Hallucination of speech recognition errors
with sequence to sequence learning
Abstract
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system’s transcription of unseen data, as well as an out-of-domain ASR system’s transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.
Index Terms:
Speech Recognition, Error Prediction, Low Resource, Sequence to Sequence Neural Networks, Hallucinated ASR ErrorsI Introduction
For several decades the speech-text data imbalance has been a significant factor in the impedance mismatch between spoken language processing systems and text-based language processing systems. Use of speech in artificial intelligence applications is increasing, however there is not always enough semantically labelled speech for individual applications to be able to build directly supervised spoken language understanding systems for them. On the other hand, wide domain cloud based automatic speech recognizer (ASR) systems are trained on a lot of data, and even as black boxes to the developer, they are able to transcribe speech to text with a lower error rate (under certain circumstances). As the availability of text resources for training the natural language understanding (NLU) system for many tasks far exceed the amount of available transcribed speech, many end developers of spoken language understanding systems utilize ASR systems as an off-the-shelf or cloud-based solution for transcribing speech and cascade them with NLU systems trained on text data [1, 2, 3].
The text obtained from ASR typically contains errors whether resulting from artifacts or biases of the speech recognizer model, its training data, etc., or from inherent phonetic confusibilities that exist in the language being recognized (e.g., homophonic or near homophonic sets of words). When off-the shelf ASR systems are deployed in technical domains such as medical use-cases, the domain mismatch can increase the word error rate (WER) of state-of-the-art systems to as much as 40% in some cases [4]; even when word error rates are lower, the semantic changes introduced by the errors can critically affect the meaning of the transcripts for downstream tasks in a manner that is much severe than typed text modalities [5].
In order to alleviate the adverse impact of ASR errors on NLU systems, one approach is to “speechify” the original input text for training an NLU system while treating it as intended spoken text. In this strategy, the NLU system is made to observe an input that contains the kind of errors expected from ASR at test time, and thus can learn to be robust to them. A crucial question is: can we predict the output behavior of an ASR system from intended spoken text, including when the system is a black box for the developer? Prior work, described in section II, has looked at approaching the task of error prediction by building models of phoneme confusability. Approaches in this category generally rely upon an FST decoding graph comprised of Pronunciation and Language Models to translate hallucinated errors from phonemes to words, thus the prediction is not optimized end to end. Additionally, prior work has been limited in the exploitation of context (at the phoneme or word levels) into the prediction of errors made by the ASR systems.
Our previous work explored sequence to sequence learning to model phoneme confusability in a context-dependent manner, which resulted in improved recall of ASR errors when combined with a confusion matrix sampling technique [6], however we still relied upon an FST decoding graph to translate errors to a word sequence space. In this work, we hypothesize that the folding of the pronunciation and language modeling ability of the decoding graph, along with confusability modeling into a single network can enable these modeling abilities to be jointly optimized for error prediction, and allow better interplay between the models. Our novel approach uses sequence to sequence learning to directly predict hypothesized ASR outputs from intended spoken text.
A key ingredient in building a machine learning model to predict the errors made by an ASR system is: data about the kinds of ASR errors made by the system. In this respect, the use of cloud-based ASR systems also brings an additional challenge i.e., the lack of publicly available error-characterization data. In prior work, we treated the task of predicting errors made by cloud based systems only as an out-of-domain task. However, we reason that limited characterization data may be collected from time to time, and thus this out-of-domain task need not be completely out-of-domain too. In this paper, we investigate the effect of passing some speech from a standard corpus through a cloud based ASR system to finetune an error prediction model for such a black box recognizer.
This study extends preliminary results presented in [7], where we explored models that directly translated word sequences of intended spoken text to word sequences of hypothesized ASR output. While these word-level end to end models allowed for an improved overall recall of ASR errors, we found that they would not recall some errors that a phonetic confusion matrix model was able to recall, suggesting complementary information in the word and phonetic representations.
In this paper, along with the aforementioned word-level model, we present a dual encoder model for error prediction that can look at both word and phoneme sequence representations of input text to further improve the fidelity of hallucinated errors. We also expand on our preliminary experiments and evaluation in several ways. For evaluation on in-domain ASR, we look at a larger test set in addition to evaluating on a smaller one for comparability to prior work. For out-of-domain ASR such as cloud-based systems, along with evaluating on read speech versions of chatted dialog turns, in this paper we include results on a dataset of realistic spoken dialog turns, looking at multiple word error rate settings, for an intrinsic as well as extrinsic evaluation. Finally, we present additional experiments in a practical middle-case where domain-specific ASR training data is available but only to a limited amount.
II Prior Work
Traditionally, approaches to the task of predicting or hallucinating speech recognition errors have characterized word errors as indirectly resulting out of phonetic substitutions, insertions, or deletions. A general framework in this direction was described by Fosler-Lussier et al. [8] wherein they built a matrix of how often each phoneme in input text was confused by the recognizer for each possible sequence of zero or more phonemes, and cast it as a Weighted Finite State Transducer (WFST) graph. Amongst ideas for developing a confusion model from the internals of an ASR system when accessible, Anguita et al. [9] looked at directly determining phone distances by looking inside the HMM-GMM acoustic model of a speech recognizer. Jyothi and Fosler-Lussier [10] combined the two aforementioned ideas and extended it to predict complete utterances of speech recognized text. Tan et al. [11] explored the idea that the confusion characteristics of a phoneme can be vary based on other phonemes in its context, and used a phrasal MT model to simulate ASR, but only evaluating the 1-best word sequence of the final output. Sagae et al. [12] and Shivakumar et al. [13] considered word level phrasal MT modeling for error prediction but did not combine it with phonetic information, or directly evaluate the fidelity of predicted errors. Our prior work [6] took the framework of Fosler-Lussier et al. with it’s applicability to black box systems, and investigated the benefit of introducing contextual phonetic information through a neural sequence to sequence model, along with introducing a sampling based paradigm to better match the stochasticity of errors and confidence of neural network acoustic models.
