Hierarchical Neural Implicit Pose Network for Animation and
Motion Retargeting
Abstract
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/f50e96ee-02fa-4d72-933c-bd8c980c3e63/teaser2.png)
1 Introduction
Placing controllable characters into a digital 3D world is a long-standing research problem with applications in digital simulation, cinematography, games, AR/VR, and recent metaverse efforts. Traditionally, digital characters are represented as 3D meshes with meticulously crafted control mechanisms (or rigs) for deforming the shape. Explicit control of deformation, for example through the simple but popular linear-blend skinning (LBS) model[30], inevitably results in artifacts, which countless prior works have attempted to remedy [32, 51, 23]. While it is possible to achieve stunning motion with these traditional rigs, they are also notoriously difficult and time-consuming to design even by skilled 3D artists.
Recently, the research community has gained interest in implicit or coordinate-based definitions of 3D shapes, for example through learned signed distance functions (SDFs) [42]. These representations naturally allow capturing intricate, context-dependent variations of geometry, but their application to control and animation of 3D shapes is still in their early stages. Our work follows the promising direction of developing controllable implicit representations for articulated 3D shapes, and makes strides in generalizability, accuracy, and amount of supervision.
We propose to learn a hierarchical part-based signed distance function, conditioned on joint positions and angles as well as a subject identity code. Our learned model, dubbed Hierarchical Implicit Pose Network (or HIPNet), is composed of joint-level SDF sub-networks, arranged hierarchically based on a skeletal graph, and a single aggregation network that fuses multiple predictions into the final SDF value. At run time, a single trained HIPNet network can be used to drive shape changes of multiple characters using skeletal poses unseen in training. We report state-of-the-art results on various multi-subject datasets, showcasing our generalization across subjects and motions.
While some prior works also use a hierarchical formulation [1, 18], crucially ours is the first neural implicit model to train on only point clouds and posed skeletons, without relying on a traditional parametric model or existing skinning weights. For example, NASA [18] relies on skinning weights of an existing 3D rig in order to learn an implicit representation. As stated earlier, good quality rigs are difficult to obtain, and the promise of implicit functions is precisely to obviate the need for such rigs to begin with. On the other hand, ImGHUM [1] relies on GHUM [52], a statistical generative 3D body model with shape and pose spaces. Our work makes an important stride in this direction, enabling training from unlabeled point clouds and driving skeletons that could be the result of 3D capture and pose estimation without heavy post-processing. In addition, our approach disentangles pose and identity, and allows retargeting motion from one character to another, or animating a character by interpolating in the learnt pose space, as shown in Fig 1. Finally, while we experiment on widely available human datasets, our method is general and can extend to any creatures driven by a known skeleton and 3D pose.
In summary, we propose a pose-driven hierarchical neural SDF model for articulated characters that:
-
•
Requires only weak supervision given poses and point clouds, no template meshes or skinning weights.
-
•
Disentangles identity from pose without relying on a traditional parametric model, allowing motion retargeting and smooth interpolation between key poses.
-
•
Supports multi-subject training and also outperforms single-subject models on all benchmarks.
-
•
Is formulated as an SDF, not occupancy, resulting in faster rendering and meshing.
-
•
Results in a generative model that generalizes to new subjects via latent code optimization.
2 Related Work
| Training | Test-time | Network | Multi-subj. | Extends to | Generative | Generative | |
| data | input | output | support | non-humans | shape | pose | |
| NASA [18] | occ., skinning weights, poses | pose | occ. | N | Y | N | Y |
| SNARF [8] | occ., poses | pose | occ. | N | Y | N | Y |
| imGHUM [1] | oriented pt. clouds, off-srf. pts., GHUM enc. | GHUM enc. | SDF, semantics | Y | N | Y∗ | Y |
| LEAP [38] | occ., verts., skinning weights, poses | shape enc., pose | occ. | Y | N | Y∗ | Y |
| NPMs [41] | T-pose and posed meshes, dense per-subj. corr. | learned ID & pose enc. (not posable) | SDF | Y | Y | Y | Y |
| Ours | oriented pt. clouds, poses | learned ID enc., pose | SDF | Y | Y | Y | Y |
Legend: occ. - occupancy, pt. - point, verts. - vertices of the surface mesh, enc. - encoding, subj. - subject, corr. - correspondences, off-surf. pts. - off-surface points.
2.1 Classical Approaches
Constructing poseable 3D character models from observations is a long-standing problem in computer graphics. A number of representations are available for driving the deformation of a 3D shape. For articulated character animation, linear blend skinning (LBS) [30] is a widely popular approach. In LBS, vertices of a 3D mesh are assigned to the bones and joints of a controlling ”skeleton” using vertex-level skinning weights, resulting in a 3D ”rig”. These weights are used to propagate bone transformations to the underlying surface geometry. There is a wealth of work on automatically creating LBS-style rigs for a character mesh [3, 23, 26, 28, 53], however this representation is far from perfect. Simple LBS formula is known to introduce artifacts and sometimes wildly unrealistic deformations (known as the ”candy-wrapper” effects), prompting research on alternative formulations [25], and on incorporating pose-specific examples to correct the final shape [29]. Such pose-specific guidance is still used today, and most production rigs are intricate works requiring hours of highly skilled labor. The need for pose-specific control over deformation and the labour-intensive nature of explicit 3D rigs makes neural implicit representations for articulated characters a promising direction for new solutions in this space.
2.2 Neural Implicit Approaches
Implicit representations, such as Signed Distance Fields (SDF), have found use in representing and tracking deforming shapes [17, 39]. Most of these grid-based representations faced a trade-off between quality of representation and a prohibitive growth in memory requirements. Various approaches resorted to space-partitioning data structures or hashing functions to address this limitation [19, 40]. Neural implicit representations [4, 42, 37, 9, 10] have surpassed these approaches in terms of both quality and scalability.
