Human Shape and Clothing Estimation
Abstract
Human shape and clothing estimation has gained significant prominence in various domains, including online shopping, fashion retail, augmented reality (AR), virtual reality (VR), and gaming. The visual representation of human shape and clothing has become a focal point for computer vision researchers in recent years. This paper presents a comprehensive survey of the major works in the field, focusing on four key aspects: human shape estimation, fashion generation, landmark detection, and attribute recognition. For each of these tasks, the survey paper examines recent advancements, discusses their strengths and limitations, and qualitative differences in approaches and outcomes. By exploring the latest developments in human shape and clothing estimation, this survey aims to provide a comprehensive understanding of the field and inspire future research in this rapidly evolving domain.
1 Introduction
Human shape and clothing estimation is a complex and challenging task with a wide range of applications across various domains. Accurate estimation of human shape and clothing has numerous practical applications. In the realm of fashion retail, virtual try-on systems ghodhbani2022you (11) empower customers to visualize how different garments would appear on their bodies without physically trying them on. This technology enhances the online shopping experience, reduces returns, and improves customer satisfaction. Moreover, personalized fashion recommendations based on individual body shapes and style preferences can be facilitated. The field of virtual reality (VR) and augmented reality (AR) also greatly benefit from human shape and clothing estimation liu2020comparing (26). By accurately replicating users’ physical appearances and clothing choices, immersive virtual environments can offer a more personalized and engaging experience. Applications include gaming, social VR, virtual meetings, and virtual fashion shows. In animation and visual effects, precise estimation of human shape and clothing is crucial for creating realistic characters and enhancing the visual quality of films, video games, and visual effects. Accurate modeling and rendering of body shape and clothing details contribute to a visually appealing and immersive experience.
However, the task of human shape and clothing estimation is non-trivial due to several challenges. Variations in body shapes, sizes, and poses present difficulties in accurately estimating body shape and proportions. The diversity of clothing styles, textures, and patterns adds further complexity to the task. Occlusions caused by overlapping clothing layers, objects, or body parts, along with variations in image quality, lighting conditions, and camera viewpoints, further hinder accurate estimation. Moreover, obtaining a large amount of labeled training data with precise annotations poses a challenge for building accurate and robust estimation models.
Several prior works have contributed to the understanding and advancement of clothing analysis techniques and clothing image retrieval technology. In a survey by Liu et al. liu2014fashion (25), a comprehensive overview of clothing analysis techniques is presented, including clothing modeling, retrieval, and recommendations. The survey also delves into makeover analysis, exploring topics such as facial makeup, hair beauty, and related areas. Another significant work by Ning et al. ning2022survey (36) focuses specifically on clothing image retrieval technology, which has gained substantial popularity in e-commerce platforms and search fields, such as Taobao, Jingdong, Baidu, Google, among others. The authors primarily investigate clothing image retrieval in cross-domain situations, where the image to be queried and the image retrieval database originate from two distinct domains.
In this survey paper, we present an overview of the field of human shape and clothing estimation with the objective of exploring and analyzing the existing research in this area, focusing on the background, methods, and findings related to human shape estimation, fashion generation, landmark detection, and attribute recognition.
The paper is structured as follows: Section 2 provides a detailed explanation of the background, highlighting the critical requisite knowledge of human shape estimation and clothing estimation in various domains. It discusses the non-trivial nature of the tasks, and the motivation to solve the clothing estimation problem. In Section 3, we delve into the methods employed for human shape estimation, fashion generation, landmark detection, and attribute recognition. We perform the critical analysis in this section. The section also covers different approaches, algorithms, and models utilized to accurately estimate human shape, generate realistic virtual clothing, detect landmarks on the human body, and recognize clothing attributes. We discuss these methods in terms of strengths, motivations, underlying reasons, limitations, and qualitative differences in approaches and outcomes. Finally, in Section 4, we conclude the paper by summarizing our findings and insights regarding human shape and clothing estimation. We highlight the key takeaways from the surveyed literature, identify the current challenges and future research directions, and discuss the potential applications and implications of the advancements in this field.
Through this survey paper, we aim to provide a comprehensive understanding of the state-of-the-art techniques and developments in human shape and clothing estimation. We hope that the insights and knowledge gained from this survey will contribute to the ongoing research in this field and inspire new avenues of exploration and innovation.
2 Background
Before we explore the latest methods for estimating human body shape and clothing, we describe how we can represent the human body using shape and pose parameters. We give an overview of the computer vision tasks involved in estimating human shapes and clothing in the field of fashion technology in the subsequent subsection.
2.1 Human Body 3D Representation
Understanding and accurately modeling the human body has been a persistent challenge in computer graphics, animation, virtual reality, and bio-mechanics 10.1145/2816795.2818013 (31). Estimating human body pose and shape from 2D images is particularly complex due to the loss of information from the 3D space. The highly articulated nature of the human body, along with the dimensional complexity, unusual and complex poses, and contrast variations introduced by clothing, further complicate the modeling difficulties.
Numerous research works inproceedings (2, 33, 16, 10) have explored approaches to accurately capture the human body shape using 3D models. These methods often rely on incorporating priors such as contours, silhouettes, cylindrical representations, or meta-balls models. However, these earlier techniques encountered significant challenges, resulting in ill-posed, and unrealistic representations of the human body. The fundamental issue with these approaches was the inability to achieve a precise and reliable model that accurately reflected the complexities of the human form. The resulting models often suffered from mismatches, lacked robustness, and failed to capture the true realism of the human body. This limitation hindered the progress in achieving more realistic and versatile representations, preventing the applications of these models from reaching their full potential.
Skinned Multi-Person Linear Model (SMPL) 10.1145/2816795.2818013 (31) is a vertex-based parametric model to represent human body shapes accurately. SMPL is a generative model in which there are two key components namely shape and pose . The shape parameter represents the variation in height, weight, body proportions, contours and the pose parameter represents the 3D surface deformation with articulation. SMPL presents a differentiable function - which outputs a triangulated mesh with N = 6980 vertices. Given the body mesh, the body joints X can be modeled as linear combination of vertices, hence a pre-trained linear regression W is defined for k joints of interest to derive X .
Given this parametric model, the human shape estimation papers described in subsequent sections are based on estimating the aforementioned shape and pose parameters. The main pivot of all the methods is training these parameters by extracting features from single/multiple RGB images. These methods deploy various strategies like adversarial training kanazawa2018endtoend (17), iterative model fitting kolotouros2019learning (19), pressure imaging clever2020bodies (9), neural mesh rendering Yang2022 (55), synthetic data augmentation sengupta2020synthetic (43), to improve the training, and model the shape parameters accurately. Another significant class of body estimation methods involves Body Mesh points jrna (57), pixel aligned implicit functions pifu (40, 41), volumetric performance capture and novel-view rendering li2020monocular (22). More details of these methods with critical analysis are described in the subsequent sections.
