Hierarchical Conditional Semi-paired Image-to-image Translation for Multi-task Image Defect Correction on Shopping Websites
Abstract
On shopping websites, product images of low quality negatively affect customer experience. Although there are plenty of work in detecting images with different defects, few efforts have been dedicated to correct those defects at scale. A major challenge is that there are thousands of product types and each has specific defects, therefore building defect specific models is unscalable. In this paper, we propose a unified Image-to-Image (I2I) translation model to correct multiple defects across different product types. Our model leverages an attention mechanism to hierarchically incorporate high-level defect groups and specific defect types to guide the network to focus on defect-related image regions. Evaluated on eight public datasets, our model reduces the Frechet Inception Distance (FID) by 24.6% in average compared with MoNCE, the state-of-the-art I2I method. Unlike public data, another practical challenge on shopping websites is that some paired images are of low quality. Therefore we design our model to be semi-paired by combining the L1 loss of paired data with the cycle loss of unpaired data. Tested on a shopping website dataset to correct three image defects, our model reduces (FID) by 63.2% in average compared with WS-I2I, the state-of-the art semi-paired I2I method.
Index Terms— Image to Image translation, Computer Vision, Image defect auto-correction
1 Introduction
On shopping websites, product images provide customers with visual perception on the appearance of the products, thus play a critical role for customers’ shopping decisions. However, images provided by sellers usually contain various kinds of defects, such as non-white background or watermark. Given the definition of different defects and the corresponding training data (defective and non-defective images), it is straightforward to build an image classification model to detect defective images. However, re-shooting defect-free images is expensive and time-consuming for most sellers, which motivates us to build an ML framework to correct image defects automatically.
Image-to-image (I2I) translation is a promising approach because it can transform images from a source domain (defective) to a target domain (non-defective). I2I has a wide range of applications, such as image synthesis [1, 2], semantic segmentation [3, 4], image inpainting [5, 6], etc. I2I algorithms can be broadly classified into three categories: paired I2I [7, 3], unpaired I2I [8, 9, 10, 11, 12, 13], and semi-paired I2I [14, 15]. In paired I2I, each image in the source domain is paired with an image in the target domain. In unpaired I2I, data from both domains are available but not paired. Semi-paired I2I uses both paired and unpaired data.
There are two major limitations of I2I methods for the image defects correction on shopping websites: First, I2I methods mainly focus on transforming images from one source domain to one or multiple target domains. They cannot support a single model that transforms multiple source domains to their corresponding target domains. On shopping websites, there are thousands of product types (e.g., shirt) and each has specific defects (e.g., non-white background). Using the existing I2I methods, we need to train thousands of models to cover all the defects, which is unscalable. Second, defects on shopping websites are usually local, i.e., the defects only occupy a certain proportion of the whole image. Most local I2I methods, such as InstaGAN [16] or InstaFormer [17], require mask or bounding box labels, which are expensive to obtain for all the defects. Although there are I2I methods [18, 19, 20] that use attention modules to identify local regions without requiring labels, they do not perform well when the images are from multiple product types with different defects.
To enable the correction of multiple image defects with a single model while accurately locating the defect-related local regions, we design a hierarchical attention module. The module leverages the high-level defect groups (e.g., background related) and specific defect types (e.g., non-white background and watermark are two specific defects within the background-related group) to guide the generator to focus on the defect-related regions when trained on images of different defects and product types. Furthermore, on shopping websites, due to the lack of human-audited paired data, the proposed model leverages synthesized paired data. To improve the model’s robustness against synthesized pairs of low quality, we design our model to be semi-paired by adopting cycle loss on unpaired data. In summary, our contributions include: (1) We propose a unified I2I pipeline that can correct multiple image defects across different product types, (2) We hierarchically inject the high-level defect groups and specific defect types using attention modules, which guides the network to focus on defect-related local regions, (3) The proposed model can consume both paired data and unpaired data, while being robust against the synthesized pairs of low quality, (4) The proposed model achieves better FID scores on eight public datasets and a shopping website dataset compared with the state-of-the-art I2I methods.
2 Method
Our proposed framework is shown in Figure 1. It contains two generators and to transform images from domain to and from Y to X respectively. For each pair of images from domain and , we train a discriminator to distinguish and the transformed image using L1 loss. For each unpaired image in domain , we train a discriminator to distinguish and , the generated image by transforming to domain and further transforming it back to . We insert the high level defect group and specific defect type to guide the two generators to focus on the defect related regions.
