Hierarchical Cross-modal Transformer for RGB-D Salient Object Detection
Abstract
Most of existing RGB-D salient object detection (SOD) methods follow the CNN-based paradigm, which is unable to model long-range dependencies across space and modalities due to the natural locality of CNNs. Here we propose the Hierarchical Cross-modal Transformer (HCT), a new multi-modal transformer, to tackle this problem. Unlike previous multi-modal transformers that directly connecting all patches from two modalities, we explore the cross-modal complementarity hierarchically to respect the modality gap and spatial discrepancy in unaligned regions. Specifically, we propose to use intra-modal self-attention to explore complementary global contexts, and measure spatial-aligned inter-modal attention locally to capture cross-modal correlations. In addition, we present a Feature Pyramid module for Transformer (FPT) to boost informative cross-scale integration as well as a consistency-complementarity module to disentangle the multi-modal integration path and improve the fusion adaptivity. Comprehensive experiments on a large variety of public datasets verify the efficacy of our designs and the consistent improvement over state-of-the-art models.
Introduction
Salient object detection (SOD), which aims to simulate human visual systems to identify the most attractive objects in a scene, has benefited a large variety of computer vision tasks such as object detection (Jiao et al. 2019), image recognition (Sukanya, Gokul, and Paul 2016) and tracking (Ciaparrone et al. 2020).


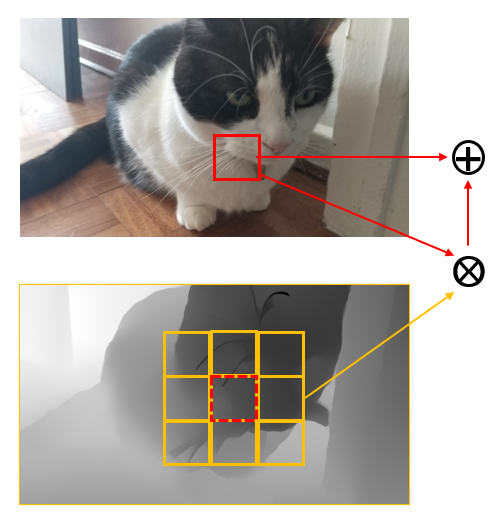
Recently, RGB-D SOD has attracted increasing attention for the additional spatial structure cues from depth to complement the RGB inference on challenging cases such as when the background and the foreground hold similar appearance. Most of existing RGB-D SOD methods (Cheng et al. 2014; Cong et al. 2016; Shigematsu et al. 2017; Sun et al. 2021; Zhao et al. 2022) follow the CNN-based paradigm. With powerful CNN backbones (Simonyan and Zisserman 2014; He et al. 2016) to extract feature hierarchies, their most efforts focus on designing various cross-modal cross-level interaction and fusion paths (Chen, Li, and Su 2019; Zhao et al. 2019; Sun et al. 2021) to explore the heterogeneous feature complementarity, and diverse strategies such as attention modules (Zhou et al. 2018; Chen and Li 2019), dynamic convolution (Chen et al. 2020b), feature disentanglement (Chen et al. 2020a) and knowledge distillation (Chen et al. 2021) to boost the adaptivity in selecting complementary cues. These methods, although greatly advance the RGB-D SOD community, hold an intrinsic limitation in capturing global contexts as the natural locality of convolutions. However, it has been widely acknowledged in (Goferman, Zelnik-Manor, and Tal 2011; Zhao et al. 2015; Liu, Han, and Yang 2018) that global contexts are dominated to correctly localize the SOD. Even some strategies try to enhance the global understanding by appending fully connected (Liu and Han 2016a) or global pooling layers (Liu, Han, and Yang 2017) on restricted layers, they still struggle with large computational cost or limited capability in modelling global correlations.
Recently, Transformer (Vaswani et al. 2017), which experts in capturing long-range dependencies, overcomes the limitation in CNNs, thus carrying great potential in modelling complex cross-modal complementarity and studying global contexts to infer the SOD. Given this, the VST (Liu et al. 2021a) model, using the transformer as the backbone, has been proposed for RGB(D) SOD. Specifically, VST adopts T2T ViT (Yuan et al. 2021) as the encoder and the cross-modal fusion problem is solved by a cross-modal attention module, formed by the similarity between a query from one modality and all the keys from the paired modality. Compared to the CNN-based counterpart, VST catches long range dependencies within/cross modalities, thus achieves state-of-the-art results on RGB-D SOD.

However, two key questions in selecting cross-modal and cross-level complements are still remaining.
