HEDE:
Heritability estimation in high dimensions
by Ensembling Debiased Estimators
Estimating heritability remains a significant challenge in statistical genetics. Diverse approaches have emerged over the years that are broadly categorized as either random effects or fixed effects heritability methods. In this work, we focus on the latter. We propose HEDE, an ensemble approach to estimate heritability or the signal-to-noise ratio in high-dimensional linear models where the sample size and the dimension grow proportionally. Our method ensembles post-processed versions of the debiased lasso and debiased ridge estimators, and incorporates a data-driven strategy for hyperparameter selection that significantly boosts estimation performance. We establish rigorous consistency guarantees that hold despite adaptive tuning. Extensive simulations demonstrate our method’s superiority over existing state-of-the-art methods across various signal structures and genetic architectures, ranging from sparse to relatively dense and from evenly to unevenly distributed signals. Furthermore, we discuss the advantages of fixed effects heritability estimation compared to random effects estimation. Our theoretical guarantees hold for realistic genotype distributions observed in genetic studies, where genotypes typically take on discrete values and are often well-modeled by sub-Gaussian distributed random variables. We establish our theoretical results by deriving uniform bounds, built upon the convex Gaussian min-max theorem, and leveraging universality results. Finally, we showcase the efficacy of our approach in estimating height and BMI heritability using the UK Biobank.
Abstract
Keywords: Signal-to-noise ratio estimation, Debiased Lasso estimator, Debiased ridge estimator, Convex Gaussian min-max theorem, Ensemble estimation, Proportional asymptotics, Universality.
1 Introduction
Accurate heritability estimation presents a significant challenge in statistical genetics. Distinguishing the contributions of genetic versus environmental factors is crucial for understanding how our genetic makeup influences the development of complex diseases. Importantly, genetic research over the past decade has highlighted a significant discrepancy between heritability estimates from twin studies and those from Genome-Wide Association Studies (GWAS) (Manolio et al.,, 2009; Yang et al.,, 2015) This discrepancy, known as the “missing heritability problem”, underscores the importance of developing reliable heritability estimation methods to understand the extent of missing heritability. In this paper, we propose an ensemble method for heritability estimation, using high-dimensional Single Nucleotide Polymorphisms (SNPs) commonly collected in GWAS, that exhibits superior performance across a wide variety of settings and significantly outperforms existing methods in practical scenarios of interest. We focus on the narrow-sense heritability yang2011gcta, which refers to the proportion of phenotypic variance explained by additive genotypic effects. For conciseness, we henceforth refer to this simply as the heritability.
GWAS data typically contains more SNPs than individuals. This presents a challenge when estimating heritability. Addressing this challenge necessitates modeling assumptions. Previous work in this area can be broadly categorized into two classes based on these assumptions: random effects models and fixed effects models.
Random effects models treat the underlying regression coefficients as random variables and have been widely used for heritability estimation. Arguably, the most popular approach in this vein is GCTA, introduced by yang2011gcta. GCTA employs the classical restricted maximum likelihood method (REML) (also called genomic REML/GREML in their work) within a linear mixed effects model. It assumes that the regression coefficients are i.i.d. draws from a Gaussian distribution with zero mean and a constant variance. Since the genetic effect sizes/regression coefficients might depend on the design matrix (the genotypes), subsequent work provides various improvements that relax this assumption, including GREML-MS (lee2013estimation), GREML-LDMS (yang2015genetic), BOLT-LMM (loh2015efficient), among others. Specifically, GREML-MS allows the signal variance to depend on minor allele frequencies (MAFs), while GREML-LDMS allows it to depende on linkage disequilibrium (LD) levels/quantiles. Prior statistical literature has studied the theoretical properties of several random effects methods (jiang2016high; bonnet2015heritability; dicker2016maximum; hu2022misspecification).
Despite this rich literature, a major limitation of random effects model based heritability estimation method is that its consistency often relies on the correct parametric assumptions of regression coefficients. Specifically, these methods assume that regression coefficients are either i.i.d, or depend on the design matrix in specific ways. When these assumptions are violated, random effects methods can produce significantly biased heritablity estimates. The issue is magnified when SNPs are in linkage disequilibrium (LD) or when there is additional heterogeneity across the LD blocks not captured by the random effects assumptions. We elaborate this issue further in Figure 1, where we demonstrate that GREML, GREML-MS and GREML-LDMS all incur significant biases when their respective random effects assumptions are violated.
These challenges associated with random effects methods have spurred a distinct strand of methods by positing regression coefficients to be fixed while treating the design matrix to be random. Referred to as fixed effects methods, these approaches often exhibit greater robustness to diverse realizations of the underlying signal without the need to make parametric assumptions on regression coefficients (Figure 1). Consequently, our focus lies on estimating the heritability within this fixed effects model framework.
Several fixed effects methods have emerged for heritability estimation. However, a substantial body of the proposed work requires the underlying signal to be sparse (fan2012variance; sun2012scaled; tony2020semisupervised; guo2019optimal), and they are subject to loss of efficiency when these sparsity assumptions are violated (dicker2014variance; janson2017eigenprism; bayati2013estimating), see Sections 5.2, 3.3, 2, respectively. The methods proposed by several authors (chen2022statistical; dicker2014variance; janson2017eigenprism) operate under less stringent assumptions regarding the signal, but they depend on ridge-regression-analogous concepts. Therefore they are expected to have good efficiency when the signal is dense, and are subject to loss of efficiency when signals are sparse. We illustrate these issues further in Section 5.2. In practice, the underlying genetic architecture for a given trait is unknown, i.e., the signal could be sparse or dense. Hence, it is desirable to develop a robust method across a broad spectrum of signal regimes from sparse to dense. In addition, fixed effects methods often rely on assuming the covariate distribution to be Gaussian (bayati2013estimating; dicker2014variance; janson2017eigenprism; verzelen2018adaptive). This assumption fails to capture genetic data where genotypes are discrete, taking values in .
To address these issues, we propose a robust ensemble heritability estimation method HEDE (Heritability Estimation via Debiased Ensemble), which ensembles the debiased Lasso and ridge estimators, with degrees-of-freedom corrections (bellec2019biasing; javanmard2014hypothesis). Debiased estimators, originally proposed to correct the bias for Lasso/ridge estimators (zhang2014confidence; van2014asymptotically; javanmard2014confidence), have been employed for tasks such as confidence interval construction and hypothesis testing, and have nice properties such as optimal testing properties javanmard2014confidence. Unlike these methods, HEDE utilizes debiasing for heritability estimation. To develop HEDE, we first demonstrate that a reliable estimator for heritability can be formulated using any linear combination of these debiased estimators, in which we devise a consistent bias correction strategy. Subsequently, we refine the linear combination based on this bias correction strategy. This methodology enables the consistent estimation of heritability using any linear combination of the debiased Lasso and the debiased Ridge. HEDE then uses a data-driven approach to selecting an optimal ensemble from the array of possible linear combinations. Finally, we introduce an adaptive method for determining the underlying regularization parameters. We develop both adaptive strategies—ensemble selection and tuning parameter selection for the Lasso and the Ridge—by minimizing a certain mean square error. This results in enhanced statistical performance for heritability estimation.
Underpinning our method is a rigorous statistical theory that ensures consistency under minimal assumptions. Specifically, we operate under sub-Gaussian assumptions, which are consistent with a broad class of designs observed in GWAS that motivates this paper. We show that the consistency of heritability estimation using HEDE guarantees remain intact despite employing adaptive strategies for selecting the tuning parameters and the debiased Lasso and ridge ensemble, all while accommodating sub-Gaussian designs.
We perform extensive simulation studies to evaluate the finite sample performance of HEDE compared with the existing methods in a range of settings mimicking GWAS data. We demonstrate that HEDE overcomes the limitations in random effects methods, remaining unbiased across a wide variety of signal structures, specifically signals with different amplitudes across various combinations of MAF and LD levels, as well as LD blocks. our simulation also illustrates that HEDE consistently achieves the lowest mean square error when compared to popular fixed effects methods across a wide spectrum of sparse and dense signals, as well as low and high heritability values. We compare HEDE’s performance with both random and fixed effects methods on the problems of estimating height and BMI heritability using the UK Biobank data.
The rest of this paper is organized as follows. Section 2 introduces the problem setup. Section 3 presents our HEDE while Section 4 discusses its theoretical properties. Section 5 presents extensive simulation studies while Section 6 complements these numerical investigations with a real-data application on the UK Biobank data (sudlow2015uk). Finally, Section 7 concludes with discussions.
2 Problem Setup
In this section, we formally introduce our problem setup. We consider a high-dimensional regime where the covariate dimension grows with the sample size. To elaborate, we consider a sequence of problem instances that satisfies a linear model
| (1) |
where represents observations of a real-valued phenotype of interest, such as height, BMI, blood pressure, for unrelated individuals from a population. The unknown regression coefficient vector, , captures the effects of SNPs and is assumed to be fixed parameters. The environmental noise, , is independent of , with each entry also independent. Lastly, signifies the matrix of observed genotypes with i.i.d. rows , which are normalized as follows
| (2) |
where is the genotype containing the minor allele count (the number of copies of the less frequent allele) at SNP for individual and is the minor allele frequency of SNP in the sample.
We assume the covariates have sub-Gaussian distributions. Since is random and is deterministic, we have placed ourselves in the fixed effects framework. Moving forward, we suppress the dependence on when the meaning is clear from the context. Our parameter of interest is the heritability, which is the proportion of variance in explained by features in defined as
| (3) |
We emphasize the following remark regarding the aforementioned definition. We assume that and diverge with . This setting–also known as the proportional asymptotics regime–has gained significant recent attention in high-dimensional statistics. A major advantage of this regime is that theoretical results derived under such asymptotics demonstrate attractive finite sample performance (sur2019likelihood; sur2019modern; candes2020phase; zhao2022asymptotic; liang2022precise; jiang2022new). Furthermore, prior research in heritability estimation (jiang2016high; dicker2016maximum; janson2017eigenprism) utilized this framewrok to characterize theoretical properties of GREML and its variants. In practical situations, we observe a single value for and , so we may substitute the corresponding ratio into our theory in place of to execute data analyses. Formal assumptions on the covariate and noise distributions, and the signal are deferred to Section 4.
3 Methodology of HEDE: Heritability estimation Ensembling Debiased Estimators
We begin by describing the overarching theme underlying our method. For simplicity, we discuss the case where has independent columns, deferring the extension to correlated columns to Section 3.4. The denominator of in (3) can be consistently estimated using the sample variance of . The numerator of in (3) simplifies to in the setting of independent columns. Consequently, we seek to develop an accurate estimator for this norm.
To this end, we turn to the debiased Lasso estimator and the debiased ridge estimator. Denote the Lasso and the ridge by and respectively. These penalized estimators are known to shrink estimated coefficients to , therefore inducing bias. The existing literature provides debiased versions of these estimators, denoted as and . These debiased estimators roughly satisfy the following property: , meaning that each entry of is approximately centered around the corresponding true signal coefficient with Gaussian fluctuations and variances given by respectively. By taking norms on both sides, we obtain that , where depending on whether we consider the Lasso or the ridge. Thus, precise estimates for the variances ’s produce accurate estimates for starting from each debiased estimator.
This intuition extends to any linear combination of the debiased Lasso and ridge in the form of . A similar relationship holds for the norm: . We establish that for any , we can derive a consistent estimator for the ensemble variance . Among all possible ensemble choices with different ensembling parameter and different tuning parameters for calculating the Lasso and the ridge, we adaptively choose the combination that minimizes the mean square error of the ensemble estimator. This method, dubbed HEDE, harnesses the strengths of and regression and demonstrates strong practical performance, since we design our adaptive tuning process to particularly enhance statistical accuracy. We provide further elaboration on HEDE in the subsequent subsections: Section 3.1, discusses the specific forms of the debiased estimators utilized in our framework; Section 3.2 describes our ensembling approach, and Section 3.3 discusses the final HEDE method with our adaptive tuning strategy.
3.1 Debiasing Regularized Estimators
Define the Lasso and ridge estimators as follows
| (4) |
where and denote the respective tuning parameters. We remark that the different scaling in the regularization terms ensure comparable scales for the solutions in our high-dimensional regime (this is easy to see by noting that if each entry of satisfies , then whereas ). These estimators incur a regularization bias. To tackle this issue, several authors proposed debiased versions of these estimators that remain asymptotically unbiased with Gaussian fluctuations (zhang2014confidence; van2014asymptotically; javanmard2014confidence; bellec2019biasing; bellec2023debiasing).
Specifically, we work with the following debiased estimators:
| (5) |
Detailed in bellec2019biasing, these versions are known as debiasing with degrees-of-freedom (DOF) correction, since the second term in the denominator is precisely the degrees-of-freedom of the regularized estimator. Prior debiasing theory (bellec2019second; celentano2021cad; bellec2022observable) roughly established that under suitable conditions, for each coordinate , the debiased estimators jointly satisfy (asymptotically)
| (6) |
for appropriate variance and covariance parameters . We remark that this is a non-rigorous statement (hence the “” sign, and a precise statement is presented in Theorem 4.3. Additionally, these parameters can be consistently estimated using the following (celentano2021cad):
| (7) | ||||
This serves as the basis of our HEDE heritability estimator.