Within animation, the promise of neural implicit representations is representing rich pose-dependent geometry of an articulated character by learning from observations alone. Our work follows this motivating principle and requires only points and normals sampled from the surface of the deforming geometry and the corresponding skeletal poses for training. While several recent works also aim to represent articulated 3D humans using a deep implicit representation (See Tab. 1), almost none follow the same low-supervision regime as our method. NASA [18] and imGHUM [1] both devise a hierarchical or part-based models, similar to ours, but are supervised by difficult to obtain data: imGHUM requires a parametric template mesh and is trained using existing GHUM parameterization [52], and NASA training relies on skinning weights, which are not only expensive to generate but might also constrain the model to the space of LBS rigs. Like NASA, LEAP [38] relies on skinning weights, and NPMs [41] need a canonical pose and dense correspondences for every subject. NPMs are also not directly posable, requiring test-time optimization to find a pose encoding for any new pose. In addition, imGHUM [1] and LEAP [38] are closely tied to existing parametric models of the human body, namely GHUM [52] and SMPL [34], respectively, which makes them difficult to extend to other classes of articulated characters. Additionally, LEAP [38] and more recent work like SCANimate [46] rely on LBS within their model, inheriting the artifacts of traditional skinning. This was also noted in the follow-up work Neural-GIF [49]. Out of prior work focused on articulated neural implicit models (Table 1), only SNARF [8] follows our philosophy of low-supervision regime.
While SNARF [8] demonstrates superior results compared to NASA [18], especially on out-of-domain poses, and is trained in a low-supervision regime, it introduces an expensive root-finding step at inference time and cannot handle multiple subjects with a single network or generalize across identities. The key insight behind SNARF is learning a single pose-independent forward skinning transform to represent the bulk of the deformation, unlike approaches like [38, 24], which learn a pose-specific backward skinning function in order to look up occupancy values in the canonical space. Learning pose-specific transform makes these methods vulnerable to over-fitting to the training poses and introduces discontinuities when the same point in the posed space (e.g. touching hands) maps to very disparate locations in the canonical space. However, this key insight is also the cause of SNARF’s limitations, such as the root-finding step. In our work, we show that a careful set of design decisions can extend simpler feed-forward hierarchical approaches [18, 1] to superior generalization to novel poses as well as multi-subject training, all in a low-supervision regime and with an ability to generalize beyond humans, like SNARF. As the result, our work is an important step in this new and exciting line of research.
Other recent works address modeling moving human characters in slightly different regime, for example by learning a controllable neural radiance fields from carefully calibrated multi-camera footage [31] or by focusing on a mesh representation [14]. In addition, an extensive line of research on implicit representations focuses on the problem of reconstructing and completing 3D shapes from partial or 2D inputs [11, 13, 22, 44, 45]. We omit a detailed discussion of these works to maintain focus on articulated neural implicit representations of 3D shape through occupancy or signed distance functions, the subject of our study.
3 Approach
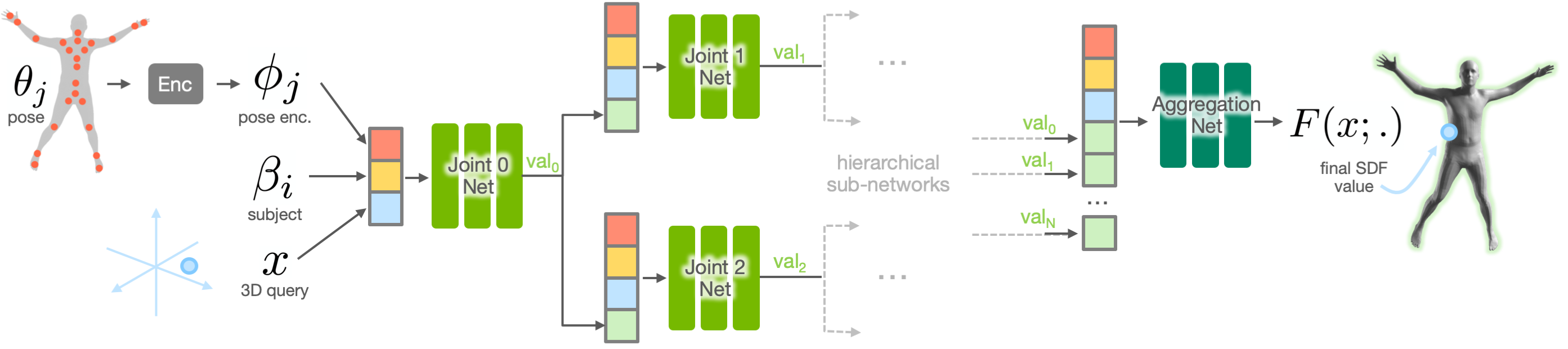
3.1 Problem Formulation
Given a dataset of oriented point clouds (i.e., points and normals) for different subjects that share the same underlying skeleton (e.g., human), as well as the 3D pose of that skeleton for each point cloud, our goal is to train a coordinate-based model, conditioned on pose and subject, that generates a valid SDF with a zero-crossing at the given surface points. In effect, we aim to learn an articulated SDF that can be animated by novel skeletal poses and can represent a number of subjects with a single trained model.
3.2 Our Model
Overview: Given a skeletal pose and subject encoding , our model HIPNet predicts SDF values at input query points . Like some prior modern approaches [18, 1], our model is composed of part-based MLPs. We rely on a consistent skeletal structure of the training dataset and structure our model hierarchically, with a separate MLP sub-network for each of joints in the skeleton. The output of every sub-network is a signed distance value that goes to zero at the surface with a gradient equal to the surface normal. Unlike [18] and [1], we hierarchically propagate the intermediate predictions based on the skeleton’s connectivity graph. The output of a sub-network is therefore concatenated with the input and fed to its children down the graph, allowing child nodes more information to refine the region of overlap with the parent. In addition, we train a final aggregation network to fuse the separate predictions of all sub-networks into the final SDF value . The overall architecture of our system is illustrated in Fig. 2.
