(eccv) Package eccv Warning: Package ‘hyperref’ is loaded with option ‘pagebackref’, which is *not* recommended for camera-ready version
Group Testing for Accurate and Efficient Range-Based Near Neighbor Search for Plagiarism Detection
Abstract
This work presents an adaptive group testing framework for the range-based high dimensional near neighbor search problem. Our method efficiently marks each item in a database as neighbor or non-neighbor of a query point, based on a cosine distance threshold without exhaustive search. Like other methods for large scale retrieval, our approach exploits the assumption that most of the items in the database are unrelated to the query. Unlike other methods, it does not assume a large difference between the cosine similarity of the query vector with the least related neighbor and that with the least unrelated non-neighbor. Following a multi-stage adaptive group testing algorithm based on binary splitting, we divide the set of items to be searched into half at each step, and perform dot product tests on smaller and smaller subsets, many of which we are able to prune away. We experimentally show that, using softmax-based features, our method achieves a more than ten-fold speed-up over exhaustive search with no loss of accuracy, on a variety of large datasets. Based on empirically verified models for the distribution of cosine distances, we present a theoretical analysis of the expected number of distance computations per query and the probability that a pool with a certain number of members will be pruned. Our method has the following features: (i) It implicitly exploits useful distributional properties of cosine distances unlike other methods; (ii) All required data structures are created purely offline; (iii) It does not impose any strong assumptions on the number of true near neighbors; (iv) It is adaptable to streaming settings where new vectors are dynamically added to the database; and (v) It does not require any parameter tuning. The high recall of our technique makes it particularly suited to plagiarism detection scenarios where it is important to report every database item that is sufficiently similar item to the query.
Keywords:
near neighbor search, group testing, image retrieval1 Introduction
Near neighbor (NN) search is a fundamental problem in machine learning, computer vision, image analysis and recommender systems. Consider a database of vectors given as where each . Given a query vector , our aim is to determine all those vectors in such that , where denotes some similarity measure, and denotes some threshold on sim. This is called a similarity measure based NN query. Another variant is the nearest neighbor (KNN) search where the aim is to find the most similar neighbors to .
A significant portion of the literature on NN search focusses on approximate methods, often resulting in less than perfect recall rates, i.e. many database images that are similar to the query image are not retrieved. This deficiency renders them unsuitable for applications requiring high recall, such as plagiarism detection. In such scenarios, the query vectors, such as images or music files, are compared to an existing database of similar entities, and all vectors exhibiting high similarity with the query need to be retrieved for plagiarism assessment. The failure to retrieve a near neighbor could potentially lead to unfair evaluation of submissions to photography or music competitions, or online forums.
Related Work on NN Search: There exists a large body of literature on approximate NN search in higher dimensions. One of the major contributions in this area is called Locality Sensitive Hashing (LSH) [30]. Here, a hashing function partitions the dataset into buckets, such that only close vectors are likely to be hashed to the same bucket. The LSH family of algorithms consists of many variants such as those involving multiple buckets per query vector, data-driven or machine learning based construction of LSH functions [15, 20], and count-based methods [34]. In general, LSH based methods are difficult to implement for very high dimensions owing to the curse of dimensionality in constructing effective hash tables. Dimensionality reduction algorithms can mitigate this issue to some extent, but they are themselves expensive to implement and incur some inevitable data loss. There is also significant research in graph-based methods for nearest neighbor (NN) search, as explored in [36, 24, 27]. These methods typically achieve high accuracy and efficient query times. However, they often need relatively high pre-processing times, making them less suitable for dynamic datasets that require frequent addition of new points. In addition, various randomized variants of KD-trees and priority search K-means trees have been investigated for efficient approximate NN search in high-dimensional spaces, as seen in [40] and [37]. Despite their efficiency, these approaches involve numerous parameters, which can complicate tuning, especially for large datasets.
Overview of Group Testing: In this work, we present a group testing (GT) based approach for the NN problem. We start by presenting a brief overview of the field of GT. Consider items (also called ‘samples’ in many references), out of which only a small number are ‘defective’. We consider the th item to be defective if and non-defective if . GT involves testing a certain number of ‘pools’ () to identify the defective items from . Each pool (also called ‘group’) is created by mixing together or combining subsets of the items. Thus the th pool () is represented as , where stands for bit-wise OR, and is a binary pooling matrix where if the th item participates in the th pool and 0 otherwise. GT has a rich literature dating back to the seminal ‘Dorfman’s method’ [21] which is a popular two-round testing strategy. In the first round of Dorfman’s method, some pools, each consisting of items, are tested. The items that participated in pools that test negative (i.e., pools that are deemed to contain no defective item) are declared non-defective, whereas all items that participated in the positive pools (i.e., pools that are deemed to contain at least one defective item) are tested individually in the second round. Theoretical analysis shows that for , this method requires much fewer than tests in the worst case. This algorithm was extended to some rounds in [33], where positive groups are further divided into smaller groups, and individual testing is performed only in the th round. The methods in [21, 33] are said to be adaptive in nature, as the results of one round are given as input to the next one. The GT literature also contains a large number of non-adaptive algorithms that make predictions in a single round. A popular algorithm is called Comp or combinatorial orthogonal matching pursuit, which declares all items participating in a negative pool to be negative, and all the rest to be positive [14]. Many variants of Comp such as Noisy Comp (NComp) or Definite Defectives (Dd) are also popular [14]. A popular class of non-adaptive GT algorithms [25] draw heavily from the compressed sensing (CS) literature [18, 43]. Such algorithms can consider quantitative information for each so that each , and every pool also gives a real-valued result. The pooling matrix remains binary, and we have the relation . Given and , the unknown vector can be recovered using efficient convex optimization methods such as the Lasso given by , where is a regularization parameter [28]. As proved in [28, 19], the Lasso estimator produces provably accurate estimates of given a sufficient number of measurements (or pools) in and a carefully designed matrix .
Overview of our work: GT algorithms have been applied to the NN search problem recently in [41, 31, 22]. However in these papers, the nearest neighbor queries are of an approximate nature, i.e. the results may contain a number of vectors which are not near neighbors of the query vector , and/or may miss some genuine near neighbors. On the other hand, we focus on accurate query results with good computational efficiency in practice. Our approach is based on an adaptive GT approach called binary splitting. Like existing GT based algorithms such as [41, 31, 22], our approach is also based on the assumption that in high-dimensional NN search, most vectors in the database are dissimilar to a query vector , and very few vectors qualify as near neighbors. However, our method does not require the distance between the most unrelated neighbor and the most closely related non-neighbor to be large, unlike [22]. Additionally, many existing approaches [22, 31, 41, 37, 15, 39, 26, 1, 16] require parameter tuning in a manner that is not fully data driven. It is also a tedious process for large databases, particularly when dealing with algorithms with large index building times. Moreover, algorithms with large index building times or those unable to efficiently handle the addition of new points are ill-suited for streaming settings. In this work, we present a range-based near neighbor search algorithm in high dimensions built on a group testing framework that has the following appealing properties for softmax-based feature descriptors: (i) low index building time, (ii) perfect precision and recall without exhaustive search, (iii) no parameter tuning, (iv) low time complexity () for addition of new vectors making the algorithm suitable for streaming tasks, and (v) a unique method of incorporating distributional properties of the similarity values between query and database vectors into the search process.
Organization of the paper: The core method is presented in Sec. 2. We present detailed analytical comparisons with existing GT-based techniques for NN search in Sec. 3. Experimental results and comparisons to a large number of recent NN search methods are presented in Sec. 4. A theoretical analysis of our approach is presented in Sec. 5. We conclude in Sec. 6.
