High-Dimensional Data Set Simplification by Laplace-Beltrami Operator
Abstract
With the development of the Internet and other digital technologies, the speed of data generation has become considerably faster than the speed of data processing. Because big data typically contain massive redundant information, it is possible to significantly simplify a big data set while maintaining the key information it contains. In this paper, we develop a big data simplification method based on the eigenvalues and eigenfunctions of the Laplace-Beltrami operator (LBO). Specifically, given a data set that can be considered as an unorganized data point set in high-dimensional space, a discrete LBO defined on the big data set is constructed and its eigenvalues and eigenvectors are calculated. Then, the local extremum and the saddle points of the eigenfunctions are proposed to be the feature points of a data set in high-dimensional space, constituting a simplified data set. Moreover, we develop feature point detection methods for the functions defined on an unorganized data point set in high-dimensional space, and devise metrics for measuring the fidelity of the simplified data set to the original set. Finally, examples and applications are demonstrated to validate the efficiency and effectiveness of the proposed methods, demonstrating that data set simplification is a method for processing a maximum-sized data set using a limited data processing capability.
Index Terms:
Data simplification, Big data, Laplace-Beltrami operator, Feature point detection1 Introduction
It is well known that big data concern large-volume, complex, and growing data sets with multiple sources [1]. With the development of the Internet and other digital technologies, increasingly larger amounts of data are generated at a speed considerably greater than the data processing speed of human beings. Because big data typically contain massive redundant information, it is possible to significantly simplify a big data set while maintaining the key information it contains. Therefore, data set simplification is a feasible method to process a maximum-sized data set using a limited data processing capability.
The purpose of big data simplification is to maintain the maximum amount of information a big data set contains, while deleting the maximum amount of redundant information. In this paper, a big data set is considered as an unorganized point set with points in a high-dimensional space. Based on this consideration, we developed a data set simplification method by classifying the points in a big data set as feature points and trivial points, and then considering the feature point set as the simplification of the big data set because it contains a majority of the information that the original big data set contained.
Feature point detection is a fundamental problem in numerous research fields including computer vision and computer graphics. These fields focus on the process of one-dimensional (1D) and two-dimensional (2D) manifolds, such that the main tool for the feature point detection is the curvature, including both Gauss and mean curvatures. However, in high-dimensional space, the definition of curvature is complicated and practical computational methods for calculating the curvature of a high-dimensional manifold are not available. Therefore, it is necessary for the big data process to develop practical and efficient methods for detecting feature points in big data sets.
It is well known that the eigenvalues and eigenvectors of a Laplace-Beltrami operator (LBO) defined on a manifold are closely related to its geometry properties. Moreover, whatever the dimension of the manifold, after discretization, the LBO (called a discrete LBO) becomes a matrix. That is, the discrete LBO is unrelated to the dimension of the manifold where it is defined. Therefore, the eigenvalues and eigenvectors of LBOs and the related heat kernel functions are desirable tools for studying the geometric properties of big data sets in high-dimensional space, including the detection of feature points.
In this paper, we developed a data simplification method for high-dimensional big data sets based on feature point detection using the eigenvectors of LBO. Moreover, three metrics are devised for measuring the fidelity of the simplified data set to the original data set. Finally, the capability of the proposed big data simplification method is extensively discussed using several examples and applications.
This paper is organized as follows: In Section 2, related work is briefly reviewed, including the calculations and applications of eigenvalues and eigenvectors of LBO, feature point detection methods in computer graphics and computer vision, and sampling techniques on high-dimensional data. In Section 3, after introducing the technique for calculating the eigenvalues and eigenvectors of LBO on high-dimensional big data sets, we develop the data simplification method by detecting feature points of the big data sets, and propose three metrics to measure the fidelity of the simplified data set to the original data set. In Section 4, the capabilities of the proposed data simplification method are illustrated and discussed. Finally, the paper is concluded in Section 5.
2 Related work
In this section, we review the related work in three aspects. First, we address the computation techniques and applications of eigenvalues and eigenvectors of LBO in dimensionality reduction (DR), shape descriptors, and mesh saliency detection. Secondly, the feature point detection methods are introduced. Finally, data sampling techniques on machine learning and deep learning are discussed.
Computation and applications of LBO. To calculate the eigenvalues and eigenfunctions of an LBO defined on a triangular mesh or big data set, it must first be discretized. One commonly employed technique for the discretization of an LBO is the cotangent Laplacian [2], which requires only the one-ring neighbors of a vertex to construct the discrete LBO at the vertex. Although the cotangent Laplacian has intuitive geometric meaning, it does not converge in generic cases [3]. In 2008, Belkin et al. proposed the mesh Laplacian scheme [4], where the Euclidean distance between each pair of the complete data set is required for the calculation of the matrix weight. Furthermore, by discretizing the integration of certain continuous functions defined over the manifold, a symmetrizable discrete LBO was developed to ensure its eigenvectors were orthogonal [5].
The LBO has been extensively employed in mesh processing in the fields of computer graphics and computer vision. Based on the spectral analysis of the graph Laplacian, Taubin et al. [6] designed low-pass filters for mesh smoothing. Moreover, by first modulating the eigenvalues and eigenvectors of an LBO on a mesh and then reconstructing the shape of the mesh model, mesh editing tasks can be fulfilled, including mesh smoothing, shape detail enhancement, and change of model posture [7, 8].
Using the information in the spectral domain of the LBO, the mesh saliency points or regions can be detected. By defining a geometric energy related to the eigenvalues of an LBO, Hu et al. proposed a method to extracts the salient geometric feature points [9]. Considering the properties of the log-Laplacian spectrum of a mesh, Song et al. developed a method for detecting mesh saliency by capturing the saliency in the frequency domain [10].
