HouseX: A Fine-Grained House Music Dataset and Its Potential in the Music Industry
Abstract
Machine sound classification has been one of the fundamental tasks of music technology. A major branch of sound classification is the classification of music genres. However, though covering most genres of music, existing music genre datasets often do not contain fine-grained labels that indicate the detailed sub-genres of music. In consideration of the consistency of genres of songs in a mixtape or in a DJ (live) set, we have collected and annotated a dataset of house music that provide 4 sub-genre labels, namely future house, bass house, progressive house and melodic house. Experiments show that our annotations well exhibit the characteristics of different categories. Also, we have built baseline models that classify the sub-genre based on the mel-spectrograms of a track, achieving strongly competitive results. Besides, we have put forward a few application scenarios of our dataset and baseline model, with a simulated sci-fi tunnel as a short demo built and rendered in a 3D modeling software, with the colors of the lights automated by the output of our model.
music datasets, neural networks, genre classification, music visualization
1 Introduction
One of the fundamental tasks of music information retrieval is the classification of music. For the task of audio classification, one of the most popular methods is to classify the spectrograms or mel-spectrograms of sounds using computer vision models like convolutional neural networks (CNN) [1] or vision transformers (ViT) [2]. Jaiswal et al. [3] has proposed the CNN-based approach that significantly improved the performance of sound classification. Researchers have delicately annotated datasets like the GTZAN [4] and the FMA [5], etc. In view of the popularity of electronic dance music, we have collected a dataset that specifically features house music, which is the primary focus of production by many world-known DJ/producers. Our dataset consists of 160 labelled tracks covering 4 popular sub-genres, which are future house, bass house, progressive house and melodic house. We have also manually annotated the start and the end of the drop of each track. Besides, we have fine-tuned several CNN architectures pretrained on ImageNet [6] and trained a vanilla vision transformer, as baseline models for classification on this dataset. These models can achieve strongly competitively classification results on our test set. Finally, we have proposed two real-world scenarios that could benefit from our dataset and baseline model. The dataset along with the baseline models can be accessed via this link. For conciseness, in tables and figures, we denote future house by ”FH”, bass house by ”BH”, progressive house by ”PH” and melodic house by ”MH”. In all, our main contributions are:
-
•
To the best of our knowledge, we have proposed the first house music dataset with sub-genre labels and drop annotations.
-
•
We have provided a bunch of fine-tuned models on the task of sub-genre classification on this dataset.
-
•
We have proposed a few real-world scenarios where our dataset and models could be applied. With a demo project presented, we have brought forward a new paradigm for automated music visualization.
2 Related Works
2.1 Music Genre Datasets
In the past decades, previous researchers annotated a few music genre datasets. Among them, one of the most widely used is called GTZAN [4]. Its audio data includes 10 genres, with 100 audio files each genre, all having a duration of 30 seconds. Besides, they have also provided the converted mel-spectrograms, together with the mean and variance of multiple acoustic features, including the spectral centroid and the root mean square (RMS). Defferrard et al. have built the FMA dataset [5] which includes 8 genres and is also annotated in the style of GTZAN. Other works like the MedleyDB dataset [7] contains classical, rock, world/folk, fusion, jazz, pop, musical Theatre and rap songs. Besides genre labels, it also provides processed stems for its 194 tracks.
2.2 Limitations
However, most music genre datasets, including the ones mentioned in the last paragraph, are annotated with general genres like pop, country, rock, etc. One shortcoming is that models trained on these datasets could hardly distinguish the differences among songs within a general genre. In one mixtape or one live set, the songs usually belong to one or few general genres. For example, all the tracks selected in our dataset would be classified as ”Electronic” in datasets like the FMA dataset [5]. Therefore, using models trained on these datasets, the retrievable information would be extremely confined. In view of such limitation, our work is devoted to building datasets that feature electronic music belonging to the same general genre but differ in their sub-genres.
3 Approaches
In this section, we discuss how we process the data, and the classification task in a rigorous, mathematical format. Also, we would present our deep learning approach, including the pipeline of setting up baseline models.
