Heuristic Search for Multi-Objective Probabilistic Planning
Abstract
Heuristic search is a powerful approach that has successfully been applied to a broad class of planning problems, including classical planning, multi-objective planning, and probabilistic planning modelled as a stochastic shortest path (SSP) problem. Here, we extend the reach of heuristic search to a more expressive class of problems, namely multi-objective stochastic shortest paths (MOSSPs), which require computing a coverage set of non-dominated policies. We design new heuristic search algorithms MOLAO* and MOLRTDP, which extend well-known SSP algorithms to the multi-objective case. We further construct a spectrum of domain-independent heuristic functions differing in their ability to take into account the stochastic and multi-objective features of the problem to guide the search. Our experiments demonstrate the benefits of these algorithms and the relative merits of the heuristics.
1 Introduction
Stochastic shortest path problems (SSPs) are the de facto model for planning under uncertainty. Solving an SSP involves computing a policy which maps states to actions so as to minimise the expected (scalar) cost to reach the goal from a given initial state. Multi-objective stochastic shortest path problems (MOSSPs) are a useful generalisation of SSPs where multiple objectives (e.g. time, fuel, risk) need to be optimised without the user being able to a priori weigh these objectives against each other (Roijers and Whiteson 2017). In this more complex case, we now aim to compute a set of non-dominated policies whose vector-valued costs represent all the possible trade-offs between the objectives.
There exist two approaches to solving MOMDPs (Roijers and Whiteson 2017), a special case of MOSSPs: inner loop planning which consists in extending SSP solvers by generalising single objective operators to the multi-objective (MO) case, and outer loop planning which consists in solving a scalarised MOSSP multiple times with an SSP solver. We focus on the former. The canonical inner loop method, MO Value Iteration (MOVI) (White 1982) and its variants (Wiering and de Jong 2007; Barrett and Narayanan 2008; Roijers and Whiteson 2017), require enumerating the entire state space of the problem and are unable to scale to the huge state spaces typically found in automated planning.
Therefore, this paper focuses on heuristic search methods which explore only a small fraction of the state space when guided with informative heuristics. Heuristic search has been successfully applied to a range of optimal planning settings, including single objective (SO) or constrained SSPs (Hansen and Zilberstein 2001; Bonet and Geffner 2003; Trevizan et al. 2017), and MO deterministic planning (Mandow and Pérez-de-la-Cruz 2010; Khouadjia et al. 2013; Ulloa et al. 2020). Moreover, a technical report by Bryce et al. (2007) advocated the need for heuristic search and outlined an extension of LAO* (Hansen and Zilberstein 2001) for finite horizon problems involving multiple objectives and partial observability. Convex Hull Monte-Carlo Tree-Search (Painter, Lacerda, and Hawes 2020) extends the Trial-Based Heuristic Tree Search framework (Keller and Helmert 2013) to the MO setting but applies only to finite-horizon MOMDPs. Yet to the best of our knowledge there is no investigation of heuristic search for MOSSPs.
This paper fills this gap in heuristic search for MOSSPs. First, we characterise the necessary conditions for MOVI to converge in the general case of MOSSPs. We then extend the well-known SSP heuristic search algorithms LAO* (Hansen and Zilberstein 2001) and LRTDP (Bonet and Geffner 2003) to the multi-objective case, leading to two new MOSSP algorithms, MOLAO* and MOLRTDP, which we describe along with sufficient conditions for their convergence. We also consider the problem of guiding the search of these algorithms with domain-independent heuristics. A plethora of domain-independent heuristics exist for classical planning, but works on constructing heuristics for (single objective) probabilistic or multi-objective (deterministic) planning are much more recent (Trevizan, Thiébaux, and Haslum 2017; Klößner and Hoffmann 2021; Geißer et al. 2022). Building on these recent works, we investigate a spectrum of heuristics for MOSSPs differing in their ability to account for the probabilistic and multi-objective features of the problem.
Finally, we conduct an experimental comparison of these algorithms and of the guidance obtained via these heuristics. We observe the superiority of heuristic search over value iteration methods for MOSSPs, and of heuristics that are able to account for the tradeoffs between competing objectives.
2 Background
A multi-objective stochastic shortest path problem (MOSSP) is a tuple where: is a finite set of states, one of which is the initial state , is a set of goal states, is a finite set of actions, is the probability of reaching after applying action in , and is the -dimensional vector representing the cost of action . Two special cases of MOSSPs are stochastic shortest path problems (SSPs) and bi-objective SSPs which are obtained when equals 1 and 2, respectively.
A solution for an SSP is a deterministic policy , i.e., a mapping from states to actions. A policy is proper or closed w.r.t. if the probability of reaching when following from is 1; if this probability of reaching is less than 1, then is an improper policy. We denote by the set of states visited when following a policy from . The expected cost of reaching when using a proper policy from a state is given by the policy value function defined as
| (1) |
for and for . An optimal policy for an SSP is any proper policy such that for all proper policies . Although might not be unique, the optimal value function is unique and equals for any .
Stochastic policies are a generalisation of deterministic policies which map states to probability distributions of actions. The definitions of proper, improper and policy value function are trivially generalised to stochastic policies. A key result for SSPs is that at least one of its optimal policies is deterministic (Bertsekas and Tsitsiklis 1991); thus it suffices to search for deterministic policies when solving SSPs.
