Hyperparameter Optimization for SecureBoost via Constrained Multi-Objective Federated Learning
Abstract
SecureBoost is a tree-boosting algorithm that leverages homomorphic encryption (HE) to protect data privacy in vertical federated learning. SecureBoost and its variants have been widely adopted in fields such as finance and healthcare. However, the hyperparameters of SecureBoost are typically configured heuristically for optimizing model performance (i.e., utility) solely, assuming that privacy is secured. Our study found that SecureBoost and some of its variants are still vulnerable to label leakage. This vulnerability may lead the current heuristic hyperparameter configuration of SecureBoost to a suboptimal trade-off between utility, privacy, and efficiency, which are pivotal elements toward a trustworthy federated learning system. To address this issue, we propose the Constrained Multi-Objective SecureBoost (CMOSB) algorithm, which aims to approximate Pareto optimal solutions that each solution is a set of hyperparameters achieving an optimal trade-off between utility loss, training cost, and privacy leakage. We design measurements of the three objectives, including a novel label inference attack named instance clustering attack (ICA) to measure the privacy leakage of SecureBoost. Additionally, we provide two countermeasures against ICA. The experimental results demonstrate that the CMOSB yields superior hyperparameters over those optimized by grid search and Bayesian optimization regarding the trade-off between utility loss, training cost, and privacy leakage.
Index Terms:
Vertical Federated Learning, Multi-Objective Optimization, Hyperparameter Optimization, Privacy Preservation, Gradient Boosted TreesI Introduction
Federated learning (FL) [1] is a novel distributed machine learning paradigm that enables multiple participants to train machine learning models without compromising data privacy. Federated learning can be categorized into horizontal federated learning and vertical federated learning based on how the data is distributed among participating parties [2]. Vertical federated learning (VFL) [3] refers to the scenario where feature data is vertically partitioned among multiple parties, with one party possessing the data labels. In VFL, each party holds different parts of the feature data, and they collaborate to train machine learning models without directly sharing their raw data. SecureBoost [4] is a widely adopted vertical federated tree-boosting algorithm for its interpretability and privacy-preserving ability. Nevertheless, It has the following two limitations.
Limitation 1: SecureBoost still faces the possibility of label leakage [5] through intermediate information, despite employing homomorphic encryption to protect instance gradients. Our experimental results in Sec. VII-B reveal that up to 84% of labels can be leaked stemming from the absence of protection on instance distributions. Therefore, defense mechanisms are required for SecureBoost to protect the label privacy in addition to HE.
Limitation 2: Heuristic hyperparameter configuration may lead to suboptimal trade-off between utility, efficiency, and privacy of the SecureBoost model. Existing FL platforms [6, 7] typically determine the hyperparameters of SecureBoost heuristically, which may lead to suboptimal hyperparameter choices that do not maximize utility, efficiency, and privacy - the pivotal elements of trustworthy federated learning.
To address the two limitations, we propose Constrained Multi-Objective SecureBoost (CMOSB) [8] to find Pareto optimal solutions of hyperparameters that can simultaneously minimize three conflicting objectives: utility loss, training cost, and privacy leakage. Each solution represents an optimal trade-off between the three objectives [9]. Consequently, Pareto optimal solutions not only provide optimal hyperparameters for SecureBoost but also cater to the flexible requirements of VFL participants concerning privacy and resource constraints. For example, participants can select the most appropriate hyperparameters from the Pareto optimal solutions that align with their preference for utility, efficiency, and privacy. Our main contributions are summarized as follows:
-
•
We formalize the Constrained Multi-Objective SecureBoost (CMOSB) problem and correspondingly propose a CMOSB algorithm to identify Pareto optimal solutions of hyperparameters that simultaneously minimize utility loss, training cost, and privacy leakage. Our CMOSB algorithm can be readily extended to optimize other objectives, providing a versatile and effective approach to addressing the complex trade-offs in training federated tree-boosting models.
-
•
We design measurements of utility loss, training cost, and privacy leakage. In particular, we propose a novel label inference attack named instance clustering attack to measure privacy leakage. We also develop two countermeasures against this attack.
-
•
We conduct experiments on four datasets, demonstrating that our CMOSB can find better hyperparameters than grid search and Bayesian optimization in terms of the trade-off between privacy leakage, utility loss, and training cost. Moreover, CMOSB can find Pareto optimal solutions of hyperparameters that achieve better trade-offs between utility loss, training cost, and privacy leakage than state-of-the-art solutions.
