Harnessing PU Learning for Enhanced Cloud-based DDoS Detection: A Comparative Analysis
Abstract.
This paper explores the application of Positive-Unlabeled (PU) learning for enhanced Distributed Denial-of-Service (DDoS) detection in cloud environments. Utilizing the BCCC-cPacket-Cloud-DDoS-2024 dataset, we implement PU Learning with four machine learning algorithms: XGBoost, Random Forest, Support Vector Machine, and Naïve Bayes. Our results demonstrate the superior performance of ensemble methods, with XGBoost and Random Forest achieving Scores exceeding 98%. We quantify the efficacy of each approach using metrics including Score, ROC AUC, Recall, and Precision. This study bridges the gap between PU Learning and cloud-based anomaly detection, providing a foundation for addressing Context-Aware DDoS Detection in multi-cloud environments. Our findings highlight the potential of PU Learning in scenarios with limited labeled data, offering valuable insights for developing more robust and adaptive cloud security mechanisms.
1. Introduction
The rapid evolution of cloud computing has brought about unprecedented challenges in cybersecurity, particularly in the realm of Distributed Denial-of-Service (DDoS) attacks. As these attacks grow in sophistication and frequency, traditional detection methods often fall short. This paper explores the potential of Positive-Unlabeled (PU) learning, a semi-supervised machine learning technique, in revolutionizing DDoS detection within cloud environments.
PU Learning offers a unique approach to anomaly detection by leveraging a set of known positive instances and a pool of unlabeled data. This method is particularly suited to scenarios where obtaining comprehensive labeled datasets is challenging or impractical. In the context of cloud security, PU Learning could potentially overcome limitations associated with traditional supervised learning approaches, which often struggle with the dynamic and evolving nature of DDoS attacks.
1.1. Research Objectives
This study aims to:
-
(1)
Investigate the efficacy of PU Learning in identifying anomalous cloud traffic, with a specific focus on DDoS attacks.
-
(2)
Evaluate the impact of various underlying machine learning methods on PU Learning performance in the context of DDoS detection.
-
(3)
Contribute to the nascent field of Context-Aware DDoS Detection by exploring PU Learning’s adaptability to multi-cloud environments.
1.2. Paper Structure
The remainder of this paper is organized as follows:
-
•
Section 2 provides a comprehensive overview of PU Learning, its mechanisms, and potential applications.
-
•
Section 3 explores the theoretical applications of PU Learning in cloud computing environments.
-
•
Section 4 delves into anomaly-based DDoS detection strategies.
-
•
Section 5 details our experimental design, including dataset selection and implementation of various PU Learning approaches.
-
•
Section 6 presents and discusses our findings on the effectiveness of PU Learning in DDoS detection.
-
•
Section 7 compares our PU Learning approach with a state-of-the-art DDoS detection model.
-
•
Section 8 reframes the task of DDoS detection as an NU Learning problem and analyzes the performance of the original PU configuration against the reconceptualized NU setup.
-
•
Section 9 concludes the paper and suggests directions for future research.
1.3. Paper Contributions
This work unites two previously unrelated concepts: the machine learning approach of PU Learning and cloud anomaly detection with an emphasis on Distributed Denial-of-Service (DDoS) attacks. Based on the lack of published literature, there is little research that has adequately addressed the utility of PU Learning in a cloud computing environment. Furthermore, this work will:
-
•
Quantify the predictive and detective efficacy of PU Learning implementations using common machine learning methods: Naïve Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), and XGBoost.
-
•
Provide the necessary groundwork to address Context-Aware DDoS Detection, a problem we have identified in multi-cloud environments.
-
•
Demonstrate how PU Learning may play a crucial role in distinguishing between legitimate traffic spikes and cyber attacks, by leveraging its ability to extrapolate insights from datasets with limited or poor labeling.
2. Understanding PU Learning
PU Learning, or Positive-Unlabeled learning, is a semi-supervised machine learning approach that addresses scenarios where only positive and unlabeled data are available for training. This section delves into the fundamentals of PU Learning and its potential applications across various domains.
2.1. Core Principles of PU Learning
In PU Learning, the training data consists of two components:
-
(1)
Positive (P) examples: Instances known to belong to the positive class.
-
(2)
Unlabeled (U) examples: Instances with unknown class labels (positive or negative).
The primary objective of PU Learning is to construct a classifier capable of accurately predicting class labels for unlabeled examples, given only positive examples and unlabeled data. This approach differs significantly from traditional supervised learning methods, which require both positive and negative labeled examples during the training process.
2.2. PU Learning Techniques
PU Learning methods can be broadly categorized into three main approaches (Bekker and Davis, 2020):
-
(1)
Two-step techniques
-
(2)
Biased learning
-
(3)
Class prior incorporation
2.2.1. Two-step Techniques
This approach involves:
-
a)
Identifying reliable negative examples
-
b)
Learning based on labeled positives and reliable negatives
2.2.2. Biased Learning
This method treats PU data as fully labeled data with class label noise for the negative class.