ASR error modeling has also been used to train language models discriminatively such that they complement the shortcomings, i.e., error characteristics of ASR models and help prevent errors where possible. Jyothi and Fosler-Lussier [14] applied their aforementioned error prediction model trained from ASR behavior on a certain dataset to improve WER on the same dataset. Kurata et al. [15] applied an error prediction model trained from ASR characteristics on one dataset to improve WER on another dataset. Sagae et al. [12] tried different methods for error prediction for discriminative training of a language model, and found that modeling confusability amongst phoneme phrase cohorts i.e., sequences of phonemes instead of individual phonemes helped obtain a larger improvement in WER, showing a benefit in modeling errors in a contextual manner. Shivakumar et al. [13] explored modeling confusability at the level of phrases of words, and improved WER in a ASR system with a hybrid DNN-HMM acoustic model.
Knowledge of ASR errors has been used in training of NLU for various spoken language understanding tasks. Tsvetkov et al. [1] improve a phrasal machine translation system’s response to spoken input by augmenting phrases in it’s internal tables with variants containing hallucinated ASR errors derived from a phonetic confusion matrix approach. Ruiz et al. [16] construct a spoken machine translation system that conditions on phoneme sequence inputs which are generated with hallucinated ASR errors at train time to build robustness to their nature. Stiff et al. [2] utilized our aforementioned sampling based phonetic confusion matrix approach and randomly chose to hallucinate ASR on typed text input to an NLU system at train time to improve its performance on a test set with real ASR errors. Rao et al. [17] improved their NLU classifier’s robustness to ASR errors by conditioning it on ASR hidden states instead of direct text to expose it to ASR confusability information, focusing on a scenario where all training data for NLU was in the spoken domain.
III System Description
We use convolutional sequence to sequence models [18] for the purpose of translating true text (gold transcripts free from ASR errors) to recognized text (transcription hypotheses with hallucinated ASR errors).
III-A Word level ASR prediction
The architecture for the word level ASR prediction model is shown in Figure 1. An encoder takes a word sequence representation of the true text as input, and embeds it into a sequence of 256-dimensional vector representations (combined with position embeddings) . A stack of four residual CNN layers [19] transforms into a final hidden representation . Both the hidden representation and the embedded input are provided to an attention mechanism.
The decoder is comprised of three residual CNN layers. The decoder takes as input the sequence of predicted words prior to the current timestep, and embeds them into a sequence of vector representations , we use 256 dimensional embeddings here as well. Along with these embeddings, each decoder layer also conditions upon an attended representation from the encoder derived through the mechanism explained below. The output of the final layer is passed through a linear transformation followed by a softmax, to give a probability distribution over the target vocabulary at step . Cumulatively, this model has 37M parameters.
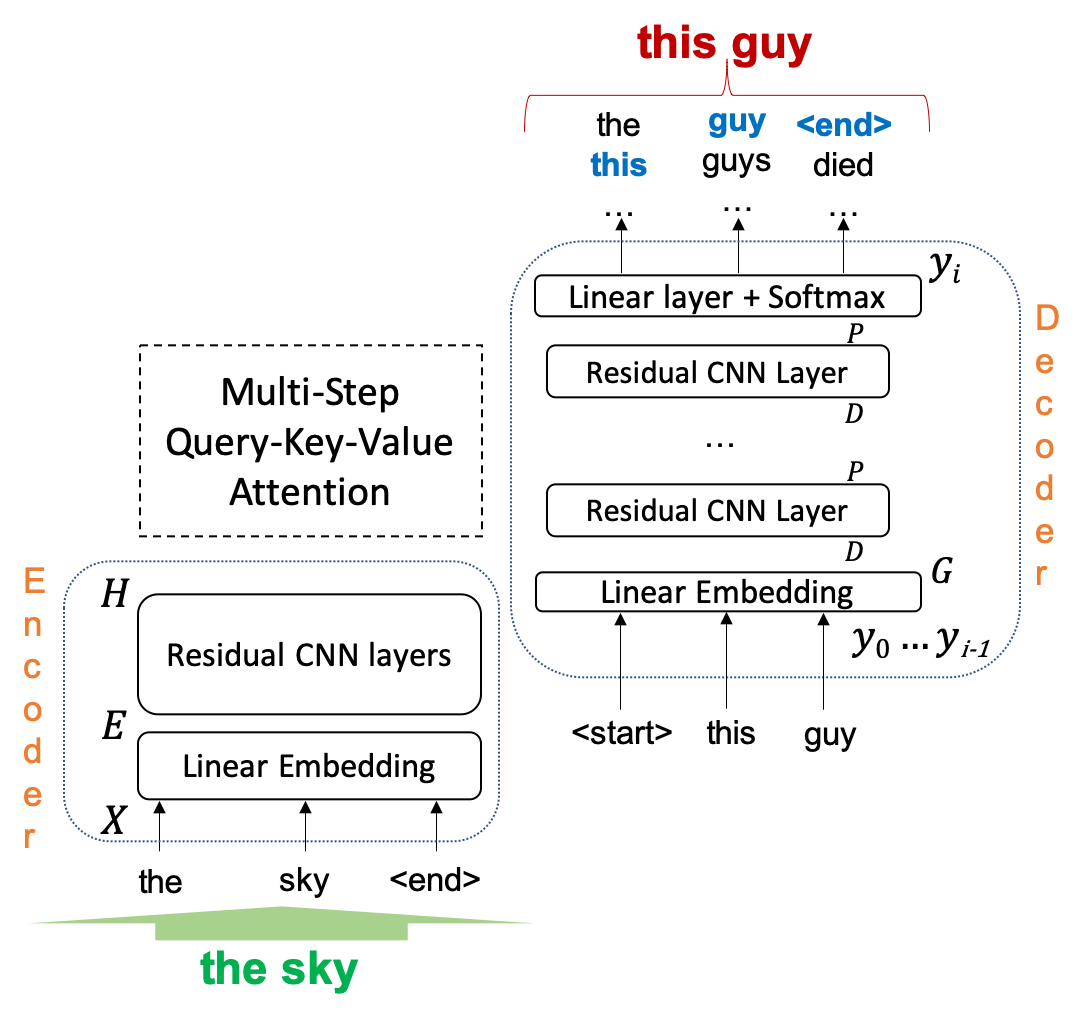
III-A1 Attention Mechanism
For every decoder layer with input and output , the attention computation can be expressed in a query-key-value formulation [20], wherein an output is calculated as a weighted sum of value vectors, with the weights determined as a function of the query vector and respective key vectors corresponding to the value vectors.
