Guiding AMR Parsing with Reverse Graph Linearization
Abstract
Abstract Meaning Representation (AMR) parsing aims to extract an abstract semantic graph from a given sentence. The sequence-to-sequence approaches, which linearize the semantic graph into a sequence of nodes and edges and generate the linearized graph directly, have achieved good performance. However, we observed that these approaches suffer from structure loss accumulation during the decoding process, leading to a much lower F1-score for nodes and edges decoded later compared to those decoded earlier. To address this issue, we propose a novel Reverse Graph Linearization (RGL) enhanced framework. RGL defines both default and reverse linearization orders of an AMR graph, where most structures at the back part of the default order appear at the front part of the reversed order and vice versa. RGL incorporates the reversed linearization to the original AMR parser through a two-pass self-distillation mechanism, which guides the model when generating the default linearizations. Our analysis shows that our proposed method significantly mitigates the problem of structure loss accumulation, outperforming the previously best AMR parsing model by 0.8 and 0.5 Smatch scores on the AMR 2.0 and AMR 3.0 dataset, respectively. The code are available at https://github.com/pkunlp-icler/AMR_reverse_graph_linearization.
1 Introduction
Abstract Meaning Representation (AMR) (Banarescu et al., 2013) is a formalization of a sentence’s meaning using a directed acyclic graph that abstracts away from shallow syntactic features and captures the core semantics of the sentence. AMR parsing involves transforming a textual input into its AMR graph, as illustrated in Figure 1. Recently, sequence-to-sequence (seq2seq) based AMR parsers (Xu et al., 2020b; Bevilacqua et al., 2021; Wang et al., 2021; Bai et al., 2022; Yu and Gildea, 2022b; Chen et al., 2022; Cheng et al., 2022) have significantly improved the performance of AMR parsing. In these models, the AMR graph is first linearized into a token sequence during traditional seq2seq training, and the output sequence is then restored to the graph structure after decoding. AMR parsing has proven beneficial for many NLP tasks, such as summarization (Liao et al., 2018; Hardy and Vlachos, 2018), question answering (Mitra and Baral, 2016; Sachan and Xing, 2016), dialogue systems (Bonial et al., 2020; Bai et al., 2021), and information extraction (Rao et al., 2017; Wang et al., 2017; Zhang and Ji, 2021; Xu et al., 2022).



In this study, we aim to address the issue of structure loss accumulation in seq2seq-based AMR parsing. Our analysis (Figure 2) shows that the F1-score of structure prediction (node and relation) decreases as the generation direction progresses. This phenomenon is a consequence of the error accumulation in the auto-regressive decoding process, a common problem in natural language generation (Ing, 2007; Zhang et al., 2019c; Liu et al., 2021).
However, unlike natural language, the linearization of AMR graphs does not follow a strict order, as long as the sequence preserves all nodes and relations in the AMR graph. To this end, we define two linearization orders based on the depth-first search (DFS) traversal, namely Left-to-Right (L2R) and Right-to-Left (R2L). The L2R order is the conventional linearization used in most previous works (Bevilacqua et al., 2021; Bai et al., 2022; Chen et al., 2022), where the leftmost child corresponding to the penman annotation is traversed first. In contrast, the R2L order is its reverse, where the structures at the end of the L2R order appear at the beginning of the R2L order. By training AMR parsing models with R2L linearization, it improves the accuracy of predictions for the structures at the end of the L2R order, which are less affected by the accumulation of structure loss.
We propose to enhance AMR parsing with reverse graph linearization (RGL). Specifically, we incorporate an additional encoder to integrate the reverse linearization graph and replace the original transformer decoder with a mixed decoder that utilizes gated dual cross-attention, taking input from both the hidden states of the sentence encoder and the graph encoder. We design a two-pass self-distillation mechanism to prevent the model from overfitting to the gold reverse linearized graph as well as to further utilize it to guide the model training. Our analysis shows that our proposed method significantly mitigates the problem of structure loss accumulation, outperforming the previously best AMR parsing model (Bai et al., 2022) by 0.8 Smatch score on the AMR 2.0 dataset and 0.5 Smatch score on the AMR 3.0 dataset.