2 Description of Method
In our technique, a pool of high-dimensional vectors is created by simply adding together the participating vectors, which may for example be (vectorized) images or features extracted from them. Consider a query vector and the database consisting of where each . Throughout this paper, we consider the similarity measure . For simplicity, we consider the query vector as well as the vectors in to be element-wise non-negative. This constraint is satisfied by images or their features based on ReLU or softmax non-linearities (see the end of this section for a method to handle negative-valued descriptors). We also consider that the vectors in question have unit magnitude, without any loss of generality. Due to this, acts as a cosine similarity measure.
Our aim is to retrieve all ‘defective’ members of , i.e. each member for which , where is some pre-specified threshold. With this aim in mind, we aim to efficiently prune away any vector from for which it is impossible to have . Vector pooling using summations proves to be beneficial for this purpose. Consider the toy example of a pool . If (i.e. the pooled result is negative), then one can clearly conclude that for each . However if , i.e. it yields a positive result, then we need to do further work to identify the defective members (if any). For this, we split the original pool and create two pools and , each with approximately half the number of members of the original pool. We recursively compute , and then obtain (where both and have already been computed earlier, and hence is directly obtained from the difference between them). Thereafter, we proceed in a similar fashion for both branches.
We now consider the case of searching within the entire database defined earlier. We initiate this recursive process with a pool that is obtained from the summation of all vectors. If yields a positive result, we test the query vector with two pools: obtained from a summation of vectors through to , and obtained from a summation of vectors through to . If tests negative, then all its members are declared negative and no further tests are required on its members, which greatly reduces the total number of tests. If tests positive, then it is split into two pools with roughly equal number of members. Tests are carried out further on these two pools recursively. The same treatment is accorded to , which would be split into pools if it were to test positive. This recursive process stops when the pools obtained after splitting contain just a single vector each, in which case each such single vector is tested against . Clearly, the depth of this recursive process is given vectors in . This procedure is called binary splitting, and it is a multi-round adaptive group testing approach, applied here to NN search. For efficiency of implementation, it is important to be able to create the different pools such as , etc., efficiently. For this purpose, we maintain cumulative sums of the following form in memory:
| (1) |
The cumulative sums are useful for efficient creation of various pools. They are created purely offline, independent of any query vector. The pools are created using simple vector difference operations, given these cumulative sums. For example, notice that and . The overall binary splitting procedure is presented in Alg. 1 (a schematic diagram is provided in [13]). For the sake of greater efficiency, it is implemented non-recursively using a simple stack data structure.
This binary splitting approach is quite different from Dorfman’s algorithm [21], which performs individual testing in the second round. Our approach is more similar to Hwang’s generalized binary splitting approach, a GT procedure which was proposed in [29] (see also [8], Alg. 1.1 of [14]). However compared to Hwang’s technique, our approach allows for creation of all pools either in a purely offline manner or with simple updates involving a single vector-subtraction operation (for example, in the earlier example). On the other hand, the method in [29] detects defectives one at a time, after going through all levels of recursion. Once a defective item is detected, it is discarded and all pools are created again. The entire set of levels of recursion are again executed. This process is repeated until all defectives have been detected and discarded one at a time. The method from [29] is computationally inefficient for high-dimensional NN search, as the pools must be created afresh for each level of recursion. This is because if a vector at index is discarded, all cumulative sums from index to need to be updated. Such updates are not required in our method. We also emphasize that the techniques in [21, 14, 29, 33] have all been applied only for binary GT and not for NN search (see the beginning of Sec. 5 for an important difference between binary GT and NN search). The binary splitting procedure saves on a large number of tests because in high dimensional search, we observe that most vectors in are dissimilar to a given query vector , as will be demonstrated in Sec. 4. After the first round where pool is created, all other pools are essentially created randomly (since the initial arrangement of the vectors in is random). As a result, across the different rounds, many pools test negative and are dropped out, especially in later rounds. In particular, we note that there is no loss of accuracy in this method, although we save on the number of tests by a factor more than ten on some large datasets (as will be shown in Sec. 4).
Pooling using Element-wise Maximum: We have so far described pool creation using vector summation. However, pools can also be created by computing the element-wise maximum of all vectors participating in the pool. Given a subset of vectors , such a pool is given by: where stands for the th element of . We denote this operation as . If , it follows that for every that contributed to . Hence pools created using an element-wise maximum are also well suited for iterative binary splitting in a similar fashion as in Alg. 1. Separate element-wise maximum vectors need to be stored in memory for each pool. In case of negative values in the query and/or database vectors, the element-wise maximum can be replaced by an element-wise minimum for every index for which . Unlike the summation technique, this handles negative-valued descriptors, albeit at the cost of more memory in order to store both element-wise maximum and element-wise minimum values for each pool.
3 Comparison to other Group Testing Methods for NN Search
GT algorithms of different flavors have been applied to the NN search problem in [41, 31, 22]. A detailed description of these techniques is presented in the supplemental material at [13, Sec. 2]. Compared to these three afore-mentioned techniques, our method is exact, with the same accuracy as exhaustive search. The methods [41, 31, 22] require choice of various hyper-parameters (, the number of backpropagation steps, for [41]; sparse coding parameters in [31]; bloom filter and hash function parameters () in [22] – see [13, Sec. 2]) for which there is no clear data-driven selection procedure. Our method, however, requires no parameter tuning. In experiments, we have observed a speed up of more than ten-fold in querying time with our method as compared to exhaustive search on some datasets. Like [41], and unlike [22, 31], our method does have a large memory requirement, as we require all pools to be in memory. Some techniques such as [22] require the nearest neighbors to be significantly more similar than all other members of (let us call this condition ). Our method does not have such a requirement. However, our method will perform more efficiently for queries for which a large number of similarity values turn out to be small, and only a minority are above the threshold (let us call this condition ). In our experimental study on diverse datasets, we have observed that is true always. On the other hand, does not hold true in a large number of cases, as also reported in [22, Sec. 5.3].
We also experimented with applying the latest developments in the compressed sensing (CS) literature [43] (which is closely related to GT) to the approximate NN search problem, albeit unsuccessfully. The theoretical reasons for the failure of the latest CS techniques for NN search are described in [13, Sec. 3].
4 Experimental Results
In this section, we present experimental results conducted in two settings: (i) Non-streaming setting with a static database, and (ii) Streaming setting with incremental additions of new vectors to the database. In both the settings, we tested our algorithms on the following publicly available image datasets, of which the first two are widely used in retrieval and NN search problems: (i) MIRFLICKR, a set of 1 million (1M) images from the MIRFLICKR dataset (subset of images from Flickr) available at [11], with an additional 6K images from the Paris dataset available at [12], as followed in [41]; (ii) ImageNet, a set of 1M images used in the ImageNet Object Localization Challenge, available at [2]; (iii) IMDB-Wiki, a set of all 500K images from the IMDB-Wiki face image dataset from [9]; (iv) InstaCities, a set of 1M images of 10 large cities [10]. Although, we have worked with image datasets, our method is equally applicable to any other modalities such as speech, genomics, etc.