For timestep of the decoder, the query vector for layer is the combination of the current decoder state at timestep at the output of layer , and embedding of the target predicted at the previous timestep, .
From timestep of the encoder, the value vector is computed from the encoder representation i.e. by a sum of the final hidden representation and the input embedding at that timepoint, whereas the key vector is just the final hidden representation.
The attention weight matrix from layer l is computed by a softmax over the product of the query and key vectors.
These weights are then used to compute the attended input to decoder layer l+1, from the value vectors.
By letting be a combination of the and , we believe is enabled to effectively focus on learning confusion modes and/or likelihoods for the word in the sequence, and let the information about the word itself be contained in .
III-A2 Decoding Mechanisms
We use the output of the decoder to construct an N-best hypothesis list for recognized text, comparing two methods for list construction. In the first method (Beam Search Decoding), we use a left-to-right beam search as applied to sequence to sequence networks [21], tracking running hypotheses sequences at a time. We select the 100-best complete hypotheses based on the cumulative length-normalized sequence probability. Our second method is based on the success of sampling in prior work for error prediction [6]: we investigate a sampling based decoding technique, wherein at each timepoint , we sample a word from the target vocabulary based on the output probability distribution of the decoder (Sampled Decoding). For every timestep , the input contains embeddings of the target words chosen from timestep . We generate a minimum of 250, and generate until we have 100 unique sequences, or hit a maximum of 1000 word sequence samples. If we obtain more than 100 unique sequences, we select the most frequently occurring 100.
III-B Incorporating Phonetics into ASR prediction
For words and word-pairs where the model is unable to capture enough examples of possible recognitions or mis-recognitions, if we can make additional information about how each word sounds like (through the phonemes), the model could learn to “backoff” to the phoneme representation as needed. Thus, to improve generalizability and aid learning, we look at incorporating a phonetic representation of the true text as an additional input.
Accordingly, we propose a sequence to sequence model with two encoders and one decoder as shown in Figure 2. Encoder A takes a word sequence corresponding to the true text whereas encoder B takes the phoneme sequence corresponding to the same. The decoder attends to both encoders to produce predictions for the recognized word sequence.

In this model, we use the same four layer decoder architecture as in the word level ASR prediction model, but in the encoders we use wider kernels and increase the number of layers, so as to account for phoneme sequences being longer than word sequences, while keeping the number of parameters comparable. Each encoder comprises of three residual convolutional layers with 64 filters and a kernel size of 11, followed by two residual layers with 128 filters and a kernel size of 7, and finally one residual layer with 256 filters and a kernel size of 5. Cumulatively, this model has 38M parameters, which is comparable to the word level model.
To allow the decoder to look at both word and phoneme sequence encoders, we propose a dual attention mechanism detailed in III-B1 below, and to further encourage it to learn to incorporate both sources of information, we introduce an encoder dropout mechanism as detailed in III-B2. In limited experimentation, we also tried adding a second decoder with an auxiliary objective of predicting the phoneme sequence representation of the recognized text, but it did not seem to change the results much, as a result we did not explore it further.
III-B1 Dual Attention Mechanism
We propose to adapt the attention mechanism from section III-A1 to two encoders. For every decoder layer with input , output , the attention computation can be expressed in a similar query-key-value formulation as follows.
For timestep of the decoder, the query vector for layer corresponding to encoder is the combination of the current decoder state at timestep at the output of layer , and embedding of the target predicted at the previous timestep, .
From timestep of encoder , the value vector is computed from the corresponding encoder representation i.e. by a sum of the final hidden representation and the input embedding at that timepoint, whereas the key vector is just the final hidden representation.
The attention weight matrix from layer l is computed by a softmax over the product of the query and key vectors.
These weights are then used to compute the attended input to decoder layer l+1, from the value vectors. The weighted representations from the heads attending to both the encoders are concatenated and then combined using a linear transformation.
III-B2 Encoder dropout
In our dual encoder model, we allow the decoder to attend to multiple encoders simultaneously, however, the decoder could learn to just use the information from one of the encoders and ignore the other. For example, in Figure 2 the decoder, can learn to just focus on the words encoded by Encoder B and discard the phonetic information from Encoder A, thus defeating the dual attention mechanism. We propose an encoder dropout scheme to encourage the decoder to learn to focus on both encoders, by letting it have access to only one of the encoders at certain times.
For an encoder dropout factor , with probability we decide to drop exactly one of the two encoders picked at random. Specifically, for every example in a training batch:
1. With probability , we drop encoder A in the following manner:
2. Else, with of the remaining probability, we drop encoder B in the following manner:
3. Else, with of the remaining probability, we drop neither of and , i.e., leave them both untouched.
For every example that one of the encoders is dropped, the other corresponding encoder’s attended representation is multiplied by a factor of 2 to compensate for the additional input. Additionally, with the chance of no dropout, we encourage the decoder to learn not only to attend to each encoder individually, but also learn to attend to both of them simultaneously. We apply this encoder dropout in addition to using conventional dropout at the output of every layer in the encoder and decoder.
