Graph rules for recurrent neural network dynamics: extended version
Contents
toc
1 Introduction
Neurons in the brain are constantly flickering with activity, which can be spontaneous or in response to stimuli [Luczak-Neuron]. Because of positive feedback loops and the potential for runaway excitation, real neural networks often possess an abundance of inhibition that serves to shape and stabilize the dynamics [Yuste-inhibition, Karnani-inhibition, Yuste-CPG]. The excitatory neurons in such networks exhibit intricate patterns of connectivity, whose structure controls the allowed patterns of activity. A central question in neuroscience is thus: how does network connectivity shape dynamics?
For a given model, this question becomes a mathematical challenge. The goal is to develop a theory that directly relates properties of a nonlinear dynamical system to its underlying graph. Such a theory can provide insights and hypotheses about how network connectivity constrains activity in real brains. It also opens up new possibilities for modeling neural phenomena in a mathematically tractable way.
Here we describe a class of inhibition-dominated neural networks corresponding to directed graphs, and introduce some of the theory that has been developed to study them. The heart of the theory is a set of parameter-independent graph rules that enables us to directly predict features of the dynamics from combinatorial properties of the graph. Specifically, graph rules allow us to constrain, and in some cases fully determine, the collection of stable and unstable fixed points of a network based solely on graph structure.
Stable fixed points are themselves static attractors of the network, and have long been used as a model of stored memory patterns [Hopfield1982, Hopfield1984]. In contrast, unstable fixed points have been shown to play an important role in shaping dynamic (non-static) attractors, such as limit cycles [core-motifs]. By understanding the fixed points of simple networks, and how they relate to the underlying architecture, we can gain valuable insight into the high-dimensional nonlinear dynamics of neurons in the brain.
For more complex architectures, built from smaller component subgraphs, we present a series of gluing rules that allow us to determine all fixed points of the network by gluing together those of the components. These gluing rules are reminiscent of sheaf-theoretic constructions, with fixed points playing the role of sections over subnetworks.
First, we review some basics of recurrent neural networks and a bit of historical context.
Basic network setup.
A recurrent neural network is a directed graph together with a prescription for the dynamics on the vertices, which represent neurons (see Figure 1A). To each vertex we associate a function that tracks the activity level of neuron as it evolves in time. To each ordered pair of vertices we assign a weight, , governing the strength of the influence of neuron on neuron . In principle, there can be a nonzero weight between any two nodes, with the graph providing constraints on the allowed values , depending on the specifics of the model.
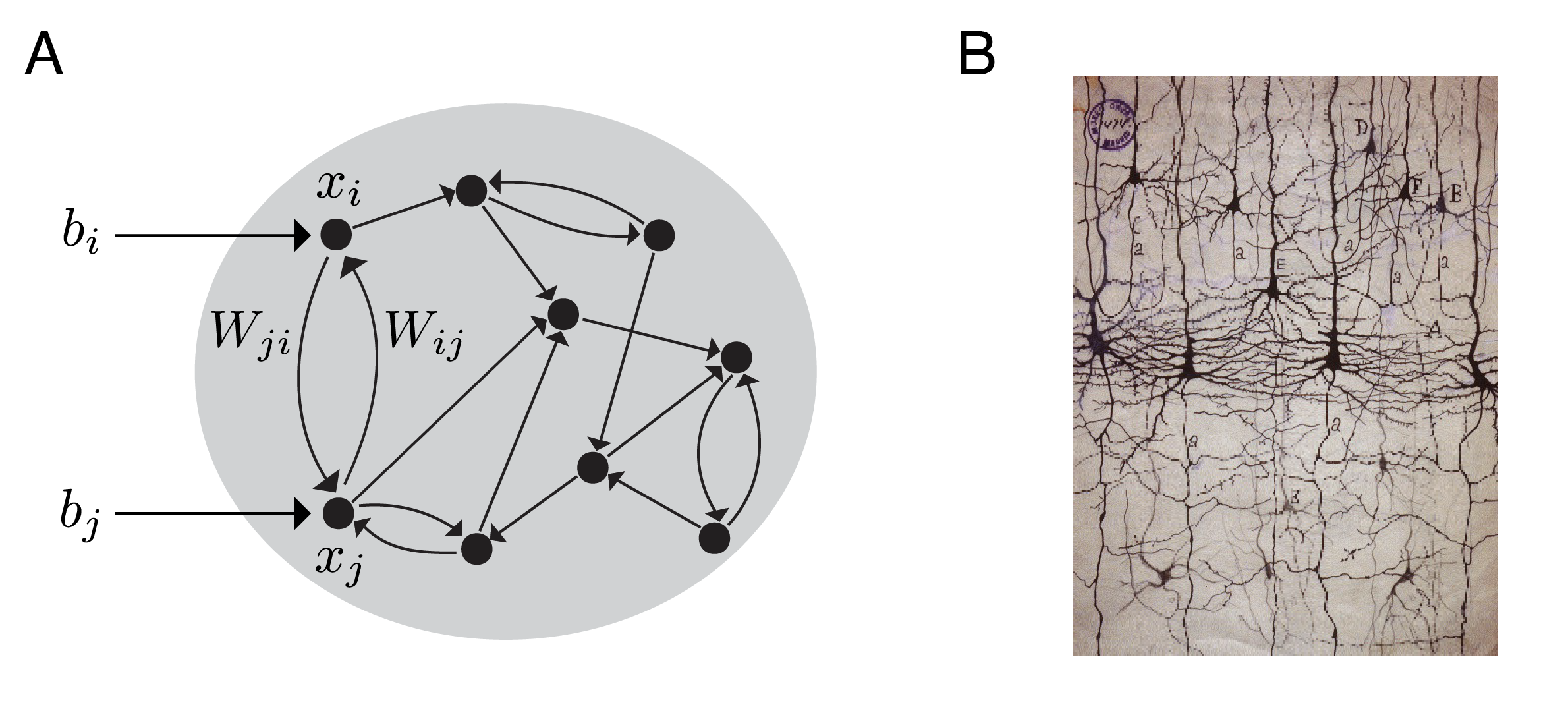
The dynamics often take the form of a system of ODEs, called a firing rate model [Dayan-Abbott, ErmentroutTerman, AppendixE]:
for The various terms in the equation are illustrated in Figure 1, and can be thought of as follows:
-
•
is the firing rate of a single neuron (or the average activity of a subpopulation of neurons);
-
•
is the “leak” timescale, governing how quickly a neuron’s activity exponentially decays to zero in the absence of external or recurrent input;
-
•
is a real-valued matrix of synaptic interaction strengths, with representing the strength of the connection from neuron to neuron ;
-
•
is a real-valued external input to neuron that may or may not vary with time;
-
•
is the total input to neuron as a function of time; and
-
•
is a nonlinear, but typically monotone increasing function.
Of particular importance for this article is the family of threshold-linear networks (TLNs). In this case, the nonlinearity is chosen to be the popular threshold-linear (or ReLU) function,
TLNs are common firing rate models that have been used in computational neuroscience for decades [AppendixE, Tsodyks-JN-1997, Seung-Nature, Fitzgerald2022]. The use of threshold-linear units in neural modeling dates back at least to 1958 [Hartline-Ratliff-1958]. In the last 20 years, TLNs have also been shown to be surprisingly tractable mathematically [XieHahnSeung, HahnSeungSlotine, net-encoding, pattern-completion, CTLN-preprint, book-chapter, fp-paper, stable-fp-paper, seq-attractors], though much of the theory remains under-developed. We are especially interested in competitive or inhibition-dominated TLNs, where the matrix is non-positive so the effective interaction between any pair of neurons is inhibitory. In this case, the activity remains bounded despite the lack of saturation in the nonlinearity [CTLN-preprint]. These networks produce complex nonlinear dynamics and can possess a remarkable variety of attractors [CTLN-preprint, book-chapter, seq-attractors, core-motifs].
Firing rate models of the form (1) are examples of recurrent networks because the matrix allows for all pairwise interactions, and there is no constraint that the architecture (i.e., the underlying graph ) be feedforward. Unlike deep neural networks, which can be thought of as classifiers implementing a clustering function, recurrent networks are primarily thought of as dynamical systems. And the main purpose of these networks is to model the dynamics of neural activity in the brain. The central question is thus:
Question 1.
Given a firing rate model defined by (1) with network parameters and underlying graph , what are the emergent network dynamics? What can we say about the dynamics from knowledge of alone?
We are particularly interested in understanding the attractors of such a network, including both stable fixed points and dynamic attractors such as limit cycles. The attractors are important because they comprise the set of possible asymptotic behaviors of the network in response to different inputs or initial conditions (see Figure 2).