The rest of the paper is organized as follows. We first review related work in Sec. II and introduce the preliminary in Sec. III. Then, we describe the CMOSB problem in Sec. IV and elaborate on our proposed label inference attack and the corresponding defense methods in Sec. V. Next, we provide the CMOSB algorithm in Sec. VI. We report our experimental results in Sec. VII and conclude this paper in Sec. VIII.
II Related Work
In this section, we review related work from three categories: tree-based models in VFL, label leakage in VFL, and multi-objective federated learning.
II-A Tree-based Models in VFL
Tree-based models are a common type of machine learning algorithm, and their applications in federated learning require the design of appropriate privacy protection methods. SecureBoost [4] is an XGBoost-based model that protects data privacy by applying homomorphic encryption to intermediate gradients. SecureBoost+ [10] extends the SecureBoost algorithm to multi-class tasks and improves SecureBoost’s training efficiency. VF2Boost [7] is a system based on SecureBoost that reduces model training costs through parallel computation. HEP-XGB [11] employs a customized secret sharing method to achieve efficient two-party XGBoost model construction. Pivot [12] utilizes a combination of homomorphic encryption and secure multi-party computation to train XGBoost models, ensuring that no intermediate results are leaked during the training process.
II-B Label Leakage in VFL
Label leakage in vertical federated learning refers to the situation where the passive party is able to obtain the label information of the active party during the training process. Fu et al. [5] systematically classified the label leakage in vertical federated learning into three categories: active attack, passive attack, and direct attack, and provided an attack method for each category. Zou et al. [13] proposed a label attack method on the black-boxed VFL and presented a privacy protection method. Xie et al. [14] demonstrated that split learning remains vulnerable to label inference attacks. Qiu et al. [15] found that the training of GNNs in VFL may also lead to the leakage of sample relationships. Tan et al. [16] proposed a gradient inversion attack that utilizes the gradients of local models to reconstruct label data. Pan et al. [17] implements an efficient data federation system using secure multi-party computation to avoid label leakage.
II-C Multi-objective Federated Learning
Multi-objective federated learning is a collaborative optimization approach in which participants of FL aim to optimize multiple conflicting objectives simultaneously and find Pareto optimal solutions. Personalized Federated Learning aims to optimize the federated model structure for each participating party’s data distribution[18, 19]. Cui et al. [20] considered the utility of participating parties as the optimization objective, model disparity as the constraint, and optimized the objectives of all participants to calculate the Pareto front. This approach ensures the fairness of federated learning and enables obtaining the optimal performance model. Zhu et al. [21] formulated the accuracy and communication cost of federated learning as the optimization objectives and adjusted the model sparsity to minimize both the communication cost and test errors. The algorithm proposed in [8] is a multi-objective federated learning algorithm with constraints, which adds constraints to the optimization objectives and finds the Pareto front more efficiently within the feasible range.
III Preliminary
In this section, we introduce some preliminaries of vertical federated learning (VFL) and SecureBoost.
III-A Vertical Federated Learning
Vertical Federated Learning [2, 3] is one of the scenarios in Federated Learning. In this setting, feature data is vertically partitioned among multiple parties, with one party possessing the data labels (Fig. 1). Specifically, the active party holds both features and labels, while the passive parties hold only features.
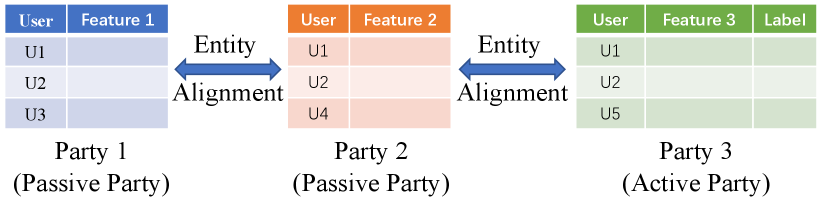
All participating parties in VFL first align their instances by private set intersection (PSI) [22], and then perform federated model training and inference. During the training process, each party is not allowed to reveal its training data to others [23]. After the federated training is completed, the federated model is obtained, which is jointly held by all participating parties, i.e., model is split into . In the inference phase, all participating parties collaboratively make the prediction, but only the active party can access the final predicted result.
III-B SecureBoost
SecureBoost [4] is a widely used gradient boosting tree algorithm designed for the vertical federated learning scenario. The core idea of SecureBoost is to use federated decision trees to fit instance labels.
For each iteration, SecureBoost constructs a new tree from the root node based on a node split finding algorithm, which is summarized in Algo. 1. In this process, the active party sends the homomorphically encrypted gradients , , and instance space of the current node to passive parties. The passive parties then calculate the gradient statistics and send them back to the active party. The active party finds the optimal split of the current node with the maximal splitting score and informs the corresponding parties to split the instance space into child nodes. The split-finding process continues until the maximum depth is reached. For a more detailed description, please refer to [4].