In the following, we denote a query image by . For every dataset containing images , feature vectors were extracted as follows: First, each image was passed through the popular VGGNet [42] (as its features are known to be useful for building good perceptual metrics [44]) to obtain intermediate feature vector . Second, a softmax-based feature vector of dimension , corresponding to the 1000 classes in ImageNet, was extracted further from the VGGNet output vector . In our experiments, we observed that the softmax-based features yielded superior retrieval recall (defined as # points retrieved belonging to the same class as the query point / # points of the same class as the query point) as compared to the baseline VGGNet features, with exhaustive search on different datasets (see [13, Table 1] for more details), even on those datasets which are different from ImageNet. Higher recall is particularly beneficial for NN search application in scenarios such as image plagiarism detection. The feature vectors were all non-negative and were subsequently unit-normalized. For every dataset, NN search was carried out using different methods (see below) on the same unit-normalized feature vectors extracted from 10,000 query images. That is, the aim was to efficiently identify those indices for which the dot products between (the feature vector of query image ) and (both feature vectors unit-normalized) exceeded some specified threshold . For all datasets, the intrinsic dimensionality was computed using the number of singular values of the data matrix that accounted for 99% of its Frobenius norm. The intrinsic dimensionality for all datasets was more than 200 (for ).
Our binary splitting approach, using pool creation with summation (Our-Sum) and element-wise maximum (Our-Max), was compared to the following recent and popular techniques: (i) Exhaustive search (Exh) through the entire database, for every query image; (ii) The recent GT-based technique from [22], known as Flinng (Filters to Identify Near-Neighbor Groups), using code from [3]; (iii) The popular randomized KD-tree and K-means based technique Flann for approximate NN search [37], using code from [7] with default parameters; (iv) The Falconn technique from [15] which uses multi-probe LSH, using the code from [4]; (v) Falconn++ [39], an enhanced version of Falconn which filters out potentially distant points from any hash bucket before querying using code from [5]; (vi) Ivf, the speedy inverted multi-index technique implemented in the highly popular Faiss library from Meta/Facebook [1, 16]; (vii) Hnsw, a graph-based technique also used in [1]; (viii) The Scann library [6, 26] which implements an anisotropic vector quantization (KMeans) algorithm. Our methods have no hyperparameters, but for all competing methods, results are reported by tuning hyperparameters so as to maximize the recall (defined below) – see [13, Sec. 5] for more details.
We did not compare with the GT-based techniques from [41] and [31] as we could not find full publicly available implementations for these. Moreover, the technique from [22] is claimed to outperform those in [41] and [31]. We did implement the algorithm from [41], but it yielded significantly large query times. This may be due to subtle implementation differences in the way image lists are re-ranked in each of the iterations of their algorithm (see Sec. 3). In any case, our method produces 100% recall and precision, unlike [41, 31].
Non-streaming Setting: The different methods are compared in terms of Mean Query Time (MQT), Mean Precision (MP) and Mean Recall (MR) for 10K queries as reported in Table 1. The similarity threshold () chosen for this setting is . The recall is defined as as . The precision is defined as . For each dataset, we have also mentioned the average number of neighbours () having similarity greater than . The cumulative sums in Eqn. 1 for Our-Sum and the cumulative element-wise maximums for Our-Max were computed offline. The query implementation was done in C++ with the highest level of optimization in the g++ compiler. The codes for Flinng, Falconn++, Scann and Hnsw operate in the KNN search mode, as opposed to a range-based query for Our-Sum, Our-Max, Falconn and Ivf, for which we set . The Flann method has code support for both KNN and range-based queries, which we refer to as Flann-K and Flann-R respectively. For all KNN-based methods, we gave an appropriate as input, such that ground truth neighbors satisfy the similarity threshold of . The time taken to compute was not included in the query times reported for the KNN-based methods. All query times are reported for an Intel(R) Xeon(R) server with CPU speed 2.10GHz and 128 GB RAM. For all methods, the computed query times did not count the time taken to compute the feature vector for the query image.
Streaming Setting: We now consider experiments in a streaming setting where new vectors are added to the database on the fly, i.e. the database is modified incrementally. In our experimental setting, 80% of the full database was initially available to all algorithms for index creation. New points were incrementally added to the database, and after addition of 100 new points, a search query was fired. This process was carried out until the entire database was loaded into memory. The query images were created by introducing controlled perturbations such as dither and blur to images existing in the database (refer to [13] for more details). The similarity threshold for this setting is chosen to be . Note that this setting is analogous to a typical image plagiarism detection setting, wherein (a) the database is updated with insertion of new points (without deletion) and requires fetching high similarity vectors, and (b) the submitted images could be subtly manipulated to escape plagiarism detection. High recall is desirable in such applications.
The only update required to Our-Sum for insertion of new points will be to produce extra cumulative sums as in Eqn. 1 for a cost of . For comparison, we have selected only those algorithms that include methods for the addition of new points without necessitating the rebuilding of the entire index from scratch. These include Exh, Ivf, Hnsw and Flann-R. Table 2 reports the initial Index Build Time (IBT) for 80% of the database, Mean Insertion Time (MIT) for new points, besides MQT, MP and MR.
Discussion of Results on Static Datasets (Table 1): We observe that Our-Sum yields lower MQT on most datasets as compared to most other techniques, and that too with a guarantee of 100% precision and recall. Falconn produces higher query times than Our-Sum or Our-Max and at the loss of some recall. Falcon++ produces 100% precision and recall but with much higher query times than Our-Sum or Our-Max. Flinng and Flann-K are efficient, but have significantly lower precision and recall than Our-Sum with many of the retrieved dot products being significantly lower than the chosen . Flann-R yields very low recall despite its excellent precision and query time. Hnsw produces higher query times in cases where the number of neighbors is large with some loss of recall. The closest competitors to Our-Sum are Scann and Ivf, but they do not guarantee 100% precision and recall. In addition, we note that as reported in [26, Fig. 3a], the accuracy of the dot-products retrieved by Scann will depend on the chosen bit-rate, i.e. the chosen number of cluster centers in KMeans, whereas Our-Sum has no such dependencies or parameter choice. This is a major conceptual advantage of Our-Sum over Scann (also see the ‘Streaming’ setting below). As compared to exhaustive search, Our-Sum produces a speed gain between 4 to 120 depending on the dataset. Our-Sum outperforms Our-Max in terms of query time, but it is important note that Our-Max is capable of handling negative-valued descriptors, although we have not experimented with it in this paper.
