GT-STORM: Taming Sample, Communication, and Memory Complexities in Decentralized Non-Convex Learning
Abstract.
Decentralized nonconvex optimization has received increasing attention in recent years in machine learning due to its advantages in system robustness, data privacy, and implementation simplicity. However, three fundamental challenges in designing decentralized optimization algorithms are how to reduce their sample, communication, and memory complexities. In this paper, we propose a gradient-tracking-based stochastic recursive momentum (GT-STORM) algorithm for efficiently solving nonconvex optimization problems. We show that to reach an -stationary solution, the total number of sample evaluations of our algorithm is and the number of communication rounds is , which improve the costs of sample evaluations and communications for the existing decentralized stochastic gradient algorithms. We conduct extensive experiments with a variety of learning models, including non-convex logistical regression and convolutional neural networks, to verify our theoretical findings. Collectively, our results contribute to the state of the art of theories and algorithms for decentralized network optimization.
1. Introduction
In recent years, machine learning has witnessed enormous success in many areas, including image processing, natural language processing, online recommender systems, just to name a few. From a mathematical perspective, training machine learning models amounts to solving an optimization problem. However, with the rapidly increasing dataset sizes and the high dimensionality and the non-convex hardness of the training problem (e.g., due to the use of deep neural networks), training large-scale machine learning models by a single centralized machine has become inefficient and unscalable. To address the efficiency and scalability challenges, an effective approach is to leverage decentralized computational resources in a computing network, which could follow a parameter server (PS)-worker architecture (recht2011hogwild, ; zinkevich2010parallelized, ; dean2012large, ) or fully decentralized peer-to-peer network structure (nedic2009distributed, ; lian2017can, ). Also, thanks to the robustness to single-point-of-failure, data privacy, and implementation simplicity, decentralized learning over computing networks has attracted increasing interest recently, and has been applied in various science and engineering areas (including dictionary learning (chen2014dictionary, ), multi-agent systems (cao2012overview, ; zhou2011multirobot, ), multi-task learning (wang2018distributed, ; zhang2019distributed, ), information retrieval (ali2004tivo, ), energy allocation (jiang2018consensus, ), etc.).
In the fast growing literature of decentralized learning over networks, a classical approach is the so-called network consensus optimization, which traces its roots to the seminal work by Tsitsiklis in 1984 (tsitsiklis1984problems, ). Recently, network consensus optimization has gained a lot of renewed interest owing to the elegant decentralized subgradient descent method (DSGD) proposed by Nedic and Ozdaglar (nedic2009distributed, ), which has been applied in decentralized learning due to its simple algorithmic structure and good convergence performance. In network-consensus-based decentralized learning, a set of geographically distributed computing nodes collaborate to train a common learning model. Each node holds a local dataset that may be too large to be sent to a centralized location due to network communication limits, or cannot be shared due to privacy/security risks. A distinctive feature of network-consensus-baed decentralized learning is that there is a lack of a dedicated PS. As a result, each node has to exchange information with its local neighbors to reach a consensus on a global optimal learning model.
Despite its growing significance in practice, the design of high-performance network-consensus-based decentralized learning faces three fundamental conflicting complexities, namely sample, communication, and memory complexities. First, due to the high dimensionality of most deep learning models, it is impossible to leverage beyond first-order (stochastic) gradient information to compute the update direction in each iteration. The variability of a stochastic gradient is strongly influenced by the number of training samples in its mini-batch. However, the more training samples in a mini-batch, the higher computational cost of the stochastic gradient. Second, by using fewer training samples in each iteration to trade for a lower computational cost, the resulting stochastic gradient unavoidably has a larger variance, which further leads to more iterations (hence communication rounds) to reach a certain training accuracy (i.e., slower convergence). The low communication efficiency is particularly problematic in many wireless edge networks, where the communication links could be low-speed and highly unreliable. Lastly, in many mobile edge-computing environments, the mobile devices could be severely limited by hardware resources (e.g., CPU/GPU, memory) and they cannot afford reserving a large memory space to run a very sophisticated decentralized learning algorithm that has too many intermediate variables.
Due to the above fundamental trade-off between sample, communication, and computing resource costs, the notions of sample, communication, and memory complexities (to be formally defined in Section 2) become three of the most important measures in assessing the performances of decentralized learning algorithms. However, in the literature, most existing works have achieve low complexities in some of these measures, but not all (see Section 2 for in-depth discussions). The limitations of these existing works motivate to ask the following question: Could we design a decentralized learning algorithm that strikes a good balance between sample complexity and communication complexity? In this paper, we answer the above question positively by proposing a new GT-STORM algorithm (gradient-tracking-based stochastic recursive momentum) that achieves low sample, communication, and memory complexities. Our main results and contributions are summarized as follows:
-
•
Unlike existing approaches, our proposed GT-STORM algorithm adopts a new estimator, which is updated with a consensus mixing of the neighboring estimators of the last iteration, which helps improve the global gradient estimation. Our method achieves the nice features of previous works (tran2019hybrid, ; cutkosky2019momentum, ; di2016next, ; lu2019gnsd, ) while avoiding their pitfalls. To some extent, our GT-STORM algorithm can be viewed as an indirect way of integrating the stochastic gradient method, variance reduction method, and gradient tracking method.
-
•
We provide a detailed convergence analysis and complexity analysis. Under some mild assumptions and parameter conditions, our algorithm enjoys an convergence rate. Note that this rate is much faster than the rate of for the classic decentralized stochastic algorithms, e.g., DSGD (jiang2017collaborative, ), PSGD (lian2017can, ) and GNSD (lu2019gnsd, ). Also, we show that to reach an -stationary solution, the total number of sample evaluations of our algorithm is and the communication round is .
