Chaeyeon [email protected]1,2
\addauthorTaewoo [email protected]1,2
\addauthorHyelin [email protected]3
\addauthorSeunghwan [email protected]
\addauthorGyojung [email protected]
\addauthorSunghyun [email protected],2
\addauthorJaegul [email protected]
\addinstitution
KAIST AI
South Korea
\addinstitution
Kakao Enterprise
South Korea
\addinstitution
Chung-Ang University
South Korea
HairFIT, Pose-Invariant Hairstyle Transfer
HairFIT: Pose-Invariant Hairstyle Transfer
via Flow-based Hair Alignment and Semantic-Region-Aware Inpainting
Abstract
Hairstyle transfer is the task of modifying a source hairstyle to a target one. Although recent hairstyle transfer models can reflect the delicate features of hairstyles, they still have two major limitations. First, the existing methods fail to transfer hairstyles when a source and a target image have different poses (e.g\bmvaOneDot, viewing direction or face size), which is prevalent in the real world. Also, the previous models generate unrealistic images when there is a non-trivial amount of regions in the source image occluded by its original hair. When modifying long hair to short hair, shoulders or backgrounds occluded by the long hair need to be inpainted. To address these issues, we propose a novel framework for pose-invariant hairstyle transfer, HairFIT. Our model consists of two stages: 1) flow-based hair alignment and 2) hair synthesis. In the hair alignment stage, we leverage a keypoint-based optical flow estimator to align a target hairstyle with a source pose. Then, we generate a final hairstyle-transferred image in the hair synthesis stage based on Semantic-region-aware Inpainting Mask (SIM) estimator. Our SIM estimator divides the occluded regions in the source image into different semantic regions to reflect their distinct features during the inpainting. To demonstrate the effectiveness of our model, we conduct quantitative and qualitative evaluations using multi-view datasets, K-hairstyle and VoxCeleb. The results indicate that HairFIT achieves a state-of-the-art performance by successfully transferring hairstyles between images of different poses, which have never been achieved before.
1 Introduction
Recently, hairstyle has been considered as a way to express one’s own identity. Responding to the increasing demands, various approaches have tackled virtual hairstyle transfer, a task of modifying one’s hairstyle to a target one, based on generative adversarial networks [Goodfellow et al.(2014)Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, and Bengio]. The existing methods [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu, Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi] transfer the target hairstyle to a source image while successfully preserving delicate features of the target hairstyle. However, despite their convincing performances, hairstyle transfer still poses several challenges.
First, the existing models are hardly applicable to a source image that has a different pose (e.g\bmvaOneDot, viewing direction or face size) from a target image, which is prevalent in the real world. The first two rows of Fig. 3 present examples of the pose difference between the source and the target image. Since the same hairstyle appears different when its pose changes, the target hairstyle should have a similar pose with the source image. However, the previous approaches fail to align the target hair with the source pose when their poses are significantly different.
Additionally, the existing methods poorly generate regions originally occluded in the source image. When the source image contains the regions that are occluded by its original hair, the occlusions need to be newly generated during the transfer. For instance, the first row of Fig. 4 shows that the occluded shoulders and backgrounds should be properly inpainted when transferring the shorter hair. Moreover, the occlusions become even larger when the source and the target image have a significant pose difference. Although the existing models leverage the external inpainting networks, it is still challenging for a model to fill in the occlusions containing multiple semantic regions.
To address these issues, we propose a novel framework, Hairstyle transfer via Flow-based hair alignment and semantic-region-aware InpainTing (HairFIT), which successfully performs hairstyle transfer regardless of a pose difference between a source and a target image. HairFIT consists of two parts: 1) flow-based hair alignment and 2) hair synthesis. We first align the target hair with the source pose based on the estimated optical flow between the source and the target. Then, we apply the aligned target hair to the source image to synthesize the final output. The hair synthesis module inpaints in the occluded regions of the source image and refines the aligned target hair leveraging ALIgnment-Aware Segment (ALIAS) generator [Choi et al.(2021)Choi, Park, Lee, and Choo]. We newly present a Semantic-region-aware Inpainting Mask (SIM) estimator to support realistic occlusion inpainting. By predicting separate semantic regions, the estimator helps our generator to reflect distinctive features of diverse semantic regions (e.g\bmvaOneDot, backgrounds, clothes, and forehead) during inpainting.
We conduct quantitative and qualitative evaluations using K-hairstyle and VoxCeleb which contain images of different poses. The results indicate that our model achieves a state-of-the-art performance compared to the existing methods. Our model outperforms other models especially when the source and the target image have a significantly different pose.
Our contributions are summarized as follows:
-
•
This is the first work that proposes a pose-invariant hairstyle transfer framework by adopting the optical flow estimation for hair alignment.
-
•
We present a Semantic-region-aware Inpainting Mask (SIM) estimator which supports high-quality occlusion inpainting by allowing hair synthesis module to reflect distinctive features of each segmented inpainting region.
-
•
HairFIT achieves the state-of-the-art performance in both quantitative and qualitative evaluations with two multi-view datasets, K-hairstyle and VoxCeleb.