| Db. | Our-S | Our-M | Ivf | Falc | Flann-R | Falc++ | Flinng | Flann-K | Scann | Hnsw | Exh | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MQT | MIRFL. | 54.0 | 81 | 94 | 302 | 1 | 509 | 62 | 54 | 23 | 66 | 1222 |
| MP | () | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.268 | 0.743 | 0.996 | 0.959 | 1.0 |
| MR | 1.0 | 1.0 | 0.997 | 0.954 | 0.323 | 1.0 | 0.268 | 0.743 | 0.996 | 0.959 | 1.0 | |
| MQT | ImgN. | 4.9 | 7 | 103 | 179 | 2 | 385 | 119 | 40 | 23 | 9 | 1276 |
| MP | () | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.372 | 0.310 | 0.998 | 0.965 | 1.0 |
| MR | 1.0 | 1.0 | 0.997 | 0.958 | 0.217 | 1.0 | 0.372 | 0.310 | 0.998 | 0.965 | 1.0 | |
| MQT | IMDB. | 98.8 | 249 | 49 | 415 | 1.0 | 739 | 46 | 98 | 60 | 1076 | 800 |
| MP | () | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.351 | 0.656 | 0.997 | 0.985 | 1.0 |
| MR | 1.0 | 1.0 | 0.995 | 0.995 | 0.191 | 1.0 | 0.351 | 0.656 | 0.997 | 0.985 | 1.0 | |
| MQT | InstaC. | 58.0 | 110 | 90 | 330 | 1 | 601 | 57 | 61 | 25 | 298 | 1174 |
| MP | () | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.293 | 0.745 | 0.996 | 0.952 | 1.0 |
| MR | 1.0 | 1.0 | 0.990 | 0.964 | 0.324 | 1.0 | 0.293 | 0.745 | 0.996 | 0.952 | 1.0 |
| Index Build Time (in ms) | ||||
| Alg., Db. | ImgN. | IMDB. | MIRFL. | InstaC. |
| Our-Sum | 3789 | 2000 | 3774 | 3765 |
| Exh. | NA | NA | NA | NA |
| Ivf | 15000 | 9960 | 15410 | 18722 |
| Hnsw | 7e5 | 2e5 | 4e5 | 4e5 |
| Flann-R | 2e6 | 9e5 | 2e6 | 2e6 |
| Average Insertion Time (in ms) | ||||
| Alg., Db. | ImgN. | IMDB. | MIRFL. | InstaC. |
| Our-Sum | 0.28 | 0.29 | 0.28 | 0.29 |
| Exh. | ||||
| Ivf | 2.2 | 2.7 | 2.2 | 2.7 |
| Hnsw | 236 | 239 | 222 | 219 |
| Flann-R | 42 | 53 | 27 | 26 |
| Mean Query Time (in ms) | ||||
|---|---|---|---|---|
| Alg., Db. | ImgN. | IMDB. | MIRFL. | InstaC. |
| Our-Sum | 18 | 121 | 86 | 115 |
| Exh. | 609 | 315 | 607 | 605 |
| Ivf | 183 | 67 | 145 | 132 |
| Hnsw | 10 | 168 | 13 | 70 |
| Flann-R | 6 | 4 | 5 | 5 |
| Mean Precision , Mean Recall | ||||
|---|---|---|---|---|
| Alg., Db. | ImgN. | IMDB. | MIRFL. | InstaC. |
| Our-Sum | 1,1 | 1,1 | 1,1 | 1,1 |
| Exh. | 1,1 | 1,1 | 1,1 | 1,1 |
| Ivf | 1,0.99 | 1,0.99 | 1,0.99 | 1,0.99 |
| Hnsw | 0.96,0.96 | 0.98,0.98 | 0.97,0.97 | 0.97,0.97 |
| Flann-R | 1,0.31 | 1,0.59 | 1,0.49 | 1,0.54 |
Discussion of Results on Datasets with Streaming (Table 2): It is clear that the Index Build Time (IBT) and Mean Insertion Time (MIT) of our method clearly surpasses that of all other methods across all datasets. Furthermore, the space taken for storing the index is only in our method. Since Our-Sum only has to compute cumulative sums for the newly inserted points, the index update time is very low when compared with other methods. Flann-R consistently produces lower mean query times, but this comes at the cost of low recall and high insertion time, making it unusable for streaming applications. Similarly, Hnsw shows significant gains in MQT for MIRFLICKR, ImageNet and InstaCities datasets, but exhibits a large insertion time across all datasets.
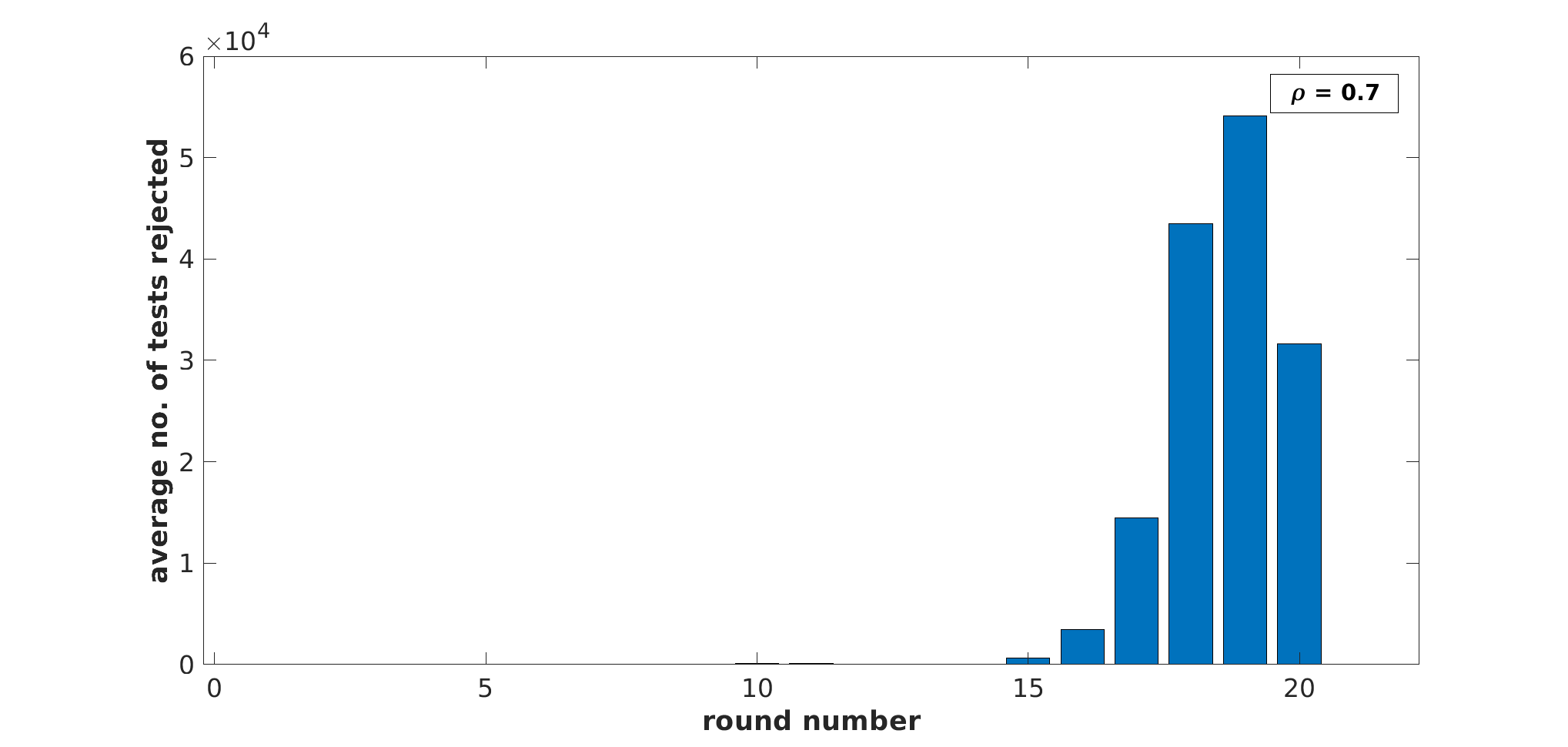
Analysis of Pruning (Non-Streaming): For each dataset, we also computed the number of pools that got rejected in every ‘round’ of binary splitting (because the dot product with the query image fell below threshold ), beginning from round 0 to . (Referring to Alg. 1, we see that the procedure implements an inorder traversal of the binary tree implicitly created during binary splitting. However the same tree can be traversed in a level-wise manner, and each level of the tree represents one ‘round’ of binary splitting.) The corresponding histograms for are plotted in Fig. 2 of [13], for Our-Sum. As can be seen, a large number of rejections occur from round 14 onward in MIRFLICKR and InstaCities, from round 11 onward in ImageNet, and from round 16 onward in IMDB-Wiki. As a result, the MQT is lowest for ImageNet than for other datasets, and also much lower for MIRFLICKR and InstaCities than for IMDB-Wiki. A similar set of histograms are plotted for Our-Max in Fig. 3 of [13]. Furthermore, we plotted histograms of dot products between every query feature vector and every gallery feature vector, across 10,000 queries for all datasets. These are plotted in Fig. 1, clearly indicating that the vast majority of dot products lie in the bin or (also see Fig. 1 of [13], which shows negative logarithms of the histograms for clearer visualization of values close to 0). This supports the hypothesis that most items in are dissimilar to a query vector. However, as seen in Fig. 1, the percentage of dot products in the bin is much larger for ImageNet, MIRFLICKR and InstaCities than for IMDB-Wiki. This tallies with the significantly larger speedup obtained by binary splitting (both Our-Sum and Our-Max) for ImageNet, MIRFLICKR and InstaCities as compared to IMDB-Wiki – see Table 1.