2.2 Intelligent Fashion
Due to the value of the fashion industry, a lot of research areas have been developed related to intelligent fashion. By the term intelligent fashion, we mean such methodologies that focus on solving fashion-related tasks using machine learning.
Fashion detection is one such broad category of tasks. Many of the fashion-related solutions utilize detection methods as a given for their method. For example, a landmark detection task liu2016deepfashion (29) might be used beforehand by a recommendation system. Landmark detection aims to predict the positions of key points such as neckline, hemline, cuff, etc on clothing. Other tasks that might also fall under this category are fashion parsing yamaguchi2012parsing (53), wherein a segmentation mask for different types of clothing items like pants or dresses is generated, and image-based fashion item retrieval.
Fashion no longer refers to just the appearance of the person, but is also linked to the personality traits and various social cues. Thus, analyzing fashion for precision marketing or for sociological reasons is important. Similarly, categorizing clothing based on various attributes such as category, pattern, neckline shape, formal or informal, can be very helpful for recommendation-based tasks or for quantifying fashion style. Although, fashion style can also be represented by directly learning discriminative features kiapour2014hipster (18) through machine learning methods for different styles like bohemian, pinup, goth, etc., and use them to understand various trends. Popularity prediction and fashion forecasting is another important analysis task, not just for marketing campaigns but also for recommendations to individuals on specific occasions. While popularity prediction is person agnostic, fashion recommendations can also be made for a particular individual or clothing item, such as fashion compatibility recommendation iwata2011fashion (15), wherein the task is to understand the compatibility between clothing items of various categories.
We can also perform synthesis-related tasks apart from detection and analysis-type tasks. Synthesis-related tasks can greatly reduce the effort of users to have to manually try different makeups, clothing items, etc, and thus are very valuable for the e-commerce industry. Style transfer tasks for instance such as facial make-up try-on li2015simulating (21) or virtual clothing try-on han2018viton (13), can greatly reduce the cost of having to order multiple candidates online and thus save transportation costs. Style transfer tasks also need to allow pose transformation flexibility for a truly in-store experience.
It is apparent from the previous paragraphs that intelligent fashion methods are trying to accomplish highly diverse tasks, resulting in the development of varied specialized techniques related to a task. Thus, in this survey paper, we restrict our focus to predominantly three fashion tasks, Fashion Generation, Landmark Detection, and Attribute Recognition. We take a deeper look into the problem formulation, as well as various methods that have been developed over the years for these tasks in further sections.
3 Methods and Critical Analysis
This section covers a detailed description of state-of-the-art methods in human shape estimation, which acts as a foundation for the intelligent fashion areas - Clothing Generation, Landmark Detection, and Attribute Recognition. The section also covers the analysis of these methods in terms of strengths, motivations, underlying reasons, limitations, and qualitative differences in approaches and outcomes.
3.1 Human Shape Estimation
The human shape estimation from a single RGB image is a challenging task in computer vision. It has several applications in the field of HCI, graphics, virtual try-on, action recognition, etc. The primary paradigm of human shape estimation as described in the background section is estimating the shape and pose parameters for the SMPL - a generative parametric model to estimate the mesh vertices. The methods described below utilize this SMPL model in some way.
The HMR (Human Mesh Recovery) kanazawa2018endtoend (17) stands as a significant early contribution to the field of estimating human shape and pose. It introduces an end-to-end framework that enables the reconstruction of a 3D mesh representing the human body from a single RGB image. The method involves passing the input image through a CNN encoder to extract relevant representations. These representations are then fed into an iterative regressor, which learns the camera, pose, and shape parameters. These parameters serve as input to the SMPL model, allowing for the generation of a 3D mesh of the human body.
The method then proceeds to generate keypoints that can be compared with the ground truth keypoints. This comparison is utilized to calculate the reprojection error, which quantifies the accuracy of the reconstructed mesh. The paper’s main contribution lies in the utilization of an unpaired 3D dataset to train an adversary, referred to as a discriminator. The discriminator’s role is to differentiate between natural parameters and the generated parameters, ensuring that the generated parameters are realistic to model human body shapes.
The main strength of HMR is that it trains the whole method in an end-to-end manner, hence resulting in better accuracy and low run time. Moreover, HMR opens up possibilities of utilizing unpaired 2D-to-3D data in an adversarial manner which is available in more abundance. Although the HMR is considered as a good performing benchmark for many of the recent papers in human shape estimation it has showcased various limitations in terms of high sensitivity to image quality and clothing variations, poor performance in complex poses, and dependency on high amounts of training data.
HMR is a regression-based method to directly estimate model parameters from RGB images, as mentioned such methods require huge amounts of supervision. Other class of methods includes classical optimization-based methods to iteratively fit SMPL-based models to 2D observations. These methods give better accuracy with lesser data (unlike HMR) but are slow and sensitive to initialization. SPIN kolotouros2019learning (19) proposes an approach which merges both the paradigms uniquely to estimate human shape. It utilizes the same regression architecture as that of HMR but the inferred output acts as an initialization to the optimization method SMPLify SMPL-X:2019 (37). Along with the reprojection error as described in HMR, the SPIN paper regularizes the loss with a parametric loss between the regressed parameters and iterative fitting parameters .
The main characteristic strength of this method is that it is self-improving in nature, good initialization from regressor leads to better fit and a good fit can give better supervision. Hence the optimization-module and regression-module form a self-improving symbiotic cycle. The paper still fails to complex challenging poses, and is prone to erroneous reconstructions due to ordinal depth ambiguities, viewpoints rarely occurring in the dataset.
Complex poses and occlusion has posed as a serious challenge to the above two methods, PressureNet clever2020bodies (9) has been one of the earliest works to tackle the complex human poses limited to body at rest position. PressureNet utilizes the generative part of the HMR network to output the differentiable mesh and proposes a novel architecture to incorporate pressure map reconstruction network that models pressure image generation to enforce consistency between estimated 3D body models and pressure image input. The paper opens up the possibility of tackling complex poses but it is still limited to the niche involving physics simulations to generate pressure images.
PressureNet addresses the occlusion problem, but its applicability is limited to a specific domain. Recognizing this limitation, Yang et al. (2022) were motivated to develop a novel approach for accurately learning human pose and shape using occlusion-aware data. The proposed method focuses on categorizing different types of occlusions, including self-occlusion, object-human occlusions, and inter-person occlusions. Their framework introduces a distinctive approach by synthesizing occlusion-aware silhouettes and 2D keypoints and directly regressing them to SMPL pose and shape parameters. A notable aspect of this paper is the utilization of a neural 3D mesh renderer, enabling real-time supervision of silhouettes. The primary objective of the paper is to address the scarcity of data in scenarios involving occlusions. However, LASOR still poses a requirement of high training time and is bottle-necked by the performance of the synthetic occlusion data generator.
