HJ-sampler: A Bayesian sampler for inverse problems of a stochastic process by leveraging Hamilton–Jacobi PDEs and score-based generative models111Tingwei Meng and Zongren Zou contributed equally to this work.
Abstract
The interplay between stochastic processes and optimal control has been extensively explored in the literature. With the recent surge in the use of diffusion models, stochastic processes have increasingly been applied to sample generation. This paper builds on the log transform, known as the Cole-Hopf transform in Brownian motion contexts, and extends it within a more abstract framework that includes a linear operator. Within this framework, we found that the well-known relationship between the Cole-Hopf transform and optimal transport is a particular instance where the linear operator acts as the infinitesimal generator of a stochastic process. We also introduce a novel scenario where the linear operator is the adjoint of the generator, linking to Bayesian inference under specific initial and terminal conditions. Leveraging this theoretical foundation, we develop a new algorithm, named the HJ-sampler, for Bayesian inference for the inverse problem of a stochastic differential equation with given terminal observations. The HJ-sampler involves two stages: (1) solving the viscous Hamilton-Jacobi partial differential equations, and (2) sampling from the associated stochastic optimal control problem. Our proposed algorithm naturally allows for flexibility in selecting the numerical solver for viscous HJ PDEs. We introduce two variants of the solver: the Riccati-HJ-sampler, based on the Riccati method, and the SGM-HJ-sampler, which utilizes diffusion models. We demonstrate the effectiveness and flexibility of the proposed methods by applying them to solve Bayesian inverse problems involving various stochastic processes and prior distributions, including applications that address model misspecifications and quantifying model uncertainty.
Keywords: Bayesian inference, Hamilton–Jacobi PDEs, uncertainty quantification, inverse problems
1 Introduction
Uncertainty Quantification (UQ) plays a vital role in scientific computing, helping to quantify and manage the inherent uncertainties in complex models and simulations [82, 79]. Within UQ, two significant areas of active research are Bayesian inference and sampling from data distributions. Bayesian inference has garnered considerable interest within the scientific computing community due to its ability to rigorously combine prior information with observational data, addressing model uncertainties and enhancing predictive capabilities [96, 64, 11, 116, 114, 113]. Meanwhile, the second area—sampling from data distributions—has gained popularity in the machine learning and AI communities. This surge in interest is largely driven by the success of generative models, particularly diffusion models, which excel at generating high-quality samples from complex, high-dimensional distributions [92, 26, 108, 107, 28, 103]. Diffusion models, and more generally score-based methods, have been employed not only for data generation but also for solving a wide range of scientific computing problems, including inverse problems [91], sampling [86, 110, 108, 7], distribution modification [98], mean-field problems [66, 111], control problems [99, 100], forward and inverse partial differential equations (PDEs) [102], and Schrödinger bridge problems [19, 85, 87, 39]. This broad applicability makes diffusion models a powerful tool in both AI and scientific computing.
In this work, we establish connections between these two subfields of UQ. Specifically, we observe that the Bayesian posterior distribution for certain inverse problems involving stochastic processes can be represented as a PDE, which is further linked to a stochastic optimal control problem. Based on this connection, we design an algorithm that solves certain Bayesian sampling problems by addressing the associated stochastic optimal control problem. This algorithm bears similarities to diffusion models, particularly a class known as Score-based Generative Models (SGMs). By highlighting this connection, our work offers a novel link between Bayesian inference, generative models, and traditional stochastic optimal control, providing new directions for exploration and development.
Theoretically, this connection arises as a special case of the log transform, where the initial condition incorporates the observation, and the terminal condition reflects the prior distribution in the Bayesian inference problem. The log transform has been extensively studied in the literature [34, 32, 37, 71] and is often referred to as the Cole-Hopf transform [30, 59, 60] when applied to Brownian motion. This transform connects the nonlinear system, consisting of Hamilton-Jacobi (HJ) equations coupled with Fokker-Planck equations, to its linear counterpart, the Kolmogorov forward and backward equations. Traditionally, the Cole-Hopf transform is used to simplify the solution of nonlinear PDEs by converting them into linear PDEs, which are generally easier to solve. In probability theory, it is also employed as a tool for sampling, known as Doob’s -transform. Beyond these established uses, we introduce a novel application of the log transform within Bayesian inference, a context that presents some open questions and opportunities for further research (see the discussion in the summary).
From a more detailed and practical perspective, we consider the Bayesian inference problem where the likelihood is determined by , with governed by a Stochastic Differential Equation (SDE). The goal is to solve the inverse problem of the stochastic process, specifically inferring the position of given an observation at its terminal position . For this class of problems, we propose an algorithm called the HJ-sampler, which generates sample paths from the posterior distribution by solving the corresponding stochastic optimal control problem. The algorithm consists of two steps: first, computing the control, and second, sampling the optimal trajectories. Different versions of the algorithm arise based on the method used to compute the control. In this paper, we present two such versions: the Riccati-HJ-sampler, which applies the Riccati method, and the SGM-HJ-sampler, which leverages the SGM method. A key advantage of the HJ-sampler is its flexibility. The first step, which computes the control, is independent of the second step, which samples the trajectories. This allows for flexibility in adjusting the observation position , the time , and the discretization size without requiring a recomputation of the control. Beyond the proposed algorithm itself, this connection between Bayesian inference and control theory allows us to harness techniques from both control algorithms and diffusion models for efficient Bayesian sampling. Additionally, it offers a potential Bayesian interpretation of diffusion models and opens up avenues for their generalization.
While the log transform has been employed in various sampling algorithms in the literature [5, 109, 106, 42, 21], our approach differs in its application. These existing methods, and also other sampling algorithms such as such as Hamiltonian Monte Carlo [74], variational inference [6, 44, 80], and Langevin-type Monte Carlo [101, 38], typically include the target distribution as part of the terminal condition, requiring an explicit analytical formula for the density function. In contrast, our approach assumes that only the prior density or prior samples are available, with the likelihood being provided by a stochastic process, which may not have an analytical form. In other words, the terminal condition in our method encodes only the prior information, while the likelihood is embedded within the stochastic process. This decoupling provides the flexibility discussed earlier and ensures that the sampling process directly corresponds to the original stochastic process, allowing us to generate entire sample paths rather than finite-dimensional sample points.
The remainder of the paper is organized as follows. In Section 2, we detail the log transform at an abstract level, followed by specific cases in Sections 2.1 and 2.2. Section 2.1 connects the log transform to stochastic optimal transport (SOT) and Schrödinger bridge problems, while Section 2.2 focuses on the special case related to Bayesian inference setups, which is the primary contribution of this paper. Based on the content in Section 2.2, an algortihm caled the HJ-sampler algorithm is presented in Section 3, and numerical results are provided in Section 4. Finally, Section 5 summarizes the findings, discusses limitations, and outlines future research directions. Additional technical details are provided in the appendix. In Figure 1, we present the roadmap of this paper, highlighting the relationships between the main concepts and methodologies discussed.

2 The log transform: bridging linear and non-linear systems in the context of stochastic processes
This section introduces the log transform, a mathematical technique that establishes a connection between linear and nonlinear systems. We investigate this transform in the context of a versatile linear operator, , which may represent differential, difference, integral operators, or combinations thereof. In Sections 2.1 and 2.2, examples are provided where functions as either the infinitesimal generator of a stochastic process or its adjoint. The subscript indicates the inclusion of a positive parameter in the operator, reflecting the degree of stochasticity in these examples. The operator may also depend on the spatial variable and the time variable . We put in the subscript because different equations may involve the operator at different times, while we omit the dependence on for simplicity of notation.
We introduce two functions, and , that map from to and comply with the linear system specified below:
| (1) |
where each operator is applied at the point for any and . The notation denotes the adjoint of in with respect to the spatial variable . The log transform establishes a nonlinear relationship between the pairs and as follows:
| (2) |
where the constant in the second equation is the same as the hyperparameter in the operator . The corresponding inverse transformation reads
| (3) |
This leads to a coupled nonlinear system for and :
| (4) |
where each operator is applied at the point for any and . We refer to the first equation in (4) as the (generalized) Fokker-Planck equation and the second as the (generalized) HJ equation. As shown in Example 2.1 and further discussed in Appendices A and C, when corresponds to an SDE, the equations in (4) reduce to the Fokker-Planck equation and the viscous HJ PDE. In such instances, we refer to the second equation in (4) as the viscous HJ PDE, but we refrain from using the term “viscous” for general cases due to the potential absence of a Laplacian term in the equation in such contexts.
This transformation illustrates the connection between linear and nonlinear systems. The log transform, particularly when acts as the infinitesimal generator of a stochastic process, is recognized in the literature. For context, we briefly touch upon this aspect in Section 2.1, offering it as part of the broader narrative. Our novel contribution emerges in Section 2.2, where we establish a new link to the Bayesian framework by considering as the adjoint of the infinitesimal generator. This insight is crucial for the algorithm we develop later in the paper. By integrating these elements into a comprehensive theoretical framework, we highlight the interconnectedness of diverse applied mathematics fields, such as stochastic processes, control theory, neural networks, and PDEs. This interdisciplinary approach fosters the potential for leveraging algorithms developed in one field to address problems in another, encouraging innovative cross-disciplinary applications.
2.1 The connection between the log transform and stochastic optimal control

In this section, we choose the linear operator in (1) and (4) to be the infinitesimal generator of a stochastic (Feller) process in from to . This operator incorporates to denote the level of stochasticity. Its adjoint is represented by . For further mathematical details on the concepts discussed here, we refer readers to [63, 77].
The linear system in equation (1) encompasses the Kolmogorov backward equation (KBE) for and the Kolmogorov forward equation (KFE) for . The non-linear system (4) constitutes a system for stochastic optimal control, with the source of stochasticity being intrinsically linked to the underlying process . Since the connection works for a general stochastic process, the stochastic nature of the controlled system may extend beyond Brownian motion, enabling consideration of jump processes as well. When adheres to an SDE, the two systems (1) and (4) become two PDE systems (see Example 2.1 and Appendix A). Furthermore, general stochastic processes could lead to systems characterized by discretized PDEs, integral equations, or integro-differential equations. An illustrative example of the scaled Poisson process is provided in Appendix B. An illustration of a general process, as well as a specific case of a scaled Brownian motion, is presented in Figure 2.
Under this setup, the log transform elucidates the relationship between the coupled forward-backward Kolmogorov equations and controlled stochastic systems. This transformation has been extensively studied in the literature (see, for example, [34, 32, 37, 71]). It is also referred to as the Cole-Hopf transform [30] in the context of Brownian motion. The efficacy of the log transform in numerical methodologies stems from its ability to linearize the nonlinear system (4), simplifying the complexity inherent in non-linear dynamics and associated stochastic optimal control challenges.
Remark 2.1 (Initial or terminal conditions)
The log transform’s effectiveness between equations (1) and (4) is invariant to the initial or terminal conditions applied, provided these conditions are consistently adapted following the transformation. This principle allows for varied applications, as demonstrated with subsequent examples linking the system to certain mean-field games (MFG), stochastic optimal control, stochastic optimal transport (SOT), and stochastic Wasserstein proximal operators, among other areas. For a general process, it is also related to the Schrödinger bridge problem. See the following example for more details.
Example 2.1 (Brownian motion)
We consider the scenario where the underlying process is a scaled Brownian motion, denoted by , where represents a Brownian motion in . The infinitesimal generator and its adjoint operator are characterized by , resulting in both the KBE and KFE in (1) being heat equations:
| (5) |
The other non-linear system (4) manifests as the Fokker-Planck PDE and the viscous HJ PDE (with a distinct sign from the usual case, see Remark 2.2):
| (6) |
In this scenario (and generally when the underlying process is described by an SDE, as detailed in Appendix A), the log transform, known as the Cole-Hopf transform, has been extensively examined in the literature [30, 59, 60]. For more applications of the Cole-Hopf transform, see [22, 75, 43, 14, 108].