3.2 Ensembling and a Primitive Heritability Estimator
We seek to combine the strengths of and regression estimators. To achieve this, we consider linear combinations of the debiased Lasso and Ridge, taking the form
| (8) |
where is held fixed for the time being. We remark that the well-known ElasticNet estimator (zou2005regularization) also combines the strengths of the Lasso and the ridge. Though our theoretical framework allows potential extensions to the ElasticNet, we do not pursue this direction due to computational concerns, discussed further in the end of Section 3.4.
Combining (6) and (7), we obtain that each coordinate of satisfies, roughly,
| (9) |
Furthermore, the Gaussianity property (9) holds on an “average” sense as well, where the result can be effectively summed across all coordinates. We describe the precise sense next. Specifically, for any Lipschitz function , the difference behaves roughly as , where . On setting with being bounded, we obtain
| (10) |
where from (8), Synthesizing these arguments, we observe that
| (11) |
yields a consistent estimator of . The clipping is crucial for ensuring that falls within the range [0,1], which is necessary considering represents a proportion. Given a fixed and within a suitable range , we can establish that is consistent for .
For our final algorithm, we set a range on the the degrees-of-freedom (the denominators in (5)), and filter out all values whose resulting degrees-of-freedom falls outside this range. Details on how we set the range is described in Supplementary Materials A.2. This results in a class of consistent estimators for the heritability, each corresponding to a different choice of . Among these, we propose to select the estimator that minimizes the mean square error in estimating the signal . This leads to our adaptive tuning strategy, which we describe in the next subsection.
3.3 The method HEDE
In order to develop our method, HEDE, we take advantage of the flexibility provided by as adjustable hyperparameters. Initially, we fix and adaptively select . To this end, we minimize the estimated variability in the ensemble estimator, given by (9), for all possible choices of . This results in a choice that consistently estimates each coordinate of with the least possible variability among all ensemble estimators of the form (8). As this holds true for every coordinate and is asymptotically unbiased for , minimizing this variance concurrently minimizes the mean squared error. Formally, minimizing (9) as a function of leads to the following data-dependent choice:
| (12) |
Once again, the maximum and minimum operations ensure that . Subsequently, by plugging in into the ensembling formula (8), we obtain the estimator
| (13) |
For any fixed tuning parameter pair , achieves the lowest mean squared error (MSE) for estimating each coordinate, among all possible ensembled estimators of the form (8). Further, the mean square error of this estimator is given by
| (14) |
Note that is evaluated at . Observe that both and are functions of the initially selected tuning parameter pair . Therefore, to construct a competitive heritability estimator, we minimize over a range of tuning parameter values, compute the corresponding , and construct a heritability estimator according to (11) using this and the minimum (in place of and , respectively). This yields our final estimator, HEDE.
3.4 Correlated Designs
In the previous subsections, we discussed our method in the setting of independent covariates. In practical situations, covariates are typically correlated, i.e., SNPs are in LD in GWAS. Thus it is more realistic to assume that each row of our design matrix takes the form , where has independent entries and denotes the covariance of . Hence, if we can develop an accurate estimate for the covariance , should have roughly independent entries. Alternately, the whitened design matrix should have roughly identity covariance and our methodology in the prior section would apply directly.
Estimation of high-dimensional covariance matrices poses challenges, and has been a rich area of research. Here, we consider a special class of covariance matrices. Our motivation stems from GWAS data, where chromosomes constitute approximately tens of thousands of independent LD blocks (berisa2016approximately), where the number of SNPs in each LD block is much smaller in size compared to the total number of SNPs. To reflect this, we assume the population covariance matrix is block-diagonal. If the size of each block is negligible compared to the total sample size, the block-wise sample covariance matrix estimates the corresponding block of the population covariance matrix well. We establish in Supplementary Materials, Proposition A.1 that stitching together these block-wise sample covariances provides an accurate estimate of the population covariance matrix in the operator norm, i.e., . The block diagonal approximation suffices for our purposes (see Section 6).
Other scenarios exist where accurate estimates for the population covariance matrix is available, but we will not discuss these further. Our final procedure, therefore, first uses the observed data to calculate , then uses to whiten the covariates, and finally applies HEDE to the whitened data.
| Input: |
| Output: |
| 0. If necessary, estimate as block-diagonal and whiten the data. |
| 1. Fix a range . For all : |
| • Calculate in (4). |
| • If or , drop . |
| • Calculate in (7). |
| • Calculate in (12), and in (14). |
| 2. Select . Denote . |
| 3. Calculate from (5), and from (13) corresponding to . |
| 4. Calculate the heritability estimator using the formula |
| (15) |
| where denotes the sample variance of the outcome. |
We algorithmically summarize HEDE in Table 1. As we can see for step , assuming our hyperparameter grids have different values of , respectively, we need glmnet calls. As for the well known ElasticNet estimator, the same grids would require glmnet calls, making it much more expensive than the current ensembling method. We also remark that we did not make full effort into the computational/algorithmic optimization. With more advanced techniques such as snpnet from (li2022fast), HEDE could potentially be scaled to very large dimensions.
4 Theoretical Properties
We turn to discuss the key theoretical properties of HEDE. We first focus on the case of independent covariates. Recall that throughout, we assume an asymptotic framework where with . We work with the following assumptions on the covariate, signal, and noise.
Assumption 1.
-
(i)
Each entry of is independent (but not necessarily identically distributed), has mean and variance , and are uniformly sub-Gaussian.
-
(ii)
The norm of the signal satisfies: .
-
(iii)
The noise has independent entries (not necessarily identically distributed) with mean and variance that is bounded (), and are uniformly sub-Gaussian. Further, and are independent.
It is worth noting that the uniform sub-Gaussianity in Assumption 1(i) implies that the ’s from (2) are bounded. This is satisfied in GWAS, as is minor allele frequency (MAF) (psychiatric2009genomewide). The remaining Assumptions 1(ii) and (iii) are all weak and natural to impose. With Assumption 1 in mind, our primary goal is to establish that HEDE consistently estimates the heritability. The following theorem establishes this result under mild additional conditions on the minimum singular values of submatrices of (Assumption 2, Supplementary Materials A.1). The proof is provided in Supplementary Materials F.3.
Theorem 4.1.
Theorem 4.1 states that HEDE is consistent when and are arbitrarily chosen in and , respectively. It follows that HEDE is consistent using our proposed choices . Here denotes the range of that we use. See details in Supplementary Materials A.2.
Proving the consistency for given fixed choices of these hyperparameters is relatively straightforward, However, establishing the uniform gurantee is non-trivial. It requires analyzing the debiased Lasso and ridge estimators jointly, and furthermore, pinning down this joint behavior uniformly over all hyperparameter choices. We achieve both these goals under relatively mild assumptions on the covariate and noise distributions. Once we establish the uniform control, Part (ii) follows trivially since the uniform result provides consistency for the particular choices produced by our algorithm. Below, we present the key theorem necessary for proving Theorem 4.1.
We now discuss how Proposition 4.2 leads to our previous Theorem 4.1. Proposition 4.2 equivalently proposes a consistent estimator for , which is directly related to by a factor of the population variance of . Since the population variance of can be consistently estimated by the sample variance of the observed outcomes, we can safely replace the former by the latter in the denominator. Theorem 4.1(i) then follows on using the final fact that clipping does not affect consistency.
Proposition is 4.2 proved in Supplementary materials F.2. Here we briefly outline our main idea. Recall from (8) that is a linear combination of and . To develop uniform guarantees for , it therefore suffices to establish the corresponding uniform guarantees for the debiased Lasso and ridge jointly, which we establish in the following theorem.
Theorem 4.3.
Theorem 4.3 is proved in Supplementary materials D. It states that the joint “Gaussianity” described in (6) occurs at the population level in terms of the value of Lipschitz functions of the estimators, in addition to a per-coordinate basis. While results of this nature have appeared in the recent literature on exact high-dimensional asymptotics, majority of these works focus on a single regularized estimator (or its debiased version) with a fixed tuning parameter value. Theorem 4.3 provides the first joint characterization of multiple debiased estimators that is uniform over a range of tuning parameter values.
Among related works, celentano2021cad established joint characterization of two estimators and their debiased versions for given fixed tuning parameter choices. Meanwhile, miolane2021distribution characterized certain properties of the Lasso and the debiased Lasso uniformly across tuning parameter values. However, developing a heritability estimator that performs well in practice across sparse to dense signals requires the stronger result of the form in Theorem 4.3. Dealing with the debiased lasso and ridge jointly, while requiring uniform characterization over tuning parameters as well as allowing sub-Gaussian covariates, poses unique challenges. We overcome these challenges in our work, building upon miolane2021distribution, celentano2020lasso, celentano2021cad and universality techniques proposed in han2022universality, which in turn rely on the Convex Gaussian Minmax Theorem (GCMT) (thrampoulidis2015regularized). We detail the connections and differences in the Supplementary Materials.
Note that Theorem 4.3 involves the variance-covariance parameters (formal definitions deferred to later (23) (24) in the interest of space. We establish in Supplementary Materials, Theorem F.1 that , defined in (7), consistently estimate these parameters. Furthermore, we show that this consistency holds uniformly over the required range of tuning parameter values. This result, coupled with Theorem 4.3, yields our key Proposition 4.2.
Finally we turn to the case where the observed features are correlated. Recall from Section 3.4 that here we consider the design matrix to take the form , where now has independent entries and satisfies the conditions in Assumption 1(i). Thus, our previous theorems apply to (which is unobserved), but not to the observed . Applying whitening with estimated results in final features of the form . When approximates accurately, behaves as the identity matrix . In this case, is close to which satisfies our previous Assumption 1. HEDE therefore continues to enjoy uniform consistency guarantees, as formalized below.
Theorem 4.4.
Consider the setting of Theorem 4.1 except that the observed features now take the form where satisfies Assumptions 1(i) and 2(i). Let be a sequence of deterministic symmetric matrices whose eigenvalues are bounded in for some . Let be a sequence of random matrices such that . If satisfies Assumption 3 and denotes the estimator 11 calculated using the whitened data , then
| (16) |
Thus, the corresponding HEDE estimator is also consistent for .
Although we present this theorem for a general sequence of covariance matrices that allow accurate estimators in operator norm, we use it only for block diagonal covariances relevant for our application, where the block sizes are relatively small compared to the sample size. In Supplementary Materials, Proposition A.1, we establish that for such covariance matrices, the block-wise sample covariance matrix provides such an acccurate estimator. Theorem 4.4 is proved in Supplementary Materials G. The key idea lies in establishing that the estimation error incurred while replacing by does not affect the uniform consistency properties of HEDE.
5 Simulation Results
We evaluate the performance of HEDE through simulation studies. In Section 5.1, we compare HEDE to some representative random effects methods for estimating the heritability under different signal structures. In Section 5.2, we compare HEDE against several fixed effect based methods for estimating the heritability.
5.1 Comparison with random effects methods
Given the widespread adoption of the random effects assumption in genetics, it is important to benchmark HEDE against various random-effects-based methods. A diverse array of such methods exist, each based on a different random effects assumption. We show that a random-effects-based method fails to provide unbiased heritability estimates when corresponding assumptions are violated (i.e. signals are not generated as assumed). In contrast, HEDE constantly offers unbiased estimates (albeit with a slightly higher variance).
For conciseness, we focus on three representative random effects methods: GREML-SC (yang2011gcta): effectively GCTA, which assumes no stratification; GREML-MS (lee2013estimation), which is a modified version of GREML that accounts for minor allele frequency (MAF) stratification; GREML-LDMS (yang2015genetic), which is a modified version of GREML that accounts for both linkage disequilibrium (LD) level and MAF stratification. Their corresponding random effects assumptions state that within respective stratifications, the signal entries are i.i.d. draws from a zero-inflated normal distribution (equivalently, the non-zero entries are randomly/evenly located and normally distributed).
For our simulations, we use genotype data from unrelated white British individuals in the UK Biobank dataset (sudlow2015uk). We select common variants with a minor allele frequency (MAF) greater than from the UK Biobank Axiom array using PLINK. Additionally, we exclude SNPs with genotype missingness over and Hardy-Weinberg disequilibrium p-values greater than . We impute the remaining small number of missing values as 0. This results in a design matrix with individuals and variants across 22 chromosomes, which is then normalized so each column has a mean of 0 and variance of 1. To expedite the process, our simulation analysis focuses on chromosome . We use randomly sampled disjoint subsets of individuals each to simulate independent random draws of . We then generate a random based on different assumptions and generate following the linear model in (1). This results in heritability estimates, which are estimated using GREML methods and HEDE. We then compare the average of these estimates with the true population heritability value.
While our formal mathematical guarantees are established under the fixed effects assumption, it is desirable to stress-test the performance of our method in the random effects simulation settings, especially since we wish to benchmark our method against popular methods from statistical genetics. We further discuss the connection between the random effect assumption and the fixed effect assumption in terms of the true population parameter (Supplementary Materials B.1), with the discussion aimed at explaining why the empirical comparison we perform here is reasonable, given the methods were developed under different assumptions.