In summary, all of these works revolve around the central concept of estimating SMPL parameters from RGB images. The primary distinction among these methods lies in their strategies for incorporating additional sources of supervision to generate realistic predictions for these parameters. The HMR method serves as a foundational model that has paved the way for the subsequent methods mentioned earlier. Accurate human shape estimation serves as a fundamental prerequisite for various intelligent fashion tasks, as discussed in the following subsections. Acquiring a deeper understanding of these shape estimation methods facilitates a better comprehension of the diverse tasks at hand.
3.2 Fashion Generation
The virtual try-on task involves creating a computer-generated simulation of trying on clothing items or accessories. It aims to generate a virtual representation of a person, , and accurately render the chosen clothing item, , onto that virtual person, , allowing users to visualize how the clothing looks and fits without physically trying it on. The task combines computer vision and computer graphics techniques to estimate the pose and shape of the person, deform the clothing model accordingly, and render the virtual try-on result, providing a convenient and immersive virtual shopping experience.
One of the early works using DL for Virtual Try-On was present in the VITONhan2018viton (13) paper. The paper presented a two-stage model for the task. The first method would take in a person representation and the target clothing to generate coarse results and a clothing mask . Then, a thin plate split (TPS) transformation, whose parameters are evaluated using shape-aware context matching, would be applied to the clothing to get warped . Finally, in the second stage model would predict a composition mask , such that the final output would be . Perceptual loss is used in both stages, along with L1 loss in the first stage and smoothing loss in the form of total variation regularizer in the second stage.
An important part of the method is the person representation used in stage-1. Typically, some variation of this representation is used in 2D virtual-try-on models. A multi-channel input is prepared of the same height and width as the reference image containing
-
•
An-18 channel pose heatmap generated using SOTA pose estimator, where each channel represents one of the 18 key points.
-
•
A 4-channel human segmentation map using SOTA human parser. The first channel in the map represents the binary mask representing the human shape, while the other 3 channels provide face and hair segmentations from the .
Notably, the reference image is not used thus making representation clothing agnostic.
However, since VITON uses a perceptual loss with a coarse prediction as well, the second stage would be biased towards coarse prediction to improve upon the perceptual loss for the refined image. Thus, leading to poor performance on clothing details transfer. CP-VTONwang2018characteristicpreserving (47) improved upon the VITON’s ability to preserve clothing details by removing the coarse prediction. Instead, the first stage predicts the TPS parameters, which are used to warp the cloth to . This stage uses L1 loss between and the ground truth warped cloth for training. In the second stage, a UNet model then predicts a composition mask and an initial prediction . The final output is again, . Note, herein the initial prediction can be thought of as a coarse prediction but all the losses are defined in terms of the final composited output. CP-VTON also uses the same cloth-agnostic person representation as VITON.
Followup work, CPVTON+Minar_CPP_2020_CVPR_Workshops (35), made several small changes in the CPVTON to get sharper and better-textured results. In the first stage, they provided a complete target body silhouette area as input allowing improvement in hair occlusion artifacts. Also, to control distortion artifacts in warped clothing, they added a grid deformation regularization to the loss. Again, for the second stage, they added face, hair, legs, and clothes to the human representation, and also provided a binary mask of warped clothing as input, to prevent confusion of warped clothing with the background.
One of the major limitations of the works that we have described so far is that the TPS transformation used to warp clothing has a limited degree of freedom(2x5x5). A more flexible approach was proposed by ClothFlowclothflow (12), wherein a dense flow is learned given the source clothing and the target segmentation map. It is important to note that Clothflow can perform both pose-guided person image generation as well as virtual try-on with a slight modification. To perform pose-guided person image generation ClothFlow also involves an initial target segmentation mask, , generation stage, before performing cloth deformation(Stage-2) and final rendering(Stage-3). Both initial generation and final rendering of utilize a UNet-based architecture with appropriate inputs. The initial generation uses a Source Image , source seg and the target pose to generate , while the final rendering utilizes warped cloth , source image , target segmentation mask and target pose to generate . The second stage for cloth deformation utilized two feature pyramid networks one for the source elements, source cloth , and source segmentation , and the other for target segmentation mask predicted in the first stage. Taking inspiration from the optical flow literature, authors used cascaded coarse to fine flow estimation to predict the final warping flow. This paper also used style loss on the final render for better learning of texture details. To use this method for the virtual try-on task, the provided cloth image is used as the source image, while the target pose is kept as the source person’s pose.
Authors of sdafn (1) proposed a single-stage virtual try-on method as compared to previous methods discussed here, wherein no loss is introduced between warped clothing and ground truth clothing. More importantly, they introduced the concept of Multi-flow Estimation for structure information. Arguably, structural information is associated with multiple locations in the feature maps, and thus a single flow is not enough to estimate the structure information correctly. To achieve the same, they take inspiration from Deformable Attentionzhu2021deformable (58) and develop Deformable Attention Flow Network(DAFN), wherein given input source and reference features, and respectively, the flow, , and attention maps, , are generated. Notably, and , where is the number of samples in deformable attention. Internally, DAFN computes self and cross-deformable attentions between source and reference features.
A separate line of work involves using 3D modeling for performing the task of virtual try-on. Specifically, CloTHVTON+ clothvton (34) argued that for complex poses, cloth deformation in 3D is much more quality-preserving and leads to natural deformation. Thus, they first construct a 3D clothing model through a reference SMPL model which has a far simpler shape and pose (A-pose) than the target person. Then, using SMPLify-X SMPL-X:2019 (37) 3D body model of the input person is generated. The 3D clothing model is then deformed to match the 3D body model to get a deformed/warped 3D clothing model. Similar to the previous approach, a target segmentation mask is also initially generated by the approach. However, for the final image generation, two different models were used. A Parts Generation Network(PGN), a UNet, is used to generate the target body skin parts. Finally, a Try-on Fusion network(TFN), another UNet, fuses target human segmentation, warped cloth, and human skin parts together to generate the final output.
3.2.1 Summary
Table-1 gives a succinct comparison of the approaches. It can be seen that all virtual try-on methods have two common steps cloth deformation step to generate an intermediate output , and a final generation step. Methods like SDAFNsdafn (1) perform both of these tasks in a single-stage manner with only final image-based supervision, while other methods usually utilize two different stages to perform these tasks. Additionally, sometimes models use an additional stage to first generate a target segmentation map, which has been argued to perform better than a coarse body silhouette. Also, usually, a UNet model is used for final image generation, wherein some older methods also generate an composition mask, which is used to combine an initial prediction with the warped clothing . Finally, the most important and varied aspect of these methods is the cloth deformation step. While earlier approaches have relied upon methods like TPS, newer approaches generally either rely on a 3D model for clothing deformation or learn a dense flow, even multiple flows, to perform clothing deformation. Techniques that learn a dense flow often also utilize a cascaded coarse-to-fine estimation approach with two FPNs inspired by the literature on optical flow estimation.
