Hypergraph Enhanced Knowledge Tree Prompt Learning for Next-Basket Recommendation
Abstract.
Next-basket recommendation (NBR) aims to infer the items in the next basket given the corresponding basket sequence. Existing NBR methods are mainly based on either message passing in a plain graph or transition modelling in a basket sequence. However, these methods only consider point-to-point binary item relations while item dependencies in real world scenarios are often in higher order. Additionally, the importance of the same item to different users varies due to variation of user preferences, and the relations between items usually involve various aspects. As pretrained language models (PLMs) excel in multiple tasks in natural language processing (NLP) and computer vision (CV), many researchers have made great efforts in utilizing PLMs to boost recommendation. However, existing PLM-based recommendation methods degrade when encountering Out-Of-Vocabulary (OOV) items. OOV items are those whose IDs are out of PLM’s vocabulary and thus unintelligible to PLM. To settle the above challenges, we propose a novel method HEKP4NBR, which transforms the knowledge graph (KG) into prompts, namely Knowledge Tree Prompt (KTP), to help PLM encode the OOV item IDs in the user’s basket sequence. A hypergraph convolutional module is designed to build a hypergraph based on item similarities measured by an MoE model from multiple aspects and then employ convolution on the hypergraph to model correlations among multiple items. Extensive experiments are conducted on HEKP4NBR on two datasets based on real company data and validate its effectiveness against multiple state-of-the-art methods.
1. Introduction
Recently, with the explosive growth in e-commerce and online platforms, recommendation algorithms have become a potential research field that attracts much attention in both academia and industry. One of the most popular topics is called Next-Basket Recommendation (NBR), which groups multiple items interacted at the same time into a basket and aims to infer the items in the basket that user will interact with given his/her basket sequence. Compared with Sequential Recommendation (SR) (Hidasi et al., 2016a; Sun et al., 2019), NBR has a wider application in real world scenarios since SR assumes that user interactions within a period of time must strictly follow a chronological order. This assumption is difficult to maintain since users often interact with multiple items simultaneously to satisfy a certain need.
A common issue of NBR task is data sparsity, meaning that each user only interacts with a small portion of items, resulting in insufficient data for learning representations of users and items (Su et al., 2023). To tackle this issue, some existing NBR methods focus on mining sequential transition patterns in the historical interaction sequences (Wu et al., 2022; Peng et al., 2022; Kou et al., 2023; Deng et al., 2023; Wang et al., 2020a). However, these methods rely solely on item IDs, which leads to underfitting in the representation and is further expressed as a degradation of recommendation performance especially for the long-tail items. Some other NBR methods attempt to mine collaborative signals by considering user interactions as graphs (Su et al., 2022, 2023; Li et al., 2023c; Yu et al., 2023). These methods model the correlations between two items by passing messages along the edges and aggregating messages from the neighbours. However, due to the data sparsity issue, those graphs often contain only shallow collaborative signals, making it difficult to mine deep semantic correlations. Furthermore, items that the user haven’t interacted with do not necessarily mean that these items do not match the user’s preferences.
Despite of the remarkable improvements that these methods have achieved, they still face the following challenges.
-
•
Existing methods are mainly based on either message passing in a plain graph or transition modelling in an interaction sequence. These methods only model point-to-point binary item relation, whereas item dependencies are beyond binary relation and are often triadic or even higher order. For example, many widely used therapies for diseases such as HIV and pulmonary tuberculosis often involve a combination of multiple medicines.
-
•
Due to variations in user preferences, the importance of items varies. For example, for users with sufficient budgets, the quality of items is often the primary consideration. However, for those on a tight budget, price is also an important factor. What’s more, the relationships between items involve various aspects, such as complementarity, substitution and cooperation.
-
•
Some methods attempt to incorporate side information such as KG to alleviate the data sparsity issue (Hidasi et al., 2016b; Wang et al., 2019a, 2020c). However, obtaining high quality item representations in large scale KG is a challenging task due to the intrinsic noise in the KG. For example, ”Insulin is a medication for diabetes” has nothing to do with ”Penicillin is a medication for bacterial infections”. However, they will infect each other through the message passing process in KG. Furthermore, the pre-trained item representations may not be suitable for the downstream task.
Recently, PLMs have shown remarkable performance in NLP (Brown et al., 2020; Raffel et al., 2020; Touvron et al., 2023) and CV (Radford et al., 2021; Ramesh et al., 2022; Li et al., 2022), demonstrating strong capabilities in comprehension and representation. As PLMs are applied to various tasks, a new learning paradigm called prompt learning has emerged. Prompt learning follows the ”pretrain-prompt-tuning” paradigm, which transforms downstream tasks into pre-train tasks of PLMs using prompt templates to bridge the gap between the downstream objectives and pre-train objectives, seamlessly transferring prior knowledge in PLMs to downstream tasks. There are many research on utilizing PLMs in recommendation (Sun et al., 2023; Li et al., 2023a; Wang et al., 2022; Zhai et al., 2023; Zhang and Wang, 2023).
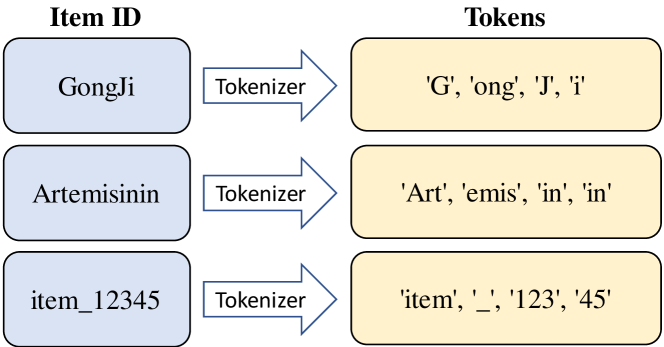
However, PLM-based recommendation is not as straightforward as described above. One of the biggest challenges is how to represent items in prompt. Since the PLM corpus cannot be infinite, it often struggles to understand words that are not present in its corpus. We define these items as Out-Of-Vocabulary (OOV) items, meaning that their item IDs are out of PLM’s vocabulary. There are mainly two ways in existing methods to represent an item. One way is to directly use its original name but many OOV item names are either terminologies (such as a medicine called Artemisinin) or non-English words (such as a Chinese poultry called GongJi). The other way is to map each item to a unique number and treat that number as its item ID (such as item_12345). As Figure 1 shows, neither of these two ways is intelligible to PLMs. For instance, Artemisinin has nothing to do with token Art and token 123 is not semantically correlated with the following token 45.
