Graph Feedback Bandits with Similar Arms
Abstract
In this paper, we study the stochastic multi-armed bandit problem with graph feedback. Motivated by the clinical trials and recommendation problem, we assume that two arms are connected if and only if they are similar (i.e., their means are close enough). We establish a regret lower bound for this novel feedback structure and introduce two UCB-based algorithms: D-UCB with problem-independent regret upper bounds and C-UCB with problem-dependent upper bounds. Leveraging the similarity structure, we also consider the scenario where the number of arms increases over time. Practical applications related to this scenario include Q&A platforms (Reddit, Stack Overflow, Quora) and product reviews in Amazon and Flipkart. Answers (product reviews) continually appear on the website, and the goal is to display the best answers (product reviews) at the top. When the means of arms are independently generated from some distribution, we provide regret upper bounds for both algorithms and discuss the sub-linearity of bounds in relation to the distribution of means. Finally, we conduct experiments to validate the theoretical results.
1 Introduction
The multi-armed bandit is a classical reinforcement learning problem. At each time step, the learner needs to select an arm. This will yield a reward drawn from a probability distribution (unknown to the learner). The learner’s goal is to maximize the cumulative reward over a period of time steps. This problem has attracted attention from the online learning community because of its effective balance between exploration (trying out as many arms as possible) and exploitation (utilizing the arm with the best current performance). A number of applications of multi-armed bandit can be found in online sequential decision problems, such as online recommendation systems [Li et al., 2011], online advertisement campaign [Schwartz et al., 2017] and clinical trials [Villar et al., 2015, Aziz et al., 2021].
In the standard multi-armed bandit, the learner can only observe the reward of the chosen arm. There has been existing research [Mannor and Shamir, 2011, Caron et al., 2012, Hu et al., 2020, Lykouris et al., 2020] that considers the bandit problem with side observations, wherein the learner can observe information about arms other than the selected one. This observation structure can be encoded as a graph, each node represents an arm. Node is linked to node if selecting provides information on the reward of .
We study a new feedback model: if any two arms are -similar, i.e., the absolute value of the difference between the means of the two arms does not exceed , an edge will form between them. This means that after observing the reward of one arm, the decision-maker simultaneously knows the rewards of arms similar to it. If , this feedback model is the standard multi-armed bandit problem. If is greater than the maximum expected reward, this feedback model turns out to be the full information bandit problem.
As a motivating example, consider the recommendation problem in Spotify and Apple Music. After a recommender suggests a song to a user, they can observe not only whether the user liked or saved the song (reward), but also infer that the user is likely to like or save another song that is very similar. Similarity may be based on factors such as the artist, songwriter, genre, and more. As another motivating example, consider the problem of medicine clinical trials mentioned above. Each arm represents a different medical treatment plan, and these plans may have some similarities such as dosage, formulation, etc. When a researcher selects a plan, they not only observe the reward of that treatment plan but also know the effects of others similar to the selected one. The treatment effect (reward) can be either some summary information or a relative effect, such as positive or negative. Similar examples also appear in chemistry molecular simulations [Pérez et al., 2020].
In this paper, we consider two bandit models: the standard graph feedback bandit problem and the bandit problem with an increasing number of arms. The latter is a more challenging setting than the standard multi-armed bandit. Relevant applications for this scenario encompass Q&A platforms such as Reddit, Stack Overflow, and Quora, as well as product reviews on websites like Amazon and Flipkart. Answers or product reviews continuously populate these platforms means that the number of arms increases over time. The goal is to display the best answers or product reviews at the top. This problem has been previously studied and referred to as "ballooning multi-armed bandits" by Ghalme et al. [2021]. However, they require the optimal arm is more likely to arrive in the early rounds. Our contributions are as follows:
-
1.
We propose a new feedback model, where an edge is formed when the means of two arms is less than some constant . We first analyze the underlying graph of this feedback model and establish that the dominant number is equal to the minimum size of an independent dominating set , while the independent number is not greater than twice the dominant number ,i.e. . This result is helpful to the design and analysis of the following algorithms.
-
2.
