Homophone Reveals the Truth: A Reality Check for Speech2Vec
Abstract
Generating spoken word embeddings that possess semantic information is a fascinating topic. Compared with text-based embeddings, they cover both phonetic and semantic characteristics, which can provide richer information and are potentially helpful for improving ASR and speech translation systems. In this paper, we review and examine the authenticity of a seminal work in this field: Speech2Vec. First, a homophone-based inspection method is proposed to check the speech embeddings released by the author of Speech2Vec. There is no indication that these embeddings are generated by the Speech2Vec model. Moreover, through further analysis of the vocabulary composition, we suspect that a text-based model fabricates these embeddings. Finally, we reproduce the Speech2Vec model, referring to the official code and optimal settings in the original paper. Experiments showed that this model failed to learn effective semantic embeddings. In word similarity benchmarks, it gets a correlation score of 0.08 in MEN and 0.15 in WS-353-SIM tests, which is over 0.5 lower than those described in the original paper. Our data and code are available111https://github.com/my-yy/s2v_rc.
1 Introduction
Word embeddings are fixed-length representations of words, which carry syntactic and semantic information and become the building block in natural language processing tasks, such as named entity recognition [24] and question answering [23]. Speech, as another carrier of information, also reflects semantic meaning, which implies the possibility of directly using it to learn semantic word representations. To this end, some attempts have been made to generate semantic speech embeddings [7, 18, 5, 6]. Compared with learning text-based embeddings, this is a much more difficult task. Because there are intrinsic interferences between phonetics and semantics [5]. For example, the words ‘ate’ and ‘eight’ have almost the same pronunciation but are semantically different. If the model can not distinguish these sound-alike inputs, it is impossible to obtain effective semantic representations.

In this paper, we focus on Speech2Vec [6, 7], one of the field’s earliest and most influential studies. It can be viewed as a speech version of Word2Vec [17], which leverages the skip-gram and CBOW strategy to learn semantic speech embeddings. Despite being an imitator of Word2Vec, it seems to have magically resolved the mentioned phonetic-semantic interference and has been reported to exceed the Word2Vec on 13 word similarity benchmarks [10]. This phenomenon aroused our interest in exploring the validity of this study. Specifically, we analyze the authenticity of Speech2Vec from two perspectives of the official-released speech embeddings and our reproduction results. The conclusions can be summarized as follows:
1) The official speech embeddings fail to reflect speech characteristics, implying that they are not generated by the Speech2Vec model.
2) Analysis of the vocabulary composition reveals that these released embeddings may come from a text-based model.
3) Our reproduction results show that the Speech2Vec model failed to generate valid semantic speech embeddings. Even after 500 epochs of training, its performance is still negligible in most benchmark metrics.
2 Recap Speech2Vec
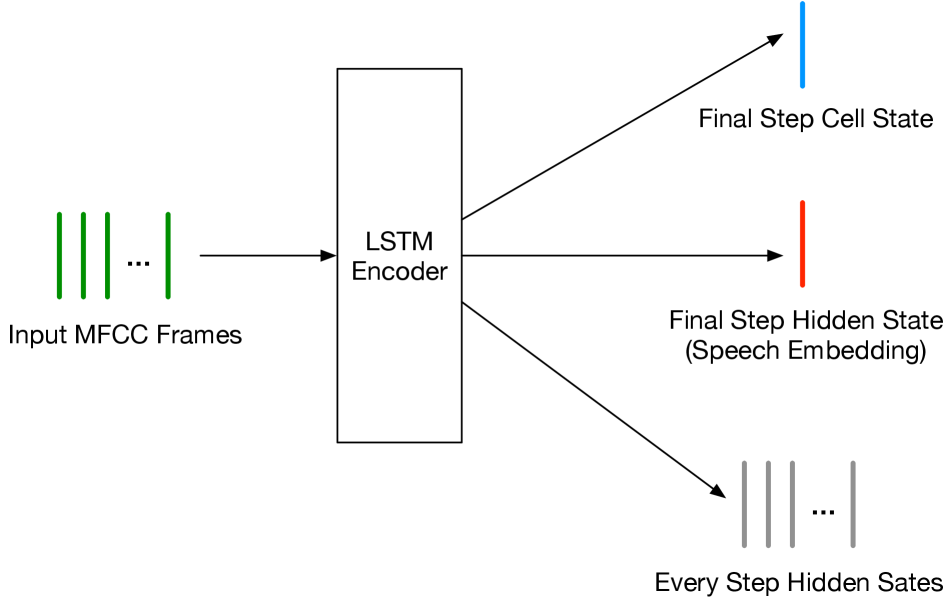
Speech2Vec can be regarded as a speech version of Word2Vec, which relies on the skip-gram or CBOW strategy to learn semantic speech embeddings. Herein, we focused on the skip-gram style of Speech2Vec, which is reported to have better performance. Fig. 1 shows its structure.
When training, the input speech sentence is segmented into spoken word sequences in advance. Then the encoder network converts the current spoken word into an embedding vector. And this vector is used for decoding context words. In the corpus, the audio segments corresponding to the same text word appear multiple times (with different speakers, environment, emotions, or talking speed). To obtain a deterministic word representation, the average of all embeddings corresponding to the same text word is taken as the final embedding.
The official code of Speech2Vec is not publicly available, but the pre-trained speech embeddings are released on GitHub 222https://github.com/iamyuanchung/speech2vec-pretrained-vectors. These embeddings are described from a skip-gram style Speech2Vec model trained on 500 hours of LibriSpeech [19] dataset:
… In this repository, we release the speech embeddings of different dimensionalities learned by Speech2Vec using skip-grams as the training methodology. The model is trained on a corpus consisting of about 500 hours of speech from LibriSpeech (the clean-360 + clean-100 subsets) …
We further provide a fork to this repository 333https://github.com/my-yy/speech2vec-pretrained-vectors.
3 Reality Check
This section aims to check the authenticity of the released speech embeddings. We analyze them from two perspectives: phonetic characteristics and vocabulary composition.
