Human Interaction Recognition Framework based on Interacting Body Part Attention
Abstract
Human activity recognition in videos has been widely studied and has recently gained significant advances with deep learning approaches; however, it remains a challenging task. In this paper, we propose a novel framework that simultaneously considers both implicit and explicit representations of human interactions by fusing information of local image where the interaction actively occurred, primitive motion with the posture of individual subject’s body parts, and the co-occurrence of overall appearance change. Human interactions change, depending on how the body parts of each human interact with the other. The proposed method captures the subtle difference between different interactions using interacting body part attention. Semantically important body parts that interact with other objects are given more weight during feature representation. The combined feature of interacting body part attention-based individual representation and the co-occurrence descriptor of the full-body appearance change is fed into long short-term memory to model the temporal dynamics over time in a single framework. We validate the effectiveness of the proposed method using four widely used public datasets by outperforming the competing state-of-the-art method.
keywords:
Human activity recognition, human-human interaction, interacting body part attention.1 Introduction
Despite many efforts in the last decades, understanding human activity from a video remains a developing and challenging task in the field of computer vision. In particular, human interaction recognition is a key component of video understanding and is indispensable because it is frequently observed in the real video. It has various applications, such as video surveillance systems, a human-computer interface, automated driving, an understanding of human behavior, and prediction.
The primary reason for the difficulty in human interaction recognition is that we need to consider both single actions and co-occurring individual activities of people to understand the complex relationship between the participants. The key to the success of this task is how to extract discriminative features that can effectively capture the motion characteristics of each person in space and time. The general approach is the implicit representation of the video, such as a bag-of-words (BoW)-based model [1]. The BoW approach describes the entire frame by clustering spatio-temporal image patch features, which are extracted from interest points [2], preset attributes, or key-poses from videos [3, 4, 5]. In recent studies, deep neural network-based video classification methods, such as 3D convolutional neural networks (CNN) [6], two-stream CNN [7], or multi-stream CNN [8], have shown promising results for video representation. One advantage of this type of approach is that the representation is robust to the failure of key-point extraction because it is the overall distribution of pixels that compose the entire image, not a specific point. However, this approach lacks high-level information, which can be a crucial property of human behavior understanding. The implicit representation of the overall frame is relatively overlooked, compared to the underlying explicit properties of the interaction, such as “where/when the feature was extracted” or “who moved how”.
In contrast to single action moves only or group activities focusing on relationships between multiple objects, human interaction includes both individual motions and relationships, and both are equally important. The acting objects directly influence the interacting objects and the reaction is decided, depending on the acting object’s individual motion. In a case of interaction, subtle differences, such as, how the body parts of each person interact with others’ body parts, can change the activity class.



Fig. 1 shows an example of three different human interactions that include the “stretch hand” motion. In the three pictures, the person on the left stretches his right hand forward; however, the type of interaction varies, depending on which body part of the person on the right interacts with it. In the case of a handshake in 1(a), the right hand of the person on the left interacts with the right hand of the person on the right; however, a punch in 1(b) can be understood as an interaction between a hand and the head of two different persons, at a faster speed. Although the hug includes the stretching motions of the right hand, the left hand and the body also move forward in 1(c). Thus, it can be understood as an interaction between the torsos and the hands of two person. As shown above, the type of human interaction can be distinguished by the subtle difference in these detailed movements. The attribute factor such as “which movements are meaningful?” or “how do they react with each other?” should be considered. However, the important attribute of the interaction is a problem-dependent factor; thus, automatic detection of these attributes, with a high-level of understanding, is necessary for efficient and robust human interaction recognition.
To address this problem, we exploit a body joint extraction method to specify the interacting parts. The explicit representation of human behavior provides a clearer interpretation of primitive human body pose and movement. Because not all joints are informative for human behavior, some less-relevant movement of joints may generate noise which can decrease clarity of behavior representation. Thus, the proposed method is designed to detect the informative part of the interaction. The joint-based feature and local image patch feature in the interacting joint are weighted in proportion to the activation degree of the interacting body part. The lack of high-level information from implicit representation supplemented by using the extracted body joints.
Human behavior can be represented by a combination of movements of body joints in 3D space. The release of cost-effective RGB-D sensors has encouraged plenty of skeleton based human activity recognition methods. The dynamic human skeletons usually convey significant information that is complementary to others [9, 10, 11, 12, 13, 14]. In recent studies, the deep learning-based human pose estimation at RGB video has achieved excellent advances [15, 16, 17, 18]. Thus, it has become possible to utilize the advantage of dynamic human skeleton information while using widely used RGB sensors in real-time. The exploitation of an estimated skeleton can provide sophisticated information about articulated human poses with fewer environmental constraints. Although the pose estimation result from the RGB sensor can provide significant information about human behavior, it is still rougher information than the RGB-D sensor-based skeleton estimation. The partial missing of the joints estimation often occur due to camera angle or occlusion. It reduces the quality of skeleton-based human behavior modeling. We designed the body joint extraction procedure from the pose estimation result to exploit the imperfect body joint information for the rest parts of the proposed framework.
In this paper, we present a novel human activity recognition framework that can consider the interacting body parts with local image patches based on the imperfect state joints, and the full-body image, simultaneously. The interacting body part attention allows the proposed framework to selectively focus on informative points of interaction in each video, automatically. Focusing on important joints reduces the influence of the less important joints on the descriptor. The spatial ambiguity of the local image patch is minimized by combining local image feature with body joint information while retaining the advantage of implicit representation. The full-body image represents the co-occurrence of individual human action with the importance of the sub-volume at each time step. The movement of five body parts is explicitly represented with motion and posture feature representation.
In summary, our three main contributions to this paper are as follows: (1) We develop an interacting body part attention mechanism, which can selectively focus on the important local movement of the participants. The body joint, in its imperfect state, can be exploited in this method. (2) We propose a framework that simultaneously considers both implicit and explicit representation of human interaction by fusing local image patch features where the interactions actively occurred, local motion with posture feature, and co-occurrence of overall appearance of multi-person. Explicit and implicit representations work complementarily to obtain a fine-grained representation of human interaction. (3) We demonstrate that the proposed method achieves state-of-the-art performance and shows its extensibility. The subsequent sections of the paper are organized as follows: In Section 2, we present the studies related to our work. We discuss the overall model in Section 3. The experimental results are detailed in Section 4. Finally, we present the conclusions of this work in Section 5.