1. How to combine cross-modal cues is the key to multi-modal understanding. VST answers this question by involving the depth patches to form a multi-modal token pool to model the cross-modal long-range dependencies. As shown in Fig. 1 (a), each patch in RGB will be compared to all regions in the paired depth image and vice verse to generate cross-modal dependencies. However, measuring the dependencies between cross-modal tokens that lie distant in space (e.g., the cat in RGB and the floor in depth) makes little sense due to the severe cross-modal representation gap. Hence, this strategy is difficult to model the cross-modal global contexts and the improvement is quite limited. Additionally, such global cross-modal fusion overlooks the inborn spatial-alignment in RGB-D pairs and the similarity between cross-modal spatial-distant patches will introduce noise to the query from the keys in other areas. Hence, we argue that the modality gap and spatial discrepancy should not concurrent when measuring cross-modal dependencies for complementing. Based on this insight, we propose a Hierarchical Cross-modal Transformer (HCT), which customizes the cross-modal complementarity from two views: I) Intra-modal global contexts. As illustrated in Fig. 1 (b), The within-modal self-attention reveals global contrasts and contexts in each modality. Combining this global understanding from two modalities will facilitate the discrimination between foreground from background a lot. II) Cross-modal local spatial-aligned enhancement. As a local region aligned in two modalities carry the same local context (Fig. 1 (c)), the cross-modal attention restricted in the same small aligned region can well capture the cross-modal correlation and mapping, thereby bridging the cross-modal gap and easing multi-modal feature fusion. With the complements from above two perspectives, our HCT can well exploit the cross-modal global/local contexts for complementary global reasoning and local enhancement. On top of this, we draw inspiration from (Zhao et al. 2022) to disentangle heterogeneous multi-modal complements and boost the fusion by explicitly constraining the consistency and complementarity between two transformer streams.
2. As different transformer layers characterize an object with varying scales, directly concatenating such heterogenous cross-level representations without explicit selecting and adaptive weighting will result in deficient feature integration. (Li et al. 2022) finds deep semantic features from a transformer-based encoder dominate the dense prediction tasks. However, the VST model treats all features from different scales equally during the fusion process. To tackle this issue, we design a Feature Pyramid for Transformer (FPT) to adaptively propagate the high-level semantics to progressively guide the selection and integration of shallow features.
By solving the above two problems, our HCT enjoys long-range dependencies, adaptive cross-scale integration, hierarchical cross-modal contextual complements, fine-grained cross-modal interactions, and explicit disentanglement of complex cross-modal relationships. Extensive experiments verify the efficacy of our designs and the large improvement over state-of-the-art on 6 benchmark datasets.



Related Work
RGB-D Salient Object Detection
As handcrafted saliency cues (Ciptadi, Hermans, and Rehg 2013; Peng et al. 2014; Cong et al. 2016) are weak in learning global contexts and hold limited generalization ability, recent RGB-D SOD models mainly focus on designing CNN architectures and cross-modal fusion paths to better study the complements. For example, Qu et al. (2017) integrate handcrafted cues from two modalities as a joint input to train a shared CNN. PCF (Chen and Li 2018) proposes a progressive multi-scale fusion strategy and TANet (Chen and Li 2019) introduces a three-stream architecture to explicitly select complementary cues in each level.
Apart from the basic fusion architectures (i.e., single stream, two-stream, and three-stream), some other works introduce various feature combination strategies (Han et al. 2018), cross-modal cross-level interaction paths (Liu, Zhang, and Han 2020), and other strategies such as knowledge distillation (Chen et al. 2021) and dynamic convolution (Pang et al. 2020) to boost the fusion sufficiency.
In summary, the prior CNN-based RGB-D SOD community has achieved noticable advances. Nonetheless, the locality nature of CNNs make them weak in learning global contexts. Different from previous remediation strategies such as using global pooling (Liu, Han, and Yang 2017) or fully connected layers (Liu and Han 2016a), Liu et al. (2021a) eschew this intrinsic limitation by designing a transformer-based architecture to extract intra/inter-modal long-rang dependencies. They use ViTs as encoders for each modality and stitch the tokens from two modalities for cross-modal fusion. Benefit from the long-range self-attention mechanism, VST achieves large improvement over previous CNN-based methods. Whereas, it ignores the large cross-modal gap. Consequently, directly computing the cross-modal dependency between distant regions contributes little contexts and even tends to introduce noises. Also, simply concatenating features in the decoder without differentiating neglects the varying contributions of different layers in inference. Differently, we customize a hierarchical cross-modal fusion module to carefully model the cross-modal transformer complements from two views, as well as a feature pyramid module to enable adaptive cross-level integration.
Transformer in Computer Vision
The transformer (Vaswani et al. 2017) is first proposed for machine translation and achieves impressive results in various natural language processing tasks with its powerful ability in modeling global contexts. Inspired by its great potential, increasing vision transformers have been put forward in the computer vision community. Dosovitskiy et al. (2020) successfully introduce transformer (ViT) into image classification by splitting an image into patches. Since then, various transformers are introduced, e.g., T2T ViT (Yuan et al. 2021) aggregates adjacent tokens to model local structure and reduce the computational cost, PVT (Wang et al. 2021) proposes spatial-reduction attention to learn multi-scale feature maps flexibly. Swin transformer (Liu et al. 2021b) fully takes advantages of displacement invariance and size invariance and integrates them into an transformer. These transformers are widely applied in other computer vision tasks as backbones, including detection (Carion et al. 2020), segmentation (Kirillov et al. 2019), video processing (Sun et al. 2019), etc.
Transformers are also widely used in multi-modal learning for its flexible input. For instance, Sun et al. (2019) straightly project the video and audio into patches and throws them into a shared transformer backbone. Zheng et al. (2021) design a transformer structure to handle embeded acoustic input and text simultaneously. However, these methods concatenate embeddings straightly and achieve intra-modal and inter-modal combinations at the same time, leading to uninformative fusion and even introducing noisy features. The VST (Liu et al. 2021a) model tackles this issue by extracting RGB and depth features individually and adopting a cross attention module for cross-modal fusion. However, the cross-modal attention module in VST introduces cross-modal gap and spatial discrepancy simultaneously, making it difficult to explore the heterogeneous cross-modal complements clearly. Hence, we decouple the complex cross-modal transformer complements and propose a hierarchical cross-modal attention to control the modality/spatial gaps and progressively incorporate cross-modal complements.