3.1 Homophone Inspection
Homophones refer to words that have the same pronunciation but reflect different meanings (e.g., ‘ate, eight’,‘ dear, deer’, and ‘whine, wine’). Since these spoken words are consistent in pronunciation, in a speech recognition system, the speech context and language model [3] are usually required to distinguish them. For the skip-gram style Speech2Vec, its input is a single spoken word that does not contain context information. Therefore, this model should not be able to distinguish these homophones effectively. And the embedding similarity of the homophone pair should have a higher value. We used 307 homophone pairs444 Sourced from: http://www.singularis.ltd.uk/bifroest/misc/homophones-list.html and calculated their similarities. The results are shown in Tab. 1.
| Embedding | Dim | Pair Similarity | |
|---|---|---|---|
| Homophone | Random | ||
| Official | 50 | 0.33±0.15 | 0.39±0.17 |
| 100 | 0.28±0.14 | 0.35±0.15 | |
| 200 | 0.23±0.12 | 0.31±0.14 | |
| 300 | 0.21±0.11 | 0.29±0.14 | |
| Ours | 50 | 0.95±0.05 | 0.77±0.10 |
As we can see, for the official embeddings, their homophone similarities are counterintuitively lower than the random results. It suggested that the official model may not be affected by phonetic similarity and can successfully distinguish these highly similar inputs. However, our reproduced model did not ‘show the magic’. Although it had a 0.77 similarity for random pairs (which implies the embedding space is ill-distributed), it still obtained a higher similarity of 0.95 for the homophone pairs.
| Homophone Pair | Similarity | |||
| Raw | Official | Ours | ||
| ate | eight | 1.00 | 0.22 | 1.00 |
| hail | hale | 0.99 | 0.34 | 0.97 |
| know | no | 1.00 | 0.63 | 0.97 |
| made | maid | 1.00 | 0.25 | 0.98 |
| meat | meet | 1.00 | 0.13 | 0.99 |
| peace | piece | 1.00 | 0.15 | 0.99 |
| sea | see | 1.00 | 0.31 | 0.98 |
| steal | steel | 1.00 | 0.19 | 0.99 |
| tale | tail | 1.00 | 0.23 | 1.00 |
| whine | wine | 1.00 | 0.13 | 0.97 |
| MEAN | 0.99 | 0.32 | 0.95 | |
| Word | Official | Ours | ||||||
|---|---|---|---|---|---|---|---|---|
| K Nearest Neighbor | HR | K Nearest Neighbor | HR | |||||
| ate | eating | drank | eat | 25,099 | eight | agent | aid | 1 |
| hail | thunder | blast | thunders | 15,253 | hell | handle | held | 9 |
| know | tell | think | why | 2,305 | narrow | natural | no | 3 |
| made | making | gave | make | 35,582 | me | mid | necessity | 15 |
| meat | roasting | roasted | venison | 33,108 | meet | mate | mute | 1 |
| peace | tranquility | liberty | deliverer | 33,609 | plates | place | patience | 7 |
| sea | ocean | shore | waters | 18,610 | city | safety | succeed | 100 |
| steal | flay | stealing | kill | 29,506 | still | steel | special | 2 |
| tale | story | adventure | tales | 28,617 | tail | title | tackle | 1 |
| whine | snarling | growls | growl | 34,575 | watering | washing | wide | 4 |
| MEAN | 25,626 | 14 | ||||||
Tab. 2 further gives some pair examples. In this table, we introduce a ‘Raw’ metric to measure the similarity of audio input. This metric is the cosine similarity of extracted features from a pre-trained wav2vec [21] model.
It is clear to see that most homophone pairs have a Raw score close to 1.0, which means there is a high degree of similarity between these homophone words. And the wav2vec model failed to distinguish them. In addition, our reproduced model has similar behavior, which gets an average similarity of 0.95. However, the official embeddings get relatively lower similarities. Taking the ‘ate, eight’ pair as an example, the similarities of Raw and ours are both 1.00, while the official gives a 0.22 similarity score.
The k-nearest neighbor results (Tab. 3) further reveals the anomaly of the official embedding. Although the official’s nearest neighbors reflect similar semantics, there are considerable differences in pronunciation. For example, the nearest neighbors of ‘hail’ are ‘thunder, blast, thunders’, while its homophone counterpart (‘hale’) is ranked as high as 15,253. In contrast, the homophone rank in our reproduction is 9.
The above anomaly behavior of the official embeddings can be explained by a bold hypothesis: the official embeddings come from a text-based model. As in a text-based model (like Word2Vec), words of different spellings are assigned with different coding values. In the learning process, the model does not rely on pronunciation to identify words; therefore, it will not be disturbed by them. Moreover, because homophone pairs have different meanings, their similarities may be smaller than the random pairs. This explains why the official results have smaller similarities than the random in Tab. 1.
3.2 Vocabulary Analysis
3.2.1 Checking the Released Vocabulary
| Corpus Division | Hours | Speakers | |||
|---|---|---|---|---|---|
| Clean | train-clean-100 | 100.6 | 475 | 251 | 1,252 |
| train-clean-360 | 363.6 | 921 | |||
| dev-clean | 5.4 | 40 | |||
| test-clean | 5.4 | 40 | |||
| Other | train-other-500 | 496.7 | 507 | 1,166 | 1,232 |
| dev-other | 5.3 | 33 | |||
| test-other | 5.1 | 33 | |||
The Seepch2Vec paper claimed that the training is based on 500 hours of LibriSpeech [19], which contains 1,252 speakers. We refer to this dataset as Libri-Clean. Its statistics are shown in Tab. 4. We counted distinct words in Libri-Clean’s transcripts and compared them with the official. The results are shown in Tab. 5.
| Official | Libri-Clean | Libri-All | ||
|---|---|---|---|---|
| - | count5 | count5 | ||
| Vocab | 37,622 | 66,721 | 27,454 | 37,622 |
| Missing | - | 1,685 | 10,168 | 0 |
We found that 1.6k official words are not in the Libri-Clean. If we only consider frequent words of occurrence count 5, this number rises to 10k. However, if we use the entire LibriSpeech corpus and filter out infrequent words, the vocabulary composition is exactly the same as the official. This proves that the released embeddings are derived from all LibriSpeech corpus, not the claimed ‘500 hours’ data.