For the GREML methods, we use LD bins generated from the quantiles of individual LD values (evans2018comparison), and MAF bins: , and . For HEDE, we perform the whitening step by estimating the population covariance as a block diagonal with blocks specified in (berisa2016approximately). We estimate the block-wise population covariances using sample covariances. Given that and for each LD block, this approach results in minimal high-dimensional error.
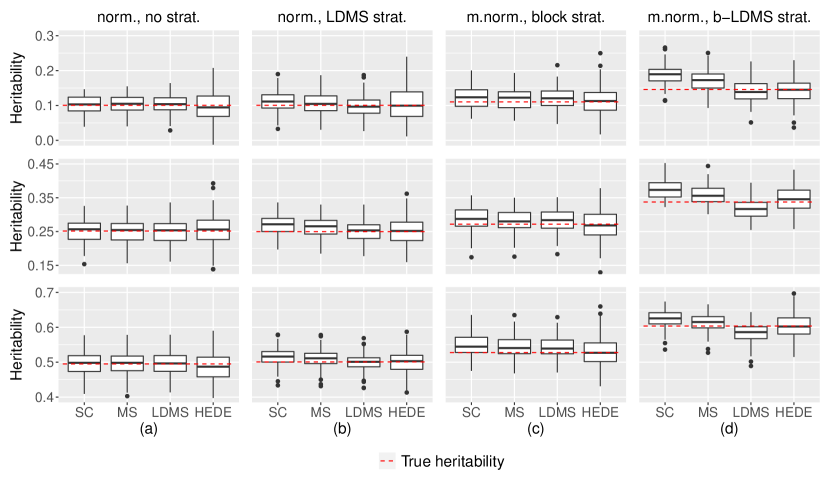
To assess the robustness of different methods against the misspecification of typical random effects assumptions on the regression coefficients, we created types of random signals. These signals vary in the locations and distributions of non-zero entries (causal variants) as shown in Figure 1. In Figure 1a, the non-zero locations of are uniformly distributed, with non-zero components normally distributed. Here the assumptions for all three GREML methods are satisfied. In Figure 1b, the non-zero locations of vary in concentration across LDMS strata, with non-zero components normally distributed. Here only the assumption for GREML-LDMS is satisfied. In Figure 1c, the non-zero locations of are more concentrated in the last LD block, with non-zero components distributed as a mixture of two normals (centered symmetrically around zero). Here none of the assumptions of the three GREML methods is satisfied. In Figure 1d, the non-zero locations of vary in concentrations across both LD blocks and LDMS strata, with non-zero components distributed as a mixture of two normals. Here none of the assumptions of the three GREML methods are satisfied, with varying degrees of violations. The full details of the signal generation process are described in Supplementary Materials B.2.
Figure 1 clearly demonstrates that the GREML methods are susceptible to signal distribution misspecifications, exhibiting increased bias as the extent of assumption violation rises. In contrast, HEDE is robust and provides unbiased estimates in all cases, despite exhibiting higher variance. This pattern remains robust across various levels of true population heritability ( and shown).
We believe these findings are likely to apply to other random-effects-based methods. A random effects method can only guarantee unbiased estimates when its underlying random effects assumptions are satisfied—a condition that is often difficult to verify with real data. In contrast, HEDE is not susceptible to such biases, demonstrating that the fixed effect based HEDE method applies under much diverse signal structures.
5.2 Comparison of HEDE with other fixed effects methods
In this section, we compare the performance of HEDE with other fixed effects heritability estimation methods. Recall we showed in Section 3.4 and Theorem 4.4 that HEDE remains consistent under accurate covariance estimation strategies. Also, fixed effects heritability estimation methods all assume is known or can be accurately estimated. In light of these, we assume without loss of generality that , in order to directly compare the relative performance of fixed effect methods. To mimic discrete covariates in genetic scenarios, we generate the design matrix via (2), where and , representing common variants with a minor allele frequency of at least . We generate the true signal as i.i.d. zero-inflated normals with non-zero co-ordinate weight and heritability : . We generate the noise with i.i.d. entries. We vary across our simulation settings.
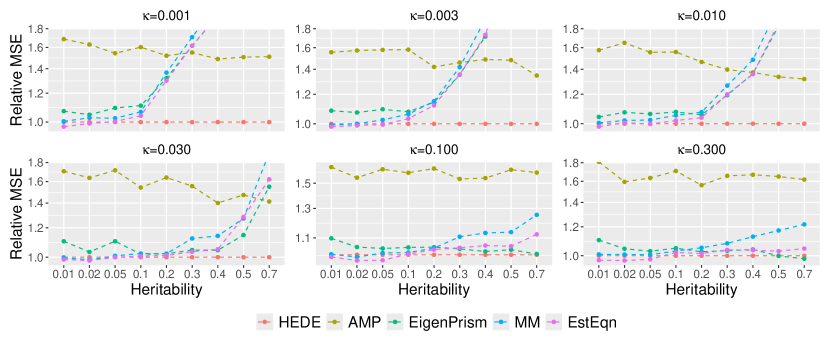
For each simulation setting, we compare HEDE with a Lasso-based method, AMP (bayati2013estimating)111We label this method as AMP, since it was created based on approximate message passing (AMP) algorithms., and three Ridge-based methods: Dicker’s moment-based method (dicker2014variance), Eigenprism (janson2017eigenprism), and Estimating Equation (chen2022statistical). For AMP, (bayati2013estimating) does not provide a strategy for tuning the regularization parameter. Therefore, we choose the tuning parameter based on cross validation (specifically the Approximate Leave one Out (ALO) rad2020scalable approach) performed over smaller datasets with the same values of . All aforementioned methods operate under similar fixed effects assumption as HEDE, except that Eigenprism only handles in its current form. We first compared these methods in terms of bias and found that they all remain unbiased across a wide variety of settings. In Supplementary Matrials B.3, we demonstrate their unbiasedness for a specific choice of . In light of this, here we present comparisons between these estimators in terms of their mean square errors (MSEs).
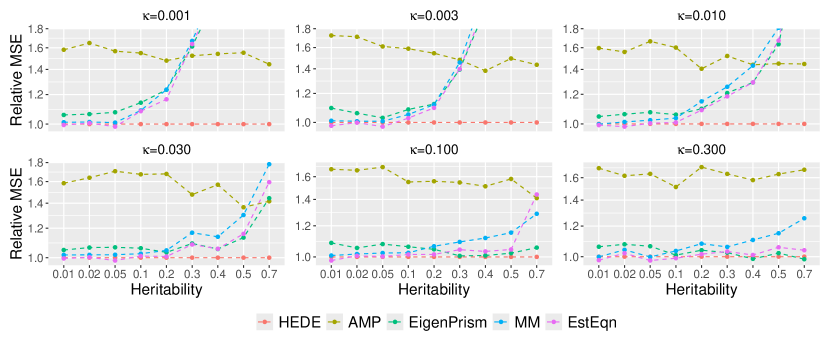
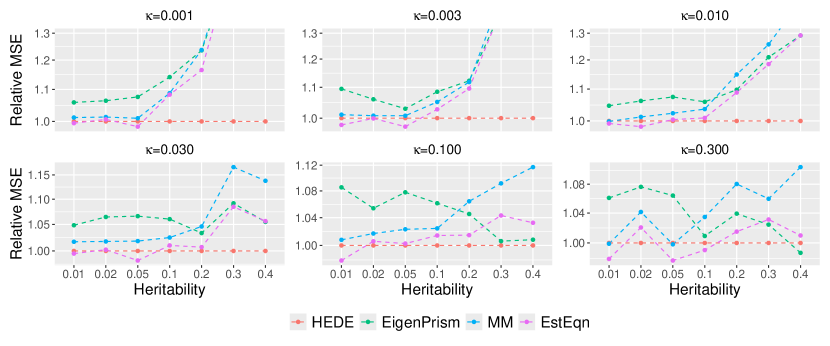
In Figure 2, we display the relative MSEs of heritability estimates in relation to and , while fixing sample size and number of variants . We vary sparsity from to on a roughly evenly spaced log scale, and vary heritability from to . This range mimics the potential true heritability values for traits such as autoimmune disorders (lower heritability) and height (higher heritability) (hou2019accurate). Although the methods under comparison operate under fixed effects assumptions, we still simulate signals to mitigate the influence of any particular signal choice. For each signal, we generate random samples and calculate the MSE for estimating heritability. We then average the error over the 10 signals.
We observe that HEDE outperforms ridge-type methods particularly when the true signal is sparse and relatively strong, while performing comparably in other scenarios. Since HEDE utilizes the strengths of both Lasso and ridge, the performance gain over pure ridge-based methods, such as EigenPrism, MM and EstEqn, is natural. The pure Lasso-based method (AMP, green) performs sub-optimal compared to all the others, and its higher MSE values are dominating the y-axis range. For a closer view, we present a zoomed in version of the plot in Figure 5 where we exclude AMP (we defer the figure to Supplementary Materials B.3 in light of space). Figures 2 and 5 clearly demonstrate the efficacy of our ensembling strategy. It leads to a superior heritability estimator across signals ranging from less sparse to highly sparse.
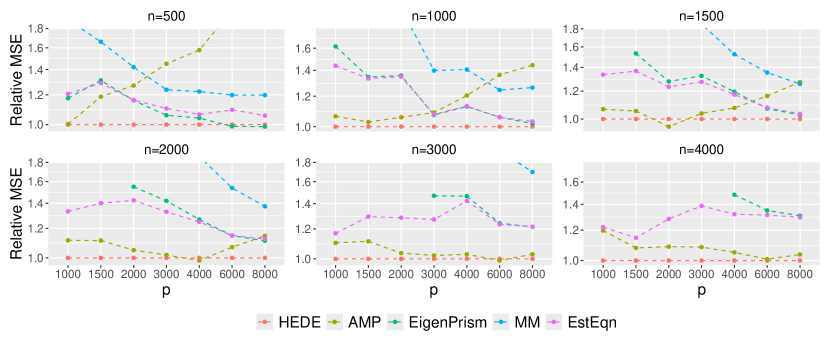
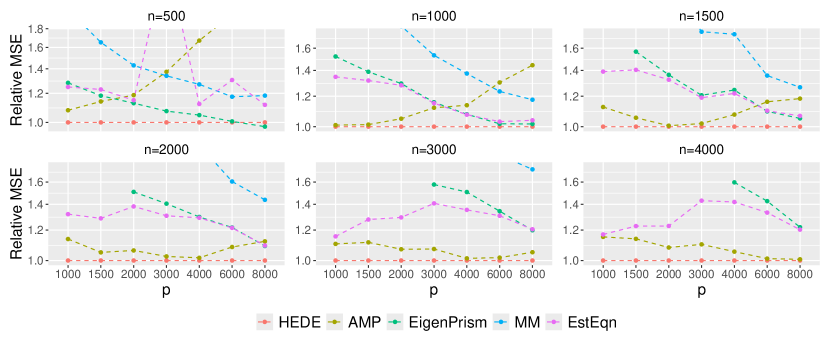
To better investigate our relative performance, in Figure 3, we consider a specific setting——where HEDE has a moderate advantage in Figure 2, We vary and so the ratio ranges from to . We clearly observe that HEDE’s advantage across a broad spectrum of configurations. Note that Eigenprism’s results are missing for as it currently only supports . Also observe that AMP’s relative performance degrades sharply with larger values, as shown in the first panel of Figure 3. This explains its sub-optimal performance in Figure 2 when . Figure 3 demonstrates that HEDE leads to superior performance over a wide range of sample sizes, dimensions and dimension-to-sample ratios. It consistently outperforms the other methods for the setting examined.
To determine if HEDE’s superior performance extends to broader contexts, we conducted additional investigations. We examined settings where the designs contain larger sub-Gaussian norms, and in addition, settings where the non-zero entries of the signal were drawm from non-normal distributions and/or are distributed with stratifications (see Section 5.1). Results for the former investigation are presented in Supplementary Materials. B.4, whereas we omit those for the latter in light of the performances looking similar. Across the board, we observed that HEDE maintained maintains its competitive advantage over other methods. We also investigated a Lasso-based method CHIVE (tony2020semisupervised) in our experiments. However, CHIVE exhibited considerable bias in many settings, particularly when its underlying sparsity assumptions were violated. For this reason, we have omitted CHIVE from our result displays.
6 Real data application
We next describe our real data experiments. We apply HEDE on the unrelated white British individuals from the UK biobank GWAS data which contain common variants (sudlow2015uk) to estimate the heritability for two commonly studied phenotypes: height and BMI. For the design matrix , we follow the preprocessing steps outlined in Section 5.1, but include all chromosomes, unlike Section 5.1 which considers only chromosome . For each phenotype, we exclude individuals with missing values. We center the outcomes and denote the resultant vector by . We account for non-genetic factors by including covariates for age, age2, sex as well as ancestral principal components. We derive the final response vector by regressing out the influence of these non-genetic covariates from using Ordinary Least Squares (OLS). The large sample size of approximately individuals compared to only non-genetic covariate, ensures that OLS can be confidently applied.
