difficulty, the terminal weight matrix spectrum has the phase transition from HT BT LT.
-
3.
Leveraging on this finding, we propose a spectral criterion to guide the early stopping without access of testing data. The HT(BT)-based spectral criterion could not only cut off a large training time with just a little drop of test accuracy, but also avoid over-fitting even when the training accuracy is increasing.
2 Experiments with Gaussian Data
Most deep neural networks are applied to real world data. These networks are however too complex in general for developing a rigorous theoretical analysis on the spectral behavior. For a theoretical investigation, a widely used and simplified model is the Gaussian input model (Lee et al., 2018). By examining a well-defined Gaussian model for classification, we establish the evidence for a classification difficulty driving regularization via the confirmation of a transition phenomenon in the spectra of network’s weight matrices in the order of HT BT LT. Moreover, the transition is quantitatively controlled by a single parameter of data quality in the Gaussian model, namely its signal-to-noise ratio (SNR).
Empirically Results: Signal-to-noise ratio (SNR) is a common indicator to measure data quality and greatly impacts the classification difficulty from a Gaussian model. We empirically examine the spectra by tuning SNR in different architectures:
-
1.
Different NN structures: wider but shallower, or narrower but deeper. These structures are similar to the various well known NNs’ fully connected denser layers, such as LeNet and MiniAlexNet, etc.;
-
2.
Different layers in neural networks: all weight matrices in different layers have spectrum transition driven by SNR;
-
3.
Different class numbers in input data: the spectrum transition is always observed in different class numbers, and HT is more likely to emerge with increment of .
Table 1 gives a short summary of the findings.
| Type of spectra | Number of spikes | ||||
|---|---|---|---|---|---|
| Weak | Heavy Tail | or | |||
| Middle |
|
or | |||
| Strong | Light Tail (MP Law) | or |
We empirically observe the spectrum transition in all settings. The transition is fully driven by the classification difficulty. Therefore, in this Gaussian model, the indicated implicit regularization in the trained DNN is data-effective, directly determined by the difficulty. Precisely, under low level SNR or high class numbers, the weight matrices of a DNN deviates far away from the common MP model. Instead, they are connected to very different complex Random Matrix models. The decrease of classification difficulty drives the weight matrices from Heavy Tailed model into MP models at the final training epoch.
2.1 Gaussian Data Sets
In the multi-classification task, Gaussian model is a commonly used model for assessing theoretical properties of a learning system (Lee et al., 2018). In this model with classes, data from a class are -dimensional vector of the form
| (1) |
where is the class mean, are Gaussian noise, is the total number of observation from class . (This Gaussian data model is referred to as the -way ANOVA model in the statistics literature.) The signal-to-noise ratio (SNR) for this -class Gaussian model is defined as
| (2) |
Here denotes the Euclidean norm in , and the average is taken over the pairs of classes.
We aim to examine the impact of classification difficulty on the weight matrices spectra in a trained NN for such Gaussian data. We thus consider two settings for the class means which lead to different families of SNRs. In all the remaining discussions, we will take .
Dataset : class means with randomly shuffled locations
Consider a base mean vector where half of the components are , and the other half, . For the class means , we reshuffle the locations of these components randomly (and independently). Formally, for each class , we pick a random subset , of size , and define the mean for this class as
| (3) |
Here for a subset , is the indicator vector of with coordinates ().
This setting with randomized locations is motivated by an essential empirical finding from exploring a few classical trained DNNs such as MiniAlexNet and LeNet. Indeed, we found that in these DNNs, the global histograms of the features from all the neurons are pretty similar, with very comparable means and variances, for various NNs; the differences across the NNs are that high and low values of the features appear in different neurons (locations). The randomly shuffled means used in our experiments are designed to imitate these working mechanisms observed in real-world NNs.
It follows that for the difference from two classes , its coordinates take on the values , 0 and with probability , and , respectively. Clearly, the model SNR will depend on the tuning parameter . By Hoeffding inequality, we first conclude that
or equivalently,
Note that , when . By taking , we conclude that with probability at least ,
Therefore at a first-order approximation, the SNR (2) in this Gaussian model is (with ),
| (4) |
Dataset : class means of ETF type
Consider the family of vectors where is defined by
So has support on and . The normalized family is called a -standard ETF structure (Papyan et al., 2020).
We define the -th class mean as , and use the scale parameter to tune the SNR of the model. It is easy to see that so that the model SNR is
| (5) |
(Papyan et al., 2020) has shown that the ETF structure is an optimal position for the final training outputs. Many experiments on real data sets lead to ETF structure for final engineered features. From a layer-peered perspective as mentioned in (Ji et al., 2021), each layer in NN can be regarded as an essential part of feature engineering, and the feature is extracted layer by layer. The ETF structure model considers that the first Dense layer behind the convolution layer is already close to the end of feature extraction.
| SNR interval | SNR interval | ||||
|---|---|---|---|---|---|
| NN1 | 0.01 | [0.01, 1.19] | 0.08 | [0.08, 4.80] | |
| 0.05 | [1.20, 2.00] | ||||
| NN2 | 0.005 | [0.005, 0.4] | 0.08 | [0.08, 4.80] | |
In our experiments, we take (and ). The size of each class is in the training dataset, and in test dataset. The number of classes takes on the values on all datasets. Table 2 gives the ranges of the model SNR observed in different dataset/NN combinations with the chosen values of tuning parameters and .
2.1.1 Structure of neural networks
We consider two different neural networks, a narrower but deeper NN1, and a wider but shallower NN2. The number of layers and their dimensions are shown in Figure 1:
NN1:
NN2:
The activation function is . We do not apply any activation function on the last layer.
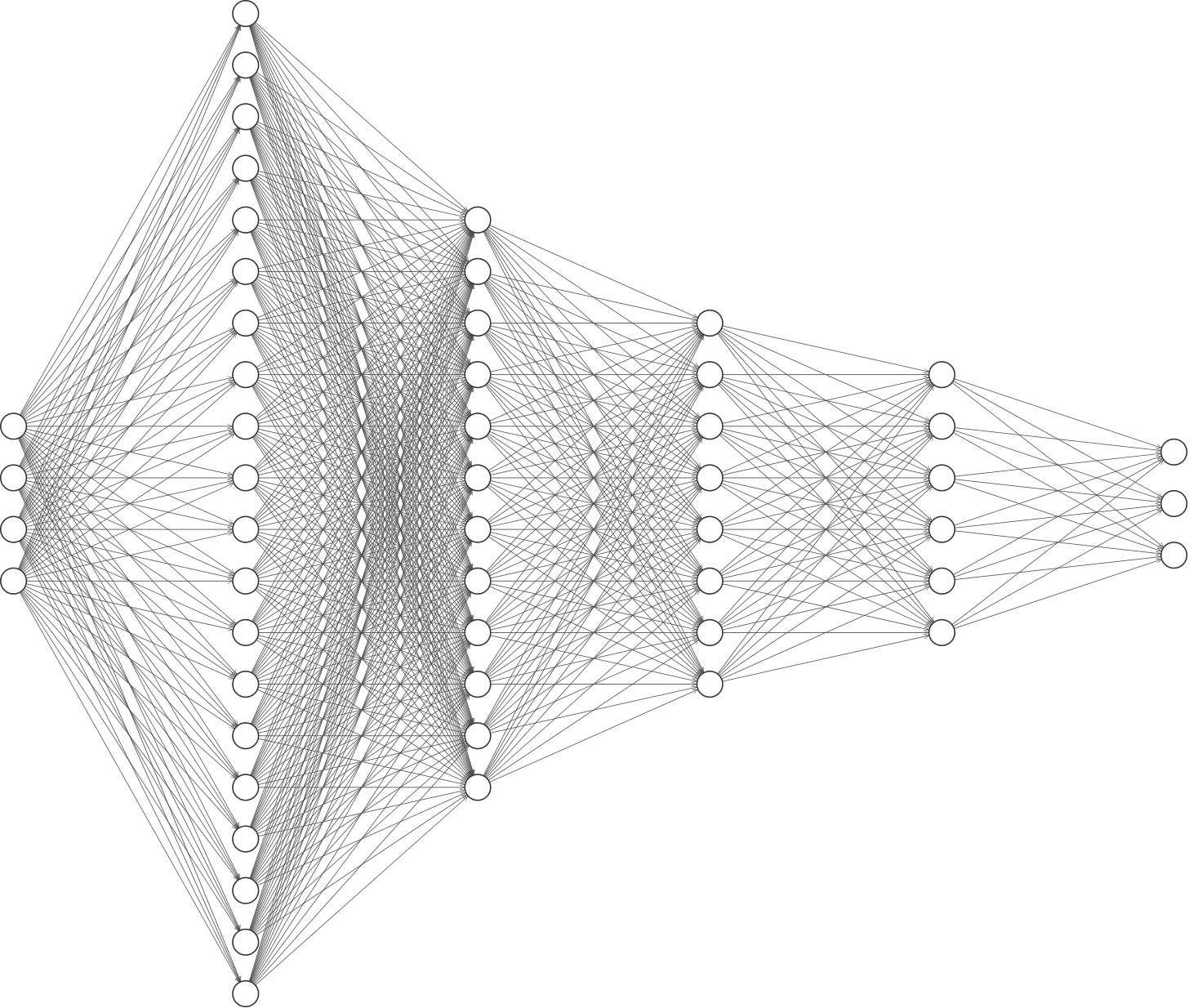
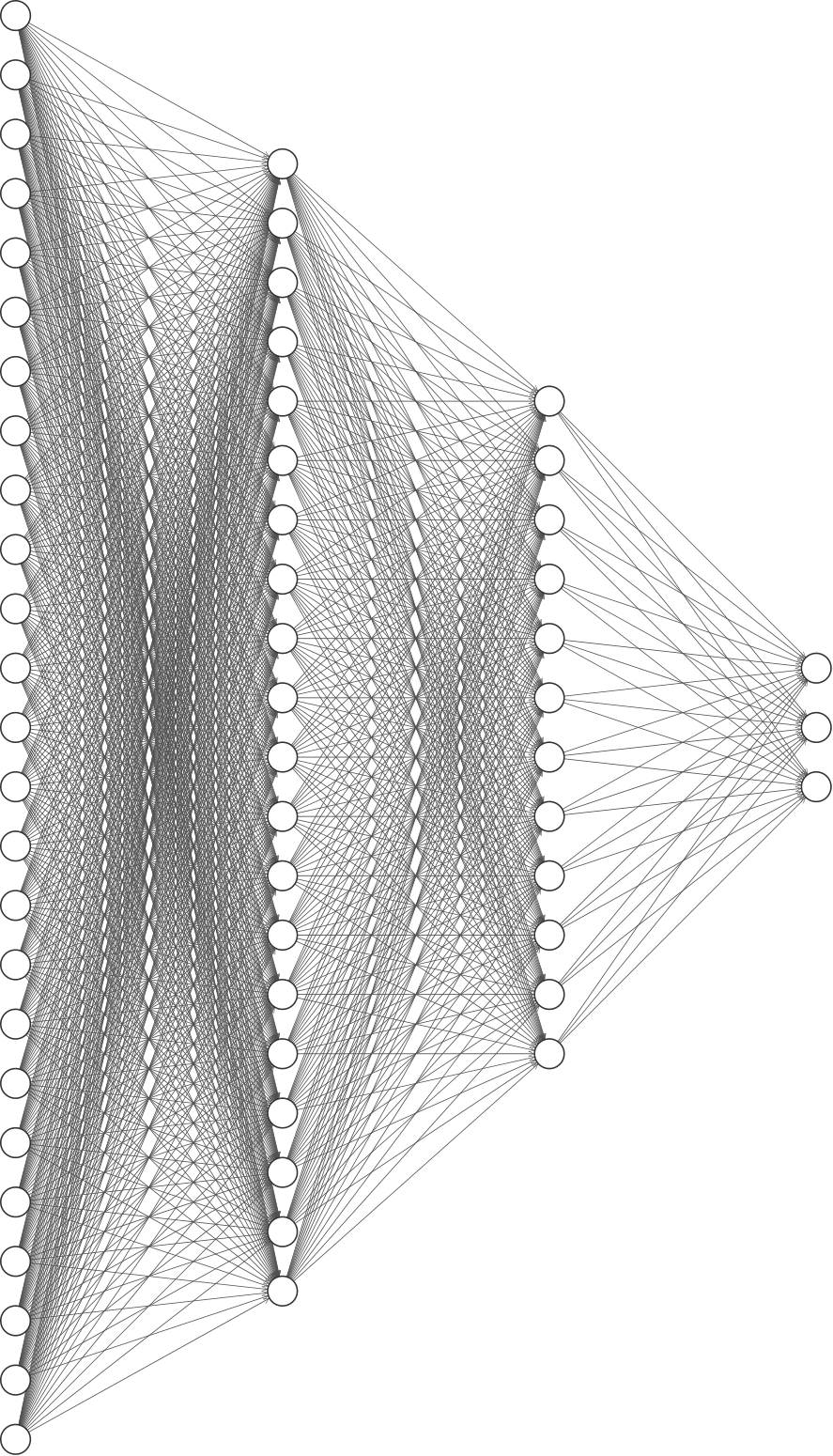
2.1.2 Optimization Methodology
Following common practice, we minimize the cross-entropy loss using stochastic gradient descend with momentum . All the datasets are trained with batch size =64 on a single GPU, for 248 epochs. Trained NNs are saved for the first 10, and then every four epochs. The total number of saved NNs is . The initialization is Pytorch’s default initialization, which follows a uniform distribution. The learning rate is .
2.2 Results on synthetic data experiments
To investigate the influence of the data SNR on the whole training process, we first report synthetic data experiments results.
2.2.1 Three types of spectrum bulk
We use SNR to measure the data quality and focus on the non-zero eigenvalues of the matrix . The SNR could directly reflect the classification difficulty. The weight matrices we consider in this section are those at the final epoch (248th). In the Gaussian data sets, with different values of SNR, we have observed the following three typical types for the bulk spectrum of the weight matrices:
| HT | |||
| BT | |||
| LT |
We increase gradually the SNR of the Gaussian model and report in the figures 2-4 the spectra of weight matrices at the end of training (in each figure, the SNR is increasing from (a) to (d)). As we can see in Figure 2 with relatively low SNR, spectra from weight matrices (in blue) shows significant departure of the spectrum from a typical MP spectrum (in red). This defines the class HT. In contrary, spectra in Figure 4 with relatively high SNR, well match an MP spectrum, and this corresponds to the LT class. More complex structures appear in figure 3, corresponding to medium values of the SNR. A transition is in place from Figure 3(a), which is closer to the HT spectra, to Figure 3(d), which is now closer to a MP spectrum. We call this a bulk transition class BT.
We now describe the evolution of spikes during the full transition from type HT to BT and LT. It is reported in Papyan (2020) that the total spikes are grouped in two clusters with spikes (determined by the between-class covariance matrix) and the singleton one (determined by the general mean), respectively. At the begining (Figure 2(a)), all the spikes are hidden in the bulk. When the SNR increases, the group of 7 spikes emerge from the bulk and stay outside the spectrum for ever. The movement of the single spike is more complex, hiding in and leaving the bulk repeatedly. There is particular moment where the two groups meet and stay close each other: we then see a group of 8 spikes.
We use “XX(m,n)” to describe the whole ESD type of the spectrum of weight matrices. Here “XX” means one of the three bulk types in {HT, BT, LT}. The number “m” or “n” gives us position information of the two groups of the spikes, numbered in increasing order. For instance, BT(1,7) displayed in Figure 3(d), means the bulk type is BT, the single spike lays between the bulk and the group of spikes; HT(0,8) means two groups of spikes are mixed; HT(0,7) means we see only the group of spikes.
Remark 1.
The spectrum transition from HT to BT and LT can also be assessed by more quantitative criteria. (i) The transition from HT to BT is related to the distance between the group of spikes and the bulk edge. When this distance is large enough, the HT type ends and the BT phase starts. Note that here the bulk type is heavy-tailed in both regimes HT and BT. (ii) The transition from BT to LT can be directly detected by comparing the bulk spectrum to the reference MP spectrum. Precisely, this can be achieved using our spectral distance statistic defined in section 4.












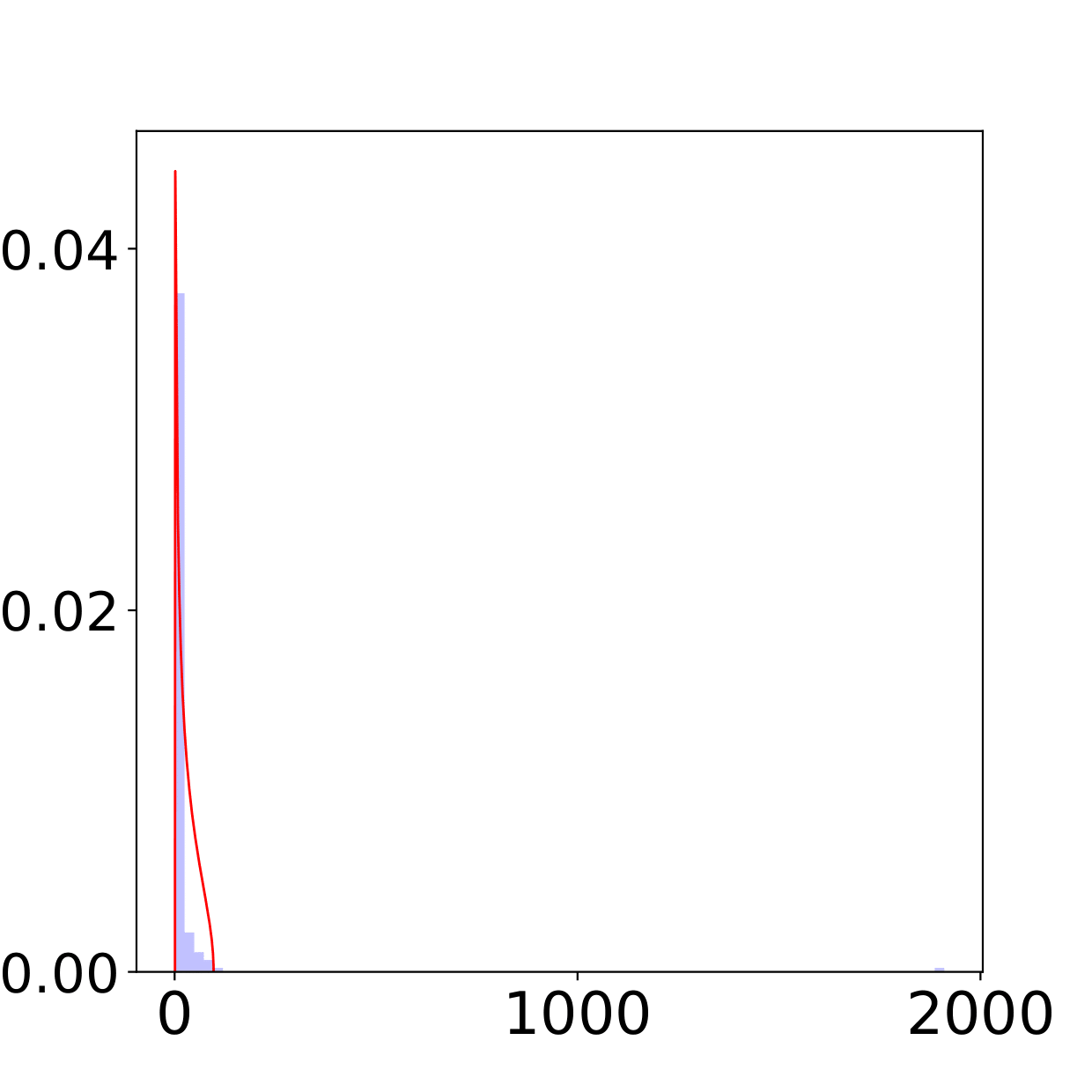
Rank Collapse: One special case, Rank Collapse, occasionally emerges in our experiments especially when SNR is small. Rank Collapse is the phenomenon that the spike is huge, making the bulk in the picture ’needle like’ as shown in Figure 5. By tuning up SNR, Rank collapse gradually disappears and turns into Light Tail or Heavy Tail.
2.2.2 Phase Transition
We now describe evidence that the spectrum bulks of weight matrices undergo a phase transition controlled by the data SNR. The phase transition operates in the direction of
when the SNR increases. The complete experimental results, with recorded phase transition periods (in terms of intervals of SNR values) in all NN layers, are given in Table 3-4, for the four NNs/datasets combinations respectively. These tables are summarized in Figure 6 as a graphical summary.
The main findings from these results are as follows: (1) When data SNR increases, all spectrum bulks in weight matrices fall into the LT type at final epoch. The four subfigures for the NNs/datasets combinations all contain the Same Transition Period Direction:
In our experiments, the bulk transition (BT) period starts when the block eigenvalues become distant, and the Heavy Tailed spectrum bulk gradually changes into BT and LT with an increment of SNR. It is also noted that some weight matrices start from BT type and LT type. The transition from HT to LT all starts from low SNR to high SNR, in line with less and less difficulty to classify. All the transitions above provide us evidence on data-effective regularization in the training, and strong impact of classification difficulty on the weight matrices spectra.
(2) For a given layer in the neural network at the same SNR level, HT has higher possibility to emerge as the number of classes increases. When the SNR level is the same, the more classes number the data set has, the higher difficulty to classify them all clearly. The emergence of HT indicates some implicit regularization that attempt to improve generalization error. The phenomenon that HT emerges with an increased number of classes also gives direct evidence on data-effective regularization and strong impact of classification difficulty on weight matrices spectra.
 |
 |
| (a) NN1+ | (b) NN1+ |
 |
 |
| (c) NN2+ | (d) NN2+ |
(3) One interesting phenomenon is that when one travels from the initial layer to deeper layers (FC2FC4 in NN1, FC1FC2 in NN2), the layers become narrower and the tails of spectrum bulks become lighter. This is true for both NNs and all SNR levels. In line with the previous work in Hodgkinson and Mahoney (2021), the statement that the wider layers will more likely to bring in HT is validated in our synthetic data experiments. The total factors cause HT are complex, we emphasize data classification difficulty and model architectures here to convince that the spectra in weight matrices could be regarded as a training information encoder. Without prior information during training procedure, spectra analysis inspires us to design wide fully connected layers to encode the training information instead of narrow layers. The benefits are not for the testing error improvement but for the training procedure monitoring. Indeed, HT usually emerges if the data classification is difficult. It could be regarded as an alarm on the hidden and problematic issues in the bad cases such as the training data quality is poor, or an indication of the emergence of implicit regularization which improves generalization error, especially in the case that the features in data are complex for extraction. The spectra in weight matrices encode training information to some extent, and bring new insights into Deep Learning. Based on these, we propose spectral criterion in section 4 to guide early stopping without access of testing data.