Note that Question 1 is posed for a fixed connectivity matrix , but of course can change over time (e.g., as a result of learning or training of the network). Here we restrict ourselves to considering constant matrices; this allows us to focus on understanding network dynamics on a fast timescale, assuming slowly varying synaptic weights. Understanding the dynamics associated to changing is an important topic, currently beyond the scope of this work.
Historical interlude: memories as attractors.
Attractor neural networks became popular in the 1980s as models of associative memory encoding and retrieval. The best-known example from that era is the Hopfield model [Hopfield1982, Hopfield1984], originally conceived as a variant on the Ising model from statistical mechanics. In the Hopfield model, the neurons can be in one of two states, , and the activity evolves according to the discrete time update rule:
Hopfield’s famous 1982 result is that the dynamics are guaranteed to converge to a stable fixed point, provided the interaction matrix is symmetric: that is, for every . Specifically, he showed that the “energy” function,
decreases along trajectories of the dynamics, and thus acts as a Lyapunov function [Hopfield1982]. The stable fixed points are local minima of the energy landscape (Figure 2A). A stronger, more general convergence result for competitive neural networks was shown in [CohenGrossberg1983].
These fixed points are the only attractors of the network, and they represent the set of memories encoded in the network. Hopfield networks perform a kind of pattern completion: given an initial condition , the activity evolves until it converges to one of multiple stored patterns in the network. If, for example, the individual neurons store black and white pixel values, this process could input a corrupted image and recover the original image, provided it had previously been stored as a stable fixed point in the network by appropriately selecting the weights of the matrix. The novelty at the time was the nonlinear phenomenon of multistability: namely, that the network could encode many such stable equilibria and thus maintain an entire catalogue of stored memory patterns. The key to Hopfield’s convergence result was the requirement that be a symmetric interaction matrix. Although this was known to be an unrealistic assumption for real (biological) neural networks, it was considered a tolerable price to pay for guaranteed convergence. One did not want an associative memory network that wandered the state space indefinitely without ever recalling a definite pattern.
Twenty years later, Hahnloser, Seung, and others followed up and proved a similar convergence result in the case of symmetric inhibitory threshold-linear networks [HahnSeungSlotine]. Specifically, they found a Lyapunov-like function
following the notation in (1) with . For fixed , it can easily be shown that is strictly decreasing along trajectories of the TLN dynamics, and minima of correspond to steady states – provided is symmetric and is copositive [HahnSeungSlotine, Theorem 1]. More results on the collections of stable fixed points that can be simultaneously encoded in a symmetric TLN can be found in [flex-memory, net-encoding, pattern-completion], including some unexpected connections to Cayley-Menger determinants and classical distance geometry.
In all of this work, stable fixed points have served as the model for encoded memories. Indeed, these are the only types of attractors that arise for symmetric Hopfield networks or symmetric TLNs. Whether or not guaranteed convergence to stable fixed points is desirable, however, is a matter of perspective. For a network whose job it is to perform pattern completion or classification for static images (or codewords), as in the classical Hopfield model, this is exactly what one wants. But it is also important to consider memories that are temporal in nature, such as sequences and other dynamic patterns of activity. Sequential activity, as observed in central pattern generator circuits (CPGs) and spontaneous activity in hippocampus and cortex, is more naturally modeled by dynamic attractors such as limit cycles. This requires shifting attention to the asymmetric case, in order to be able to encode attractors that are not stable fixed points (Figure 2B).
Beyond stable fixed points.
When the symmetry assumption is removed, TLNs can support a rich variety of dynamic attractors such as limit cycles, quasiperiodic attractors, and even strange (chaotic) attractors. Indeed, this richness can already be observed in a special class of TLNs called combinatorial threshold-linear networks (CTLNs), introduced in Section 3. These networks are defined from directed graphs, and the dynamics are almost entirely determined by the graph structure. A striking feature of CTLNs is that the dynamics are shaped not only by the stable fixed points, but also the unstable fixed points. In particular, we have observed a direct correspondence between certain types of unstable fixed points and dynamic attractors (see Figure 3) [core-motifs]. This is reviewed in Section 4.

Despite exhibiting complex, high-dimensional, nonlinear dynamics, recent work has shown that TLNs – and especially CTLNs – are surprisingly tractable mathematically. Motivated by the relationship between fixed points and attractors, a great deal of progress has been made on the problem of relating fixed point structure to network architecture. In the case of CTLNs, this has resulted in a series of graph rules: theorems that allow us to rule in and rule out potential fixed points based purely on the structure of the underlying graph [fp-paper, book-chapter, seq-attractors]. In Section 5, we give a novel exposition of graph rules, and introduce several elementary graph rules from which the others can be derived.
Inhibition-dominated TLNs and CTLNs also display a remarkable degree of modularity. Namely, attractors associated to smaller networks can be embedded in larger ones with minimal distortion [core-motifs]. This is likely a consequence of the high levels of background inhibition: it serves to stabilize and preserve local properties of the dynamics. These networks also exhibit a kind of compositionality, wherein fixed points and attractors of subnetworks can be effectively “glued” together into fixed points and attractors of a larger network. These local-to-global relationships are given by a series of theorems we call gluing rules, given in Section 6.
2 TLNs and hyperplane arrangements
For firing rate models with threshold-nonlinearity the network equations (1) become
for We also assume for each . Note that the leak timescales have been set to for all . We thus measure time in units of this timescale.
For constant matrix and input vector , the equations
define a hyperplane arrangement in . The -th hyperplane is defined by , with normal vector population activity vector , and affine shift . If , then intersects the -th coordinate axis at the point . is parallel to the -th axis.
The hyperplanes partition the positive orthant into chambers. Within the interior of any chamber, each point is on the plus or minus side of each hyperplane . The equations thus reduce to a linear system of ODEs, with the equation for each being either
or
In particular, TLNs are piecewise-linear dynamical systems with a different linear system, , governing the dynamics in each chamber [CTLN-preprint].
A fixed point of a TLN (2) is a point that satisfies for each . In particular, we must have
| (3) |
where is evaluated at the fixed point. We typically assume a nondegeneracy condition on [fp-paper, CTLN-preprint], which guarantees that each linear system is nondegenerate and has a single fixed point. This fixed point may or may not lie within the chamber where its corresponding linear system applies. The fixed points of the TLN are precisely the fixed points of the linear systems that lie within their respective chambers.

Figure 4 illustrates the hyperplanes and chambers for a TLN with . Each chamber, denoted as a region , has its own linear system of ODEs, for or . The fixed point corresponding to each linear system is denoted by , in matching color. Note that only chamber contains its own fixed point (in red). This fixed point, , is thus the only fixed point of the TLN.
Figure 5 shows an example of a TLN on neurons. The matrix is constructed from a -cycle graph and for each . The dynamics fall into a limit cycle where the neurons fire in a repeating sequence that follows the arrows of the graph. This time, the TLN equations define a hyperplane arrangement in , again with each hyperplane defined by (Figure 5C). An initial condition near the unstable fixed point in the all + chamber (where for each ) spirals out and converges to a limit cycle that passes through four distinct chambers. Note that the threshold nonlinearity is critical for the model to produce nonlinear behavior such as limit cycles; without it, the system would be linear. It is, nonetheless, nontrivial to prove that the limit cycle shown in Figure 5 exists. A recent proof was given for a special family of TLNs constructed from any -cycle graph [Horacio-paper].