In order to tackle the aforementioned challenges, we propose Hypergraph Enhanced Knowledge Tree Prompt Learning for Next-Basket Recommendation (HEKP4NBR) in this paper. First, inspired by P5 (Geng et al., 2022), we propose to construct a masked user prompt (MUP) according to the user’s basket sequence, where each token in MUP corresponds to an item in the next basket. In this way, we can transform the NBR task of predicting items in the next basket into a pre-train task called mask prediction which predicts tokens corresponding to the tokens. Then, in order to help PLMs encode the OOV items in MUP, we propose to construct knowledge tree prompts (KTP) by building a knowledge tree based on user’s historical interaction and KG inspired by (Zhai et al., 2023). In this way, we are able to provide rich information of those OOV items while avoiding brutal encoding of the whole KG to mitigate the noise issue. What’s more, inspired by several works on hypergraphs (Yang et al., 2022; Li et al., 2023c; Yu et al., 2023), we design a multi-item relation encoder, which employs an MoE model to measure item similarity from multiple aspects and builds a hypergraph based on item similarity. Then we use a hypergraph convolutional module to model the correlations among multiple items. Lastly, we use a simple yet effective frequency base gating module to dynamically matching basket sequence to each item by the frequency of the user interaction. Extensive experiments show that our method outperforms state-of-the-art methods on multiple metrics in two real world datasets. The contributions of this paper can be summarized as follows:
-
•
We proposed HEKP4NBR which mines the transition pattern in the basket sequence with the help of PLMs and KG while utilizing hypergraph to model the correlations among multiple items.
-
•
We construct MUP to transform NBR task into mask prediction task following the prompt learning paradigm. In order to encode the OOV items in MUP, we construct another prompt KTP to leverage knowledge in KG.
-
•
We design a multi-item relation encoder model the correlations among multiple items with an MoE model and a hypergraph convolutional module.
-
•
We conduct extensive experiments on two datasets, Poultry and Pharmacy. They are based on two real world companies providing B2B and B2C service each. The results demonstrate the effectiveness of our method.
2. Related Work
2.1. Next-Baket Recommendation
Next-basket recommendation aims at inferring multiple items in the next basket. Early works (Rendle et al., 2010; Wan et al., 2015) utilize Markov Chain (MC) which strictly modelling transaction between every two nearby baskets, limiting the exploration of user interest. With the development of deep learning, RNN-based methods such as DREAM (Yu et al., 2016), CLEA (Qin et al., 2021) and Beacon (Le et al., 2019) apply RNN to capture the long-term dependency in basket sequence. Similarly, some attention-based methods (Wang et al., 2020a, b) adaptively mine the different contributions of each item to user preferences using attention mechanism. Recently, (Peng et al., 2022) takes the users general preferences, items global popularities and sequential transition patterns among items into consideration. SecGT (Kou et al., 2023) models user preference by collaboratively modeling the joint user-seller-product interactions and sequentially exploring the user-agnostic basket transitions. MMNR (Deng et al., 2023) normalizes the number of interactions from both user and item views to obtain differentiated representation and aggregates item representations within baskets from multi aspects. While these methods have produced competitive results, relying solely on item IDs leads to the model treating each item independently. Consequently, the model can only capture shallow ID transition patterns and lack the ability to discern deeper semantic-level correlations.
2.2. Graph-Based Recommendation
Graph is a data structure that represents the associations between entities by connectivity and there’s consistency between graph structure and user interaction. Early works (Perozzi et al., 2014; Grover and Leskovec, 2016) employ random walk to extract some node sequences in graph and encode each node in an embedding. Some fundamental works such as GCN (Kipf and Welling, 2017), GAT (Velickovic et al., 2018), GraphSage(Hamilton et al., 2017) and LightGCN (He et al., 2020b) design various GNNs for learning representations of nodes in graph, after which KGCN (Wang et al., 2019d) and KGAT (Wang et al., 2019a) extend these works to Knowledge Graph (KG). Recently, GCSAN (Xu et al., 2019) uses self-attention layers to assign different weights for each item by constructing a directed graph from item sequences. SINE (Tan et al., 2021) mines multiple aspects of interest from item sequence to effectively model several diverse conceptual prototypes. These methods only model point-to-point binary item relation while in real world scenarios, especially in B2B scenarios, item dependencies are often higher order. To tackle this issue, DigBot (Li et al., 2023c) constructs a hypergraph that connects each item in a basket by a hyperedge. BRL (Yu et al., 2023) employs hypergraph convolution on hypergraph to explore correlations among different items. However, these methods fail to mine deep semantic correlations since the hypergraphs are built only based on the inclusion relationship between baskets and items.
2.3. PLM for Recommendation
PLMs have achieved remarkable success in various tasks, and there is a large number of PLM-based recommendation methods have been proposed recently. PEPLER (Li et al., 2023b) uses GPT-2 as an interpreter to give personalized explanations for recommendation results. NRMS (Wu et al., 2021) serves PLMs as item encoders for news recommendation and Prompt4NR (Zhang and Wang, 2023) designs several discrete and continuous prompt templates following prompt learning paradigm. P5 (Geng et al., 2022) is a unified framework that integrates several recommendation tasks by transforming them into NLP tasks. Following P5, KP4SR (Zhai et al., 2023) further incorporates KG into prompt and use masks to block attention between irrelevant triplets. GenRec (Sun et al., 2023) generate each item in the next basket one by one in an auto-regressive manner to simulate the process of users satisfying their needs step by step. However, none of these works take into consideration how items are represented in prompts, resulting in performance degradation when encountering OOV items.
3. Methodology
3.1. Problem Formulation and Preliminary
We first give a formulation on Next-Basket Recommendation. Let denotes the user set and denotes the item set. A basket is a set of items which are interacted by a user at the same time. Let denotes the set of all basket. The history interaction sequence of a user can be denoted as a basket sequence arranged in chronological order, i.e., where . The NBR task is to predict the next basket that user may interact given his basket sequence .
Then, we provide a definition on knowledge graph (KG). A KG is a heterogeneous graph consists of an entity set and a relation set , which can be defined as . A triplet indicates that relation connects the head entity and the tail entity .
Next, we define the basket-item bipartite graph as a bipartite graph between basket set and item set , denoted by , where each edge in edges set indicates that item is contained in basket .
Lastly, we briefly introduce hypergraph. An hypergraph consists of a vertex set and a hyperedge set . Each hyperedge is a subset of , indicating that multiple vertices are connected by . The degree of a vertex , denoted by , is the number of hyperedges that is incident to. Similarly, the degree of a hyperedge , denoted by , is the number of vertices that are incident to .
3.2. Overview
We propose a model called HEKP4NBR, which transforms KG into prompt to alleviate the ambiguity when PLM modelling OOV items and models the correlation among multiple items by hypergraph convolutional operation. It mainly consists of three modules: knowledge aware prompt learning module (Section 3.3), multi-item relation encoder module (Section 3.4) and frequency based gating module (Section 3.5). The overall framework and pipeline of HEKP4NBR is shown in Figure 2.

