captionskip=0pt
Hierarchical Modeling for Task Recognition and Action Segmentation in Weakly-Labeled Instructional Videos
Abstract
This paper 111 https://github.com/rezaghoddoosian/Hierarchical-Task-Modeling focuses on task recognition and action segmentation in weakly-labeled instructional videos, where only the ordered sequence of video-level actions is available during training. We propose a two-stream framework, which exploits semantic and temporal hierarchies to recognize top-level tasks in instructional videos. Further, we present a novel top-down weakly-supervised action segmentation approach, where the predicted task is used to constrain the inference of fine-grained action sequences. Experimental results on the popular Breakfast and Cooking 2 datasets show that our two-stream hierarchical task modeling significantly outperforms existing methods in top-level task recognition for all datasets and metrics. Additionally, using our task recognition framework in the proposed top-down action segmentation approach consistently improves the state of the art, while also reducing segmentation inference time by 80-90 percent.
1 Introduction
Millions of people watch instructional videos online every day, to learn to perform tasks such as cooking or changing a car tire. Also, new models of assistant robots [1] can learn from such videos how to assist humans in their daily lives. Hence, there has been extensive research in recent years on automated understanding of the top-level tasks and their sub-actions in such videos [8, 10, 46, 50].
From a theoretical point of view, instructional videos can be seen as videos illustrating hierarchical activities. Each instructional video illustrates a single top-level activity, for which we use the term “task” throughout this paper. Examples of such video-level tasks are “making coffee” or “cooking eggs”. Each video-level task is composed of a sequence of lower level activities, such as “pouring milk” or “adding sugar”. Throughout the paper, we will refer to such lower-level activities using the term “action”. Consequently, using this terminology, each instructional video illustrates a task that consists of a sequence of actions.
For instructional videos, and hierarchical activity videos in general, we would like to have automated systems that both recognize the overall task and also understand what lower-level actions take place, and when those actions start and end. Fully-supervised training would require not only annotating the top level task, but also marking the start and end frame of each lower-level action. With the ever-growing size of instructional video datasets, manually annotating such start and end frames can quickly become a bottleneck. To address this issue, weakly-supervised action segmentation methods require, as training data, only the sequence of actions that takes place at each video, and no start/end frame information for those actions [4, 6, 7, 29, 44].

Our goal in this paper is to jointly address the problems of top-level task recognition and lower-level action segmentation, in the weakly supervised setting (given sequences of actions, not given start/end frames). The main novelty is a method for top-level task recognition that uses, in parallel, two different hierarchical decompositions of the problem. One module models the semantic hierarchy between the top-level task and lower-level attributes. These attributes correspond to either the set of actions, or the set of the object/verb components of those actions, e.g., “take” and “cup” in the action “take cup”. This module jointly learns to identify the presence of attributes in the video and to recognize the top-level task based on the estimated attributes.
A parallel second stream models the temporal hierarchy between the entire video and equal-duration subdivisions of the video. Tasks are usually performed in a relative order of stages, and some stages are particularly useful for distinguishing tasks from each other. For example, preparing tea typically involves three stages: taking a cup, adding a tea bag, and pouring water from the kettle. The first and last stages are visually similar with corresponding stages of the “preparing coffee” task. The temporal hierarchy module can capture the importance of adding the tea bag in distinguishing the “preparing tea” task from the “preparing coffee” task. This module learns the relation between stages and their importance in classifying the video task.
We also propose a novel top-down approach for action segmentation (i.e., frame-level action labeling), that combines our task recognition method with existing weakly-supervised segmentation methods. In this approach (Fig.1), the video-level task is estimated first, and is subsequently used to constrain the search space for action segmentation. In summary, the contributions of this paper are these:
1) We introduce a two-stream framework that exploits both semantic and temporal hierarchies to recognize tasks in weakly-labeled instructional videos.
2) We provide specific, non-trivial implementations of these two streams. Our ablation studies demonstrate that our implementation choices have a significant impact on performance. A highlight of such an implementation choice is using TF-IDF weights to model the discriminative power of each attribute for each task (see Section 3.2.2).
3) We present a novel top-down approach for weakly-supervised action segmentation, where the video-level task is used to constrain the segmentation output.
4) We present results on two benchmark datasets: Breakfast [23] and MPII Cooking 2 [46]. In top-level task recognition, our method significantly outperforms the state of the art on both datasets for all metrics. For weakly supervised action segmentation (frame-level labeling), applying the proposed top-down approach on top of existing methods [29, 44] again leads to state of the art results, and also cuts the inference time by 80-90 percent.
2 Related Work
Instructional Video Analysis. In recent years, untrimmed instructional videos have been studied in areas like video retrieval [8, 33, 34], quality assessment [9, 38], future action planning [5], and key-step segmentation [10, 26, 30, 43, 46, 50, 56]. Fully-supervised action segmentation methods [12, 24, 25, 28, 41, 45, 48] learn to identify action segments in the presence of frame-level ground-truth. For example, [50] use a bottom-up technique to aggregate initial action proposal scores to classify the top-level video task, before modifying its preliminary frame labels in a fully supervised way. Also, [46] analyze a host of holistic and regional features to train shared low-level classifiers to recognize tasks and detect fine-grained actions.
Recently, unsupervised learning of instructional videos has seen increased attention [10, 11, 26, 47]. In [26], an unsupervised approach performs video segmentation and task clustering through learned feature embeddings. In [10], a network is trained using only video task labels, for unsupervised discovery of procedure steps and task recognition.
The above-mentioned methods are either fully supervised or unsupervised, and thus they are not direct competitors for our method, which uses weak labels.
In the scope of activity recognition, most works [13, 20, 53] study short-range or trimmed videos. Our work is closest to [18, 19, 54], where the focus is recognizing minutes-long activities. However, unlike them, our paper is on instructional videos, and on how recognition can aid segmentation, so it relies on hierarchical activity labels (top-level task, lower-level attributes as targets for segmentation).
Weakly-Supervised Key-Step Localization. In the context of weakly-labeled instructional videos, many methods [2, 27, 32, 57] are trained under the supervision of narration and subtitle. Directly relevant to our work are [4, 6, 7, 17, 29, 42, 44], where, as in our method, only the sequence of actions is known for each training video. In particular [29, 44] deploy a factorized probabilistic model to tackle the segmentation problem using dynamic programming. Also, [4] formulate a differential dynamic programming framework for end-to-end training of their model.
