Heterogeneous Federated Learning with Convolutional and Spiking Neural Networks
Abstract
Federated learning (FL) has emerged as a promising paradigm for training models on decentralized data while safeguarding data privacy. Most existing FL systems, however, assume that all machine learning models are of the same type, although it becomes more likely that different edge devices adopt different types of AI models, including both conventional analogue artificial neural networks (ANNs) and biologically more plausible spiking neural networks (SNNs). This diversity empowers the efficient handling of specific tasks and requirements, showcasing the adaptability and versatility of edge computing platforms. One main challenge of such heterogeneous FL system lies in effectively aggregating models from the local devices in a privacy-preserving manner. To address the above issue, this work benchmarks FL systems containing both convoluntional neural networks (CNNs) and SNNs by comparing various aggregation approaches, including federated CNNs, federated SNNs, federated CNNs for SNNs, federated SNNs for CNNs, and federated CNNs with SNN fusion. Experimental results demonstrate that the CNN-SNN fusion framework exhibits the best performance among the above settings on the MNIST dataset. Additionally, intriguing phenomena of competitive suppression are noted during the convergence process of multi-model FL.
1 Introduction
Embedded artificial intelligence and heterogeneous edge devices will be in increasing demand in various industrial and IoT systems. Alongside devices incorporating traditional convolutional neural networks (CNNs) Rashid et al. (2022); Merenda et al. (2020), those utilizing spiking neural networks (SNNs) Koo et al. (2020); Yang et al. (2022) will also emerge as strong contenders due to their advantage of low power consumption. Effectively and securely leveraging data from these heterogeneous devices will be key to this scenario.
Both CNNs and SNNs are artificial neural networks that can be used to solve various AI tasks, however, they have distinct architectures and operate in different ways. CNNs Gu et al. (2018) are primarily used for tasks involving grid-structured data, such as images, videos, and signals. They are composed of multiple layers, including convolutional layers, pooling layers, and fully connected layers. CNNs are widely used in image recognition, object detection, image segmentation, and other computer vision tasks due to their ability to capture spatial dependencies in data efficiently.
SNNs Ghosh-Dastidar and Adeli (2009) are a type of neural network model inspired by biological neurons, particularly in their use of spikes or action potentials for information processing. Unlike CNNs, SNNs operate in discrete time steps, with neurons firing spikes in response to input stimuli. SNNs can process temporal information efficiently and are well-suited for tasks involving spatiotemporal data, such as time series prediction, speech recognition, and sensor data processing. Due to its event-driven and energy-efficient nature, SNNs are more suitable for mobile and edge devices.
Given the distinct suitability of CNNs and SNNs for different scenarios, exploring the potential of combining their capabilities across various modalities presents a practical challenge for addressing their individual limitations. By integrating the diverse modal data processed by CNNs and SNNs into joint learning frameworks, we can leverage the complementary strengths of each architecture to enhance overall model performance and robustness. However, the establishment of a secure and privacy-preserving environment for CNN-SNN interaction is another critical challenge.
Federated learning (FL) Ji et al. (2024); McMahan et al. (2017) has emerged as a promising solution to this problem, offering a decentralized approach to model training that respects data privacy and security. While existing federated CNN Lu and Fan (2020) and federated SNN Venkatesha et al. (2021); Skatchkovsky et al. (2020); Wang et al. (2023) frameworks enable training within a single modality, the exploration of multi-modal learning techniques that leverage both SNN and CNN capabilities remains unclear. By bridging this gap and developing novel approaches for multi-modal learning, we can unlock the full potential of CNN-SNN fusion in federated environment.
In this paper, we present a novel approach to multi-modal federated learning, leveraging the fusion of CNNs and SNNs. The contributions of this study are as follows:
-
•
This paper pioneers the integration of CNN-SNN models within an FL framework.
-
•
To elucidate the efficacy of our proposed framework, we conduct a thorough comparative analysis against various federated learning approaches. Specifically, we compare our CNN-SNN fusion framework with federated CNNs, federated SNNs, federated CNNs for SNNs, and federated SNNs for CNNs.
-
•
Our CNN-SNN fusion outperforms the CNN for SNN and SNN for CNN frameworks and we observe interesting competitive suppression phenomena during the training process of CNN-SNN fusion.
2 Preliminaries
In this section, we introduce the preliminaries relevant to our work, namely FL and SNNs.