-
•
We conduct extensive experiments to examine the performance of our algorithm, including both a non-convex logistic regression model on the LibSVM datasets and convolutional neural network models on MNIST and CIFAR-10 datasets. Our experiments show that the our algorithm outperforms two state-of-the-art decentralized learning algorithms (lian2017can, ; lu2019gnsd, ). These experiments corroborate our theoretical results.
The rest of the paper is organized as follows. In Section 2, we first provide the preliminaries of network consensus optimization and discuss related works with a focus on sample, communication, and memory complexities. In Section 3, we present our proposed GT-STORM algorithm, as well as its communication, sample, and memory complexity analysis. We provide numerical results in Section 4 to verify the theoretical results of our GT-STORM algorithm. Lastly in Section 5, we provide concluding remarks.
2. Preliminaries and Related Work
To facilitate our technical discussions, in Section 2.1, we first provide an overview on network consensus optimization and formally define the notions of sample, communication, and memory complexities of decentralized optimization algorithms for network consensus optimization. Then, in Section 2.2, we first review centralized stochastic first-order optimization algorithms for solving non-convex learning problems from a historical perspective and with a focus on sample, communication, and memory complexities. Here, we introduce several acceleration techniques that motivate our GT-STORM algorithmic design. Lastly, we review the recent developments of optimization algorithms for decentralized learning and compare them with our work.
2.1. Network Consensus Optimization
As mentioned in Section 1, in decentralized learning, there are a set of geographically distributed computing nodes forming a network. In this paper, we represent such a networked by an undirected connected network , where and are the sets of nodes and edges, respectively, with . Each node can communicate with their neighbors via the edges in . The goal of decentralized learning is to use the nodes to distributively and collaboratively solve a network-wide optimization problem as follows:
| (1) |
where each local objective function is only observable to node and not necessarily convex. Here, represents the distribution of the dataset at node , and represents a loss function that evaluates the discrepancy between the learning model’s output and the ground truth of a training sample . To solve Problem (1) in a decentralized fashion, a common approach is to rewrite Problem (1) in the following equivalent form:
| (2) | Minimize | |||||
| subject to | ||||||
where and is an introduced local copy at node . In Problem (2), the constraints ensure that the local copies at all nodes are equal to each other, hence the term “consensus.” Thus, Problems (1) and (2) share the same solutions. The main goal of network consensus optimization is to design an algorithm to attain an -stationary point defined as follows:
| (3) |
where denotes the global average across all nodes. Different from the traditional -stationary point in centralized optimization problems, the metric in Eq. (3) has two terms: the first term is the gradient magnitude for the (non-convex) global objective and the second term is the average consensus error of all local copies. To date, many decentralized algorithms have been developed to compute the -stationary point (see Section 2.2). However, most of these algorithms suffer limitations in sample, communication, and memory complexities. In what follows, we formally state the definitions of sample, communication, and memory complexities used in the literature (see, e.g., (sun2019improving, )):
Definition 1 (Sample Complexity).
The sample complexity is defined as the total number of the incremental first-order oracle (IFO) calls required across all the nodes to find an -stationary point defined in Eq. (3), where one IFO call evaluates a pair of on a sample and parameter at node
Definition 2 (Communication Complexity).
The communication complexity is defined as the total rounds of communications required to find an -stationary point defined in Eq. (3), where each node can send and receive a -dimensional vector with its neighboring nodes in one communication round.
Definition 3 (Memory Complexity).
The memory complexity is defined as total dimensionality of all intermediate variables in the algorithm run by a node to find an -stationary point in Eq. (3).
To make sense of these three complexity metrics into perspective, consider the standard centralized gradient descent (GD) method as an example. Note that the GD algorithm has an convergence rate for non-convex optimization, which suggests communication complexity. Also, it takes a full gradient evaluation in each iteration, i.e., per-iteration sample complexity, where is the total number of samples. This implies sample complexity to converge to an -stationary point. Hence, the sample complexity of GD is high if the dataset size is large.
In contrast, consider the classical stochastic gradient descent (SGD) algorithm that is widely used in machine learning. The basic idea of SGD is to lower the gradient evaluation cost by using only a mini-batch of samples in each iteration. However, due to the sample randomness in mini-batches, the convergence rate of SGD for non-convex optimization is reduced to (ghadimi2013stochastic, ; bottou2018optimization, ; zhou2018new, ). Thus, to reach an -stationary point with , SGD has sample complexity, which could be either higher or lower than the sample complexity of the GD method, depending on the relationship between and . Also, for -dimensional problems, both GD and SGD have memory complexity , since they only need a -dimensional vector to store (stochastic) gradients.
2.2. Related Work
1) Centralized First-Order Methods with Low Complexities: Now, we review several state-of-the-art low-complexity centralized stochastic first-order methods that are related to our GT-STORM algorithm. To reduce the overall sample and communication complexities of the standard GD and SGD algorithms, a natural approach is variance reduction. Earlier works following this approach include SVRG (johnson2013accelerating, ; reddi2016stochastic, ), SAGA (defazio2014saga, ) and SCSG (lei2017non, ). These algorithms has an overall sample complexity of . A more recent variance reduction method is the stochastic path-integrated differential estimator (SPIDER) (fang2018spider, ), which is based on the SARAH gradient estimator developed by Nguyen et al. (nguyen2017sarah, ). SPIDER further lowers the sample complexity to , which attains the theoretical lower bound for finding an -stationary point for . More recently, to improve the small step-size in SPIDER, a variant called SpiderBoost was proposed in (wang2019spiderboost, ), which allows a larger constant step-size while keeping the same sample complexity. It should be noted, however, that the significantly improved sample complexity of SPIDER/SpiderBoost is due to a restrictive assumption that a universal Lipschitz smoothness constant exists for all local objectives . This means that the objectives are “similar” and there are no “outliers” in the training samples. Meanwhile, to obtain the optimal communication complexity, SpiderBoost require a (nearly) full gradient every iterations and a mini-batch of stochastic gradient evaluation with batch size in each iteration.