2 Related Work
2.1 Conditional Image Generation
Conditional image generation is the task of synthesizing images based on the given conditions such as category labels [Brock et al.(2019)Brock, Donahue, and Simonyan, Odena et al.(2017)Odena, Olah, and Shlens], text [Reed et al.(2016)Reed, Akata, Yan, Logeswaran, Schiele, and Lee, Zhang et al.(2018a)Zhang, Xu, Li, Zhang, Wang, Huang, and Metaxas], and images [Isola et al.(2017)Isola, Zhu, Zhou, and Efros, Park et al.(2019a)Park, Liu, Wang, and Zhu]. Recent studies on image-conditioned generation have proposed various approaches to modify specific features (e.g\bmvaOneDot, face shape, hairstyle, etc.) on facial images [Lee et al.(2020)Lee, Liu, Wu, and Luo, Jo and Park(2019), Portenier et al.(2018)Portenier, Hu, Szabó, Bigdeli, Favaro, and Zwicker, Yang et al.(2020)Yang, Wang, Liu, and Guo]. In particular, MaskGAN [Lee et al.(2020)Lee, Liu, Wu, and Luo] enables facial image manipulation based on a user-edited semantic mask as a conditional input. Also, SC-FEGAN [Jo and Park(2019)], FaceShop [Portenier et al.(2018)Portenier, Hu, Szabó, Bigdeli, Favaro, and Zwicker], and Deep Plastic Surgery [Yang et al.(2020)Yang, Wang, Liu, and Guo] allow modification of facial attributes based on human-drawn sketches. However, the existing methods require a non-trivial amount of user interaction to obtain the desired conditional inputs to change specific target attributes. In this paper, we propose a framework that transfers a hairstyle without any user-modified conditional input or user interaction.
2.2 Hairstyle Transfer
Hairstyle transfer aims to modify a hairstyle of a source image to a target one while preserving other features of the source. Along with the researches on facial attribute modification [Portenier et al.(2018)Portenier, Hu, Szabó, Bigdeli, Favaro, and Zwicker, Jo and Park(2019), Yang et al.(2020)Yang, Wang, Liu, and Guo], hairstyle transfer has also been actively tackled in the recent few years [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu, Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi]. MichiGAN [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu] successfully transfers a hairstyle reflecting its delicate features using disentangled hair attributes and conditional synthesis modules of each attribute. In addition, LOHO [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi] generates realistic hairstyle-transferred images by decomposing hairstyle features and optimizing latent space to inpaint missing hair structure details. However, these works only tackle the cases where poses of a source and a target image are similar. Therefore, they fail to generate realistic images when the source and the target have significantly different viewing directions or face sizes. Unlike the existing approaches, our model successfully transfers a hairstyle even when the source and the target image have a significant pose difference.
2.3 Optical Flow Estimation
Optical flow represents apparent pixel-level motion patterns between two images using a vector field. There are several approaches based on neural networks that directly predict an optical flow map between two consecutive frames of a video [Dosovitskiy et al.(2015)Dosovitskiy, Fischer, Ilg, Häusser, Hazırbaş, Golkov, v.d. Smagt, Cremers, and Brox, Ilg et al.(2017)Ilg, Mayer, Saikia, Keuper, Dosovitskiy, and Brox, Hui et al.(2018)Hui, Tang, and Loy] and warp the raw pixels of a frame to generate the unseen frame [Liu et al.(2017)Liu, Yeh, Tang, Liu, and Agarwala, Liang et al.(2017)Liang, Lee, Dai, and Xing, Gao et al.(2019)Gao, Xu, Cai, Wang, Yu, and Darrell, Park et al.(2021)Park, Kim, Lee, Choo, Lee, Kim, and Choi]. The optical flow estimation is also leveraged to transfer motions from another video by learning the motion difference between a source and a target frame [Siarohin et al.(2019b)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe, Siarohin et al.(2019a)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe]. To achieve pose-invariant hairstyle transfer, we utilize the optical flow to deform the target hairstyle according to the pose of the source image. To the best of our knowledge, this is the first work that applies optical flow estimation to hairstyle transfer.
3 Method
3.1 Overview
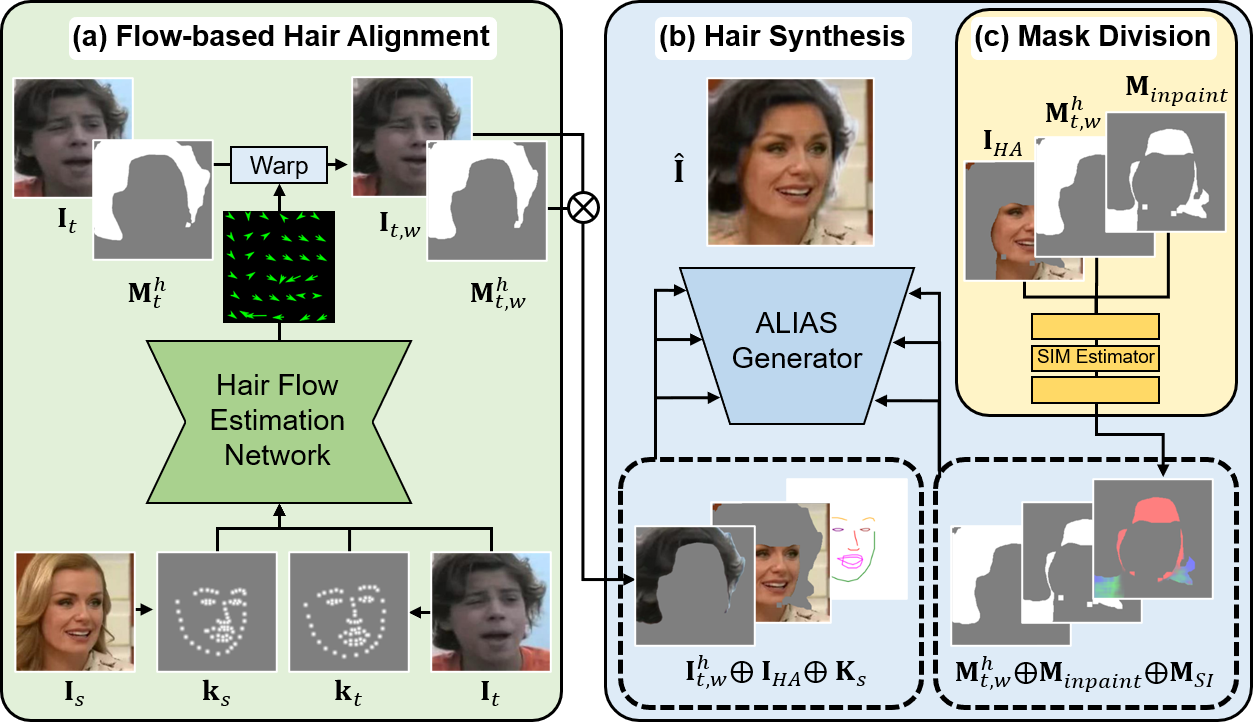
We employ a two-stage approach with two separate modules: 1) flow-based hair alignment module and 2) hair synthesis module. When given a source image and a target image containing the target hairstyle, the flow-based hair alignment module first warps the target image and its hair segmentation mask to align the target hairstyle with the source face. Here, we utilize the optical flow predicted by our hair flow estimation network. Then, the hair synthesis module generates the final image based on the aligned target hair and the source image via semantic-region-aware inpainting and hair refinement. Fig. 1 describes the overall architecture of HairFIT.