2 Related Works
In this section, we briefly review some of the literature that is relevant to our work.
2.1 Human activity recognition from RGB video
The recognition in RGB video is the most representative and traditional study and has a wide range of applications [5, 9, 19, 20, 21, 22, 23, 24]. Conventional methods for human activity recognition typically use hand-crafted features to represent the video. Many studies emphasized the importance of spatio-temporal local features. The BoW-based paradigm, with 3D XYT volume, is one of the most popular approaches [1, 2, 3, 4, 5]. The key attributes of interacting people were captured using preset motion attributes, such as interactive phrases [25], discriminative key components [26], action attributes [27], or poselets [28]. Kong et al. [25] proposed multiple interactive phrases as the latent mid-level feature to represent human interaction from individual actions. Sefidgar et al. [26] represented the interaction by a set of key temporal moments and the spatial structures they entail. Despite these studies, human interaction has a subtle difference in detailed movements, such as between a punch and a pat, which is too small to be described by a specific number of phrases.
For the past few years, the deep learning-based video representation methods, such as 3D CNN [6], two-stream CNN [7], and multi-stream CNN [8] have shown their effectiveness in video representation by overcoming the problem-dependent limitation of the hand-crafted features. Ibrahim et al. [29] captured the temporal dynamics of the whole activity based on the dynamics of the individual people. A combination of multi-level representations is modeled with a temporal link. Shu et al. [30] proposed a hierarchical long short-term concurrent memory (H-LSTCM) to effectively address the problem of human interaction recognition with multiple persons by learning the dynamic inter-related representation over time. They aggregated the inter-related memory from individuals by capturing the concurrently long-term inter-related dynamics among multiple persons rather than the dynamics of individuals. Tang et al. [31] proposed coherence constrained graph LSTM (CCG-LSTM) to learn the discriminative representation of a group activity. The CCG-LSTM modeled the motion of individuals relevant to the whole activity, while suppressing the irrelevant motions. Shu et al. [32] proposed concurrence-aware long short-term sub-memories to model the long-term inter-related dynamics between two interacting people. Lee et al. [33] proposed a human activity representation method, based on the co-occurrence of individual action, to predict partially observed interaction with the aid of a pre-trained CNN. Mahmood et al. [34] segmented full-body silhouettes and identified key body points to extract features that had distinct characteristics. Deng et al. [35] utilized CNN to obtain a single person action label and a group activity label and explore the relation between the actions of all individuals. However, because most studies focused on modeling individuals of the relationships in the scene, attention to subtle movements of individual human behavior and the other person’s detailed reactions was relatively less considered.
2.2 Human activity recognition using RGB-D sensor
With the advance of RGB-D sensors, such as Microsoft Kinect, Asus Xtion, and Intel RealSense, action recognition using 3D skeleton sequences has received significant attention and many advanced approaches have been proposed during the past few years [9, 13, 14, 12, 10, 11]. Liu et al. [13] proposed a novel kernel enhanced bag of semantic moving words (BSW) approach to represent the dynamic property of skeleton trajectories. A structured multi-feature representation is composited by aggregating BSW with the geometric feature of skeleton data. In other work, a novel HDS-SP descriptor that consists of both spatial and temporal information from specific viewpoints was proposed by Liu et al. [14]. The HDS-SP projects 3D trajectories on specific planes and creates reasonable histograms. The most suitable viewpoint is sought out through both local search and particle swarm optimization. In other recent studies of skeleton-based human action recognition, attention-based human action recognition was attempted, owing to greater accessibility of individual body parts. Liu et al. [12] proposed a new class of long short-term memory (LSTM) [36], which is capable of selectively focusing on the informative joints in each frame, using a global context memory cell. Song et al. [10] proposed an end-to-end framework with two types of attention modules, a spatial attention module and temporal attention module, which allocate different attention to different joints and frames, respectively.
Recently, a graph neural network (GCN)-based approach received significant attention for skeleton representation, owing to the kinematic dependency between the joints of the human body. Shi et al. [11] proposed a directed graph neural network to extract the dependencies of joints, bones, and their relationships, for the final action recognition task. Yang et al. [37] achieved outstanding performance, based on a feedback graph convolutional network, which adopted a feedback mechanism to the GCN. Multi-stage temporal sampling and a dense connections-based feedback graph convolutional block is proposed to introduce feedback connections into the GCN. Although a human skeleton can provide sophisticated information about human behavior, to maximize the effectiveness of a skeleton-based modeling method, accurate and delicate skeleton joint information is essential. However, most of cost efficient RGB-D sensors are currently limited to indoor applications in close distance. The imperfect joint state, such as missing joints or jittering joints, is often observed when the joints are estimated from RGB video in the wild.
2.3 Pose estimation
With the success of the new era of deep learning-based approaches, some stuides have achieved excellent results in extracting the human body joints from RGB videos through pose estimation [15, 16, 38, 17, 18, 39]. Toshev et al. [18] proposed the first deep neural network-based pose estimation method, called DeepPose. They formulated the pose estimation problem to a CNN-based regression problem toward body joints. Wei et al. [16] proposed a convolutional pose machine (CPM), which consists of an image feature computation module, followed by a prediction module. The CPM can handle long-range dependencies between variables in a structured prediction task by designing a sequential architecture, composed of convolutional networks that directly operate on a belief map from the previous stage. Sun et al. [15] proposed the HRNet model, which has achieved great performance by maintaining a high-resolution representation throughout the process. Cao et al. [17] successfully estimated body joints using part affinity fields (PAFs). The proposed PAF can efficiently detect the 2D pose of multiple people in real-time with high accuracy, regardless of the number of people, using the bottom-up approach. The proposed method uses a nonparametric representation to learn to associate body parts with individuals in the image. In this paper, we utilized OpenPose method [17] to estimate initial human body joint from video, to take advantage of its high accuracy and real-time performance, which are essential properties for practical real-world applications.
Because pose estimation and action recognition are two closely related problems, there are some studies that have performed both tasks simultaneously. Luvizon et al. [40] proposed a multi-task deep learning approach and performed joint 2D and 3D pose estimation from still images and human action recognition in a single framework. Nie et al. [41] proposed an AND-OR graph-based action recognition approach, which exploited the hierarchical part composition analysis. Even though the end-to-end approach has advantages regarding task optimization, it has limited extensibility to videos in varying real-world environments, such as activity scenarios. Furthermore, an approach to research involving interactions, rather than single human actions, is methodologically distinct.