The instance distributions of leaf nodes in SecureBoost are not protected, which may lead to privacy leakage. Some methods [12, 11] use a combination of Homomorphic Encryption (HE) and Secure Multi-Party Computation (MPC) to address this issue and enhance privacy protection. However, these methods may result in significant training cost, making it challenging to apply them in practical and trustworthy federated learning scenarios.
IV Constrained Multi-Objective SecureBoost Problem
The Constrained Multi-Objective SecureBoost Learning (CMOSB) problem aims to find Pareto optimal solutions that each is a set of hyperparameters leading to an optimal trade-off between three objectives under constraints: utility loss, training cost, and privacy leakage. Inspired by [8], we formulate the CMOSB problem as follows:
| (1) |
where is a solution in the decision space ; , , and denote the objectives of utility loss, training cost, and privacy leakage, respectively; , , and are the upper bounds of , , and , respectively.
Remark 1.
In this paper, a solution refers to a collection of hyperparameters, such as the depth of decision trees, batch size, protection strength parameters, and so on. Each set of hyperparameters corresponds to specific values of privacy leakage, utility loss, and training cost.
During multi-objective SecureBoost training, SecureBoost participants put constraints on utility loss, training cost, and privacy leakage to ensure that the utility meets the specified requirements. These constraints also serve to limit training cost and privacy leakage within the allocated budget. By doing so, SecureBoost participants can strike a balance between utility, cost, and privacy in a controlled manner.
Formally, SecureBoost participants aim to find Pareto front and corresponding Pareto optimal solutions for the Constrained Multi-Objective SecureBoost problem. We provide the definitions of Pareto dominance, Pareto optimal solution, Pareto set, and Pareto front as follows.
Definition 1 (Pareto Dominance).
Let , is said to dominate , denoted as , if and only if and .
Definition 2 (Pareto Optimal Solution).
A solution is called a Pareto optimal solution if there does not exist a solution such that .
A Pareto optimal solution refers to a solution that achieves an optimal trade-off among different conflicting objectives. The collection of all Pareto optimal solutions forms the Pareto set, while the corresponding objective values for the Pareto optimal solutions form the Pareto front. The definitions of the Pareto set and Pareto front are formally given as follows.
Definition 3 (Pareto Set and Front).
The set of all Pareto optimal solutions is called the Pareto set, and its image in the objective space is called the Pareto front.
We use hypervolume (HV) indicator [24] as a metric to measure the Pareto front. The definition of hypervolume indicator is provided below.
Definition 4 (Hypervolume Indicator).
Let be a reference point that is an upper bound of the objectives , such that , . The hypervolume indicator measures the region between and and is formulated as:
| (2) |
where refers to the Lebesgue measure.
To address the CMOSB problem outlined in Eq.(1), we must first quantify the utility loss, training cost, and privacy leakage of a given solution. Measuring utility loss and training cost is straightforward, which we will discuss in Section VI-A. Evaluating privacy leakage requires a more sophisticated approach, as it involves assessing the extent to which an individual’s private information can be inferred from the model’s outputs. To address this challenge, we propose a novel label inference attack that exploits a vulnerability in SecureBoost, allowing us to infer private label information. In the next section, we will delve deeper into the threat model, the label inference attack, and potential countermeasures.
V Privacy Leakage in SecureBoost
In this section, we first elaborate on the threat model. Then, we design a label inference attack and explain how this attack can lead to the leakage of labels owned by the active party. Finally, we propose two defense methods against this attack.
V-A Threat Model
Below, we discuss the threat model, which includes the attacker’s objective, capability, and knowledge.
Attacker’s objective. We consider the passive party as the attacker, who aims to infer labels owned by the active party.
Attacker’s capability. We assume the attacker is semi-honest, meaning that the attacker faithfully follows the SecureBoost protocol but may attempt to infer labels of the active party.
Attacker’s knowledge. The passive party can access instance distributions of leaf nodes since SecureBoost does not protect this information. Additionally, we assume that the passive party holds several labeled instances for each class, similar to the assumption made in [5].
V-B Label Inference Attack
Gradient boost decision tree (GBDT) construction involves computing information gain based on instance features owned by different parties. To ensure that private features are not disclosed to other parties during the process of calculating information gain, the active party needs to share instance gradients and distributions with passive parties in a privacy-preserving manner. While SecureBoost and its variant [10] utilize homomorphic encryption to protect gradient information passed between the active party and passive parties, they do not protect the instance distribution of each leaf node owned by the passive party. This indicates that the passive party (i.e., the attacker) can exploit this information to infer the active party’s labels through clustering.