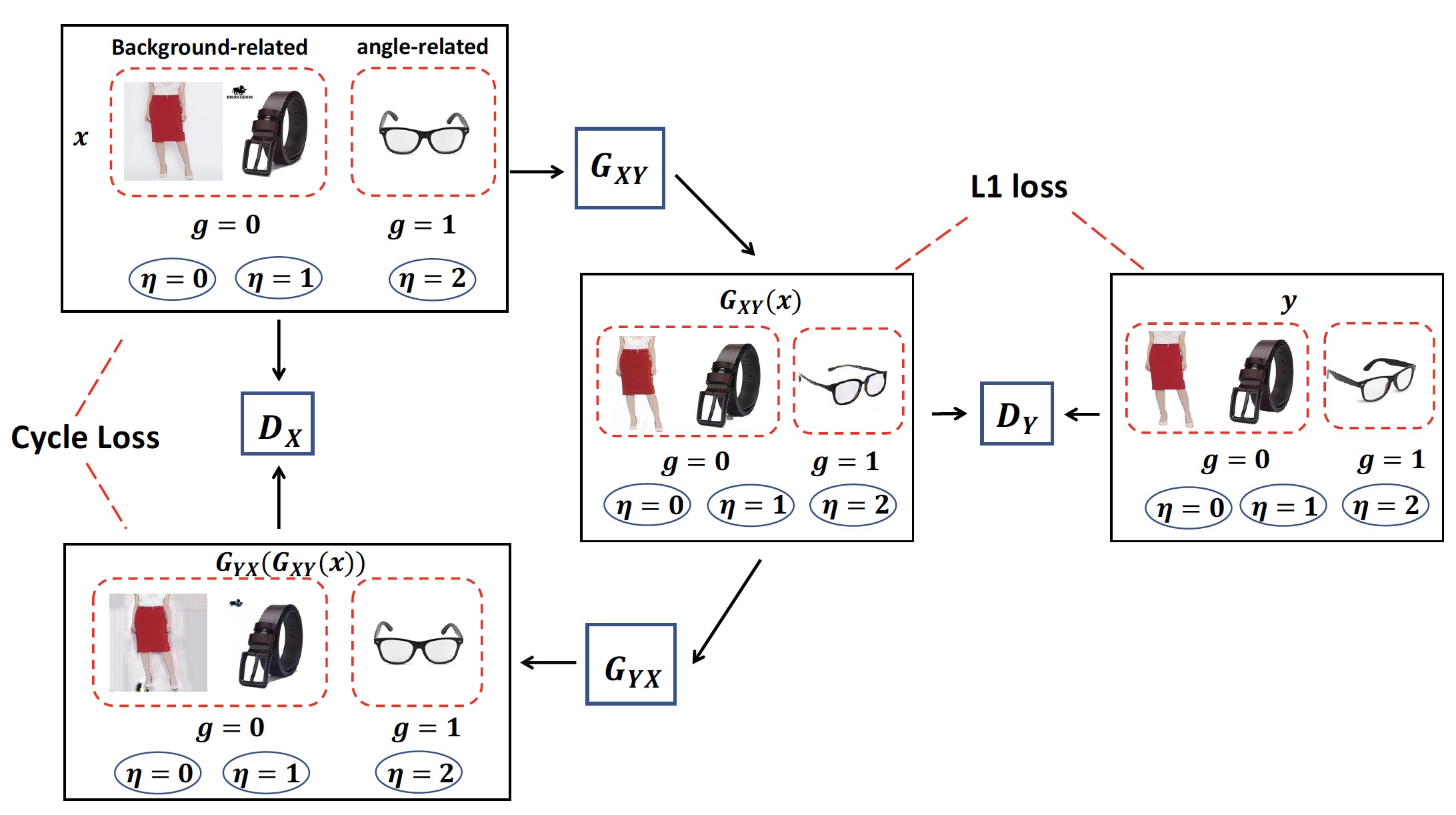

2.1 Attention Guided Conditional Generator
To cover multiple defects with a single model, we propose an attention-guided conditional generator as shown in Fig.2. It hierarchically consumes the high-level defect group and specific defect type. For example, image defects such as non-white background and watermark are background-related and incorrect sunglasses angle is angle-related. The high-level defect group (0 = background-related, 1 = angle-related) helps the generator decide whether to focus on distinguishing the background and foreground, or identifying the angle of the object. Furthermore, although non-white background and watermark belong to the same group, watermark usually only occupies a small region. Adding specific defect type (0 = non-white background, 1 = watermark, 2 = incorrect sunglasses angle) further helps the model tell the difference of the intra-group tasks. Inspired by [21], the red block in Fig. 2 illustrates the procedure of inserting into the model. Let denote the feature map of an image , we first project into a -dimensional vector through a linear transformation with activation, and perform spatial duplication to broadcast it into the same dimension as . Subsequently, we use computed as to measure the relevance of each element in to , where is the element-wise multiplication, and is a convolution layer with 1 × 1 kernel. Then , the summation of across all the channels, represents the relevance of each spatial position in to . Finally, we denote as the element-wise multiplication between each channel of and as the updated feature map, which scales each position of by its relevance to . The similar process of inserting specific defect type is shown in the green box. The conditional labels and enable the model to cover multiple defects while focusing on the defect-related image regions.