3.1 Data Annotation
After our evaluation on its wide usage on music festivals, we have chosen house music as the general genre of our dataset, naming it ”HouseX”. The dataset includes 4 sub-genres of house music, with 40 tracks each. These 160 tracks are all produced by the most popular DJ/producers around the world, including [8, 9].
| Number of Tracks (train) | 128 |
| Number of Tracks (val) | 20 |
| Number of Tracks (test) | 12 |
| Number of Mel-spectrograms (train) | 13932 |
| Number of Mel-spectrograms (val) | 2184 |
| Number of Mel-spectrograms (test) | 1364 |
| Number of Mel-spectrograms (train, drops only) | 2183 |
| Number of Mel-spectrograms (val, drops only) | 339 |
| Number of Mel-spectrograms (test, drops only) | 204 |
| BPM Range | 122-130 |
| Total Length (HH:MM:SS) | 09:07:54 |

Though having similar or even identical tempos, these four sub-genres of house music possess substantially different characteristics. Future house tracks include plenty of electronic sounds, and their groove can be very bouncy (note that a major sub-branch of future house is future bounce). Bass house music is also filled with synthesized electronic elements. However, the sounds in bass house are generally dirtier and more distorted. These tracks could be so aggressive that one can hardly discern a clear melody line. Though sometimes bass house could sound similar to future house, future house tracks usually have a bright lead sound while bass house would possess mush more richness and saturation on the low end of the frequency spectrum. Progressive house is known to be uplifting and emotional. Beside the widely used supersaw lead sound, many progressive house producers would use real instruments like the piano, the guitar and strings to make the sounds more natural and organic. Melodic house tracks are characterized by the use of pluck sounds and pitch shifting techniques. These elements produce a happy and rhythmical atmosphere.
We have counted a few statistics of our dataset. The tempo of these tracks range from BPM to BPM, and most of them equal . The total duration of them is around hours and minutes. Most house tracks have a time signature of /. Therefore, suppose a track has a tempo of bpm, then one bar in the track has a duration of seconds. We set the length of the sound clip for each mel-spectrogram as seconds, which are is approximately bars for every track. In total, we derive around mel-spectrograms for classification. Some detailed statistics are presented in Tab. 1.
Additionally, we have annotated the timestamps that indicate the start and the end of the drop of each track, using Label Studio [10]. Since the drop is the climax of a track, with respect to energy and emotion, it is the section where the characteristics of its sub-genre are best exhibited. For example, the metallic lead sound in the drop and heavily distorted bass would characterize a bass house track, while the supersaw lead layered with strings and piano would highlight an emotional melody line of a progressive house track. Therefore, we specifically annotated the start and the end of the drop of each track in our dataset, as shown in Fig. 1. These drops would form a subset of the original dataset. In order to make this subset balanced, we only choose one drop with a length of bars, from each track. Normally, a track includes two drops. We choose the first one unless it is not long enough. Sometimes, especially for emotional progressive house tracks, the first drop only contains -bars while the length of the second one is doubled. In these cases, we annotate the start and the end of the second drop. Though fairly smaller than the whole set, this subset that only contains drops still yields a considerable amount of mel-spectrograms, as listed in Tab. 1. Another thing to note is that the split of the whole set should be done before the conversion from audio to mel-spectrograms. That is to say, we should split the set of tracks, rather than the set of pictures, into parts, for training, validation and testing respectively. The reason is that electronic music usually contains many loops, and if we split the set of pictures, for a mel-spectrogram in the test set, similar mel-spectrograms would almost surely appear in the training set, which makes the validation and testing process meaningless.









3.2 Task Definition
Rigorously, the classification task is defined as follows. A track of house music is given as a wave file and the goal is to assign a proper sub-genre to slices of the track, from the sub-genres mentioned in the data collection part. Since our wave files are stereo, for each track, we get an array of shape where is the total number of samples, and the sample rate of the waveform (Hz). To get reasonable amount of mel-spectrograms, we set the number of bars per slice as . Then, since all tracks in our dataset have a tempo of BPM (or close to BPM) and a time signature of , we have
, as the number of samples for each slice. Then, without overlapping, we cut the track into slices, each as an array with shape . Using functions implemented in Librosa [11], we convert these Numpy arrays into mel-spectrograms, each with a shape of
, where and as default. After saving these mel-spectrograms rendered by the function of Librosa, we can load them as JPEG files, transform them into PyTorch tensors [12] and proceed with the standard image classification workflow. A few saved mel-spectrograms are shown in Fig. 2 as examples.