2.2.3 Additional experiments on different batch sizes
Batch size also has great impact on the training stability together with data features. (Keskar et al., 2016; Goyal et al., 2017) observe that different batch sizes may give different influence on the training dynamics. To give more comprehensive evidence of the impact of classification difficulty on weight matrices spectra, we change data SNR on different batch sizes, and conduct experiments on NN1+ and NN2+ with , and two additional batch sizes (previous experiments all used a batch size of 64).
 |
 |
| (a) NN1+ | (b) NN1+ |
We check the transition. The phase transition of the spectrum bulk is still observed in the same direction as previously (HTBTLT). Full results are given in Table 5. Again, a summarized visualization is given in Figure 7. The settings are all similar to those used previously.
| (NN1+) | (NN1+) | ||||||||||||
| FC2 | FC3 | FC4 | FC2 | FC3 | FC4 | ||||||||
| [0.01,0.03] | HT(0,1) | - | - | [0.08,0.24] | HT(0,1) | - | - | ||||||
| [0.04,0.09] | HT(1,1) | [0.32,0.4] | HT(1,1) | ||||||||||
| [0.1,0.44] | BT(1,1) | [0.01,0.29] | BT(1,1) | - | [0.48,2.16] | BT[1,1] | [0.08,1.44] | BT[1,1] | - | ||||
| [0.45,2] | LT(1,1) | [0.3,0.38] | LT(1,1) | [0.01,2] | LT(0,1) | [2.24,4.8] | LT(1,1) | [1.52,2.64] | LT(1,1) | [0.48,4.8] | LT(0,1) | ||
| [0.39,2] | LT(0,1) | [2.72,4.8] | LT(0,1) | ||||||||||
| (NN1+) | (NN1+) | ||||||||||||
| FC2 | FC3 | FC4 | FC2 | FC3 | FC4 | ||||||||
| [0.01,0.15] | HT(0,1) | - | - | [0.08,0.48] | HT(0,1) | - | - | ||||||
| [0.16,0.2] | HT(4,1) | [0.56,0.64] | HT(4,1) | ||||||||||
| [0.21,0.28] | HT(0,5) | [0.72,1.04] | HT(0,5) | ||||||||||
| [0.29,0.66] | BT(1,4) | [0.01,0.59] | BT(1,4) | - | [1.12,3.2] | BT(1,4) | [0.08,2.72] | BT(1,4) | - | ||||
| [0.67,1.04] | LT(1,4) | [0.6,1.9] | LT(1,4) | [0.01,2] | LT(0,4) | [3.28,4.8] | LT(1,4) | [2.8,4.8] | LT(1,4) | [0.08,4.8] | LT(0,4) | ||
| [1.05,2] | LT(0,5) | [1.95,2] | LT(0,5) | ||||||||||
| (NN1+) | (NN1+) | ||||||||||||
| FC2 | FC3 | FC4 | FC2 | FC3 | FC4 | ||||||||
| [0.01,0.19] | HT(0,1) | [0.01,0.32] | HT(0,8) | - | [0.08,0.56] | HT(0,1) | [0.08,1.12] | HT(7,1) | - | ||||
| [0.2,0.25] | HT(7,1) | [0.64,0.96] | HT(7,1) | [1.2,1.44] | HT(0,8) | ||||||||
| [0.26,0.36] | HT(0,8) | [1.04,1.36] | HT(0,8) | ||||||||||
| [0.37,0.72] | BT(1,7) | [0.32,0.63] | BT(1,7) | - | [1.44,3.52] | BT(1,7) | [1.52,3.12] | BT(1,7) | - | ||||
| [0.73,1.01] | LT(1,7) | [0.64,1.15] | LT(1,7) | [0.01,2] | LT(0,7) | [3.6,4.64] | LT(1,7) | [3.2,4.8] | LT(1,7) | [0.08,4.8] | LT(0,7) | ||
| [1.02,1.9] | LT(0,8) | [1.16,1.95] | LT(0,8) | [4.72,4.8] | LT(0,8) | ||||||||
| [1.95,2] | LT(0,7) | [2,2] | LT(0,7) | ||||||||||
* The interval is the range of tuning parameters which tune data SNR.
| (NN2+) | (NN2+) | ||||||||
| FC1 | FC2 | FC1 | FC2 | ||||||
| [0.005,0.015] | HT(0,1) | - | [0.08,0.16] | HT(0,1) | - | ||||
| [0.02,0.055] | BT(1,1) | - | [0.24,1.52] | BT[1,1] | [0.08,0.48] | BT[1,1] | |||
| [0.06,0.235] | LT(1,1) | [0.005,0.4] | LT(1,1) | [1.6,1.92] | LT(1,1) | [0.56,1.6] | LT(1,1) | ||
| [0.24,0.4] | LT(0,1) | [2,4.8] | LT(0,1) | [1.68,4.8] | LT(0,1) | ||||
| (NN2+) | (NN2+) | ||||||||
| FC1 | FC2 | FC1 | FC2 | ||||||
| [0.005,0.015] | HT(0,1) | - | [0.08,0.48] | HT(0,0) | - | ||||
| [0.02,0.035] | HT(4,1) | [0.56,0.56]] | HT(0,1) | ||||||
| [0.04,0.045] | HT(0,5) | [0.64,0.88] | HT(0,5) | ||||||
| [0.05,0.12] | BT(1,4) | [0.005,0.125] | BT(1,4) | [0.96,2.24] | BT(1,4) | [0.08,2.16] | BT(0,4)BT(1,4) | ||
| [0.125,0.4] | LT(1,4) | [0.03,0.38] | LT(1,4) | [2.32,2.48] | LT(1,4) | [2.24,4.8] | LT(1,4) | ||
| [0.385,0.4] | LT(0,5) | [2.56,4.8] | LT(0,4) | ||||||
| (NN2+) | (NN2+) | ||||||||
| FC1 | FC2 | FC1 | FC2 | ||||||
| [0.005,0.025] | HT(0,1) | - | [0.08,0.8] | HT(0,0) | - | ||||
| [0.03,0.06] | HT(7,1) | [0.88,0.96] | HT(0,1) | ||||||
| [0.065,0.065] | HT(0,8) | [1.04,1.12] | HT(0,8) | ||||||
| [0.07,0.135] | BT(1,7) | [0.005,0.095] | BT(1,7) | [1.2,2.72] | BT(1,7) | [0.08,2.4] | BT(1,7) | ||
| [0.14,0.4] | LT(1,7) | [0.1,0.24] | LT(1,7) | [2.8,3.04] | LT(1,7) | [2.48,4.64] | LT(1,7) | ||
| [0.245,0.4] | LT(0,8) | [3.12,4.8] | LT(0,7) | [4.72,4.8] | LT(0,8) | ||||
* The interval is the range of tuning parameters which tune data SNR.
| Batchsize (NN1+) | Batchsize (NN2+) | ||||||||||
| FC2 | FC3 | FC4 | FC1 | FC2 | |||||||
| [0.01,0.17] | HT(0,1) | [0.01,0.44] | RC | - | [0.08,0.8] | HT(0,0) | - | ||||
| [0.18,0.46] | HT(7,1) | [0.45,0.52] | HT(7,1) | ||||||||
| [0.47,0.55] | HT(0,8) | [0.52,0.59] | HT(0,8) | ||||||||
| [0.56,0.84] | BT(1,7) | [0.6,0.78] | BT(1,7) | [0.15,0.45] | HT(0,7) | [0.88,3.6] | BT(0,7) | [0.08,3.28] | RCBT(1,7) | ||
| [0.85,1.08] | LT(1,7) | [0.79,1.12] | LT(1,7) | [0.46,2] | LT(0,7) | [3.68,4.8] | LT(0,7) | [3.36,4.8] | LT(1,7) | ||
| [1.09,2] | LT(0,8) | [1.13,2] | LT(0,8) | ||||||||
| Batchsize (NN1+) | Batchsize (NN2+) | ||||||||||
| FC2 | FC3 | FC4 | FC1 | FC2 | |||||||
| [0.01,0.19] | HT(0,1) | [0.01,0.32] | HT(0,8) | - | [0.08,0.8] | HT(0,0) | - | ||||
| [0.2,0.25] | HT(7,1) | [0.88,0.96] | HT(0,1) | ||||||||
| [0.26,0.36] | HT(0,8) | [1.04,1.12] | HT(0,8) | ||||||||
| [0.37,0.72] | BT(1,7) | [0.33,0.63] | BT(1,7) | - | [1.2,2.72] | BT(1,7) | [0.08,2.4] | BT(1,7) | |||
| [0.73,1.01] | LT(1,7) | [0.64,1.15] | LT(1,7) | [0.01,2] | LT(0,7) | [2.8,3.04] | LT(1,7) | [2.48,4.64] | LT(1,7) | ||
| [1.02,1.9] | LT(0,8) | [1.16,1.95] | LT(0,8) | [3.12,4.8] | LT(0,7) | [4.72,4.8] | LT(0,8) | ||||
| [1.95,2] | LT(0,7) | [2,2] | LT(0,7) | ||||||||
| Batchsize (NN1+) | Batchsize (NN2+) | ||||||||||
| FC2 | FC3 | FC4 | FC1 | FC2 | |||||||
| [0.01,0.16] | HT(0,0) | - | - | - | - | ||||||
| [0.17,0.22] | HT(0,8) | ||||||||||
| [0.23,0.55] | BT(0,7)BT(1,7) | [0.01,0.4] | BT(1,7) | - | - | - | |||||
| [0.56,2] | LT(1,7) | [0.41,1.01] | LT(1,7) | [0.01,2] | LT(0,7) | [0.08,1.2] | LT(0,0) | [0.08,4.64] | LT(1,7) | ||
| [1.02,1.95] | LT(0,8) | [1.28,4.8] | LT(0,7) | [4.72,4.8] | LT(0,8) | ||||||
| [2,2] | LT(0,7) | ||||||||||
* The interval is the range of tuning parameters which tune data SNR.
3 Experiments with Real Data
The previous results are based on synthetic Gaussian data. Here we conduct experiments with real data sets to show the impact of complex features in data on weight matrices spectra. The DNNs chosen for these experiments are LeNet, MiniAlexNet and VGG11 (LeCun et al., 1998; Krizhevsky et al., 2012), which are the most classic and representative DNNS in pattern recognition. We consider two data sets, the MNIST and CIFAR10. Note that in Martin and Mahoney’s work, the data sets such as CIFAR10, CIFAR100 and Image1000 all bring in HT type spectra due to complex features unlike the MNIST data set. In our experiments, we select MiniAlexNet instead of the more extensive AlexNet to reduce computing complexity. Table 6 gives the type of spectra obtained in the trained NNs with each data set.
| LeNet | MiniAlexNet | VGG11 | |
|---|---|---|---|
| MNIST | LT (99%) | LT (99%) | LT (99%) |
| CIFAR10 | HT (64%) | HT (76%) | HT (81%) |
In training with MNIST, the spectra of weight matrices are always LT type, independently of the used NN; for CIFAR10, the spectra are always HT type in all networks. The testing accuracies of detection on MNIST are 99% in all networks, while those on CIFAR10 are 64% with LeNet, 76% with MiniAlexNet and 81% with VGG11 respectively. The differences in testing accuracy give evidence that CIFAR10 has much more complex features than MNIST, and the complex features indicate more classification difficulty in CIFAR10 than MNIST. In the real data experiments, it shows that training on CIFAR10 is more likely to bring in the HT, which gives new evidence on the impact of classification difficulty on weight matrices spectra. Moreover, The complex features will also bring in the complex correlations during training procedure and thus HT emerges. Full details for these experimental results are reported in Section 3.2.
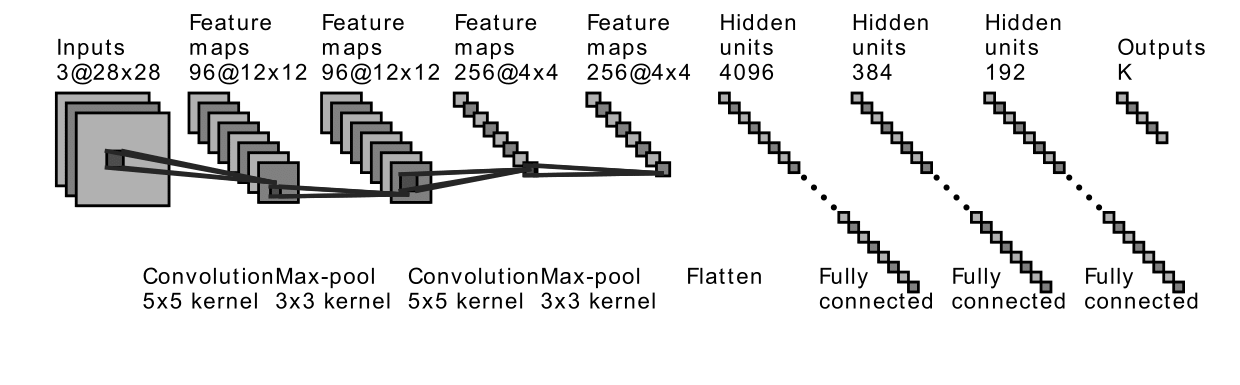
3.1 Experimental Design
The structures of LeNet and MiniAlexNet are shown in Figure 8. Readers could refer the structure of VGG in Simonyan and Zisserman (2014). The data sets we use are MNIST and CIFAR10. We tune batch sizes to have different practical architectures, then check spectra type in the different data sets under such different practical architectures. As before, we save trained models for the first 10 epochs and every four epochs afterward. The optimization methodology is the same as previously (See Section 2.1.2).
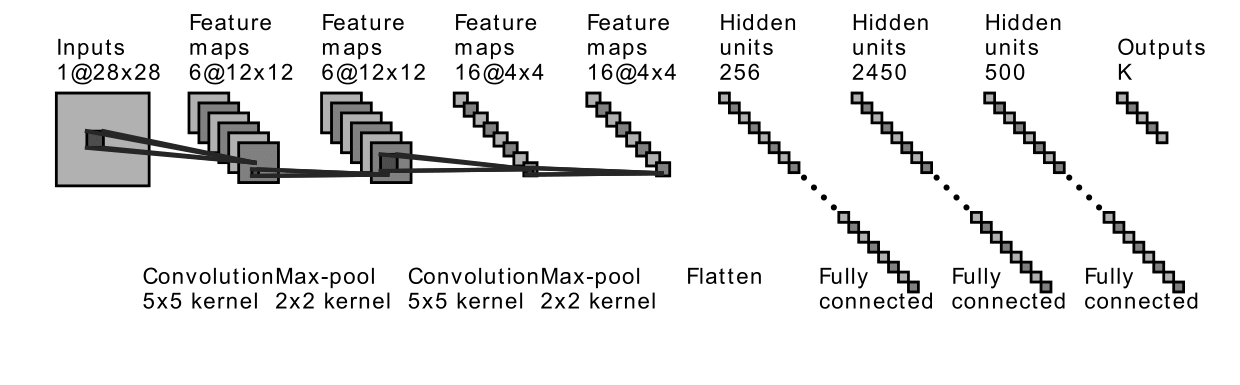
3.2 Results on real data experiments
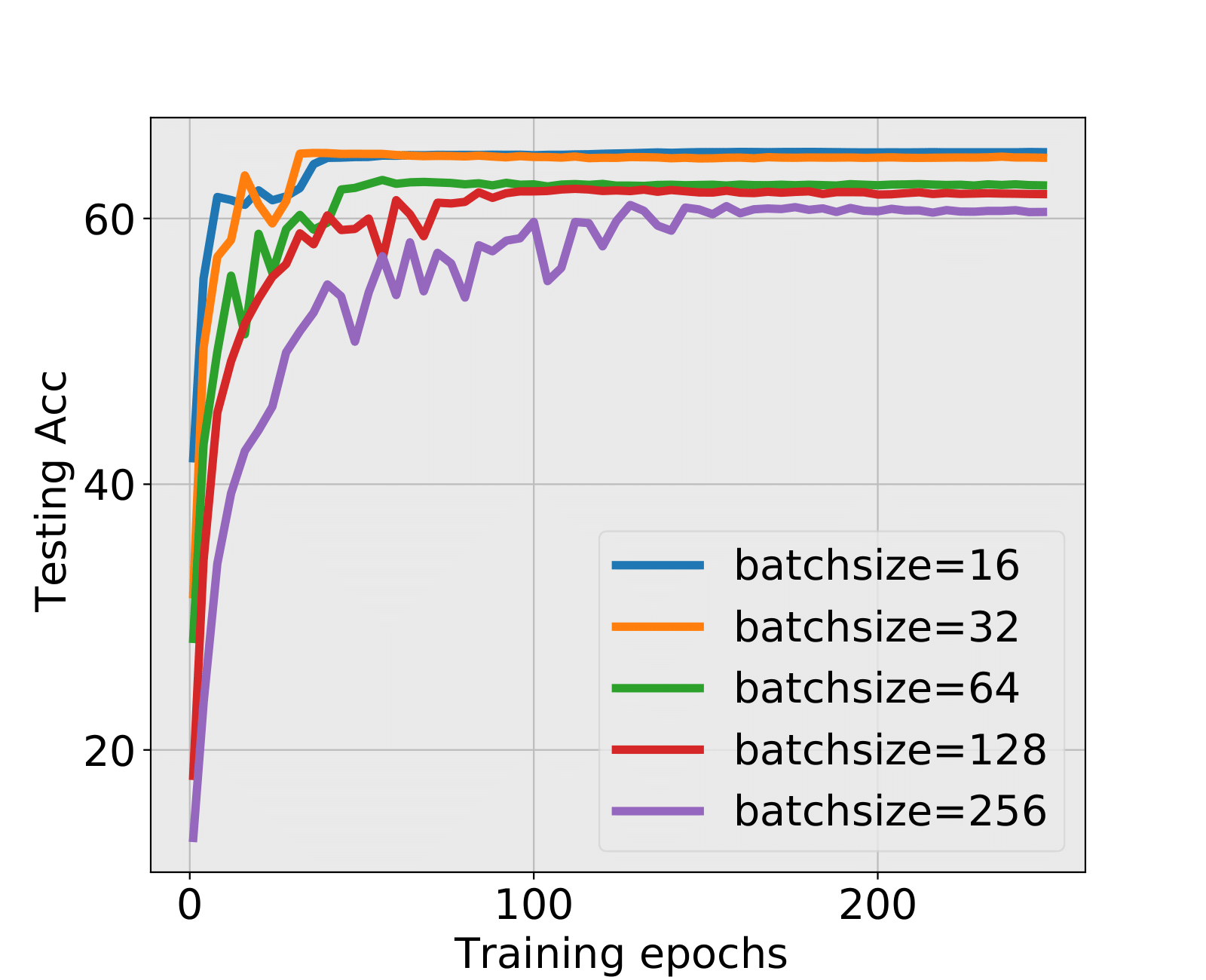
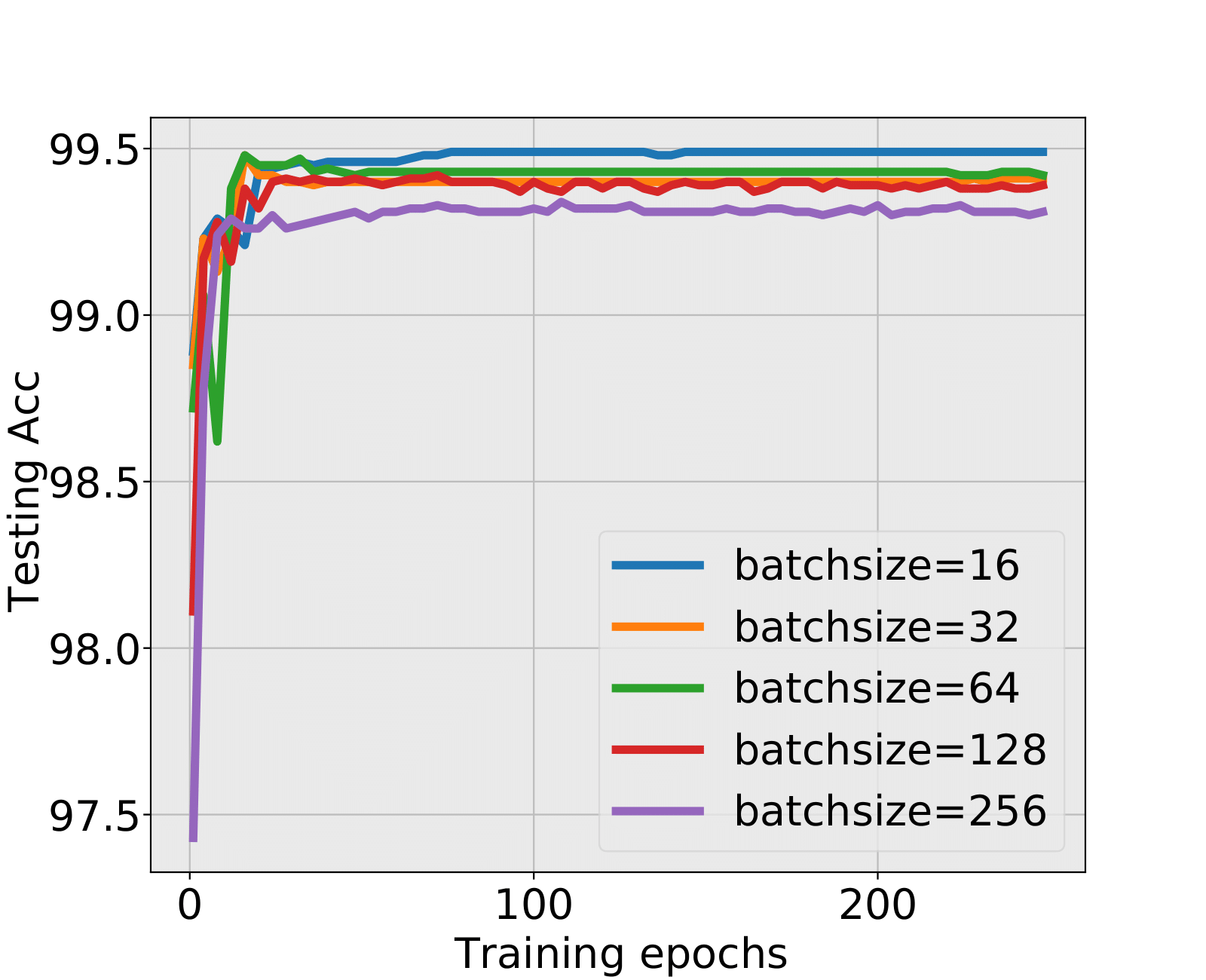
In this section, we check the weight matrices spectra on various NNs with two different data sets, see whether the complex features in data sets have great impact on the formation of HT. At the final epoch, the ESDs in LeNet, MiniAlexNet and VGG essentially reflect the characteristic features of the data in MNIST and CIFAR10. We concentrate on weight matrices in Fully connected layers and display the results in Figure 9-10.
The weight matrix has the structure in LeNet, in MiniAlexNet and in VGG. As figures 9 and 10 show, the spectra are very different under the two training data sets on all neural networks. The type detection method is illustrated in section 2.2.1. In LeNet+MNIST, the spectra are BT type except batch size 256 with LT type, these BT types are slightly different from MP Law; In LeNet+CIFAR10, the spectra are also BT type but similar to HT except batch size 16. In MiniAlexNet+MNIST, the spectra are LT type except batch size 16 and 32 with BT type; In MiniAlexNet+CIFAR10, the spectra are HT and BT which visibly different from MP Law. In VGG+MNIST, the spectra are all LT type; In VGG+CIFAR10, the spectra transit from BT (visibly similar to HT) to LT with increment of batch size.