5 Theoretical Analysis
For the problem of binary GT, different variants of the binary splitting approach have been shown to require just or tests, depending on some implementation details [14, Theorems 1.2 and 1.3]. Here stands for the number of defectives out of . However in binary GT, a positive result on a pool necessarily implies that at least one of the participants was defective. In our application for NN search, a pool can produce for query vector , even if none of the vectors that contributed to produce a dot product with that exceeds or equals . Due to this important difference, the analysis from [14] does not apply in our situation. Furthermore, it is difficult to pin down a precise deterministic number of tests in our technique. Instead, we resort to a distributional assumption on each dot product . We assume that these dot products are independently distributed as per a truncated normalized exponential (TNE) distribution:
| (2) |
This distribution is obtained by truncating the well-known exponential distribution to the range and normalizing it so that it integrates to one. Larger the value of , the more rapid is the ‘decay’ in the probability of dot product values from 0 towards 1. Our empirical studies show that for softmax features, this is a reasonable model for dot product values commonly encountered in queries in image retrieval, as can be seen in Fig. 1 for all datasets we experimented with. Also, the best-fit values for MIRFLICKR, ImageNet, IMDB-Wiki and InstaCities are respectively . The TNE model fit may not be perfect, but less than perfect adherence to the TNE model does not change the key message that will be conveyed in this section.




Our aim now is to determine the probability that a pool with some participating vectors will produce a dot product value below a threshold . Note again that such a pool will get pruned away in binary splitting, and therefore we would like this probability to be high. Now, the individual dot-products (of with vectors that contributed to ) are independent and they are all distributed as per the TNE from Eqn. 2. The mean and variance of a TNE variable with parameter are respectively given by and . We now apply the central limit theorem (CLT), due to which we can conclude that is (approximately) Gaussian distributed with a mean and variance . With this, we can easily compute given a value of and . Our numerical experiments, illustrated in Fig. 3 of [13], reveal that this probability increases with and decreases as increases. This tallies with intuition, and supports the hypothesis that a larger number of pools will be pruned away in a given round if there is more rapid decrease in the probability of dot product values from 0 to 1.
We are now equipped to determine the expected number of tests (dot products) to be computed per query, given such a TNE distribution for the dot products. Given a value of , let us denote the probability that a pool with participants will get pruned away, by . For Our-Sum, for any , the probability is computed using the TNE and CLT based method described earlier. For , the Gaussian distribution can be replaced by a truncated Erlang distribution, as the sum of independent exponential random variables follows an Erlang distribution. Even in this case, increases with and decreases with .
In round 1, there is only one pool and it contains all vectors. It will get pruned away with probability , for a given fixed threshold and fixed . The expected number of pools in round 2 will be , each of which will be pruned away with probability . The factor 2 is because each pool gets split into two before sending it to the next round of binary splitting. The expected number of pools in round 3 will be . Likewise, in the th round, the expected number of pools is . Hence the expected number of tests per query in our approach will be given by:
| (3) |
as there are at most rounds. The factor is due to the fact that the number of tests (i.e. dot product computations) is always half the number of pools (see second para. of Sec. 2). The value of decreases with as all increase with . A similar analysis for Our-Max is presented in [13, Sec. 4].
| Database | |||
|---|---|---|---|
| MIRFLICKR, | |||
| Empirical (Sum) | 51690 | 44194 | 37788 |
| Empirical (Max) | 75782 | 60752 | 47531 |
| Theoretical (Sum) | 63838 | 57553 | 50094 |
| Theoretical U.B. (Max) | 371672 | 270408 | 195140 |
| ImageNet, | |||
| Empirical (Sum) | 13852 | 12339 | 10801 |
| Empirical (Max) | 6946 | 5713 | 4551 |
| Theoretical (Sum) | 34524 | 32603 | 31345 |
| Theoretical U.B. (Max) | 14160 | 6267 | 2775 |
| IMDB-Wiki, | |||
| Empirical (Sum) | 160020 | 141290 | 125050 |
| Empirical (Max) | 240947 | 197370 | 158284 |
| Theoretical (Sum) | 113600 | 99552 | 87835 |
| Theoretical U.B. (Max) | 1426259 | 1336543 | 1249448 |
| InstaCities, | |||
| Empirical (Sum) | 72729 | 62741 | 54125 |
| Empirical (Max) | 105122 | 85188 | 67441 |
| Theoretical (Sum) | 71021 | 63453 | 57944 |
| Theoretical U.B. (Max) | 566498 | 445181 | 346927 |
Our theoretical analysis depends on , but note that our algorithm is completely agnostic to and does not use it in any manner. For values of , we compared the theoretically predicted average number of dot products () to the experimentally observed number for all datasets. These are presented in Tab. 3, where we observe that for MIRFLICKR, ImageNet and InstaCities, the theoretical number for Our-Sum is generally greater than the empirical one. This is because the dot products for these datasets decay slightly faster than what is predicted by a TNE distribution, as can be seen in Fig. 1. Conversely, for IMDB-Wiki, the theoretical number for Our-Sum is less than the empirical one because the dot products decay slower for this dataset than what is predicted by a TNE distribution. For Our-Max, the difference between empirical and theoretical values is larger, as explain in [13].
6 Conclusion
We have presented a simple and intuitive multi-round group testing approach for range-based near neighbor search. Our method outperforms exhaustive search by a large factor in terms of query time without losing accuracy, on datasets where query vectors are dissimilar to the vast majority of vectors in the gallery. The larger the percentage of dissimilar vectors, the greater is the speedup our algorithm will produce. Our technique has no tunable parameters. It is also easily applicable to situations where new vectors are dynamically added to an existing gallery, without requiring any expensive updates. Apart from this, our technique also has advantages in terms of accuracy of query results (especially recall) over many recent, state of the art methods. A significant limitation of our method is that it currently only supports cosine distances and is applicable only to databases with a sharp decay in feature similarity distribution, as in the case with softmax features. At present, a pool may produce a large dot product value with a query vector, even though many or even all the members of the pool are dissimilar to the query vector. Developing techniques to reduce the frequency of such situations, possibly using various LSH techniques, as well as testing on billion-scale datasets, are important avenues for future work. The implementation of our algorithms can be found at https://github.com/Harsh-Sensei/GroupTestingNN.
Acknowledgement: The authors thank the Amazon IIT Bombay AI-ML Initiative for support for the work in this paper.