We propose a label inference attack named Instance Clustering Attack (ICA) to infer the label information owned by the active party and leverage ICA to measure the privacy leakage of the SecureBoost algorithm. The procedure of ICA is illustrated in Fig. 2 and described in Algo. 2.
The idea behind the attack is straightforward: samples with the same label are highly likely to be grouped into the same leaf node. The attacker first constructs the similarity matrix based on the instance distribution of each leaf node using Eq. (3) (line 1 of Algo. 2).
| (3) |
where denotes the number of decision trees, and denotes the index of the leaf node.
Then, the attacker utilizes this similarity matrix to categorize instances into clusters (line 2). We employ spectral clustering [25], a straightforward yet effective method for clustering instances based on the similarity matrix. This stage essentially involves learning a mapping from cluster IDs to the actual labels. If the attacker possesses more labeled data, it can establish a better mapping, which improves the accuracy of ICA. We assume the attacker knows the label of one instance in each cluster. Hence, the attacker assigns instances in each cluster with the known labels (lines 3-5).
We use the accuracy of the instance clustering attack to measure the privacy leakage (see Sec. VI-A).
V-C Defense Methods
Due to the high communication and computational overhead associated with directly preserving the privacy of the instance distribution, Secure Multi-Party Computation (MPC) is often challenging to apply in real-world scenarios. In this work, we propose two defense methods that can mitigate privacy leakage caused by the instance clustering attack (ICA).
The performance of ICA depends on the purity of leaf nodes owned by the attacker (i.e., the passive party). We define the purity of a node as the ratio of instances belonging to the majority class to all instances in that node. A higher purity implies a more accurate similarity matrix, which can lead to more precise clustering results and, consequently, more privacy leakage. Therefore, our proposed defense methods mitigate privacy leakage by reducing node purity, and we name the two defense methods: (1) local trees 111 Our defense method has been implemented in FATE v1.11.2. ; (2) purity threshold.
Local Trees.
The mechanism of ICA (see Sec. V-B) indicates that the stronger the correlation between the instance distribution and true labels, the higher the likelihood of label privacy leakage.
We utilize mutual information [26] to measure the correlation between labels and the instance distribution on each tree during the training of SecureBoost, to investigate the occurrence of label leakage. Specifically, we trained 10 SecureBoost models, each consisting of 50 trees. Fig. 3 illustrates the average variation of mutual information with respect to iterations (each representing a tree). It indicates that the mutual information is relatively high in the first few iterations of training, suggesting a higher likelihood of privacy leakage during the initial stages of SecureBoost training.