IV Data Preparation and Task Setups
The task of hallucination or prediction of errors is treated as a translation problem, from true text to recognized text. Figure 3 shows a schematic of how various sets of data are used for training or evaluation of the error prediction systems, and the construction of those sets is described below. The primary training data is derived using the Fisher corpus, and an “in-domain” evaluation is performed on unseen examples from the same corpus and same ASR system observed at train-time. For an “out-of-domain” evaluation, we follow prior work to utilize a set based on data from The Ohio State University’s Virtual Patient project (described in subsection IV-B), where the ASR system and corpus are both unobserved at train-time. We also conduct a “scarce-resource” evaluation with other data from the aforementioned Virtual Patient project, wherein we collect some examples of recognition with the test-time ASR system to make a “finetuning set” from the Fisher corpus as well as from the Virtual Patient project. Along with evaluating the quality of our hallucinated ASR hypotheses, we study the downstream impact of our hallucination; this “extrinsic evaluation” is performed on the Virtual Patient spoken question classification task.

IV-A Fisher Data
Fisher is a conversational telephonic speech corpus in English containing 2000 hours of audio data paired with human annotated transcriptions [22], segmented into 1.8 million odd utterances. We transcribe Fisher using multiple ASR systems, in order to create pairs of “true text” (human annotated or corrected) and “recognized text” (ASR transcribed), used for training and evaluation of the error prediction system.
IV-A1 In-domain Set (Fisher_base)
Our primary source ASR system utilizes the Kaldi Switchboard recipe, training a DNN with the sMBR criterion, and decoding with a trigram language grammar trained exclusively on the text in the Switchboard corpus [23]. We use this recognizer to obtain 1-best transcriptions for the 1.8 million odd utterances in the Fisher corpus at a roughly 30% word error rate. The standard train split was used for training, and standard validation split for validation, for all versions of ASR hallucination models except for the “only-finetune” case in the scarce resource evaluation setting (III). For testing the in the in-domain setting, the standard test split of 5000 examples was used in conjunction with a smaller randomly chosen subset of 500 examples used in prior work.
IV-A2 Finetuning Set (Fisher_finetune)
Our secondary source is a commercially available cloud-based ASR system used in late 2020, that is the same as the one we intended to use for transcription in one version of our target spoken language understanding task; we do not have further access to the internals or the details of the training of this system. Since transcription requests to this system were rate-limited, and had a cost associated to them, we randomly selected a subset of 100k utterances from the training set of the Fisher corpus, corresponding to about 104 hours of audio. We used LDC’s sph2pipe software to read and convert the audio corresponding to these selected utterances to wav files, and subsequently interpolated them to a sample rate of 16khz using Librosa [24] to match the input specification for the ASR. These resampled utterances were then transcribed using the ASR at a roughly 17% word error rate. The resulting set was used for finetuning or training the ASR hallucination model in the post-finetune and only-finetune cases of the scarce resource evaluation setting, respectively (Table III). It was also used in the finetuning of the error hallucination models used in the downstream evaluation setting (Table IV). Except for the zero in-domain ASR case in the downstream evaluation setting, the finetuning set for the ASR hallucination model also included 4991 annotated and cloud-ASR transcript pairs from the “training set” portion of the Virtual Patient Conversational Speech Set (VP_conv) described below, along with the set described in herein.
IV-B Virtual Patient Data
The virtual patient is a graphical avatar based spoken dialog system for doctors to practise interviewing patients (see figure 4). The virtual patient is designed to be capable of answering a limited set of questions (that have fixed and pre-written answers), creating the task of question classification based on user input. The following are different sets of virtual patient data we use:

IV-B1 Text Set (VP_text)
The Virtual Patient Text Set consists of 259 type-written dialogues of users interacting with an older version of the Virtual Patient prior to incorporation of speech input [25]. We use this data as part of the training set for the question classification model in the extrinsic evaluation. As the nature of this text is typed, there exists a mismatch with speech recognized text, and thus also a potential for ASR hallucination. The set contains a total of 6711 examples of user turns paired with human-annotated question/answer labels.
IV-B2 Read Speech Subset (VP_read)
To evaluate our error prediction model in an out-of-domain setting in a comparative manner to prior work [6], we utilize the read speech set. It consists of 756 utterances that were taken as a subset from the text set, read by volunteers, and transcribed with a commercially available cloud based ASR service in 2018, with a word error rate of slightly over 10% [2].
IV-B3 Conversational Speech Set (VP_conv)
To evaluate our error prediction model in a realistic spoken dialog setting, we utilize data collected from a spoken dialog version of the Virtual Patient, where speech input from users was fed through a commercially available cloud based ASR service in late 2018, and the resulting natural language was passed to a question classifier that was a combination of a machine learning system trained on the text set IV-B1 along with hand-crafted patterns. This contained 11,960 user turns over 260 conversations or dialogues. Human annotations were performed to obtain text transcripts (“true text”) as well as question/answer labels. This led to one set of pairs of “true text” and “recognized text”, where the word error rate for these transcriptions from 2018 was calculated to be around 12.5%.
The ASR transcriptions from the cloud based system used in 2018, with a word error rate of around 12.5% formed one “recognized text” version of the data. However, it is important to understand how well the error prediction generalizes across ASR systems in cases where domain data is seen for finetuning; these should correspond to several points along the accuracy spectrum. We resampled the speech collected with the 2018 cloud-based system to 16KHz and passed it through two more speech recognizers to create more versions of recognized text for this data. First, it was passed through a separate commercially available cloud-based ASR service in 2020 (identical to IV-A2), this had a word error rate of 8.9%. Second, it was passed through an ASR model trained on the Librispeech corpus using SpeechBrain [26]. As there is a significant mismatch in terms of domain, style of speech, and vocabulary, the Librispeech-based system has a word error rate of 41.1%, which serves as a “worst case” system.