3.3. Knowledge Aware Prompt Learning
The pretrain-prompt-tuning paradigm has achieved great success in NLP and CV, and many efforts have been made to apply prompt learning in recommender systems (Geng et al., 2022; Zhai et al., 2023). In this section, we construct two kinds of prompt, namely masked user prompt (MUP) and knowledge tree prompt (KTP), which describe the interacted basket sequence of a user and knowledge of items in the basket sequence respectively. Combining MUP and KTP, we can not only utilize generic knowledge in PLM, but also alleviate the detriment of OOV items on PLM.
3.3.1. Masked user prompt
Inspired by (Geng et al., 2022), we construct a masked user prompt to transform NBR task into a pre-train task, i.e., mask prediction. In this way, our model can bridge the gap between pre-train task and downstream task.
Specifically, we manually design some templates to transform into MUP, that is,
| (1) |
For instance, suppose the basket sequence of user is . Its corresponding MUP is ”User has purchase 3 baskets. Basket_0 consists of , . Basket_1 consists of , . Basket_2 will consists of , ”, where and correspond to items in the next basket, i.e., and .
As mentioned above, when faced with OOV items, these words may not be as simple as , or , but words that are beyond PLM’s knowledge, or even non-English words. In this scenario, we argue that these unintelligible words would do harm to PLM while introducing side information such as KG will help. Therefore, we also construct the following KTP to incorporate KG into prompts.
3.3.2. Knowledge tree prompt
Many research (Wang et al., 2019c, 2021) has shown that introducing KG as side information in recommendation may significantly boost performance. However, as mentioned before, it’s still a open problem about how to corporate KG into prompts since brutally flattening structured KG into linear words would lead to inevitable structural information loss. In order to settle this challenge, we proposed to readout KTP from KG by constructing a knowledge tree based on basket sequence .
In order to build the knowledge tree, we first construct the augmented KG, denoted by , following Equation 2,
| (2) |
where is a new entity representing the basket sequence and consist_of is a new relation. Then we perform beam search in starting from the new entity to all entities within hops from , after which the beam search tree is called as knowledge tree. Next, we traverse knowledge tree in breadth-first manner and sequentially record every triplet during the traversal to create a triplet sequence ,
| (3) |
where is the number of all triplets, noted that each triplet indicates an edge of relation points from head entity to tail entity in . The KTP can be defined as Equation 4,
| (4) |
where is the KTP template that converts a triplet into a string. In this paper, we define .
3.3.3. PLM encoding and fine-tuning
After we construct MUP and KTP base on user’s basket sequence and KG, we input them into PLM and obtain the output embeddings of tokens. Noted that there might be multiple tokens, we just simply employ a mean pooling over all embeddings to get the sequence embedding , where denotes hidden size of PLM.
| (5) |
Following (Geng et al., 2022), we use the auto-regressive Negative Log Likelihood (NLL) loss to supervise PLM fine-tuning following Equation 6,
| (6) |
where represents the predicted output and represents the parameters in PLM.
3.4. Multi-item Relation Encoder
3.4.1. Item Semantic Encoder with MoE model
We argue that there is a greater similarity between items within the same basket. Thus, we conduct layers of GCN convolution to the basket-item bipartite graph to obtain an initial embedding for each item , denoted by , and each basket , denoted by , where represents the size of embeddings.
In order to encode the correlations and dependencies among items, we introduce an item semantic encoder to obtain the item similarity matrix , whose -th entry represents the similarity between item and item . We employ a Mixture-of-Experts, or MoE, model to learn from multiple aspects following Equation 7 and Equation 8,
| (7) | ||||
| (8) |
where represents the number of experts and is learnable parameter. is a similarity metric function. is an aggregating function that aggregate from all experts to obtain the final similarity.
We design two pair-wise ranking losses of two different levels. The first ranking loss, denoted , is based on the hypothesis that the embedding of a basket should be more similar with the embedding of an item that includes in basket than it of an item that excludes. Given a basket , we randomly sample a positive item and another negative item then compute as Equation 9,
| (9) |
where represents the inner product of vectors and is the sigmoid function.
The second ranking loss, denoted , is based on the hypothesis that the similarity of an item pair that appears in the same basket should be higher than it of an item pair that doesn’t. Given a basket and for each item , we randomly sample an positive item and another negative item and compute as Equation 10,
| (10) |
where represents the size of basket .
3.4.2. Item hypergraph Convolution
With the item similarity matrix encoded by the MoE model, we then construct a item hypergraph by connecting each item with its top- most similar items using a hyperedge. Specifically, given the item similarity matrix , we define the adjacent matrix of item hypergraph as , whose -th entry is calculated by Equation 11,
| (11) |
where represents the set of the top- similar items of item according to .
Inspired by (Yang et al., 2022), we design a hypergraph convolution module by applying message passing paradigm on hyperedges to capture the correlations among multiple items. Specifically, we design our hypergraph convolutional layer as Equation 12,
| (12) |
where and denotes the diagonal matrices composed of the degrees of each nodes and hyperedges in the hypergraph respectively. represents the learable feed forward layer. Each embedding is initalized by the former GCN convolutional layers, i.e., . We conduct layers of convolution to the hypergraph and take each embedding of the last layer as the refined item embedding, i.e., .
3.5. Frequency Based Gating
In this section, we propose a gating mechanism based on user’s interaction frequency to dynamically match the basket sequence to each item. This idea is built upon the prior knowledge that users tend to have a higher preference for those frequently interacted items.
Specifically, given the basket sequence , the probability of item containing in the next basket is computed as Equation 13,
| (13) |
where is the normalized vector whose -th entry represents the frequency of user interacting with item . is the indicator vector of the positive entry in , i.e., , while gating vector . , and are learnable parameters. represents the vector concatenate operation.
The recommendation loss is calculated as subsection 3.5,
| (14) |
where denotes the ground-truth next basket following and denotes the label indicating whether .
3.6. Recommendation and Training
For convenience, the size of the next basket is usually given as a hyperparameter by the algorithm. At the recommendation stage, we just recommend basket to the user following Equation 15,
| (15) |
where topn function returns a set of indices corresponding to the largest elements.
We optimize our HEKP4NBR model by a multi-task learning strategy as Equation 16,
| (16) |
For clarity, we demonstrate the training procedure of HEKP4NBR in Algorithm 1.
Input: List of basket sequence , origin KG , PLM pre-trained parameters , epoch number .
Output: PLM fine-tuned parameters , overhead parameters .
4. Experiments
We conduct extensive experiments on two real world datasets to evaluate the effectiveness of the HEKP4NBR model. These experiments are designed to answering the following research questions:
-
•
RQ1: How does the proposed HEKP4NBR model perform compared to the state-of-the-art baselines in next-basket recommendation task?