2.2 Semi-paired Structure
Another challenge on shopping websites is the lack of high-quality paired data. Although we can synthesize paired data, we cannot always guarantee the quality. For example, given an image of non-white background, we can synthesize its paired image of white background by detecting the foreground object and changing the background color to white. However, the synthesized image is not accurate if the foreground object is semi-transparent, of similar color of the background, or placed on another object (see the first line in Fig 6). The I2I model trained using such paired data will memorize the patterns of those low-quality pairs. To mitigate such effect, we leverage the cycle loss of unpaired data to ensure that the transformed images can be converted back.
2.3 Training Loss
The training loss consists of the following components. First, adversarial losses in Eq.1 and Eq.2 ensure the generated images look realistic. Specifically, we adopt the relativistic discriminator [22], i.e., , to measure the probability that looks more realistic than , where refers to the non-transformed output of the discriminator. Eq.1 trains the discriminator to favor a real image against a generative image , while Eq.2 trains the generator to generate a that looks more realistic than .
|
|
(1) |
|
|
(2) |
We denote the sum of these two losses as , i.e., the total adversarial loss from domain to . Similarly, we denote as the total adversarial loss from to . Second, for paired data, we use reconstruction loss (Eq.3) to minimize the distance between an image in the target domain and the image generated from the paired image in the source domain.
| (3) |
For unpaired data, we use cycle loss (Eq.4) to ensure the generated images can be transformed back to the source domain, which prevents the model from overfitting to the paired images of low quality.
|
|
(4) |
Besides, we add identity loss (Eq. 5), which encourages the generators to be close to an identity mapping when images from the target domain are fed to the generators [23, 8].
|
|
(5) |
At last, the total loss is defined as
|
|
(6) |
3 Experiments
3.1 Datasets
3.1.1 Public Datasets
We evaluate our model on eight public datasets, including four paired datasets: (\romannum1) maps: 1,296 map-to-aerial photo paired images [3], (\romannum2) facades (FA): 606 facade-to-segmentation paired images [24], (\romannum3) edges2shoes (E2S): 50K paired images from UT Zappos50K dataset [25], (\romannum4) edges2handbags (E2H): 20K Amazon Handbag images [26], and four unpaired datasets: (\romannum1) horse2zebra (H2Z): 1,267 horse images and 1,474 zebra images [27], (\romannum2) apple2orange (A2O): 1,261 apple images and 1,529 orange images [27], monet2photo (M2P): 1,193 Monet’s paintings and 7,038 photos [8], (\romannum4) vangogh2photo (V2P): 800 Vangogh’s paintings and 7,038 photos [8]. We split each dataset into training and test (80/20). We combine the four paired datasets where we assign maps and FA to the segmentation-related group ( = 0), and E2S and E2H to the colorization-related group ( = 1). Similarly, we combine the four unpaired datasets where we assign H2Z and A2O to the color-related group ( = 0), and M2P and V2P to the style-related group ( = 1).
3.1.2 Image Defects Dataset
We collected images with three different defects including non-white background (non-Wbg), watermark (WM) and incorrect sunglasses angle (in-SA) from a shopping website. For non-Wbg and WM images, we use salient object detection [28] to detect the objects and clean up the background to construct paired images of white background or no watermarks. We construct the pairs of in-SA images using the main and secondary image of each sunglasses product. In total there are 2,703 non-Wbg image pairs, 4,465 WM image pairs and 8,070 in-SA pairs. We assign these three specific defect types two high level defect groups where non-white background and watermark belongs to the background-related group () and incorrect sunglasses angle belongs to the angle-related group ().