For the purpose of our experiments, we randomly split the 260 dialogues into a training set of utterances from 100 dialogues (4991 turns), a validation set of 60 dialogues (1693 turns), and a test set consisting of the remaining 100 dialogues (5118 turns).
For training and validating the spoken question classification model, the human annotated transcripts of the inputs along with labels are used in the zero ASR data case, whereas in the case for some ASR data being available, the cloud-ASR transcripts of the inputs from 2020 are additionally employed. For testing the question classification model, we look at transcripts from all aforementioned ASR systems as well as human annotated transcripts.
For the ASR hallucination model, the cloud-ASR transcripts from 2020 are used for training, validation, and testing in the post-finetune and only-finetune cases of the scarce-resource evaluation setting (Table III).
IV-C Data Preprocessing
The true text and recognized text are converted into word sequences using a tokenization scheme that mainly relies on lowercasing the text, removing punctuations, and splitting the on whitespaces. These word sequences are then deterministically transformed into corresponding phoneme sequence representations, by relying on a lexicon of word pronunciations, in conjunction with a grapheme-to-phoneme model to approximate pronunciations for unknown words. Following prior work [6, 2], we use the pronunciation lexicon provided as part of the Switchboard corpus [27], and use Phonetisaurus to train our grapheme-to-phoneme model on data from the same pronunciation lexicon. Special tokens such as noise, laughter, silence, end of utterance, were removed due to their absence in text data not of a spoken nature. A small number of examples ( 2.2%) in the Fisher data that contained zero words or phonemes in the “true text” as a result of this preprocessing were taken out prior to experimentation.
V Experiments and Intrinsic Evaluation
V-A Training Details
For the word level or single encoder model, we train the our network akin to a translation model using the Fairseq toolkit [28]. For each pair of true and speech-recognized word sequences, the encoder is fed the true word sequence, and for each , we feed the decoder the first words from the speech-recognized sequence and give as a target the th word of the speech-recognized word sequence, with a cross-entropy loss. We train with a Nesterov accelerated gradient descent [29] optimizer for 60 epochs with a learning rate of 0.1 and a momentum of 0.99, with an optional 15 additional epochs in the finetune setting. To prevent overfitting, we employ a dropout of 0.2 on the input of every CNN layer, and on the output of the last CNN layer.
For the dual encoder model, we train our network similar to the word level model, except for two things. Firstly, Encoder A is fed the phoneme sequences corresponding to the true word sequence that is fed to Encoder B. Secondly, an Encoder Dropout of 0.5 is employed in addition to conventional dropout as used in the word level model i.e., on the input of every CNN layer, and on the output of the last CNN layer.
V-B Evaluation Metrics
Following prior work [10, 6, 7], we use two metrics to evaluate the effectiveness of our models in hallucinating ASR errors, in addition to measuring the impact of our hallucinated ASR errors on the question classification model.
The first metric measures the percentage of real test set Error Chunks recalled in a set of “K best” simulated speech recognized utterances for each gold word sequence. The error chunks are again determined by aligning the gold word sequence with the errorful word sequence and removing the longest common subsequence. For example, if the gold sequence is “do you take any other medications except for the tylenol for pain” and the errorful sequence is “you take any other medicine cations except for the tylenol for pain,” the error chunks would be the pairs and . Our detection of error chunks is strict — for an error chunk to qualify as predicted, the words adjacent to the predicted error chunk should be error-free.
The second metric measures the percentage of times the complete test set utterance is recalled in a set of “K best” simulated utterances for each gold text sequence (including error-free test sequences). We aimed to produce 100 unique simulated speech recognized utterances for each gold word sequence, so for both of these metrics, we evaluate the performance at K=100. These are both “hard” metrics since the possibilities of various kinds of errors is quite endless, and the metrics only give credit when the utterance/error chunk exactly matches what was produced.
| Model | Error Chunks Predicted | Complete Utterances Predicted | ||
| Smaller Test Set | Full Test Set | Smaller Test Set | Full Test Set | |
| ConfMat w/ Direct decoding [6] | 14.9% | - | 39.2% | - |
| ConfMat w/ Sampled decoding [6] | 25.6% | - | 38.8% | - |
| Word level Seq2Seq w/ Beam Search decoding | 45.0% | 43.4% | 57.8% | 57.5% |
| Word level Seq2Seq w/ Sampled decoding | 47.0% | 46.2% | 56.8% | 57.5% |
| Dual encoder Seq2Seq w/ Beam Search decoding | 47.6% | 44.9% | 57.8% | 58.2% |
| Dual encoder Seq2Seq w/ Sampled decoding | 48.8% | 47.1% | 56.2% | 57.9% |
V-C In-Domain Evaluation
In the in-domain evaluation setting, we measure our models’ ability to predict errors on audio from the same corpus, and transcribed using the same speech recognizer, as used to generate their training data.
Table I shows the results on the held out test sets from the Fisher corpus (IV-A1) for our word level and dual encoder end to end models, comparing with our prior reported results using a confusion matrix based model on the smaller test set. Both the end to end models greatly improve over the previous best reported results with sampled decoding on the confusion matrix, in terms of real error chunks recalled, as well as complete speech-recognized utterances recalled. The dual encoder model outperforms the word-level end to end model on both metrics on the full test set, corroborating previous observations about the usefulness of phonetic information in improving generalization to words with limited or no examples in the training set.