By introducing distinct sets of initial or terminal conditions, the coupled PDE system (6) can be linked to first-order optimality conditions of various problems, including specific MFG, stochastic optimal control, SOT, or stochastic Wasserstein proximal operator. For instance, if we assign the initial condition to and the terminal condition to , the coupled PDE system (6) is linked to the following MFG:
| (7) |
which is also associated with the stochastic Wasserstein proximal point of at (see [93, 62, 40]). Specifically, if represents a Dirac mass centered at a point , this MFG problem reduces to the following stochastic optimal control problem:
| (8) |
whose value equals . Alternatively, if we specify both initial and terminal conditions for (denoted by and ), the PDE system (6) becomes associated with the following SOT problem:
| (9) |
Similar results hold for a general SDE. More details are provided in Appendix A.
The exploration of these connections can be broadened to encompass scenarios characterized by a wider range of stochastic behaviors. This expansion necessitates the consideration of controlled stochastic processes that incorporate stochastic elements beyond the realm of Brownian motion. Furthermore, these connections are intricately linked to the large deviation principle governing the underlying stochastic processes. While the literature has thoroughly examined cases involving Brownian motion from the perspective of the large deviation principle, as detailed in [8, 10, 34, 27, 20], more complex stochastic processes have been explored in [9, 36, 84, 37, 12, 61, 67, 25, 47]. Additional research has been directed towards elucidating the connections between these models and gradient flows within certain probabilistic spaces, as seen in [1, 31, 81, 78, 49]. However, extending the gradient flow concept to encompass jump processes demands a novel approach to defining geometry within probability spaces, diverging from traditional interpretations based on Wasserstein space, as discussed in [70, 72, 71, 13, 29]. Consequently, establishing a direct correlation between the general logarithmic transformation and gradient flow remains elusive.
Remark 2.2
[Regarding the time direction] The viscous HJ PDE in (6) exhibits a different sign in front of the diffusion term compared to the traditional viscous HJ PDE. This discrepancy arises from the direction of time. To maintain consistency with the controlled stochastic process in MFG or SOT, the time direction is reversed. In essence, upon applying time reversal to and subsequently taking the negative sign, the function satisfies the traditional viscous HJ PDE:
With this discrepancy in signs, the log transform becomes , thereby restoring the correct sign in the traditional Cole-Hopf transform applied to .
2.2 The connection between log transform and Bayesian inference

In this section, we delve into the scenario where the linear operator is the adjoint operator to the infinitesimal generator of an underlying stochastic process , and we illustrate its relevance to Bayesian inference. To our knowledge, this connection, along with related algorithms for a general process, has yet to be documented in existing literature. The relationship between the Cole-Hopf formula and Bayesian inference has been previously examined in [22], albeit with a focus on scaled Brownian motion as the underlying process and on computing the posterior mean rather than conducting posterior sampling.
Consider an -dimensional stochastic (Feller) process , with representing the adjoint of its infinitesimal generator. In contrast to the previous section, the first equation in (1) describes the KFE, while the second corresponds to the KBE. The initial condition for is defined as the marginal density function of , and for , it is set as the scaled Dirac delta function at a fixed point . According to the properties of the KFE, the density function evolves to match the marginal density of . For , the KBE ensures that . Through the log transform (2), the function is given by
| (10) |
indicating that represents the conditional density of given . If is the observed value of , then provides the Bayesian posterior density for .
From a Bayesian perspective, given the initial and terminal conditions, evolves from the prior density at to the data density at , while evolves from the Dirac delta at for to the posterior density at . In terms of the nonlinear system for and , the function satisfies (10) when the following initial and terminal conditions are applied for and :
| (11) |
An illustration is provided in Figure 3.
Throughout this paper, we assume that the distribution is either continuous or a mixture of continuous and discrete components, allowing us to represent it either as a density function or as a finite combination of Dirac masses. The terms “distribution” and “density function” will be used interchangeably as appropriate in the context.
Remark 2.3 (Partial observation)
A significant consideration in Bayesian inference involves scenarios of partial observation, relevant in applications such as image inpainting. The computations above remain valid even with only a partial observation of . For example, if is a concatenation of and , and only an observation for is available, the analysis adapts accordingly. In this remark, for any generic variable , the notation with a subscript ‘’ refers to the vector comprising the first elements of , while , denoted with a subscript ‘’, encompasses the remaining elements. The formulation of the function remains as previously described, but the initial condition for is modified to for any vector . Following a computation akin to the earlier one, we derive that . Consequently, the function satisfies
| (12) |
for any and . While the computation is feasible in this scenario, the primary challenge in implementing the proposed algorithm in Section 3 lies in sampling from , that is, determining how to draw samples from the conditional distribution . Advancing the proposed algorithm to address this issue necessitates additional research.
This section, along with Section 2.1, presents two distinct examples of the log transform using different instances of the operator . In Section 2.1, we investigated the log transform’s role when acts as the infinitesimal generator of a stochastic process , linking it to certain MFG, SOT, stochastic optimal control, and the stochastic Wasserstein proximal operator – fields that are at the forefront of current research. In contrast, this section explores the application of the log transform when is the adjoint operator of the infinitesimal generator of , and its relation to Bayesian inference. In scenarios where the infinitesimal generator is self-adjoint (such as in a Brownian motion process), these two situations are the same. When considering SDEs, these two cases are intuitively related in a reversed manner, highlighting a compelling research path into this duality and its potential to connect Bayesian inference with MFGs and related areas.
Until now, our discussion has focused on theoretical connections. In the next section, we will utilize these insights to develop a Bayesian sampling algorithm, named the HJ-sampler, which is designed to solve the inverse problem related to the process within a Bayesian framework.
3 A Bayesian sampling method for inverse problems: HJ-sampler
As explored in Section 2.2, the log transform establishes a connection to the Bayesian framework under specific initial and terminal conditions. This section aims to harness this connection by introducing an algorithm, the HJ-sampler, designed for a particular subset of inverse problems.
Initially, we outline the category of problems addressed. Considering an underlying stochastic process , with a prior distribution on , our objective is to infer the solution for based on the terminal observation . Essentially, we aim to tackle the inverse problem associated with within the Bayesian framework. Setting the marginal distribution of as the prior distribution , our task becomes to obtain samples from the posterior distribution for . Starting from the observation , the HJ-sampler produces a sequence of posterior samples for , moving backwards in time from to , through the resolution of the associated stochastic optimal control problem.
Subsequently, the discussion will progress in two phases. Firstly, in Section 3.1, we introduce the HJ-sampler for general stochastic processes, entailing two primary steps: solving and thereafter sampling from as defined in equation (4). Following this, in Section 3.2, attention shifts to SDE scenarios, delving into the numerical details of each step.
3.1 HJ-sampler for general stochastic processes
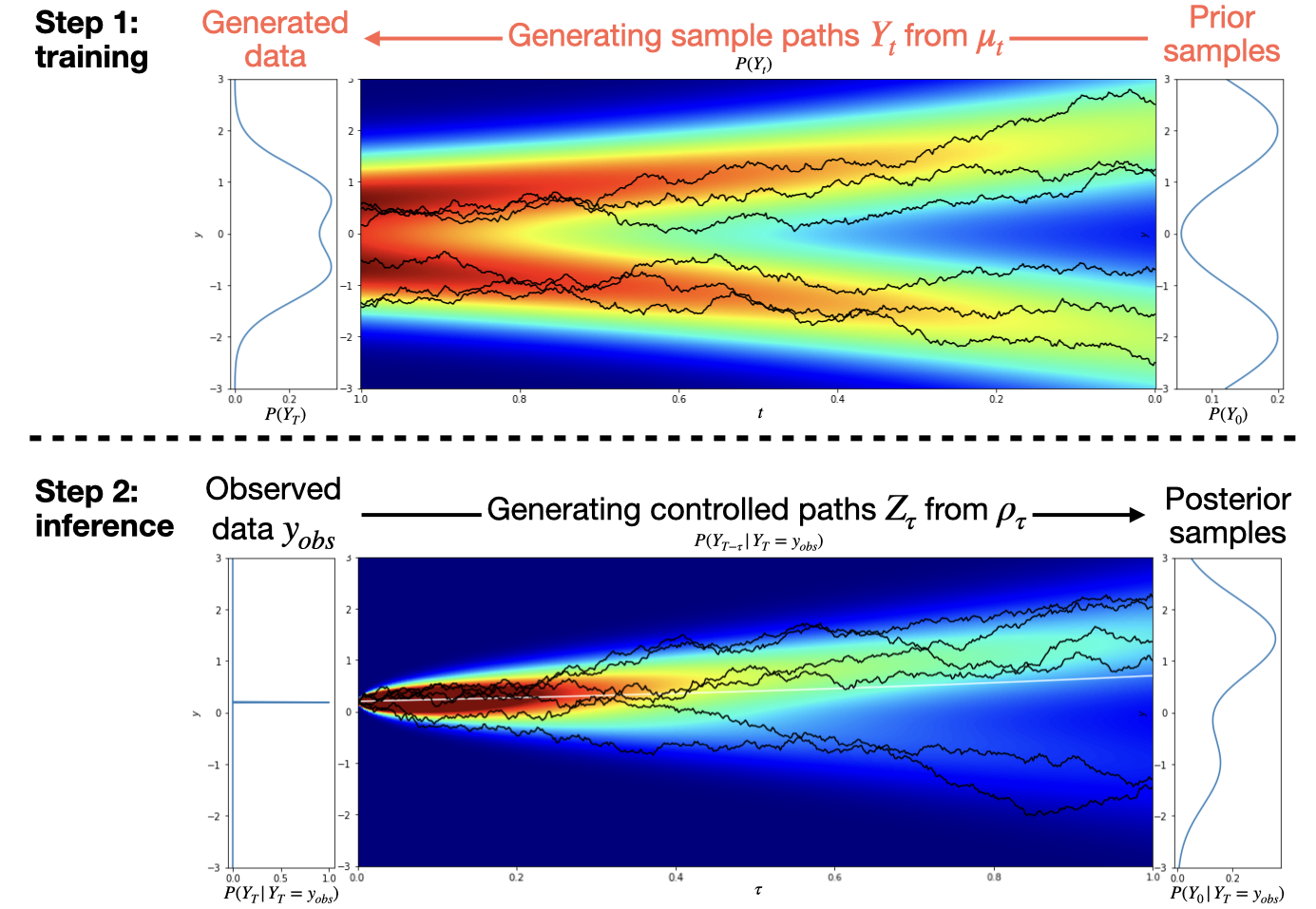
In this section, we present the HJ-sampler, an algorithm designed for a broad class of stochastic processes , where the underlying stochasticity is not limited to traditional Brownian motion dynamics. As delineated in Section 2.2, by setting the terminal condition for to and the initial condition for to , we derive that represents the conditional distribution of given . This enables the acquisition of posterior samples for given , utilizing . By sampling from over the interval from to , we construct a continuous flow of posterior samples that traces the evolution from back to , conditional on .
Building upon this foundational understanding, we introduce an algorithm named the HJ-sampler, which comprises two primary stages:
Remark 3.1 (Flexibility of the observation time )
The HJ-sampler is designed to sample the posterior distribution of given for . However, it can be generalized to sample the distribution of given as long as . This flexibility means that the observation time does not need to be fixed at the start. If the observation time is initially unknown, the algorithm can be modified by first solving the HJ equation for a sufficiently large that is guaranteed to exceed . In the second step, instead of using the original , the time-shifted version is applied to the PDE governing . Sampling from then provides posterior samples for . Consequently, if the underlying process and prior distribution remain unchanged, adjusting the observation time and location does not require re-solving the HJ equation in the first step.