Table-2 gives a quantitative comparison between the approaches discussed in this review on the VITON dataset han2018viton (13). VITON was collected by crawling the web for Women, frontal view, and top clothing image pairs, and contains 14,221 pairs for training and 2,032 pairs for testing. Due to the change in metrics over the years, some of the spaces have been left empty. It can be seen that newer approaches such as SDAFN and ClothVTON+ are naturally performing better than the older approaches.
| Method | Stages | 3D modelling | Target Segmentation Map used | Cloth deformation method | Generation |
| VITON han2018viton (13) | 2 | ✗ | ✗ | TPS transformation with shape context matching 993558 (3) - from VITON paper | Coarse generation in stage 1 and refinement in stage 2 by composition |
| CPVTON wang2018characteristicpreserving (47), CPVTON+ Minar_CPP_2020_CVPR_Workshops (35) | 2 | ✗ | ✗ | Learnable TPS transformation | 2nd stage UNet provide initial prediction along with composition mask for merging and warped clothing |
| ClothFlow clothflow (12) | 3 | ✗ | ✓ | Two FPNs with cascaded coarse to fine dense flow estimation | 3rd stage UNet provide initial prediction along with composition mask for merging and warped clothing |
| SDAFN sdafn (1) | 1 | ✗ | ✗ | Two FPNs with cascaded coarse to fine multi-dense flow estimation using DAFN | Shallow Encoder-Decoder |
| Cloth-VTON+ clothvton (34) | 4 | SMPL and SMPLifyX | ✓ | 3D cloth reconstruction and 3d cloth deformation | Parts generation UNet and Try-on fusion UNet |
3.3 Landmark Detection
| Method | Approach & Key Contributions | Limitations |
|---|---|---|
| FashionNet fashionnet (28) | Simultaneously predicts clothes attributes and landmarks using a single CNN network. | Limited to a single CNN architecture and may have difficulty capturing complex spatial dependencies. |
| DFA liu2016fashion (30) | Three-stage CNN framework. Introduces pseudo-labels and offset predictions. | Performance heavily relies on the accuracy of the initial bounding box and may struggle with extreme pose variations. |
| DLAN yan2017unconstrained (54) | Estimation of landmarks without the requirement for clothing bounding boxes. Introduces joint bounding box and landmark estimation. | May face challenges in cases where clothing details are occluded or heavily distorted. |
| BCRNN attentivenet (49) | Predicts confidence maps for each landmark. Considers kinetic and symmetric relations between landmarks. | Performance may be impacted by complex clothing deformations and occlusions. |
| Global-Local Embedding Module lee2019globallocal (20) | Uses non-local operations for global feature extraction. Incorporates global features as a residual connection. | May have limitations in handling large-scale datasets due to computational complexity. |
| Spatial-Aware Non-Local Attention li2019spatialaware (23) | Incorporates spatial awareness using Grad-CAM in non-local attention operations. Pre-trains a ResNet-18 network on DeepFashion-C category annotations. | Spatial constraints may not generalize well to different poses, scales, and clothing styles. |
| Dual Attention 9022135 (8) | Combines spatial and channel-wise attention. Replaces the spatial attention block with a Spatial Attentive Upsampling (SAU) block. | Attention mechanisms may produce redundant attention maps and can be computationally expensive. |
| Deep Residual Spatial Attention Network 9643316 (48) | Embeds direction-aware information using Direction-Aware Spatial Attention Module. Fuses multi-level features. | Limited explanation of the direction-aware information. |
Landmark detection refers to the task of identifying N fashion landmarks on a given Image I. These landmarks locate positions like Left Collar, Right Sleeve, etc. It should be noted that the fashion/clothing landmark detection task is different and more difficult than Human Pose Estimation task. Clothes may undergo non-rigid deformations or scale variations, which is not possible for human joints because of restricted movements and positions.
Earlier works on Fashion Landmark detection worked on the assumption that clothes bounding boxes are given for images, i.e., cropped images focussing only on the cloth for which the landmark needs to be predicted is focussed. A typical dataset used was DeepFashion. Fashion landmark detection was first introduced by fashionnet (28) under the same assumption of clothing boundary box. They introduced FashionNet which simultaneously predicts the clothes attributes and landmarks. It has three branches for predicting landmarks, local features, and global features. FashionNet first predicts the Landmarks and then uses landmark predictions to pool or gate the features in the local branch to extract the local features around each predicted landmark. Then concatenate local and global features to predict clothes attributes. To be specific for landmark detection, FashionNet simply used one CNN network based on VGG-16 for predicting the landmark positions. In their next work, Liu et al liu2016fashion (30) proposed another framework Deep Fashion Alignment (DFA) which has three stages for Deep Convolution Neural Network. At each stage of CNN, they try to improve the prediction of landmarks. The model predicts landmark positions/offset to landmark positions and pseudo-labels at each stage. At stage-1, The CNN predicts landmarks in the space of landmark configuration. It also predicts pseudo-labels which are achieved by clustering absolute landmark positions. At stage-2, CNN takes the original image and predictions from stage-1 (landmarks and pseudo-labels) as input and predicts the offset in landmark position and pseudo-labels. At this stage, the model is learning in the space of landmark offset. The pseudo-labels here also represent the typical error patterns and their magnitude. At stage-3, the model has two branches for predicting the offset in landmarks after stage-2. To choose the branch in stage-3, the model uses error patterns predicted in stage-2. This model did not just use one CNN network to predict the landmarks and stages of the CNN model to refine the prediction in each stage. Stage-1 can be thought of as making coarse predictions, and stage-3 can be thought of as making fine predictions by predicting the offsets. The framework is similar to Residual Networks where in a way you are learning offsets to your features.
Previous works assumed the bounding boxes on clothes which removed background clutters, and variations in human poses and scales, which are expensive to obtain and incapable in practice. Yan et al yan2017unconstrained (54) introduced Unconstrained Fashion Landmark Detection, where clothes bounding boxes are not provided in training and test data. They also introduced the DLAN where bounding boxes and landmarks are jointly estimated. DLAN is built upon DFA by first making it a full convolution Network and introducing two modules 1. Selective Dilated Convolutions to cope with the scale discrepancies and 2. Hierarchical Recurrent Spatial Transformer (HR-ST) to remove background clutters. Selective Dilated Convolutions are achieved by obtaining exponentially expanded receptive fields yu2016multiscale (56) of feature maps in layer I and applying kernel to each scale response. For HR-ST, they used the property of Spatial transformers to align feature maps for subsequent tasks. Given the feature map, the spatial transformer seeks to find the geometric transformation that will produce aligned feature maps. They recurrently updated geometric transformation in three stages to learn to remove background clutter in each stage. This geometric transformation helped them build the pseudo-boundary box they lacked in their dataset. This model was the first model to successfully handle the scale variations in the images as well as to use spatial transformers to make predictions better.