-
•
RQ2: What are the impacts of different key components and hyperparameters in HEKP4NBR?
-
•
RQ3: What kind of PLM backbone is more suitable for HEKP4NBR?
-
•
RQ4: How is HEKP4NBR’s generalization to unseen templates?
4.1. Experiments Settings
4.1.1. Datasets
| Statistics | Poultry | Pharmacy | |
|---|---|---|---|
| Interactions | # Users | 11723 | 12946 |
| # Items | 238 | 6262 | |
| # Baskets | 45746 | 63072 | |
| Avg. basket size | 4.133 | 3.366 | |
| Avg. sequence length | 7.504 | 7.305 | |
| KG | # Relations | 3 | 2 |
| # Entities | 253 | 6324 | |
| # Triplets | 1428 | 25048 |
We constructed two datasets based on the real sales data from two companies facing different types of customers. The first dataset, namely Poultry, consists of users’ interactions with a large agribusiness in China. This company mainly provides B2B services, suggesting that users are highly adhesive wholesalers. The item names and attributes of Poultry dataset are all in Chinese which is not easy to translate into English. The second dataset, namely Pharmacy, is built upon the sales data of a medicine store in Shenzhen, China, which mainly focuses on B2C business. The names of the medicines are either professional medical terms or traditional Chinese herbal medicine names.
We generate a basket sequence for each user by grouping every items interact at the same timestamp into a basket and then sorting the baskets in chronological order according to their timestamps. Following the well-known NBR method (Le et al., 2019), we filter out the baskets that contain fewer than 2 items and randomly select 5 items for those containing more than 5 items.Similarly, we filter out basket sequences whose length is less than 4 and keep the last 10 baskets for those longer than 10. Here, we set the maximum length of the basket sequence to 10, considering the limitation of the PLM input sequence’s length. In Section 4.4, we will demonstrate the impact of maximum basket sequence lengths on overall performance. For each datasets, we divide all basket sequences into training set, validating set and testing set in the ratio of 8:1:1.
Since the datasets are based on non-public data, we manually build a knowledge graph for each dataset. For Poultry dataset, we connect each kind of poultry to its level, gender and category using relation level_is, gender_is and category_is respectively. For Pharmacy dataset, we connect each kind of medicine to its therapeutic function and category using relation function_is and category_is respectively. Some detailed statistics of two datasets after preprocessing are shown in Table 1.
4.1.2. Evaluation Metrics
Following (Zhai et al., 2023; Peng et al., 2022), we adopt three widely used metrics to evaluate the performance of our HEKP4NBR model, namely F1-score@ (F1@), Hit Rate@ (HR@) and Normalized Discounted Cumulative Gain@ (NDCG@). We report the metrics corresponding to and in the following section. Given , we predict the next basket containing items for each user.
4.1.3. Baselines
To verify the effectiveness of our HEKP4NBR model, we choose the following state-of-the-art NBR methods as baselines in our experiments:
-
•
GRU4Rec (Hidasi et al., 2016a) introduces Gating Recurrent Unit (GRU) to model the sequential dependency hidden in the users’ interaction sequences. GRU4RecKG is a variant of GRU4Rec that incorporate KG to obtain better representation of items.
-
•
STAMP (Liu et al., 2018) captures users’ general interests by long-term attention and propose to model the current intention by a short-term memory mechanism.
-
•
SASRec (Kang and McAuley, 2018) apply self-attentive encoder to the interaction sequences to generate the potential next item in a auto-regressive manner.
-
•
NextItNet (Yuan et al., 2019) encode the interaction sequence by a masked convolutional residual network composed of stacked 1 dimension dilated convolutional layers
-
•
LightSANs (Fan et al., 2021) assume that users’ interests only concentrate in a constant number of aspects and generate the context-aware representation by the low-rank self-attention.
-
•
(Peng et al., 2022) is a next-basket recommendation method which takes the users’ general preferences, items’ global popularities and transition patterns among items into consideration.
-
•
GCSAN (Xu et al., 2019) is a graph-based recommendation method that model the users’ global interest by self-attention mechanism.
-
•
SINE (Tan et al., 2021) attempts to infer a set of interests for each user adaptively to model the current intention of users.
-
•
BERT4Rec (Sun et al., 2019) is the first attempt to leverage Transformer based BERT encoder to encode the interaction sequence.
-
•
P5 (Geng et al., 2022) is a PLM-based recommendation method that unified multiple recommendation tasks into a single framework by designing the personalized prompt sets.
Our baselines can be divided into three classes: (1) the models that focusing on modelling sequential patterns, i.e., GRU4Rec, GRU4RecKG, STAMP, SASRec, NextItNet, LightSANs, , BERT4Rec and P5; (2) the models that based on graph, i.e., GCSAN and SINE.
4.1.4. Implementation Details
In our experiment, we utilize a pre-trained T5-small model (Raffel et al., 2020) as the PLM backbone of HEKP4NBR. T5 is a text-to-text model based on encoder-decoder architecture whose encoder and decoder are both composed of 6 Transformer layers respectively with a hidden dimension . Due to the length limitation of PLM, we set the maximum length of input tokens to 512 and only explore the entities within hops from the root entity when constructing KTP. We only set the number of GCN layer and hypergraph convolutional layer, i.e., and , to 2 considering the oversmoothing problem occuring with too-deep GNNs. We set the number of experts in the MoE model to 8. For the embeddings dimensions, we set , . We randomly initialized the parameters in the overhead part of HEKP4NBR, i.e., the multi-item relation encoder and the frequency based gating module. We use 1 NVIDIA A800 GPU to train our model with a batch size of 64 and 100 epoch. We fully fine-tune the T5 backbone with a peak learning rate of 1e-5 and optimize the overhead with a peak learning rate of 1e-4 using AdamW optimizer.