References
- [1] https://github.com/facebookresearch/faiss
- [2] https://www.kaggle.com/competitions/imagenet-object-localization-challenge/data
- [3] https://github.com/JoshEngels/FLINNG
- [4] https://github.com/FALCONN-LIB/FALCONN
- [5] https://github.com/NinhPham/FalconnLSF
- [6] https://github.com/google-research/google-research/tree/master/scann
- [7] FLANN - fast library for approximate nearest neighbors: wbia-pyflann 4.0.4. https://pypi.org/project/wbia-pyflann/
- [8] Generalized binary splitting algorithm. https://en.wikipedia.org/wiki/Group_testing#Generalised_binary-splitting_algorithm
- [9] Imdb-wiki – 500k+ face images with age and gender labels. https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
- [10] The InstaCities1M Dataset. https://gombru.github.io/2018/08/01/InstaCities1M/
- [11] MIRFLICKR download. https://press.liacs.nl/mirflickr/mirdownload.html
- [12] Oxford and paris buildings dataset. https://www.kaggle.com/datasets/skylord/oxbuildings
- [13] Supplemental material. Uploaded on conference portal
- [14] Aldridge, M., Johnson, ., Scarlett, J.: Group testing: an information theory perspective. Foundations and Trends in Communications and Information Theory 15(3-4), 196–392 (2019)
- [15] Andoni, A., Razenshteyn, I.: Optimal data-dependent hashing for approximate near neighbors. In: Proceedings of the forty-seventh annual ACM symposium on Theory of computing. pp. 793–801 (2015)
- [16] Babenko, A., Lempitsky, V.: The inverted multi-index. IEEE Transactions on Pattern Analysis and Machine Intelligence 37(6), 1247–1260 (2014)
- [17] Bloom, B.H.: Space/time trade-offs in hash coding with allowable errors. Communications of the ACM 13(7), 422–426 (1970)
- [18] Candès, E.J., Wakin, M.B.: An introduction to compressive sampling. IEEE signal processing magazine 25(2), 21–30 (2008)
- [19] Davenport, M., Duarte, M., Eldar, Y., Kutyniok, G.: Introduction to compressed sensing. (2012)
- [20] Dong, Y., Indyk, P., Razenshteyn, I., Wagner, T.: Learning space partitions for nearest neighbor search. In: ICLR (2019)
- [21] Dorfman, R.: The detection of defective members of large populations. The Annals of mathematical statistics 14(4), 436–440 (1943)
- [22] Engels, J., Coleman, B., Shrivastava, A.: Practical near neighbor search via group testing. In: Advances in Neural Information Processing Systems. vol. 34, pp. 9950–9962 (2021)
- [23] Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In: 2004 Conference on Computer Vision and Pattern Recognition Workshop. pp. 178–178 (2004). https://doi.org/10.1109/CVPR.2004.383
- [24] Fu, C., Xiang, C., Wang, C., Cai, D.: Fast approximate nearest neighbor search with the navigating spreading-out graph 12(5), 461–474 (2019)
- [25] Ghosh, S., Agarwal, R., Rehan, M.A., Pathak, S., Agarwal, P., Gupta, Y., Consul, S., Gupta, N., Goenka, R., Rajwade, A., Gopalkrishnan, M.: A compressed sensing approach to pooled RT-PCR testing for COVID-19 detection. IEEE Open Journal of Signal Processing 2, 248–264 (2021)
- [26] Guo, R., Sun, P., Lindgren, E., Geng, Q., Simcha, D., Chern, F., Kumar, S.: Accelerating large-scale inference with anisotropic vector quantization. In: International Conference on Machine Learning. pp. 3887–3896 (2020)
- [27] Hajebi, K., Abbasi-Yadkori, Y., Shahbazi, H., Zhang, H.: Fast approximate nearest-neighbor search with k-nearest neighbor graph. In: IJCAI. pp. 1312–1317 (2011)
- [28] Hastie, T., Tibshirani, R., Wainwright, M.: Statistical learning with sparsity: the lasso and generalizations. CRC press (2015)
- [29] Hwang, F.: A method for detecting all defective members in a population by group testing. Journal of the American Statistical Association 67(339), 605–608 (1972)
- [30] Indyk, P., Motwani, R.: Approximate nearest authoneighbors: towards removing the curse of dimensionality. In: STOC. p. 604–613 (1998)
- [31] Iscen, A., Chum, O.: Local orthogonal-group testing. In: Proceedings of the European Conference on Computer Vision (ECCV). pp. 449–465 (2018)
- [32] Kirsch, A., Mitzenmacher, M.: Distance-sensitive bloom filters. In: Proceedings of the Eighth Workshop on Algorithm Engineering and Experiments (ALENEX). pp. 41–50 (2006)
- [33] Li, C.H.: A sequential method for screening experimental variables. Journal of the American Statistical Association 57(298), 455–477
- [34] Lv, Q., Josephson, W., Wang, Z., Charikar, M., Li, K.: Multi-probe LSH: efficient indexing for high-dimensional similarity search. In: Proceedings of the 33rd international conference on Very large data bases. pp. 950–961 (2007)
- [35] Maji, S., Bose, S.: Cbir using features derived by deep learning. ACM/IMS Trans. Data Sci. 2(3) (sep 2021). https://doi.org/10.1145/3470568, https://doi.org/10.1145/3470568
- [36] Malkov, Y., Yashunin, D.: Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence 42(4), 824–836 (2018)
- [37] Muja, M., Lowe, D.: Scalable nearest neighbor algorithms for high dimensional data. IEEE Transactions on Pattern Analysis and Machine Intelligence 36(11), 2227–2240 (2014)
- [38] Ortega-Binderberger, M.: Corel Image Features. UCI Machine Learning Repository (1999), DOI: https://doi.org/10.24432/C5K599
- [39] Pham, N., Liu, T.: Falconn++: A locality-sensitive filtering approach for approximate nearest neighbor search. In: Advances in Neural Information Processing Systems. vol. 35, pp. 31186–31198 (2022)
- [40] Ram, P., Sinha, K.: Revisiting kd-tree for nearest neighbor search. In: SIGKDD. pp. 1378–1388 (2019)
- [41] Shi, M., Furon, T., Jégou, H.: A group testing framework for similarity search in high-dimensional spaces. In: ACMMM. pp. 407–416 (2014)
- [42] Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2015)
- [43] Vidyasagar, M.: An introduction to compressed sensing. SIAM (2019)
- [44] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR. pp. 586–595 (2018)
Supplementary Material
7 Contents
This supplemental material contains the following:
-
1.
A figure showing the negative logarithm of the normalized histograms of dot products between feature vectors of query images and those of all gallery images from each of the four datasets we experimented with in the main paper. These are shown in Fig. 3. Compare with Fig. 2 of the main paper where normalized histograms are shown.
- 2.
-
3.
A discussion regarding the limitation of using the recent advances in the compressed sensing literature to the NN search problem is presented in Sec. 9.
-
4.
Statistics for the average number of points pruned away in each round of binary splitting in our method on each of the four databases, are presented in Fig. 4 for Our-Sum and Fig. 5 for Our-Max. Notice that for both the proposed algorithms (Our-Sum and Our-Max) there is nearly no pruning encountered during the initial rounds. But as the adaptive tests continue, negative tests are encountered in further rounds, and hence pools get pruned away. Surprisingly, most negative tests for Our-Max are encountered in the last round in contrast to that for Our-Sum.
-
5.
Our numerical experiments, illustrated in Fig. 6 reveal that increases with and decreases as increases. This tallies with intuition, and supports the hypothesis that a larger number of pools will be pruned away in a given round if there is more rapid decrease in the probability of dot product values from 0 to 1.