The eigenvalues and eigenvectors of an LBO have been used in shape analysis and shape retrieval. Reuter et al.[11] used the sequence of eigenvalues of an LBO defined on a mesh as a numerical fingerprint or signature of the mesh, and called this the Shape DNA, which has been successfully applied in fields such as shape retrieval, copyright protection, and mesh quality assessment. Using the concept of heat kernel, which contains the information for the eigenvalues and eigenvectors of the LBO defined on a mesh, Sun et al. [3] proposed the heat kernel signature (HKS) for shape analysis. With the intrinsic invariant property of HKS, Ovsjanikov [12] proposed a one-point isometric matching algorithm to determine the intrinsic symmetries of shapes. Bronstein [13] developed the scale-invariant heat kernel signatures(SI-HKS) for non-rigid shape recognition, based on a logarithmically sampled scale-space.
More importantly, the LBO has been successfully applied in high-dimensional data processing. A well-known application of the LBO in high-dimensional data processing is Laplacian eigenmaps [14]. To appropriately represent high-dimensional data for machine learning and pattern recognition, Belkin et al.[14] proposed a locality-preserving method for nonlinear DR using the LBO eigenfunctions, which has a natural connection to clustering, and can be computed efficiently.
Feature point detection. Following the presentation of scale invariant feature transform(SIFT) [15] and histogram of oriented gradients(HOG) [16], a series of feature point detection methods were proposed using the Difference of Gaussians(DoG) [15]. Castellani et al. [17] designed a 3D saliency measure basing on DoG, which allows a small number of sparse salient points to characterize distinctive portions of a surface. Zou et al.[18] defined the DoG function over a curved surface in a geodesic scale space and calculated the local extrema of the DoG, called saliency-driven keypoints, which is robust and stable to noisy input [19, 20, 21].
Similarly, geometric function-based methods have been proposed. Two widely known surface descriptors based on surface geometry are 3D spin images [19] and 3D shape contexts [20]. Schlattmann et al.[21] developed a novel scale space generalization to detect surface features based on the averaged mean curvature flow.
Another kind of feature point detection approach is based on geometric diffusion equation. Heat kernel signature (HKS) can be used for feature point detection, which discerns the global feature and local feature points by adjusting the time parameter [3]. Moreover, by integrating the eigenvalues into the eigenvectors of an LBO on a mesh, global point signature (GPS) was developed in [22] for feature point detection. For 2D surface quadrangulation, Shen et al. [23] used the extremes of the Laplacian eigenfunctions to build a Morse-Smale complex and construct a well-shaped quadrilateral mesh.
In recent years, deep networks[24] have achieved excellent success in feature point detection [25]. Luo et al. [26] proposed a novel face parser approach by detecting faces at both the part- and component-levels, and then computing the pixel-wise label maps, where the feature points can then be easily obtained from the boundary of the label maps. Sun et al. [27] presented an approach for detecting the positions of face keypoints with three-level carefully designed convolution networks. In addition to convolutional neural networks(CNN), recurrent neural networks(RNN) have also been developed on feature point detection, especially on facial feature point detection [28, 25, 29].
Data sampling. In the early machine learning field, to solve the imbalanced data problem in classification, over-sampling and under-sampling approaches were proposed. Tomek et al. [30] proposed the ’Tomek links’, which is computed by two examples belonging to different classes. ’Tomek links’ can determine if one of two examples is noise or borderline. One noted over-sampling method is SMOTE [31], which creates synthetic minority class examples by interpolating among several minority class examples that lie together. Hybrid methods have been proposed based on the above two methods, including ’SMOTE-Tomek links’ [32], ’Boderline-SMOTE’ [33] and ’Safe-Level-SMOTE’ [34].
In the deep learning field, to reduce annotation effort and clean the data before training, following data under-sampling methods were proposed. In biomedical imaging applications, Zhou et al.[35] presented AFT* to seek ’worthy’ samples for annotation, which reduces the annotation cost by half compared with random selection. Vodrahalli et al. [36] used the gradient in stochastic gradient descent (SGD) to measure the importance of training data, demonstrating that a small subsample is indeed sufficient for training in certain cases.
3 High-dimensional data set simplification
In this section, we develop the high-dimensional data set simplification method, which first detects the feature points in the high-dimensional data set, and then uses the feature point set as the simplified data set. Moreover, three metrics are proposed for measuring the fidelity of the simplified data set to the original data set.
Feature point detection on 1D and 2D manifolds typically depends on the curvature information. However, in high-dimensional space, the definition and computation of the curvature is complicated. Hence, feature point detection using curvature information on high-dimensional data sets is infeasible.
As stated above, whatever the dimension of a space is, the discrete LBO defined on the space is a matrix. Because the eigenvectors of a discrete LBO are closely related to the geometric properties of the space where the LBO is defined, and because there are sophisticated methods for computing the eigenvectors of a matrix (which is a discrete LBO), the discrete LBO and its eigenvectors are desirable tools for feature point detection in high-dimensional data sets.
3.1 Spectrum of LBO and Feature Points
Let be a Riemannian manifold (differentiable manifold with Riemannian metric), and be a real-valued function defined on . The LBO on is defined as
| (1) |
where is the gradient of , and is the divergence on . The LBO (1) can be represented in local coordinates. Let be a local parametrization
of a sub-manifold of with
where , is the dot product, and is the determinant. In the local coordinates, the LBO (1) can be transformed as,
| (2) |
The eigenvalues and eigenfunctions of the LBO (1) (2) can be calculated by solving the Helmholtz equation:
| (3) |
where is a real number. The spectrum of LBO is a list of eigenvalues such as
| (4) |
with the corresponding eigenfunctions,
| (5) |
which are orthogonal.
In the case of a closed manifold, the first eigenvalue is always zero. Moreover, the eigenvalues (4) specify the discrete frequency domain of an LBO, and the eigenfunctions are the extensions of the basis functions in Fourier analysis to a manifold. Eigenfunctions of larger eigenvalues contain higher frequency information. It is well known that the eigenvalues and eigenfunctions of an LBO are closely related to the geometric properties of the manifold where the LBO is defined, including its curvature [37], volume of , volume of , and Euler characteristic of [11].