3.2 Training Details
We resize each image to 256 x 256. For both datasets, we train the models for 300 epochs using Adam optimizer [12] with batch size 1. Following Pix2Pix [3], we set an initial learning rate of 0.0002, which is fixed for first 150 epochs and decays linearly to zero afterwards. We set , , , to be 1, 150, 10 and 10 following WS-I2I [14]. WS-I2I is a semi-paired I2I model which leverages the same loss functions as in this paper. The difference is WS-I2I cannot cover multiple tasks due to the lack of guidance from and . We use Frechet Inception Distance (FID) [29] as the evaluation metric, which measures the distance between the distributions of generated images and real images. Lower FID score means better performance.
3.3 Performance Comparison
On the combined four paired public data, we compare the proposed model with the baseline method Pix2Pix[3] and the state-of-the-art method MoNCE [12]. Since there are no unpaired data, we set and to . Table 1 (Paired) shows that our method is consistently better than Pix2Pix and MoNCE. As shown Figure 3, when trained on multiple tasks, MoNCE tends to transform an image from the source domain of a task to the target domain of another task (e.g., transforming a google map to a segmentation instead of an aerial-photo) due to the lack of guidance from and . On the combined four unpaired public data, we compare our method with the baseline method CycleGAN [8] and MoNCE [12]. Since there are no paired data, we set to . We observe similar pattern as the paired data as shown in Table 1 (Unpaired) and Fig 4.
| Paired | Unpaired | |||||||
|---|---|---|---|---|---|---|---|---|
| Map | FA | E2S | E2H | H2Z | A2O | M2P | V2P | |
| Baseline | 301 | 266 | 166 | 111 | 185 | 288 | 197 | 141 |
| MoNCE | 200 | 198 | 131 | 99 | 135 | 203 | 178 | 135 |
| Proposed | 107 | 155 | 86 | 89 | 90 | 170 | 145 | 113 |
On the Image Defects Dataset to correct three image defects including non-Wbg, WM and in-SA, to avoid the model from memorizing the patterns of the low-quality synthesized pairs of non-Wbg and WM images, we configure our model to be semi-paired by combining the reconstruction loss (Eq. 3) of paired data with the cycle loss (Eq. 4) and the identity loss (Eq. 5) of non-Wbg and WM images. Therefore instead of MoNCE [12], we compare the proposed model with WS-I2I [14], the state-of-the-art semi-paired I2I model to the best of our knowledge. As shown in Table 2, our proposed model performs better in all three tasks. Fig 5 shows some examples where our proposed model can transform the images correctly while WS-I2I cannot.
| non-Wbg | WM | in-SA | |
|---|---|---|---|
| proposed | 22 | 20 | 66 |
| WS-I2I | 55 | 89 | 138 |
3.4 Ablation Study
We conduct the ablation study in Table 3 to demonstrate the effect of adding high-level group , specific defect type and using unpaired data. We can conclude that hierarchically adding and into the model can significantly improve the model performance (by comparing the FID scores in the first line with the second and third line in Table 3). The results also demonstrate the benefit of leveraging unpaired data (by comparing the first line and the fourth line in Table 3). We visualize the benefit of using unpaired data when some of the paired data are of low quality in Fig 6. When the object is semi-transparent, of similar color of the background, or placed on another object (first line in Fig 6), the synthesized paired images will be of low quality, which will negatively affect the model performance if trained using only paired data (second line in Fig 6). In comparison, our proposed model (third line in Fig 6) is robust against such situation.
4 Conclusion
In this paper, we propose a unified Image-to-Image translation framework to transform images from multiple source domains to their corresponding target domains. By hierarchically injecting high-level defect groups and specific defect types using attention modules, the framework can capture different levels of image defect patterns for better defect correction. The model is semi-paired so that it is robust against the low-quality paired data. Our framework is scalable to multiple image defects in various domains and can significantly improve FID compared to the state-of-the-art I2I methods.



| non-Wbg | WM | in-SA | |
|---|---|---|---|
| proposed | 22 | 20 | 66 |
| w/o | 27 | 25 | 70 |
| w/o , | 55 | 89 | 138 |
| w/o unpaired data | 43 | 53 | 68 |

References
- [1] Krishna Regmi and Ali Borji, “Cross-view image synthesis using conditional gans,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 3501–3510.
- [2] Peihao Zhu, Rameen Abdal, Yipeng Qin, and Peter Wonka, “Sean: Image synthesis with semantic region-adaptive normalization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 5104–5113.
- [3] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros, “Image-to-image translation with conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1125–1134.
- [4] Daiqing Li, Junlin Yang, Karsten Kreis, Antonio Torralba, and Sanja Fidler, “Semantic segmentation with generative models: Semi-supervised learning and strong out-of-domain generalization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8300–8311.