To overcome the above limitations, a hybrid stochastic gradient descent (Hybrid-SGD) method is recently proposed in (tran2019hybrid, ), where a convex combination of the SARAH estimator (nguyen2017sarah, ) and an unbiased stochastic gradient is used as the gradient estimator. The Hybrid-SGD method relaxes the universal Lipschitz constant assumption in SpiderBoost to an average Lipschitz smoothness assumption. Moreover, it only requires two samples to evaluate the gradient per iteration. As a result, Hybrid-SGD has a sample complexity that is independent of dataset size. Although Hybrid-SGD is for centralized optimization, the interesting ideas therein motivate our GT-STORM approach for decentralized learning following a similar token. Interestingly, we show that in decentralized settings, our GT-STORM method can further improve the gradient evaluation to only one sample per iteration, while not degrading the communication complexity order. Lastly, we remark that all algorithms above have memory complexity at least for -dimensional problems. In contrast, GT-STORM enjoys a memory complexity.
2) Decentralized Optimization Algorithms In the literature, many decentralized learning optimization algorithms have been proposed to solve Problem (1), e.g., first-order methods (nedic2009distributed, ; yuan2016convergence, ; shi2015extra, ; di2016next, ), prime-dual methods (sun2019distributed, ; mota2013d, ), Newton-type methods (mokhtari2016decentralized, ; eisen2017decentralized, ) (see in (nedic2018network, ; chang2020distributed, ) for comprehensive surveys). In this paper, we consider decentralized first-order methods for the non-convex network consensus optimization in (2). In the literature, the convergence rate of the well-known decentralized gradient descent (DGD) algorithm (nedic2009distributed, ) was studied in (zeng2018nonconvex, ), which showed that DGD with a constant step-size converges with an rate to a step-size-dependent error ball around a stationary point. Later, a gradient tracking (GT) method was proposed in (di2016next, ) to find an -stationary point with an convergence rate under constant step-sizes. However, these methods require a full gradient evaluation per iteration, which yields sample complexity. To reduce the per-iteration sample complexity, stochastic gradients are adopted in the decentralized optimization, e.g., DSGD (jiang2017collaborative, ), PSGD (lian2017can, ), GNSD (lu2019gnsd, ). Due to the randomness in stochastic gradients, the convergence rate is reduced to Thus, the sample and communication complexities of these stochastic methods are and , two orders of magnitude higher than their deterministic counterparts. To overcome the limitations in stochastic methods, a natural idea is to use variance reduction techniques similar to those for centralized optimization to reduce the sample and communication complexities for the non-convex network consensus optimization. So far, existing works on the decentralized stochastic variance reduction methods include DSA (mokhtari2016dsa, ), diffusion-AVRG (yuan2018variance, ) and GT-SAGA (xin2019variance, ) etc., all of which focus on convex problems. To our knowledge, the decentralized gradient estimation and tracking (D-GET) algorithm in (sun2019improving, ) is the only work for non-convex optimization. D-GET integrates the decentralized gradient tracking (lu2019gnsd, ) and the SpiderBoost gradient estimator (wang2019spiderboost, ) to obtain dataset-size-dependent sample complexity and communication complexity. Recall that the sample and communication complexities of GT-STORM are and , respectively. Thus, if dataset size , D-GET has a higher sample complexity than GT-STORM. As an example, when , is on the order of , which is common in modern machine learning datasets. Also, the memory complexity of D-GET is as opposed to the memory complexity of GT-STORM. This implies a huge saving with GT-STORM if is large, e.g., in many deep learning models.
3. A Gradient-Tracking Stochastic Recursive Momentum Algorithm
In this section, we introduce our gradient-tracking-based stochastic recursive momentum (GT-STORM) algorithm for solving Problem (2) in Section 3.1. Then, we will state the main theoretical results and their proofs in Sections 3.2 and 3.3, respectively.
3.1. The GT-STORM Algorithm
In the literature, a standard starting point to solve Problem (2) is to reformulate the problem as (nedic2009distributed, ):
| (4) | Minimize | ||||
| subject to |
where denotes the -dimensional identity matrix, the operator denotes the Kronecker product, and is often referred to as the consensus matrix. We let represent the element in the -th row and the -th column in . For Problems (4) and (2) to be equivalent, should satisfy the following properties:
-
(a)
Doubly Stochastic: .
-
(b)
Symmetric: , .
-
(c)
Network-Defined Sparsity Pattern: if otherwise , .
The above properties imply that the eigenvalues of are real and can be sorted as . We define the second-largest eigenvalue in magnitude of as for the further notation convenience. It can be seen later that plays an important role in the step-size selection and the algorithm’s convergence rate.
As mentioned in Section 2.1, our GT-STORM algorithm is inspired by the GT method (di2016next, ; nedich2016geometrically, ) for reducing consensus error and the recursive variance reduction (VR) methods (fang2018spider, ; wang2019spiderboost, ) developed for centralized optimization. Specifically, in the centralized GT method, an estimator is introduced to track the global gradient:
| (5) |
where is the gradient estimation in the th iteration. Meanwhile, to reduce the stochastic error, a gradient estimator in VR methods is updated recursively based on a double-loop structure as follows:
| (6) |
where is the stochastic gradient dependent on parameter and a data sample and is the number of the inner loop iterations. On the other hand, if , takes a full gradient. Note that these two estimators have a similar structure: Both are recursively updating the previous estimation based on the difference of the gradient estimations between two consecutive iterations (i.e., momentum). This motivates us to consider the following question: Could we somehow “integrate” these two methods to develop a new decentralized gradient estimator to track the global gradient and reduce the stochastic error at the same time? Unfortunately, the GT and VR estimators can not be combined straightforwardly. The major challenge lies in the structural difference in the outer loop iteration (i.e., ), where the VR estimator requires full gradient and does not follow the recursive updating structure.
