HYDEN: Hyperbolic Density Representations for Medical Images and Reports
Abstract
In light of the inherent entailment relations between images and text, hyperbolic point vector embeddings, leveraging the hierarchical modeling advantages of hyperbolic space, have been utilized for visual semantic representation learning. However, point vector embedding approaches fail to address the issue of semantic uncertainty, where an image may have multiple interpretations, and text may refer to different images, a phenomenon particularly prevalent in the medical domain. Therefor, we propose HYDEN, a novel hyperbolic density embedding based image-text representation learning approach tailored for specific medical domain data. This method integrates text-aware local features alongside global features from images, mapping image-text features to density features in hyperbolic space via using hyperbolic pseudo-Gaussian distributions. An encapsulation loss function is employed to model the partial order relations between image-text density distributions. Experimental results demonstrate the interpretability of our approach and its superior performance compared to the baseline methods across various zero-shot tasks and different datasets.
1 Introduction
In recent years, cross-modal text-image representation learning has achieved tremendous success and drawn widespread attention in many tasks such as zero-shot learning and image-text retrieval. This success is largely due to the use of large volumes of weakly-supervised image-text pair data to enhance vision-language representation learning (Radford et al., 2021). In the field of medical imaging, cross-modal representation learning tailored to specific domain data, such as chest radiographs and their associated radiology reports, can yield robust and powerful foundation models in specialized areas (Zhang and Metaxas, 2023).
As the proverb goes, ’A picture is worth a thousand words.’ This suggests that an image inherently contains more information than a textual description of it, which can be seen as merely a simplified abbreviation of the image. This relationship, where the text may serve as an entailment of the image, can be considered as visual-semantic hierarchy (Vendrov et al., 2016). Consequently, it is a plausible hypothesis that incorporating such inductive biases of visual semantic hierarchies into cross-modal alignment tasks could enhance the generalizability of representations and improve the interpretability of learning representations. Vendrov et al. (2016) introduced an order embedding strategy considering these hierarchical semantic during the text-image alignment process. However, numerous studies (Nickel and Kiela, 2017, 2018; Xu et al., 2022, 2023; Fu et al., 2023) have demonstrated that modeling data with inherent hierarchical features in non-Euclidean hyperbolic spaces can provide superior representations. By leveraging the advantages of hyperbolic space in modeling hierarchical structures and the generalization capabilities of cross-modal contrastive learning in zero-shot scenarios, Desai et al. (2023) has proposed cross-modal hyperbolic representation learning. This approach employs the Lorentz manifold to map both image and text features into hyperbolic space, utilizing angular constraints based on entailment to learn the hierarchical order between text and images.


However, representing image-text with point vectors has a clear limitation: it cannot express semantic uncertainty (Vilnis and McCallum, 2014; Qian et al., 2021), meaning that a single image can generate different descriptions from various perspectives, and similarly, a single textual description can describe different but related images. This phenomenon is particularly evident in medical imaging and radiology reports. For instance, as depicted in Fig.1(a), consider a patient with a rib fracture suspected of having right-sided pneumothorax. In the radiology report for this patient, the physician describes the imaging findings related to pneumothorax, highlighting the presence of a white line around the visceral pleural edge. Clinically, numerous pulmonary diseases, such as tuberculosis, cystic fibrosis, and pneumocystis jiroveci pneumonia, predispose individuals to pneumothorax. In domains such as document embedding (Zhu et al., 2023) and graph embedding (Gourru et al., 2022), the utilization of probability density embedding to represent objects as distributions within the target space effectively addresses this semantic uncertainty, resulting in significantly improved performance compared to point vector embedding.
Building on the motivation outlined above, which focuses on the hierarchical visual semantic features and inherent semantic uncertainty in medical imaging, we propose HYDEN, a hyperbolic density representations for medical images and reports. This approach leverages the advantages of hyperbolic space for capturing visual-semantic hierarchy, while incorporating a probability density embedding strategy to model semantic uncertainty. The main contributions are as follows:
-
•
To the best of our knowledge, this is the first model to apply cross-modal representation learning to medical image-text data within hyperbolic space.
-
•
We introduce a text-aware image local feature extraction method that focuses on local regions, enhancing the granularity of analysis; moreover, we employ encapsulation constraints to model the density order between images and text, fostering a deeper semantic connection.
-
•
Extensive experiments were conducted to validate the performance of our algorithm against baseline models through both quantitative and qualitative analyses. These experiments demonstrate the superior capabilities of our approach in achieving semantic alignment.
2 Related Work
Image-text representation learning has garnered substantial interest due to its potential to enhance visual representation. Traditional methods predominantly employ contrastive metric learning approaches, with CLIP (Radford et al., 2021) being a notable example that has demonstrated remarkable results. These methods typically operate in the Euclidean space and have been extensively applied across various general domains.
However, the medical field presents unique challenges due to the domain-specific nature and the complex prior knowledge embedded in medical image-text data. In response, several studies have explored image-text representation learning specifically tailored to medical contexts (Wang et al., 2024; Müller et al., 2022a; Cheng et al., 2023a; Huang et al., 2021). Despite their advancements, these approaches continue to operate within the confines of Euclidean space. The inherent hierarchical semantics between images and texts, particularly pronounced in medical datasets, suggest that hyperbolic space could offer significant advantages. Hyperbolic space naturally accommodates hierarchical data structures, making it a compelling alternative for modeling complex semantic relationships. Building on this premise, the MERU framework introduced hyperbolic image-text embedding (Desai et al., 2023), representing a significant departure from traditional Euclidean methods.