The sampled decoding mechanism does the best on the error chunk prediction metric, which agrees with previous observations about the peaky nature of errors made by modern neural network based speech recognizers. However, it also brings a slight penalty on the complete utterance prediction metric, compared with the beam search decoding, perhaps because we sample the final output words independently for each time step, whereas beam search scores the word sequences by cumulative weight.
| Model | Error Chunks Predicted | Complete Utterances Predicted |
|---|---|---|
| ConfMat w/ Direct decoding [6] | 8.5% | 66.9% |
| ConfMat w/ Sampled decoding [6] | 36.4% | 72.4% |
| Word level Seq2Seq w/ Beam Search decoding | 39.2% | 74.1% |
| Word level Seq2Seq w/ Sampled decoding | 42.3% | 74.2% |
| Dual encoder Seq2Seq w/ Beam Search decoding | 41.9% | 74.5% |
| Dual encoder Seq2Seq w/ Sampled decoding | 43.4% | 73.8% |
| Data | Model | Error Chunks Predicted | Complete Utterances Predicted |
|---|---|---|---|
| Fisher_base | Word level Seq2Seq w/ Beam Search decoding | 40.7% | 82.0% |
| Word level Seq2Seq w/ Sampled decoding | 47.0% | 81.7% | |
| Dual encoder Seq2Seq w/ Beam Search decoding | 42.7% | 82.6% | |
| Dual encoder Seq2Seq w/ Sampled decoding | 49.1% | 82.3% | |
| Fisher_base | Word level Seq2Seq w/ Beam Search decoding | 72.3% | 90.8% |
| Word level Seq2Seq w/ Sampled decoding | 72.2% | 90.8% | |
| +Fisher_finetune | Dual encoder Seq2Seq w/ Beam Search decoding | 75.0% | 91.5% |
| +VP_conv | Dual encoder Seq2Seq w/ Sampled decoding | 74.2% | 91.4% |
| Fisher_finetune | Word level Seq2Seq w/ Beam Search decoding | 65.9% | 89.0% |
| Word level Seq2Seq w/ Sampled decoding | 65.9% | 88.9% | |
| +VP_conv | Dual encoder Seq2Seq w/ Beam Search decoding | 70.1% | 89.0% |
| Dual encoder Seq2Seq w/ Sampled decoding | 69.9% | 89.3% |
V-D Out-of-Domain and Scarce-Resource Evaluation
In practice, we are hoping for error hallucination to help in the various scenarios where task-specific labeled speech data is limited or unavailable, and thus we also measure the quality of our models’ hallucinated transcripts in out-of-domain and limited-resource settings.
Table II shows the results on predicting recognition errors made by the cloud based ASR service from 2018 on the Virtual Patient read speech subset (IV-B2), for comparing results to prior work. We use the same models from Table I so this is a completely out-of-domain evaluation where the recognizer as well as audio domains are unseen at train time. All our end to end models again improve on the best prior reported results on both error chunk and complete utterance prediction metrics, although the improvements are more modest in this case compared to the in-domain setting. In preliminary published work [7], we reported how the output of the word level end to end model was different compared to the output of the phonetic confusion matrix model in this out-of-domain case, and the diversity of information gained from phonetics is again underscored again here by the gains seen due to use of the dual encoder model.
We also evaluate our models’ ability to predict recognition errors seen on audio from the Virtual Patient conversational speech set (VP_conv), made by a recent 2020 version of a cloud-based ASR service. Table III shows the results for predicting recognition errors on this set from our models trained in settings with zero as well as limited recognizer-specific ASR data available.
First, we evaluate base versions of our models i.e., the same as the ones evaluated in Tables I and II, just trained on transcripts of the Fisher training set from an unrelated speech recognizer as compared to test time test-time (Fisher_base). Perhaps unsuprisingly, the results are comparable to what we see on the read speech data in Table II.
Further, we take the base versions of our models and train them further with the finetuning sets from the same speech recognizer as test-time, viz.: the Fisher finetuning set (Fisher_finetune) and the train portion of VP Conversational Speech Set (VP_conv) for up to 15 epochs. This results in an over 50% relative increase in error chunk recall on this test set, and approximately 9% absolute increase in complete utterance recall, showing a great benefit from the finetuning on recognizer-specific data including some domain-specific data.
As we see great benefit from finetuning,, we evaluate versions of our models that are train for 75 epochs only on the finetune sets i.e., data from the same recognizer as test time. While these models perform better than the base models trained only on unmatched recognizer data (Fisher_base), they are not as good as the finetuned versions of the base models.
Overall, in Table III, we find that our finetuned models that learn from both the larger but unmatched recognizer data (Fisher_base), as well as the smaller but matched recognizer data (Fisher_finetune and VP_conv), perform better than those only trained on either of them. The dual-encoder architecture still does the best, showing the continued benefit of the phonetic representation. Surprisingly, unlike what we see with the base version of the models Tables I, II, and the Fisher_base rows of Table III), the sampled decoding no longer helps improve error chunk recall on the finetuned models, in fact it hurts slightly. Our hypothesis for the cause behind this is that: with the Fisher_finetune and VP_conv sets, we are able to better model contextual errors resulting from the recent cloud based recognizer, and beam search’s ability to consider the likelihood of sequences of words in the output outweighs the benefits of sampling that we see in other scenarios.
| Test ASR system | WER | % Accuracy/F1 with zero ASR data | % Accuracy/F1 with some ASR data | ||
|---|---|---|---|---|---|
| W/o hallucination | W/ hallucination | W/o hallucination | W/ hallucination | ||
| Gold | 0% | 79.7/59.8 | 79.8/60.2 | 80.4/60.3 | 80.6/60.4 |
| Cloud-2020 | 8.9% | 78.0/57.8 | 78.3/58.3 | 79.3/58.7 | 79.5/59.0 |
| Cloud-2018 | 12.5% | 76.1/56.6 | 77.4/58.0 | 77.0/57.4 | 77.8/57.8 |
| Librispeech | 41.1% | 65.6/45.8 | 67.9/48.6 | 66.7/47.3 | 67.5/48.5 |
VI Extrinsic Evaluation
In order to investigate the benefit of our hallucination approach to spoken language understanding, we perform an extrinsic evaluation on the Virtual Patient task. We use our models to simulate the effect of speech recognized input during the training of a question classification system, to see if they help alleviate degradations in performance caused by ASR errors in the input.