2.2.3. Class Prior Incorporation
This technique modifies standard learning methods by applying mathematics from the Selected Completely At Random (SCAR) assumption–a sampling method where individuals or items are selected randomly from a population without any specific criteria or bias–utilizing the provided class prior.
2.3. Applications of PU Learning
PU Learning has shown promise in various fields, including:
Its ability to handle scenarios with limited labeled data makes it particularly valuable in domains where obtaining comprehensive labeled datasets is challenging or resource-intensive.
2.4. Assumptions and Limitations
According to Bekker et al. (Bekker and Davis, 2020), the common assumptions about data distributions in PU Learning are:
-
•
All unlabeled examples are negative
-
•
The classes are separable
-
•
The classes have a smooth distribution
However, these assumptions may not always hold in real-world scenarios, particularly in the context of cloud computing and DDoS detection. For instance:
-
•
The assumption that all unlabeled examples are negative may lead to a \sayclose-world assumption, which, while simplistic, can be serviceable in certain contexts. This means that in situations where it is difficult or impractical to obtain labels for all examples, treating unlabeled data as negative can simplify the analysis and decision-making process, even though it may not accurately reflect the true nature of the data.
-
•
The separability of classes is often clear in log data and traffic patterns, where deviations from normal behavior are typically distinct.
-
•
The assumption of smooth distribution may not always apply, as log data trends can be irregular.
3. PU Learning in Cloud Computing and Security
The unique characteristics of PU Learning make it a promising candidate for addressing various challenges in cloud computing. This section explores potential applications of PU Learning within these domains, with a particular focus on anomaly detection and DDoS mitigation.
3.1. Anomaly Detection in Cloud Infrastructure
PU Learning can be employed to identify unusual behavior patterns in cloud environments, such as:
-
(1)
Suspicious network traffic
-
(2)
Unauthorized access attempts
-
(3)
Atypical resource utilization patterns
By training a PU Learning model on known \saypositive (malicious or anomalous) examples and \sayunlabeled (potentially benign or normal) data, the system can learn to flag potential security threats or system malfunctions effectively.
3.2. Vulnerability Detection
PU Learning can aid in proactively identifying vulnerabilities in cloud-based applications, services, or infrastructure. The model can be trained on known \saypositive examples of vulnerabilities and \sayunlabeled data, enabling security teams to address potential weaknesses before they can be exploited.
3.3. Malware Detection
In cloud environments, PU Learning can be utilized to detect malware by training models on known malware samples (positive examples) and unlabeled data that may or may not contain malware. This approach can enhance the protection of cloud-based systems and data against evolving malware threats.
3.4. User Behavior Analysis
PU Learning can be applied to analyze user behavior patterns in cloud environments, including:
-
(1)
Login patterns
-
(2)
Resource usage
-
(3)
Access trends
This analysis can help identify anomalous user behavior that may indicate account compromise, insider threats, or other security risks.
3.5. Cloud Resource Optimization
While not directly related to security, PU Learning can contribute to optimizing cloud resource allocation and utilization. By training models on known examples of efficient resource usage and unlabeled data, the system can learn to identify and recommend ways to optimize cloud resource utilization, potentially reducing costs and improving overall cloud performance.
4. Anomaly-based DDoS Detection: A Focus on PU Learning
This section explores the application of PU Learning in the context of anomaly-based DDoS detection, comparing it with traditional statistical and machine learning approaches (Osanaiye et al., 2016).
4.1. Categories of Anomalies
Anomalies in network traffic can be classified into three main categories:
-
(1)
Point anomalies: Individual data instances considered anomalous compared to the rest of the data (e.g., application-bug level attacks resulting in DoS).
-
(2)
Contextual anomalies: Data instances anomalous in specific contexts but not in others, determined by the dataset structure.
-
(3)
Collective anomalies: Groups of data instances flagged as anomalous with respect to the entire dataset (e.g., DDoS flooding attacks).
4.2. Traditional Approaches to Anomaly Detection
4.2.1. Statistical Anomaly Detection
This method involves:
-
a)
Compiling statistical features of normal traffic to generate a baseline pattern
-
b)
Comparing incoming traffic with the baseline using statistical inference tests
-
c)
Determining the legitimacy of behavior without prior knowledge of normal system activities
4.2.2. Machine Learning Anomaly Detection
This approach utilizes:
-
a)
Training algorithms on datasets of normal behavior to learn patterns and characteristics
-
b)
Identifying instances that deviate significantly from learned normal behavior
-
c)
Common techniques include one-class support vector machines, isolation forests, autoencoders, clustering, and density estimation
4.3. PU Learning for DDoS Detection
PU Learning offers a unique approach to DDoS detection by leveraging:
-
(1)
Known positive examples of DDoS traffic
-
(2)
Unlabeled traffic data that may contain both normal and malicious patterns
This method can potentially overcome limitations of traditional approaches, particularly in scenarios where comprehensive labeled datasets are unavailable or impractical to obtain.