The HJ-sampler operates through a sequential two-step process. In the first step, prior information is used to set up the terminal condition for , after which the function is solved to compute the control for the second step. Since this step does not depend on observational data , it can be precomputed offline using traditional numerical solvers [76, 48, 45, 2, 104, 68, 24, 51, 50, 15] or scientific machine learning techniques [23, 73, 41, 3, 97, 17, 16, 113]. The second step, dependent on the outcomes of the first, uses the observational data to set the initial condition for . This structured separation between prior information and observational data allows for flexibility and precomputation, with the precomputed control applied to generate Bayesian samples once the data is available. In Section 3.2.2, the application of SGMs for SDEs further illustrates this process, with the first step corresponding to the training phase and the second step to the inference stage.
The main challenge in implementing the HJ-sampler lies in efficiently sampling from , which evolves according to the dynamics in (14). These dynamics relate to stochastic optimal control problems with a terminal cost of . Optimal control strategies, denoted by , are derived by applying operators to , allowing posterior samples to be generated by sampling optimally controlled stochastic trajectories. The type of stochasticity in directly influences the nature of the control problem; for example, if follows jump process dynamics, the control problem will involve a controlled jump process rather than a traditional controlled SDE. In the remainder of this paper, we focus specifically on cases where the underlying process is governed by an SDE, reducing the HJ equation (13) to a traditional viscous HJ PDE, corresponding to a stochastic optimal control problem. Section 3.2 introduces the details of the HJ-sampler algorithm and its variants for this case, while Section 4 presents the numerical results. Extensions of the HJ-sampler to more general processes are left for future exploration.
3.2 HJ-sampler for SDEs
In this section, and throughout the remainder of this paper, we concentrate on stochastic processes described by an -dimensional SDE , where acts as the drift component, and represents Brownian motion in . While our results are broadly applicable to general SDEs, additional details are provided in Appendix C. Here, the operator is defined as , and the HJ equation (13) becomes:
| (15) |
The corresponding Fokker-Planck equation (14) evolves into:
| (16) |
where the solution is the same as the marginal distribution of an underlying SDE. Consequently, we obtain posterior samples by sampling from this underlying SDE.
In this scenario, our HJ-sampler algorithm comprises two primary steps:
-
1.
Numerically solve the HJ PDE (15) to determine ;
- 2.
Thus, the samples obtained from the discretized SDE serve as approximations of the posterior samples for given . An informal error estimation for the HJ-sampler is provided in Appendix C.3.
In the HJ-sampler algorithm, the choice of the numerical solver in each step can be adapted based on the practical requirements of the application. For instance, in the second step, the Euler–Maruyama method can be replaced with higher-order schemes to achieve higher accuracy. However, solving the viscous HJ PDE (15) in the first step is more challenging, particularly in high-dimensional settings, making the selection of numerical solvers for this step critical. In lower-dimensional cases, grid-based numerical solvers such as Essentially Non-Oscillatory (ENO) schemes [76], Weighted ENO schemes [48], or the Discontinuous Galerkin method [45] can be employed.
In addition to these grid-based methods, this paper introduces two grid-free numerical solvers that have the potential for application to high-dimensional problems:
Since the sampling process only requires , our focus is on determining rather than solving for itself.
3.2.1 Riccati-HJ-sampler
In scenarios where the prior distribution is Gaussian and the drift term of the SDE is linear in , expressed as , where (throughout this paper, denotes the space of matrices with rows and columns) and are continuous functions, both the Hamiltonian and the initial condition in (15) adopt quadratic forms. Consequently, the HJ PDE (15) can be efficiently solved using Riccati ODEs [105, 35]. We apply a numerical ODE solver to solve the corresponding Riccati ODEs and call this version of the HJ-sampler the Riccati-HJ-sampler.
Specifically, if we assume the prior density follows , with and (in this paper, denotes the set containing all symmetric positive definite matrices) representing the mean and covariance matrix, respectively, the solution to the viscous HJ PDE (15) is expressed as:
where , , and satisfy the Riccati ODE system outlined below:
| (19) |
To facilitate sampling, it is sufficient to compute and , from which can be derived as follows:
| (20) |
For Gaussian mixture priors, assume the prior distribution is a convex combination of Gaussian distributions:
| (21) |
Here, serves as the mixture coefficient, determining the relative contribution of each Gaussian component in the mixture and satisfying . Additionally, and are the mean vectors and covariance matrices of , respectively. Utilizing the log transform, solving the viscous HJ PDE (15) becomes equivalent to solving the KFE with the initial condition set as , which results in a linear equation. Consequently, the solution is expressed as , where satisfies the KFE for the initial condition . Therefore, the solution to the viscous HJ PDE (15) is formulated as:
| (22) |
where addresses the viscous HJ PDE (15) with the terminal condition and can be computed using , , and that solve the Riccati ODEs (19) for each -th Gaussian prior . The optimal control is then given by:
|
|
(23) |
In summary, to manage a mixed Gaussian prior , the Riccati-HJ-sampler initially involves solving for , , and using the Riccati ODEs described in (19) for each -th Gaussian component, . The control is then derived from (23).
3.2.2 SGM-HJ-sampler
In many complex scenarios, traditional numerical solvers struggle to efficiently and flexibly solve the viscous HJ PDE (15), especially in higher dimensions. To overcome these limitations, neural network-based methods can be employed. These approaches allow for approximating either the entire solution or its gradient , which is essential for determining the control dynamics in the second step of the HJ-sampler. In this section, we propose an algorithm called the SGM-HJ-sampler, which integrates a diffusion model known as SGM [92, 26, 108, 107, 28] within the HJ-sampler framework. In the literature, SGMs are used to approximate the score function using a neural network trained on samples of . Within our framework, this function corresponds to according to the log transform. The neural network is then utilized as a scaled control to generate posterior samples. For more insights into diffusion models and their recent applications, we refer to the survey in [103]. Additionally, other neural network approaches for approximating or can also be explored in future research.
The SGM approach is structured into two phases: training and inference. During the training phase, the model learns the score function by minimizing a score-matching loss function using data sampled from a stochastic process. In the inference phase, this learned score function is used to reverse the process, starting from an initial “noise” state to generate samples that reflect the data distribution. These two phases closely correspond to the two steps of the HJ-sampler. The first step of the HJ-sampler is similar to the training stage of the SGM, where the goal is to train a neural network to approximate the score function , using data derived from the process . Similarly, the second step of the SGM-HJ-sampler aligns with the inference phase of the SGM, where samples are generated from a controlled stochastic process utilizing the learned score function. This alignment makes the SGM method well-suited for integration into the HJ-sampler framework.
While our method shares foundational similarities with SGMs, it introduces distinct variations that set it apart. Standard SGMs and other diffusion models typically involve a forward process that transitions from data to noise, followed by a reverse process that reconstructs the data from the noise. In contrast, our model follows a different structure. We utilize two distinct processes: the first moves from the prior distribution to the data distribution , while the second transitions from an observed datum to the posterior distribution . As a result, unlike conventional diffusion models that use data points for training and prior samples for inference, our model uses prior samples for training and observation points for inference. These similarities and differences may provide a new perspective on diffusion models, enriching both the theoretical and practical understanding of these methods.
The SGM-HJ-sampler utilizing the SGM approach comprises two distinct steps:
-
1.
Training stage: Data is generated by sampling using the Euler–Maruyama method as follows:
(24) where are i.i.d. standard Gaussian, and are prior samples, for and . Here, denotes the -th sample for . We use to denote the number of time discretizations and to denote the number of sample paths in training. A neural network (where denotes the trainable parameters) is trained to fit using the implicit score-matching function:
(25) where are tunable weighting hyperparameters. For high-dimensional problems, it is standard practice to enhance scalability by employing the sliced version [90, 92]:
(26) where are i.i.d. samples from a standard Gaussian distribution. For more details and discussion about the loss function, see Appendix C.2.2.
-
2.
Inference stage: The discretized process is sampled according to the equation:
(27) where are i.i.d. standard Gaussian samples for , distinct from those used in the training stage. This is the Euler–Maruyama discretization for , and is a sample for . Note that we use different notations for the sample size and time grid size in training ( and ) and inference ( and ) to emphasize that these two discretizations do not need to be the same. Note that the inference stage of the SGM-HJ-sampler differs from that of the standard SGM: rather than starting from an initial “noise” state, the process begins at the observation point .
This structured approach ensures that our model is both innovative and aligned with established methodologies while offering potential for future exploration. In this method, we do not require an explicit prior probability density function, nor do we obtain the posterior probability density function directly. Instead, the approach relies on prior samples and generates posterior samples.
| HJ-sampler | prior distribution | data distribution | Dirac mass on observation | posterior distribution |
| Diffusion models | data distribution | prior distribution |
Remark 3.2 (Difference between SGM-HJ-sampler and SGM)
Although our training and inference stages share similar formulas with diffusion models, the key differences lie in the practical interpretation of the initial and terminal conditions, the specific problems each method is designed to address, the nature of the challenges inherent in these problems, and the directions for future improvements.
Diffusion models or SGMs are designed to generate samples from the underlying distribution of the data. Therefore, their data density function (which corresponds to our ) is unknown. A stochastic process is chosen to transform the data distribution into a simpler distribution (which corresponds to our ). This process is manually selected to balance complexity and implementation difficulty, ensuring that is easy to sample. In this setup, functions like a prior. A large number of samples are drawn from this prior and then transformed using the reverse process to generate samples in the original data distribution. The training and inference steps correspond to the forward and reverse processes, enabling the use of ODEs or their solution operators, rather than the reverse SDE, to enhance the efficiency of the sampling stage.
However, in our method, we aim at Bayesian inference rather than sample generation from a distribution described by data. Moreover, the stochastic processes of and are not in a forward and reverse relationship; they differ by a factor of . Thus, we have four different initial and terminal densities: , , , and , instead of just two. Our interpretation of these four densities also differs. See Table 1 for more details. In our case, the process is governed by the model of the underlying dynamics, which may be complicated, but we assume that samples from can still be obtained in the first step. In terms of the second step, we cannot apply the techniques designed for SGMs to accelerate the inference process, as and are not reverse processes of each other, and the control differs from . According to the theory connecting SDEs and ODEs, the marginal distribution for is the same as the marginal distribution of the following ODE:
| (28) |
provided that the initial distributions of and are the same. However, we cannot use the ODE for to accelerate the inference process due to the lack of information on . Even if we can generate samples from this ODE, the sample paths of differ from those of , and only the marginal distributions match. Consequently, the advantage of trajectory sampling is lost.
While the previous two paragraphs outline the differences between the SGM and SGM-HJ-sampler methods, these distinctions also point to divergent directions for future development. In the literature [89, 88, 52, 53], key directions in the development of diffusion models include finding effective ways to add noise (i.e., SDE design), improving the training process by adjusting loss weights and data generation methods, and accelerating inference processes. The future improvements for the SGM-HJ-sampler are different. Since the underlying SDE process is determined by the problem setup and is usually complicated, we cannot design the SDE or the training data distribution. Moreover, as discussed earlier, we cannot utilize ODE-based sampling techniques like those in diffusion models. Thus, future work may focus on enhancing the loss design by integrating more model-specific knowledge into the loss function (see [46] for example). In the context of Bayesian inference problems, a simpler form of the prior distribution could allow for more efficient incorporation of prior information, providing a basis for further algorithmic extensions.