Building upon the concept introduced by MERU, our work proposes a novel approach by integrating density embedding to capture semantic uncertainty, which is a feature not adequately addressed by point vector embeddings. While density embedding has been previously utilized for capturing the uncertainty of semantics and modeling asymmetric relationships like entailment (Vilnis and McCallum, 2014; Qian et al., 2021; Bojchevski and Günnemann, 2018), these implementations have been confined to Euclidean space. Our method extends this concept into hyperbolic space.
3 Preliminaries
Hyperbolic Geometry Hyperbolic geometry is a non-Euclidean geometry with a constant negative curvature, and it can be visualized as the forward sheet of the two-sheeted hyperboloid. In this study, we will use the Lorentz model on the upper half of a two-sheeted hyperboloid, as claimed in (Nickel and Kiela, 2018), comes with a simpler closed form of the geodesics and does not suffer from the numerical instabilities in approximating the distance. Lorentz model processing a constant curvature can be represented as a set of points . Lets , the Lorentzian product . And, . The distance between and is given by
| (1) |
which is also the length of the geodesic that connects and . We will refer to the one-hot vector as the origin of the hyperbolic space.
Tangent Space of Hyperbolic Space The tangent space at a point is a Euclidean space composed of vectors. Denoted by , this tangent space represents the set of vectors in the same ambient space where is embedded. The vectors in satisfy an orthogonality condition relative to the Lorentzian product, defined as . This set can be visualized as the tangent space at the point on the forward hyperboloid sheet. Specifically, at the origin of , the tangent space consists of vectors . The norm , given by the Lorentzian inner product, simplifies to the Euclidean norm , defined as .
Exponential Map
The exponential map provides a method for mapping a vector from a tangent space to its corresponding point on the surface of the hyperbolic space. For every , the exponential map allows us to project a vector in onto such that the distance from to the destination point of the map coincides with the Lorentzian norm of . In the context of hyperbolic space, the exponential map is given by the equation:
| (2) |
In this paper, we specifically consider exponential maps where represents the origin of the hyperboloid ().
4 Method
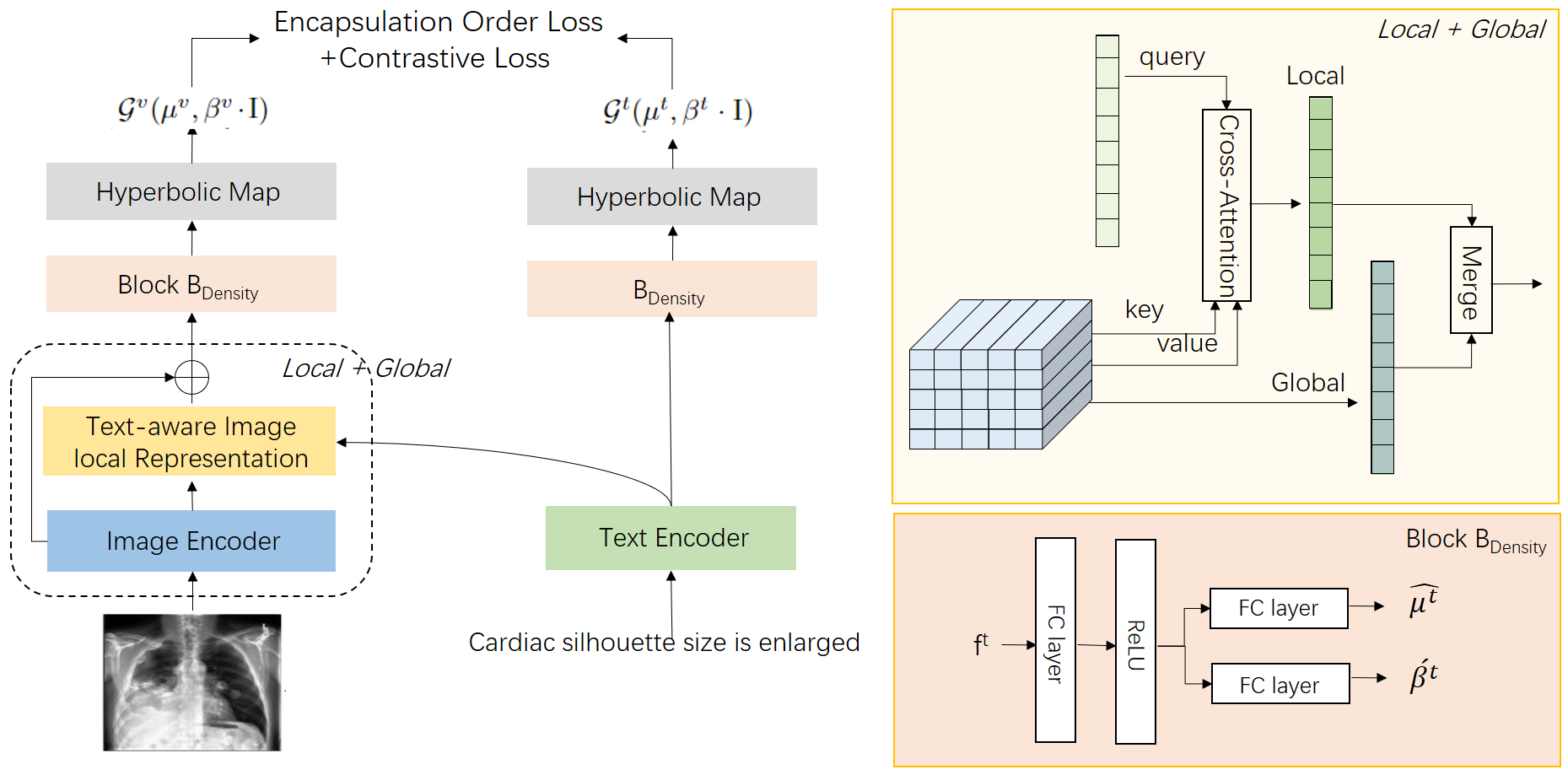
In this section, we present a comprehensive introduction to the HYDEN model. Drawing on the foundation laid by the MERU model (Desai et al., 2023) and the widely acclaimed, user-friendly CLIP framework (Radford et al., 2021), our model adapts and extends these frameworks to address specific challenges in medical image-text representation learning. Figure 2 depicts the overall architecture of our model. Distinct from CLIP and MERU, our HYDEN model incorporates several innovative features designed to enhance its functionality and applicability in medical contexts: (1) Text-aware Local Image Representation: We refine the image analysis process by integrating text-aware local features that allow for a more nuanced understanding of medical images. This approach helps to align specific image regions with relevant textual descriptions, enhancing the model’s ability to handle complex medical datasets. (2)Hyperbolic Density Embedding: Utilizing the properties of hyperbolic space, we introduce hyperbolic density embedding to generate and transfer probability density features from Euclidean to hyperbolic space. This method leverages the natural hierarchical structure of hyperbolic space to more effectively represent the intrinsic complexities of medical data. (3)Loss Function for Hyperbolic Density Embedding: To complement our embedding technique, we have developed a specialized loss function that focuses on the encapsulation relationships within the partial order of image-text semantic distributions. This loss function is tailored to strengthen the correlation between images and texts by capturing their hierarchical semantic relationships.