4.4. Statistical and Machine Learning Anomaly Detection Methods
Based on Shafi et al.’s (Shafi et al., 2024) prior work, we scrutinize and employ four well-established machine learning algorithms: Naïve Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), and XGBoost.
-
•
XGBoost: A supervised gradient boosting decision tree model, falling under the machine learning anomaly detection category.
-
•
Naïve Bayes (NB): A statistical approach using probability and Bayesian inference, categorized under statistical anomaly detection.
-
•
Support Vector Machines (SVMs): A machine learning technique, particularly the one-class variant used for unsupervised anomaly detection.
-
•
Random Forests (RF): An ensemble of decision tree models, classified under machine learning anomaly detection.
It is important to note that PU Learning is distinct from these supervised learning algorithms. Specifically, PU Learning is not a technique like XGBoost, Support Vector Machines (SVMs), Random Forests, or Bayesian methods. PU Learning is a specific type of semi-supervised learning problem. While XGBoost, Random Forests, and SVMs require both positive and negative examples during training, PU Learning leverages only positive and unlabeled data. This unique characteristic makes PU Learning particularly suitable for scenarios where obtaining negative examples is difficult or expensive, such as in the case of DDoS detection in cloud environments.
5. Experimental Design and Methodology
This section outlines our approach to evaluating the effectiveness of PU Learning in DDoS detection within cloud environments.
5.1. Dataset Selection
We utilize the BCCC-cPacket-Cloud-DDoS-2024 dataset (Shafi et al., [n. d.]), developed by Shafi et al. (Shafi et al., 2024), which addresses 15 identified weaknesses in existing DDoS datasets. This comprehensive dataset includes:
-
(1)
Over eight benign user activities
-
(2)
17 DDoS attack scenarios
-
(3)
More than 300 extracted features from network and transport layers
Dataset Preprocessing
To prepare the dataset for machine learning algorithms, we follow a structured preprocessing approach. The primary goals of this preprocessing include handling missing values, converting categorical variables into numerical representations, managing extreme values, and ensuring that all data types are compatible for model input.
-
(1)
Loading the Dataset: The first step involves loading the dataset from a text file. We utilize the pandas library to read the CSV-formatted data, ensuring that no header row is considered, which allows us to treat all rows uniformly. Before evaluating the DDoS dataset, we first had to adjust the .csv file. Specifically, we created a new column named and populated it with either a 1 or 0 based on the value stored in the label column. The label column identified the row of collected data as either Benign or !Benign; we populated the new column with a value of 1 for Benign and 0 for !Benign. Likewise, we stripped the column names from the .csv and converted it into a text file.
-
(2)
Handling Missing Values: After loading the data, we address any missing values within the dataset. Empty entries, denoted by consecutive commas or empty strings, are replaced with NaN (Not a Number) values. This replacement facilitates easier handling of missing data in subsequent steps, as NaN is a standard placeholder in pandas for missing or undefined values.
-
(3)
Identifying and Processing Categorical Variables: To convert these categorical variables into a format suitable for machine learning models, we employ a hashing function. This function takes each categorical value, converts it into a string, encodes it, and generates a fixed-size numerical representation. By applying this hashing function, we ensure that each categorical variable is transformed into a unique integer, thus eliminating any string-based entries from the dataset.
-
(4)
Managing Extreme Values: As part of the preprocessing, we also need to address any extreme values in the dataset that may skew results or lead to errors during model training. We define a threshold for what constitutes an \sayextreme value. For any numeric entry that exceeds this threshold, we replace the value with a hashed representation of the original value. This transformation helps maintain numerical stability while ensuring that extreme values do not negatively impact the learning algorithms.
-
(5)
Converting to Numeric Types: With categorical variables hashed and extreme values managed, we convert all remaining data in the DataFrame to numeric types. This conversion is done using the pandas function that forces any non-convertible values to be set as NaN. After this conversion, we fill any remaining NaN values with a specified default value, such as 0.
-
(6)
Final Data Preparation: Finally, we ensure that all entries in the DataFrame are of integer type, making the dataset ready for input into machine learning models. This final conversion confirms that no string or non-numeric data remains, and that the dataset is in a uniform format suitable for model training and evaluation.
Through these preprocessing steps, we transform the raw dataset into a clean, structured format that is suitable for use with machine learning algorithms, enhancing both the accuracy and efficiency of subsequent analyses. The adjusted dataset, as a result of the above preprocessing, consists of 700,775 rows and 325 columns (or 227,751,875 cells).