- [5] Raymond Yeh, Chen Chen, Teck Yian Lim, Mark Hasegawa-Johnson, and Minh N Do, “Semantic image inpainting with perceptual and contextual losses,” arXiv preprint arXiv:1607.07539, vol. 2, no. 3, 2016.
- [6] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang, “Generative image inpainting with contextual attention,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5505–5514.
- [7] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu, “Semantic image synthesis with spatially-adaptive normalization,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 2337–2346.
- [8] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2223–2232.
- [9] Taeksoo Kim, Moonsu Cha, Hyunsoo Kim, Jung Kwon Lee, and Jiwon Kim, “Learning to discover cross-domain relations with generative adversarial networks,” in International conference on machine learning. PMLR, 2017, pp. 1857–1865.
- [10] Jianxin Lin, Yijun Wang, Tianyu He, and Zhibo Chen, “Learning to transfer: Unsupervised meta domain translation,” arXiv preprint arXiv:1906.00181, 2019.
- [11] Taesung Park, Alexei A Efros, Richard Zhang, and Jun-Yan Zhu, “Contrastive learning for unpaired image-to-image translation,” in European conference on computer vision. Springer, 2020, pp. 319–345.
- [12] Fangneng Zhan, Jiahui Zhang, Yingchen Yu, Rongliang Wu, and Shijian Lu, “Modulated contrast for versatile image synthesis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18280–18290.
- [13] Xueqi Hu, Xinyue Zhou, Qiusheng Huang, Zhengyi Shi, Li Sun, and Qingli Li, “Qs-attn: Query-selected attention for contrastive learning in i2i translation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18291–18300.
- [14] Samarth Shukla, Luc Van Gool, and Radu Timofte, “Extremely weak supervised image-to-image translation for semantic segmentation,” in 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW). IEEE, 2019, pp. 3368–3377.
- [15] Soumya Tripathy, Juho Kannala, and Esa Rahtu, “Learning image-to-image translation using paired and unpaired training samples,” in Asian Conference on Computer Vision. Springer, 2018, pp. 51–66.
- [16] Sangwoo Mo, Minsu Cho, and Jinwoo Shin, “Instagan: Instance-aware image-to-image translation,” arXiv preprint arXiv:1812.10889, 2018.
- [17] Soohyun Kim, Jongbeom Baek, Jihye Park, Gyeongnyeon Kim, and Seungryong Kim, “Instaformer: Instance-aware image-to-image translation with transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 18321–18331.
- [18] Junho Kim, Minjae Kim, Hyeonwoo Kang, and Kwanghee Lee, “U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation,” arXiv preprint arXiv:1907.10830, 2019.
- [19] Hao Tang, Hong Liu, Dan Xu, Philip HS Torr, and Nicu Sebe, “Attentiongan: Unpaired image-to-image translation using attention-guided generative adversarial networks,” IEEE Transactions on Neural Networks and Learning Systems, 2021.
- [20] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena, “Self-attention generative adversarial networks,” in International conference on machine learning. PMLR, 2019, pp. 7354–7363.
- [21] Zhe Ma, Jianfeng Dong, Zhongzi Long, Yao Zhang, Yuan He, Hui Xue, and Shouling Ji, “Fine-grained fashion similarity learning by attribute-specific embedding network,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2020, vol. 34, pp. 11741–11748.
- [22] Alexia Jolicoeur-Martineau, “The relativistic discriminator: a key element missing from standard gan,” arXiv preprint arXiv:1807.00734, 2018.
- [23] Mihaela Rosca, Balaji Lakshminarayanan, David Warde-Farley, and Shakir Mohamed, “Variational approaches for auto-encoding generative adversarial networks,” arXiv preprint arXiv:1706.04987, 2017.
- [24] Radim Tyleček and Radim Šára, “Spatial pattern templates for recognition of objects with regular structure,” in German conference on pattern recognition. Springer, 2013, pp. 364–374.
- [25] Aron Yu and Kristen Grauman, “Fine-grained visual comparisons with local learning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2014, pp. 192–199.
- [26] Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman, and Alexei A Efros, “Generative visual manipulation on the natural image manifold,” in European conference on computer vision. Springer, 2016, pp. 597–613.
- [27] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [28] Min Seok Lee, WooSeok Shin, and Sung Won Han, “Tracer: Extreme attention guided salient object tracing network (student abstract),” in Proceedings of the AAAI Conference on Artificial Intelligence, 2022, vol. 36, pp. 12993–12994.
- [29] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” Advances in neural information processing systems, vol. 30, 2017.