Coverage sets and solutions for MOSSPs
In the context of MOSSPs, given a policy , we denote by the vector value function for . The function is computed by replacing and by and in (1), respectively. In order to define the solution of an MOSSP, we need to first define how to compare two different vectors: a cost vector dominates , denoted as , if for . A coverage set for a set of vectors , denoted as , is any set satisfying s.t. and .111We will denote sets of vectors or functions which map to sets of vectors with bold face, e.g. , and single vectors or functions which map to single vectors with vector notation, e.g. . An example of a coverage set is the Pareto coverage set () which is the largest possible coverage set. For the remainder of the paper we focus on the convex coverage set () (Barrett and Narayanan 2008; Roijers and Whiteson 2017) which is defined as the convex hull of the . Details for computing the of a set with a linear program (LP) can be found in (Roijers and Whiteson 2017, Sec. 4.1.3). We say that a set of vectors dominates another set of vectors , denoted by , if for all there exists such that .
Given an MOSSP define the optimal value function by . Then we define a solution to the MOSSP to be any set of proper policies such that the function with is a bijection. By choosing as our coverage set operator, we may focus our attention to only non-dominated deterministic policies, where non-dominated stochastic policies are implicitly given by the points on the surface of the polyhedron drawn out by the . In this way, we avoid having to explicitly compute infinitely many non-dominated stochastic policies.
To illustrate this statement, consider the MOSSP in Fig. 1 with actions and where and and . One solution consists of only two deterministic policies and with corresponding expected costs and . Notice that there are uncountably many stochastic policies obtained by the convex combinations of and , i.e., for . The expected cost of each is and these stochastic policies do not dominate each other. Therefore, if the is used instead of the in the definition of optimal value function, then would be and the corresponding solution would be . The allows us to compactly represent the potentially infinite by storing only the deterministic policies: in this example, the actual solution is and the optimal value function is .
Value Iteration for SSPs
We finish this section by reviewing how to compute the optimal value function for SSPs and extend these results to MOSSPs in the next section. The optimal (scalar) value function for an SSP can be computed using the Value Iteration (VI) algorithm (Bertsekas and Tsitsiklis 1996): given an initial value function it computes the sequence where is obtained by applying a Bellman backup, that is if and, for ,
| (2) | ||||
| (3) |
VI guarantees that converges to as under the following conditions: (i) for all , there exists a proper policy w.r.t. ; and (ii) all improper policies have infinite cost for at least one state. The former condition is known as the reachability assumption and it is equivalent to requiring that no dead ends exist, while the latter condition can be seen as preventing cycles with 0 cost. Notice that finite-horizon Markov Decision Processes (MDPs) and infinite-horizon discounted MDPs are special cases of SSPs in which all policies are guaranteed to be proper (Bertsekas and Tsitsiklis 1996).
3 Value Iteration for MOSSPs
Value Iteration has been extended to the MO setting in special cases of SSPs, e.g. infinite-horizon discounted MDPs (White 1982). In this section, we present the MO version of Value Iteration for the general MOSSP case. While the changes in the algorithm are minimal, the key contribution of this section is the generalisation of the assumptions needed for convergence. We start by generalising the Bellman backup operation from the SO, i.e. (2) and (3), to the MO case. For we have
| (4) | ||||
| (5) |
and for where denotes the sum of two sets of vectors and defined as , and is the generalised version of to several sets.
Alg. 1 illustrates the MO version of Value Iteration (MOVI) which is very similar to the single-objective VI algorithm with the notable difference that the convergence criterion is generalised to handle sets of vectors. The Hausdorff distance between two sets of vectors and is given by
| (6) |
for some choice of metric such as the Euclidean metric. We use this distance to define residuals in line 1. As with VI, MOVI converges to the optimal value function at the limit (White 1982; Barrett and Narayanan 2008) under certain strong assumptions presented in the next section. We can extract policies with the choice of a scalarising weight from the value function (Barrett and Narayanan 2008).
Assumptions for the convergence of MOVI
Similarly to the SO version of VI, MOVI requires that the reachability assumption holds; however, the assumption that improper policies have infinite cost needs to be generalised to the MO case. One option is to require that all improper policies cost which we call the strong improper policy assumption and, if it holds with the reachability assumption, then MOVI (Alg. 1) is sound and complete for MOSSPs. The strong assumption is very restrictive because it implies that any cycle in an MOSSP must have a cost greater than zero in all dimensions; however, it is common for MOSSPs to have zero-cost cycles in one or more dimensions. For instance, in navigation domains where some actions such as wait, load and unload do not consume fuel and can be used to generate zero-fuel-cost loops.
Another possible generalisation for the cost of improper policies is that they cost infinity in at least one dimension. This requirement is not enough as illustrated by the (deterministic) MOSSP in Fig. 2. The only deterministic proper policy is with cost , and the other deterministic policy is which is improper and costs . Since neither or dominate each other, two issues arise: MOVI tries to converge to infinity and thus never terminates; and even if it did, the cost of an improper policy would be wrongly added to the CCS.
These issues stem from VI and its generalisations not explicitly pruning improper policies. Instead they rely on the assumption that improper policies have infinite cost to implicitly prune them. This approach is enough in the SO case because any proper policy dominates all improper policies since domination is reduced to the ‘’ operator; however, as shown in this example, the implicit pruning approach for improper policies is not correct for the MO case.
We address these issues by providing a version of MOVI that explicitly prunes improper policies and to do so we need a new assumption:
Assumption 1 (Weak Improper Policy Assumption).
There exists a vector such that for every improper policy and , , and for every proper policy and , and .
The weak assumption allows improper policies to have finite cost in some but not all dimensions at the expense of knowing an upper bound on the cost of all proper policies. This upper bound lets us infer that a policy is improper whenever , i.e., that is greater than in at least one dimension.