2.1 Federated Learning
FL is a distributed machine learning paradigm in which each of the participants trains a model on local data and uploads the parameters of the updated model to the server. Then the server aggregates the local models to obtain a global model. Compared with traditional machine learning techniques, FL cannot only improve learning efficiency but also solve the problem of data silos and protect local data privacy Custers et al. (2019).
In horizontal FL (HFL) Yang et al. (2019); Zhang et al. (2023), the feature space is shared across all parties, but each party may have a distinct sample space in their datasets, representing one of the most prevalent frameworks in federated learning. Initially, the server initializes a model with random parameters and distributes it to all participating clients. Subsequently, a subset of out of clients receive the model and compute training gradients locally based on their respective datasets. These updated models are then transmitted back to the server, which aggregates the gradients from all participating clients to compute the global parameters:
| (1) |
Federated Averaging (FedAvg) McMahan et al. (2017); Wang et al. (2020) is one of the most widely adopted methods in FL. Its pseudocode is delineated in Algorithm 1.
In this method, stochastic gradient descent (SGD) Johnson and Zhang (2013) is utilized to minimize the global dropout and accuracy function . In Federated Stochastic Gradient Descent (FedSGD)McMahan et al. (2017), all clients are involved (), and each client updates its local parameters as follows:
| (2) |
Subsequently, the server aggregates these updated parameters into a global parameter using weighted averaging:
| (3) |
If clients conduct multiple updates within their local datasets, the local parameters are iteratively updated by:
| (4) |



| CNN | SNN | ||||||||
| Layer name | Param shape | Output shape | Layer name | Param shape | Output shape | ||||
| Input | - | None×1×32×32 | Input | - | None×T×1×32×32 | ||||
| Conv2d | Weights: 32×1×3×3 | None×32×32×32 | Conv2d | Weights: 32×1×3×3 | None×T×32×32×32 | ||||
| BatchNorm2d |
|
None×32×32×32 | BatchNorm2d |
|
None×T×32×32×32 | ||||
| Sigmoid | - | None×32×32×32 | IFNode | - | None×T×32×32×32 | ||||
| MaxPool2d | - | None×32×16×16 | MaxPool2d | - | None×T×32×16×16 | ||||
| Conv2d | Weights: 32×1×3×3 | None×32×16×16 | Conv2d | Weights: 32×1×3×3 | None×T×32×16×16 | ||||
| BatchNorm2d |
|
None×32×16×16 | BatchNorm2d |
|
None×T×32×16×16 | ||||
| Sigmoid | - | None×32×16×16 | IFNode | - | None×T×32×16×16 | ||||
| MaxPool2d | - | None×32×8×8 | MaxPool2d | - | None×T×32×8×8 | ||||
| Linear | Weights: 512×2048 | None×512 | Linear | Weights: 512×2048 | None×T×512 | ||||
| Sigmoid | - | None×512 | IFNode | - | None×T×512 | ||||
| Linear | Weights: 10×512 | None×10 | Linear | Weights: 10×512 | None×T×10 | ||||
| Sigmoid | - | None×10 | IFNode | - | None×T×10 | ||||
| - | Surrogate function of IFNode: sigmoid | ||||||||
2.2 Spiking Neural Networks
In an SNN, information is encoded in the timing of these spikes Lobo et al. (2020). The Leaky Integrate-and-Fire (LIF) Kornijcuk et al. (2016); Hunsberger and Eliasmith (2015) neuron model is one of the simplest and most commonly used neuron models in SNNs. It captures the basic behavior of biological neurons by integrating incoming input signals over time and emitting an output spike when a certain threshold is reached.
An LIF neuron in layer with index can formally be described in differential form:
| (5) |
where is the membrane potential, is the resting potential, is the membrane time constant, is the input resistance, and is the input current.
Figure 1 describes the basic calculation process of the SNN. Considering a neuron receiving input from a set of neurons , the incoming spikes from these input neurons are weighted by the parameters for all belonging to and are accumulated to form the neuron. Upon reaching a predefined threshold , the neuron generates an output spike. Following this spike, the membrane potential undergoes a reset process.
In SNNs, the input current is typically generated by synaptic currents induced by the arrival of presynaptic spikes . When working with differential equations, a spike train as a sum of Dirac delta functions is denoted, where iterates over the firing times of neuron in layer .
