11email: {2015-116-770, 2015-116-815}@student.cse.du.ac.bd
11email: {akmmrahman, aminmdashraful, aminali}@iub.edu.bd
Hierarchical Self Attention Based Autoencoder for Open-Set Human Activity Recognition
Abstract
Wearable sensor based human activity recognition is a challenging problem due to difficulty in modeling spatial and temporal dependencies of sensor signals. Recognition models in closed-set assumption are forced to yield members of known activity classes as prediction. However, activity recognition models can encounter an unseen activity due to body-worn sensor malfunction or disability of the subject performing the activities. This problem can be addressed through modeling solution according to the assumption of open-set recognition. Hence, the proposed self attention based approach combines data hierarchically from different sensor placements across time to classify closed-set activities and it obtains notable performance improvement over state-of-the-art models on five publicly available datasets. The decoder in this autoencoder architecture incorporates self-attention based feature representations from encoder to detect unseen activity classes in open-set recognition setting. Furthermore, attention maps generated by the hierarchical model demonstrate explainable selection of features in activity recognition. We conduct extensive leave one subject out validation experiments that indicate significantly improved robustness to noise and subject specific variability in body-worn sensor signals. The source code is available at: github.com/saif-mahmud/hierarchical-attention-HAR
Keywords:
Attention Mechanism Human Activity Recognition Autoencoder Open-Set Recognition .1 Introduction
Automated Human Activity Recognition (HAR) has a pivotal role in mobile health, physical activity monitoring, and rehabilitation. Body-worn sensor based HAR can broadly be defined as classification of human physical activity based on signals from multitude of wearable sensors worn at different body locations. Human physical activities include activities of daily living as well as complex activities comprised of multiple simpler micro-activities. Increasing usage of smart handheld devices with multi-modal sensors has paved the way to deploy HAR system in applications of elderly activity monitoring, physiotherapy exercise evaluation, and smart home solutions.
HAR techniques rely on spatial information and temporal dynamics of physical activity captured from heterogeneous sensors placed at different human body locations. Activities involve different dominant body parts and thus hierarchical fusion of sensor signals from different sensor placements is able to capture salient information required for the task. Most human activities can be viewed as a session comprising a number of short time windows containing low level actions. Hierarchical fusion of temporal information is able to take this phenomenon into account. Further, HAR systems in real world scenarios are likely to encounter samples different from training classes. An optimal framework should be able to distinguish them from known classes with explainable visualizations.
Though initial works relied on domain knowledge and heuristic based statistical feature representation [19] for activity recognition, recent end-to-end deep learning models utilize convolutional [8] and recurrent [16] architectures for learning representations. Attention mechanism, described as weighted average of feature representations, is adopted to model HAR task like other sequence modeling problem such as NLP in recent works [15, 29, 12, 31, 13]. However, such approaches do not utilize hierarchical modelling of spatio-temporal information. Moreover, these approaches follow conventional training method under closed set assumption where unknown samples are forced to be recognised as one of the prior known classes.
Considering the aforementioned requirement towards hierarchical fusion of spatio-temporal features, the methodological approach taken in this paper incorporates hierarchical aggregation of sensor signals from different placements across time to construct representation for a specific window. Feature representations from different windows within the same session are aggregated to yield representation for that session. In the case of predicting label for specific window, we utilize session information guided window feature representation instead. The proposed approach models HAR under open set assumption where test samples are identified as seen or unseen and labeled as one of the known classes from training set simultaneously. Such capabilities are highly desirable in the scenario of a subject performing an activity in a completely unexpected way e.g. doing rehabilitation exercise incorrectly due to physical limitations or malfunctioning of sensor devices. In this regard, we have designed autoencoder architecture along with hierarchical encoder to model the distribution of the known activity classes where unseen activities are supposed to yield higher reconstruction loss. Explainable feature attention maps are obtained from hierarchical self-attention layers to demonstrate dominant sensor placement and temporal importance within session to classify specific physical activity.