Alg. 2 outlines the new MOVI where the differences can be found in lines 2 and 2. In line 2, we use a modified Bellman backup which detects vectors associated to improper policies and assigns them the upper bound given by the weak improper policy assumption. The modified backup is given by
| (7) | ||||
| (8) |
where is a modified set addition operator defined on pairwise vectors and by
| (9) |
and similarly for the generalised version . Also define to be the modified coverage set operator which does not prune away if it is in the input set. The modified backup (7) enforces a cap on value functions (i.e., ) through the operator (9). This guarantees that a finite fixed point exists for all and, as a result, that Alg. 2 terminates. Once the algorithm converges, we need to explicitly prune the expected cost of improper policies which is done in line 2. By Assumption 1, we have that no proper policy costs thus we can safely remove from the solution. Note that the overhead in applying this modified backup and post-processing pruning is negligible. Theorem 3.1 shows that MOVI converges to the correct solution.
Theorem 3.1.
Given an MOSSP in which the reachability and weak improper policy assumptions hold for an upper bound , and given a set of vectors such that , the sequence computed by MOVI converges to the MOSSP solution as .
Proof sketch.
By the assumption that , we have that MOVI will not prune away vectors associated with proper policies which contribute to a solution. If , e.g., for all , then Alg. 2 is not guaranteed to find the optimal value function since it will incorrectly prune proper policies. Otherwise, we have that converges to if the original MOVI in Alg. 1 does not converge, and otherwise. For example, in the example seen in Fig. 2 but if we choose .
This convergence result follows by noticing that, by definition of the modified backup in (7), every vector in for all dominates . We may then apply the proof for the convergence of MOVI with convex coverage sets by Barrett and Narayanan (2008) which reduces to the convergence of scalarised SSPs using VI in the limit, of which there are finitely many since the number of deterministic policies is finite. Here, we have for every that is an upper bound for the problem scalarised by . Finally, we have that line 7 removes from such that we correctly return . ∎
Note that the original proof for MOMDPs by Barrett and Narayanan (2008) does not directly work for MOSSPs as some of the scalarised SSPs have a solution of infinite expected cost such that VI never converges. The upper bound we introduce solves this issue as achieving this bound is the same as detecting improper policies. The proof remains correct in the original setting applied to discounted MOMDPs in which there are no improper policies.
Relaxing the reachability assumption
The reachability assumption can also be relaxed by transforming an MOSSP with dead ends into a new MOSSP without dead ends. Formally, given an MOSSP with dead ends, let ; for all and any ; for all ; and .
Then the MOSSP does not have dead ends (i.e., the reachability assumption holds) since the give-up action is applicable in all states . This transformation is similar to the finite-penalty transformation for SSPs (Trevizan, Teichteil-Königsbuch, and Thiébaux 2017); however it does not require a large penalty constant. Instead, the MOSSP transformation uses an extra cost dimension to encode the cost of giving up and the value of the -th dimension of is irrelevant as long as it is greater than 0. Since the give-up action can only be applied once, defining the cost of give-up as 1 let us interpret the -th dimension of any as the probability of giving up when following from .
4 Heuristic search
Value iteration gives us one method for solving MOSSPs but is limited by the fact that it requires enumerating over the whole state space. This is impractical for planning problems, as their state space grows exponentially with the size of the problem encoding. This motivates the need for heuristic search algorithms in the vein of LAO∗ and LRTDP for SSPs (Hansen and Zilberstein 2001; Bonet and Geffner 2003), which perform backups on a promising subset of states at each iteration. To guide the choice of the states to expand and explore at each iteration, they use heuristic estimates of state values initialised when the state is first encountered. In this section, we extend the concept of heuristics to the more general MOSSP setting, discuss a range of ways these heuristics can be constructed, and provide multi-objective versions of LAO∗ and LRTDP.
Heuristics
For the remainder of the paper, we will call a set of vectors a value. Thus, a heuristic value for a state is a set of vectors . We implicitly assume that any heuristic value has already been pruned with some coverage set operator. The definition of an admissible heuristic for MOSSPs should be at most as strong as the definition for deterministic MO search (Mandow and Pérez-de-la-Cruz 2010).
Definition 4.1.
A heuristic for an MOSSP is admissible if where is the optimal value function, and .
For example, if for some MOSSP we have for a state , then and for all other is an admissible heuristic. As in the single-objective case, admissible heuristics ensure that the algorithms below converge to near optimal value functions for with finitely many iterations and to optimal value functions with possibly infinitely many iterations when .
Definition 4.2.
A heuristic for an MOSSP is consistent if we have for all that
The definition of consistent heuristic is derived and generalised from the definition of consistent heuristics for deterministic search: . The main idea is that assuming non-negative costs, state costs increase monotonically which results in no re-expansions of nodes in A∗ search. Similarly, we desire monotonically increasing value functions for faster convergence.
We now turn to the question of constructing domain-independent heuristics satisfying these properties from the encoding of a planning domain. This question has only recently been addressed in the deterministic multi-objective planning setting (Geißer et al. 2022): with the exception of this latter work, MO heuristic search algorithms have been evaluated using “ideal-point” heuristics, which apply a single-objective heuristic to each objective in isolation, resulting in a single vector . Moreover, informative domain-independent heuristics for single objective SSPs are also relatively new (Trevizan, Thiébaux, and Haslum 2017; Klößner and Hoffmann 2021): a common practice was to resort to classical planning heuristics obtained after determinisation of the SSP (Jimenez, Coles, and Smith 2006).
We consider a spectrum of options when constructing domain-independent heuristics for MOSSPs, which we instantiate using the most promising families of heuristics identified in (Geißer et al. 2022) for the deterministic case: critical paths and abstraction heuristics. All heuristics are consistent and admissible unless otherwise mentioned.