Synaptic currents exhibit distinct temporal dynamics. A common simplification is to model their time evolution as an exponentially decaying current following each presynaptic spike. Additionally, we assume linearity in the summation of synaptic currents. The dynamics of these operations can be encapsulated by the following expression:
| (6) |
Here, the summation extends over all presynaptic neurons , with representing the corresponding afferent weights from the layer below. Additionally, denotes explicit recurrent connections within each layer. We can represent a single LIF neuron through two linear differential equations, where the initial conditions undergo instantaneous modification upon each spike occurrence. Leveraging this property, we can introduce a reset term via an additional factor that immediately decreases the membrane potential by whenever the neuron emits a spike:
| (7) |
| N/P:10/2 | C-C | S-S | C-SC | S-SC | SC-SC | ||||
|---|---|---|---|---|---|---|---|---|---|
| CNN | SNN | CNN | SNN | CNN | SNN | CNN | SNN | ||
| IID | 98.930 | 99.160 | 95.680 | 89.310 | 47.780 | 95.870 | 97.470 | 95.690 | |
| Non-IID | Alpha=1 | 98.950 | 98.610 | 97.740 | 93.570 | 54.240 | 97.560 | 95.6500 | 94.2700 |
| Alpha=0.5 | 98.570 | 97.890 | 97.900 | 92.770 | 45.300 | 97.360 | 97.500 | 90.710 | |
| Alpha=0.125 | 62.790 | 74.100 | 57.620 | 51.210 | 38.960 | 73.110 | 58.920 | 61.710 | |

3 CNN-SNN Fusion Framework
In the federated framework, a centralized server orchestrates multiple clients, each potentially equipped with either an SNN or a CNN model. The overarching goal is to train a global model without necessitating the transmission of raw data from the clients. It includes three phases, initialization, local training, and aggregation.
-
•
Initialization: The federated learning process commences with the initialization phase, during which a global model is instantiated and distributed to all participating clients by the centralized server.
Each client receives the initial model parameters, serving as the foundational framework for subsequent training iterations.
-
•
Local training phase: In the local training phase, individual clients train their respective local datasets to fine-tune the global model parameters. For SNNs, local training entails fine-tuning synaptic weights, thresholds, and other parameters critical for optimizing spike timings and firing rates. Employing the FedAvg algorithm, clients update model parameters and upload their parameters to the server.
-
•
Aggregation: After receiving the parameters, the server conducts an aggregation with the average function and outputs the final result, which is the global model.