Specifically, consider a heat diffusion equation defined on a closed manifold (i.e., ):
| (6) |
where , is the heat value of the point at time , and is the initial heat distribution on . The solution of the heat diffusion equation (6) can be expressed as:
where, is the fundamental solution of the heat diffusion equation (6), called heat kernel. The heat kernel measures the amount of heat transferred from to within time , and can be rewritten as,
| (7) |
where (4) are the eigenvalues of the LBO (1) (2), and (5) are the corresponding eigenfunctions.
When in Eq. (7), , called HKS, quantifies the change of heat at along the time . It has been shown that [38, 39, 37], when the time approaches sufficiently close, the heat kernel can be represented as,
| (8) |
where is the scalar curvature at point on . Especially, when is a 2-dimensional manifold, is the Gaussian curvature at .
From Eq. (8), we can see that, the eigenfunctions (5) of a LBO are closely related to the scale curvature at the point .
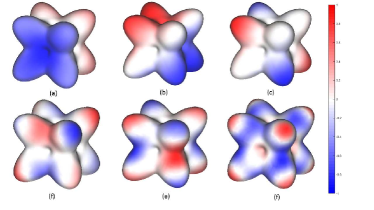
As stated above, the eigenfunctions (5) are the extension of the trigonometric functions. In the trigonometric function system, the local extrema of a trigonometric function with a lower frequency hold in the trigonometric function with a higher frequency (Fig. 1). This property is preserved by the eigenfunctions (5) on manifolds. In Fig. 2, eigenfunctions of an LBO defined on a 2D manifold are illustrated with their local extrema. We can observe that, the local extrema in the lower frequency eigenfunctions remain the local extrema in the higher frequency eigenfunctions (Fig. 2). Because the local extrema of hold in , and the heat kernel (8) is a weighted sum of , the local extrema of , especially the eigenfunctions with low frequency, are the candidates of the local extrema of the heat kernel (8), and the scale curvature (8). In conclusion, the local extrema of the eigenfunctions contain the features of the manifold where the LBO is defined. Therefore, in this paper, we use the local extrema of the eigenfunctions of the LBO defined on a high-dimensional data set as its feature points, which constitute the simplified data set.

3.2 Discrete Computation
To solve the Helmholtz equation (3) for calculating the eigenvalues and eigenfunctions of the LBO (2), the Helmholtz equation (3) must be discretized into a linear system of equations. Traditionally, Eq. (3) is discretized on a mesh with connectivity information between two mesh vertices [4, 14, 2]. However, in this paper, we are addressing an unorganized data point set in a high-dimensional space, where the connectivity information is missing. Hence, we use the discretization method developed in [14] to construct the discrete LBO. Because only the Euclidean distances between points are involved in the construction of the discrete LBO, it can be employed for LBO discretization in high-dimensional space.
The LBO discretization method [14] contains the two steps:
-
•
adjacency graph construction,
-
•
weight computation,
which are explained in detail in the following.
Adjacency graph construction. There are two methods for constructing an adjacency graph: (a) nearest neighbors (KNN). For any vertex , its nearest neighbors are determined using the KNN algorithm [40]. Then, the connection between the vertex and each neighbor is established, thus constructing the adjacent graph. Because the nearest neighbors are not symmetric, i.e., it is possible that the vertex is in the nearest neighbors of the vertex , yet, is not in the nearest neighbors of , the weight matrix (see below) constructed by the KNN method is not guaranteed to be symmetric. (b) -neighbors. For a vertex , a hypersphere is first constructed, which uses as the center, and as its radius. The adjacency graph is constructed by connecting the vertex and each vertex lying in the hypersphere. Although the weight matrix constructed based on the -neighbors is symmetric, there is a serious problem in that the value of is difficult to choose. An overly small will cause certain rows of the weight matrix to be zero; and overly large will create a matrix that is excessively dense. Therefore, in our implementation, we employ the nearest neighbors to construct the adjacency matrix.
Weight computation. Using the adjacency graph for each point in the given data set, the connections between point and the other points in the data set are established. Based on the adjacency graph, the weights between point and each of the other points can be calculated as follows:
| (9) |
Because only the Euclidean distance is required in the computation of , it is appropriate for addressing high-dimensional data sets.
As stated above, the weight matrix (9) constructed by the KNN method is not symmetric, so we take the following matrix:
as the weight matrix, which is a symmetric matrix. Moreover, we construct a diagonal matrix
where (refer to Eq. (9)). Then the LBO can be discretized into the matrix,
whatever the dimension of the space the LBO defined on. Meanwhile, the Helmholtz equation (3) is discretized as,
where is the eigenvalue of the Laplace matrix , and is the corresponding eigenvector. It is equivalent to,
| (10) |
Because the matrix is symmetric, and the matrix is diagonal, it has been shown that the eigenvalues are all non-negative real numbers satisfying [3]:
and the corresponding eigenvectors are orthogonal, i.e.,
3.3 Data Simplification by Feature Point Detection
By solving Eq. (10), the eigenvalues and the corresponding eigenvectors are determined. The local maximum, minimum, and saddle points of the eigenvectors are used as the feature points. As stated above, the eigenvalue measures the ’frequency’ of its corresponding eigenvector . The larger the eigenvalue, the higher the frequency of the eigenvector , and then the greater number of feature points in the eigenvector . The data simplification algorithm first detects the feature points of the eigenvector , and adds them to the simplified data set. Then, it detects and adds the feature points of to the simplified data set. This procedure is performed iteratively until the simplified data set satisfies a preset fidelity threshold to the original data point set, according to the metrics defined in Section 3.4.