Remark 3.3 (Theoretical unification of SGM-HJ-sampler and SGM)
These two methods can be understood within the same theoretical framework. Through the log transform, the diffusion model is a special case where the function is constantly equal to 1, and represents the data distribution. In contrast, the SGM-HJ-sampler is a special case where is a scaled Dirac delta function at the observation point , and corresponds to the prior distribution. From this perspective, both methods can be viewed as applications of the log transform, albeit with different interpretations of the initial conditions. A related perspective on SGMs is also explored in [4], which interprets diffusion models through the lens of optimal control.
From the perspective of diffusion models, the SGM-HJ-sampler can also be viewed as a conditional sampling variant of SGM. According to diffusion model theory, the following SDE
| (29) |
where denotes equality in distribution, provides the reverse process of , meaning is distributionally equivalent to . If we change the distribution of from that of to a Dirac mass while keeping the SDE unchanged, we obtain the process in (17). Since the SDE does not change, the conditional distribution of given is the same as the distribution of given , which equals the posterior distribution of given . This reasoning underpins the SGM-HJ-sampler from the perspective of diffusion model theory.
4 Numerical examples
In this section, we demonstrate the accuracy, flexibility, and generalizability of our proposed HJ-sampler by applying it to four test problems. In Section 4.1, we begin with a verification test, using 1D and 2D scaled Brownian motions to present quantitative results that showcase the HJ-sampler’s performance. In Section 4.2, we consider the underlying process to be an Ornstein–Uhlenbeck (OU) process, demonstrating how the HJ-sampler can handle model uncertainty and misspecification in ODEs [115]. Specifically, in the model misspecification part of this example, a second-order ODE is incorrectly modeled as a linear ODE. We introduce uncertainty by adding white noise to this misspecified ODE, transforming it into an OU process, and then solve the inference problem using the HJ-sampler. The third example, detailed in Section 4.3, illustrates the method’s potential in addressing model misspecification in nonlinear ODEs. Finally, Section 4.4 demonstrates the method’s scalability by solving a 100-dimensional problem.
For the first example and the 1D OU process case, we have analytical formulas for the posterior density functions, which serve as ground truths for quantitative comparison. These cases also have analytical solutions to the viscous HJ PDEs (15). We refer to the version of the HJ-sampler that utilizes this analytical solution as the analytic-HJ-sampler, which serves as a baseline to isolate and distinguish errors from the first and second steps of the HJ-sampler. The analytical formulas and ground truths are provided in Appendix E. The algorithm’s flexibility in sampling from for and (see Remark 3.1) is demonstrated by selecting various and in several examples. Single precision is used in all numerical experiments for illustration purposes. Additional details on the numerical implementations can be found in Appendix D, with further results in Appendix F. The code for these examples will be made publicly available upon acceptance of this paper.
4.1 Brownian motion
In this section, we consider scaled 1D and 2D Brownian motions , where is a standard Brownian motion and is the hyperparameter indicating the level of stochasticity, as the underlying process. We solve the Bayesian inverse problem by sampling from , where , using the proposed HJ-sampler. The objective is to infer the value of from the underlying stochastic model, given the observation and the prior on . The posterior distribution for this problem has an analytical solution, serving as the ground truth for error computation and quantitative analysis of the HJ-sampler’s performance. Additionally, since the viscous HJ PDE (15) also has an analytical solution, we can compare the performance of the SGM-HJ-sampler and the analytic-HJ-sampler to isolate the errors arising from the first and second steps.
4.1.1 1D cases
| analytic-HJ-sampler | ||||||
| SGM-HJ-sampler |
| Metric | |||||
| analytic- | |||||
| HJ-sampler | Wall time (s) | ||||
| SGM- | |||||
| HJ-sampler | Wall time (s) |
In this section, we validate the proposed HJ-sampler through numerical experiments on 1D problems with different prior distributions, including Gaussian, Gaussian mixture, and a mixture of uniform distributions.
We first assume a standard Gaussian prior for , where with and . For the SGM-HJ-sampler, the interval is uniformly discretized with a step size of in (24) to generate training data. In the inference stage, we set in (27) to obtain posterior samples by solving the controlled SDE. To quantitatively evaluate the posterior samples, we compute the Wasserstein-1 distance () between the exact posterior samples and those obtained using both the analytic-HJ-sampler and SGM-HJ-sampler. The results for specific values of the observation for are presented in Table 2(a) and Figure 12, which demonstrate that both samplers produce high-quality posterior samples, though the analytic-HJ-sampler consistently outperforms the SGM-HJ-sampler. This difference highlights the errors arising from the two steps of the HJ-sampler: the analytic-HJ-sampler only incurs error from discretizing the controlled SDE in the second step, whereas the SGM-HJ-sampler also introduces error from the neural network approximation in the first step. We also assess their performance over 1,000 random samples of drawn from , reporting the mean and standard deviation of in the rightmost column of Table 2(a). Next, we analyze the performance and computational wall time of both HJ-samplers with varying . Table 2(b) shows the trade-off between accuracy and efficiency in both samplers. Notably, for the SGM-HJ-sampler, the errors improve at a slower rate when is reduced from to compared to the analytic-HJ-sampler. This indicates that the error from the neural network, trained with , becomes the dominant factor, constraining further error reduction despite a smaller . Wall times are measured on a standard laptop CPU (13th Gen Intel(R) Core(TM) i9-13900HX, 2.20 GHz, 16 GB RAM).



| analytic-HJ-sampler | |||||
| SGM-HJ-sampler |

We then apply the HJ-sampler to a 1D Gaussian mixture prior. Specifically, the prior of is a mixture of three Gaussians, , , and , with equal weights, and we set , , and . We demonstrate the flexibility of the SGM-HJ-sampler by generating posterior samples for the following cases:
-
(a)
for and ,
-
(b)
for , , and ,
-
(c)
for and .
The results, shown in Figure 5(a), (b), and (c), indicate that the posterior samples from the SGM-HJ-sampler agree with the exact posterior density functions. Table 3 provides quantitative results for case (c). Notably, in all cases, the neural network is trained once before knowing the observation and time , and after receiving the data, the second step of the HJ-sampler generates posterior samples without needing re-training. This flexibility is discussed in Remark 3.1.
Finally, we test the method on a more challenging case where the prior distribution is compactly supported. We consider a prior consisting of a mixture of two uniform distributions, and , with equal weights, and set , , and . Using both the analytic-HJ-sampler and SGM-HJ-sampler, we generate posterior samples of given different observation points for various observation times . Results are presented in Figure 6, showing that both HJ-samplers are capable of producing reliable posterior samples that align closely with the exact posterior density functions. However, the analytic-HJ-sampler outperforms the SGM-HJ-sampler due to the latter’s neural network approximation error.
4.1.2 A 2D case








| analytic-HJ-sampler | ||||
| SGM-HJ-sampler |
We now consider a 2D case with the prior for given as a mixture of two Gaussian distributions with means and , and covariance matrices and , respectively. We set and , and uniformly discretize with a step size to generate training data. For the inference, we set when solving the controlled SDE. Posterior samples of for different values of (where ) are generated using both the analytic-HJ-sampler and the SGM-HJ-sampler. The results from the SGM-HJ-sampler are displayed in Figure 7, which show strong agreement between the posterior samples and the exact density functions. To quantitatively assess the sample quality, we compute the sliced distance between the posterior samples and the exact distributions. The results, shown in Table 4, indicate that while both methods perform well, the analytic-HJ-sampler generally yields better results. The sliced distance between two -dimensional distributions and is computed as:
where is the uniform distribution on the unit sphere, is the projection along direction (i.e., ), and and denote the push-forwards of the distributions and , respectively. The distance, , is computed between samples of and . The sliced distance is then calculated by taking the expectation over random directions sampled from . To compute this sliced distance, we use a Monte Carlo approximation with 50 samples for , utilizing the Python Optimal Transport library [33].
4.2 Ornstein–Uhlenbeck process
In this section, we consider the OU process
| (30) |
where is a constant matrix whose eigenvalues have positive real parts, and is a Brownian motion in . The prior distribution is assumed to be either Gaussian or a Gaussian mixture. This setup is a specific instance of the process discussed in Section 3.2.1, where and . A more general version of the OU process, such as , involving an additional constant vector and a constant matrix , can also be solved in a similar manner (as a special case discussed in Appendix C.2). However, we focus on the simpler case here for illustrative purposes. Both the Riccati-HJ-sampler and SGM-HJ-sampler can be applied to solve this problem. Additionally, in the 1D case, the viscous HJ PDE (15) has an analytical solution, enabling the use of the analytic-HJ-sampler for comparison as a sanity check.
In this scenario, the functions and in the Riccati ODE (19) have analytical solutions, given by and . The other function, , can be solved using an ODE solver. Although the Riccati ODE method for solving the marginal density function of the OU process is known in the literature (e.g., [57]), we extend this by connecting it to the viscous HJ PDE and control problems via the log transform.
| analytic-HJ-sampler | Riccati-HJ-sampler | SGM-HJ-sampler |
We first perform a sanity check for the presented algorithm by inferring the value of given for a 1D OU process, , with and . The prior distribution is assumed to be the standard Gaussian distribution , and we set . We apply the analytic-HJ-sampler, Riccati-HJ-sampler, and SGM-HJ-sampler to obtain posterior samples of . The forward Euler scheme with a step size of is used to solve the Riccati ODE in the Riccati-HJ-sampler, while is employed in the inference stage of all three HJ-samplers to solve the controlled SDE. We sample 1,000 values of randomly from and compute the distance between the posterior samples generated by the HJ-samplers and the exact posterior distribution of (Gaussian). The mean and standard deviation of the distances across different values of are presented in Table 5, showing that all three HJ-samplers perform well in producing posterior samples.
After this sanity check, in the following two sections, we demonstrate the ability of the proposed HJ-samplers to handle model uncertainty and misspecification problems. In the first case (Section 4.2.1), we examine a first-order linear ODE system with model uncertainty present in both equations. In the second case (Section 4.2.2), we address a model misspecification problem where a second-order ODE is incorrectly modeled as a second-order linear ODE. This misspecification is captured by the corresponding linear SDE. By reformulating the SDE as a first-order linear system, only the second equation contains the white noise term, illustrating the algorithm’s capability to handle partial uncertainty within a system. In both cases, the SDE models yield an OU process, allowing us to apply the HJ-samplers developed for OU processes to effectively solve these Bayesian inference problems.
4.2.1 The first case: model uncertainty in a first-order linear ODE system







In this section, we demonstrate how to apply the proposed method to handle model uncertainty. We consider the first-order ODE system:
| (31) |
Model uncertainty is introduced by adding white noise to the right-hand sides of the equations, leading to the OU process (30) with and . Assume the prior distribution of is a mixture of two Gaussians with means and and covariance matrices and , respectively, with equal weights. We set and , and discretize uniformly with to generate the training data for the SGM-HJ-sampler. We apply both the Riccati-HJ-sampler and SGM-HJ-sampler to solve the Bayesian inverse problem, i.e., sampling from , where , for some specific values of .
Since is non-diagonal, the exact posterior cannot be derived analytically, and we do not have access to the analytic-HJ-sampler in this case. Therefore, the Riccati-HJ-sampler is used as the reference method to obtain posterior samples of . We set to solve the controlled SDE in both HJ-samplers, and the forward Euler scheme with a step size of is employed to solve the Riccati ODE in the Riccati-HJ-sampler.
Results are presented in Figure 8, demonstrating that the SGM-HJ-sampler produces results that closely align with those from the Riccati-HJ-sampler, validating the effectiveness of the SGM-HJ-sampler.
