Heatmap Regression via Randomized Rounding
Abstract
Heatmap regression has become the mainstream methodology for deep learning-based semantic landmark localization, including in facial landmark localization and human pose estimation. Though heatmap regression is robust to large variations in pose, illumination, and occlusion in unconstrained settings, it usually suffers from a sub-pixel localization problem. Specifically, considering that the activation point indices in heatmaps are always integers, quantization error thus appears when using heatmaps as the representation of numerical coordinates. Previous methods to overcome the sub-pixel localization problem usually rely on high-resolution heatmaps. As a result, there is always a trade-off between achieving localization accuracy and computational cost, where the computational complexity of heatmap regression depends on the heatmap resolution in a quadratic manner. In this paper, we formally analyze the quantization error of vanilla heatmap regression and propose a simple yet effective quantization system to address the sub-pixel localization problem. The proposed quantization system induced by the randomized rounding operation 1) encodes the fractional part of numerical coordinates into the ground truth heatmap using a probabilistic approach during training; and 2) decodes the predicted numerical coordinates from a set of activation points during testing. We prove that the proposed quantization system for heatmap regression is unbiased and lossless. Experimental results on popular facial landmark localization datasets (WFLW, 300W, COFW, and AFLW) and human pose estimation datasets (MPII and COCO) demonstrate the effectiveness of the proposed method for efficient and accurate semantic landmark localization. Code is available at http://github.com/baoshengyu/H3R.
Index Terms:
Semantic landmark localization, heatmap regression, quantization error, randomized rounding.1 Introduction
Semantic landmarks are sets of points or pixels in images containing rich semantic information. They reflect the intrinsic structure or shape of objects such as human faces [1, 2], hands [3, 4], bodies [5, 6], and household objects [7]. Semantic landmark localization is fundamental in computer and robot vision [8, 9, 7, 10]. For example, semantic landmark localization can be used to register correspondences between spatial positions and semantics (semantic alignment), which is extremely useful in visual recognition tasks such as face recognition [8, 11] and person re-identification [12, 13]. Therefore, robust and efficient semantic landmark localization is extremely important in applications requiring accurate semantic landmarks including robotic grasping [7, 10] and facial analysis applications such as face makeup [14, 15], animation [16, 17], and reenactment [18, 9].
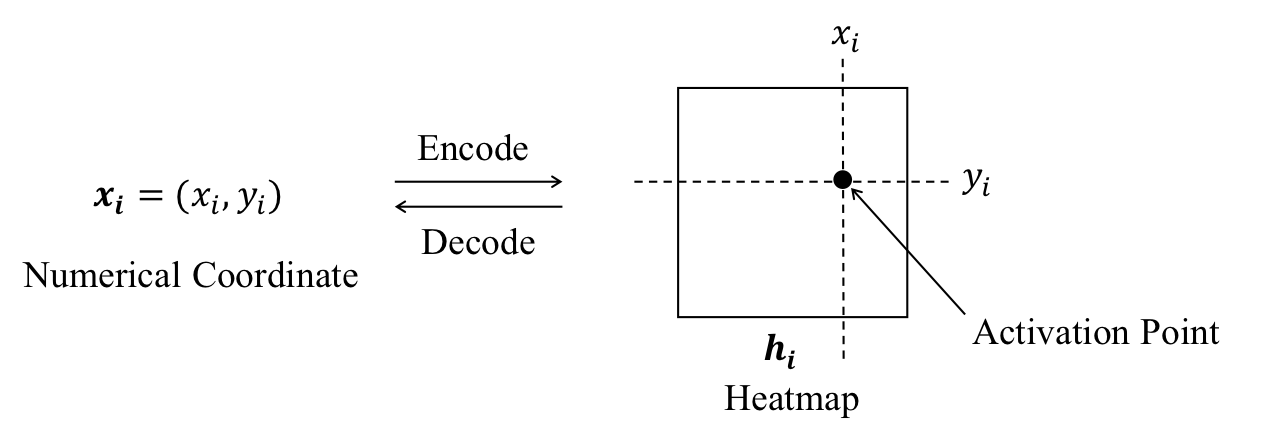
Coordinate regression and heatmap regression are two widely-used methods for deep learning-based semantic landmark localization [1, 19]. Rather than directly regressing the numerical coordinate with a fully-connected layer, heatmap-based methods aim to predict the heatmap where the maximum activation point corresponds to the semantic landmark in the input image. An intuitive example of heatmap representation is shown in Fig. 1. Due to the effective spatial generalization of heatmap representation, heatmap regression method is robust to large variations in pose, illumination, and occlusion in unconstrained settings [19, 20]. Heatmap regression has performed particularly well in semantic landmark localization tasks including facial landmark detection [2, 21] and human pose estimation [6, 22]. Despite this promise, heatmap regression method suffers from an inherent drawback, namely that the indices of the activation points in heatmaps are always integers. Vanilla heatmap-based methods therefore fail to predict the numerical coordinates in sub-pixel precision. Sub-pixel localization is nevertheless important in real-world scenarios with the fractional part of numerical coordinates originating from: 1) the input image being captured either by a low-resolution camera and/or at a relatively large distance; and 2) the heatmap is usually at a much lower resolution than the input image due to the downsampling stride of convolutional neural networks. As a result, low-resolution heatmaps significantly degrade heatmap regression performance. Considering that the computational cost of convolutional neural networks usually depends quadratically on the resolution of the input image or the feature map, there is a trade-off between the localization accuracy and the computational cost for heatmap regression [6, 23, 24, 25, 26]. Furthermore, the downsampling stride of heatmap is not always equal to the downsampling stride of feature map: given an original image of pixels, a heatmap regression model with the input size pixels, and the feature map with a downsampling stride pixels, we then have the size of heatmap pixels, i.e., the downsampling stride of heatmap pixels. For simplicity, we do not distinguish between the above two settings to address the quantization error in a unified manner. Unless otherwise mentioned, we refer to as the downsampling stride of the heatmap.
In vanilla heatmap regression, 1) during training, the ground truth numerical coordinates are first quantized to generate the ground truth heatmap; and 2) during testing, the predicted numerical coordinates can be decoded from the maximum activation point in the predicted heatmap. However, typical quantization operations such as floor, round, and ceil discard the fractional part of the ground truth numerical coordinates, making it difficult to reconstruct the fractional part even from the optimal predicted heatmap. This error induced by the transformation between numerical coordinates and heatmap is known as the quantization error. To address the problem of quantization error, here we introduce a new quantization system to form a lossless transformation between the numerical coordinates and the heatmap. In our approach, during training, the proposed quantization system uses a set of activation points, and the fractional part of the numerical coordinate is encoded as the activation probabilities of different activation points. During testing, the fractional part can then be reconstructed according to the activation probabilities of the top maximum activation points in the predicted heatmap. To achieve this, we introduce a new quantization operation called randomized rounding, or random-round, which is widely used in combinatorial optimization to convert fractional solutions into integer solutions with provable approximation guarantees [27, 28]. Furthermore, the proposed method can easily be implemented using a few lines of source code, making it a plug-and-play replacement for the quantization system of existing heatmap regression methods.
In this paper, we address the problem of quantization error in heatmap regression. The remainder of the paper is structured as follows. In the preliminaries, we briefly review two typical semantic landmark localization methods, coordinate regression and heatmap regression. In the methods, we first formally introduce the problem of quantization error by decomposing the prediction error into the heatmap error and the quantization error. We then discuss quantization bias in vanilla heatmap regression and prove a tight upper bound on the quantization error in vanilla heatmap regression. To address quantization error, we devise a new quantization system and theoretically prove that the proposed quantization system is unbiased and lossless. We also discuss uncertainty in heatmap prediction as well as the unbiased annotation when forming a robust semantic landmark localization system. In the experimental section, we demonstrate the effectiveness of our proposed method on popular facial landmark detection datasets (WFLW, 300W, COFW, and AFLW) and human pose estimation datasets (MPII and COCO).
2 Related Work
Semantic landmark localization, which aims to predict the numerical coordinates for a set of pre-defined semantic landmarks in a given image or video, has a variety of applications in computer and robot vision including facial landmark detection [1, 29, 2], hand landmark detection [3, 4], human pose estimation [5, 6, 22], and household object pose estimation [7, 10]. In this section, we briefly review recent works on coordinate regression and heatmap regression for semantic landmark localization, especially in facial landmark localization applications.
2.1 Coordinate Regression
Coordinate regression has been widely and successfully used in semantic landmark localization under constrained settings, where it usually relies on simple yet effective features [30, 31, 32, 33]. To improve the performance of coordinate regression for semantic landmark localization in the wild, several methods have been proposed by using cascade refinement [1, 34, 35, 36, 37, 38], parametric/non-parametric shape models [39, 29, 36, 40], multi-task learning [41, 42, 43], and novel loss functions [44, 45].
2.2 Heatmap Regression
The success of deep learning has prompted the use of heatmap regression for semantic landmark localization, especially for robust and accurate facial landmark localization [2, 46, 47, 23] and human pose estimation [19, 48, 6, 49, 50, 51, 52]. Existing heatmap regression methods either rely on large input images or empirical compensations during inference to mitigate the problem of quantization error [6, 53, 54, 22]. For example, a simple yet effective compensation method known as “shift a quarter to the second maximum activation point” has been widely used in many state-of-the-art heatmap regression methods [6, 55, 22].
Several methods have been developed to address the problem of quantization error in three aspects: 1) jointly predicting the heatmap and the offset in a multi-task manner [56]; 2) encoding and decoding the fractional part of numerical coordinates via a modulated 2D Gaussian distribution [24, 26]; and 3) exploring differentiable transformations between the heatmap and the numerical coordinates [57, 20, 58, 59]. Specifically, [24] generates the fractional part sensitive ground truth heatmap for video-based face alignment, which is known as fractional heatmap regression. Under the assumption that the predicted heatmap follows a 2D Gaussian distribution, [26] decodes the fractional part of numerical coordinates from the modulated predicted heatmap. The soft-argmax operation is differentiable [60, 61, 62, 59], and has been intensively explored in human pose estimation [57, 20].
3 Preliminaries
In this section, we introduce two widely-used semantic landmark localization methods, coordinate regression and heatmap regression. For simplicity, we use facial landmark detection as an intuitive example.
Coordinate Regression. Given a face image, semantic landmark detection aims to find the numerical coordinates of a set of pre-defined facial landmarks , where , indicate the indices of different facial landmarks (e.g., a set of five pre-defined facial landmarks can be left eye, right eye, nose, left mouth corner, and right mouth corner). It is natural to train a model (e.g., deep neural networks) to directly regress the numerical coordinates of all facial landmarks. The coordinate regression model then can be optimized via a typical regression criterion such as mean squared error (MSE) and mean absolute error (MAE). For the MSE criterion (also the L2 loss), we have
| (1) |
where and indicate the predicted and the ground truth numerical coordinates, respectively. When using the MAE criterion (also the L1 loss), the loss function can be defined in a similar way to (1).