The models that we studied until now used regression to predict landmarks however, studies in pose estimation tompson2014joint (45, 38) demonstrate this regression is highly non-linear and very difficult to learn directly, due to the fact that only one single value needs to be correctly predicted. Wang et al weng (50) proposed to instead of regressing landmark positions directly, we learn to predict a confidence map of positional distribution (i.e., heatmap) for each landmark, given the input image. The ground truth heatmap is obtained by adding a 2D Gaussian filter at the ground truth location of the landmark. They also introduced kinetics and symmetric relations between clothing landmarks. For example, the Left collar, Left waistline, and left Hem are connected and the Left collar is symmetrical to the right collar. It introduced Bidirectional Convolutional Recurrent Neural Network (BCRNN), which is achieved by extending classical fully connected RNNs with convolution operation for message parsing over fashion grammar. It also used Landmark-aware attention and clothing-aware attention to concentrate on functional clothing regions and to discover all the informative locations to classify diverse fashion categories and attributes respectively accurately. This paper was the first paper to use the kinetics constraints and extensively used attention modules for landmark and clothing categories. But Kinetic and symmetric constraints may not work well due to large spatial variances across poses, scales and styles of clothing items. Lee et al lee2019globallocal (20) addressed this issue and introduced a Global-Local Embedding Module for embedding fashion landmark information by employing a non-local block wang2018nonlocal (51) followed by convolution. The non-local operation is used to capture the long dependencies of two points in feature maps on each other, hence it is able to extract the global features. The features extracted from non-local are added to the original feature map as a residual connection. To capture the local features they applied two convolution operations on the output of the non-local operation. This mechanism is quite simple and works better than the constraints model.
The previous method used a non-local block and its receptive field is the whole feature map. Because only the cloth area is the most useful area for fashion landmark detection tasks, maybe just focusing on this area might help the model to learn better representations by focusing on the target area. Keeping all these in mind Li et al li2019spatialaware (23) introduced Spatial-Aware Non-Local Attention. They used Gradient-weighted Class Activation Mapping (Grad-CAM) gradcam (42) to incorporate Spatial awareness in non-local Attention operations. They used Grad-CAM to produce spatial aware maps which will be used to attend to original feature maps in the SANL block instead of the feature map attending to itself. They pre-trained a ResNet-18 network on the DeepFashion-C category annotations and computed spatial maps for the SANL block by computing the gradients of the feature maps as weights of the feature map channels. The spatial feature basically gave the regions important for the prediction of clothes category and those are essentially the area of the clothes.
Previous models proved that Attention models perform better than other models for landmark detection by giving more weight to the important spatial features and suppressing the less relevant positions. There have been some Graph-based models like fashion13 (4) which gave comparable performance but SOTA models are based on attention mechanisms in the current state. The latest SOTA methods use attention in different ways. Chen et al 9022135 (8) introduced Dual attention, while previous methods only focussed on spatial attention they proposed to have channel-wise attention. They also changed the spatial attention block with Spatial Attentive Upsampling (SAU) block which integrates low-level details into final feature maps and recovers the image size and spatial details based on the non-local block and skip connections. But non-local operations may produce redundant attention maps and are computationally expensive because it generates an attention map for each element. Deep Residual Spatial Attention Network was introduced by 9643316 (48) to tackle this issue. First, they proposed Direction-Aware Spatial Attention Module to embed direction-aware information. Instead of attending the whole feature map, they attended the feature map using horizontal attention and vertical attention i.e. only in two directions. Then they proposed Spatial Attention ResBlock by integrating the DSAM with a ResBlock, i.e., input to DSAM is also added to its output after some convolution operations. They also fused multi-level features as in Feature Pyramid Network(FPN) lin2017feature (24).
3.3.1 Summary
We summarize the methods we discussed in Table-3. The earliest work used a single CNN to predict landmarks’ locations. Then we moved to an approach that used 3-stages of CNN refining the landmark prediction at each stage. But attention-based models are now the norm. The use of attention started with the introduction of DLAN which used spatial transformation to transform the feature maps that are more aligned. The Global-Local embedding module used attention to extract global features and convolution on top of them to infuse local features. Spatial-Aware attention attended feature maps focusing on the cloth area using Grad-CAM. Dual Attention was introduced to attend channels-wise attention. Deep Residual Spatial Attention showed that attending feature maps in Horizontal and Vertical directions is enough. A few approaches took interesting approaches like BCRNN used kinetic and symmetric relations of landmarks for prediction and Dual Attention also introduced Spatial upsampling to get the same resolution as the original image.
3.4 Attribute Recognition
Attribute recognition in clothing refers to the task of automatically recognizing and categorizing various visual attributes or characteristics associated with clothing items. These attributes can include properties such as color, pattern, texture, style, sleeve length, neckline type, fabric type, and many others. The goal is to extract meaningful information from images of clothing items and assign labels or tags to them based on their visual features.
An early work on attribute recognition was “Describing Clothing by Semantic Attributes” by Chen et al chen2012describing (7). They proposed a fully automated system that can generate a list of clothing attributes in unconstrained images. This system first performs human pose estimation to find locations of the upper torso and arms in input images, and extracts features from these regions using traditional methods like SIFT lowe2004distinctive (32), maximum response filters varma2005statistical (46), skin detector, etc. Each attribute has its own classifier which outputs a probability score using extracted features as input. The score reflects the confidence of attribute prediction. Finally, a Conditional Random Field (CRF) model is employed to determine stylistic relationships between attributes.
This is one of the early methods of attribute recognition and unlike more recent methods (which will be discussed later), it does not utilize deep learning models. It uses pose estimation as a first step because estimated poses help the model to focus on parts of the input image that provide more information about clothing attributes. This is also the reason why pose estimation or landmark detection is a very common first step in models that perform attribute recognition. This step will appear again in the papers which will be discussed later. Moreover, in this method, each attribute has a dedicated SVM classifier which makes the system inefficient and not scalable for scenarios where the number of attributes is large. Instead, a multi-class classifier would better suit this classification task as it can be scaled easily with the number of attributes to be predicted. Further, by feeding the CRF model with the probability scores from the attribute classifiers, the dependencies and correlations between attributes are explored, allowing the model to retain relevant attributes and throw away incompatible ones. This makes the predictions better mimic the ground truth attributes and results in better performance than independently using the attribute classifiers.
Owing to the success of deep learning-based methods in a variety of tasks, Liu et al fashionnet (28) came up with a deep learning model for attribute recognition called FashionNet which is based on Convolutional neural networks. Similar to the previous work, FashionNet first performs landmark detection on the input image to focus on informative portions of the image. Estimated landmarks are used to compute local features. These local features are fused with global image features (obtained from a CNN) to form the final feature vector which is then passed through fully connected layers to predict clothing category and attributes.
Since deep learning models perform better than traditional approaches in a large data setup, FashionNet recognizes attributes with better accuracy than previous work. Also, unlike previous work that uses an existing pose estimation model, FashionNet has a dedicated convolutional neural network to learn to detect landmarks from data and this aids in extracting better local features.