-
•
The baseline option is to ignore both the MO and stochastic aspects of the problem, and resort to an ideal-point heuristic constructed from the determinised problem. In our experiments below, we apply the classical heuristic (Bonet and Geffner 2001) to each objective and call this .
-
•
A more elaborate option is to consider only the stochastic aspects of the problem, resulting in an ideal-point SSP heuristic. In our experiments, we apply the recent SSP canonical PDB abstraction heuristic by Klößner and Hoffmann (2021) to each objective which we call and for patterns of size 2 and 3, respectively.
-
•
Alternatively, one might consider only the multi-objective aspects, by applying some of the MO deterministic heuristics (Geißer et al. 2022) to the determinised SSP. The heuristics we consider in our experiments are the MO extension of and canonical PDBs: , , and . These extend classical planning heuristics by using MO deterministic search to solve subproblems and combining solutions by taking the maximum of two sets of vectors with the admissibility preserving operator (Geißer et al. 2022).
-
•
The best option is to combine the power of SSP and MO heuristics. We do so with a novel heuristic which extends the SSP PDB abstraction heuristic (Klößner and Hoffmann 2021) to the MO case by using an MO extension of topological VI (TVI) (Dai et al. 2014) to solve each projection and the operator to combine the results. Our experiments use and .
(i)MOLAO∗
Readers familiar with the LAO∗ heuristic search algorithm and the multi-objective backup can convince themselves that an extension of LAO∗ to the multi-objective case can be obtained by replacing the backup operator with the multi-objective version. This idea was first outlined by Bryce, Cushing, and Kambhampati (2007) for finite-horizon MDPs which is a special case of SSPs without improper policies. In the same vein as (Hansen and Zilberstein 2001), we provide MOLAO∗ alongside an ‘improved’ version, iMOLAO∗, in Alg. 3 and 4 respectively.
MOLAO∗ begins in line 1 by lazily assigning an initial value function to each state with the heuristic function, as opposed to explicitly initialising all initial values at once. is a dictionary representing our partial solution which maps states to sets of optimal actions corresponding to their current value function. The main while loop of the algorithm terminates once there are no nongoal states on the frontier as described in line 3, at which point we have achieved a set of closed policies.
The loop begins with lines 3-5 by removing a nongoal state from the frontier representing a state on the boundary of the partial solution graph, and adding it to the interior set . The nodes of the partial solution graph are partial solution states, and the edges are the probabilistic transitions under all partial solution actions. Next in line 6 we add the set of yet unexplored successors of to the frontier: any state such that . Then we extract the set of all ancestor states of in the partial solution using graph search in line 7. We run MOVI to -consistency on the MOSSP problem restricted to the set of states and update the value functions for the corresponding states in line 8. The partial solution is updated in line 9 by extracting the actions corresponding to the value function with
| (10) |
This function can be seen as a generalisation of to the MO case where here we select the actions whose value at contribute to the current value . Next, we extract the set of states corresponding to all states reachable from by the partial solution in line 10.
The completeness and correctness of MOLAO∗ follows from the same reasoning as LAO∗ extended to the MO case. Specifically, we have that given an admissible heuristic the algorithm achieves -consistency upon termination.
One potential issue with MOLAO∗ is that we may waste a lot of backups while running MOVI to convergence several times on partial solution graphs which do not end up contributing to the final solution. The original authors of LAO∗ proposed the iLAO∗ algorithm to deal with this. We provide the MO extension, namely iMOLAO∗. The main idea with iMOLAO∗ is that we only run one set of backups every time we (re-)expand a state instead of running VI to convergence in the loop in lines 5 to 9. Backups are also performed asynchronously using DFS postorder traversal of the states in the partial solution graph computed in line 4, allowing for faster convergence times.
To summarise, the two main changes required to extend (i)LAO∗ to the MO case are (1) replacing the backup operator with the MO version, and (2) storing possibly more than one greedy action at each state corresponding to incomparable vector -values, resulting in a larger set of successors associated to each state. These ideas can be applied to other asynchronous VI methods such as Prioritised VI (Wingate and Seppi 2005) and Topological VI (Dai et al. 2014).
MOLRTDP
LRTDP (Bonet and Geffner 2003) is another heuristic search algorithm for solving SSPs. The idea of LRTDP is to perform random trials using greedy actions based on the current value function or heuristic for performing backups, and labelling states as solved when the consistency threshold has been reached in order to gradually narrow down the search space and achieve a convergence criterion. A multi-objective extension of LRTDP is not as straightforward as extending the backup operator given that each state has possibly more than one greedy action to account for. The two main changes from the original LRTDP are (1) the sampling of a random greedy action before sampling successor states in the main loop, and (2) defining the descendants of a state by considering successors of all greedy actions (as opposed to just one in LRDTP). Alg. 5 outlines the MO extension of LRTDP.
MOLRTDP consists of repeatedly trialing paths through the state space and performing backups until the initial state is marked as solved. Trials are run by randomly sampling a greedy action from at each state followed by a next state sampled from the probability distribution of until a goal state is reached as in the first inner loop from lines 5 to 10. The second inner loop from lines 11 to 13 calls the routine in the reverse trial order to label states as solved by checking whether the residual of all its descendant states under greedy actions are less than the convergence criterion.
The routine begins with inserting into the open set if it has not been solved, and returns true otherwise due to line 2. The main loop in lines 3 to 10 collects the descendent states under all greedy actions (lines 8-10) and checks whether the residual of all the descendent states are small (lines 5-7). If true, all descendents are labelled as solved as in line 11. Otherwise, backups are performed in the reverse order of explored states as in lines 12 to 15.
The completeness and correctness of MOLRTDP follows similarly from its single objective ancestor. We note specifically that the labelling feature works similarly in the sense that whenever a state is marked as solved, it is known for certain that all its descendents’ values are -consistent and remain unchanged when backups are performed elsewhere.