In this feedback setting, we first establish a problem-dependent regret lower bound related to . Then, we introduce two algorithms tailored for this specific feedback structure: Double-UCB (D-UCB), utilizing twice UCB algorithms sequentially, and Conservative-UCB (C-UCB), employing a more conservative strategy during the exploration. Regret upper bounds are provided for both algorithms, with D-UCB obtaining a problem-independent bound, while C-UCB achieves a problem-dependent regret bound. Additionally, we analyze the regret bounds of UCB-N [Lykouris et al., 2020] applied to our proposed setting and prove that its regret upper bound shares the same order as D-UCB.
-
3.
We extend D-UCB and C-UCB to the scenario where the number of arms increases over time. Our algorithm does not require the optimal arm to arrive early but assumes that the means of each arrived arm are independently sampled from some distribution, which is more realistic. We provide the regret upper bounds for D-UCB and C-UCB, along with a simple regret lower bound for D-UCB. The lower bound of D-UCB indicates that it achieves sublinear regret only when the means are drawn from a normal-like distribution, while it incurs linear regret for means drawn from a uniform distribution. In contrast, C-UCB can achieve a problem-dependent sublinear regret upper bound regardless of the means distribution.
2 Related Works
Bandits with side observations was first introduced by Mannor and Shamir [2011] for adversarial settings. They proposed two algorithms: ExpBan, a hybrid algorithm combining expert and bandit algorithms based on clique decomposition of the side observations graph; ELP, an extension of the well-known EXP3 algorithm [Auer et al., 2002b]. Caron et al. [2012], Hu et al. [2020] considered stochastic bandits with side observations. They proposed the UCB-N, UCB-NE, and TS-N algorithms, respectively. The regret upper bounds they obtain are of the form , where is the clique covering of the side observation graph.
There has been some works that employ techniques beyond clique partition. Buccapatnam et al. [2014, 2018] proposed the algorithm named UCB-LP, which combine a version of eliminating arms [Even-Dar et al., 2006] suggested by Auer and Ortner [2010] with linear programming to incorporate the graph structure. This algorithm has a regret guarantee of , where is a particularly selected dominating set, is the number of arms. Cohen et al. [2016] used a method based on elimination and provides the regret upper bound as , where is the independence number of the underlying graph. Lykouris et al. [2020] utilized a hierarchical approach inspired by elimination to analyze the feedback graph, demonstrating that UCB-N and TS-N have regret bounds of order , where is an independent set of the graph. There is also some work that considers the case where the feedback graph is a random graph [Alon et al., 2017, Ghari and Shen, 2022, Esposito et al., 2022].
Currently, there is limited research considering scenarios where the number of arms can change. Chakrabarti et al. [2008] was the first to explore this dynamic setting. Their model assumes that each arm has a lifetime budget, after which it automatically disappears, and will be replaced by a new arm. Since the algorithm needs to continuously explore newly available arms in this setting, they only provided the upper bound of the mean regret per time step. Ghalme et al. [2021] considered the "ballooning multi-armed bandits" where the number of arms will increase but not disappear. They show that the regret grows linearly without any distributional assumptions on the arrival of the arms’ means. With the assumption that the optimal arm arrives early with high probability, their proposed algorithm BL-MOSS can achieve sublinear regret. In this paper, we also only consider the "ballooning" settings but without the assumption on the optimal arm’s arrival pattern. We use the feedback graph model mentioned above and assume that the means of each arrived arm are independently sampled from some distribution.
Clustering bandits Gentile et al. [2014], Li et al. [2016], Yang et al. [2022], Wang et al. [2024] are also relevant to our work. Typically, these models assume that a set of arms (or items) can be classified into several unknown groups. Within each group, the observations associated to each of the arms follow the same distribution with the same mean. However, we do not employ a defined concept of clustering groups. Instead, we establish connections between arms by forming an edge only when their means are less than a threshold , thereby creating a graph feedback structure.
3 Problem Formulation
3.1 Graph Feedback with Similar Arms
We consider a stochastic -armed bandit problem with an undirected feedback graph and time horizon (). At each round , the learner select arm , obtains a reward . Without losing generality, we assume that the rewards are bounded in or -subGaussian111This is simply to provide a uniform description of both bounded rewards and subGaussian rewards. Our results can be easily extended to other subGaussian distributions.. The expectation of is denoted as . Graph denotes the underlying graph that captures all the feedback relationships over the arms set . An edge in means that and are -similarty, i.e.,
where is some constant greater than . The learner can get a side observation of arm when pulling arm , and vice versa. Let denote the observation set of arm consisting of and its neighbors in . Let and denote the number of pulls and observations of arm till time respectively. We assume that each node in graph contains a self-loops, i.e., the learner will observe the reward of the pulled arm.