5.2. PU Learning Implementation
We adapt the PU Learning implementation (Agmon, [n. d.]) by Agmon (Agmon, 2020), based on the work of Bekker et al. (Bekker and Davis, 2020). The process involves:
-
(1)
Training a classifier to predict the probability of a sample being labeled
-
(2)
Using the classifier to predict the probability of positive samples being labeled
-
(3)
Predicting the probability of a given sample being labeled
-
(4)
Estimating the probability of a sample being positive
Code Overview
The table, Table 1, provides a summary of the key functions and classes within our code, which was designed to evaluate multiple machine learning models on the BCCC-cPacket-Cloud-DDoS-2024 dataset (Shafi et al., [n. d.]) using a Positive-Unlabeled (PU) learning approach.
| Function/Class | Description |
|---|---|
| ModelEvaluator | Class that handles the evaluation of machine learning models based on metrics like , ROC, Recall, and Precision. |
| evaluate_results(y_test, y_predict) | Static method that evaluates model performance and returns a dictionary with Score, ROC AUC score, Recall, and Precision. |
| PULearning | Class implementing the Positive-Unlabeled learning approach, allowing different classifiers to be used. |
| fit_PU_estimator(X, y, hold_out_ratio) | Fits the model using PU Learning by holding out a portion of the positive samples for estimation. |
| predict_PU_prob(X, prob_s1y1) | Predicts probabilities using the fitted PU estimator, adjusting for the estimated probability of positive samples. |
| compare_models(models, x_train, y_train, x_test, y_test) | Compares multiple machine learning models, fitting each to the same dataset and evaluating performance metrics. |
| evaluate_pu_model(model_class, x_train, y_train, x_test, y_test, hold_out_ratio) | Evaluates a Positive-Unlabeled (PU) learning model by fitting it to the training data, making predictions, and printing evaluation metrics. |
| main() | Main function that orchestrates the loading of the dataset, preprocessing, model training, and evaluation. Allows toggling of evaluations for base ML models and PU learning models. |
5.3. Machine Learning Models
We evaluate four established machine learning algorithms within our PU Learning framework:
-
(1)
Naïve Bayes (NB) (GaussianNB)
-
(2)
Support Vector Machine (SVM) (LinearSVC)
-
(3)
Random Forest (RF) (RandomForestClassifier)
-
(4)
XGBoost (XGBClassifier)
5.4. Evaluation Metrics
To evaluate the performance of PU Learning in DDoS detection, we employ Bekker et al.’s (Bekker and Davis, 2020) modified score, adapted for PU Learning scenarios:
Where:
-
•
: The conditional probability that an example is truly positive given that it is classified as positive.
-
•
: The conditional probability that an example is classified as positive given that it is truly positive.
-
•
: The probability that an example is classified as positive.
To clearly illustrate what is, we provide an example. Take a training set with the following variables: Age, Familial Diabetes Diagnosis, Presence of Fatigue, Frequency of Urination Per Day, and the Presence of Blurred Vision. From what little positive data samples a research team possesses, they determined that the following vector, , corresponds to or is indicative of the presence of some arbitrary disease. As such, , or the indicator variable for an example to be positive, is set to 1. A value of 1 means that the thing we are trying to detect is present based on the previously defined vector, which is shorthanded to . As a result, simply represents the collection of positive indicator variables, , with a value of 1. This set of indicator variables is tied to the vector of attributes . In this way, captures the set of attributes, that when appraised in concert, leads to a positive conclusion, be that the existence of something or some other analogous example.
This metric allows us to assess the performance of our PU Learning models in a context where traditional metrics like Precision and Recall may not be directly applicable due to the absence of labeled negative examples.
Metrics for Evaluating Machine Learning Models in PU Learning
In the context of evaluating machine learning models, particularly within a Positive-Unlabeled (PU) learning approach, several key metrics provide insights into the performance of the computational techniques. Here, we discuss four important metrics: Score, ROC AUC Score, Recall, and Precision.
-
•
Score: Continuing from our earlier discussion, the Score is the harmonic mean of Precision and Recall, providing a single metric that balances both concerns. It is especially useful when dealing with imbalanced datasets, such as in PU Learning, where positive instances may be scarce compared to unlabeled instances. The Score takes into account both false positives and false negatives, making it a robust measure for evaluating model performance.
-
•
Precision: Precision measures the proportion of true positive predictions among all positive predictions made by the model. In a PU Learning context, where only positive and unlabeled instances are available, Precision indicates how many of the instances classified as positive (or belonging to the target class) are indeed correct. High Precision suggests that the model is good at avoiding false positives.
-
•
Recall: Recall, also known as sensitivity, measures the proportion of true positives correctly identified by the model out of all actual positive instances. In a PU setting, Recall assesses how well the model captures the actual positives when it has to infer from unlabeled data. A high Recall indicates that most of the relevant instances are being identified.
-
•
ROC AUC Score: The ROC AUC (Receiver Operating Characteristic - Area Under the Curve) score evaluates the model’s ability to distinguish between the positive and negative classes across various thresholds. The AUC represents the likelihood that the model will rank a randomly chosen positive instance higher than a randomly chosen negative instance. In PU Learning, where negative instances may not be explicitly labeled, a high ROC AUC score indicates a model’s effectiveness in distinguishing true positives from unlabeled instances.
These metrics collectively provide a comprehensive evaluation of model performance, particularly in scenarios characterized by the challenges of Positive-Unlabeled learning, where traditional metrics may not suffice.