In addition, we believe that these embeddings are generated by a text-based model, which directly uses text transcripts for training. Because the LibriSpeech dataset needs to be pre-processed for training, each speech sentence should be aligned with the transcript to locate word boundaries. However, this alignment process is not ideal, which may cause data loss.
In our analysis, we used the alignment results based on the widely used Montreal Forced Aligner [16] 555https://github.com/CorentinJ/librispeech-alignments. It aligned the entire corpus of 292,367 speech sentences and encountered 127 failures (0.04% fail rate). After removing these unaligned speeches, the corpus changes, which causes additional 17 missing words in the vocabulary. Therefore, if the authors of Speech2Vec do not realize an ideal alignment, their vocab size will not equal 37,622 exactly. Otherwise, their embeddings come from a text-based model.
| Benchmark | Not Found Pairs | |
|---|---|---|
| Paper Data | Libri-Clean | |
| MEN [4] | 122 | 231 |
| MTurk-287 [20] | 13 | 29 |
| MTurk-771 [12] | 22 | 43 |
| Rare-Word [15] | 783 | 1027 |
| SimLex-999 [13] | 0 | 11 |
| SimVerb-3500 [11] | 126 | 118 |
| Verb-143 [2] | 0 | 5 |
| WS-353 [26] | 21 | 34 |
| WS-353-REL [1] | 12 | 24 |
| WS-353-SIM [1] | 7 | 16 |
| YP-130 [26] | 0 | 9 |
3.2.2 Checking The Paper Data
Although the vocabulary size is not mentioned in the paper of Speech2Vec, we can still find some clues from the word similarity benchmark results. In the original paper, these benchmarks are used to evaluate the semantic information carried by embeddings. Each benchmark contains a series of predefined word pairs with the corresponding oracle correlation. In an early version of Speech2vec [6], the author reported the ‘not found’ pairs in these benchmarks (Tab. 6).
If we use all the 66,721 words in Libri-Clean to construct the vocabulary, there are still more not found pairs in these tests (except for SimVerb-3500). For example, the original paper reported 122 not found pairs in the MEN test, but we found 231. This illustrates that the authors of Speech2Vec used a larger corpus other than the claimed 500h Libri-Clean.
4 Our Reproduction
4.1 Reproduction Details
4.1.1 Code Implementation
Our reproduction is based on the incomplete code provided by the author of Speech2Vec. This code covers the model implementation and training logic while lacking the data pre-processing. We complement the missing parts and train the Speech2Vec, referring to the optimal setting in the original paper. Specifically, the embedding dimension is set as 50. The window size is taken as 3. The encoder is a single-layer bidirectional LSTM. And the decoder is a single-layer unidirectional LSTM. During the decoding process, the attention mechanism [14] is used to reference the encoder’s outputs (Fig. 5 in the appendix gives a detailed overview of its structure).
4.1.2 Training Details
In accordance with Speech2Vec’s paper, the Libri-Clean dataset is used for training. Each speech sentence is segmented into spoken words in advance. Then we filter out the low-frequency words that appear less than four times and finally get a vocabulary of size 30,788. For each spoken word, we convert it into 13-dim MFCC frames.
During the mini-batch construction, we set batch size as 4096 and trained the model for 500 epochs with SGD optimizers of 0.001 learning rate. This training process took 8.4 days on an AMD 3900XT + RTX3090 device. The output models of every epoch are saved, and the 500th epoch’s model is used for evaluation.


4.2 Results & Analysis
Same with the official, we tested our reproduced model on 13 similarity benchmarks [10]. The evaluation score is Spearman’s rank correlation coefficient . It has a range of [-1,1], and a larger value represents a better result. The results are shown in Fig. 2.
Obviously, the reproduced model gives trivial results on these benchmarks. Compared with the random initialization, the 500-epoch model only has minor improvements or even decreases in indicators of SimLex-999 and SimVerb-3500. Moreover, compared with the claimed paper data, there is a substantial performance drop, even over 0.5 in some metrics (MC-30, MEN, RG-65, WS-353-SIM).
We further depicted the training process in Fig. 3. With the loss decreasing, most indicators showed a rising trend. But the increasing speed is relatively slow and is finally limited to a small range (e.g., 00.022 for MTurk-287). More training epochs may provide better results on these metrics, but it should be much larger than the claimed ‘500 epochs’. Moreover, two indicators seem to have passed their peak period, with performance turning from rising to falling (WS-353-REL and MEN). However, their peak performance is still relatively lower than the original paper. There are two indicators whose performance is consistently declining, which means that the required semantics have not been learned successfully (SimLex-999 and SimVerb-3500).
As mentioned in Sec. 2, each text word corresponds to multiple speech segments. In Fig. 4, we visualize the embedding distribution of specific words. Specifically, the multi-dimensional scaling (MDS) [25] is used for visualization. Compared with the popular T-SNE, the MDS preserves distance and global structure.
As we can see, the homophone words are mixed, while words with different pronunciations tend to be separated. This result confirms that Speech2Vec’s encoder can not successfully distinguish homophones. Moreover, we noticed some mixed points for the ‘need-thus’ pair. This shows that the model did not have a good discernibility even for not sound-alike pairs, which may be caused by the interference between phonetics and semantics.




5 Related Works
5.1 Works on Learning Semantic Speech Embeddings
Five years since the Speech2Vec was proposed, there is rarely work in the field of learning semantic speech embeddings. The Speech2Vec has received 158 citations so far, but no article has directly compared with it, and no subsequent work has proved its validity.