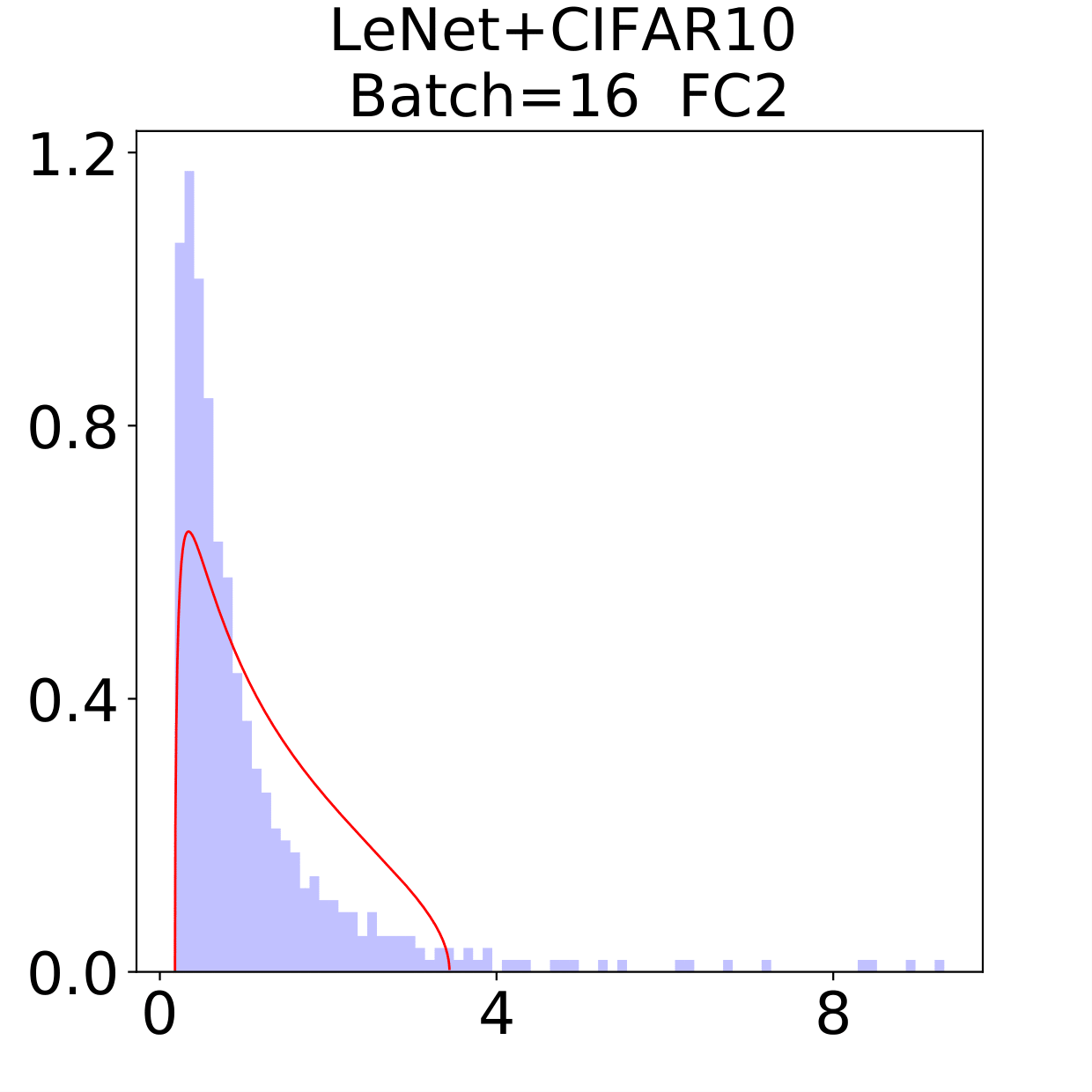
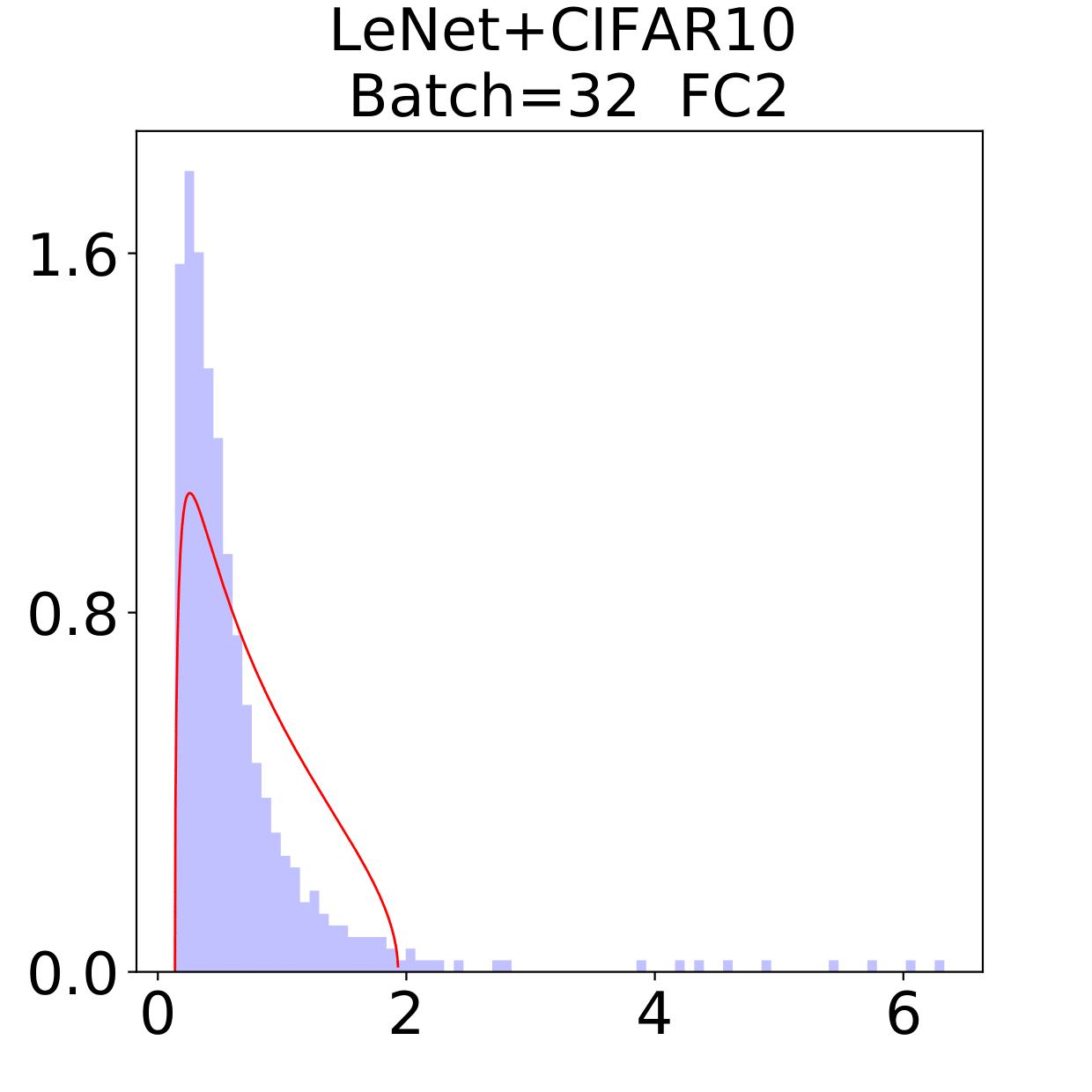
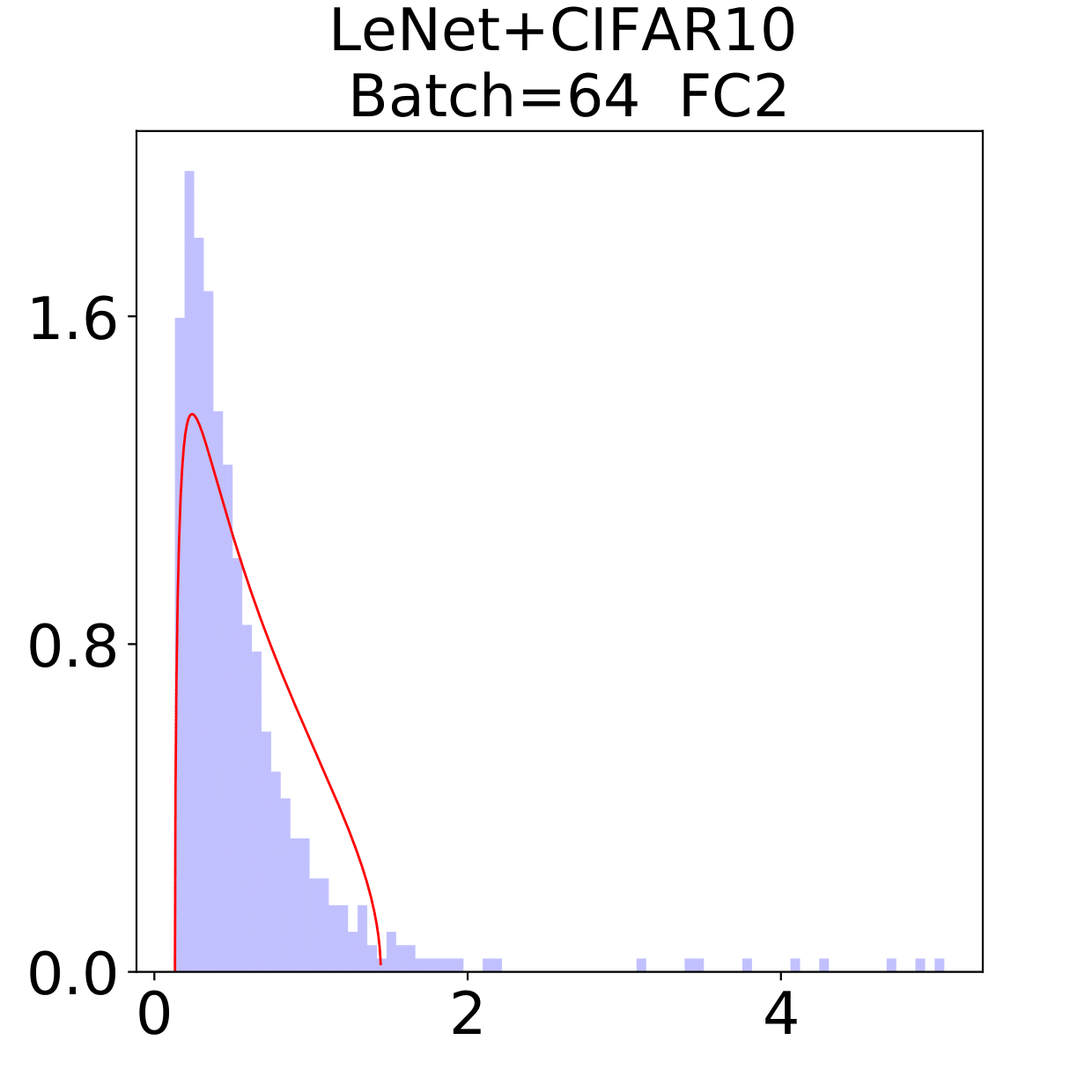
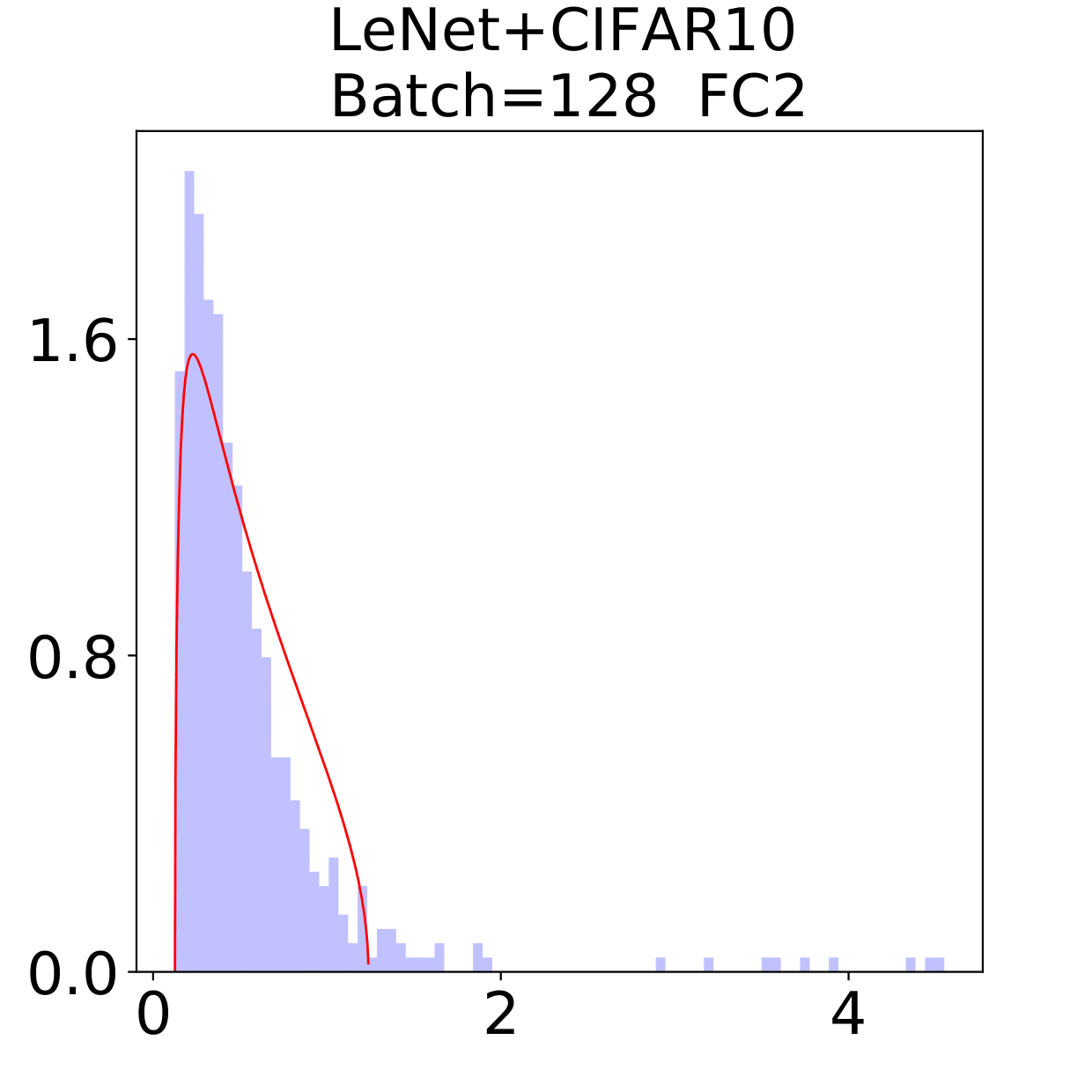
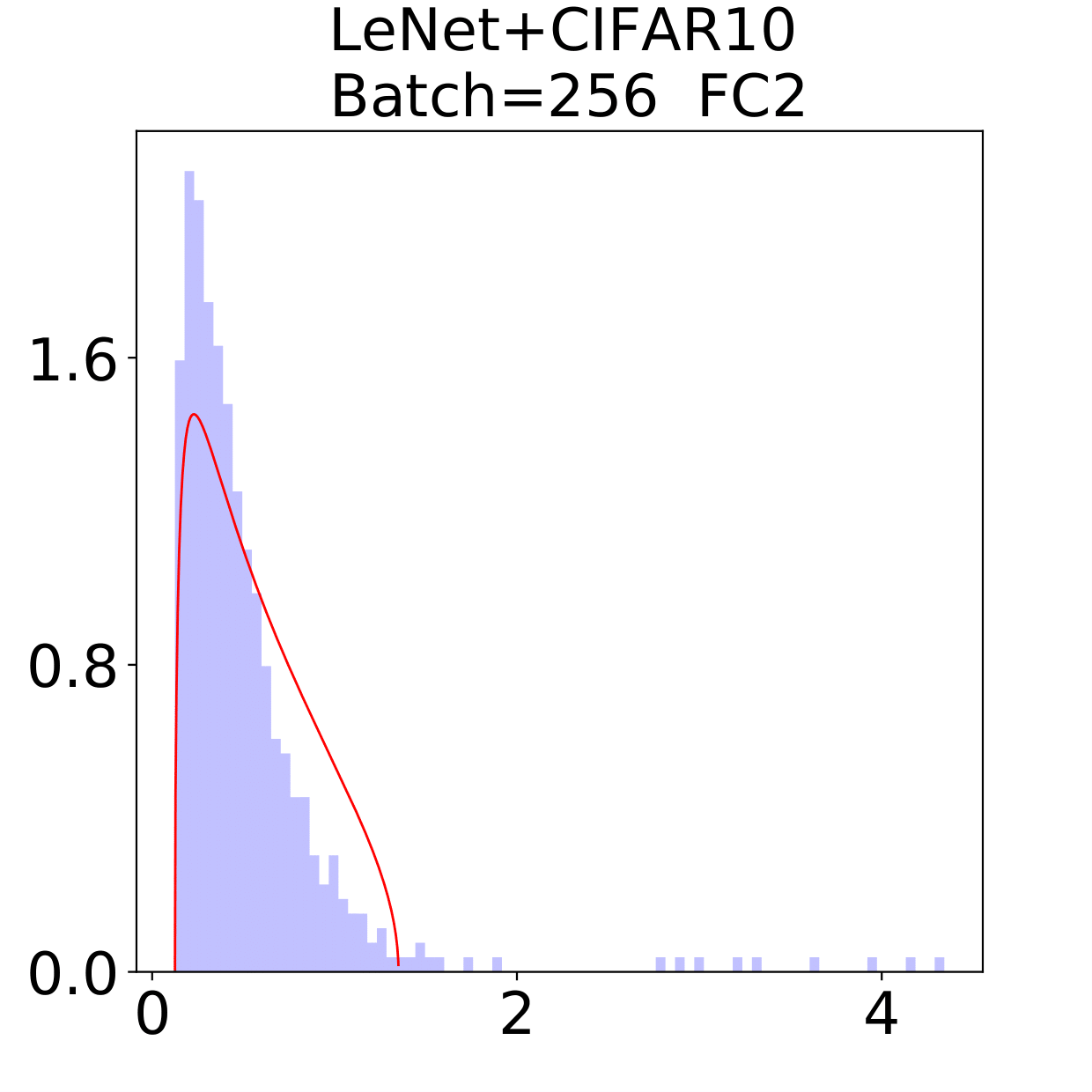
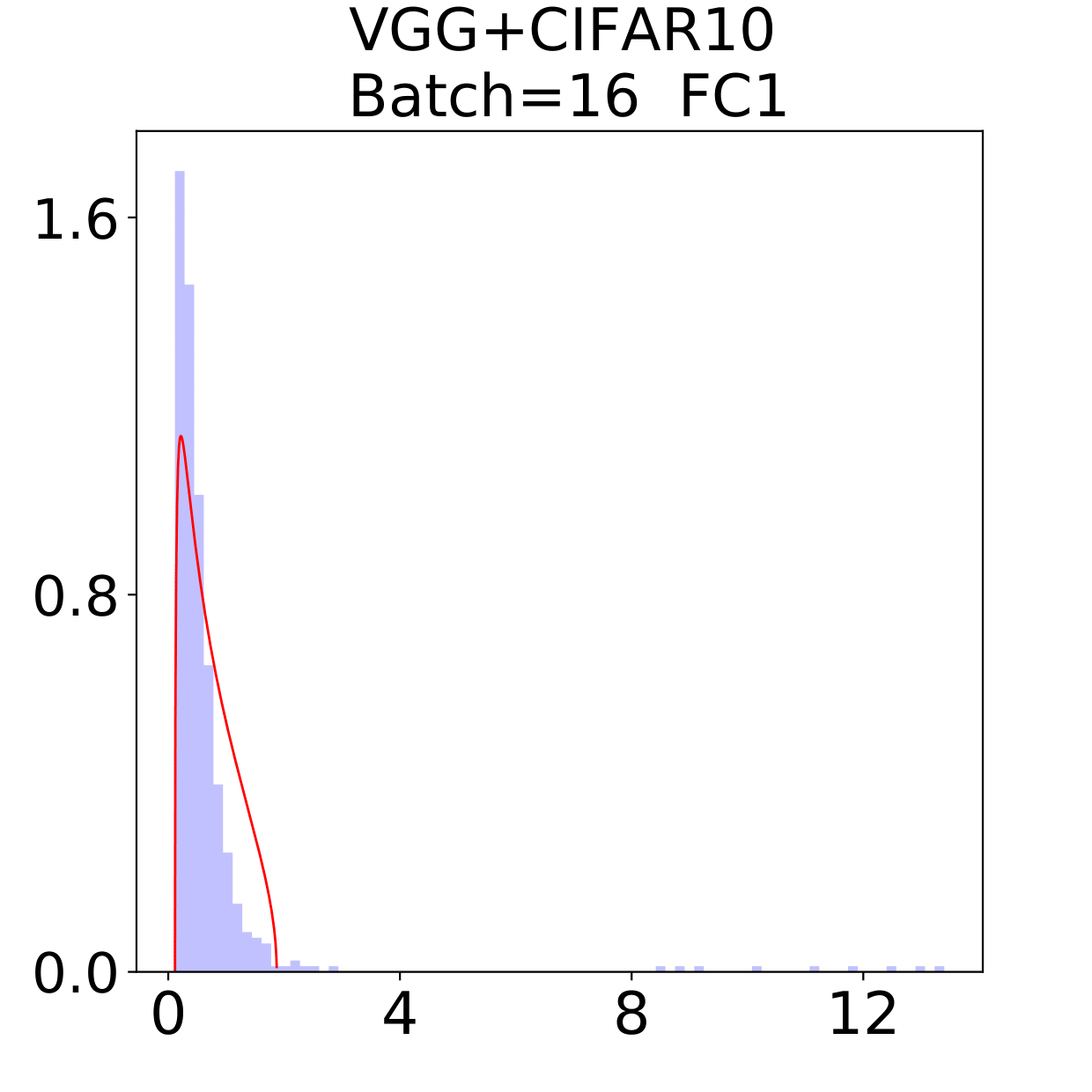
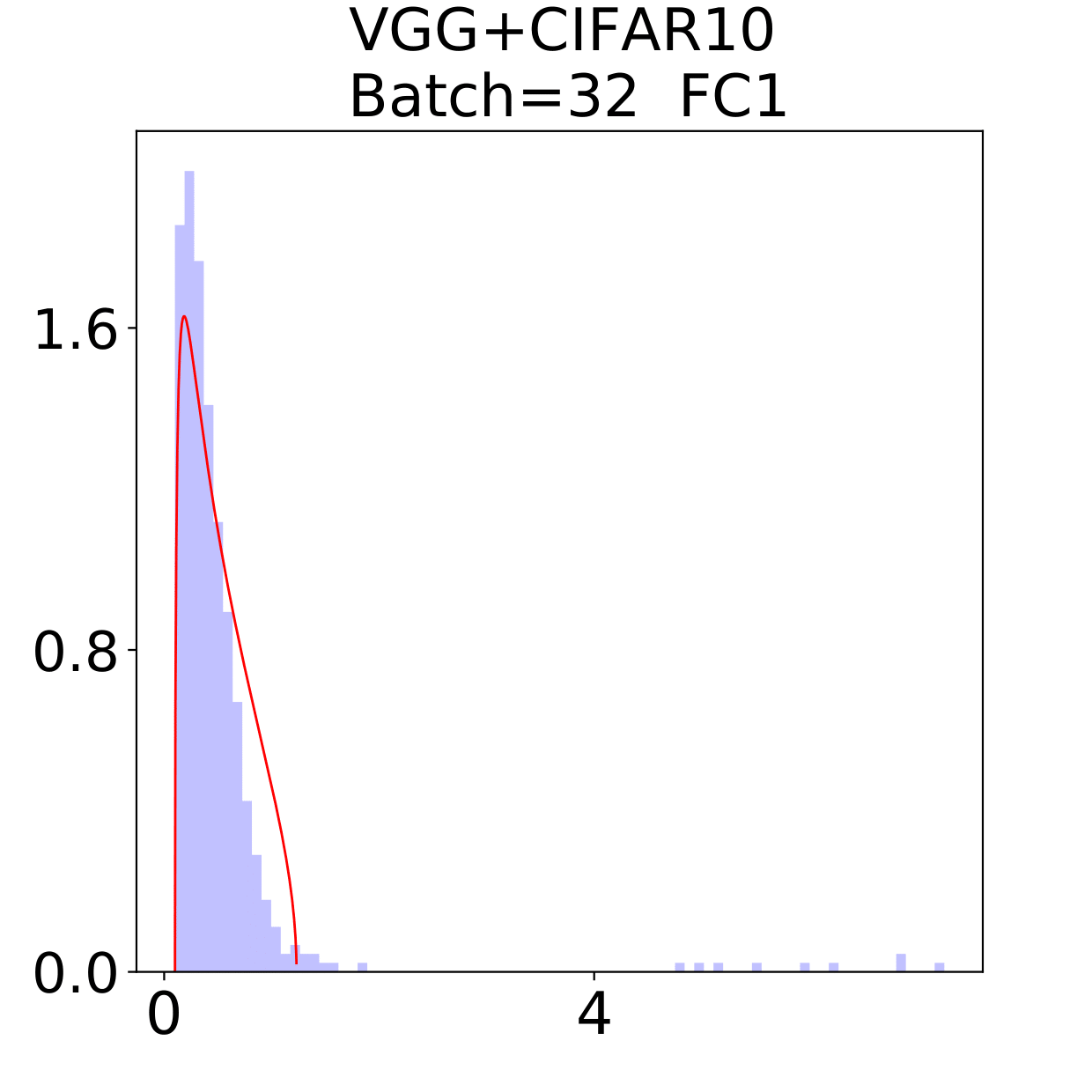
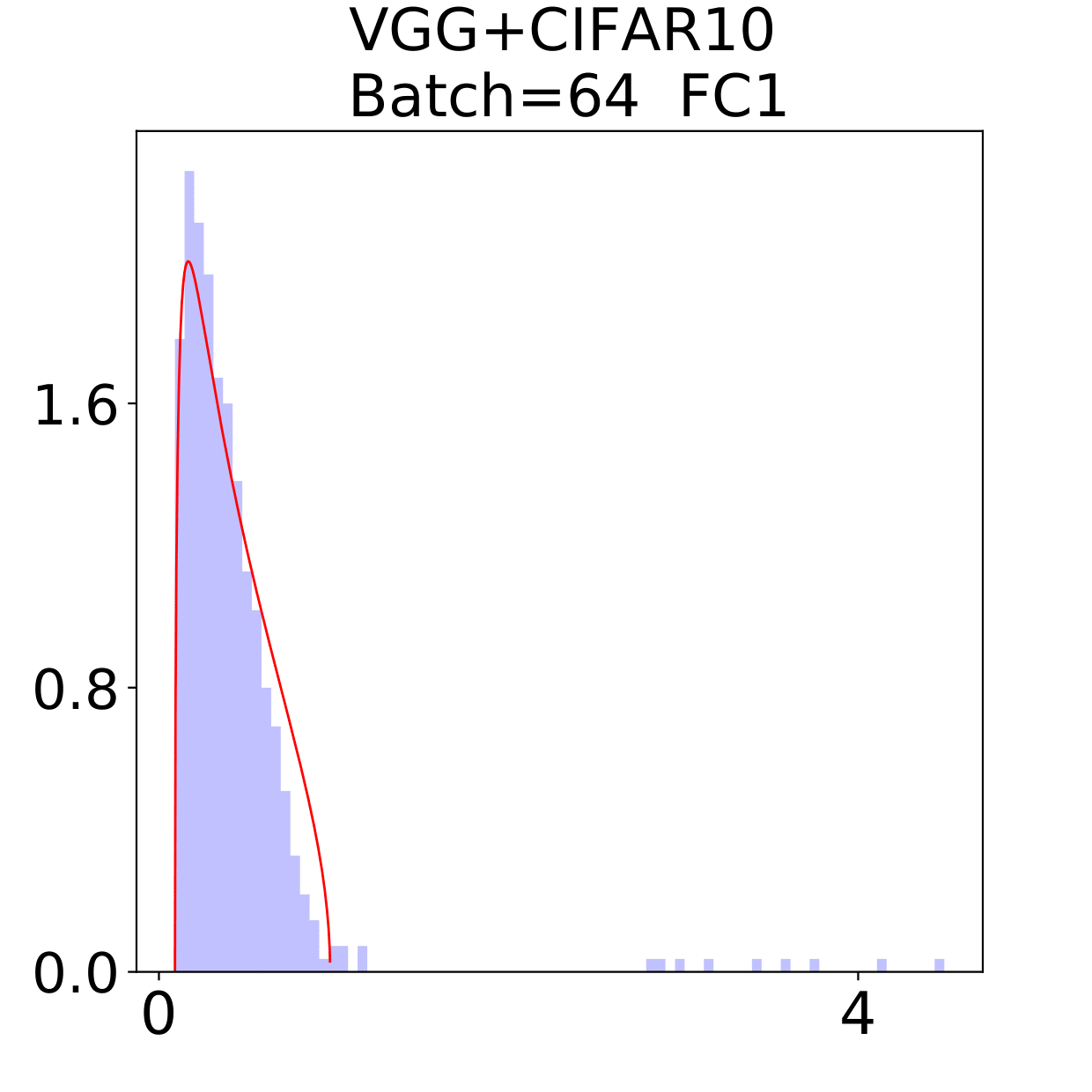
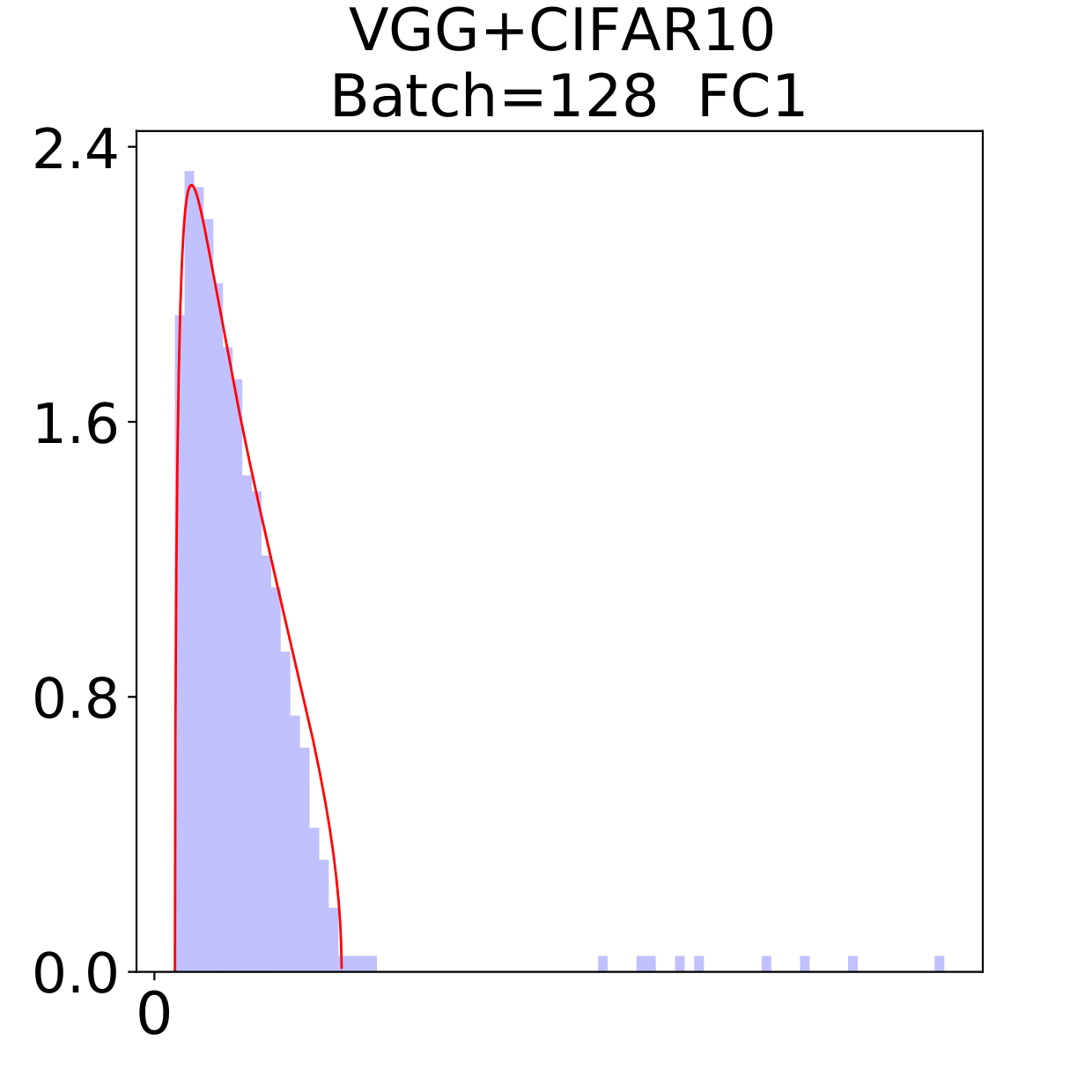
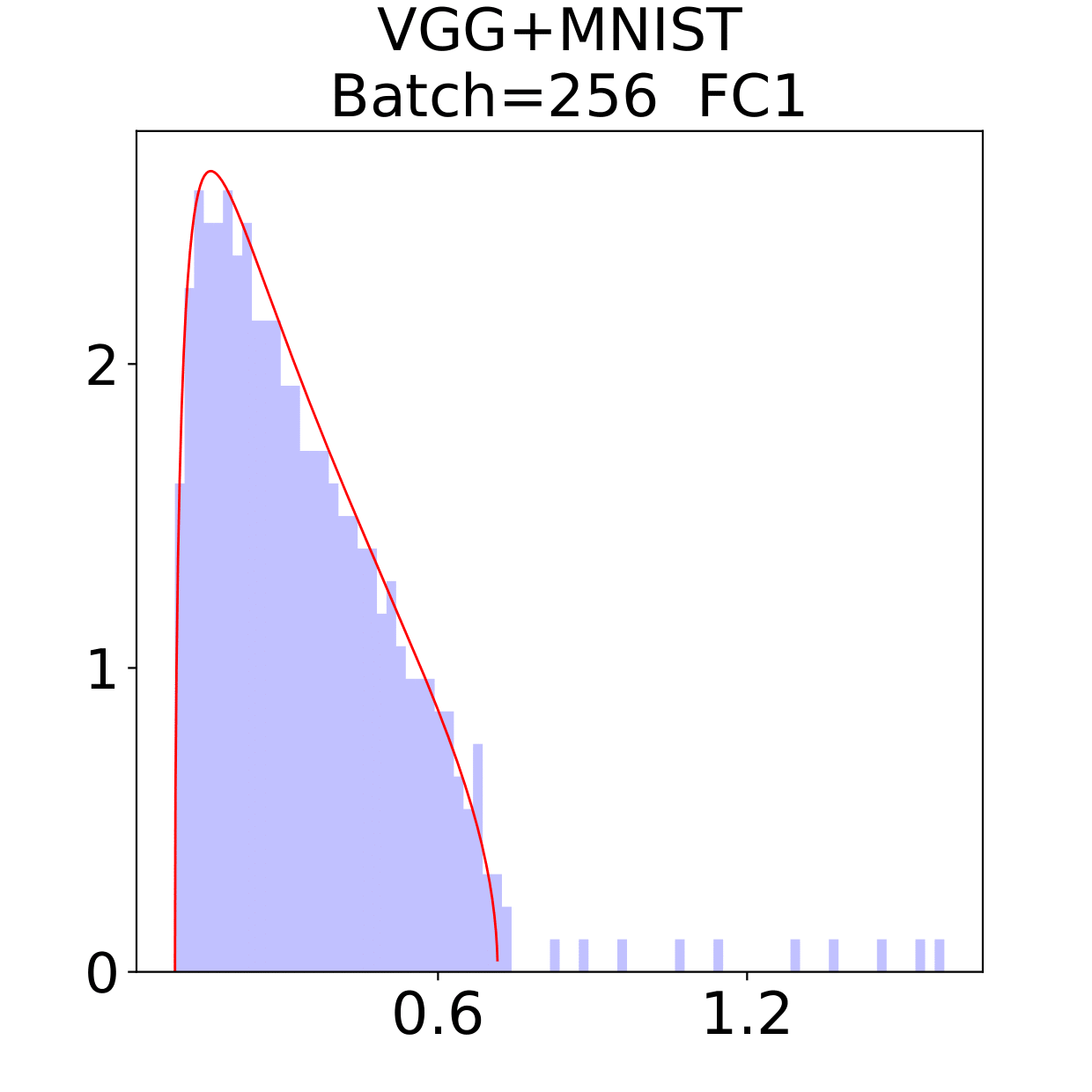
Although different hyper parameters and model architectures may have great impact on weight matrices spectra type, we could not ignore the impact from data itself. Different data classification difficulty also has great impact on the weight matrices spectra type. Compared with Figure 9 and 10, the NNs trained on CIFAR10 are more likely to have HT, nevertheless the increment of batch size makes the spectra gradually approximate to the LT type. The complex features in CIFAR10 could increase the data classification difficulty and bring in HT, and the weight matrices spectra display HT shapes, which implicitly reflects the status of whole training procedure. Especially when HT emerges, the indication of some implicit regularization happened gives us new insights that spectra could be regarded as training information encoder. According to this, we propose spectral criterion for early stopping in section 4.