3 Proposed Method
In this section, we present the details of the proposed framework for human interaction recognition based on interacting body part attention. The overview of framework is shown in Fig. 2. From a video, we extract human body joints based on combination of object detection and pose estimation. We then pass it through three different streams: full-body feature stream, local image patch feature stream, and motion and posture feature stream. The motion feature and the local image patch feature were concatenated and they feed into the sub-LSTM after it is weighted by interacting body part attention. The outputs of the sub-LSTM and the co-occurrence descriptor are concatenated, then fed into the LSTM for final classification.
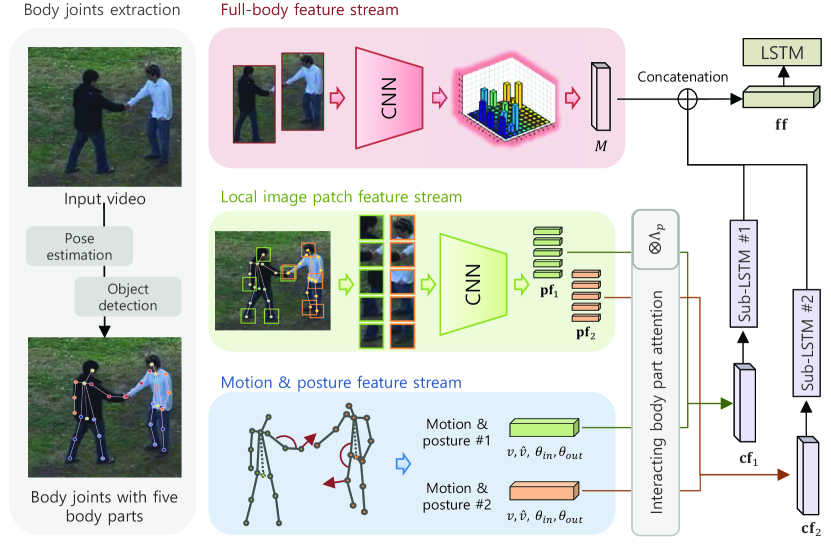
3.1 Body joint extraction
From a given video clip, to estimate a multi-person body joint, we first utilize a publicly available pre-trained object detection model to obtain the bounding box of the object; we used the Faster-RCNN [42] with the Inception-resnet-v2 network [43]. The detection result provides coordinates with the height and width of each object. We also perform initial pose estimation using a publicly available real-time multi-person 2D pose estimation method, based on bottom-up approach, i.e., OpenPose [17]. OpenPose provides the first combined body and foot key-point detector, which enables us to obtain joints even though the links between joints are disconnected.
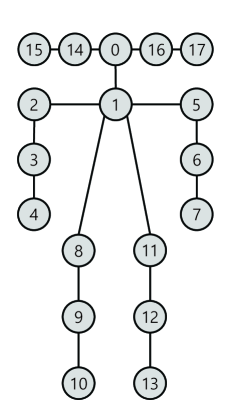
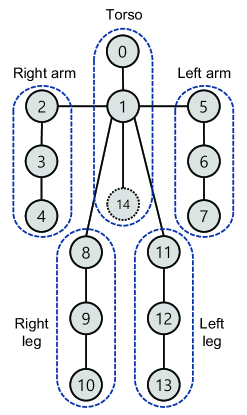
The initial pose estimation result consists of eighteen joints for each human object, from to . The composition of the joints of the estimated pose is shown in Fig. 3(a). We first select fifteen joints, out of nineteen, to generate five body parts. For each human subject, we convert each joint to , as illustrated in Fig. 3(b). Additionally, the coordinate of the center of the joints between and is designated as joint , for utilization of the torso information; this is referred to as the hip. The five body parts consist of three different joints, from to , defined as follows: right arm =(, , ), left arm (, , ), right leg (, , ), left leg (, , ), and torso (, , ). Each number denotes the joint index and their 2D coordinates are defined as , where denotes the body part index and denotes the joint index in each body part.
Although the pose estimation shows promising results, it often fails to detect body joints still at an individual frame-level. We performed two additional procedures to increase the usability and dependability of body joints to manage the noisy pose estimation. To complement the occasional absence of joint information, if the previous frames have failed to estimate a joint, we restore the missing joint by linearly interpolating the coordinate between the current joint at and the last successfully detected joint at the frame. We also utilized the bounding box from the human detection to filter out some residual, or unsuccessful, body joint estimation results, the majority of which are the partial detection of a human object, due to occlusion. First, both the head and torso of each object must be included in the bounding box. If an estimation failure occurs about the head position , the average value of the non-failure joint among {} is used as the head position, . By performing two additional post-processing steps, we obtained the stability and reliability of the body joints from real-time multi-person pose estimation results.
3.2 Body joint-based local features
Motion and posture feature: To express the overall motion and posture of an individual human behavior, we extract two types of motion features and two types of posture features based on body part status. At each time step, for fifteen body joints of five body parts, the average value of the 2D coordinate difference between each previous point and each current point of the sequence is used to calculate the motion velocity and acceleration . This is a simple, but effective, way to express the explicit motion of the body parts and joints by changing the position of each joint. We also calculate the inner angle within the body parts to represent the relative position of the joint inside the body part. The angle of each part is calculated using the following equation:
| (1) | |||
We also calculate the angle between body parts using Eq. (1). The outer angle denotes the angle between the connected body part, which is calculated using the following joint indexes, as the input in each frame: =(, , ), (, , ), (, , ), (, , ). The outer angle represents the overall shape of the body part. and are simple; however, they effectively express scale-invariant human posture information.
Local image patch feature: To consider the local image where interactions actively occurred, the -size local image patch features are extracted from each joint of the potential major interaction area. This is motivated by the fact that most human interactions are performed using their hand or foot. We chose the following five joints from each part, which are expected to have mainly contact when interaction occurs: (head position), (right hand), (left hand), (right foot), and (left foot). The input image patches are extracted where , when the center is in position . The feature representation for a specific joint is the activation value of the last fully connected layer of the convolutional network , with parameters , taking a local image patch as the input, at the joint position of object :
| (2) |
3.3 Interacting body part attention
In this section, we present the body joint based interacting body part attention mechanism. The fundamental idea of interacting part-based attention is based on the assumption that the body parts composing each behavior will have different importance when human interaction occurs. For example, if two people shake hands, person #1 will reach for person #2 and person #2 will similarly reach for person #1. The hands of the two persons get closer, touch, and then become distant from each other. However, if person #1 punches person #2, person #1 reaches out to person #2’s head and person #2 will be pushed back without motion toward person #1. If person #1 performs a push action, person #2’s response will look similar to a punch; however, person #1 will reach out to person #2’s torso with two hands. These subtle differences between similar behaviors are maximized to generate discriminative features by assigning weight to interacting body parts.