Pose Conditioning: We next discuss how our networks are conditioned on pose. First, the input pose parameters (joint transformations) from a sequence are encoded into a latent representation . Our encoder is trained jointly with the model in an end-to-end fashion. Thus, learns to project an input pose into a subspace of the plausible poses that the skeleton can deform into. Note that we ensure that pose parameters for all subjects are first transformed into a canonical global frame. Given that all the subjects share the same skeleton, and therefore are of comparable sizes, this has no negative effect on our model’s representational power. The entire pose embedding is passed to all of the sub-networks and the aggregation network as input, thus making all predictions conditioned on the global pose. This can help disambiguate shape for challenging poses with interaction between different parts of the skeletal graph. Unlike NASA’s deformable model [18], we employ the hierarchy of the skeleton for propagation and we do not try to learn to cluster the subject into deformable components.
Subject Conditioning: For multi-subject training, our networks are further conditioned on a learned subject embedding . The subject codes are directly optimized during training. This follows the generative latent optimization (GLO) framework [7], where the model is effectively an autodecoder [42]. Similarly to the pose embedding, conditions all of the sub-networks and the aggregation network. Note that in order to evaluate on datasets with only one subject and to fairly compare to single-subject baselines, we dropped the subject codes from all the inputs to all our networks.
3.3 Training Data
To train HIPNet, our method requires oriented 3D point clouds along with subject id and 3D pose parameters of the skeleton for each point cloud. We denote the pose parameters transformed to the canonical global frame with for subject in frame , and their encoding as .
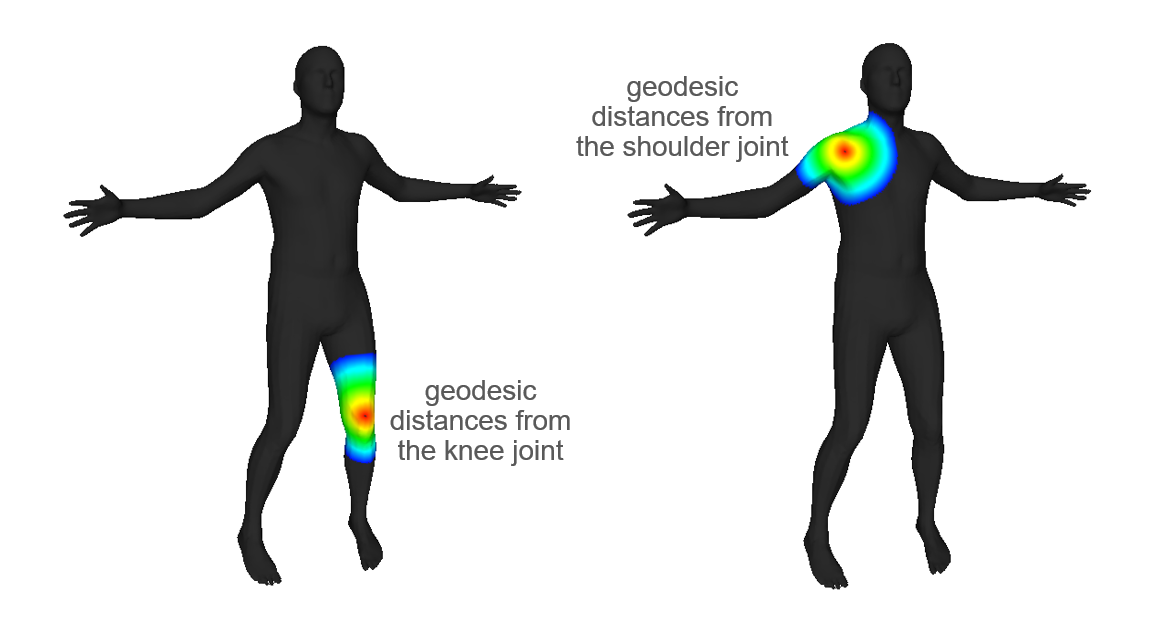
We additionally process the input point clouds offline for approximate vertex-joint assignments. To this end, we process each point cloud individually, finding a proxy surface point on for every joint, and then estimating the approximate Geodesic distance between all points and the joints [16, 33]. Each point is then assigned to the closest joint. See Figure 3 for an illustration. This assignment is only needed at training time for an additional loss term and is not needed during evaluation. Please refer to Section 3.4 for details.
3.4 Loss and Training
Weak Supervision: Unlike prior and concurrent work that requires uniform SDF or occupancy point samples to train an implicit model [42, 18, 41, 8], our method needs point samples only on the zero-crossing of the SDF, or the surface of the moving body. Such data is much more readily available, and in principle could be the result of raw capture.
In a manner similar to IGR [21], we utilize geometric initialization [2] to initialize the surface to a sphere and train our model to output a solution to the Eikonal equation [15]:
| (1) |
Loss Function: For each input point cloud with normals , we train our model with network parameters using the following loss function:
| (2) |
where all the denote hyper-parameters to weigh terms in relative importance.
The data terms in the previous equation are the surface loss and the normal loss , and are defined as:
| (3) |
| (4) |
where is the encoded pose.
The Eikonal regularization term is defined as:
| (5) |
where we sample points uniformly during training within a canonical bounding box as well as near the surface to enforce the unit-norm constraint on the gradient of the SDF.