We train our model with multi-view datasets, which contain diverse views for each individual. In particular, we sample two images (i.e\bmvaOneDot, a source and a target image), which have different views with the same identity and hairstyle. Then, our model is required to reconstruct the source image by transferring the hairstyle of the target image to the source. Here, the source image works as the ground truth the model aims to generate. In this manner, the flow-based hair alignment module learns to align the target hair with the source pose according to the pose difference, and the hair synthesis module learns to reconstruct the original source image based on the aligned target hairstyle.
Ideally, when given a source and a target image with different poses, identities, and hairstyles, the ground truth image with the source pose and identity and the target hairstyle can provide HairFIT with direct supervision. In this case, the ground truth image can guide the model to align and apply the target hairstyle to the source face. However, a hairstyle dataset containing such images does not exist since it is expensive and time-consuming to collect them. Instead, we utilize the multi-view datasets for training our model. Although our model uses only image pairs of the same identity and hairstyle during the training, our model successfully transfers the hairstyle of the target image that has a different identity and hairstyle from the source.
3.2 Flow-based Hair Alignment
The flow-based hair alignment module aims to align the pose (i.e\bmvaOneDot, view and scale) of a target image with a source image.
As described in Fig. 1 (a), our hair flow estimation network estimates a dense optical flow map that represents a pose difference between the source image and the target image with the source keypoints , target keypoints , and given as inputs ( and , where , , and denote the image height, width, and the number of keypoints, respectively). Then, we warp as well as its hair segmentation mask according to the estimated optical flow. As a result, we gain the warped target hairstyle in and its hair mask aligned with the source face, where indicates hair and means the image or mask is warped.
Hair flow estimation network. Hair flow estimation network predicts the dense optical flow with the given and . To obtain the coarse pose difference, the network first converts and into a Gaussian keypoint heatmap , respectively. Then, we obtain the keypoint heatmap difference , calculated as . With and deformed by the keypoint difference , which is , the network predicts the -channel mask and . contains the estimated local regions to apply each channel of to. Also, indicates a refinement flow map that reflects additional detailed optical flow. Finally, we obtain the dense optical flow for the entire image by adding the coarse optical flow and refinement flow map as . Here, repeats the input tensor by times and denotes element-wise multiplication.
More details of the network architectures are described in supplementary materials. For training, we use the reconstruction loss , which is calculated as . For the implementation, we referred to the existing keypoint-based optical flow estimation networks [Siarohin et al.(2019b)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe, Siarohin et al.(2019a)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe].
Facial keypoints. Our hair flow estimation network utilizes keypoints to predict the flow map between the source and the target image. Here, the predicted optical flow needs to reflect the pixel-wise pose difference effectively, thus the keypoints should represent the overall view and scale of an image [Siarohin et al.(2019b)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe, Wang et al.(2021)Wang, Mallya, and Liu]. In this regard, we utilize the facial keypoints, which consistently represent a person’s view (e.g\bmvaOneDot, head pose) or scale (e.g\bmvaOneDot, face size), regardless of his/her identity. Facial keypoints are simple but robust pose representations that guide the network to capture the key differences in poses. Since the datasets do not include ground truth facial keypoints, we extract 68 facial keypoints from each image using the pre-trained keypoint detector [Bulat and Tzimiropoulos(2017)].

3.3 Hair Synthesis
The goal of the hair synthesis module is to transfer the target hairstyle to the source image using the aligned target hairstyle obtained from the previous stage. To achieve this, we utilize ALIAS generator [Choi et al.(2021)Choi, Park, Lee, and Choo] with a newly-proposed hair-agnostic image and a Semantic-region-aware Inpainting Mask (SIM) estimator.
Hair-agnostic image. At test time, our model needs to transfer hairstyle between the images of different identities and hairstyles, unlike the training phase. Therefore, the difference between the target hairstyle and the source hairstyle during the test is much larger than during the training. To minimize the difference, we obtain the hair-agnostic image with the hair region of the source image removed as presented in Fig. 2. To be specific, we exclude the region of the source hair mask and the forehead mask from . The warped target hair mask is also subtracted from . During the training, and have only a slight difference since we use image pairs of the same hairstyle. Therefore, we sample a random image from the training set and warp its hair mask to fit the source pose, resulting in . Then, the region of is removed from the hair-agnostic image. This successfully mimics the inference situations by providing the model with the chance to fill in larger occluded regions. In this regard, the proposed enhances our hair synthesis generator’s generalization ability at test time.