4.1 Image-Text Feature Embedding
In our model, the features are derived from respective image and text encoders. For text data, we employ BioClinicalBERT (Alsentzer et al., 2019a), a model that has been pre-trained on the MIMIC III dataset (Shen et al., 2016), to generate token-level embeddings. Consistent with practices outlined in (Cheng et al., 2023b), the output of the token is used as the medical text feature , encapsulating the overall semantic content of the input text.
For image encoding, we utilize the widely-used Vision Transformer (ViT) architecture (Mu et al., 2022). We assume that captures the outputs from the image encoder. Recognizing that pathological symptoms often occupy only a portion of a medical image, relying solely on global representations may not adequately capture essential local semantic features. Thus, similar to approaches in (Huang et al., 2021; Cheng et al., 2023b; Müller et al., 2022b), we enhance the global features by integrating text-aware image local representations.
Specifically, we implement a Self-attention module (Vaswani et al., 2017), widely used in cross-modal feature extraction. In this setup, acts as both the keys () and values (), while the text embedding functions as the query (). This configuration allows us to derive a text-aware image local representation, denoted as . By synthesizing both global and local representations, we achieve the final image feature , effectively capturing both the broad and nuanced semantic details present in medical images.
4.2 Hyperbolic Density Embedding
Our objective is to transform image-text features into density representations within hyperbolic space. Previous studies such as (Nagano et al., 2019) and (Mathieu et al., 2019) proposed methods like the pseudo-hyperbolic Gaussian distribution based on the Lorentz manifold. Due to the computational demands and numerical instabilities of the Poincaré-disk model, we opt for the more stable pseudo-hyperbolic Gaussian distribution for our hyperbolic density embedding. The tangent space of hyperbolic space is a Euclidean space, and in , vectors satisfy where , aligning with the dimensional properties.
To begin, we introduce separate deep nonlinear network blocks, , for processing image and text features independently. These blocks do not share parameters, ensuring distinct representations for each modality. As in Figure 2, for text features, and are the outputs of .
Instead of generating covariance matrices directly, which can introduce numerical instability, we use matrices based on diagonal or spherical assumptions. These are known for their computational efficiency and effectiveness in embedding tasks, particularly in the context of word distribution embedding where spherical covariance matrices have been shown to better model distributional partial order relationships (Vilnis and McCallum, 2014). We thus employ a covariance matrix based on the spherical assumption: .
To ensure that our covariance matrix is positively definite, necessary for the stability of the pseudo-hyperbolic Gaussian distribution, we modify using the expression referring to solution in VAE(Kingma and Welling, 2019). This adjustment is crucial for maintaining the mathematical integrity of our model when dealing with real-world data. For the embedding vector , our aim is to project this vector onto hyperboloid space, which is achieved by mapping it through the exponential function as detailed in Equation 2.
The vector resides in and belongs to the tangent space at the origin of the hyperboloid, . The norm , which equals , ensures that the mapping preserves the distances inherent to the model’s geometric structure. We apply the exponential map to , decomposing the transformation into two parts:
| (3) |
| (4) |
Upon applying the exponential map, we derive the expectation of the hyperbolic density representation:
| (5) |
This projection results in the hyperbolic density representation . Following a similar procedure, we also derive for the image features, thereby ensuring a uniform approach to handling different modalities within our framework.
4.3 Loss Function Based on Density Embedding
Traditional point vector embedding often utilizes entailment angle constraints to define relationships between entities (Desai et al., 2023). However, when dealing with probability densities, the notion of partial order can be more complexly captured through the concept of encapsulation. Specifically, a density is considered more specific than another density if is entirely encompassed by , formally expressed as , for any , where indicates the degree of encapsulation necessary for one distribution to entail another.
Imposing such partial order constraints on distributions poses significant challenges. Drawing inspiration from Athiwaratkun and Wilson (2018), we employ asymmetric divergence measures between probability densities to address this. We introduce a simple penalty function, , which serves as a violation penalty rather than as a strict constraint of encapsulation. Here, represents the divergence measure used to quantify the extent of difference between distributions, and is a threshold defining the acceptable range of difference.