Recent weakly-supervised segmentation methods [4, 6, 29, 44] are formulated to identify the action taking place at each frame, and not the top-level video task. At the same time, the output of these methods implicitly specifies the top-level task, because only one task is compatible with the detected sequence of actions. We use these implicit task predictions of [29, 44] to compare those methods to ours on task recognition accuracy. In contrast to these bottom-up approaches (going from actions to task), our method explicitly learns to classify video-level tasks, and this classification is used in a top-down fashion (from task to actions) to constrain the detected action sequence.
3 Hierarchical Task Modeling Method
In this section, we present an overview of our two-stream hierarchical task modeling. Full details of our implementation choices and architecture are provided in Sec. 3.2.
As our formulation uses many terms and symbols, the supplementary material provides a glossary of terms and a table of all symbols we use.
3.1 Method Overview
Problem Definition. The training set consists of N videos . From each we extract a feature vector , that consists of frames of -dimensional features. We denote by the set of all top-level task labels, and by the set of all lower-level attribute labels. As an implementation choice, these attributes can be the set of actions in the dataset, or the set of verb/object components of those actions. Each video is labeled by a task , and also by a set of attributes, so that . At test time, given an input video, the system estimates the top-level task.
Semantic Hierarchy Stream (SHS). To recognize the task, one approach is to directly estimate . However, this approach is prone to overfitting when the number of video samples per task is limited. As attributes can be shared among tasks, the average number of training videos per attribute is typically greater than the average number of videos per task. Using attribute information also helps the model learn similarities and differences of spatio-temporal patterns in different tasks.
Thus, we model task recognition as , where is an intermediate vector of attribute scores that is computed for each . The system learns a mapping function , that maps each vector to attribute score vector . It also learns a function , that maps each attribute score vector to a task score vector (Fig.2).
Temporal Hierarchy Stream (THS). Tasks in instructional videos are usually performed in a relative order of steps. Understanding the task-discriminative stages of a video is essential in distinguishing tasks that share similar-looking actions. Thus, we divide each video into stages of equal duration, and train a classifier for each stage . The system also learns an aggregation function , that maps stage-wise predictions to classification scores of the entire video.
Stream Fusion Module. In the end, we fuse the predictions of the SHS and THS streams to output the final task prediction scores of the entire model. A high-level diagram of the overall network is shown on Fig.2. The network is optimized using a loss function for the fusion module, as well as separate loss functions for the SHS and THS streams.

3.2 Detailed Architecture
In this section we explain in detail the architecture of our two-stream hierarchical model (Fig.3), and we derive the three proposed loss functions.
3.2.1 Feature Extraction
Video task recognition is highly dependent not only on motion patterns, but also on object appearance. Ignoring object appearance can lead to misclassifications when the motion patterns of two tasks are very similar, e.g., making coffee and making tea. Hence, instead of the mostly motion-based iDT features[51] used in [4, 29, 44], we adopt the I3D network, pre-trained on the Kinetics dataset[3]. I3D extracts, for each frame, 1024-dimensional feature vectors respectively from the RGB and optical flow channels. We use PCA separately on RGB and flow features, to reduce the dimensions from 1024 to 128.
The 256-dimensional concatenated RGB and optical flow features of each frame are stored in video-level feature vector , where is the total number of frames in video . In principle, any spatio-temporal network can be used instead of I3D. In the supplementary material, we show that I3D outperforms iDT for task recognition.
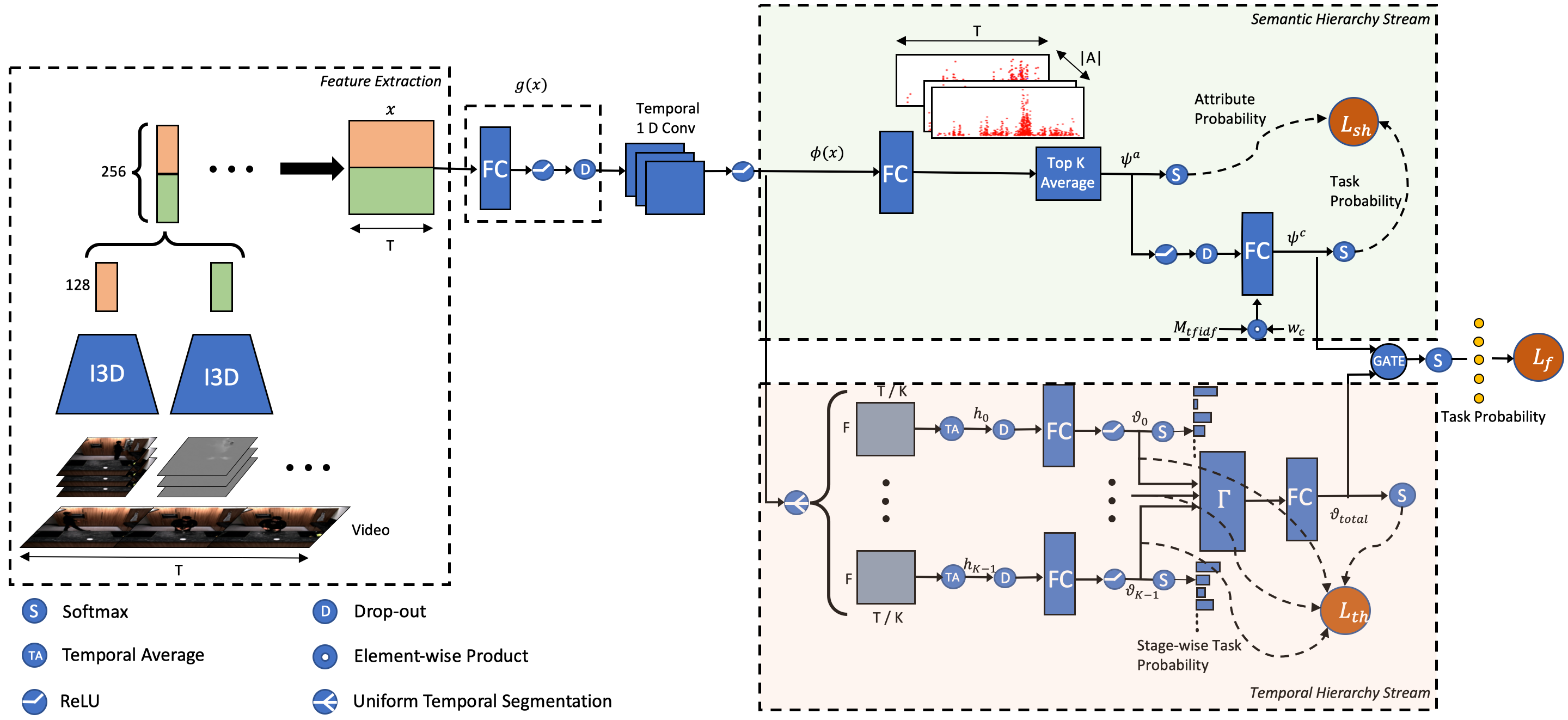
3.2.2 Semantic Hierarchy Loss
In order to obtain a data-specific representation of video-level feature vector , we pass each frame-level subvector of through a fully-connected layer with bias and output dimension of 256, then apply temporal convolution to the output of . Using such 1D temporal convolutions with a set of learnable kernels of size , is eventually mapped to a -dimensional feature encoding .