Sub-network Loss: The surface and normal losses denoted and , respectively, are added to specialize the sub-networks to points close to their corresponding joints. The assignment of points to joints is estimated using an approximate geodesic distance on the input point clouds directly [16, 33]. In practice, we saw significant improvement over our metrics by encouraging this sub-network specialization. We ablate this choice in our experiments.
Estimating the geodesic distance on the input point clouds is only needed during training. During evaluation we simply feed our input points through the entire network. We observe that the sub-network that tends to have the highest impact on the final SDF value is the one corresponding to the joint closest to the input point.
3.5 Implementation Details
In all our experiments, we set and . The surface terms have no associated weight.
The subject codes are randomly initialized from , a zero-mean Gaussian with standard deviation, where the dimensionality of the subject latent space is .
All our MLPs are of size with a single skip connection at layer 4, similar to [42]. We train on individual points clouds sampled at 25k points per batch. We sample another 25k points uniformly within the bounding box and near the surface for the Eikonal regularization term.
We train HIPNet using ADAM [27] with a fixed learning rate of . Our training runs for 50 epochs on 4 Tesla V100 GPUs for a little over 3 days.
4 Experiments
We describe our datasets in section 4.1, evaluate our model qualitatively and quantitatively and compare to the state-of-the-art methods in 4.2, and finally conclude by ablating the various design choices in 4.3.
4.1 Datasets
We trained our model on various motion capture datasets. We used various datasets of minimally clothed humans from the AMASS motion capture archive [36], in addition to CAPE [35], the recent clothed human dataset.
-
•
Transitions is a single subject dataset with 110 motion sequences. We randomly selected 80 sequences for training and the remaining 30 for testing.
-
•
CMU111The homepage of the original dataset is at http://mocap.cs.cmu.edu. is a dataset of multiple subjects. Initially released as the Human Interaction subset of the CMU Motion Capture dataset, it was re-exported and added to AMASS. CMU contains over 100 subjects, but we dropped subjects with less than 5 motion sequences, leaving 89 subjects for our evaluation.
-
•
DFAUST [6] is another dataset that has 10 unique subjects performing varying motion sequences.
-
•
CAPE [35] is a dataset of real scans with 10 male and 5 female subjects in various clothing combinations. While the total number of subjects is 15, there are 41 unique subject-clothing combinations overall.
For the multi subject datasets, we select 75% of sequences for training and 25% for each subject so no subjects are unseen during inference, similar to recent work [38, 41]. Testing on unseen subjects is explored later in this section. We also randomly sample frames within each motion sequence when dealing with larger datasets. We randomly sampled 3% of the frames within each sequence for CMU and 50% of the frames in each sequence for CAPE. Overall with both train and test sets, there are over 80k, 80k, 30k, and 70k samples used in the Transitions, CMU, DFAUST, and CAPE datasets respectively.
For all these experiments we randomly sample 25k surface points alongside their normals on the input meshes. While all of these datasets rely on SMPL [34] for the consistent topology and the skinning weights, our approach is completely agnostic to both.
4.2 Evaluation
Metrics: We report the mean Intersection over Union (mIoU) and the Chamfer-L1 distance [20]. The mIoU is calculated using points randomly sampled within a tight bounding box around the subject which is stretched along the diagonal by 10% [18]. We also report the mIoU for near surface points for our method which has sampled by taking surface points from the ground truth mesh and then adding isotropic noise with , a zero-mean Gaussian with standard deviation.
The Chamfer-L1 distance is the mean of an accuracy and a completeness metric. The accuracy metric is the mean distance of points on the reconstructed mesh to their closest point on the ground truth mesh, and the completeness metric is defined in the same way in the opposite direction. Similar to prior work [37, 20], we randomly sample 100k points from both meshes and use times the maximal edge length of the mesh’s bounding box as unit to normalize our distance estimation.
Baselines: We compare to the reported mIoU for various recent baselines, NASA [18], NPM [41], and SNARF [8]. We also reproduced NASA within our setup. In that setup, we reduced the number of surface and non-surface point samples to 25k from the original 100k, and we switched the surface point sampling strategy to triangle area-weighted uniform sampling instead of Poisson-Disc sampling.
Quantitative Results: We first compare our model, HIPNet, to NASA using the same point sampling strategy, the same number of points per mesh, and the same dataset split. We report the uniform mean IoU in Tab. 2. As shown, both our single and multi subject models outperform the deformable NASA model on all four datasets. Notably, NASA significantly underperforms on CAPE where subjects are the most diverse. It is worth noting that NASA requires skinning weights as additional input while our model (both variants) does not need any input beyond the point cloud and the 3D pose.
| mIoU (%) | Transitions | CMU | DFAUST | CAPE |
| Ours (multi subj) | 96.64 | 97.15 | 97.39 | 89.27 |
| Ours (single subj) | 97.74 | 95.55 | 96.24 | 89.45 |
| NASA | 95.21 | 89.96 | 92.43 | 75.65 |
We next report our uniform and near-surface mean IoU on DFAUST and CAPE in Tab. 3 and Tab. 4, respectively. With the uniform IoU setting, all methods performed competitively. The surprising exception is NPM [41], which wile very competitive on CAPE, underperformed significantly on DFAUST. Our numbers are state-of-the-art on both datasets and in all metrics, outperforming all baselines.
| DFAUST | ||
| mIoU (%) | Uniform | Near-Surface |
| Ours (multi subj) | 97.39 | 95.61 |
| Ours (single subj) | 96.24 | 93.85 |
| SNARF | 97.31 | 90.38 |
| NASA | 96.14 | 86.98 |
| NPM | 83 | - |
| CAPE | ||
| mIoU (%) | Uniform | Near-Surface |
| Ours (multi subj) | 87.70 | 82.48 |
| Ours (single subj) | 84.96 | 79.07 |
| NPM | 83 | - |

| Chamfer-L1 | Transitions | CMU | DFAUST | CAPE |
| Ours (multi subj) | 3.625 | 4.5 | 1.95 | 139.5 |
| Ours (single subj) | 3.875 | 6.125 | 4.0 | 181.5 |
Finally, we report the Chamfer-L1 distance on all four datasets in Tab. 5. We report the Chamfer-L1 distance scaled per-mesh such that times the maximal edge length of the mesh’s bounding box as unit [33, 37]. Our multi-subject model consistently outperforms the single-subject model on this metric.