Among the choices for divergence measures, -divergence provides a more flexible and generalized asymmetric measure (Renyi, 1961), allowing for adjustments in the zero-force penalty. This flexibility means that higher values can enforce stricter encapsulation conditions . The general form of -divergence, for , is given by:
| (6) |
This equation not only quantifies the differences between distributions but also facilitates a deeper understanding of the encapsulation relationships critical for effective density embedding.
We observe that as approaches 0 or 1, it governs the degree of zero forcing, where minimizing for high values results in becoming more concentrated in regions of with high density. Conversely, for low values, tends to be mass-covering, encompassing regions of even including those with low density. Notably, there exists a mathematical relationship between KL divergence and -divergence, as indicated by: and (Pardo, 2006). Therefore, in our model, we opt for the more flexible and robust -divergence as our metric.
For image-text embedded density and , the encapsulation loss can be expressed as follows:
| (7) |
Let the batch sample , where denotes the positive image-text sample set, and represents the negative set. We define the encapsulation loss function as follows:
| (8) |
For the positive samples, a definite partial order relationship exists, enabling the direct application of the density penalty . For the negative samples, we enforce the penalty to exceed a margin due to the absence of an order relationship.
Our goal is to enhance the similarity of semantic distributions between image-text pairs. Therefore, we also employ the classic CLIP contrastive solution (Radford et al., 2021) to compute the geodesic distance between the expectation values of image and text in hyperbolic densities as defined in Equation 1, applying Softmax normalization. We define as the contrastive loss, which is computed as an average of the contrastive losses from both image and text perspectives.
5 Experiments
In this section, we aim to rigorously evaluate the performance of our algorithm. We first introduce the baseline model, followed by a description of the medical image-text data and training details used for model pre-training. Then, we discuss the advantages of our proposed model in medical image-text alignment from both quantitative and qualitative perspectives.
A key innovation of our algorithm lies in the use of density representations in hyperbolic space for image-text alignment. To validate the superiority of our approach, we compare it with two methods: CLIP, which aligns image-text pairs in Euclidean space using point embeddings (Radford et al., 2021), and MERU, which aligns image-text pairs in hyperbolic space using point embeddings (Desai et al., 2023). For the baseline model training, we primarily utilize the open-source code provided by the MERU project111https://github.com/facebookresearch/meru. While some variations of CLIP have been successfully applied in the medical image-text alignment domain, our primary focus is on comparing the differences between alignment in Euclidean space and hyperbolic space, as well as between point vector embeddings and distribution embeddings. The reason for retraining the models is that the publicly available CLIP models for the medical domain are mainly intended for downstream fine-tuning tasks and do not include the corresponding text encoder parameters. Since our main objective is to address zero-shot problems, retraining the models on this dataset is necessary.
| RSNA Pneumonia | SIIM-ACR | CheXpert 14x100 | ||||
|---|---|---|---|---|---|---|
| AUC | F1 | AUC | F1 | Micro-AUC | Micro-F1 | |
| CLIP | 0.725 | 0.489 | 0.718 | 0.474 | 0.583 | 0.168 |
| MERU | 0.784 | 0.551 | 0.754 | 0.499 | 0.634 | 0.2 |
| HYDEN | 0.613 | 0.510 | 0.642 | 0.2 | ||
| Prec@3 | Prec@5 | Prec@10 | NDCG@3 | NDCG@5 | NDCG@10 | Recall@10% | |
|---|---|---|---|---|---|---|---|
| TextImage | |||||||
| CLIP | 40.00 | 32.00 | 30.00 | 0.588 | 0.588 | 0.576 | 4.63% |
| MERU | 37.78 | 34.67 | 29.33 | 0.534 | 0.616 | 0.635 | 4.97% |
| HYDEN | 46.67 | 41.33 | 40.67 | 0.676 | 0.723 | 0.736 | 4.2% |
| ImageImage | |||||||
| CLIP | 26.67 | 22.67 | 24.00 | 0.603 | 0.598 | 0.600 | 6.79% |
| MERU | 33.33 | 32.00 | 26.00 | 0.484 | 0.478 | 0.463 | 6.99% |
| HYDEN | 37.78 | 38.67 | 34.67 | 0.659 | 0.765 | 0.766 | 4.30% |
5.1 Training Details
Datasets: We train our alignment model using the MIMIC-CXR v2 dataset (Johnson et al., 2019), comprising over 227,000 studies of paired image-report data sourced from 65,379 patients undergoing various scans. Each study may contain one or two images, representing different scan views, resulting in a total of 377,110 images. During training, we perform random cropping, flipping, rotation, and other data augmentation techniques on the images, while also resizing them to a [224,224] dimension. Additionally, for the text data, we augment the reports by randomly adding medical entity prefixes to enhance semantic information, such as ’event_list: report’.
Settings: We employ ViT-B (Mu et al., 2022) with a patch size of 16 as the image encoder, as it has demonstrated competitive performance in hyperbolic space (Desai et al., 2023). Our initialization strategy for image/text encoders follows a similar style to MERU, with the exception of utilizing ClinicalBERT (Alsentzer et al., 2019b) as the pre-trained text encoder, which has been pre-trained on large-scale medical text data. For HYDEN, we initialize the learnable curvature parameter to 1.0 and clamp it within the range of [0.1, 10.0] to prevent training instability. All experiments were conducted using two NVIDIA A40 GPU and the PyTorch framework
Optimization: We adopt the AdamW optimizer with a weight decay of 0.2 and . Weight decay is disabled for all gains, biases, and learnable scalars. Models are trained for 13,000 iterations with a batch size of 256. The maximum learning rate is set to , linearly increased for the first 500 iterations, followed by cosine decay to zero. We leverage mixed precision to expedite training, except when computing exponential maps and losses, where FP32 precision is used for numerical stability.