We conduct extensive experiments on five publicly available benchmark activity recognition datasets: PAMAP2, Opportunity, USC-HAD, Daphnet and Skoda. Our model outperforms prior methods in several datasets. Furthermore, we evaluate the robustness of the model to noise and subject-specific variability through leave-one-subject-out validation experiments. Moreover, we evaluate open-set recognition performance and generate feature attention maps to demonstrate the activity distinguishing characteristics in the learned representation. In brief, the key contributions of our work are listed below:
-
1.
Proposed hierarchical self attention encoder models spatial and temporal information of raw sensor signals in learned representations which are used for closed-set classification as well as detection of unseen activity class with decoder part of the autoencoder network in open-set problem definition
-
2.
Interpretable visualization of feature attention maps indicate fusion of causal and coherent features for activity recognition
-
3.
Our extensive experiments achieve superior performance in several benchmark datasets and demonstrate robustness to subject-specific variability in sensor readings
2 Related Work
Wearable Sensor Based HAR The earlier research works on HAR mostly relied on hand-crafted statistical or distribution-based [11, 20] features that have been designed based on domain expertise [9]. However, recent works for wearable-based HAR have mostly focused on end to end deep learning systems for modeling effective feature representation. In that regard, various forms of convolutional, recurrent and hybrid architectures such as [8, 7, 16] were proposed and demonstrated varying levels of success in recognition of the activities under consideration. In recent years, the incorporation of attention mechanism with deep learning-based architectures [15, 29, 31, 12] have demonstrated significant performance improvement. However, most of these works [4, 18] do not rely on hierarchical modeling of spatio-temporal information from wearable sensors.
Self Attention Architecture Recently, self-attention [27] based models have emerged as a popular alternative to recurrent networks for various NLP tasks and has also been proposed for HAR [13]. Using self-attention in a hierarchical manner has been proposed for various tasks such as classifying text documents [6], generating recommendations [10] etc. in order to break up the task into relevant hierarchical parts. However, no such work exists for wearable sensor data to the best of our knowledge though such hierarchy allows for intuitive representation of complex human activities.
Interpretability and Open-Set Recognition The data from wearable sensor devices are usually high dimensional involving different body placements over some time duration. Furthermore, most of the deep-learning based models used for classification of such data offer little to zero interpretability towards the predicted outcome. Some progress has been made in this regard for video based action recognition task [14, 21]. Although attention-based models for wearable HAR offer more interpretability using the attention-scores, it is still scarce in HAR community. With regards to HAR systems, it is often useful to be able to identify previously unseen activities. Class conditioned [17] or variational [26, 2] autoencoder for unseen sample detection has been proposed for image data. Although unseen activity recognition for skeleton data [25] & smart-home environment [1, 5] have been proposed, autoencoder architectures for unseen sample detection in wearable based HAR are very scarce.
3 Proposed Method
3.1 Task Definition
We assume that is the set of sensors placed at different locations on the body of human subjects. Generally, an Inertial Measurement Unit (IMU) or smart-device contains sensors and records data at a sampling rate of Hz from multiple axes (e.g. tri-axial accelerometer or gyroscope yields signal along , and -axis). Therefore, there will be record of signals at any particular time-step where number of axes at . In a dataset containing sensor signal recording of time-steps, the readings along time is represented as a multidimensional time-series as in (1) and reading at particular time-step can be represented as in (2). The human activity recognition problem can be defined as the task to detect physical activity class labels given the multidimensional time-series of sensor signals of particular duration.
| (1) |
| (2) |
We propose to represent sensor signals hierarchically as an activity session composed of windows representing short segments within the sequence. On the other hand, a window is composed of a fixed number of data-points representing the sensor signal at the corresponding time-stamps. We use the proposed hierarchical encoder to learn representation for a session which is used for both classification and open-set detection. The different components of the model are described in the following subsections.