5.1.1 Chen et al.’s Work
Chen et al. [5] pointed out that when learning semantic speech embeddings, the phonetics and semantics inevitably disturb each other. Therefore, they designed a two-stage learning scheme to reduce the learning difficulty. In the first stage, an encoder-decoder structure generates phonetic embeddings in which the speaker characteristics are disentangled. In the second stage, these embeddings possess semantic meaning through a context prediction task. Experiments have verified their embeddings’ phonetic and semantic characteristics. However, this work is not compared with Speech2Vec on the similarity benchmarks.
5.1.2 CAWE
CAWE [18] is an encoder-decoder-based speech recognition model, which relies on an attention mechanism to automatically segment speech sentences into spoken words and generate speech embeddings. This model is tested on 16 sentence evaluation tasks and shows competitive results to Word2Vec. Compared with skip-gram style Speech2Vec, the CAWE can leverage the context information. Thus their effectiveness can not laterally prove Speech2Vec’s validity. Moreover, we have not found any successful third-party replications of CAWE.
5.1.3 Audio2Vec
Audio2Vec [22] is a CNN-based model which uses skip-gram, CBOW, and temporal-gap strategies to generate fixed-length audio representations. Although it has a similar training style to Speech2Vec, the goal of Audio2Vec is to produce general-purpose audio representations. In the training process, the speech sentence is segmented into fixed-length slices without reference to word boundaries. Thus this model was not tested on the word similarity benchmarks and not compared with Speech2Vec.
5.2 Works Directly Based on Speech2Vec Embedding
Ideally, if the experimental data is questionable, the conclusion’s validity cannot be guaranteed. We note that there are some works [8, 9, 27] directly based on the embeddings of Speech2Vec. Among them, two works come from the authors of Speech2vec [8, 9], which align the speech space and text space to realize cross-language speech-to-text translation.
Yi et al. [27] reported that they successfully improved punctuation prediction performance by involving the released Speech2Vec embeddings in their input. But they did not explore how these speech embeddings work. We think their results are authentic but unintentionally provide a wrong interpretation. As we have analyzed, these Speech2Vec embeddings cannot reflect phonetic information. Thus their improvements come from involving more input features. And it has nothing to do with whether these features come from a text-based or speech-based model. Therefore, we believe that the above works cannot provide evidence for the authenticity of Speech2Vec.
5.3 Replication Attempts by Other Researchers
We investigated the replication attempts by other researchers, including Jang’s666https://github.com/yjang43/Speech2Vec and Wang’s777https://github.com/ZhanpengWang96/pytorch-speech2vec. Like us, they fail to achieve the results claimed in Speech2Vec’s paper. Jang reported that the model gets trivial results. As for Wang’s, the reproduced model is also vulnerable, which only gets in WS-353-REL and in YP-130.
6 Disscussion
“If I have seen further, it is by standing on the shoulders of Giants. ——Isaac Newton,1675.”
Scientific progress builds on the innovations of predecessors. If an influential innovation is falsified, it is not ‘the shoulder of a giant’. Instead, it becomes a stumbling block and brings huge obstacles to developing the field. We think science is not a kind of religion, especially when it comes to computer science. The authenticity of innovation should depend on reproducibility rather than the reputation of the author, institution, or paper grade.
In 2018, a master’s student was assigned to begin his academic research in an emerging field. Unluckily, he took faith in a bogus study and get off the wrong road. He was passionate about it, striving for years to achieve an impossible goal, and ended up with nothing. Four years after setting out, he reflected on the failures of his life and wrote this article. To prevent others from repeating his past, this is the value of this study.
References
- [1] Eneko Agirre, Enrique Alfonseca, Keith Hall, Jana Kravalova, Marius Pasca, and Aitor Soroa. A study on similarity and relatedness using distributional and wordnet-based approaches. 2009.
- [2] Simon Baker, Roi Reichart, and Anna Korhonen. An unsupervised model for instance level subcategorization acquisition. In EMNLP, pages 278–289, 2014.
- [3] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. Advances in neural information processing systems, 13, 2000.
- [4] Elia Bruni, Gemma Boleda, Marco Baroni, and Nam-Khanh Tran. Distributional semantics in technicolor. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 136–145, 2012.
- [5] Yi-Chen Chen, Sung-Feng Huang, Chia-Hao Shen, Hung-Yi Lee, and Lin-Shan Lee. Phonetic-and-semantic embedding of spoken words with applications in spoken content retrieval. In 2018 IEEE Spoken Language Technology Workshop (SLT), pages 941–948. IEEE, 2018.
- [6] Yu-An Chung and James Glass. Learning word embeddings from speech. arXiv preprint arXiv:1711.01515, 2017.
- [7] Yu-An Chung and James Glass. Speech2vec: A sequence-to-sequence framework for learning word embeddings from speech. In INTERSPEECH, 2018.
- [8] Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass. Unsupervised cross-modal alignment of speech and text embedding spaces. Advances in neural information processing systems, 31, 2018.
- [9] Yu-An Chung, Wei-Hung Weng, Schrasing Tong, and James Glass. Towards unsupervised speech-to-text translation. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7170–7174. IEEE, 2019.
- [10] Manaal Faruqui and Chris Dyer. Community evaluation and exchange of word vectors at wordvectors. org. In Proceedings of 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 19–24, 2014.
- [11] Daniela Gerz, Ivan Vulić, Felix Hill, Roi Reichart, and Anna Korhonen. Simverb-3500: A large-scale evaluation set of verb similarity. arXiv preprint arXiv:1608.00869, 2016.
- [12] Guy Halawi, Gideon Dror, Evgeniy Gabrilovich, and Yehuda Koren. Large-scale learning of word relatedness with constraints. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1406–1414, 2012.
- [13] Felix Hill, Roi Reichart, and Anna Korhonen. Simlex-999: Evaluating semantic models with (genuine) similarity estimation. Computational Linguistics, 41(4):665–695, 2015.
- [14] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015.
