ifaamas \acmConference[AAMAS ’24]Proc. of the 23rd International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2024)May 6 – 10, 2024 Auckland, New ZealandN. Alechina, V. Dignum, M. Dastani, J.S. Sichman (eds.) \copyrightyear2024 \acmYear2024 \acmDOI \acmPrice \acmISBN \acmSubmissionID427 \affiliation \institutionCornell University \cityIthaca \stateNY \countryUSA \affiliation \institutionCornell University \cityIthaca \stateNY \countryUSA
High-Level, Collaborative Task Planning Grammar and Execution for Heterogeneous Agents
Abstract.
We propose a new multi-agent task grammar to encode collaborative tasks for a team of heterogeneous agents that can have overlapping capabilities. The grammar allows users to specify the relationship between agents and parts of the task without providing explicit assignments or constraints on the number of agents required. We develop a method to automatically find a team of agents and synthesize correct-by-construction control with synchronization policies to satisfy the task. We demonstrate the scalability of our approach through simulation and compare our method to existing task grammars that encode multi-agent tasks.
Key words and phrases:
Formal methods, multiagent coordination, task planning, robotics1. Introduction
Agents working together to achieve common goals have a variety of applications, such as warehouse automation or disaster response. Multi-agent tasks have been defined in different ways in the scheduling and planning literature. For example, in multi-agent task allocation Jia and Meng (2013); Gerkey and Matarić (2004); Korsah et al. (2013) and coalition formation Xu et al. (2015); Li et al. (2009), each task is a single goal with an associated utility. Individual agents or agent teams then automatically assign themselves to a task based on some optimization metric. Swarm approaches Schmickl et al. (2006); Wang and Rubenstein (2020) consider emergent behavior of an agent collective as the task, for example, aggregation or shape formation.
Recently, formal methods, such as temporal logics for task specifications and correct-by-construction synthesis, have been used to solve different types of multi-agent planning tasks Ulusoy et al. (2012); Schillinger et al. (2018); Chen et al. (2021). Tasks written in temporal logic, such as Linear Temporal Logic (LTL), allow users to capture complex tasks with temporal constraints. Existing work has extended LTL Luo and Zavlanos (2022); Sahin et al. (2017) and Signal Temporal Logic Leahy et al. (2022) to encode tasks that require multiple agents.
In this paper, we consider tasks that a team of heterogeneous agents are required to collaboratively satisfy. For instance, consider a precision agriculture scenario in which a farm contains agents with different on-board sensors to monitor crop health. The user may want to take a moisture measurement in one region, and then take a soil sample of a different region. Depending on the agents’ sensors and sensing range, the agents may decide to collaborate to satisfy the task. For example, one agent may perform the entire task on its own if it has both a moisture sensor and an arm mechanism to pick up a soil sample and can move between the two regions. However, another possible solution is for two agents to team up so that one takes a moisture measurement and the other picks up the soil. Existing task grammars Luo and Zavlanos (2022); Sahin et al. (2017); Leahy et al. (2022) capture tasks such as the above by providing explicit constraints on the types or number of agents for each part of the task, i.e. the task must explicitly encode whether it should be one agent, two agents, or either of these options. In this paper, we create a task grammar and associated control synthesis that removes the need to a priori decide on the number of agents necessary to accomplish a task, allowing users to focus solely on the actions required to achieve the task (e.g. “take a moisture measurement and then pick up a soil sample, irrespective of which or how many agents perform which actions”).
Our task grammar has several unique aspects. First, this grammar enables the interleaving of agent actions, alleviating the need for explicit task decomposition in order to assign agents to parts of the task. Second, rather than providing explicit constraints on the types or number of agents for each part of the task, the task encodes, using the concept of bindings (inspired by Luo and Zavlanos (2022)), the overall relationship between agent assignments and team behavior; we can require certain parts of the task to be satisfied by the same agent without assigning the exact agent or type of agent a priori. Lastly, the grammar allows users to make the distinction between the requirements “for all agents” and “at least one agent”. Given these types of tasks, agents autonomously determine, based on their capabilities, which parts of the task they can and should do for the team to satisfy the task.
Tasks may require collaboration between different agents. Similar to Kloetzer and Belta (2010); Tumova and Dimarogonas (2016); Chen et al. (2011), to ensure the actions are performed in the correct order, our framework takes the corresponding synchronization constraints into account while synthesizing agent behavior; agents must wait to execute the actions together. In our approach, execution of the synchronous behavior for each agent is decentralized; agents carry out their plan and communicate with one another when synchronization is necessary.
Depending on the task and the available agents, there might be different teams (i.e., subsets of the agent set) that can carry out the task; our algorithm for assigning a team and synthesizing behavior for the agents finds the largest team of agents that satisfies the task. This means that the team may have redundancies, i.e. agents can be removed while still ensuring the overall task is satisfied. This is beneficial both for robustness and optimality; the user can choose a subset of the team (provided that all the required bindings are still assigned) to optimize different metrics, such as cost or overall number of agents.
Related work: One way to encode tasks is to first decompose them into independent sub-tasks and then allocate them to the agents. For example, Schillinger et al. (2018); Faruq et al. (2018) address finite-horizon tasks for multi-agent teams. The authors first automatically decompose a global automaton representing the task into independent sub-tasks. To synthesize control policies, the authors build product automata for each heterogeneous agent. Each automaton is then sequentially linked using switch transitions to reduce state-space explosion in synthesizing parallel plans. In our prior work Fang and Kress-Gazit (2022), we address infinite-horizon tasks that have already been decomposed into sub-tasks. Given a new task, we proposed a decentralized framework for agents to automatically update their behavior based on a new task and their existing tasks, allowing agents to interleave the tasks.
The works discussed above make the critical assumption that tasks are independent, i.e. agents do not collaborate with one another. One approach to including collaborative actions is to explicitly encode the agent assignments in the tasks. To synthesize agent control for these types of tasks, in Tumova and Dimarogonas (2016), the authors construct a reduced product automaton in which the agents only synchronize when cooperative actions are required. The work in Kantaros and Zavlanos (2020) proposes a sampling-based method that approximates the product automaton of the team by building trees incrementally while maintaining probabilistic completeness. In this paper, we consider the more general setting in which agents may need to collaborate with each other, but are not given explicit task assignments a priori.