The Proposed Method
In this section, we first introduce the overall architecture of our model. And then, we will detail our key designs, including the hierarchical cross-modal attention module (HCA), the feature pyramids for transformer (FPT) and the disentangled complementing module (DCM).
Overall Architecture
Fig. 2 shows the architecture of our proposed model. Two T2T ViT backbones pretrained on ImageNet are applied to extract RGB and depth features, respectively. And then the HCA module is tailored to explicitly take advantage of the cross-modal spatial alignment to boost the global/local contextual fusion. Next, the feature pyramid is constructed to selectively assimilate shallower layers with the guidance of the deep semantics. Finally, the DCM is introduced to bifurcate the heterogeneous complementary cues to modal-shared and modal-specific ones to boost the fusion sufficiency and their combination is used to generate the final joint prediction.
Hierarchical Cross-Modal Attention

As shown in Fig. 3 (a), our HCA consists of two stages: Global self-attention (GSA) and Local-aligned cross-attention (LCA) as illustrated in Fig. 3 (b) and Fig. 3 (c), respectively. In the GSA stage, RGB and depth features will calculate their intra-modal self-attention maps individually, and then swap their global self-attention maps to achieve complementary global contexts. The attention scores are calculated by the following formulas:
| (1) |
| (2) |
where , , denotes query, key and value generated from RGB features, and , , come from depth features. Unlike self-attention, we swap the attention map which describes the within-modal self-relation globally. The and will finally add back to RGB and depth features respectively as a residual part.
After swapping the structural information, we adopt a local cross-attention module to reinforce the fusion of cross-modal local semantics. The main difference between LCA and traditional cross attention lies in a mask operation, which will keep attention similarity in adjacent area and set similarity to 0 in remote areas. Specifically, the global cross-attention map will add with a mask matrix where 0 denotes adjacent area and -100 represents remote area, after softmax the attention scores from remote area are close to 0, thus remote areas make no contribution to the further fusion process. This process can be formulated as follows:
| (3) |
| (4) |
Fig. 4 details the process of mask generation. After embedding RGB and depth features into , and forms, we multiply with to obtain a unified attention map. For example, the first line in attention map depicts the similarity between the first patch in RGB features and all the patches in the paired depth. Then, we design a mask for each line according to its distance to the target patch and get the flitted attention map. The masked attention map, carrying complementary local contexts and cross-modal correlation, is then multiplied with the to generate the final depth features. Note that a symmetrical interaction line is also performed to enhance RGB features. To further encourage the extraction and selection of cross-modal complementary cues, updated features will be forced to predict the saliency maps by optimizing:
| (5) |
| (6) |
where means sigmoid function, y denotes the groundtruth labels, and denote the predicted results from RGB feature and depth feature, respectively.
Feature Pyramid for Transformer
After we have obtained the complemented features from the HCA module, we draw inspiration from the Feature Pyramid Networks (FPN) (Lin et al. 2017) to combine the transformer features from different levels to get multi-level multi-modal representations. Unlike previous methods (Chen, Li, and Su 2019; Liu et al. 2021a; Zhao et al. 2022) that construct feature pyramid using CNN features and distribute the features to each level equally, we highlight the contribution of the deepest level in the pyramid with a larger proportion and use the deep semantics to guide the selection of shallow features.
The architecture of the FPT is shown in Fig. 5. The features (14*14*384, 28*28*64, 56*56*64) from two T2T ViT encoder are aligned by progressively upsampling and concatenated with channel ratios 6:1, 2:1 and 1:1, respectively.

Disentangled Complementing Module
Considering the complementarity among cross-modal features are heterogeneous, we draw inspiration from (Zhao et al. 2022; Chen et al. 2020a) to disentangle the cross-modal complements into consistent and complementary ones to improve the fusion adaptivity. Specifically shown in the DCM in Fig. 6, the input RGB features and depth features will first be mapped to the same feature space by a linear projection and fed to two branches to extract consistent and complementary features, respectively. The branch above explores the consistency by point multiplication and a residual connection:
| (7) |
where and mean the RGB features and depth features after mapping, depicts element-wise multiplication, means element-wise addition and is the convolution layer. The branch below explores the complementarity by substraction:
| (8) |
where depicts element-wise subtraction.
To encourage the disentanglement of complements, we append the saliency groundtruth mask to supervise the prediction of the fused feature . Specifically, the saliency map , predicted by the former DCM, carries important global contexts and localization cues. Hence, we use to guide this disentanglement in the i-th level by point multiplication with and respectively to avoid noisy backgrounds in shallower layers. The constrained features are calculated as following formulas:
| (9) |
| (10) |
Finally, and will be combined with an addition and a convolution operation:
| (11) |
The prediction loss in the i-th DCM is
| (12) |
where is the saliency map generated by the i-th DCM.

Compared with undifferentiated concatenation, our proposed DCM will explicitly diversify the complex cross-modal complements into the consistent and complementary elements.