Let be the number of unique attributes in the dataset. We pass each frame-level subvector of through a fully connected layer with bias and output dimension of to obtain , which is the sequence of attribute scores for each of the frames. is also known as temporal class activation map (T-CAM)[36].
Similar to [39, 40], we compute a video-level attribute score vector by average-pooling the highest T-CAM scores of each attribute separately over time, where is a hyperparameter:
| (1) |
Intuitively, these selected scores highlight the most important parts of a task in video .
To denote the set of attributes present in video , we define a multihot ground-truth attribute vector , where for every , if , otherwise . However, this representation fails to capture the fact that different attributes have different levels of relevance for recognizing each task. For example, attributes “take out” and “open” are present in most videos, and thus not discriminative. As a second example, for the “preparing avocado” task, “avocado” is a more informative attribute compared to “knife”.
Inspired by text retrieval methods [21, 31], we compute the TF-IDF weight matrix , so that captures the importance of attribute for task . Initially, we formulate and as follows:
| (2) | ||||
| (3) |
where denotes the indicator function and and are, respectively, the percentage of times attribute is present in videos of task , and the log inverse of percentage of all tasks that entail attribute in at least one of their videos. We then define the elements of the TF-IDF weight matrix as:
| (4) |
with set to a very small value to avoid division by zero.
Using these TF-IDF weights, we intorduce the TF-IDF-weighted attribute ground-truth vector as:
| (5) |
We also define a TF-IDF mask , where is 1 if the corresponding TF-IDF weight is nonzero, otherwise it is 0. We use the TF-IDF mask to form a mapping from attribute score vectors to task probability scores , as:
| (6) |
In the above, and mean the softmax and element-wise product operations respectively, and are weights to be learned. Using the TF-IDF mask allows the model to focus only on relevant attributes for each task.
Let be the one-hot task ground-truth vector and . The semantic hierarchy loss is then defined as:
| (7) |
denotes “expected value”, and is a design parameter that decides how fast each term is trained comparatively.
3.2.3 Temporal Hierarchy Loss
We model the temporal hierarchy by dividing each video into stages of equal duration , and training a classifier for each stage. Formally, given the frame-level feature encoding of video , we define as the feature summary of the -th stage and produce unnormalized task scores (logits) :
| (8) | ||||
| (9) |
where and are parameters of each stage. During the training process, for each stage, the loss function is defined on the softmax of the stage-wise task prediction logits .
Stage Aggregation Function. As mentioned earlier, certain stages of a task are more discriminative than others. We define the auxiliary function , that maps stage-level task score vectors to a video-level task score vector. While training, randomly masks out one of its input prediction vectors entirely and multiplies the rest of the input predictions by . acts similar to the spatial drop out operation by promoting independence between predictions of each stage, to avoid overfitting to a single stage. We form our stage aggregation function using and aggregation parameters to produce video-level task probability values :
| (10) |
Finally, we present our temporal hierarchy loss to incorporate the aggregated and stage-wise predictions:
| (11) |
3.2.4 Stream Fusion Loss
We explore three different mechanisms for fusing the predictions of the SHS and THS streams, to produce the final task prediction logits . We provide experimental results of each in Section 5.2.
Average Fusion. Here, we treat results of semantic and temporal hierarchies equally, and we backpropagate the same gradient to both streams at training time.
| (12) |
Weighted Average Fusion. Here, the final prediction is a linear combination of streams, whose predictions are weighted by learned weights . .
| (13) |
Task-wise Switching Gates. Sometimes, wrong predictions of one stream can negatively impact the final fused classification scores at test time. We introduce task-wise switching gates to allow the system enough freedom to learn, for each task independently, to switch between stream predictions. We define switching gate as the sigmoid function of learnable parameters . The sigmoid function makes sure our gates stay in the range of 0 to 1. Then, for training and test time, is defined as:
| (14) |
where denotes the Heaviside step function shifted to x. At test time, given task , our final prediction is discretely chosen from the SHS stream if or is selected from the THS stream otherwise.
In cases of the weighted average fusion and switching gates, our fusion loss is added to the previous losses to form our final loss with the design parameter . Finally we train the whole network end-to-end but stop the gradients of flowing back to the streams to isolate the fusion module from the rest.
| (15) |
4 Top-Down Action Segmentation
We now present our top-down segmentation approach. In the segmentation problem, the goal is to partition a video temporally into a sequence of action labels and their corresponding durations . The input in our approach is a video of frames, represented by , as the sequence of per-frame features. Let be the set of all action sequences in the training set given the top-level task . Then, grammar lists an ordered sequence of action labels taking place in the video of task . The goal is to identify the most likely sequence of action labels and their durations associated with a specific grammar :
| (16) | ||||
| (17) |
where is modeled by a neural network and the Bayes rule as in [42, 44], and is any given duration model, e.g., Poisson[44] or DurNet[14].