Heatmap Regression. Heatmaps (also known as confidence maps) are simple yet effective representations of semantic landmark locations. Given the numerical coordinate for the -th semantic landmark, it then corresponds to a specific heatmap as shown in Fig. 1. For simplicity, we assume is the same size as the input image in this section and leave the problem of quantization error to the next section. With the heatmap representation, the problem of semantic landmark localization can be translated into heatmap regression via two heatmap subroutines: 1) encode (from the ground truth numerical coordinate to the ground truth heatmap ); and 2) decode (from the predicted heatmap to the predicted numerical coordinate ). The main deep learning-based heatmap regression for semantic landmark localization framework is shown in Fig. 2.
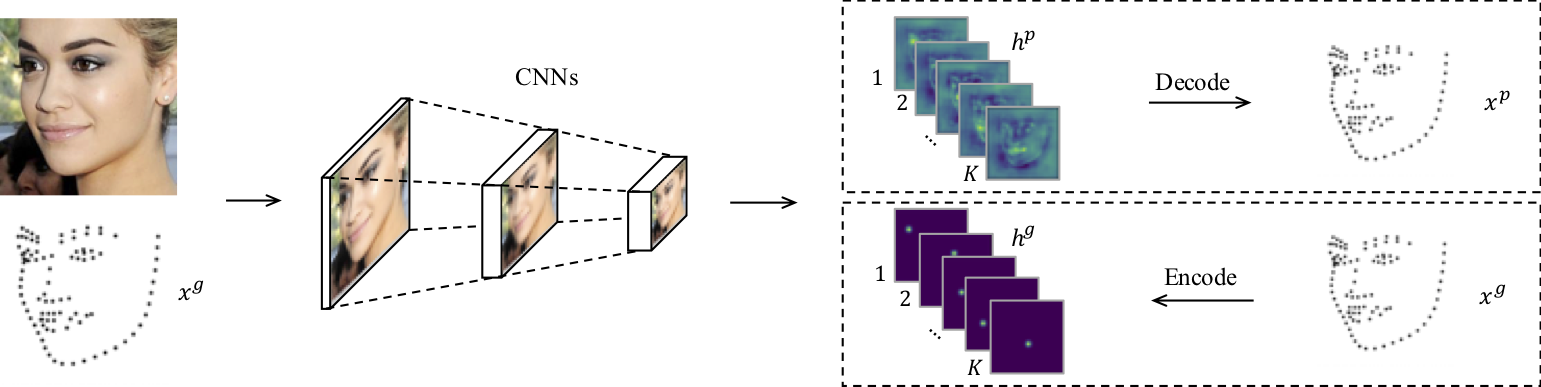
Specifically, during the inference stage, given a predicted heatmap , the value indicates the confidence score that the -th landmark is located at coordinate . Then, we can decode the predicted numerical coordinate from the predicted heatmap using the argmax operation, i.e.,
| (2) |
Therefore, with the decode operation in (2), the problem of semantic landmark localization can be solved by training a deep model to predict heatmap .
To train a heatmap regression model, the ground truth heatmap is indispensable, i.e., we need to encode the ground truth coordinate into the ground truth heatmap . We introduce two widely-used methods to generate the ground truth heatmap, Gaussian heatmap and binary heatmap, as follows. Given the ground truth coordinate , the ground truth Gaussian heatmap can be generated by sampling and normalizing from a bivariate normal distribution , i.e., the ground truth heatmap at location can be evaluated as
| (3) |
where is the covariance matrix (a positive semi-definite matrix) and is the standard deviation in both directions, i.e.,
| (4) |
When , the ground truth heatmap can be generated by assigning a positive value at the ground truth numerical coordinate , i.e.,
| (5) |
Specifically, when , the ground truth heatmap defined in (5) is also known as the binary heatmap.
Given the ground truth heatmap, the heatmap regression model then can be optimized using typical pixel-wise regression criteria such as MSE, MAE, or Smooth-L1 [44]. Specifically, for Gaussian heatmaps, the heatmap regression model is usually optimized with the pixel-wise MSE criterion, i.e.,
| (6) |
When using the MAE/Smooth-L1 criteria, the loss function can be defined in a similar way to (6). For binary heatmap, the heatmap regression model can also be optimized with the pixel-wise cross-entropy criterion, i.e.,
| (7) |
where indicates the cross-entropy criterion with a softmax function as the activation/normalization function. A comprehensive review of different loss functions for semantic landmark localization is beyond the scope of this paper, but we refer interested readers to [45] for descriptions of coordinate regression and [21] for heatmap regression. Unless otherwise mentioned, we use the MSE criterion for Gaussian heatmap and the cross-entropy criterion for binary heatmap in this paper.
4 Method
In this section, we first introduce the quantization system in heatmap regression and then formulate the quantization error in a unified way by correcting the quantization bias in a vanilla quantization system. Lastly, we devise a new quantization system via randomized rounding to address the problem of quantization error.
4.1 Quantization System
Heatmap regression for semantic landmark localization usually contains two key components: 1) heatmap prediction; and 2) transformation between the heatmap and the numerical coordinates. The quantization system in heatmap regression is a combination of the encode and decode operations. During training, when the ground truth numerical coordinates are floating-point numbers, we then need to calculate a specific Gaussian kernel matrix using (3) for each landmark, since different numerical coordinates usually have different fractional parts. As a result, it will significantly increase the training loads of the heatmap regression model. For example, given landmarks per face image, the kernel size , and a mini-batch of training samples, we then have to run (3) for times in each training iteration. To address this issue, existing heatmap regression methods usually first quantize numerical coordinates into integers, where a standard kernel matrix can then be shared for efficient ground truth heatmap generation [6, 2, 55, 23]. However, the above-mentioned existing heatmap regression methods usually suffer from the inherent drawback of failing to encode the fractional part of numerical coordinates. Therefore, how to efficiently encode the fractional information in numerical coordinates still remains challenging. Furthermore, during the inference stage, the predicted numerical coordinates obtained by a decode operation in (2) are also integers. As a result, typical heatmap regression methods usually fail to efficiently address the fractional part of the numerical coordinate during both training and inference, resulting in localization error.
To analyze the localization error caused by the quantization system in heatmap regression, we formulate the localization error as the sum of heatmap error and quantization error as follows:
| (8) |
where indicates the numerical coordinate decoded from the optimal predicted heatmap. Generally, the heatmap error corresponds to the error in heatmap prediction, i.e., , and the quantization error indicates the error caused by both the encode and decode operations. If there is no heatmap error, the localization error then all originates from the error of the quantization system, i.e.,
| (9) |
The generalizability of deep neural networks for heatmap prediction, i.e., the heatmap error, is beyond the scope of this paper. We do not consider the heatmap error during the analysis of quantization error in this paper.
To obtain integer coordinates for the generation of the ground truth heatmap, typical integer quantization operations such as floor, round, and ceil have been widely used in previous heatmap regression methods. To unify the quantization error induced by different integer operations, we first introduce a unified integer quantization operation as follows. Given a downsampling stride and a threshold , the coordinate then can be quantized according to its fractional part , i.e.,
| (10) |
That is, for integer quantization operations floor, round, and ceil, we have , , and , respectively. Furthermore, when the downsampling stride , the decode operation in (2) then becomes
| (11) |
A vanilla quantization system for heatmap regression can then be formed by the encode operation in (10) and the decode operation in (11). When applied to a vector or a matrix, the integer quantization operation defined in (10) is an element-wise operation.

4.2 Quantization Error
In this subsection, we first correct the bias in a vanilla quantization system to form an unbiased vanilla quantization system. With the unbiased quantization system, we then provide a tight upper bound on the quantization error for vanilla heatmap regression.
Let denote the fractional part of , and denote the fractional part of . Given the downsampling stride of the heatmap , we then have
| (12) |
Given the assumption of a “perfect” heatmap prediction model or no heatmap error, i.e., , we then have the predicted numerical coordinates
If data samples satisfy the i.i.d. assumption and the fractional parts , the bias of as an estimator of can then be evaluated as
Considering that are independent variables, we thus have the quantization bias in the vanilla quantization system as follows:
Therefore, only the encode operation in (10), i.e., the round operation, is unbiased. Furthermore, given for the encode operation in (10), we can correct the bias of the encode operation with a shift on the decode operation, i.e.,
| (13) |
For simplicity, we use the round operation, i.e., , to form an unbiased quantization system as our baseline. Though the vanilla quantization system defined by (10) and (13) is unbiased, it causes non-invertible localization error. An intuitive explanation for this is that the encode operation in (10) directly discards the fractional part of the ground truth numerical coordinates, thus making it impossible for the decode operation to accurately reconstruct the numerical coordinates.
Theorem 1.
Given an unbiased quantization system defined by the encode operation in (10) and the decode operation in (13), we then have that the quantization error tightly upper bounded, i.e.,
where indicates the downsampling stride of the heatmap.
Proof.
In Appendix. ∎
From Theorem 1, we know that the vanilla quantization system defined by (10) and (13) will cause non-invertible quantization error and that the upper bound of the quantization error linearly depends on the downsampling stride of the heatmap. As a result, given the heatmap regression model, it will cause extremely large localization error for large faces in the original input image, making it a significant problem in many important face-related applications such as face makeup, face swapping, and face reenactment.

4.3 Randomized Rounding
In vanilla heatmap regression, each numerical coordinate corresponds to a single activation point in the heatmap, while the indices of the activation point are all integers. As a result, the fractional part of the numerical coordinate is usually ignored during the encode process, making it an inherent drawback of heatmap regression for sub-pixel localization. To retain the fractional information when using heatmap representations, we utilize multiple activation points around the ground truth activation point. Inspired by the randomized rounding method [27], we address the quantization error in vanilla heatmap regression by using a probabilistic approach. Specifically, we encode the fractional part of the numerical coordinate to different activation points with different activation probabilities. An intuitive example is shown in Fig. 3.