Let denote the expected reward of the optimal arm, i.e., . The gap between the expectation of the optimal arm and the suboptimal arm is denoted as A policy, denoted as , that selects arm to play at time step based on the history plays and rewards. The performance of the policy is measured as
| (1) |
3.2 Ballooning bandit setting
This setting is the same as the graph feedback with similar arms above, except that the number of arms is increased over time. Let denote the set of available arms at round . We consider a tricky case that a new arm will arrive at each round, the total number of arms is . We assume that the means of each arrived arms are independently sampled from some distribution . Let denote the arrived arm at round ,
The newly arrived arm may be connected to previous arms, depending on whether their means satisfy the -similarity. In this setting, the optimal arm may vary over time. Let denote the expected reward of the optimal arm, i.e., . The regret is given by
| (2) |
4 Stationary Environments
In this section, we consider the graph feedback with similar arms in stationary environments, i.e., the number of arms remains constant. We first analyze the structure of the feedback graph. Then, we provide a problem-dependent regret lower bound. Following that, we introduce the D-UCB and C-UCB algorithm and provide the regret upper bounds.
Dominating and Independent Dominating Sets. A dominating set in a graph is a set of vertices such that every vertex not in is adjacent to a vertex in . The domination number of , denoted as , is the smallest size of a dominating set.
An independent set contains vertices that are not adjacent to each other. An independent dominating set in is a set that both dominates and is independent. The independent domination number of , denoted as , is the smallest size of such a set. The independence number of , denoted as , is the largest size of an independent set in . For a general graph , it follows immediately that .
Proposition 4.1.
Let denote the feedback graph with similar arms setting, we have
Proof sketch. The first equation can be obtained by proving that is a claw-free graph and using Lemma A.2. The second inequality can be obtained by a double counting argument. The details are in the appendix.
Proposition 4.1 shows that . Once we obtain the bounds based on independence number, we also simultaneously obtain the bounds based on the domination number. Therefore, we can obtain regret bounds based on the minimum dominating set without using the feedback graph to explicitly target exploration. This cannot be guaranteed in the standard graph feedback bandit problem [Lykouris et al., 2020].
4.1 Lower Bounds
Before presenting our algorithm, we first investigate the regret lower bound of this problem. Without loss of generality, we assume the reward distribution is -subGaussian.
Let . We assume that in our analysis. In other words, we do not consider the easily distinguishable scenario where the optimal arm and the suboptimal arms are clearly separable. If , our analysis method is also applicable, but the terms related to will vanish in the expressions of both the lower and upper bounds. Caron et al. [2012] has provided a lower bound of , and we present a more refined lower bound specifically for our similarity feedback.
Theorem 4.2.
If a policy is uniform good222For more details, see [Lai et al., 1985]., for any problem instance, it holds that
| (3) |
where .
Proof.
Let denote an independent dominant set that includes . From Proposition 4.1, . The second-best arm is denoted as , Since , .
Let’s construct another policy for another problem-instance on without side observations. If select arm at round , select the arm as following: if , select arm too. If , will select the arm of with the largest mean. Since , policy is well-defined. It is clearly that . By the classical result of [Lai et al., 1985],
| (4) |
. is some positive integer smaller than . Since is an independent set, , we have . Therefore, we can complete this proof by
∎
Consider two simple cases. (1) . The feedback graph is a complete graph or some graph with independence number less than . Then , the lower bound holds strictly when is not a complete graph. (2) , . In this case, the terms in the lower bound involving have the same order as the corresponding terms in the upper bound of the following proposed algorithms.
4.2 Double-UCB
This particular feedback structure inspires us to distinguish arms within the independent set first. This is a straightforward task because the distance between the mean of each arm in the independent set is greater than . Subsequently, we learn from the arm with the maximum confidence bound in the independent set and its neighborhood, which may include the optimal arm. Our algorithm alternates between the two processes simultaneously.