Eq.17 is formulated similarly to the probabilistic model in [44]. However, we explicitly integrate the task variable into this equation, which dictates the choice of the fine-grained action sequence . Specifically we introduce the task model as the probability output of a task classification network. Without loss of generality, we used the output of our two-stream hierarchical network , so that for the predicted task and otherwise. In [44], the task is a by-product of the inferred segments (,). In contrast, our proposed approach eliminates all segmentations whose inferred actions do not belong to of the predicted task by setting to 0 for those segmentations, and to 1 otherwise. We follow the Viterbi algorithm in [44] to solve Eq. 17.
5 Experiments
We compare our method to several existing methods on two popular instructional video datasets, both for task classification and for action segmentation using weakly-labeled videos as training. Further, in ablation studies we evaluate the contribution of each component of our model.
Datasets. 1) The Breakfast Dataset (BD) [23] consists of around 1.7k untrimmed cooking videos of few seconds to over ten minutes long. There are 48 action labels demonstrating 10 breakfast dishes with a mean of 4.9 actions per video, and the evaluation metrics are conventionally calculated over four splits. 2) The MPII Cooking 2 (C2) [46] has training and test subject-wise splits of 201 and 42 long and high quality videos respectively. Particularly, these videos are 1 to 40 mins long adding to 27 hours of data from 29 subjects who prepare 58 different dishes. This dataset offers different challenges compared to the BD dataset for two main reasons; First, the annotated 155 objects and 67 actions (verbs) are extremely fine-grained, so that there are on average 51.8 non-background action segments per video. Second, despite the great number of frames in the dataset, the number of samples per class is unbalanced and limited.
Metrics. We evaluate task classification performance using two metrics: 1) t-acc is the standard mean task accuracy over all videos. 2) t-mAP denotes the mean Average Precision of task predictions. mAP is used in [46] to assign soft class-wise scores to give insight about how far off the wrong predictions are. Further, we use four metrics as [7] to measure the segmentation results: acc and acc-bg are the frame-level accuracies with and without background frames, while IoU and IoD define the average non-background intersection over union and detection, respectively.
Implementation. We extracted I3D features on the C2 dataset using TV-L1 optical flow [55] on a moving window of 32 frames with stride 2, and the pre-computed I3D features of the BD dataset were obtained from [12]. We noticed that it is not necessary to process the whole video. Instead, we followed the sampling strategy in [39] to maintain the length of the videos in a batch to be less than a pre-defined length mins while training. This approach speeds up training, lowers memory demands, and applies temporal augmentation. Also, we divided videos into stages for the THS stream (analysis in Section 5).
Our model is trained with a batch size of 10 using the Adam [22] optimizer with learning rate and 0.005 weight decay for 20k iterations. For both datasets, we adjust to 0.9, and is set to 0.25 and 0.01 for the BD and C2 datasets, respectively. The 1D convolutions are done with as the number of kernels, and as their size. and we use a drop-out keep rate of 0.3. The set of verbs and objects are used as our attributes.
capposition=top
| Breakfast (%) | Cooking (%) | ||||
| Supervision | Models | t-acc | t-mAP | t-acc | t-mAP |
| Full | Rohrbach et al.[46] | - | - | - | 57.40 |
| Unsupervised | CTE[26] | 31.80‡ | - | - | - |
| NNViterbi[44]∗ | 70.98‡ | - | 23.80† | - | |
| CDFL[29]∗ | 74.86‡ | - | 28.57† | - | |
| Weak | W-TALC[39]∗ | 76.19† | 80.98† | 33.33† | 43.07† |
| 3C-Net[35]∗ | 75.23† | 80.99† | 30.95† | 46.30† | |
| Timeception[18]∗ | 76.37† | 80.80† | 21.43† | 25.14† | |
| VideoGraph[19]∗ | 78.70† | - | 23.80† | - | |
| Our Method | 80.04 | 86.36 | 45.24 | 54.49 | |
5.1 Comparison to State-of-the-Art Methods
We used the standard dish labels in both datasets as task labels. All experiments on the BD dataset for all models, except the unsupervised CTE [26], were done for 9 tasks after we combined the two dishes of frying and scrambling eggs as the top-level task of making eggs, because both share almost the same set of actions. For CTE, we report the results on the original 10 classes, as given by the authors. We note that CTE is unsupervised and not a direct competitor.
Task Classification. Table 1 shows quantitative results on task recognition, for our method as well as other methods that use different types of supervision. Particularly, [29, 44] are the state-of-the-art open-source weakly-supervised segmentation methods. They implicitly identify the task corresponding to the inferred sequence of actions during inference. Our explicit task modeling significantly outperforms them in accuracy by around 5 to 9 percent on the BD dataset, and by 16 to 21 percent in the 58 tasks of the C2 dataset.
Originally, [35, 39] are the state-of-the-art open-source weakly-supervised methods with specific loss functions to classify and localize sparse action instances in videos. To compare with them, we trained both to classify tasks. Also, [18] and [19] classify tasks in long videos by training multi-scale temporal convolutions and graph based representations respectively. Both networks make heavy use of memory and suffer from overfitting specifically in the C2 dataset, where using low-level attributes is key. While such direct task modelings under weak supervision prove to be more effective than the implicit classification using fine-grained action segments [29, 44], our hierarchical approach outperforms all competitors considerably in all metrics and datasets. Table 1 shows our t-mAP on the C2 dataset comes close to the fully-supervised baseline [46], which is trained on frame-level action ground-truth. Comparison results on 10 classes of the BD dataset are in the supp. material.