4.2.2 The second case: model misspecification of a second-order ODE




In this section, we illustrate how the proposed method addresses model misspecification. Consider an exact but unknown ODE given by , which is misspecified as . This discrepancy necessitates modeling the error and quantifying the uncertainty induced by the incorrect model, as discussed in [115]. By defining and introducing the auxiliary variable , the exact ODE transforms into:
| (32a) | ||||
| (32b) | ||||
Similarly, letting and , the misspecified model becomes:
| (33a) | ||||
| (33b) | ||||
To account for the model uncertainty, we reformulate the misspecified ODE system (33) into the following SDE:
| (34) |
where we use capital letters and to denote random variables, which approximate the corresponding deterministic values denoted by lowercase letters and from the exact ODE model (32). The capital letters represent the stochastic versions of the corresponding lowercase variables, reflecting the uncertainty in the misspecified model. Here, is a hyperparameter controlling the level of uncertainty in the system; a larger corresponds to greater uncertainty in the model equations, while a smaller indicates higher confidence in the misspecified ODE.
Our goal is to infer the values of and for based on the values of and , with , while accounting for the model uncertainty in (34) using the SGM-HJ-sampler. Specifically, the data for and , which are based on the exact ODE solutions and , as well as the reference trajectories and for , are generated by numerically solving the exact nonlinear ODE (32) with the initial conditions and using the SciPy odeint function [95]. We consider three levels of uncertainty, , and assume the prior distributions of and are independent log-normal distributions, specifically . Since the prior distribution is neither Gaussian nor a Gaussian mixture, the Riccati-HJ-sampler is not applicable. Therefore, we use the SGM-HJ-sampler with to solve this problem.
We present the results in Figure 9, where each panel displays the reference trajectories and as solid lines. In the leftmost panel, we show the inference of and for , based solely on and , by solving the misspecified linear ODE (33) backward in time. The gap between the reference trajectories and the inferred trajectories highlights the necessity of incorporating model uncertainty when addressing model misspecification.
The remaining panels in Figure 9 show the results from the SGM-HJ-sampler, with each panel corresponding to a different uncertainty level, . Specifically, after obtaining the posterior samples () using the SGM-HJ-sampler, we compute the posterior means and standard deviations. The posterior means are represented by dashed lines, while the 2-standard-deviation regions are shown in color, visualizing the uncertainty in the inferred solutions. From these panels, we observe that the uncertainty in the inferred values of and increases as increases. In practice, can be interpreted as a confidence hyperparameter for the model (33b), where higher confidence corresponds to a smaller .
In this example, three distinct neural networks () were trained, one for each value of , leading to three separate SGM-HJ-samplers. To enhance flexibility with respect to the confidence hyperparameter , we could include as an input to the neural network, allowing it to adapt to different confidence levels without requiring retraining. This example also highlights the capability of our method to handle partial uncertainty, where only certain equations within the system are subject to uncertainty.
4.3 Model misspecification for a nonlinear ODE








In this section, we demonstrate the effectiveness of the proposed approach in addressing model misspecification in a nonlinear 1D ODE through a Bayesian inverse problem. Specifically, we consider the following ODE:
| (35) | ||||
where is the initial condition, is the known source term, and is the term that is misspecified as . Our objective is to infer the values of for , given the observed value , while accounting for uncertainty due to the misspecification of . To model this uncertainty, we reformulate the ODE as the following SDE:
| (36) |
where is a positive constant that controls the level of uncertainty. The parameter can be interpreted as a confidence level: smaller values of indicate higher confidence in the model. The prior distribution of is assumed to be . We discretize the time domain uniformly with to generate the training data.
We assume and consider two distinct cases of model misspecification:
-
(a)
The exact model is , but it is misspecified as .
-
(b)
The exact model is , but it is misspecified as .
In Case (a), the model form is correct but the coefficient is wrong, while in Case (b), the model itself is misspecified. The values of and the reference solutions for , for , are obtained by numerically solving the correctly specified ODE with initial conditions in (a) and in (b).
The results are presented in Figure 10, following a similar presentation style as Figure 9. The leftmost panel shows the consequences of model misspecification, where the inferred solution is computed by solving the misspecified ODE backward in time. The remaining three panels show the posterior mean (dashed lines) and 2-standard-deviation regions (colored areas) computed from the posterior samples () generated by the SGM-HJ-sampler, with different levels of uncertainty corresponding to , , and . We set in solving the controlled SDE. The solid lines represent the reference solutions for from the correctly specified ODE. These results show that as decreases, the uncertainty in the inferred values of decreases accordingly. Overall, this example demonstrates the SGM-HJ-sampler’s capability to effectively account for model misspecification in nonlinear systems.
4.4 A high-dimensional example










This section presents an example where the proposed algorithm is applied to a Bayesian inference problem for a function defined on . The domain is discretized using a uniform grid, and we focus on the grid points. The values of at each grid point can be represented as an -dimensional vector, where is the number of grid points. We denote this vector, with components , as . The underlying stochastic process for is modeled as a scaled Brownian motion, . The objective is to solve the inverse problem of inferring the value of , given an observation of and prior knowledge of . This example also evaluates the algorithm’s capability to handle high-dimensional problems. The prior information assumes that corresponds to the grid values of the function [69, 112]:
| (37) |
where are i.i.d. random variables uniformly distributed on .
We set , , and . The SGM-HJ-sampler is used to solve the problem, utilizing the sliced score matching loss function (26), which enhances scalability when direct computation of the divergence in the loss (25) becomes inefficient. The training data for are generated by sampling from (37) and numerically discretizing the Brownian motion with . The inference step is carried out with . We generate posterior samples of , given two specific values of , randomly selected from the test set. The results are shown in Figure 11, where we depict the posterior mean (red cross) and uncertainty (two standard deviation intervals, colored areas) of for certain , based on 1,000 posterior samples from the SGM-HJ-sampler. Unlike Figures 9 and 10, the x-axis in these figures represents the spatial domain for the underlying function , rather than the temporal domain . Each figure is a snapshot for a specific , and since contains the grid values of an underlying 1D function, we visualize the results by connecting the component values with lines to represent the reference, posterior mean, and uncertainties.
The results indicate that when is close to , such as , the uncertainty is small, and the posterior mean of is close to the observed value . As decreases, the posterior mean becomes smoother. In both cases, when , the reference values (black lines and crosses) lie within the two-standard-deviation regions around the posterior mean, demonstrating the effectiveness of the SGM-HJ-sampler in quantifying uncertainty for this high-dimensional problem.
5 Summary
In this paper, we leverage the log transform to establish connections between certain Bayesian inference problems, stochastic optimal control, and diffusion models. Building on this connection, we propose the HJ-sampler, an algorithm designed to sample from the posterior distribution of inverse problems involving SDE processes. We have developed three specific HJ-samplers: the analytic-HJ-sampler, Riccati-HJ-sampler, and SGM-HJ-sampler, applying them to various SDEs and different prior distributions of the initial condition. Notably, we have demonstrated the potential of these algorithms in addressing (1) uncertainty induced by model misspecification [115] in nonlinear ODEs, (2) mixtures of certainty and uncertainty in ODE systems, and (3) high dimensionality. The results showcase the accuracy, flexibility, and generalizability of our approach, highlighting new avenues for solving such inverse problems by utilizing techniques originally developed for control problems and diffusion models. Despite these advancements, several open problems and extensions remain to be explored.
There are multiple ways to generalize the current method. First, although the method is initially applied to a single observational data point, it can be extended sequentially to handle multiple observations. After obtaining posterior samples from several observation points, the prior distribution can be updated, and the HJ-sampler can be reapplied to the updated prior as new observations become available. When employing the machine learning-based version of the HJ-sampler, this process can be integrated with operator learning to potentially eliminate the need for retraining neural networks, enabling more efficient updates. Second, while the HJ-sampler is tailored for cases where is governed by an SDE, the underlying log transform framework is applicable to any process with a well-defined infinitesimal generator. The SDE case represents a specific instance, and future research will focus on extending the numerical implementation of the HJ-sampler to more general processes. This broader perspective also hints at potential extensions of diffusion models to handle non-continuous distributions or processes driven by more complex noise structures.
Beyond generalization, several improvements to the current HJ-sampler method are possible. For instance, alternative numerical methods for solving viscous HJ PDEs or stochastic optimal control problems could be incorporated, leading to new variants of the HJ-sampler. Additionally, various machine learning techniques could be integrated with the HJ-sampler to enhance efficiency and accuracy. This could involve the development of novel loss functions or improved strategies for generating training data. Moreover, in cases where certain parts of the model are poorly understood or lack sufficient information, neural network surrogate models could be used to shift from a model-driven to a data-driven approach. For example, if the underlying process is not well-characterized, NeuralODE [18], NeuralSDE [54, 65], or reinforcement learning methods could be employed to approximate the dynamics.
Acknowledgement
We would like to express our gratitude to Dr. Molei Tao for providing valuable references on Sequential Monte Carlo (SMC) methods, and to Dr. Arnaud Doucet for contributing the idea presented in the second paragraph of Remark 3.3. T.M. is supported by ONR MURI N00014-20-1-2787. Z.Z., J.D., and G.E.K. are supported by the MURI/AFOSR FA9550-20-1-0358 project and the DOE-MMICS SEA-CROGS DE-SC0023191 award.
References
- [1] S. Adams, N. Dirr, M. A. Peletier, and J. Zimmer, From a large-deviations principle to the Wasserstein gradient flow: a new micro-macro passage, Communications in Mathematical Physics, 307 (2011), pp. 791–815.
- [2] M. Akian, S. Gaubert, and A. Lakhoua, The max-plus finite element method for solving deterministic optimal control problems: basic properties and convergence analysis, SIAM Journal on Control and Optimization, 47 (2008), pp. 817–848.
- [3] A. Bachouch, C. Huré, N. Langrené, and H. Pham, Deep neural networks algorithms for stochastic control problems on finite horizon: numerical applications, Methodology and Computing in Applied Probability, 24 (2022), pp. 143–178.
- [4] J. Berner, L. Richter, and K. Ullrich, An optimal control perspective on diffusion-based generative modeling, arXiv preprint arXiv:2211.01364, (2022).
- [5] E. Bernton, J. Heng, A. Doucet, and P. E. Jacob, Schrödinger bridge samplers, arXiv preprint arXiv:1912.13170, (2019).
- [6] D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, Variational inference: A review for statisticians, Journal of the American statistical Association, 112 (2017), pp. 859–877.
- [7] J. Bruna and J. Han, Posterior sampling with denoising oracles via tilted transport, arXiv preprint arXiv:2407.00745, (2024).
- [8] A. Budhiraja and P. Dupuis, A variational representation for positive functionals of infinite dimensional Brownian motion, Probability and mathematical statistics-Wroclaw University, 20 (2000), pp. 39–61.
- [9] , Analysis and approximation of rare events, Representations and Weak Convergence Methods. Series Prob. Theory and Stoch. Modelling, 94 (2019).
- [10] A. Budhiraja, P. Dupuis, and V. Maroulas, Variational representations for continuous time processes, in Annales de l’IHP Probabilités et statistiques, vol. 47, 2011, pp. 725–747.
- [11] D. Calvetti and E. Somersalo, An introduction to Bayesian scientific computing: ten lectures on subjective computing, vol. 2, Springer Science & Business Media, 2007.
- [12] P. Catuogno and A. d. O. Gomes, Large deviations for Lévy diffusions in small regime, arXiv preprint arXiv:2207.07081, (2022).
- [13] F. A. Chalub, L. Monsaingeon, A. M. Ribeiro, and M. O. Souza, Gradient flow formulations of discrete and continuous evolutionary models: a unifying perspective, Acta Applicandae Mathematicae, 171 (2021), p. 24.
- [14] P. Chaudhari, A. Oberman, S. Osher, S. Soatto, and G. Carlier, Deep relaxation: partial differential equations for optimizing deep neural networks, Research in the Mathematical Sciences, 5 (2018), pp. 1–30.