To mitigate the label leakage, we propose a local training stage preceding SecureBoost, where the active party trains decision trees locally. The objective is to reduce the mutual information between the instance distribution and instance labels in the federated SecureBoost model.
The decision trees obtained from the local training stage are stored exclusively on the active party’s side, ensuring no information leakage while still participating in the federated prediction process. Once the local training stage is completed, the federated learning stage begins, where all participants collectively train decision trees according to the SecureBoost protocol. These two stages together establish the SecureBoost model with privacy protection.

Purity Threshold.
The purity threshold mitigates privacy leakage by preventing the sharing of instance distributions of high-purity nodes with passive parties. The active party sends the instance distributions to passive parties, calculates the information gain based on the returned statistical data, and identifies the optimal split point of a node . Subsequently, the active party calculates its purity , and if the purity exceeds the pre-specified threshold , passive parties are excluded from the federated training of the subtree rooted at node , and the active party proceeds to train this subtree locally. Otherwise, all participants continue with the SecureBoost algorithm.
Although the two defense methods can effectively thwart the instance clustering attack, they may introduce utility loss. Therefore, trade-offs need to be made between utility and privacy. We consider their hyperparameters as decision variables when optimizing the Constrained Multi-Objective SecureBoost problem (Sec. VI).
VI Constrained Multi-Objective SecureBoost Algorithm
In this section, we elaborate on our Constrained Multi-Objective SecureBoost algorithm (CMOSB).
VI-A Measurements of Objectives
Prior to delving into the algorithmic aspects, we first establish the measurements used to evaluate the three objectives we aim to optimize: utility loss, training cost, and privacy leakage.
Utility Loss. The utility loss measures the amount of decrease in utility when certain defense methods are applied to thwart the label inference attack:
| (4) |
where , , and denote the SecureBoost model, the test dataset, and the performance metric, respectively. is AUC for binary classification and accuracy for multi-class classification.
Training Cost. We use training time to measure the training cost of SecureBoost. Since HE operations dominate training time, we estimate the training cost by summing the time spent on each HE operation:
| (5) |
where , , and denote the number of encryption, decryption, and addition operations, respectively, while , , and represent the average time required for each corresponding HE operation.
Privacy Leakage. We use the accuracy of the instance clustering attack (see Sec. V-B) to measure the privacy leakage . The attack is evaluated based on a randomly sampled set of instances denoted as , where the number of instances belonging to each class is the same. The privacy leakage can be measured as follows:
| (6) |
where denotes the label inferred by the instance clustering attack, and denotes the true label, and denotes the indicator function.
VI-B The CMOSB Algorithm
In this section, we propose the Constrained Multi-Objective SecureBoost algorithm (CMOSB), which aims to obtain approximate Pareto optimal solutions and front. It achieves a balance between the three optimization objectives and provides guidance for hyperparameter selection.
CMOSB is based on NSGA-II and described in Algo. 3. Offspring solutions of the current generation are generated by performing crossover and mutation using solutions found during the previous generation (line 3). All newly generated candidate solutions are evaluated using Algo. 4 (line 5). The algorithm adds a constraint to limit the search space of the solutions (lines 6-7). Lines 8-9 sort the candidate solutions and select the top for the next generation.
Algo. 4 aims to measure the utility loss, training cost, and privacy leakage while training a SecureBoost model. The variable represents a set of hyperparameters for SecureBoost, and Table III provides a detailed description of these hyperparameters. Lines 3-5 correspond to the local training stage mentioned in Sec. V-C, while lines 6-19 constitute the federated learning stage, forming the SecureBoost framework. In line 10, the active party calculates the purity of node , and if it is below the threshold , all participants will jointly calculate the split point; otherwise, only the active party will calculate it locally. Training cost and privacy leakage will be calculated during the iteration process, while utility will be calculated after the training is completed.
VII Experiments
In this section, we empirically investigate the effectiveness of our proposed attacking method, defense methods, and the hyperparameter optimization algorithm CMOSB.
VII-A Experimental Settings
Dataset and setting. We conduct experiments on two synthetic datasets and two real-world datasets. The synthetic datasets, generated using the sklearn library222https://scikit-learn.org/stable/, consist of Synthetic1 for binary classification and Synthetic2 for multi-class classification. The DefaultCredit 333https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset dataset involves predicting whether users can repay their loans on time, while the Sensorless 444https://archive.ics.uci.edu/dataset/325/ dataset is used for sensorless drive diagnosis.
To create datasets for the federated scenario, each dataset was vertically partitioned into two sub-datasets. We used 2/3 of the data as the training set and the remaining as the test set. Table I summarizes these datasets.
We implement all the methods with Python 3.8. The experiments were conducted on two Intel(R) Xeon(R) Platinum 8269CY 3.10GHz CPUs each with 4 cores.
| Name | S | AF | PF | C |
| Synthetic1 | 2,000 | 5 | 5 | 2 |
| DefaultCredit | 30,000 | 12 | 13 | 2 |
| Synthetic2 | 10,000 | 5 | 5 | 10 |
| Sensorless | 58,509 | 12 | 36 | 11 |
Baseline. We compared our Constrained Multi-objective SecureBoost (CMOSB) method with the following methods:
-
•
Empirical Selection (ES): Empirical Selection represents the default hyperparameters that are typically determined empirically.
-
•
Grid Search (GS): Grid Search is a traditional hyperparameter optimization method that exhaustively evaluates different combinations for the optimal hyperparameter combination [27].
-
•
Bayesian Optimization (BO): Bayesian Optimization [28] is a classic hyperparameter optimization method for machine learning algorithms. It utilizes Gaussian processes to improve search efficiency. However, BO is only suitable for single-objective optimization. For multi-objective optimization, we leverage BO to optimize each objective separately.
Hyperparameter. We chose three sets of hyperparameters for the ES baseline. The first two sets of hyperparameters are chosen from the default hyperparameters of FATE [6] and VF2Boost [7], respectively. The third set of hyperparameters is the average of the first two.
To make a fair comparison, the sampling rate is set to , and complete secure is set to true.
The complete secure corresponds to the local tree defense method, where is set to , indicating that local training of a single tree is performed before federated learning.
The specific hyperparameter settings are shown in Table II.
| Baseline | complete secure | ||||
| FATE | 5 | 3 | 0.3 | 0.8 | true |
| VF2Boost | 20 | 7 | 0.1 | 0.8 | true |
| Average | 10 | 5 | 0.3 | 0.8 | true |
| Variable | Range | Chromosome Type | Description |
| Binary | The number of iterations for boosting in federated learning | ||
| Binary | The number of iterations for boosting locally | ||
| Binary | Maximum depth of each decision tree | ||
| Real-value | Subsample ratio of the training instances | ||
| Real-value | The purity threshold to stop the federated learning | ||
| Real-value | Step size shrinkage used in update to prevents overfitting |
CMOSB Setup. The proposed CMOSB algorithm is based on NSGA-II. Thus, we follow the setup proposed in literature [21]. We apply a single-point crossover for binary chromosomes with a probability of 0.9 and a bit-flip mutation with a probability of 0.1. We apply a simulated binary crossover (SBX) [29] for real-valued chromosome with a probability of 0.9 and = 2, and a polynomial mutation with a probability of 0.1 and = 20, where and denote spread factor distribution indices for crossover and mutation, respectively. The number of generations for CMOSB is set to 40.
VII-B Effectiveness of Defense Methods
In this section, we investigate the efficacy of our proposed defense methods in mitigating privacy leakage. The experiments are conducted on Synthetic1 dataset, with the default hyperparameter set as follows: , , , .