We describe the proposed quantization system as follows. Given the ground truth numerical coordinate and a downsampling stride of the heatmap , the ground truth activation point in the heatmap is , which are usually floating-point numbers, and we are unable to find the corresponding pixel in the heatmap. If we ignore the fractional part using a typical integer quantization operation, e.g., round, the ground truth activation point will be approximated by one of the activation points around the ground truth activation point, i.e., , , , and . However, the above process is not invertible. To address this, we randomly assign the ground truth activation point to one of the alternative activation points around the ground truth activation point, and the activation probability is determined by the fractional part of the ground truth activation point as follows:
| (14) |
To achieve the encode scheme in (14) in conjunction with current minibatch stochastic gradient descent training algorithms for deep learning models, we introduce a new integer quantization operation via randomized rounding, i.e., random-round:
| (15) |
Given the encode operation in (15), if we do not consider the heatmap error, we then have the activation probability at :
| (16) |
As a result, the fractional part of the ground truth numerical coordinate can be reconstructed from the predicted heatmap via the activation probabilities of all activation points, i.e.,
| (17) |
where indicates the set of activation points around the ground truth activation point, i.e.,
| (18) |
4.4 Activation Points Selection
The fractional information of the numerical coordinate is well-captured by the randomized rounding operation, allowing us to reconstruct the ground truth numerical coordinate without the quantization error. However, during the inference phase, the ground truth numerical coordinate is unavailable and heatmap error always exists in practice, making it difficult to identify the proper set of ground truth activation points . In this section, we describe a way to form a set of alternative activation points in practice.
We introduce two activation point selection methods as follows. The first solution is to estimate all activation points via the points around the maximum activation point. As shown in Fig. 4, given the maximum activation point, we then have four different sets of alternative activation points, . Therefore, given the predicted heatmap in practice, we then take a risk of choosing an incorrect set of alternative activation points. To find a robust set of alternative activation points, we may use all nine activation points around the maximum activation point, i.e.,
| (19) |
Another solution of alternative activation points is to generalize the argmax operation with the argtopk operation, i.e., we decode the predicted heatmap to obtain the numerical coordinate according to the top largest activation points,
| (20) |
If there is no heatmap error, the two alternative activation points solutions presented above, i.e., the alternative activation points in (18) and (19), are equal to each other when using the decode operation in (17). Specifically, we find that the activation points in (19) achieve comparable performance to the activation points in (20) when . For simplicity, unless otherwise mentioned, we use the set of alternative activation points defined by (20) in this paper. Furthermore, when we take the heatmap error into consideration, the values of different then forms a trade-off on the selection of activation points, i.e., a larger will be robust to activation point selection whilst also increasing the risk of noise from the heatmap error. See more discussion in Section 4.5 and the experimental results in Section 5.5.
4.5 Discussion
In this subsection, we provide some insights into the proposed quantization system with respect to: 1) the influence of human annotators on the proposed quantization system in practice; and 2) the underlying explanation behind the widely used empirical compensation method “shift a quarter to the second maximum activation point”.
Unbiased Annotation. We assume the “ground truth numerical coordinates” are always accurate, while the ground truth numerical coordinates are usually labelled by human annotators at the risk of the annotation bias. Given an input image, the ground truth numerical coordinates can be obtained by clicking a specific pixel in the image, which is a simple but effective annotation pipeline provided by most image annotation tools. For sub-pixel numerical coordinates, especially in low-resolution input images, the annotators may click either one of all possible pixels around the ground truth numerical coordinates due to human visual uncertainty. As shown in Fig. 5, clicking any one of the four possible pixels causes annotation error, which corresponds to the fractional part of the ground truth numerical coordinate . Given enough data samples, if the annotators click the pixel according to the following distribution, i.e.,
| (21) |
the fractional part then can be well captured by the heatmap regression model and we refer to it as an unbiased annotation.

If we take the downsampling stride into consideration, is then a joint result of both the downsampling of the heatmap and the annotation process, i.e.,
| (22) |
On the one hand, if the heatmap regression model uses a low input resolution (or a large downsampling stride ), the fractional part then mainly comes from the downsampling of the heatmap; on the other hand, if the heatmap regression model uses a high input resolution, the annotation process will also have a significant influence on the heatmap regression. Therefore, when using a high input resolution model in practice, a diverse set of human annotators help reduce the bias in annotation process.
Empirical Compensation. “Shift a quarter to the second maximum activation point” has become an effective and widely used empirical compensation method for heatmap regression [6, 55, 22], but it still lacks a proper explanation. We thus provide an intuitive explanation according to the proposed quantization system. The proposed quantization system encodes the ground truth numerical coordinates into multiple activation points, and the activation probability of each activation point is decided by the fractional part, i.e., the activation probability indicates the distance between the activation point and the ground truth activation point. Therefore, the ground truth activation point is closer to the -th maximum activation point than the -th maximum activation point. We demonstrate the averaged activation probabilities for the top activation points on the WFLW dataset in Table I.
| k=1 | k=2 | k=3 | k=4 | |
|---|---|---|---|---|
| 0.44 | 0.26 | 0.17 | 0.13 | |
| NME(%) | 6.45 | 5.07 | 4.71 | 4.68 |
We find that the marginal improvement decreases as the number of activation points increases, i.e., the second maximum activation points provides the maximum improvement to the reconstruction of the fractional part. This observation partially explains the effectiveness of the compensation method “shift a quarter to the second maximum activation point”, which can be seen as a special case of the proposed method (20) with .
Furthermore, the proposed quantization system shares the same motivation with the bilinear interpolation. Specifically, the bilinear interpolation usually aims to find the value of the unknown function given its neighbors , , , and . For the proposed quantization system, we have , which indicates the location of landmarks. Specifically, if there is no heatmap error, we then have , , , and . If we take heatmap error into consideration, the ground truth activation points are usually unknown. Therefore, the number of alternative activation points also controls the trade-off between the robustness of the quantization system and the risk of noise from the heatmap error (Also see details in Section 4.4).
| Method | NME (%), Inter-ocular | ||||||
| test | pose | expression | illumination | make-up | occlusion | blur | |
| ESR [29] | 11.13 | 25.88 | 11.47 | 10.49 | 11.05 | 13.75 | 12.20 |
| SDM [31] | 10.29 | 24.10 | 11.45 | 9.32 | 9.38 | 13.03 | 11.28 |
| CFSS [36] | 9.07 | 21.36 | 10.09 | 8.30 | 8.74 | 11.76 | 9.96 |
| DVLN [63] | 6.08 | 11.54 | 6.78 | 5.73 | 5.98 | 7.33 | 6.88 |
| LAB [64] | 5.27 | 10.24 | 5.51 | 5.23 | 5.15 | 6.79 | 6.32 |
| Wing [45] | 5.11 | 8.75 | 5.36 | 4.93 | 5.41 | 6.37 | 5.81 |
| 3DDE [65] | 4.68 | 8.62 | 5.21 | 4.65 | 4.60 | 5.77 | 5.41 |
| DeCaFA [66] | 4.62 | 8.11 | 4.65 | 4.41 | 4.63 | 5.74 | 5.38 |
| HRNet [23] | 4.60 | 7.86 | 4.78 | 4.57 | 4.26 | 5.42 | 5.36 |
| AVS [67] | 4.39 | 8.42 | 4.68 | 4.24 | 4.37 | 5.60 | 4.86 |
| LUVLi [68] | 4.37 | - | - | - | - | - | - |
| AWing [21] | 4.21 | 7.21 | 4.46 | 4.23 | 4.02 | 4.99 | 4.82 |
| H3R (ours) | 3.81 | 6.45 | 4.07 | 3.70 | 3.66 | 4.48 | 4.30 |
| Method | NME (%), Inter-ocular | NME (%), Inter-pupil | ||||||
| private | full | common | challenge | private | full | common | challenge | |
| SAN [69] | - | 3.98 | 3.34 | 6.60 | - | - | - | - |
| DAN [70] | 4.30 | 3.59 | 3.19 | 5.24 | - | 5.03 | 4.42 | 7.57 |
| SHN [71] | 4.05 | - | - | - | - | 4.68 | 4.12 | 7.00 |
| LAB [64] | - | 3.49 | 2.98 | 5.19 | - | 4.12 | 3.42 | 6.98 |
| Wing [45] | - | - | - | - | - | 4.04 | 3.27 | 7.18 |
| DeCaFA [66] | - | 3.39 | 2.93 | 5.26 | - | - | - | - |
| DFCE [72] | 3.88 | 3.24 | 2.76 | 5.22 | - | 4.55 | 3.83 | 7.54 |
| AVS [67] | - | 3.86 | 3.21 | 6.49 | - | 4.54 | 3.98 | 7.21 |
| HRNet [23] | 3.85 | 3.32 | 2.87 | 5.15 | - | - | - | - |
| HG-HSLE [73] | - | 3.28 | 2.85 | 5.03 | - | 4.59 | 3.94 | 7.24 |
| LUVLi [68] | - | 3.23 | 2.76 | 5.16 | - | - | - | - |
| 3DDE [65] | 3.73 | 3.13 | 2.69 | 4.92 | - | 4.39 | 3.73 | 7.10 |
| AWing [21] | 3.56 | 3.07 | 2.72 | 4.52 | - | 4.31 | 3.77 | 6.52 |
| H3R (ours) | 3.48 | 3.02 | 2.65 | 4.58 | 5.07 | 4.24 | 3.67 | 6.60 |
5 Facial Landmark Detection
In this section, we perform facial landmark detection experiments. We first introduce widely used facial landmark detection datasets. We then describe the implementation details of our proposed method. Finally, we present our experimental results on different datasets and perform comprehensive ablation studies on the most challenging dataset.
5.1 Datasets
We use four widely used facial landmark detection datasets:
- •
-
•
300W [75]. 300W contains training images, including images from AFW [30], images from the training set of HELEN [76], and images from the training set of LFPW [39]. For testing, there are four different settings: 1) common: images, including and images from the testsets of HELEN and LFPW, respectively; 2) challenge: images from IBUG; 3) full: images as a combination of common and challenge; and 4) private: indoor/outdoor images. All images are manually annotated with facial landmarks.
-
•
COFW [34]. COFW contains images, including training and testing images. All images are manually annotated with facial landmarks.
-
•
AFLW [77]. AFLW contains face images, including images for training and images for testing. For testing, there are two settings: 1) full: all images for testing; and 2) front: frontal images selected from the full set. All images are manually annotated with facial landmarks. For fair comparison, we use facial landmarks, i.e., the landmarks on two ears are ignored.
5.2 Evaluation Metrics
We use the normalized mean error (NME) as the evaluation metric in this paper, i.e.,
| (23) |
where indicates the normalization distance. For fair comparison, we report the performances on WFLW, 300W, and COFW using two the normalization methods, inter-pupil distance (the distance between the eye centers) and inter-ocular distance (the distance between the outer eye corners). We report the performance on AFLW using the size of the face bounding box as the normalization distance, i.e., the normalization distance can be evaluated by , where and indicate the width and height of the face bounding box, respectively.