We attempt to selectively focus on both the body part of the person who leads the interaction and the body part of the other person that is most involved. The different weights are multiplied by the terms of each part of each person. To express the movement of each part, the spatial difference for time segments is defined as follows:
| (3) |
where denotes the relative distance between each pair of body parts of the interacting persons. The interacting body part attention between each person is calculated as follows:
| (4) |
The body part velocity and body part acceleration are multiplied by the part weight to determine the weight of each part:
| (5) | |||
A movement that is actively participating in the interaction, which is also called the interacting body part, is emphasized by representing individual human motion, using the weighted velocity of the body part and the acceleration of the body part .
The image patch feature vector from each joint is also multiplied by the weight. Since an interacting body part with high weight significant to the interaction, also gives a high weight to the joint-based image feature extracted from the position of the body part as follows:
| (6) |
Each individual object’s behavior with the interacting body part attention is represented by the combination of the following five variables of the five body parts: two posture variables , , two weighted motions variable , , and one weighted local image feature .
3.4 Full body feature stream
Apart from the body joint-based feature and local image patch feature extraction, we also performed full-body image-based activity descriptor generation to consider the overall appearance change with co-occurrence of multi-person behaviors. Extracting a feature vector from a full-body image through CNN has proved its robustness in human activity recognition [32, 33, 29, 35]. Because the occasional failure of body joint extraction may negatively affect the interaction representation, the imperfectness of local features is compensated by a full-body image descriptor. The full-body image descriptor generation method was inspired from the sub-volume co-occurrence matrix descriptor for human interaction prediction [33].
From the detected object region, we first extract the activation from the last fully connected layer of the inception-resnet-v2 network to obtain a feature vector of an object image. Subsequently, we generate a sub-volume for each object , where denotes the average of the image representation feature vector in a sub-volume. A series of frame-level image feature vectors of object , at time for consecutive frames, are averaged into a single vector . Second, -means clustering is performed on the training video to generate codewords , where denotes the number of clusters. Each of the sub-volume features is assigned to the corresponding cluster , following the BoW paradigm. The index of the corresponding cluster is the codeword index, which is also the index of the row and column of the descriptor. Finally, we construct a descriptor using sub-volume features. From each sub-volume of an object , we first measure the spatial distance between sub-volumes and as follows:
| (7) |
The overall spatial distance between sub-volume and the other in segment for , where , is aggregated as follows:
| (8) |
The difference in distance between sub-volume and to the global motion activation represents the participation ratio of the pair in segment . The feature scoring function, based on sub-volume clustering, is calculated as follows:
| (9) |
After computing all required values between all sub-volumes, we finally construct the full-body image descriptor, as follows:
| (10) |
where is the normalization term. The value of the sub-volume between and is assigned to the full-body image descriptor using the corresponding cluster index, and , of each sub-volume. Each of the descriptors is generated for every non-overlapped time step. Therefore, the descriptor is cumulatively constructed from the beginning.
3.5 Feature fusion and classification
In this section, we generate the combined vectors after the three-stream feature generation. From an individual object, we extract five local image features , which represent the local image appearance. We select a feature vector from the most activate body part, where the is maximized. The local image patch feature is concatenated with the motion feature and posture feature, as a combined vector of individual , . The representation of individual was the fed into the sub-LSTM to model the temporal dynamics of each person. At each time step, the hidden unit of the sub-LSTM , is concatenated with a full body image co-occurrence descriptor as . Finally, the concatenated vector is used as the input to the LSTM and the activity classification task is the output of the LSTM after segments.
4 Experiments
4.1 Datasets
We validated the effectiveness of the proposed method by comparing with the state-of-the-art methods on the (1) BIT-Interaction dataset [44]; (2) UT-Interaction dataset [45]; (3) VIRAT 1.0 Ground dataset and VIRAT 2.0 Ground dataset [46]. The first two datasets are common and widely used in human-human interaction recognition research. The VIRAT 1.0 and VIRAT 2.0 Ground dataset consists of human-vehicle interaction tasks, which we chose with the aim of exhibiting the extensibility of our work.








The BIT-Interaction dataset used in the experimental evaluation consists of eight classes of human interactions: bow, boxing, handshake, high-five, hug, kick, pat, and push. Each class contains 50 clips. The videos were captured in a very realistic environment, including partial occlusion, movement, complex background, varying sizes, view-point changes, and lighting changes. For the evaluation, the training set is composed of 34 videos per class (272 in total), and the remaining 16 videos per class (128 in total) are used as the test set following in [25, 4, 47, 33, 32]. Fig. 4(a)-4(b) shows an example snapshot of the BIT-Interaction dataset. In 4(a), the lower half of the body of the person bowing on the left is occluded by a parked vehicle. There is a vending machine in the background in 4(b). Both images show the environmental difficulties in analyzing the human activity.
The UT-Interaction dataset used in the experimental evaluation consists of six classes of human interactions: push, kick, hug, point, punch, and handshake. The dataset is composed of two sets of videos; UT-set #1 and UT-set #2, which were captured in different environments. Each class contains 10 clips for each set. We performed a leave-one-out cross-validation for the evaluation of each set, following competing methods [3, 28, 47, 25, 48, 32, 33]. The set #1 videos were captured in a parking lot background (Fig. 4(c)-4(d)). However, the backgrounds in set #2 of the UT-Interaction dataset (Fig. 4(e)-4(f)) consisted of grass and shaking twigs, which may add noise to local patches of interest points.
VIRAT 1.0 and VIRAT 2.0 Ground datasets used in the experimental evaluation, consist of six classes of human-object interactions: a person opening a vehicle trunk (OAT), a person closing a vehicle trunk (CAT), a person loading an object to a vehicle (LAV), a person unloading an object from a vehicle (UAV), a person getting into a vehicle (GIV), and a person getting out of a vehicle (GOV). The VIRAT 1.0 Ground dataset and VIRAT 2.0 Ground dataset consist of approximately 3 hours and 8 hours of video in several parking lot backgrounds, respectively. Fig. 4(g) demonstrates that the acting person is not fully observable until he gets out of the vehicle in the shadow. The carrying object is fully occluded by the acting person in 4(h), which can disturb the understanding of the context of opening a vehicle trunk. For the evaluation, half of the video clips were used as the training set, and the remaining half were used as a testing set following previous studies [49, 50, 51, 33, 52].