6. Results and Discussion
In this section, we will present and analyze the results of our experiments, comparing the performance of different PU Learning implementations using Naïve Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), and XGBoost algorithms. We will discuss the implications of these results for DDoS detection in cloud environments.
6.1. Performance Comparison





6.2. Analysis of Results
The results of our PU Learning trials reveal significant variations in performance across the four machine learning algorithms tested: XGBoost, Random Forest, Support Vector Machine (SVM), and Naïve Bayes.
XGBoost demonstrated the best overall performance, achieving the highest scores across all metrics. Its Score of 99.045, ROC AUC of 98.7433, Recall of 99.4516, and Precision of 98.6418 indicate exceptional ability to detect DDoS attacks while minimizing false positives and negatives.
Random Forest closely followed XGBoost, with only slightly lower scores across all metrics (: 98.7349, ROC AUC: 98.3806, Recall: 99.0702, Precision: 98.4018). This suggests that ensemble methods are particularly effective for DDoS detection in PU Learning scenarios.
SVM showed moderate performance, with an Score of 66.4401 and ROC AUC of 67.6693. Its lower Recall (57.3895) but higher Precision (78.8798) suggest it may be more conservative in its predictions, potentially missing some attacks but having higher confidence in the ones it does identify.
Naïve Bayes showed mixed performance. It had the lowest Score (40.3212) and Recall (26.0191), indicating it struggled to identify a large portion of the DDoS attacks. However, it demonstrated a high Precision (89.5384), suggesting that when it did classify an instance as a DDoS attack, it was correct nearly 90% of the time. This high Precision but low Recall indicates that Naïve Bayes might be overly conservative in its classifications, missing many attacks but having high confidence in the ones it does identify.
6.3. Implications for Cloud-based DDoS Detection
These results have several important implications for cloud-based DDoS detection:
-
(1)
Ensemble methods (XGBoost and Random Forest) appear to be the most effective for DDoS detection in PU Learning scenarios, likely due to their ability to capture complex patterns in network traffic.
-
(2)
The high performance of XGBoost and Random Forest suggests that PU Learning can be highly effective for DDoS detection, even with limited labeled data.
-
(3)
The poor performance of Naïve Bayes indicates that simpler probabilistic models may not be suitable for the complex patterns involved in DDoS attacks.
-
(4)
The moderate performance of SVM suggests that linear separation may not be sufficient for distinguishing between normal and DDoS traffic in all cases.
-
(5)
The high Recall rates of XGBoost and Random Forest are particularly important for DDoS detection, as missing an attack (false negative) can have severe consequences for cloud services.
7. Experimental Comparison with State-of-the-Art Approaches
In this section, we compare our PU Learning approach with a state-of-the-art DDoS detection model proposed by Shafi et al. (Shafi et al., 2024). Their work introduces a sophisticated traffic characterization model that employs a multi-layered structure for distinguishing between normal and malicious network activities.
7.1. Shafi et al.’s Proposed Model
Shafi et al. present a dual-path architecture that enhances flexibility and interpretability in DDoS detection. Their model consists of two primary layers:
-
(1)
An initial layer trained on labeled data to establish input classification.
-
(2)
A second layer featuring two distinct models:
-
•
One trained exclusively with benign data
-
•
Another trained solely with attack data
-
•
The second layer’s routing is determined by the first layer’s classification: benign inputs are directed to the benign model, while attack inputs are sent to the attack model. This approach aims to mitigate overfitting and address the black-box nature often associated with deep learning-based algorithms.
7.2. Experimental Scenario Comparison
Shafi et al. defined seven distinct experiment scenarios, with Task 6 being most comparable to our experiment. Task 6 focuses on identifying attack activities and the benign label, which aligns closely with our PU Learning approach for DDoS detection.
7.3. Methodology Comparison
Both our study and Shafi et al.’s work employ four well-established machine learning algorithms: Naïve Bayes (NB), Support Vector Machine (SVM), Random Forest (RF), and XGBoost. This commonality in algorithm selection allows for a meaningful comparison between the two approaches.
The evaluation metrics used in both studies also show significant overlap, with both considering Precision, Recall, and -Score. While our study additionally employs the ROC AUC metric, the shared metrics provide a solid basis for comparison.
7.4. Performance Comparison
To facilitate a clear comparison between Shafi et al.’s results and our PU Learning approach, we present their findings alongside ours in Table 2.
| Model | Shafi et al. | Our PU Learning | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | -Score | Precision | Recall | -Score | |
| NB | 0.58 | 0.29 | 0.19 | 0.8954 | 0.2602 | 0.4032 |
| SVM | 0.35 | 0.50 | 0.40 | 0.7888 | 0.5739 | 0.6644 |
| RF | 0.88 | 0.86 | 0.87 | 0.9840 | 0.9907 | 0.9873 |
| XGBoost | 0.91 | 0.86 | 0.87 | 0.9864 | 0.9945 | 0.9905 |
| Proposed | 0.97 | 0.96 | 0.97 | – | – | – |

Analyzing the results, we observe several key points:
-
(1)
Both approaches demonstrate the superiority of ensemble methods (RF and XGBoost) over traditional algorithms (NB and SVM) for DDoS detection.