4 Spectral Criterion
As a regularization technology in Deep Learning, early stopping is adopted to improve generalization accuracy of a DNN. People may use testing data set to obtain convenient stopping time in practice, but when we model the data set, it is a trade off to separate data set into training and testing. Sometimes as Martin et al. (2021) pointed out, it is more expensive to acquire the testing data set. There are also situations where practioners of Deep Learning are laid to use pre-trained and existing DNNs without access to test data.
So an important question we address here is: Without any testing data set, shall we early stop or not? And how to define an early stopping time?
The spectra of weight matrices encode information during the training time, according to this we construct an application to guide the early stopping through a Spectral Criterion. Precisely, we introduce a distance between an observed weight matrix spectrum and the reference MP Law. When this distance is judged large enough, we obtain evidence for the formation of a HT or BT type spectrum, thus the implicit regularization in the DNN leads to the decision of stopping the training process. Note that this spectral criterion for early stopping does not need any test data.
We now describe this spectral criterion in more detail. Consider a () weight matrix and let be the non-zero eigenvalues of the square matrix . (These are also, by definition, the squares of the singular values of the matrix . The initialization of has been rescaled with .) We then construct a histogram estimator for the joint density of the eigenvalues using bins. Next, let be the reference Marčenko-Pastur density (Appendix A) depending on a scale parameter and a shape parameter , with a compact support (). In practice, the parameters and in the reference MP density are also estimated by using . This leads to an estimated MP density function . The estimation of distance between the distribution of the eigenvalues and the MP density is defined as distance
| (6) |
Under the null hypothesis that the eigenvalues follow the MP law, we have a precise rate for , which leads to our spectral criterion.
Spectral criterion. Set and consider a threshold value with ,
For each training epoch, calculate
in equation (6) by the Algorithm in
Appendix C. The training is stopped if .
(To gain more robustness in this stopping procedure, in all the
experiments, we will stop the training at three consecutive epochs
where happen (instead of at the first such epoch).)
The whole details on the determination of the distance value and the threshold value are given later in Section 4.1. One may ask why the appearance of a HT spectrum is a good early stopping time? Let us elaborate more on the important reasons for the early stopping rule above based on the appearance of a HT spectrum. Martin et al. (2021) mentioned that MP Law spectra could not evaluate the performance of the trained model, but Heavy Tail spectra could. The Heavy Tail spectra may correspond to better or worse test performance. From information encoder perspective, we argue that the emergence of Heavy Tail or Rank Collapse in weight matrices could be viewed in two ways:
-
•
Indication of the poor quality in the training data or the poor ability in the whole system: in synthetic data experiments, the poor training data or system quality will lead to instability or overfitting during the whole training dynamics. So the emergence of Heavy Tail can be treated as an alarm for these hidden and problematic issues in the network.
-
•
Indication of a regularized structure that has acquired considerable information from the training data: from another point of view, the HT phenomenon is far from the initial MP Laws introduced with random weight initialization. Its emergence can be viewed as an indication of a well-trained structure that has already captured sufficient information from the input data. Such structure will somehow ensure the testing accuracy of the whole system, and additional training will not bring much improvement.
The spectra criterion is validated in both synthetic and real data experiments. Evidence for this spectral criterion is developed in details with extensive experimental results in Sections 4.2 and 4.3. In synthetic data experiments, the spectral criterion provides an early stopping epoch where the testing accuracy is much higher than the final testing accuracy, even when the training accuracy is still increasing. In real data experiments, the spectral criterion could also offer high-quality stopping time, ensuring testing accuracy and cutting off a large unnecessary training time.
4.1 Technical details of the spectral criterion
Consider data points , supported on an interval , with . Consider a mesh net on the interval on bins of binsize ,
The histogram estimator for the density function of the data is
is the bin belongs to.
With respect to Random Matrix Theory Results given in Appendix A, the density function of the standard MP Law is
with and . We thus use the following distance between the two density functions to measure the departure of the data points from the MP law:
| (7) |
We have the following estimated rate for under the null hypothesis that the data points follow the MP-law.
Proposition 2.
Suppose are generated independently from , then the distance in eq7 satisfies
is the standard convergence notation in probability. The proof is given in Appendix B.1. Due to the fact that MP density has unbounded derivatives at its edge points , the above estimated rate is obtained via a special adaptation of the existing rate from the literature.
In practice, we do not know the parameters and of the reference MP density . Then we use the observed extreme statistics , and to estimate and , respectively. These lead to corresponding estimates and for the parameters and , respectively. The MP density function with estimated parameters is then
Finally, the distance between the data set and the MP law is estimated by
The following proposition guarantees a convergence rate for the estimator ,
Proposition 3.
As defined above, we have
| (8) |
The proof of the proposition is given in Appendix B.2.
The proposition is next used to define a rejection region for the null hypothesis. Consider . From (8), under the null hypothesis, will converge to zero at the optimal rate of . In contrast, under a deviation of ESDs in weight matrices such as emergence of Heavy Tails, will no longer tend to . This result, combined with the previous finding of data-effective regularization in weight matrices spectra, permits the definition of the spectral criterion for early stopping of the training process in a DNN introduced in section 4.
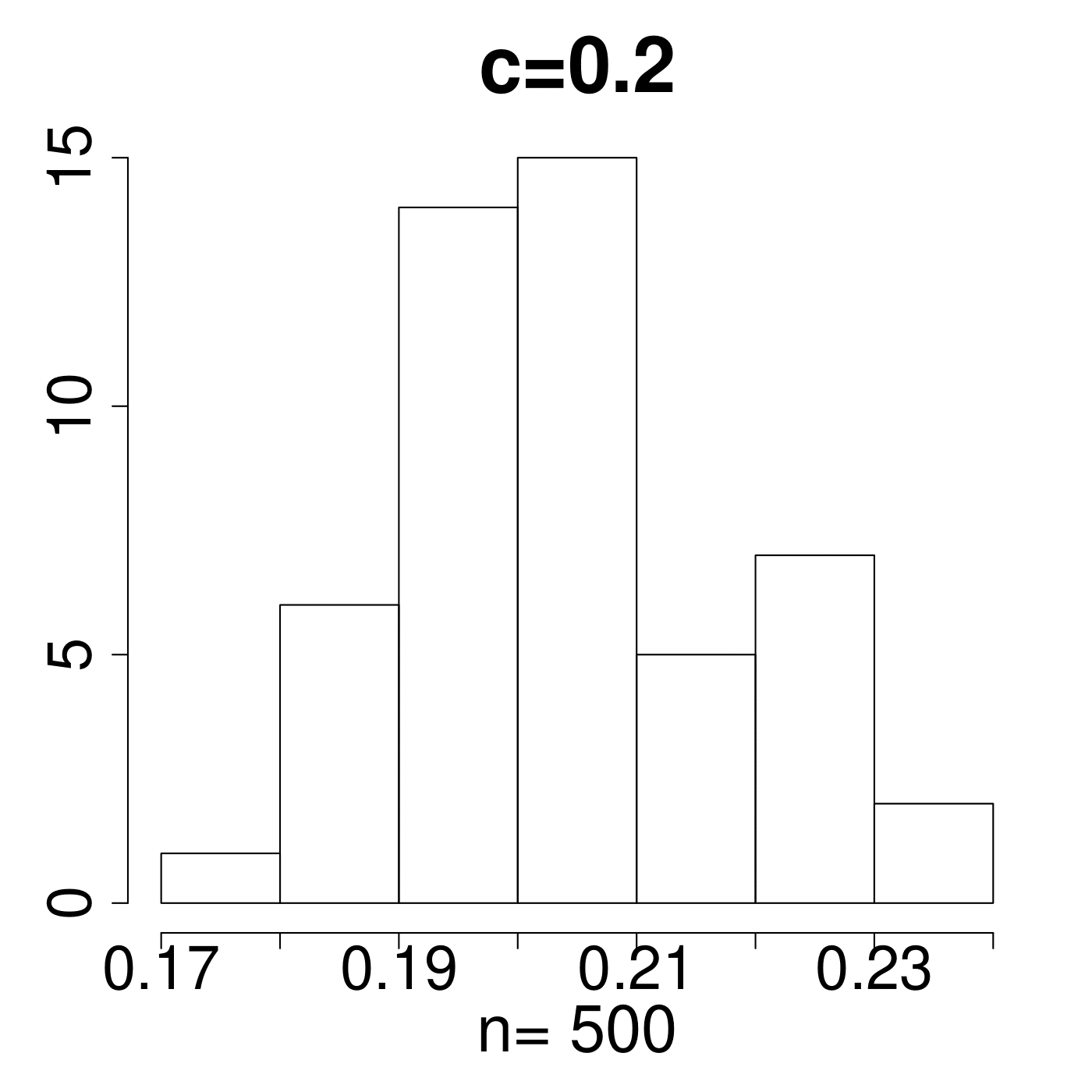
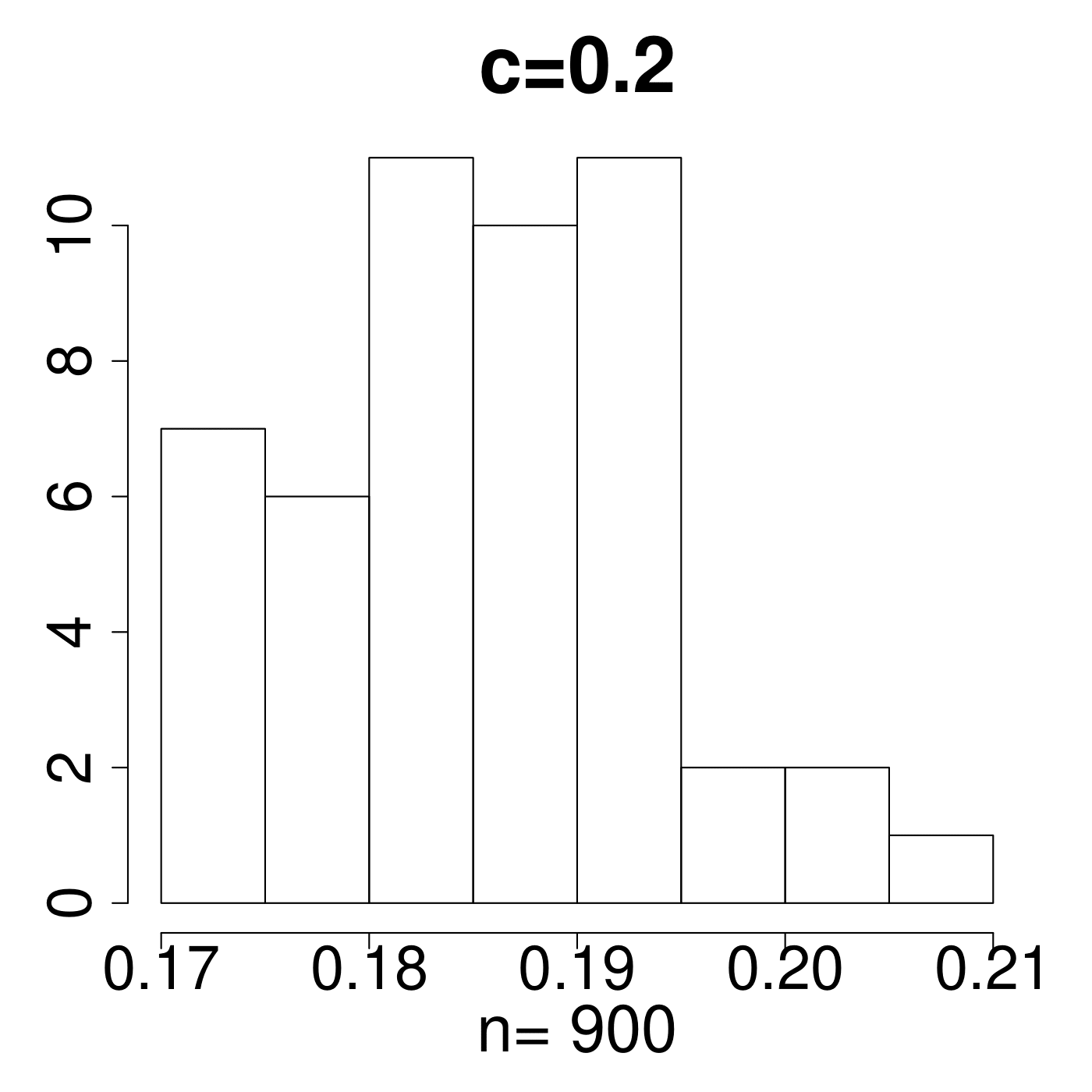
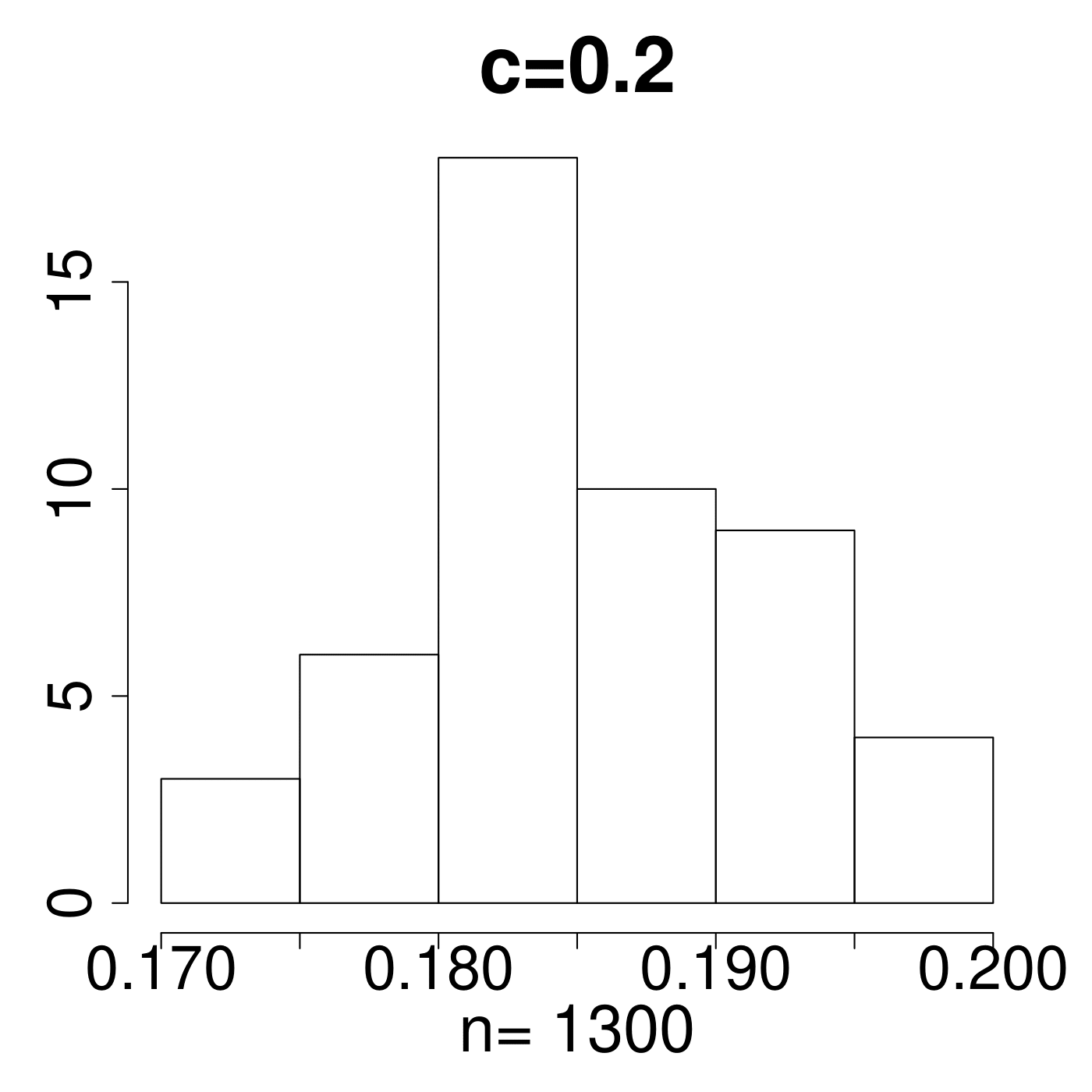
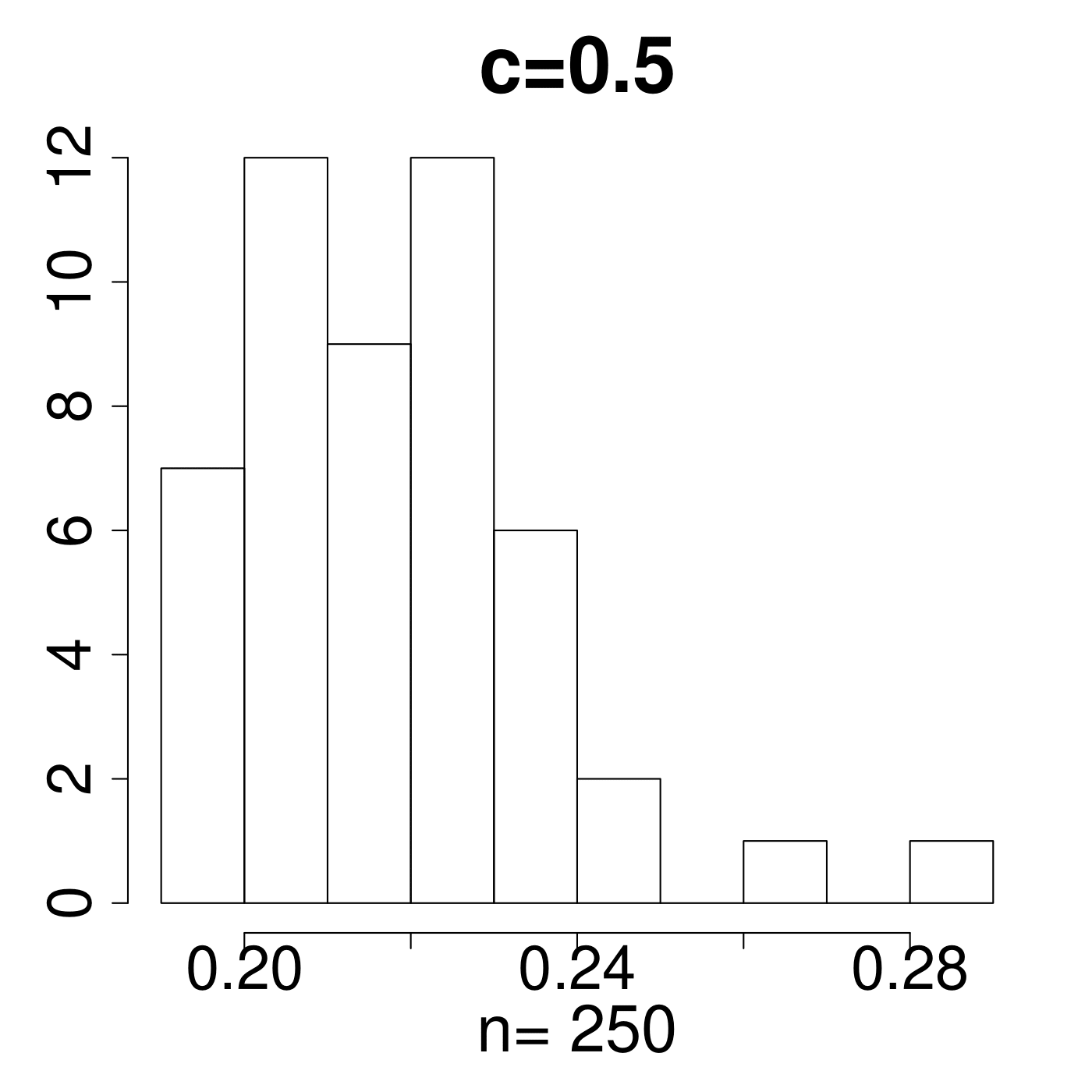
Remark 4.