Because each of the eigenvectors is a scalar function defined on an unorganized point set in a high-dimensional space, the detection of the maximum, minimum, and saddle points on the defined function is not straightforward. Suppose is a scalar function defined on each point of an unorganized data point set. For each point in the data set, we construct its neighbor using the KNN algorithm, discussed previously in Section3.2. The methods for detecting the maximum, minimum, and saddle points of the function are elucidated in the following.
Maximum and minimum point detection: For a data point in the data set and any data point , if , , the data point is a local maximum point of . Conversely, if , , the data point is a local minimum point of .
Saddle point detection: To detect the saddle points of defined on an unorganized high-dimensional data point set, the points of the set are projected into a 2D plane, using the DR methods [14]. The data point projected into a 2D plane continues to be denoted as . For a point , the points in its KNN neighbor comprise its one-ring neighbor (see Fig. 3). Each point in has a sole preceding point and a sole succeeding point in a counter-clockwise direction. As illustrated in Fig. 3, if , the point is labeled as ; otherwise, it is labeled as . Now, we initialize a counter and traverse the one-ring neighbor of point from an arbitrary point. If the signs of two neighbor points in are different (marked with dotted lines), . Finally, if the counter , point is a saddle point; otherwise, it is not a saddle point (Fig. 3). Examples of saddle points and non-saddle points are demonstrated in Fig. 3.




3.4 Measurement of Fidelity of the Simplified Data Set
As stated in Section 3.3, the data simplification method detects the feature points of the eigenvectors , and adds them to the simplified data set iteratively, until the simplified data set satisfies a preset threshold of fidelity to the original data set. In this section, three metrics are devised to measure the fidelity of the simplified data set to the original high-dimensional data set ; these are the Kullback-Leibler divergence (KL divergence) [41]-based metric, Hausdorff distance [42], and determinant of covariance matrix [43]. They measure the fidelity of the simplified data set to the original data set from three aspects:
-
•
entropy of information (KL-divergence-based metric),
-
•
distance between two sets (Hausdorff distance),and
-
•
’volume’ of a data set (determinant of covariance matrix).
KL-divergence-based metric. KL-divergence [41], also called relative entropy, is typically employed to measure the difference between two probability distributions and , i.e.,
| (11) |
To define the KL-divergence-based metric, the original data set and simplified data set are represented as an matrix , and an matrix , where are the number of data points in the data sets and , respectively. Each row of the matrices and stores a data point in the dimensional Euclidean space. First, we calculate the probability distribution for each dimension of the data points in the original data set , corresponding to the column of matrix . To do this, the column elements of matrix are normalized into the interval , which is divided into subintervals, (in our implementation, we use ). By counting the number of elements of the column of matrix whose values lie in the subintervals, the value distribution histogram is generated, which is then used as the probability distribution of the column of matrix . Similarly, the probability distribution of the column of matrix can be calculated. Then, the KL-divergence for the column elements of matrix and is
And the KL-divergence-based metric is defined as
| (12) |
The KL-divergence-based metric (12) transforms the high-dimensional data set into its probability distribution, and measures the difference between the probability distributions of the original and simplified data sets. As the simplified data set becomes increasingly closer to the original data set , the KL-divergence-based metric becomes increasingly smaller. When , .
Hausdorff distance. The Hausdorff distance [42] measures how far two sets are away from each other. Suppose and are two data set in dimensional space, and denote
the maximum distance from an arbitrary point in set to set , where is the Euclidean distance between two points and . The Hausdorff distance between the original data set and simplified data set is defined as
Note that the simplified data set is a subset of the original data set , and then, . Therefore, the Hausdorff distance between and can be calculated by
| (13) |
That is, the Hausdorff distance is the maximum distance from an arbitrary point in the original data set to the simplified data set .
Determinant of covariance matrix. The covariance matrix is frequently employed in statistics and probability theory to measure the joint variability of several variables [43]. Suppose
are samples in a dimensional sample space , and denote
where is the mean value of the -th random variable. The covariance between the -th and -th random variables is
which is the element of the covariance matrix of the data set . According to [43], the determinant of the covariance matrix of , i.e., , can express the ’volume’ of the data set . When the simplified data set approaches the original data set , they are expected to have increasingly ’volumes’, namely, the determinants of covariance matrices. Therefore, the difference of the determinants of the covariance matrices of and :
| (14) |
can measure the fidelity of the simplified data set to the original data set .
4 Results, Discussion, and Applications
In this section, the proposed method is employed to simplify four well-known high-dimensional data sets (refer to Fig. 4), including the swiss roll data set [44] (Fig. 4) with points in 3D space, MNIST handwritten digital data set [45] (Fig. 4) which contains 60000 images () of handwritten digits from ’0’ to ’9’, human face data set [44] (Fig. 4) which includes 698 images() of a plaster head sculpture, and CIFAR-10 classification data set [46] (Fig. 4) with RGB-images(). The fidelity of the simplified data sets to the original data sets are measured with the three metrics described in Section 3.4. Moreover, two applications of a simplified data set are also demonstrated including the speedup of DR and a training data simplification in supervised learning.
The proposed method is implemented using C++ with OpenCV and ARPACK [47], and executes on a PC with a GHz Intel Core CPU, GTX GPU, and memory. We employed the OpenCV function ’cv::flann’ to perform the KNN operation [40] and ARPACK to solve the sparse symmetric matrix eigen-equation (10).




4.1 Simplification Results
In this section, we will illustrate several data simplification results.






Swiss roll: In Fig. 5, we use the swiss roll data set in 3D space to illustrate the intuitive simplification procedure by the proposed data simplification algorithm. In Fig 5, the simplified data set is generated by detecting the feature points of the first five eigenvectors, which captures the critical points at the head and tail positions of the roll (marked in red and blue colors). In Figs. 5- 5, by detecting higher frequency eigenvectors, increasingly more feature points are added into the simplified data set and it approaches increasingly closer to the original data set (Fig. 5). Note that the simplified data set in Fig. 5, which contains data points (approximately points of the entire data set), includes the majority of the information of the original data set. Please refer to Section 4.2 for the quantitative fidelity analysis of the simplified data set to the original data set measured by the metrics (12), (13), and (14).