Qualitative Results: A gallery of our extracted meshes for 5 unique subjects from DFAUST performing the same set of test-time poses is rendered in Fig. 4. By varying the subject code and maintaining the same pose we effectively perform motion retargeting for in-distribution subjects.
| mIoU (%) | DFAUST |
| base model | 86.55 |
| + sub-network losses | 96.17 |
| + hierarchical aggregation | 96.24 |
| + subject latent codes | 97.39 |
4.3 Ablation Studies
We next performed various ablations on DFAUST to evaluate the impact of various design choices on the reported metrics. We report our findings in Tab. 6 to motivate our final network design. The baseline model does not use the sub-network loss and aggregates the sub-network predictions in one step (i.e., a flat hierarchy). The biggest impact is clearly due to the sub-network specialization, significantly contributing to the final performance. The hierarchical aggregation and the latent codes further improve the performance as well.
5 Discussion
5.1 Applications
Animation: Unlike various prior works, our model does not require a traditional morphable model during training. Our shape space is entirely learnt and is not based on a pre-trained shape space of SMPL [34] or GHUM [52]. This makes our model suitable for downstream tasks in animation and motion retargeting, where only the skeleton and 3D pose might be available. This also makes it suitable to animate characters or animals that cannot envelope a human skeleton.
Generating New Subjects: Following the Generative Latent Optimization (GLO) framework [7], we can fit a multivariate Gaussian with a full covariance matrix to our subject latent codes. We can then sample from that distribution new characters to showcase the diversity of the data and the representational power of the model. We showcase some samples from our model in Fig. 5.
Test Time Optimization: Similar to [41], we can apply test-time optimization to fit a subject code to an input point cloud, even for an out-of-distribution subject. This approach parallels traditional online fitting of shape space parameters, studied in earlier body and hand personalization work [5, 48, 50, 47]. We showcase this application in Fig. 6. The code is initialized to the mean of the subject codes and optimized for 100 iterations with a learning rate of . The mIoU and quality of the predicted mesh increase with the number of input points. More crucially, with only 1k points on the front of the mesh we are competitive with 10k points uniformly sampled everywhere. This specific settings simulates points coming from a front-facing depth sensor and is of practical importance.

5.2 Limitations
One major limitation of our work stems from the inability of implicit models to represent open and thin surfaces. This is negatively impacting results on datasets with clothed humans, and generally thin extremities like fingers, tails, and so on. There is a recent interest in investigating the right representation for these surfaces [12].
Another question that is generally under-investigated in the field is the impact of modeling muscles on surface deformations. Our work in a way overcomes the limitations of LBS [30] and PSD [29] by directly learning to deform from the data. However, modeling the physics of muscles will likely yield a much more data-efficient approach that relies equally on priors from the physical world.
6 Conclusion
In this paper we introduced HIPNet, a hierarchical neural implicit pose network that can represent a variety of subjects under different poses. Unlike prior work, we do not need a traditional morphable model, skinning weights, or dense correspondences during training. Our model can learn directly from input point clouds and 3D poses. Consequently, our model can learn to represent any class of objects, and not just humans, assuming a common skeleton is available. This makes it suitable for downstream animation and motion retargeting tasks. We report state-of-the-art results on four datasets, outperforming recent baselines. In the future we would like to incorporate a render-and-compare pipeline to learn directly from depth images. We also plan to investigate neural implicit representations for clothes, which is an open and interesting problem.
References
- [1] Thiemo Alldieck, Hongyi Xu, and Cristian Sminchisescu. imghum: Implicit generative models of 3d human shape and articulated pose. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5461–5470, 2021.
- [2] Matan Atzmon and Yaron Lipman. Sal: Sign agnostic learning of shapes from raw data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2565–2574, 2020.
- [3] Ilya Baran and Jovan Popovic. Automatic rigging and animation of 3D characters. ACM Transactions on Graphics (TOG), 26(3):72, July 2007.
- [4] Bharat Lal Bhatnagar, Cristian Sminchisescu, Christian Theobalt, and Gerard Pons-Moll. Combining implicit function learning and parametric models for 3d human reconstruction. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 311–329. Springer, 2020.
- [5] Federica Bogo, Angjoo Kanazawa, Christoph Lassner, Peter Gehler, Javier Romero, and Michael J Black. Keep it smpl: Automatic estimation of 3d human pose and shape from a single image. In European conference on computer vision, pages 561–578. Springer, 2016.
- [6] Federica Bogo, Javier Romero, Gerard Pons-Moll, and Michael J Black. Dynamic faust: Registering human bodies in motion. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6233–6242, 2017.
- [7] Piotr Bojanowski, Armand Joulin, David Lopez-Paz, and Arthur Szlam. Optimizing the latent space of generative networks. arXiv preprint arXiv:1707.05776, 2017.
- [8] Xu Chen, Yufeng Zheng, Michael J Black, Otmar Hilliges, and Andreas Geiger. Snarf: Differentiable forward skinning for animating non-rigid neural implicit shapes. arXiv preprint arXiv:2104.03953, 2021.
- [9] Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5939–5948, 2019.
- [10] Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. Implicit functions in feature space for 3d shape reconstruction and completion. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, jun 2020.