The set of all fixed points .
A central object that is useful for understanding the dynamics of TLNs is the collection of all fixed points of the network, both stable and unstable. The support of a fixed point is the subset of active neurons,
Our nondegeneracy condition (that is generically satisfied) guarantees we can have at most one fixed point per chamber of the hyperplane arrangement , and thus at most one fixed point per support. We can thus label all the fixed points of a given network by their supports:
| (4) | |||||
where
For each support , the fixed point itself is easily recovered. Outside the support, for all . Within the support, is given by:
Here and are the column vectors obtained by restricting and to the indices in , and is the induced principal submatrix obtained by restricting rows and columns of to .
From (3), we see that a fixed point with must satisfy the “on-neuron” conditions, for all , as well as the “off-neuron” conditions, for all , to ensure that for each and for each . Equivalently, these conditions guarantee that the fixed point of lies inside its corresponding chamber, Note that for such a fixed point, the values for depend only on the restricted subnetwork . Therefore, the on-neuron conditions for in are satisfied if and only if they hold in . Since the off-neuron conditions are trivially satisfied in , it follows that is a necessary condition for . It is not, however, sufficient, as the off-neuron conditions may fail in the larger network. Satisfying all the on- and off-neuron conditions, however, is both necessary and sufficient to guarantee [book-chapter, fp-paper].
Conveniently, the off-neuron conditions are independent and can be checked one neuron at a time. Thus,
When satisfies all the off-neuron conditions, so that , we say that survives to the larger network; otherwise, we say dies.
The fixed point corresponding to is stable if and only if all eigenvalues of have negative real part. For competitive (or inhibition-dominated) TLNs, all fixed points – whether stable or unstable – have a stable manifold. This is because competitive TLNs have for all . Applying the Perron-Frobenius theorem to , we see that the largest magnitude eigenvalue is guaranteed to be real and negative. The corresponding eigenvector provides an attracting direction into the fixed point. Combining this observation with the nondegeneracy condition reveals that the unstable fixed points are all hyperbolic (i.e., saddle points).
3 Combinatorial threshold-linear
networks
Combinatorial threshold-linear networks (CTLNs) are a special case of competitive (or inhibition-dominated) TLNs, with the same threshold nonlinearity, that were first introduced in [CTLN-preprint, book-chapter]. What makes CTLNs special is that we restrict to having only two values for the connection strengths , for . These are obtained as follows from a directed graph , where indicates that there is an edge from to and indicates that there is no such edge:
| (5) |
Additionally, CTLNs typically have a constant external input for all in order to ensure the dynamics are internally generated rather than inherited from a changing or spatially heterogeneous input.
A CTLN is thus completely specified by the choice of a graph , together with three real parameters: and . We additionally require that , , and . When these conditions are met, we say the parameters are within the legal range. Note that the upper bound on implies , and so the matrix is always effectively inhibitory. For fixed parameters, only the graph varies between networks. The network in Figure 5 is a CTLN with the standard parameters , , and .
We interpret a CTLN as modeling a network of excitatory neurons, whose net interactions are effectively inhibitory due to a strong global inhibition (Figure 6). When , we say strongly inhibits ; when , we say weakly inhibits . The weak inhibition is thought of as the sum of an excitatory synaptic connection and the background inhibition. Note that because , when , neuron inhibits more than it inhibits itself via its leak term; when , neuron inhibits less than it inhibits itself. These differences in inhibition strength cause the activity to follow the arrows of the graph.

The set of fixed point supports of a CTLN with graph is denoted as:
is precisely , where and are specified by a CTLN with graph and parameters and . Note that is independent of , provided is constant across neurons as in a CTLN. It is also frequently independent of and . For this reason we often refer to it as , especially when a fixed choice of and is understood.
The legal range condition, is motivated by a theorem in [CTLN-preprint]. It ensures that single directed edges are not allowed to support stable fixed points . This allows us to prove the following theorem connecting a certain graph structure to the absence of stable fixed points. Note that a graph is oriented if for any pair of nodes, implies (i.e., there are no bidirectional edges). A sink is a node with no outgoing edges.
Theorem 3.1.
[CTLN-preprint, Theorem 2.4] Let be an oriented graph with no sinks. Then for any parameters in the legal range, the associated CTLN has no stable fixed points. Moreover, the activity is bounded.
The graph in Figure 5A is an oriented graph with no sinks. It has a single fixed point, , irrespective of the parameters (note that we use “” as shorthand for the set ). This fixed point is unstable and the dynamics converge to a limit cycle (Figure 5C).

Even when there are no stable fixed points, the dynamics of a CTLN are always bounded [CTLN-preprint]. In the limit as , we can bound the total population activity as a function of the parameters and :
| (6) |
In simulations, we observe a rapid convergence to this regime. Figure 7 depicts four solutions for the same CTLN on neurons. The graph was generated as a directed Erdos-Renyi random graph with edge probability ; note that it is not an oriented graph. Since the network is deterministic, the only difference between simulations is the initial conditions. While panel A appears to show chaotic activity, the solutions in panels B, C and D all settle into a fixed point or a limit cycle within the allotted time frame. The long transient of panel B is especially striking: around , the activity appears as though it will fall into the same limit cycle from panel D, but then escapes into another period of chaotic-looking dynamics before abruptly converging to a stable fixed point. In all cases, the total population activity rapidly converges to lie within the bounds given in (6), depicted in gray.
Fun examples.
Despite their simplicity, CTLNs display a rich variety of nonlinear dynamics. Even very small networks can exhibit interesting attractors with unexpected properties. Theorem 3.1 tells us that one way to guarantee that a network will produce dynamic – as opposed to static – attractors is to choose to be an oriented graph with no sinks. The following examples are of this type.

The Gaudi attractor. Figure 8 shows two solutions to a CTLN for a cyclically symmetric tournament111A tournament is a directed graph in which every pair of nodes has exactly one (directed) edge between them. graph on nodes. For some initial conditions, the solutions converge to a somewhat boring limit cycle with the firing rates all peaking in the expected sequence, (bottom middle). For a different set of initial conditions, however, the solution converges to the beautiful and unusual attractor displayed at the top.
Symmetry and synchrony. Because the pattern of weights in a CTLN is completely determined by the graph , any symmetry of the graph necessarily translates to a symmetry of the differential equations, and hence of the vector field. It follows that the automorphism group of also acts on the set of all attractors, which must respect the symmetry. For example, in the cyclically symmetric tournament of Figure 8, both the Gaudi attractor and the “boring” limit cycle below it are invariant under the cyclic permutation : the solution is preserved up to a time translation.

Another way for symmetry to manifest itself in an attractor is via synchrony. The network in Figure 9A depicts a CTLN with a graph on nodes that has a nontrivial automorphism group , cyclically permuting the nodes and . In the corresponding attractor, the neurons perfectly synchronize as the solution settles into the limit cycle. Notice, however, what happens for the network in Figure 9B. In this case, the limit cycle looks very similar to the one in A, with the same synchrony among neurons and . However, the graph is missing the edge, and so the graph has no nontrivial automorphisms. We refer to this phenomenon as surprise symmetry.
On the flip side, a network with graph symmetry may have multiple attractors that are exchanged by the group action, but do not individually respect the symmetry. This is the more familiar scenario of spontaneous symmetry breaking.
Emergent sequences. One of the most reliable properties of CTLNs is the tendency of neurons to fire in sequence. Although we have seen examples of synchrony, the global inhibition promotes competitive dynamics wherein only one or a few neurons reach their peak firing rates at the same time. The sequences may be intuitive, as in the networks of Figures 8 and 9, following obvious cycles in the graph. However, even for small networks the emergent sequences may be difficult to predict.
The network in Figure 10A has neurons, and the graph is a tournament with no nontrivial automorphisms. The corresponding CTLN appears to have a single, global attractor, shown in Figure 10B. The neurons in this limit cycle fire in a repeating sequence, 634517, with 5 being the lowest-firing node. This sequence is highlighted in black in the graph, and corresponds to a cycle in the graph. However, it is only one of many cycles in the graph. Why do the dynamics select this sequence and not the others? And why does neuron 2 drop out, while all others persist? This is particularly puzzling given that node 2 has in-degree three, while nodes 3 and 5 have in-degree two.