Fig. 5 shows that both methods can trade-off model performance for privacy protection. The lack of protection on instance distribution resulted in up to 84% of instance label leakage. As shown in Fig. 5 (a), training 10 decision trees locally reduced privacy leakage risk by 25.1% while sacrificing only 1.6% of utility. The impact of the purity threshold is illustrated in Fig. 5(b), where we observe a decrease in privacy leakage as the active party constructs more nodes locally.
VII-C Optimal Tradeoffs between Utility, Efficiency, and Privacy achieved by CMOSB
In this section, we use CMOSB (Algo. 3) without constraints to find the Pareto optimal solutions of hyperparameters for SecureBoost. Each solution is a set of hyperparameters that achieves an optimal tradeoff between utility loss, training cost, and privacy leakage.
We summarize the variables and their descriptions involved in multi-objective optimization in Table III. Among the variables, the definitions of , , , and are the same as those used in SecureBoost [4]. refers to the number of iterations for boosting locally, and refers to the threshold of purity. For binary classification problems, we further constrain the range of to to improve search efficiency.
We first present the comparison between CMOSB and the baselines through 3D plots illustrated in Fig. 6 and Fig. 7 on the four datasets (see Table I).


(a) Synthetic1

(b) DefaultCredit

(c) Synthetic2

(d) Sensorless
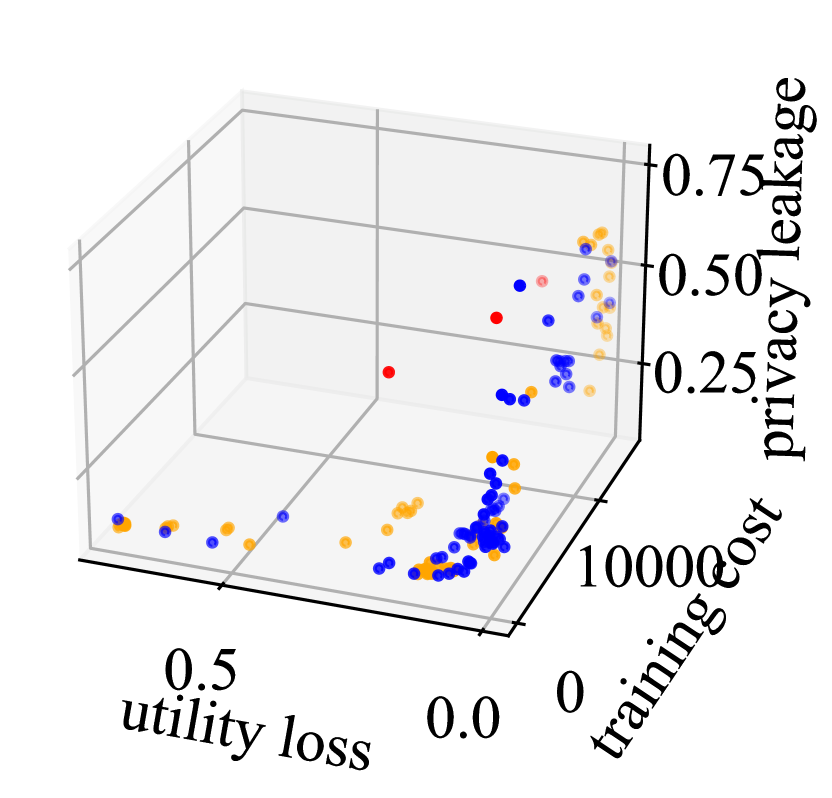
Fig. 6 illustrates the comparison between CMOSB and Grid Search. The red, green, and blue dots represent solutions obtained from Empirical Selection (ES), Grid Search (GS), and CMOSB, respectively. It can be observed that the solutions found by CMOSB dominate those found by ES and GS, indicating that CMOSB achieves a better Pareto front (closer to the origin).
Fig. 7 illustrates the comparison between CMOSB and Bayesian optimization. The red, orange, and blue dots represent solutions obtained from Empirical Selection (ES), Bayesian Optimization (BO), and CMOSB, respectively. Similar to Fig. 6, CMOSB outperforms BO and ES overall, achieving a better Pareto front.


(a) Synthetic1

(b) DefaultCredit

(c) Synthetic2
(d) Sensorless




To provide a more intuitive observation of the experimental results, we project each 3D plot onto two 2D plots: one for training cost vs. utility loss and another for privacy leakage vs. utility loss, as shown in Fig. 8 and Fig. 9, respectively. In Fig. 8 and Fig. 9, the blue, green, orange, and red dots represent CMOSB, GS (Grid Search), BO (Bayesian Optimization), and ES (Empirical Selection), respectively. Each dot represents a solution, and each line represents a Pareto front.
For the trade-off between training cost and utility loss (see Fig. 8), all four datasets demonstrate that the training cost increases as the utility loss decreases. CMOSB (in blue) can find a better Pareto front than GS (in green), BO (in orange), and ES (in red). More specifically, BO (in orange) can find a set of decent solutions but is slightly inferior to CMOSB. This is because BO optimizes one objective at a time and does not consider all three objectives as a whole for optimization. The solutions found by GS are noticeably inferior to CMOSB, as GS only heuristically searches for solutions. The solutions achieved by ES are farther away from the lower-left corner, indicating that ES performs poorly in simultaneously optimizing utility loss, training cost, and privacy leakage. This suggests that the default hyperparameters set by FATE [6] and VF2Boost [7] were not suitable for multi-objective SecureBoost.
For the trade-off between privacy leakage and utility loss (see Fig. 9), all four datasets demonstrate that as the utility loss decreases, the privacy leakage increases. CMOSB outperforms all baseline methods in terms of the Pareto front. BO performs slightly worse than CMOSB because it is a single-objective optimization algorithm and thus cannot simultaneously optimize privacy leakage, utility loss, and efficiency. GS demonstrates inferior search results, as applying grid search to optimize continuous hyperparameters is often challenging. More specifically, the privacy protection threshold , which significantly impacts privacy leakage, is a continuous variable, and the performance of grid search is limited in this case. ES overall performs quite badly in preserving label privacy (the worst among all methods) because FATE and VF2Boost were not well-prepared for defending against ICA.
| Baseline | Synthetic1 | Credit | Synthetic2 | Sensorless |
| ES | 0.516 | 0.094 | 0.368 | 0.134 |
| GS | 0.826 | 0.746 | 0.706 | 0.822 |
| BO | 0.902 | 0.900 | 0.805 | 0.964 |
| CMOSB | 0.920 | 0.920 | 0.879 | 0.968 |
We also compare the hypervolume of CMOSB with those of baseline methods (see Table IV) for a clear performance comparison between the four hyperparameter tuning methods. We normalize the three objectives for each dataset to ensure a fair comparison. The performance of ES varies widely across the four datasets due to its empirical selection of default hyperparameters for SecureBoost. While obtaining relatively stable results by searching a large number of hyperparameters, GS suffers from a heuristically pre-specified discrete hyperparameter search space, which is not well-suited for our proposed two defense methods, as they are sensitive to their defense parameters (i.e., and ). BO performs better than ES and GS but worse than CMOSB because BO optimizes each objective separately and does not consider all objectives as a whole for optimization.
VII-D Multi-Objective SecureBoost under Constraints
In real-world VFL scenarios, participants typically have specific requirements or constraints on objectives. Hence, we apply the CMOSB algorithm (with constraints) to ensure that the Pareto optimal solutions found satisfy the constraints as much as possible. Adding constraints focuses the search space of the CMOSB algorithm on the feasible region, which improves the efficiency of finding better Pareto optimal solutions.
We conduct this experiment on Synthetic1 and constrain the training cost and privacy leakage to be below 100 seconds and 0.6, respectively. We set the penalty coefficient to 20 (see lines 6-7 of Algorithm 3).