SIM estimator. As previously mentioned, the hairstyle transfer model is required to inpaint the occlusions in the source image and refine the aligned target hair. To address the challenges, we propose a SIM estimator, which separates the occluded regions into different semantic areas. With and as inputs, SIM estimator predicts a semantic-region-aware inpainting mask by dividing into face, clothes, background, and unknown. Here, is calculated by subtracting from the occluded region of . The fifth column in Fig. 4 presents examples of . The separated mask effectively guides our ALIAS generator to inpaint each semantic region by reflecting its distinctive features, leading to high-quality image generation.
ALIAS generator. As described in Fig. 1 (b), the inputs and are injected into each layer of ALIAS generator, where is an RGB-rendered source keypoint image. In each layer, the features are normalized separately based on the inpainting mask in a similar manner to general region normalization [Yu et al.(2020)Yu, Guo, Jin, Wu, Chen, Li, Zhang, and Liu, Choi et al.(2021)Choi, Park, Lee, and Choo]. The normalized features are then modulated by and , which are predicted based on . As a semantic guidance map of inpainting, allows the modulation parameters and to reflect distinctive semantic features of each divided region, increasing the overall quality of occlusion inpainting of the output. The hair synthesis module generates the final output after a series of ALIAS residual blocks with up-sampling layers. Additional details of ALIAS generator are provided in our supplementary material.
Losses. We train the ALIAS generator with the conditional adversarial loss , the feature matching loss , the perceptual loss , and the hairstyle loss , referring to SPADE [Park et al.(2019b)Park, Liu, Wang, and Zhu], pix2pixHD [Wang et al.(2018)Wang, Liu, Zhu, Tao, Kautz, and Catanzaro], and LOHO [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi]. Since the training pairs have the same identity and hairstyle, the losses can be computed between a synthesized image and the ground truth (source) image, working as direct supervision. We use the Hinge loss as the adversarial loss [Zhang et al.(2019)Zhang, Goodfellow, Metaxas, and Odena]. The is computed between Gram matrix [Gatys et al.(2016)Gatys, Ecker, and Bethge] feature maps of the generated hair image and the source hair image to support detailed hairstyle refinement. The generated hair image is extracted from the final output using the pre-trained hair segmentation model [Gong et al.(2019)Gong, Gao, Liang, Shen, Wang, and Lin]. Additionally, we train SIM estimator with SIM loss . is calculated using the binary cross-entropy loss between the estimated and the ground truth segmentation masks obtained by the pre-trained face parsing model [Yu et al.(2018)Yu, Wang, Peng, Gao, Yu, and Sang]. The total loss of the hair synthesis module is as follows:
| (1) |
where we set both and as 10, as 50, and as 100. More details of the losses are described in the supplementary material.
4 Experiments
To demonstrate the effectiveness of HairFIT, we conduct quantitative and qualitative evaluations compared to baseline models, using two multi-view datasets. We also conduct an ablation study to present the effect of key components in our model.
4.1 Experimental Setup
Dataset. As mentioned in Section 3.1, we leverage multi-view datasets for the experiments. First, we utilize K-hairstyle [Kim et al.(2021)Kim, Chung, Park, Gu, Nam, Choe, Lee, and Choo] which contains 500,000 high-resolution hairstyle images. The dataset consists of multi-view images including more than 6,400 identities. The viewing angle of images ranges from 0 to 360 degrees. Also, each image in the dataset has a hair segmentation mask as well as various hairstyle attributes. Since our goal is to transfer a hairstyle, we excluded images whose hairstyle is significantly occluded. Also, we removed images whose face is extremely rotated, such as images of a person facing the side or the back, since we cannot extract facial keypoints from them. Accordingly, our training set consists of randomly sampled 60,584 images with 5,407 identities, and the test set includes 6,717 images with 611 identities. While the maximum image resolution is 4,0323,024, we resized the images into 256256 and 512512 in our experiments.
Additionally, we use VoxCeleb [Nagrani et al.(2017)Nagrani, Chung, and Zisserman] which consists of more than 100,000 utterance videos with 1,251 identities. For the training data, we randomly sampled 16,847 videos, each of which contains 30 frames on average. The frames of a video can be considered as multi-view images of a single identity. The test set includes randomly sampled 2,209 videos. For the experiments, we resized the images into 256256.
For both datasets, the training set consists of image pairs that have the same identity and hairstyle, while the test set contains image pairs that have different identities and hairstyles. We utilize one image of a pair as a source image and the other as a target image.
Evaluation metrics. As a quantitative evaluation, we use the fréchet inception distance (FID) score [Heusel et al.(2017)Heusel, Ramsauer, Unterthiner, Nessler, and Hochreiter]. The FID score measures how similar the distributions of the synthesized images and the real images are. The lower FID score indicates a higher similarity between the images.
| Dataset | K-hairstyle | VoxCeleb | |
| Resolution | 256 256 | 512 512 | 256 256 |
| MichiGAN | 30.52 | 36.12 | 81.14 |
| LOHO | 62.44 | 71.79 | 66.97 |
| HairFIT (Ours) | 18.53 | 19.01 | 17.66 |
4.2 Comparison to Baselines
Quantitative evaluations. First, we compare the FID scores between our model and the baseline models, MichiGAN [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu] and LOHO [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi]. We train both models with the same datasets, K-hairstyle and VoxCeleb, based on their official implementation codes. We utilize a gated convolution network [Yu et al.(2019)Yu, Lin, Yang, Shen, Lu, and Huang] for the inpainting modules in MichiGAN and LOHO, as described in LOHO paper. As presented in Table 1, our model achieves the lowest FID score with a large margin compared to the baseline models.