- [15] Minh-Thang Luong, Richard Socher, and Christopher D Manning. Better word representations with recursive neural networks for morphology. In Proceedings of the seventeenth conference on computational natural language learning, pages 104–113, 2013.
- [16] Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. Montreal forced aligner: Trainable text-speech alignment using kaldi. In Interspeech, volume 2017, pages 498–502, 2017.
- [17] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems, 26, 2013.
- [18] Shruti Palaskar, Vikas Raunak, and Florian Metze. Learned in speech recognition: Contextual acoustic word embeddings. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6530–6534. IEEE, 2019.
- [19] Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206–5210. IEEE, 2015.
- [20] Kira Radinsky, Eugene Agichtein, Evgeniy Gabrilovich, and Shaul Markovitch. A word at a time: computing word relatedness using temporal semantic analysis. In Proceedings of the 20th international conference on World wide web, pages 337–346, 2011.
- [21] Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition. arXiv preprint arXiv:1904.05862, 2019.
- [22] Marco Tagliasacchi, Beat Gfeller, Félix de Chaumont Quitry, and Dominik Roblek. Self-supervised audio representation learning for mobile devices. arXiv preprint arXiv:1905.11796, 2019.
- [23] Stefanie Tellex, Boris Katz, Jimmy Lin, Aaron Fernandes, and Gregory Marton. Quantitative evaluation of passage retrieval algorithms for question answering. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, pages 41–47, 2003.
- [24] Joseph Turian, Lev Ratinov, and Yoshua Bengio. Word representations: a simple and general method for semi-supervised learning. In Proceedings of the 48th annual meeting of the association for computational linguistics, pages 384–394, 2010.
- [25] Florian Wickelmaier. An introduction to mds. Sound Quality Research Unit, Aalborg University, Denmark, 46(5):1–26, 2003.
- [26] Dongqiang Yang and David MW Powers. Verb similarity on the taxonomy of WordNet. Masaryk University, 2006.
- [27] Jiangyan Yi and Jianhua Tao. Self-attention based model for punctuation prediction using word and speech embeddings. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 7270–7274. IEEE, 2019.
Appendix A Encoding-Decoding Details
Fig. 5 depicts the encoding-decoding process. For clarity, this illustration takes a single spoken word as input, while the model is trained in batch mode. Since the input words have various time lengths, the length uniformity is implemented in the official code. The official code lacks the data processing part, and we don’t know the exact time length. According to statistics, our dataset has an average MFCC frame of 10, and there are 94.6% of words less than 21 frames. Thus we padded (or truncated) the input word to fixed 20 MFCC frames.
In the encoding stage, the official code used the pack_padded_sequence of PyTorch to eliminate the padding effects.
However, in the decoding stage,
the reconstruction loss corresponding to the padded frames is still considered.
We fixed this issue in our reproduction.
More details can be found in our released code.

Appendix B Comparisons on Similarity Benchmarks
We note that the optimizer in the official code is the Adam optimizer (not the described SGD in the official paper). To exclude the optimizer’s impact, we tried the Adam setting. However, we did not observe essential differences in the results, as shown in Tab. 7.
| Benchmark | Paper Data | SGD | Adam | ||
|---|---|---|---|---|---|
| Rand Init | 500-Epoch | Rand Init | 500-Epoch | ||
| MC-30 | 0.85 | 0.18 | 0.24↓0.60 | 0.37 | -0.28↓1.13 |
| MEN | 0.62 | 0.08 | 0.08↓0.54 | 0.06 | 0.04↓0.58 |
| MTurk-287 | 0.47 | 0.00 | 0.02↓0.45 | 0.04 | 0.08↓0.39 |
| MTurk-771 | 0.52 | -0.00 | 0.03↓0.49 | -0.00 | 0.04↓0.48 |
| RG-65 | 0.79 | 0.11 | 0.18↓0.61 | 0.25 | 0.05↓0.74 |
| Rare-Word | 0.32 | 0.10 | 0.12↓0.21 | 0.10 | 0.04↓0.28 |
| SimLex-999 | 0.29 | 0.02 | -0.05↓0.34 | -0.06 | -0.04↓0.33 |
| SimVerb-3500 | 0.16 | 0.00 | -0.02↓0.17 | -0.03 | -0.03↓0.18 |
| Verb-143 | 0.32 | 0.24 | 0.29↓0.02 | 0.34 | 0.24↓0.07 |
| WS-353 | 0.51 | 0.11 | 0.14↓0.36 | 0.18 | 0.12↓0.39 |
| WS-353-REL | 0.35 | 0.10 | 0.11↓0.24 | 0.12 | 0.11↓0.24 |
| WS-353-SIM | 0.66 | 0.10 | 0.15↓0.51 | 0.22 | 0.16↓0.51 |
| YP-130 | 0.32 | 0.01 | 0.07↓0.25 | 0.11 | -0.01↓0.33 |
Appendix C The Homophone List
The full 307 homophone pairs are listed in LABEL:tab:homo_full_list. Since our reproduction is based on Libri-Clean, which has a smaller vocab than the released embedding. Thus there are 33 missing pairs in our reproduction (marked by ‘-’).