5 Experiments
In this section we empirically evaluate the different algorithms and heuristics for MOSSPs in several domains. Since no benchmark domains for MOSSPs exist, we adapt domains from a variety of sources to capture challenging features of both SSPs and MO deterministic planning. Our benchmark set is introduced in the next section and it is followed by our experiments setup and analysis of the results.
Benchmarks
-d Exploding Blocksworld
Exploding Blocksworld (ExBw) was first introduced by Younes et al. (2005) and later slightly modified for the IPPC’08 (Bryce and Buffet 2008). In ExBw, a robot has to pick up and stack blocks on top of each other to get a target tower configuration. Blocks have a chance of detonating and destroying blocks underneath or the table. We consider a version with no dead ends using an action to repair the table (Trevizan et al. 2017). We extend ExBw to contain multi-objective costs. ExBw-2d has two objectives: the number of actions required to stack the blocks and number of times we need to repair the table. ExBw-3d has an additional action to repair blocks with an objective to minimise the number of block repairs.
MO Search and Rescue
Search and Rescue (SAR-) was first introduced by Trevizan et al. (2017) as a Constrained SSP. The goal is to find, board and escort to a safe location any one survivor in an grid as quickly as possible, constrained by a fuel limit. Probabilities are introduced when modelling fuel consumption and partial observability of whether a survivor exists in a given location. The location of only one survivor is known for certain. We extend the problem by making fuel consumption as an additional objective instead of a constraint. A solution for a SAR MOSSP is a set of policies with different trade-offs between fuel and time.
MO Triangle Tireworld
Triangle Tireworld, introduced by Little and Thiébaux (2007) as a probabilistically interesting problem, consists of a triangular grid of locations. The goal is to travel from an initial to a target location where each location has a probability of getting a flat tire. Some locations contain a spare tire which the agent can load into the car for future use. These problems have dead ends and they occur when a tire is flat and no spare is available. We apply the give-up transformation from Section 3 resulting in an MOSSP with two objectives: total number of actions and probability of using the give-up action.
Probabilistic VisitAll
The deterministic MO VisitAll (Geißer et al. 2022) is a TSP problem on a grid, where the agents must collectively visit all locations, and each agent’s objective is to minimise its own number of moves. This problem is considered MO interesting because any admissible ideal-point heuristic returns the zero vector for all states since it is possible for a single agent to visit all locations while no actions are performed by the other agents. We extend this domain by adding a probabilistic action move-risky which has probability 0.5 of acting as the regular move action and 0.5 of teleporting the agent back to its initial location. The cost of the original move action was changed to 2 while the cost of the move-risky action is 1.
VisitAllTire
This domain combines features of both the probabilistic Tireworld and the deterministic MO VisitAll domains into one that is probabilistically and MO interesting. The underlying structure and dynamics is the same as the deterministic MO VisitAll except that the move action now can result in a flat tire with probability 0.5. We also added the actions for loading and changing tires for each of the agents. Similarly to Triangle Tireworld, the problems in this domain can have dead ends when a flat tire occurs and no spare tire is available. Applying the give-up transformation from Section 3 to this domain results in cost functions where is the number of agents.
Setup
We implemented the MO versions of the VI, TVI, (i)LAO∗ and LRTDP algorithms and the MO version of the PDB abstraction heuristics () in C++.222Code at https://github.com/DillonZChen/cpp-mossp-planner PDB heuristics are computed using TVI, and . We include in our experiments the following heuristics for deterministic MO planning from (Geißer et al. 2022): the ideal-point version of (); the MO extension of (); and the MO canonical PDBs of size 2 and 3 ( and ). The SO PDB heuristics for SSPs from (Klößner and Hoffmann 2021) of size 2 and 3 ( and ) are also included in our experiments. All problem configurations are run with a timeout of 1800 seconds, memory limit of 4GB, and a single CPU core. The experiments are run on a cluster with Intel Xeon 3.2 GHz CPUs. We used CPLEX version 22.1 as the LP solver for computing CCS. The consistency threshold is set to and we set . Each experimental configuration is run 6 times and averages are taken to reduce variance in the data.
We also modify the inequality constraint in Alg. 4.3 from Roijers and Whiteson 2017 for computing CCS to with to deal with inevitable numerical precision errors when solving the LP. If the term is not added, the function may fail to prune unnecessary points such as those corresponding to stochastic policies in the CCS, resulting in slower convergence. However, an overly large may return incorrect results by discarding important points in the CCS. One may alternatively consider the term as an MO parameter for trading off solution accuracy and search time, similarly to the parameter.
Fig. 3 shows the distribution of CCS sizes for different domains. Recall that the CCS implicitly represents a potentially infinite set of stochastic policies and their value functions. As a result, a small CCS is sufficient to dominate a large number of solutions, for instance, in Triangle Tireworld, a CCS of size 3 to 4 is enough to dominate all other policies even though the number of deterministic policies for this domain is double exponential in its parameter .