Motivated by the success of FashionNet, Wang et al attentivenet (49) introduced “Attentive Fashion Grammar Network for Fashion Landmark Detection and Clothing Category Classification” (AttentiveNet). As the title suggests, they developed a fashion grammar network to improve landmark detection in FashionNet and determine clothing attributes with higher accuracy. Additionally, the model incorporates two attention mechanisms – landmark-aware attention and clothing category-driven attention – to directly improve the accuracy of attribute classification.
Landmark detection has a strong influence on attribute recognition because it tells the model which part to focus on to determine the attributes. So naturally, improvement in landmark detection leads to better attribute classification. Moreover, landmark-aware attention enables the model to interpret semantic portions of the input image. These portions provide useful information about clothing styles. But landmark-aware attention alone is not enough to perform accurate predictions. Like in FashionNet, a global feature is required to complement local information from landmark-aware attention. This is where the other attention mechanism i.e. clothing category-driven attention, comes into the picture. It propagates global information extracted from the input image and the global information combined with the local information, enhances the features to accurately predict clothing category and attributes. In contrast, FashionNet does not have any attention mechanisms and its landmark detection network is not as sophisticated as in this work. All these reasons contribute to the success of AttentiveNet.
All the models so far perform pose estimation or landmark detection explicitly, before determining attributes. But the work by Fereira et al quintino2019pose (39) titled “Pose Guided Attention for Multi-label Fashion Image Classification” develops a model named VSAM (visual semantic attention model) which uses pose estimation only as a guide to predict category and attributes. VSAM uses a spatial attention module (a concatenation of max and average pooling across the channel axis), to highlight informative regions in the features. These features are then regularized with ground-truth heatmaps of the relevant joints obtained by OpenPose openpose (5). The regularizer uses pixel-wise L2-norm difference between the estimated and the ground-truth heatmaps which acts like another loss in addition to the cross entropy loss at the category level and the focal loss at the attribute level.
In VSAM, heatmaps from OpenPose guide the attention module to learn discriminative features from certain informative regions without abandoning other regions completely unlike previous models that perform explicit pose estimation and focus only on the regions suggested by the output of pose estimation. In a way, the regularizer in VSAM is a soft guidance from OpenPose whereas in comparison, the explicit pose estimation in previous models works like a hard supervision. Moreover, previous models are completely dependent on the output of pose estimation to determine the attributes whereas VSAM is only partially dependent on ground truth pose.
Based on the models discussed so far, the general recipe for attribute recognition consists of the following steps :-
-
1.
Pose estimation/landmark detection for soft/hard supervision of features.
-
2.
Extraction of features using CNN and poses estimated in the previous step.
-
3.
Category and attribute prediction by passing the extracted features through fully connected layers.
There is another class of models that deviates from the general recipe stated above. Instead of performing attribute recognition as a separate task, these models focus on jointly performing both human fashion segmentation and attribute recognition. The first model in this category is FashionFormer xu2022fashionformer (52), a model based on Detection Transformer (DETR) dettransformer (6). FashionFormer first extracts image features for each input image using a feature extractor that contains a backbone network (Convolution Network he2016deep (14) or Vision Transformer liu2021swin (27)) with Feature Pyramid Network lin2017feature (24) as neck. This results in a set of multiscale features which are summed up/fused into one high-resolution feature map. The multiscale features and fused features along with special attribute queries are used to decode the output attributes of the input image (along with the segmentation masks).
Another work in this category is a model by Tian et al tian2023detr (44), titled “DETR-based Layered Clothing Segmentation and Fine-Grained Attribute Recognition”. It is similar to FashionFormer as it is also based on detection transformer and jointly models the task of segmentation and attribute recognition. The novelty of this work is a multi-layered attention module in the decoder that aggregates features from different scales and merges them together.
By jointly modeling segmentation and attribute recognition, the attribute decoder in DETR-based models benefits from information learned by the segmentation part of the decoder model and this improves the accuracy of attribute detection. Moreover, FashionFormer and the model by Tian et al, extract multiscale features from the input image which allows the decoder to attend to information hidden in different scales. In contrast, previous models work only with a single scale, and unlike DETR-based models, they don’t have the superior learning capability of transformers. Another interesting point is that DETR-based models do not use pose estimation in their pipeline, unlike models discussed previously. And, the segmentation task in DETR-based models is quite similar to pose estimation in previous models. This might suggest that human segmentation is better suited to facilitate attribute recognition than human pose estimation.
3.4.1 Summary
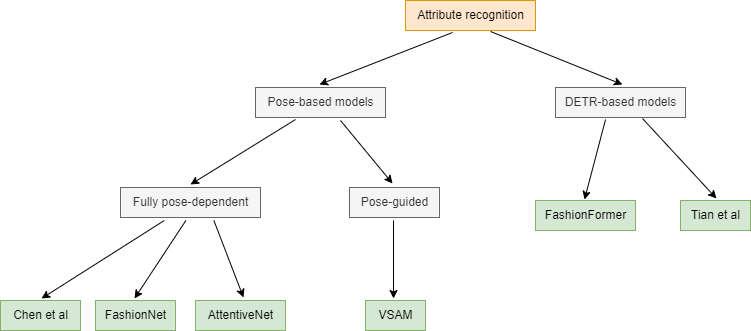
Figure 1 shows the categorization of models for the task of attribute prediction. Models can be classified into multiple classes - fully pose-dependent, pose-guided, and DETR-based. Model by Chen et al, FashionNet, and AttentiveNet are fully pose-dependent models, VSAM is a pose-guided model, and FashionFormer and the model by Tian et al are DETR-based models.
| Method | Category | Texture | Fabric | Shape | Part | Style | All | |||||||
| top-3 | top-5 | top-3 | top-5 | top-3 | top-5 | top-3 | top-5 | top-3 | top-5 | top-3 | top-5 | top-3 | top-5 | |
| Chen et al chen2012describing (7) | 43.73 | 66.26 | 24.21 | 32.65 | 25.38 | 36.06 | 23.39 | 31.26 | 26.31 | 33.24 | 49.85 | 58.68 | 27.46 | 35.37 |
| FashionNet fashionnet (28) | 82.58 | 90.17 | 37.46 | 49.52 | 39.30 | 49.84 | 39.47 | 48.59 | 44.13 | 54.02 | 66.43 | 73.16 | 45.52 | 54.61 |
| AttentiveNet attentivenet (49) | 90.99 | 95.78 | 50.31 | 65.48 | 40.31 | 48.23 | 53.32 | 61.05 | 40.65 | 56.32 | 68.70 | 74.25 | 51.53 | 60.95 |
| VSAM quintino2019pose (39) | - | - | 56.28 | 65.45 | 41.73 | 52.01 | 55.69 | 65.40 | 43.20 | 53.95 | - | - | - | - |
Table 4 compares the four methods analyzed above in terms of classification accuracy for different types of attributes on DeepFashion-C dataset. The huge gap between the model by Chen et al and all other models signifies the superiority of deep learning over traditional SVM classification for predicting clothing attributes. Also, AttentiveNet reports better accuracy than FashionNet supporting our insight that improvement in landmark detection leads to better attribute classification. It also confirms the role of attention in enhancing the features learned by AttentiveNet. Further, soft guidance from pose estimation in VSAM, as opposed to complete reliance on pose in other models, results in higher accuracy for some types of attributes. Overall, the low accuracy numbers for some attribute types like texture, fabric, shape, and part show that there is still a big scope for improvement in attribute prediction.