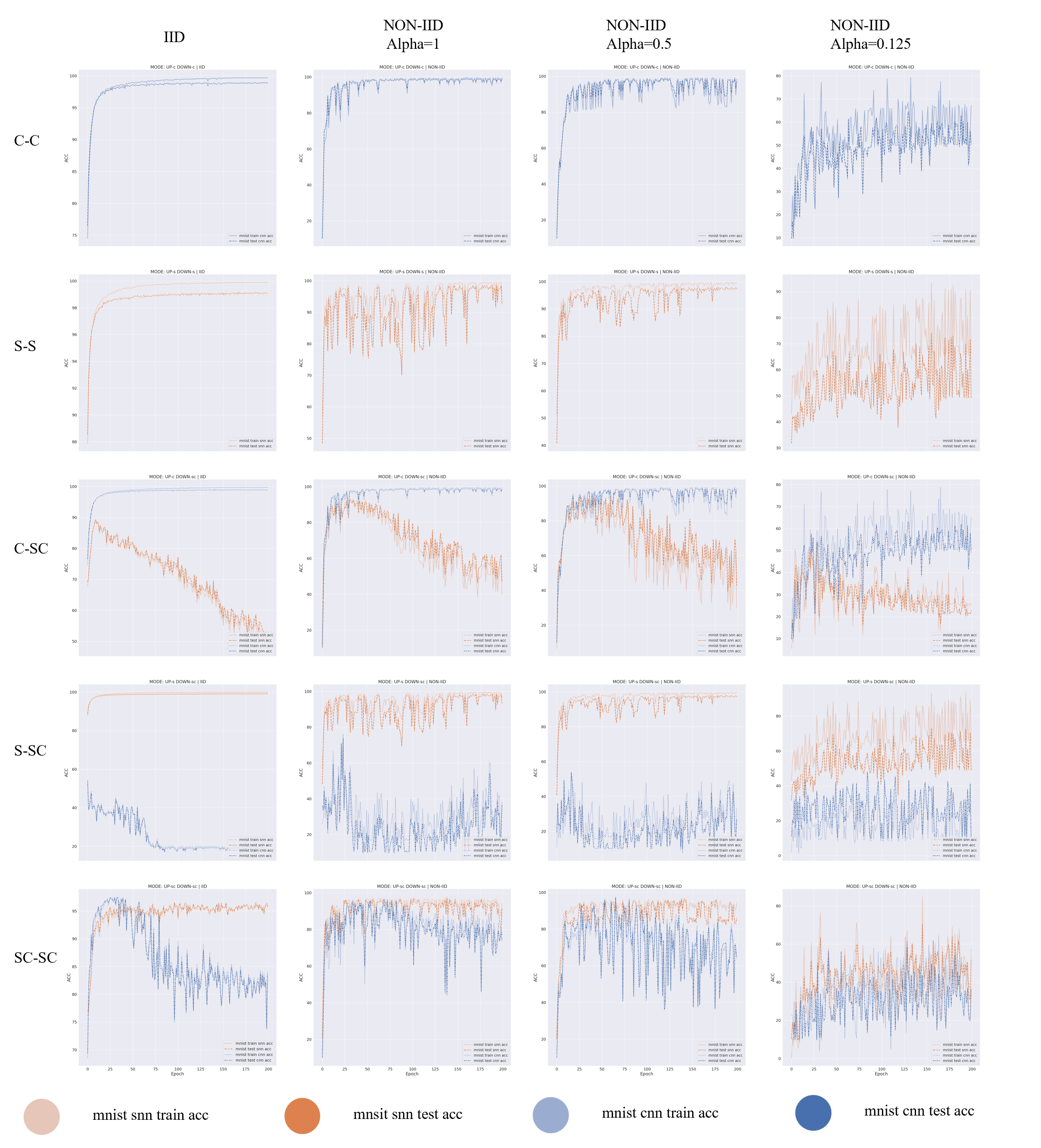
To fully demonstrate the effectiveness of the CNN-SNN fusion framework, we have devised five distinct modes, refer to Fig. 3, each tailored to specific functionalities and scenarios:
-
•
Federated CNN Mode (C-C): In this mode, the algorithm exclusively operates in the domain of CNNs. The training process encompasses all CNN clients, fostering a unified and optimized CNN-based approach across the network.
-
•
Federated SNN Mode (S-S): By copntrast, the federated SNN mode focuses solely on SNNs. It orchestrates the training of all SNN clients.
-
•
Federated CNN for SNN Mode (C-SC): This mode intertwines the modalities of both CNNs and SNNs. Initially, CNN models undergo training and are then uploaded to a centralized server. Then, all clients, regardless of whether they are using CNN or SNN, get these CNN weights from the server. This hybrid approach optimizes resources by leveraging CNN weights across the network.
-
•
Federated SNN for CNN Mode (S-SC): Similarly, the federated SNN for CNN mode combines CNN and SNN capabilities. Here, SNN models undergo training and are uploaded to the server. All clients, regardless of their inherent modality, then fetch these SNN weights from the server. This strategy optimizes network efficiency by capitalizing on SNN weights across diverse client devices.
-
•
CNN-SNN Fusion Mode (SC-SC): The CNN-SNN fusion mode amalgamates the modalities of both CNNs and SNNs. Clients independently train their local models, contributing to a diverse and robust set of weights. The server orchestrates weight aggregation, culminating in a unified, comprehensive model. Subsequently, all clients retrieve these aggregated weights, embodying a fusion of CNN and SNN capabilities across the network.
4 Experimental Results
The experiments assess five distinct frameworks using the MNIST dataset Deng (2012). In each framework, an equal number of CNN and SNN clients undergo 200 global epochs, with each client performing 2 local epochs.
4.1 Model Architectures and Data Processing
Table 1 presents the architectures of the CNN and SNN models utilized in the experiments. The inputs to the SNN clients are temporal discrete pulse signals, generated from continuous signals with a temporal length set to 20 time steps and following a Poisson distribution Heeger and others (2000). The activation function in the SNN is based on the Integrate-and-Fire neuron model, corresponding to IFNode in Table 1, which enables the SNN to process spiking signals. Furthermore, a sigmoid surrogate gradient function is employed to facilitate backpropagation training in the SNN.