| Homophone Pairs | Raw | Official | Ours | Homophone Pairs | Raw | Official | Ours | ||
|---|---|---|---|---|---|---|---|---|---|
| ad | add | 0.99 | 0.09 | 0.92 | lieu | loo | 0.98 | 0.43 | 0.91 |
| ail | ale | 0.98 | 0.49 | 0.75 | links | lynx | 1.00 | 0.24 | 0.96 |
| air | heir | 1.00 | 0.07 | 0.97 | lo | low | 0.99 | 0.22 | 0.98 |
| all | awl | - | 0.40 | - | loan | lone | 1.00 | 0.09 | 0.94 |
| allowed | aloud | 1.00 | 0.21 | 0.96 | loot | lute | 0.99 | 0.17 | 0.92 |
| alms | arms | 0.95 | 0.26 | 0.95 | made | maid | 1.00 | 0.25 | 0.98 |
| altar | alter | 0.99 | 0.13 | 0.95 | male | 1.00 | 0.23 | 0.98 | |
| arc | ark | 0.98 | 0.19 | 0.91 | main | mane | 0.99 | 0.17 | 0.97 |
| aren’t | aunt | 0.96 | 0.44 | 0.95 | maize | maze | 0.99 | 0.25 | 0.93 |
| ate | eight | 1.00 | 0.22 | 1.00 | manna | manner | 0.97 | 0.33 | 0.89 |
| auger | augur | - | 0.51 | - | mantel | mantle | 1.00 | 0.43 | 0.95 |
| awe | oar | 0.92 | 0.26 | 0.78 | mare | mayor | 0.99 | 0.38 | 0.96 |
| axel | axle | 0.99 | 0.41 | 0.86 | marshal | martial | 1.00 | 0.60 | 0.98 |
| aye | eye | 0.99 | 0.29 | 0.89 | marten | martin | - | 0.36 | - |
| bail | bale | 0.99 | 0.36 | 0.98 | mask | masque | - | 0.51 | - |
| bait | bate | 0.98 | 0.41 | 0.95 | mean | mien | 0.98 | 0.24 | 0.90 |
| baize | bays | 0.99 | 0.50 | 0.91 | meat | meet | 1.00 | 0.13 | 0.99 |
| bald | bawled | 0.99 | 0.21 | 0.96 | medal | meddle | 0.99 | 0.11 | 0.90 |
| bard | barred | 0.98 | 0.01 | 0.96 | metal | mettle | 1.00 | 0.31 | 0.92 |
| bare | bear | 1.00 | 0.51 | 1.00 | meter | metre | 0.99 | 0.59 | 0.95 |
| bark | barque | 0.96 | 0.33 | 0.86 | might | mite | 0.99 | 0.38 | 0.96 |
| baron | barren | 1.00 | 0.07 | 0.97 | mind | mined | - | 0.21 | - |
| base | bass | 0.99 | 0.28 | 0.98 | miner | minor | 1.00 | 0.17 | 0.95 |
| bazaar | bizarre | 0.98 | 0.12 | 0.92 | missed | mist | 0.99 | 0.20 | 0.98 |
| be | bee | 0.99 | 0.35 | 0.98 | moat | mote | 0.99 | 0.46 | 0.93 |
| beach | beech | 1.00 | 0.47 | 0.97 | mode | mowed | 0.99 | 0.21 | 0.94 |
| bean | been | 0.92 | 0.29 | 0.96 | moor | more | 0.99 | 0.41 | 0.94 |
| beat | beet | - | 0.41 | - | morning | mourning | 1.00 | 0.46 | 0.99 |
| beer | bier | 0.99 | 0.24 | 0.96 | muscle | mussel | 0.99 | 0.48 | 0.95 |
| bel | bell | 0.99 | 0.29 | 0.98 | naval | navel | - | 0.34 | - |
| berry | bury | 0.99 | 0.16 | 0.97 | nay | neigh | - | 0.34 | - |
| berth | birth | 1.00 | 0.08 | 1.00 | none | nun | 0.99 | 0.35 | 0.84 |
| bitten | bittern | - | 0.63 | - | ode | owed | 0.99 | 0.30 | 0.95 |
| blew | blue | 1.00 | 0.48 | 1.00 | oh | owe | 0.97 | 0.55 | 0.82 |
| boar | bore | 0.99 | 0.39 | 0.96 | one | won | 1.00 | 0.39 | 1.00 |
| board | bored | 1.00 | 0.13 | 0.99 | pail | pale | 1.00 | 0.27 | 0.99 |
| boarder | border | 0.99 | 0.34 | 0.92 | pain | pane | 1.00 | 0.38 | 0.98 |
| bold | bowled | 0.99 | 0.50 | 0.92 | pair | pare | 0.99 | 0.35 | 0.95 |
| born | borne | 1.00 | 0.29 | 0.99 | palate | palette | 0.98 | 0.50 | 0.88 |
| bough | bow | 0.99 | 0.48 | 0.97 | pause | paws | 1.00 | 0.34 | 0.99 |
| boy | buoy | 0.96 | 0.35 | 0.88 | pea | pee | 0.93 | 0.54 | 0.87 |
| braid | brayed | - | 0.60 | - | peace | piece | 1.00 | 0.15 | 0.99 |
| brake | break | 1.00 | 0.38 | 0.99 | peak | peek | - | 0.30 | - |
| bread | bred | 1.00 | 0.24 | 0.99 | peal | peel | 0.99 | 0.21 | 0.96 |
| bridal | bridle | 1.00 | 0.36 | 0.97 | peer | pier | 0.99 | 0.33 | 0.96 |
| broach | brooch | 0.98 | 0.52 | 0.89 | plain | plane | 1.00 | 0.40 | 0.99 |
| but | butt | 0.97 | 0.37 | 0.92 | pleas | please | - | 0.42 | - |
| buy | by | 0.99 | 0.25 | 0.98 | plum | plumb | 0.99 | 0.57 | 0.96 |
| calendar | calender | 0.98 | 0.39 | 0.95 | pole | poll | 0.98 | 0.19 | 0.96 |
| canvas | canvass | 0.99 | 0.41 | 0.98 | practice | practise | 1.00 | 0.74 | 0.99 |