| Pose difference level | Medium | Difficult | Extremely difficult |
| MichiGAN | 31.58 | 34.41 | 40.41 |
| LOHO | 57.80 | 62.34 | 95.89 |
| HairFIT (Ours) | 21.95 | 21.76 | 24.60 |
For further analysis, we also conduct quantitative comparisons with three different levels of pose difference. We split our test pairs of K-hairstyle into three categories of 2,000 images, ‘Medium’, ‘Difficult’, and ’Extremely difficult’. As in LOHO [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi], we use 68 facial keypoints extracted by the pre-trained keypoint detector [Bulat and Tzimiropoulos(2017)] to measure the pose distance (PD) between the source and the target keypoints as follows: . The result in Table 2 describes that HairFIT outperforms the other baselines with a larger margin as the degree of pose difference increases from ‘Medium’ to ‘Extremely difficult’. MichiGAN and LOHO show poor hairstyle transfer performance on images with significant pose differences, as they stated in their paper.
| Dataset | K-hairstyle | VoxCeleb | ||
| Metric | SSIM↑ | LPIPS↓ | SSIM↑ | LPIPS↓ |
| MichiGAN | 0.7210 | 0.2432 | 0.7021 | 0.2282 |
| LOHO | 0.7852 | 0.1452 | 0.6389 | 0.2419 |
| HairFIT(Ours) | 0.8041 | 0.0841 | 0.7147 | 0.1262 |
Additionally, to demonstrate that HairFIT successfully aligns the target hair with the source pose, we conduct a quantitative evaluation on hairstyle reconstruction. We compare our model to MichiGAN [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu] and LOHO [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi]. Given a source image and a target image which have the same identity and hairstyle but different poses, a model reconstructs the source image by applying the target hairstyle extracted from the target image to the source image. We measure the structural similarity (SSIM) [Wang et al.(2004)Wang, Bovik, Sheikh, and Simoncelli] and learned perceptual image patch similarity (LPIPS) [Zhang et al.(2018b)Zhang, Isola, Efros, Shechtman, and Wang] using the same 3,000 image pairs. The higher the SSIM and the lower the LPIPS, the better. As described in Table 3, our model achieves superior performance over the baseline models.

| Method |
|
|
|
|
|
||||||||||
| FID (256) | 25.58 | 22.89 | 19.40 | 19.16 | 18.53 |
Qualitative evaluations. As presented in Fig. 3, qualitative results also present the superiority of HairFIT for both of the two datasets. While the baseline models generate unrealistic images, our model robustly transfers target hairstyles to the source images even when they have significantly different poses or the source image has occluded regions.
4.3 Ablation Study
Quantitative evaluations. We conduct an ablation study to validate the effectiveness of each component in our model. Starting from ALIAS generator, we gradually add flow-based hair alignment module, subtraction in a hair-agnostic image , SIM estimator with SIM loss, and hairstyle loss, which is our full model. indicates warped random hair mask in as described in Section 3.3. The results show that all of our design decisions lead to an improvement of the FID score, successfully addressing both pose differences and occlusion inpainting.

Qualitative evaluations. Furthermore, we conduct a qualitative evaluation on the effect of SIM estimator. As mentioned in Section 3.3, SIM estimator guides our model to effectively inpaint occlusions by reflecting distinctive features of each region. According to Fig. 4, outputs of HairFIT with SIM estimator present more realistic inpainting quality compared to HairFIT without SIM estimator. In particular, while the output without SIM on the first row of Fig. 4 has blue artifacts on its clothes, the output with SIM does not. Moreover, unlike the output without SIM on the second row, the output with SIM has a clean forehead without brown artifacts.
5 Conclusion
We propose a two-stage pose-invariant hairstyle transfer model, HairFIT, which successfully transfers a target hairstyle to a source image when the source and the target have a different pose. In our model, a flow-based hair alignment network first aligns the target hairstyle with the source leveraging optical flow estimation. Then, a hair synthesis module generates output via an ALIAS generator with the help of a hair-agnostic image and a SIM estimator. Our SIM estimator guides the generator to inpaint occlusions in the source image which contain multiple semantic regions. The quantitative and qualitative results demonstrate the superiority of HairFIT over the existing methods.
Acknowledgement
This work was supported by the Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2019-0-00075, Artificial Intelligence Graduate School Program (KAIST) and No. 2020-0-00368, A Neural-Symbolic Model for Knowledge Acquisition and Inference Techniques)), the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (No. NRF-2019R1A2C4070420), and Kakao Enterprise.
References
- [Brock et al.(2019)Brock, Donahue, and Simonyan] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. In Proc. the International Conference on Learning Representations (ICLR), 2019.
- [Bulat and Tzimiropoulos(2017)] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem? (and a dataset of 230,000 3d facial landmarks). In Proc. of the IEEE international conference on computer vision (ICCV), 2017.
- [Choi et al.(2021)Choi, Park, Lee, and Choo] Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton-hd: High-resolution virtual try-on via misalignment-aware normalization. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2021.
- [Choi et al.(2020)Choi, Uh, Yoo, and Ha] Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2020.
- [Deng et al.(2019)Deng, Guo, Niannan, and Zafeiriou] Jiankang Deng, Jia Guo, Xue Niannan, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019.
- [Dosovitskiy et al.(2015)Dosovitskiy, Fischer, Ilg, Häusser, Hazırbaş, Golkov, v.d. Smagt, Cremers, and Brox] A. Dosovitskiy, P. Fischer, E. Ilg, P. Häusser, C. Hazırbaş, V. Golkov, P. v.d. Smagt, D. Cremers, and T. Brox. Flownet: Learning optical flow with convolutional networks. In Proc. of the IEEE international conference on computer vision (ICCV), 2015.