| Methods | Poultry | Pharmacy | ||||||||||
| F1@5 | HR@5 | NDCG@5 | F1@10 | HR@10 | NDCG@10 | F1@5 | HR@5 | NDCG@5 | F1@10 | HR@10 | NDCG@10 | |
| GRU4Rec | 0.451 | 0.579 | 0.574 | 0.374 | 0.769 | 0.661 | 0.172 | 0.231 | 0.327 | 0.116 | 0.258 | 0.338 |
| GRU4RecKG | 0.460 | 0.581 | 0.575 | 0.374 | 0.770 | 0.657 | 0.175 | 0.233 | 0.328 | 0.116 | 0.256 | 0.338 |
| STAMP | 0.418 | 0.537 | 0.518 | 0.357 | 0.736 | 0.609 | 0.171 | 0.229 | 0.326 | 0.114 | 0.254 | 0.337 |
| SASRec | 0.443 | 0.568 | 0.561 | 0.372 | 0.767 | 0.6548 | 0.173 | 0.233 | 0.327 | 0.117 | 0.260 | 0.337 |
| NextItNet | 0.390 | 0.501 | 0.472 | 0.346 | 0.712 | 0.564 | 0.174 | 0.233 | 0.327 | 0.116 | 0.259 | 0.338 |
| LightSANs | 0.440 | 0.561 | 0.547 | 0.366 | 0.746 | 0.6532 | 0.172 | 0.232 | 0.326 | 0.116 | 0.258 | 0.338 |
| BERT4Rec | 0.445 | 0.571 | 0.526 | 0.391 | 0.802 | 0.631 | 0.179 | 0.244 | 0.327 | 0.118 | 0.268 | 0.336 |
| 0.486 | 0.6520 | 0.594 | 0.386 | 0.791 | 0.670 | 0.197 | 0.266 | 0.342 | 0.142 | 0.315 | 0.362 | |
| P5 | 0.510 | 0.635 | 0.516 | 0.391 | 0.818 | 0.691 | 0.184 | 0.246 | 0.341 | 0.142 | 0.354 | 0.376 |
| GCSAN | 0.434 | 0.557 | 0.544 | 0.366 | 0.753 | 0.634 | 0.172 | 0.232 | 0.327 | 0.117 | 0.259 | 0.336 |
| SINE | 0.450 | 0.579 | 0.571 | 0.371 | 0.762 | 0.656 | 0.172 | 0.231 | 0.328 | 0.116 | 0.259 | 0.339 |
| HEKP4NBR | 0.627 | 0.793 | 0.807 | 0.439 | 0.896 | 0.783 | 0.273 | 0.368 | 0.447 | 0.170 | 0.377 | 0.428 |
| Improv. | 22.94% | 24.88% | 35.85% | 12.27% | 9.54% | 13.31% | 38.57% | 38.34% | 30.70% | 19.71% | 6.49% | 13.82% |
4.2. Performance Comparison (RQ1)
The performance comparison results of all baselines and the proposed HEKP4NBR model are shown in Table 2. According to the experimental results, we may conclude the following observations.
The proposed HEKP4NBR model demonstrates considerable performance improvements across all evaluation metrics and datasets. On one hand, improvements in NDCG metric suggest that our method can not only accurately predict items in the next basket, but also demonstrates a strong comprehensions on the significance and relevance between the next basket and each potential item. This is likely attributed to the prior knowledge encoded in the PLM corpus and KG, which empowers our model to alleviate the OOV item issue and obtain better representations of items. On the other hand, our method also achieves competitive improvements in the HR metric, indicating its capability to cover a large portion of ground truth items in the next basket. We believe that this improvement stems from the modelling of correlation among multiple items by the multi-item relation encoder. It’s worth noting that P5 achieves almost the highest performance among all baselines, solely utilizing PLM to encode the prompt text corresponding to the interaction sequence without using any additional side information. Nevertheless, P5 requires 300 epochs and about twice as much training time as HEKP4NBR to converge. In light of this, we argue that using MUP to transform recommendation task into a pre-trained mask prediction task significantly contributes to the convergence speed of model.
Some baselines (GRU4Rec, SASRec, BERT4Rec) attempt to precisely leverage sequential encoders, such as GRU, self-attention mechanism and Transformers, to accurately model the transition patterns from basket to basket in the interaction sequence for each user. While these methods have produced competitive results, relying solely on item IDs leads to the model treating each item independently. Consequently, the model can only capture shallow ID transition patterns and lack the ability to discern deeper semantic-level correlations. Some baselines like GRU4RecKG make efforts to integrate side information such as KG at an early stage. These methods indeed benefit to boost performance but still cannot achieve the best results. This is mainly because obtaining high quality item representations in large scale KG is a challenging task due to intrinsic noise in the KG. Furthermore, the pre-trained item representations may not be suitable for the recommendation task. Unlike the trivial way in GRU4RecKG, HEKP4NBR leverages KG at a finer granularity by transforming the most relevant knowledge into KTP. In this way, we are able to model the deep semantic correlations while alleviating the effects of noise in KG by exploiting the excellent comprehension capabilities of PLM. We also notice that can achieve better results than GRU4RecKG even without any prior knowledge to items. This is because is the only baseline that explicitly model user preference. In Section 4.3, we will show that modelling user preference by simply counting purchase frequency will significantly boost performance.
Other baseline (GCSAN, SINE) introduce graph structure to facilitate sequence modelling and thus achieves relatively competitive performance. Specifically, SINE mine different aspects of user interest from the user’s session graph and performs better compared with GCSAN in Poultry dataset. This indicates that mining multiple patterns from the interaction sequence will benefit the model, which shares the same idea with MoE component in HEKP4NBR.
4.3. Ablation Study (RQ2)
| Datasets | Settings | F1@5 | HR@5 | NDCG@5 |
|---|---|---|---|---|
| Poultry | w/o GCN | 0.453 | 0.577 | 0.545 |
| w/o Hyper-GCN | 0.547 | 0.692 | 0.684 | |
| w/o FBG | 0.471 | 0.591 | 0.605 | |
| w/o KTP | 0.511 | 0.649 | 0.632 | |
| HEKP4NBR | 0.627 | 0.793 | 0.807 | |
| Pharmacy | w/o GCN | 0.234 | 0.319 | 0.392 |
| w/o Hyper-GCN | 0.212 | 0.291 | 0.363 | |
| w/o FBG | 0.190 | 0.258 | 0.348 | |
| w/o KTP | 0.238 | 0.325 | 0.398 | |
| HEKP4NBR | 0.273 | 0.368 | 0.447 |
We validate the effectiveness of several components of HEKP4NBR by designing ablation study on two datasets. The setting of each variant is described below:
-
•
w/o GCN: We remove the GCN part to obtain initial item embeddings and randomly initialize instead.
-
•
w/o Hyper-GCN: We remove the hypergraph convolutional module and MoE model and directly feed into the FBG module.
-
•
w/o FBG: We replace the dynamic gating module with a simple inner product operation between and , that is,
(17) -
•
w/o KTP: We remove the KTP and only feed MUP into PLM.
The results of ablation study are shown in Table 3. We can see that the performance degenerate in different degrees of all four variants, which verifies the effectiveness of our components. Specifically, it’s evident that on the Poultry dataset, which comprises relatively fewer items and denser interactions, the lack of GCN and FBG will significantly deteriorate performance, resulting in a degradation of more than 30%. This indicates that utilizing collaborative signal between baskets and items in the basket-item bipartite graph can enhance the quality of item embeddings. Similarly, a smaller item set implies denser purchase frequency vectors of users, hence implying that users have more distinct preferences and re-purchase patterns. In this case, the proposed FBG is more powerful in mining these patterns.