| cast | caste | 0.99 | 0.33 | 0.98 | praise | prays | 0.99 | 0.51 | 0.99 |
| caught | court | 0.95 | 0.11 | 0.91 | principal | principle | 1.00 | 0.48 | 1.00 |
| ceiling | sealing | 1.00 | 0.63 | 0.95 | profit | prophet | 1.00 | 0.30 | 0.99 |
| cell | sell | 0.99 | 0.06 | 0.95 | quarts | quartz | 0.99 | 0.49 | 0.95 |
| censer | censor | 0.98 | 0.35 | 0.78 | rain | reign | 1.00 | 0.18 | 0.99 |
| cent | scent | 0.99 | 0.00 | 0.98 | raise | rays | 1.00 | 0.10 | 0.99 |
| check | cheque | 0.99 | 0.61 | 0.98 | rap | wrap | 0.99 | 0.40 | 0.96 |
| chord | cord | 1.00 | 0.42 | 0.98 | raw | roar | 0.96 | 0.18 | 0.88 |
| cite | sight | 0.99 | 0.24 | 0.97 | read | reed | 0.97 | 0.28 | 0.97 |
| clew | clue | 0.99 | 0.83 | 0.96 | real | reel | 1.00 | 0.27 | 0.97 |
| climb | clime | 0.99 | 0.29 | 0.93 | reek | wreak | 0.98 | 0.33 | 0.92 |
| coarse | course | 1.00 | 0.20 | 0.99 | rest | wrest | 0.99 | 0.54 | 0.95 |
| coign | coin | - | 0.37 | - | right | rite | 1.00 | 0.19 | 0.96 |
| colonel | kernel | 0.98 | 0.02 | 0.94 | ring | wring | 0.99 | 0.48 | 0.97 |
| complacent | complaisant | - | 0.54 | - | road | rode | 1.00 | 0.66 | 0.96 |
| complement | compliment | 1.00 | 0.27 | 0.96 | roe | row | 0.95 | 0.23 | 0.80 |
| coo | coup | 0.98 | 0.35 | 0.87 | role | roll | 1.00 | 0.18 | 0.99 |
| cops | copse | 0.98 | 0.39 | 0.96 | rood | rude | - | 0.32 | - |
| council | counsel | 1.00 | 0.52 | 0.99 | root | route | 0.98 | 0.06 | 0.98 |
| creak | creek | 0.99 | 0.37 | 0.98 | rose | rows | 1.00 | 0.37 | 0.99 |
| crews | cruise | 1.00 | 0.67 | 0.95 | rote | wrote | 0.98 | 0.46 | 0.91 |
| currant | current | 0.99 | 0.11 | 0.97 | rough | ruff | 0.99 | 0.51 | 0.94 |
| dam | damn | 0.99 | 0.21 | 0.95 | rung | wrung | 1.00 | 0.33 | 0.97 |
| days | daze | 0.99 | 0.47 | 0.94 | rye | wry | 0.99 | 0.35 | 0.92 |
| dear | deer | 0.99 | 0.08 | 0.98 | sale | sail | 1.00 | 0.32 | 0.99 |
| descent | dissent | 1.00 | 0.42 | 0.98 | sane | seine | - | 0.09 | - |
| desert | dessert | 0.99 | 0.14 | 0.97 | sauce | source | 0.97 | 0.22 | 0.97 |
| dew | due | 1.00 | 0.25 | 0.98 | saw | soar | 0.96 | 0.33 | 0.92 |
| die | dye | 0.99 | 0.26 | 0.89 | scene | seen | 1.00 | 0.41 | 1.00 |
| done | dun | 0.99 | 0.21 | 0.97 | sea | see | 1.00 | 0.31 | 0.98 |
| draft | draught | 0.99 | 0.30 | 0.96 | seam | seem | 0.98 | 0.30 | 0.93 |
| dual | duel | 0.98 | 0.48 | 0.88 | sear | seer | 0.98 | 0.57 | 0.86 |
| earn | urn | 0.99 | 0.04 | 0.89 | seas | sees | 0.99 | 0.18 | 0.96 |
| ewe | yew | 0.99 | 0.45 | 0.90 | sew | so | 0.99 | 0.55 | 0.98 |
| faint | feint | 0.99 | 0.55 | 0.95 | shear | sheer | 0.99 | 0.25 | 0.94 |
| fair | fare | 1.00 | 0.42 | 0.99 | side | sighed | 1.00 | 0.31 | 0.99 |
| farther | father | 0.98 | 0.29 | 0.99 | sign | sine | - | 0.39 | - |
| feat | feet | 1.00 | 0.37 | 0.99 | slay | sleigh | 0.99 | 0.30 | 0.97 |
| few | phew | - | 0.38 | - | sole | soul | 1.00 | 0.43 | 0.98 |
| find | fined | 0.99 | 0.24 | 0.97 | some | sum | 0.99 | 0.34 | 0.99 |
| fir | fur | 1.00 | 0.32 | 0.99 | son | sun | 1.00 | 0.26 | 1.00 |
| flaw | floor | 0.97 | 0.30 | 0.87 | sort | sought | 0.96 | 0.21 | 0.96 |
| flea | flee | 0.99 | 0.36 | 0.98 | staid | stayed | 1.00 | 0.55 | 0.99 |
| floe | flow | 0.99 | 0.42 | 0.89 | stair | stare | 1.00 | 0.27 | 0.99 |
| flour | flower | 1.00 | 0.30 | 0.99 | stake | steak | 1.00 | 0.19 | 0.98 |
| for | fore | 0.95 | 0.26 | 0.99 | stalk | stork | 0.96 | 0.55 | 0.92 |
| fort | fought | 0.95 | 0.42 | 0.93 | stationary | stationery | 0.99 | 0.27 | 0.85 |
| forth | fourth | 1.00 | 0.25 | 1.00 | steal | steel | 1.00 | 0.19 | 0.99 |
| foul | fowl | 1.00 | 0.36 | 0.97 | stile | style | 0.99 | 0.21 | 0.89 |
| franc | frank | 0.98 | 0.31 | 0.95 | storey | story | 0.99 | 0.37 | 0.95 |
| freeze | frieze | - | 0.38 | - | straight | strait | 1.00 | 0.39 | 0.97 |