5.2 Quantitative Analysis
We evaluate all baselines and HYDEN on three categories of zero-shot downstream tasks, classification, text-image retrieval and image-image retrieval. We use three public datasets for the evaluation, where both RSNA Pneumonia (Shih et al., 2019) and SIIM-ACR Pneumothorax (Kaggle, 2019) are used for binary classification, ChestXray14(Wang et al., 2017a) is used for multi-label classification, text-image retrieval and image-image retrieval. For the two binary classification tasks, we report the Area Under the Curve (AUC) and F1 score; for the multi-label task, we provide the Micro-AUC and Micro-F1. For the retrieval task, Top-k Precision (abbreviated as Prec@k) and Tok-k Normalized Discounted Cumulative Gain (abbreviated as NDCG@k) are used to evaluate the retrieval performance. Refer Appendix B for details about our evaluation tasks and datasets.
Zero-shot Image Classification Table 1 presents the performance of the baselines and HYDEN across three classification datasets. The results indicate that HYDEN consistently demonstrates robust transfer classification performance, both in binary classification tasks and multi-label classification task. Compared to CLIP, both MERU and HyperMed achieved improved accuracy. This suggests that using hyperbolic space for text-image representations, especially for medical data characterized by a visual semantic hierarchy, is more effective. Relative to MERU, HYDEN achieved the highest accuracy across almost all of metrics, highlighting the advantages of density embedding-based representation methods over point vector embedding, particularly in addressing the challenges of semantic uncertainty.
Zero-shot Retrieval Table 2 displays the performance of two baseline models and HYDEN in "image-to-text" and "image-to-image" retrieval tasks. The results demonstrate that representation learning in hyperbolic space mostly outperforms that in Euclidean space; among the methods, HYDEN exhibits the best retrieval performance. Furthermore, we observed a significant enhancement in the ranking quality of HYDEN’s retrieval results compared to the two baseline methods. We hypothesize that this improvement is linked to the method of density embedding. Similar to findings in the recommendation systems domain (Dos Santos et al., 2017), unlike point vector embeddings, density embeddings enable better handling of uncertainties, information sparsity, ambiguity, and even contradictions, which are common challenges in medical image-text data.
| Text2Image@10 | Image2Image@10 | RSNA | SIIM | |||||
|---|---|---|---|---|---|---|---|---|
| Prec | NDCG | Prec | NDCG | AUC | F1 | AUC | F1 | |
| HYDEN | 40.67 | 0.736 | 34.67 | 0.766 | 0.845 | 0.613 | 0.778 | 0.510 |
| 1. w KL Divergence | 34 | 0.609 | 31.33 | 0.642 | 0.842 | 0.609 | 0.759 | 0.466 |
| 2. w/o encapsulation loss | 19.33 | 0.384 | 16.67 | 0.416 | 0.669 | 0.503 | 0.663 | 0.440 |
| 3. w/o local representation | 20.67 | 0.532 | 34 | 0.643 | 0.772 | 0.566 | 0.768 | 0.434 |
| Text2Image@10 | Image2Image@10 | RSNA | SIIM | |||||
|---|---|---|---|---|---|---|---|---|
| Prec | NDCG | Prec | NDCG | AUC | F1 | AUC | F1 | |
| 31.33 | 0.566 | 30.0 | 0.653 | 0.853 | 0.609 | 0.746 | 0.457 | |
| 40.67 | 0.736 | 34.67 | 0.766 | 0.845 | 0.613 | 0.778 | 0.510 | |
| 31.33 | 0.703 | 29.33 | 0.619 | 0.845 | 0.614 | 0.788 | 0.462 | |
| 29.33 | 0.592 | 32.0 | 0.679 | 0.800 | 0.576 | 0.784 | 0.474 | |
Ablation Studies In this section, we examine the impact of different design choices using HYDEN. Specifically, we trained three ablation models with default hyperparameters, and the results are presented in Table 3. From Table 3, we observe that: (1) Using -divergence in the loss function instead of KL divergence better aligns with the encapsulation’s partial order properties of text-image distribution embeddings. The experimental results also indicate that replacing -divergence with KL divergence leads to performance degradation across all tasks. (2) Omitting the encapsulation loss, i.e., not using as defined in Equation 8 and relying primarily on , results in performance degradation across all tasks. This is because not using encapsulation loss implies that the prior partial order of text and image cannot be utilized in hyperbolic space, thus losing the benefits introduced by hyperbolic geometry. (3) The model experiences a performance drop across all tasks when not using text-aware image representation. This is primarily due to the nature of medical image-text features. As discussed in the Introduction, most regions in medical images may differ in texture and morphology but not in clinical significance, while actual pathological changes are localized. The results also show that enhancing text-aware local features is meaningful for medical image-text alignment.
Parameters Impacts In this section, we focus on adjusting the crucial predefined parameter within the HyperMed model to observe its impact on the results. The experimental outcomes are displayed in Figure 4. The table reveals that different values directly influence the evaluation outcomes. The performance does not continually increase with larger values; instead, it exhibits a quasi-convex distribution, initially increasing and then decreasing, which may be related to the distribution of the training data. In the experiments mentioned above, we employ a hyperparameter setting of .