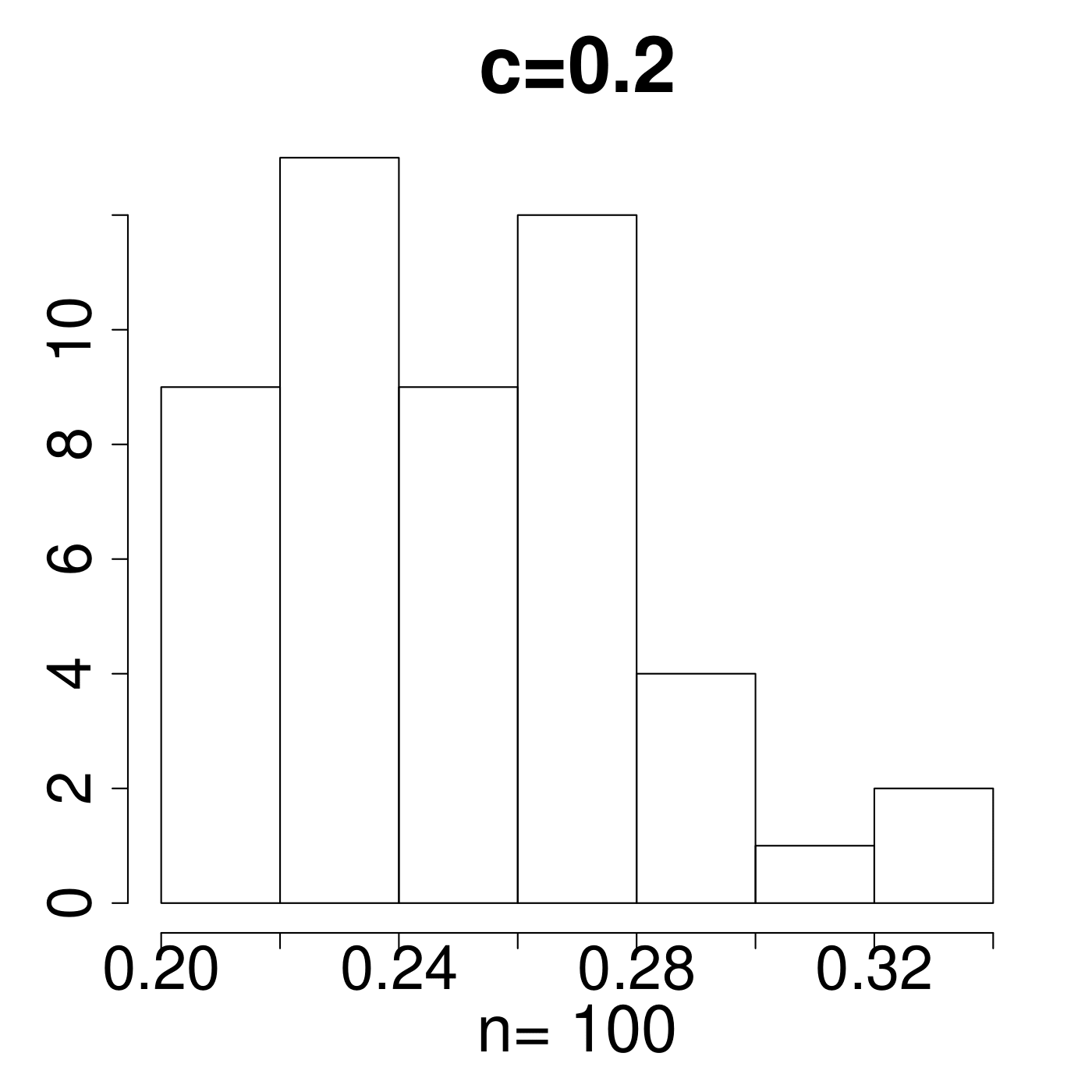
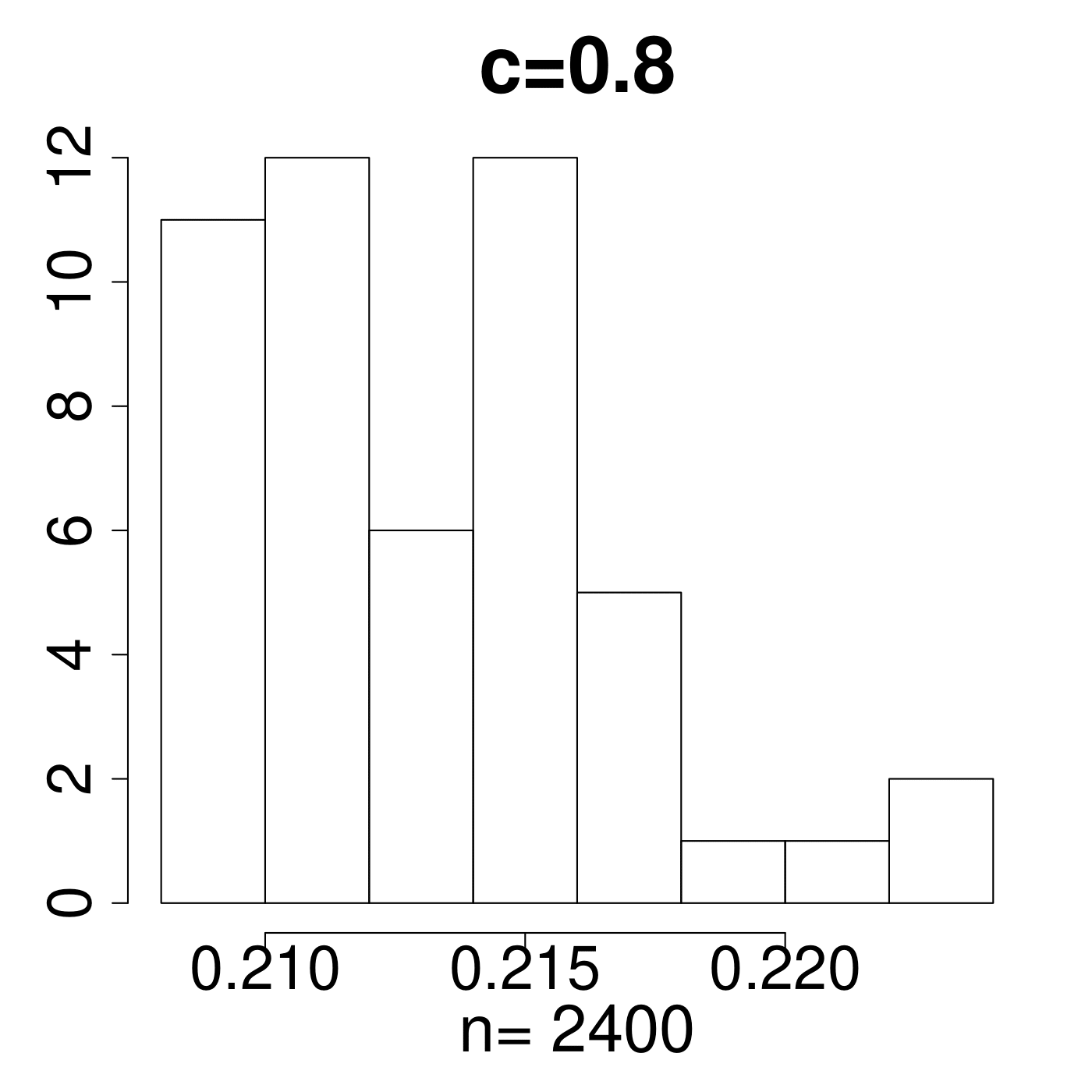
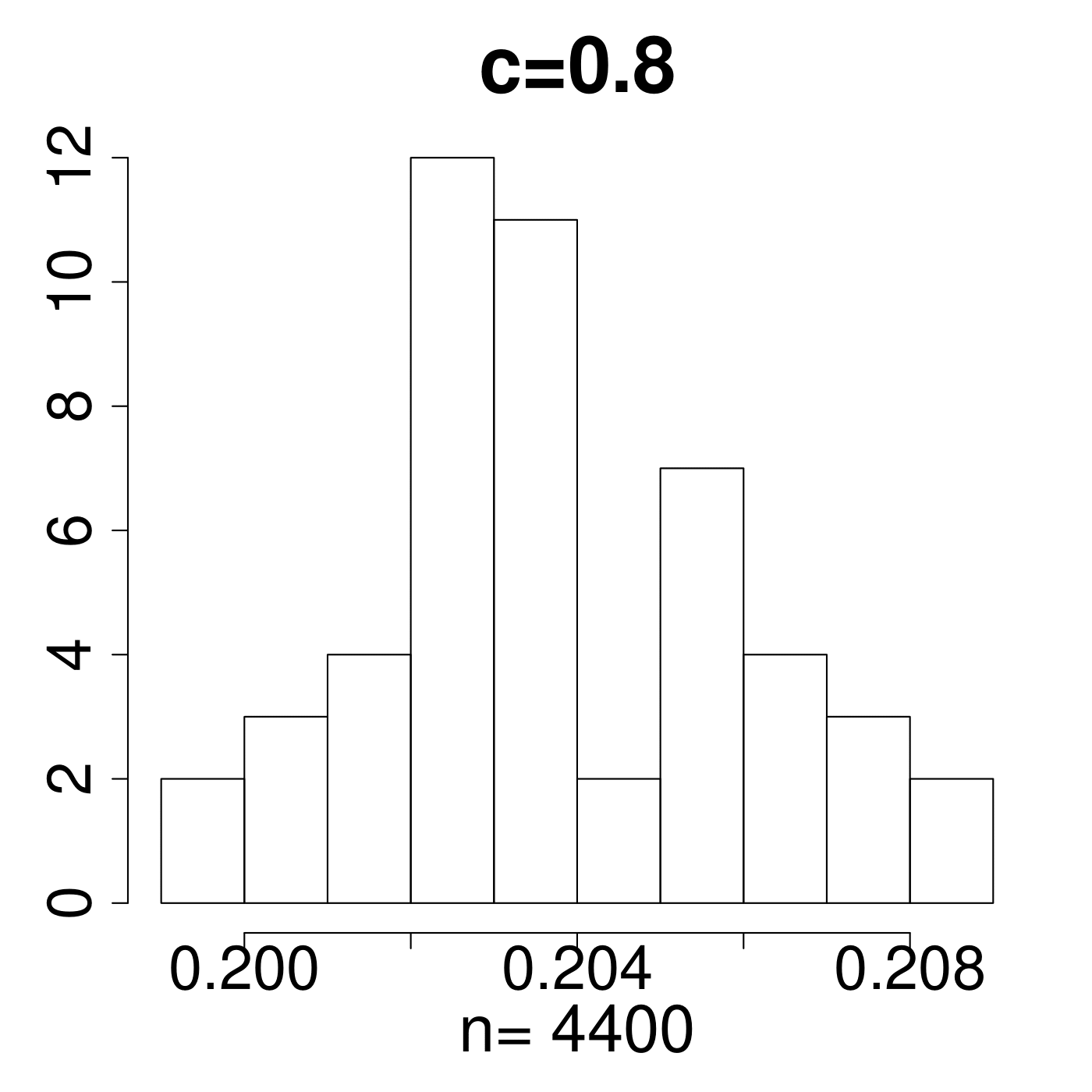
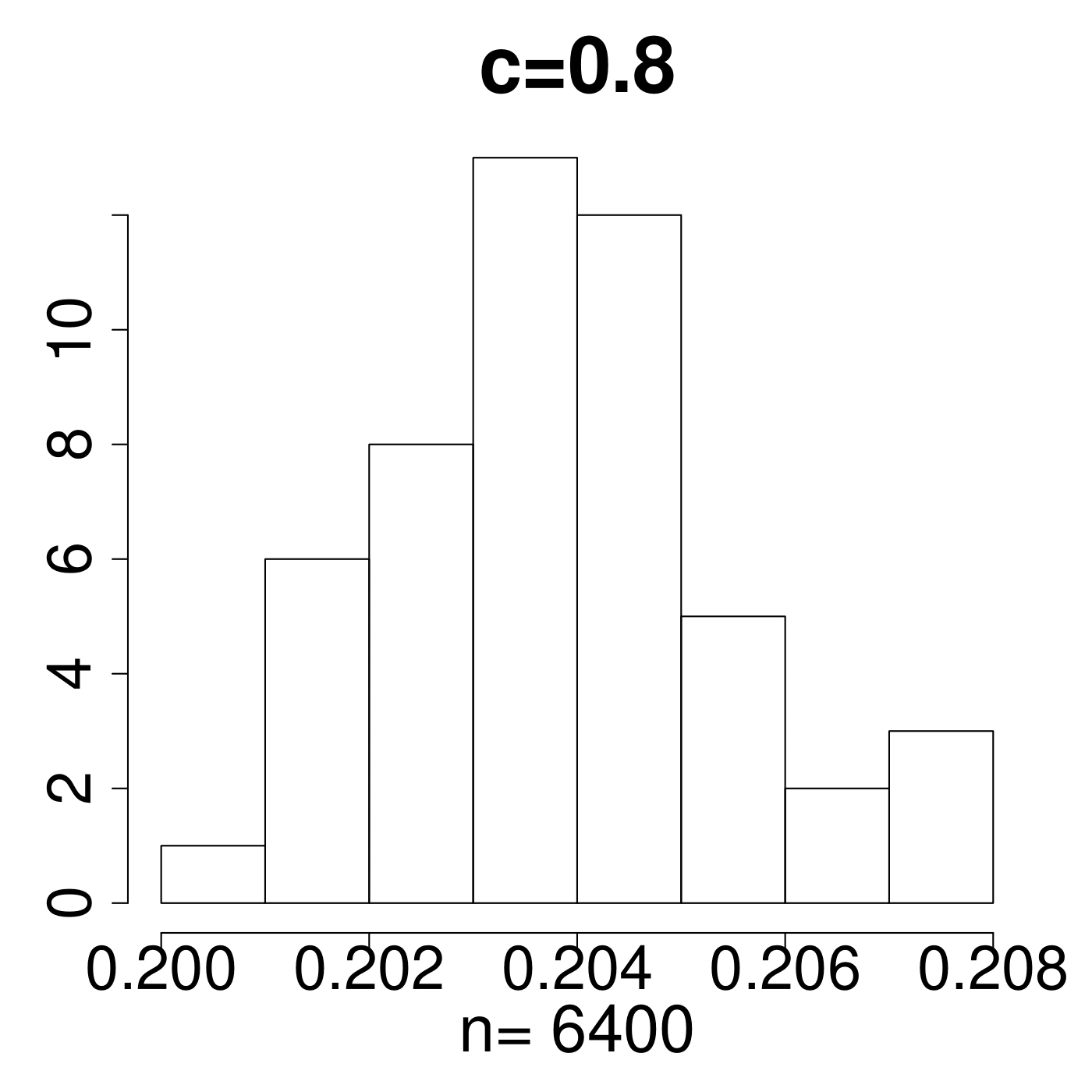
In the simulation for different MP Laws, we generate eigenvalues and get histograms of . As shown in Figure 11, the value always lies in the interval [0.15,0.25]. We empirically suggest the critical line with from theoretical simulations with comparison to the extreme value 0.35 displayed in Figure 11. The value of C is set a little higher due to the fact that any slight deviation from MP law will make the value in a high level. The satisfactory results selected by the spectral criterion from to are all acceptable in our experiments. Basically, any value of in the range of can be recommended for the spectral criterion from our experimental results.
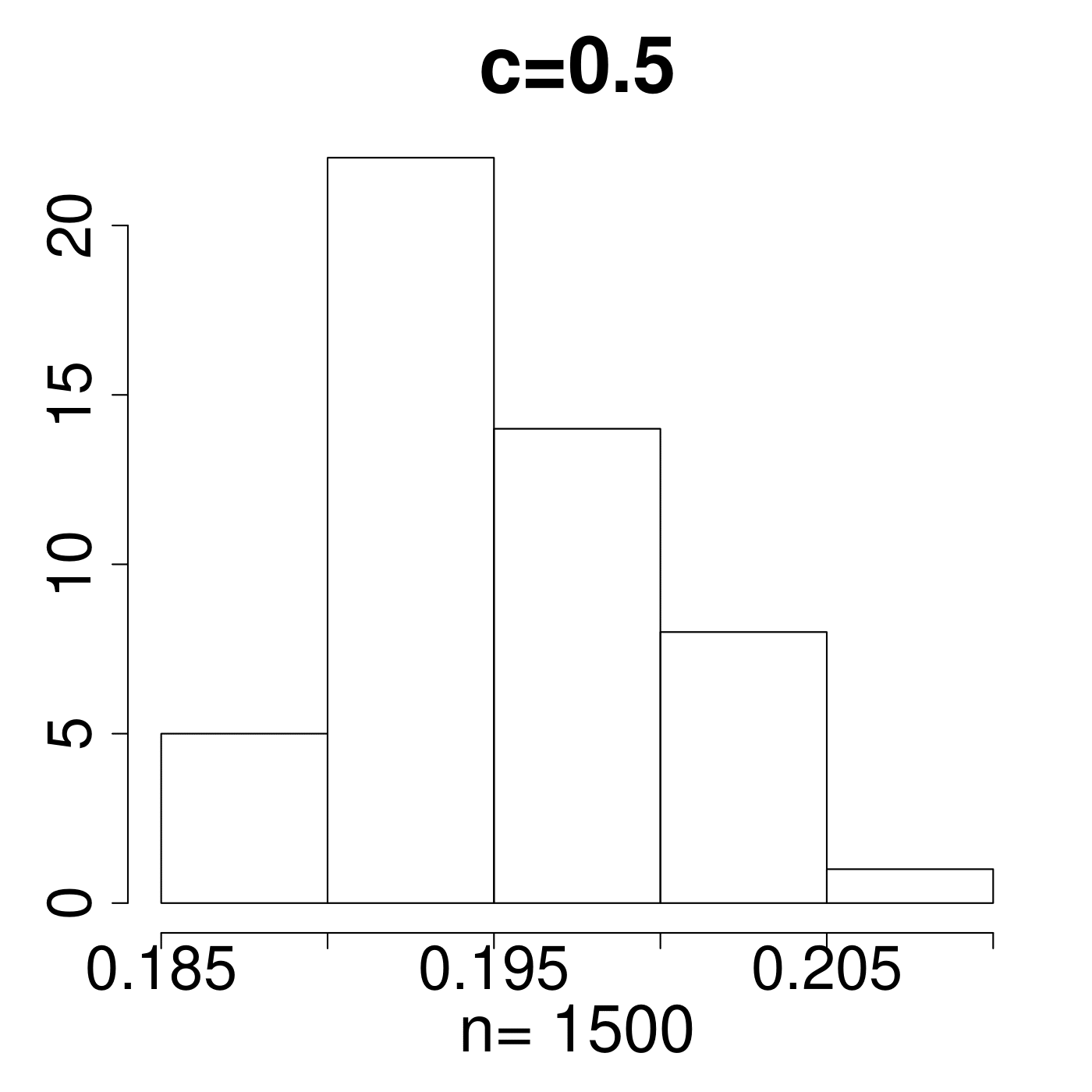
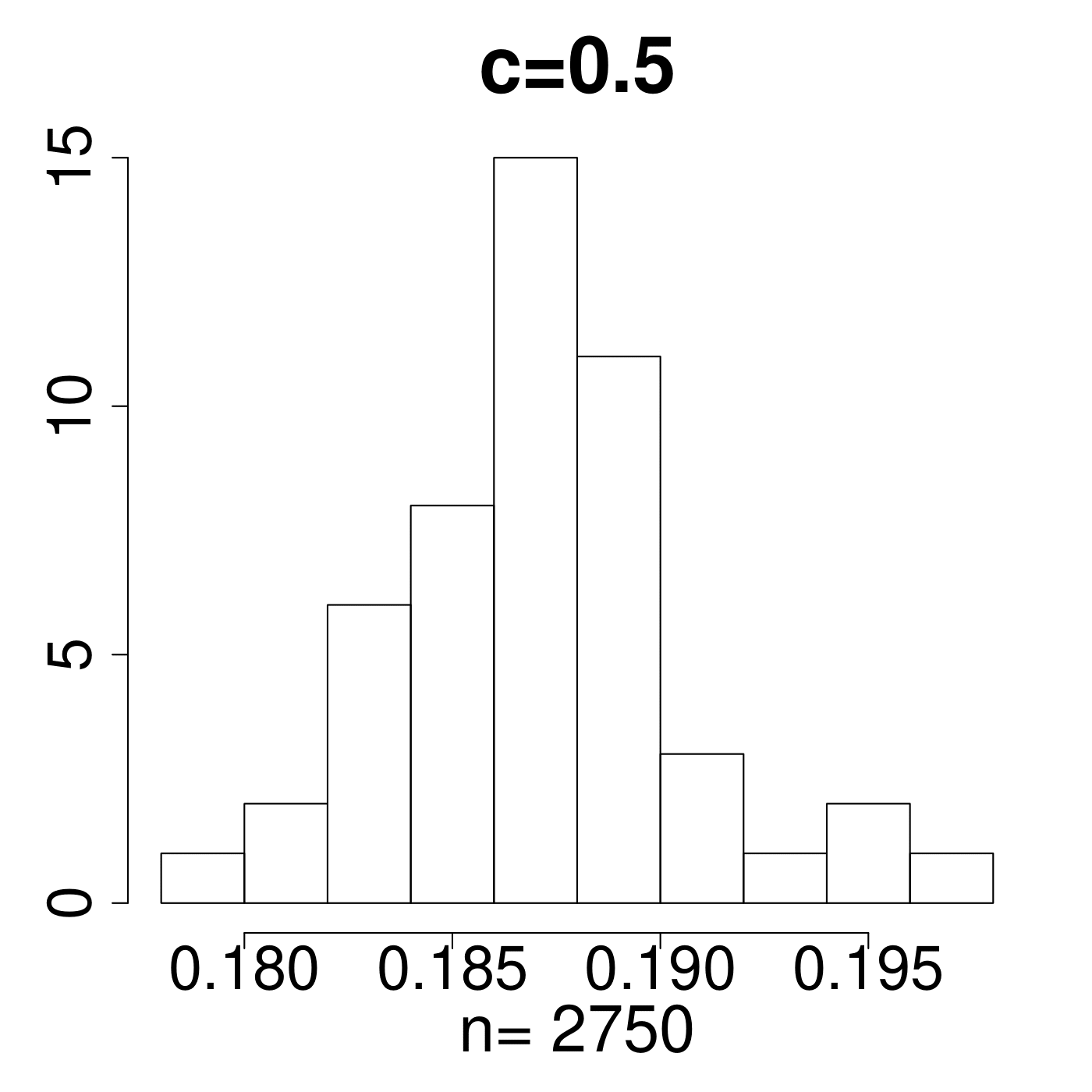
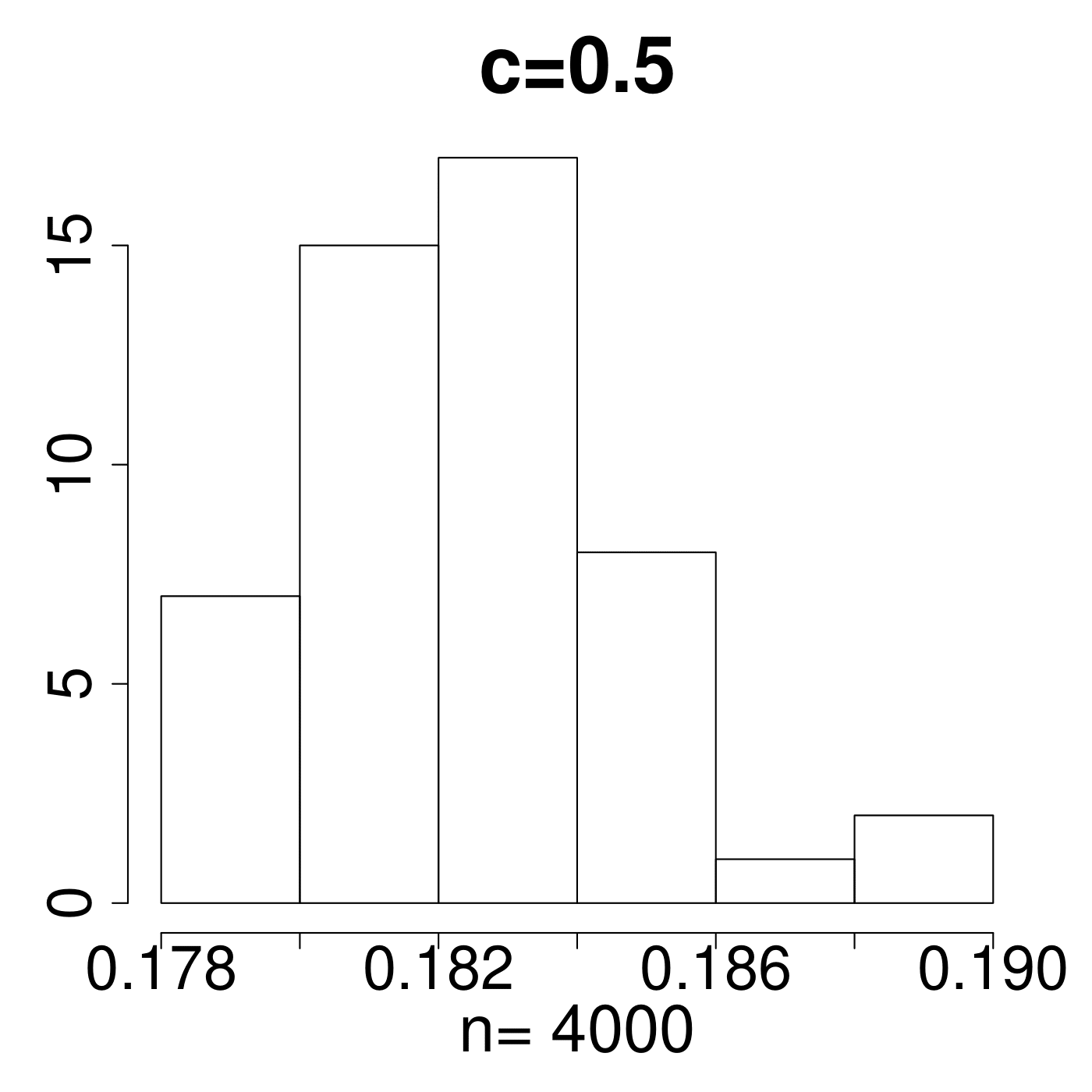
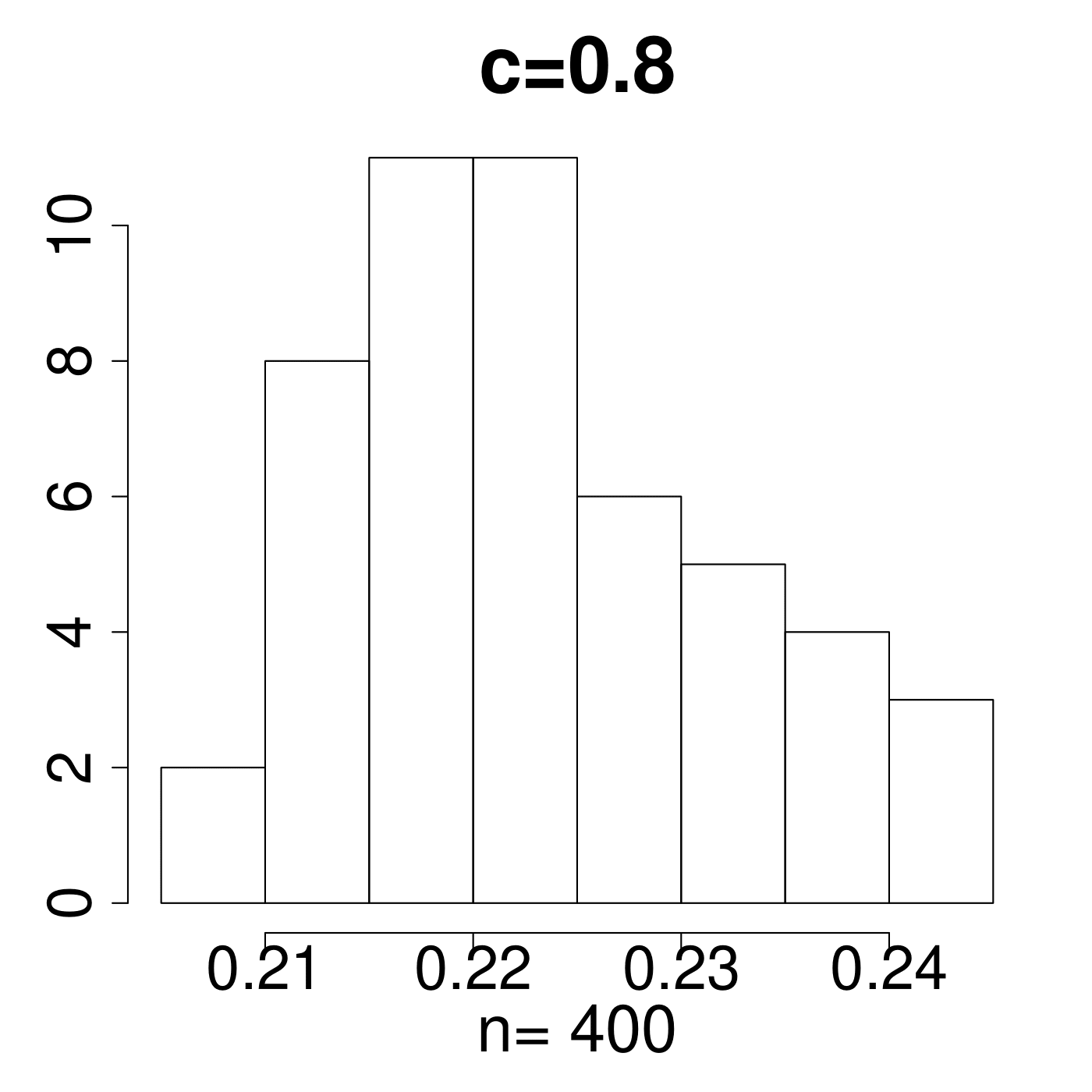
4.2 Early stopping in synthetic data experiments
Because of huge amount of data under analysis, we conduct experiments, stock the relevant data, and then check the results offline. The epochs where we save trained NNs for different architectures are all fixed at 0, 1, 2,…, 9, 10, 12, 16, 20,…, 248, the latter epochs having an increment of four. Even in such sparse data reservation, the total data we obtained is larger than 1TB.