(a) PL Constraint

(b) TC Constraint
Fig. 10 illustrates the hypervolume comparison between CMOSB and MOSB when applying constraints to training cost and privacy leakage, respectively. For the privacy leakage constraint, CMOSB grows more rapidly in the first few generations and surpasses MOSB in the final generation, indicating that it can effectively find better Pareto solutions. For the training cost constraint, CMOSB also surpasses MOSB after the 10th generation and maintains a lead until the last generation.


(a) PL vs UL

(b) TC vs UL
We further compare the Pareto fronts (at the 40th generation) obtained by the CMOSB and MOSB algorithms. Fig. 11(a) demonstrates the effect of adding a privacy leakage constraint, showing a reduction of approximately 3% in privacy leakage of the Pareto solutions at the same level of utility loss. The Pareto front found by CMOSB in Fig. 11(b) is also superior to that found by MOSB, especially for solutions with lower utility loss.
VIII Conclusion
In this paper, we address two main limitations of the SecureBoost algorithm: privacy leakage and hyperparameter optimization. We first propose the instance clustering attack (ICA) that can infer the labels of active party and then we develop two defense methods that can thwart ICA. Next, we propose the Constrained Multi-Objective SecureBoost (CMOSB) algorithm, which identifies Pareto optimal solutions of hyperparameters for SecureBoost by simultaneously minimizing utility loss, training cost, and privacy leakage. We conduct experiments on four datasets to validate the effectiveness of the proposed ICA and the corresponding defense methods. Furthermore, experimental results demonstrate that the Pareto optimal solutions of hyperparameters found by CMOSB outperform those obtained by the baselines in terms of the Pareto front.
References
- [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
- [2] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Transactions on Intelligent Systems and Technology, vol. 10, no. 2, pp. 12:1–12:19, 2019.
- [3] Y. Liu, Y. Kang, T. Zou, Y. Pu, Y. He, X. Ye, Y. Ouyang, Y. Zhang, and Q. Yang, “Vertical federated learning: Concepts, advances, and challenges,” IEEE Transactions on Knowledge Data Engineering, pp. 1–20, 2024.
- [4] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, D. Papadopoulos, and Q. Yang, “Secureboost: A lossless federated learning framework,” IEEE Intelligent Systems, vol. 36, no. 6, pp. 87–98, 2021.
- [5] C. Fu, X. Zhang, S. Ji, J. Chen, J. Wu, S. Guo, J. Zhou, A. X. Liu, and T. Wang, “Label inference attacks against vertical federated learning,” in 31st USENIX Security Symposium, USENIX Security 2022, 2022, pp. 1397–1414.
- [6] Y. Liu, T. Fan, T. Chen, Q. Xu, and Q. Yang, “FATE: an industrial grade platform for collaborative learning with data protection,” Journal of Machine Learning Research, vol. 22, pp. 226:1–226:6, 2021.
- [7] F. Fu, Y. Shao, L. Yu, J. Jiang, H. Xue, Y. Tao, and B. Cui, “Vfboost: Very fast vertical federated gradient boosting for cross-enterprise learning,” in International Conference on Management of Data, 2021, pp. 563–576.
- [8] Y. Kang, H. Gu, X. Tang, Y. He, Y. Zhang, J. He, Y. Han, L. Fan, and Q. Yang, “Optimizing privacy, utility and efficiency in constrained multi-objective federated learning,” arXiv preprint arXiv:2305.00312, 2023.
- [9] X. Zhang, Y. Kang, K. Chen, L. Fan, and Q. Yang, “Trading off privacy, utility, and efficiency in federated learning,” ACM Trans. Intell. Syst. Technol., vol. 14, 2023.
- [10] W. Chen, G. Ma, T. Fan, Y. Kang, Q. Xu, and Q. Yang, “Secureboost+ : A high performance gradient boosting tree framework for large scale vertical federated learning,” CoRR, vol. abs/2110.10927, 2021.
- [11] W. Fang, D. Zhao, J. Tan, C. Chen, C. Yu, L. Wang, L. Wang, J. Zhou, and B. Zhang, “Large-scale secure XGB for vertical federated learning,” in The 30th ACM International Conference on Information and Knowledge Management, 2021, pp. 443–452.