We apply HEDE to preprocessed and . For comparison, we also apply GREML-SC and GREML-LDMS (see Section 5.1 for details) from the random effects methods family, as well as MM and AMP from the fixed effects methods family. We did not include Eigenprism and EstEqn since their runtimes are both (assuming ), so they could not be completed within a reasonable time frame. We calculate standard errors using the standard deviation of point estimates from disjoint random subsets, each containing individuals.222In our high-dimensional setting, it is known that traditional resampling techniques for estimating standard errors such as the bootstrap, subsampling, etc. fail (el2018can; clarte2024analysis; bellec2024asymptotics). Corrections have been proposed to address issues with using these for estimating standard errors while inferring individual regression vector coefficients and closely related problems. However, such strategies for heritability estimation are yet to be developed. To circumvent this issue, we use disjoint subsets of observed data to mimic independent training data draws from the population. Additionally, due to memory constraints, many methods (including HEDE) could not process all chromosomes simultaneously. Therefore, for all methods, we estimate the total heritability by summing the heritabilities calculated for each chromosome separately. This approach is expected to introduce minimal error, given the widely accepted assumption of independence across chromosomes.
| Trait | HEDE | MM | AMP | GREML-SC | GREML-LDMS |
|---|---|---|---|---|---|
| Height | 0.681 | 0.813 | 0.436 | 0.741 | 0.605 |
| (SE) | (7.47E-02) | (9.30E-02) | (3.01E-01) | (2.87E-02) | (3.19E-02) |
| BMI | 0.279 | 0.369 | 0.510 | 0.316 | 0.265 |
| (SE) | (5.20E-02) | (6.66E-02) | (3.52E-01) | (2.85E-02) | (3.22E-02) |
We summarize the results in Table 2. First, we observe that MM and AMP estimates differ more from HEDE compared to other methods. This is consistent with Figure 2, where we observe that AMP often has larger MSE than other fixed effects methods. Thus, we expect AMP estimates to differ significantly from HEDE, and MM. For MM, the situation is more nuanced. Prior work suggests the true height heritability should be on the higher end of the range shown in Figure 2. In this region, MM has higher MSE than HEDE across all sparsity levels. Therefore, MM estimates of height heritability may be less accurate than HEDE. For BMI, prior work provides heritability estimates within the range to using various methods. Referring to Figure 2, we see that MM’s relative MSE compared to HEDE depends on the sparsity level in this BMI heritability range. Without knowing the exact sparsity, it is difficult to draw conclusions. However, we still observe the general trend of MM producing larger estimates than other methods for BMI, similar to height.
Comparing HEDE to the two random effect methods, we observe that HEDE point estimates fall between GREML-SC and GREML-LDMS ones. For both height and BMI, HEDE estimates lie between GREML-SC and GREML-LDMS,, with the latter always undershooting. This is consistent with the trend observed in the last column of Figure 1. This difference may indicate a heterogeneous underlying genetic signal, especially in a way that differentiates the SC and LDMS approaches within the GREML framework.
7 Discussion
In this paper, we introduce HEDE, a new method for heritability estimation that harnesses the strengths of and regression in high-dimensional settings through a sophisticated ensemble approach. We develop data-driven techniques for selecting an optimal ensemble and fine-tuning key hyperparameters, aiming to enhance statistical performance in heritability estimation. As a result, we present a competitive estimator that surpasses existing fixed effects heritability estimators across diverse signal structures and heritability values. Notably, our approach circumvents bias issues inherent in random effects methods. In summary, our contribution offers a dependable heritability estimator tailored for high-dimensional genetic problems, effectively accommodating underlying signal variations. Importantly, our method maintains consistency guarantees even with adaptive tuning and under minimal assumptions on the covariate distribution. We validate the efficacy of our approach through comprehensive simulations and real-data analysis.
HEDE’s computational complexity is primarily driven by the Lasso/ridge solutions, making it more efficient than many existing heritability estimators (e.g. Eigenprism (janson2017eigenprism), where an SVD is required, and EstEqn (chen2022statistical), where chained matrix inversions are involved). HEDE is potentially scalable to much larger dimensions via snpnet (rad2020scalable). Furthermore, with proper Lasso/ridge solving techniques, HEDE only needs knowledge of summary statistics and . This makes it an attractive option in situations where individual data sharing is difficult due to privacy concerns. However, it is important to note that these discussions assume the availiability of an accurate estimate of the LD blocks and strength. This is a common limitation that other fixed effects methods also face. Any potential errors in covariance estimation could naturally lead to additional errors in heritability estimation. Therefore, improving and scaling covariance estimation in high dimensions could independently benefit heritability estimation. We manage to circumvent this issue by leveraging the hypothesis of independence across chromosomes, which significantly aids us computationally.
Our theoretical framework relied on two pivotal assumptions: the independence of observed samples and a sub-Gaussian tailed distribution for covariates. Natural settings occur where these assumptions are violated. Within the genetics context, familial relationships and repeated measures in longitudinal studies among observed samples can introduce dependence. For the broader problem of signal-to-noise ratio estimation in various scientific fields, both assumptions might be violated. For instance, applications such as wireless communications (eldar2003asymptotic) and magnetic resonance imaging (benjamini2013shuffle) may introduce challenges such as temporal dependence or heavier-tailed covariate distributions. Exploring analogues of HEDE under such conditions presents an intriguing avenue for future study. Recent advancements in high-dimensional regression, which extend debiasing methodology and proportional asymptotics theory for regularized estimators to these complex scenarios (li2023spectrum; lahiry2023universality), offer valuable insights for further exploration. We defer these investigations to future research.
We focus on continuous traits in this paper. Discrete disease traits occur commonly in genetics. Such situations are typically modeled using logistic, probit, or binomial regression models, depending on the number of possible categorical values of the response. Adapting our current methodology to these scenarios is a crucial avenue for future research. Debiasing methodologies for generalized linear models exist in the literature. A compelling question would be to understand how various debiasing techniques can be ensembled to optimize their benefits for heritability estimation, similar to our approach in this work for the linear model.
References
- Bayati et al., (2013) Bayati, M., Erdogdu, M. A., and Montanari, A. (2013). Estimating lasso risk and noise level. Advances in Neural Information Processing Systems, 26.
- Bellec, (2022) Bellec, P. C. (2022). Observable adjustments in single-index models for regularized m-estimators. arXiv preprint arXiv:2204.06990.
- Bellec and Koriyama, (2024) Bellec, P. C. and Koriyama, T. (2024). Asymptotics of resampling without replacement in robust and logistic regression. arXiv preprint arXiv:2404.02070.
- Bellec and Zhang, (2019) Bellec, P. C. and Zhang, C.-H. (2019). Second order poincaré inequalities and de-biasing arbitrary convex regularizers when p/n→ . arXiv preprint arXiv:1912.11943, 2:15–34.
- Bellec and Zhang, (2022) Bellec, P. C. and Zhang, C.-H. (2022). De-biasing the lasso with degrees-of-freedom adjustment. Bernoulli, 28(2):713–743.
- Bellec and Zhang, (2023) Bellec, P. C. and Zhang, C.-H. (2023). Debiasing convex regularized estimators and interval estimation in linear models. The Annals of Statistics, 51(2):391–436.
- Benjamini and Yu, (2013) Benjamini, Y. and Yu, B. (2013). The shuffle estimator for explainable variance in fmri experiments. The Annals of Applied Statistics, pages 2007–2033.
- Berisa and Pickrell, (2016) Berisa, T. and Pickrell, J. K. (2016). Approximately independent linkage disequilibrium blocks in human populations. Bioinformatics, 32(2):283.
- Bonnet et al., (2015) Bonnet, A., Gassiat, E., and Lévy-Leduc, C. (2015). Heritability estimation in high dimensional sparse linear mixed models.
- Cai and Guo, (2020) Cai, T. and Guo, Z. (2020). Semisupervised inference for explained variance in high dimensional linear regression and its applications. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(2):391–419.
- Candès and Sur, (2020) Candès, E. J. and Sur, P. (2020). The phase transition for the existence of the maximum likelihood estimate in high-dimensional logistic regression.
- Celentano and Montanari, (2021) Celentano, M. and Montanari, A. (2021). Cad: Debiasing the lasso with inaccurate covariate model. arXiv preprint arXiv:2107.14172.
- Celentano et al., (2020) Celentano, M., Montanari, A., and Wei, Y. (2020). The lasso with general gaussian designs with applications to hypothesis testing. arXiv preprint arXiv:2007.13716.
- Chen, (2022) Chen, H. Y. (2022). Statistical inference on explained variation in high-dimensional linear model with dense effects. arXiv preprint arXiv:2201.08723.
- Clarté et al., (2024) Clarté, L., Vandenbroucque, A., Dalle, G., Loureiro, B., Krzakala, F., and Zdeborová, L. (2024). Analysis of bootstrap and subsampling in high-dimensional regularized regression. arXiv preprint arXiv:2402.13622.
- Dicker, (2014) Dicker, L. H. (2014). Variance estimation in high-dimensional linear models. Biometrika, 101(2):269–284.
- Dicker and Erdogdu, (2016) Dicker, L. H. and Erdogdu, M. A. (2016). Maximum likelihood for variance estimation in high-dimensional linear models. In Artificial Intelligence and Statistics, pages 159–167. PMLR.
- El Karoui and Purdom, (2018) El Karoui, N. and Purdom, E. (2018). Can we trust the bootstrap in high-dimensions? the case of linear models. Journal of Machine Learning Research, 19(5):1–66.
- Eldar and Chan, (2003) Eldar, Y. C. and Chan, A. M. (2003). On the asymptotic performance of the decorrelator. IEEE Transactions on Information Theory, 49(9):2309–2313.
- Evans et al., (2018) Evans, L. M., Tahmasbi, R., Vrieze, S. I., Abecasis, G. R., Das, S., Gazal, S., Bjelland, D. W., De Candia, T. R., Consortium, H. R., Goddard, M. E., et al. (2018). Comparison of methods that use whole genome data to estimate the heritability and genetic architecture of complex traits. Nature genetics, 50(5):737–745.
- Fan et al., (2012) Fan, J., Guo, S., and Hao, N. (2012). Variance estimation using refitted cross-validation in ultrahigh dimensional regression. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 74(1):37–65.
- Guo et al., (2019) Guo, Z., Wang, W., Cai, T. T., and Li, H. (2019). Optimal estimation of genetic relatedness in high-dimensional linear models. Journal of the American Statistical Association, 114(525):358–369.
- Han and Shen, (2022) Han, Q. and Shen, Y. (2022). Universality of regularized regression estimators in high dimensions. arXiv preprint arXiv:2206.07936.
- Hou et al., (2019) Hou, K., Burch, K. S., Majumdar, A., Shi, H., Mancuso, N., Wu, Y., Sankararaman, S., and Pasaniuc, B. (2019). Accurate estimation of snp-heritability from biobank-scale data irrespective of genetic architecture. Nature genetics, 51(8):1244–1251.
- Hu and Li, (2022) Hu, X. and Li, X. (2022). Misspecification analysis of high-dimensional random effects models for estimation of signal-to-noise ratios. arXiv preprint arXiv:2202.06400.
- Janson et al., (2017) Janson, L., Barber, R. F., and Candes, E. (2017). Eigenprism: inference for high dimensional signal-to-noise ratios. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 79(4):1037–1065.
- (27) Javanmard, A. and Montanari, A. (2014a). Confidence intervals and hypothesis testing for high-dimensional regression. The Journal of Machine Learning Research, 15(1):2869–2909.
- (28) Javanmard, A. and Montanari, A. (2014b). Hypothesis testing in high-dimensional regression under the gaussian random design model: Asymptotic theory. IEEE Transactions on Information Theory, 60(10):6522–6554.
- Jiang et al., (2016) Jiang, J., Li, C., Paul, D., Yang, C., and Zhao, H. (2016). On high-dimensional misspecified mixed model analysis in genome-wide association study. The Annals of Statistics, 44(5):2127–2160.
- Jiang et al., (2022) Jiang, K., Mukherjee, R., Sen, S., and Sur, P. (2022). A new central limit theorem for the augmented ipw estimator: Variance inflation, cross-fit covariance and beyond. arXiv preprint arXiv:2205.10198.
- Knowles and Yin, (2017) Knowles, A. and Yin, J. (2017). Anisotropic local laws for random matrices. Probability Theory and Related Fields, 169(1):257–352.
- Lahiry and Sur, (2023) Lahiry, S. and Sur, P. (2023). Universality in block dependent linear models with applications to nonparametric regression. arXiv preprint arXiv:2401.00344.
- Lee et al., (2013) Lee, S. H., Yang, J., Chen, G.-B., Ripke, S., Stahl, E. A., Hultman, C. M., Sklar, P., Visscher, P. M., Sullivan, P. F., Goddard, M. E., et al. (2013). Estimation of snp heritability from dense genotype data. The American Journal of Human Genetics, 93(6):1151–1155.
