Group Sparse Coding for Image Denoising
Abstract
Group sparse representation has shown promising results in image debulrring and image inpainting in GSR [3] , the main reason that lead to the success is by exploiting Sparsity and Nonlocal self-similarity (NSS) between patches on natural images, and solve a regularized optimization problem. However, directly adapting GSR[3] in image denoising yield very unstable and non-satisfactory results, to overcome these issues, this paper proposes a progressive image denoising algorithm that successfully adapt GSR [3] model and experiments shows the superior performance than some of the state-of-the-art methods.
1 Introduction
Image denoising as a classical problem has been studied in past century due to its practical significance, aiming at reconstruct high quality image from its degraded noisy version. The problem is formulated as solving a linear inverse problem: given observed noisy image with additive white Gaussian noise with standard deviation , we want to recover the original image , which is:
For most natural images, it is easy to observe there are many repeating patterns with low texture, thus, sparse coding would be ideal to represent low texture region. Simultaneously, it is hard for sparse coding to capture dense texture such as white noise, therefore appropriate level of sparse coding can capture desirable texture of original image while removing the white noise. Such idea has been explored by Ksvd [2], a sparse coding denoising method, by iterating sparse coding and dictionary learning, more sparse representation and higher quality image can be reconstructed. However, this requires to solve a large scale optimization problem on a global dictionary, which is highly computational demanding. In addition to sparse coding, BM3D [1] also exploit NSS as an effective prior for natural images, and is one of the state of the art image denoiser. Similar patches are stacked into 3D group, and then uses two stage collaborative filtering on transformed domain of the 3D group, which exploit both sparsity and NSS. However, its performance tend to get poorer when noise level gets high, because the patch matching phase is directly performed on noisy image.
GSR [3] is an improved version of Ksvd, changing unit from patch to patch group and learn adaptive dictionaries for each group, which helps prevent the large scale sparse coding for the entire image by one pass, and also acknowledge that a global dictionary is far from enough to capture rich texture features on different regions of an image, adaptive dictionaries helps yielding promising reconstruction quality. However, GSR suffers from the instability in hyper-parameter choosing to determine the trade-off between data fidelity and representation sparsity, for different images and noise levels, the optimal hyper-parameter differs significantly, which dramatically limits the possibility for large-scale batch processing. Hence, this paper’s contribution focus on adapting GSR [3] to image denoising to yield stable and superior denoisng result, also, proposes a better patch similarity search scheme to further boost denoising quality.
This paper is organized as follows: first introduces the optimization problem for image denoising. Second, discusses the iterative optimization steps and finalize with an overview of the entire algorithm. Third part presents the experimental results.
2 Group Sparse Representation Learning
2.1 Similar Patch Grouping
In Figure 1, for an image , with size is divided into overlapped patches of size , Then for each patch , its most similar patches are selected from an sized searching window to form a set . After this, all the patches in are stacked into a matrix , which contains every element of as its column, , where denotes the -th similar patch (column form) of the -th group. The similarity measurement simply uses the mean square error to determine the distance between different patches.

In this paper, the similarity measurement is based on more and more better denoised images, therefore producing better results than purely search on the noisy image, related experiments is displayed at the third section.
2.2 The Minimization Problem for Image Denoising
Each group can be sparsely represented by a dictionary and a coefficient vector . We want to make sure that the dictionary can partially fit the noise image to capture the local texture, and also, the coefficient vector can be sparse enough to filtered out the white noise. Hence, we want to solve the optimization problem:
Where , , is the trade-off between representation sparsity and data fidelity, larger encourages more sparse representation while sacrificing the data fidelity, which is more likely to filter out the white noise, but more sparsity generally means the recovered patches are more smooth and more local texture might be lost. Therefore, a carefully selected can remove the noise while preserving most local texture.
In GSR[3], the optimization problem is solved by iteratively solving 2 sub-problems:
The first sub-problem is to learn a set of adaptive dictionaries for each group, GSR[3] uses SVD decomposition for each group , the k-th group , then for each local dictionary , where m = .
The second sub-problem is solved by Split Bregman Iteration (SBI), the answer is approximated as, , where , , is the number of pixels of image . The hyper-parameter and are empirically selected, is the trade-off term as mentioned above. However, varies a lot for different images and different noise level in order to obtain the best denoise effect, which means SBI approximated solution can be sub-optimal. However there still exists a ’golden-ratio’ trade-off factor between texture fitting (the data fidelity term) and denoising effect (the sparsity regularization term). By experimenting on multiple images, when the mean absolute difference between reconstructed image and the current denoising image is , or the difference stops increasing when more sparse is being thresholded (only happens when ), the best threshoulding is obtained. is the learning rate to produce a less noisy image in each iteration by superimposing the currently denoised images over the noisy image, and is empirically selected as 0.1, to achieve better denoising effect in follow-up iterations.
2.3 GSR Denoising Step
The overall denoising step is as as follows, the first step is patch grouping for each patch by searching on the noisy image, so as to obtain . The second step is iterative optimization. Before doing optimization, the current noise level need to be estimated, in the first iteration, the image to be denoised is the original noisy image and is the already known standard deviation of the white noise, but for following up iterations, the noisy level need to be estimated. Then for each group , learn its adaptive dictionary by SVD decomposition and its coefficient by threshoulding untill its mean absolute reconstruction difference is very close to . The third step is to put all sparsely represented patch in each patch group back to the image, and average the intensity by the number of times each pixel is counted to reconstruct a partially denoised version of the noisy image. Then this partially denoised image superimposes the noisy image as the image to be denoised in the next iteration, and search similar patches on the superimposed noisy image, and repeat the second and third step until maximum allowed iteration is reached. Algorithm 1 gives a complete description of the GSR image denoising process.
3 Experimental Results
This section displays all experimental results bwteen proposed method and other state-of-the-art methods. Also, the efficacy of improved similar patch seraching secheme, which search on the gradually less noisy image is compared with searching only on noisy image. Both quantitative and qualitative results are reported. All the test images are shown below, with size .