Algorithm 1 shows the pseudocode of our method. Steps 4-9 identify an independent set in , play each arm in the independent set once. This process does not require knowledge of the complete graph structure and requires at most rounds. Step 10 calculates the arm with the maximum upper confidence bound in the independent set. After a finite number of rounds, the optimal arm is likely to fall within . Step 11 use the UCB algorithm again to select arm in . This algorithm employs UCB rules twice for arm selection, hence it is named Double-UCB.
4.2.1 Regret Analysis of Double-UCB
We use to denote the set of all independent dominating sets of graph formed by . Let
Note that, the elements in are independent sets rather than individual nodes, and , .
Theorem 4.3.
Assume that the reward distribution is -subgaussian or bounded in , set the regret of Double-UCB after rounds is upper bounded by
| (5) | ||||
where
Recall that we assume , then . The index set in the summation of the first term is non-empty. If , . The first term will vanish.
Proof sketch. The regret can be analyzed in two parts. The first part arises from Step 9 selecting whose neighborhood does not contain the optimal arm. The algorithm can easily distinguish the suboptimal arms in from the optimal arm. The regret caused by this part is . The second part of the regret comes from selecting a suboptimal arm in . This part can be viewed as applying UCB rule on a graph with an independence number less than 2.
Since , , we have
Therefore, the regret upper bound can be denoted as
| (6) |
Our upper bound suffers an extra logarithm term compared to the lower bound Theorem 4.2. The inclusion of this additional logarithm appears to be essential if one uses a gap-based analysis similar to [Cohen et al., 2016]. This issue has been discussed in [Lykouris et al., 2020].
From Theorem 4.3, we have the following gap-free upper bound
Corollary 4.4.
The regret of Double-UCB is bounded by
4.3 Conservative UCB
Double-UCB is a very natural algorithm for similar arms setting. For this particular feedback structure, we propose the conservative UCB, which simply modifies Step 10 of Algorithm 1 to . This form of the index function is conservative when exploring arms in . It does not immediately try each arm but selects those that have been observed a sufficient number of times. Algorithm 2 shows the pseudocode of C-UCB.
4.3.1 Regret Analysis of Conservative UCB
Let denote the subgraph with arms . The set of all independent dominating sets of graph is denoted as . We can also define in this way. Define .
We divide the regret into two parts. The first part is the regret caused by choosing arm in , and the analysis for this part follows the same approach as D-UCB.
The second part is the regret of choosing the suboptimal arms in . It can be proven that if the optimal arm is observed more than times, the algorithm will select the optimal arm with high probability. Intuitively, for any arm , the following events hold with high probability:
| (7) |
and
| (8) |
Since the optimal arm satisfies Equation 7 and the suboptimal arms satisfy Equation 8 with high probability, the suboptimal arms are unlikely to be selected.
The key to the problem lies in ensuring that the optimal arm can be observed times. Since in the graph formed by , all arms are connected to . As long as the time steps are sufficiently long, arm will inevitably be observed more than times, then the arms with means less than will be ignored (similar to Equation 7 and Equation 8). Choosing arms that the means between will always observe the optimal arm, so the optimal arm can be observed times. Therefore, we have the following theorem:
Theorem 4.5.
Under the same conditions as Theorem 4.3, the regret of C-UCB is upper bounded by
| (9) |
The regret upper bound of C-UCB decreases by a logarithmic factor compared to D-UCB, but with an additional problem-dependent term . This upper bound still does not match the lower bound in Theorem 4.2, as . If we ignore the terms independent of , the regret upper bound of C-UCB matches the lower bound of .
4.4 UCB-N
UCB-N has been analyzed in the standard graph feedback model [Caron et al., 2012, Hu et al., 2020, Lykouris et al., 2020]. One may wonder whether UCB-N can achieve similar regret upper bounds. In fact, if UCB-N uses the same upper confidence function as ours, UCB-N has a similar regret upper bound to D-UCB. We have the following theorem:
Theorem 4.6.
Remark 4.7.