- Li et al., (2022) Li, R., Chang, C., Justesen, J. M., Tanigawa, Y., Qian, J., Hastie, T., Rivas, M. A., and Tibshirani, R. (2022). Fast lasso method for large-scale and ultrahigh-dimensional cox model with applications to uk biobank. Biostatistics, 23(2):522–540.
- Li and Sur, (2023) Li, Y. and Sur, P. (2023). Spectrum-aware adjustment: A new debiasing framework with applications to principal components regression. arXiv preprint arXiv:2309.07810.
- Liang and Sur, (2022) Liang, T. and Sur, P. (2022). A precise high-dimensional asymptotic theory for boosting and minimum-l1-norm interpolated classifiers. The Annals of Statistics, 50(3):1669–1695.
- Loh et al., (2015) Loh, P.-R., Tucker, G., Bulik-Sullivan, B. K., Vilhjalmsson, B. J., Finucane, H. K., Salem, R. M., Chasman, D. I., Ridker, P. M., Neale, B. M., Berger, B., et al. (2015). Efficient bayesian mixed-model analysis increases association power in large cohorts. Nature genetics, 47(3):284–290.
- Manolio et al., (2009) Manolio, T. A., Collins, F. S., Cox, N. J., Goldstein, D. B., Hindorff, L. A., Hunter, D. J., McCarthy, M. I., Ramos, E. M., Cardon, L. R., Chakravarti, A., et al. (2009). Finding the missing heritability of complex diseases. Nature, 461(7265):747–753.
- Miolane and Montanari, (2021) Miolane, L. and Montanari, A. (2021). The distribution of the lasso: Uniform control over sparse balls and adaptive parameter tuning. The Annals of Statistics, 49(4):2313–2335.
- Psychiatric GWAS Consortium Coordinating Committee, (2009) Psychiatric GWAS Consortium Coordinating Committee, . (2009). Genomewide association studies: history, rationale, and prospects for psychiatric disorders. American Journal of Psychiatry, 166(5):540–556.
- Rad and Maleki, (2020) Rad, K. R. and Maleki, A. (2020). A scalable estimate of the out-of-sample prediction error via approximate leave-one-out cross-validation. Journal of the Royal Statistical Society Series B: Statistical Methodology, 82(4):965–996.
- Rockafellar, (2015) Rockafellar, R. T. (2015). Convex analysis.
- Sudlow et al., (2015) Sudlow, C., Gallacher, J., Allen, N., Beral, V., Burton, P., Danesh, J., Downey, P., Elliott, P., Green, J., Landray, M., et al. (2015). Uk biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS medicine, 12(3):e1001779.
- Sun and Zhang, (2012) Sun, T. and Zhang, C.-H. (2012). Scaled sparse linear regression. Biometrika, 99(4):879–898.
- Sur and Candès, (2019) Sur, P. and Candès, E. J. (2019). A modern maximum-likelihood theory for high-dimensional logistic regression. Proceedings of the National Academy of Sciences, 116(29):14516–14525.
- Sur et al., (2019) Sur, P., Chen, Y., and Candès, E. J. (2019). The likelihood ratio test in high-dimensional logistic regression is asymptotically a rescaled chi-square. Probability theory and related fields, 175:487–558.
- Thrampoulidis et al., (2015) Thrampoulidis, C., Oymak, S., and Hassibi, B. (2015). Regularized linear regression: A precise analysis of the estimation error. In Conference on Learning Theory, pages 1683–1709. PMLR.
- Van de Geer et al., (2014) Van de Geer, S., Bühlmann, P., Ritov, Y., and Dezeure, R. (2014). On asymptotically optimal confidence regions and tests for high-dimensional models.
- Vershynin, (2010) Vershynin, R. (2010). Introduction to the non-asymptotic analysis of random matrices. arXiv preprint arXiv:1011.3027.
- Vershynin, (2018) Vershynin, R. (2018). High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press.
- Verzelen and Gassiat, (2018) Verzelen, N. and Gassiat, E. (2018). Adaptive estimation of high-dimensional signal-to-noise ratios. Bernoulli, 24(4B):3683–3710.
- Wainwright, (2019) Wainwright, M. J. (2019). High-dimensional statistics: A non-asymptotic viewpoint, volume 48. Cambridge university press.
- Wellner et al., (2013) Wellner, J. et al. (2013). Weak convergence and empirical processes: with applications to statistics. Springer Science & Business Media.
- Yang et al., (2015) Yang, J., Bakshi, A., Zhu, Z., Hemani, G., Vinkhuyzen, A. A., Lee, S. H., Robinson, M. R., Perry, J. R., Nolte, I. M., van Vliet-Ostaptchouk, J. V., et al. (2015). Genetic variance estimation with imputed variants finds negligible missing heritability for human height and body mass index. Nature genetics, 47(10):1114–1120.
- Yang et al., (2011) Yang, J., Lee, S. H., Goddard, M. E., and Visscher, P. M. (2011). Gcta: a tool for genome-wide complex trait analysis. The American Journal of Human Genetics, 88(1):76–82.
- Zhang and Zhang, (2014) Zhang, C.-H. and Zhang, S. S. (2014). Confidence intervals for low dimensional parameters in high dimensional linear models. Journal of the Royal Statistical Society: Series B: Statistical Methodology, pages 217–242.
- Zhao et al., (2022) Zhao, Q., Sur, P., and Candes, E. J. (2022). The asymptotic distribution of the mle in high-dimensional logistic models: Arbitrary covariance. Bernoulli, 28(3):1835–1861.
- Zou and Hastie, (2005) Zou, H. and Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society Series B: Statistical Methodology, 67(2):301–320.
Appendix A Additional Methodology Details
A.1 Additional Technical Assumptions
We present additional technical assumptions needed for our mathematical guarantees in Section 4. The following assumption is needed for independent covariates:
Assumption 2.
-
1.
The design matrix satisfies for any , there exists a constant such that as , where denotes the minimum singular value of over all subsets of the columns with .
-
2.
The tuning parameters are bounded, that is, there exists such that .
Assumption 2(1) states that the minimum singular value of , across all subsets of a certain size, is lower bounded by some positive constant with high probability. This assumption is required for our universality proof. In fact, we conjecture that this assumption is true given Assumption 1(1) and Assumption 1(2) (c.f. Section B.5.4 in celentano2020lasso for a proof in Gaussian case). We leave the proof of this assumption to future work.
Assumption 2(2) restricts the range of to a predetermined range. We require a specific lower bound . The specific functional form is complicated, but plays a crucial role in our proof in Section I (which builds upon results from han2022universality). On the other hand, is not restricted and can take any proper value. See Section A.2 for a heuristic method that we use to determine in practice.
The following assumption is needed for estimated covariance under correlated case, effectively perturbing HEDE by a matrix :
Assumption 3.
Let be a sequence of random matrices. Denote to be the perturbed Lasso cost function when we replace by , and denote to be the perturbed Lasso solution. We say satisfies Assumption 3 if
-
1.
for some constant with probability converging to as
-
2.
with probability converging to as .
A.2 Hyperparameter Selection
Our algorithm necessitates a tuning parameter range . Assumption 2(2) defines as a function of the unknown , as well as an unconstrained , for completely technical reasons, both of which give little practical guidance. Here we propose to determine the range by the empirical degrees-of-freedom from Lasso and Ridge, defined in 19.
For , there is no point increasing it infinitely since will approach , yielding very similar values. Thus, we choose , therefore filtering out excessively large values.
For , we will similarly pick an upper bound for and . Due to numerical precision/stability issue, glmnet (and possibly other numerical solvers) yields incorrect solutions for tiny values of . Also, the lower bound -although unknown-prohibits tiny values of . Therefore, simply choosing an upper bound such as does not suffice. Heuristically, we find any value from to acceptable, and we take for simplicity.
Once the range for are determined, we discretize it on the log scale with grid width . This yields the final discrete collection of , from which we minimize .
A.3 Covariance Estimation
In Section 3.4, we discussed estimating the blocked population covariance matrix by block-wise sample covariance matrices. The following proposition supports its consistency under mind conditions:
Proposition A.1.
Let be a real symmetric matrix whose spectral distribution has bounded support with . Further suppose that is block-diagonal with blocks such that the size of each block is bounded by some constant . Let with each row satisfying where has independent sub-Gaussian entries with bounded sub-Gaussian norm. If we estimate as also block-diagonal with blocks where are corresponding sample covariances, then as , we have .
Proof.
The proof is straightforward by applying (wainwright2019high, Theorem 6.5) on each block component, in conjunction with a union bound. Thus we omit it here. ∎
Appendix B Additional Simulation Details
B.1 Random effects comparison: Heritability definition
The common setting in Section 5.1 assumes both and are zero-mean random and that has population covariance . Under random effects setting, a random is allowed, and the denominator in the heritability definition (3) reads
which is a well-defined population quantity. Yet, does not have a closed form formula if is generated with stratifications as in Section 5.1, so we approximated it with iterations.
Under fixed effect setting, conditioning on a given , the same definition reads
which is an empirical quantity that fluctuates around the population quantity . Now with random , estimating the corresponding individual approximately constitutes as estimating its expectation. This, therefore, facilitates fair comparisons between random and fixed effects methods.
B.2 Random effects comparison: Signal generation details
To generate with varying non-zero entry locations and distributions, we employed the following generation process. 1) We fixed two levels of concentration: and . 2) We determine , the number of stratifications needed. For uniformly distributed non-zero entries . For LDMS stratification, : the cross product of LD stratifications and MAF stratifications mentioned in Section 5.1. For LDMS plus block stratification, : the cross product of the previous LDMS stratifications and blocks: the last LD block vs the rest, specified in berisa2016approximately. 3) For each of the stratifications determined, we alternatively assign and as the concentration, and generate non-zero entries uniformly randomly with the assigned concentration. In the special case , is assigned. 4) After selecting non-zero entry locations, count the number of non-zero entries , and then calculate the entrywmeshyise variance where is the desired heritability value. 5) Lastly, pick the non-zero entry distribution. For random normal entries, the distribution is . For mixture-of-normal entries, the distribution is (an equal mixture of two symmetric normals).
B.3 Fixed effects comparisons: Unbiasedness and a closer look
In this section, we present two plots. The first investigates the bias properties of different fixed effects methods. For a representative example, we chose a setting with , and , though this selection is not particularly unique. Using a specific , we generated 100 random instances of . The box plots in Figure 4 depict the heritability estimates from all the methods under consideration. We observe that every method is (approximately) unbiased, which was confirmed by in additional settings. We also note that truncating negative estimates to would yield lower MSEs but more bias, so we opted to keep the negative estimates.
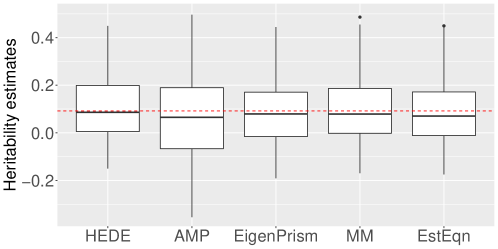
As a second line of investigation, we recall Figure 2 from the main manuscript, which showed that the AMP MSEs are often much higher than the remaining. In this light, we zoom into Figure 2 to obtain a clearer picture for the performance of our method relative to others. Figure 5 shows this zoomed in version. Note that our relative superiority is mostly maintained across diverse settings.
B.4 Fixed effects comparison: Designs with larger sub-Gaussian norms
To generate with larger sub-Gaussian norms, we followed the exact same setup as in Section 5.2, except that instead of in (2). This mimicks lower-frequency variants, leading to larger sub-Gaussian norms in the normalized . Comparing Figures 6, 7 with Figures 2, 3, we observe similar trends across the board, with HEDE having either similar or dominating performance.
Appendix C Proof Notations and Conventions
This section introduces notations that we will use through the rest of the proof. We consider both the Lasso and ridge estimators in the context of linear models. Several important quantities in our calculations appear in two versions—one computed based on the ridge and the other based on the Lasso. We use subscripts respectively to denote the versions of these quantities corresponding to the ridge and the Lasso. Recall that the setting we study may be expressed via the linear model where denote the responses, the design matrix, the unknown regression coefficients, and the noise. Then for , the corresponding Lasso and Ridge estimators are defined as
| (17) |
where .
Our methodology relies on debiased versions of these estimators, defined as
| (18) |
where are terms that may be interpreted as degrees-of-freedom, and are defined in each of the aforementioned cases as follows,
| (19) | ||||
Our proofs use some intermediate quantities that we introduce next. First, we will require intermediate quantities that replace by a set of parameters that rely on underlying problem parameters. For , we define these to be
| (20) |
The exact definition of is involved, so we defer its presentation to 24. Second, we need another set of intermediate quantities that form solutions to optimization problems of the form (17), but where the observed data is replaced by random variables that can be expressed as gaussian perturbations of the true signal, with appropriate adjustments to the penalty function. For , these are defined as follows:
| (21) |
| (22) |
with of the form
| (23) |
for suitable choices of that we define later in (24). Our exposition so far refrains from providing additional insights regarding the necessity of these intermediate quantities–however, the role of these quantities will unravel in due course through the proof. As an aside, note that the randomness in comes from , which is independent of the observed data. We use the superscript ‘f’ (standing for fixed) to denote that these do not depend on our observed data.