The evaluation metric is peak signal-to-noise ratio (PSNR):
The quantitative result is displayed at Table 2, white noise with level are exhibited, in each grid, the top left is the result for Ksvd [1], the top right is the result for BM-3d [2], the bottom left is the result for GSR image denoising without similar patch search scheme improved, the bottom left is the result for GSR image denoising with similar patch search scheme improved, while the bottom right is the result for GSR image denoising with similar patch search scheme improved. As we can see from the table, GSR-image denoising almost beated all results of Ksvd [1] and BM-3d [2], the top two results are labeled as bold font, most of them are from GSR-image denoising results. Also, it is clear to see that with improved patch similarity search scheme, GSR-image denoising can always produce better results.
| Lena | Boat | Bird | Brab | Couple | Man | Fish | ||||||||
| 10 | 34.50 | 34.68 | 33.03 | 33.52 | 35.20 | 35.51 | 33.04 | 33.39 | 32.67 | 32.89 | 31.71 | 31.96 | 30.52 | 30.90 |
| 34.80 | 35.09 | 33.41 | 33.68 | 35.42 | 35.75 | 33.63 | 33.91 | 32.78 | 33.02 | 31.94 | 32.19 | 30.94 | 31.13 | |
| 20 | 30.25 | 31.14 | 29.25 | 29.70 | 31.78 | 32.04 | 29.55 | 29.89 | 28.41 | 29.09 | 27.55 | 27.91 | 26.44 | 26.90 |
| 31.31 | 31.78 | 30.01 | 30.23 | 32.01 | 32.49 | 30.21 | 30.61 | 29.12 | 29.59 | 27.89 | 28.42 | 27.01 | 27.32 | |
| 30 | 28.89 | 29.11 | 27.50 | 27.67 | 29.70 | 29.99 | 27.45 | 27.75 | 26.34 | 26.96 | 25.50 | 25.78 | 24.40 | 24.73 |
| 29.44 | 29.91 | 28.09 | 28.43 | 30.21 | 30.62 | 28.14 | 28.72 | 27.23 | 27.78 | 26.08 | 26.40 | 24.87 | 25.24 | |
| 100 | 22.00 | 22.21 | 21.01 | 21.13 | 20.98 | 21.18 | 20.70 | 20.86 | 21.01 | 21.13 | 18.53 | 18.77 | 17.76 | 17.99 |
| 22.36 | 22.93 | 21.60 | 22.17 | 21.21 | 21.31 | 21.94 | 22.25 | 22.07 | 22.40 | 18.89 | 19.44 | 18.20 | 18.84 | |

In Figure 3, qualitative results are displayed for all test images, GSR with improved search scheme preserves major parts of local texture while smoothing the flat area of original image, and this helps produce the most natural presentations. GSR lost a little bit local texture and looks over-smoothed because using not well matched groups tend to average out the local texture. BM-3d preserves most local textures but also produces lots of artifacts in the flat area or the original image. Ksvd produces the worst denosing effect with noticeable artifacts and damaged local textures.

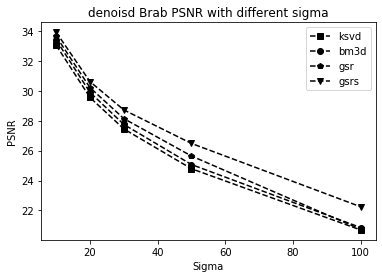


Better similar patch searching scheme significantly helps denoising quality. In Figure 4, it is clear to see that at all noise levels, GSR image denoising with improved search scheme (GSRS) beats GSR and other two methods on test images Lena and Brab. Also, the advantage is clearly exhibited in iterative denoising process, as shown in Figure 5, better searching scheme significantly boost denoising quality in the first few iterations, while the iterative improvement for naive similar patch search method only helps little.
4 Conclusion
This paper proposes a Group Sparse Representation based method for image denoising, that is, solving sparse coding problems for each similar patch group and iterate this process on more and more better quailty image. This method also naturally incorporate with a better patch search scheme, that is, searching on more and more better quality image. Finally this method is evaluated against by two state-of-the-art algorithms Ksvd and BM-3d, both qualitative and quantitative results are reported, and shows superior performance. In addition, improved similar patch search scheme is also evaluated by comparing with naive search scheme, it helps reaching better denoising quality both visually and statistically.
References
- [1] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Transactions on image processing, 16(8):2080–2095, 2007.
- [2] Michael Elad and Michal Aharon. Image denoising via sparse and redundant representations over learned dictionaries. IEEE Transactions on Image processing, 15(12):3736–3745, 2006.
- [3] Jian Zhang, Debin Zhao, and Wen Gao. Group-based sparse representation for image restoration. IEEE transactions on image processing, 23(8):3336–3351, 2014.