Results



| planner + heuristic | coverage | heuristic | coverage | |
| LRTDP | ||||
| LRTDP | ||||
| LRTDP | ||||
| iLAO∗ | ||||
| iLAO∗ | ||||
| LRTDP | ||||
| LRTDP | ||||
| iLAO∗ | blind | |||
| planner | coverage | PDB | coverage | |
| LRTDP | ||||
| iLAO∗ | ||||
| LAO∗ | ||||
| TVI | ||||
| VI | ||||
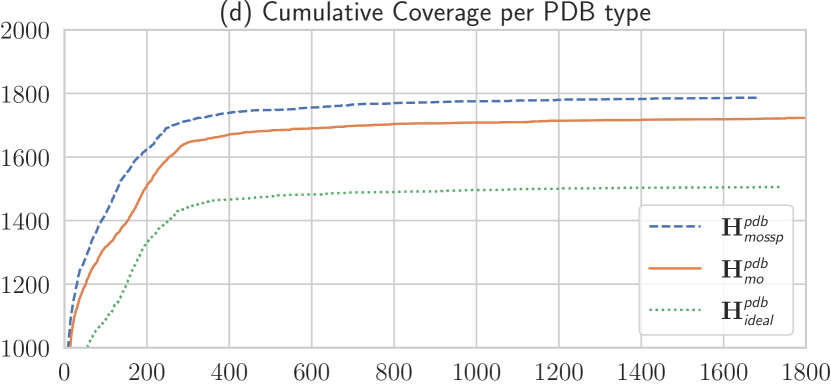
Fig. 4 summarises our results by showing the cumulative coverage of different planners and heuristics across all considered problems. The following is a summary of our findings (we omit the MO in the planner names for simplicity):
What is the best planner and heuristic combination?
Referring to the overall cumulative coverage plot in Fig. 4 and coverage tables in Tab. 1, we notice that LRTDP+ performs best followed by LRDTP+, LRTDP+ and iLAO∗+. The ranking of the top 3 planners remain the same if we normalise the coverage by domain.
We note that the considered Exbw3 problems had several improper policies resulting in slow convergence of TVI for solving PDBs of size 3. This is due to Assumption 1 and the chosen for our experiments which that requires the cost of improper policies in each PDB to cost at least in one of its dimensions. Ignoring the Exbw3 domain, the top 3 configurations are LRTDP+, LRTDP+ and iLAO∗+ and their 95% confidence intervals all overlap. The ranking of the top few planners remain the same if the coverage is normalised.
What planner is best?
To answer this question, we look at the cumulative coverage marginalised over heuristics, that is, we sum the coverage of a planner across the different heuristics. The results are shown in Fig. 4 and Tab. 1 and the best three planners in order are LRTDP, iLAO∗ and LAO∗. Notice that the difference in coverage between LRTDP and iLAO∗ is at solved instances while the difference between TVI and VI is only . The ranking between planners remains the same when the coverage is normalised per domain. Considering domains individually, LRTDP is the best planner for Exbw and VisitAllTire while for iLAO∗ is the best planner for SAR and Probabilistic VisitAll. For MO Tireworld, both LRTDP and iLAO∗ are tied in first place.
| Crit. Path | Abstractions | ||||||||
|---|---|---|---|---|---|---|---|---|---|
|
blind |
|
|
|
|
|
|
|
|
|
| SAR-4 | 100 | 97 | 44 | 93 | 92 | 44 | 44 | 38 | 26 |
| SAR-5 | 100 | 97 | 43 | 93 | 92 | 43 | 43 | 37 | 27 |
| ExBw-2d | 100 | 59 | 22 | 51 | 45 | 51 | 45 | 51 | 45 |
| ExBw-3d | 100 | 58 | 22 | 52 | 44 | 52 | 44 | 52 | 44 |
| Tireworld | 100 | 100 | 68 | 100 | 100 | 68 | 68 | 57 | 13 |
| VisitAll | 100 | 100 | 54 | 100 | 100 | 61 | 53 | 22 | 12 |
| VisitAllTire | 100 | 100 | 50 | 100 | 100 | 66 | 45 | 66 | 45 |
What heuristic is best?
The cumulative coverage marginalised over planners for selected heuristics is shown in Fig. 4 and Tab. 1. The MOSSP PDB heuristic of size 3 () has the best performance followed by , and . We note there is a large overlap in the 95% confidence intervals of and due to the slow computation of on Exbw3. The overlap disappears when we remove the Exbw3 results with coverage and confidence intervals given by and for and , respectively. We further quantify heuristic accuracy using the directed Hausdorff distance between heuristic and optimal values in Tab. 2. We notice that achieves strong accuracy relative to other heuristics but has the worst coverage of due to its high computation time.
What feature of MOSSPs is more important to capture in a heuristic?
To answer this question, consider the performance of the 3 classes of PDB heuristics: probabilistic-only PDBs (), MO only PDBs (), and MO probabilistic PDBs (). The cumulative coverage marginalised over the different PDB heuristics shown in Fig. 4 and Tab. 1 highlights the effectiveness of MO PDBs. is able to solve and more instances than and , respectively. The ranking remains the same when the coverage is normalised per domain. Moreover, notice in Tab. 2 that heuristics are at least as informative as heuristics on all domains. Lastly, we note that an admissible ideal point heuristic is upper bounded by where for . These results suggest that it is more important for a heuristic to maintain the MO cost structure of MOSSPs than the stochastic structure of actions.
6 Conclusion
In this work we define a new general class of problems, namely multi-objective stochastic shortest path problems (MOSSPs). We adapt MOVI which was originally constructed for solving multi-objective Markov Decision Processes to our MOSSP setting with conditions for convergence. We further design new, more powerful heuristic search algorithms (i)MOLAO∗ and MOLRTDP for solving MOSSPs. The algorithms are complemented by a range of MOSSP heuristics and an extensive set of experiments on several benchmarks with varying difficulty and features. Through our evaluation, we can conclude that MOLRTDP is the best performing MOSSP solver, and abstraction heuristics which consider both the MO and probabilistic aspects of MOSSPs the best performing MOSSP heuristic. Our future work includes adding probabilistic LTL constraints as additional multi-objectives in order to compute solutions to MO-PLTL SSPs (Baumgartner, Thiébaux, and Trevizan 2018) that are robust to the choice of probability thresholds.