4.2 Implementation details
In this experiment, the initial pose estimation of human objects over all video frames was done using OpenPose [17]. The bounding boxes of person are detected by Faster-RCNN [42] with the Inception-resent-v2 network [43]. To extract image patch features from joints and full body image features, we used the weight of the pre-trained Inception-resnet-v2 network, as a backbone network. The learning rate was set to and the lambda_loss set to . The length of the time step was set to 20 and the minibatch of size 32. We set the values of the full-body feature clustering is set to 20. The number of memory cell nodes of the sub-LSTMs and the second LSTM was set to 200 and 625, respectively. The weights and biases of the LSTMs are initialized with random values having normal distributions. We used Adam optimizer [53] for all experiments. We implemented all modules in this framework using Tensorflow [54], and an NVIDIA Titan XP was used to run the experiments.
In these experiments, we additionally conduct two baseline methods to show the effect of each feature stream on the proposed framework as follows:
baseline #1: This baseline only used body joint-based features, with attention from the joint-based feature stream and local image patch feature stream. The interacting body part attention is applied to this baseline. The concatenated features at all time steps are only pooled from the LSTM of an individual object.
baseline #2: This baseline used the full-body feature, without the body joint-based feature and interacting body part attention. The co-occurrence descriptor of the image-based full-body feature stream was directly fed into final LSTM. This baseline is similar to that of the sub-volume co-occurrence matrix [33].
4.3 Results on BIT-Interaction dataset
The experimental results on the BIT-Interaction dataset are compared with the latest studies, i.e. dynamic BoW [3], mixture of training video segment sparse coding (MSSC) [55], multiple temporal scale support vector machine (MTSSVM) [56], max-margin action prediction machine (MMAPM) [4], Lan et al. [57], Liu et al. [27], Kong et al. [25, 47], Donahue et al. [58], sub-volume co-occurrence matrix (SCM) [33], concurrence-aware long short-term sub-memories (Co-LSTM) [32], and hierarchical long short-term concurrent memory(H-LSTCM) [30]. We also compared the proposed method with two baseline performances.
| Method | Accuracy(%) |
|---|---|
| Dynamic BoW [3] | 53.13 |
| MSSC [55] | 67.97 |
| MTSSVM [56] | 76.56 |
| MMAPM [4] | 79.69 |
| Lan et al. [57] | 82.03 |
| Liu et al. [27] | 84.37 |
| Kong et al. [47] | 85.38 |
| Kong et al. [25] | 90.63 |
| Donahue et al. [58] | 80.13 |
| SCM [33] | 88.70 |
| Co-LSTM [32] | 92.88 |
| H-LSTCM [30] | 94.03 |
| Baseline #1 | 77.25 |
| Baseline #2 | 88.50 |
| Proposed Method | 93.10 |
Table 1 shows the classification results of the proposed method for a quantitative comparison with competing methods. The proposed method achieved higher recognition accuracy on average than all baseline methods and most of the competing approaches. In this experiment, the very recent H-LSTCM [30] shows 0.8% higher accuracy owing to the dynamic inter-related representation of the Co-LSTM unit, but the proposed method also achieved a comparable accuracy with remarkable representation power itself. Specifically, the proposed method with all three feature streams achieved a higher accuracy than baseline #1 and baseline #2, by combining implicit and explicit representation. Thus, the body joint-based representation with attention complements the lack of high-level information on the low-level image feature representation.It is better to use the high-level information than to utilize the low-level image features alone. The comprehensive consideration of individual human motions, co-occurrence of overall appearance, and local importance representation let achieve robust human interaction recognition.
4.3.1 Ablation study of body joint extraction
We also conducted an experiment to show the effectiveness of proposed indexes of body joints with five body parts. In this experiment, we extracted motion features only using , and local image patches were extracted at the same coordinates. If the pose estimation was failed at a certain frame, the coordinate of joints at the last successful frame was used. We performed an experiment in four different settings; original body joints/the proposed indexes of body joints with/without the interacting body part attention. In the ablation study on the BIT-Interaction dataset, the original body joints from pose estimation achieved 67.25% without interacting body part attention and 74.37% with the interacting body part attention, respectively. Meanwhile, the proposed indexes of body joints achieved 70.67% and 77.25% accuracy at the same condition. The stable extraction of each body joint also influences the weight of interacting body part attention. The result shows that the proposed index with five body parts shows slightly better performance than the original indexes, and the proposed interacting body part attention also effectively works for a fine-grained representation of the interaction.
4.4 Results on UT-Interaction dataset
UT-set #1: We compared the recognition accuracy of the proposed method with a competing state-of-the-art method, including some traditional methods and two baselines, i.e. dynamic BoW [3], Lan et al. [59], MSSC [55], MMAPM [4], Wang et al. [51], Donahue et al. [58], SCM [33], Co-LSTM [32], H-LSTCM [30], Mahmood et al. [34], and Slimani et al. [48].
| Method | Accuracy(%) |
|---|---|
| Bag-of-Words(BoW) | 81.67 |
| Integral BoW [3] | 81.70 |
| Dynamic BoW [3] | 85.00 |
| MSSC [55] | 83.33 |
| MMAPM [4] | 95.00 |
| Poselet [28] | 93.30 |
| Kong et al. [47] | 93.33 |
| Kong et al. [25] | 91.67 |
| Donahue et al. [58] | 85.00 |
| SCM et al. [33] | 90.22 |
| Co-LSTM [32] | 95.00 |
| Wang et al. [51] | 95.00 |
| H-LSTCM [30] | 98.33 |
| Mahmood et al. [34] | 83.50 |
| Slimani et al. [48] | 90.00 |
| Baseline #1 | 88.50 |
| Baseline #2 | 90.00 |
| Proposed Method | 93.33 |
The comparison of the interaction recognition performance between the proposed method with two baselines and competing methods, on the UT-set #1, is shown in Table 2. It can be seen that the combination of interacting body part attention and co-occurrence descriptor could improve the performance, which prove that specific information from different types of features can complement each other. In this experiment, the proposed method achieved 93.22% recognition accuracy, which is slightly lower than the competing state-of-the-art methods [50, 4, 32, 30]. We believe that the reason for very high performances in UT-set #1 is the superiority of the competing methods as well as the environmental simplicity. The UT-set #1 is recorded against a gray asphalt background, which allows for the clear identification of the appearance of a person, without noise. Here, it is noted that Wang et al. [51] adopt deep context feature on the event neighborhood, the size of which requires manual definition. Thus, all the competing methods achieved high performance, with ideal and rich appearance information, while the proposed method experienced difficulty in extracting body joints from some frames, owing to their occlusion.