The gap-free upper bound of UCB-N is also . Due to the similarity assumption, the regret upper bound of UCB-N is improved compared to [Lykouris et al., 2020]. D-UCB and C-UCB are specifically designed for similarity feedback structures and may fail in the case of standard graph feedback settings. This is because the optimal arm may be connected to an arm with a very small mean, so the selected in Step 9 may not necessarily include the optimal arm. However, under the ballooning setting, UCB-N cannot achieve sublinear regret. D-UCB and C-UCB can be naturally applied in this setting and achieve sublinear regret under certain conditions.
5 Ballooning Environments
This section considers the setting where arms are increased over time. This problem is highly challenging, as prior research relied on strong assumptions to achieve sublinear regret. The graph feedback structure we propose is particularly effective for this setting. Intuitively, if an arrived arm has a mean very close to arms that have already been distinguished, the algorithm does not need to distinguish it further. This may lead to a significantly smaller number of truly effective arrived arms than , making it easier to obtain a sublinear regret bound.
5.1 Double-UCB for Ballooning Setting
Algorithm 3 shows the pseudocode of our method Double-UCB-BL. For any set , let denote the set of arms linked to , i.e., . Upon the arrival of each arm, first check whether it is in . If it is not, add it to to form a new independent set. The construction of the independent set is formed online as arms arrive, while the other parts remain entirely consistent with Double-UCB.
5.1.1 Regret Analysis
Let denote the independent set at time and denote the arm that include the optimal arm . Define . To simplify the problem, we only consider the problem instances that satisfy the following assumption:
Assumption 5.1.
, is some constant.
The first challenge in ballooning settings is the potential existence of many arms with means very close to the optimal arm. That is, the set may be very large. We first define a quantity that is easy to analyze as the expected upper bound for all arms falling into . Define
| (11) | ||||
It’s easy to verify that . We have
The second challenge is that our regret is likely related to the independence number, yet under the ballooning setting, the graph’s independence number is a random variable. Denote the independence number as . We attempt to address this issue by providing a high-probability upper bound for the independence number. Let , then
| (12) |
where is the probability density function of . Let , Lemma A.3 has proved a high-probability upper bound of related to .
Now, we can give the following upper bound of Double-UCB.
Theorem 5.2.
Assume that the reward distribution is -subgaussian or bounded in , set the regret of Double-UCB after rounds is upper bounded by
| (13) | ||||
If is Gaussian distribution, we have the following corollary:
Corollary 5.3.
If is the Gaussian distribution , we have and . The asymptotic regret upper bound is of order
The order of is smaller than any power of . For example, if , is a positive integer, we have .
Lower Bounds of Double-UCB Define . Then we have . Let
We have . If arm arrives and falls into set at round , then the arm will be selected at least once, unless the algorithm select in Step 9. Note that if an arm in is selected at some round, the resulting regret is at least . Once we estimate the size of and the number of rounds with , a simple regret lower bound can be obtained. We have the following lower bound:
Theorem 5.4.
Assume that the reward distribution is -subgaussian or bounded in , set the regret lower bound of Double-UCB is
| (14) |
If is the uniform distribution , we can calculate that . If is the half-triangle distribution with probability density function as . We can also calculate . Therefore, their regret lower bounds are of linear order.
5.2 C-UCB for Ballooning Setting
The failure on the common uniform distribution limits the D-UCB’s application. The fundamental reason is the aggressive exploration strategy of the UCB algorithm, which tries to explore every arm that enters set as much as possible. In this section, we apply C-UCB to ballooning settings, which imposes no requirements on the distribution .
Algorithm 4 shows the pseudocode of conservative UCB (C-UCB). This algorithm is almost identical to D-UCB, with the only change being that the rule for selecting an arm is . This improvement avoids exploring every arm that enters . It is only chosen if it has been observed a sufficient number of times and its confidence lower bound is the largest. We have the following regret upper bound for C-UCB:
Theorem 5.5.
Assume that the reward distribution is -subgaussian or bounded in , set the regret of C-UCB is upper bounded by
| (15) | ||||
The arms arrive one by one in ballooning setting, and the optimal arm may change over time. Therefore, the regret upper bound depends on rather than . Compared to Theorem 5.2, the upper bound for C-UCB does not involve , making it independent of the distribution . Under the conditions of 5.1, it achieves a regret upper bound of .