The final loss includes 2 losses from the HCA module and 4 losses from DCMs:
| (13) |
Experiments
| Dataset | Metric | CMW | Cas-Gnn | HDFNet | CoNet | BBS-Net | SSP | VST | SPSN | MVSalNet | Base | HCT |
| NJUD | 0.870 | 0.911 | 0.908 | 0.896 | 0.921 | 0.909 | 0.922 | 0.918 | 0.910 | 0.925 | 0.933 | |
| 0.871 | 0.916 | 0.911 | 0.893 | 0.919 | 0.923 | 0.920 | - | 0.922 | 0.924 | 0.932 | ||
| 0.927 | 0.948 | 0.944 | 0.937 | 0.949 | 0.951 | 0.939 | 0.950 | 0.939 | 0.956 | 0.960 | ||
| 0.061 | 0.036 | 0.039 | 0.046 | 0.035 | 0.039 | 0.035 | 0.032 | 0.035 | 0.037 | 0.030 | ||
| NLPR | 0.917 | 0.919 | 0.923 | 0.912 | 0.931 | 0.922 | 0.932 | 0.923 | 0.927 | 0.925 | 0.934 | |
| 0.903 | 0.906 | 0.917 | 0.893 | 0.918 | 0.889 | 0.920 | - | 0.929 | 0.913 | 0.924 | ||
| 0.951 | 0.955 | 0.963 | 0.948 | 0.961 | 0.960 | 0.962 | 0.958 | 0.959 | 0.957 | 0.963 | ||
| 0.027 | 0.028 | 0.027 | 0.027 | 0.023 | 0.025 | 0.023 | 0.024 | 0.021 | 0.030 | 0.023 | ||
| DUTLF | 0.797 | 0.920 | 0.908 | 0.923 | 0.882 | 0.929 | 0.943 | - | - | 0.939 | 0.947 | |
| 0.779 | 0.926 | 0.915 | 0.932 | 0.870 | 0.947 | 0.948 | - | - | 0.945 | 0.950 | ||
| 0.864 | 0.953 | 0.945 | 0.959 | 0.912 | 0.958 | 0.969 | - | - | 0.964 | 0.969 | ||
| 0.098 | 0.030 | 0.041 | 0.029 | 0.058 | 0.029 | 0.024 | - | - | 0.030 | 0.023 | ||
| STERE | 0.852 | 0.899 | 0.900 | 0.905 | 0.908 | 0.904 | 0.913 | 0.907 | 0.911 | 0.914 | 0.923 | |
| 0.837 | 0.901 | 0.900 | 0.901 | 0.903 | 0.914 | 0.907 | - | 0.920 | 0.907 | 0.918 | ||
| 0.907 | 0.944 | 0.943 | 0.947 | 0.942 | 0.939 | 0.951 | 0.943 | 0.946 | 0.949 | 0.955 | ||
| 0.067 | 0.039 | 0.042 | 0.037 | 0.041 | 0.039 | 0.038 | 0.035 | 0.035 | 0.042 | 0.034 | ||
| RGBD135 | 0.934 | 0.894 | 0.926 | 0.914 | 0.934 | 0.936 | 0.943 | - | 0.931 | 0.934 | 0.946 | |
| 0.931 | 0.894 | 0.921 | 0.902 | 0.928 | 0.944 | 0.940 | - | 0.934 | 0.922 | 0.945 | ||
| 0.99 | 0.937 | 0.970 | 0.948 | 0.966 | 0.978 | 0.978 | - | 0.971 | 0.968 | 0.978 | ||
| 0.022 | 0.028 | 0.022 | 0.024 | 0.021 | 0.017 | 0.017 | - | 0.019 | 0.022 | 0.016 | ||
| SIP | 0.705 | - | 0.886 | 0.860 | 0.879 | 0.888 | 0.904 | 0.892 | - | 0.918 | 0.922 | |
| 0.677 | - | 0.894 | 0.873 | 0.884 | 0.909 | 0.915 | - | - | 0.930 | 0.935 | ||
| 0.804 | - | 0.930 | 0.917 | 0.922 | 0.927 | 0.944 | 0.934 | - | 0.955 | 0.958 | ||
| 0.141 | - | 0.048 | 0.048 | 0.055 | 0.046 | 0.040 | 0.042 | - | 0.037 | 0.031 |
Datasets
We evaluate the proposed model on seven public RGB-D SOD datasets which are NJUD (Ju et al. 2014) (1985 image pairs), NLPR (Peng et al. 2014) (1000 image pairs), DUTLF (Piao et al. 2019)(1200 image pairs), STERE (Niu et al. 2012) (1000 image pairs), RGBD135 (Cheng et al. 2014) (135 image pairs), SIP (Fan et al. 2020a) (929 image pairs) and COME15K (Zhang et al. 2021) (15625 image pairs). We follow the consistent setting in previous works (Liu et al. 2021a; Zhang et al. 2021) and choose 1485 image pairs in NJUD, 700 image pairs in NLPR, 800 image pairs in DUTLF and 8025 pairs image in COME15K as the training set and the remaining are for testing. Similarly. we also adopt some data augmentation techniques such as resize, random crop and random flipping to avoid overfitting.