Indeed, local properties of a network, such as the in- and out-degrees of individual nodes, are insufficient for predicting the participation and ordering of neurons in emergent sequences. Nevertheless, the sequence is fully determined by the structure of . We just have a limited understanding of how. Recent progress in understanding sequential attractors has relied on special network architectures that are cyclic like the ones in Figures 8 and 9 [seq-attractors]. Interestingly, although the graph in Figure 10 does not have such an architecture, the induced subgraph generated by the high-firing nodes 1, 3, 4, 6, and 7 is isomorphic to the graph in Figure 8. This graph, as well as the two graphs in Figure 9, have corresponding networks that are in some sense irreducible in their dynamics. These are examples of graphs that we refer to as core motifs [core-motifs].
4 Minimal fixed points, core motifs, and attractors
Stable fixed points of a network are of obvious interest because they correspond to static attractors [HahnSeungSlotine, net-encoding, pattern-completion, stable-fp-paper]. One of the most striking features of CTLNs, however, is the strong connection between unstable fixed points and dynamic attractors [book-chapter, core-motifs, seq-attractors].
Question 2.
For a given CTLN, can we predict the dynamic attractors of the network from its unstable fixed points? Can the unstable fixed points be determined from the structure of the underlying graph ?
Throughout this section, is a directed graph on nodes. Subsets are often used to denote both the collection of vertices indexed by and the induced subgraph . The corresponding network is assumed to be a nondegenerate CTLN with fixed parameters and .
Figure 11 provides two example networks to illustrate the relationship between unstable fixed points and dynamic attractors. Any CTLN with the graph in panel A has three fixed points, with supports . The collection of fixed point supports can be thought of as a partially ordered set, ordered by inclusion. In our example, and are thus minimal fixed point supports, because they are minimal under inclusion. It turns out that the corresponding fixed points each have an associated attractor (Figure 11B). The one supported on , a sink in the graph, yields a stable fixed point, while the (unstable) fixed point, whose induced subgraph is a -cycle, yields a limit cycle attractor with high-firing neurons , , and . Figure 11C depicts all three fixed points in the state space. Here we can see that the third one, supported on , acts as a “tipping point” on the boundary of two basins of attraction. Initial conditions near this fixed point can yield solutions that converge either to the stable fixed point or the limit cycle.
Figure 11D-F provides another example network, called “baby chaos,” in which all fixed points are unstable. The minimal fixed point supports, and , all correspond to core motifs (embedded -cycles in the graph). The corresponding attractors are chaotic, and are depicted as firing rate curves (panel E) and trajectories in the state space (panel F). Note that the graph has an automorphism group that exchanges core motifs and their corresponding attractors.

Not all minimal fixed points have corresponding attractors. In [core-motifs] we saw that the key property of such a is that it be minimal not only in but also in , corresponding to the induced subnetwork restricted to the nodes in . In other words, is the only fixed point in . This motivates the definition of core motifs.
Definition 4.1.
Let be the graph of a CTLN on nodes. An induced subgraph is a core motif of the network if .

When the graph is understood, we sometimes refer to itself as a core motif if is one. The associated fixed point is called a core fixed point. Core motifs can be thought of as “irreducible” networks because they have a single fixed point which has full support. Since the activity is bounded and must converge to an attractor, the attractor can be said to correspond to this fixed point. A larger network that contains as an induced subgraph may or may not have . When the core fixed point does survive, we say refer to the embedded as a surviving core motif, and we expect the associated attractor to survive. In Figure 11, the surviving core motifs are and , and they precisely predict the attractors of the network.
The simplest core motifs are cliques. When these survive inside a network , the corresponding attractor is always a stable fixed point supported on all nodes of the clique [fp-paper]. In fact, we conjectured that any stable fixed point for a CTLN must correspond to a maximal clique of – specifically, a target-free clique [fp-paper, stable-fp-paper].

Up to size , all core motifs are parameter-independent. For size , of core motifs are parameter-independent. Figure 12 shows the complete list of all core motifs of size , together with some associated attractors. The cliques all correspond to stable fixed points, the simplest type of attractor. The -cycle yields the limit cycle attractor in Figure 5, which may be distorted when embedded in a larger network (see Figure 11B). The other core motifs whose fixed points are unstable have dynamic attractors. Note that the -cycu graph has a symmetry, and the rate curves for these two neurons are synchronous in the attractor. This synchrony is also evident in the -ufd attractor, despite the fact that this graph does not have the symmetry. Perhaps the most interesting attractor, however, is the one for the fusion -cycle graph. Here the -cycle attractor, which does not survive the embedding to the larger graph, appears to “fuse” with the stable fixed point associated to (which also does not survive). The resulting attractor can be thought of as binding together a pair of smaller attractors.
Figure 13A depicts a larger example of a network whose fixed point structure is predictive of the attractors. Note that only four supports are minimal: , , , and . The first two correspond to surviving cliques, and the last two correspond to -cycles with surviving fixed points. An extensive search of attractors for this network reveals only four attractors, corresponding to the four surviving core motifs. Figure 13B shows trajectories converging to each of the four attractors. The cliques yield stable fixed points, as expected, while the -cycles correspond to dynamic attractors: one limit cycle, and one strange or chaotic attractor.

We have performed extensive tests on whether or not core motifs predict attractors in small networks. Specifically, we decomposed all 9608 non-isomorphic directed graphs on nodes into core motif components, and used this to predict the attractors [n5-github]. We found that 1053 of the graphs have surviving core motifs that are not cliques; these graphs were thus expected to support dynamic attractors. The remaining 8555 graphs contain only cliques as surviving core motifs, and were thus expected to have only stable fixed point attractors. Overall, we found that core motifs correctly predicted the set of attractors in 9586 of the 9608 graphs. Of the 22 graphs with mistakes, 19 graphs have a core motif with no corresponding attractor, and 3 graphs have no core motifs for the chosen parameters [n5-github].
Across the 1053 graphs with core motifs that are not cliques, we observed a total of 1130 dynamic attractors. Interestingly, these fall into distinct equivalence classes determined by (a) the core motif, and (b) the details of how the core motif is embedded in the larger graph. In the case of oriented graphs on nodes, we performed a more detailed analysis of the dynamic attractors to determine a set of attractor families [core-motifs]. Here we observed a striking modularity of the embedded attractors, wherein the precise details of an attractor remained nearly identical across large families of non-isomorphic graphs with distinct CTLNs. Figure 14 gives a sampling of these common attractors, together with corresponding graph families. Graph families are depicted via “master graphs,” with solid edges being shared across all graphs in the family, and dashed edges being optional. Graph counts correspond to non-isomorphic graphs. See [core-motifs] for more details.
5 Graph rules
We have seen that CTLNs exhibit a rich variety of nonlinear dynamics, and that the attractors are closely related to the fixed points. This opens up a strategy for linking attractors to the underlying network architecture via the fixed point supports . Our main tools for doing this are graph rules.
Throughout this section, we will use greek letters to denote subsets of corresponding to fixed point supports (or potential supports), while latin letters denote individual nodes/neurons. As before, denotes the induced subgraph obtained from by restricting to and keeping only edges between vertices of . The fixed point supports are:
The main question addressed by graph rules is:
Question 3.
What can we say about from knowledge of alone?
For example, consider the graphs in Figure 15. Can we determine from the graph alone which subgraphs will support fixed points? Moreover, can we determine which of those subgraphs are core motifs that will give rise to attractors of the network? We saw in Section 4 (Figure 12) that cycles and cliques are among the small core motifs; can cycles and cliques produce core motifs of any size? Can we identify other graph structures that are relevant for either ruling in or ruling out certain subgraphs as fixed point supports? The rest of Section 5 focuses on addressing these questions.

Note that implicit in the above questions is the idea that graph rules are parameter-independent: that is, they directly relate the structure of to via results that are valid for all choices of and (provided they lie within the legal range). In order to obtain the most powerful results, we also require that our CTLNs be nondegenerate. As has already been noted, nondegeneracy is generically satisfied for TLNs [fp-paper]. For CTLNs, it is satisfied irrespective of and for almost all legal range choices of and (i.e., up to a set of measure zero in the two-dimensional parameter space for and ).
5.1 Examples of graph rules
We’ve already seen some graph rules. For example, Theorem 3.1 told us that if is an oriented graph with no sinks, the associated CTLN has no stable fixed points. Such CTLNs are thus guaranteed to only exhibit dynamic attractors. Here we present a set of eight simple graph rules, all proven in [fp-paper], that are easy to understand and give a flavor of the kinds of theorems we have found.
We will use the following graph theoretic terminology. A source is a node with no incoming edges, while a sink is a node with no outgoing edges. Note that a node can be a source or sink in an induced subgraph , while not being one in . An independent set is a collection of nodes with no edges between them, while a clique is a set of nodes that is all-to-all bidirectionally connected. A cycle is a graph (or an induced subgraph) where each node has exactly one incoming and one outgoing edge, and they are all connected in a single directed cycle. A directed acyclic graph (DAG) is a graph with a topological ordering of vertices such that whenever ; such a graph does not contain any directed cycles. Finally, a target of a graph is a node such that for all . Note that a target may be inside or outside .
The graph rules presented here can be found, with detailed proofs, in [fp-paper]. We also summarize them in Table 1 and Figure 16.
Examples of graph rules:
Rule 1 (independent sets): If is an independent set, then if and only if each is a sink in .
Rule 2 (cliques): If is a clique, then if and only if there is no node of , , such that for all In other words, if and only if is a target-free clique. If , the corresponding fixed point is stable.
Rule 3 (cycles): If is a cycle, then if and only if there is no node of , , such that receives two or more edges from . If , the corresponding fixed point is unstable.
Rule 4 (sources): (i) If contains a source , with for some , then . (ii) Suppose , but is a source in . Then if and only if .
Rule 5 (targets): (i) If has target , with and for some (), then and thus . (ii) If has target , then and thus .
Rule 6 (sinks): If has a sink , then if and only if .
Rule 7 (DAGs): If is a directed acyclic graph with sinks , then , the set of all unions of sinks.
Rule 8 (parity): For any , is odd.