UT-set #2: We separately compared the recognition accuracy of the proposed method on the UT-set #2, for a fair comparison. Table 3 shows the performance of competing state-of-the-art methods with some traditional methods and two baselines, i.e., dynamic BoW [3], Lan et al. [59], MSSC [55], SC [55], MMAPM [4], SCM [33], Mahmood et al. [34], and Slimani et al. [48].
| Method | Accuracy(%) |
|---|---|
| Bag-of-Words(BoW) | 80.00 |
| Dynamic BoW [3] | 70.00 |
| Lan et al. [59] | 83.33 |
| MSSC [55] | 81.67 |
| SC [55] | 80.00 |
| MMAPM [4] | 86.67 |
| SCM [33] | 89.40 |
| Mahmood et al. [34] | 72.50 |
| Slimani et al. [48] | 83.90 |
| Baseline #1 | 78.33 |
| Baseline #2 | 88.50 |
| Proposed Method | 91.33 |
We can see that different from UT-set #1, the proposed method outperformed all the competing methods with 91.33% recognition accuracy on UT-set #2. The proposed method exhibits outstanding recognition performance considering that the accuracy of the competing methods on UT-set #2 were decreased approximately 2%-15% on average compare to UT-set #1. The recognition performances of dynamic BoW [3], MSSC [55], MMAPM [4], Mahmood et al. [34], Slimani et al. [48] decreased from 85.00%, 83.33%, 95.00%, 83.50%, and 90.00% to 70.00%, 81.67%, 86.67%, 72.50%, and 83.90%, respectively. This is because UT-set #2 has more complicated background than UT-set #1; thus, the proposed method of using human structural features through joint estimation performs better than the competing methods. We believe that the proposed method is highly effective, considering the complexities of the environmental change in real-world scenarios.
4.5 Results on VIRAT Ground datasets
We also evaluate the proposed framework on the VIRAT 1.0 Ground dataset and VIRAT 2.0 Ground dataset, to show the extensibility of our method. We compared the performance with Zhu et al. [49], Bayesian network (BN) [50], a deep hierarchical context model (DHCM) [51], SCM [33], and WSCF [52]. Because these two datasets consist of human-object interaction tasks, each human and object (mainly vehicle or box) are treated as separate objects. Here, we should note that in this experiment, the object does not have a body joint; the center of the detected object is set to the coordinates of the interacting joint. In the body joint extraction procedure, the failure of the head and torso estimation of non-human objects was exceptionally handled in this experiment.
| Method | VIRAT 1.0(%) | VIRAT 2.0(%) |
|---|---|---|
| SVM-STIP | - | 41.74 |
| Zhu et al. [49] | 62.90 | - |
| BN [50] | 65.80 | 58.70 |
| DHCM [51] | 69.90 | 66.45 |
| SCM [33] | 76.30 | 79.53 |
| WSCF [52] | 73.14 | 74.41 |
| Baseline #1 | 65.58 | 61.83 |
| Baseline #2 | 75.33 | 77.83 |
| Proposed Method | 79.83 | 81.50 |
Table 4 lists the recognition accuracies of human-vehicle interactions, using VIRAT 1.0 Ground dataset and VIRAT 2.0 Ground dataset. The proposed method outperformed all the competing methods, with recognition accuraccy of 79.83% and 81.50%, respectively.
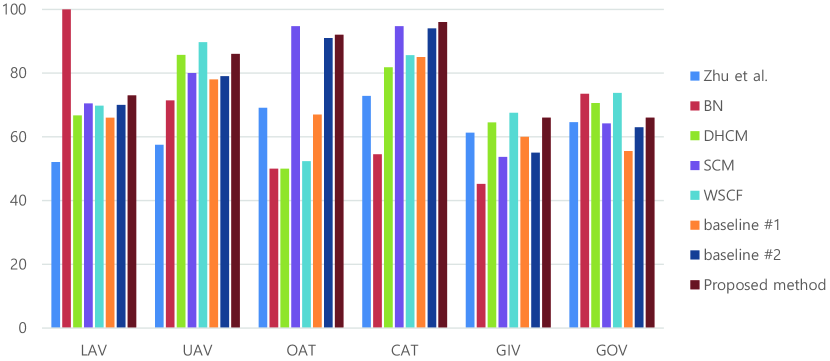
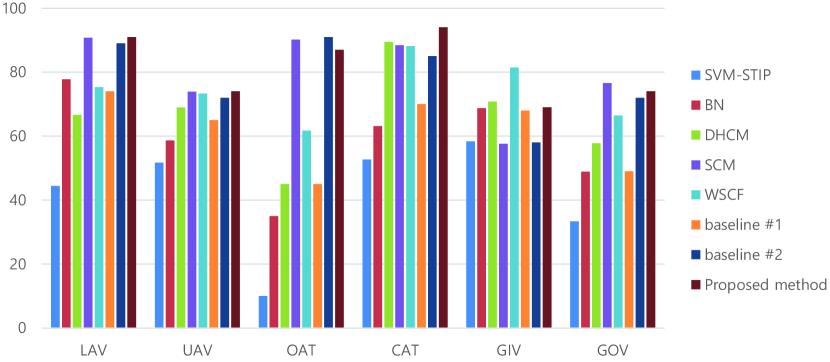
In both datasets, the baseline #1 shows a lower performance. Owing to the characteristics of the type of interaction in the dataset, body joint extraction failures occur very frequently when occlusion occurs with the vehicle. Moreover, the vehicle has no reaction to human action at the joints. The absence of mutual interacting body parts also makes it difficult to use a local image patch and body joint-based feature. However, the proposed method shows a much higher performance than baselines #1 and #2, considering the full-body image together. The representation power of the full-body image feature is sufficient to describe the behavior of the acting objects. Moreover, the local image patch feature, extracted from the joint of the acting object, provides information about the directly interacting part of the vehicle, such as the trunk or the door. We can observe the recognition results of the VIRAT 1.0 and VIRAT 2.0 Ground dataset for each class in Fig. 5 and Fig. 6, respectively. We can see that the baseline #1 result does not show the worst accuracies on some interactions, despite the difficulty in body joint extraction. We conduct a similar experiment on the VIRAT 2.0 Ground dataset. As expected, the proposed method achieved a better performance than other methods. Even though, for the same reasons mentioned for the VIRAT 1.0 Ground dataset, baseline #1 shows a lower accuracy, the propose framework achieved the best performance by complementary modeling of human activity with full-body co-occurrence with interacting body part attention.