MNIST: For clarity of the visual analysis, we selected units of the gray images for the digits ’0’ to ’4’, from the MNIST data set, and resized each image as . The selected handwritten digit images were projected into the 2D-plane using the DR method T-SNE [48]. Whereas in Fig. 6, colorful digits are placed at the projected 2D points, in Fig. 6, the images themselves are located at the projected points. The simplified data sets with data points, which were generated by detecting the feature points of the first LBO eigenvectors are displayed in Fig. 6- 6. For illustration, their positions in the 2D-plane are extracted from the dimensionality reduced data set (Fig. 6). In the simplified data set in Fig. 6, which has data points (approximately of the points of the original data set), all five categories of the digits are represented. In the simplified data set in Fig. 6, which has data points (approximately of the points of the original data set), virtually all of the key features of the data set are represented, including the subset of digit ’2’ in the class of digit ’1’. In Fig. 6, the simplified data set contains data points (approximately of the points of the original data set). We can observe that the boundary of each class of data points has formed (Fig. 6), and the geometric shape of each class is similar to that of the corresponding class in the original data set (Fig. 6).






Human face: The human face data set (Fig. 4) contains gray-images() of a plaster head sculpture. The images of the data set were captured by adjusting three parameters: up-down pose, left-right pose, and lighting direction. Therefore, the images in the data set can be regarded as distributing on a 3D-manifold. Thus, as illustrated in Fig. 7, after the human face data set is dimensionally reduced into a 2D-plane using PCA [49], it can observed that the longitudinal axis represents the sculpture’s rotation in the right-left direction, and the horizontal axis indicates the change of lighting.
In Fig. 7, the images marked with red frames constitute the simplified data set. The simplified data sets in Figs. 7- 7 which consist of data points, are generated by detecting the feature points of the first LBO eigenvectors, respectively. In the simplified data set in Fig. 7, the critical points at the boundary are captured. In Figs. 7- 7, increasingly more critical points at the boundary and interior are added into the simplified data sets. In Fig. 7, virtually all of the images at the boundary are added into the simplified set. For clarity, we display the feature points of the first five LBO eigenvectors in Fig. 7, which indeed capture several ’extreme’ images in the human face data set. Specifically, the two feature points of the first eigenvector, , are two images with ’leftmost pose + most lighting’ and ’rightmost pose + most lighting’. In the feature point set of the second eigenvector, , an image with ’leftmost pose + fewest lighting’ is added. Similarly, in the feature point sets of the eigenvectors , and , there are ’extreme’ images of the pose and lighting (Fig. 7).
CIFAR-10: The data set CIFAR-10 (Fig. 4) was also simplified by the proposed method. Similarly, increasingly more critical points of the data set were added into the simplified data set as a consequence of the simplification procedure.
The fidelity of the simplified data sets was quantitatively measured as per Section 4.2. In Table I, The running time in seconds of the proposed method is listed. It can be seen that the operations of KNN and eigen-solving consume the majority of the time, and the data simplification time ranged from to seconds.
| Data set | Data size | KNN | Eigen | Simplification |
|---|---|---|---|---|
| Swiss roll | 5.535 | 6.986 | 0.044 | |
| MNIST | 57.579 | 178.933 | 6.544 | |
| Human face | 3.604 | 1.079 | 0.035 | |
| CIFAR-10 | 115.919 | 146.113 | 4.759 |
4.2 Quantitative Measurement of the Fidelity
In this section, the fidelity of the simplified data set to the original data set is quantitatively measured by the three metrics developed in Section 3.4, i.e., KL-divergence-based metric (12), Hausdorff distance (13), and determinant of covariance matrix (14). Specifically, for the data simplification procedure of each of the four data sets mentioned above, a series of simplified data sets was first generated. Then, we calculated the simplification rate , i.e., the ratio between the cardinality of each data set and that of the original data set , i.e.,
| (15) |
and the three metrics
which were normalized into . Finally, the diagrams of v.s. , v.s. , and v.s. were plotted as displayed in Figs. 8, 9, and 10, respectively.

KL-divergence-based metric: (12) measures the similarity of the distributions of the simplified data set and the original data set . If is exactly the same as , then .
Fig. 8 displays the diagrams of v.s. the normalized of the four data sets. It can be observed that in the simplification procedures of all of four data sets, the metric is rapidly reduced to a small value (less than 0.1), when , approximately, i.e., the simplified data set contains approximately of the data points of the original data set. Using the data set swiss roll as an example (blue line) when the simplified data set is composed of of the data points of the original data set (i.e., ), the normalized is less than ; when ( contains of the data points of ), the normalized is close to , meaning that the simplified data set contains virtually all of the information embraced by the original data set .

The Hausdorff distance (13) measures the geometric distance between two sets. In Fig. 9, the diagram between
is illustrated. Because the Hausdorff distances between the original data set and two adjacent simplified data sets, e.g., and , are possibly the same, the diagrams demonstrated in Fig. 9 are step-shaped. Based on Fig. 9, in the data simplification procedures of the four data sets, the Hausdorff distances decrease when increasingly more data points are contained in the simplified data sets. Moreover, the convergence speed of with respect to (15) is related to the intrinsic dimension of the data set: The lower the intrinsic dimension of a data set, the faster the convergence speed. For example (refer to Fig. 9), the intrinsic dimension of the data set swiss roll is (the smallest of the four data sets), and the convergence speed of the diagram for the simplification procedure of swiss roll is the fastest. The intrinsic dimension of the data set human face is , greater than that of swiss roll, and the convergence speed of its diagram is slower than that of swiss roll. The intrinsic dimensions of the data sets MNIST and CIFAR-10 are greater than those of swiss roll and human face, and the convergence speeds of their diagrams are the slowest.