Rather than providing predetermined task assignments, another approach for defining collaborative tasks is to capture information about the number and type of agents needed for parts of the specification. For example, Sahin et al. (2017) imposes constraints on the number of agents necessary in regions using counting LTL. Leahy et al. (2022) uses Capability Temporal Logic to encode both the number and capabilities necessary in certain abstracted locations in the environment and then formulates the problem as a MILP to find an optimal teaming strategy. The authors of Luo and Zavlanos (2022) introduce the concept of induced propositions, where each atomic proposition not only encodes information about the number, type of agents, and target regions, but also has a connector that binds the truth of certain atomic propositions together. To synthesize behavior for the agents, they propose a hierarchical approach that first constructs the automaton representing the task and then decomposes the task into possible sub-tasks. The temporal order of these sub-tasks is captured using partially ordered sets and are used in the task allocation problem, which is formulated as a MILP.
Inspired by Luo and Zavlanos (2022) and the concept of induced propositions, we create a task grammar that includes information about how the atomic propositions are related to one another, which represents the overall relationship between agents and task requirements. Unlike Luo and Zavlanos (2022), which considers navigation tasks in which the same set of agents of a certain type may need to visit different regions, we generalize these tasks to any type of abstract action an agent may be able to perform. In addition, a key assumption we relax is that we do not require each agent to be only categorized as one type. As a result, agents can have overlapping capabilities. To our knowledge, no other grammars have been proposed for these generalized types of multi-agent collaborative tasks.
Contributions: We propose a task description and control synthesis framework for heterogeneous agents to satisfy collaborative tasks. Specifically, we present a new, LTL-based task grammar for the formulation of collaborative tasks, and provide a framework to form a team of agents and synthesize control and synchronization policies to guarantee the team satisfies the task. We demonstrate our approach in simulated precision agriculture scenarios.
2. Preliminaries
2.1. Linear Temporal Logic
LTL formulas are defined over a set of atomic propositions , where are Boolean variables Emerson (1990). We abstract agent actions as atomic propositions. For example, captures an agent taking UV measurement.
Syntax: An LTL formula is defined as:
where (“not”) and (“or”) are Boolean operators, and (“next”) and (“until”) are temporal operators. From these operators, we can define: conjunction , implication , eventually , and always .
Semantics: The semantics of an LTL formula are defined over an infinite trace , where is the set of true at position . We denote that satisfies LTL formula as .
Intuitively, is satisfied if there exists a in which is true. is satisfied if is true at every position in . To satisfy , must remain true until becomes true. See Emerson (1990) for the full semantics.
2.2. Büchi Automata
An LTL formula can be translated into a Nondeterministic Büchi Automaton that accepts infinite traces if and only if they satisfy . A Büchi automaton is a tuple , where is the set of states, is the initial state, is the input alphabet, is the transition relation, and is a set of accepting states. An infinite run of over a word , is an infinite sequence of states such that . A run is accepting if and only if Inf() , where Inf() is the set of states that appear in infinitely often Baier and Katoen (2008).
2.3. Agent Model
Following Fang and Kress-Gazit (2022), we create an abstract model for each agent based on its set of capabilities. A capability is a weighted transition system , where is a finite set of states, is the initial state, is the set of atomic propositions, is a transition relation where for all , such that , is the labeling function such that is the set of propositions that are true in state , and is the cost function assigning a weight to each transition. Since we are considering a group of heterogeneous agents, agent has its own set of capabilities .
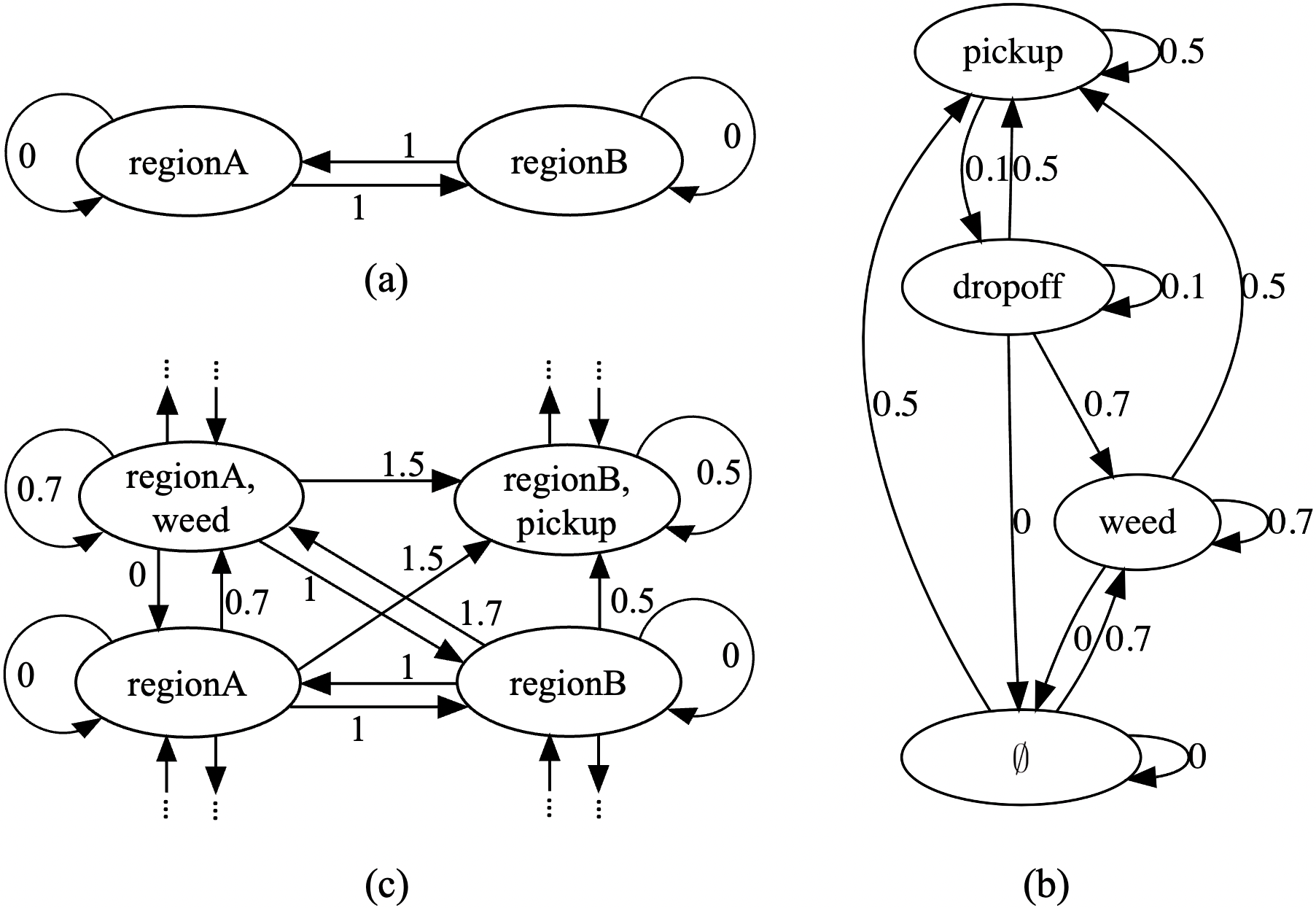
An agent model is the product of its capabilities: such that , where is the set of states, is the initial state, is the set of propositions, is the transition relation such that , where , if and only if for all , is the labeling function where , and is the cost function that combines the costs of the capabilities. Fig. 1c depicts a snippet of an agent model where we treat the cost as additive. Fig. 1a represents the agent’s sensing area ; the agent can orient its sensors to take measurements in different regions of a partitioned workspace (in this case, regions A and B). Fig. 1b represents the agent’s robot manipulator, which can pick up and drop off soil samples, as well as pull weeds.