On the contrary, on the larger and sparser Pharmacy dataset, the hypergraph convolutional module plays an important role, which will cause over 25% degradation if removed. This is because there are more combinations of items and preferences vary among users in Pharmacy dataset while the hypergraph convolutional module is suitable for modelling semantic correlations of different item combinations.
We also find that leveraging KG as side information can improve performance by approximately 20% and 10% for the Poultry and Pharmacy datasets, respectively. We can conclude that the proposed KTP can enable our model to mine the deep semantic information of items and thus boost performance especially for long tail items and cold start items.
4.4. Hyperparameter Analysis (RQ2)

In Section 4.2 and Section 4.3, we have shown that transforming KG into KTP and feeding KTP together with MUP into PLM can benefit the recommendation performance. However, since the input token sequence length of PLM cannot be infinite, how to balance between the length of MUP and KTP becomes a trade-off problem and we are trying to investigate the reasonable proportion between the two lengths in this section.
We first fix the maximum input token sequence length to 512 tokens and then change the maximum basket sequence length to 3, 5, 10, 15 and 20 respectively, noting that a longer basket sequence means that a longer MUP and thus a shorter KTP. We examine the overall performance corresponding to different maximum basket sequence length and report the results on Poultry dataset in Figure 3.
We can see that all of the three metrics peak when the maximum basket sequence length is set to 10, which is consistent with our setting in the previous study. As the maximum basket sequence length decreases, all three metrics decline sharply, even though more side information is fed into PLM. This implies that the importance of user’s interaction history outweighs the prior knowledge of items. When the interaction history is incomplete, the model exhibits significant bias in modelling user preferences. However, a longer basket sequences do not necessarily guarantee better performance. This is because user preferences often change over time. Recent interactions tend to represent the user’s latest preferences more accurately while interactions from too long ago will introduce noise into the model. Additionally, MUP that is too long can result in insufficient knowledge input to PLM, leading to performance degradation.
4.5. Impact of PLM (RQ3)
| PLM | Architecture | Layers | Dimension | Parameters |
|---|---|---|---|---|
| T5 (Raffel et al., 2020) | encoder-decoder | 6+6 | 512 | 60M |
| BART (Lewis et al., 2019) | encoder-decoder | 6+6 | 768 | 140M |
| BERT (Devlin et al., 2018) | encoder-only | 12 | 768 | 110M |
| DeBerta (He et al., 2021) | encoder-only | 12 | 768 | 100M |

We wonder what kind of PLM is more suitable for HEKP4NBR, thus we examine the performance based on four PLM backbones which can be divided into two architectures: encoder-decoder (T5, BART) and encoder-only (BERT, DeBerta). Some basic information of four PLMs is listed in Table 4. The results on Poultry dataset are shown in Figure 4. We can conclude the following observations from the results.
First of all, the encoder-decoder architecture PLMs significantly surpass those of the encoder-only architecture. This is because encoder-decoder PLMs perform better at chronological modelling and therefore are more suitable for sequence-to-sequence generation tasks such as mask prediction, translation and question answering. On the contrary, encoder-only PLMs are designed to extract global contextual features of the input sequence and thus perform better on global comprehension tasks like sentence classification.
What’s more, large number of parameters is not sufficient for good performance, while the gap between pre-train task and downstream task has a significant impact. Although BART has more parameters than T5, it fails to surpass in performance. This is because BART is pre-trained by reconstructing documents corrupted by text infilling and sentence shuffling (Lewis et al., 2019), while T5 is pre-trained on BERT-style mask prediction task (Raffel et al., 2020) which is perfectly suited to the recommendation task. Therefore, we are able to bridge the gap between the T5’s pre-train task and downstream task by MUP.
4.6. Generalization on unseen templates (RQ4)

In the previous study, we use the same MUP and KTP template for all basket sequences in the training, validating and testing sets. In this section, we want to determine whether HEKP4NBR is sensitive to the designed template. We manually design 3 different templates for the Poultry dataset and train, validate and test HEKP4NBR using one template each. The performance of HEKP4NBR when testing on seen and unseen template is reported in Figure 5. We can see that the performance only slightly declined on unseen template by 5% at most, indicating that our method can generalize across different templates.
5. Conclusion
In this paper, we propose HEKP4NBR, which is a hypergraph enhanced PLM-based NBR method. Firstly, we transform KG into KTP to help PLM encode the OOV item IDs in the user’s basket sequence. In this way, we are able to transform NBR task into mask prediction pre-train task following the prompt learning paradigm. Secondly, we proposed a novel hypergraph convolutional module. Specifically, we build a hypergraph based on item similarities measured by an MoE model from multiple aspects and employ convolution on hypergraph to model correlations among multiple items. Finally, extensive experiments demonstrate the effectiveness of HEKP4NBR. In future work, we will continue to explore how to use large scale PLMs to boost performance in a parameter efficient way.
6. Acknowledgments
References
- (1)
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin (Eds.). https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
- Deng et al. (2023) Zhiying Deng, Jianjun Li, Zhiqiang Guo, Wei Liu, Li Zou, and Guohui Li. 2023. Multi-view Multi-aspect Neural Networks for Next-basket Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-Jou (Edward) Duh, Hen-Hsen Huang, Makoto P. Kato, Josiane Mothe, and Barbara Poblete (Eds.). ACM, 1283–1292. https://doi.org/10.1145/3539618.3591738
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. CoRR abs/1810.04805 (2018). arXiv:1810.04805 http://arxiv.org/abs/1810.04805
- Fan et al. (2021) Xinyan Fan, Zheng Liu, Jianxun Lian, Wayne Xin Zhao, Xing Xie, and Ji-Rong Wen. 2021. Lighter and better: low-rank decomposed self-attention networks for next-item recommendation. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 1733–1737.
- Feng et al. (2019) Yifan Feng, Haoxuan You, Zizhao Zhang, Rongrong Ji, and Yue Gao. 2019. Hypergraph neural networks. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 3558–3565.
- Geng et al. (2022) Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In Proceedings of the 16th ACM Conference on Recommender Systems. 299–315.
- Grover and Leskovec (2016) Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, Balaji Krishnapuram, Mohak Shah, Alexander J. Smola, Charu C. Aggarwal, Dou Shen, and Rajeev Rastogi (Eds.). ACM, 855–864. https://doi.org/10.1145/2939672.2939754
- Hamilton et al. (2017) William L. Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (Eds.). 1024–1034. https://proceedings.neurips.cc/paper/2017/hash/5dd9db5e033da9c6fb5ba83c7a7ebea9-Abstract.html
- He et al. (2021) Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION. In International Conference on Learning Representations. https://openreview.net/forum?id=XPZIaotutsD
- He et al. (2020a) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020a. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648.