- [Gao et al.(2019)Gao, Xu, Cai, Wang, Yu, and Darrell] Hang Gao, Huazhe Xu, Qi-Zhi Cai, Ruth Wang, Fisher Yu, and Trevor Darrell. Disentangling propagation and generation for video prediction. In Proc. of the IEEE international conference on computer vision (ICCV), 2019.
- [Gatys et al.(2016)Gatys, Ecker, and Bethge] Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Image style transfer using convolutional neural networks. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2016.
- [Gong et al.(2019)Gong, Gao, Liang, Shen, Wang, and Lin] Ke Gong, Yiming Gao, Xiaodan Liang, Xiaohui Shen, Meng Wang, and Liang Lin. Graphonomy: Universal human parsing via graph transfer learning. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019.
- [Goodfellow et al.(2014)Goodfellow, Pouget-Abadie, Mirza, Xu, Warde-Farley, Ozair, Courville, and Bengio] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Proc. the Advances in Neural Information Processing Systems (NeurIPS), 2014.
- [Heusel et al.(2017)Heusel, Ramsauer, Unterthiner, Nessler, and Hochreiter] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Proc. the Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [Huang and Belongie(2017)] Xun Huang and Serge J. Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In Proc. of the IEEE international conference on computer vision (ICCV), 2017.
- [Hui et al.(2018)Hui, Tang, and Loy] Tak-Wai Hui, Xiaoou Tang, and Chen Change Loy. Liteflownet: A lightweight convolutional neural network for optical flow estimation. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2018.
- [Ilg et al.(2017)Ilg, Mayer, Saikia, Keuper, Dosovitskiy, and Brox] E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2017.
- [Isola et al.(2017)Isola, Zhu, Zhou, and Efros] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. 2017.
- [Jo and Park(2019)] Youngjoo Jo and Jongyoul Park. Sc-fegan: Face editing generative adversarial network with user’s sketch and color. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019.
- [Kim et al.(2021)Kim, Chung, Park, Gu, Nam, Choe, Lee, and Choo] Taewoo Kim, Chaeyeon Chung, Sunghyun Park, Gyojung Gu, Keonmin Nam, Wonzo Choe, Jaesung Lee, and Jaegul Choo. K-hairstyle: A large-scale korean hairstyle dataset for virtual hair editing and hairstyle classification. In Proc. of the IEEE International Conference on Image Processing (ICIP), 2021.
- [Kingma and Ba(2015)] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proc. the International Conference on Learning Representations (ICLR), 2015.
- [Lee et al.(2020)Lee, Liu, Wu, and Luo] Cheng-Han Lee, Ziwei Liu, Lingyun Wu, and Ping Luo. Maskgan: Towards diverse and interactive facial image manipulation. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2020.
- [Liang et al.(2017)Liang, Lee, Dai, and Xing] Xiaodan Liang, Lisa Lee, Wei Dai, and Eric P Xing. Dual motion gan for future-flow embedded video prediction. In Proc. of the IEEE international conference on computer vision (ICCV), 2017.
- [Liu et al.(2017)Liu, Yeh, Tang, Liu, and Agarwala] Ziwei Liu, Raymond A. Yeh, Xiaoou Tang, Yiming Liu, and Aseem Agarwala. Video frame synthesis using deep voxel flow. In Proc. of the IEEE international conference on computer vision (ICCV), 2017.
- [Nagrani et al.(2017)Nagrani, Chung, and Zisserman] A. Nagrani, J. S. Chung, and A. Zisserman. Voxceleb: a large-scale speaker identification dataset. In INTERSPEECH, 2017.
- [Odena et al.(2017)Odena, Olah, and Shlens] Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional image synthesis with auxiliary classifier gans. In Proc. the International Conference on Learning Representations (ICLR), 2017.
- [Park et al.(2021)Park, Kim, Lee, Choo, Lee, Kim, and Choi] Sunghyun Park, Kangyeol Kim, Junsoo Lee, Jaegul Choo, Joonseok Lee, Sookyung Kim, and Yoonjae Choi. Vid-ode: Continuous-time video generation with neural ordinary differential equation. In Proc. the AAAI Conference on Artificial Intelligence (AAAI), 2021.
- [Park et al.(2019a)Park, Liu, Wang, and Zhu] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019a.
- [Park et al.(2019b)Park, Liu, Wang, and Zhu] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019b.
- [Portenier et al.(2018)Portenier, Hu, Szabó, Bigdeli, Favaro, and Zwicker] Tiziano Portenier, Qiyang Hu, Attila Szabó, Siavash Arjomand Bigdeli, Paolo Favaro, and Matthias Zwicker. Faceshop: Deep sketch-based face image editing. ACM Transactions on Graphics (TOG), 37(4), 2018.
- [Reed et al.(2016)Reed, Akata, Yan, Logeswaran, Schiele, and Lee] Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. Generative adversarial text to image synthesis. In Proc. the International Conference on Learning Representations (ICLR), 2016.
- [Saha et al.(2021)Saha, Duke, Shkurti, Taylor, and Aarabi] Rohit Saha, Brendan Duke, Florian Shkurti, Graham Taylor, and Parham Aarabi. Loho: Latent optimization of hairstyles via orthogonalization. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2021.
- [Siarohin et al.(2019a)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. First order motion model for image animation. Proc. the Advances in Neural Information Processing Systems (NeurIPS), 2019a.
- [Siarohin et al.(2019b)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. Animating arbitrary objects via deep motion transfer. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2019b.
- [Simonyan and Zisserman(2015)] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Proc. the International Conference on Learning Representations (ICLR), 2015.