The determinant of covariance matrix of a data set reflects its ’volume’. The metric (14) measures the difference between the ’volume’ of the original data set and that of the simplified data set . In Fig. 10, the diagram of (15) v.s. the normalized is illustrated. In the region with small (15), the simplified data set contains a small number of data points and the diagrams oscillate. This is because the ’volume’ of a simplified data set with a small number of data points is heavily influenced by each of its points, and adding merely one point into the set can change its ’volume’ significantly. However, with increasingly more data points inserted into the simplified data set (i.e., with increasingly greater ), the diagrams of all four data sets converge to zero. Considering the data set CIFAR-10 as an example, when the simplified data set contains of the data points of the original data set (), the metric (14) is nearly zero, meaning that the ’volume’ of the simplified data set has approached that of the original data very closely.
4.3 Applications
In this section, two applications of the proposed data set simplification method are demonstrated; there are the speedup of DR and training data simplification in supervised learning.
Speedup of DR: The computation of the DR algorithms for a high-dimensional data set is typically complicated. Given an original data set (), if we first perform the DR on the simplified data set (), and then employ the ’out-of-sample’ algorithm [50] to calculate the DR coordinates of the remaining data points, the computation requirement can be reduced significantly. Because the simplified data set captures the feature points of the original data set, the result generated by DR on simplified set + ’out-of-sample’ is similar as that by DR on original set.






First, we compare the results of DR on the simplified data sets and that of DR on the original data set. Here, the data set human face is used as the original set and its simplified data sets are , consisting of the feature points of the first LBO eigenvectors, respectively. In Figs 11, 11, and 11, the DR results (by PCA) on the simplified data set are presented, respectively. For comparison, the DR (by PCA) of the original data set human face was performed and the subsets of the DR results corresponding to the points in are extracted and demonstrated in Figs. 11, 11, and 11. It can be observed that the shapes and key geometric structures in the DR results of the original data set hold in the DR results of the simplified data sets.




Beginning with the DR result on the simplified data set (Fig. 11), the DR coordinates of the remaining points in the original data set human face were calculated by the ’out-of-sample’ algorithm [50]. The DR result thus generated is illustrated in Fig. 12, where the images marked with red frames are the DR results of , and the other image positions are calculated by the ’out-of-sample’ algorithm [50]. The DR result on the original set human face is demonstrated in Fig. 12. For clarity of visual comparison, the two results in Figs. 12 and 12 are displayed in an overlapping manner in Fig. 12. The correspondence error between the two DR results, i.e., the distance between the two DR coordinates of the same data point, were counted and displayed in Fig. 12, where the -axis is the interval of the correspondence error and the -axis is the number of points with correspondence errors in the intervals. Because the simplified data set captures the feature points of the original data set, the DR result by ’DR on simplified set + out of sample’ is similar to that by ’DR on original set’. They have a highly repeated distribution and small correspondence error.
| Data set | DR (PCA) | out-of-sample | Total |
|---|---|---|---|
| Human face | 7.975 | / | 7.975 |
| Simplified data | 0.079 | 0.001 | 0.080 |
In Table II, the running time for the methods ’DR on simplified set + out of sample’ and ’DR on original set’ are listed. Whereas the method ’DR on original set’ required seconds, the method ’DR on simplified set + out of sample’ required only seconds, a run-time savings of two orders of magnitude.
Training data simplification: With the increase of the use of training data in supervised learning [51], the cost of manual annotation has become increasingly more expensive. Moreover, repeated samples or ’bad’ samples can be added into the training data set, adding confusion and complication to the training data, and influencing the convergence of the training. Therefore, in supervised and active learning [52], simplifying the training data set by retaining the feature points and deleting the repeated or ’bad’ samples can
-
1.
lighten the burden of the manual annotation,
-
2.
reduce the number of epochs, and,
-
3.
save storage space.

To validate the superiority of the simplified data set in supervised learning, we constructed a CNN to perform an image classification task. The CNN consisted of two convolution layers, followed by two fully connected layers. Cross-entropy was used as the loss function, and Adam [53] was employed to minimize the loss function.
First, we studied the relationship between the simplification rate (15) and test accuracy with two experiments. In the first experiment, the data set MNIST was employed, which contained training images and test images. In the second experiment, we used the data set CIFAR-10 with training images and test images. In the two experiments, the training image set was first simplified using the proposed method; then, the CNN was trained for epochs using the simplified training sets. Finally, the test accuracy was calculated by the test images. In Fig. 13, the diagram of the simplification rate v.s. test accuracy is illustrated. For the data set MNIST, when = 0.177 (the simplified training set contained nearly images), the test accuracy achieved , which was near to the test accuracy of using the original training data ( images). For the data set CIFAR-10, when = 0.584 and the simplified training data set contained nearly images, the test accuracy was , whereas using the original training images ( images), the test accuracy was . Therefore, with the proposed simplification method, the simplified data was sufficient for training in the two image classification tasks.

Furthermore, with the simplified training set, the training process can terminate earlier than that with the original training set, thus reducing the number of epochs. In Fig. 14, the diagrams of the number of epochs v.s. test accuracy are illustrated. The ’early stopping’ criterion proposed in [54] was used to determine the stopping time (indicated by arrows). For the data set MNIST, the training process with the original training set (including images) stopped at epochs, with a test accuracy ; with the simplified training set (including images), the training process stopped as early as at epochs, with a test accuracy . For the data set CIFAR-10, the training process stopped at epochs with the simplified training set (including images), whereas the training process with the original training set (including images) stopped at epochs. Therefore, with the simplified training data set, the training epochs can be reduced significantly.