3.2 Hierarchical Self Attention Encoder
The proposed model incorporates two distinct types of hierarchy - temporal and body location-based. These hierarchies are implemented by the Hierarchical Window Encoder (HWE) and Session Encoder (SE), respectively. Self attention is the core element in both of the aforementioned components and is used in two ways within the components. We refer to them as Modular Self Attention and Aggregator Self Attention, respectively.
Modular Self Attention: Modular self attention consists of identical blocks of multi-headed self attention and position-wise feed forward layers. For each time-step, three linear transformations referred to as key (), query (), and value () are learned. Attention score is obtained by applying softmax function on the scaled dot products of queries and keys and is used to get a weighted version of the values. This operation is performed in matrix form as defined in (3).
| (3) |
Here, where are weight matrices; X is the input and . Furthermore, multi-head self attention is defined in (4) where each attention head uses different and the output from different attention heads are combined according to (4).
| (4) |
where, . Position-wise feed forward refers to identical fully connected feed forward network composed of two feed forward layers with ReLU activation in between applied independently to each time-step. In addition, layer normalization is used after self-attention and position-wise feed forward layers and the aforementioned layers contain residual connections.
Aggregator Self Attention: In order to obtain an aggregate representation from all the time-steps in the input sequence, we use Aggregator Self Attention. The primary difference between Modular and Aggregator blocks is in the learned linear representations used in (5). The construction of query and value are the same as the former. The key matrix in (5) is initialized randomly and learned during optimization with the rest of the parameters.
| (5) |
Where, are weight matrices; is the input to the layer and . In contrast to Modular Self Attention, the position-wise feed forward layer is applied both before and after the self attention operation. Moreover, we use single headed attention in this block in order to simplify the use of the attention scores for interpretability.
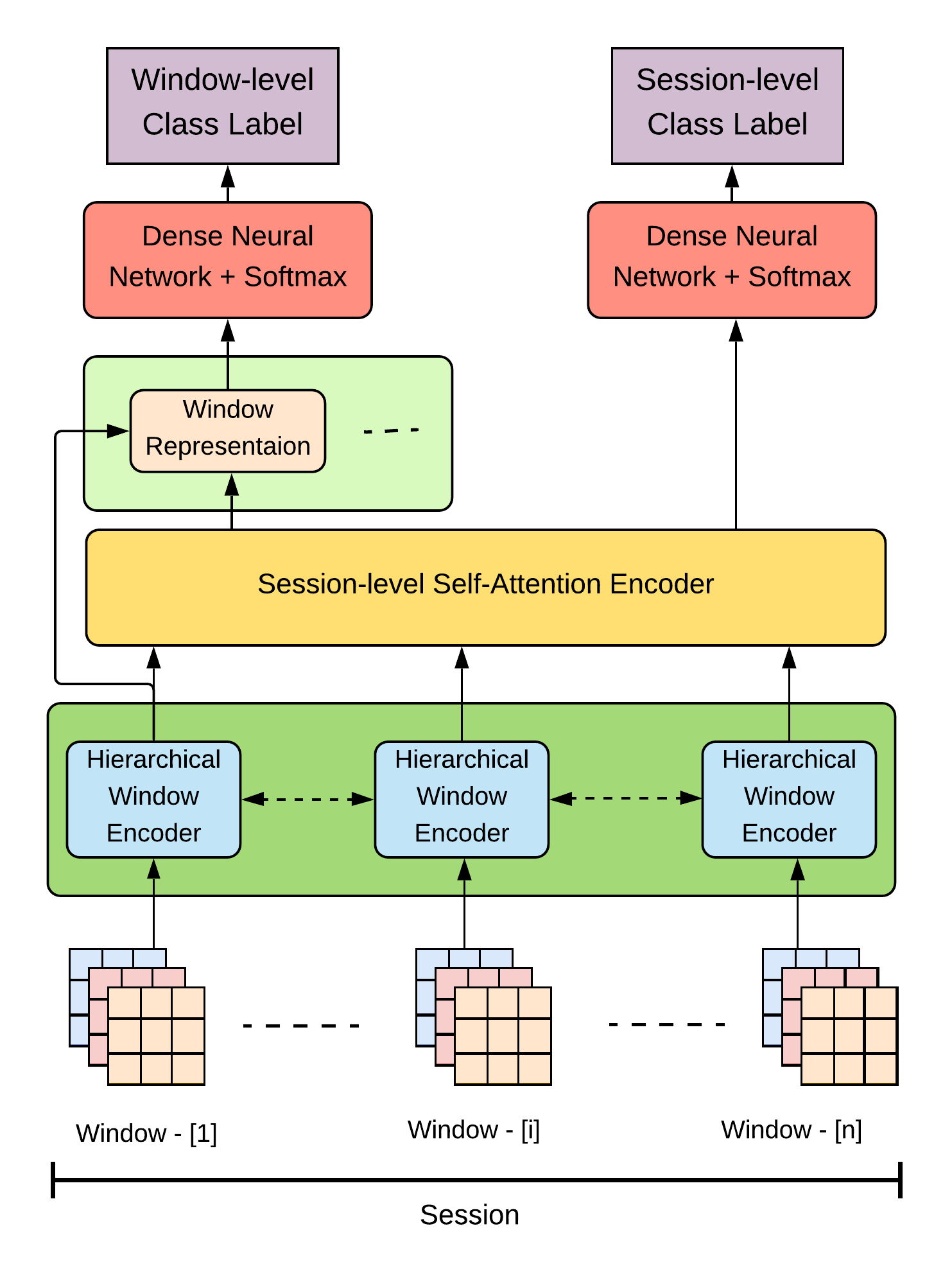