- He et al. (2020b) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. 2020b. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 639–648. https://doi.org/10.1145/3397271.3401063
- Hidasi et al. (2016a) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016a. Session-based Recommendations with Recurrent Neural Networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.). http://arxiv.org/abs/1511.06939
- Hidasi et al. (2016b) Balázs Hidasi, Massimo Quadrana, Alexandros Karatzoglou, and Domonkos Tikk. 2016b. Parallel Recurrent Neural Network Architectures for Feature-rich Session-based Recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, September 15-19, 2016, Shilad Sen, Werner Geyer, Jill Freyne, and Pablo Castells (Eds.). ACM, 241–248. https://doi.org/10.1145/2959100.2959167
- Kang and McAuley (2018) Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=SJU4ayYgl
- Kou et al. (2023) Ziyi Kou, Saurav Manchanda, Shih-Ting Lin, Min Xie, Haixun Wang, and Xiangliang Zhang. 2023. Modeling Sequential Collaborative User Behaviors For Seller-Aware Next Basket Recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21-25, 2023, Ingo Frommholz, Frank Hopfgartner, Mark Lee, Michael Oakes, Mounia Lalmas, Min Zhang, and Rodrygo L. T. Santos (Eds.). ACM, 1097–1106. https://doi.org/10.1145/3583780.3614973
- Le et al. (2019) Duc-Trong Le, Hady W. Lauw, and Yuan Fang. 2019. Correlation-Sensitive Next-Basket Recommendation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, Sarit Kraus (Ed.). ijcai.org, 2808–2814. https://doi.org/10.24963/IJCAI.2019/389
- Lewis et al. (2019) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. CoRR abs/1910.13461 (2019). arXiv:1910.13461 http://arxiv.org/abs/1910.13461
- Li et al. (2023a) Lei Li, Yongfeng Zhang, and Li Chen. 2023a. Personalized Prompt Learning for Explainable Recommendation. ACM Trans. Inf. Syst. 41, 4 (2023), 103:1–103:26. https://doi.org/10.1145/3580488
- Li et al. (2023b) Lei Li, Yongfeng Zhang, and Li Chen. 2023b. Personalized Prompt Learning for Explainable Recommendation. ACM Trans. Inf. Syst. 41, 4 (2023), 103:1–103:26. https://doi.org/10.1145/3580488
- Li et al. (2022) Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. 2022. Grounded Language-Image Pre-training. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. IEEE, 10955–10965. https://doi.org/10.1109/CVPR52688.2022.01069
- Li et al. (2023c) Ran Li, Liang Zhang, Guannan Liu, and Junjie Wu. 2023c. Next Basket Recommendation with Intent-aware Hypergraph Adversarial Network. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-Jou (Edward) Duh, Hen-Hsen Huang, Makoto P. Kato, Josiane Mothe, and Barbara Poblete (Eds.). ACM, 1303–1312. https://doi.org/10.1145/3539618.3591742
- Liu et al. (2018) Qiao Liu, Yifu Zeng, Refuoe Mokhosi, and Haibin Zhang. 2018. STAMP: short-term attention/memory priority model for session-based recommendation. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1831–1839.
- Peng et al. (2022) Bo Peng, Zhiyun Ren, Srinivasan Parthasarathy, and Xia Ning. 2022. M2: Mixed Models With Preferences, Popularities and Transitions for Next-Basket Recommendation. IEEE transactions on knowledge and data engineering 35, 4 (2022), 4033–4046.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: online learning of social representations. In The 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’14, New York, NY, USA - August 24 - 27, 2014, Sofus A. Macskassy, Claudia Perlich, Jure Leskovec, Wei Wang, and Rayid Ghani (Eds.). ACM, 701–710. https://doi.org/10.1145/2623330.2623732
- Qin et al. (2021) Yuqi Qin, Pengfei Wang, and Chenliang Li. 2021. The World is Binary: Contrastive Learning for Denoising Next Basket Recommendation. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 859–868. https://doi.org/10.1145/3404835.3462836
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 8748–8763. http://proceedings.mlr.press/v139/radford21a.html
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research 21, 140 (2020), 1–67. http://jmlr.org/papers/v21/20-074.html
- Ramesh et al. (2022) Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. 2022. Hierarchical Text-Conditional Image Generation with CLIP Latents. CoRR abs/2204.06125 (2022). https://doi.org/10.48550/ARXIV.2204.06125 arXiv:2204.06125
- Rendle et al. (2012) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Rendle et al. (2010) Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, WWW 2010, Raleigh, North Carolina, USA, April 26-30, 2010, Michael Rappa, Paul Jones, Juliana Freire, and Soumen Chakrabarti (Eds.). ACM, 811–820. https://doi.org/10.1145/1772690.1772773
- Su et al. (2022) Ting-Ting Su, Zhen-Yu He, Mansheng Chen, and Chang-Dong Wang. 2022. Basket Booster for Prototype-based Contrastive Learning in Next Basket Recommendation. In Machine Learning and Knowledge Discovery in Databases - European Conference, ECML PKDD 2022, Grenoble, France, September 19-23, 2022, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 13713), Massih-Reza Amini, Stéphane Canu, Asja Fischer, Tias Guns, Petra Kralj Novak, and Grigorios Tsoumakas (Eds.). Springer, 574–589. https://doi.org/10.1007/978-3-031-26387-3_35
- Su et al. (2023) Ting-Ting Su, Chang-Dong Wang, Wu-Dong Xi, Jian-Huang Lai, and S Yu Philip. 2023. Hierarchical Alignment with Polar Contrastive Learning for Next-basket Recommendation. IEEE Transactions on Knowledge and Data Engineering (2023).
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Sun et al. (2023) Wenqi Sun, Ruobing Xie, Junjie Zhang, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2023. Generative Next-Basket Recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems, RecSys 2023, Singapore, Singapore, September 18-22, 2023, Jie Zhang, Li Chen, Shlomo Berkovsky, Min Zhang, Tommaso Di Noia, Justin Basilico, Luiz Pizzato, and Yang Song (Eds.). ACM, 737–743. https://doi.org/10.1145/3604915.3608823
- Tan et al. (2021) Qiaoyu Tan, Jianwei Zhang, Jiangchao Yao, Ninghao Liu, Jingren Zhou, Hongxia Yang, and Xia Hu. 2021. Sparse-Interest Network for Sequential Recommendation. In WSDM ’21, The Fourteenth ACM International Conference on Web Search and Data Mining, Virtual Event, Israel, March 8-12, 2021, Liane Lewin-Eytan, David Carmel, Elad Yom-Tov, Eugene Agichtein, and Evgeniy Gabrilovich (Eds.). ACM, 598–606. https://doi.org/10.1145/3437963.3441811
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. CoRR abs/2302.13971 (2023). https://doi.org/10.48550/ARXIV.2302.13971 arXiv:2302.13971
- Velickovic et al. (2018) Petar Velickovic, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=rJXMpikCZ
- Wan et al. (2015) Shengxian Wan, Yanyan Lan, Pengfei Wang, Jiafeng Guo, Jun Xu, and Xueqi Cheng. 2015. Next Basket Recommendation with Neural Networks. In Poster Proceedings of the 9th ACM Conference on Recommender Systems, RecSys 2015, Vienna, Austria, September 16, 2015 (CEUR Workshop Proceedings, Vol. 1441), Pablo Castells (Ed.). CEUR-WS.org. https://ceur-ws.org/Vol-1441/recsys2015_poster15.pdf
- Wang et al. (2019c) Hongwei Wang, Fuzheng Zhang, Miao Zhao, Wenjie Li, Xing Xie, and Minyi Guo. 2019c. Multi-task feature learning for knowledge graph enhanced recommendation. In The world wide web conference. 2000–2010.