5.3 Implementation Details
We implement the proposed heatmap regression method for facial landmark detection using PyTorch [78]. Following the practice in [23], we use HRNet [22] as our backbone network, which is an efficient counterpart of ResNet [79], U-Net [80], and Hourglass [6] for semantic landmark localization. Unless otherwise mentioned, we use HRNet-W18 as the backbone network in our experiments. All face images are cropped and resized to pixels and the downsampling stride of the feature map is pixels. For training, we perform widely-used data augmentation for facial landmark detection as follows We horizontally flip all training images with probability and randomly change the brightness (), contrast (), and saturation () of each image. We then randomly rotate the image (), rescale the image (), and translate the image ( pixels). We also randomly erase a rectangular region in the training image [81]. All our models are initialized from the weights pretrained on ImageNet [82]. We use the Adam optimizer [83] with batch size . The learning rate starts from and is divided by for every epochs, with training epochs in total. During the testing phase, we horizontally flip testing images as the data augmentation and average the predictions.
5.4 Comparison with Current State-of-the-Art
To demonstrate the effectiveness of the proposed method, we compare it with recent state-of-the-art facial landmark detection methods as follows. As shown in Table II, the proposed method outperforms recent state-of-the-art methods on the most challenging dataset, WFLW, with a clear margin for all different settings. For the 300W dataset, we try to report the performances under different settings for fair comparison. As shown in Table III, the proposed method achieves comparable performances for all different settings. Specifically, LAB [64] uses the boundary information as the auxiliary supervision; compared to Wing [45], which uses the coordinate regression for semantic landmark localization, the heatmap-based methods usually achieve better performance on the challenge subset. In Table IV, we see that the proposed method outperforms recent state-of-the-art methods with a clear margin on COFW dataset. AFLW captures a wide range of different face poses, including both frontal faces and non-frontal faces. As shown in Table V, the proposed method achieves consistent improvements for both frontal faces and non-frontal faces, suggesting robustness across different face poses.
5.5 Ablation Studies
To better understand the proposed quantization system in different settings, we perform ablation studies the most challenging dataset, WFLW [64].

The influence of different input resolutions. Heatmap regression models use a fixed input resolution, e.g., pixels, but training and testing images usually represent a wide range of resolutions, e.g., most faces in the WFLW dataset have an inter-ocular distance of between and pixels. Therefore, we compare the proposed method with the baseline using an input resolution from pixels to pixels, i.e., a heatmap resolution from pixels to pixels. In Fig. 6, the proposed method significantly improves heatmap regression performance when using a low input resolution. The increasing number of high-resolution images/videos in real-world applications is a challenge with respect to the computational cost and device memory needed to overcome the problem of sub-pixel localization by increasing the input resolution of deep learning-based heatmap regression models. For example, in the film industry, it has sometimes become necessary to swap the appearance of a target actor and a source actor to generate higher fidelity video frames in visual effects, especially when an actor is unavailable for some scenes [84]. The manipulation of actor faces in video frames relies on accurate localization of different facial landmarks and is performed at megapixel resolution, inducing a huge computational cost for extensive frame-by-frame animation. Therefore, instead of using high-resolution input images, our proposed method delivers another efficient solution for dealing with accurate semantic landmark localization.
| Resolution | NME (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| best | |||||||||||||
| 3.980 | 3.946 | 3.930 | 3.923 | 3.916 | 3.912 | 3.909 | 3.906 | 3.903 | 3.901 | 3.898 | 3.897 | 3.890/ | |
| 3.932 | 3.875 | 3.855 | 3.850 | 3.842 | 3.837 | 3.833 | 3.830 | 3.828 | 3.827 | 3.826 | 3.826 | 3.825/ | |
| 4.005 | 3.881 | 3.836 | 3.832 | 3.819 | 3.815 | 3.810 | 3.808 | 3.807 | 3.807 | 3.807 | 3.808 | 3.807/ | |
| 4.637 | 4.164 | 4.029 | 4.023 | 3.997 | 3.991 | 3.988 | 3.989 | 3.991 | 3.994 | 3.998 | 4.002 | 3.988/ | |
| NME (%) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| best | |||||||||||||
| 4.235 | 4.102 | 4.069 | 4.065 | 4.090 | 4.202 | 4.427 | 4.775 | 5.219 | 5.719 | 6.256 | 6.802 | 4.065/ | |
| 4.162 | 4.045 | 4.010 | 4.008 | 3.991 | 3.990 | 3.988 | 3.992 | 3.998 | 4.014 | 4.047 | 4.108 | 3.988/ | |
| 4.037 | 3.928 | 3.898 | 3.908 | 3.871 | 3.877 | 3.876 | 3.876 | 3.871 | 3.861 | 3.855 | 3.857 | 3.855/ | |
| 4.032 | 3.927 | 3.901 | 3.918 | 3.873 | 3.879 | 3.885 | 3.882 | 3.878 | 3.864 | 3.857 | 3.860 | 3.855/ | |
| 4.086 | 3.983 | 3.953 | 3.969 | 3.923 | 3.931 | 3.937 | 3.931 | 3.925 | 3.909 | 3.902 | 3.907 | 3.894/ | |
| Policy | NME (%), Inter-ocular | |||||||
| training | testing | test | pose | expression | illumination | make-up | occlusion | blur |
| P1 | P1 | 3.81 | 6.45 | 4.07 | 3.70 | 3.66 | 4.48 | 4.30 |
| P2 | P2 | 3.95 | 6.74 | 4.17 | 3.89 | 3.81 | 4.73 | 4.51 |
| P1 | P2 | 5.34 | 9.68 | 5.24 | 5.25 | 5.57 | 6.55 | 6.14 |
| P2 | P1 | 4.04 | 6.90 | 4.24 | 3.99 | 3.90 | 4.87 | 4.65 |
The influence of different numbers of alternative activation points. In the proposed quantization system, the activation probability indicates the distance between activation point to the ground truth activation point . If there is no heatmap error, the alternative activation points in (20) then give the same result as in (18). If the heatmap error cannot be ignored, there will be a trade-off on the number of alternative activation points: 1) a small increases the risk of missing the ground truth alternative activation points; 2) a large introduces the noise from irrelevant activation points, especially for large heatmap error. We demonstrate the performance of the proposed method by using different numbers of alternative activation points in Table VI. Specifically, we see that 1) when using a high input resolution, the best performance is achieved with a relatively large ; and 2) the performance is smooth near the optimal number of alternative activation points, making it easy to find a proper for validation data. As introduced in Section 3, binary heatmaps can be seen as a special case of Gaussian heatmaps with standard deviation . Considering that Gaussian heatmaps have been widely used in semantic landmark localization applications, we generalize the proposed quantization system to Gaussian heatmaps and demonstrate the influence of different numbers of alternative activation points in Table VII. Specifically, we see that 1) when applying the proposed quantization system to the model using Gaussian heatmap, it achieves comparable performance to the model using binary heatmap; and 2) the optimal number of alternative activation points increases with the standard deviation .
The influence of different “bounding box” annotation policies. For facial landmark detection, a reference bounding box is required to indicate the position of the facial area. However, there is a performance gap when using different reference bounding boxes [21]. A comparison between two widely used “bounding box” annotation policies is shown in Fig. 7, and we introduce two different bounding box annotation policies as follows:
-
•
P1: This annotation policy is usually used in semantic landmark localization tasks, especially in facial landmark localization. Specifically, the rectangular area of the bounding box tightly encloses a set of pre-defined facial landmarks.
-
•
P2: This annotation policy has been widely used in face detection datasets [74]. The bounding box contains the areas of the forehead, chin, and cheek. For the occluded face, the bounding box is estimated by the human annotator based on the scale of occlusion.


We demonstrate the experimental results using different annotation policies in Table VIII. Specifically, we find that the policy P1 usually achieves better results, possibly because the occluded forehead (e.g., hair) introduces additional variations to the face bounding boxes when using the policy P2. Furthermore, the model trained using the policy P2 is more robust to different bounding box policy during testing, suggesting its robustness to inaccurate bounding boxes from face detection algorithms.
Qualitative Analysis. As shown in Fig. 8, we present some “good” and “bad” facial landmark detection examples according to NME. Specifically, for the good cases presented in the first row, most images are of high quality; For the bad cases in the second row, most images contain heavy blurring and/or occlusion, making it difficult to accurately identify the contours of different facial parts.
| Backbone | Input | H3R | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean | [email protected] |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 | - | 96.3 | 95.2 | 89.0 | 82.9 | 88.2 | 83.7 | 79.4 | 88.4 | 29.8 | |
| ResNet-50 | * | 96.4 | 95.3 | 89.0 | 83.2 | 88.4 | 84.0 | 79.6 | 88.5 | 34.0 | |
| ResNet-50 | ✓ | 96.3 | 95.2 | 88.8 | 83.4 | 88.5 | 84.3 | 79.8 | 88.6 | 34.9 | |
| ResNet-101 | - | 96.7 | 95.8 | 89.3 | 84.2 | 87.9 | 84.2 | 80.7 | 88.9 | 30.0 | |
| ResNet-101 | * | 96.9 | 95.9 | 89.5 | 84.4 | 88.4 | 84.5 | 80.7 | 89.1 | 34.0 | |
| ResNet-101 | ✓ | 96.7 | 96.0 | 89.3 | 84.4 | 88.5 | 84.3 | 80.6 | 89.1 | 35.0 | |
| ResNet-152 | - | 97.0 | 95.8 | 89.9 | 84.7 | 89.1 | 85.4 | 81.3 | 89.5 | 31.0 | |
| ResNet-152 | * | 97.0 | 95.9 | 90.0 | 85.0 | 89.2 | 85.3 | 81.3 | 89.6 | 35.0 | |
| ResNet-152 | ✓ | 96.8 | 95.9 | 90.1 | 84.9 | 89.3 | 85.3 | 81.3 | 89.6 | 36.2 | |
| HRNet-W32 | - | 97.0 | 95.7 | 90.1 | 86.3 | 88.4 | 86.8 | 82.9 | 90.1 | 32.8 | |
| HRNet-W32 | * | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 | 37.7 | |
| HRNet-W32 | ✓ | 97.1 | 96.1 | 90.8 | 86.1 | 89.2 | 86.4 | 82.6 | 90.3 | 39.3 |
| Backbone | Input | H3R | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HRNet-W32 | - | 0.674 | 0.890 | 0.771 | 0.648 | 0.732 | 0.739 | 0.932 | 0.828 | 0.700 | 0.795 | |
| HRNet-W32 | * | 0.710 | 0.892 | 0.792 | 0.682 | 0.771 | 0.770 | 0.933 | 0.844 | 0.732 | 0.827 | |
| HRNet-W32 | ✓ | 0.720 | 0.892 | 0.797 | 0.691 | 0.784 | 0.777 | 0.933 | 0.846 | 0.739 | 0.834 | |
| HRNet-W32 | - | 0.723 | 0.904 | 0.811 | 0.690 | 0.788 | 0.782 | 0.941 | 0.859 | 0.741 | 0.841 | |
| HRNet-W32 | * | 0.744 | 0.905 | 0.819 | 0.708 | 0.810 | 0.798 | 0.942 | 0.865 | 0.757 | 0.858 | |
| HRNet-W32 | ✓ | 0.750 | 0.906 | 0.820 | 0.715 | 0.817 | 0.802 | 0.942 | 0.865 | 0.761 | 0.861 | |
| HRNet-W48 | - | 0.730 | 0.904 | 0.817 | 0.693 | 0.798 | 0.788 | 0.943 | 0.864 | 0.745 | 0.852 | |
| HRNet-W48 | * | 0.751 | 0.906 | 0.822 | 0.715 | 0.818 | 0.804 | 0.943 | 0.867 | 0.762 | 0.864 | |
| HRNet-W48 | ✓ | 0.756 | 0.906 | 0.825 | 0.718 | 0.825 | 0.806 | 0.941 | 0.868 | 0.763 | 0.869 | |
| HRNet-W32 | - | 0.748 | 0.904 | 0.826 | 0.712 | 0.816 | 0.802 | 0.941 | 0.871 | 0.759 | 0.864 | |
| HRNet-W32 | * | 0.758 | 0.906 | 0.825 | 0.720 | 0.827 | 0.809 | 0.943 | 0.869 | 0.767 | 0.871 | |
| HRNet-W32 | ✓ | 0.762 | 0.905 | 0.830 | 0.725 | 0.833 | 0.812 | 0.942 | 0.873 | 0.769 | 0.874 | |
| HRNet-W48 | - | 0.753 | 0.907 | 0.823 | 0.712 | 0.823 | 0.804 | 0.941 | 0.867 | 0.759 | 0.869 | |
| HRNet-W48 | * | 0.763 | 0.908 | 0.829 | 0.723 | 0.834 | 0.812 | 0.942 | 0.871 | 0.767 | 0.876 | |
| HRNet-W48 | ✓ | 0.765 | 0.907 | 0.829 | 0.724 | 0.838 | 0.814 | 0.941 | 0.871 | 0.769 | 0.878 |
6 Human Pose Estimation
In this section, we perform human pose estimation experiments to further demonstrate the effectiveness of the proposed quantization system for accurate semantic landmark localization.