5.3 Qualitative Analysis
In this section, we explore the trained models to deduce the characteristics of the model in capturing the visual semantic hierarchy structure. The concept of ’Embedding distances from [ROOT]’ was introduced by Desai et al. (2023) to depict the generality differences between text and image embeddings in hyperbolic space. This concept highlights that in a representation space that effectively captures the visual semantic hierarchy, text embeddings are typically more general than image embeddings and, therefore, should be closer to the root node [ROOT].
Here, we visualize the differences in distance distributions between text and image embeddings. Given that our approach utilizes distribution embeddings, we specifically visualize the expectations of the distance distributions of text and image density embeddings. Figure 3 demonstrates that the distribution differences generated by our model lie between those produced by MERU and CLIP, with some overlapping distribution areas. This suggests that our model is capable of capturing the visual semantic hierarchy. Compared to the diversity of natural text, medical image-text data is relatively uniform, and the introduction of distributions diminishes the effect of prior entailments, explaining why our model achieves significantly higher accuracy and ranking quality in both text-image and image-image retrieval tasks.



6 Conclusion
In this paper, we propose a novel approach, HYDEN, to text-image representation learning based on hyperbolic density embeddings. It is a representation learning method tailored for specific medical domain data. Experimental results demonstrate the interpretability of our method and its superior performance compared to baseline methods across various zero-shot tasks and different datasets.
Limitations. Our work is not without limitations. While our method performs well in zero-shot retrieval and image classification tasks, it cannot be directly applied as a pre-trained model to downstream fine-tuning tasks. This is because downstream fine-tuning tasks mainly involve classification, segmentation, recognition, etc., based on Euclidean space. Applying our model to other tasks involving few-shot learning or full-model fine-tuning is also beyond the scope of this paper.
References
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021.
- Zhang and Metaxas [2023] Shaoting Zhang and Dimitris Metaxas. On the challenges and perspectives of foundation models for medical image analysis, 2023.
- Vendrov et al. [2016] Ivan Vendrov, Ryan Kiros, Sanja Fidler, and Raquel Urtasun. Order-embeddings of images and language, 2016.
- Nickel and Kiela [2017] Maximilian Nickel and Douwe Kiela. Poincaré embeddings for learning hierarchical representations. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6341–6350, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Nickel and Kiela [2018] Maximillian Nickel and Douwe Kiela. Learning continuous hierarchies in the Lorentz model of hyperbolic geometry. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 3779–3788. PMLR, 10–15 Jul 2018.
- Xu et al. [2022] Yi.shi Xu, Dongsheng Wang, Bo Chen, Ruiying Lu, Zhibin Duan, and Mingyuan Zhou. Hyperminer: Topic taxonomy mining with hyperbolic embedding. In Advances in Neural Information Processing Systems, volume 35, pages 31557–31570. Curran Associates, Inc., 2022.
- Xu et al. [2023] Shu-Lin Xu, Yifan Sun, Faen Zhang, Anqi Xu, Xiu-Shen Wei, and Yi Yang. Hyperbolic space with hierarchical margin boosts fine-grained learning from coarse labels. In Advances in Neural Information Processing Systems, volume 36, pages 71263–71274. Curran Associates, Inc., 2023.
- Fu et al. [2023] Xingcheng Fu, Yuecen Wei, Qingyun Sun, Haonan Yuan, Jia Wu, Hao Peng, and Jianxin Li. Hyperbolic geometric graph representation learning for hierarchy-imbalance node classification. In Proceedings of the ACM Web Conference 2023, WWW ’23, page 460–468, New York, NY, USA, 2023. Association for Computing Machinery. ISBN 9781450394161.
- Desai et al. [2023] Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Ramakrishna Vedantam. Hyperbolic image-text representations. In Proceedings of the 40th International Conference on Machine Learning, ICML’23, 2023.
- Vilnis and McCallum [2014] Luke Vilnis and Andrew McCallum. Word representations via gaussian embedding, 2014.
- Qian et al. [2021] Chen Qian, Fuli Feng, Lijie Wen, and Tat seng Chua. Conceptualized and contextualized gaussian embedding. In AAAI Conference on Artificial Intelligence, 2021. URL https://api.semanticscholar.org/CorpusID:235363478.
- Zhu et al. [2023] Xi Zhu, Xue Han, Shuyuan Peng, Shuo Lei, Chao Deng, and Junlan Feng. Beyond layout embedding: Layout attention with gaussian biases for structured document understanding. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://openreview.net/forum?id=WLIFsPSq3t.
- Gourru et al. [2022] Antoine Gourru, Julien Velcin, Christophe Gravier, and Julien Jacques. Dynamic gaussian embedding of authors. In Proceedings of the ACM Web Conference 2022, WWW ’22, page 2109–2119. Association for Computing Machinery, 2022. ISBN 9781450390965.
- Wang et al. [2024] Fuying Wang, Yuyin Zhou, Shujun Wang, Varut Vardhanabhuti, and Lequan Yu. Multi-granularity cross-modal alignment for generalized medical visual representation learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22. Curran Associates Inc., 2024. ISBN 9781713871088.
- Müller et al. [2022a] Philip Müller, Georgios Kaissis, Congyu Zou, and Daniel Rueckert. Joint learning of localized representations from medical images and reports. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI, page 685–701. Springer-Verlag, 2022a. ISBN 978-3-031-19808-3.
- Cheng et al. [2023a] Pujin Cheng, Li Lin, Junyan Lyu, Yijin Huang, Wenhan Luo, and Xiaoying Tang. Prior: Prototype representation joint learning from medical images and reports. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 21304–21314, 2023a. doi: 10.1109/ICCV51070.2023.01953.
- Huang et al. [2021] Shih-Cheng Huang, Liyue Shen, Matthew P. Lungren, and Serena Yeung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 3922–3931, 2021. doi: 10.1109/ICCV48922.2021.00391.