| Model | Val | Test | ||||||||||
| Acc.a (%) | F1-score | Acc.a (%) | F1-score | |||||||||
| FH | BH | PH | MH | Weighted Avg | FH | BH | PH | MH | Weighted Avg | |||
| MobileNetV3 | 57.46 | 0.4 | 0.67 | 0.55 | 0.64 | 0.57 | 61.95 | 0.37 | 0.71 | 0.62 | 0.68 | 0.6 |
| ResNet18b | 67.4 | 0.57 | 0.76 | 0.67 | 0.69 | 0.68 | 75.29 | 0.58 | 0.79 | 0.83 | 0.78 | 0.75 |
| VGG16 | 71.79 | 0.64 | 0.74 | 0.74 | 0.75 | 0.72 | 71.48 | 0.47 | 0.79 | 0.79 | 0.75 | 0.71 |
| DenseNet121 | 60.16 | 0.51 | 0.71 | 0.53 | 0.64 | 0.6 | 66.13 | 0.51 | 0.72 | 0.67 | 0.69 | 0.65 |
| ShuffleNetV2 | 60.62 | 0.52 | 0.63 | 0.63 | 0.64 | 0.61 | 68.55 | 0.49 | 0.79 | 0.75 | 0.69 | 0.69 |
| (Vanilla) ViT | 53.25 | 0.4 | 0.56 | 0.5 | 0.63 | 0.53 | 59.02 | 0.45 | 0.71 | 0.53 | 0.63 | 0.58 |
| Model | Val (Drops Only) | Test (Drops Only) | ||||||||||
| Acc.a (%) | F1-score | Acc.a (%) | F1-score | |||||||||
| FH | BH | PH | MH | Weighted Avg | FH | BH | PH | MH | Weighted Avg | |||
| MobileNetV3 | 66.96 | 0.61 | 0.77 | 0.64 | 0.63 | 0.66 | 68.63 | 0.59 | 0.73 | 0.78 | 0.62 | 0.68 |
| ResNet18b | 74.34 | 0.68 | 0.76 | 0.85 | 0.68 | 0.74 | 80.39 | 0.7 | 0.82 | 0.93 | 0.74 | 0.8 |
| VGG16 | 76.99 | 0.74 | 0.8 | 0.77 | 0.77 | 0.77 | 81.37 | 0.66 | 0.83 | 0.92 | 0.83 | 0.81 |
| DenseNet121 | 69.62 | 0.66 | 0.75 | 0.72 | 0.65 | 0.7 | 76.47 | 0.72 | 0.8 | 0.8 | 0.74 | 0.76 |
| ShuffleNetV2 | 70.5 | 0.64 | 0.76 | 0.78 | 0.65 | 0.71 | 74.51 | 0.62 | 0.77 | 0.87 | 0.71 | 0.75 |
| (Vanilla) ViT | 54.57 | 0.35 | 0.79 | 0.42 | 0.54 | 0.52 | 57.84 | 0.58 | 0.61 | 0.72 | 0.32 | 0.56 |
-
a
The accuracy scores are calculated on the entire validation/test set, over all categories.
-
b
In the demo of the first proposed application, we choose ResNet18 [13] due to its high accuracy and relatively small number of parameters, which leads to comparatively fast inference speed.
3.3 Pipeline
As shown in the Fig. 3, the pipeline consists of two major components. The first step is the conversion from sliced sound waveforms to mel-spectrograms, and the second procedure is to feed mel-spectrograms through a neural network to get the output scores for these mel-spectrograms. Each output score is a vector.
In the training phase, we iterate through the training set to minimize the negative log likelihood loss between the output logits and the label tensor. Denoting as the dataset and as the set of labels, mathematically, we need to minimize the objective
, where represents the parameters of the model, each is a image-label pair, and are the predicted probabilities and is the indicator function.
In the inference phase, we apply to the logits to get the sub-genre that is most probable for a slice of a track. Furthermore, if we need to predict the sub-genre of the entire track, the simplest method is to add a voting classifier on top of the predictions of slices. Other approaches include applying a weighted sum over the logits of slices of one track. The weights can even be set as trainable parameters, since some parts of a track like the intro can sometimes be less significant, while other parts like the drop would be crucial.





3.4 Neural Architecture
We have tried several architectures, including 3 traditional convolutional neural networks [14, 13, 15], 2 lightweight convolutional neural networks [16, 17] and a vanilla vision transformer [2] as backbones for the classification task. For these 5 CNN architectures, we put them before one dropout layer [18] and one linear layer from to . The input dimension is since the ImageNet dataset [6] contains categories. Besides, we have also train a -layer vanilla vision transformer from scratch, which is built upon the attention mechanism instead of convolutional kernels. The details of our implementation can be viewed by the link provided in the introduction.
4 Experiments
We have conducted experiments using different types of neural networks as our backbone. As shown in Fig. 4 and 5, all these neural architectures achieve competitive results for both the whole set and the drops-only subset.