- [Tan et al.(2020)Tan, Chai, Chen, Liao, Chu, Yuan, Tulyakov, and Yu] Zhentao Tan, Menglei Chai, Dongdong Chen, Jing Liao, Qi Chu, Lu Yuan, Sergey Tulyakov, and Nenghai Yu. Michigan: Multi-input-conditioned hair image generation for portrait editing. ACM Transactions on Graphics (TOG), 39(4):1–13, 2020.
- [Wang et al.(2018)Wang, Liu, Zhu, Tao, Kautz, and Catanzaro] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2018.
- [Wang et al.(2021)Wang, Mallya, and Liu] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. One-shot free-view neural talking-head synthesis for video conferencing. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2021.
- [Wang et al.(2004)Wang, Bovik, Sheikh, and Simoncelli] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004.
- [Yang et al.(2020)Yang, Wang, Liu, and Guo] Shuai Yang, Zhangyang Wang, Jiaying Liu, and Zongming Guo. Deep plastic surgery: Robust and controllable image editing with human-drawn sketches. In Proc. of the European Conference on Computer Vision (ECCV), 2020.
- [Yu et al.(2018)Yu, Wang, Peng, Gao, Yu, and Sang] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proc. of the European Conference on Computer Vision (ECCV), 2018.
- [Yu et al.(2019)Yu, Lin, Yang, Shen, Lu, and Huang] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In Proc. of the IEEE international conference on computer vision (ICCV), 2019.
- [Yu et al.(2020)Yu, Guo, Jin, Wu, Chen, Li, Zhang, and Liu] Tao Yu, Zongyu Guo, Xin Jin, Shilin Wu, Zhibo Chen, Weiping Li, Zhizheng Zhang, and Sen Liu. Region normalization for image inpainting. In Proc. the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- [Zhang et al.(2018a)Zhang, Xu, Li, Zhang, Wang, Huang, and Metaxas] Han Zhang, Tao Xu, Hongsheng Li, Shaoting Zhang, Xiaogang Wang, Xiaolei Huang, and Dimitris N Metaxas. Stackgan++: Realistic image synthesis with stacked generative adversarial networks. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 41(8):1947–1962, 2018a.
- [Zhang et al.(2019)Zhang, Goodfellow, Metaxas, and Odena] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. In Proc. the International Conference on Machine Learning (ICML), 2019.
- [Zhang et al.(2018b)Zhang, Isola, Efros, Shechtman, and Wang] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In Proc. of the IEEE conference on computer vision and pattern recognition (CVPR), 2018b.
Supplementary Material
Appendix A Model Architecture and Implementation Details
A.1 Flow-based Hair Alignment
As described in Section 3.2 of our paper, the flow-based hair alignment module aligns the target hairstyle with the source pose using a dense optical flow estimated by the hair flow estimation network. We obtain the dense optical flow map by combining a coarse keypoint difference and the refinement flow map .
To be specific, our module first converts facial keypoints into the Gaussian keypoint heatmap , where denotes the number of keypoints. Then, we obtain the keypoint heatmap difference , which is calculated as , where and indicate a target and a source, respectively. With and the warped , the flow estimation network, , predicts the -channel mask and . Here, the target image is warped by the keypoint difference , which is calculated as . Accordingly, and are obtained as follows:
| (2) |
and indicate concatenation and warping operation, respectively. means an image is warped by . The warping operation is implemented using a bilinear sampler. consists of two convolutional (Conv) blocks, five down blocks, and five up blocks [Siarohin et al.(2019b)Siarohin, Lathuilière, Tulyakov, Ricci, and Sebe].
Finally, we obtain the dense optical flow map as . Here, repeats the input tensor by times and denotes element-wise multiplication. We adopt the Adam optimizer [Kingma and Ba(2015)] with , and the learning rate 0.0002. Also, we train the flow-based hair alignment for 240,000 iterations with batch size 8 in case of K-hairstyle dataset and 110,000 iterations with batch size 16 for VoxCeleb.
A.2 Hair Synthesis
The detailed architecture of the hair synthesis module is shown in Fig. 5. Our hair synthesis module synthesizes the aligned target hairstyle with the source image. The network needs to refine and apply the warped target hairstyle while preserving the source features such as the faces, clothes, or backgrounds. Furthermore, the network is also required to inpaint occluded regions in the source image with appropriate face, clothes, or backgrounds. To achieve this, we utilize ALIgnment-Aware Segmen (ALIAS) [Choi et al.(2021)Choi, Park, Lee, and Choo] generator with Semantic-region-aware Inpainting Mask (SIM) estimator.

ALIAS generator and discriminator. As described in Fig. 5 (a), the generator contains a series of ALIAS residual blocks (ResBlk), along with up-sampling layers. We use the multi-scale discriminator [Huang and Belongie(2017), Choi et al.(2021)Choi, Park, Lee, and Choo].
ALIAS ResBlk. As presented in Fig. 5 (b), each ALIAS ResBlk consists of three sets of ALIAS normalization layer (ALIAS Norm), ReLU, and Conv layer. First, a resized hair-agnostic image , an RGB-rendered facial keypoint image , and the warped target hair image are concatenated and fed to a Conv layer to obtain . Then, is concatenated with , the feature from the previous layer, and injected to -th ALIAS ResBlk.
ALIAS Norm. ALIAS Norm normalizes separately based on the resized inpainting mask . Then, the normalized features are de-normalized with affine parameters and , estimated based on the resized . consists of three components, the warped target hair mask , semantic-region-aware inpainting mask , and .
SIM estimator. The network separates into face, clothes, background, and unknown region. SIM estimator consists of two Down blocks, one Conv layer, and two Up blocks. Each Down block has a Conv, Batch-Norm, and ReLU layer. Also, each Up block has an up-sampling layer, Conv, Batch-Norm, and ReLU layer. SIM estimator is trained end-to-end with ALIAS generator.