The data for the CNN and SNN clients are randomly distributed, non-overlapping, and remain constant across epochs from the MNIST dataset. In non-IID scenarios, a Dirichlet distribution is employed to allocate sample proportions among different clients for each class, generating non-IID data Zhu et al. (2021), with the parameter alpha governing the degree of non-IIDness, where lower values indicate higher degrees of non-IIDness.
4.2 Comparison of Five Frameworks
In this series of experiments, we configured the number of clients to 10 and uploaded one SNN weight and one CNN weight each time. Additionally, the non-IID data set is further divided into three different levels of non-independence, represented by different alpha values. Lower alpha values indicate higher non-independence, which makes the task of generalizing the model more challenging.
From the results in Figure 4, we observe that the proposed CNN-SNN fusion framework (SC-SC) can converge under both IID and various degrees of non-IID data. Secondly, within the SC-SC framework, there exists a convergence difference between SNN and CNN due to the misalignment of different modal data. Their gradients compete during fusion, with the dominant side suppressing the performance of the weaker side during training. In this experiment, SNN clients are the dominant side.
Additionally, compared to the C-SC and S-SC frameworks, the SC-SC framework exhibits smaller convergence differences between SNN and CNN. This is because the SC-SC framework merges the gradients of two modal models, allowing the server to simultaneously learn knowledge from both SNN and CNN clients, while C-SC and S-SC models can only learn from one type of client. Furthermore, as the degree of Non-IID data increases, the differences between CNN and SNN results gradually decrease in the C-SC, S-SC, and SC-SC frameworks. This indicates that non-IID data helps alleviate competition suppression issues in training different modalities.
Finally, compared to the C-C and S-S frameworks, the performance of the SC-SC framework on each modality is slightly lower than the corresponding single-modality frameworks (S-S and C-C). This is because the current framework does not consider mutual promotion between different modalities. We will explore this direction in future research.
4.3 Competitive Suppression in SC-SC
This set of experiments investigates the SC-SC framework by varying the number of clients (denoted as N) and the number of uploads (denoted as P). This variation aims to further explore the issue of competition suppression within the framework. Each configuration of N/P considers both IID and non-IID (with alpha=0.5) scenarios.
Observations from Figure 5 are as follows. As the values of N/P increase, the convergence discrepancy between SNN and CNN decreases gradually. In the IID scenario, role reversal between superior and inferior parties is more likely to occur. Initially, in the IID column, CNN clients (blue curve) tend to be dominant, but later, it transitions to SNN clients (orange curve) becoming more dominant. However, non-IID significantly reduces the competition suppression problem in SC-SC federated training.
5 Conclusion
In this paper, we investigate a variety of approaches to multi-device federated learning that integrates CNNs and SNNs. To provide a comprehensive understanding of this framework, we conduct a thorough comparison with various existing approaches, including federated CNN, federated SNN, federated CNN for SNN, federated SNN for CNN, and federated CNN with SNN fusion. The experimental results reveal superiority of the SNN-CNN fusion compared with other heterogeneous frameworks and also explore the phenomenon of competition suppression in the SNN-CNN fusion training process.
However, due to the differences and misalignment between modalities, the SNN-CNN fusion framework is slightly worse than than the single-modality framework. In the future, we aim to explore alignment and transfer learning techniques within this fusion framework to further enhance its accuracy and robustness. This future work holds promise for advancing the capabilities of multi-device federated learning and extending its applicability to diverse real-world scenarios.
References
- Custers et al. [2019] Bart Custers, Alan M Sears, Francien Dechesne, Ilina Georgieva, Tommaso Tani, and Simone Van der Hof. EU personal data protection in policy and practice. Springer, 2019.
- Deng [2012] Li Deng. The mnist database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- Ghosh-Dastidar and Adeli [2009] Samanwoy Ghosh-Dastidar and Hojjat Adeli. Spiking neural networks. International journal of neural systems, 19(04):295–308, 2009.
- Gu et al. [2018] Jiuxiang Gu, Zhenhua Wang, Jason Kuen, Lianyang Ma, Amir Shahroudy, Bing Shuai, Ting Liu, Xingxing Wang, Gang Wang, Jianfei Cai, et al. Recent advances in convolutional neural networks. Pattern recognition, 77:354–377, 2018.
- Heeger and others [2000] David Heeger et al. Poisson model of spike generation. Handout, University of Standford, 5(1-13):76, 2000.