| Rule name | structure | graph rule |
|---|---|---|
| Rule 1 | independent set | and is a union of sinks |
| Rule 2 | clique | and is target-free |
| Rule 3 | cycle | and each |
| receives at most one edge with | ||
| Rule 4(i) | a source | if for some |
| Rule 4(ii) | a source | |
| Rule 5(i) | a target | and if for some |
| Rule 5(ii) | a target | and |
| Rule 6 | a sink | |
| Rule 7 | DAG | |
| Rule 8 | arbitrary | is odd |
In many cases, particularly for small graphs, our graph rules are complete enough that they can be used to fully work out . In such cases, is guaranteed to be parameter-independent (since the graph rules do not depend on and ). As an example, consider the graph on nodes in Figure 15A; we will show that is completely determined by graph rules. Going through the possible subsets of different sizes, we find that for only (as those are the sinks). Using Rules 1, 2, and 4, we see that the only elements in are the clique and the independent set . A crucial ingredient for determining the fixed point supports of sizes and is the sinks rule, which guarantees that , , and are the only supports of these sizes. Finally, notice that the total number of fixed points up through size is odd. Using Rule 8 (parity), we can thus conclude that there is no fixed point of full support – that is, with . It follows that ; moreover, this result is parameter-independent because it was determined purely from graph rules. Although the precise values of the fixed points will change for different choices of the parameters and , the set of supports is invariant.
We leave it as an exercise to use graph rules to show that for the graph in Figure 15B, and for the graph in Figure 15C. For the graph in C, it is necessary to appeal to a more general rule for uniform in-degree subgraphs, which we review next.
Rules 1-7, and many more, all emerge as corollaries of more general rules. In the next few subsections, we will introduce the uniform in-degree rule, graphical domination, and simply-embedded subgraphs. Then, in Section 5.5, we will pool together the more general rules into a complete set of elementary graph rules from which all others follow.
5.2 Uniform in-degree rule
It turns out that Rules 1, 2, and 3 (for independent sets, cliques, and cycles) are all corollaries of a single rule for graphs of uniform in-degree.
Definition 5.1.
We say that has uniform in-degree if every node has incoming edges from within .
Note that an independent set has uniform in-degree , a cycle has uniform in-degree , and an -clique is uniform in-degree with . But, in general, uniform in-degree graphs need not be symmetric. For example, the induced subgraph in Figure 15A is uniform in-degree, with .

For CTLNs, a fixed point with support satisfies:
where is a vector of all ’s restricted to the index set . If has uniform in-degree , then the row sums of are identical, and so is an eigenvector. In particular,
where is the (uniform) row sum for the matrix . For in-degree , we compute
Uniform in-degree fixed points with support thus have the same value for all :
| (7) |
(See also [fp-paper, Lemma 18].) From the derivation, it is clear that this formula holds for all uniform in-degree graphs, even those that are not symmetric.
We can use the formula (7) to verify that the on-neuron conditions, for each , are satisfied for within the legal range. Using it to check the off-neuron conditions, we find that for ,
where . From here, it is not difficult to see that the off-neuron condition, , will be satisfied if and only if . This gives us the following theorem.
Theorem 5.2 ([fp-paper]).
Let be an induced subgraph of with uniform in-degree . For , let denote the number of edges for . Then , and
In particular, if and only if there does not exist such that .
5.3 Graphical domination
We have seen that uniform in-degree graphs support fixed points that have uniform firing rates (equation (7)). More generally, fixed points can have very different values across neurons. However, there is some level of “graphical balance” that is required of for any fixed point support . For example, it can be shown that if contains a pair of neurons that have the property that all neurons sending edges to also send edges to , and but , then cannot be a fixed point support. Intuitively, this is because is receiving a strict superset of the inputs to , and this imbalance rules out their ability to coexist in the same fixed point support. This property motivates the following definition.
Definition 5.3.
We say that graphically dominates with respect to in if the following three conditions all hold:
-
1.
For each , if then .
-
2.
If , then .
-
3.
If , then .
We refer to this as “inside-in” domination if (see Figure 18A). In this case, we must have and . If , , we call it “outside-in” domination (Figure 18B). On the other hand, “inside-out” domination is the case where , , and “outside-out” domination refers to (see Figure 18C-D).

What graph rules does domination give us? Intuitively, when inside-in domination is present, the “graphical balance” necessary to support a fixed point is violated, and so . When outside-in dominates , with and , again there is an imbalance, and this time it guarantees that neuron turns on, since it receives all the inputs that were sufficient to turn on neuron . Thus, there cannot be a fixed point with support since node will violate the off-neuron conditions. We can draw interesting conclusions in the other cases of graphical domination as well, as Theorem 5.4 shows.
Theorem 5.4 ([fp-paper]).
Suppose graphically dominates with respect to in . Then the following all hold:
-
1.
(inside-in) If , then and thus .
-
2.
(outside-in) If , , then and thus .
-
3.
(inside-out) If , , then .
-
4.
(outside-out) If , then .
The four cases of Theorem 5.4 are illustrated in Figure 18. This theorem was originally proven in [fp-paper]. Here we provide a more elementary proof, using only the definition of CTLNs and ideas from Section 2.
Proof.
Suppose that graphically dominates with respect to in . To prove statements 1 and 2 in the theorem, we will also assume that there exists a fixed point of the associated CTLN with support . This will allow us to arrive at a contradiction.
If is a fixed point, we must have for all (see equation (3) from Section 2). Recalling that , and that for , it follows that for any , we have:
Since graphically dominates with respect to , we know that for all . This is because the off-diagonal values are either , for , or , for ; and . It now follows from the above equations that . Equivalently,
| (8) |
We will refer frequently to (8) in what follows. There are four cases of domination to consider. We begin with the first two:
-
1.
(inside-in) If , then and , and so at the fixed point we must have But domination in this case implies and , so that and . Plugging this in, we obtain . This results in a contradiction, since and . We conclude that . More specifically, since the contradiction involved only the on-neuron conditions, it follows that .
-
2.
(outside-in) If and , then and with . It follows from (8) that . Since this case of domination also has , we obtain , a contradiction. Again, we can conclude that , and more specifically that .
This completes the proof of statements 1 and 2.
To prove statements 3 and 4, we assume only that , so that a fixed point with support exists in the restricted network , but does not necessarily extend to larger networks. Whether or not it extends depends on whether for all .
-
3.
(inside-out) If and , then and , and so (8) becomes Domination in this case implies , so we obtain . This shows that is guaranteed to satisfy the required off-neuron condition. We can thus conclude that .
-
4.
(outside-out) If , then , and so (8) tells us that . This is true irrespective of whether or not or (and both are optional in this case). Clearly, if then . We can thus conclude that if , then .
∎
Rules 4, 5, and 7 are all consequences of Theorem 5.4. To see how, consider a graph with a source that has an edge for some . Since is a source, it has no incoming edges from within . If , then inside-in dominates and so . If , then outside-in dominates and again . Rule 4(i) immediately follows. We leave it as an exercise to prove Rules 4(ii), 5(i), 5(ii), and 7.
5.4 Simply-embedded subgraphs and covers
Finally, we introduce the concept of simply-embedded subgraphs. This is the last piece we need before presenting the complete set of elementary graph rules.
Definition 5.5 (simply-embedded).
We say that a subgraph is simply-embedded in if for each , either
-
(i)
for all , or
-
(ii)
for all .
In other words, while can have any internal structure, the rest of the network treats all nodes in equally (see Figure 19A). By abuse of notation, we sometimes say that the corresponding subset of vertices is simply-embedded in .