-
6.
A theoretical analysis of the Our-Max algorithm is presented in Sec. 10.
-
7.
The hyper-parameters for various competing algorithms are presented in Sec. 11.
- 8.
- 9.
-
10.
Experiments with a low similarity value, i.e. (=0.3), and experiments on a dataset with 12-million points are presented in Sec. 14.













8 Comparison to other Group Testing Methods for NN Search
The oldest work on GT for NN search was presented in [41]. In this method, the original data vectors are represented as a matrix . The pools are represented as a matrix obtained by pre-multiplying by a randomly generated balanced binary matrix of size where . Given a query vector , its similarity with the th pool is computed, yielding a score , where is the th group vector (and the th row of ). This is repeated for every . Let be the set of pools in which the th vector, i.e. , belongs. Then, a likelihood score is computed for every vector. The vector from with the largest likelihood score (denote this vector by ) is considered to be one of the nearest neighbors of . Next, the value is computed and the pool-level similarity scores for all pools containing are updated to yield new scores of the form . Thereafter, all likelihood scores are updated. This process is called back-propagation in [41]. Again, the vector from with the highest likelihood is identified and this procedure is repeated some times, and finally a sort operation is performed in order to rank them. In [41], it is argued that the time complexity of this procedure is . However, this is an approximate search method, and there is no guarantee that the neighbors thus derived will indeed be the nearest ones. As a result, a large number of false positives may be generated by this method.
The work in [31] clusters the collection into disjoint groups such that the members of a group are as orthogonal to each other as possible. As a result, the similarity measure between and a group vector is almost completely dominated by the similarity between and exactly one member of the group. A careful sparse coding and decoder correction step is also used, and the sparsity of the codes plays a key role in the speedup achieved by this method. However, this method is again an approximate method and heavily relies on the near-orthogonality of each group.
The work in [22] randomly distributes the collection of vectors over some cells. This is independently repeated times, creating a grid of cells. Within each cell, we have a collection of participating members and a corresponding group test . The group test is essentially a binary classifier which determines whether contains at least one member which is similar to the query vector . This is an approximate query, with a true positive rate and false positive rate . It is implemented via a distance-sensitive bloom filter [17, 32], which allows for very fast querying. The bloom filter is constructed with binary arrays, with some concatenated hash functions used in each array. For all positive tests , a union set of all their members is computed. This is repeated times to create candidate sets, and the intersection of these sets is created. Each union can contain many false positives, but this intersection filters out non-members effectively. Precise bounds on are derived in [22], and the time complexity of a single query is proved to be where where stands for the similarity between and the th most similar vector in . The query time is provably sub-linear for queries for which . This is obeyed in data which are distributed as per a Gaussian mixture model with components that have well spread out mean vectors and with smaller variances. But for many distributions, this condition could be violated, leading to arbitrarily high query times in the worst case. This method, too, produces a large number of false negatives and false positives.
Compared to these three afore-mentioned techniques, our method is exact, with the same accuracy as exhaustive search. The methods [41, 31, 22] require hyper-parameters ( for [41], sparse coding parameters in [31], in [22]) for which there is no clear data-driven selection procedure. Our method, however, requires no parameter tuning. In experiments, we have observed a speed up of more than ten-fold in querying time with our method as compared to exhaustive search on some datasets. Like [41], and unlike [22, 31], our method does have a large memory requirement, as we require all pools to be in memory. Some techniques such as [22] require the nearest neighbors to be significantly more similar than all other members of (let us call this condition ). Our method does not have such a requirement. However, our method will perform more efficiently for queries for which a large number of similarity values turn out to be small, and only a minority are above the threshold (let us call this condition ). In our experimental study on diverse datasets, we have observed that is true always. On the other hand, does not hold true in a large number of cases, as also reported in [22, Sec. 5.3].
9 A Discussion on using Compressed Sensing Techniques for NN Search
Sec. 3 of the main paper describes three recent papers [41, 31, 22] which apply the principles of group testing to near neighbor search, and compares them to our technique. In this section, we describe our attempts to apply the latest developments from the compressed sensing (CS) literature to this problem. Note that CS and GT are allied problems, and hence it makes sense to comment on the application of CS to near neighbor search.
Consider that the original data vectors are represented as a matrix . The pools are represented as a matrix obtained by pre-multiplying by a randomly generated balanced binary matrix of size where . We considered the relation , where contains the dot products of the query vector with each of the pool vectors in , i.e. . Likewise contains the dot products of the query vector with each of the vectors in the collection , i.e. . The aim is to efficiently recover the largest elements of from . Since algorithms such as Lasso [28] are of an iterative nature, we considered efficient non-iterative algorithms from the recent literature for recovery of nearly sparse vectors [43, Alg. 8.3]. These are called expander recovery algorithms. Theorem 8.4 of [43] guarantees recovery of the largest elements of using this algorithm, but the bounds on the recovery error are too high to be useful, i.e. . Here, the vector is constructed as follows: the largest elements of are copied into at the corresponding indices, and all other elements of are set to 0. Clearly, for most situations, will be too large to be useful. Indeed, in some of our numerical simulations, we observed to be several times larger than the sum of the largest elements of , due to which Alg. 8.3 from [43] is rendered ineffective for our application. Moreover, for Theorem 8.4 of [43] to hold true, the matrix requires each item in to participate in a very large number of pools, rendering the procedure inefficient for our application. Given these restrictive conditions, we did not continue with this approach.
10 Theoretical Analysis for Our-Max
In Sec. 4 of the main paper, we have presented a theoretical analysis of the expected number of dot product computations required for Our-Sum, which is the binary splitting procedure using summations for pool creation. A similar analysis for estimating the number of dot products required for Our-Max using solely the distribution assumption on dot products (truncated normalized exponential or TNE) is challenging. Consider a pool vector created by the summation of participating vectors . In Our-Sum, the dot product between the query vector and the pool vector is exactly equal to the sum of the dot products between and individual members of the pool. Hence an analysis via the central limit theorem or the truncated Erlang distribution is possible, as explained in Sec. 5 of the main paper. For Our-Max, the pool vector is constructed in the following manner: where stands for the th element of vector . The dot product is an upper bound on (assuming that all values in and in each are non-negative). One can of course use the TNE assumption of the individual dot products and use analytical expressions for the maximum of TNE random variables. However the fact that is an upper bound on complicates the analysis as compared to the case with Our-Sum. Hence, it is difficult to determine an expected number of dot-products per query for Our-Max, but it is possible to determine an upper bound on this quantity. This can be done as described below.
Let . Let denote the similarity of the query vector with the pool vector , and let denote the set of vectors that participated in that pool. We can bound with a constant such that (see later in this section regarding the value of ). Let . Then using this bound, we have the following relation:
| (4) |
where the last inequality is based on order statistics, and where denotes the CDF of the TNE. From the main paper, recall that stands for the expected number of pools in round . Using the recursive relation for in terms of , we have the following:
| (5) |
Using this, an upper bound on can be obtained in the following manner:
| (6) |
Notice there is no factor (in contrast to for Our-Sum) here. This is because even after splitting, the similarity needs to be calculated for both the divided pools unlike in the Our-sum algorithm. The constant can be theoretically as large as the dimension of the dataset (that is, for the datasets used here), giving a very loose upper bound. However, in order to obtain a sharper upper bound, we find the distribution of for each pool in a given dataset and use the 90 percentile value (denoted by ) to evaluate the bound. Details for this are provided next.