(b) Hierarchical Window Encoder, where sensor signals from different body locations within short time span are separately transformed and fused later using self attention
Hierarchical Window Encoder (HWE) consists of modular self attention blocks and an aggregator self attention block where is the number of sensor placements. First, the values from all sensor modalities placed in a body location are combined using -D convolution over single time-step to create a sized vector. The position information is incorporated by adding positional encoding based on sine and cosine function. Afterwards, the sequence from each sensor placement goes through modular self attention block. Finally, the transformed time-steps are concatenated along the temporal axis and aggregator self attention is used to obtain a representation for the window as defined in (6) and (7).
| (6) |
| (7) |
Session Encoder (SE) comprises identical HWEs where is the number of windows within the session. All of the HWE within the session have shared parameters. The input to the session encoder is the output from temporally ordered window encoders where is the number of windows within the session. Similar to the HWE, the input goes through Modular Self Attention and Aggregator Self Attention as defined in (8) and (9) to obtain a representation for the session.
| (8) |
| (9) |
Window and Session Classification: For session-level classification, the output from SE is passed to dense and softmax layers to obtain the class label. However, for widow-level classification we concatenate the output from SE with each window representation and pass that to dense and softmax layers. Therefore, we utilize the hierarchical structure to augment the window representation with session information to guide the window-level classification.
3.3 Open Set Human Activity Recognition
Autoencoder, constructed upon the proposed hierarchical self-attention encoder, models the relationship between random variable representing low-dimensional latent space and random variable denoting learned representation vector to be reconstructed. We have designed the decoder as multi-layer feed-forward neural network estimating the approximation of distribution where is the learned decoder parameters. On the other hand, the encoder is trained to model the posterior distribution where indicates encoder network parameters.