-
(2)
Our PU Learning approach shows consistently higher performance across all metrics for each algorithm, particularly for NB and SVM.
-
(3)
The performance gap between ensemble methods and traditional algorithms is more pronounced in our PU Learning approach.
-
(4)
Both Shafi et al.’s proposed model and our PU Learning implementation of XGBoost achieve the highest overall performance in their respective studies.
7.5. Comparative Analysis
While both approaches demonstrate high effectiveness in DDoS detection, our PU Learning method shows superior performance across all evaluated algorithms. This is particularly evident in the substantial improvements observed for NB and SVM, which struggle in Shafi et al.’s implementation but perform notably better in our PU Learning framework.
The exceptional performance of our PU Learning approach, especially with ensemble methods, suggests that it may be more adept at capturing the complex patterns inherent in DDoS attacks, even with limited labeled data. This capability is crucial in real-world scenarios where comprehensive labeled datasets are often unavailable or impractical to obtain.
However, it’s important to note that Shafi et al.’s proposed model offers additional benefits, such as enhanced interpretability and a dual-path architecture that separates benign and attack data processing. These features could provide valuable insights in operational settings and may offer advantages in terms of model explainability.
7.6. Approach Determination
Based on the comparative analysis, our PU Learning approach demonstrates superior performance in terms of raw metrics. However, both approaches offer unique strengths. Our method excels in scenarios with limited labeled data and shows remarkable performance across various algorithms. Shafi et al.’s model, while slightly lower in raw performance, offers enhanced interpretability and a specialized architecture for separating benign and attack traffic.
The choice between these approaches may depend on specific use case requirements, such as the availability of labeled data, the need for model interpretability, or the importance of raw performance metrics. Future work could explore combining elements of both approaches to leverage their respective strengths in cloud-based DDoS detection systems.
8. Contrastive Study of PU Learning and NU Learning Approaches in DDoS Detection
In this section, we conduct a comparative analysis between the PU Learning and NU Learning approaches for Cloud-based DDoS detection. By analyzing the differences in how each framework handles the labeling of data and the impact of these strategies on model performance, we aim to highlight the strengths and limitations of each approach.
8.1. Preprocessing and Binary Label Assignment
In our preprocessing stage, we assign a binary label to each data instance based on its prior classification as Benign or !Benign. If the prior data is labeled as benign, it receives a value of 0; otherwise, it receives a value of 1. This binary labeling system enables the classification of data into two distinct categories, which is foundational to the PU Learning framework that we apply in our problem setup.
8.2. PU Learning Problem Setup
Our problem setup is structured within the framework of PU Learning (Positive-Unlabeled Learning). In this context, instances labeled as !Benign represent the positive class (value of 1), while the benign instances are treated as the unlabeled class (value of 0). PU Learning is particularly suitable for scenarios in which only a subset of data instances is confidently labeled as positive, while the rest remain unlabelled rather than explicitly negative.
Our PU Learning model implementation follows the two-step approach detailed earlier in this paper. First, the model trains on the positive samples (labeled as !Benign) and treats the unlabeled samples as potential positive examples. In the second step, it refines the model to better distinguish between true positives and false positives among the unlabeled data. This approach is crucial in instances where data is asymmetrically labeled, as is the case with our dataset of interest: BCCC-cPacket-Cloud-DDoS-2024.
8.3. NU Learning: Concept and Setup
NU Learning (Negative-Unlabeled Learning) is the converse of the PU Learning problem setup. In NU Learning, the positively labeled examples are treated as \sayunlabeled, while the negative examples (originally Benign) are the primary focus for learning. In the context of our prior preprocessing, this would mean that instances labeled as 0 (benign) are now treated as the positive class, while those labeled as 1 (!Benign) are treated as the unlabeled class.
The implementation of NU Learning involves a similar two-step approach, wherein the model trains on the available negative (benign) samples and progressively learns to distinguish between benign and potentially non-benign instances. NU Learning is applied to understand how well the model can classify an instance based on its alignment with known benign features.
8.4. Extending the Comparative Analysis
To deepen our analysis, we extend the study to compare the efficacy of framing Cloud-based DDoS detection as either a PU Learning or NU Learning problem. By examining both setups, we can assess which approach more accurately captures the nuanced patterns in the dataset and thus enables more effective detection of anomalous (or potentially malicious) instances.
8.5. Dataset Modification for NU Learning
To implement NU Learning, we modify the dataset by flipping the binary label values in the last column. Every instance of a 0 in the last column is changed to a 1 and vice versa. After this modification, we output the count of rows ending in 0 and 1 both before and after the transformation to confirm the accuracy of the modification. We then re-run our analysis code with the modified dataset to generate a new bar chart for the NU Learning approach, allowing for a direct comparison between the PU and NU Learning outcomes.