5 Conclusion
In this paper, we proposed a big data simplification method by detecting the feature points of the eigenvectors of an LBO defined on the data set. Specifically, we first clarified the close relationship between the feature points of the eigenvectors of an LBO and the scalar curvature of the manifold the LBO defined. Then, we proposed methods for detecting the feature points of an LBO defined on an unorganized high-dimensional data set. The simplified data set consisted of the feature points of the LBO. Moreover, three metrics were developed to measure the fidelity of the simplified data set to the original data set from three perspectives, i.e., information theory, geometry, and statistics. Finally, the proposed method was validated by simplifying some high-dimensional data sets, Applications of the simplified data set were demonstrated, including the speedup of DR and training data simplification. These demonstrated that the simplified data set can capture the main features of the original data set and can replace the original data set in data processing tasks, thus improving the data processing capability significantly.
Acknowledgement
The authors would like thank to Zihao Wang for the helpful advices and JiaMing Ai, JinCheng Lu for the help in dimensionality reduction. This work is supported by the National Natural Science Foundation of China under Grant no. 61872316, and the National Key R&D Plan of China under Grant no. 2016YFB1001501.
References
- [1] X. Wu, X. Zhu, G. Wu, and W. Ding, “Data Mining with Big Data,” IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 1, pp. 97–107, 2013.
- [2] U. Pinkall and K. Polthier, “Computing Discrete Minimal Surfaces and their Conjugates,” Experimental Mathematics, vol. 2, no. 1, pp. 15–36, 1993.
- [3] J. Sun, M. Ovsjanikov, and L. Guibas, “A Concise and Provably Informative Multi-scale Signature Based on Heat Diffusion,” Computer Graphics Forum, vol. 28, no. 5, pp. 1383–1392, 2009.
- [4] M. Belkin and Y. Wang, “Discrete Laplace Operator on Meshed Surfaces,” in Twenty-Fourth Symposium on Computational Geometry, pp. 278–287, 2008.
- [5] Y. Liu, B. Prabhakaran, and X. Guo, “Point-Based Manifold Harmonics,” IEEE Transactions on Visualization & Computer Graphics, vol. 18, no. 10, pp. 1693–1703, 2012.
- [6] G. Taubin, “A Signal Processing Approach to Fair Surface Design,” in Conference on Computer Graphics and Interactive Techniques, pp. 351–358, 1995.
- [7] B. Levy, “Laplace-Beltrami Eigenfunctions Towards an Algorithm that ”Understands” Geometry,” in IEEE International Conference on Shape Modeling and Applications, pp. 13–13, 2006.
- [8] B. Vallet and B. Levy, “Spectral Geometry Processing with Manifold Harmonics,” Computer Graphics Forum, vol. 27, no. 2, pp. 251–260, 2008.
- [9] J. Hu and J. Hua, “Salient Spectral Geometric Features for Shape Matching and Retrieval,” Visual Computer, vol. 25, no. 5-7, pp. 667–675, 2009.
- [10] R. Song, Y. Liu, R. R. Martin, and P. L. Rosin, “Mesh Saliency via Spectral Processing,” Acm Transactions on Graphics, vol. 33, no. 1, pp. 1–17, 2014.
- [11] M. Reuter, F. E. Wolter, and N. Peinecke, “Laplace-Beltrami Spectra as Shape-DNA of Surfaces and Solids,” Computer-Aided Design, vol. 38, no. 4, pp. 342–366, 2006.
- [12] M. Ovsjanikov, Q. M rigot, F. M moli, and L. Guibas, “One Point Isometric Matching with the Heat Kernel,” Computer Graphics Forum, vol. 29, no. 5, pp. 1555–1564, 2010.
- [13] M. M. Bronstein and I. Kokkinos, “Scale-Invariant Heat Kernel Signatures for Non-rigid Shape Recognition,” in Computer Vision and Pattern Recognition, pp. 1704–1711, 2010.
- [14] M. Belkin and P. Niyogi, “Laplacian Eigenmaps for Dimensionality Reduction and Data Representation,” Neural computation, vol. 15, no. 6, pp. 1373–1396, 2003.
- [15] D. G. Lowe, “Distinctive Image Features from Scale-Invariant Keypoints,” International Journal of Computer Vision, vol. 60, no. 2, pp. 91–110, 2004.
- [16] N. Dalal and B. Triggs, “Histograms of Oriented Gradients for Human Detection,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 886–893, 2005.
- [17] U. Castellani, M. Cristani, S. Fantoni, and V. Murino, “Sparse Points Matching by Combining 3D Mesh Saliency with Statistical Descriptors,” Computer Graphics Forum, vol. 27, no. 2, pp. 643–652, 2010.
- [18] G. Zou, J. Hua, M. Dong, and H. Qin, “Surface Matching with Salient Keypoints in Geodesic Scale Space,” Computer Animation & Virtual Worlds, vol. 19, no. 3-4, pp. 399–410, 2008.
- [19] A. E. Johnson and M. Hebert, “Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes,” IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 21, no. 5, pp. 433–449, 2002.
- [20] M. Kortgen, “3D Shape Matching with 3D Shape Contexts,” in Central European Seminar on Computer Graphics, 2003.
- [21] M. Schlattmann, P. Degener, and R. Klein, “Scale Space Based Feature Point Detection on Surfaces,” in ASME 2012 Internal Combustion Engine Division Fall Technical Conference, pp. 893–905, 2008.
- [22] R. M. Rustamov, “Laplace-Beltrami Eigenfunctions for Deformation Invariant Shape Representation,” in Eurographics Symposium on Geometry Processing, pp. 225–233, 2007.
- [23] D. Shen, P. T. Bremer, M. Garland, V. Pascucci, and J. C. Hart, “Spectral Surface Quadrangulation,” Acm Transactions on Graphics, vol. 25, no. 3, pp. 1057–1066, 2006.