We apply the spectra criterion developed in Section 4 to the stocked training epochs, and decide the early stopping time if the criterion is met. When this happens, we compare the test accuracy of the corresponding NN with that of the NN trained till the final epoch (248th). This comparison serves to measure the quality of the early stopping using the spectral criterion. Experiment results with are shown in Table 7 and Figure 12.
Comments:
-
•
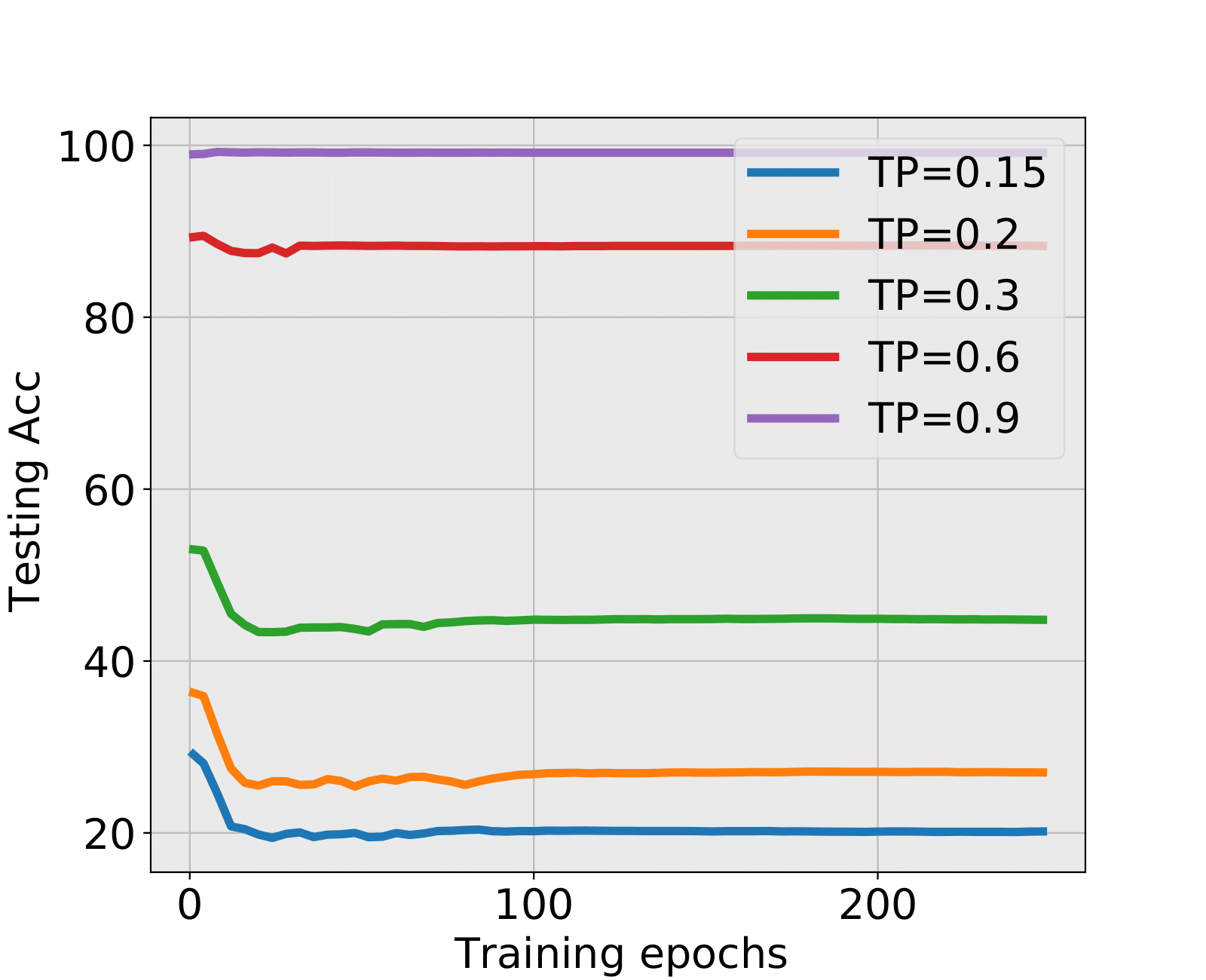
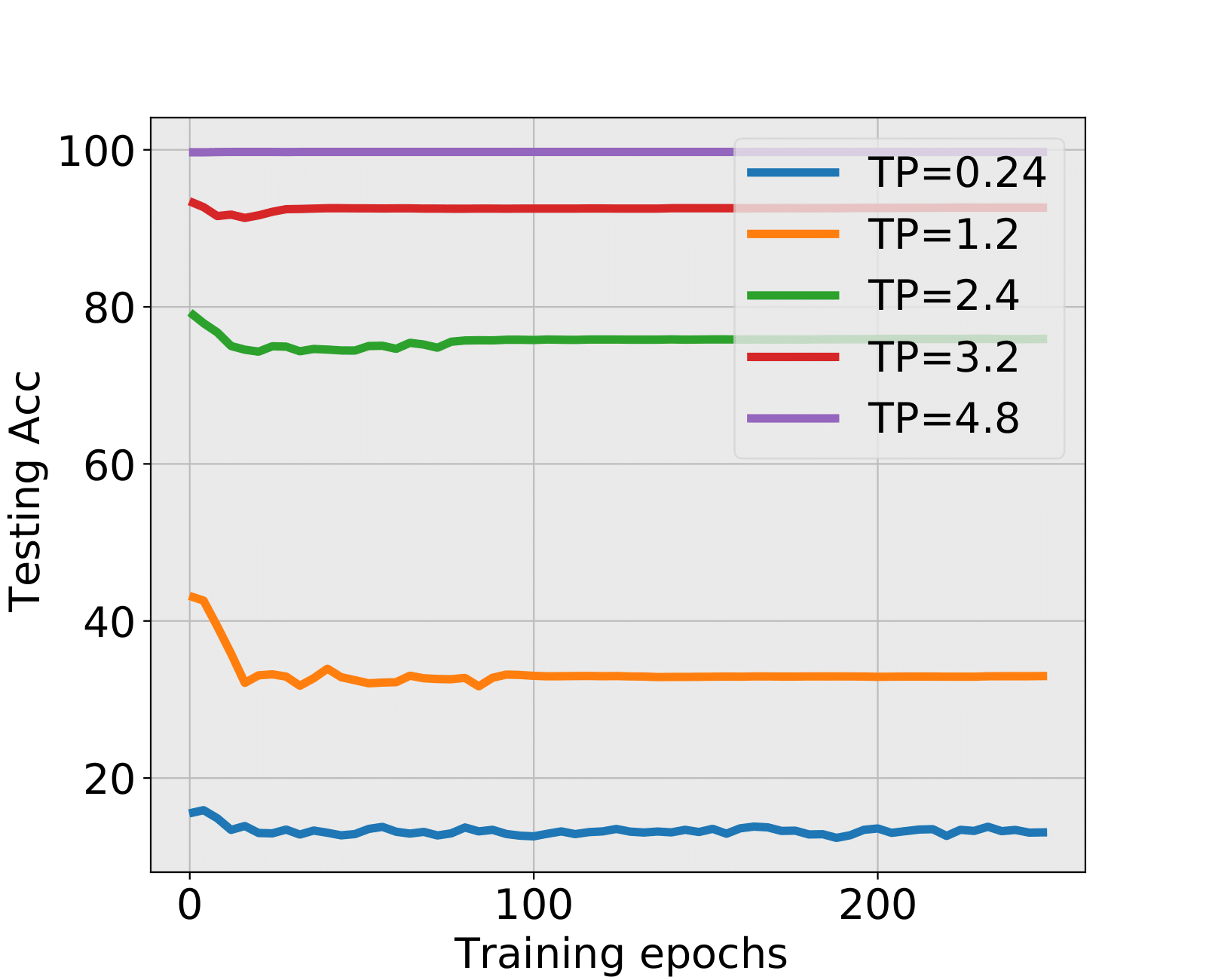
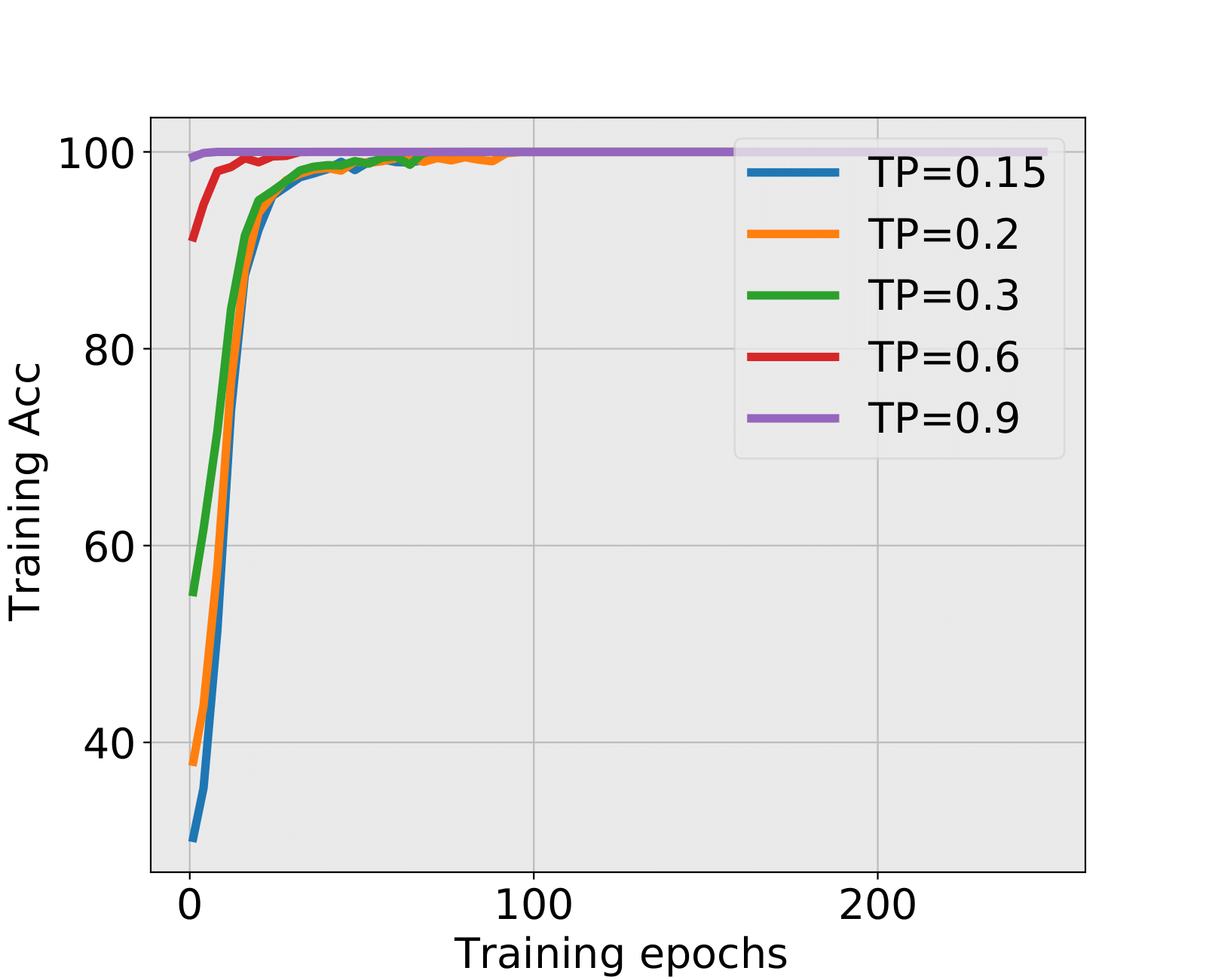
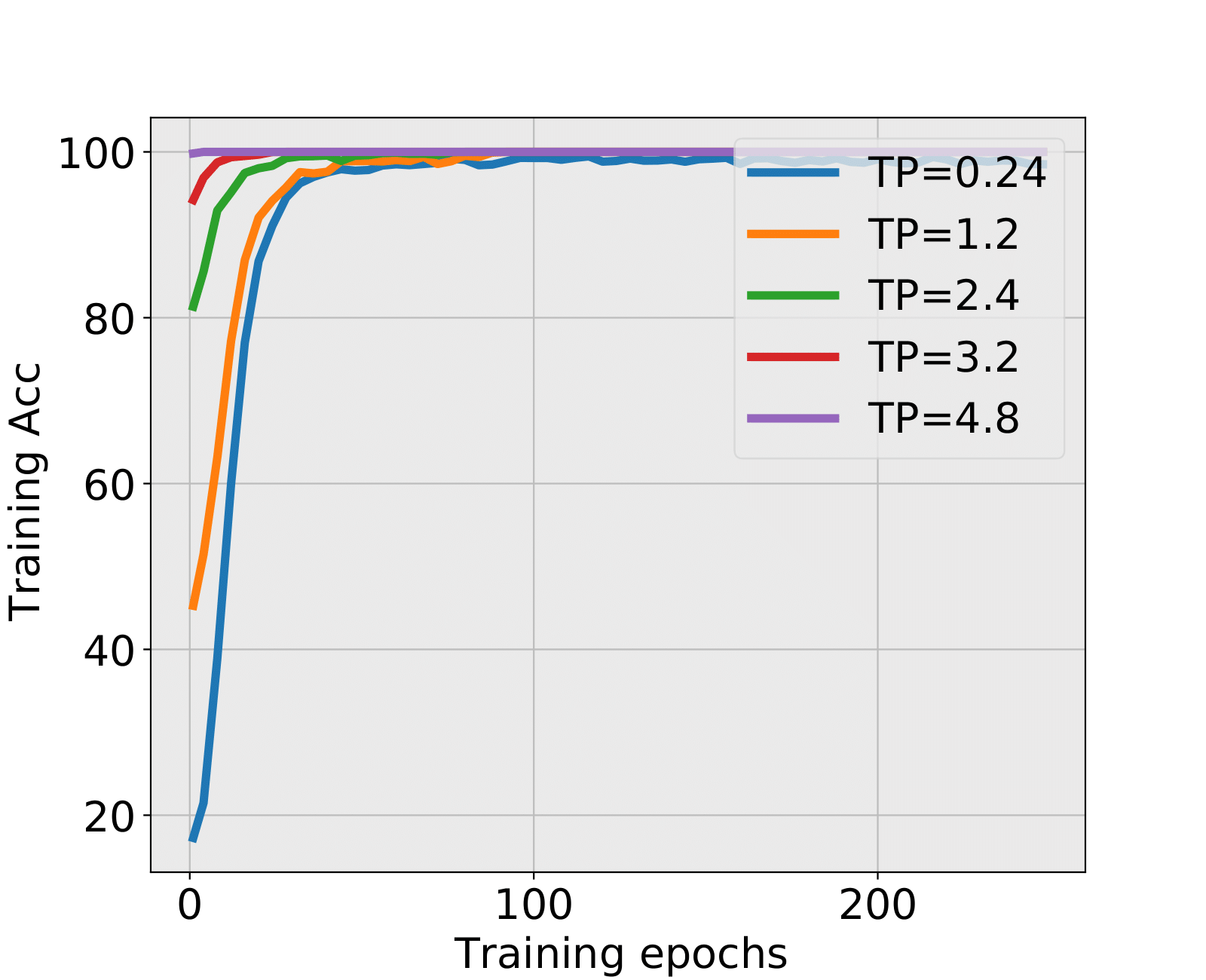
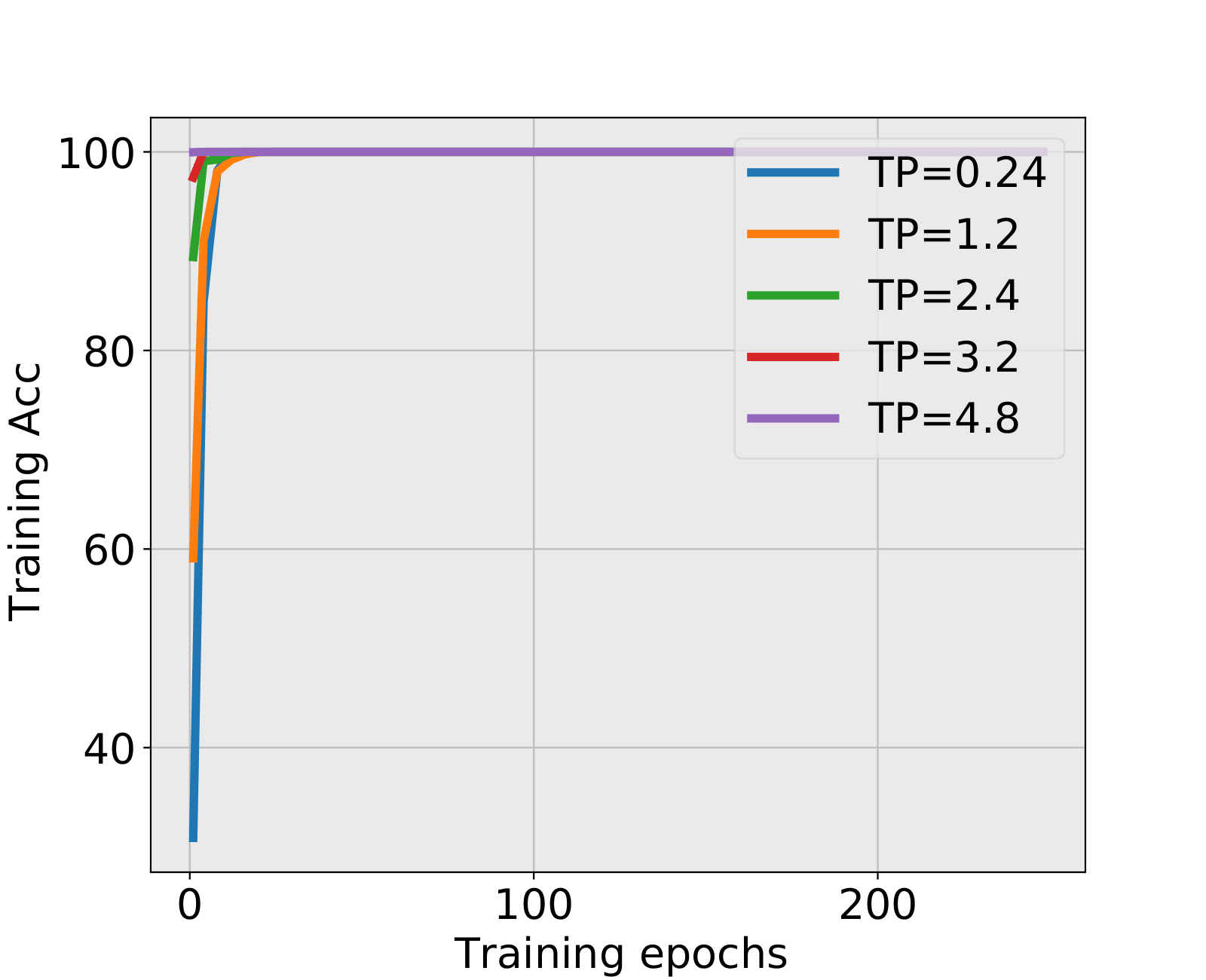
NN1+ and NN1+: During the first 20 epochs when SNR is low, the testing accuracy is decreasing while the training accuracy is increasing. Spectral criterion detects such hidden and problematic issues and recommends to early stop. It is truly remarkable that almost all early stopped NNs have higher test accuracies than the corresponding NNs trained till the end. The advantage is particularly important when the SNR is low. When SNR is large, there might be no alarm by the spectral criterion, see the situation of TP=0.9 in NN1+ and TP=4.8 in NN1+. This is in fact a consistency of the spectral criterion, no early stopping is needed, and the fully trained NNs have indeed higher test accuracies.