Our contributions can be listed as follows:
1. We explore the structure loss accumulation problem in sequence-to-sequence AMR parsing.
2. We propose a novel RGL framework to alleviate the structure loss accumulation by incorporating reverse graph linearization into the model, which outperforms previously best AMR parser.
3. Extensive experiments and analysis demonstrate the effectiveness and superiority of our proposed method.
2 Backgrounds
2.1 Seq2Seq based AMR Parsing
In our work, we followed previous methods Ge et al. (2019); Bevilacqua et al. (2021); Bai et al. (2022), which formulate AMR parsing as a sequence-to-sequence generation problem. Formally, given a sentence , the model needs to generate a linearized AMR graph in an auto-regressive manner.
Assuming that we have a training set containing sentence-linearized graph pairs , the total training loss of the model is computed by the cross-entropy loss which is listed as follows:
| (1) |
where is the length of linearized AMR graph, and is the previous tokens.
2.2 Graph Linearization Order
As shown in Table LABEL:tab:gf, we formalize two types of graph linearization, the corresponding AMR graph is shown in Figure 1. Left-to-Right (L2R) denotes that when we use the depth-first search (DFS) to traverse the children of a node, we first start from the leftmost child and then traverse to the right, which is identical to the order of penman annotation and is the default order of sequence-to-sequence based AMR parsers Bevilacqua et al. (2021); Bai et al. (2022); Chen et al. (2022). In contrast, Right-to-Left (R2L) traverses from the rightmost child to the leftmost child, which is the reverse of the standard traversal order. When the input sentence is long or contains multi-sentence, most of the nodes or relationships that are positioned later in the L2R sequence will appear earlier in the R2L sequence.
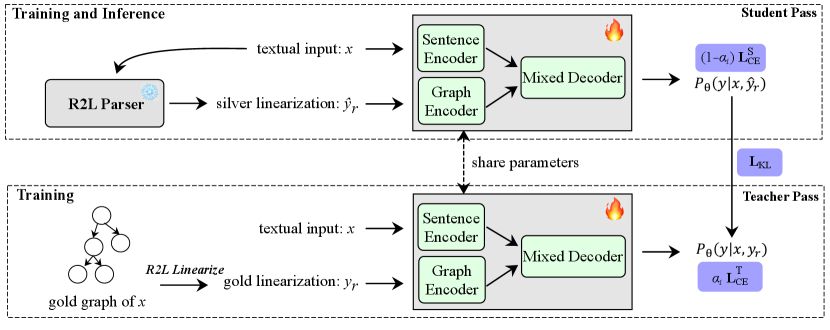
3 Methodology
4 Experiments
4.1 Datasets
We conducted our experiments on two AMR benchmark datasets, AMR 2.0 and AMR 3.0. AMR 2.0 contains , , and sentence-AMR pairs in training, validation, and testing sets, respectively. AMR 3.0 has , , and sentence-AMR pairs for training validation and testing set, respectively.
4.2 Evaluation Metrics
4.3 Main Compared Systems
AMRBART
We use the current state-of-the-art sequence-to-sequence AMR Parser proposed by Bai et al. (2022) as our main baseline model.
RGL
We initialize our model using AMRBART (Bai et al., 2022). The sentence encoder and the graph encoder are initialized the same as the AMRBART encoder, but they have individual gradients during training. Full details of the compared systems are listed in Appendix LABEL:sec:_training_details.
5 Analysis
6 Related Work
7 Conclusion
References
- Bai et al. (2021) Xuefeng Bai, Yulong Chen, Linfeng Song, and Yue Zhang. 2021. Semantic representation for dialogue modeling. ArXiv, abs/2105.10188.
- Bai et al. (2022) Xuefeng Bai, Yulong Chen, and Yue Zhang. 2022. Graph pre-training for AMR parsing and generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6001–6015, Dublin, Ireland. Association for Computational Linguistics.
- Banarescu et al. (2013) Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. 2013. Abstract meaning representation for sembanking. In Proceedings of the 7th linguistic annotation workshop and interoperability with discourse, pages 178–186.
- Bevilacqua et al. (2021) Michele Bevilacqua, Rexhina Blloshmi, and Roberto Navigli. 2021. One spring to rule them both: Symmetric amr semantic parsing and generation without a complex pipeline. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence.