As illustrated in Fig. 2, the objective of proposed autoencoder is to approximate the intractable true posterior with . The approximation depends on the network parameters and they are tuned based on reconstruction loss and Kullback–Leibler (KL) divergence . As the KL divergence cannot be computed directly from feature representation and latent space representation , the loss is minimized through maximizing summation of Evidence Lower Bound (ELBO). Therefore, the loss of autoencoder is computed as, , where is defined as below in (10):
| (10) |
Here, is the Evidence Lower Bound on the marginal likelihood of the -th learned representation, . indicates prior probability and modeled as unit Gaussian. The expected value defined in the first term indicates reconstruction loss of learned representations. It is assumed according to the characteristics of autoencoder that known activity classes will demonstrate lower reconstruction loss whereas unseen or novel ones should yield higher. The novel activities are detected based on reconstruction loss threshold which is tuned as hyperparameter. The threshold is set from the range where is the reconstruction loss of autoencoder on training data containing known activity classes and .

4 Experiments
Datasets: We use five publicly available benchmark datasets - PAMAP2 [22], Opportunity [23], USC-HAD [30], Daphnet [3] and Skoda [24] for our experiments. A summary of the datasets used is presented in Table 1.
| Dataset |
|
|
|
|
|
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PAMAP2 | 100 Hz | 12 | 9 | 105 | 106 | A, G | ||||||||||||
| Opportunity | 30 Hz | 18 | 4 | 1 (run 2) | 2, 3 (run 4, 5) | A, G, M | ||||||||||||
| USC-HAD | 100 Hz | 12 | 14 | 11, 12 | 13, 14 | A, G | ||||||||||||
| Daphnet | 64 Hz | 2 | 10 | 9 | 2 | A | ||||||||||||
| Skoda | 98 Hz | 11 | 1 | 1 (10%) | 1 (10%) | A |
Construction of Activity Window & Session: Activity sessions are constructed using overlapping sliding-window across the temporal axis. Each activity session comprises a number of non-overlapping short activity segments which we refer to as windows.
Open-set Experiment: We randomly hold out the data for a fraction of the classes (22% and 27% of the classes in case of Oppotunity & Skoda, 33.33% for rest) as part of the open-set and include the benchmark test data as defined in Table 1 to construct the test set for evaluation. We train the model with the remaining data and report the cross validation results.
Training and Hyperparameters: We implement the proposed model in Tensorflow and train on eight Tesla K80 GPUs. We use Adam optimizer with learning rate set to with momentum and and weight decay . The number of identical blocks and head for multi-headed self-attention is set to and respectively for our experimental setup. The dropout applied to placement specific encoder block and the size of the representation vector learned from each session is configured to and respectively.
5 Results and Discussion
Evaluation Metric: For the evaluation of activity recognition performance, we use the macro average F1-score defined in (11) as metric where and in (11) indicate number of classes and the set of classes respectively.
| (11) |
5.0.1 Baselines and Performance Comparison
We compare the proposed method with a number of baselines which includes most of the prominent feature-based deep learning methods for HAR as well as the recent state-of-the-art models. In particular, we compare our approach with recurrent, convolutional, hybrid and attention-based models. Recurrent network based baselines include LSTM and b-LSTM [8]. For convolutional baselines we compare with simple CNN as well as convolutional autoencoder. Hybrid baselines include DeepConvLSTM (4 CNN and 2 LSTM layers). Attention based baselines include attention augmented DeepConvLSTM as well as SADeepSense [28] (CNN, GRU and sensor & temporal self-attention modules) and AttnSense [12] (attention based modality fusion subnet and GRU subnet). We also compare with self-attention based transformer classifier[13] which does not use any hierarchical modelling.