Evaluation Metrics
We adopt four widely used evaluation metrics to evaluate our model. Specifically, Structure-measure (Fan et al. 2017) evaluates region-aware and object-aware structural similarity. E-measure (Fan et al. 2018) simultaneously considers pixel-level errors and image-level errors. Maximum F-measure (Achanta et al. 2009) jointly considers precision and recall under the optimal threshold. Mean Absolute Error (MAE) computes pixel-wise average absolute error.
Implementation Details
We implement our model on the base of VST (Liu et al. 2021a) using Pytorch and train it on a RTX 3090. The training parameters are set as follows: batch size is 8, epoch is 50. For the optimizer, we use Adam with the learning rate gradually decaying from to .
Comparisons with State-of-the-art
To quantitatively measure our model, we compare it with 6 SOTA RGB-D SOD methods, including CMW (Li et al. 2020), Cas-Gnn (Luo et al. 2020), HDFNet (Pang et al. 2020), CoNet (Ji et al. 2020), BBS-Net (Fan et al. 2020b) and VST (Liu et al. 2021a). Tab. 1 shows the comparison in terms of the S-measure, F-measure, E-measure and MAE scores. To fairly demonstrate the advantages of our cross-modal fusion scheme, we select the VST without the edge detection task and retrain it with our training set as the baseline model (denoted by ”base”), as we argue that edge detection is a trick requiring additional edge labels and not related to multimodal fusion. The quantitative results illustrate that VST achieves consistent improvement over CNN-based methods, denoting the superiority of the transformer. Our model outperforms previous RGB-D SOD models, including VST on all datasets, demonstrating the advantages of our cross-modal fusion scheme and designs.










































To visually measure our model, we compare it with 3 recent SOTA RGB-D SOD methods, including CoNet (Ji et al. 2020), BBS-Net (Fan et al. 2020b) and the Base(Liu et al. 2021a). The visualized results on some representative challenging scenes are illustrated in Fig. 7. In the case of large intra-difference in the foreground (see the , and rows), previous models often fail to completely detect the correct salient objects, while our model can achieve more accurate and uniform detection. When the foreground and background hold similar appearance or depth (see the , and rows), previous methods may mistake some background areas as foreground, while our model successfully handles this confusion and well leverage the discriminating modality. For scenes having multiple salient objects (see the , and rows), other models tends to overlook some regions, while our method can highlight all salient objects. The success on these difficult cases demonstrates our advantages in modeling within/cross-modal long-range dependencies and local correlations.
Ablation Study
| Settings | COME-E (Zhang et al. 2021) | COME-H (Zhang et al. 2021) | |||||||
| Base | 0.902 | 0.899 | 0.940 | 0.042 | 0.865 | 0.865 | 0.903 | 0.067 | |
| Base-CA | 0.904 | 0.901 | 0.940 | 0.039 | 0.866 | 0.866 | 0.903 | 0.065 | |
| +HCA | 0.906 | 0.904 | 0.942 | 0.038 | 0.868 | 0.869 | 0.907 | 0.062 | |
| +HCA+FPT | 0.908 | 0.906 | 0.943 | 0.037 | 0.871 | 0.871 | 0.908 | 0.061 | |
| +HCA+FPT+DCM | 0.911 | 0.910 | 0.945 | 0.035 | 0.873 | 0.872 | 0.910 | 0.059 | |
In this section, we will verify the effectiveness of each proposed structure by comprehensive ablation experiments. The experiments are implemented on 2 largest datasets, i.e., COME-EASY and COME-HARD. We select the Base as the baseline model (noted as ”Base”).
Effectiveness of hierarchical cross-modal attention. As shown in Tab. 2, compared to the original VST baseline (denoted by ”Base”), removing the global cross-attention layer in VST (denoted by ”Base-CA”) surprisingly improves the performance, suggesting the cross-modal gap and the irrationality of using spatial-distant cross-modal dependencies as complementary contexts. In contrast, our hierarchical cross-modal attention scheme (denoted by ”+HCA”) shows noticeable improvement, which well supports our motivation that cross-modal gap and spatial discrepancy should not be concurrent when measuring cross-modal correlations.



