6.1 Datasets
We perform experiments on two popular human pose estimation datasets,
-
•
MPII [85]: The MPII Human Pose dataset contains around 28,821 images with 40,522 person instances, in which 11,701 images for testing and the remaining 17,120 images for training. Following the experimental setup in [22], we use 22,246 person instances for training and evaluate the performance on the MPII validation set with 2,958 person instances, which is a heldout subset of MPII training set.
- •
6.2 Implementation Details
We utilize recent state-of-the-art heatmap regression method for human pose estimation, HRNet [22], as our baseline. Specifically, the proposed quantization system can be easily integrated into most heatmap regression models and we have made the source code of human pose estimation based on the HRNet baseline publicly available. For the MPII Human Pose dataset, we use the standard evaluation metric, head-normalized probability of correct keypoint or PCKh [85]. Specifically, a correct keypoint should fall within pixels of the ground truth position, where indicates the normalization distance and is the matching threshold. For fair comparison, we apply two different matching thresholds, [email protected] and [email protected], where a smaller matching threshold, , indicates a more strict evaluation metric for accurate semantic landmark localization [22]. For the COCO dataset, we use the standard evaluation metric, averaged precision (AP) and averaged recall (AR), where the object keypoint similarity or OKS is used as the similarity measure between the ground truth objects and the predicted objects [86].
6.3 Results
The experimental results on the MPII dataset are shown in Table IX. Specifically, when using a coarse evaluation metric, [email protected], both the proposed method and the compensation method achieve comparable performance to the baseline method, suggesting that the quantization error is trivial in coarse semantic landmark localization; When using a more strict evaluation metric, [email protected], the compensation method, which can be seen as a special case of H3R with , significantly improves the baseline, e.g., from to , while the proposed method H3R further improves the performance from to . The experimental results on the COCO dataset are shown in Table X. Specifically, the proposed method clearly improves the averaged precision (AP) in different settings and the major improvements on AP come from: 1) a strict evaluation metric, e.g., AP0.75; and 2) large/medium person instances, i.e., AP(M) and AP(L). Furthermore, we also find that the improvement decreases when increasing the input resolution, e.g., from to for , from to for , and from to for .
7 Conclusion
In this paper, we address the problem of sub-pixel localization for heatmap-based semantic landmark localization. We formally analyze quantization error in vanilla heatmap regression and propose a new quantization system via randomized rounding operation, which we prove is unbiased and lossless. Experiments on facial landmark localization and human pose estimation datasets demonstrate the effectiveness of the proposed quantization system for efficient and accurate sub-pixel localization.
Acknowledgement
Dr. Baosheng Yu is supported by ARC project FL-170100117.
References
- [1] Y. Sun, X. Wang, and X. Tang, “Deep convolutional network cascade for facial point detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013, pp. 3476–3483.
- [2] A. Bulat and G. Tzimiropoulos, “How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks),” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1021–1030.
- [3] A. Sinha, C. Choi, and K. Ramani, “Deephand: Robust hand pose estimation by completing a matrix imputed with deep features,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
- [4] U. Iqbal, P. Molchanov, T. Breuel Juergen Gall, and J. Kautz, “Hand pose estimation via latent 2.5 d heatmap regression,” in European Conference on Computer Vision (ECCV), 2018, pp. 118–134.
- [5] A. Toshev and C. Szegedy, “Deeppose: Human pose estimation via deep neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1653–1660.
- [6] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in European Conference on Computer Vision (ECCV), 2016, pp. 483–499.
- [7] A. Saxena, J. Driemeyer, and A. Y. Ng, “Robotic grasping of novel objects using vision,” International Journal of Robotics Research (IJRR), vol. 27, no. 2, pp. 157–173, 2008. [Online]. Available: https://doi.org/10.1177/0278364907087172
- [8] Y. Sun, Y. Chen, X. Wang, and X. Tang, “Deep learning face representation by joint identification-verification,” in Neural Information Processing Systems (NIPS), 2014, pp. 1988–1996.
- [9] J. Thies, M. Zollhofer, M. Stamminger, C. Theobalt, and M. Nießner, “Face2face: Real-time face capture and reenactment of rgb videos,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 2387–2395.
- [10] C. Wang, D. Xu, Y. Zhu, R. Martín-Martín, C. Lu, L. Fei-Fei, and S. Savarese, “Densefusion: 6d object pose estimation by iterative dense fusion,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [11] J. Deng, J. Guo, X. Niannan, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [12] H. Zhao, M. Tian, S. Sun, J. Shao, J. Yan, S. Yi, X. Wang, and X. Tang, “Spindle net: Person re-identification with human body region guided feature decomposition and fusion,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1077–1085.
- [13] L. Zheng, Y. Huang, H. Lu, and Y. Yang, “Pose-invariant embedding for deep person re-identification,” IEEE Transactions on Image Processing (TIP), vol. 28, no. 9, pp. 4500–4509, 2019.
- [14] Y.-C. Chen, X. Shen, and J. Jia, “Makeup-go: Blind reversion of portrait edit,” in IEEE International Conference on Computer Vision (ICCV), Oct 2017.
- [15] H. Chang, J. Lu, F. Yu, and A. Finkelstein, “Pairedcyclegan: Asymmetric style transfer for applying and removing makeup,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 40–48.
- [16] C. Cao, Y. Weng, S. Lin, and K. Zhou, “3d shape regression for real-time facial animation,” ACM Transactions on Graphics (TOG), vol. 32, no. 4, pp. 1–10, 2013.
- [17] C. Cao, Q. Hou, and K. Zhou, “Displaced dynamic expression regression for real-time facial tracking and animation,” ACM Transactions on Graphics (TOG), vol. 33, no. 4, pp. 1–10, 2014.
- [18] J. Thies, M. Zollhöfer, M. Nießner, L. Valgaerts, M. Stamminger, and C. Theobalt, “Real-time expression transfer for facial reenactment.” ACM Transactions on Graphics (TOG), vol. 34, no. 6, pp. 183–1, 2015.
- [19] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler, “Joint training of a convolutional network and a graphical model for human pose estimation,” in Neural Information Processing Systems (NIPS), 2014, pp. 1799–1807.
- [20] A. Nibali, Z. He, S. Morgan, and L. Prendergast, “Numerical coordinate regression with convolutional neural networks,” arXiv preprint arXiv:1801.07372, 2018.
- [21] X. Wang, L. Bo, and L. Fuxin, “Adaptive wing loss for robust face alignment via heatmap regression,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 6971–6981.
- [22] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 5693–5703.
- [23] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu, and B. Xiao, “Deep high-resolution representation learning for visual recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2020.
- [24] Y. Tai, Y. Liang, X. Liu, L. Duan, J. Li, C. Wang, F. Huang, and Y. Chen, “Towards highly accurate and stable face alignment for high-resolution videos,” in AAAI Conference on Artificial Intelligence (AAAI), vol. 33, 2019, pp. 8893–8900.
- [25] W. Li, Z. Wang, B. Yin, Q. Peng, Y. Du, T. Xiao, G. Yu, H. Lu, Y. Wei, and J. Sun, “Rethinking on multi-stage networks for human pose estimation,” arXiv preprint arXiv:1901.00148, 2019.
- [26] F. Zhang, X. Zhu, H. Dai, M. Ye, and C. Zhu, “Distribution-aware coordinate representation for human pose estimation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7093–7102.
- [27] P. Raghavan and C. D. Tompson, “Randomized rounding: a technique for provably good algorithms and algorithmic proofs,” Combinatorica, vol. 7, no. 4, pp. 365–374, 1987.
- [28] B. Korte, J. Vygen, B. Korte, and J. Vygen, Combinatorial optimization. Springer, 2012, vol. 2.
- [29] X. Cao, Y. Wei, F. Wen, and J. Sun, “Face alignment by explicit shape regression,” International Journal of Computer Vision (IJCV), vol. 107, no. 2, pp. 177–190, 2014.
- [30] X. Zhu and D. Ramanan, “Face detection, pose estimation, and landmark localization in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012, pp. 2879–2886.
- [31] X. Xiong and F. De la Torre, “Supervised descent method and its applications to face alignment,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2013, pp. 532–539.
- [32] S. Ren, X. Cao, Y. Wei, and J. Sun, “Face alignment at 3000 fps via regressing local binary features,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1685–1692.
- [33] V. Kazemi and J. Sullivan, “One millisecond face alignment with an ensemble of regression trees,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 1867–1874.
- [34] X. P. Burgos-Artizzu, P. Perona, and P. Dollár, “Robust face landmark estimation under occlusion,” in IEEE International Conference on Computer Vision (ICCV), 2013, pp. 1513–1520.