6 Experiments
6.1 Stationary Settings
We first compared the performance of UCB-N under standard graph feedback and graph feedback with similar arms 333Our code is available at https://github.com/qh1874/GraphBandits_SimilarArms. The purpose of this experiment is to show that the similarity structure improves the performance of the original UCB algorithm. To ensure fairness, the problem instances we use in both cases have roughly the same independence number. In the standard graph feedback, we also use a random graph, generating edges with a probability calculated by Equation 12. The graph generated in this way has roughly the same independence number as the graph in the -similarity setting. In particular, if is the Gaussian distribution , then
If is the uniform distribution ,
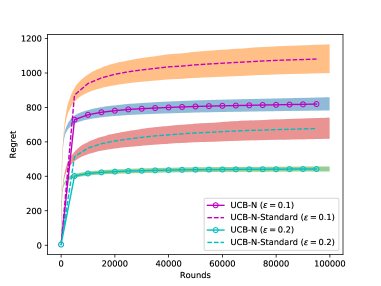
For each value of , we generate different problem instances. The expected regret is averaged on the instances. The 95% confidence interval is shown as a semi-transparent region in the figure. Figure 1 shows the performance of UCB-N under Gaussian rewards. It can be observed that the regret of UCB-N in our settings is smaller than standard graph feedback, thanks to the similarity structure. Additionally, the regret decreases as increases, consistent with theoretical results.


We then compared the performance of UCB-N, D-UCB, and C-UCB algorithms. Figure 2 shows the performance of the three algorithms with Gaussian and Bernoulli rewards. Although D-UCB and UCB-N have similar regret bounds, the experimental performance of D-UCB and C-UCB is better than UCB-N. This may be because D-UCB and C-UCB directly learn on an independent set, effectively leveraging the graph structure features of similar arms.
6.2 Ballooning Settings



UCB-N is not suitable for ballooning settings since it would select each arrived arm at least once. The BL-Moss algorithm [Ghalme et al., 2021] is specifically designed for the ballooning setting. However, this algorithm assumes that the optimal arm is more likely to appear in the early rounds and requires prior knowledge of the parameter to characterize this likelihood, which is not consistent with our setting. We only compare D-UCB and C-UCB with different distributions .
Figure 3 show the experimental results of ballooning settings. When follows a standard normal distribution, D-UCB and C-UCB exhibit similar performance. However, when is a uniform distribution or half-triangle distribution with distribution function as , D-UCB fails to achieve sublinear regret, while C-UCB still performs well. These results are consistent across different values of .
7 Conclusion
In this paper, we have introduced a new graph feedback bandit model with similar arms. For this model, we proposed two different UCB-based algorithms (D-UCB, C-UCB) and provided regret upper bounds. We then extended these two algorithms to the ballooning setting. In this setting, the application of C-UCB is more extensive than D-UCB. D-UCB can only achieve sublinear regret when the mean distribution is Gaussian, while C-UCB can achieve problem-dependent sublinear regret regardless of the mean distribution.
References
- Abramowitz et al. [1988] Milton Abramowitz, Irene A Stegun, and Robert H Romer. Handbook of mathematical functions with formulas, graphs, and mathematical tables, 1988.
- Allan and Laskar [1978] Robert B Allan and Renu Laskar. On domination and independent domination numbers of a graph. Discrete mathematics, 23(2):73–76, 1978.
- Alon et al. [2017] Noga Alon, Nicolo Cesa-Bianchi, Claudio Gentile, Shie Mannor, Yishay Mansour, and Ohad Shamir. Nonstochastic multi-armed bandits with graph-structured feedback. SIAM Journal on Computing, 46(6):1785–1826, 2017.
- Auer and Ortner [2010] Peter Auer and Ronald Ortner. Ucb revisited: Improved regret bounds for the stochastic multi-armed bandit problem. Periodica Mathematica Hungarica, 61(1-2):55–65, 2010.
- Auer et al. [2002a] Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem. Machine learning, 47:235–256, 2002a.
- Auer et al. [2002b] Peter Auer, Nicolo Cesa-Bianchi, Yoav Freund, and Robert E Schapire. The nonstochastic multiarmed bandit problem. SIAM journal on computing, 32(1):48–77, 2002b.