-
•
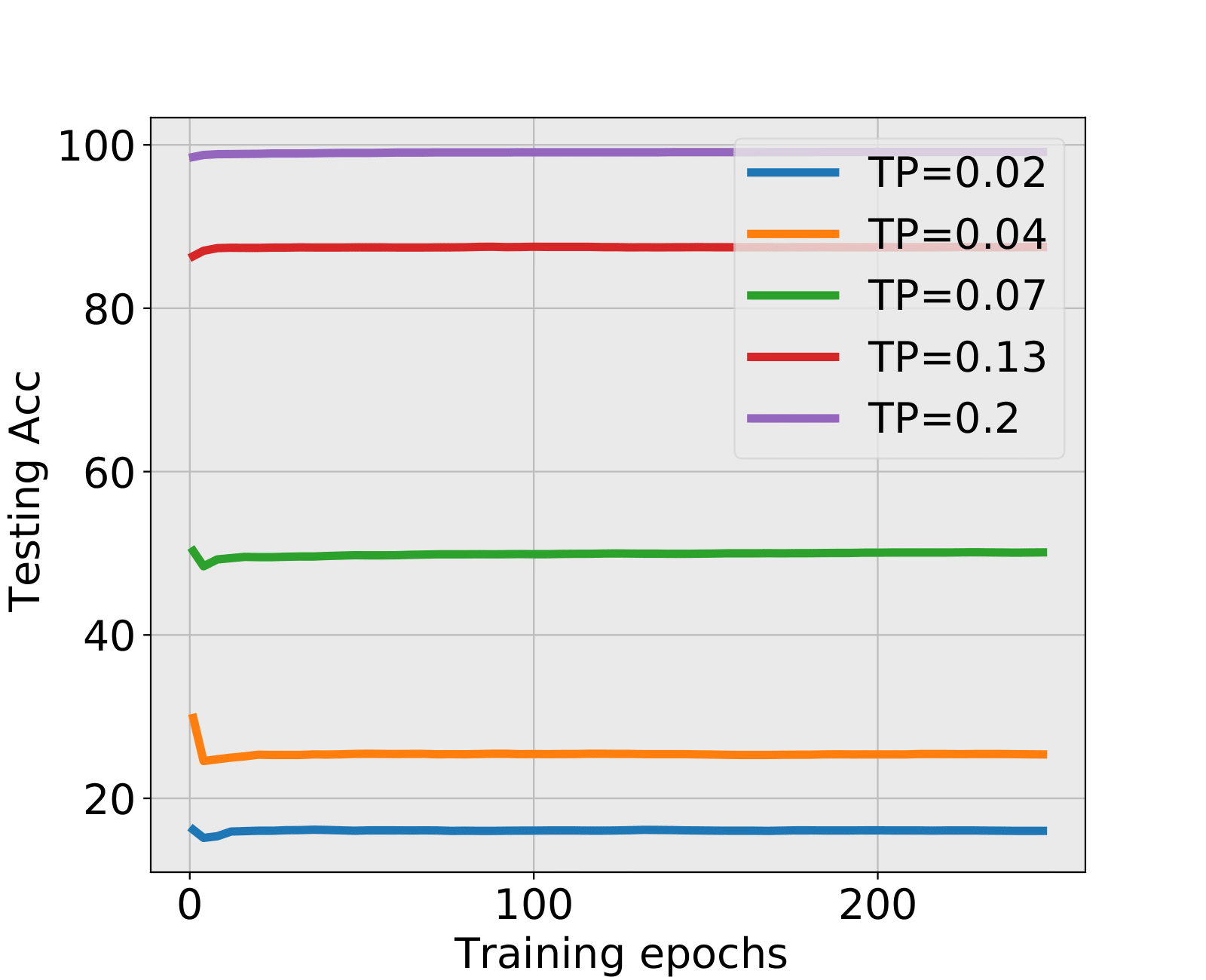
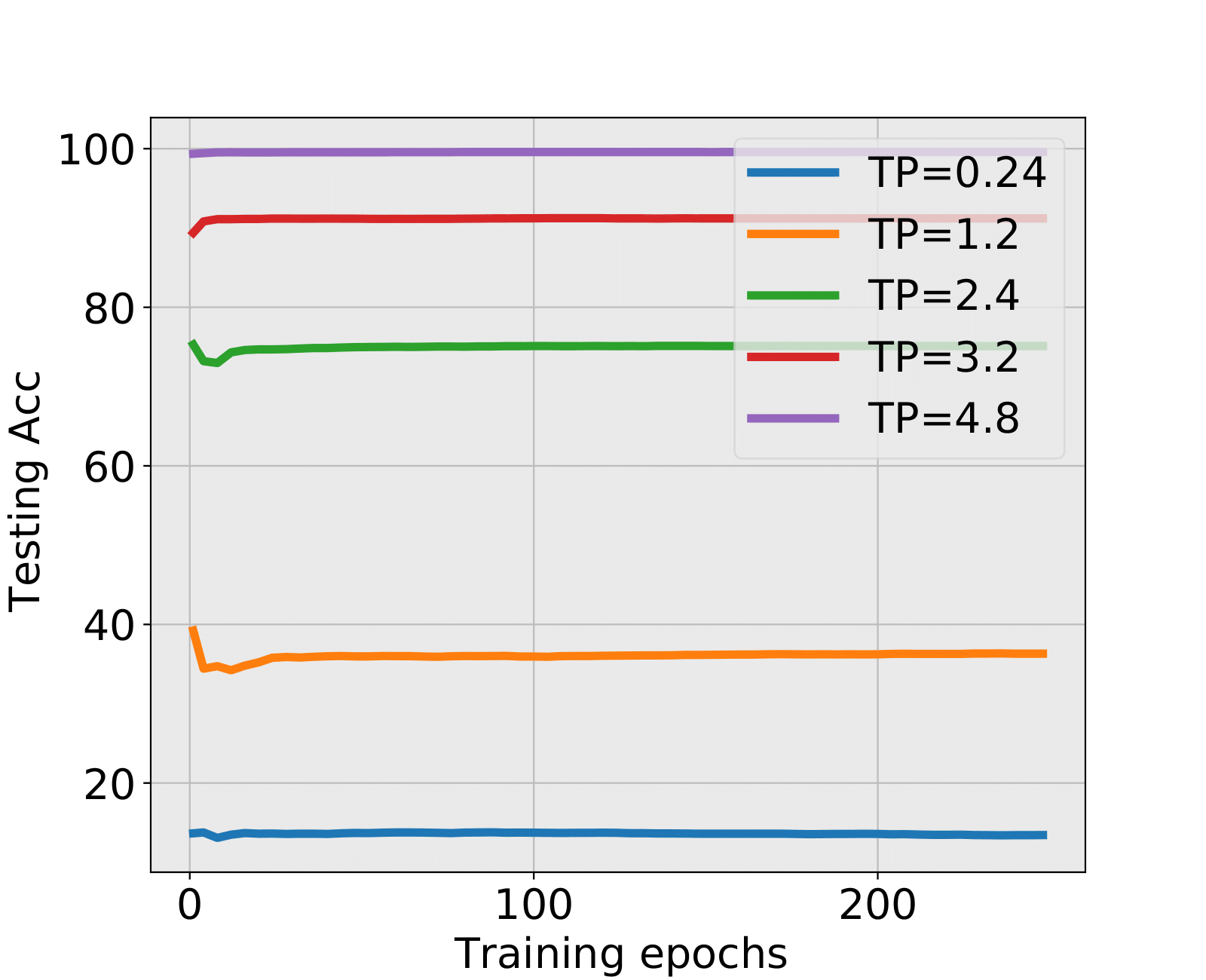
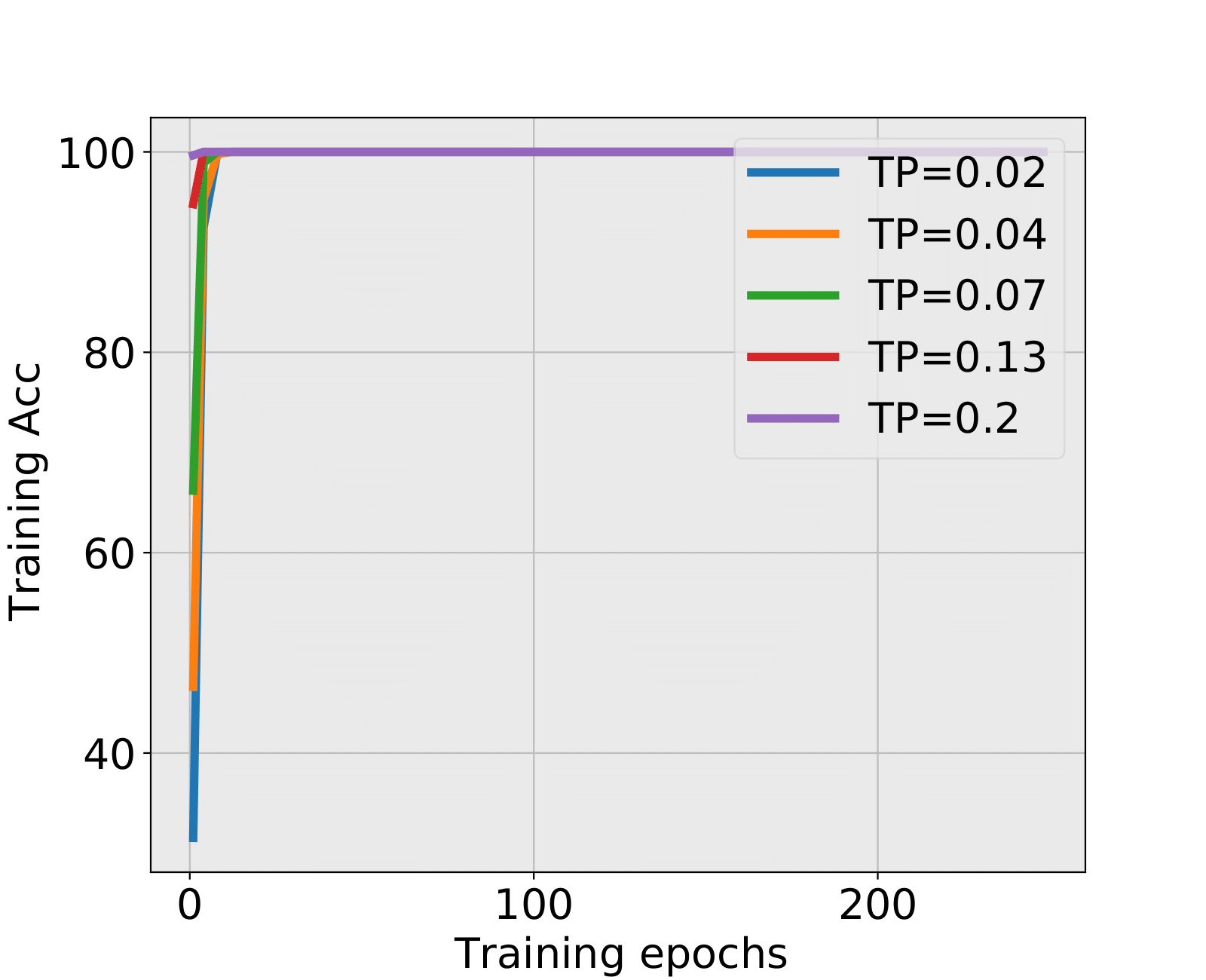
NN2+ and NN2+: Spectral Criterion detects stopping time under low SNR, nonetheless the testing accuracy is a little lower than the final testing accuracy. As the differences are very small, huge training time is cut off, and testing accuracy is ensured due to the emergence of well-trained structure that already seized sufficient information.
| The combination NN1+ | |||||||
|---|---|---|---|---|---|---|---|
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC2) | Test Acc | epoch(FC3) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.15 | 7 | 25.84% | 10 | 23.23% | HT | HT | 20.17% |
| 0.2 | 7 | 32.70% | 12 | 27.48% | HT | HT | 27.03% |
| 0.3 | 7 | 49.36% | 12 | 45.48% | HT | HT | 44.80% |
| 0.6 | 8 | 88.52% | 32 | 88.32% | BT | BT | 88.30% |
| 0.9 | - | - | LT | LT | 99.13% | ||
| The combination NN1+ | |||||||
|---|---|---|---|---|---|---|---|
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC2) | Test Acc | epoch(FC3) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.24 | 9 | 14.69% | 16 | 13.89% | HT | HT | 13.08% |
| 1.2 | 7 | 38.61% | 12 | 35.84% | HT | HT | 32.98% |
| 2.4 | 7 | 77.19% | 16 | 74.55% | BT | BT | 75.92% |
| 3.2 | 9 | 92.11% | - | BT | LT | 92.64% | |
| 4.8 | - | - | LT | LT | 99.73% | ||
| The combination NN2+ | |||||||
|---|---|---|---|---|---|---|---|
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.02 | 6 | 14.89% | 7 | 15.84% | HT | BT | 16.02% |
| 0.04 | 8 | 24.78% | 7 | 23.34% | HT | BT | 25.38% |
| 0.07 | 5 | 48.31% | 6 | 48.63% | BT | BT | 50.12% |
| 0.13 | 6 | 87.03% | - | BT | LT | 87.50% | |
| 0.2 | - | - | LT | LT | 99.14% | ||
| The combination NN2+ | |||||||
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.24 | 10 | 13.08% | 6 | 12.89% | HT | BT | 13.44% |
| 1.2 | 12 | 34.22% | 5 | 34.63% | BT | BT | 36.31% |
| 2.4 | 5 | 72.59% | 16 | 74.61% | BT | BT | 75.12% |
| 3.2 | - | - | LT | LT | 91.20% | ||
| 4.8 | - | - | LT | LT | 99.59% | ||
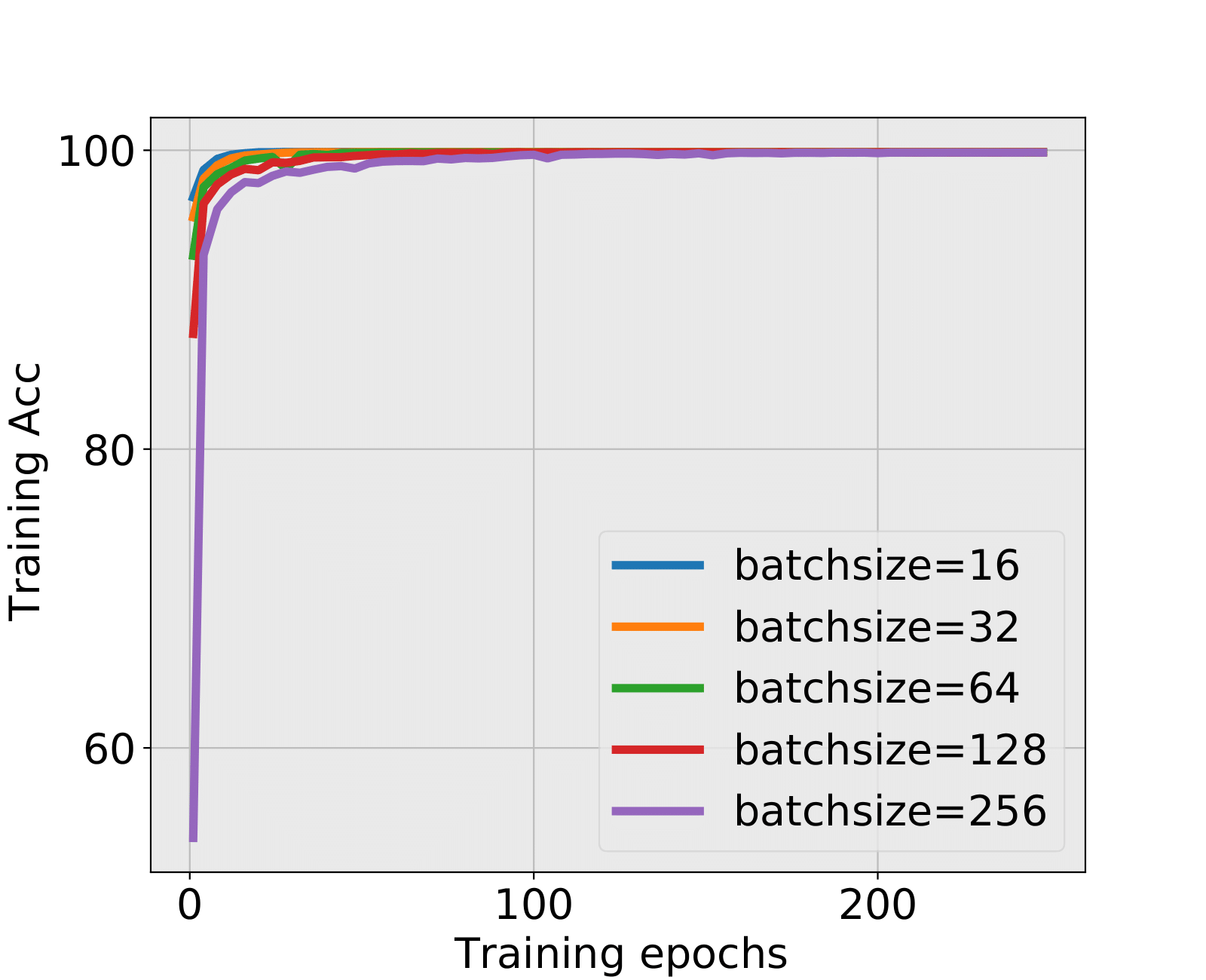
The spectral criterion is valid when overfitting appears in training. In such situation, the training and testing accuracies do not have the same tendency. As training epochs increase, Figure 12 shows that training accuracy tends to 100% while testing accuracy is highly related with the tuning parameter or . Without testing data, the spectral criterion could propose an early stopping time even when the training accuracy is increasing.
When the spectral criterion gives different epochs in different layers, there is a question that how to decide a stopping time? From our experimental results, we empirically suggest that any epoch after the time some layer hits the critical value is suitable to stop, and it is strongly recommended to stop training if there is more than one layer hitting the critical value. For example, TP=0.15 in NN1+, epochs in 7-10 are all suitable early stopping time with a guaranteed test accuracy.
4.3 Early stopping in real data experiments
In real data experiments, we still follow the settings in section 4.2 to evaluate the quality of early stopping time using the spectral criterion by checking LeNet/MiniAlexNet+MNIST/CIFAR10. Experiment results are shown in Table 8.
Comments:
-
•
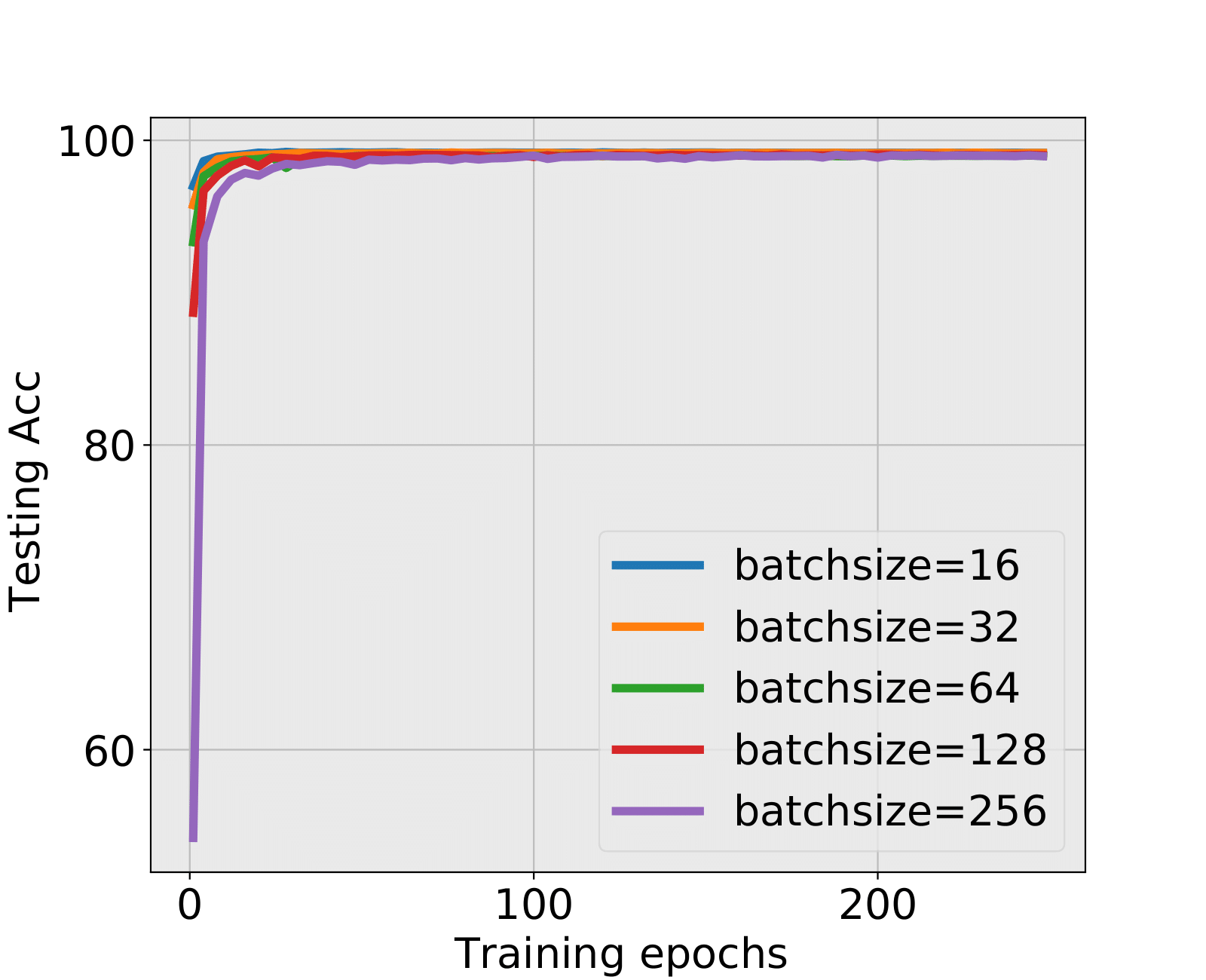
LeNet+MNIST and LeNet+CIFAR10: Testing accuracy and training accuracy are both increasing during the training process. The FC2 layer in LeNet hits the critical value first, and provides a time which could stop. For MNIST, the test accuracy in the early stopped epoch only has the negligible difference with the final test accuracy; For CIFAR10, the test accuracy is lower but still guaranteed compared with the final test accuracy. We check the FC1 layer for CIFAR10, find that the “strongly suggested” stopping epochs in batch sizes 16 and 32 have much higher test accuracies, and in larger batch sizes, we could stop for saving time or keep training for a higher test accuracy.