- [35] J. Zhang, S. Shan, M. Kan, and X. Chen, “Coarse-to-fine auto-encoder networks (cfan) for real-time face alignment,” in European Conference on Computer Vision (ECCV), 2014, pp. 1–16.
- [36] S. Zhu, C. Li, C. Change Loy, and X. Tang, “Face alignment by coarse-to-fine shape searching,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 4998–5006.
- [37] J. Carreira, P. Agrawal, K. Fragkiadaki, and J. Malik, “Human pose estimation with iterative error feedback,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4733–4742.
- [38] V. Belagiannis and A. Zisserman, “Recurrent human pose estimation,” in IEEE International Conference on Automatic Face & Gesture Recognition (FG), 2017, pp. 468–475.
- [39] P. N. Belhumeur, D. W. Jacobs, D. J. Kriegman, and N. Kumar, “Localizing parts of faces using a consensus of exemplars,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 35, no. 12, pp. 2930–2940, 2013.
- [40] X. Miao, X. Zhen, X. Liu, C. Deng, V. Athitsos, and H. Huang, “Direct shape regression networks for end-to-end face alignment,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 5040–5049.
- [41] Z. Zhang, P. Luo, C. C. Loy, and X. Tang, “Facial landmark detection by deep multi-task learning,” in European Conference on Computer Vision (ECCV), 2014, pp. 94–108.
- [42] K. Zhang, Z. Zhang, Z. Li, and Y. Qiao, “Joint face detection and alignment using multitask cascaded convolutional networks,” IEEE Signal Processing Letters (SPL), vol. 23, no. 10, pp. 1499–1503, 2016.
- [43] R. Ranjan, V. M. Patel, and R. Chellappa, “Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), vol. 41, no. 1, pp. 121–135, 2017.
- [44] R. Girshick, “Fast r-cnn,” in IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [45] Z.-H. Feng, J. Kittler, M. Awais, P. Huber, and X.-J. Wu, “Wing loss for robust facial landmark localisation with convolutional neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2235–2245.
- [46] A. Bulat and G. Tzimiropoulos, “Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources,” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 3706–3714.
- [47] D. Merget, M. Rock, and G. Rigoll, “Robust facial landmark detection via a fully-convolutional local-global context network,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 781–790.
- [48] T. Pfister, J. Charles, and A. Zisserman, “Flowing convnets for human pose estimation in videos,” in IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1913–1921.
- [49] L. Pishchulin, E. Insafutdinov, S. Tang, B. Andres, M. Andriluka, P. V. Gehler, and B. Schiele, “Deepcut: Joint subset partition and labeling for multi person pose estimation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4929–4937.
- [50] A. Newell, Z. Huang, and J. Deng, “Associative embedding: End-to-end learning for joint detection and grouping,” in Neural Information Processing Systems (NIPS), 2017, pp. 2277–2287.
- [51] W. Yang, S. Li, W. Ouyang, H. Li, and X. Wang, “Learning feature pyramids for human pose estimation,” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 1281–1290.
- [52] G. Papandreou, T. Zhu, L.-C. Chen, S. Gidaris, J. Tompson, and K. Murphy, “Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model,” in European Conference on Computer Vision (ECCV), 2018, pp. 269–286.
- [53] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, “Convolutional pose machines,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 4724–4732.
- [54] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7291–7299.
- [55] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun, “Cascaded pyramid network for multi-person pose estimation,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 7103–7112.
- [56] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy, “Towards accurate multi-person pose estimation in the wild,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4903–4911.
- [57] X. Sun, B. Xiao, F. Wei, S. Liang, and Y. Wei, “Integral human pose regression,” in European Conference on Computer Vision (ECCV), 2018, pp. 529–545.
- [58] D. C. Luvizon, D. Picard, and H. Tabia, “2d/3d pose estimation and action recognition using multitask deep learning,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 5137–5146.
- [59] D. C. Luvizon, H. Tabia, and D. Picard, “Human pose regression by combining indirect part detection and contextual information,” Computers & Graphics, vol. 85, pp. 15–22, 2019.
- [60] K. M. Yi, E. Trulls, V. Lepetit, and P. Fua, “Lift: Learned invariant feature transform,” in European Conference on Computer Vision (ECCV), 2016, pp. 467–483.
- [61] S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” Journal of Machine Learning Research (JMLR), vol. 17, no. 1, pp. 1334–1373, 2016.
- [62] J. Thewlis, H. Bilen, and A. Vedaldi, “Unsupervised learning of object landmarks by factorized spatial embeddings,” in IEEE International Conference on Computer Vision (ICCV), 2017, pp. 5916–5925.
- [63] W. Wu and S. Yang, “Leveraging intra and inter-dataset variations for robust face alignment,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 150–159.
- [64] W. Wu, C. Qian, S. Yang, Q. Wang, Y. Cai, and Q. Zhou, “Look at boundary: A boundary-aware face alignment algorithm,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 2129–2138.
- [65] R. Valle, J. M. Buenaposada, A. Valdés, and L. Baumela, “Face alignment using a 3d deeply-initialized ensemble of regression trees,” Computer Vision and Image Understanding (CVIU), vol. 189, p. 102846, 2019.
- [66] A. Dapogny, K. Bailly, and M. Cord, “Decafa: Deep convolutional cascade for face alignment in the wild,” in IEEE International Conference on Computer Vision (ICCV), October 2019.
- [67] S. Qian, K. Sun, W. Wu, C. Qian, and J. Jia, “Aggregation via separation: Boosting facial landmark detector with semi-supervised style translation,” in IEEE International Conference on Computer Vision (ICCV), 2019, pp. 10 153–10 163.
- [68] A. Kumar, T. K. Marks, W. Mou, Y. Wang, M. Jones, A. Cherian, T. Koike-Akino, X. Liu, and C. Feng, “Luvli face alignment: Estimating landmarks’ location, uncertainty, and visibility likelihood,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8236–8246.
- [69] X. Dong, Y. Yan, W. Ouyang, and Y. Yang, “Style aggregated network for facial landmark detection,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 379–388.
- [70] M. Kowalski, J. Naruniec, and T. Trzcinski, “Deep alignment network: A convolutional neural network for robust face alignment,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 88–97.
- [71] J. Yang, Q. Liu, and K. Zhang, “Stacked hourglass network for robust facial landmark localisation,” in IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017, pp. 79–87.
- [72] R. Valle, J. M. Buenaposada, A. Valdés, and L. Baumela, “A deeply-initialized coarse-to-fine ensemble of regression trees for face alignment,” in European Conference on Computer Vision (ECCV), 2018, pp. 585–601.
- [73] X. Zou, S. Zhong, L. Yan, X. Zhao, J. Zhou, and Y. Wu, “Learning robust facial landmark detection via hierarchical structured ensemble,” in IEEE International Conference on Computer Vision (ICCV), October 2019.
- [74] S. Yang, P. Luo, C.-C. Loy, and X. Tang, “Wider face: A face detection benchmark,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5525–5533.
- [75] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, and M. Pantic, “300 faces in-the-wild challenge: The first facial landmark localization challenge,” in IEEE International Conference on Computer Vision Workshops (ICCVW), 2013, pp. 397–403.
- [76] V. Le, J. Brandt, Z. Lin, L. Bourdev, and T. S. Huang, “Interactive facial feature localization,” in European Conference on Computer Vision (ECCV), 2012, pp. 679–692.
- [77] M. Koestinger, P. Wohlhart, P. M. Roth, and H. Bischof, “Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization,” in IEEE International Conference on Computer Vision Workshops (ICCVW), 2011, pp. 2144–2151.
- [78] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high-performance deep learning library,” in Neural Information Processing Systems (NeurIPS), H. Wallach, H. Larochelle, A. Beygelzimer, F. d Alché-Buc, E. Fox, and R. Garnett, Eds. Curran Associates, Inc., 2019, pp. 8024–8035.
- [79] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [80] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Springer, 2015, pp. 234–241.
- [81] Z. Zhong, L. Zheng, G. Kang, S. Li, and Y. Yang, “Random erasing data augmentation,” AAAI Conference on Artificial Intelligence (AAAI), 2020.
- [82] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009, pp. 248–255.
- [83] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations (ICLR), 2015.
- [84] J. Naruniec, L. Helminger, C. Schroers, and R. Weber, “High-resolution neural face swapping for visual effects,” Eurographics Symposium on Rendering, vol. 39, no. 4, 2020.
- [85] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele, “2d human pose estimation: New benchmark and state of the art analysis,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 3686–3693.
- [86] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in European Conference on Computer Vision (ECCV), 2014, pp. 740–755.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/763ccd7f-c292-4b99-ab86-4252377fa106/BaoshengYu.png) |
Baosheng Yu received a B.E. from the University of Science and Technology of China in 2014, and a Ph.D. from The University of Sydney in 2019. He is currently a Research Fellow in the School of Computer Science and the Faculty of Engineering at The University of Sydney, NSW, Australia. His research interests include machine learning, computer vision, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/763ccd7f-c292-4b99-ab86-4252377fa106/DachengTao.png) |
Dacheng Tao (F’15) is the President of the JD Explore Academy and a Senior Vice President of JD.com. He is also an advisor and chief scientist of the digital science institute in the University of Sydney. He mainly applies statistics and mathematics to artificial intelligence and data science, and his research is detailed in one monograph and over 200 publications in prestigious journals and proceedings at leading conferences. He received the 2015 Australian Scopus-Eureka Prize, the 2018 IEEE ICDM Research Contributions Award, and the 2021 IEEE Computer Society McCluskey Technical Achievement Award. He is a fellow of the Australian Academy of Science, AAAS, and ACM. |
Appendix A Proofs of Theorem 1 and Theorem 2
Theorem 1.
Given an unbiased quantization system defined by the encode operation in (10) and the decode operation in (13), we then have that the quantization error tightly upper bounded, i.e.,
where indicates the downsampling stride of the heatmap.
Proof.
Given the ground truth numerical coordinate , the predicted numerical coordinate , and the downsampling stride of the heatmap , if there is no heatmap error, we then have
where and indicate the ground truth heatmap and the predicted heatmap, respectively. Therefore, according to the decode operation in (13), we have the predicted numerical coordinate as
where and . The quantization error of vanilla quantization system then can be evaluated as follows:
The maximum quantization error is achieved when . Similarly, we have the maximum quantization error is achieved with . Considering that and are linearly independent variables, we thus have
The maximum quantization error is achieved with . That is, the quantization error in vanilla quantization system is tightly upper bounded by .
∎
Theorem 2.
Given the encode operation in (15) and the decode operation in (17), we then have that the 1) encode operation is unbiased; and 2) quantization system is lossless, i.e., there is no quantization error.
Proof.