Surprisingly, in this paper, we show that there exists an “indirect” way to achieve the salient features of both GT and VR. Our approach is to abandon the double-loop structure of VR and pursue a single-loop structure. Yet, this single-loop structure should still be able to reduce the variance and consistently track the global gradient. Specifically, we introduce a parameter in the recursive update and integrate it with a consensus step as follows:
| (7) |
where and are the parameter, gradient estimator, and random sample in the th iteration at node , respectively. Note that the estimator reduces to the classical stochastic gradient estimator when . On the other hand, if we set , the estimator becomes the (stochastic) gradient tracking estimator based on a single sample (implying low sample complexity). Then, the key to the success of our GT-STORM design lies in meticulously choosing parameter to mimic the gradient estimator technique in centralized optimization (cutkosky2019momentum, ; tran2019hybrid, ). Lastly, the local parameters can be updated by the conventional decentralized stochastic gradient descent step:
| (8) |
where is the step-size in iteration . To summarize, we state our algorithm in Algorithm 1 as follows.
Algorithm 1: Gradient-Tracking-based Stochastic Recursive Momentum Algorithm (GT-STORM). Initialization:
-
1.
Choose and let . Set at node . Calculate at node .
Main Loop:
-
2.
In the -th iteration, each node sends and local gradient estimator to its neighbors. Meanwhile, upon the reception of all neighbors’ information, each node performs the following:
-
a)
Update local parameter: .
-
b)
Update local gradient estimator: .
-
a)
-
3.
Stop if ; otherwise, let and go to Step 2.
Two remarks for Algorithm 1 are in order. First, thanks to the single-loop structure, GT-STORM is easier to implement compared to the low-sample-complexity D-GET (sun2019improving, ) method, which has in a double-loop structure. Second, GT-STORM only requires memory space due to the use of only one intermediate vector at each node. In contrast, the memory complexity of D-GET is (cf. and in (sun2019improving, )). This 50% saving is huge particularly for deep learning models, where the number of parameters could be in the range of millions.
3.2. Main Theoretical Results
In this section, we will establish the complexity properties of the proposed GT-STORM algorithm. For better readability, we state the main theorem and its corollary in this section and provide the intermediate lemmas to Section 3.3. We start with the following assumptions on the global and local objectives:
Assumption 1.
The objective function with satisfies the following assumptions:
-
(a)
Boundedness from below: There exists a finite lower bound
-
(b)
-average smoothness: is -average smooth on , i.e., there exists a positive constant such that ;
-
(c)
Bounded variance: There exists a constant such that ;
-
(d)
Bounded gradient: There exists a constant such that .
In the above assumptions, (a) and (c) are standard in the stochastic non-convex optimization literature; (b) is an expected Lipschitz smoothness condition over the data distribution, which implies the conventional global Lipschitz smoothness (ghadimi2013stochastic, ) by the Jensen’s inequality. Note that (b) is weaker than the individual Lipschitz smoothness in (fang2018spider, ; wang2019spiderboost, ; sun2019improving, ): if there exists an outlier data sample, then the individual objective function might have a very large smoothness parameter while the average smoothness can still be small; (d) is equivalent to the Lipschitz continuity assumption, which is also commonly used for non-convex stochastic algorithms (zhou2018generalization, ; karimireddy2019error, ; koloskova2019decentralized, ) and is essential for analyzing the decentralized gradient descent method (yuan2016convergence, ; zeng2018nonconvex, ; jiang2017collaborative, ).111Note that under the assumption (b), as long as the parameter is bounded, (d) is satisfied.
For convenience, in the subsequent analysis, we define , and and for . Then, the algorithm can be compactly rewritten in the following matrix-vector form:
| (9) | ||||
| (10) |
Furthermore, since we have We first state the convergence result for Algorithm 1 as follows:
Theorem 1.
Under Assumption 1 and with the positive constants and satisfying , if we set and , with and , then we have the following result for Algorithm 1:
| (11) |
where and the constants and are:
| (12) | ||||
| (13) | ||||
| (14) |
In Theorem 1, and are two constants depending on the network topology, which in turn will affect the step-size and convergence: with a sparse network, i.e., is close to but not exactly one (recall that ). In order for to hold, needs to be large and needs be close to zero, which leads to small and Note that the step-size is of the order which is larger than the order for the classical decentralized SGD algorithms. With this larger step-size, the convergence rate is and faster than the rate for the decentralized SGD algorithms. Based on Theorem 1, we have the sample and communication complexity results for Algorithm 1:
Corollary 2.
Under the conditions in Theorem 1, if and , then to achieve an -stationary solution, the total communication rounds are on the order of and the total samples evaluated across the network is on the order of
3.3. Proofs of the Theoretical Results
Due to space limitation, we provide a proof sketch for Theorem 1 here and relegate the details to the appendices. First, we bound the error of gradient estimator as follows:
It can be seen that the upper bound depends on the error in the previous step with a factor . This will be helpful when we construct a potential function. Then, according to the algorithm updates (9)–(10), we show the following descent inequality:
Lemma 2 (Descent Lemma).
Under Assumption 1, Algorithm 1 satisfies: .
We remark that the right-hand-side (RHS) of the above inequality contains the consensus error of local parameters , which makes the analysis more difficult than that of the centralized optimization. Next, we prove the contraction of iterations in the following lemma, which is useful in analyzing the decentralized gradient tracking algorithms.