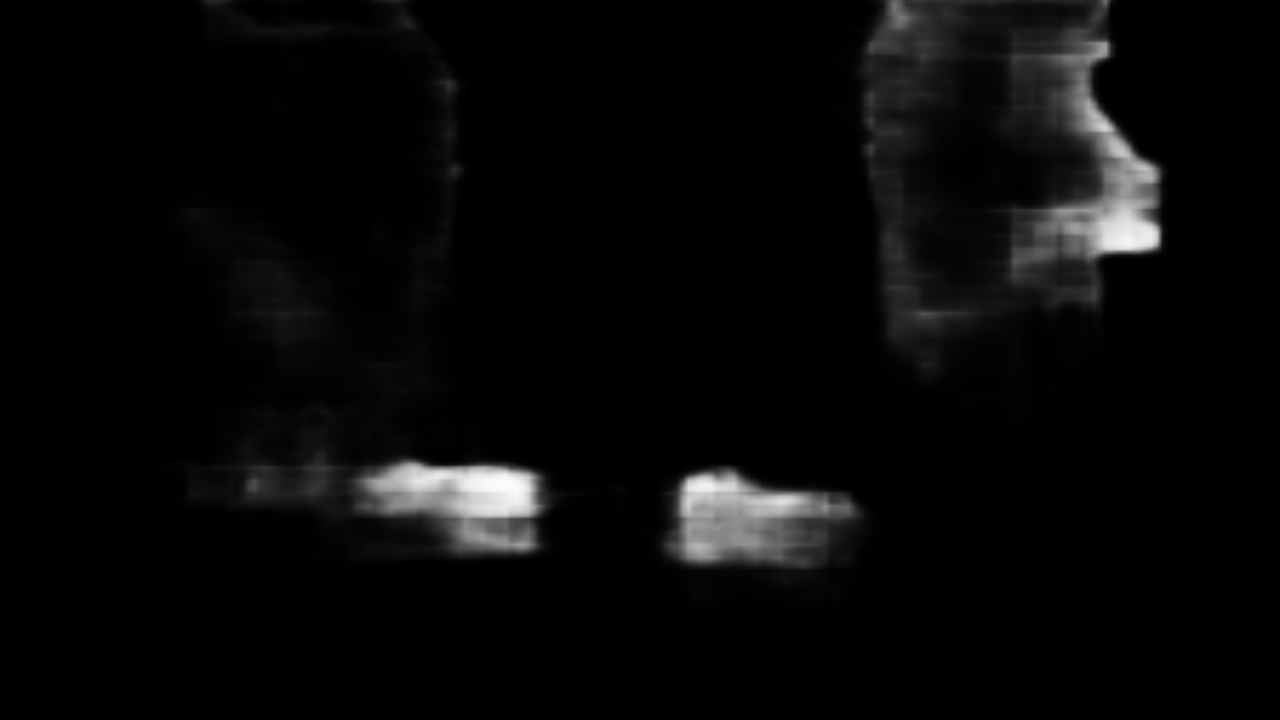
























Fig. 8 shows the effectiveness of the global cross-attention (GSA) and local-aligned cross attention (LCA) components in HCA visually. As we predict, the global cross-attention in VST (see ”Base” in Fig. 8) will introduce noises from other distant areas to wrongly identify the background and foreground. With global self-attention (denoted by ”+GSA”) to complement the global contexts, the model has stronger global reasoning ability to localize the salient object. With the local-aligned cross attention additionally (denoted by ”+HCA”), the cross-modal fusion process takes advantages of the local cross-modal correlations to remove the noises and enhance the object details.
Effectiveness of feature pyramid for transformer. The comparison between ”+HCA+FPT” and ”+HCA” in Tab. 2 illustrates the improvement of our FPT design, indicating its contribution to boost the cross-level feature selection. The saliency maps in Fig. 9 visually shows the benefits of FPT. In FPT, cross-level features are integrated progressively and selectively with the guidance from deep to shallow, thus enabling informative and adaptive multi-level combination. As a result, our model can better infer the location of the salient objects and highlight their boundaries precisely.




















Effectiveness of the disentangled complementing module. The comparison between line ”+HCA+FPT” and ”+HCA+FPT+DCM” in Tab. 2 shows the considerable improvement of DCM, indicating that diversifying the complex cross-modal complements into consistent and complementary ones will boost the fusion adaptivity.
The visualization results are shown in Fig. 10. Undifferentiated concatenation is too ambiguous to explore the detailed consistent information between modalities, thus the predicted maps are bad in details, especially around the object boundaries (see the , and rows). Instead, DCM explicitly decouples the difference and consistency between modalities and combine them adaptively for varying scenes to localize the salient objects accurately and highlight salient regions uniformly.
Conclusion
In this paper, we propose a new transformer-based architecture for RGB-D salient object detection. To tackle the modality gap and spatial discrepancy when combining cross-modal transformer features, we tailor a hierarchical cross-modal attention to explore the cross-modal complements in terms of the global contexts and local correlations successively. Also, a feature pyramid for transformer is designed to achieve adaptive cross-level feature selection, and a disentangled complementing module is introduced to disentangle complex complements into consistent and complementary ones to boost the cross-modal fusion adaptivity. Extensive experiments verify the advantages of our multi-modal transformer and the efficacy of our designs.
References
- Achanta et al. (2009) Achanta, R.; Hemami, S.; Estrada, F.; and Susstrunk, S. 2009. Frequency-tuned salient region detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1597–1604. IEEE.
- Carion et al. (2020) Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), 213–229. Springer.
- Chen et al. (2020a) Chen, H.; Deng, Y.; Li, Y.; Hung, T.-Y.; and Lin, G. 2020a. RGBD Salient Object Detection via Disentangled Cross-Modal Fusion. IEEE Transactions on Image Processing (TIP), 29: 8407–8416.
- Chen and Li (2018) Chen, H.; and Li, Y. 2018. Progressively complementarity-aware fusion network for RGB-D salient object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3051–3060.
- Chen and Li (2019) Chen, H.; and Li, Y. 2019. Three-stream attention-aware network for RGB-D salient object detection. IEEE Transactions on Image Processing (TIP), 28(6): 2825–2835.
- Chen et al. (2021) Chen, H.; Li, Y.; Deng, Y.; and Lin, G. 2021. CNN-Based RGB-D Salient Object Detection: Learn, Select, and Fuse. International Journal of Computer Vision (IJCV).