Given the ground truth numerical coordinate , the predicted numerical coordinate , and the downsampling stride of the heatmap , we then have
Similarly, we have . Considering that and are linearly independent variables, we thus have
Therefore, the encode operation in (15), i.e., random-round, is an unbiased encode operation for heatmap regression.
We then prove that the quantization system is losses as follows. For the decode operation in (17), if there is no heatmap error, we then have
We can reconstruct the fractional part of , i.e.,
That is, , i.e., there is no quantization error.
∎
Appendix B Experiments
In this section, we provide additional experimental results on facial landmark detection and human pose estimation.
B.1 Facial Landmark Detection
| #Samples | NME (%) | ||
|---|---|---|---|
| 256 | 5.67/5.46 | 6.02/5.47 | 7.74/6.20 |
| 1024 | 4.79/4.63 | 5.27/4.77 | 7.13/5.43 |
| 4096 | 4.14/3.97 | 4.81/4.17 | 6.57/4.76 |
| 7500 | 4.00/3.81 | 4.62/3.99 | 6.50/4.62 |
| Backbone | Input | Heatmap | FLOPs | #Params | NME (%), Inter-ocular | ||||||
| test | pose | expression | illumination | make-up | occlusion | blur | |||||
| HRNet-W18 | 4.84G | 9.69M | 3.81 | 6.45 | 4.07 | 3.70 | 3.66 | 4.48 | 4.30 | ||
| HRNet-W18 | 4.98G | 9.69M | 3.91 | 6.83 | 4.09 | 3.82 | 3.70 | 4.59 | 4.41 | ||
| U-Net | 60.55G | 31.46M | 4.93 | 9.30 | 5.08 | 4.74 | 4.82 | 6.43 | 5.72 | ||
| HRNet-W18 | 1.21G | 9.69M | 3.99 | 6.78 | 4.26 | 3.89 | 3.84 | 4.65 | 4.46 | ||
| HRNet-W18 | 1.24G | 9.69M | 4.06 | 6.89 | 4.41 | 3.97 | 3.95 | 4.78 | 4.52 | ||
| U-Net | 15.14G | 31.46M | 4.17 | 7.10 | 4.45 | 4.06 | 4.03 | 5.00 | 4.73 | ||
| HRNet-W18 | 0.30G | 9.69M | 4.64 | 7.77 | 5.05 | 4.52 | 4.59 | 5.31 | 4.96 | ||
| HRNet-W18 | 0.31G | 9.69M | 4.61 | 7.70 | 5.00 | 4.44 | 4.58 | 5.28 | 4.94 | ||
| U-Net | 3.79G | 31.46M | 4.37 | 7.18 | 4.69 | 4.26 | 4.30 | 5.12 | 4.80 | ||
The influence of different numbers of training samples. The proposed quantization system does not rely on any assumption about the number of training samples, and is lossless for heatmap regression if there is no heatmap error. However, heatmap prediction performance will be influenced by the number of training samples: increasing the number of training samples improves the model generalizability from the learning theory perspective. Therefore, we perform experiments to evaluate the influence of the proposed method when using different numbers of training samples in practice. As shown in Table XI, we find that 1) the proposed method delivers consistent improvements when using different numbers of training samples; and 2) increasing the number of training samples significantly improves the performance of heatmap regression models with low-resolution input images.
The influence of different backbone networks. If we do not take the heatmap prediction error into consideration, the quantization error in heatmap regression is then caused by the downsampling of heamaps: 1) the downsampling of input images and 2) the downsampling of CNN feature maps. Though the analysis of heamap prediction error is out the scope of this paper, we perform some experiments to demonstrate the influence of different feature maps from the backbone networks in practice. Specifically, we perform experiments using the following two settings: 1) upsampling the feature maps from HRNet [22]; or 2) using the feature maps from U-shape backbone networks, i.e., U-Net [80]. As shown in Table XII, we see that 1) directly upsampling the feature maps achieves comparable performance with the baseline method; 2) U-Net performs better than HRNet-W18 when using a small input resolution (e.g., pixels), while is significantly worse than HRNet when using a large input resolution (e.g., pixels); and 3) U-Net contains more parameters and requires much more computations than HRNet when using the same input resolution. It would be interesting to further explore more efficient U-shape networks for low-resolution heatmap-based semantic landmark localization.
| Heatmap | NME (%) | ||
|---|---|---|---|
| Gaussian | 3.86 | 4.21 | 4.99 |
| Binary | 3.81 | 3.99 | 4.62 |
The influence of different types of heatmap. We perform some experiments to demonstrate the influence when using different types of heatmap, Gaussian heatmap and binary heatmap. As shown in Table XIII, 1) when using a large input resolution, the heatmap regression model using either Gaussian heatmap or binary heatmap achieves comparable performance; and 2) when using a low input resolution, the heatmap regression model achieves better performance with the binary heatmap. We demonstrate the differences between binary heatmap and Gaussian heatmap in Figure 9. Specifically, the Gaussian heatmap improves the robustness of heatmap prediction, while at the risk of increasing the uncertainty on the maximum activation point in the predicted heatmap. Therefore, when training very efficient heatmap regression models using a low input resolution, we recommend the binary heatmap.

The qualitative comparison between the vanilla quantization system and the proposed quantization system. We provide some demo images for facial landmark detection using both the baseline method (i.e., ) and the proposed quantization method (i.e., ) to demonstrate the effectiveness of the proposed method for accurate semantic landmark localization. As shown in Fig. 10, we see that the black landmarks are closer to the blue landmarks than the yellow landmarks, especially when using low resolution models (e.g., pixels).

B.2 Human Pose Estimation
To utilize the proposed method for accurate semantic landmark localization, it contains only one hyper-parameter , i.e., the number of activation points. To better understand the effectiveness of the proposed method for human pose estimation, we perform ablation studies using different numbers of alternative activation points on both MPII and COCO datasets. As shown in Table XIV and Table XV, we find that the proposed method achieves comparable performance when is between and , making it easy to choose a proper on the validation data for human pose estimation applications.
| Backbone | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| HRNet-W32 | - | 0.744 | 0.905 | 0.819 | 0.708 | 0.810 | 0.798 | 0.942 | 0.865 | 0.757 | 0.858 |
| HRNet-W32 | 1 | 0.723 | 0.904 | 0.811 | 0.690 | 0.788 | 0.782 | 0.941 | 0.859 | 0.741 | 0.841 |
| HRNet-W32 | 2 | 0.738 | 0.905 | 0.817 | 0.702 | 0.805 | 0.793 | 0.942 | 0.864 | 0.752 | 0.854 |
| HRNet-W32 | 3 | 0.743 | 0.905 | 0.819 | 0.708 | 0.810 | 0.797 | 0.942 | 0.865 | 0.756 | 0.857 |
| HRNet-W32 | 4 | 0.743 | 0.904 | 0.819 | 0.709 | 0.809 | 0.797 | 0.941 | 0.866 | 0.756 | 0.857 |
| HRNet-W32 | 5 | 0.747 | 0.904 | 0.819 | 0.712 | 0.814 | 0.800 | 0.940 | 0.866 | 0.759 | 0.859 |
| HRNet-W32 | 6 | 0.747 | 0.905 | 0.820 | 0.711 | 0.814 | 0.799 | 0.941 | 0.865 | 0.759 | 0.859 |
| HRNet-W32 | 7 | 0.745 | 0.905 | 0.820 | 0.709 | 0.812 | 0.798 | 0.941 | 0.864 | 0.757 | 0.857 |
| HRNet-W32 | 8 | 0.746 | 0.905 | 0.819 | 0.711 | 0.813 | 0.799 | 0.942 | 0.863 | 0.759 | 0.858 |
| HRNet-W32 | 9 | 0.746 | 0.905 | 0.819 | 0.710 | 0.812 | 0.798 | 0.942 | 0.863 | 0.758 | 0.857 |
| HRNet-W32 | 10 | 0.749 | 0.905 | 0.820 | 0.713 | 0.815 | 0.801 | 0.943 | 0.864 | 0.760 | 0.860 |
| HRNet-W32 | 11 | 0.750 | 0.906 | 0.820 | 0.715 | 0.817 | 0.802 | 0.942 | 0.865 | 0.761 | 0.861 |
| HRNet-W32 | 12 | 0.750 | 0.906 | 0.821 | 0.714 | 0.817 | 0.801 | 0.942 | 0.865 | 0.760 | 0.861 |
| HRNet-W32 | 13 | 0.749 | 0.906 | 0.821 | 0.713 | 0.816 | 0.800 | 0.942 | 0.865 | 0.760 | 0.860 |