5 Conclusion and Future Work
In this paper, we present a novel framework for human interaction recognition, which considers both the implicit and explicit representations of the human behavior. Specifically, the subtle differences in behaviors of interacting persons are captured through interacting body part attention, which maximizes the discriminative power of feature representation. The complex activity of two or more people interacting with each other requires a higher-level understanding of both individual human behavior and their relationships. Both implicit and explicit representations are successfully learned through the individual behavior of the person represented, based on interacting body part attention with their local image patch, after stabilized body joint extraction. The image-based full-body feature models the interaction, based on the co-occurrence of human behaviors and their activations. Each of the three features feeds into the LSTM to model individual level behavior and video level interaction, while working complementarily. Experimental results on four publicly accessible datasets, i.e., the BIT-Interaction dataset, UT-Interaction dataset, VIRAT 1.0 Ground dataset, and the VIRAT 2.0 Ground dataset, demonstrated the superiority of the proposed method compared to state-of-the-art methods. The attention to the interacting body part showed a weakness when the human body joint estimation fails owing to heavy occlusion. Nevertheless, if the body joint is extracted even a little including neighbor frames, it demonstrates good results, owing to the local image patch feature with actively interacting body parts. The proposed method provides a convenient and straightforward understanding of accurate human interaction recognition. However, the use of the proposed method is not established for more than three-person interaction such as collective activity, currently. We expect that the multi-person interaction problem can be addressed by adaptive fusing the result of individual human action modeling. Thus, the extension of the proposed method to the complex multi-person activity will be our future work.
Acknowledgment
This work was supported by Institute for Information & Communications Technology Planning & Evaluation(IITP) grant funded by the Korea government (MSIT) [No. 2019-0-00079, Department of Artificial Intelligence, Korea University] and [No. 2014-0-00059, Development of Predictive Visual Intelligence Technology].
References
- [1] I. Laptev, M. Marszalek, C. Schmid, B. Rozenfeld, Learning realistic human actions from movies, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2008, pp. 1–8.
- [2] I. Laptev, On space-time interest points, International Journal of Computer Vision 64 (2-3) (2005) 107–123.
- [3] M. S. Ryoo, Human activity prediction: Early recognition of ongoing activities from streaming videos, in: Proceedings of the IEEE International Conference on Computer Vision, 2011, pp. 1036–1043.
- [4] Y. Kong, Y. Fu, Max-margin action prediction machine, IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (9) (2016) 1844–1858.
- [5] M. Ziaeefard, R. Bergevin, Semantic human activity recognition: a literature review, Pattern Recognition 48 (8) (2015) 2329–2345.
- [6] S. Ji, W. Xu, M. Yang, K. Yu, 3d convolutional neural networks for human action recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (1) (2013) 221–231.
- [7] K. Simonyan, A. Zisserman, Two-stream convolutional networks for action recognition in videos, in: Advances in Neural Information Processing Systems, 2014, pp. 568–576.
- [8] Z. Tu, W. Xie, Q. Qin, R. Poppe, R. C. Veltkamp, B. Li, J. Yuan, Multi-stream cnn: Learning representations based on human-related regions for action recognition, Pattern Recognition 79 (2018) 32–43.
- [9] B. Liu, H. Cai, Z. Ju, H. Liu, Rgb-d sensing based human action and interaction analysis: A survey, Pattern Recognition 94 (2019) 1–12.
- [10] S. Song, C. Lan, J. Xing, W. Zeng, J. Liu, An end-to-end spatio-temporal attention model for human action recognition from skeleton data., in: AAAI, Vol. 1, 2017, pp. 4263–4270.
- [11] L. Shi, Y. Zhang, J. Cheng, H. Lu, Skeleton-based action recognition with directed graph neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 7912–7921.
- [12] J. Liu, G. Wang, L.-Y. Duan, K. Abdiyeva, A. C. Kot, Skeleton-based human action recognition with global context-aware attention lstm networks, IEEE Transactions on Image Processing 27 (4) (2018) 1586–1599.
- [13] B. Liu, Z. Ju, H. Liu, A structured multi-feature representation for recognizing human action and interaction, Neurocomputing 318 (2018) 287–296.
- [14] J. Liu, Z. Wang, H. Liu, Hds-sp: A novel descriptor for skeleton-based human action recognition, Neurocomputing 385 (2020) 22–32.
- [15] K. Sun, B. Xiao, D. Liu, J. Wang, Deep high-resolution representation learning for human pose estimation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 5693–5703.
- [16] S.-E. Wei, V. Ramakrishna, T. Kanade, Y. Sheikh, Convolutional pose machines, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4724–4732.
- [17] Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, Y. Sheikh, OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields, in: arXiv preprint arXiv:1812.08008, 2018.
- [18] A. Toshev, C. Szegedy, Deeppose: Human pose estimation via deep neural networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 1653–1660.
- [19] B. Heinrich, S.-W. Lee, T. Poggio, Biologically motivated computer vision, Springer-Verlag, 2003.
- [20] D. Xi, I. T. Podolak, S.-W. Lee, Facial component extraction and face recognition with support vector machines, in: Proceedings of Fifth IEEE International Conference on Automatic Face Gesture Recognition, IEEE, 2002, pp. 83–88.
- [21] D. Kang, H. Han, A. K. Jain, S.-W. Lee, Nighttime face recognition at large standoff: Cross-distance and cross-spectral matching, Pattern Recognition 47 (12) (2014) 3750–3766.
- [22] U. Park, H.-C. Choi, A. K. Jain, S.-W. Lee, Face tracking and recognition at a distance: A coaxial and concentric ptz camera system, IEEE transactions on information forensics and security 8 (10) (2013) 1665–1677.
- [23] M.-C. Roh, H.-K. Shin, S.-W. Lee, View-independent human action recognition with volume motion template on single stereo camera, Pattern Recognition Letters 31 (7) (2010) 639–647.