Acknowledgements
This work was supported by ARC project DP180103446, On-line planning for constrained autonomous agents in an uncertain world. The computational resources for this project were provided by the Australian Government through the National Computational Infrastructure (NCI) under the ANU Startup Scheme.
References
- Barrett and Narayanan (2008) Barrett, L.; and Narayanan, S. 2008. Learning All Optimal Policies with Multiple Criteria. In Proc. 25th International Conference on Machine Learning (ICML), 41–47.
- Baumgartner, Thiébaux, and Trevizan (2018) Baumgartner, P.; Thiébaux, S.; and Trevizan, F. 2018. Heuristic Search Planning With Multi-Objective Probabilistic LTL Constraints. In Proc. of 16th Int. Conf. on Principles of Knowledge Representation and Reasoning (KR).
- Bertsekas and Tsitsiklis (1991) Bertsekas, D. P.; and Tsitsiklis, J. N. 1991. An Analysis of Stochastic Shortest Path Problems. Mathematics of Operations Research, 16(3): 580–595.
- Bertsekas and Tsitsiklis (1996) Bertsekas, D. P.; and Tsitsiklis, J. N. 1996. Neuro-Dynamic Programming, volume 3 of Optimization and neural computation series. Athena scientific.
- Bonet and Geffner (2001) Bonet, B.; and Geffner, H. 2001. Planning as Heuristic Search. Artif. Intell., 129(1-2): 5–33.
- Bonet and Geffner (2003) Bonet, B.; and Geffner, H. 2003. Labeled RTDP: Improving the Convergence of Real-Time Dynamic Programming. In Proc. 13th International Conference on Automated Planning and Scheduling (ICAPS), 12–21.
- Bryce and Buffet (2008) Bryce, D.; and Buffet, O. 2008. 6th Int. Planning Competition: Uncertainty Track. 3rd Int. Probabilistic Planning Competition.
- Bryce, Cushing, and Kambhampati (2007) Bryce, D.; Cushing, W.; and Kambhampati, S. 2007. Probabilistic Planning is Multi-Objective. Technical Report 07-006, ASU CSE.
- Dai et al. (2014) Dai, P.; Mausam; Weld, D. S.; and Goldsmith, J. 2014. Topological Value Iteration Algorithms. J. Artif. Intell. Res., 42: 181–209.
- Geißer et al. (2022) Geißer, F.; Haslum, P.; Thiébaux, S.; and Trevizan, F. 2022. Admissible Heuristics for Multi-Objective Planning. In Proc. 32nd International Conference on Automated Planning and Scheduling (ICAPS), 100–109.
- Hansen and Zilberstein (2001) Hansen, E. A.; and Zilberstein, S. 2001. LAO: A Heuristic search algorithm that finds solutions with loops. Artif. Intell., 129(1-2): 35–62.
- Jimenez, Coles, and Smith (2006) Jimenez, S.; Coles, A.; and Smith, A. 2006. Planning in Probabilistic Domains using a Deterministic Numeric Planner. In Proc. 25th Workshop of the UK Planning and Scheduling Special Interest Group (PLANSIG), 74–79.
- Keller and Helmert (2013) Keller, T.; and Helmert, M. 2013. Trial-Based Heuristic Tree Search for Finite Horizon MDPs. In Proc. 23rd International Conference on Automated Planning and Scheduling (ICAPS). AAAI.
- Khouadjia et al. (2013) Khouadjia, M.; Schoenauer, M.; Vidal, V.; Dréo, J.; and Savéant, P. 2013. Pareto-Based Multiobjective AI Planning. In Proc. 23rd International Joint Conference on Artificial Intelligence (IJCAI), 2321–2327.
- Klößner and Hoffmann (2021) Klößner, T.; and Hoffmann, J. 2021. Pattern Databases for Stochastic Shortest Path Problems. In Ma, H.; and Serina, I., eds., Proc. 14th International Symposium on Combinatorial Search (SOCS), 131–135.
- Little and Thiébaux (2007) Little, I.; and Thiébaux, S. 2007. Probabilistic Planning vs Replanning. In Proc. ICAPS Workshop International Planning Competition: Past, Present and Future.
- Mandow and Pérez-de-la-Cruz (2010) Mandow, L.; and Pérez-de-la-Cruz, J. 2010. Multiobjective A∗ search with consistent heuristics. J. ACM, 57(5): 27:1–27:25.
- Painter, Lacerda, and Hawes (2020) Painter, M.; Lacerda, B.; and Hawes, N. 2020. Convex Hull Monte-Carlo Tree-Search. In Proc. 30th International Conference on Automated Planning and Scheduling (ICAPS), 217–225.
- Roijers and Whiteson (2017) Roijers, D. M.; and Whiteson, S. 2017. Multi-Objective Decision Making. Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool Publishers.
- Trevizan, Teichteil-Königsbuch, and Thiébaux (2017) Trevizan, F.; Teichteil-Königsbuch, F.; and Thiébaux, S. 2017. Efficient Solutions for Stochastic Shortest Path Problems with Dead Ends. In Proc. 33rd International Conference on Uncertainty in Artificial Intelligence (UAI).
- Trevizan et al. (2017) Trevizan, F.; Thiébaux, S.; Santana, P.; and Williams, B. 2017. I-dual: Solving Constrained SSPs via Heuristic Search in the Dual Space. In Proc. 26th International Joint Conference on Artificial Intelligence (IJCAI).
- Trevizan, Thiébaux, and Haslum (2017) Trevizan, F. W.; Thiébaux, S.; and Haslum, P. 2017. Occupation Measure Heuristics for Probabilistic Planning. In Proc. 27th International Conference on Automated Planning and Scheduling (ICAPS), 306–315.