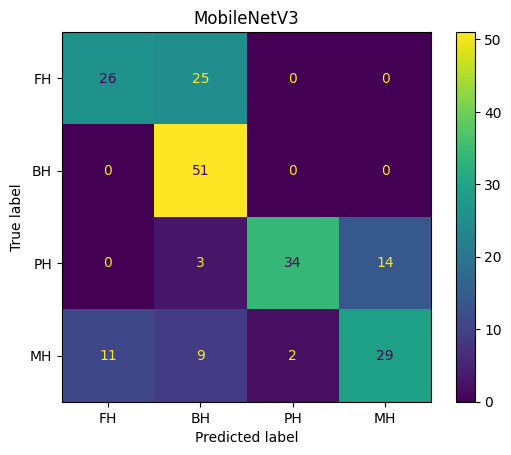
From Fig. 6, the first remark is that, it is challenging to distinguish future house tracks from melodic house tracks. Fortunately, even for human listeners, this dilemma can be tricky since some future house music possess a happy chord progression like those used in melody house tracks, while melody house tracks often have a synthesized lead which is bouncy and futuristic. Indeed, our classifiers have limited predictive power for these two sub-genres, but this is not necessarily bad. On the contrary, it is consistent with the fact that a single electronic track sometimes exhibit multiple styles.
Secondly, deeper and larger neural networks generally perform better than lightweight models. As listed in Tab. 2, traditional deep architectures in our experiments, like ResNet [13] and VGG [14], show better performance. This observation corresponds to our expectation that the timbre of sounds is a relatively high-level feature, which, on the spectrograms, should also need functions with stronger expressiveness to represent. For neural networks, deep architectures usually outperform wide ones, as shown by prior work [19, 20].
Finally, comparing Fig. 6 and 7, we could verify that the drops-only subset indeed shows significance with respect to the characteristics of each sub-genre. Fig. 7 shows that future house (FH) and bass house (BH) could be almost perfectly distinguished from progressive house (PH) and melodic house (MH), if we only focus on the drops of tracks. Such results are in line with the intrinsic features, or specifically, the use of sounds of these four sub-genres. A great common ground of future house and bass house is the massive use of synthesizer that makes a track sounds extremely electronic. On the contrary, acoustic (real) instruments are widely used in progressive house and melodic house tracks. For example, orchestral instruments like the violin are frequently used to create emotional atmosphere, while guitar strumming and piano chords often support the vocal, to give more emotions as well. Therefore, if we group future house and bass house as the ”cool” category, and, group progressive house and melodic house as the ”emotional” category, then models like VGG [14] could achieve around accuracy on the classification of these two general categories. The classifiers perform better on the drops-only subset since this subset is ”cleaner” in short. Beside the drop, other sections such as the intro of a track could exhibit variant peculiarities. For example, in the intro, future house tracks could include some bouncy piano chords, while melodic house tracks might contain some synthesized plucky sounds.
5 Application Scenarios
As mentioned in the introduction part, our work is specifically targeting at real-world application scenarios. In this section, we propose two cases where our dataset and models can be applied.
5.1 Automation in Music Visualization
A straightforward application is the automation of certain properties, such as the colors of lights, in the visualization of a mixtape. Normally, we want the real-time colors of the lights to reflect the atmosphere of the currently playing segment of the mixtape. Therefore, visual effects engineers would manually control the colors of lights throughout the whole mixtape. Using our model, the control of colors can be automated, which would bring more flexibility. For example, usually a DJ would fix the track list to be played before a show begins, to make sure the music matches up with the visual effects. Using our approach, the DJ performing onstage would be given more freedom to decide what to play next according to the reaction of the crowds, rather than the predetermined track list. We believe that such AI-assisted visualizer would bring much convenience for artists as a new paradigm.
As a result of our survey on the correspondence between music genres and colors, we have pre-defined a mapping from sub-genres of house music, to triple tuples of colors, which could be modified in practice. Note that the following mapping is not completely the same as the one determined by choosing the top- colors for each sub-genre according to the survey. We have made slight modification on the colors of progressive house and future house to make the visualization more contrastive.
-
•
Future House: blue, red, purple.
-
•
Bass House: black, white, purple.
-
•
Progressive House: orange, yellow, purple.
-
•
Melodic House: green, blue, yellow.
Then, after building a basic sci-fi environment in Blender [21], we have rendered a demo for house music mixtape visualization, which can be viewed via this link. Note that this small set (mixtape) contains songs, mixed together in FL Studio 20 [22]. These songs are future house, bass house, progressive house and melodic house in chronological order. The screenshots of the rendered results are shown in Fig. 8.







5.2 Music Recommendation System
Besides, this model can be integrated in fine-grained music recommendation system. Currently, many popular music streaming services have deployed recommendation systems for users to easily look for music that matches their appetite. With our approaches that extract information on the sub-genre level, the accuracy, or precisely, the level of customization of recommendation service could be brought to the next level.