- Hunsberger and Eliasmith [2015] Eric Hunsberger and Chris Eliasmith. Spiking deep networks with lif neurons. arXiv preprint arXiv:1510.08829, 2015.
- Ji et al. [2024] Shaoxiong Ji, Yue Tan, Teemu Saravirta, Zhiqin Yang, Yixin Liu, Lauri Vasankari, Shirui Pan, Guodong Long, and Anwar Walid. Emerging trends in federated learning: From model fusion to federated x learning. International Journal of Machine Learning and Cybernetics, pages 1–22, 2024.
- Johnson and Zhang [2013] Rie Johnson and Tong Zhang. Accelerating stochastic gradient descent using predictive variance reduction. Advances in neural information processing systems, 26, 2013.
- Koo et al. [2020] Minsuk Koo, Gopalakrishnan Srinivasan, Yong Shim, and Kaushik Roy. Sbsnn: Stochastic-bits enabled binary spiking neural network with on-chip learning for energy efficient neuromorphic computing at the edge. IEEE Transactions on Circuits and Systems I: Regular Papers, 67(8):2546–2555, 2020.
- Kornijcuk et al. [2016] Vladimir Kornijcuk, Hyungkwang Lim, Jun Yeong Seok, Guhyun Kim, Seong Keun Kim, Inho Kim, Byung Joon Choi, and Doo Seok Jeong. Leaky integrate-and-fire neuron circuit based on floating-gate integrator. Frontiers in neuroscience, 10:212, 2016.
- Lobo et al. [2020] Jesus L Lobo, Javier Del Ser, Albert Bifet, and Nikola Kasabov. Spiking neural networks and online learning: An overview and perspectives. Neural Networks, 121:88–100, 2020.
- Lu and Fan [2020] Yanyang Lu and Lei Fan. An efficient and robust aggregation algorithm for learning federated cnn. In Proceedings of the 2020 3rd International Conference on Signal Processing and Machine Learning, pages 1–7, 2020.
- McMahan et al. [2017] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017.
- Merenda et al. [2020] Massimo Merenda, Carlo Porcaro, and Demetrio Iero. Edge machine learning for ai-enabled iot devices: A review. Sensors, 20(9):2533, 2020.
- Rashid et al. [2022] Nafiul Rashid, Berken Utku Demirel, and Mohammad Abdullah Al Faruque. Ahar: Adaptive cnn for energy-efficient human activity recognition in low-power edge devices. IEEE Internet of Things Journal, 9(15):13041–13051, 2022.
- Skatchkovsky et al. [2020] Nicolas Skatchkovsky, Hyeryung Jang, and Osvaldo Simeone. Federated neuromorphic learning of spiking neural networks for low-power edge intelligence. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8524–8528. IEEE, 2020.
- Venkatesha et al. [2021] Yeshwanth Venkatesha, Youngeun Kim, Leandros Tassiulas, and Priyadarshini Panda. Federated learning with spiking neural networks. IEEE Transactions on Signal Processing, 69:6183–6194, 2021.
- Wang et al. [2020] Hongyi Wang, Mikhail Yurochkin, Yuekai Sun, Dimitris Papailiopoulos, and Yasaman Khazaeni. Federated learning with matched averaging. arXiv preprint arXiv:2002.06440, 2020.
- Wang et al. [2023] Yuan Wang, Shukai Duan, and Feng Chen. Efficient asynchronous federated neuromorphic learning of spiking neural networks. Neurocomputing, 557:126686, 2023.
- Yang et al. [2019] Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. Federated machine learning: Concept and applications. ACM Transactions on Intelligent Systems and Technology (TIST), 10(2):1–19, 2019.
- Yang et al. [2022] Helin Yang, Kwok-Yan Lam, Liang Xiao, Zehui Xiong, Hao Hu, Dusit Niyato, and H Vincent Poor. Lead federated neuromorphic learning for wireless edge artificial intelligence. Nature communications, 13(1):4269, 2022.
- Zhang et al. [2023] Xunzheng Zhang, Alex Mavromatis, Antonis Vafeas, Reza Nejabati, and Dimitra Simeonidou. Federated feature selection for horizontal federated learning in iot networks. IEEE Internet of Things Journal, 10(11):10095–10112, 2023.
- Zhu et al. [2021] Hangyu Zhu, Jinjin Xu, Shiqing Liu, and Yaochu Jin. Federated learning on non-iid data: A survey. Neurocomputing, 465:371–390, 2021.