- [15] P. Chen, J. Darbon, and T. Meng, Hopf-type representation formulas and efficient algorithms for certain high-dimensional optimal control problems, Computers & Mathematics with Applications, 161 (2024), pp. 90–120.
- [16] P. Chen, T. Meng, Z. Zou, J. Darbon, and G. E. Karniadakis, Leveraging Hamilton-Jacobi PDEs with time-dependent Hamiltonians for continual scientific machine learning, in 6th Annual Learning for Dynamics & Control Conference, PMLR, 2024, pp. 1–12.
- [17] , Leveraging Multitime Hamilton–Jacobi PDEs for Certain Scientific Machine Learning Problems, SIAM Journal on Scientific Computing, 46 (2024), pp. C216–C248.
- [18] R. T. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud, Neural ordinary differential equations, Advances in neural information processing systems, 31 (2018).
- [19] T. Chen, G.-H. Liu, and E. A. Theodorou, Likelihood training of Schrödinger bridge using forward-backward SDEs theory, arXiv preprint arXiv:2110.11291, (2021).
- [20] R. Chetrite and H. Touchette, Variational and optimal control representations of conditioned and driven processes, Journal of Statistical Mechanics: Theory and Experiment, 2015 (2015), p. P12001.
- [21] N. Chopin, O. Papaspiliopoulos, et al., An introduction to sequential Monte Carlo, vol. 4, Springer, 2020.
- [22] J. Darbon and G. P. Langlois, On Bayesian posterior mean estimators in imaging sciences and Hamilton–Jacobi partial differential equations, Journal of Mathematical Imaging and Vision, 63 (2021), pp. 821–854.
- [23] J. Darbon, G. P. Langlois, and T. Meng, Overcoming the curse of dimensionality for some hamilton–jacobi partial differential equations via neural network architectures, Research in the Mathematical Sciences, 7 (2020), p. 20.
- [24] J. Darbon and S. Osher, Algorithms for overcoming the curse of dimensionality for certain Hamilton–Jacobi equations arising in control theory and elsewhere, Research in the Mathematical Sciences, 3 (2016), p. 19.
- [25] A. de Acosta, Large deviations for vector-valued Lévy processes, Stochastic Processes and their Applications, 51 (1994), pp. 75–115.
- [26] V. De Bortoli, J. Thornton, J. Heng, and A. Doucet, Diffusion Schrödinger bridge with applications to score-based generative modeling, Advances in Neural Information Processing Systems, 34 (2021), pp. 17695–17709.
- [27] F. Delarue, D. Lacker, and K. Ramanan, From the master equation to mean field game limit theory: Large deviations and concentration of measure, (2020).
- [28] T. Deveney, J. Stanczuk, L. M. Kreusser, C. Budd, and C.-B. Schönlieb, Closing the ODE-SDE gap in score-based diffusion models through the Fokker-Planck equation, arXiv preprint arXiv:2311.15996, (2023).
- [29] M. Erbar, Gradient flows of the entropy for jump processes, in Annales de l’IHP Probabilités et statistiques, vol. 50, 2014, pp. 920–945.
- [30] L. C. Evans, Partial differential equations, vol. 19, American Mathematical Society, 2022.
- [31] M. Fathi, A gradient flow approach to large deviations for diffusion processes, Journal de Mathématiques Pures et Appliquées, 106 (2016), pp. 957–993.
- [32] J. Feng and T. G. Kurtz, Large deviations for stochastic processes, no. 131, American Mathematical Soc., 2006.
- [33] R. Flamary, N. Courty, and A. Gramfort et al., POT: Python optimal transport, Journal of Machine Learning Research, 22 (2021), pp. 1–8.
- [34] W. H. Fleming, A stochastic control approach to some large deviations problems, in Recent Mathematical Methods in Dynamic Programming: Proceedings of the Conference held in Rome, Italy, March 26–28, 1984, Springer, 1985, pp. 52–66.
- [35] W. H. Fleming and R. W. Rishel, Deterministic and stochastic optimal control, vol. 1, Springer Science & Business Media, 2012.
- [36] W. H. Fleming and H. M. Soner, Asymptotic expansions for Markov processes with Levy generators, Applied Mathematics and Optimization, 19 (1989), pp. 203–223.
- [37] Y. Gao and J.-G. Liu, Revisit of macroscopic dynamics for some non-equilibrium chemical reactions from a Hamiltonian viewpoint, Journal of Statistical Physics, 189 (2022), p. 22.
- [38] M. Girolami and B. Calderhead, Riemann manifold Langevin and Hamiltonian Monte Carlo methods, Journal of the Royal Statistical Society Series B: Statistical Methodology, 73 (2011), pp. 123–214.
- [39] M. Hamdouche, P. Henry-Labordere, and H. Pham, Generative modeling for time series via Schrödinger bridge, arXiv preprint arXiv:2304.05093, (2023).
- [40] F. Han, S. Osher, and W. Li, Tensor train based sampling algorithms for approximating regularized Wasserstein proximal operators, arXiv preprint arXiv:2401.13125, (2024).
- [41] J. Han, A. Jentzen, and W. E, Solving high-dimensional partial differential equations using deep learning, Proceedings of the National Academy of Sciences, 115 (2018), pp. 8505–8510.
- [42] C. Hartmann, L. Richter, C. Schütte, and W. Zhang, Variational characterization of free energy: Theory and algorithms, Entropy, 19 (2017), p. 626.
- [43] H. Heaton, S. Wu Fung, and S. Osher, Global solutions to nonconvex problems by evolution of Hamilton-Jacobi PDEs, Communications on Applied Mathematics and Computation, (2023), pp. 1–21.
- [44] M. D. Hoffman, D. M. Blei, C. Wang, and J. Paisley, Stochastic variational inference, Journal of Machine Learning Research, (2013).
- [45] C. Hu and C. Shu, A discontinuous Galerkin finite element method for Hamilton–Jacobi equations, SIAM Journal on Scientific Computing, 21 (1999), pp. 666–690.
- [46] Z. Hu, Z. Zhang, G. E. Karniadakis, and K. Kawaguchi, Score-based physics-informed neural networks for high-dimensional Fokker-Planck equations, arXiv preprint arXiv:2402.07465, (2024).
- [47] E. R. Jakobsen and A. Rutkowski, The master equation for mean field game systems with fractional and nonlocal diffusions, arXiv preprint arXiv:2305.18867, (2023).
- [48] G. Jiang and D. Peng, Weighted ENO schemes for Hamilton–Jacobi equations, SIAM Journal on Scientific Computing, 21 (2000), pp. 2126–2143.
- [49] R. Jordan, D. Kinderlehrer, and F. Otto, The variational formulation of the Fokker–Planck equation, SIAM journal on mathematical analysis, 29 (1998), pp. 1–17.
- [50] D. Kalise and K. Kunisch, Polynomial approximation of high-dimensional Hamilton–Jacobi–Bellman equations and applications to feedback control of semilinear parabolic PDEs, SIAM Journal on Scientific Computing, 40 (2018), pp. A629–A652.
- [51] W. Kang and L. C. Wilcox, Mitigating the curse of dimensionality: sparse grid characteristics method for optimal feedback control and HJB equations, Computational Optimization and Applications, 68 (2017), pp. 289–315.
- [52] T. Karras, M. Aittala, T. Aila, and S. Laine, Elucidating the design space of diffusion-based generative models, Advances in neural information processing systems, 35 (2022), pp. 26565–26577.
- [53] T. Karras, M. Aittala, J. Lehtinen, J. Hellsten, T. Aila, and S. Laine, Analyzing and improving the training dynamics of diffusion models, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 24174–24184.
- [54] P. Kidger, J. Foster, X. Li, and T. J. Lyons, Neural SDEs as infinite-dimensional GANs, in International conference on machine learning, PMLR, 2021, pp. 5453–5463.
- [55] D. P. Kingma, Adam: A method for stochastic optimization, arXiv preprint arXiv:1412.6980, (2014).
- [56] P. E. Kloeden and E. Platen, Numerical solution of stochastic differential equations, vol. 23 of Applications of Mathematics (New York), Springer-Verlag, Berlin, 1992.
- [57] V. N. Kolokoltsov, Nonlinear Markov processes and kinetic equations, vol. 182, Cambridge University Press, 2010.
- [58] D. Kwon, Y. Fan, and K. Lee, Score-based generative modeling secretly minimizes the Wasserstein distance, Advances in Neural Information Processing Systems, 35 (2022), pp. 20205–20217.
- [59] F. Léger, A geometric perspective on regularized optimal transport, Journal of Dynamics and Differential Equations, 31 (2019), pp. 1777–1791.
- [60] F. Léger and W. Li, Hopf–Cole transformation via generalized Schrödinger bridge problem, Journal of Differential Equations, 274 (2021), pp. 788–827.
- [61] C. Léonard, Large deviations for Poisson random measures and processes with independent increments, Stochastic processes and their applications, 85 (2000), pp. 93–121.
- [62] W. Li, S. Liu, and S. Osher, A kernel formula for regularized Wasserstein proximal operators, arXiv preprint arXiv:2301.10301, (2023).
- [63] T. M. Liggett, Continuous time Markov processes: an introduction, vol. 113, American Mathematical Soc., 2010.
- [64] J. S. Liu and J. S. Liu, Monte Carlo strategies in scientific computing, vol. 10, Springer, 2001.
- [65] X. Liu, T. Xiao, S. Si, Q. Cao, S. Kumar, and C.-J. Hsieh, Neural SDE: Stabilizing neural ODE networks with stochastic noise, arXiv preprint arXiv:1906.02355, (2019).
- [66] J. Lu, Y. Wu, and Y. Xiang, Score-based transport modeling for mean-field Fokker-Planck equations, Journal of Computational Physics, 503 (2024), p. 112859.
- [67] J. Lynch and J. Sethuraman, Large deviations for processes with independent increments, The annals of probability, 15 (1987), pp. 610–627.
- [68] W. M. McEneaney, Max-plus methods for nonlinear control and estimation, vol. 2, Springer Science & Business Media, 2006.
- [69] X. Meng, L. Yang, Z. Mao, J. del Águila Ferrandis, and G. E. Karniadakis, Learning functional priors and posteriors from data and physics, Journal of Computational Physics, 457 (2022), p. 111073.
- [70] A. Mielke, A gradient structure for reaction–diffusion systems and for energy-drift-diffusion systems, Nonlinearity, 24 (2011), p. 1329.
- [71] A. Mielke, M. A. Peletier, and D. M. Renger, On the relation between gradient flows and the large-deviation principle, with applications to Markov chains and diffusion, Potential Analysis, 41 (2014), pp. 1293–1327.
- [72] A. Mielke, D. M. Renger, and M. A. Peletier, A generalization of Onsager’s reciprocity relations to gradient flows with nonlinear mobility, Journal of Non-Equilibrium Thermodynamics, 41 (2016), pp. 141–149.
- [73] T. Nakamura-Zimmerer, Q. Gong, and W. Kang, QRnet: Optimal regulator design with LQR-augmented neural networks, IEEE Control Systems Letters, 5 (2021), pp. 1303–1308.
- [74] R. M. Neal, MCMC using Hamiltonian dynamics, arXiv preprint arXiv:1206.1901, (2012).
- [75] S. Osher, H. Heaton, and S. Wu Fung, A Hamilton–Jacobi-based proximal operator, Proceedings of the National Academy of Sciences, 120 (2023), p. e2220469120.
- [76] S. Osher and C. Shu, High-order essentially nonoscillatory schemes for Hamilton-Jacobi equations, SIAM Journal on Numerical Analysis, 28 (1991), pp. 907–922.