8.6. NU Learning Results
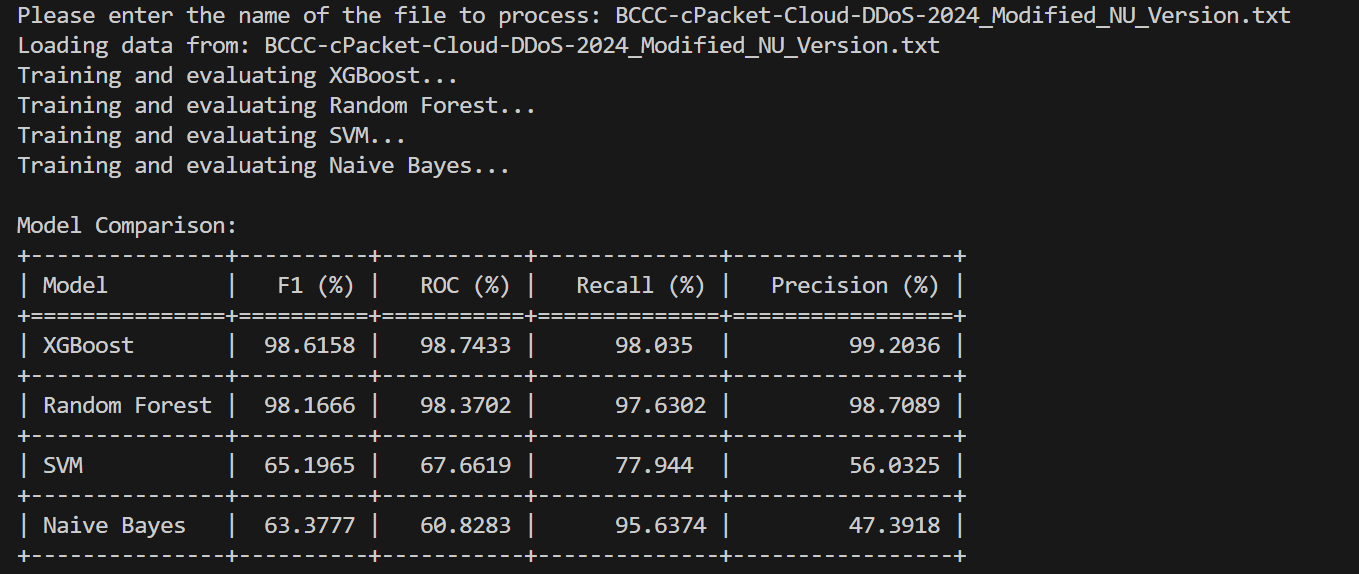


| Model | -Score | ROC AUC | Recall | Precision |
|---|---|---|---|---|
| XGBoost | 0.986158 | 0.987433 | 0.980350 | 0.992036 |
| Random Forest | 0.981666 | 0.983702 | 0.976302 | 0.987089 |
| SVM | 0.651965 | 0.676619 | 0.779440 | 0.560325 |
| Naïve Bayes | 0.633777 | 0.608283 | 0.956374 | 0.473918 |

In terms of the -Score (as exhibited in Figure 11), both PU and NU Learning show consistent performance, with the exception of NU Learning’s Naïve Bayes implementation, which achieves a slightly higher score. When considering Recall, NU Learning surpasses PU Learning, particularly with its Naïve Bayes and Support Vector Machine (SVM) models. The performance of Random Forest and XGBoost, however, remains nearly identical across both learning frameworks. Similarly, the ROC AUC scores for both models are virtually the same. On the other hand, PU Learning excels in Precision when paired with Naïve Bayes and SVM, while Random Forest and XGBoost once again demonstrate comparable results in both setups.
8.7. Assessment Deliberation
The comparison of PU and NU Learning results shows that both approaches yield high performance with the XGBoost and Random Forest algorithms. However, XGBoost consistently achieves higher precision and recall scores across both setups, indicating it is particularly effective for identifying the nuanced distinctions in DDoS attack patterns. Meanwhile, SVM and Naïve Bayes underperform in both settings, suggesting that these algorithms may be less suitable for this problem due to their lower adaptability to the complex feature sets associated with DDoS detection.
As an aside, it is infeasible for us to incorporate prior knowledge into the Naïve Bayes implementation, which may account for its poorer performance. Similarly, the use of a linear support vector machine (SVM) likely contributes to SVM’s limited efficacy in this context.
Based on these findings, the PU Learning approach with the XGBoost algorithm is recommended for implementation, as it provides a more balanced and reliable model for distinguishing between benign and malicious traffic in Cloud-based DDoS detection tasks.
9. Conclusion and Future Work
This study has explored the application of Positive-Unlabeled (PU) learning in the context of cloud-based DDoS detection, addressing a critical gap in the existing literature. By leveraging the BCCC-cPacket- Cloud-DDoS-2024 dataset (Shafi et al., [n. d.]) and implementing PU Learning with four established machine learning algorithms, we have demonstrated the potential of this approach in enhancing anomaly detection capabilities in cloud environments.