3. Task Grammar - LTLψ
We define the task grammar LTLψ that includes atomic propositions that abstract agent action, logical and temporal operators, as in LTL, and bindings that connect actions to specific agents; any action labeled with the same binding must be satisfied by the same agent(s) (the actual value of the binding is not important). We define a task recursively over LTL and binding formulas.
| (1) | ||||
| (2) | ||||
| (3) |
where , the binding formula, is a Boolean formula excluding negation over , and is an LTL formula. An LTLψ formula consists of conjunction, disjunction, and temporal operators; we define eventually as . An example of an LTLψ formula is shown in Eq. 4.
Semantics: The semantics of an LTLψ formula are defined over and ; is the team trace where is agent ’s trace, and . is the set of binding assignments, where is the set of that are assigned to agent . Once a team is established, is constant, i.e. an agent’s binding assignment does not change throughout the task execution. For example, denotes that agent 1 is assigned bindings 2 and 3, and agent 2 is assigned binding 1.
Given agents and a set of binding propositions , we define the function such that is the set of all possible combinations of that satisfy . For example, .
The semantics of LTLψare:
-
•
iff s.t. () and ( s.t. , )
-
•
iff s.t. () and ( s.t. , )
-
•
iff s.t. () and ( s.t. , )
-
•
iff and
-
•
iff or
-
•
iff
-
•
iff s.t. and
-
•
iff
Intuitively, the behavior of an agent team and their respective binding assignments satisfy if there exists a possible binding assignment in in which all the bindings are assigned to (at least one) agent, and the behavior of all agents with a relevant binding assignment satisfy . An agent can be assigned more than one binding, and a binding can be assigned to more than one agent.
Remark 1. For the sake of clarity in notation, is equivalent to . For example, .
Remark 2. Note the subtle but important difference between and . Informally, the former requires all agents with binding assignments that satisfy to satisfy ; the latter requires the formula to be violated, meaning that at least one agent’s trace violates , i.e. satisfies .
Remark 3. Unique to LTLψis the ability to encode both tasks that include constraints on all agents or on at least one agent; “For all agents” is captured by ; “at least one agent” is encoded as , which captures “at least one agent assigned a binding in satisfies ”. This allows for multiple agents to be assigned the same binding, but only one of those agents is necessary to satisfy . This can be particularly useful in tasks with safety constraints; for example, we can write , which says “if any agent assigned binding 1 is in region A, all agents assigned binding 2 must take a picture of the region.”
Example.
Let ,
, and , where
| (4a) | |||
| (4b) | |||
captures “Agent(s) assigned bindings 2 and 3 should take a moisture measurement and a UV measurement in the region B at the same time that agent(s) assigned binding 1 picks up a soil sample in region A.” captures “Before the soil sample can be picked up, agent(s) assigned binding 2 needs to either take a thermal image or a visual image (but not both) of region A.”
Note that, since multiple bindings can be assigned to the same agent, an agent can be assigned both bindings 2 and 3, provided that it has the capabilities to satisfy the corresponding parts of the formula. In addition, depending on the final assignments, the agents may need to synchronize with one another to perform parts of the task. For example, agents assigned with any subset of bindings need to synchronize their respective actions to satisfy .
4. Control Synthesis for LTLψ
Problem statement: Given heterogeneous agents and a task in LTLψ, find a team of agents , their binding assignments , and synthesize behavior for each agent such that . This behavior includes synchronization constraints for agents to satisfy the necessary collaborative actions. We assume that each agent is able to wait in any state (i.e. every state in the agent model has a self-transition).
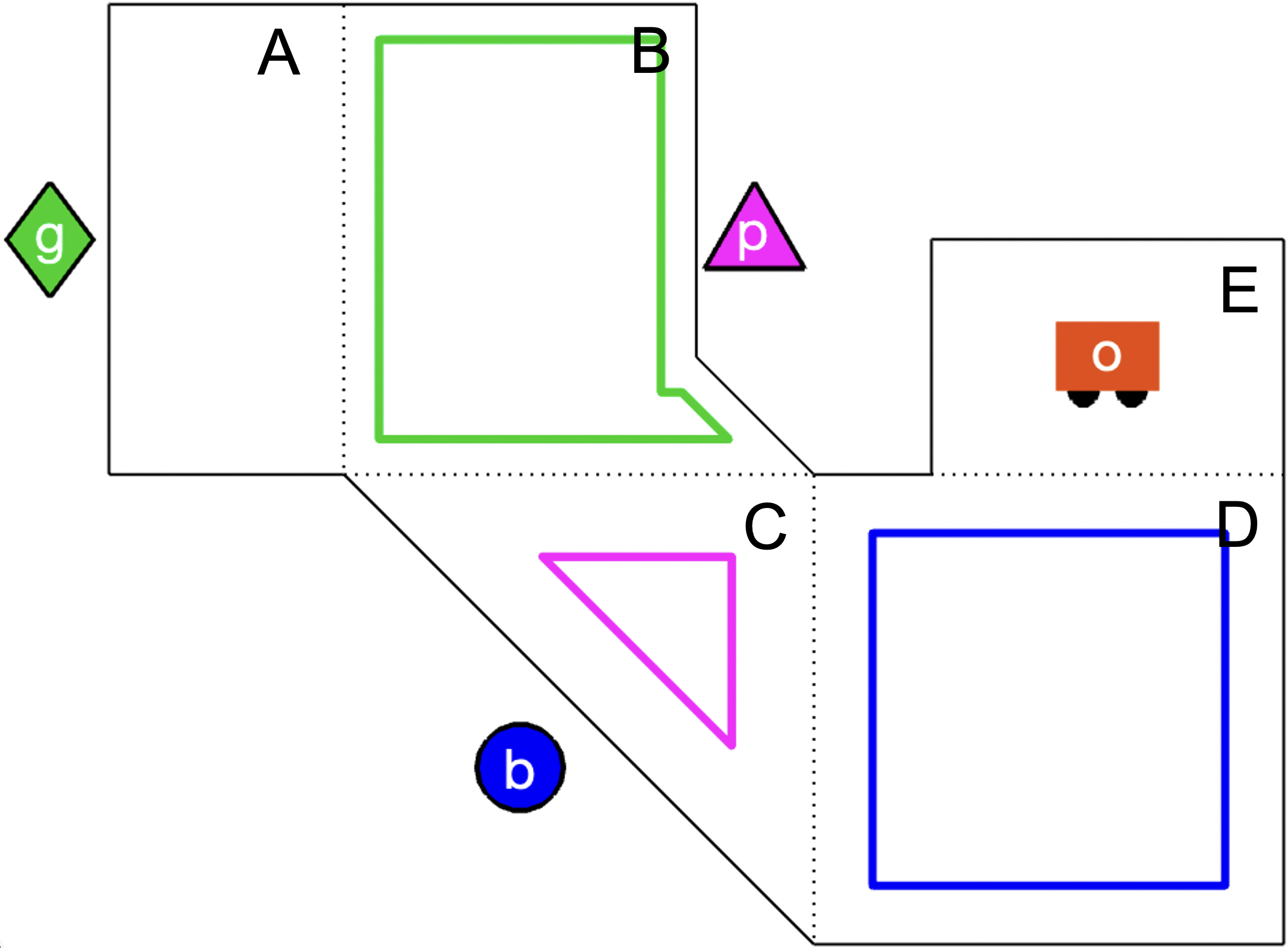
Example. Consider a group of four agents , , , in a precision agriculture environment composed of 5 regions, as illustrated in Fig. 2. is a mobile robot manipulator, such as Harvest Automation’s HV-100, while the other agents are stationary with different onboard sensing capabilities. The set of all capabilities is ,, , , , , , where , is agent ’s sensing area model. The green agent can orient its arm to reach either region A or B. The blue agent can orient its sensors to see one of three regions, B, C, or D; in order to reorient its sensors from regions B to D, its sensing range must first pass through region C. Similarly, the pink agent can orient its sensors to see either region A, B, or C, and its sensing range must pass through region B to get from regions A to C. The orange agent’s ability to move between adjacent regions is represented by the capability . Its sensing region is whichever region it is in. is an abstraction of a robot manipulator that represents different actions the arm can perform, such as picking up soil samples or pulling weeds. , , , all contain a single proposition representing a agent’s ability to take UV measurements, soil moisture measurements, visual images, and thermal images, respectively. has more states (see Fig. 1b). Each agent may have distinct cost functions corresponding to individual capabilities.