Lemma 3 (Iterates Contraction).
The following contraction properties of the iterates produced by Algorithm 1 hold:
| (15) |
| (16) |
where is a positive constant. Additionally, we have
| (17) |
Finally, we define a potential function in (4), based on which we prove the convergence bound:
Lemma 4.
(Convergence of Potential Function) Define the following potential function:
| (18) |
where is a positive constant. Under Assumption 1, if we set and , where are three constants, then it holds that:
| (19) |
where and are following constants: , .
Finally, by properly selecting the parameters, constants and can be made non-negative, which leads to Theorem 1.
4. Experimental Results
In this section, we conduct experiments using several non-convex machine learning problems to evaluate the performance of our method. In particular, we compare our algorithm with the following state-of-art single-loop algorithms:
-
•
DSGD (nedic2009distributed, ; yuan2016convergence, ; jiang2017collaborative, ): Each node performs: , where the stochastic gradient corresponds to random sample . Then, each node exchanges the local parameter with its neighbors.
-
•
GNSD (lu2019gnsd, ): Each node keeps two variables and . The local parameter is updated as and the tracked gradient is updated as
Here, we compare with the above two classes of stochastic algorithms because they all employ a single-loop structure and do not require full gradient evaluations. We note that it is hard to have a direct and fair comparison with D-GET (sun2019improving, ) numerically, since D-GET uses full gradients and has a double-loop structure.
Network Model: The communication graph is generated by the Erds-Rnyi graph with different edge connectivity probability and number of nodes . We set and the edge connectivity probability as . The consensus matrix is chosen as where is the Laplacian matrix of , and denotes the largest eigenvalue of .
1) Non-convex logistic regression: In our first experiment, we consider the binary logistic regression problem with a non-convex regularizer (wang2018cubic, ; wang2019spiderboost, ; tran2019hybrid, ):
| (20) |
where the label the feature and .
1-a) Datasets: We consider three commonly used binary classification datasets from LibSVM: , and . The dataset has samples, features, the dataset has samples, features, and the dataset has samples, features. We evenly divide the dataset into sub-datasets corresponding to the nodes.
1-b) Parameters: For all algorithms, we set the batch size as one and the initial step-size is tuned by searching over the grid For DSGD and GNSD, the step-size is set to , which is on the order of following the state-of-the-art theoretical result (lu2019gnsd, ). For GT-STORM, the step-size is set as , which is on the order of as specified in our theoretical result. In addition, we choose the parameter for GT-STORM as , so that in the first step.
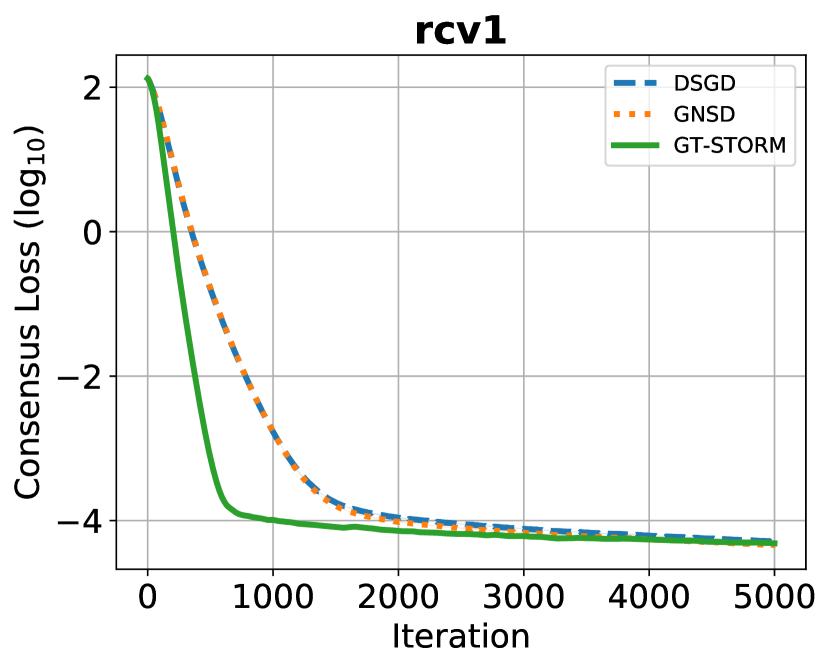
1-c) Results: We first compare the convergence rates of the algorithms. We adopt the consensus loss defined in the left-hand-side (LHS) of (3) as the criterion. After tuning, the best initial step-sizes are and for , and respectively. The results are shown in Figs. 4–4. It can be seen that our algorithm has a better performance: for and datasets, all algorithms reach almost the same accuracy but our algorithm has a faster speed; for dataset, our algorithm outperforms other methods both in the speed and accuracy.







Next, we examine the effect of the parameter on our algorithm. We focus on the dataset and fix the initial step-size as . We choose from Note that is corresponding to the case The results are shown in Fig. 4. It can be seen that the case has the best performance, which is followed by the case Also, as decreases, the convergence speed becomes slower (see the cases and ).
In addition, we examine the effect of the network topology. We first fix the number of workers as and change the the edge connectivity probability from to Note that with a smaller the network becomes sparser. We set and The results are shown in Fig. 8. Under different -values, our algorithm has a similar performance in terms of convergence speed and accuracy. But with a larger -values i.e., a denser network, the convergence speed slightly increases (see the zoom-in view in Fig. 8. Then, we fix the the edge connectivity probability but change the number of workers from to We show the results in Fig. 8. It can be seen that with more workers, the algorithm converges faster and reaches a better accuracy.