We allow as a trivial case, meaning that is simply-embedded in itself. At the other extreme, all singletons and the empty set are simply-embedded in , also for trivial reasons. Note that a subset of a simply-embedded set, , need not be simply-embedded. This is because nodes in may not treat those in equally.
Now let’s consider the CTLN equations for neurons in a simply-embedded subgraph , for . For each , the equations for the dynamics can be rewritten as:
where the term is identical for all . This is because , if , and if ; so the fact that treats all equally means that the matrix entries are identical for fixed . We can thus define a single time-varying input function,
that is the same independent of the choice of . This gives us:
In particular, the neurons in evolve according to the dynamics of the local network in the presence of a time-varying input , in lieu of the constant .
Suppose we have a fixed point of the full network , with support . At the fixed point,
which is a constant. We can think of this as a new choice of the CTLN input parameter, , with the caveat that we may have . It follows that the restriction of the fixed point to , , must be a fixed point of subnetwork . If , this will be the zero fixed point corresponding to support. If , this fixed point will have nonempty support . From these observations, we have the following key lemma (see Figure 19B):
Lemma 5.6.
Let be simply-embedded in . Then for any ,
What happens if we consider more than one simply-embedded subgraph? Lemma 5.7 shows that intersections of simply-embedded subgraphs are also simply-embedded. However, the union of two simply-embedded subgraphs is only guaranteed to be simply-embedded if the intersection is nonempty. (It is easy to find a counterexample if the intersection is empty.)
Lemma 5.7.
Let be simply-embedded in . Then is simply-embedded in . If then is also simply-embedded in .
Proof.
If , then the intersection is trivially simply-embedded. Assume , and consider . If , then treats all vertices in equally and must therefore treat all vertices in equally. By the same logic, if then it must treat all vertices in equally. It follows that is simply-embedded in .
Next, consider for a pair of subsets such that Let and . If , then for all since ; moreover, for all since . If, on the other hand, , then by the same logic for any and for any . It follows that is simply-embedded in . ∎
If we have two simply-embedded subgraphs, and , we know that for any , must restrict to a fixed point and in each of those subgraphs. But when can we glue together such a and to produce a larger fixed point support in ?
Lemma 5.8 precisely answers this question. It uses the following notation:
Lemma 5.8 (pairwise gluing).
Suppose are simply-embedded in , and consider and that satisfy (so that agree on the overlap ). Then
if and only if one of the following holds:
-
(i)
and or
-
(ii)
and or
-
(iii)
Parts (i-ii) of Lemma 5.8 are essentially the content of [fp-paper, Theorem 14]. Part (iii) can also be proven with similar arguments.
5.5 Elementary graph rules
In this section we collect a set of elementary graph rules from which all other graph rules can be derived. The first two elementary rules arise from general arguments about TLN fixed points stemming from the hyperplane arrangement picture. They hold for all competitive/inhibition-dominated nondegenerate TLNs, as does Elem Rule 3 (aka Rule 8). The last three elementary graph rules are specific to CTLNs, and recap results from the previous three subsections. As usual, is a graph on nodes and is the set of fixed points supports.
There are six elementary graph rules:
-
Elem Rule 1
(unique supports): For a given , there is at most one fixed point per support . The fixed points can therefore be labeled by the elements of .
-
Elem Rule 2
(restriction/lifting): Let . Then
Moreover, whether survives to depends only on the outgoing edges for , not on the backward edges .
-
Elem Rule 3
(parity): The total number of fixed points, is always odd.
-
Elem Rule 4
(uniform in-degree): If has uniform in-degree , then
-
(a)
, and
-
(b)
in
In particular, there does not exist that receives more than edges from .
-
(a)
-
Elem Rule 5
(domination): Suppose graphically dominates with respect to .
-
(a)
(inside-in) If , then and thus .
-
(b)
(outside-in) If , , then
and thus . -
(c)
(inside-out) If , , then
. -
(d)
(outside-out) If , then
.
-
(a)
-
Elem Rule 6
(simply-embedded): Suppose that are simply-embedded in , and recall the notation We have the following restriction and gluing rules:
-
(a)
(restriction)
-
(b)
(pairwise gluing) If , and (so that agree on the overlap ), then if and only if one of the following holds:
-
i.
and
-
ii.
and
-
iii.
Moreover, if we are also guaranteed that and are simply-embedded in . Thus, . If, additionally, , then
-
i.
-
(c)
(lifting) If is a simply-embedded cover of and for each , then
-
(a)

Elem Rule 6 is illustrated in Figure 20. It collects several results related to simply-embedded graphs. Elem Rule 6(a) is the same as Lemma 5.6, while Elem Rule 6(b) is given by Lemmas 5.7 and 5.8. Note that this rule is valid even if or is empty. Elem Rule 6(c) applies to simply-embedded covers of , a notion we will define in the next section (see Definition 6.1, below). The forward direction, , follows from Elem Rule 2. The backwards direction is the content of [fp-paper, Lemma 8].
6 Gluing rules
So far we have seen a variety of graph rules and the elementary graph rules from which they are derived. These rules allow us to rule in and rule out potential fixed points in from purely graph-theoretic considerations. In this section, we consider networks whose graph is composed of smaller induced subgraphs, , for . What is the relationship between and the fixed points of the components, ?
It turns out we can obtain nice results if the induced subgraphs are all simply-embedded in . In this case, we say that has a simply-embedded cover.
Definition 6.1 (simply-embedded covers).
We say that is a simply-embedded cover of if each is simply-embedded in , and for every vertex there exists an such that . In other words, the ’s are a vertex cover of . If the ’s are all disjoint, we say that is a simply-embedded partition of .
Every graph has a trivial simply-embedded cover, with , obtained by taking for each . This is also a simply-embedded partition. At the other extreme, since the full set of vertices is a simply-embedded set, we also have the trivial cover with and . These covers, however, do not yield useful information about . In contrast, nontrivial simply-embedded covers can provide strong constraints on, and in some cases fully determine, the set of fixed points . Some of these constraints can be described via gluing rules, which we explain below.
In the case that has a simply-embedded cover, Lemma 5.6 tells us that all “global” fixed point supports in must be unions of “local” fixed point supports in the , since every restricts to . But what about the other direction?
Question 4.
When does a collection of local fixed point supports , with each nonempty , glue together to form a global fixed point support ?
To answer this question, we develop some notions inspired by sheaf theory. For a graph on nodes, with a simply-embedded cover , we define the gluing complex as:
In other words, consists of all that can be obtained by gluing together local fixed point supports . Note that in order to guarantee that for each , it is necessary that the ’s agree on overlaps (hence the last requirement). This means that is equivalent to:
using the notation
It will also be useful to consider the case where is not allowed to be empty for any . In this case, we define
Translating Lemma 5.6 into the new notation yields the following:
Lemma 6.2.
A CTLN with graph and simply-embedded cover satisfies
The central question addressed by gluing rules (Question 4) thus translates to: What elements of are actually in ?
Some examples. Before delving into this question, we make a few observations. First, note that although is never empty (it must contain ), the set may be empty.
For example, in Figure 21A, , because the only option for is , and this would imply ; but there is no such option in On the other hand, if we are allowed , we can choose and satisfy both and . In fact, this is the only such choice and therefore . Since , it follows from Lemma 6.2 that . In this case, .

Figure 21B displays another graph, , that has a simply-embedded cover with three components, and . Each set of local fixed point supports, (shown at the bottom of Figure 21B), can easily be computed using graph rules. Applying the definitions, we obtain:
Since , this narrows down the list of candidate fixed point supports in . Using Elem Rule 5 (domination), we can eliminate supports and , since dominates with respect to every . On the other hand, Elem Rule 4 (uniform in-degree) allows us to verify that and are all fixed point supports of , while Rule 1 and Rule 6 (sinks) tell us that . We can thus conclude that
Note that for both graphs in Figure 21, we have . While the second containment is guaranteed by Lemma 6.2, the first one need not hold in general.
As mentioned above, the central gluing question is to identify what elements of are in . Our strategy to address this question will be to identify architectures where we can iterate the pairwise gluing rule, Lemma 5.8 (a.k.a. Elem Rule 6(b)). Iteration is possible in a simply-embedded cover provided the unions at each step, are themselves simply-embedded (this may depend on the order). Fortunately, this is the case for several types of natural constructions, including connected unions, disjoint unions, clique unions, and linear chains, which we consider next. Finally, we will examine the case of cyclic unions, where pairwise gluing rules cannot be iterated, but for which we find an equally clean characterization of . All five architectures result in theorems, which we call gluing rules, that are summarized in Table 2.
6.1 Connected unions
Recall that the nerve of a cover is the simplicial complex:
The nerve keeps track of the intersection data of the sets in the cover. We say that a vertex cover of is connected if its nerve is a connected simplicial complex. This means one can “walk” from any to any other through a sequence of steps between ’s that overlap. (Note that a connected nerve does not imply a connected , or vice versa.)