The agent capabilities and label on the initial state are:
,
The team receives the task (Eq. 4) and must determine a teaming assignment and behavior to satisfy the task. During execution, the agents must also synchronize with each other when necessary.
5. Approach
To find a teaming assignment and synthesize the corresponding synchronization and control, we first automatically generate a Büchi automaton for the task (Sec. 5.1). Each agent then constructs a product automaton (Sec. 5.2). For each binding , it checks whether or not it can perform the task associated with that binding by finding a path to an accepting cycle in . Each agent creates a copy of the Büchi automaton pruned to remove any unreachable transitions and stores information about which combinations of binding assignments it can do.
For parts of the task that require collaboration (e.g., when a transition calls for actions with bindings and ), we need agents to synchronize. Thus, we synthesize behavior that allows for parallel execution while also guaranteeing that the team’s overall behavior satisfies the global specification.
To find a team of agents that can satisfy the task and their assignments, we need to guarantee that 1) every binding is assigned to at least one agent and 2) the agents synchronize for the collaborative portions of the task. To do so, we first run a depth-first search (DFS) to find a path through the to an accepting cycle in which there exists a team of agents such that for every transition in the path, every proposition in is assigned to at least one agent (Sec. 5.4). Each agent then synthesizes behavior to satisfy this path and communicates to other agents when synchronization is necessary.
5.1. Büchi Automaton for an LTLψ Formula
When constructing a Büchi automaton for an LTLψ specification, we automatically rewrite the specification such that the binding propositions are only over individual atomic proposition (i.e. the formula is composed of ). For instance, the formula is rewritten as
In our running example, we rewrite the formula in Eq. 4a as
| (5) | ||||
Remark 4. In rewriting the specification, negation follows bindings in the order of operations. For example, , and .
From and , we define the set of propositions , where and , . Given , we automatically translate the specification into a Büchi automaton using Spot Duret-Lutz et al. (2016).
To facilitate control synthesis, we transform any transitions in the Büchi automaton labeled with disjunctive formulas into disjunctive normal form (DNF). We then replace the transition labeled with a DNF formula containing conjunctive clauses with transitions between the same states, each labeled with a different conjunction of the original label.
In general, when creating a Büchi automaton from an LTL formula , are Boolean formulas over , the atomic propositions that appear in , as seen in Fig. 3. In the following, for creating the product automaton, we use an equivalent representation, where and contains the set of propositions that must be true, , and the set of propositions that must be false, , for the Boolean formula over a transition to evaluate to True. These sets are unique in our case since each transition is labeled with a conjunctive clause (i.e. no disjunction). Note that and ; propositions that do not appear in can have any truth value.
Given a Büchi automaton for an LTLψ specification , we define the following functions:

Definition 1 (Binding Function). such that for is the set . Intuitively, it is the set of bindings that appear in label of a Büchi transition.
Definition 2 (Capability Function). such that for , , where and . Here, and are the sets of action propositions that are True/False and appear with binding in label of a Büchi transition.
5.2. Agent Behavior for an LTLψ Specification
To synthesize behavior for an agent, we find an accepting trace in its product automaton , where is the agent model, and is the Büchi automaton.
Since the set of propositions of may not be equivalent to the set of propositions of , we borrow from the definition of the product automaton in Fang and Kress-Gazit (2022). We first define the following function:
Definition 3 (Binding Assignment Function). Let , , . Then and .
Intuitively, outputs all possible combinations of binding propositions that the agent can be assigned for a transition . An agent can be assigned if and only if the agent’s next state is labeled with all the action and motion propositions that appear in as , and all the propositions that appear in as are not part of the state label (i.e. the agent is not performing that action). If a proposition is in and is not in (e.g. and the agent does not have ), the agent may be assigned . Note that may include any binding propositions that are not in , since there are no actions required by those bindings in that transition. For example, if and , then will be in the set for all .