Our aforementioned notations are complete once we define the parameters from (20), from (21), and from (23). We define these as solutions to the following system of equations in the variables .
| (24) | ||||
where is defined as the divergence of with respect to its first argument and recall that we defined in (21).
Extracting the first and the last entries of the first equation in (24), we observe that depends on and not on , and similarly for the corresponding Ridge parameters. We also note that depends on both and . We will use this observation multiple times in our proofs later.
The system of equations 24 first arose in the context of the problem studied in celentano2021cad and Lemma C.1 from the aforementioned paper establishes the uniqueness of the solutions. Furthermore, it follows that there exist positive constants such that
| (25) |
for where denotes the unique solution to equation (24).
Whenever we mention constants in our proof below, we mean values that only depend on the model parameters laid out in Assumptions 1 and 2, and do not depend on any other variable (especially , and realization of any random quantities).
Finally in Sections D–H.4, we prove our results under the stylized setting where the design matrix entries are i.i.d. and the noise vector entries are i.i.d. . In Section I we establish universality results that show that the same conclusions hold under the setting of Assumptions 1 and 2, where the covariate and error distributions are more general. To avoid confusion, we define below a stylized version of Assumptions 1 and 2, where everything remains the same except the design, error distributions are taken to be i.i.d. Gaussian. So, Sections D-H.4 work under Assumption 4, while Section I works under Assumptions 1 and 2.
Assumption 4.
Note that we don’t need Assumption 2(1) since it is true for Gaussians (see B.5.4 in celentano2020lasso).
Appendix D Proof of Theorem 4.3
Theorem 4.3 forms the backbone of our results so we begin by presenting its proof here. Towards this goal, we first prove the following slightly different version.
Theorem D.1.
Theorem D.1 differs from Theorem 4.3 in that is now replaced by . The difference between these lies in the fact that is replaced by from the former to the latter (c.f. Eqns 18 and 20).
Given Theorem D.1, the proof of Theorem 4.3 follows a two step procedure: we first establish that the empirical quantities and the parameters are uniformly close asymptotically. This allows us to establish that and are asymptotically close. Theorem 4.3 thereby follows from here, when applied in conjunction with Theorem D.1 and the fact that is Lipschitz. We formalize these arguments below.
Proof.
(miolane2021distribution, Theorem F.1.) established the aformentioned for .
For , (celentano2021cad, Lemma H.1) (which further cites (knowles2017anisotropic, Theorem 3.7)) showed that that converges to for any fixed . So for our purposes it suffices to extend this proof to all simultaneously. We achieve this below.
Recall from Eqn. 24 that , where the trace on the right hand side is the negative resolvent of evaluated at and normalized by . (knowles2017anisotropic, Theorem 3.7) (with some notation-transforming algebra) states that this negative normalized resolvent converges in probability to with fluctuation of level , where is the distance from to the spectrum of . Therefore, concentrates around with fluctuation of level , for all . ∎
As a direct consequence, we have
Corollary D.1.
Under Assumption 4, we have for ,
Proof.
From here, one can derive the following Lemma using the definitions of , . One should compare the following to (celentano2021cad, Lemma H.1.ii) that proved a pointwise version of this result without any supremum over the tuning parameters.
Lemma D.3.
Under Assumption 4, for ,
Proof.
We next turn to prove Theorem 4.3.
Proof of Theorem 4.3.
Thus, our proof of Theorem 4.3 is complete if we prove Theorem D.1. We present this in the next sub-section.
D.1 Proof of Theorem D.1
The overarching structure of our proof of Theorem D.1 is inspired by (celentano2021cad, Section D). However, unlike in our setting below, the results in the aforementioned paper do not require uniform convergence over a range of values of the tuning parameter. This leads to novel technical challenges in our setting that we handle as we proceed.
To prove Theorem D.1, we introduce an intermediate quantity that conditions on (recall the definition from (22)) taking on a specific value defined as follows:
| (26) |
where are defined as in (24). Recall from (25) that so that the square root above is well-defined.
Remark.
The definition of is non-trivial. However, the takeaway is that the realization should be understood as the coupling of and such that equals , respectively. We refer readers to (celentano2021cad, Section F.1 and Section L) for the underlying intuition as well as the proof of this equivalence.
Since becomes conditioning on , we have , where the randomness inside the expectation comes from , and is fixed. In fact, analogous to , approximates , as formalized in the result below.
Lemma D.4.
Under Assumption 4,
With these definitions in hand, the proof is complete on combining the following two lemmas.
Lemma D.5.
Lemma D.6.
Under Assumption 4, for any -Lipschitz function ,
We present the proofs of these supporting lemmas in the following subsection.
D.2 Proof of Lemmas D.4–D.6
We start with the proof of Lemma D.4 since it plays a crucial role in the proofs of the others. To this end, perhaps the most important step is the following lemma that establishes the boundedness and limiting behavior of certain special entities.
Lemma D.7.
For , define as
| (28) |
Under Assumption 4,
-
•
Convergence:
-
•
Boundedness: there exists positive constants such that with probability ,
D.2.1 Proof of Lemma D.4
Proof of Lemma D.4.
(celentano2021cad, Section J.1) proved a pointwise version of this lemma, without any supremum over the tuning parameters. Thus, with Lemma D.7 at our disposal, the proof of Lemma D.4 follows by a suitable combination with the strategy in celentano2021cad. Recall from Eqns. 26 and 28, we have
Next recall the definition of from (20) and that from our system of equations (24). On applying triangle inequality and Lemma H.5, we obtain that
| (29) | ||||
For the first summand, note that by Lemma D.7, . Thus it suffices to show that the first term in the first summand in (29) is . To see this, observe that we can simplify this as follows
We turn to the second summand in (29). It suffices to show that the first term is since the second is by Lemma D.7. But this follows from the same result on observing that
and that is bounded below by a positive constant by (25). This completes the proof. ∎
D.2.2 Proof of Lemma D.5
For the purpose of clarity, we sometimes make the dependence of estimators on and/or explicit (by writing , for example). We first introduce a supporting Lemma that characterizes a convergence result individually for the Lasso and Ridge.
Lemma D.8.
Under Assumption 4, for and any -Lipschitz function ,
Proof.
First we consider . From Lemma E.1, we know
for any -Lipschitz function . Since is a Lipschitz function of by Lemma D.14, the proof follows by the definition of these from (22).
Now for , however, is not necessarily a Lipschitz function of . Thus, we turn to the -smoothed Lasso () instead celentano2020lasso, defined as
Based on this, can be similarly defined. We omit the full details for simplicity since they are similar to (18)-(24), but we note that they satisfy the following relation by KKT conditions:
where and is defined similarly as (24). (celentano2020lasso, Theorem B.1) establishes a pointwise version of Lemma E.1 for the -smoothed Lasso, i.e. without supremum over the tuning parameter range, but uniform control results can be easily obtained following our techniques for Lemma E.1. Furthermore, (celentano2020lasso, Section B.5.2) shows that is an -Lipschitz function of for some positive constant (by checking the Lipschitzness of ). Combining these, we obtain that for a fixed
| (30) |
In addition, (celentano2020lasso, Lemma B.8 and Section B.5.1) establishes the closeness of (debiased) Lasso and (debiased) -smoothed Lasso as follows: there exists a constant such that
| (31) |
which can be easily extended to the uniform version since and constants hiding in do not depend on , and estimators for all share the same source of randomness.
Finally, (celentano2020lasso, Lemma A.5) shows there exists constants and such that :
| (32) |
which can be extended to uniform version similarly.
As a consequence of Lemmas D.4 and D.8, we obtain the following corollary. An analogous result was established in (celentano2021cad, Corollary J.2) but unlike their case, our guarantee here is uniform over the tuning parameter space. Thus the result below relies crucially on our earlier results that provide such uniform guarantees.
Corollary D.2.
Proof.
To prove Lemma D.5, that is, (27), we need to establish a convergence result that is uniform over and . We divide this goal into a two-step strategy, where we first establish that (27) holds with the supremum only over (Lemma D.9) Then by appropriate Lipschitzness arguments (Lemma D.10), we extend the result to hold with supremum simultaneously over and .
Lemma D.9.
Denote the quantity as . Then under Assumption 4,
| (33) |
Proof.
From the definition, we know , since, per the remark below (26), equals conditional on .
Therefore, we just need to show
which follows from Corollary D.2, if we can show that is a Lipschitz function. The Lipschitzness follows by an argument similar to (celentano2021cad, Section J.2), so we omit the details here. ∎
Note that Corollary D.2, which in turn relies on Lemmas D.4 and D.8, forms a crucial ingredient for the preceding proof.
Lemma D.10.
Under Assumption 4, with probability , is an M-Lipschitz function of for some positive constant , where
Proof of Lemma D.10.
We define (with a slight overload of notations) an auxiliary function:
First, and therefore does not depend on . Also, where , is -Lipschitz in from Lemma H.2. Thus, we have
which yields is -Lipschitz in . Next note that conditioning on necessitates to take the following value so that their joint covariance structure matches (23),
| (34) |
This means that conditional on , , whereas never depends on . Also, from 25 and Lemma H.2, is bounded in and is -Lipschitz in while both and are bounded in and -Lipschitz in , and . Combining Lemma D.4 and D.3 yields that with probability . In conjunction with Lemma D.8, this yields that with probability . Thus,
Thus, we conclude that is -Lipschitz in with probability .
Therefore, with probability , is an -Lipschitz function of for . Notice that does not depend on . Therefore, by Lemma H.9, is also an -Lipschitz function of , hence completing the proof. ∎
Now we are ready to prove Lemma D.5.
D.2.3 Proof of Lemma D.6
Recall the definition of from (28). We define a loss function that yields as the minimizer:
We next introduce some supporting lemmas.
Lemma D.11.
Proof.
From part of (celentano2021cad, Lemma F.4), we know that
The proof is then completed by the fact that as in (celentano2021cad, Lemma F.4), only hides constants that do not depend on . ∎
Lemma D.12.
Under Assumption 4, there exists a positive constant such that
Proof.
We have
Further, with probability at least we have , and therefore
Hence is bounded with high probability and so is , which completes the proof. ∎
Lemma D.13.
Under Assumption 4, for any , consider any such that . Then with probability , we have
for some constant (that does not depend on ), where .
We defer the proof to Section E.2 We remark that this is a slightly weaker condition than the Lipschitzness of in , but it suffices for our purpose. For convenience, we call this ”weak-Lipschitz” condition.
Lemma D.14.
Under Assumption 4, is an -Lipschitz function of for some constant .
Proof.
Proof of Lemma D.6.
Let as given by Lemma D.11, let as given by Lemma D.12, and let as given by Lemma D.13. Consider any , define . Let . Further define for . By Lemma D.11, the event
| (35) |
has probability . Now define with (so we know ) and similarly for . On the intersection of event 35 and the event in Lemma D.12, which has probability we have that
This implies (since we are on event 35) that , where . Thus we have
with probability , where the second-to-last inequality follows from Lemma D.13 and the fact that . Finally we note that is a Lipschitz function of , in fact, , (by definition). This in turn equals . If we define this to be , then , once again by definition. Then (LABEL:eq:intermcalc) yields the desired result. ∎
Appendix E Proof of supporting lemmas for Section D.2
E.1 Proof of Lemma D.7
We introduce two supporting Lemmas:
Lemma E.1.
Under Assumption 4, for and any -Lipschitz function ,
Lemma E.2.
Proof of Lemma D.7.
First consider . From Lemma E.1, we know that for any -Lipschitz function ,
where recall from Eqn. 21 that is a -Lipschitz function of due to the Lipschitzness of the proximal mapping operator, where with and . Also, . Moreover, from (21) and (24), is bounded by 25. Therefore, by Lemma H.3, we know
We also know that by 25. Thus, by Lemma H.7,
As a direct corollary, with probability , and for all , so is bounded both above and below for all with probability . Similarly, convergence of follows by starting from Lemma E.2 on combining with (25) and Lemmas (H.3), (H.7).
Finally we consider . We know and that is bounded with probability (Corollary H.1). Thus,
which is bounded above with probability . This completes the proof. ∎
E.2 Proof of Lemma D.13
We introduce another Lemma:
Lemma E.3.
Under Assumption 4, for any , consider any such that , then with probability , we have
for some positive constant that does not depend on .
Proof.
The first line follows directly from Lemma D.7 and the fact that . For the second line, consider any . It is a direct consequence of Lemma E.1 that
| (36) |
For any , by triangle inequality, we have
Now, and with probability by (36). Further, recalling the definition of in (21) and notice that the minimization problem is separable, we know the -th entry of satisfies
where and
the soft-thresholding operator, is -Lipshitz in both and . Thus,
for some constant with probability , where we used 25, Lemma H.8, and the facts that are bounded Lipschitz functions of (from Lemma H.2) and is bounded with probability . Combining the above, we know with probability ,
which concludes the proof. ∎
As a corollary, we have the following lemma:
Lemma E.4.