2) Convolutional neural networks We use all three algorithms to train a convolutional neural network (CNN) model for image classification on MNIST and CIFAR-10 datasets. We adopt the same network topology as in the previous experiment. We use a non-identically distributed data partition strategy: the th machine can access the data with the th label. We fix the initial step-size as for all three algorithms and the remaining settings are the same as in the previous experiment.
2-a) Learning Models: For MNIST, the adopted CNN model has two convolutional layers (first of size and then of size ), each of which is followed by a max-pooling layer with size , and then a fully connected layer. The ReLU activation is used for the two convolutional layers and the “softmax” activation is applied at the output layer. The batch size is 64 for the CNN training on MNIST. For CIFAR-10, we apply the CNN model with two convolutional layers (first of size and then of size ). Each of the convolutional layers is followed by a max-pooling layer of size , and then three fully connected layers. The ReLU activation is used for the two convolutional layers and the first two fully connected layers, and the “softmax” activation is applied at the output layer. The batch size is chosen as 128 for the CNN training on CIFAR-10.
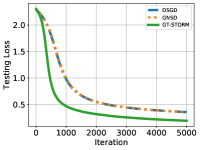
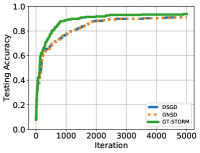
2-b) Results: Fig. 8 illustrates the testing accuracy of different algorithms versus iterations on MNIST and CIFAR-10 datasets. It can be seen from Fig. 8 that on the MNIST dataset, GNSD and GT-STORM have similar performance, but our GT-STORM maintains a faster speed and a better prediction accuracy. Compared with DSGD, our GT-STORM can gain about more accuracy. On the CIFAR-10 dataset (see Fig. 8), the performances of DSGD and GNSD deteriorate, while GT-STORM can achieve a better accuracy. Specifically, the accuracy of GT-STORM is around higher than that of GNSD and higher than that of DSGD.
5. Conclusion
In this paper, we proposed a gradient-tracking-based stochastic recursive momentum (GT-STORM) algorithm for decentralized non-convex optimization, which enjoys low sample, communication, and memory complexities. Our algorithm fuses the gradient tracking estimator and the variance reduction estimator and has a simple single-loop structure. Thus, it is more practical compared to existing works (e.g. GT-SAGA/SVRG and D-GET) in the literature. We have also conducted extensive numerical studies to verify the performance of our method, including non-convex logistic regression and neural networks. The numerical results show that our method outperforms the state-of-the-art methods when training on the large datasets. Our results in this work contribute to the increasingly important field of decentralized network training.
References
- (1) B. Recht, C. Re, S. Wright, and F. Niu, “Hogwild: A lock-free approach to parallelizing stochastic gradient descent,” in Advances in neural information processing systems, 2011, pp. 693–701.
- (2) M. Zinkevich, M. Weimer, L. Li, and A. J. Smola, “Parallelized stochastic gradient descent,” in Advances in neural information processing systems, 2010, pp. 2595–2603.
- (3) J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang et al., “Large scale distributed deep networks,” in Advances in neural information processing systems, 2012, pp. 1223–1231.
- (4) A. Nedic and A. Ozdaglar, “Distributed subgradient methods for multi-agent optimization,” IEEE Transactions on Automatic Control, vol. 54, no. 1, p. 48, 2009.
- (5) X. Lian, C. Zhang, H. Zhang, C.-J. Hsieh, W. Zhang, and J. Liu, “Can decentralized algorithms outperform centralized algorithms? A case study for decentralized parallel stochastic gradient descent,” in Advances in Neural Information Processing Systems, 2017, pp. 5330–5340.
- (6) J. Chen, Z. J. Towfic, and A. H. Sayed, “Dictionary learning over distributed models,” IEEE Transactions on Signal Processing, vol. 63, no. 4, pp. 1001–1016, 2014.
- (7) Y. Cao, W. Yu, W. Ren, and G. Chen, “An overview of recent progress in the study of distributed multi-agent coordination,” IEEE Transactions on Industrial informatics, vol. 9, no. 1, pp. 427–438, 2012.
- (8) K. Zhou and S. I. Roumeliotis, “Multirobot active target tracking with combinations of relative observations,” IEEE Transactions on Robotics, vol. 27, no. 4, pp. 678–695, 2011.
- (9) W. Wang, J. Wang, M. Kolar, and N. Srebro, “Distributed stochastic multi-task learning with graph regularization,” arXiv preprint arXiv:1802.03830, 2018.
- (10) X. Zhang, J. Liu, and Z. Zhu, “Distributed linear model clustering over networks: A tree-based fused-lasso admm approach,” arXiv preprint arXiv:1905.11549, 2019.
- (11) K. Ali and W. Van Stam, “Tivo: Making show recommendations using a distributed collaborative filtering architecture,” in Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 2004, pp. 394–401.
- (12) Z. Jiang, K. Mukherjee, and S. Sarkar, “On consensus-disagreement tradeoff in distributed optimization,” in 2018 Annual American Control Conference (ACC). IEEE, 2018, pp. 571–576.
- (13) J. N. Tsitsiklis, “Problems in decentralized decision making and computation.” Massachusetts Inst of Tech Cambridge Lab for Information and Decision Systems, Tech. Rep., 1984.
- (14) Q. Tran-Dinh, N. H. Pham, D. T. Phan, and L. M. Nguyen, “Hybrid stochastic gradient descent algorithms for stochastic nonconvex optimization,” arXiv preprint arXiv:1905.05920, 2019.
- (15) A. Cutkosky and F. Orabona, “Momentum-based variance reduction in non-convex sgd,” in Advances in Neural Information Processing Systems, 2019, pp. 15 210–15 219.