Given and , we define the product automaton :
Definition 4 (Product Automaton). The product automaton , where
-
•
is a finite set of states
-
•
is the initial state
-
•
is the transition relation, where for and , if and only if and such that and
-
•
is the labeling function s.t. for ,
-
•
is the cost function s.t. for , , ,
-
•
is the set of accepting states
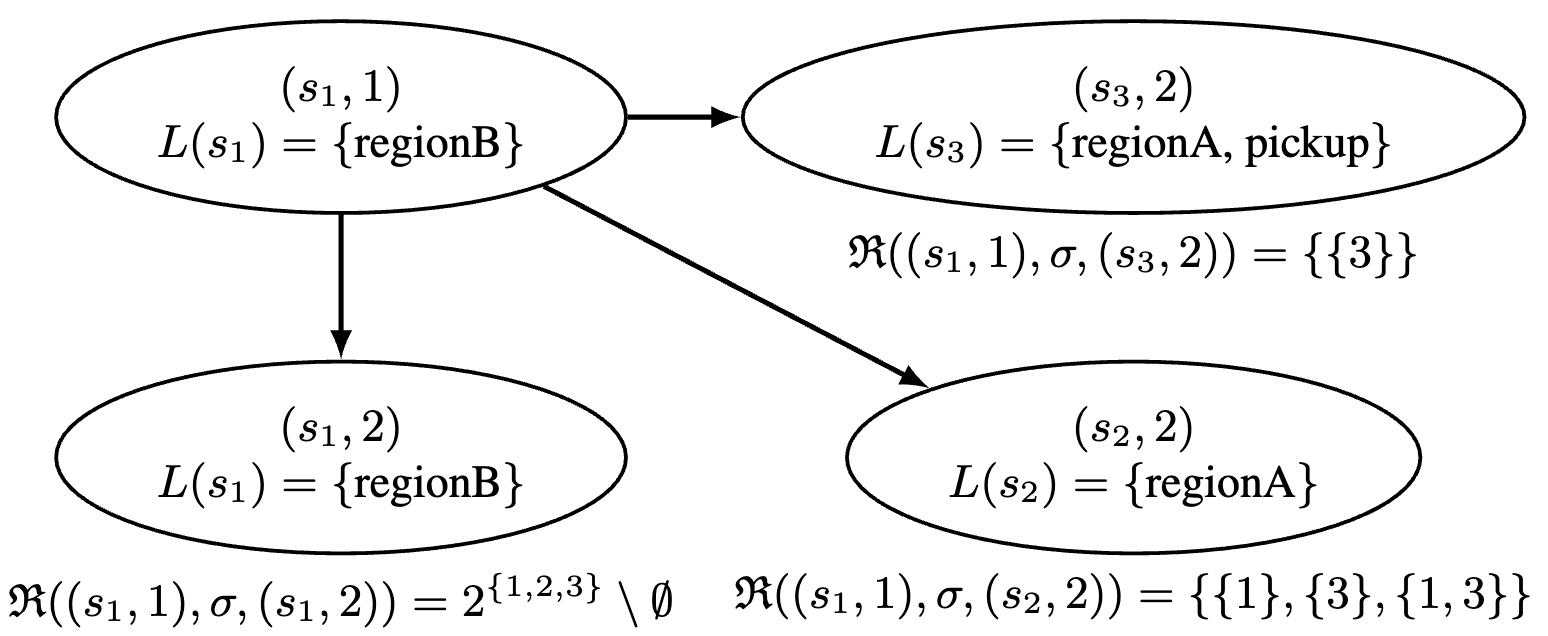
Example. Fig. 4 depicts a small portion of ; for the self-transition in that is labeled with , (labeled as in Fig. 3), and for states in where , , , then the possible binding assignments are and . When the agent is in , it cannot be assigned either bindings 1 or 2, but since no propositions appear with binding 3 in , .
5.3. Finding Possible Individual Agent Bindings
To construct a team, we first reason about each agent and the sets of bindings it can perform. For example, for a formula , an agent may be assigned or but not , since it cannot be in two regions at the same time.
To find the set of possible binding assignments , we search for an accepting trace in for every binding assignment . We start from the full set of bindings . Given an assignment to check, we find an accepting trace in such that for all transitions in the trace, . This ensures that the agent can satisfy its binding assignment for the entirety of its execution (i.e. does not change). Since every subset of a binding assignment is itself a possible binding assignment, if the agent can be assigned all bindings, then we know it can also be assigned every possible subset of . If not, we check the combinations, and continue iterating until we have determined the agent’s ability to perform every combination of the bindings.
Once an agent determines its possible binding assignments , it creates the Büchi automaton by removing any transition in that cannot be traversed by any assignment in . In our example (Fig. 3), each agent can be assigned at least one binding over every transition in . Thus, .
5.4. Agent Team Assignment
A team of agents can perform the task if 1) all the bindings are assigned, with each agent maintaining the same binding assignment for the entirety of the task, and 2) the agents satisfy synchronization requirements. For a viable team, the agents’ control follows the same path in the Büchi automaton to an accepting cycle. We perform DFS over to find an accepting trace (Alg. 1), where each tuple in contains the current edge , the current team of agents , and the path traversed so far .
We initialize the team with all agents and all possible binding assignments , and each path starts from state of . When checking a transition , we remove any agent if , there are no possible binding assignments it can satisfy. This is done by checking each agent’s pruned Büchi automaton in update_team (line 1). We want the agent’s behavior to satisfy not only the current transition, but also the entire path with a consistent binding assignment. Thus, we update possible bindings (update_bindings, lines 1-1).
To guarantee the overall team behavior, we need to ensure agents are able to “wait in a state” before they synchronize, as they may reach states at different times. This means that each state in the trace must have a corresponding self-transition. Thus, for every that we add to the path in which , the next edge to traverse must be a self-transition from to itself; the same holds vice-versa. In line 1, we check if the current transition is self-looping or not, and add subsequent transitions into the stack accordingly. If there is no self-transition on (i.e. ), then we do not consider to be valid and do not add it to the path.
Once we find a valid path to an accepting cycle, we parse it into , the path without self-transitions, and , which contains the corresponding self-transition for each state in the path. Fig. 3 shows a valid path in for the example in Sec. 4 and the corresponding team assignment and bindings , . Note that we find a valid path rather than a globally optimal one. However, the algorithm is complete; it will find a feasible path if one exists.
5.5. Synthesis and Execution of Control and Synchronization Policies
Given an accepting trace through and the corresponding self-transitions that are valid for all agents in , we synthesize control and synchronization for each agent such that the overall team execution satisfies (Alg. 2). For each transition in , we find , which contains the binding assignments of all agents that require synchronization at state . Agent participates in the synchronization step if contains a binding that is required by and is not the only agent assigned bindings from (line 2).
Subsequently, agent finds an accepting trace in that reaches with minimum cost, following self-transitions stored in if necessary. As it executes this behavior, it communicates with other agents the tuple , which contains 1) its ID, 2) the state it is currently going to, and 3) if it is ready for synchronization (line 2). If no synchronization is required (line 2), the agent can simply execute the behavior. Otherwise, to guarantee that the behavior does not violate the requirements of the task, the agent executes the synthesized behavior up until the penultimate state, .