| Method | Flops(B) | Params (M) | |
|---|---|---|---|
| FashionFormer xu2022fashionformer (52) | 442.5 | 100.6 | 46.5 |
| Tian et al tian2023detr (44) | 423.8 | 94.7 | 46.9 |
Table 5 summarizes the performance of DETR-based models on the FashionPedia dataset. The last column is a joint metric to evaluate models on the joint task of segmentation and attribute prediction. It is clear from the table that there is a slight improvement in score as we go from FashionFormer to the model by Tian et al. But the more important observation is that the number of floating point operations and parameters in the model by Tian et al is lesser than that in FashionFormer. This is probably because Tian et al’s method takes fused features and queries as inputs for the mask prediction module instead of generating mask by mask grouping and query learning like in FashionFormer. This makes Tian et al’s model computationally more efficient than FashionFormer.
4 Conclusion
This survey paper has provided valuable insights into the advancements made in Human Shape and Clothing Estimation using machine learning techniques. Specifically, we delved deeper and discussed methodologies and approaches that have demonstrated significant progress in accurately predicting human body shape, generating diverse and stylish clothing options, detecting landmarks on human bodies, and recognizing clothing attributes. The advancements discussed here have paved the way for more realistic virtual experiences, personalized fashion recommendations, and an improved understanding of clothing attributes. However, there are still challenges to overcome, such as dataset biases, scalability, and real-time performance. As the field continues to evolve, it is expected that further innovations and breakthroughs will be made, leading to even more sophisticated and accurate human shape and clothing estimation systems. These developments will undoubtedly lead to enhanced virtual experiences, personalized fashion solutions, and a deeper understanding of human shape and clothing attributes.
References
- (1) Shuai Bai et al. “Single Stage Virtual Try-on via Deformable Attention Flows”, 2022 arXiv:2207.09161 [cs.CV]
- (2) Adam Baumberg and David Hogg “Learning Flexible Models from Image Sequences”, 1994, pp. 299–308 DOI: 10.1007/3-540-57956-7_34
- (3) S. Belongie, J. Malik and J. Puzicha “Shape matching and object recognition using shape contexts” In IEEE Transactions on Pattern Analysis and Machine Intelligence 24.4, 2002, pp. 509–522 DOI: 10.1109/34.993558
- (4) Qirong Bu, Kai Zeng, Rui Wang and Jun Feng “Multi-depth dilated network for fashion landmark detection with batch-level online hard keypoint mining” In Image Vis. Comput. 99, 2020, pp. 103930 DOI: 10.1016/j.imavis.2020.103930
- (5) Zhe Cao, Tomas Simon, Shih-En Wei and Yaser Sheikh “Realtime multi-person 2d pose estimation using part affinity fields” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 7291–7299
- (6) Nicolas Carion et al. “End-to-end object detection with transformers” In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, 2020, pp. 213–229 Springer
- (7) Huizhong Chen, Andrew Gallagher and Bernd Girod “Describing clothing by semantic attributes” In Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, October 7-13, 2012, Proceedings, Part III 12, 2012, pp. 609–623 Springer
- (8) Ming Chen, Yingjie Qin, Lizhe Qi and Yunquan Sun “Improving Fashion Landmark Detection by Dual Attention Feature Enhancement” In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), 2019, pp. 3101–3104 DOI: 10.1109/ICCVW.2019.00374
- (9) Henry M. Clever et al. “Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data”, 2020 arXiv:2004.01166 [cs.CV]
- (10) D.M Gavrila “The Visual Analysis of Human Movement: A Survey” In Computer Vision and Image Understanding 73.1, 1999, pp. 82–98 DOI: https://doi.org/10.1006/cviu.1998.0716
- (11) Hajer Ghodhbani, Mohamed Neji, Imran Razzak and Adel M Alimi “You can try without visiting: a comprehensive survey on virtually try-on outfits” In Multimedia Tools and Applications 81.14 Springer, 2022, pp. 19967–19998
- (12) Xintong Han, Weilin Huang, Xiaojun Hu and Matthew Scott “ClothFlow: A Flow-Based Model for Clothed Person Generation”, 2019, pp. 10470–10479 DOI: 10.1109/ICCV.2019.01057
- (13) Xintong Han et al. “VITON: An Image-based Virtual Try-on Network”, 2018 arXiv:1711.08447 [cs.CV]
- (14) Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun “Deep residual learning for image recognition” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
- (15) Tomoharu Iwata, Shinji Watanabe and Hiroshi Sawada “Fashion coordinates recommender system using photographs from fashion magazines” In Twenty-Second International Joint Conference on Artificial Intelligence, 2011
- (16) L. Kakadiaris and D. Metaxas “Model-based estimation of 3D human motion” In IEEE Transactions on Pattern Analysis and Machine Intelligence 22.12, 2000, pp. 1453–1459 DOI: 10.1109/34.895978
- (17) Angjoo Kanazawa, Michael J. Black, David W. Jacobs and Jitendra Malik “End-to-end Recovery of Human Shape and Pose”, 2018 arXiv:1712.06584 [cs.CV]
- (18) M Hadi Kiapour, Kota Yamaguchi, Alexander C Berg and Tamara L Berg “Hipster wars: Discovering elements of fashion styles” In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I 13, 2014, pp. 472–488 Springer
- (19) Nikos Kolotouros, Georgios Pavlakos, Michael J. Black and Kostas Daniilidis “Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop”, 2019 arXiv:1909.12828 [cs.CV]
- (20) Sumin Lee, Sungchan Oh, Chanho Jung and Changick Kim “A Global-Local Emebdding Module for Fashion Landmark Detection”, 2019 arXiv:1908.10548 [cs.CV]
- (21) Chen Li, Kun Zhou and Stephen Lin “Simulating makeup through physics-based manipulation of intrinsic image layers” In Proceedings of the IEEE Conference on computer vision and pattern recognition, 2015, pp. 4621–4629
- (22) Ruilong Li et al. “Monocular Real-Time Volumetric Performance Capture”, 2020 arXiv:2007.13988 [cs.CV]
- (23) Yixin Li, Shengqin Tang, Yun Ye and Jinwen Ma “Spatial-Aware Non-Local Attention for Fashion Landmark Detection”, 2019 arXiv:1903.04104 [cs.CV]