Any graph admits vertex covers that are connected. Having a connected cover that is also simply-embedded, however, is quite restrictive. We call such architectures connected unions:
Definition 6.3.
A graph is a connected union of induced subgraphs if is a simply-embedded cover of that is also connected.
If has a connected simply-embedded cover, then without loss of generality we can enumerate the sets in such a way that each partial union is also simply-embedded in , by ensuring that for each (see Lemma 5.7). This allows us to iterate the pairwise gluing rule, Elem Rule 6(b)iii. In fact, by analyzing the different cases with the empty or nonempty, we can determine that all gluings of compatible fixed points supports are realized in . This yields our first gluing rule theorem:
Theorem 6.4.
If is a connected union of subgraphs , with , then
It is easy to check that this theorem exactly predicts for the graphs in Figure 20E,F and Figure 21A.
Example.
To see the power of Theorem 6.4, consider the graph on nodes in Figure 22. is a rather complicated graph, but it has a connected, simply-embedded cover with subgraphs given in Figure 22A. Note that for this graph, the simply-embedded requirement automatically determines all additional edges in . For example, since in , and , we must also have . In contrast, in , and hence we must have and .
Using simple graph rules, it is easy to compute and as these are small graphs. It would be much more difficult to compute the full network’s in this way. However, because is a connected union, Theorem 6.4 tells us that By simply checking compatibility on overlaps of the possible , we can easily compute:
Note that the minimal fixed point supports, and are all core motifs: is a -ufd graph, while the others are -cycles. Moreover, they each have corresponding attractors, as predicted from our previous observations about core motifs [core-motifs]. The attractors are shown in Figure 22C.
6.2 Disjoint unions, clique unions, cyclic unions, and linear chains
Theorem 6.4 gave us a nice gluing rule in the case where has a connected simply-embedded cover. At the other extreme are simply-embedded partitions. If is a simply-embedded partition, then all ’s are disjoint and the nerve is completely disconnected, consisting of the isolated vertices .
The following graph constructions all arise from simply-embedded partitions.
Definition 6.5.
Consider a graph with induced subgraphs corresponding to a vertex partition . Then
-
–
is a disjoint union if there are no edges between and for . (See Figure 23A.)
-
–
is a clique union if it contains all possible edges between and for . (See Figure 23B.)
-
–
is a linear chain if it contains all possible edges from to , for , and no other edges between distinct and . (See Figure 23C.)
-
–
is a cyclic union if it contains all possible edges from to , for , as well as all possible edges from to , but no other edges between distinct components , . (See Figure 23D.)
Note that in each of these cases, is a simply-embedded partition of .

| s-e architecture | fixed point supports | theorem | |
|---|---|---|---|
| connected union | depends on overlaps | Thm 6.4 | |
| disjoint union | Thm 6.6 | ||
| = | |||
| clique union | Thm 6.7 | ||
| = | |||
| linear chain | Thm 6.8 | ||
| cyclic union | Thm 6.7 | ||
| = |
Since the simply-embedded subgraphs in a partition are all disjoint, Lemma 5.8(i-ii) applies. Consequently, fixed point supports and will glue together if and only if either and both survive to yield fixed points in , or neither survives. For both disjoint unions and clique unions, it is easy to see that all larger unions of the form are themselves simply-embedded. We can thus iteratively use the pairwise gluing Lemma 5.8. For disjoint unions, Lemma 5.8(i) applies, since every survives in . This yields our first gluing theorem. Recall that .
Theorem 6.6.
[fp-paper, Theorem 11] If is a disjoint union of subgraphs , with , then
Note that this looks identical to the result for connected unions, Theorem 6.4. One difference is that compatibility of ’s need not be checked, since the ’s are disjoint, so is particularly easy to compute. In this case the size of is also the maximum possible for a graph with a simply-embedded cover :
On the other hand, for clique unions, we must apply Lemma 5.8(ii), which shows that only gluings involving a nonempty from each component are allowed. Hence . Interestingly, the same result holds for cyclic unions, but the proof is different because the simply-embedded structure does not get preserved under unions, and hence Lemma 5.8 cannot be iterated. These results are combined in the next theorem.
Theorem 6.7.
[fp-paper, Theorems 12 and 13] If is a clique union or a cyclic union of subgraphs , with , then
In this case,
Finally, we consider linear chain architectures. In the case of a linear chain (Figure 23C), the gluing sequence must respect the ordering in order to guarantee that the unions are all simply-embedded. (In the case of disjoint and clique unions, the order didn’t matter.) Now consider the first pairwise gluing, with and . Each has a target in , and hence does not survive to (by Rule 5(ii)). On the other hand, any has no outgoing edges to , and is thus guaranteed to survive. Elem Rule 6(b) thus tells us that unless . Therefore, . Iterating this procedure, adding the next at each step, we see that . In the end, we obtain our fourth gluing theorem:
Theorem 6.8.
[seq-attractors] If is a linear chain of subgraphs , then
Clearly, in this case.
Table 2 summarizes the gluing rules for connected unions, disjoint unions, clique unions, cyclic unions, and linear chains.
6.3 Applications of gluing rules to core motifs
Using the above results, it is interesting to revisit the subject of core motifs. Recall that core motifs of CTLNs are subgraphs that support a unique fixed point, which has full-support: . We denote the set of surviving core motifs by
For small CTLNs, we have seen that core motifs are predictive of a network’s attractors [core-motifs]. We also saw this in Figure 22, with attractors corresponding to the core motifs in a CTLN for a connected union.
What can gluing rules tell us about core motifs? Consider the architectures in Table 2. In the case of disjoint unions, we know that we can never obtain a core motif, since whenever there is more than one component subgraph. In the case of connected unions, however, we have a nice result in the situation where all components are core motifs. In this case, the additional compatibility requirement on overlaps forces .
Corollary 6.9.
If is a connected union of core motifs, then is a core motif.
Proof.
Let be the component core motifs for the connected union , a graph on nodes. Since is a connected cover, and each component has , the only possible arises from taking in each component, so that . (By compatibility, taking an empty set in any component forces choosing an empty set in all components, yielding , which is not allowed in .) Applying Theorem 6.4, we see that . Hence, is a core motif. ∎
As of this writing, we have no good reason to believe the converse is true. However, we have yet to find a counterexample.
In the case of clique unions and cyclic unions, however, , and gluing in empty sets is again not allowed on components. In these cases, we obtain a similar result, and the converse is also true.
Corollary 6.10.
Let be a clique union or a cyclic union of components . Then
In particular, is a core motif if and only if every is a core motif.
Proof.
We will prove the second statement. The expression for easily follows from this together with Elem Rule 6(c). Let be a clique union or a cyclic union for a simply-embedded partition . Theorem 6.7 tells us that . Observe that any must have nonempty for each . () If each is a core motif, it follows that for each , and hence . () If the component graphs are not all core, then will necessarily have more than one fixed point and cannot be core.∎
Going back to Figure 12, we can now see that all core motifs up to size are either clique unions, cyclic unions, or connected unions of smaller core motifs. For example, the -cycu graph is the cyclic union of a singleton (node ), a -clique (nodes and ), and another singleton (node ). The fusion -cycle is a clique union of a -cycle and a singleton. Finally, the -ufd is the connected union of a -cycle and a -clique. Infinite families of core motifs can be generated in this way, each having their own particular attractors.
6.4 Modeling with cyclic unions
The power of graph rules is that they enable us to reason mathematically about the graph of a CTLN and make surprisingly accurate predictions about the dynamics. This is particularly true for cyclic unions, where the dynamics consistently appear to traverse the components in cyclic order. Consequently, these architectures are useful for modeling a variety of phenomena that involve sequential attractors. This includes the storage and retrieval of sequential memories, as well as CPGs responsible for rhythmic activity, such as locomotion [Marder-CPG, Yuste-CPG].
Recall that the attractors of a network tend to correspond to core motifs in . Using Corollary 6.10, we can easily engineer cyclic unions that have multiple sequential attractors. For example, consider the cyclic union in Figure 24A, with comprised of all cycles of length 5 that contain exactly one node per component. For parameters , , the CTLN yields a limit cycle (Figure 24B), corresponding to one such core motif, with sequential firing of a node from each component. By symmetry, there must be an equivalent limit cycle for every choice of 5 nodes, one from each layer, and thus the network is guaranteed to have limit cycles. Note that this network architecture, increased to 7 layers, could serve as a mechanism for storing phone numbers in working memory ( for digits ).