When the agent reaches , it signals to other agents that it is ready for synchronization. Since all agents know the overall teaming assignment, the agent continues to wait in state until it receives a signal that all other agents in are ready (line 2). These agents then move to the next state in the behavior simultaneously. Agent continues synthesizing behavior through until synchronization is necessary again, and this process is repeated.
6. Results and Discussion
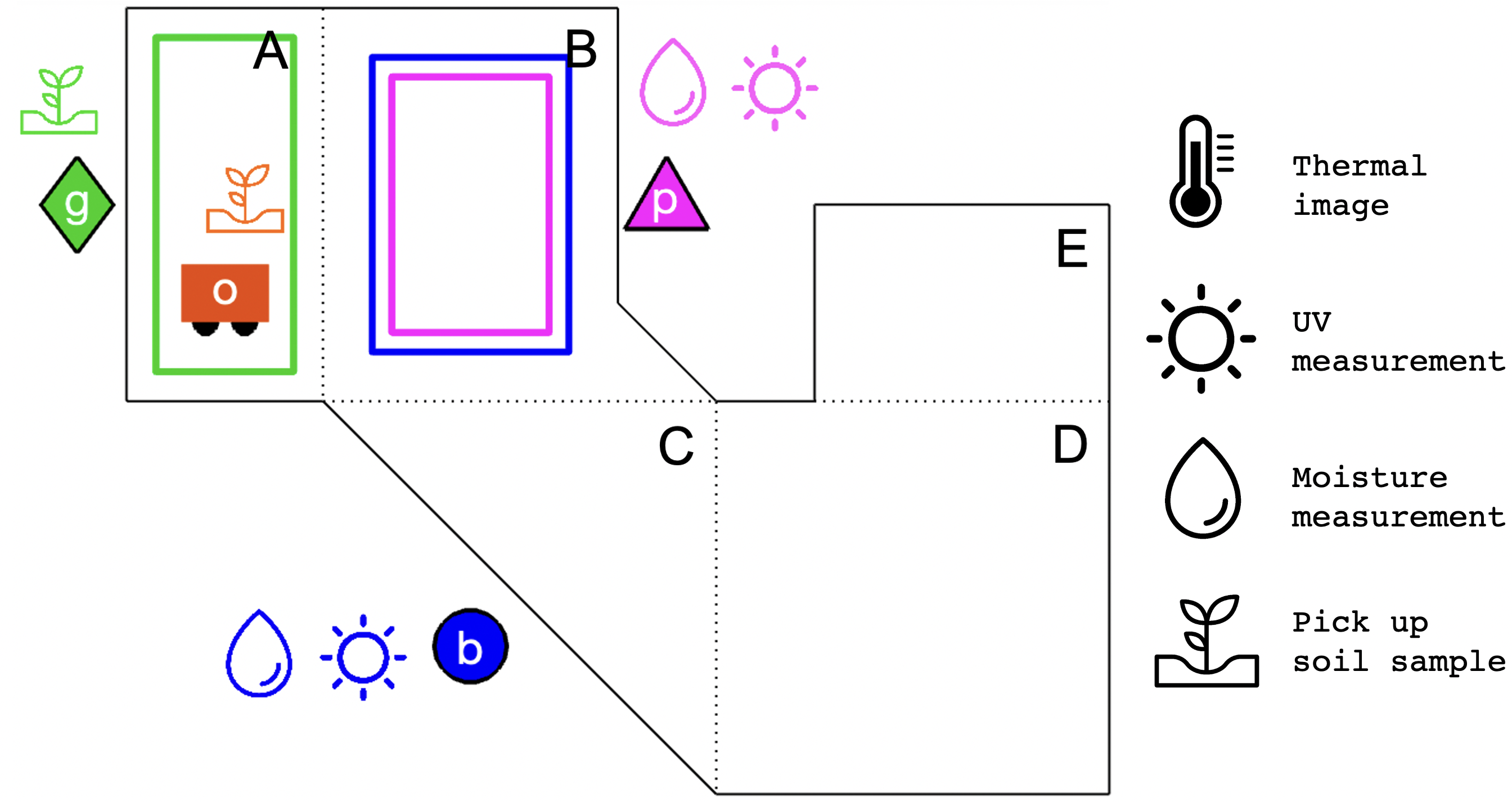
Fig. 5 shows the final step of the synchronized behavior of the agent team for the example in Section 4, where , , , with binding assignments , . A simulation of the full behavior is shown in the accompanying video.
Optimizing teams: Our synthesis algorithm can be seen as a greatest fixpoint computation, where we start with the full set of agents and remove those that cannot contribute to the task. As a result, the team may have redundancies, i.e. agents can be removed while still ensuring the overall task will be completed; this may be beneficial for robustness. Furthermore, we can choose a sub-team to optimize different metrics, as long as the agent bindings assignments still cover all the required bindings. For example, minimizing the number of bindings per agent could result in , ; minimizing the number of agents results in , .
To illustrate other possible metrics, we consider a set of 20 agents and create a team for the specification in Eq. 4. Their final binding assignments and costs are shown in Table 1. Minimizing cost results in a team . Minimizing cost while requiring each binding to be assigned to two agents results in .
| Agent | Agent | Agent | Agent | Agent | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1.2 | 5 | 3 | 2.75 | 9 | 3 | 2.6 | 13 | 3 | 2.0 | 17 | 2,3 | 3.275 |
| 2 | 3 | 1.0 | 6 | 1 | 0.95 | 10 | 1 | 2.8 | 14 | 1 | 1.2 | 18 | 3 | 2.55 |
| 3 | 1 | 1.2 | 7 | 1 | 0.65 | 11 | 2,3 | 0.9 | 15 | 3 | 1.1 | 19 | 1 | 1.9 |
| 4 | 2,3 | 1.3 | 8 | 1 | 1.0 | 12 | 2,3 | 1.825 | 16 | 1 | 0.775 | 20 | 2,3 | 2.35 |
Computational complexity: The control synthesis algorithm (Alg. 2) is agnostic to the number of agents, since each agent determines its own possible bindings assignments and behavior. For the team assignment (Alg. 1), since it is a DFS algorithm, we need to store the agent team and their possible binding assignments as we build an accepting trace. Thus, it has both a space and time complexity of , where is the number of edges in , is the number of bindings, and is the number of agents.