- [24] P.-S. Kim, D.-G. Lee, S.-W. Lee, Discriminative context learning with gated recurrent unit for group activity recognition, Pattern Recognition 76 (2018) 149–161.
- [25] Y. Kong, Y. Jia, Y. Fu, Interactive phrases: Semantic descriptionsfor human interaction recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 36 (9) (2014) 1775–1788.
- [26] Y. S. Sefidgar, A. Vahdat, S. Se, G. Mori, Discriminative key-component models for interaction detection and recognition, Computer Vision and Image Understanding 135 (2015) 16–30.
- [27] J. Liu, B. Kuipers, S. Savarese, Recognizing human actions by attributes, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2011, pp. 3337–3344.
- [28] M. Raptis, L. Sigal, Poselet key-framing: A model for human activity recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2650–2657.
- [29] M. S. Ibrahim, S. Muralidharan, Z. Deng, A. Vahdat, G. Mori, A hierarchical deep temporal model for group activity recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 1971–1980.
- [30] X. Shu, J. Tang, G. Qi, W. Liu, J. Yang, Hierarchical long short-term concurrent memory for human interaction recognition, IEEE transactions on pattern analysis and machine intelligence (2019).
- [31] J. Tang, X. Shu, R. Yan, L. Zhang, Coherence constrained graph lstm for group activity recognition, IEEE transactions on pattern analysis and machine intelligence (2019).
- [32] X. Shu, J. Tang, G.-J. Qi, Y. Song, Z. Li, L. Zhang, Concurrence-aware long short-term sub-memories for person-person action recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017, pp. 1–8.
- [33] D.-G. Lee, S.-W. Lee, Prediction of partially observed human activity based on pre-trained deep representation, Pattern Recognition 85 (2019) 198–206.
- [34] M. Mahmood, A. Jalal, M. Sidduqi, Robust spatio-temporal features for human interaction recognition via artificial neural network, in: International Conference on Frontiers of Information Technology, IEEE, 2018, pp. 218–223.
- [35] Z. Deng, A. Vahdat, H. Hu, G. Mori, Structure inference machines: Recurrent neural networks for analyzing relations in group activity recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4772–4781.
- [36] S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Computation 9 (8) (1997) 1735–1780.
- [37] H. Yang, D. Yan, L. Zhang, D. Li, Y. Sun, S. You, S. J. Maybank, Feedback graph convolutional network for skeleton-based action recognition, arXiv preprint arXiv:2003.07564 (2020).
- [38] H.-D. Yang, S.-W. Lee, Reconstruction of 3d human body pose from stereo image sequences based on top-down learning, Pattern Recognition 40 (11) (2007) 3120–3131.
- [39] M.-C. Roh, T.-Y. Kim, J. Park, S.-W. Lee, Accurate object contour tracking based on boundary edge selection, Pattern Recognition 40 (3) (2007) 931–943.
- [40] D. C. Luvizon, D. Picard, H. Tabia, 2d/3d pose estimation and action recognition using multitask deep learning, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5137–5146.
- [41] B. Xiaohan Nie, C. Xiong, S.-C. Zhu, Joint action recognition and pose estimation from video, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1293–1301.
- [42] S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, in: Advances in Neural Information Processing Systems, 2015, pp. 91–99.
- [43] C. Szegedy, S. Ioffe, V. Vanhoucke, A. A. Alemi, Inception-v4, inception-resnet and the impact of residual connections on learning., in: AAAI, Vol. 4, 2017, p. 12.
- [44] Y. Kong, Y. Jia, Y. Fu, Learning human interaction by interactive phrases (2012) 300–313.
- [45] M. S. Ryoo, J. K. Aggarwal, UT-Interaction Dataset, ICPR contest on Semantic Description of Human Activities (SDHA), http://cvrc.ece.utexas.edu/SDHA2010/Human_Interaction.html (2010).
- [46] S. Oh, A. Hoogs, A. Perera, N. Cuntoor, C.-C. Chen, J. T. Lee, S. Mukherjee, J. Aggarwal, H. Lee, L. Davis, et al., A large-scale benchmark dataset for event recognition in surveillance video, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2011, pp. 3153–3160.
- [47] Y. Kong, Y. Fu, Close human interaction recognition using patch-aware models, IEEE Transactions on Image Processing 25 (1) (2015) 167–178.
- [48] K. N. el houda Slimani, Y. Benezeth, F. Souami, Learning bag of spatio-temporal features for human interaction recognition, in: International Conference on Machine Vision, Vol. 11433, 2020, p. 1143302.
- [49] Y. Zhu, N. M. Nayak, A. K. Roy-Chowdhury, Context-aware modeling and recognition of activities in video, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2491–2498.
- [50] X. Wang, Q. Ji, A hierarchical context model for event recognition in surveillance video, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2561–2568.
- [51] X. Wang, Q. Ji, Hierarchical context modeling for video event recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (9) (2016) 1770–1782.
- [52] M. Ajmal, F. Ahmad, M. Naseer, M. Jamjoom, Recognizing human activities from video using weakly supervised contextual features, IEEE Access 7 (2019) 98420–98435.
- [53] D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980 (2014).
-
[54]
M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado,
A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving,
M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg,
D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens,
B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan,
F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu,
X. Zheng, TensorFlow: Large-scale
machine learning on heterogeneous systems, software available from
tensorflow.org (2015).
URL https://www.tensorflow.org/ - [55] Y. Cao, D. Barrett, A. Barbu, S. Narayanaswamy, H. Yu, A. Michaux, Y. Lin, S. Dickinson, J. Mark Siskind, S. Wang, Recognize human activities from partially observed videos, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2658–2665.
- [56] Y. Kong, D. Kit, Y. Fu, A discriminative model with multiple temporal scales for action prediction, in: European Conference on Computer Vision, Springer, 2014, pp. 596–611.
- [57] T. Lan, Y. Wang, W. Yang, S. N. Robinovitch, G. Mori, Discriminative latent models for recognizing contextual group activities, IEEE Transactions on Pattern Analysis and Machine Intelligence 34 (8) (2011) 1549–1562.
- [58] J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, T. Darrell, Long-term recurrent convolutional networks for visual recognition and description, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2625–2634.
- [59] T. Lan, T.-C. Chen, S. Savarese, A hierarchical representation for future action prediction, in: European Conference on Computer Vision, Springer, 2014, pp. 689–704.