- Bojchevski and Günnemann [2018] Aleksandar Bojchevski and Stephan Günnemann. Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking, 2018.
- Alsentzer et al. [2019a] Emily Alsentzer, John R. Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew B. A. McDermott. Publicly available clinical bert embeddings, 2019a.
- Shen et al. [2016] Lu Shen, Alistair Edward William Johnson, Li-Wei Pollard, Tom Josephand Lehman, Mengling Feng, Mohammad Mahdi Ghassemi, Benjamin Edward Moody, Peter Szolovits, Leo Anthony G. Celi, and Roger G Mark. Mimic-iii, a freely accessible critical care database, 2016.
- Cheng et al. [2023b] Pujin Cheng, Li Lin, Junyan Lyu, Yijin Huang, Wenhan Luo, and Xiaoying Tang. Prior: Prototype representation joint learning from medical images and reports. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21361–21371, October 2023b.
- Mu et al. [2022] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI, page 529–544, Berlin, Heidelberg, 2022. Springer-Verlag. ISBN 978-3-031-19808-3.
- Müller et al. [2022b] Philip Müller, Georgios Kaissis, Congyu Zou, and Daniel Rueckert. Joint learning of localized representations from medical images and reports. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXVI, page 685–701, Berlin, Heidelberg, 2022b. Springer-Verlag. ISBN 978-3-031-19808-3.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NIPS’17, page 6000–6010, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964.
- Nagano et al. [2019] Yoshihiro Nagano, Shoichiro Yamaguchi, Yasuhiro Fujita, and Masanori Koyama. A wrapped normal distribution on hyperbolic space for gradient-based learning, 2019.
- Mathieu et al. [2019] Emile Mathieu, Charline Le Lan, Chris J. Maddison, Ryota Tomioka, and Yee Whye Teh. Continuous hierarchical representations with poincaré variational auto-encoders, 2019.
- Kingma and Welling [2019] Diederik P. Kingma and Max Welling. An introduction to variational autoencoders. 12(4):307–392, nov 2019. ISSN 1935-8237.
- Athiwaratkun and Wilson [2018] Ben Athiwaratkun and Andrew Gordon Wilson. Hierarchical density order embeddings. In ICLR. Curran Associates, Inc., 2018.
- Renyi [1961] Alfred Renyi. On measures of entropy and information. In In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, 1961.
- Pardo [2006] Leandro Pardo. In Statistical Inference Based on Divergence Measures, 2006.
- Johnson et al. [2019] Alistair E. W. Johnson, Tom J. Pollard, Nathaniel R. Greenbaum, Matthew P. Lungren, Chih ying Deng, Yifan Peng, Zhiyong Lu, Roger G. Mark, Seth J. Berkowitz, and Steven Horng. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs, 2019.
- Alsentzer et al. [2019b] Emily Alsentzer, John R. Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew B. A. McDermott. Publicly available clinical bert embeddings, 2019b.
- Shih et al. [2019] George Shih, Carol C. Wu, Safwan S. Halabi, Marc D. Kohli, Luciano M. Prevedello, Tessa S. Cook, Arjun Sharma, Judith K. Amorosa, Veronica Arteaga, Maya Galperin-Aizenberg, Ritu R. Gill, Myrna C.B. Godoy, Stephen Hobbs, Jean Jeudy, Archana Laroia, Palmi N. Shah, Dharshan Vummidi, Kavitha Yaddanapudi, and Anouk Stein. Augmenting the national institutes of health chest radiograph dataset with expert annotations of possible pneumonia. Radiology: Artificial Intelligence, 1, January 2019. ISSN 2638-6100. doi: 10.1148/ryai.2019180041.
- Kaggle [2019] Kaggle. Society for imaging informatics in medicine: Siim-acr pneumothorax segmentation. 2019. doi: https://www.kaggle.com/c/siim-acr-pneumothorax-segmentation.
- Wang et al. [2017a] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M. Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3462–3471, 2017a.
- Dos Santos et al. [2017] Ludovic Dos Santos, Benjamin Piwowarski, and Patrick Gallinari. Gaussian embeddings for collaborative filtering. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’17, page 1065–1068, New York, NY, USA, 2017. Association for Computing Machinery. ISBN 9781450350228.
- Zhang et al. [2022] Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D. Manning, and Curtis P. Langlotz. Contrastive learning of medical visual representations from paired images and text, 2022.
- Wang et al. [2017b] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M. Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3462–3471, 2017b.
Appendix A Material
Rnyi -Divergence is a general family of divergences that introduce varying degrees of zero-forcing penalty. The general form of the -divergence for is described as below,
| (9) |
It is notable that as approaches 0 or 1, the -divergence converges to the KL divergence and the reverse KL divergence, respectively. For two multivariate Gaussians and , the Rényi -Divergence can be expressed as:
| (10) |
Here, the parameter modulates the extent of zero forcing: minimizing for high values results in being concentrated towards the high-density regions of . Conversely, for low , tends to have broader support, covering regions of including those with low density.
Appendix B Evaluation Tasks & Data
Zero-shot Image Classification: We evaluate the pre-trained model on three representative medical image classification tasks:
-
1.
RSNA Pneumonia Dataset[Shih et al., 2019]: Comprising over 260,000 frontal chest radiographs collected by the Radiological Society of North America (RSNA). These images can be classified into a binary classification task: pneumonia vs. normal. For evaluation purposes, we randomly sample 4003 images for evaluation.
-
2.