- Bonial et al. (2020) Claire Bonial, L. Donatelli, Mitchell Abrams, Stephanie M. Lukin, Stephen Tratz, Matthew Marge, Ron Artstein, David R. Traum, and Clare R. Voss. 2020. Dialogue-amr: Abstract meaning representation for dialogue. In LREC.
- Cai and Lam (2020) Deng Cai and Wai Lam. 2020. AMR parsing via graph-sequence iterative inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1290–1301, Online. Association for Computational Linguistics.
- Cai and Knight (2013) Shu Cai and Kevin Knight. 2013. Smatch: an evaluation metric for semantic feature structures. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 748–752, Sofia, Bulgaria. Association for Computational Linguistics.
- Chen et al. (2022) Liang Chen, Peiyi Wang, Runxin Xu, Tianyu Liu, Zhifang Sui, and Baobao Chang. 2022. ATP: AMRize then parse! enhancing AMR parsing with PseudoAMRs. In Findings of the Association for Computational Linguistics: NAACL 2022, pages 2482–2496, Seattle, United States. Association for Computational Linguistics.
- Cheng et al. (2022) Ziming Cheng, Z. Li, and Hai Zhao. 2022. Bibl: Amr parsing and generation with bidirectional bayesian learning. In International Conference on Computational Linguistics.
- Damonte et al. (2017) Marco Damonte, Shay B. Cohen, and Giorgio Satta. 2017. An incremental parser for Abstract Meaning Representation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pages 536–546, Valencia, Spain. Association for Computational Linguistics.
- Fernandez Astudillo et al. (2020) Ramón Fernandez Astudillo, Miguel Ballesteros, Tahira Naseem, Austin Blodgett, and Radu Florian. 2020. Transition-based parsing with stack-transformers. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 1001–1007, Online. Association for Computational Linguistics.
- Flanigan et al. (2014) Jeffrey Flanigan, Sam Thomson, Jaime Carbonell, Chris Dyer, and Noah A. Smith. 2014. A discriminative graph-based parser for the Abstract Meaning Representation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1426–1436, Baltimore, Maryland. Association for Computational Linguistics.
- Ge et al. (2019) DongLai Ge, Junhui Li, Muhua Zhu, and Shoushan Li. 2019. Modeling source syntax and semantics for neural amr parsing. In IJCAI, pages 4975–4981.
- Hardy and Vlachos (2018) Hardy Hardy and Andreas Vlachos. 2018. Guided neural language generation for abstractive summarization using abstract meaning representation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 768–773.
- Ing (2007) Ching-Kang Ing. 2007. Accumulated prediction errors, information criteria and optimal forecasting for autoregressive time series.
- Lee et al. (2020) Young-Suk Lee, Ramón Fernandez Astudillo, Tahira Naseem, Revanth Gangi Reddy, Radu Florian, and Salim Roukos. 2020. Pushing the limits of amr parsing with self-learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 3208–3214.
- Lewis et al. (2020) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
- Liao et al. (2018) Kexin Liao, Logan Lebanoff, and Fei Liu. 2018. Abstract meaning representation for multi-document summarization. In Proceedings of the 27th International Conference on Computational Linguistics, pages 1178–1190.
- Liu et al. (2021) Yijin Liu, Fandong Meng, Yufeng Chen, Jinan Xu, and Jie Zhou. 2021. Scheduled sampling based on decoding steps for neural machine translation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 3285–3296. Association for Computational Linguistics.
- Lyu and Titov (2018) Chunchuan Lyu and Ivan Titov. 2018. AMR parsing as graph prediction with latent alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 397–407, Melbourne, Australia. Association for Computational Linguistics.
- Mitra and Baral (2016) Arindam Mitra and Chitta Baral. 2016. Addressing a question answering challenge by combining statistical methods with inductive rule learning and reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 30.
- Naseem et al. (2019) Tahira Naseem, Abhishek Shah, Hui Wan, Radu Florian, Salim Roukos, and Miguel Ballesteros. 2019. Rewarding smatch: Transition-based amr parsing with reinforcement learning. arXiv preprint arXiv:1905.13370.
- Rao et al. (2017) Sudha Rao, Daniel Marcu, Kevin Knight, and Hal Daumé III. 2017. Biomedical event extraction using abstract meaning representation. In BioNLP 2017, pages 126–135.