| Methods | PAMAP2 | Opportunity | USC-HAD | Daphnet | Skoda |
|---|---|---|---|---|---|
| LSTM (2014) | 0.75 | 0.63 | 0.38 | 0.68 | 0.89 |
| CNN (2015) | 0.82 | 0.59 | 0.41 | 0.59 | 0.85 |
| b-LSTM [8] (2016) | 0.84 | 0.68 | 0.39 | 0.74 | 0.91 |
| DeepConvLSTM [16] (2016) | 0.75 | 0.67 | 0.38 | 0.84 | 0.91 |
| Conv AE [9] (2017) | 0.80 | 0.72 | 0.46 | 0.73 | 0.79 |
| DeepConvLSTM + Attn [15] (2018) | 0.88 | 0.71 | 0.51 | 0.76 | 0.91 |
| SADeepSense [28] (2019) | 0.66 | 0.66 | 0.49 | 0.80 | 0.90 |
| AttnSense [12] (2019) | 0.89 | 0.66 | 0.49 | 0.80 | 0.93 |
| Transformer Encoder [13] (2020) | 0.96 | 0.67 | 0.55 | 0.82 | 0.93 |
| Proposed HSA Autoencoder | 0.99 | 0.68 | 0.55 | 0.85 | 0.95 |
Performance on Benchmark Test Set: Table 2 shows that the proposed model outperforms the baseline methods for all of the datasets except Opportunity in terms of window-based results. Specifically, the proposed method outperforms the other methods for PAMAP2, Skoda and Daphnet dataset. On USC-HAD dataset, the performance of the proposed model is on par with the transformer encoder which can be explained by the fact that the dataset contains sensor readings from only one body location (waist) thus not being able to take advantage of sensor location hierarchy. With regards to the Opportunity dataset, some of the mid-level gestures are very short (e.g less than one second) for which the hierarchical model does not improve much on the existing results. However, the advantage of the proposed hierarchy becomes apparent when we consider the performance on longer and more complex activities. In particular, for the recognition of high level complex activities in the Opportunity dataset, we observe better performance compared to the others (proposed model obtains macro-F1 of compared with , , , for CNN, LSTM, DeepConvLSTM and AROMA [18] respectively). Therefore, the proposed hierarchical method not only produces better performance in case of longer complex activities (session-wise) but also improves the recognition of shorter activities (window-wise).
| Dataset | Proposed Model |
|
DeepConvLSTM | Conv AE | |
|---|---|---|---|---|---|
| PAMAP2 | 0.94 | 0.92 | 0.61 | 0.48 | |
| Opportunity | 0.43 | 0.42 | 0.44 | 0.42 | |
| USC-HAD | 0.68 | 0.60 | 0.59 | 0.63 | |
| Daphnet | 0.72 | 0.71 | 0.69 | 0.67 |
Performance on Leave-One-Subject-Out (LOSO) Experiment: In order to demonstrate the proposed hierarchical model’s robustness to subject specific variability in sensor reading, we perform leave-one-subject-out (LOSO) validation experiments. In this regard, we hold data of one subject out for evaluation. Table 3 presents macro F1 score of LOSO experiments on four datasets (Skoda contains single subject) used for experiments. As can be seen from the table, the model demonstrates better performance on LOSO experiments compared to benchmark test data while other models suffer from subject specific variable sensor reading patterns for the same activity.
Attention Maps for Interpretability: We can obtain temporal and sensor-placement specific attention maps based on the attention scores obtained from SE and HWE respectively. The attention maps are useful for understanding the predictions made by the model. With regards to temporal attention maps, a snapshot of which time frames were of more importance for the prediction is useful for understanding both the model output and activity itself in case of unseen activities. Moreover, such attention maps demonstrate good correspondence with mid-level or micro activities that comprise the action. One such example is illustrated in Fig. 3 for a complex activity from the Opportunity dataset using the annotated mid level actions and locomotion. It is evident that more emphasis is given on the relevant actions for recognition of the activity. Furthermore, the sensor-placement based attention maps provide a finer granularity of information regarding which placements played more prominent roles at different times which is in line with the intuitive understanding that distinct micro activities may be dominated by different body parts.