- Wang et al. (2019d) Hongwei Wang, Miao Zhao, Xing Xie, Wenjie Li, and Minyi Guo. 2019d. Knowledge Graph Convolutional Networks for Recommender Systems. In The World Wide Web Conference, WWW 2019, San Francisco, CA, USA, May 13-17, 2019, Ling Liu, Ryen W. White, Amin Mantrach, Fabrizio Silvestri, Julian J. McAuley, Ricardo Baeza-Yates, and Leila Zia (Eds.). ACM, 3307–3313. https://doi.org/10.1145/3308558.3313417
- Wang et al. (2020a) Shoujin Wang, Liang Hu, Yan Wang, Quan Z. Sheng, Mehmet A. Orgun, and Longbing Cao. 2020a. Intention Nets: Psychology-Inspired User Choice Behavior Modeling for Next-Basket Prediction. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020. AAAI Press, 6259–6266. https://doi.org/10.1609/AAAI.V34I04.6093
- Wang et al. (2020b) Shoujin Wang, Liang Hu, Yan Wang, Quan Z. Sheng, Mehmet A. Orgun, and Longbing Cao. 2020b. Intention2Basket: A Neural Intention-driven Approach for Dynamic Next-basket Planning. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, Christian Bessiere (Ed.). ijcai.org, 2333–2339. https://doi.org/10.24963/IJCAI.2020/323
- Wang et al. (2019a) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019a. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM, 950–958. https://doi.org/10.1145/3292500.3330989
- Wang et al. (2019b) Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019b. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval. 165–174.
- Wang et al. (2021) Xiang Wang, Tinglin Huang, Dingxian Wang, Yancheng Yuan, Zhenguang Liu, Xiangnan He, and Tat-Seng Chua. 2021. Learning intents behind interactions with knowledge graph for recommendation. In Proceedings of the web conference 2021. 878–887.
- Wang et al. (2022) Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. 2022. Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning. In KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, Aidong Zhang and Huzefa Rangwala (Eds.). ACM, 1929–1937. https://doi.org/10.1145/3534678.3539382
- Wang et al. (2020c) Ze Wang, Guangyan Lin, Huobin Tan, Qinghong Chen, and Xiyang Liu. 2020c. CKAN: Collaborative Knowledge-aware Attentive Network for Recommender Systems. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 219–228. https://doi.org/10.1145/3397271.3401141
- Wu et al. (2021) Chuhan Wu, Fangzhao Wu, Tao Qi, and Yongfeng Huang. 2021. Empowering News Recommendation with Pre-trained Language Models. In SIGIR ’21: The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, Canada, July 11-15, 2021, Fernando Diaz, Chirag Shah, Torsten Suel, Pablo Castells, Rosie Jones, and Tetsuya Sakai (Eds.). ACM, 1652–1656. https://doi.org/10.1145/3404835.3463069
- Wu et al. (2022) Yuxia Wu, Ke Li, Guoshuai Zhao, and Xueming Qian. 2022. Personalized Long- and Short-term Preference Learning for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 34, 4 (2022), 1944–1957. https://doi.org/10.1109/TKDE.2020.3002531
- Xia et al. (2022) Lianghao Xia, Chao Huang, and Chuxu Zhang. 2022. Self-supervised hypergraph transformer for recommender systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2100–2109.
- Xu et al. (2019) Chengfeng Xu, Pengpeng Zhao, Yanchi Liu, Victor S Sheng, Jiajie Xu, Fuzhen Zhuang, Junhua Fang, and Xiaofang Zhou. 2019. Graph contextualized self-attention network for session-based recommendation.. In IJCAI, Vol. 19. 3940–3946.
- Yang et al. (2022) Yuhao Yang, Chao Huang, Lianghao Xia, Yuxuan Liang, Yanwei Yu, and Chenliang Li. 2022. Multi-behavior hypergraph-enhanced transformer for sequential recommendation. In Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 2263–2274.
- Ying et al. (2018) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. 2018. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018, Yike Guo and Faisal Farooq (Eds.). ACM, 974–983. https://doi.org/10.1145/3219819.3219890
- Yu et al. (2016) Feng Yu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2016. A Dynamic Recurrent Model for Next Basket Recommendation. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, July 17-21, 2016, Raffaele Perego, Fabrizio Sebastiani, Javed A. Aslam, Ian Ruthven, and Justin Zobel (Eds.). ACM, 729–732. https://doi.org/10.1145/2911451.2914683
- Yu et al. (2023) Yalin Yu, Enneng Yang, Guibing Guo, Linying Jiang, and Xingwei Wang. 2023. Basket Representation Learning by Hypergraph Convolution on Repeated Items for Next-basket Recommendation. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China. ijcai.org, 2415–2422. https://doi.org/10.24963/IJCAI.2023/268
- Yuan et al. (2019) Fajie Yuan, Alexandros Karatzoglou, Ioannis Arapakis, Joemon M Jose, and Xiangnan He. 2019. A simple convolutional generative network for next item recommendation. In Proceedings of the twelfth ACM international conference on web search and data mining. 582–590.
- Zhai et al. (2023) Jianyang Zhai, Xiawu Zheng, Chang-Dong Wang, Hui Li, and Yonghong Tian. 2023. Knowledge Prompt-tuning for Sequential Recommendation. In Proceedings of the 31st ACM International Conference on Multimedia. 6451–6461.
- Zhang and Wang (2023) Zizhuo Zhang and Bang Wang. 2023. Prompt Learning for News Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2023, Taipei, Taiwan, July 23-27, 2023, Hsin-Hsi Chen, Wei-Jou (Edward) Duh, Hen-Hsen Huang, Makoto P. Kato, Josiane Mothe, and Barbara Poblete (Eds.). ACM, 227–237. https://doi.org/10.1145/3539618.3591752