- Sachan and Xing (2016) Mrinmaya Sachan and Eric Xing. 2016. Machine comprehension using rich semantic representations. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 486–492.
- Wang et al. (2021) Peiyi Wang, Liang Chen, Tianyu Liu, Baobao Chang, and Zhifang Sui. 2021. Hierarchical curriculum learning for amr parsing. In Annual Meeting of the Association for Computational Linguistics.
- Wang et al. (2017) Yanshan Wang, Sijia Liu, Majid Rastegar-Mojarad, Liwei Wang, Feichen Shen, Fei Liu, and Hongfang Liu. 2017. Dependency and amr embeddings for drug-drug interaction extraction from biomedical literature. In Proceedings of the 8th acm international conference on bioinformatics, computational biology, and health informatics, pages 36–43.
- Wu et al. (2019) Ledell Wu, Fabio Petroni, Martin Josifoski, Sebastian Riedel, and Luke Zettlemoyer. 2019. Scalable zero-shot entity linking with dense entity retrieval. arXiv preprint arXiv:1911.03814.
- Xie et al. (2021) Binbin Xie, Jinsong Su, Yubin Ge, Xiang Li, Jianwei Cui, Junfeng Yao, and Bin Wang. 2021. Improving tree-structured decoder training for code generation via mutual learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 14121–14128.
- Xu et al. (2020a) Benfeng Xu, Licheng Zhang, Zhendong Mao, Quan Wang, Hongtao Xie, and Yongdong Zhang. 2020a. Curriculum learning for natural language understanding. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6095–6104, Online. Association for Computational Linguistics.
- Xu et al. (2020b) Dongqin Xu, Junhui Li, Muhua Zhu, Min Zhang, and Guodong Zhou. 2020b. Improving amr parsing with sequence-to-sequence pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2501–2511.
- Xu et al. (2022) Runxin Xu, Peiyi Wang, Tianyu Liu, Shuang Zeng, Baobao Chang, and Zhifang Sui. 2022. A two-stream amr-enhanced model for document-level event argument extraction. In North American Chapter of the Association for Computational Linguistics.
- Yu and Gildea (2022a) Chen Yu and Daniel Gildea. 2022a. Sequence-to-sequence AMR parsing with ancestor information. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 571–577, Dublin, Ireland. Association for Computational Linguistics.
- Yu and Gildea (2022b) Chenyao Yu and Daniel Gildea. 2022b. Sequence-to-sequence amr parsing with ancestor information. In Annual Meeting of the Association for Computational Linguistics.
- Zhang et al. (2019a) Sheng Zhang, Xutai Ma, Kevin Duh, and Benjamin Van Durme. 2019a. AMR parsing as sequence-to-graph transduction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 80–94, Florence, Italy. Association for Computational Linguistics.
- Zhang et al. (2019b) Sheng Zhang, Xutai Ma, Kevin Duh, and Benjamin Van Durme. 2019b. Broad-coverage semantic parsing as transduction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3786–3798, Hong Kong, China. Association for Computational Linguistics.
- Zhang et al. (2019c) Wen Zhang, Yang Feng, Fandong Meng, Di You, and Qun Liu. 2019c. Bridging the gap between training and inference for neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4334–4343, Florence, Italy. Association for Computational Linguistics.
- Zhang and Ji (2021) Zixuan Zhang and Heng Ji. 2021. Abstract meaning representation guided graph encoding and decoding for joint information extraction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 39–49.
- Zhou et al. (2021) Jiawei Zhou, Tahira Naseem, Ramón Fernandez Astudillo, and Radu Florian. 2021. AMR parsing with action-pointer transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5585–5598, Online. Association for Computational Linguistics.
- Zhou et al. (2019a) Long Zhou, Jiajun Zhang, and Chengqing Zong. 2019a. Synchronous bidirectional neural machine translation. Transactions of the Association for Computational Linguistics, 7:91–105.
- Zhou et al. (2019b) Long Zhou, Jiajun Zhang, Chengqing Zong, and Heng Yu. 2019b. Sequence generation: From both sides to the middle. arXiv preprint arXiv:1906.09601.
- Zhou et al. (2020) Qiji Zhou, Yue Zhang, Donghong Ji, and Hao Tang. 2020. AMR parsing with latent structural information. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4306–4319, Online. Association for Computational Linguistics.