VI-A Downstream Model
We use a self-attention RNN [30] based question-classification model adapted for the Virtual patient task [25]. This model uses a single layer BiGRU as the RNN. For the attention mechanism, we use 8 attention heads. Each attention head produces a representation of the input attending to different parts of the text. The vector representations from the 8 heads are then concatenated and fed into a fully connected classification layer with softmax activations to predict a distribution over 376 classes. Unlike the originally proposed model [30], we do not impose an orthogonality constraint on the attention scores from different attention heads. We found that doing so hurt the classification performance.
VI-B Training and the use of Hallucination
We train our model to minimize the cross-entropy loss using the Adam optimizer [31] with a learning rate of 0.001, a dropout rate of 0.5, and early stopping with a patience of 15 epochs. In the baseline case i.e., without error hallucination, the training uses the gold or typed versions of the text as input along with corresponding class labels. In the settings with some real ASR training data, the speech recognized versions of the input from the Virtual Patient Conversational Speech set are added to the training set.
In the error hallucination case, we use a sampling strategy [2] wherein, at train time, the input text for the question classifier is randomly transmuted with a pseudo-speech-recognized utterance sampled from the output of our finetuned ASR error prediction model (best one from Table III), except that in the zero domain-specific ASR data case the VP_conv portion is excluded during finetuning. The sampling rate is treated as a hyperparameter and chosen from the set by tuning on the development set. A sample rate of means that the a training instance is replaced by a corresponding errorful alternative with a probability.
VI-C Results
Table IV shows question classification performance with and without ASR hallucination, to measure changes in Accuracy and Macro-F1 scores averaged across 5 random seeds. We observe that our proposed approach for hallucination helps improve downstream performance in multiple WER settings whether real ASR training data for the NLU task is available or not. We also observe that with increase in WER, the benefit from improvements from performing ASR hallucination can even be higher than using real ASR data. In the 12.5% WER setting, adding hallucinated ASR in addition to some real ASR data, improved accuracy from 76.1% to 77.8% i.e., about twice as much as the improvement from real ASR data alone. In the 41.1% WER setting, even with zero ASR data, our hallucination approach allowed an absolute 2.3% improvement in downstream task accuracy, whereas real ASR data alone gave an improvement of 1.1%. Notably, this shows that our hallucination approach can improve the NLU system performance even more than by adding some real ASR data. We reason that this happens because the use of real ASR data provided at most one alternative transcript containing ASR errors per training example, whereas our hallucination approach allows the model to see multiple plausible errorful transcripts per training example, potentially even a different one every epoch.
It is worth noting that error hallucination also improves performance slightly on gold transcripts which suggests that it acts like a soft data augmentation as proposed in [32]. However, this improvement is not as high as that in noisy scenarios especially in higher WER settings.
VII Conclusion and Future work
We show that our sequence to sequence models greatly improve the error prediction performance over confusion matrix prediction approaches, which we attribute to their ability to model speech recognition behavior in a context dependent manner. We also observe that a combined use of phonetic and word level representations on input text through a dual encoder approach further improves the fidelity of its hallucination to actual behavior of the ASR system being characterized. With regards to sampling, which is a strategy that has helped improve error chunk recall in prior work, we found sampling to help when the characterized ASR system is out-of-domain or just simpler and trained on a single corpus. However, we think that our naive incorporation of it may be inhibiting the contextual model of the decoder network by taking away ability to search through full sequences, opening up the potential for future work, such as a variational sampling approach.
We also find that our ASR hallucination approach helps train a language understanding model to be robust to real ASR errors at test-time, and that the diversity of hallucinated ASR errors allow for an even greater benefit than training with some real ASR data in higher WER scenarios.
VIII Acknowledgements
This material is based upon work supported by the National Science Foundation under Grant No. 1618336. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Quadro P6000 GPU used for this research. Additional computing resources provided by the Ohio Supercomputer Center [33]. We thank Adam Stiff, Doug Danforth, and others involved in the Virtual Patient project at The Ohio State University for sharing various data from the project for our experiments. We thank Peter Plantinga and Speech Brain team for providing the trained Librispeech ASR model used.
References
- [1] Y. Tsvetkov, F. Metze, and C. Dyer, “Augmenting translation models with simulated acoustic confusions for improved spoken language translation,” in Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, 2014, pp. 616–625.
- [2] A. Stiff, P. Serai, and E. Fosler-Lussier, “Improving human-computer interaction in low-resource settings with text-to-phonetic data augmentation,” in ICASSP, 2019, pp. 7320–7324.
- [3] M. Namazifar, G. Tur, and D. H. Tür, “Warped language models for noise robust language understanding,” in SLT 2021-2021 IEEE IEEE Spoken Language Technology Workshop (SLT). IEEE, 2021.
- [4] A. Mani, S. Palaskar, N. V. Meripo, S. Konam, and F. Metze, “Asr error correction and domain adaptation using machine translation,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6344–6348.
- [5] L. Zhou, S. V. Blackley, L. Kowalski, R. Doan, W. W. Acker, A. B. Landman, E. Kontrient, D. Mack, M. Meteer, D. W. Bates et al., “Analysis of errors in dictated clinical documents assisted by speech recognition software and professional transcriptionists,” JAMA network open, vol. 1, no. 3, pp. e180 530–e180 530, 2018.