SIIM-ACR Pneumothorax Dataset[Kaggle, 2019]: Contains more than 12,000 frontal chest radiographs collected by the Society for Imaging Informatics in Medicine and the American College of Radiology (SIIM-ACR). Similar to the RSNA Pneumonia dataset, it is used for a binary classification task to determine the presence or absence of pneumothorax. We use all 10,675 images for evaluation.
-
3.
ChestXray14 Dataset[Wang et al., 2017a]: NIH ChestXray14 has 112,120 chest X-ray images with 14 disease labels from 30,805 unique patients. The official test set released by the NIH, comprising 22,433 images, are distinctively annotated by board certified radiologists. For multi-label evaluation, we only test on the official test set.
Zero-shot Text-Image Retrieval: For pre-training methods akin to CLIP, text-image retrieval tests are standard practice. Following the practices of CLIP [Radford et al., 2021] and MERU [Desai et al., 2023], we also introduce downstream tasks for text-image retrieval. In medical imaging reports, the same diagnosis often has varied textual descriptions, making retrieval from image to text impractical. Thus, we do not use images to query text; instead, we use text to retrieve specific categories of images as described in [Zhang et al., 2022]. For this purpose, we first construct a text-image retrieval evaluation dataset. As described in the multi-label classification task, ChestXray14 Wang et al. [2017b] encompasses 14 different disease classes and one ’normal’ class, totaling 15 categories. Based on these class labels, we randomly extract 100 images for each class (exclusive), forming the ChestXray14x100 dataset, which consists of 1,500 images. We then write representative text prompts for each of the 15 categories. During testing, for each query, we encode its text using the learned text encoder, then retrieve from the candidate images in a similar manner. This evaluation assesses not only the quality of the learned image representations but also the consistency between text and image representations.
Zero-shot Image-Image Retrieval: This evaluation task is similar to traditional content-based image retrieval tasks and is also a common downstream task in medical imaging. It involves using a query image to search for images of specific categories. To evaluate, a set of query images, image category label prompts, and a candidate image set are provided to the pre-trained representation model. We encode each query and candidate image using the encoder of the pre-trained model, then rank all candidate images in descending order of their reciprocal geodesic distance from the query’s expected distribution.
Prompts Design:
To create the textual queries for each category on each evaluation task, we consulted a board-certified radiologist to draft at least five distinct sentences describing each abnormality as it would appear in radiology reports. Drawing inspiration from ConVIRT[Zhang et al., 2022], we established the following criteria: 1) The sentences must clearly describe the specific category without ambiguity and should not reference other categories.
2) The sentences must be varied and distinct from one another.
3) The sentences should avoid mentioning highly specific anatomical locations or rare clinical findings.
Finally, we aggregated the results and selected the best textual queries for each abnormality category. For reference, examples of the textual queries are presented in Table 5.
| Disease Category | Prompts for RSNA Pneumonia Tasks |
|---|---|
| Normal | The chest image can not find any symptoms. |
| Pneumonia | The chest image shows the pneumonia. |
| Disease Category | Prompts for SIIM Pneumothorax Tasks |
| Normal | The chest image can not find any symptoms. |
| Pneumothorax | The chest image shows the pneumothorax. |
| Disease Category | Prompts for Text to Image Retrieval Tasks |
| Atelectasis | A subtle opacity in the lung base could be attributed to a patch of atelectasis. |
| Cardiomegaly | The cardiac silhouette is prominently enlarged, pointing to possible cardiomegaly. |
| Effusion | Fluid levels observed within the pleural cavity. |
| Infiltration | Hazy densities throughout the lung parenchyma, indicative of infiltration. |
| Mass | A mass lesion is noted, warranting further evaluation. |
| Nodule | A solitary small pulmonary density suggestive of a nodule. |
| Pneumonia | Airspace disease with lobar distribution points to possible pneumonia. |
| Pneumothorax | The chest film shows pneumothorax with lung collapse. |
| Consolidation | Areas of dense opacity suggest alveolar consolidation. |
| Edema | Pulmonary edema is suggested by perihilar haziness. |
| Emphysema | Lung parenchyma shows large areas of low attenuation, suggesting emphysema. |
| Fibrosis | Linear and nodular opacities indicative of lung fibrosis. |
| Pleural Thickening | The pleural surfaces show signs of fibrotic changes, suggesting pleural thickening. |
| Hernia | There is evidence of a diaphragmatic hernia. |
| No Finding | The chest radiograph shows no abnormality. |
| Disease Category | Prompts for Image to Image Retrieval Tasks |
| Atelectasis | Linear areas of opacity are consistent with areas of atelectasis. |
| Cardiomegaly | Cardiomegaly is indicated by an increased cardiothoracic ratio. |
| Effusion | There is fluid accumulating in the pleural space indicative of pleural effusion. |
| Infiltration | The presence of diffuse lung markings suggests pulmonary infiltration. |
| Mass | An abnormal density is identified, consistent with a mass lesion. |
| Nodule | A well-defined rounded opacity suggests the presence of a pulmonary nodule. |
| Pneumonia | An area of consolidation with air bronchograms indicates pneumonia. |
| Pneumothorax | The presence of free air in the pleural space suggests a pneumothorax. |
| Consolidation | Consolidation is suspected due to a region of lung opacification. |
| Edema | Pulmonary edema is suggested by perihilar haziness. |
| Emphysema | Hyperinflation and flattened diaphragms suggest emphysema. |
| Fibrosis | Fibrosis is indicated by reticular opacities in the lung fields. |
| Pleural Thickening | The pleura appears thickened, indicating pleural thickening. |
| Hernia | An organ protrusion through the diaphragm suggests a hernia. |
| No Finding | The imaging shows no significant abnormalities. |