Action Segmentation. Table 2 shows results for action segmentation. In our experiments, we combined our two-stream task prediction framework on top of the state-of-the-art weakly-supervised segmentation methods [29, 44] and achieved new state-of-the art results on both datasets, manifested more vividly in acc-bg, because background frames are independent of the task. Therefore, excluding background frames highlights the contribution of the correct task label in segmentation. This consistent improvement in all metrics, while decreasing the inference time by 80-90% (Table 3), demonstrates the potential of the proposed top-down approach for weakly-supervised segmentation. Moreover, CDFL+GT in Table 2 represents CDFL segmentation results constrained by ground-truth task labels, which serves as an upper bound for our proposed top-down model.
| Breakfast (%) | Cooking (%) | |||||||
| Models | acc | acc-bg | IoU | IoD | acc | acc-bg | IoU | IoD |
| TCFPN[7]∗ | 38.4 | 38.4 | 24.2 | 40.6 | 26.9 | 30.3 | 9.5 | 17.0 |
| D3TW[4]∗∗ | 45.7 | - | - | - | - | - | - | - |
| DP-DTW[6]∗∗ | 50.8 | - | 35.6 | 45.1 | - | - | - | - |
| NNViterbi[44]∗ | 43.6 | 42.5 | 27.8 | 39.2 | 23.5 | 21.2 | 7.7 | 10.9 |
| CDFL[29]∗ | 50.2 | 50.4 | 33.5 | 45.6 | 29.9 | 32.2 | 11.0 | 13.8 |
| NNViterbi+Ours | 46.2 | 46.1 | 30.2 | 42.2 | 26.9 | 25.0 | 9.6 | 12.7 |
| CDFL+Ours | 51.4 | 52.0 | 34.5 | 46.7 | 31.3 | 34.5 | 12.8 | 15.6 |
| CDFL+GT | 59.8 | 63.0 | 41.3 | 55.2 | 35.0 | 39.7 | 14.4 | 17.6 |
| Models | Breakfast (split 4) | Cooking |
| NNViterbi[44] | 100 | 840 |
| CDFL[29] | 144 | 1070 |
| NNViterbi+Ours | 21 | 64 |
| CDFL+Ours | 25 | 110 |
| Breakfast (%) | Cooking (%) | |||
| Stream | t-acc | t-mAP | t-acc | t-mAP |
| Semantic hierarchy | 73.1 | 77.2 | 42.9 | 52.6 |
| Temporal hierarchy-stage 1 | 62.7 | - | 16.7 | - |
| Temporal hierarchy-stage 2 | 68.9 | - | 28.6 | - |
| Temporal hierarchy-stage 3 | 64.7 | - | 23.8 | - |
| Temporal hierarchy-aggregated | 80.0 | 86.4 | 31.0 | 45.2 |
| Two streams fused | 80.0 | 86.4 | 45.2 | 54.5 |
5.2 Analysis and Ablation Study in Task Modeling
Stream-Specific Results. We evaluated the contribution of the SHS and THS streams separately in Table 4. The SHS stream is more effective on the C2 dataset because of two main reasons: First, the average number of videos per task (3.4) is low compared to that of videos per attribute (28.4), so any direct way of task modeling is prone to overfitting. Second, the large number of attributes per task allows the learning of a discriminative attribute-to-task mapping. Meanwhile in the THS stream, despite the weak classification power of the stage-specific classifiers, our hierarchical modeling is able to aggregate stage-wise predictions effectively and produce significantly superior results. This shows that different stages provide complimentary information. Note that the THS stream alone achieves state-of-the-art on the BD dataset with only task label supervision.
Semantic Hierarchy Ablation. As shown in Table 5a, removing the attributes from the semantic hierarchy loss (Eq.7), and directly classifying tasks from the feature encoding , leads to around drop in t-acc on the C2 dataset. Simply sharing low-level attributes among tasks is beneficial, and using the TF-IDF weights led to an additional difference in t-acc (Table 5b).
| (a) | (b) | ||||||||||||||||||
|
|
Temporal Hierarchy Analysis. Modeling tasks as a temporal hierarchy of multiple stages improves the performance compared to the single-stage approach. Furthermore, as indicated by Table 7, such an approach is not sensitive to the number of stages () in the hierarchy. This concludes that these stages provide complimentary information for the stage-aggregation function regardless of their exact positioning or duration in the video.
captionskip=2pt
[4] \ttabbox Stages t-acc t-mAP 1 74.2 82.1 2 79.6 86.4 3 80.0 86.4 4 80.0 86.4 5 79.2 85.8 \ttabbox Fusion Type t-acc t-mAP Average 77.2 84.2 Weighted Average 78.4 84.9 Switching Gate 80.0 86.4
capposition=bottom

Comparison of the Stream Fusion Mechanisms. Table 7 compares different mechanisms to fuse the predictions of SHS and THS streams. Specifically, the Task-wise Switching Gates are trained to identify the stronger stream per task and perform best, while the vanilla and weighted averaging compromise between both streams and produce sub-optimal results. In the BD dataset these gates propagate the results of the THS stream, whereas in the C2 dataset they switch between both for different tasks and combine predictions (see row 1, 5 and 6 of Table 4).
5.3 Qualitative Results
Fig.4 compares results of the THS stream with the single-stage baseline on four challenging videos from the BD dataset. Due to similar-looking actions shared between tasks, the single stage baseline misclassifies the video task, whereas our THS stream outputs the correct task under different stage-wise settings. Specifically, in the first and third videos, our model classifies the task correctly although only one of the stage predictions is correct. For example, according to the stage-wise accuracy of the task making chocolate milk in Fig.4, the last stage of this task is the most discriminative one. Thus, our model learns to put more weight on the predictions of this stage, which compensates for the first two stages outputting the wrong class of making cereal.
The two tasks of making coffee and making tea share similar-looking actions in the first and second videos, so analyzing the entire video in one step produces wrong predictions for both cases. The second video, in particular, provides an interesting case where similar visuals of the action taking cup between tasks of making chocolate milk and making tea led to confusion of the first stage. Also, the later two stages mistakenly predicted the task of making coffee, because the two actions of pouring and stirring are shared between both tasks of making coffee and making tea. Although all three stage-wise predictions are wrong, the aggregated result of those stages is correct. This shows that the proposed hierarchical model not only considers the predicted class of each stage, but also learns the relationship between stages and their fine-grained prediction scores.
In a given stage, the short discriminative part may be dominated by the longer ambiguous section. For example, the final stage of the last video depicts how stirring while occluding the bowl dominates the shorter and more discriminative action of pouring milk. This effectively resembles the appearance and motion of flipping a pancake by spatula, but the complementary information of the first two stages eventually results in the correct aggregated recognition.