6 Future Works
To sum up, we have annotated a house music dataset with sub-genre labels and built a baseline model for the classification task. Additionally, we have put forward a few real-world application scenarios where our work would be of great advantage. As shown in our demo videos, our approach could be considered as a new schema of music visualization. Still, there are several aspects that can be continued in the future.
Firstly, from the PCA analysis shown in Fig. 9, it seems that it is more challenging to distinguish future house from bass house, rather than melodic house. This does not perfectly match with our observation from the confusion matrices. Further investigation should be done to address this issue.
Secondly, there are other popular sub-genres of house music, like tropical house, to be included in our dataset. The reason why we have temporarily excluded it is that tropical house appear less frequently in music festivals compared to future house, progressive house, etc. Though less intense, tropical house tracks are so radio-friendly that they are also welcome by massive listeners. In view of such popularity, we might include dozens of tropical house tracks in our future work.
Lastly, many other visual effects could also be automated by the information outputted by the model, such as the strength of the displacement of some geometry objects in a 3D environment. Hopefully, we would collaborate with 3D modeling experts to create visual effects that are more impactful and immersive.
Acknowledgment
We thank members from New York University who have filled the questionnaire of the correspondence between colors and the music sub-genres, for our choices of colors in our demo. Besides, the Blender environment used in the demo is inspired by the work of Ducky 3D[23]. Also, we thank Wang et al. for assistance on the use of the high performance computing cluster (NYU HPC).
References
- [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems (F. Pereira, C. Burges, L. Bottou, and K. Weinberger, eds.), vol. 25, Curran Associates, Inc., 2012.
- [2] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” CoRR, vol. abs/2010.11929, 2020.
- [3] K. Jaiswal and D. Kalpeshbhai Patel, “Sound classification using convolutional neural networks,” in 2018 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM), pp. 81–84, 2018.
- [4] A. Olteanu, “Gtzan dataset - music genre classification,” Mar 2020.
- [5] M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “FMA: A dataset for music analysis,” in 18th International Society for Music Information Retrieval Conference (ISMIR), 2017.
- [6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009.
- [7] R. Bittner, J. Salamon, M. Tierney, M. Mauch, C. Cannam, and J. Bello, “MedleyDB: A multitrack dataset for annotation-intensive mir research,” in 15th International Society for Music Information Retrieval Conference (ISMIR 2014), 10 2014.
- [8] M. G. Garritsen, Martin Garrix Official Website. STMPD RCRDS, Amsterdam, Netherlands, 2022.
- [9] T. Burkovskis, Tobu Official Website. NoCopyrightSounds, Latvia, 2022.
- [10] M. Tkachenko, M. Malyuk, A. Holmanyuk, and N. Liubimov, “Label Studio: Data labeling software,” 2020-2022. Open source software available from https://github.com/heartexlabs/label-studio.
- [11] B. McFee, A. Metsai, M. McVicar, S. Balke, C. Thomé, C. Raffel, F. Zalkow, A. Malek, Dana, K. Lee, O. Nieto, D. Ellis, J. Mason, E. Battenberg, S. Seyfarth, R. Yamamoto, viktorandreevichmorozov, K. Choi, J. Moore, R. Bittner, S. Hidaka, Z. Wei, nullmightybofo, A. Weiss, D. Hereñú, F.-R. Stöter, P. Friesch, M. Vollrath, T. Kim, and Thassilo, “librosa/librosa: 0.9.1,” Feb. 2022.
- [12] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32, pp. 8024–8035, Curran Associates, Inc., 2019.
- [13] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” CoRR, vol. abs/1512.03385, 2015.
- [14] S. Liu and W. Deng, “Very deep convolutional neural network based image classification using small training sample size,” in 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), pp. 730–734, 2015.
- [15] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” Jan 2018.
- [16] X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6848–6856, 2018.
- [17] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” CoRR, vol. abs/1704.04861, 2017.
- [18] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,” Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014.
- [19] Z. Lu, H. Pu, F. Wang, Z. Hu, and L. Wang, “The expressive power of neural networks: A view from the width,” CoRR, vol. abs/1709.02540, 2017.
- [20] I. Safran and O. Shamir, “Depth separation in relu networks for approximating smooth non-linear functions,” CoRR, vol. abs/1610.09887, 2016.
- [21] B. O. Community, Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2018.
- [22] F. S. Community, FL Studio 20. Image-Line Software, Ghent, Belgium, 2022.
- [23] “Simple eevee environment for beginners! (blender 2.8) - youtube,” Mar 2019.