- Aziz et al. [2021] Maryam Aziz, Emilie Kaufmann, and Marie-Karelle Riviere. On multi-armed bandit designs for dose-finding clinical trials. The Journal of Machine Learning Research, 22(1):686–723, 2021.
- Buccapatnam et al. [2014] Swapna Buccapatnam, Atilla Eryilmaz, and Ness B Shroff. Stochastic bandits with side observations on networks. In The 2014 ACM international conference on Measurement and modeling of computer systems, pages 289–300, 2014.
- Buccapatnam et al. [2018] Swapna Buccapatnam, Fang Liu, Atilla Eryilmaz, and Ness B Shroff. Reward maximization under uncertainty: Leveraging side-observations on networks. Journal of Machine Learning Research, 18(216):1–34, 2018.
- Caron et al. [2012] Stéphane Caron, Branislav Kveton, Marc Lelarge, and Smriti Bhagat. Leveraging side observations in stochastic bandits. arXiv preprint arXiv:1210.4839, 2012.
- Chakrabarti et al. [2008] Deepayan Chakrabarti, Ravi Kumar, Filip Radlinski, and Eli Upfal. Mortal multi-armed bandits. Advances in neural information processing systems, 21, 2008.
- Cohen et al. [2016] Alon Cohen, Tamir Hazan, and Tomer Koren. Online learning with feedback graphs without the graphs. In International Conference on Machine Learning, pages 811–819. PMLR, 2016.
- Esposito et al. [2022] Emmanuel Esposito, Federico Fusco, Dirk van der Hoeven, and Nicolò Cesa-Bianchi. Learning on the edge: Online learning with stochastic feedback graphs. Advances in Neural Information Processing Systems, 35:34776–34788, 2022.
- Even-Dar et al. [2006] Eyal Even-Dar, Shie Mannor, Yishay Mansour, and Sridhar Mahadevan. Action elimination and stopping conditions for the multi-armed bandit and reinforcement learning problems. Journal of machine learning research, 7(6), 2006.
- Gentile et al. [2014] Claudio Gentile, Shuai Li, and Giovanni Zappella. Online clustering of bandits. In International conference on machine learning, pages 757–765. PMLR, 2014.
- Ghalme et al. [2021] Ganesh Ghalme, Swapnil Dhamal, Shweta Jain, Sujit Gujar, and Y Narahari. Ballooning multi-armed bandits. Artificial Intelligence, 296:103485, 2021.
- Ghari and Shen [2022] Pouya M Ghari and Yanning Shen. Online learning with probabilistic feedback. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4183–4187. IEEE, 2022.
- Hu et al. [2020] Bingshan Hu, Nishant A Mehta, and Jianping Pan. Problem-dependent regret bounds for online learning with feedback graphs. In Uncertainty in Artificial Intelligence, pages 852–861. PMLR, 2020.
- Lai et al. [1985] Tze Leung Lai, Herbert Robbins, et al. Asymptotically efficient adaptive allocation rules. Advances in applied mathematics, 6(1):4–22, 1985.
- Li et al. [2011] Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. In Proceedings of the fourth ACM international conference on Web search and data mining, pages 297–306, 2011.
- Li et al. [2016] Shuai Li et al. The art of clustering bandits. 2016.
- Lykouris et al. [2020] Thodoris Lykouris, Eva Tardos, and Drishti Wali. Feedback graph regret bounds for thompson sampling and ucb. In Algorithmic Learning Theory, pages 592–614. PMLR, 2020.
- Mannor and Shamir [2011] Shie Mannor and Ohad Shamir. From bandits to experts: On the value of side-observations. Advances in Neural Information Processing Systems, 24, 2011.
- Pérez et al. [2020] Adrià Pérez, Pablo Herrera-Nieto, Stefan Doerr, and Gianni De Fabritiis. Adaptivebandit: a multi-armed bandit framework for adaptive sampling in molecular simulations. Journal of chemical theory and computation, 16(7):4685–4693, 2020.
- Schwartz et al. [2017] Eric M Schwartz, Eric T Bradlow, and Peter S Fader. Customer acquisition via display advertising using multi-armed bandit experiments. Marketing Science, 36(4):500–522, 2017.