6 Conclusion
We have introduced a two-stream framework, that exploits semantic and temporal hierarchies to recognize tasks in weakly-labeled instructional videos. We have also proposed a novel top-down segmentation approach, where the predicted task constrains the fine-grained action labels. We report experimental results on two public datasets. Our two-stream task recognition method outperforms existing methods. Similarly, our top-down segmentation approach improves the accuracy of existing state-of-the-art methods, while simultaneously improving runtime by 80-90%.
References
- [1] ’Robotic kitchen assistant on a rail’, May 2020. [Online]. Available: https://www.roboticsresear.ch/articles/19606/robotic-kitchen-assistant-on-a-rail. [Accessed: 15- November- 2020].
- [2] Jean-Baptiste Alayrac, Piotr Bojanowski, Nishant Agrawal, Josef Sivic, Ivan Laptev, and Simon Lacoste-Julien. Unsupervised learning from narrated instruction videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4575–4583, 2016.
- [3] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017.
- [4] Chien-Yi Chang, De-An Huang, Yanan Sui, Li Fei-Fei, and Juan Carlos Niebles. D3tw: Discriminative differentiable dynamic time warping for weakly supervised action alignment and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3546–3555, 2019.
- [5] Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. arXiv preprint arXiv:1907.01172, 2019.
- [6] Xiaobin Chang, Frederick Tung, and Greg Mori. Learning discriminative prototypes with dynamic time warping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8395–8404, 2021.
- [7] Li Ding and Chenliang Xu. Weakly-supervised action segmentation with iterative soft boundary assignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6508–6516, 2018.
- [8] Hazel Doughty, Ivan Laptev, Walterio Mayol-Cuevas, and Dima Damen. Action modifiers: Learning from adverbs in instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 868–878, 2020.
- [9] Hazel Doughty, Walterio Mayol-Cuevas, and Dima Damen. The pros and cons: Rank-aware temporal attention for skill determination in long videos. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7862–7871, 2019.
- [10] Ehsan Elhamifar and Dat Huynh. Self-supervised multi-task procedure learning from instructional videos. European Conference on Computer Vision, 2020.
- [11] Ehsan Elhamifar and Zwe Naing. Unsupervised procedure learning via joint dynamic summarization. In Proceedings of the IEEE International Conference on Computer Vision, pages 6341–6350, 2019.
- [12] Yazan Abu Farha and Jurgen Gall. Ms-tcn: Multi-stage temporal convolutional network for action segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3575–3584, 2019.
- [13] Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 203–213, 2020.
- [14] Reza Ghoddoosian, Saif Sayed, and Vassilis Athitsos. Action duration prediction for segment-level alignment of weakly-labeled videos. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2053–2062, 2021.
- [15] Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6546–6555, 2018.
- [16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [17] De-An Huang, Li Fei-Fei, and Juan Carlos Niebles. Connectionist temporal modeling for weakly supervised action labeling. In European Conference on Computer Vision, pages 137–153. Springer, 2016.
- [18] Noureldien Hussein, Efstratios Gavves, and Arnold WM Smeulders. Timeception for complex action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 254–263, 2019.
- [19] Noureldien Hussein, Efstratios Gavves, and Arnold WM Smeulders. Videograph: Recognizing minutes-long human activities in videos. arXiv preprint arXiv:1905.05143, 2019.
- [20] Boyuan Jiang, MengMeng Wang, Weihao Gan, Wei Wu, and Junjie Yan. Stm: Spatiotemporal and motion encoding for action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2000–2009, 2019.
- [21] Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 1972.
- [22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [23] Hilde Kuehne, Ali Arslan, and Thomas Serre. The language of actions: Recovering the syntax and semantics of goal-directed human activities. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 780–787, 2014.
- [24] Hilde Kuehne, Ali Arslan, and Thomas Serre. The language of actions: Recovering the syntax and semantics of goal-directed human activities. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 780–787, 2014.
- [25] Hilde Kuehne, Juergen Gall, and Thomas Serre. An end-to-end generative framework for video segmentation and recognition. In 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1–8. IEEE, 2016.
- [26] Anna Kukleva, Hilde Kuehne, Fadime Sener, and Jurgen Gall. Unsupervised learning of action classes with continuous temporal embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 12066–12074, 2019.
- [27] Ivan Laptev, Marcin Marszałek, Cordelia Schmid, and Benjamin Rozenfeld. Learning realistic human actions from movies. 2008.
- [28] Colin Lea, Michael D Flynn, Rene Vidal, Austin Reiter, and Gregory D Hager. Temporal convolutional networks for action segmentation and detection. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 156–165, 2017.
- [29] Jun Li, Peng Lei, and Sinisa Todorovic. Weakly supervised energy-based learning for action segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 6243–6251, 2019.
- [30] Jun Li and Sinisa Todorovic. Set-constrained viterbi for set-supervised action segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10820–10829, 2020.
- [31] Hans Peter Luhn. The automatic creation of literature abstracts. IBM Journal of research and development, 2(2):159–165, 1958.
- [32] Jonathan Malmaud, Jonathan Huang, Vivek Rathod, Nick Johnston, Andrew Rabinovich, and Kevin Murphy. What’s cookin’? interpreting cooking videos using text, speech and vision. arXiv preprint arXiv:1503.01558, 2015.
- [33] Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning of visual representations from uncurated instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9879–9889, 2020.
- [34] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE international conference on computer vision, pages 2630–2640, 2019.
- [35] Sanath Narayan, Hisham Cholakkal, Fahad Shahbaz Khan, and Ling Shao. 3c-net: Category count and center loss for weakly-supervised action localization. In Proceedings of the IEEE International Conference on Computer Vision, pages 8679–8687, 2019.
- [36] Phuc Nguyen, Ting Liu, Gautam Prasad, and Bohyung Han. Weakly supervised action localization by sparse temporal pooling network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6752–6761, 2018.
- [37] Phuc Xuan Nguyen, Deva Ramanan, and Charless C Fowlkes. Weakly-supervised action localization with background modeling. In Proceedings of the IEEE International Conference on Computer Vision, pages 5502–5511, 2019.
- [38] Paritosh Parmar and Brendan Tran Morris. What and how well you performed? a multitask learning approach to action quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 304–313, 2019.