- [11] Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. Implicit functions in feature space for 3d shape reconstruction and completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6970–6981, 2020.
- [12] Julian Chibane, Aymen Mir, and Gerard Pons-Moll. Neural unsigned distance fields for implicit function learning. arXiv preprint arXiv:2010.13938, 2020.
- [13] Julian Chibane and Gerard Pons-Moll. Implicit feature networks for texture completion from partial 3d data. In European Conference on Computer Vision, pages 717–725. Springer, 2020.
- [14] Hongsuk Choi, Gyeongsik Moon, and Kyoung Mu Lee. Pose2mesh: Graph convolutional network for 3d human pose and mesh recovery from a 2d human pose. In European Conference on Computer Vision (ECCV), 2020.
- [15] Michael G Crandall and Pierre-Louis Lions. Viscosity solutions of hamilton-jacobi equations. Transactions of the American mathematical society, 277(1):1–42, 1983.
- [16] Keenan Crane, Clarisse Weischedel, and Max Wardetzky. Geodesics in heat: A new approach to computing distance based on heat flow. ACM Transactions on Graphics (TOG), 32(5):1–11, 2013.
- [17] Brian Curless and Marc Levoy. A volumetric method for building complex models from range images. In Proceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 303–312, 1996.
- [18] Boyang Deng, John P Lewis, Timothy Jeruzalski, Gerard Pons-Moll, Geoffrey Hinton, Mohammad Norouzi, and Andrea Tagliasacchi. Nasa neural articulated shape approximation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VII 16, pages 612–628. Springer, 2020.
- [19] Mingsong Dou, Sameh Khamis, Yury Degtyarev, Philip Davidson, Sean Ryan Fanello, Adarsh Kowdle, Sergio Orts Escolano, Christoph Rhemann, David Kim, Jonathan Taylor, et al. Fusion4d: Real-time performance capture of challenging scenes. ACM Transactions on Graphics (ToG), 35(4):1–13, 2016.
- [20] Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 605–613, 2017.
- [21] Amos Gropp, Lior Yariv, Niv Haim, Matan Atzmon, and Yaron Lipman. Implicit geometric regularization for learning shapes. In Proceedings of Machine Learning and Systems 2020, pages 3569–3579. 2020.
- [22] Tong He, John Collomosse, Hailin Jin, and Stefano Soatto. Geo-pifu: Geometry and pixel aligned implicit functions for single-view human reconstruction. arXiv preprint arXiv:2006.08072, 2020.
- [23] Alec Jacobson, Ilya Baran, Jovan Popovic, and Olga Sorkine. Bounded biharmonic weights for real-time deformation. ACM Trans. Graph., 30(4):78, 2011.
- [24] Timothy Jeruzalski, David IW Levin, Alec Jacobson, Paul Lalonde, Mohammad Norouzi, and Andrea Tagliasacchi. Nilbs: Neural inverse linear blend skinning. arXiv preprint arXiv:2004.05980, 2020.
- [25] Ladislav Kavan, Steven Collins, Jirí Zára, and Carol O’Sullivan. Geometric skinning with approximate dual quaternion blending. ACM Trans. Graph., 2008.
- [26] L Kavan, P P Sloan, and C O’Sullivan. Fast and Efficient Skinning of Animated Meshes. Computer Graphics Forum, 29(2):327–336, May 2010.
- [27] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [28] Binh Huy Le and Zhigang Deng. Robust and accurate skeletal rigging from mesh sequences. ACM Trans. Graph., 33(4):84–10, 2014.
- [29] John P Lewis, Matt Cordner, and Nickson Fong. Pose space deformation: a unified approach to shape interpolation and skeleton-driven deformation. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 165–172. ACM Press/Addison-Wesley Publishing Co., 2000.
- [30] Erik Lindholm, Mark J Kilgard, and Henry Moreton. A user-programmable vertex engine. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques, pages 149–158, 2001.
- [31] Lingjie Liu, Marc Habermann, Viktor Rudnev, Kripasindhu Sarkar, Jiatao Gu, and Christian Theobalt. Neural actor: Neural free-view synthesis of human actors with pose control. arXiv preprint arXiv:2106.02019, 2021.
- [32] Songrun Liu, Alec Jacobson, and Yotam Gingold. Skinning cubic bézier splines and catmull-clark subdivision surfaces. ACM Transactions on Graphics (TOG), 33(6):1–9, 2014.
- [33] Yang Liu, Balakrishnan Prabhakaran, and Xiaohu Guo. Point-based manifold harmonics. IEEE Transactions on visualization and computer graphics, 18(10):1693–1703, 2012.
- [34] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. ACM transactions on graphics (TOG), 34(6):1–16, 2015.
- [35] Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, and Michael J Black. Learning to dress 3d people in generative clothing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6469–6478, 2020.
- [36] Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5442–5451, 2019.
- [37] Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4460–4470, 2019.
- [38] Marko Mihajlovic, Yan Zhang, Michael J Black, and Siyu Tang. Leap: Learning articulated occupancy of people. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10461–10471, 2021.
- [39] Richard A Newcombe, Shahram Izadi, Otmar Hilliges, David Molyneaux, David Kim, Andrew J Davison, Pushmeet Kohi, Jamie Shotton, Steve Hodges, and Andrew Fitzgibbon. Kinectfusion: Real-time dense surface mapping and tracking. In 2011 10th IEEE international symposium on mixed and augmented reality, pages 127–136. IEEE, 2011.
- [40] Matthias Nießner, Michael Zollhöfer, Shahram Izadi, and Marc Stamminger. Real-time 3d reconstruction at scale using voxel hashing. ACM Transactions on Graphics (ToG), 32(6):1–11, 2013.