Fig. 6(a) shows the computation time of the synthesis framework (Sec. 5.2 – 5.4) for simulated agent teams in which we vary the number of agents from 3 to 20, running 30 simulations for each set of agents and randomizing their capabilities. The task for each simulation is the example in Eq. 4. We also ran simulations in which we increase the number of bindings from 3 to 10 and randomized the capabilities of 4 agents (Fig. 6(b)). The variance in computation time is a result of the randomized agent capabilities, which affects the computation time of possible binding assignments (Sec. 5.3). All simulations ran on a 2.5 GHz quad-core Intel Core i7 CPU.
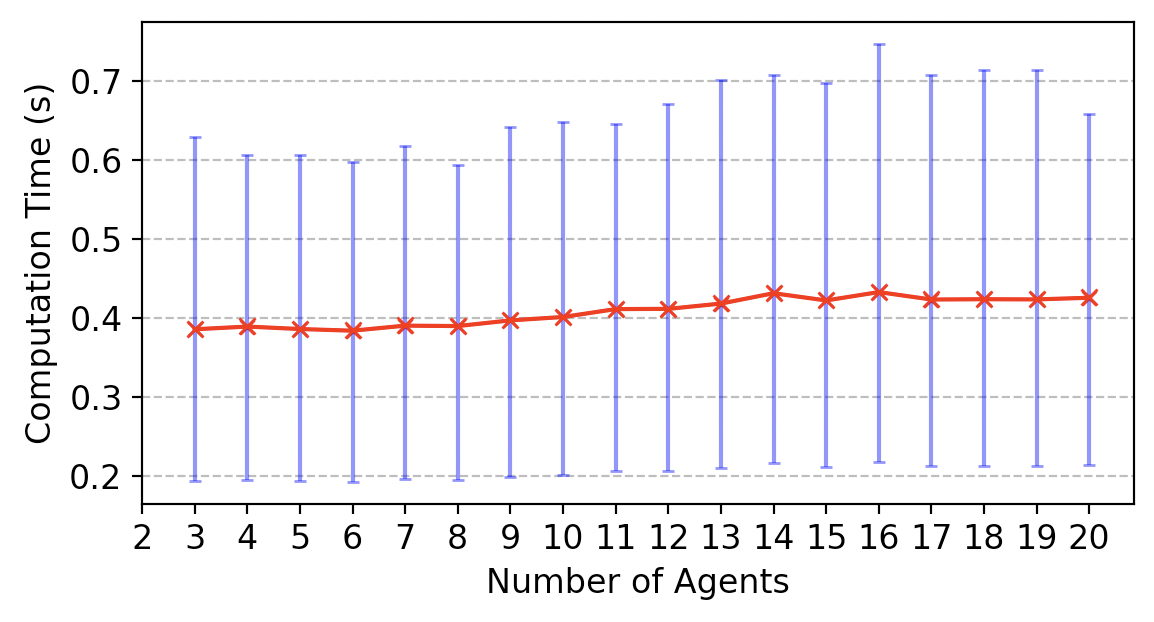
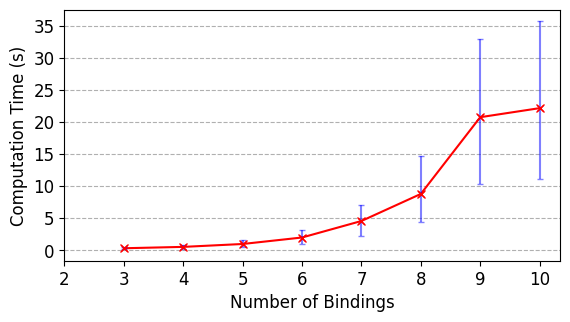
Task expressivity with respect to other approaches: We compare LTLψ to other approaches that encode collaborative heterogeneous multi-agent tasks using temporal logic.
Standard LTL: One approach is to use LTL to express the task by enumerating all possible assignments in the specification. In our example, Eq. 4a would be rewritten as:
where each agent has its own unique set of , denoted here by each proposition’s superscript. As a result, the number of propositions increases exponentially with the number of agents. The task complexity also increases, as the specification must include all possible agent assignments. Another drawback of using LTL for such tasks is that the specification is not generalizable to any number of agents; it must be rewritten when the set of agents change.
LTLχ: In Luo and Zavlanos (2022), tasks are written in LTLχ, where proposition is true if at least agents of type are in region with binding . We can express (Eq. 4a) of our example as . The truth value of is not dependent on any particular action an agent might take. LTLχ can be extended to action propositions, but since an agent can only be categorized as one type, each type of agent must have non-overlapping capabilities (here, we have written the LTLχ formula such that each type of agent only has one capability). In addition, (Eq. 4b) cannot be written in LTLχ because the negation defined in our grammar cannot be expressed in LTLχ. On the other hand, the negative proposition from Luo and Zavlanos (2022) is equivalent to “less than agents of type are in region ”, which our logic cannot encode.
Capability Temporal Logic (CaTL): Tasks in CaTL Leahy et al. (2022) are constructed over tasks , where is a duration of time, is a region in AP, denotes that at least agents with capability are required. Similar to our grammar, CaTL allows agents to have multiple capabilities, but each task must specify the number of agents required. Since it is an extension of Signal Temporal Logic, tasks provide timing requirements, which our logic cannot encode. However, it does not include the concept of binding assignments; in our example (Eq. 4a), CaTL cannot express that we require the same agent that took a UV measurement to also take a thermal image. Ignoring binding assignments and adding timing constraints, (Eq. 4a) can be rewritten in CaTL as . Each capability in CaTL is represented as a sensor and therefore cannot include more complex capabilities, such as a robot arm that can perform several different actions. In addition, because CaTL requires the formula to be in positive normal form (i.e. no negation), we cannot express (Eq. 4b) in this grammar.
7. Conclusion
We define a new task grammar for heterogeneous teams of agents and develop a framework to automatically assign the task to a (sub)team of agents and synthesize correct-by-construction control policies to satisfy the task. We include synchronization constraints to guarantee that the agents perform the necessary collaborations.
In future work, we plan to demonstrate the approach on physical systems where we need to ensure that the continuous execution satisfies all the collaboration and safety constraints. In addition, we will explore different notions of optimality when finding a teaming plan, as well as increase the expressivity of the grammar by allowing reactive tasks where agents modify their behavior at runtime in response to environment events.
This work is supported by the National Defense Science & Engineering Graduate Fellowship (NDSEG) Fellowship Program.
References
- (1)
- Baier and Katoen (2008) Christel Baier and Joost-Pieter Katoen. 2008. Principles of Model Checking. The MIT Press.