Under Assumption 4, for any , consider any such that , then with probability , we have
for some constant (that does not depend on ).
Proof.
Recall Eqn. 26, and note the following:
-
•
are bounded Lipschitz functions of , and as a simple corollary, is also a bounded Lipschitz function of .
- •
-
•
, so with probability , where we used Corollary H.1. Also is bounded with probability for the same reason.
-
•
By the same argument, with probability and is bounded with probability .
Then the proof is complete on iteratively applying Lemma H.8 on the above displays. ∎
We are now ready to prove Lemma D.13.
Proof of Lemma D.13.
By Jensen’s inequality and the fact that is 1-Lipschitz, we only need to show that conditional on , satisfies the “weak-Lipschitz” condition in with probability , where by Eqn. 40,
Now we note the following observations.
- •
- •
-
•
By Lemma H.2, is bounded and Lipschitz in both and , and is bounded and Lipschitz in .
- •
-
•
Further, does not depend on , and by Lemma E.4, satisfy the ”weak-Lipschitz” condition w.r.t. with probability .
-
•
Hence, by Lemma H.8, satisfies the aforementioned condition w.r.t. both with some constant with probability .
Combining the above steps completes the proof. ∎
E.3 Proof of Lemma E.1
For the case of the Lasso, (miolane2021distribution, Theorem 3.1) proved an analogous result for convergence. Although this does not directly yield our current lemma, the ideas therein sometimes prove to be useful. Below we present the proof of Lemma E.1 for the case of the ridge. Our approach towards handling convergence can be adapted to extend (miolane2021distribution, Theorem 3.1) for the lasso to an convergence result as well. For simplicity, we drop the subscript for this section. For convenience, we also make the dependence explicit for certain expressions in this section (via writing , for instance).
E.3.1 Converting the optimization problem
First, although the original optimization problem is
it is more convenient to work with , which satisfies
| (37) | ||||
where we used the fact that . We call this the Primary Optimization (PO) problem, which involves a random matrix . We then define the following Auxiliary Optimization (AO) that involves only independent random vectors . We call its solution .
| (38) | ||||
Note to obtain the third equality we set . Section E.3.3 will establish a formal connection between PO and AO.
Next we perform some non-rigorous calculations using the AO to gain insights and show that it should asymtotically behave as a much simpler scalar optimization problem. To this end, we use the fact that and obtain
We know in the asymptotic limit . Substituting in and optimizing first, we have
Plugging in and using the fact that , , and , we arrive at a Scalar Optimization (SO) problem in the asymptotic limit:
| (39) | ||||
By some algebra, it turns out that the solution to 39 and the Ridge part of (24) can be related as in and . So by the discussion before 25, we know is unique and bounded. We in turn define
| (40) |
By some algebra, this satisfies
| (41) |
We will rigorously prove the above conversion of AO to SO in Section E.3.2
E.3.2 Connecting AO with SO
First we show that AO has a minimizer.
Proposition E.5.
admits almost surely a unique minimizer on .
Proof.
First, is a convex function that goes to at , so it has a minimizer.
Case 1: there exists a minimizer such that .
In that case, there exists a neighborhood of such that for all , . Thus for all is strictly convex, because is strictly convex (due to its first argument being linear and its second argument being positively quadratic) and remains positive on and is strictly increasing. Hence is the only minimizer of .
Case 2: for all minimizer we have .
In this case, from optimality condition, any minimizer must satisfies , which implies and has a unique minimizer. ∎
Then we show that the minimizer is close to :
Lemma E.6.
Proof.
The proof follows analogous to (miolane2021distribution, Theorem B.1), which handles the case of the Lasso. For conciseness, we refer readers to their proof. Note that we can safely add the sup in front since hides constants that do not depend on . ∎
E.3.3 Connecting PO with AO
We introduce a useful corollary that follows from the Convex Gaussian Min-Max Theorem (Theorem H.1) and connects PO with AO.
Corollary E.1.
-
•
Let be a closed set. We have for all ,
-
•
Let be a convex closed set. We have for all ,
Proof.
We will only prove the first point, since the second follows similarly. Suppose that live on the same probability space and are independent. Let . Let denote the largest singular value of . By tightness we can find a constant such that the event
| (42) |
has probability at least . Let be a non-empty closed set. Fix some , on event 42 both and are bounded by some constant . Now for any such that , we have .
This means that there exists such that on event (42). Since this is true for all such , then the minimum of over is achieved on . Similarly, the minimum of over is achieved on . WLOG, we can assume . On event 42 we have
for some non-random . Thus, for all , we have
and similarly
Now we know that and are compact, we can apply Theorem H.1 to get
The corollary then follows from the fact that one can take arbitrarily small. ∎
Now for a fixed , consider the set . Obviously this is a closed set. By first applying parts 1 and 2 from Corollary E.1 to the convex closed domain , then applying part 1 to the closed domain , we can show the following proposition:
Lemma E.7.
For all ,
Proof.
The proof of Lemma E.7 is similar to Section C.1.1 in miolane2021distribution, where the above was established for the Lasso. ∎
Lemma E.8.
There exists a constant such that for all ,
E.3.4 Uniform Control over
We now establish the result with uniform control over (i.e. bring the in Lemma E.8) inside).
We first prove the following Lemma:
Lemma E.9.
There exists constant such that
Proof.
The proof follows directly from Lemma D.12. ∎
Then we prove the following proposition:
Lemma E.10.
For , we have for some constant
Proof.
First, by noting that , as well as applying Lemma H.2 and Lemma H.8, we know and are bounded in some respectively, and they are both continuous functions of . Let . Next, recall from (41) that . Thus,
where is the th entry of and . For the first summand,
We know both and are bounded, is Lipschitz, and
Thus, we know the first part is bounded by some . Similarly, the second part is bounded by some . Combining them completes the proof. ∎
We are now ready to prove Lemma E.1.
proof of Lemma E.1.
Let as given by Lemma E.8, let as given by Lemma E.9, and let as given by Lemma E.10. Fix and define . Let . Further define for By Lemma E.8, the event
| (43) |
has probability at least . Therefore, on the intersection of event 43 and the event in Lemma E.9, which has probability , we have for all ,
where is such that . This implies (since we are on the event 43) that .
Consider any Lipschitz function . Since is a -Lipschitz function of for some constant (recall (40)), then by concentration of Lipschitz function of Gaussian random variables, we know the event
| (44) |
E.3.5 Proof of Lemma E.2
Appendix F Proof of main results
In this section we utilize Theorem D.1 and some preceding supporting Lemmas to prove the remaining results in the main text, that is, Proposition 4.2 and Theorem 4.1.
F.1 Variance Parameter Estimation
We present the theorem that makes rigorous the consistency of (7).
The proof of Theorem F.1 crucially relies on the following Lemma, which is the counterpart to Theorem 4.3 in the context of residuals:
F.2 Ensembling: Proof of Proposition 4.2
F.3 Heritability Estimation: Proof of Theorem 4.1
Proof of Theorem 4.1.
which further implies that
| (47) |
Recalling the definitions of from Assumption 4, and the fact that ’s are independent with mean and variance , we know that
where denotes the sample variance of . Moreover, is bounded by , and is positive (otherwise the problem becomes trivial). Thus we can safely replace the denominator in (47) with . The proof is then completed by the fact that clipping does not effect consistency. ∎
Appendix G Robustness under Accurate Covariance Estimation: Proof of Theorem 4.4
In this section we prove Theorem 4.4. To maintain notational consistency with the rest of the proofs, we refrain from using and use instead. A simple derivation reveals that assuming with covariance is equivalent to assuming has independent columns but use to denote the design matrix. For all quantities in this section. we include in a parenthesis or a subscript to denote the corresponding perturbed quantity if we replace by for the design matrix. We first introduce a sufficient condition of Theorem 4.4.
Lemma G.1.
Let be a sequence of random matrices such that . Under Assumption 4, we have
| (48) | ||||
Lemma G.1 is proved in Sections G.1 and G.2 for Ridge and Lasso, respectively. Compared to the assumptions in Theorem 4.4, besides reducing Assumption 1 to 4 under Gaussian design and replacing assumptions about , with those about , we also dropped Assumption 3 as it can be proved under Gaussian design. Taking Lemma G.1 momentarily, we prove Theorem 4.4 below.
Proof of Theorem 4.4.
First we show that is a corollary of the assumptions in Theorem 4.4. Notice that Proposition A.1 guarantees . We have since and eigenvalues of are bounded. Let , then the Neumann series converges to in operator norm since . Hence converges to in operator norm. In other words, .
We are now left with arguing that under the assumptions of Lemma G.1, (48) yields (16). Recall the definition of debiased estimators in (18). We have the following:
G.1 Proof of Lemma G.1, Ridge case
In this section, we drop the subscript R for simplicity. First we show that
Recall the Ridge estimator and its perturbed version:
We know both and are bounded by , uniformly for all . Further, their difference satisfies
Then we know by observing that is bounded with probability , , and applying Lemma H.6. Another application of Lemma H.6 with additionally the fact that is bounded concludes that .
Next, for and its perturbed counterpart, we have
where the third equality follows from and its perturbed counterpart. Hence the proof is complete.
G.2 Proof of Lemma G.1, Lasso case
We drop the subscript L in this section for simplicity. The proof of the Lasso case is more involved. Denote
the Lasso objective function and its perturbed counterpart. We first argue that is close to where is the perturbed Lasso solution (Lemma G.2), then we utilize techniques around the local stability of Lasso objective (c.f. miolane2021distribution, celentano2020lasso) to prove the desired results in Sections G.2.1 and G.2.2.
Lemma G.2 (Closeness of Lasso objectives).
Under the assumptions in Lemma G.1, we have
Proof.
By optimality, and . Further, we have
We know from Lemma D.7 that is uniformly bounded with probability . Further, replacing Lemma E.1 with (celentano2020lasso, Theorem 6), we can use similar proof as Lemma D.7 to show that is also uniformly bounded with probability . Therefore, utilizing Lemma H.6,
and similarly . Hence,
as desired. ∎
G.2.1 Closeness of Lasso solutions
We introduce a sufficient Lemma for the first line of (48):
Lemma G.3 (Uniform local strong convexity of the Lasso objective).
Under the assumptions in Lemma G.1, there exists a constant such that for any -dependent vector ,
Proof of Lemma G.3.
Notice that this Lemma is the uniform extension of (celentano2020lasso, Lemma B.9) (their statement only involves with an additional constraint, but our statement naturally follows from the proof procedure). Thus we only elaborate the necessary extensions of their proof here:
Consider the critical event in the proof:
where as in (24) and is the Lasso subgradient. We want to show that there exist constants such that event happens with probability , uniformly for .
For , it does not depend on , so Corollary H.1 guarantees the high probability.
For , we know from (25), and we also know for any by the definition of . Therefore the high-probability (which is proved in (celentano2020lasso, Section B.5.4)) naturally extends uniformly.
Finally, follows from (miolane2021distribution, Theorem E.5) by an -net argument (c.f. (miolane2021distribution, Section E.3.4) and Section E.3.4), which we omit here for conciseness.
Now that we have established happens uniformly with probability , the rest of the proof extends almost verbatim the proof in (celentano2020lasso, Section B.5.4) by taking the supremum in all inequalities. ∎
G.2.2 Closeness of Lasso sparsities
Taking inspiration from miolane2021distribution, we prove the convergence from above and below using different strategies. We state and prove two supporting Lemmas G.4 and G.5. Taking those lemmas momentarily and noticing the fact that a nonzero entry in the Lasso solution guarantees a gradient, we immediately have
The second line of (48) then follows by further applying Lemma D.2.
Lemma G.4.
Under the assumptions in Lemma G.1, for any ,
Proof.
From (miolane2021distribution, Lemma F.4), we know
| (50) |
for some constant .
From (celentano2020lasso, Lemma B.12), we know
| (51) |
for some constant , where we write subscript to make the dependence on explicit when necessary.
Now let and be the constants mentioned above, and let be the constant in Lemma H.2(b) Consider any . Define . Let , and let . Applying a union bound on (50) yields
| (52) |
Lemma G.5.
Denote
the Lasso subgradient and its perturbed counterpart. Under the assumptions in Lemma G.1, for any ,
Proof.
We define an auxiliary loss function and its perturbed counterpart :
where is some large enough constant. For any , consider the following three high probability event statements:
| (53) |
| (54) |
for some constants and ;
| (55) |
for some constant .
Observe the exact same forms of statements (53), (54), (55) and statements (49), (50), (51). Hence, upon proving statements (53), (54), (55), we can use a similar -net argument as in the proof of Lemma G.4 to complete the proof of Lemma G.5.
First we prove (53). Fixing any and denoting , we have
where the inequality follows from optimaility of , and the convergence follows from Lemma H.6 and the fact that .
Writing out a symmetric argument yields the other direction (details omitted):
Therefore, we know , which leads to (53).