- (16) P. Di Lorenzo and G. Scutari, “Next: In-network nonconvex optimization,” IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 2, pp. 120–136, 2016.
- (17) S. Lu, X. Zhang, H. Sun, and M. Hong, “GNSD: a gradient-tracking based nonconvex stochastic algorithm for decentralized optimization,” in 2019 IEEE Data Science Workshop, DSW 2019. Institute of Electrical and Electronics Engineers Inc., 2019, pp. 315–321.
- (18) Z. Jiang, A. Balu, C. Hegde, and S. Sarkar, “Collaborative deep learning in fixed topology networks,” in Advances in Neural Information Processing Systems, 2017, pp. 5904–5914.
- (19) H. Sun, S. Lu, and M. Hong, “Improving the sample and communication complexity for decentralized non-convex optimization: A joint gradient estimation and tracking approach,” ICML 2020, 2019.
- (20) S. Ghadimi and G. Lan, “Stochastic first-and zeroth-order methods for nonconvex stochastic programming,” SIAM Journal on Optimization, vol. 23, no. 4, pp. 2341–2368, 2013.
- (21) L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large-scale machine learning,” Siam Review, vol. 60, no. 2, pp. 223–311, 2018.
- (22) P. Zhou, X. Yuan, and J. Feng, “New insight into hybrid stochastic gradient descent: Beyond with-replacement sampling and convexity,” in Advances in Neural Information Processing Systems, 2018, pp. 1234–1243.
- (23) R. Johnson and T. Zhang, “Accelerating stochastic gradient descent using predictive variance reduction,” in Advances in neural information processing systems, 2013, pp. 315–323.
- (24) S. J. Reddi, A. Hefny, S. Sra, B. Póczos, and A. Smola, “Stochastic variance reduction for nonconvex optimization,” in International conference on machine learning, 2016, pp. 314–323.
- (25) A. Defazio, F. Bach, and S. Lacoste-Julien, “Saga: A fast incremental gradient method with support for non-strongly convex composite objectives,” in Advances in neural information processing systems, 2014, pp. 1646–1654.
- (26) L. Lei, C. Ju, J. Chen, and M. I. Jordan, “Non-convex finite-sum optimization via scsg methods,” in Advances in Neural Information Processing Systems, 2017, pp. 2348–2358.
- (27) C. Fang, C. J. Li, Z. Lin, and T. Zhang, “Spider: Near-optimal non-convex optimization via stochastic path-integrated differential estimator,” in Advances in Neural Information Processing Systems, 2018, pp. 689–699.
- (28) L. M. Nguyen, J. Liu, K. Scheinberg, and M. Takác, “Sarah: A novel method for machine learning problems using stochastic recursive gradient,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 2613–2621.
- (29) Z. Wang, K. Ji, Y. Zhou, Y. Liang, and V. Tarokh, “Spiderboost and momentum: Faster variance reduction algorithms,” in Advances in Neural Information Processing Systems, 2019, pp. 2403–2413.
- (30) K. Yuan, Q. Ling, and W. Yin, “On the convergence of decentralized gradient descent,” SIAM Journal on Optimization, vol. 26, no. 3, pp. 1835–1854, 2016.
- (31) W. Shi, Q. Ling, G. Wu, and W. Yin, “Extra: An exact first-order algorithm for decentralized consensus optimization,” SIAM Journal on Optimization, vol. 25, no. 2, pp. 944–966, 2015.
- (32) H. Sun and M. Hong, “Distributed non-convex first-order optimization and information processing: Lower complexity bounds and rate optimal algorithms,” IEEE Transactions on Signal processing, vol. 67, no. 22, pp. 5912–5928, 2019.
- (33) J. F. Mota, J. M. Xavier, P. M. Aguiar, and M. Püschel, “D-admm: A communication-efficient distributed algorithm for separable optimization,” IEEE Transactions on Signal Processing, vol. 61, no. 10, pp. 2718–2723, 2013.
- (34) A. Mokhtari, W. Shi, Q. Ling, and A. Ribeiro, “A decentralized second-order method with exact linear convergence rate for consensus optimization,” IEEE Transactions on Signal and Information Processing over Networks, vol. 2, no. 4, pp. 507–522, 2016.
- (35) M. Eisen, A. Mokhtari, and A. Ribeiro, “Decentralized quasi-newton methods,” IEEE Transactions on Signal Processing, vol. 65, no. 10, pp. 2613–2628, 2017.
- (36) A. Nedić, A. Olshevsky, and M. G. Rabbat, “Network topology and communication-computation tradeoffs in decentralized optimization,” Proceedings of the IEEE, vol. 106, no. 5, pp. 953–976, 2018.
- (37) T.-H. Chang, M. Hong, H.-T. Wai, X. Zhang, and S. Lu, “Distributed learning in the non-convex world: From batch to streaming data, and beyond,” arXiv preprint arXiv:2001.04786, 2020.
- (38) J. Zeng and W. Yin, “On nonconvex decentralized gradient descent,” IEEE Transactions on signal processing, vol. 66, no. 11, pp. 2834–2848, 2018.
- (39) A. Mokhtari and A. Ribeiro, “DSA: decentralized double stochastic averaging gradient algorithm,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2165–2199, 2016.
- (40) K. Yuan, B. Ying, J. Liu, and A. H. Sayed, “Variance-reduced stochastic learning by networked agents under random reshuffling,” IEEE Transactions on Signal Processing, vol. 67, no. 2, pp. 351–366, 2018.
- (41) R. Xin, U. A. Khan, and S. Kar, “Variance-reduced decentralized stochastic optimization with gradient tracking,” arXiv preprint arXiv:1909.11774, 2019.