- [39] Sujoy Paul, Sourya Roy, and Amit K Roy-Chowdhury. W-talc: Weakly-supervised temporal activity localization and classification. In Proceedings of the European Conference on Computer Vision (ECCV), pages 563–579, 2018.
- [40] Maheen Rashid, Hedvig Kjellstrom, and Yong Jae Lee. Action graphs: Weakly-supervised action localization with graph convolution networks. In The IEEE Winter Conference on Applications of Computer Vision, pages 615–624, 2020.
- [41] Alexander Richard and Juergen Gall. Temporal action detection using a statistical language model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3131–3140, 2016.
- [42] Alexander Richard, Hilde Kuehne, and Juergen Gall. Weakly supervised action learning with rnn based fine-to-coarse modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 754–763, 2017.
- [43] Alexander Richard, Hilde Kuehne, and Juergen Gall. Action sets: Weakly supervised action segmentation without ordering constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5987–5996, 2018.
- [44] Alexander Richard, Hilde Kuehne, Ahsan Iqbal, and Juergen Gall. Neuralnetwork-viterbi: A framework for weakly supervised video learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7386–7395, 2018.
- [45] Marcus Rohrbach, Sikandar Amin, Mykhaylo Andriluka, and Bernt Schiele. A database for fine grained activity detection of cooking activities. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, pages 1194–1201. IEEE, 2012.
- [46] Marcus Rohrbach, Anna Rohrbach, Michaela Regneri, Sikandar Amin, Mykhaylo Andriluka, Manfred Pinkal, and Bernt Schiele. Recognizing fine-grained and composite activities using hand-centric features and script data. International Journal of Computer Vision, 119(3):346–373, 2016.
- [47] Fadime Sener and Angela Yao. Unsupervised learning and segmentation of complex activities from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8368–8376, 2018.
- [48] Bharat Singh, Tim K Marks, Michael Jones, Oncel Tuzel, and Ming Shao. A multi-stream bi-directional recurrent neural network for fine-grained action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1961–1970, 2016.
- [49] Yaser Souri, Alexander Richard, Luca Minciullo, and Juergen Gall. On evaluating weakly supervised action segmentation methods. arXiv preprint arXiv:2005.09743, 2020.
- [50] Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1207–1216, 2019.
- [51] Heng Wang and Cordelia Schmid. Action recognition with improved trajectories. In Proceedings of the IEEE international conference on computer vision, pages 3551–3558, 2013.
- [52] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision, pages 20–36. Springer, 2016.
- [53] Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7794–7803, 2018.
- [54] Tianshu Yu, Yikang Li, and Baoxin Li. Rhyrnn: Rhythmic rnn for recognizing events in long and complex videos. In European Conference on Computer Vision, pages 127–144. Springer, 2020.
- [55] Christopher Zach, Thomas Pock, and Horst Bischof. A duality based approach for realtime tv-l 1 optical flow. In Joint pattern recognition symposium, pages 214–223. Springer, 2007.
- [56] Luowei Zhou, Chenliang Xu, and Jason J Corso. Towards automatic learning of procedures from web instructional videos. arXiv preprint arXiv:1703.09788, 2017.
- [57] Dimitri Zhukov, Jean-Baptiste Alayrac, Ramazan Gokberk Cinbis, David Fouhey, Ivan Laptev, and Josef Sivic. Cross-task weakly supervised learning from instructional videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3537–3545, 2019.
7 Supplementary Material
In this supplementary material, we show comparisons of I3D [3] and iDT [51] features in task recognition on two datasets, and present comparison results on the original 10 classes of the Breakfast dataset [23]. We also provide a glossary of terms and a table of symbols we use in the paper.
7.1 I3D and iDT Feature Comparison in Task Recognition of Weakly-Labeled Videos
In this section, we compare I3D and iDT features for the purpose of task recognition in weakly-labeled instructional videos. Specifically, we present results of existing models using I3D (Table 8) and iDT (Table 9) features on the MPII Cooking 2 dataset [46] as well as the first split of the Breakfast dataset [23].
We used the Fisher vectors of iDT features as in [23, 43]. The Fisher vectors for each frame are extracted over a sliding window of 20 frames. They are first projected to a 64-dimensional space by PCA, and then normalized along each dimension. Also, we extracted the I3D features of the Cooking 2 dataset using TV-L1 optical flow [55] on a moving window of 32 frames with a stride of 2, and the pre-computed I3D features of the Breakfast dataset were obtained from [12]. Furthermore, we applied PCA to the extracted I3D features to reduce the dimensionality of RGB and optical flow channels from 1024 to 128. We fed the same features to all competitors except [54] in Table 10 whose code is not publicly available, so we compare with their reported result on ResNet101 [16] features.
In the Cooking 2 dataset, we train the models on the training split and test on the test split. However as [29] and [44] take a long time to train and infer the segments, in Tables 8 and 9, we only use the first split of the Breakfast dataset to evaluate the difference in performance of all models when using I3D and iDT features as input. Note that the reported task recognition results on the Breakfast dataset in the paper are the average of all four splits using the best case for each method.
Explicit task classification methods, e.g., ours, W-TALC [39] and 3C-Net [35], consistently perform better with I3D features on both datasets, whereas the bottom-up inference of tasks in NNViterbi [44] and CDFL [29] produces mixed result. In particular, the performance of [29] and [44] on the Breakfast dataset considerably improves upon using iDT features. Overall, the more significant presence of object information in I3D features helps to classify top-level tasks more accurately, while detecting fine-grained actions seems to be less affected by such appearance information.