- [12] Y. Wu, S. Cai, X. Xiao, G. Chen, and B. C. Ooi, “Privacy preserving vertical federated learning for tree-based models,” Proceedings of the VLDB Endowment, vol. 13, no. 11, pp. 2090–2103, 2020.
- [13] T. Zou, Y. Liu, Y. Kang, W. Liu, Y. He, Z. Yi, Q. Yang, and Y.-Q. Zhang, “Defending batch-level label inference and replacement attacks in vertical federated learning,” IEEE Transactions on Big Data, pp. 1–12, 2022.
- [14] S. Xie, X. Yang, Y. Yao, T. Liu, T. Wang, and J. Sun, “Label inference attack against split learning under regression setting,” CoRR, vol. abs/2301.07284, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2301.07284
- [15] P. Qiu, X. Zhang, S. Ji, T. Du, Y. Pu, J. Zhou, and T. Wang, “Your labels are selling you out: Relation leaks in vertical federated learning,” IEEE Transactions on Dependable and Secure Computing, pp. 1–16, 2022.
- [16] J. Tan, L. Zhang, Y. Liu, A. Li, and Y. Wu, “Residue-based label protection mechanisms in vertical logistic regression,” in 8th International Conference on Big Data Computing and Communications, 2022, pp. 356–364.
- [17] X. Pan, Y. Tong, C. Xue, Z. Zhou, J. Du, Y. Zeng, Y. Shi, X. Zhang, L. Chen, Y. Xu, K. Xu, and W. Lv, “Hu-fu: A data federation system for secure spatial queries,” Proceedings of the VLDB Endowment, vol. 15, no. 12, pp. 3582–3585, 2022.
- [18] Y. Wang, Y. Tong, Z. Zhou, R. Zhang, S. J. Pan, L. Fan, and Q. Yang, “Distribution-regularized federated learning on non-iid data,” in 39th IEEE International Conference on Data Engineering, 2023, pp. 2113–2125.
- [19] W. Zhang, Z. Zhou, Y. Wang, and Y. Tong, “Dm-pfl: Hitchhiking generic federated learning for efficient shift-robust personalization,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 3396–3408.
- [20] S. Cui, W. Pan, J. Liang, C. Zhang, and F. Wang, “Addressing algorithmic disparity and performance inconsistency in federated learning,” in Advances in Neural Information Processing Systems, 2021, pp. 26 091–26 102.
- [21] H. Zhu and Y. Jin, “Multi-objective evolutionary federated learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 4, pp. 1310–1322, 2020.
- [22] M. J. Freedman, K. Nissim, and B. Pinkas, “Efficient private matching and set intersection,” in Advances in Cryptology - EUROCRYPT 2004, International Conference on the Theory and Applications of Cryptographic Techniques, ser. Lecture Notes in Computer Science, vol. 3027, 2004, pp. 1–19.
- [23] Y. Tong, X. Pan, Y. Zeng, Y. Shi, C. Xue, Z. Zhou, X. Zhang, L. Chen, Y. Xu, K. Xu, and W. Lv, “Hu-fu: Efficient and secure spatial queries over data federation,” Proceedings of the VLDB Endowment, vol. 15, no. 6, pp. 1159–1172, 2022.
- [24] E. Zitzler and S. Künzli, “Indicator-based selection in multiobjective search,” in Parallel Problem Solving from Nature, ser. Lecture Notes in Computer Science, vol. 3242, 2004, pp. 832–842.
- [25] A. Y. Ng, M. I. Jordan, and Y. Weiss, “On spectral clustering: Analysis and an algorithm,” in Advances in Neural Information Processing Systems, 2001, pp. 849–856.
- [26] A. Kraskov, H. Stögbauer, and P. Grassberger, “Estimating mutual information,” Physical Review E, vol. 69, p. 066138, 2004.
- [27] S. Holly, T. Hiessl, S. R. Lakani, D. Schall, C. Heitzinger, and J. Kemnitz, “Evaluation of hyperparameter-optimization approaches in an industrial federated learning system,” in Proceedings of the 4th International Data Science Conference, 2022, pp. 6–13.
- [28] J. Snoek, H. Larochelle, and R. P. Adams, “Practical bayesian optimization of machine learning algorithms,” in Advances in Neural Information Processing Systems, 2012, pp. 2960–2968.
- [29] K. Deb and A. Kumar, “Real-coded genetic algorithms with simulated binary crossover: Studies on multimodal and multiobjective problems,” Complex Systems, vol. 9, no. 6, 1995.