As another application of cyclic unions, consider the graph in Figure 25A which produces the quadruped gait ‘bound’ (similar to gallop), where we have associated each of the four colored nodes with a leg of the animal. Notice that the clique between pairs of legs ensures that those nodes co-fire, and the cyclic union structure guarantees that the activity flows forward cyclically. A similar network was created for the ‘trot’ gait, with appropriate pairs of legs joined by cliques.

Figure 25B shows a network in which both the ‘bound’ and ‘trot’ gaits can coexist, with the network selecting one pattern (limit cycle) over the other based solely on initial conditions. This network was produced by essentially overlaying the two architectures that would produce the desired gaits, identifying the two graphs along the nodes corresponding to each leg. Notice that within this larger network, the induced subgraphs for each gait are no longer perfect cyclic unions (since they include additional edges between pairs of legs), and are no longer core motifs. And yet the combined network still produces limit cycles that are qualitatively similar to those of the isolated cyclic unions for each gait. It is an open question when this type of merging procedure for cyclic unions (or other types of subnetworks) will preserve the original limit cycles within the larger network.
7 Conclusions
Recurrent network models such as TLNs have historically played an important role in theoretical neuroscience; they give mathematical grounding to key ideas about neural dynamics and connectivity, and provide concrete examples of networks that encode multiple attractors. These attractors represent the possible responses, e.g. stored memory patterns, of the network.
In the case of CTLNs, we have been able to prove a variety of results, such as graph rules, about the fixed point supports – yielding valuable insights into the attractor dynamics. Many of these results can be extended beyond CTLNs to more general families of TLNs, and potentially to other threshold nonlinearities. The reason lies in the combinatorial geometry of the hyperplane arrangements. In addition to the arrangements discussed in Section 2, there are closely related hyperplane arrangements given by the nullclines of TLNs, defined by for each . It is easy to see that fixed points correspond to intersections of nullclines, and thus the elements of are completely determined by the combinatorial geometry of the nullcline arrangement. Intuitively, the combinatorial geometry of such an arrangement is preserved under small perturbations of and . This allows us to extend CTLN results and study how changes as we vary the TLN parameters and . These ideas, including connections to oriented matroids, were further developed in [oriented-matroids-paper].
In addition to gluing rules, we have also studied graphs with simply-embedded covers and related structures in order to predict the sequential attractors of a network [seq-attractors]. This has led us to introduce the notions of directional graphs and directional covers, allowing us to generalize cyclic unions and DAGs. In particular, we were able to prove various nerve theorems for CTLNs, wherein the dynamics of a network with a directional cover can be described via the dynamics of a reduced network defined on the nerve [nerve-thms-ctlns].
Finally, although the theory of TLNs and CTLNs has progressed significantly in recent years, many open questions remain. We end with a partial list.
7.1 Open Questions
We group our open questions into four categories.
The first category concerns the bifurcation theory of TLNs, focusing on changes in as one varies or :
-
1.
Recall the definition, in equation (4), of for an arbitrary TLN . How does the set of fixed point supports change as we vary or ? What are the possible bifurcations? For example, what pairs of supports, , can disappear or co-appear at the same time?
This first question is very general. The next two questions focus on special cases where partial progress has already been made.
-
2.
If we look beyond CTLNs, but constrain the matrix to respect a given architecture , how does this constrain the possibilities for ?
In the case of constant across neurons, we have identified robust motifs, graphs for which is invariant across all compatible choices of [robust-motifs]. What graphs allow only a few possibilities for ? What are the most flexible graphs for which can vary the most?
-
3.
What happens if we fix and vary ? What features of the connectivity matrix control the repertoire of possible fixed point regimes, ? What matrices allow a core motif region, for which ? And how do the dynamic attractors of a network change as we transition between different regions in -space?
The second category concerns the relationship between TLNs and the geometry of the associated hyperplane arrangements:
-
4.
To what extent does the hyperplane arrangement of a TLN, as described in Section 2, determine its dynamics? What are all the choices that have the same hyperplane arrangement? Same nullcline arrangement?
-
5.
What happens if we change the nonlinearity in equation (1) from to a sigmoid function, a threshold power-law nonlinearity [ken-miller-thresh-power-law], or something else? Can we adapt the proofs and obtain similar results for and in these cases?
Note that the combinatorial geometry approach in [oriented-matroids-paper] suggests that the results should not depend too heavily on the details of the nonlinearity. Instead, it is the resulting arrangement of nullclines that is essential for determining the fixed points.
The third category concerns graph rules, core motifs, and the corresponding attractors:
-
6.
What other graph rules or gluing rules follow from the elementary graph rules? We believe our current list is far from exhaustive.
-
7.
Classify all core motifs for CTLNs. We already have a classification for graphs up to size [n5-github], but beyond this little is known. Note that gluing rules allow us to construct infinite families of core motifs from gluing together smaller component cores (see Section 6.3). Are there other families of core motifs that cannot be obtained via gluing rules? What can we say about the corresponding attractors?
-
8.
Computational evidence suggests a strong correspondence between core motifs and the attractors of a network, at least in the case of small CTLNs [core-motifs, n5-github]. Can we make this correspondence precise? Under what conditions does the correspondence between surviving core fixed points and attractors hold?
-
9.
How does symmetry affect the attractors of a network? The automorphism group of a graph naturally acts on an associated CTLN by permuting the variables, . This translates to symmetries of the defining vector field (2), and a group action on the set of attractors. The automorphism group can either fix attractors or permute them. Moreover, a network may also have “surprise symmetry,” as in Figure 9, where the attractors display additional symmetry that was not present in the original graph . How do we make sense of these various phenomena?
Finally, the fourth category collects various conjectures about dynamic behaviors that we have observed in simulations.
-
10.
In [CTLN-preprint, stable-fp-paper] we conjectured that all stable fixed points of a CTLN correspond to target-free cliques. While [stable-fp-paper] provides proofs of this conjecture in special cases, the general question remains open.
-
11.
The Gaudi attractor from Figure 8 appears to have constant total population activity. In other words, appears to be constant in numerical experiments, once the trajectory has converged to the attractor. Can we prove this? For what other (non-static) TLN/CTLN attractors is the total population activity conserved?
-
12.
Prove that the “baby chaos” network in Figure 11D-F is chaotic. I.e., prove that the individual attractors are chaotic (or strange), in the same sense as the Lorenz or Rossler attractors.
-
13.
A proper source of a graph is a source node that has at least one outgoing edge, for . In numerical experiments, we have observed that proper sources of CTLNs always seem to “die” – that is, their activity tends to zero as , regardless of initial conditions. Can we prove this?
Some progress on this question was made in [caitlin-thesis], but the general conjecture remains open. Note that although the sources Rule 4(i) guarantees that proper sources do not appear in any fixed point support of , this alone does not imply that the activity at such nodes converges to zero.
-
14.
In our classification of attractors for small CTLNs, we observed that if two CTLNs with distinct graphs have the “same” attractor, as in Figure 14, then this attractor is preserved for the entire family of TLNs whose matrices linearly interpolate between the two CTLNs (and have the same constant for all ). In other words, the attractor persists for all TLNs with and , where and are the two CTLN connectivity matrices. (Note that the interpolating networks for are not CTLNs.) Can we prove this?
More generally, we conjecture that if the same attractor is present for a set of TLNs , then it is present for all TLNs with in the convex hull of the matrices.
Acknowledgments
We would like to thank Zelong Li, Nicole Sanderson, and Juliana Londono Alvarez for a careful reading of the manuscript. We also thank Caitlyn Parmelee, Caitlin Lienkaemper, Safaan Sadiq, Anda Degeratu, Vladimir Itskov, Christopher Langdon, Jesse Geneson, Daniela Egas Santander, Stefania Ebli, Alice Patania, Joshua Paik, Samantha Moore, Devon Olds, and Joaquin Castañeda for many useful discussions. The first author was supported by NIH R01 EB022862, NIH R01 NS120581, NSF DMS-1951165, and a Simons Fellowship. The second author was supported by NIH R01 EB022862 and NSF DMS-1951599.