| HRNet-W32 | 14 | 0.749 | 0.905 | 0.820 | 0.713 | 0.816 | 0.800 | 0.941 | 0.864 | 0.760 | 0.860 |
| HRNet-W32 | 15 | 0.749 | 0.906 | 0.820 | 0.713 | 0.817 | 0.800 | 0.942 | 0.863 | 0.760 | 0.860 |
| HRNet-W32 | 16 | 0.749 | 0.905 | 0.820 | 0.713 | 0.816 | 0.800 | 0.941 | 0.863 | 0.760 | 0.860 |
| HRNet-W32 | 17 | 0.750 | 0.905 | 0.821 | 0.714 | 0.817 | 0.801 | 0.942 | 0.863 | 0.761 | 0.860 |
| HRNet-W32 | 18 | 0.750 | 0.905 | 0.820 | 0.713 | 0.817 | 0.801 | 0.942 | 0.864 | 0.760 | 0.860 |
| HRNet-W32 | 19 | 0.750 | 0.904 | 0.820 | 0.714 | 0.816 | 0.801 | 0.941 | 0.864 | 0.760 | 0.860 |
| HRNet-W32 | 20 | 0.749 | 0.904 | 0.820 | 0.713 | 0.816 | 0.800 | 0.940 | 0.864 | 0.760 | 0.859 |
| HRNet-W32 | 21 | 0.747 | 0.904 | 0.819 | 0.712 | 0.813 | 0.799 | 0.940 | 0.862 | 0.758 | 0.858 |
| HRNet-W32 | 22 | 0.749 | 0.904 | 0.819 | 0.713 | 0.815 | 0.799 | 0.941 | 0.863 | 0.759 | 0.859 |
| HRNet-W32 | 23 | 0.749 | 0.904 | 0.819 | 0.713 | 0.816 | 0.800 | 0.941 | 0.863 | 0.760 | 0.860 |
| HRNet-W32 | 24 | 0.749 | 0.904 | 0.820 | 0.713 | 0.817 | 0.800 | 0.941 | 0.863 | 0.759 | 0.860 |
| HRNet-W32 | 25 | 0.749 | 0.905 | 0.820 | 0.713 | 0.817 | 0.800 | 0.941 | 0.864 | 0.760 | 0.860 |
| HRNet-W32 | 30 | 0.749 | 0.905 | 0.819 | 0.714 | 0.818 | 0.800 | 0.941 | 0.862 | 0.759 | 0.859 |
| HRNet-W32 | 35 | 0.748 | 0.902 | 0.819 | 0.712 | 0.816 | 0.799 | 0.940 | 0.862 | 0.758 | 0.859 |
| HRNet-W32 | 40 | 0.746 | 0.901 | 0.818 | 0.710 | 0.814 | 0.797 | 0.939 | 0.861 | 0.756 | 0.857 |
| HRNet-W32 | 45 | 0.746 | 0.901 | 0.815 | 0.710 | 0.814 | 0.796 | 0.939 | 0.860 | 0.755 | 0.857 |
| HRNet-W32 | 50 | 0.746 | 0.901 | 0.814 | 0.710 | 0.816 | 0.797 | 0.938 | 0.859 | 0.755 | 0.857 |
| HRNet-W32 | 75 | 0.741 | 0.899 | 0.811 | 0.705 | 0.810 | 0.792 | 0.936 | 0.856 | 0.751 | 0.853 |
| HRNet-W32 | 100 | 0.734 | 0.897 | 0.805 | 0.697 | 0.803 | 0.785 | 0.934 | 0.850 | 0.743 | 0.846 |
| HRNet-W32 | 125 | 0.717 | 0.893 | 0.795 | 0.682 | 0.785 | 0.770 | 0.930 | 0.841 | 0.727 | 0.831 |
| HRNet-W32 | 150 | 0.651 | 0.889 | 0.755 | 0.629 | 0.702 | 0.713 | 0.925 | 0.809 | 0.680 | 0.762 |
| Backbone | Head | Shoulder | Elbow | Wrist | Hip | Knee | Ankle | Mean | [email protected] | |
|---|---|---|---|---|---|---|---|---|---|---|
| HRNet-W32 | - | 97.1 | 95.9 | 90.3 | 86.4 | 89.1 | 87.1 | 83.3 | 90.3 | 37.7 |
| HRNet-W32 | 1 | 97.033 | 95.703 | 90.131 | 86.312 | 88.402 | 86.802 | 82.924 | 90.055 | 32.808 |
| HRNet-W32 | 2 | 97.033 | 95.856 | 90.302 | 86.416 | 88.818 | 87.004 | 83.325 | 90.247 | 35.912 |
| HRNet-W32 | 3 | 97.135 | 95.975 | 90.302 | 86.347 | 89.250 | 86.741 | 83.018 | 90.271 | 37.668 |
| HRNet-W32 | 4 | 97.237 | 95.907 | 90.643 | 86.141 | 89.164 | 86.862 | 83.089 | 90.294 | 36.997 |
| HRNet-W32 | 5 | 97.203 | 95.839 | 90.677 | 86.141 | 89.147 | 87.124 | 82.994 | 90.315 | 38.774 |
| HRNet-W32 | 6 | 97.101 | 95.839 | 90.677 | 86.262 | 89.181 | 86.923 | 83.089 | 90.310 | 38.548 |
| HRNet-W32 | 7 | 97.135 | 95.822 | 90.609 | 86.313 | 89.199 | 86.943 | 83.113 | 90.312 | 37.913 |
| HRNet-W32 | 8 | 97.033 | 95.822 | 90.557 | 86.175 | 89.147 | 86.922 | 82.876 | 90.245 | 38.129 |
| HRNet-W32 | 9 | 97.067 | 95.822 | 90.694 | 86.329 | 89.112 | 86.942 | 82.876 | 90.284 | 38.457 |
| HRNet-W32 | 10 | 97.033 | 95.873 | 90.626 | 86.141 | 89.372 | 86.862 | 82.995 | 90.297 | 39.024 |
| HRNet-W32 | 11 | 97.101 | 95.907 | 90.592 | 86.244 | 89.406 | 86.842 | 82.853 | 90.302 | 39.139 |
| HRNet-W32 | 12 | 97.101 | 95.822 | 90.660 | 86.175 | 89.475 | 86.761 | 82.900 | 90.297 | 38.996 |
| HRNet-W32 | 13 | 97.101 | 95.822 | 90.694 | 86.141 | 89.475 | 86.741 | 82.829 | 90.289 | 38.855 |
| HRNet-W32 | 14 | 97.033 | 95.822 | 90.728 | 86.141 | 89.337 | 86.640 | 82.806 | 90.250 | 38.616 |
| HRNet-W32 | 15 | 97.169 | 95.754 | 90.609 | 86.124 | 89.337 | 86.801 | 82.475 | 90.211 | 38.798 |
| HRNet-W32 | 16 | 97.101 | 95.771 | 90.694 | 86.141 | 89.199 | 86.882 | 82.569 | 90.226 | 38.691 |
| HRNet-W32 | 17 | 97.067 | 95.822 | 90.609 | 86.142 | 89.285 | 86.821 | 82.617 | 90.224 | 39.053 |
| HRNet-W32 | 18 | 97.033 | 95.822 | 90.626 | 86.004 | 89.250 | 86.801 | 82.522 | 90.193 | 39.048 |
| HRNet-W32 | 19 | 97.033 | 95.839 | 90.626 | 85.953 | 89.250 | 86.822 | 82.593 | 90.198 | 39.058 |
| HRNet-W32 | 20 | 96.999 | 95.788 | 90.626 | 86.039 | 89.389 | 86.801 | 82.664 | 90.226 | 39.014 |
| HRNet-W32 | 21 | 96.999 | 95.771 | 90.677 | 85.935 | 89.337 | 86.862 | 82.451 | 90.187 | 38.855 |
| HRNet-W32 | 22 | 96.999 | 95.856 | 90.626 | 86.090 | 89.268 | 86.741 | 82.475 | 90.198 | 38.842 |
| HRNet-W32 | 23 | 96.999 | 95.890 | 90.609 | 86.038 | 89.164 | 86.801 | 82.499 | 90.187 | 39.037 |
| HRNet-W32 | 24 | 96.862 | 95.754 | 90.592 | 86.021 | 89.233 | 86.842 | 82.333 | 90.146 | 39.089 |
| HRNet-W32 | 25 | 96.930 | 95.754 | 90.506 | 86.055 | 89.302 | 86.721 | 82.309 | 90.135 | 39.126 |
| HRNet-W32 | 30 | 96.862 | 95.788 | 90.438 | 86.004 | 89.372 | 86.660 | 82.144 | 90.101 | 38.759 |
| HRNet-W32 | 35 | 96.623 | 95.873 | 90.523 | 85.936 | 89.354 | 86.701 | 81.884 | 90.075 | 38.964 |
| HRNet-W32 | 40 | 96.385 | 95.856 | 90.523 | 85.816 | 89.406 | 86.721 | 81.908 | 90.049 | 38.618 |
| HRNet-W32 | 45 | 96.317 | 95.669 | 90.506 | 85.746 | 89.285 | 86.660 | 82.026 | 89.990 | 38.579 |
| HRNet-W32 | 50 | 96.214 | 95.686 | 90.506 | 85.678 | 89.268 | 86.439 | 81.648 | 89.899 | 38.584 |
| HRNet-W32 | 55 | 96.044 | 95.669 | 90.404 | 85.335 | 89.337 | 86.439 | 81.506 | 89.815 | 38.496 |
| HRNet-W32 | 60 | 95.805 | 95.533 | 90.302 | 85.147 | 89.147 | 86.419 | 81.270 | 89.672 | 38.332 |
| HRNet-W32 | 65 | 95.703 | 95.618 | 90.251 | 85.079 | 89.164 | 86.419 | 81.081 | 89.646 | 38.218 |
| HRNet-W32 | 70 | 95.498 | 95.584 | 90.165 | 85.215 | 89.302 | 86.378 | 80.963 | 89.633 | 38.197 |
| HRNet-W32 | 75 | 95.259 | 95.533 | 90.029 | 85.147 | 89.147 | 86.318 | 80.467 | 89.487 | 38.054 |
| HRNet-W32 | 80 | 95.020 | 95.516 | 90.046 | 84.907 | 89.216 | 86.197 | 80.255 | 89.404 | 37.684 |
| HRNet-W32 | 85 | 94.679 | 95.465 | 89.927 | 84.925 | 89.337 | 86.258 | 80.042 | 89.357 | 37.463 |
| HRNet-W32 | 90 | 94.407 | 95.431 | 89.790 | 84.907 | 89.233 | 86.197 | 79.735 | 89.251 | 37.208 |
| HRNet-W32 | 95 | 94.065 | 95.414 | 89.773 | 84.890 | 89.302 | 86.097 | 79.263 | 89.165 | 36.719 |
| HRNet-W32 | 100 | 93.827 | 95.482 | 89.603 | 84.737 | 89.320 | 86.076 | 78.578 | 89.032 | 36.180 |
| HRNet-W32 | 105 | 93.520 | 95.448 | 89.603 | 84.599 | 89.199 | 85.996 | 77.964 | 88.884 | 35.532 |
| HRNet-W32 | 110 | 93.008 | 95.448 | 89.518 | 84.273 | 89.147 | 85.835 | 77.114 | 88.657 | 34.770 |
| HRNet-W32 | 115 | 92.565 | 95.296 | 89.501 | 84.085 | 89.112 | 85.794 | 76.405 | 88.483 | 33.352 |
| HRNet-W32 | 120 | 92.121 | 95.262 | 89.398 | 83.930 | 89.060 | 85.533 | 75.272 | 88.238 | 31.814 |
| HRNet-W32 | 125 | 91.473 | 95.160 | 89.160 | 83.554 | 88.991 | 85.472 | 74.162 | 87.939 | 30.065 |
| HRNet-W32 | 130 | 90.825 | 94.939 | 89.211 | 83.023 | 89.095 | 85.089 | 72.910 | 87.609 | 27.528 |
| HRNet-W32 | 135 | 90.246 | 94.667 | 89.006 | 82.577 | 88.852 | 84.807 | 71.209 | 87.164 | 24.757 |
| HRNet-W32 | 140 | 89.529 | 94.463 | 88.853 | 82.046 | 88.679 | 83.800 | 69.792 | 86.659 | 21.788 |
| HRNet-W32 | 145 | 88.404 | 94.124 | 88.717 | 81.310 | 88.645 | 82.773 | 67.997 | 86.053 | 19.136 |
| HRNet-W32 | 150 | 87.756 | 93.886 | 88.614 | 80.146 | 88.575 | 81.383 | 66.084 | 85.373 | 16.586 |
| HRNet-W32 | 175 | 82.401 | 90.829 | 86.927 | 71.515 | 86.014 | 70.504 | 56.826 | 80.109 | 9.204 |
| HRNet-W32 | 200 | 68.008 | 87.075 | 82.325 | 62.146 | 79.176 | 58.737 | 41.120 | 72.009 | 5.988 |