Performance on Open set HAR: Furthermore, the proposed model also produces noteworthy results in the case of open set recognition as shown in Table 4. The proposed auto-encoder obtains good performance in terms of accuracy and macro F1-score on PAMAP2, Opportunity and USC HAD dataset indicating the capability to distinguish between the activities belonging to the known & unknown classes. With regards to Daphnet dataset, the scores are lower compared to rest since the unknown class includes transition activities in between the two known classes resulting in similar distribution for known and unknown activities.
| Dataset |
|
|
Accuracy |
|
||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PAMAP2 | 12 | 4 | 0.85 | 0.69 | ||||||
| Opportunity | 18 | 4 | 0.75 | 0.58 | ||||||
| USC HAD | 12 | 3 | 0.61 | 0.52 | ||||||
| Skoda | 11 | 3 | 0.55 | 0.44 | ||||||
| Daphnet | 3 | 1 | 0.42 | 0.39 |
6 Conclusion
The aim of this work was to design self-attention based model with hierarchical fusion of spatial and temporal features. Our extensive experiments confirmed that hierarchical aggregation leads to better modelling of spatio-temporal dependency in multimodal time-series sensor signal. These findings have significant implications for the understanding of how to construct feature representation that leverages better separability for classification and unseen class detection. The findings reported here lays the groundwork of future research into natural language description generation from multimodal sensor signals. However, publicly available benchmark HAR dataset is limited by the lack of complex activity annotations. Notwithstanding these limitations, the hierarchical self-attention model demonstrates interpretable activity recognition as well as robust feature representation.
Acknowledgments
This project is supported by ICT Division, Government of Bangladesh, and Independent University, Bangladesh (IUB).
References
- [1] Al Machot, F., R. Elkobaisi, M., Kyamakya, K.: Zero-shot human activity recognition using non-visual sensors. Sensors 20(3), 825 (Feb 2020)
- [2] An, J., Cho, S.: Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE 2(1), 1–18 (2015)
- [3] Bachlin, M., Plotnik, M., Roggen, D., Maidan, I., Hausdorff, J.M., Giladi, N., Troster, G.: Wearable assistant for parkinson’s disease patients with the freezing of gait symptom. IEEE Transactions on Information Technology in Biomedicine 14(2) (2010)
- [4] Cheng, W., Erfani, S., Zhang, R., Kotagiri, R.: Predicting complex activities from ongoing multivariate time series. In: IJCAI-18. pp. 3322–3328 (2018)
- [5] Du, Lim, Tan: A novel human activity recognition and prediction in smart home based on interaction. Sensors 19(20), 4474 (Oct 2019)
- [6] Gao, S., Qiu, J.X., Alawad, M., Hinkle, J.D., Schaefferkoetter, N., Yoon, H.J., Christian, B., Fearn, P.A., Penberthy, L., Wu, X.C., Coyle, L., Tourassi, G., Ramanathan, A.: Classifying cancer pathology reports with hierarchical self-attention networks. Artificial Intelligence in Medicine (2019)
- [7] Guan, Y., Plötz, T.: Ensembles of deep lstm learners for activity recognition using wearables. ACM IMWUT (2017)
- [8] Hammerla, N.Y., Halloran, S., Plötz, T.: Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv preprint arXiv:1604.08880 (2016)
- [9] Haresamudram, H., Anderson, D.V., Plötz, T.: On the role of features in human activity recognition. In: Proceedings of the 23rd International Symposium on Wearable Computers. ISWC ’19, ACM (2019)
- [10] He, Y., Wang, J., Niu, W., Caverlee, J.: A hierarchical self-attentive model for recommending user-generated item lists. In: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. pp. 1481–1490 (2019)
- [11] Kwon, H., Abowd, G.D., Plötz, T.: Adding structural characteristics to distribution-based accelerometer representations for activity recognition using wearables. In: Proceedings of the 2018 ACM ISWC. ACM (2018)