- (24) Tsung-Yi Lin et al. “Feature pyramid networks for object detection” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
- (25) Si Liu, Luoqi Liu and Shuicheng Yan “Fashion analysis: Current techniques and future directions” In IEEE MultiMedia 21.2 IEEE, 2014, pp. 72–79
- (26) Yuzhao Liu et al. “Comparing VR-and AR-based try-on systems using personalized avatars” In Electronics 9.11 MDPI, 2020, pp. 1814
- (27) Ze Liu et al. “Swin transformer: Hierarchical vision transformer using shifted windows” In Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012–10022
- (28) Ziwei Liu et al. “DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations” In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 1096–1104 DOI: 10.1109/CVPR.2016.124
- (29) Ziwei Liu et al. “Deepfashion: Powering robust clothes recognition and retrieval with rich annotations” In Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1096–1104
- (30) Ziwei Liu et al. “Fashion Landmark Detection in the Wild”, 2016 arXiv:1608.03049 [cs.CV]
- (31) Matthew Loper et al. “SMPL: A Skinned Multi-Person Linear Model” In ACM Trans. Graph. 34.6 New York, NY, USA: Association for Computing Machinery, 2015 DOI: 10.1145/2816795.2818013
- (32) David G Lowe “Distinctive image features from scale-invariant keypoints” In International journal of computer vision 60 Springer, 2004, pp. 91–110
- (33) D. Metaxas and D. Terzopoulos “Shape and nonrigid motion estimation through physics-based synthesis” In IEEE Transactions on Pattern Analysis and Machine Intelligence 15.6, 1993, pp. 580–591 DOI: 10.1109/34.216727
- (34) Matiur Rahman Minar, Thai Thanh Tuan and Heejune Ahn “CloTH-VTON+: Clothing Three-Dimensional Reconstruction for Hybrid Image-Based Virtual Try-ON” In IEEE Access 9, 2021, pp. 30960–30978 DOI: 10.1109/ACCESS.2021.3059701
- (35) Matiur Rahman Minar et al. “CP-VTON+: Clothing Shape and Texture Preserving Image-Based Virtual Try-On” In The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2020
- (36) Chen Ning, Yang Di and Li Menglu “Survey on clothing image retrieval with cross-domain” In Complex & Intelligent Systems 8.6 Springer, 2022, pp. 5531–5544
- (37) Georgios Pavlakos et al. “Expressive Body Capture: 3D Hands, Face, and Body from a Single Image” In Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2019
- (38) Tomas Pfister, James Charles and Andrew Zisserman “Flowing ConvNets for Human Pose Estimation in Videos”, 2015 arXiv:1506.02897 [cs.CV]
- (39) Beatriz Quintino Ferreira et al. “Pose guided attention for multi-label fashion image classification” In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0
- (40) Shunsuke Saito et al. “PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization” In CoRR abs/1905.05172, 2019 arXiv: http://arxiv.org/abs/1905.05172
- (41) Shunsuke Saito, Tomas Simon, Jason Saragih and Hanbyul Joo “PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization”, 2020 arXiv:2004.00452 [cs.CV]
- (42) Ramprasaath R. Selvaraju et al. “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization” In International Journal of Computer Vision 128.2 Springer ScienceBusiness Media LLC, 2019, pp. 336–359 DOI: 10.1007/s11263-019-01228-7
- (43) Akash Sengupta, Ignas Budvytis and Roberto Cipolla “Synthetic Training for Accurate 3D Human Pose and Shape Estimation in the Wild”, 2020 arXiv:2009.10013 [cs.CV]
- (44) Hao Tian, Yu Cao and PY Mok “DETR-based Layered Clothing Segmentation and Fine-Grained Attribute Recognition” In arXiv preprint arXiv:2304.08107, 2023
- (45) Jonathan Tompson, Arjun Jain, Yann LeCun and Christoph Bregler “Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation”, 2014 arXiv:1406.2984 [cs.CV]
- (46) Manik Varma and Andrew Zisserman “A statistical approach to texture classification from single images” In International journal of computer vision 62 Springer, 2005, pp. 61–81
- (47) Bochao Wang et al. “Toward Characteristic-Preserving Image-based Virtual Try-On Network”, 2018 arXiv:1807.07688 [cs.CV]
- (48) Rui Wang, Jun Feng and Qirong Bu “Fashion Landmark Detection via Deep Residual Spatial Attention Network” In 2021 IEEE 33rd International Conference on Tools with Artificial Intelligence (ICTAI), 2021, pp. 745–752 DOI: 10.1109/ICTAI52525.2021.00118
- (49) Wenguan Wang, Yuanlu Xu, Jianbing Shen and Song-Chun Zhu “Attentive Fashion Grammar Network for Fashion Landmark Detection and Clothing Category Classification” In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4271–4280 DOI: 10.1109/CVPR.2018.00449
- (50) Wenguan Wang, Yuanlu Xu, Jianbing Shen and Song Zhu “Attentive Fashion Grammar Network for Fashion Landmark Detection and Clothing Category Classification”, 2018 DOI: 10.1109/CVPR.2018.00449
- (51) Xiaolong Wang, Ross Girshick, Abhinav Gupta and Kaiming He “Non-local Neural Networks”, 2018 arXiv:1711.07971 [cs.CV]
- (52) Shilin Xu et al. “Fashionformer: A simple, effective and unified baseline for human fashion segmentation and recognition” In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVII, 2022, pp. 545–563 Springer
- (53) Kota Yamaguchi, M Hadi Kiapour, Luis E Ortiz and Tamara L Berg “Parsing clothing in fashion photographs” In 2012 IEEE Conference on Computer vision and pattern recognition, 2012, pp. 3570–3577 IEEE
- (54) Sijie Yan et al. “Unconstrained Fashion Landmark Detection via Hierarchical Recurrent Transformer Networks”, 2017 arXiv:1708.02044 [cs.CV]
- (55) Kaibing Yang et al. “LASOR: Learning Accurate 3D Human Pose and Shape via Synthetic Occlusion-Aware Data and Neural Mesh Rendering” In IEEE Transactions on Image Processing 31 Institute of ElectricalElectronics Engineers (IEEE), 2022, pp. 1938–1948 DOI: 10.1109/tip.2022.3149229
- (56) Fisher Yu and Vladlen Koltun “Multi-Scale Context Aggregation by Dilated Convolutions”, 2016 arXiv:1511.07122 [cs.CV]
- (57) Jianfeng Zhang et al. “Body Meshes as Points” In CoRR abs/2105.02467, 2021 arXiv: https://arxiv.org/abs/2105.02467
- (58) Xizhou Zhu et al. “Deformable DETR: Deformable Transformers for End-to-End Object Detection”, 2021 arXiv:2010.04159 [cs.CV]