Key findings of our study include:
-
(1)
Ensemble methods, particularly XGBoost and Random Forest, demonstrate superior performance in PU Learning-based DDoS detection, with Scores exceeding 98%.
-
(2)
There is a significant performance gap between ensemble methods and traditional algorithms like SVM and Naïve Bayes in this context.
-
(3)
PU Learning shows great promise for effective DDoS detection in cloud environments, even with limited labeled data.
These results highlight the promise of PU Learning in addressing the challenges of DDoS detection in cloud computing, particularly in scenarios where obtaining comprehensive labeled datasets is impractical or resource-intensive.
9.1. Contributions
This work has made several significant contributions to the field:
-
(1)
We have bridged the gap between PU Learning and cloud-based anomaly detection, demonstrating the applicability and effectiveness of this approach in DDoS detection.
-
(2)
We have quantified the predictive and detective efficacy of PU Learning implementations using common machine learning methods, providing a comprehensive comparison of their performance.
-
(3)
We have laid the groundwork for addressing Context-Aware DDoS Detection–which takes into account various contextual factors, such as user behavior, traffic patterns, application characteristics, and environmental conditions–in multi-cloud environments, a critical challenge in modern cloud security.
9.2. Future Work
While this study has made significant strides in applying PU Learning to cloud-based DDoS detection, several avenues for future research remain:
-
(1)
Exploring the application of PU Learning to other types of cloud security threats beyond DDoS attacks.
-
(2)
Conducting a more in-depth analysis of feature importance in the high-performing models to gain insights into the most relevant indicators of DDoS attacks in cloud environments.
-
(3)
Developing adaptive PU Learning models that can evolve with changing attack patterns and cloud infrastructure configurations.
-
(4)
Extending the research to real-time DDoS detection scenarios, considering the computational efficiency and scalability of PU Learning approaches in production environments.
In conclusion, this work has demonstrated the potential of PU Learning in enhancing cloud-based DDoS detection capabilities. As cloud computing continues to evolve and face increasingly sophisticated security threats, approaches like PU Learning will play a crucial role in developing more robust and adaptive defense mechanisms.
References
- (1)
- Agmon ([n. d.]) Alon Agmon. [n. d.]. pu-learn. https://github.com/a-agmon/pu-learn
- Agmon (2020) Alon Agmon. 2020. Semi-Supervised Classification of Unlabeled Data (PU Learning). https://towardsdatascience.com/semi-supervised-classification-of-unlabeled-data-pu-learning-81f96e96f7cb
- Bekker and Davis (2020) Jessa Bekker and Jesse Davis. 2020. Learning from positive and unlabeled data: a survey. Machine Learning 109 (4 2020), 719–760. Issue 4. https://doi.org/10.1007/s10994-020-05877-5
- Duan et al. (2024) Li Duan, Jing Wang, Bing Luo, and Qiao Sun. 2024. Simple knowledge graph completion model based on PU learning and prompt learning. Knowledge and Information Systems 66 (4 2024), 2683–2697. Issue 4. https://doi.org/10.1007/s10115-023-02040-z
- Kumagai et al. (2024) Atsutoshi Kumagai, Tomoharu Iwata, and Yasuhiro Fujiwara. 2024. Meta-learning for Positive-unlabeled Classification. (6 2024).
- Long et al. (2024) Lin Long, Haobo Wang, Zhijie Jiang, Lei Feng, Chang Yao, Gang Chen, and Junbo Zhao. 2024. Positive-Unlabeled Learning by Latent Group-Aware Meta Disambiguation. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 23138–23147. https://doi.org/10.1109/CVPR52733.2024.02183
- Osanaiye et al. (2016) Opeyemi Osanaiye, Kim-Kwang Raymond Choo, and Mqhele Dlodlo. 2016. Distributed denial of service (DDoS) resilience in cloud: Review and conceptual cloud DDoS mitigation framework. Journal of Network and Computer Applications 67 (5 2016), 147–165. https://doi.org/10.1016/j.jnca.2016.01.001
- Shafi et al. (2024) MohammadMoein Shafi, Arash Habibi Lashkari, Vicente Rodriguez, and Ron Nevo. 2024. Toward Generating a New Cloud-Based Distributed Denial of Service (DDoS) Dataset and Cloud Intrusion Traffic Characterization. Information 15 (3 2024), 195. Issue 4. https://doi.org/10.3390/info15040195
- Shafi et al. ([n. d.]) Mohammad Moein Shafi, Arash Habibi Lashkari, Vicente Rodriguez, and Ron Nevo. [n. d.]. Cloud-base DDoS Attack Classification using ML/DL. https://www.kaggle.com/datasets/bcccdatasets/bccc-cpacket-cloud-ddos-2024
- Zhang et al. (2024) Yan Zhang, Chun Li, Zhaoxia Liu, and Ming Li. 2024. Semi-Supervised Disease Classification based on Limited Medical Image Data. (5 2024).