- Ulloa et al. (2020) Ulloa, C. H.; Yeoh, W.; Baier, J. A.; Zhang, H.; Suazo, L.; and Koenig, S. 2020. A Simple and Fast Bi-Objective Search Algorithm. In Proc. 30th International Conference on Automated Planning and Scheduling (ICAPS), 143–151.
- White (1982) White, D. J. 1982. Multi-objective infinite-horizon discounted Markov decision processes. Journal of Mathematical Analysis and Applications, 89(2): 639–647.
- Wiering and de Jong (2007) Wiering, M. A.; and de Jong, E. D. 2007. Computing Optimal Stationary Policies for Multi-Objective Markov Decision Processes. In Proc. 1st IEEE International Symposium on Approximate Dynamic Programming and Reinforcement Learning, 158–165.
- Wingate and Seppi (2005) Wingate, D.; and Seppi, K. D. 2005. Prioritization Methods for Accelerating MDP Solvers. J. Mach. Learn. Res., 6: 851–881.
- Younes et al. (2005) Younes, H. L. S.; Littman, M. L.; Weissman, D.; and Asmuth, J. 2005. The First Probabilistic Track of the International Planning Competition. J. Artif. Intell. Res., 24: 851–887.
Appendix
Critical Path
Abstractions
blind
Sum
SAR-4
(120)
VI
39.7
39.0
-
39.0
39.0
35.0
38.0
39.0
39.0
307.7
TVI
40.0
40.0
-
40.0
40.0
40.0
40.0
40.0
40.0
320.0
LAO∗
51.0
54.0
83.0
62.0
66.0
76.0
77.0
84.3
91.0
644.3
iLAO∗
80.0
90.0
75.0
94.0
100.0
90.0
97.0
93.0
104.0
823.0
LRTDP
72.2
90.8
80.8
93.8
95.8
91.0
93.6
98.2
99.4
815.5
SAR-5
(120)
VI
-
-
-
-
-
-
-
-
0.7
0.7
TVI
-
-
-
-
-
-
-
-
0.7
0.7
LAO∗
42.0
38.0
54.0
54.0
58.0
71.0
76.7
82.0
87.7
563.3
iLAO∗
65.0
81.0
43.0
84.0
97.0
88.0
96.0
94.0
100.0
748.0
LRTDP
55.5
80.8
41.2
86.0
89.5
88.0
91.0
91.2
93.8
717.0
ExBw-2d
(155)
VI
-
-
-
-
-
-
-
-
-
-
TVI
-
-
-
-
-
-
-
-
-
-
LAO∗
4.0
29.0
10.0
7.7
11.7
18.0
20.3
16.3
22.3
139.3
iLAO∗
5.0
26.0
8.0
17.0
21.0
31.0
32.0
30.0
32.0
202.0
LRTDP
22.0
39.8
11.5
33.0
27.0
52.8
44.2
47.6
42.2
320.1
ExBw-3d
(155)
VI
-
-
-
-
-
-
-
-
-
-
TVI
-
-
-
-
-
-
-
-
-
-
LAO∗
2.0
21.0
9.0
10.0
9.0
15.0
17.3
14.7
7.3
105.3
iLAO∗
5.0
21.0
8.0
16.0
20.0
28.0
27.0
26.0
14.7
165.7
LRTDP
20.0
36.0
11.0
31.5
26.0
50.0
41.4
45.0
8.6
269.5
Tireworld
(10)
VI
3.0
3.0
2.0
3.0
3.0
3.0
3.0
3.0
3.0
26.0
TVI
2.0
2.0
2.0
3.0
3.0
3.0
2.7
3.0
3.0
23.7
LAO∗
2.0
2.0
2.0
2.0
2.0
2.0
2.0
2.0
3.0
19.0
iLAO∗
3.0
3.0
2.0
3.0
3.0
3.0
3.0
3.0
4.0
27.0
LRTDP
3.0
3.0
2.0
3.0
3.0
3.0
3.0
3.0
4.0
27.0
Pr. VisitAll
(26)
VI
13.0
13.0
12.0
13.0
13.0
12.0
12.0
13.0
15.0
116.0
TVI
13.0
13.0
12.0
13.0
13.0
12.0
12.0
13.7
14.0
115.7
LAO∗
2.0
2.0
6.0
1.0
1.0
5.0
6.0
11.7
18.0
52.7
iLAO∗
14.0
14.0
14.0
14.0
14.0
15.0
14.0
15.0
19.0
133.0
LRTDP
10.5
10.2
13.0
10.2
9.8
13.0
13.0
17.6
18.2
115.5
VisitAllTire
(24)
VI
-
-
-
-
-
-
-
-
-
-
TVI
-
-
-
-
-
-
-
-
-
-
LAO∗
-
-
1.0
-
-
1.0
1.0
1.0
1.0
5.0
iLAO∗
1.0
1.0
1.0
1.0
1.0
1.0
3.0
1.0
3.0
13.0
LRTDP
3.0
2.8
1.0
3.0
3.0
5.0
5.0
5.0
5.0
32.8
Sum
(610)
VI
55.7
55.0
14.0
55.0
55.0
50.0
53.0
55.0
57.7
450.3
TVI
55.0
55.0
14.0
56.0
56.0
55.0
54.7
56.7
57.7
460.0
LAO∗
103.0
146.0
165.0
136.7
147.7
188.0
200.3
212.0
230.3
1529.0
iLAO∗
173.0
236.0
151.0
229.0
256.0
256.0
272.0
262.0
276.7
2111.7
LRTDP
186.2
263.2
160.5
260.5
254.0
302.8
291.2
307.6
271.2
2297.3