- [6] P. Serai, P. Wang, and E. Fosler-Lussier, “Improving speech recognition error prediction for modern and off-the-shelf speech recognizers,” in ICASSP. IEEE, 2019, pp. 7255–7259.
- [7] P. Serai, A. Stiff, and E. Fosler-Lussier, “End to end speech recognition error prediction with sequence to sequence learning,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6339–6343.
- [8] E. Fosler-Lussier, I. Amdal, and H.-K. J. Kuo, “A framework for predicting speech recognition errors,” Speech Communication, vol. 46, no. 2, pp. 153–170, 2005.
- [9] J. Anguita, J. Hernando, S. Peillon, and A. Bramoullé, “Detection of confusable words in automatic speech recognition,” IEEE Signal Processing Letters, vol. 12, no. 8, pp. 585–588, 2005.
- [10] P. Jyothi and E. Fosler-Lussier, “A comparison of audio-free speech recognition error prediction methods,” in Tenth Annual Conference of the International Speech Communication Association, 2009.
- [11] Q. F. Tan, K. Audhkhasi, P. G. Georgiou, E. Ettelaie, and S. S. Narayanan, “Automatic speech recognition system channel modeling,” in Eleventh Annual Conference of the International Speech Communication Association, 2010.
- [12] K. Sagae, M. Lehr, E. Prud’hommeaux, P. Xu, N. Glenn, D. Karakos, S. Khudanpur, B. Roark, M. Saraclar, I. Shafran et al., “Hallucinated n-best lists for discriminative language modeling,” in Acoustics, Speech and Signal Processing (ICASSP), 2012 IEEE International Conference on. IEEE, 2012, pp. 5001–5004.
- [13] P. G. Shivakumar, H. Li, K. Knight, and P. Georgiou, “Learning from past mistakes: improving automatic speech recognition output via noisy-clean phrase context modeling,” APSIPA Transactions on Signal and Information Processing, vol. 8, 2019.
- [14] P. Jyothi and E. Fosler-Lussier, “Discriminative language modeling using simulated asr errors,” in Eleventh Annual Conference of the International Speech Communication Association, 2010.
- [15] G. Kurata, N. Itoh, and M. Nishimura, “Training of error-corrective model for asr without using audio data,” in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on. IEEE, 2011, pp. 5576–5579.
- [16] N. Ruiz, Q. Gao, W. Lewis, and M. Federico, “Adapting machine translation models toward misrecognized speech with text-to-speech pronunciation rules and acoustic confusability,” in Sixteenth Annual Conference of the International Speech Communication Association, 2015.
- [17] M. Rao, A. Raju, P. Dheram, B. Bui, and A. Rastrow, “Speech to Semantics: Improve ASR and NLU Jointly via All-Neural Interfaces,” in Proc. Interspeech 2020, 2020, pp. 876–880. [Online]. Available: http://dx.doi.org/10.21437/Interspeech.2020-2976
- [18] J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin, “Convolutional sequence to sequence learning,” in ICML-Volume 70, 2017, pp. 1243–1252.
- [19] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [20] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in NeurIPS, 2017, pp. 5998–6008.
- [21] I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Advances in neural information processing systems, 2014, pp. 3104–3112.
- [22] C. Cieri, D. Miller, and K. Walker, “The fisher corpus: a resource for the next generations of speech-to-text.” in LREC, vol. 4, 2004, pp. 69–71.
- [23] K. Veselỳ, A. Ghoshal, L. Burget, and D. Povey, “Sequence-discriminative training of deep neural networks.” in Interspeech, 2013, pp. 2345–2349.
- [24] B. McFee, V. Lostanlen, A. Metsai, M. McVicar, S. Balke, and et al., “librosa/librosa: 0.8.0,” Online, 2020, [Available: https://doi.org/10.5281/zenodo.3955228].
- [25] A. Stiff, Q. Song, and E. Fosler-Lussier, “How self-attention improves rare class performance in a question-answering dialogue agent,” in Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, 2020, pp. 196–202.
- [26] M. Ravanelli, T. Parcollet, A. Rouhe, P. Plantinga, E. Rastorgueva, L. Lugosch, N. Dawalatabad, C. Ju-Chieh, A. Heba, F. Grondin, W. Aris, C.-F. Liao, S. Cornell, S.-L. Yeh, H. Na, Y. Gao, S.-W. Fu, C. Subakan, R. De Mori, and Y. Bengio, “Speechbrain,” https://github.com/speechbrain/speechbrain, 2021.
- [27] J. J. Godfrey, E. C. Holliman, and J. McDaniel, “Switchboard: Telephone speech corpus for research and development,” in Acoustics, Speech, and Signal Processing, 1992. ICASSP-92., 1992 IEEE International Conference on, vol. 1. IEEE, 1992, pp. 517–520.
- [28] M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grangier, and M. Auli, “fairseq: A fast, extensible toolkit for sequence modeling,” in NAACL-HLT Demonstrations, 2019.
- [29] I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” in ICML, 2013, pp. 1139–1147.
- [30] Z. Lin, M. Feng, C. N. d. Santos, M. Yu, B. Xiang, B. Zhou, and Y. Bengio, “A structured self-attentive sentence embedding,” in 5th International Conference on Learning Representations, ICLR 2017, 2017.
- [31] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in 2015 3rd International Conference on Learning Representations (ICLR), 2015.
- [32] J. Wei and K. Zou, “EDA: Easy data augmentation techniques for boosting performance on text classification tasks,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). ACL, Nov. 2019, pp. 6382–6388.
- [33] O. S. Center, “Ohio supercomputer center,” 1987. [Online]. Available: http://osc.edu/ark:/19495/f5s1ph73