- [77] G. A. Pavliotis, Stochastic processes and applications, Texts in Applied Mathematics, 60 (2014).
- [78] M. A. Peletier, Variational modelling: Energies, gradient flows, and large deviations, arXiv preprint arXiv:1402.1990, (2014).
- [79] A. F. Psaros, X. Meng, Z. Zou, L. Guo, and G. E. Karniadakis, Uncertainty quantification in scientific machine learning: Methods, metrics, and comparisons, Journal of Computational Physics, 477 (2023), p. 111902.
- [80] R. Ranganath, S. Gerrish, and D. Blei, Black box variational inference, in Artificial intelligence and statistics, PMLR, 2014, pp. 814–822.
- [81] D. Renger, Microscopic interpretation of Wasserstein gradient flows, (2013).
- [82] C. J. Roy and W. L. Oberkampf, A comprehensive framework for verification, validation, and uncertainty quantification in scientific computing, Computer methods in applied mechanics and engineering, 200 (2011), pp. 2131–2144.
- [83] F. Santambrogio, Optimal transport for applied mathematicians, Birkäuser, NY, 55 (2015), p. 94.
- [84] S.-J. Sheu, Stochastic control and exit probabilities of jump processes, SIAM journal on control and optimization, 23 (1985), pp. 306–328.
- [85] Y. Shi, V. De Bortoli, A. Campbell, and A. Doucet, Diffusion Schrödinger bridge matching, Advances in Neural Information Processing Systems, 36 (2024).
- [86] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, Deep unsupervised learning using nonequilibrium thermodynamics, in International conference on machine learning, PMLR, 2015, pp. 2256–2265.
- [87] V. R. Somnath, M. Pariset, Y.-P. Hsieh, M. R. Martinez, A. Krause, and C. Bunne, Aligned diffusion Schrödinger bridges, in Uncertainty in Artificial Intelligence, PMLR, 2023, pp. 1985–1995.
- [88] Y. Song, P. Dhariwal, M. Chen, and I. Sutskever, Consistency models, arXiv preprint arXiv:2303.01469, (2023).
- [89] Y. Song and S. Ermon, Improved techniques for training score-based generative models, Advances in neural information processing systems, 33 (2020), pp. 12438–12448.
- [90] Y. Song, S. Garg, J. Shi, and S. Ermon, Sliced score matching: A scalable approach to density and score estimation, in Uncertainty in Artificial Intelligence, PMLR, 2020, pp. 574–584.
- [91] Y. Song, L. Shen, L. Xing, and S. Ermon, Solving inverse problems in medical imaging with score-based generative models, arXiv preprint arXiv:2111.08005, (2021).
- [92] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, Score-based generative modeling through stochastic differential equations, arXiv preprint arXiv:2011.13456, (2020).
- [93] H. Y. Tan, S. Osher, and W. Li, Noise-free sampling algorithms via regularized Wasserstein proximals, arXiv preprint arXiv:2308.14945, (2023).
- [94] P. Vincent, A connection between score matching and denoising autoencoders, Neural computation, 23 (2011), pp. 1661–1674.
- [95] P. Virtanen, R. Gommers, and T. E. Oliphant et al., SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python, Nature Methods, 17 (2020), pp. 261–272.
- [96] U. Von Toussaint, Bayesian inference in physics, Reviews of Modern Physics, 83 (2011), pp. 943–999.
- [97] K. P. Wabersich, A. J. Taylor, J. J. Choi, K. Sreenath, C. J. Tomlin, A. D. Ames, and M. N. Zeilinger, Data-driven safety filters: Hamilton-Jacobi reachability, control barrier functions, and predictive methods for uncertain systems, IEEE Control Systems Magazine, 43 (2023), pp. 137–177.
- [98] Y. Wang, L. Wang, Y. Shen, Y. Wang, H. Yuan, Y. Wu, and Q. Gu, Protein conformation generation via force-guided SE(3) diffusion models, arXiv preprint arXiv:2403.14088, (2024).
- [99] L. Wei, H. Feng, P. Hu, T. Zhang, Y. Yang, X. Zheng, R. Feng, D. Fan, and T. Wu, Closed-loop diffusion control of complex physical systems, arXiv preprint arXiv:2408.03124, (2024).
- [100] L. Wei, P. Hu, R. Feng, H. Feng, Y. Du, T. Zhang, R. Wang, Y. Wang, Z.-M. Ma, and T. Wu, A generative approach to control complex physical systems, arXiv preprint arXiv:2407.06494, (2024).
- [101] M. Welling and Y. W. Teh, Bayesian learning via stochastic gradient Langevin dynamics, in Proceedings of the 28th international conference on machine learning (ICML-11), Citeseer, 2011, pp. 681–688.
- [102] T. Wu, W. Neiswanger, H. Zheng, S. Ermon, and J. Leskovec, Uncertainty quantification for forward and inverse problems of PDEs via latent global evolution, in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 320–328.
- [103] L. Yang, Z. Zhang, Y. Song, S. Hong, R. Xu, Y. Zhao, W. Zhang, B. Cui, and M.-H. Yang, Diffusion models: A comprehensive survey of methods and applications, ACM Computing Surveys, 56 (2023), pp. 1–39.
- [104] I. Yegorov and P. M. Dower, Perspectives on characteristics based curse-of-dimensionality-free numerical approaches for solving hamilton–jacobi equations, Applied Mathematics & Optimization, 83 (2021), pp. 1–49.
- [105] J. Yong and X. Y. Zhou, Stochastic controls: Hamiltonian systems and HJB equations, vol. 43, Springer Science & Business Media, 2012.
- [106] B. Zhang, T. Sahai, and Y. Marzouk, Sampling via controlled stochastic dynamical systems, in I (Still) Can’t Believe It’s Not Better! NeurIPS 2021 Workshop, 2021.
- [107] B. J. Zhang and M. A. Katsoulakis, A mean-field games laboratory for generative modeling, arXiv preprint arXiv:2304.13534, (2023).
- [108] B. J. Zhang, S. Liu, W. Li, M. A. Katsoulakis, and S. J. Osher, Wasserstein proximal operators describe score-based generative models and resolve memorization, arXiv preprint arXiv:2402.06162, (2024).
- [109] B. J. Zhang, T. Sahai, and Y. M. Marzouk, A Koopman framework for rare event simulation in stochastic differential equations, Journal of Computational Physics, 456 (2022), p. 111025.
- [110] D. Zhang, R. T. Q. Chen, C.-H. Liu, A. Courville, and Y. Bengio, Diffusion generative flow samplers: Improving learning signals through partial trajectory optimization, arXiv preprint arXiv:2310.02679, (2023).
- [111] M. Zhou, S. Osher, and W. Li, A deep learning algorithm for computing mean field control problems via forward-backward score dynamics, arXiv preprint arXiv:2401.09547, (2024).
- [112] Z. Zou and G. E. Karniadakis, L-HYDRA: Multi-head physics-informed neural networks, arXiv preprint arXiv:2301.02152, (2023).
- [113] Z. Zou, T. Meng, P. Chen, J. Darbon, and G. E. Karniadakis, Leveraging viscous Hamilton-Jacobi PDEs for uncertainty quantification in scientific machine learning, arXiv preprint arXiv:2404.08809, (2024).
- [114] Z. Zou, X. Meng, and G. E. Karniadakis, Uncertainty quantification for noisy inputs-outputs in physics-informed neural networks and neural operators, arXiv preprint arXiv:2311.11262, (2023).
- [115] , Correcting model misspecification in physics-informed neural networks (PINNs), Journal of Computational Physics, 505 (2024), p. 112918.
- [116] Z. Zou, X. Meng, A. F. Psaros, and G. E. Karniadakis, NeuralUQ: A comprehensive library for uncertainty quantification in neural differential equations and operators, SIAM Review, 66 (2024), pp. 161–190.
Appendix A Log transform applied to a general SDE
We consider the stochastic process , represented as an SDE in , defined by . Here, denotes a Brownian motion in . The functions and ensure the SDE’s proper formulation. We introduce defined by for any and . The constant in the SDE is a positive value that indicates the level of stochasticity and corresponds to the hyperparameter in the general definition of the operator in Section 2. The specific formulation of in this SDE context and its adjoint are described by the equations:
| (38) |
with representing the -th component of the matrix . In this appendix, if the variables in a function or a formula are not explicitly specified, they default to .
The KBE and KFE in (1) are given by:
| (39) |
with all calculations based on the variables . The coupled nonlinear differential equations in (4) are:
| (40) |
where calculations and functions are evaluated at .
With terminal condition on and initial condition on , these equations form the first order conditions for optimality in the following stochastic optimal control problem:
| (41) |
whose value equals . Alterations in initial or terminal conditions for and relate these differential equations to specific MFGs or SOT problems, as discussed previously in Example 2.1. Details of the computations are provided in the following section.
A.1 Computational details
Appendix B The log transform for a one-dimensional scaled Poisson process
In this section, we consider a stochastic process defined as a one-dimensional scaled Poisson process, namely , where denotes a Poisson process with a rate of . Similar to the approach in Section 2.1, we define the linear operator as the infinitesimal generator of . Consequently, the operator and its adjoint, , are represented by:
This results in specific adaptations of the general coupled linear system (1) and the general coupled nonlinear system (4) to the case of the scaled Poisson process, represented by the following equations:
| (47) |
for the linear system, and
| (48) |
for the nonlinear system.
With the terminal condition on and the initial condition on , these PDEs serve as the first order optimality conditions for the subsequent stochastic optimal control problem:
| (49) |
The optimal control function satisfies the relation . This represents a stochastic optimal control scenario where the control influences the jump rate of a process through the function , and the running loss is derived from the entropy function of the rate . As in the SDE context, varying the initial and terminal conditions on and associates these two PDEs with specific MFGs and Schrödinger bridge problems, where the underlying stochastic process is a controlled jump process, given is a jump process. We defer exploration of more complicated jump processes to future research.
Appendix C HJ-sampler for SDE cases
In this section, we focus on the scenario where the stochastic process is described by the general SDE , where is an -dimensional Brownian motion. Here, and are functions ensuring that the SDE is well-defined. We define . Unless specified otherwise, the input variables in this appendix are assumed to be . The constant in the SDE corresponds to the hyperparameter in the general definition of the operator in Section 2. In this case, the infinitesimal generator of is defined as . Consequently, the linear operators and its adjoint are defined by
| (50) |
where denotes the -th element of the matrix . The HJ equation (13) becomes
| (51) |
which is a traditional viscous HJ PDE. The Fokker-Planck equation in (14) becomes
| (52) |
Similar to the case in Appendix A, these two PDEs are related to the following stochastic optimal control problem:
| (53) |
where represents a vector-valued function whose -th component is , with being the -th column of . To simplify notation, we denote and by and , respectively. In the scenario where is non-invertible, the following optimal control problem arises:
| (54) |
The proposed HJ-sampler algorithm consists of two main steps:
-
1.
Numerically solve the viscous HJ PDE (51) to obtain ;
-
2.
Generate samples from , which satisfies (52), by sampling from the controlled SDE given below:
(55) where denotes the -th column of the matrix . In practice, the Euler–Maruyama method is employed to discretize this SDE as follows:
(56) where are i.i.d. samples drawn from the -dimensional standard normal distribution.
The obtained samples for provide an approximation to the posterior samples of given . Computational details are presented in the subsequent section.
C.1 Computational details
In this section, we provide the computational details for the results provided in Section 3.2. By the definition of , we have
| (57) |
Therefore, the HJ equation in (4) becomes
| (58) |
Similarly, according to the formula of , we obtain
| (59) |
Then, we have
|
|
(60) |
Therefore, the Fokker-Planck equation in (4) becomes
|
|
(61) |
After specifying the terminal condition for and the initial condition for , the two PDEs relate to the following stochastic optimal control problem:
| (62) |
whose value is equal to . With different initial and terminal conditions on and , these two PDEs relate to certain MFGs or SOT problems, similar to what was discussed in Example 2.1 and Section A.