- [41] Pablo Palafox, Aljaž Božič, Justus Thies, Matthias Nießner, and Angela Dai. Npms: Neural parametric models for 3d deformable shapes. arXiv preprint arXiv:2104.00702, 2021.
- [42] Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 165–174, 2019.
- [43] Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), Nov. 2017.
- [44] Shunsuke Saito, Zeng Huang, Ryota Natsume, Shigeo Morishima, Angjoo Kanazawa, and Hao Li. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2304–2314, 2019.
- [45] Shunsuke Saito, Tomas Simon, Jason Saragih, and Hanbyul Joo. Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 84–93, 2020.
- [46] Shunsuke Saito, Jinlong Yang, Qianli Ma, and Michael J Black. Scanimate: Weakly supervised learning of skinned clothed avatar networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2886–2897, 2021.
- [47] Jamie Shotton, Andrew Fitzgibbon, Mat Cook, Toby Sharp, Mark Finocchio, Richard Moore, Alex Kipman, and Andrew Blake. Real-time human pose recognition in parts from single depth images. In CVPR 2011, pages 1297–1304. Ieee, 2011.
- [48] David Joseph Tan, Thomas Cashman, Jonathan Taylor, Andrew Fitzgibbon, Daniel Tarlow, Sameh Khamis, Shahram Izadi, and Jamie Shotton. Fits like a glove: Rapid and reliable hand shape personalization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5610–5619, 2016.
- [49] Garvita Tiwari, Nikolaos Sarafianos, Tony Tung, and Gerard Pons-Moll. Neural-gif: Neural generalized implicit functions for animating people in clothing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 11708–11718, 2021.
- [50] Anastasia Tkach, Andrea Tagliasacchi, Edoardo Remelli, Mark Pauly, and Andrew Fitzgibbon. Online generative model personalization for hand tracking. ACM Transactions on Graphics (ToG), 36(6):1–11, 2017.
- [51] Yu Wang, Alec Jacobson, Jernej Barbič, and Ladislav Kavan. Linear subspace design for real-time shape deformation. ACM Transactions on Graphics (TOG), 34(4):1–11, 2015.
- [52] Hongyi Xu, Eduard Gabriel Bazavan, Andrei Zanfir, William T Freeman, Rahul Sukthankar, and Cristian Sminchisescu. Ghum & ghuml: Generative 3d human shape and articulated pose models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6184–6193, 2020.
- [53] Zhan Xu, Yang Zhou, Evangelos Kalogerakis, Chris Landreth, and Karan Singh. Rignet: Neural rigging for articulated characters. ACM Trans. on Graphics, 39, 2020.
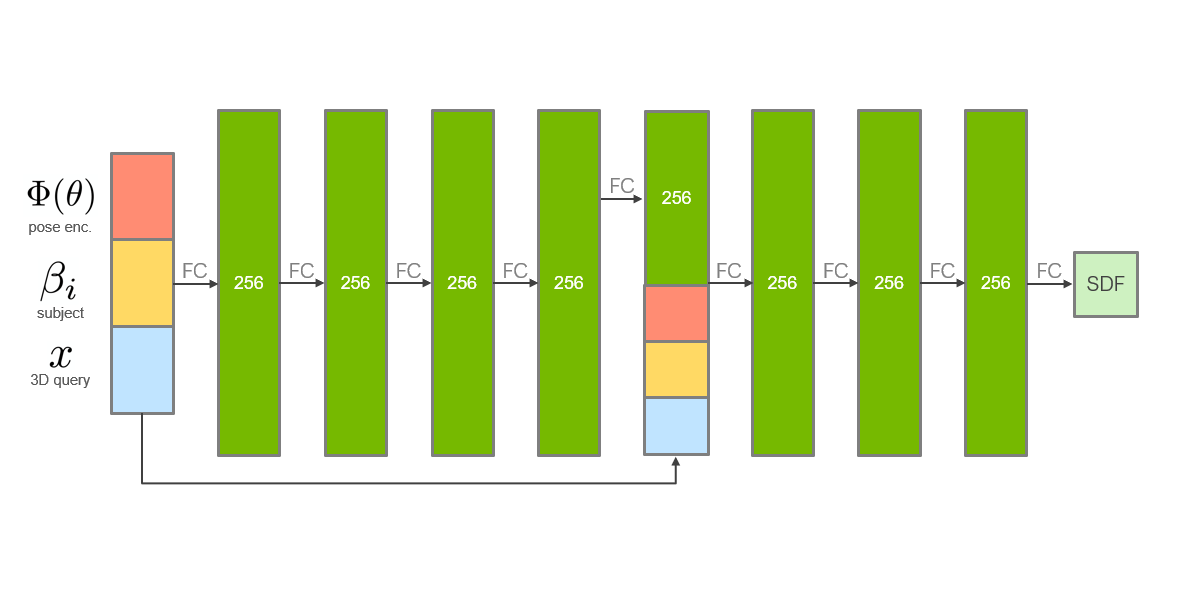
Appendix A Network Architecture
Our network is composed of a series of MLPs arranged in a hierarchical skeletal structure. We use 22 MLPs for the 22 joints in the AMASS dataset [36], which is based on the SMPL skeleton but not including the two hand joints [34]. Each of our MLPs is a series of 8 full-connected layers (of size 256) with a skip connection from the input to layer 4, as shown in Fig. 7. The input to our MLPs is the encoded pose parameters , the subject code , and the query point . The subject code is based on the autodecoder framework and it optimized during training [42, 7]. For all but the root MLP, the input is also augmented with the output of the parent MLP in the structure.