- Chen, Li, and Su (2019) Chen, H.; Li, Y.; and Su, D. 2019. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognition, 86: 376–385.
- Chen et al. (2020b) Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; and Liu, Z. 2020b. Dynamic convolution: Attention over convolution kernels. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 11030–11039.
- Cheng et al. (2014) Cheng, Y.; Fu, H.; Wei, X.; Xiao, J.; and Cao, X. 2014. Depth enhanced saliency detection method. In International Conference on Internet Multimedia Computing and Service (ICIMCS), 23–27.
- Ciaparrone et al. (2020) Ciaparrone, G.; Sánchez, F. L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; and Herrera, F. 2020. Deep learning in video multi-object tracking: A survey. Neurocomputing, 381: 61–88.
- Ciptadi, Hermans, and Rehg (2013) Ciptadi, A.; Hermans, T.; and Rehg, J. M. 2013. An in depth view of saliency. Georgia Institute of Technology.
- Cong et al. (2016) Cong, R.; Lei, J.; Zhang, C.; Huang, Q.; Cao, X.; and Hou, C. 2016. Saliency detection for stereoscopic images based on depth confidence analysis and multiple cues fusion. IEEE Signal Processing Letters, 23(6): 819–823.
- Dosovitskiy et al. (2020) Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
- Fan et al. (2017) Fan, D.-P.; Cheng, M.-M.; Liu, Y.; Li, T.; and Borji, A. 2017. Structure-measure: A new way to evaluate foreground maps. In IEEE International Conference on Computer Vision (ICCV), 4548–4557.
- Fan et al. (2018) Fan, D.-P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.-M.; and Borji, A. 2018. Enhanced-alignment measure for binary foreground map evaluation. arXiv preprint arXiv:1805.10421.
- Fan et al. (2020a) Fan, D.-P.; Lin, Z.; Zhang, Z.; Zhu, M.; and Cheng, M.-M. 2020a. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Transactions on Neural Networks and Learning Systems, 32(5): 2075–2089.
- Fan et al. (2020b) Fan, D.-P.; Zhai, Y.; Borji, A.; Yang, J.; and Shao, L. 2020b. BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network. In European Conference on Computer Vision (ECCV), 275–292. Springer.
- Goferman, Zelnik-Manor, and Tal (2011) Goferman, S.; Zelnik-Manor, L.; and Tal, A. 2011. Context-aware saliency detection. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 34(10): 1915–1926.
- Han et al. (2018) Han, J.; Chen, H.; Liu, N.; Yan, C.; and Li, X. 2018. CNNs-Based RGB-D Saliency Detection via Cross-View Transfer and Multiview Fusion. IEEE Transactions on Systems, Man, and Cybernetics.
- He et al. (2016) He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778.
- Ji et al. (2020) Ji, W.; Li, J.; Zhang, M.; Piao, Y.; and Lu, H. 2020. Accurate RGB-D salient object detection via collaborative learning. In European Conference on Computer Vision (ECCV), 52–69. Springer.
- Jiao et al. (2019) Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; and Qu, R. 2019. A survey of deep learning-based object detection. IEEE Access, 7: 128837–128868.
- Ju et al. (2014) Ju, R.; Ge, L.; Geng, W.; Ren, T.; and Wu, G. 2014. Depth saliency based on anisotropic center-surround difference. In IEEE International Conference on Image Processing (ICIP), 1115–1119. IEEE.
- Kirillov et al. (2019) Kirillov, A.; He, K.; Girshick, R.; Rother, C.; and Dollár, P. 2019. Panoptic segmentation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 9404–9413.
- Lang et al. (2012a) Lang, C.; Nguyen, T. V.; Katti, H.; Yadati, K.; Kankanhalli, M.; and Yan, S. 2012a. Depth matters: Influence of depth cues on visual saliency. In European Conference on Computer Vision (ECCV), 101–115. Springer.
- Lang et al. (2012b) Lang, C.; Nguyen, T. V.; Katti, H.; Yadati, K.; Kankanhalli, M. S.; and Yan, S. 2012b. Depth Matters: Influence of Depth Cues on Visual Saliency. European Conference on Computer Vision (ECCV).
- Li et al. (2020) Li, G.; Liu, Z.; Ye, L.; Wang, Y.; and Ling, H. 2020. Cross-modal weighting network for RGB-D salient object detection. In European Conference on Computer Vision (ECCV), 665–681. Springer.
- Li et al. (2022) Li, Y.; Mao, H.; Girshick, R.; and He, K. 2022. Exploring plain vision transformer backbones for object detection. arXiv preprint arXiv:2203.16527.
- Lin et al. (2017) Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; and Belongie, S. 2017. Feature pyramid networks for object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2117–2125.
- Liu and Han (2016a) Liu, N.; and Han, J. 2016a. DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection. Computer Vision and Pattern Recognition (CVPR).
- Liu and Han (2016b) Liu, N.; and Han, J. 2016b. Dhsnet: Deep hierarchical saliency network for salient object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 678–686.
- Liu, Han, and Yang (2017) Liu, N.; Han, J.; and Yang, M.-H. 2017. PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection. Computer Vision and Pattern Recognition (CVPR).