Lossses. The details of the losses we use are described below.
, , and . We adopt the conditional adversarial loss , the feature matching loss , and the perceptual loss , referring to VITON-HD, SPADE, and pix2pixHD [Choi et al.(2021)Choi, Park, Lee, and Choo, Park et al.(2019a)Park, Liu, Wang, and Zhu, Wang et al.(2018)Wang, Liu, Zhu, Tao, Kautz, and Catanzaro]. We use the hinge loss for [Zhang et al.(2018b)Zhang, Isola, Efros, Shechtman, and Wang]. Let be the discriminator and be the activation of the -th layer . Similarly, be the activation of the -th layer VGG19 network [Simonyan and Zisserman(2015)]. and are the number of elements in and , respectively. Each of the above loss functions is described below.
| (3) |
| (4) |
| (5) |
Hairstyle loss . To capture the fine details of hairstyle features, we utilize the Gram matrix [Gatys et al.(2016)Gatys, Ecker, and Bethge]. We compute the L2 distance between the gram matrices of the generated hair features and the target hair features extracted by 16 [Simonyan and Zisserman(2015)]. The generated hair features are obtained based on and the target hair features are obtained based on . is the -th Gram matrix, , where is the activation of the -th layer of . Here, and represent the number of channels in and in , respectively. The activations from of are used for the loss.
| (6) |
SIM estimator loss . is a ground truth segmentation mask of the inpainting mask . is obtained from the source semantic masks of a face, clothes, and backgrounds extracted by the pre-trained face-parsing network [Yu et al.(2018)Yu, Wang, Peng, Gao, Yu, and Sang]. We compute the binary cross-entropy loss between and the predicted as below.
| (7) |
The total loss of the hair synthesis module is calculated as follows:
| (8) |
where we set both and to 10, to 50, and to 100.
We adopt the Adam optimizer [Kingma and Ba(2015)] with , . The learning rate of the generator and the discriminator are set to 0.0001 and 0.0004, respectively. We train the hair synthesis module for 15,000 iterations with batch size 8 for both K-hairstyle and VoxCeleb.


Appendix B Additional Qualitative Results
We conduct an additional qualitative comparison between our model and the baseline models. Fig. 6 and Fig. 7 present qualitative results of K-hairstyle dataset and VoxCeleb dataset, respectively. The results show that HairFIT successfully transfers hairstyles even when the source and the target image have different poses. Furthermore, our model preserves delicate target hairstyle features (e.g\bmvaOneDot, curl, two-toned hair color, etc.) better than other models.
Appendix C Limitations
Although HairFIT successfully transfers a hairstyle between images of different poses, our model has several limitations. First, HairFIT has difficulty in aligning a target hair which has a significant occlusion of hair. Since our hair alignment module utilizes a warping operation to align the target hair, the module can rearrange the pixels of the existing hair but cannot newly generate the unseen hair. The first column of Fig. 8 presents an example where the right side of the target hair is extremely occluded. In this case, our model cannot transfer the right hair of the target image to the source image.
Next, a complicated texture or structure in occlusion regions degrades the quality of generated images. For instance, as described in the second column of Fig. 8, even though a person in a source image wears clothes with complex patterns, our model inpaints the region only with simple and general texture.
Lastly, HairFIT is dependent on hair segmentation masks. For example, if the target hair mask contains irrelevant regions such as the forehead, the output inevitably contains the region. On the third column of Fig. 8, the forehead of the output reflects the target forehead color which is different from the source since the target hair mask includes its forehead. Also, the last column of Fig. 8 indicates an example where the target hair mask does not contain thin hair on the forehead, leading to an inaccurate hairstyle transfer.

| Dataset | K-hairstyle | VoxCeleb |
| StarGAN v2 (Gender) | 0.5238 | 0.9938 |
| StarGAN v2 (Hair) | 0.5590 | - |
| HairFIT (Ours) | 0.9892 | 0.9993 |
Appendix D Comparison with StarGAN v2
The previous work [Kim et al.(2021)Kim, Chung, Park, Gu, Nam, Choe, Lee, and Choo] shows that StarGAN v2 [Choi et al.(2020)Choi, Uh, Yoo, and Ha] has a capability to modify the hairstyle of the source image based on the given target image. However, we found that StarGAN v2 fails to preserve other features (e.g\bmvaOneDot, skin color, face shape, clothes, etc.) of the source image, which are essential to maintain the source person’s identity. Since StarGAN v2 changes both the hairstyle and the identity of the source image, it is not appropriate to compare StarGAN v2 with our model. For this reason, none of the existing hairstyle transfer work such as MichiGAN, LOHO considered StarGAN v2 as their baseline, either.
To evaluate the identity preservation performance, we measure the face verification accuracy of StarGAN v2 compared to HairFIT using the pre-trained ArcFace [Deng et al.(2019)Deng, Guo, Niannan, and Zafeiriou], which is one of the state-of-the-art face recognition models. Since StarGAN v2 requires the domain labels for training, we utilize the gender labels and the hairstyle labels provided from K-hairstyle dataset and the gender labels from VoxCeleb dataset. As shown in Table 5, HairFIT successfully preserves the source identity in both K-hairstyle and VoxCeleb. On the other hand, StarGAN v2 trained with K-hairstyle fails to preserve the source identity. Although StarGAN v2 trained with VoxCeleb achieves the high verification accuracy, Fig. 9 demonstrates that StarGAN v2 also modifies the features (e.g\bmvaOneDot, skin color, makeup style, etc.) related to the source identity. This reason makes StarGAN v2 hardly applicable for hairstyle transfer.