C.2 Numerical solvers for the viscous HJ PDE (51)
In the proposed HJ-sampler algorithm, a numerical solver is required to address the viscous HJ PDE (51) in this general case. Similar to the approaches discussed in Sections 3.2.1 and 3.2.2, we will describe the Riccati method and the SGM method in the following sections.
C.2.1 Riccati method
The Riccati method can be applied in cases where the function depends linearly on , depends only on , and the prior distribution is Gaussian. This version of the HJ-sampler is called the Riccati-HJ-sampler. Specifically, we assume that takes the form , where and for any . We also assume that the matrix depends only on . Additionally, the prior distribution is assumed to be . Under these assumptions, the viscous HJ PDE (51) in the first step of the Riccati-HJ-sampler can be solved using Riccati ODEs, following a similar approach to that in Section 3.2.1. For simplicity, in this section, we will interchangeably use both and , as well as and , as needed.
Let , where is the solution to (51). Then, satisfies
| (63) |
Under the assumptions on , , and , this PDE simplifies to
| (64) |
In this viscous HJ PDE, both the Hamiltonian and the initial condition are quadratic, allowing the equation to be solved using Riccati ODEs. Specifically, the solution is given by , where , , and satisfy the following Riccati ODE system:
| (65) |
Since sampling only requires , it suffices to solve for and , and then obtain
| (66) |
C.2.2 SGM method
For more general cases, we can approximate the score function using a neural network trained on samples of via the SGM method, similar to the approach in Section 3.2.2. This approach is called the SGM-HJ-sampler. In this case, the training data are sampled from the discretized SDE as follows:
| (67) |
The neural network can also be trained using the loss functions (25) and (26). After training, the term in the sampling step can be approximated by the pretrained model .
There are alternative choices for the loss function in the training of diffusion models. A popular choice is:
| (68) |
where are positive weighting terms, and various methods for selecting them in diffusion models are discussed in [92, 52].
In our case, when the model for is complicated, we do not have an analytical formula for . However, using a similar derivation, we can employ the following loss instead:
| (69) |
In this scenario, the conditional distribution does not have an analytical formula, so we approximate it using the conditional distribution from the discretized process in (67). Note that this loss function requires the matrix to be invertible for all and . The equivalence of these loss functions, including the original score matching loss , is discussed in [94].
C.3 Error estimation for HJ-sampler
In this section, we present a simple error estimation for the HJ-sampler. The total error in the HJ-sampler arises from two main sources: the numerical error in solving the viscous HJ PDE during the first step, and the sampling error in the second step. Here, we focus on analyzing the impact of the first error.
Let or denote the density of the stochastic process described in (55), and let or represent the density of the following stochastic process:
| (70) |
where is an approximation of the control . We compare the error between the true distribution and its numerical approximation , measured by the Wasserstein-2 distance, denoted as .
In the case of the Riccati-HJ-sampler, can be considered as an interpolation of the spatial gradient of the Riccati solution at temporal grid points . For the SGM-HJ-sampler, the function is given by the pretrained neural network .
Following the proof in [58], we adapt the methodology to our setup. We provide an informal error estimation, focusing on the essential ideas while simplifying the analysis by omitting some technical details. We assume sufficient regularity of the functions so that the Fokker-Planck equations have smooth solutions and for any , , and . Additionally, we assume that the functions and are Lipschitz continuous with Lipschitz constants and , respectively. We further assume that depends only on and is bounded by , meaning that is positive semi-definite. We assume that and are both integrable over . Moreover, we assume that the optimal transport map from to is given by , the gradient of a convex, second-order differentiable function with invertible Hessian matrices. Note that the function may vary with , but we omit this time dependence for simplicity of notation.
Under these assumptions, the function satisfies the following equation:
| (71) |
Thus, is also the marginal density of the ODE , where is given by:
| (72) |
Similarly, the function is the marginal density of the ODE , where is given by:
| (73) |
According to [83, Cor.5.25], the Wasserstein distance between and , denoted by , satisfies
| (74) |
where is the optimal transport plan between and . For simplicity, we omit the variable in the density functions.
Next, we will bound the right-hand side of (74). Through straightforward computation, we obtain
| (75) |
Since the function is Lipschitz continuous with respect to , with uniform Lipschitz constant , the first term on the right-hand side of (75) is bounded above by . Furthermore, since the matrix is bounded above by and the function is Lipschitz with respect to with constant , the second term on the right-hand side of (75) is estimated by
| (76) |
According to optimal transport theory, there exists a convex function such that the optimal transport plan is given by , which denotes the push-forward of by (where Id denotes the identity map ). Denote by the Fenchel-Legendre transform of . Then, can also be represented by . The expectation in the last term on the right-hand side of (75) simplifies as follows:
| (77) |
where the last term is non-negative because the matrix is positive semi-definite for any .
Combining all the estimates, we have
|
|
(78) |
where is a function of . Next, we take the expectation with respect to and obtain
|
|
(79) |
where the second inequality follows from the Cauchy-Schwarz inequality, and the last one holds because following (12). Let . We obtain
| (80) |
Moreover, we have . Then, by a similar argument as in Appendix A1 of [58], we conclude that
| (81) |
where the function is defined by .
Note that is the expected squared Wasserstein-2 error of the posterior distribution with respect to the observation . According to Markov’s inequality, the probability of the error exceeding can be bounded as follows:
| (82) |
Remark C.1
In the error estimation above, beyond the regularity assumptions, one restrictive assumption is that the function depends only on . This excludes SDEs where the diffusion coefficient has dependence. This assumption is primarily utilized in the estimation in (77). Other parts of the proof can be straightforwardly generalized to cases where depends on . However, if does depend on , the term estimated in (77) may become negative. If this term can be appropriately bounded, the proof could be extended to more general cases.
Remark C.2
In the error analysis above, we examined how the numerical error from the first step of the HJ-sampler affects the continuous sampling process. The key term in the upper bound is the expectation . For the Riccati-HJ-sampler, this term can be calculated based on the errors in the solutions and to the Riccati ODE system. For the SGM-HJ-sampler, this term is related to the loss function and can be bounded by quantities derived from the loss value.
The overall error of the sampling algorithm consists of two parts: the error from the first step and the discretization error from the second step. The error in the first step, as estimated in our analysis, can guide the choice of the numerical solver for the viscous HJ PDE, including decisions on the temporal discretization size for traditional methods or the data size and neural network size for AI-based methods. The second step’s error, resulting from the SDE discretization scheme, can guide the selection of the sampling method and its temporal discretization size. Balancing these two sources of error, along with considering the computational efficiency of different methods, is crucial for achieving optimal performance.
The error analysis for the second step follows directly from the established analysis of SDE discretization schemes, so we omit the details here. In this paper, we use Euler–Maruyama discretization in the second step, yielding an order of in the strong sense and order in the weak sense. If higher accuracy is needed, higher-order schemes such as the Runge-Kutta method could be considered.
Appendix D Neural network training details for numerical examples
This section provides the details of the neural network used in the SGM-HJ-sampler for obtaining posterior samples, as well as the specifics of the training procedure. Across all numerical examples, is implemented with the activation function for the nonlinear hidden layers, and the Adam optimizer [55] is employed with a learning rate of , unless stated otherwise.
In Section 4.1, we explore three 1D cases with varying prior distributions and one 2D case. For the 1D Gaussian prior case, a fully-connected neural network (FNN) with two hidden layers of 50 neurons each is utilized. The training of involves sample paths of over , using mini-batch training with a batch size of for epochs. For the 1D Gaussian mixture case, the 1D mixture of uniform distributions case, and the 2D Gaussian mixture case, an FNN with three hidden layers and 50 neurons per layer is employed. The network is trained on sample paths of over for epochs with a batch size of .
In Section 4.2, the examples include one 1D case and two 2D cases. For the 1D case, an FNN with two hidden layers of 50 neurons each is trained on sample paths of over for epochs, using a batch size of and a learning rate of . For the 2D Gaussian mixture prior case, an FNN with three hidden layers of 50 neurons each is trained on sample paths of over for epochs with a batch size of . For the 2D case with a LogNormal prior, which considers model misspecification, an FNN with three hidden layers of 50 neurons each is trained separately for each value of . Each network is trained on sample paths of over for epochs, using a batch size of and a learning rate of .
In Section 4.3, for each value of , an FNN with three hidden layers and 50 neurons per layer is trained on sample paths of over for epochs with a batch size of . In Section 4.4, an FNN with three hidden layers and 200 neurons per layer is used, trained on sample paths of over for epochs with a batch size of and a learning rate of .
Appendix E Details of analytical formulas used in numerical results
E.1 Brownian motion
In this section, we focus on cases involving Brownian motion. Specifically, we assume the process is governed by the SDE , where is a hyperparameter, and is standard Brownian motion, with different prior distributions for .
E.1.1 One-dimensional uniform prior
Here, we provide the computational details for a one-dimensional uniform prior and a mixture of uniform priors. The generalization to higher-dimensional box-shaped domains is straightforward and therefore omitted.
First, assume the prior is a uniform distribution on . The marginal distribution for is given by:
| (83) |
where is the cumulative distribution function of the standard one-dimensional Gaussian distribution. The solution to the viscous HJ PDE (15) is:
| (84) |
The inference process, as described in (18), becomes:
| (85) |
The posterior distribution of given for is:
|
|
(86) |
When , the posterior distribution is:
| (87) |
where is the indicator function that takes the value on and otherwise.
Next, consider the prior to be a mixture of uniform distributions: , where the weights satisfy . Following the same process as above, the marginal distribution for is:
| (88) |
The solution to the viscous HJ PDE (15) is:
| (89) |
The inference process, as described in (18), becomes:
| (90) |
The posterior distribution of given for is:
|
|
(91) |
The posterior distribution of given is:
|
|
(92) |
E.1.2 -dimensional Gaussian mixture prior
We consider the -dimensional Brownian motion problem with a Gaussian mixture prior. Let the prior be as given in (21), and let the process be governed by . The marginal distribution is
| (93) |
where is the normalization constant.
The solution to the viscous HJ PDE (15) is
| (94) |
The inference process, as described in (18), becomes
|
|
(95) |
The posterior distribution of given for is
|
|
(96) |
which is a Gaussian mixture, where the -th Gaussian has covariance matrix and mean . The weight is
| (97) |
E.2 OU process
In general, if the matrix in the OU process is not diagonal, neither the posterior density function nor the sampling SDE (18) have analytical solutions. However, analytical formulas can be derived when is a diagonal matrix and the prior is a Gaussian mixture where each component has a diagonal covariance matrix.
Specifically, for one-dimensional cases, the analytical solutions can be obtained for the OU process with a Gaussian prior . Note that in this case, the matrix reduces to a scalar. The solution to the Riccati ODE system is given by , , and . The solution to the viscous HJ PDE (15) is
|
|
(98) |
The inference process, as described in (18), becomes
| (99) |
For any , the process satisfies , where is a standard Gaussian random variable independent of . The marginal distribution of is
| (100) |
The conditional distribution of given is
| (101) |
The posterior distribution of given for any is
|
|
(102) |
After simplification, this posterior distribution is Gaussian, with mean and variance given by:
| (103) |
Appendix F Supplementary results for the 1D Brownian motion example
In this section, we provide supplementary results for the 1D Brownian motion example in Section 4.1.1, illustrating the inference of given the observation of using both the analytic-HJ-sampler and the SGM-HJ-sampler. Figure 12 displays histograms of the posterior samples. For quantitative comparison, please refer to Table 2 in the main content.