- Liu, Han, and Yang (2018) Liu, N.; Han, J.; and Yang, M.-H. 2018. Picanet: Learning pixel-wise contextual attention for saliency detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3089–3098.
- Liu, Zhang, and Han (2020) Liu, N.; Zhang, N.; and Han, J. 2020. Learning Selective Self-Mutual Attention for RGB-D Saliency Detection. Computer Vision and Pattern Recognition (CVPR).
- Liu et al. (2021a) Liu, N.; Zhang, N.; Wan, K.; Shao, L.; and Han, J. 2021a. Visual saliency transformer. In IEEE International Conference on Computer Vision (ICCV), 4722–4732.
- Liu et al. (2021b) Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021b. Swin transformer: Hierarchical vision transformer using shifted windows. In IEEE International Conference on Computer Vision (ICCV), 10012–10022.
- Luo et al. (2020) Luo, A.; Li, X.; Yang, F.; Jiao, Z.; Cheng, H.; and Lyu, S. 2020. Cascade graph neural networks for RGB-D salient object detection. In European Conference on Computer Vision (ECCV), 346–364. Springer.
- Niu et al. (2012) Niu, Y.; Geng, Y.; Li, X.; and Liu, F. 2012. Leveraging stereopsis for saliency analysis. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 454–461. IEEE.
- Pang et al. (2020) Pang, Y.; Zhang, L.; Zhao, X.; and Lu, H. 2020. Hierarchical dynamic filtering network for rgb-d salient object detection. In European Conference on Computer Vision (ECCV), 235–252. Springer.
- Peng et al. (2014) Peng, H.; Li, B.; Xiong, W.; Hu, W.; and Ji, R. 2014. RGBD salient object detection: A benchmark and algorithms. In European Conference on Computer Vision (ECCV), 92–109. Springer.
- Piao et al. (2019) Piao, Y.; Ji, W.; Li, J.; Zhang, M.; and Lu, H. 2019. Depth-induced multi-scale recurrent attention network for saliency detection. In IEEE International Conference on Computer Vision (ICCV), 7254–7263.
- Qu et al. (2017) Qu, L.; He, S.; Zhang, J.; Tian, J.; Tang, Y.; and Yang, Q. 2017. RGBD salient object detection via deep fusion. IEEE Transactions on Image Processing (TIP), 26(5): 2274–2285.
- Shigematsu et al. (2017) Shigematsu, R.; Feng, D.; You, S.; and Barnes, N. 2017. Learning RGB-D salient object detection using background enclosure, depth contrast, and top-down features. In IEEE International Conference on Computer Vision Workshops (ICCV), 2749–2757.
- Simonyan and Zisserman (2014) Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Sukanya, Gokul, and Paul (2016) Sukanya, C.; Gokul, R.; and Paul, V. 2016. A survey on object recognition methods. International Journal of Science, Engineering and Computer Technology, 6(1): 48.
- Sun et al. (2019) Sun, C.; Myers, A.; Vondrick, C.; Murphy, K.; and Schmid, C. 2019. Videobert: A joint model for video and language representation learning. In IEEE International Conference on Computer Vision (ICCV), 7464–7473.
- Sun et al. (2021) Sun, P.; Zhang, W.; Wang, H.; Li, S.; and Li, X. 2021. Deep RGB-D saliency detection with depth-sensitive attention and automatic multi-modal fusion. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1407–1417.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in Neural Information Processing Systems (NIPS), 30.
- Wang et al. (2021) Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; and Shao, L. 2021. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In IEEE International Conference on Computer Vision (ICCV), 568–578.
- Yuan et al. (2021) Yuan, L.; Chen, Y.; Wang, T.; Yu, W.; Shi, Y.; Jiang, Z.; Tay, F. E. H.; Feng, J.; and Yan, S. 2021. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. In IEEE International Conference on Computer Vision (ICCV), 538–547.
- Zhang et al. (2021) Zhang, J.; Fan, D.-P.; Dai, Y.; Yu, X.; Zhong, Y.; Barnes, N.; and Shao, L. 2021. RGB-D saliency detection via cascaded mutual information minimization. In IEEE International Conference on Computer Vision (ICCV), 4338–4347.
- Zhao et al. (2019) Zhao, J.-X.; Cao, Y.; Fan, D.-P.; Cheng, M.-M.; Li, X.-Y.; and Zhang, L. 2019. Contrast prior and fluid pyramid integration for RGBD salient object detection. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3927–3936.
- Zhao et al. (2015) Zhao, R.; Ouyang, W.; Li, H.; and Wang, X. 2015. Saliency detection by multi-context deep learning. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1265–1274.
- Zhao et al. (2022) Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; and Ruan, X. 2022. Self-Supervised Pretraining for RGB-D Salient Object Detection. In AAAI Conference on Artificial Intelligence, volume 3.
- Zheng et al. (2021) Zheng, R.; Chen, J.; Ma, M.; and Huang, L. 2021. Fused acoustic and text encoding for multimodal bilingual pretraining and speech translation. In International Conference on Machine Learning (ICML), 12736–12746. PMLR.
- Zhou et al. (2018) Zhou, Y.; Huo, S.; Xiang, W.; Hou, C.; and Kung, S.-Y. 2018. Semi-supervised salient object detection using a linear feedback control system model. IEEE Transactions on Cybernetics, 49(4): 1173–1185.