Appendix B Additional Results
We report a full breakdown of our quantitative results on all datasets in Tab. 7. The multi-subject model consistenyl outperforms the single-subject datasets on the multi-subject datasets. On the only single-subject dataset (Transitions), the multi-subject model took significantly longer to train and still was unable to outperform the single-subject model. We expect that eventually it would, but the multi-subject code in this case is a hinderance to the performance. As expected, the near-surface IoU for the joints of the extremities is lower than that of the less articulated and flexible joints like the pelvis or the neck. This is particularly clear for the wrists because of the higher flexibility of the hands and their greater capacity for articulation. On CAPE [35] for instance, the IoU for the wrists is over lower than that of any other joint. It should be noted here that despite AMASS having a single joint (the wrist) for the entire hand, the hands still articulate fully in the sequences [36]. If AMASS is to incorporate a fully-articulated hand model like MANO (which is part of SMPL+H) [43], we expect the IoU for the wrists to improve as well. Hierarchical propagation is in part motivated by propagating predictions from stable, and easy to track, joints to flexible, and hard to track, joints.
| Single-Subject | Multi-Subject | |||||||
| mIoU (%) | Transitions | CMU | DFAUST | CAPE | Transitions | CMU | DFAUST | CAPE |
| Uniform | 97.74 | 95.55 | 96.24 | 84.96 | 96.64 | 97.15 | 97.39 | 87.70 |
| Near-Surface | 96.55 | 93.20 | 93.85 | 79.07 | 95.00 | 95.49 | 95.61 | 82.48 |
| 0) Pelvis | 97.93 | 95.76 | 95.17 | 80.48 | 97.85 | 97.55 | 96.92 | 84.45 |
| 1) L-Hip | 96.52 | 94.48 | 94.68 | 83.61 | 96.45 | 96.46 | 96.74 | 88.06 |
| 2) R-Hip | 93.69 | 91.56 | 93.20 | 83.26 | 93.43 | 94.17 | 95.07 | 87.81 |
| 3) Spine1 | 98.36 | 95.98 | 96.22 | 79.19 | 98.36 | 97.81 | 97.84 | 83.08 |
| 4) L-Knee | 97.64 | 95.41 | 95.90 | 82.62 | 87.96 | 97.46 | 97.32 | 86.90 |
| 5) R-Knee | 98.34 | 95.84 | 95.47 | 83.11 | 97.48 | 97.58 | 97.00 | 87.72 |
| 6) Spine-2 | 97.35 | 94.63 | 95.66 | 78.79 | 97.67 | 96.96 | 97.06 | 81.91 |
| 7) L-Ankle | 97.13 | 93.46 | 94.20 | 74.94 | 78.15 | 97.09 | 96.25 | 82.33 |
| 8) R-Ankle | 97.51 | 94.48 | 93.57 | 75.66 | 97.04 | 97.00 | 95.92 | 83.83 |
| 9) Spine3 | 98.03 | 94.55 | 95.29 | 80.62 | 98.01 | 97.34 | 97.20 | 83.68 |
| 10) L-Foot | 89.20 | 84.82 | 87.00 | 68.05 | 89.09 | 95.09 | 90.19 | 74.31 |
| 11) R-Foot | 92.82 | 89.54 | 84.37 | 68.99 | 94.17 | 95.24 | 89.48 | 73.60 |
| 12) Neck | 93.97 | 91.68 | 94.01 | 81.92 | 93.92 | 92.98 | 95.52 | 84.07 |
| 13) L-Collar | 97.60 | 94.27 | 95.71 | 82.59 | 97.48 | 96.20 | 96.94 | 84.53 |
| 14) R-Collar | 97.58 | 94.20 | 95.34 | 82.82 | 97.37 | 96.47 | 96.71 | 84.41 |
| 15) Head | 91.54 | 88.41 | 92.87 | 78.98 | 91.48 | 89.71 | 94.30 | 81.62 |
| 16) L-Shoulder | 95.23 | 90.62 | 92.45 | 81.10 | 96.61 | 93.45 | 93.40 | 82.29 |
| 17) R-Shoulder | 94.43 | 89.88 | 90.94 | 81.17 | 95.71 | 93.60 | 91.97 | 82.94 |
| 18) L-Elbow | 97.18 | 90.74 | 91.15 | 73.63 | 93.76 | 92.58 | 92.67 | 73.51 |
| 19) R-Elbow | 96.43 | 90.99 | 89.71 | 73.45 | 96.41 | 90.91 | 91.63 | 75.22 |
| 20) L-Wrist | 91.71 | 84.54 | 85.86 | 49.95 | 90.99 | 89.75 | 90.06 | 49.55 |
| 21) R-Wrist | 91.37 | 84.63 | 86.53 | 49.78 | 90.95 | 89.79 | 90.10 | 50.54 |
Appendix C Ethical Considerations
C.1 Social Impact
It is worth noting that some datasets we used are known to have an imbalance across gender and ethnicity. CAPE [35] for instance has 10 male subjects to 5 female subjects. Generally speaking, collecting a dataset of full human bodies that spans genders, ethnicities, and body shapes is a very challenging task. This is in part due to local and international regulations around the collection and use of human data, as well as due to cultural and social barriers.
Our model has applications in full body tracking with a personalized body model. This has various downstream applications in digital simulation, cinematography, games, AR/VR, and recent metaverse efforts [47, 48, 19]. Tracking people for any purpose is a sensitive topic that can potentially violate their right to privacy. Downstream applications of our model should present end-users with an informed agreement that clearly details the use of their data and allow them the right to retract their consent at any point in the future.
C.2 Human Data
The AMASS and CAPE datasets were collected through the Max Planck Institute for Intelligent Systems (MPI-IS) [36, 35]. According to the authors, all subjects were given prior, written, informed consent for the capture and use of their data for research purposes. Additionally, the experimental procedure and consent form were reviewed by the University of Tuebingen Ethics Committee with no objections.