| Breakfast (1st split) (%) | Cooking (%) | |||
| Models | t-acc | t-mAP | t-acc | t-mAP |
| NNViterbi[44]∗ | 57.14 | - | 23.80 | - |
| CDFL[29]∗ | 66.26 | - | 28.57 | - |
| W-TALC[39]∗ | 75.79 | 78.96 | 33.33 | 43.07 |
| 3C-Net[35]∗ | 75.39 | 78.50 | 30.95 | 46.30 |
| Timeception[18]∗ | 79.50 | 82.53 | 21.43 | 25.14 |
| VideoGraph[19]∗ | 80.06 | - | 23.80 | - |
| Our Method | 81.74 | 88.30 | 45.24 | 54.49 |
| Breakfast (1st split) (%) | Cooking (%) | |||
| Models | t-acc | t-mAP | t-acc | t-mAP |
| NNViterbi[44]∗ | 71.03 | - | 16.66 | - |
| CDFL[29]∗ | 77.38 | - | 21.42 | - |
| W-TALC[39]∗ | 53.17 | 54.96 | 19.04 | 25.85 |
| 3C-Net[35]∗ | 56.74 | 60.36 | 14.28 | 27.38 |
| Timeception[18]∗ | 65.87 | 71.73 | 9.52 | 14.36 |
| VideoGraph[19]∗ | 58.93 | - | 14.28 | - |
| Our Method | 60.31 | 61.72 | 23.80 | 27.66 |
7.2 Task Classification Results on 10 Classes of the Breakfast Dataset
Timception [18], VideoGraph [19] and RhyRNN [54] are the latest state-of-the-art methods to classify tasks in minutes-long videos and are the closest competitors to our work. We compared the standard four fold cross validated results of Timeception and VideoGraph over 9 classes of the Breakfast dataset in Table 1 of the paper, however, we could not compare our method to RhyRNN because the source code of RhyRNN is not publicly available to adjust that model to our evaluation settings. Hence, in Table 10, we present comparison results of our method with the reported accuracy of this method and different versions of other models over the original 10 classes of the Breakfast dataset. For a direct comparison with RhyRNN , we show results on the first split as reported in RhyRNN.
Furthermore, Table 10 shows the original reported results of Timeception and VideoGraph, which are lower than our re-implemented versions in both cases. Contrary to the standard splitting rule of the Breakfast dataset, both works have used the last 0.15% of subjects in the dataset (8 subjects) to test their performance. Our result on this split significantly outperforms previous methods (Table 10). [18] and [19] also use the output before the last average pooling layer (pre pooling) in the I3D network as features, unlike us, where we use the features after the pooling layer (post pooling). The results in Table 10 suggest the superiority of the latter, because the lower dimension after pooling allows each network to be given more features as input, which increases their input temporal range.
Interestingly, the task accuracy for most models, including ours, hardly drops upon evaluation on 10 classes and our method is still superior than different versions of state-of-the-art.
| Models | t-acc | Feature | Test Split |
| Timeception[18] | 71.3 | 3D-ResNet [15] | Last 8 subjects |
| Timeception[18] | 69.3 | I3D (pre pooling) | Last 8 subjects |
| Timeception[18]∗ | 76.6 | I3D (post pooling) | Split 1 |
| VideoGraph[19] | 69.5 | I3D (pre pooling) | Last 8 subjects |
| VideoGraph[19]∗ | 79.9 | I3D (post pooling) | Split 1 |
| RhyRNN[54] | 44.3 | ResNet101 [16] | Split 1 |
| Our Method | 81.5 | I3D (post pooling) | Split 1 |
| Our Method | 85.2 | I3D (post pooling) | Last 8 subjects |
7.3 Glossary of Terms and Symbols
As there are similar terms and many symbols used in the paper, here, we provide specific definitions of terms (Table 11) and symbols (Table 12) for readers to refer to.
| Term | Definition |
| Action | Lower level actions happening in the form of segment sequence in instructional videos. |
| Action alignment | Partitioning the video into sequence of action segments given a sequence of action labels. |
| Action detection | Classify and localize occurrences of, typically, a single action in the video among considerable background frames. |
| Action segmentation | Partitioning the video into sequence of action segments. |
| Attribute | Set of actions or the set of verb/object components of actions. |
| Fully-supervised classification | Task classification using frame-level and video-level labels. |
| Instructional videos | Videos with a top-level task and a sequence of fine-grained actions to carry out the underlying task. |
| Task | The single top-level composite activity present in the video. |
| Task recognition | Classifying the top-level task in long instructional videos. |
| Weakly-labeled videos | Videos with no frame-level annotations. In our case, only sequence of video-level action labels is available. |
| Weakly-supervised classification | Task classification without access to frame-level annotation. We use the term “weak” to distinguish from fully-supervised methods. |
| Symbol | Definition |
| The set of all attributes | |
| Attribute j | |
| Attribute j of video i | |
| The set of attributes in video i | |
| Muiltihot ground-truth attribute vector of video i | |
| TF-IDF weighted ground-truth attribute vector of video i | |
| Matrix multiplication of A transposed and B | |
| Scalar multiplication of a and b | |
| Importance factor of in the total loss | |
| The set of all tasks | |
| Task label for video i | |
| One-hot task ground-truth vector of video i | |
| Stage duration | |
| Dimension of the feature encoding | |
| Final fused classification logits | |
| The fully connected layer to produce encoding | |
| Heaviside step function shifted to x | |
| Feature summary of stage | |
| K | Number of stages in the THS stream |
| Temporal convolution kernels to produce | |
| Number of selected frames of video i from the operation | |
| L | Kernel length of |
| Sequence of S action durations in a video | |
| Loss function for the SHS stream | |
| Loss function for the THS stream | |
| Loss function of the fused streams | |
| Number of attributes in video i | |
| TF-IDF mask | |
| Mapping function from features to attributes | |
| Mapping function from attributes to tasks | |
| N | Number of videos in the training set/batch |
| Number of segments in a video | |
| Softmax operation | |
| Classifier for stage in the THS stream | |
| The parameter used in the operation | |
| Number of frames in video i | |
| Stage aggregation function in the THS stream | |
| Task variable | |
| Task prediction logits of stage | |
| Stage-aggregated task prediction logits | |
| Set/Batch of training videos | |
| Video | |
| TF-IDF weights | |
| Input feature vector for video i | |
| Learned video feature encoding | |
| Attribute score vector of video i in the SHS stream | |
| Task score vector of video i in the SHS stream | |
| T-CAM of video i | |
| Sequence of S action labels in a video | |
| Design parameter in | |
| Set of all action sequences in the training set given task | |
| Sigmoid operation | |
| Stage-wise drop out in the stage aggregation function | |
| Indicator function | |
| Element-wise product operation |