- (42) A. Nedich, A. Olshevsky, and W. Shi, “A geometrically convergent method for distributed optimization over time-varying graphs,” in 2016 IEEE 55th Conference on Decision and Control (CDC). IEEE, 2016, pp. 1023–1029.
- (43) Y. Zhou, Y. Liang, and H. Zhang, “Generalization error bounds with probabilistic guarantee for sgd in nonconvex optimization,” arXiv preprint arXiv:1802.06903, 2018.
- (44) S. P. Karimireddy, Q. Rebjock, S. U. Stich, and M. Jaggi, “Error feedback fixes SignSGD and other gradient compression schemes,” arXiv preprint arXiv:1901.09847, 2019.
- (45) A. Koloskova, S. U. Stich, and M. Jaggi, “Decentralized stochastic optimization and gossip algorithms with compressed communication,” arXiv preprint arXiv:1902.00340, 2019.
- (46) Z. Wang, Y. Zhou, Y. Liang, and G. Lan, “Cubic regularization with momentum for nonconvex optimization,” arXiv preprint arXiv:1810.03763, 2018.
- (47) X. Zhang, J. Liu, Z. Zhu, and E. S. Bentley. (2020) GT-STORM: taming sample, communication, and memory complexities in decentralized non-convex learning. [Online]. Available: https://kevinliu-osu-ece.github.io/publications/GT-STORM_TR.pdf
Appendix A Addtional Experiment Details

In our simulation, the communication graph is generated by the Erds-Rnyi graph with different edge connectivity probability and nodes number . We set and . The generated graph is shown in Figure 9.
A.1. Nonconvex Logistic Regression
In Section 4.1, we set the step-size as for DSGD and GNSD, while for GT-STORM. It can be noted that the step-size adopted for GT-STORM is diminishing slower than those for DSGD and GNSD, though the choices are following the theoretical results. Thus, here we apply the step-size as for all the three algorithms. We tune the initial step-size by searching the grid After tuning, the best initial step-sizes are and for , and respectively. We show the results in Figure 10. It can be seen that with a larger step-size, though the convergence is faster for DSGD and GNSD at the beginning, the accuracy is unsatisfactory (e.g. and ). Also, with the same step-size, our algorithm performs much better than the other two.
 |
 |
 |
A.2. Convolutional Neural Networks
Here we show the testing loss and accuracy for the CNN models on the MNIST and CIFAR-10 datasets in Figure 11-12. In all experiment results, our algorithm has a better performance: a higher accuracy and a smaller loss. The final testing accuracy results are summarized in Table 1.
 |
 |
 |
 |
| (a) I.D. data partition | (b) N.D. data partition | ||
 |
 |
 |
 |
| (a) I.D. data partition | (b) N.D. data partition | ||
| Dataset | DSGD | GNSD | GT-STORM | |
| MNIST | I.D. | 0.9102 | 0.9102 | 0.9375 |
| N.D. | 0.8203 | 0.9102 | 0.9257 | |
| CIFAR-10 | I.D. | 0.6093 | 0.6016 | 0.7734 |
| N.D. | 0.5352 | 0.6133 | 0.7695 | |
Appendix B Proof of Main Results
Due to space limitation, we provide key proof steps of the key lemmas and theorems in this appendix. We refer readers to (Zhang20:GT-STORM_TR, ) for the complete proofs.
B.1. Proof for Lemma 1
Proof.
Recall that , then
| (21) |
Note that and Taking expectation with respect to we have:
| (22) |
where (a) is because the cross term has the expectation as zero; (b) is by (c) is by and Assumption 1 (c); (d) is because of the Jensen’s inequality; (e) is by the -average smoothness. Thus, taking the full expectation, it holds that
| (23) |
∎
B.2. Proof for Lemma 2
Proof.
From the -smoothness of we have:
| (24) |
where and (a) is because of the Jensen’s inequality and (b) is by the -average smoothness. Take the full expectation on the above inequality:
| (25) |
∎
B.3. Proof for Lemma 3
Proof.
First for the iterate we have the following contraction:
| (26) |
This is because is orthogonal to which is the eigenvector corresponding to the largest eigenvalue of and Recall that hence,
| (27) |
Similarly to (B.3), we have:
| (28) |
where (a) is due to Lastly, according to the updating equation (9) in main paper, it holds
| (29) |
where (a) is because ∎
B.4. Proof for Lemma 4
Proof.
First, with we have:
| (30) |
where (a) is by and (b) is by
Then, we give the following three contractions:
Next, with the results in ii) and iii), we have:
| (36) |
Thus, for the defined potential function:
| (37) |
its differential can be calculated as
| (38) |
where (a) follows from plugging the result for from Lemma 3 and
∎
B.5. Proof for Theorem 1
Proof.
Now, we show that by properly choosing and , the coefficients and can be non-negative. Recall that:
| (43) | ||||
| (44) | ||||
| (45) |
In order to have we have:
| (46) |
With (46), it follows that:
| (47) |
Thus, if we set
| (48) |
For it follows from (46) that:
| (49) |
By choosing
| (50) | ||||
| (51) |
we have To summarize, we need to set Since is decreasing and it implies that
With the above parameter setting, we have:
| (52) |
Multiplying both side of the above inequality by we have:
| (53) |
Note that
where (a) is by from line 1 in Algorithm 1 and (b) is by Assumption 1.
Hence, it follows that
| (54) |
Since , we have:
| (55) |
where the -notation is from and
∎
B.6. Proof for Corollary 2
Proof.
First, note that holds with and Plugging these parameters into Theorem 1 yields:
| (56) |
With we have:
| (57) |
where The above result implies that the convergence rate is Thus, to achieve an -stationary solution, the total communication rounds needed are , and the total samples needed are ∎