- [12] Ma, H., Li, W., Zhang, X., Gao, S., Lu, S.: Attnsense: Multi-level attention mechanism for multimodal human activity recognition. In: Proceedings of the IJCAI-19. pp. 3109–3115 (2019)
- [13] Mahmud, S., Tonmoy, M.T.H., Bhaumik, K.K., Rahman, A.M., Amin, M.A., Shoyaib, M., Khan, M.A.H., Ali, A.A.: Human activity recognition from wearable sensor data using self-attention (ECAI 2020) (2020)
- [14] Meng, L., Zhao, B., Chang, B., Huang, G., Sun, W., Tung, F., Sigal, L.: Interpretable spatio-temporal attention for video action recognition. In: Proceedings of the IEEE international conference on computer vision workshops. pp. 0–0 (2019)
- [15] Murahari, V.S., Plötz, T.: On attention models for human activity recognition. In: 2018 ACM Int. Symposium on Wearable Computers. pp. 100–103. ACM (2018)
- [16] Ordóñez, F., Roggen, D.: Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 16, 115 (01 2016)
- [17] Oza, P., Patel, V.M.: C2ae: Class conditioned auto-encoder for open-set recognition. In: Proceedings of the IEEE CVPR. pp. 2307–2316 (2019)
- [18] Peng, L., Chen, L., Ye, Z., Zhang, Y.: Aroma: A deep multi-task learning based simple and complex human activity recognition method using wearable sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technologies (2018)
- [19] Plötz, T., Hammerla, N.Y., Olivier, P.L.: Feature learning for activity recognition in ubiquitous computing. In: Twenty-Second International Joint Conference on Artificial Intelligence (2011)
- [20] Qian, H., Pan, S.J., Da, B., Miao, C.: A novel distribution-embedded neural network for sensor-based activity recognition. In: Proceedings of the IJCAI-19 (2019)
- [21] Ramakrishnan, K., Monfort, M., McNamara, B.A., Lascelles, A., Gutfreund, D., Feris, R.S., Oliva, A.: Identifying interpretable action concepts in deep networks. In: CVPR Workshops. pp. 12–15 (2019)
- [22] Reiss, A., Stricker, D.: Introducing a new benchmarked dataset for activity monitoring. In: Proceedings of the 16th Annual International Symposium on Wearable Computers (ISWC) (2012)
- [23] Roggen, D., et al.: Collecting complex activity datasets in highly rich networked sensor environments. In: Seventh International Conference on Networked Sensing Systems (INSS) (2010)
- [24] Stiefmeier, T., Roggen, D., Troster, G., Ogris, G., Lukowicz, P.: Wearable activity tracking in car manufacturing. Pervasive Computing, IEEE 7, 42–50 (05 2008)
- [25] Tian, G., Yin, J., Han, X., Yu, J.: A novel human activity recognition method using joint points information. Jiqiren/Robot 36, 285–292 (05 2014)
- [26] Vasilev, A., Golkov, V., Meissner, M., Lipp, I., Sgarlata, E., Tomassini, V., Jones, D.K., Cremers, D.: q-space novelty detection with variational autoencoders. In: Computational Diffusion MRI, pp. 113–124. Springer (2020)
- [27] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems 30 (2017)
- [28] Yao, S., Zhao, Y., Shao, H., Liu, D., Liu, S., Hao, Y., Piao, A., Hu, S., Lu, S., Abdelzaher, T.F.: Sadeepsense: Self-attention deep learning framework for heterogeneous on-device sensors in internet of things applications. In: IEEE INFOCOM 2019-IEEE Conf. on Computer Communications. pp. 1243–1251. IEEE (2019)
- [29] Zeng, M., Gao, H., Yu, T., Mengshoel, O.J., Langseth, H., Lane, I., Liu, X.: Understanding and improving recurrent networks for human activity recognition by continuous attention. In: ACM ISWC ’18. ACM (2018)
- [30] Zhang, M., Sawchuk, A.: Usc-had: a daily activity dataset for ubiquitous activity recognition using wearable sensors. In: 2012 ACM Conf. on Ubiquitous Computing. pp. 1036–1043 (2012)
- [31] Zheng, Z., Shi, L., Wang, C., Sun, L., Pan, G.: Lstm with uniqueness attention for human activity recognition. In: Int. Conf. on Artificial Neural Networks. pp. 498–509. Springer (2019)