- [24] Y. Lecun and Y. Bengio, “Convolutional Networks for Images, Speech, and Time-Series,” in The Handbook of Brain Theory and Neural Networks, 1995.
- [25] N. Wang, X. Gao, D. Tao, H. Yang, and X. Li, “Facial Feature Point Detection: A Comprehensive Survey,” Neurocomputing, 2017.
- [26] P. Luo, “Hierarchical Face Parsing via Deep Learning,” in IEEE Conference on Computer Vision and Pattern Recognition, pp. 2480–2487, 2012.
- [27] Y. Sun, X. Wang, and X. Tang, “Deep Convolutional Network Cascade for Facial Point Detection,” in Computer Vision and Pattern Recognition, pp. 3476–3483, 2013.
- [28] X. Peng, R. S. F., W. X., and D. N. Metaxas, “RED-Net: A Recurrent Encoder-Decoder Network for Video-Based Face Alignment,” International Journal of Computer Vision, no. 2, pp. 1–17, 2018.
- [29] S. Xiao, J. Feng, J. Xing, H. Lai, S. Yan, and A. Kassim, Robust Facial Landmark Detection via Recurrent Attentive-Refinement Networks. Springer International Publishing, 2016.
- [30] I. Tomek, “Two Modifications of CNN,” IEEE Trans. Systems, Man and Cybernetics, vol. 6, pp. 769–772, 1976.
- [31] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic Minority Over-Sampling Technique,” Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002.
- [32] G. E. A. P. A. Batista, R. C. Prati, and M. C. Monard, “A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data,” ACM SIGKDD explorations newsletter, vol. 6, no. 1, pp. 20–29, 2004.
- [33] C. Bunkhumpornpat, K. Sinapiromsaran, and C. Lursinsap, “Safe-Level-Smote: Safe-Level-Synthetic Minority Over-sampling Technique for Handling the Class Imbalanced Problem,” in Pacific-Asia conference on knowledge discovery and data mining, pp. 475–482, Springer, 2009.
- [34] H. Han, W. Wang, and B. Mao, “Borderline-SMOTE: A New Over-sampling Method in Imbalanced Data Sets Learning,” in International conference on intelligent computing, pp. 878–887, Springer, 2005.
- [35] Z. Zhou, J. Y. Shin, S. R. Gurudu, M. B. Gotway, and J. Liang, “AFT*: Integrating Active Learning and Transfer Learning to Reduce Annotation Efforts,” arXiv preprint arXiv:1802.00912, 2018.
- [36] K. Vodrahalli, K. Li, and J. Malik, “Are All Training Examples Created Equal? An Empirical Study,” arXiv preprint arXiv:1811.12569, 2018.
- [37] K. Benko, M. Kothe, K. D. Semmler, and U. Simon, “Eigenvalues of the Laplacian and Curvature,” Colloquium Mathematicum, vol. 42, no. 1, pp. 19–31, 1979.
- [38] A. Pleijel, “Some Properties of Eigenfunctions of the Laplace Operator on Riemannnian Manifolds,” vol. 1, 1949.
- [39] M. Berger, “Le Spectre d’une Variete Riemannienne,” Lecture Notes in Math, vol. 194, pp. 141–241, 1971.
- [40] “FLANN: Fast library for approximate nearest neighbors.”
- [41] F. Perez-Cruz, “Kullback-Leibler Divergence Estimation of Continuous Distributions,” in IEEE International Symposium on Information Theory, 2008.
- [42] M. P. Dubuisson and A. K. Jain, “A Modified Hausdorff Distance for Object Matching,” in Proceedings of 12th international conference on pattern recognition, vol. 1, pp. 566–568, IEEE, 1994.
- [43] A. Sharma and R. Horaud, “Shape Matching Based on Diffusion Embedding and on Mutual Isometric Consistency,” in IEEE Computer Society Conference on Computer Vision & Pattern Recognition-workshops, 2010.
- [44] J. B. Tenenbaum, V. D. Silva, and J. C. Langford, “A Global Geometric Framework for Nonlinear Dimensionality Reduction,” Science, vol. 290, no. 5500, pp. 2319–2323, 2000.
- [45] Y. LeCun, C. Cortes, and C. J. Burges, “The MNIST Database of Handwritten Digits, 1998,” URL http://yann. lecun. com/exdb/mnist, vol. 10, p. 34, 1998.
- [46] A. Krizhevsky, V. Nair, and G. Hinton, “The CIFAR-10 Dataset,” online: http://www. cs. toronto. edu/kriz/cifar. html, vol. 55, 2014.
- [47] R. Lehoucq, K. Maschhoff, D. Sorensen, and C. Yang, “ARPACK Software,” Website: http://www. caam. rice. edu/software/ARPACK, 2007.
- [48] L. Maaten and G. Hinton, “Visualizing Data Using t-SNE,” Journal of machine learning research, vol. 9, no. Nov, pp. 2579–2605, 2008.
- [49] I. Jolliffe, Principal Component Analysis. Springer, 2011.
- [50] Y. Bengio, J. Paiement, P. Vincent, O. Delalleau, N. L. Roux, and M. Ouimet, “Out-of-Sample Extensions for LLE, Isomap, MDS, Eigenmaps, and Spectral Clustering,” in Advances in neural information processing systems, pp. 177–184, 2004.
- [51] T. G. Dietterich, “Approximate Statistical Tests for Comparing Supervised Classification Learning Algorithms,” Neural computation, vol. 10, no. 7, pp. 1895–1923, 1998.
- [52] R. T. Johnson and D. W. Johnson, “Active Learning: Cooperation in the Classroom,” The annual report of educational psychology in Japan, vol. 47, pp. 29–30, 2008.
- [53] D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [54] L. Prechelt, “Automatic Early Stopping Using Cross Validation: Quantifying the Criteria,” Neural Networks, vol. 11, no. 4, pp. 761–767, 1998.