| furs | furze | - | 0.56 | - | sweet | suite | 1.00 | 0.03 | 0.99 |
| gait | gate | 1.00 | 0.31 | 0.99 | tacks | tax | 0.98 | 0.25 | 0.96 |
| gamble | gambol | - | 0.41 | - | tale | tail | 1.00 | 0.23 | 1.00 |
| gild | guild | - | 0.41 | - | taught | taut | 0.99 | 0.12 | 0.93 |
| gilt | guilt | 1.00 | 0.21 | 0.99 | team | teem | - | 0.28 | - |
| gnaw | nor | 0.95 | 0.38 | 0.84 | tear | tier | 0.98 | 0.24 | 0.92 |
| grate | great | 1.00 | 0.15 | 0.97 | teas | tease | 0.99 | 0.35 | 0.97 |
| greys | graze | 0.98 | 0.65 | 0.90 | tern | turn | - | 0.32 | - |
| grisly | grizzly | 0.99 | 0.64 | 0.88 | there | their | 0.99 | 0.34 | 0.98 |
| groan | grown | 0.99 | 0.25 | 0.95 | threw | through | 0.99 | 0.39 | 0.99 |
| guessed | guest | 1.00 | 0.33 | 0.99 | throes | throws | 0.99 | 0.31 | 0.95 |
| hail | hale | 0.99 | 0.34 | 0.97 | throne | thrown | 1.00 | 0.30 | 0.96 |
| hair | hare | 1.00 | 0.32 | 0.98 | thyme | time | 0.99 | 0.25 | 0.97 |
| hall | haul | 1.00 | 0.13 | 0.93 | tide | tied | 1.00 | 0.10 | 0.99 |
| hart | heart | 0.99 | 0.23 | 0.94 | tire | tyre | 0.99 | 0.21 | 0.90 |
| haw | hoar | 0.91 | 0.12 | 0.71 | to | too | 0.97 | 0.63 | 0.97 |
| hay | hey | 0.98 | 0.37 | 0.92 | toad | toed | 0.98 | 0.55 | 0.96 |
| he’d | heed | 0.99 | 0.39 | 0.98 | told | tolled | 0.98 | 0.33 | 0.96 |
| heal | heel | 1.00 | 0.37 | 0.95 | ton | tun | - | 0.55 | - |
| hear | here | 1.00 | 0.58 | 0.98 | vain | vane | 0.99 | 0.19 | 0.96 |
| heard | herd | 0.99 | 0.32 | 0.97 | vale | veil | 1.00 | 0.65 | 0.98 |
| hew | hue | 0.99 | 0.34 | 0.94 | vial | vile | 0.99 | 0.33 | 0.94 |
| hi | high | 0.98 | 0.18 | 0.98 | wain | wane | 0.98 | 0.73 | 0.86 |
| higher | hire | 1.00 | 0.27 | 0.98 | waist | waste | 1.00 | 0.13 | 0.99 |
| him | hymn | 0.99 | 0.28 | 0.98 | wait | weight | 1.00 | 0.21 | 0.99 |
| ho | hoe | 0.98 | 0.40 | 0.96 | waive | wave | 0.99 | 0.22 | 0.95 |
| hoard | horde | 0.99 | 0.47 | 0.89 | war | wore | 0.99 | 0.23 | 0.96 |
| hoarse | horse | 1.00 | 0.21 | 0.99 | ware | wear | 0.99 | 0.32 | 0.97 |
| hour | our | 0.98 | 0.28 | 0.94 | warn | worn | 1.00 | 0.02 | 0.98 |
| idle | idol | 1.00 | 0.46 | 0.97 | watt | what | - | 0.52 | - |
| in | inn | 0.98 | 0.38 | 0.95 | wax | whacks | - | 0.48 | - |
| it’s | its | 0.99 | 0.20 | 0.95 | way | weigh | 0.99 | 0.36 | 0.96 |
| key | quay | 0.97 | 0.33 | 0.95 | we | wee | 0.97 | 0.21 | 0.96 |
| knave | nave | 0.99 | 0.06 | 0.90 | we’d | weed | 0.96 | 0.26 | 0.94 |
| knead | need | 0.99 | 0.51 | 0.98 | weak | week | 1.00 | 0.10 | 1.00 |
| knew | new | 1.00 | 0.31 | 0.99 | weal | we’ll | 0.94 | 0.15 | 0.90 |
| knight | night | 1.00 | 0.26 | 0.99 | wean | ween | - | 0.57 | - |
| knob | nob | - | 0.59 | - | weather | whether | 0.99 | 0.21 | 0.95 |
| knot | not | 1.00 | 0.26 | 0.98 | weir | we’re | - | 0.08 | - |
| know | no | 1.00 | 0.63 | 0.97 | were | whirr | 0.96 | 0.27 | 0.83 |
| knows | nose | 1.00 | 0.18 | 0.99 | which | witch | 0.99 | 0.28 | 0.94 |
| lac | lack | - | 0.10 | - | whig | wig | 0.99 | 0.16 | 0.96 |
| lain | lane | 0.99 | 0.30 | 0.96 | whine | wine | 1.00 | 0.13 | 0.97 |
| laps | lapse | - | 0.32 | - | whirl | whorl | 0.97 | 0.37 | 0.78 |
| larva | lava | - | 0.45 | - | whirled | world | 1.00 | 0.26 | 0.96 |
| law | lore | 0.96 | 0.33 | 0.89 | whit | wit | 0.99 | 0.50 | 0.96 |
| lea | lee | 0.98 | 0.53 | 0.89 | white | wight | 0.99 | 0.32 | 0.95 |
| lead | led | 0.94 | 0.59 | 0.97 | who’s | whose | 0.99 | 0.26 | 0.99 |
| lessen | lesson | 1.00 | 0.26 | 0.92 | woe | whoa | 0.97 | 0.23 | 0.90 |
| levee | levy | 0.98 | 0.45 | 0.82 | wood | would | 0.98 | 0.26 | 0.96 |
| liar | lyre | 0.99 | 0.31 | 0.93 | yoke | yolk | 0.99 | 0.32 | 0.88 |
| licence | license | 0.99 | 0.72 | 0.94 | you’ll | yule | 0.95 | 0.48 | 0.91 |
| lie | lye | 0.97 | 0.47 | 0.71 | |||||