- Chen et al. (2021) Ji Chen, Ruojia Sun, and Hadas Kress-Gazit. 2021. Distributed Control of Robotic Swarms from Reactive High-Level Specifications. In 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE). 1247–1254. https://doi.org/10.1109/CASE49439.2021.9551578
- Chen et al. (2011) Yushan Chen, Xu Chu Ding, and Calin Belta. 2011. Synthesis of distributed control and communication schemes from global LTL specifications. In 2011 50th IEEE Conference on Decision and Control and European Control Conference. 2718–2723. https://doi.org/10.1109/CDC.2011.6160740
- Duret-Lutz et al. (2016) Alexandre Duret-Lutz, Alexandre Lewkowicz, Amaury Fauchille, Thibaud Michaud, Etienne Renault, and Laurent Xu. 2016. Spot 2.0 — a framework for LTL and -automata manipulation. In Proceedings of the 14th International Symposium on Automated Technology for Verification and Analysis (ATVA’16) (Lecture Notes in Computer Science, Vol. 9938). Springer, 122–129. https://doi.org/10.1007/978-3-319-46520-3_8
- Emerson (1990) E. Allen Emerson. 1990. Temporal and Modal Logic. In Formal Models and Semantics, JAN Van Leeuwen (Ed.). Elsevier, Amsterdam, 995–1072. https://doi.org/10.1016/B978-0-444-88074-1.50021-4
- Fang and Kress-Gazit (2022) Amy Fang and Hadas Kress-Gazit. 2022. Automated Task Updates of Temporal Logic Specifications for Heterogeneous Robots. In 2022 International Conference on Robotics and Automation (ICRA). 4363–4369. https://doi.org/10.1109/ICRA46639.2022.9812045
- Faruq et al. (2018) Fatma Faruq, David Parker, Bruno Laccrda, and Nick Hawes. 2018. Simultaneous Task Allocation and Planning Under Uncertainty. In 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 3559–3564. https://doi.org/10.1109/IROS.2018.8594404
- Gerkey and Matarić (2004) Brian P. Gerkey and Maja J. Matarić. 2004. A Formal Analysis and Taxonomy of Task Allocation in Multi-Robot Systems. The International Journal of Robotics Research 23, 9 (2004), 939–954. https://doi.org/10.1177/0278364904045564 arXiv:https://doi.org/10.1177/0278364904045564
- Jia and Meng (2013) Xiao Jia and Max Q.-H. Meng. 2013. A survey and analysis of task allocation algorithms in multi-robot systems. In 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO). 2280–2285. https://doi.org/10.1109/ROBIO.2013.6739809
- Kantaros and Zavlanos (2020) Yiannis Kantaros and Michael M Zavlanos. 2020. STyLuS*: A Temporal Logic Optimal Control Synthesis Algorithm for Large-Scale Multi-Robot Systems. The International Journal of Robotics Research 39, 7 (2020), 812–836. https://doi.org/10.1177/0278364920913922 arXiv:https://doi.org/10.1177/0278364920913922
- Kloetzer and Belta (2010) Marius Kloetzer and Calin Belta. 2010. Automatic Deployment of Distributed Teams of Robots From Temporal Logic Motion Specifications. IEEE Transactions on Robotics 26, 1 (2010), 48–61. https://doi.org/10.1109/TRO.2009.2035776
- Korsah et al. (2013) G. Ayorkor Korsah, Anthony Stentz, and M. Bernardine Dias. 2013. A comprehensive taxonomy for multi-robot task allocation. The International Journal of Robotics Research 32, 12 (2013), 1495–1512. https://doi.org/10.1177/0278364913496484 arXiv:https://doi.org/10.1177/0278364913496484
- Leahy et al. (2022) Kevin Leahy, Zachary Serlin, Cristian-Ioan Vasile, Andrew Schoer, Austin M. Jones, Roberto Tron, and Calin Belta. 2022. Scalable and Robust Algorithms for Task-Based Coordination From High-Level Specifications (ScRATCHeS). IEEE Transactions on Robotics 38, 4 (2022), 2516–2535. https://doi.org/10.1109/TRO.2021.3130794
- Li et al. (2009) Zhiyong Li, Bo Xu, Lei Yang, Jun Chen, and Kenli Li. 2009. Quantum Evolutionary Algorithm for Multi-Robot Coalition Formation. In Proceedings of the First ACM/SIGEVO Summit on Genetic and Evolutionary Computation (Shanghai, China) (GEC ’09). Association for Computing Machinery, New York, NY, USA, 295–302. https://doi.org/10.1145/1543834.1543874
- Luo and Zavlanos (2022) Xusheng Luo and Michael M. Zavlanos. 2022. Temporal Logic Task Allocation in Heterogeneous Multirobot Systems. IEEE Transactions on Robotics (2022), 1–20. https://doi.org/10.1109/TRO.2022.3181948
- Sahin et al. (2017) Yunus Emre Sahin, Petter Nilsson, and Necmiye Ozay. 2017. Synchronous and asynchronous multi-agent coordination with cLTL+ constraints. In 2017 IEEE 56th Annual Conference on Decision and Control (CDC). 335–342. https://doi.org/10.1109/CDC.2017.8263687
- Schillinger et al. (2018) Philipp Schillinger, Mathias Bürger, and Dimos V. Dimarogonas. 2018. Simultaneous task allocation and planning for temporal logic goals in heterogeneous multi-robot systems. The International Journal of Robotics Research 37, 7 (2018), 818–838. https://doi.org/10.1177/0278364918774135 arXiv:https://doi.org/10.1177/0278364918774135
- Schmickl et al. (2006) Thomas Schmickl, Christoph Möslinger, and Karl Crailsheim. 2006. Collective Perception in a Robot Swarm. 144–157. https://doi.org/10.1007/978-3-540-71541-2_10
- Tumova and Dimarogonas (2016) Jana Tumova and Dimos V. Dimarogonas. 2016. Multi-agent planning under local LTL specifications and event-based synchronization. Automatica 70 (2016), 239–248. https://doi.org/10.1016/j.automatica.2016.04.006
- Ulusoy et al. (2012) Alphan Ulusoy, Stephen L. Smith, Xu Chu Ding, and Calin A. Belta. 2012. Robust multi-robot optimal path planning with temporal logic constraints. 2012 IEEE International Conference on Robotics and Automation (2012), 4693–4698.
- Wang and Rubenstein (2020) Hanlin Wang and Michael Rubenstein. 2020. Shape Formation in Homogeneous Swarms Using Local Task Swapping. IEEE Transactions on Robotics 36, 3 (2020), 597–612. https://doi.org/10.1109/TRO.2020.2967656
- Xu et al. (2015) Bo Xu, Zhaofeng Yang, Yu Ge, and Zhiping Peng. 2015. Coalition Formation in Multi-agent Systems Based on Improved Particle Swarm Optimization Algorithm. International Journal of Hybrid Information Technology 8 (03 2015), 1–8. https://doi.org/10.14257/ijhit.2015.8.3.01