Argument (54) is a direct corollary of (miolane2021distribution, Lemma E.9).
We are now left with (55). From KKT condition, on the event , which happens with probability (see proof of Lemma G.2), we have
where the permutation of min-max is authorized by (rockafellar2015convex, Corollary 37.3.2).
As a result, with probability , ,
where the inequality follows from optimality of . Statement (51) already guarantees a high probability bound for . Finally, (re)denoting , we have
with probability for some constant , where the first inequality follows from optimality of and the last inequality follows from the fact that are all bounded with high probability. The proof is thus complete. ∎
Appendix H Auxiliary Lemmas
This section introduces several auxiliary lemmas that we use repeatedly through our proofs.
H.1 Convex Gaussian Minmax Theorem
Theorem H.1.
(thrampoulidis2015regularized, Theorem 3) Let and be two compact sets and let be a continuous function. Let be independent standard Gaussian vectors. Define
Then we have:
-
•
For all ,
-
•
If and are convex and is convex-concave, then for all ,
H.2 Properties of Equation System Solution
Lemma H.2 (Lipschitzness of fixed point parameters).
Denote to be the unique solution to the fixed point equation systen (24). There exists a constant such that
-
(a)
the mapping is -Lipschitz.
-
(b)
the mapping is -Lipschitz.
-
(c)
the mappings are both -Lipschitz in both arguments, where
Proof.
Note that (a) is a direct consequence of miolane2021distribution Proposition A.3. (b) also follows from miolane2021distribution on noting that in their notation, and on applying Lemma H.8 We remark that both results from miolane2021distribution Proposition A.3 are for the case of the Lasso, but the Ridge case follows similarly.
We prove (c) here. We show that both and are Lipschitz in . The proof for follows similarly and is therefore omitted. From (23) and (24), we know that
First, we know and does not depend on while is bounded and Lipschitz by 25 and the first statement of this Lemma. Next, by Cauchy-Schwartz, we have
where is bounded and does not depend on (the equality follows from (23) and (24)). Now,
for some constant , where the last line follows verbatim the proof of Lemma E.10. Hence is Lipschitz in . Combining the two terms with Lemma H.8, we conclude that is Lipschitz in . For , note the fact that , so
Thus is also Lipschitz in , concluding the proof. ∎
H.3 Concentration of empirical second moments
Most of our results are established for Lipschitz functions of random vectors. However we will frequently need to show the concentration of second order statistics of the form . The following lemma provides the connection:
Lemma H.3.
Consider two random vectors , and a positive semi-definite matrix (all possibly dependent on ) that satisfy the following concentration guarantee:
-
•
There exist functions (dependent on ) that are -Lipschitz such that for Gaussian vectors and any -Lipschitz functions ,
and
-
•
The parameters satisfy and the singular values of are bounded by for all .
Then we have
The proof for this Lemma follows almost verbatim from the proof of Lemma G.1 in celentano2021cad, with Proposition H.5 applied in appropriate places to make sure equalities/inequalities hold uniformly over the tuning parameter range.
H.4 Largest singular value of random matrices
Lemma H.4.
(vershynin2010introduction, Corollary 5.35) Let be the largest singular value of the matrix with i.i.d. entries, then
Corollary H.1.
In the setting of Lemma H.4,
H.5 Inequalities for supremum
Our results often involve establishing that certain statements hold uniformly over the range of tuning parameter values. To this end, we frequently use the following results related to the properties of the supremum.
Lemma H.5.
-
•
For a random variable and functions parametrized by , with probability ,
-
•
For a random variable and non-negative functions parametrized by , with probability ,
-
•
For a random variable and a function parametrized by ,
The proof is straightforward and is therefore omitted.
Lemma H.6.
For sequences of bounded positive random functions such that and , we have
Proof.
Lemma H.7.
For sequences of positive random functions , such that and are bounded below with probability and , we have
Proof.
∎
H.6 Properties on Lipschitz functions
Lemma H.8.
Suppose has bounded norm in and is Lipschitz with constant , has bounded norm in and is Lipschitz with constant , then
-
•
has bounded norm in , and is Lipschitz with constant .
-
•
is positive and bounded in , and is Lipschitz with constant in
Proof.
The boundedness part is trivial. For Lipschitzness part, we have
and further,
∎
Lemma H.9.
Suppose is -Lipschitz in for all , then is also -Lipschitz in .
Proof.
Consider any . Let , then
where we have used the fact that and by optimality of and . Thus,
which shows is also -Lipschitz in . ∎
Appendix I Universality Proof
Here we extend our results from prior sections to the case of the general covariate and noise distributions mentioned under Assumptions 1 and 2.
To differentiate from the notations above, we use to denote a design matrix with i.i.d. entries, and to denote the noise vector with i.i.d. entries. Unless otherwise noted, for all other quantities, we add a superscript to denote corresponding quantities that depend on and/or . Also, our original notations from the preceding sections now refer to quantities with the general sub-Gaussian tailed design matrix and noise distribution specified by Assumptions 1 and 2.
Several results from prior sections assumed Gaussianity of the design or errors. A complete list of these results would be as follows: Lemmas D.2-D.13, Corollary D.2, Lemmas E.1-E.4 (along with several supporting lemmas that enter the proof of Lemma E.1), F.2, Lemmas G.1-G.5, H.4 and Corollary H.1. However, for many of these results, the proof uses Gaussianity only through the use of certain other lemmas/results in the aforementioned list. Thus, to prove validity of such results beyond Gaussianity, it suffices to prove validity of the other lemmas used in their proofs. We thus identify a smaller set of results so that showing these hold under the non-Gaussian setting of Assumptions 1 and 2 suffices for showing that all of the aforementioned results satisfy the same universality property. This smaller set is as follows: Lemmas D.2, D.8, D.11, D.12, Lemmas E.1 (along with some supporting results in this proof as outlined in Section I.2 below), E.2, Lemmas G.2-G.5, Lemma H.4 and Corollary H.1. In this section, we show that these results continue to hold under Assumptions 1 and 2 (and Assumption 3 for Lemmas G.2-G.5).
I.1 Replacing Lemma H.4 and Corollary H.1
This follows from prior results in the literature that we quote below. Recall that, , where is the Orcliz-2 norm or sub-Gaussian norm (see (wellner2013weak, Section 2.1) for the precise definition).
Lemma I.1.
(vershynin2018high, Theorem 4.4.5) Let be the largest singular value of the matrix with independent, mean , variance , uniformly sub-Gaussian entries, then
where is an absolute constant and
I.2 Replacing Lemmas E.1 and E.2
In this section, we will establish that the following more general version of Lemma E.1 holds. For Lemma E.2 a similar extension can be proved by using similar proof techniques as in this section, thus we omit writing the details for the latter.
The proof of the Lasso and Ridge cases are similar. We only present the case of the Ridge so it is easy for readers to compare with Section E.3. We introduce some useful supporting lemmas first. By recent results in han2022universality, the below lemma follows.
Lemma I.3.
Proof.
The first argument is a direct consequence of (han2022universality, Theorem 2.3), by specifically plugging in the formula for from (37). The second argument can be similarly proved by modifying the last lines of (han2022universality, Section 4.2). We skip the proof here for conciseness. Notice that the in comes from the difference between their scaling and ours. ∎
Further, (han2022universality, Proposition 3.3(2)), with the appropriate -rescaling in our case yields the following.
We note that Lemma I.3 also holds for the Lasso case (with a different ), and the Lasso counterpart of Lemma I.4 is given by (han2022universality, Proposition 3.7(2)).
I.2.1 Converting the optimization problem
This subsection requires no change.
I.2.2 Connecting AO with SO
Lemma I.5 (Replacing Proposition E.6).
Recall the definition of from (40). There exists a constant such that for all ,
Proof.
The proof is a direct corollary of Lemma E.6, since adding another condition in the event does not increase the probability. ∎
I.2.3 Connecting PO with AO
Lemma I.6 (Replacing Corollary E.1).
Proof.
We only prove the first argument as the second follows similarly. As a direct corollary of the second argument in I.3 (by substituting ), we have
Now consider the high probability event (42). The fact that is now sub-Gaussian instead of Gaussian does not change the fact that we can find another that ensures this event occurs with high probability. Therefore, the proof of E.1 goes through, and we have the following inequality: for any ,
Combining the two displays above finishes the proof. ∎
Now for a fixed , we instead consider the set , where is defined in Lemma I.3 and is defined in Section E.3.3.
Lemma I.7 (Replacing Lemma E.7).
For all ,
Proof.
Recall from our remark in the proof of Lemma E.7 that (miolane2021distribution, Section C.1.1) established this result for the case of the Lasso and Gaussian designs/error distributions. In their proof, their Corollaries 5.1 and B.1 played a crucial role. Now note that (miolane2021distribution, Corollary B.1) requires concentration of , which also follows if is sub-Gaussian instead of Gaussian. Thus we are left to generalize their Corollary 5.1 (the analogue of this is Corollary E.1 in our paper) to the case of the ridge under our non-Gaussian design/error setting of Assumptions 1 and 2. We achieve this via Lemma I.6. With these modifications in place, a proof analogous (miolane2021distribution, Section C.1.1) still works here. Note that the extra on the RHS comes from the extra in Lemma I.6. ∎
Lemma I.8 (Replacing Lemma E.8).
There exists a constant such that for all ,
I.2.4 Uniform Control over
Lemma I.9 (Re-stating Lemma E.9).
There exists constant such that
Proof.
Note that Lemma D.12 is equivalent to Lemma E.9 so universality follows directly from the above. Lemma E.10 remains as is since it does not involve or . We are now ready to prove Lemma I.2.
proof of Lemma I.2.
Fix and define . Let . Further define for . By Lemma I.8, the event
| (56) |
has probability at least . Therefore, on the intersection of event 56 and the event in Lemma I.9, which has probability , we have for all ,
where is such that . This implies (since we are on the event 56) that either or .
However, by Lemma I.4, we know that
with probability . Since the probability is over the randomness in and , and only depends in , then the argument holds for all .
Therefore, only with probability , there exists such that . Hence, still with probability , . The rest of the proof remains the same as in the end of Section E.3.4. ∎
I.3 Replacing Lemma D.2
The ridge case is rather straightforward: (knowles2017anisotropic, Theorem 3.7) only requires mean , variance , independence, as well as uniformly bounded th moments for the entries of , which are already satisfied by Assumptions 1 and 2 (specifically, uniform sub-Gaussianity implies uniformly bounded th moments). As for the Lasso case, we can modify the proof of (miolane2021distribution, Theorem F.1) in the same way as we modified Section E.3 in Section I.2. We omit the details here for conciseness.
I.4 Replacing Lemma D.8
The supporting Lemma E.1 has already been replaced by Lemma I.2. For the ridge case, the Lipschitz argument needs no change. For the Lasso case, the version of Lemma I.2 for -smoothed Lasso can be extended similarly, and the following Lipschitz argument requires no change. Finally, (31) relies critically on (celentano2020lasso, Lemma B.9). The corresponding proof in (celentano2020lasso, Lemma B.5.4) has been elaborated in our proof of Lemma G.3, for which we articulate the replacement in I.6.
I.5 Replacing Lemma D.11
Lemma I.10 (Replacing Lemma D.11).
We introduce another supporting Lemma.
Lemma I.11.
Proof.
This is a consequence of (han2022universality, Corollary 2.6), with necessary modifications similar to what we performed in the proof of Lemma I.3. Again notice the adjusted scaling in our setting. ∎
Now we prove Lemma I.10.
proof of Lemma I.10.
Most of the proof will follow (celentano2021cad, Lemma F.4). In their proof, they first showed their Lemma F.2: Conditional Gordon’s Inequality, which states that (as defined in (37), leaving the dependence on implicit) concentrates around , the ”conditional Auxiliary Optimization Problem” defined as in (38) conditioned on , which necessitates and taking the following values (see derivation in (celentano2021cad, Section L)):
Then, they showed the concentration of around its asymptotic limit. Here represent any convex, closed sets.
We make modifications to their proof as follows:
- 1.
-
2.
For proving that concentrates around its asymptotic limit, no modification is necessary. This is because does not involve anymore, and the fact that replacing i.i.d. Gaussianity of by independent uniform sub-Gaussianity preserves its concentration properties (with possibly different constants).
∎
I.6 Replacing Lemmas G.2-G.5
For Lemma G.2, we critically used the facts that , are bounded with probability . The former is guaranteed by applying Lemma H.3 on Lemma I.2. The latter is stated in Assumption 3(1).
For Lemma G.3, consider the critical event
happens with high probability according to Assumption 1(2). happens with high probability by Corollary I.1. Finally, (miolane2021distribution, Theorem E.5) can be extended to the universality version in the same way as we extended Section E.3 in Section I.2. As a direct corollary, happens with high probability.
For Lemma G.4, we need to extend the critical events (49), (50), (51). (49) follows naturally from the proof of the extended G.2. (50) is a Corollary of (miolane2021distribution, Theorem F.4), which again can be extended to the universality version in the same way as we extended Section E.3 in Section I.2. Lastly (51) is stated in Assumption 3(2).