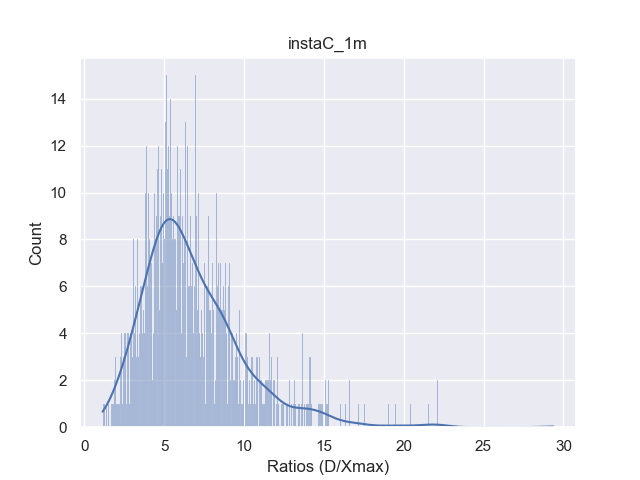
Distribution of ratios : Any upper bound on the expected number of dot products required by Our-Max is dependent on the constant . Although, theoretically can be as large as the dimension of the database vectors, the distribution of for each dataset studied and 90 percentile value of (i.e., ) can be used to obtain the upper bounds on . Fig. 7 shows the distribution of for the datasets used in our experiments. Here below, we mention the values for various datasets used in evaluating the theoretical upper bound reported in Table 2 of the main paper.
-
•
MIRFLICKR: .
-
•
ImageNet: .
-
•
IMDB-Wiki: .
-
•
InstaCities: .
Clearly, these values are significantly lower than , which facilitates better upper bounds, albeit with some probability of error.



11 Hyper-parameters for the algorithms
In order to arrive at comparable values of precision and recall of other algorithms as compared to our proposed algorithms, we performed experiments with many hyper-parameters for each algorithm. Below are the hyper-parameters we used for various experiments with the competing methods. Note that in order to select the set of hyperparameters for each algorithm, we chose the one which gives high recall without significantly increasing time. So there can be other hyperparameter sets for an algorithm with higher recall but at the cost of disproportionate increase in query time. Both streaming and non-streaming setting uses the same set of hyperparameters for each algorithm, except Flann-R (details mentioned below).
- 1.
-
2.
Falconn [15]: Number of tables = , Number of probes = . Parameters used for reporting : (250, 70) respectively
- 3.
-
4.
Hsnw from the Faiss package [1]: , Efconstruction = , Efsearch = , i.e. . Parameters used for reporting : (32, 2) respectively
- 5.
-
6.
Flann [37, 7]: We used AutotunedIndexParams with high target precision (0.85) and other parameters set to their default values. For IMDB-Wiki dataset, we used KDTreeIndexParams(32), for building the index with 32 parallel kd-trees and SearchParams(128) during search phase. This was done because AutotunedIndexParams took long time to build index (more than 20 hours) on IMDB-Wiki dataset. For streaming setting, due to excess time taken by AutotunedIndexParams (leading to high Index Build Time), we used KDTreeIndexParams(16), for building the index with 16 parallel kd-trees and SearchParams(256).
-
7.
Falconn++ [5, 39]: We used the parameters suggested in examples of Falconn++, with number of random vectors = 256, number of tables = 350, , Index Probes (iProbes) = 4, Query Probes (qProbes) = . But we have different values of for each query which can be as large as . Hence, in order to prevent qProbes from exceeding the size of dataset, we cap it to ).
| ImageNet | ||||||||
| Precision | Recall | |||||||
| Feature, | ||||||||
| Softmax | 0.7 | 0.73 | 0.76 | 0.81 | 0.74 | 0.70 | 0.66 | 0.60 |
| Penultimate | 0.66 | 0.85 | 0.96 | 0.99 | 0.2 | 0.07 | 0.015 | 0.001 |
| ImageDBCorel | ||||||||
| Precision | Recall | |||||||
| Feature, | ||||||||
| Softmax | 0.95 | 0.96 | 0.97 | 0.98 | 0.32 | 0.27 | 0.23 | 0.18 |
| Penultimate | 0.99 | 1 | 1 | 1 | 0.29 | 0.11 | 0.028 | 0.01 |
| ImageDBCaltech | ||||||||
| Precision | Recall | |||||||
| Feature, | ||||||||
| Softmax | 0.58 | 0.66 | 0.73 | 0.82 | 0.32 | 0.29 | 0.25 | 0.21 |
| Penultimate | 0.89 | 0.97 | 0.99 | 0.99 | 0.19 | 0.08 | 0.03 | 0.02 |
12 Image Augmentations
In order to create queries suitable for the streaming environment for plagiarism detection, images from the database underwent specially tailored augmentations. The augmentations included artifacts that are somewhat subtle and which do not alter the image content very signficantly, but are designed to trick the detection system: Gaussian blur (with kernel size 33), color jitter (in hue, saturation and value), horizontal flip, downscaling of images and image rotation (by 3 degrees). Figure 8 shows an example of these augmentations.

13 Comparison of VGG16 features
In this section, we provide a comparison between features extracted from penultimate layer of VGG16 (4096 dimensional) and the features extracted after the last layer (i.e. after applying the softmax functions leading to a 1000 dimensional feature vector as there are 1000 classes involved). For comparison, we use a setting akin to [35], in which database images which are similar to a given query image are retrieved. However, instead of retrieving a fixed number of images (), we have performed range-based retrieval with different similarity thresholds () on ImageNet [2], ImageDBCaltech (Caltech101) [23] and ImageDBCorel [38]. Table 4 shows the retrieval recall and retrieval precision values for the aforementioned datasets. Note that we define retrieval precision = # (images retrieved belonging to the same class as the query image) / # (images retrieved), and retrieval recall = # (images retrieved belonging to the same class as the query image) / # (images in the database having the same class as the query image). Note that the retrieval precision and retrieval recall as defined here pertain to identification of the class labels. These are different from the precision and recall reported in the main paper, which are based on near neighbors retrieved by a possibly approximate near neighbor search algorithm, in comparison to an exhaustive nearest neighbor search. Note that though the main algorithm proposed by our paper is fully accurate, the other algorithms we have compared to (i.e., [22, 4, 37]) perform only approximate near neighbor search. Observe from Table 4 that the recall rates for penultimate features noticeably lag behind those of softmax features, indicating that softmax features are better suited for plagiarism detection and other applications requiring high recall.
14 Other Experiments
Here we present results on two experiments with a static database: (i) One on retrieval with low similarity values, i.e. , and (ii) One on the complete ImageNet Database containing 12 million data-points. These results are reported in Table 5.
| 10M scale, | |||||
|---|---|---|---|---|---|
| Alg./DB. | ImgN. | IMDBW. | InstaC. | MIRFL. | ImgN. 12M |
| Ivf (Faiss) | 157,0.99,1 | 51,0.91,1 | 97,0.97,1 | 98,0.98,1 | 1342,1,1 |
| Falconn | 128,0.93,0.99 | 184,0.95,1 | 163,0.92,1 | 141, 0.89,1 | 1521,0.96,1 |
| Hnsw | 15,0.96,0.96 | 3126,0.97,0.97 | 432,0.97,0.97 | 223,0.98,0.98 | 561,0.98,0.98 |
| Our-Sum | 7,1,1 | 133,1,1 | 90,1,1 | 67,1,1 | 269,1,1 |