-
•
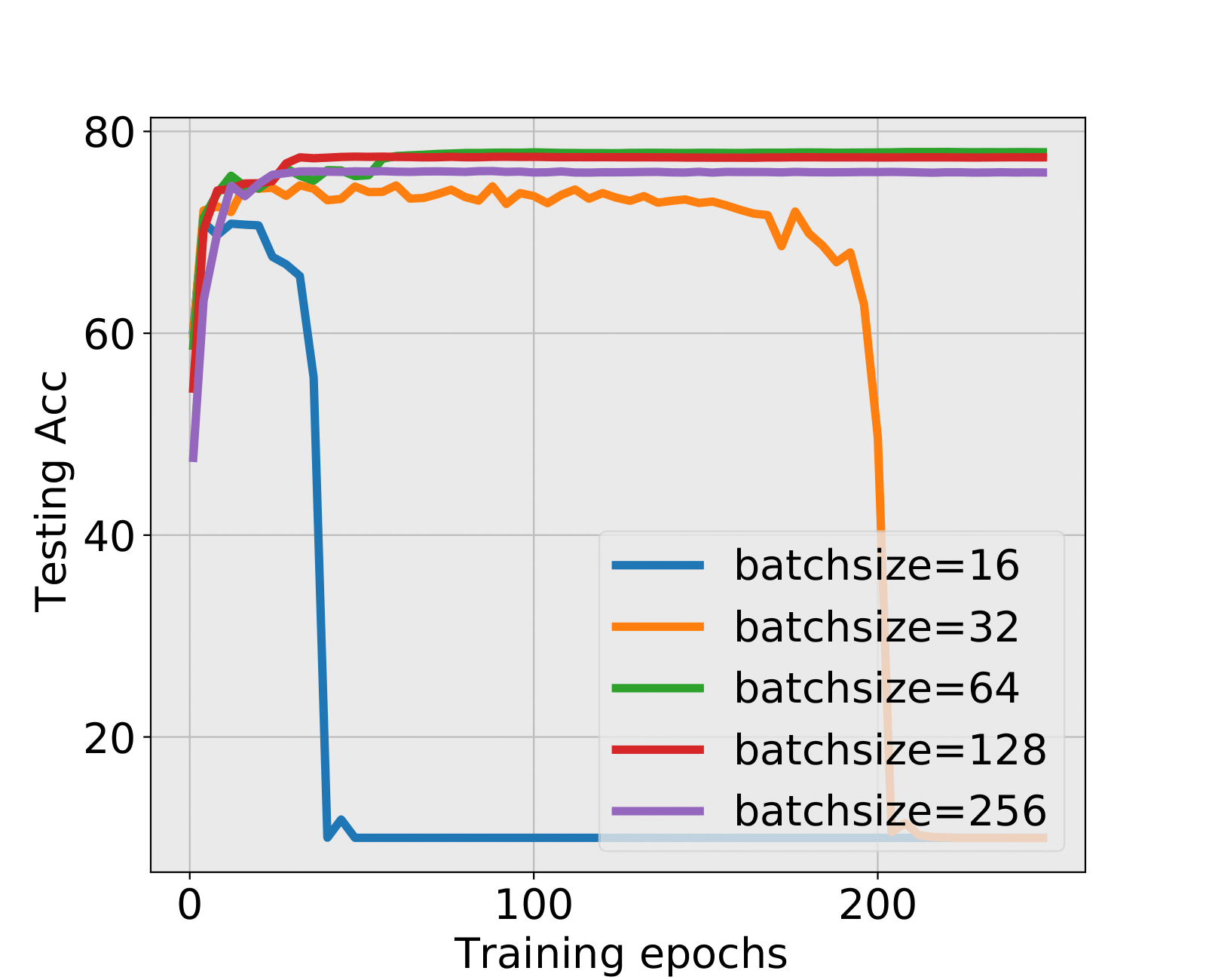
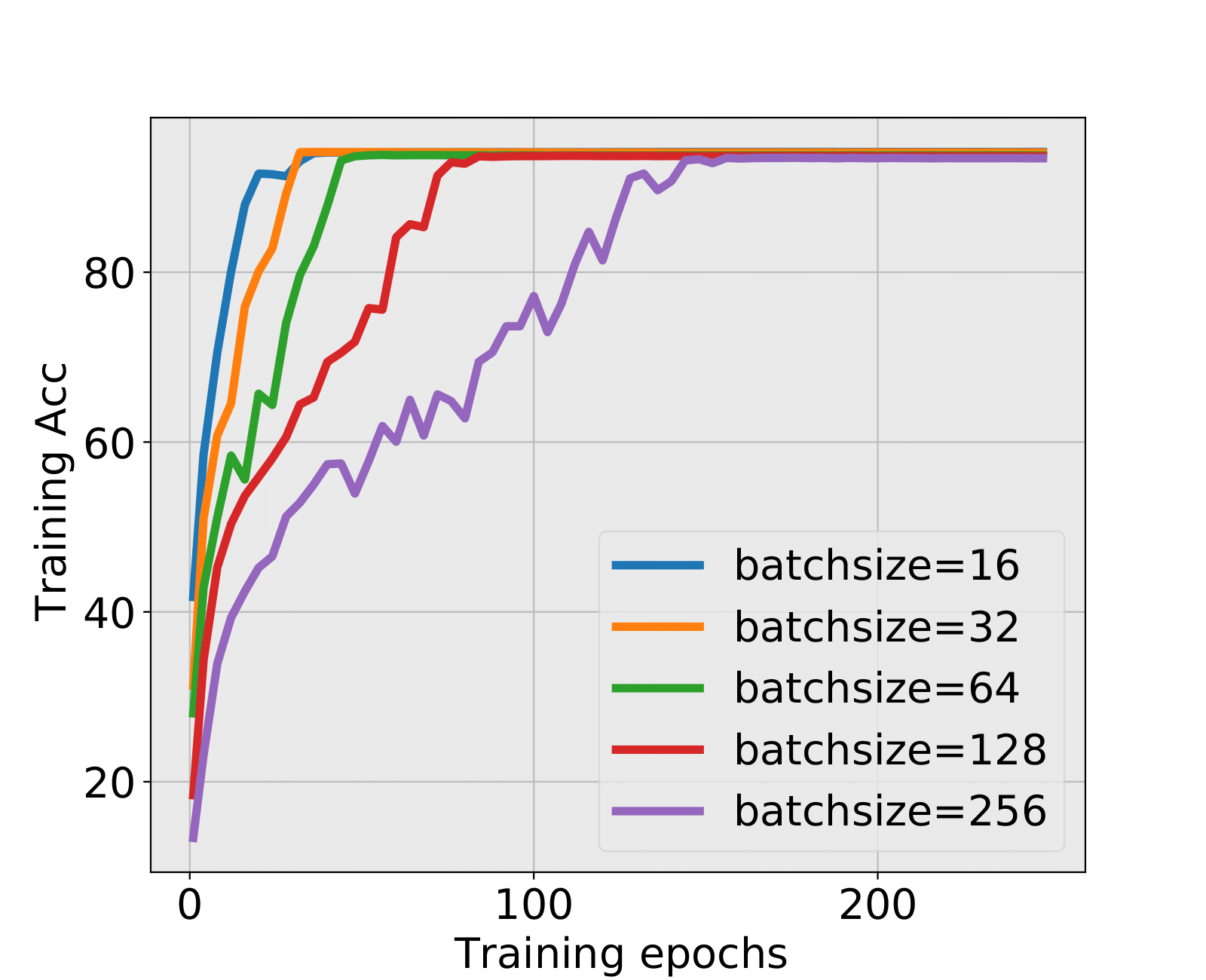
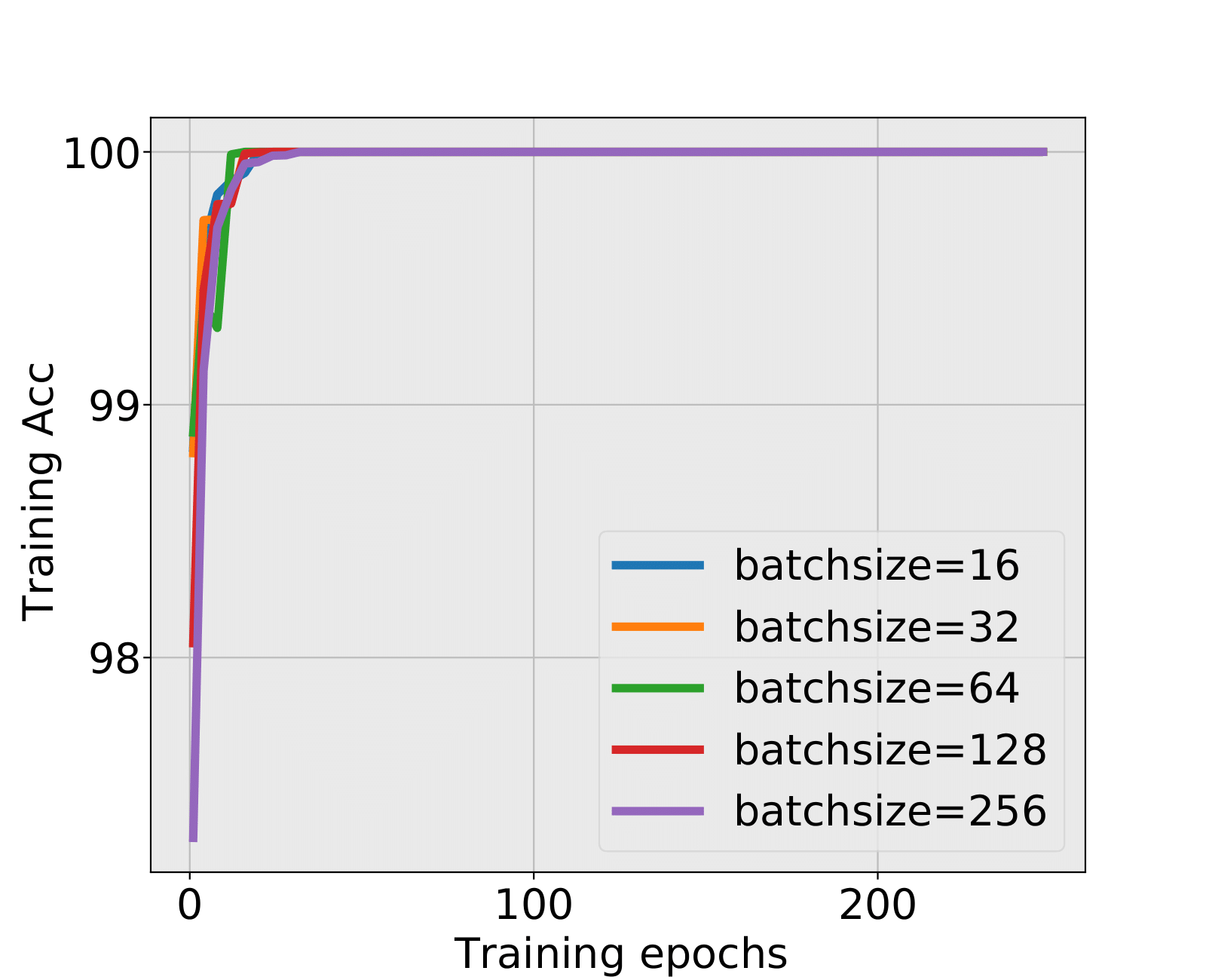
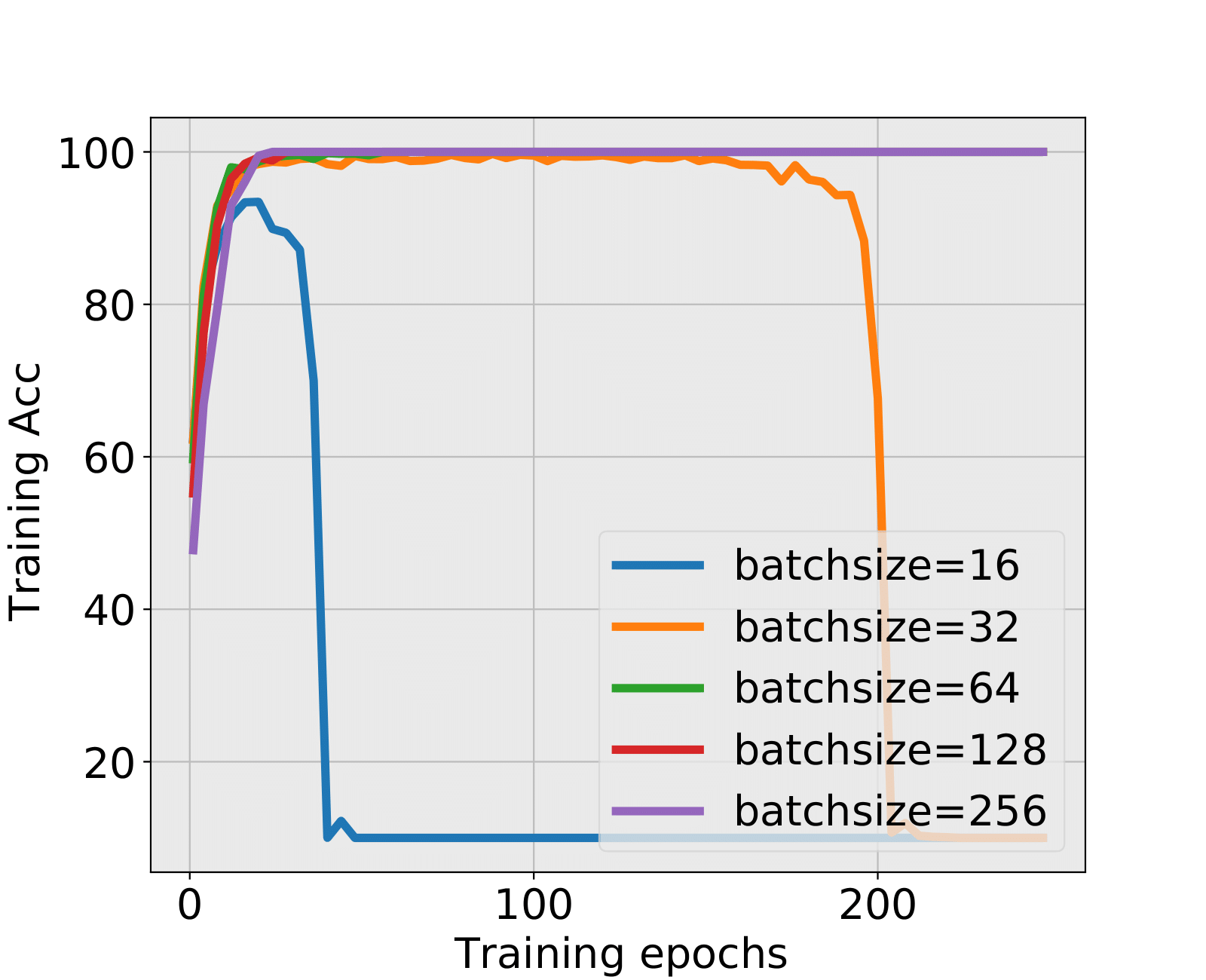
MiniAlexNet+MNIST and MiniAlexNet+CIFAR10: The FC1 layer always hits the critical value first. For MNIST, the test accuracy still has negligible difference with the final test accuracy in small batch sizes 16 and 32, and no early stopping epoch is found by the spectral criterion in large batch sizes. For CIFAR10, it is the most representative experiment because the training explosion happens in batch sizes 16 and 32. We figure out whether spectral criterion gives alarm and performs well. The answer is yes. The spectral criterion strongly suggested to stop before training explosion and has a quite high test accuracy. In large batch sizes, the test accuracies are also ensured with a large amount of cutting training time.
Table 8 shows the robustness and well performance of the spectral criterion. Actually, makes the critical value quite strict, even generated from MP Law, could achieve the extreme value 0.35, any slight deviation from MP Law could hit the critical value, which we still consider it as MP Law or MP Law + Bleeding out.
We tune the constant to give further check. Details are shown in Appendix D. An intersting thing is that when , there is nearly no early stopping or training alarm on MNIST, and high quality epochs are still offered in the training of CIFAR10. We also note that with , the spectral criterion predicts the explosion quite accurately in MiniAlexNet+CIFAR10, as the first hit on the critical line is epochs 28 and 188, the explosion begins. (We select epoch 36,196 for smoothness consideration, seen in Figure 13(d) and Table 10.)
| The combination LeNet+MNIST | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | - | 16 | 99.08% | LT | BT | 99.17% | |
| 32 | - | 40 | 99.13% | LT | BT | 99.17% | |
| 64 | - | 68 | 98.98% | LT | BT | 98.98% | |
| 128 | - | 124 | 98.91% | LT | BT | 99.03% | |
| 256 | - | - | LT | LT | 98.96% | ||
| The combination LeNet+CIFAR10 | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 24 | 61.37% | 8 | 61.62% | BT | HT | 64.99% |
| 32 | 60 | 64.78% | 10 | 57.94% | BT | HT | 64.57% |
| 64 | - | 28 | 59.19% | LT | BT | 62.49% | |
| 128 | - | 60 | 61.38% | LT | BT | 61.83% | |
| 256 | - | 84 | 54.23% | LT | BT | 60.49% | |
| The combination MiniAlexNet+MNIST | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 4 | 99.23% | - | BT | LT | 99.49% | |
| 32 | 20 | 99.42% | - | BT | LT | 99.41% | |
| 64 | - | - | LT | LT | 99.42% | ||
| 128 | - | - | LT | LT | 99.39% | ||
| 256 | - | - | LT | LT | 99.31% | ||
| The combination MiniAlexNet+CIFAR10 | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 3 | 69.05% | 9 | 72.02% | HT | RC | 10%(explode) |
| 32 | 4 | 72.17% | 16 | 74.64% | HT | RC | 10%(explode) |
| 64 | 5 | 71.61% | 28 | 76.35% | BT | BT | 77.94% |
| 128 | 10 | 74.14% | - | BT | LT | 77.43% | |
| 256 | 24 | 75.70% | - | BT | LT | 75.93% | |
5 Conclusion
Data classification difficulty has a great impact on the spectra of weight matrices. We study it from three aspects: SNR, class numbers and complex features, and find that more difficult to classify, higher probability HT emerges. Further, in line with Martin and Mahoney (2021), HT could be regarded as a training information encoder and indicates some implicit regularization. Such implicit regularization in the weight matrices provides a new way of understanding the whole training procedure. We apply this phenomenon to derive an early stopping procedure in order to avoid over-training (in case of poor data quality) and cut off large training time. From the encoded information, spectral criterion could even provide an early stopped time when the training accuracy is increasing.
Spectral Analysis provides a new way for the understanding of Deep Learning. Once understood spectra in DNNs better, more practical guidance for the whole learning procedures may be provided. Our study in weight matrices spectra also leads to several questions to explore in the future, such as how SGD generates Heavy Tail in the poor data quality but Light Tail in the high data quality in DNNs.
References
- Dauphin et al. (2014) Yann Dauphin, Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, Surya Ganguli, and Yoshua Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization, 2014.
- Ge et al. (2021) Jungang Ge, Ying-Chang Liang, Zhidong Bai, and Guangming Pan. Large-dimensional random matrix theory and its applications in deep learning and wireless communications, 2021.
- Goyal et al. (2017) Priya Goyal, Piotr Dollár, Ross B. Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch SGD: training imagenet in 1 hour. CoRR, abs/1706.02677, 2017. URL http://arxiv.org/abs/1706.02677.
- Granziol (2020) Diego Granziol. Beyond random matrix theory for deep networks, 2020.
- Gurbuzbalaban et al. (2021) Mert Gurbuzbalaban, Umut Şimşekli, and Lingjiong Zhu. The heavy-tail phenomenon in sgd, 2021.
- Hodgkinson and Mahoney (2021) Liam Hodgkinson and Michael Mahoney. Multiplicative noise and heavy tails in stochastic optimization. In International Conference on Machine Learning, pages 4262–4274. PMLR, 2021.
- Ji et al. (2021) Wenlong Ji, Yiping Lu, Yiliang Zhang, Zhun Deng, and Weijie J Su. How gradient descent separates data with neural collapse: A layer-peeled perspective. 2021.
- Keskar et al. (2016) Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. CoRR, abs/1609.04836, 2016. URL http://arxiv.org/abs/1609.04836.
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25:1097–1105, 2012.
- Kukacka et al. (2017) Jan Kukacka, Vladimir Golkov, and Daniel Cremers. Regularization for deep learning: A taxonomy, 2017.
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998.
- LeCun et al. (2015) Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. nature, 521(7553):436–444, 2015.
- Lee et al. (2018) Jaehoon Lee, Jascha Sohl-dickstein, Jeffrey Pennington, Roman Novak, Sam Schoenholz, and Yasaman Bahri. Deep neural networks as gaussian processes. In International Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=B1EA-M-0Z.
- Martin and Mahoney (2021) Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning. Journal of Machine Learning Research, 22(165):1–73, 2021. URL http://jmlr.org/papers/v22/20-410.html.
- Martin et al. (2021) Charles H Martin, Tongsu Serena Peng, and Michael W Mahoney. Predicting trends in the quality of state-of-the-art neural networks without access to training or testing data. Nature Communications, 12(1):1–13, 2021.
- Papyan (2019a) Vardan Papyan. Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians. CoRR, abs/1901.08244, 2019a. URL http://arxiv.org/abs/1901.08244.
- Papyan (2019b) Vardan Papyan. The full spectrum of deepnet hessians at scale: Dynamics with sgd training and sample size, 2019b.
- Papyan (2020) Vardan Papyan. Traces of class/cross-class structure pervade deep learning spectra, 2020.
- Papyan et al. (2020) Vardan Papyan, XY Han, and David L Donoho. Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020.
- Pennington and Worah (2019) Jeffrey Pennington and Pratik Worah. Nonlinear random matrix theory for deep learning. Journal of Statistical Mechanics: Theory and Experiment, 2019(12):124005, dec 2019. doi: 10.1088/1742-5468/ab3bc3. URL https://doi.org/10.1088/1742-5468/ab3bc3.
- Sagun et al. (2017) Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond, 2017.
- Simonyan and Zisserman (2014) K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. Computer Science, 2014.
- Yao et al. (2015) Jianfeng Yao, Shurong Zheng, and ZD Bai. Sample covariance matrices and high-dimensional data analysis. Cambridge University Press Cambridge, 2015.
- Yao et al. (2020) Zhewei Yao, Amir Gholami, Kurt Keutzer, and Michael W. Mahoney. Pyhessian: Neural networks through the lens of the hessian. In 2020 IEEE International Conference on Big Data (Big Data), pages 581–590, 2020. doi: 10.1109/BigData50022.2020.9378171.
Supplementary materials to ‘Impact of classification difficulty on the weight matrices spectra in Deep Learning’
Xuran Meng, Jianfeng Yao
Department of Statistics and Actuarial Science, University of Hong Kong,
Hong Kong SAR, China
* To whom correspondence should be addressed: [email protected]
Appendix A Preliminaries on RMT
In this section, we review the results we use from RMT. This section is aim to give readers some references to know about RMT. The reference is Yao et al. (2015). RMT provides us lots of analytic results for both square or rectangular large matrices. The well-known results in RMT: Marchenko-Pauster (MP) Law which shows eigenvalues’ distribution of rectangular matrices, and Tracy-Widom Law which describes how the max eigenvalue distributed. When analyze DNNs weight matrices, MP Law, which is applicable to rectangular matrices, will give guidance on the analysis in spectrum of DNNs weight matrices.
A.1 MP Law and stieltjes Transform
MP Law is given as follows,
Theorem 5.
(Marchenko Pauster Law) Suppose that the entries of the matrix are complex random variables with mean zero and variance , and . Define , is the eigenvalue of , then the ESD of
as , here is the indicator function, is the MP Law has the form
with an additional point mass of value at the origin if , where and .
The powerful mathematical tool to achieve the MP Law is stieltjes Transform, let be a finite measure on the real line with support , its stieltjes transform is
To reduct from Stieltjes transform, we have the equation
Details can be refered in (Yao et al., 2015).
The Stieltjes transform of standard MP Law satisfies equation
we can get results in a more generalized settings:
Theorem 6.
(Generalized MP Law) Let be the matrix defined in Theorem 5, is a sequence of nonnegative Hermitian matrices of size which is deterministic or independent with , and the sequence of the ESD of almost surely weakly converges to a nonrandom probability measure , then the ESD of weakly converges to a nonrandom probability measure , that its Stieltjes transform is implicitly defined by the equation
A.2 Spike Model
Suppose that the matrix has the limit ESD , the element in satisfies
define
we say the eigenvalue of with fixed index is a distant spike eigenvalue if
Then we have the following theorem,
Theorem 7.
The entries of the matrix are complex random variables with mean zero, variance 1 and finite fourth moment, . , is a sequence of nonnegative Hermitian matrices of size which is deterministic or independent with , and the sequence of the ESD of almost surely weakly converges to a nonrandom probability measure , is the eigenvalue of , is the eigenvalue of , suppose that with fixed index is a distant spike eigenvalue, then as ,
(1) if , then ,
(2) if , then .
A.3 Tracy-Widom Law
Theorem 8.
(Tracy-Widom Law) Let , be a double array of i.i.d. complex-valued random variables with mean , variance and finite fourth-order moment. Consider the sample covariance matrix defined same as Theorem 5, the eigenvalues of : in a decreasing order. When , we have
further, define and ,
where is the Tracy-Widom Law of order 1 whose distribution function is given by
where solves the Painleve II differential equation
with boundary condition
here is the airy function.
Appendix B Technique Proof
In this section, we prove the proposition in section 4.
B.1 Proof of proposition 2
From definition, ,
We first prove .
There exists such that , thus
similar to get , then
For , , there exists satisfies
then for , there exists between and , such that
is an absolute value. Then
Thus
We next prove that ,
Note that , by Berstein inequality,
for some constant , set , we achieve
which implies given , there , such that
for , there exists satisfies
then
Thus we achieve
which proves the proposition.
B.2 Proof of proposition 3
Recall is the order statistics. For , such that
as , then , similar to get , which implies same rate as Tracy Widom Law.
The only thing is to prove
Indeed, set , , we have
where , . Note that , by continuous mapping, , thus . Then for , we have
For the first part, the integration can be separated as
there exists such that
similar to get
by simple integration calculation, we have
Thus,
which proves the proposition.
Appendix C Algorithm
In this section, we add the algorithm to detect the spikes and the deviation from MP Law. Algorithm 1 gives an automatic method of detecting spikes. The key point in the algorithm is to detect the large gap between the bulk and the spike. The method is comparing difference between each two ordered eigenvalues. The gap between the spike and bulk is much larger than the average level.
Algorithm 1 gives an automatic method of detecting spikes. is the tuning parameter. When the gap between spikes and bulk is larger than multiply the average difference level, the gap will be detected by Algorithm 1. HS and TS represents the number of spikes larger or smaller than the value of bulk respectively.
After detecting the spikes in Algorithm 1, the deviation measurement between ESDs in weight matrices and standard MP Law is given by Algorithm 2. As described in 2.2.1, this algorithm is also used to detect the difference of BT and LT. Algorithm 2 gives the value of , discussed in section 4, a standard metric for us to measure the deviation from standard MP Law. We also apply this algorithm into detecting the indicated early stopping time.
Appendix D spectral criterion with
In this section, we add extra experimental results of spectral criterion with . The constant in the spectral criterion is set a little higher due to the fact that any slight deviation from standard MP Law will suggest to stop if we set low. Thus the value of should be determined in some reasonable ways. Combined with simulation results, we add the experimental results of to check the spectral criterion.
A higher value of means that the training time suggested by the criterion will be longer. However, we could not give the value of too large in an unreasonable way. is added below to give us a reasonable interval of . Summarized from the experiments below, also gives us good properties of spectral criterion. The spectral criterion detects the problematic issues in the numeric experiments and suggests us to stop even when the training accuracy is increasing. In the real data experiments, the spectral criterion predicts the training explosion quite accurately. Combined with the results of and , the reasonable interval value of we suggest is [0.4,0.6].
| The combination NN1+ | |||||||
|---|---|---|---|---|---|---|---|
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC2) | Test Acc | epoch(FC3) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.15 | 8 | 24.58% | 16 | 20.44% | HT | HT | 20.17% |
| 0.2 | 8 | 31.50% | 16 | 25.83% | HT | HT | 27.03% |
| 0.3 | 8 | 49.09% | 12 | 45.48% | HT | HT | 44.80% |
| 0.6 | 9 | 87.96% | - | BT | BT | 88.30% | |
| 0.9 | - | - | LT | LT | 99.13% | ||
| The combination NN1+ | |||||||
|---|---|---|---|---|---|---|---|
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC2) | Test Acc | epoch(FC3) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.24 | 9 | 14.69% | - | HT | HT | 13.08% | |
| 1.2 | 8 | 39.31% | 16 | 32.11% | HT | HT | 32.98% |
| 2.4 | 8 | 76.75% | 20 | 74.29% | HT | HT | 75.92% |
| 3.2 | 10 | 91.94% | - | HT | LT | 92.64% | |
| 4.8 | - | - | LT | LT | 99.73% | ||
| The combination NN2+ | |||||||
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.02 | - | - | HT | BT | 16.02% | ||
| 0.04 | - | - | HT | BT | 25.38% | ||
| 0.07 | - | - | HT | BT | 50.12% | ||
| 0.13 | - | - | BT | LT | 87.50% | ||
| 0.2 | - | - | LT | LT | 99.14% | ||
| The combination NN2+ | |||||||
| Typical TP | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 0.24 | 12 | 13.48% | 7 | 13.19% | HT | HT | 13.44% |
| 1.2 | 24 | 35.80% | 5 | 34.63% | HT | HT | 36.31% |
| 2.4 | 6 | 73.80% | 36 | 74.86% | BT | BT | 75.12% |
| 3.2 | - | - | LT | LT | 91.20% | ||
| 4.8 | - | - | LT | LT | 99.59% | ||
| The combination LeNet+MNIST | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | - | 32 | 99.19% | LT | BT | 99.17% | |
| 32 | - | - | LT | BT | 99.17% | ||
| 64 | - | - | LT | BT | 98.98% | ||
| 128 | - | - | LT | BT | 99.03% | ||
| 256 | - | - | LT | LT | 98.96% | ||
| The combination LeNet+CIFAR10 | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 28 | 61.66% | 8 | 61.62% | BT | HT | 64.99% |
| 32 | - | 20 | 61.06% | BT | HT | 64.57% | |
| 64 | - | 32 | 60.27% | LT | BT | 62.49% | |
| 128 | - | 60 | 61.38% | LT | BT | 61.83% | |
| 256 | - | 92 | 58.33% | LT | BT | 60.49% | |
| The combination MiniAlexNet+MNIST | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 5 | 98.64% | - | BT | LT | 99.49% | |
| 32 | - | - | BT | LT | 99.41% | ||
| 64 | - | - | LT | LT | 99.42% | ||
| 128 | - | - | LT | LT | 99.39% | ||
| 256 | - | - | LT | LT | 99.31% | ||
| The combination MiniAlexNet+CIFAR10 | |||||||
| batchsize | spectral criterion | Final Epoch 248 | |||||
| epoch(FC1) | Test Acc | epoch(FC2) | Test Acc | FC1 | FC2 | Test Acc | |
| 16 | 4 | 71.01% | 36(RC) | 55.6% | HT | RC | 10%(explode) |
| 32 | 4 | 72.17% | 196(RC) | 62.84% | HT | RC | 10%(explode) |
| 64 | 6 | 73.03% | - | BT | BT | 77.94% | |
| 128 | 12 | 74.31% | - | BT | LT | 77.43% | |
| 256 | 28 | 75.87% | - | BT | LT | 75.93% | |