- Villar et al. [2015] Sofía S Villar, Jack Bowden, and James Wason. Multi-armed bandit models for the optimal design of clinical trials: benefits and challenges. Statistical science: a review journal of the Institute of Mathematical Statistics, 30(2):199, 2015.
- Wang et al. [2024] Zhiyong Wang, Jize Xie, Xutong Liu, Shuai Li, and John Lui. Online clustering of bandits with misspecified user models. Advances in Neural Information Processing Systems, 36, 2024.
- Yang et al. [2022] Junwen Yang, Zixin Zhong, and Vincent YF Tan. Optimal clustering with bandit feedback. arXiv preprint arXiv:2202.04294, 2022.
Proofs of Theorems and Corollaries In this appendix, we provide the detailed proof of theorems and corollaries in the main text. Specifically, we provide detailed proofs of Proposition 4.1, Theorem 4.3,Theorem 4.6,Theorem 5.2,Corollary 5.3 and Theorem 5.5. The proof of Theorem 4.5 can be easily obtained from the analysis of Theorem 5.5. The proof of Theorem 5.4 is similar to that of Theorem 5.2. We omit their proofs. Beforehand, we give some well-known results to simplify the proof.
Appendix A Facts and Lemmas
Lemma A.1.
Assume that are independent random variables. . If is bounded in or -subGaussian, for any , with probability as least ,
Lemma A.2.
Allan and Laskar [1978] If is a claw-free graph, then .
Lemma A.3.
Assume that . Let denote the graph constructed by , is the independent number of . Then
| (16) |
where is some constant related to .
Proof.
Let , then
where is the probability density function of . This means that in , the probability of any two nodes being connected by an edge is . Hence, is a random graph.
Let be the number of independent sets of order . Let ,
| (17) | ||||
where uses the fact that .
If , . We have,
If ,i.e., , we have
Therefore,
∎
Lemma A.4 (Chernoff Bounds).
Let be independent Bernoulli random variable. Let denote their sum and let denote the sum’s expected value.
Lemma A.5.
Abramowitz et al. [1988] For a Gaussian distributed random variable with mean and variance , for any ,
Appendix B Proofs of Proposition 4.1
(1) We first prove . A claw-free graph is a graph that does not have a claw as an induced subgraph or contains no induced subgraph isomorphic to . From Lemma A.2, we just need to prove is claw-free.
Assuming has a claw, meaning there exists nodes , such that is connected to , while are mutually unconnected. Consider nodes . and must have a mean greater than , and the other must have a mean smaller than . Otherwise, the mean difference between and will be smaller than , and an edge will form between them. Since is connected to , this would lead to an edge between and or and . This is a contradiction. Therefore, is claw-free.
(2) . Let be a maximum independent set and be a minimum independent dominating set. Note that any vertex of is adjacent (including the vertex itself in the neighborhood) to at most two vertices in , and that each vertex of is adjacent to at least one vertex of . So by a double counting argument, when counting once the vertices of , we can choose one adjacent vertex in , and we will have counted at most twice the vertices of .
Appendix C Proofs of Theorem 4.3
Let denote the independent set obtained after running Step 4-8 in Algorithm 1. The obtained may vary with each run. We first fix for analysis and then take the supremum of the results with respect to , obtaining an upper bound independent of .
Let denotes the arm that includes the optimal arm, i.e., . Let . The regret can be divided into two parts: one part is the selection of arms and the other part is the selection of arms :
| (18) |
We first focus on the expected regret incurred by the first part. Let , denote the arm linked to the selected arm (Step 9 in Algorithm 1).
| (19) |
The last inequality uses the following two facts:
and
Recall that denotes the number of observations of arm till time . Let , denote average reward of arm after observed times, . For any ,
| (20) | ||||
Following the same argument as in Auer et al. [2002a], choosing , we have
From Lemma A.1,
Hence,
Plug into Equation 18, we can get
| (21) | ||||
Now we focus on the second part in Equation 18.
For any , we have . This means the gap between suboptimal and optimal arms is bounded. Therefore, this part can be seen as using UCB-N Lykouris et al. [2020] on the graph formed by . We can directly use their results by adjusting some constant factors. Following Theorem 6 in Lykouris et al. [2020], this part has a regret upper bound as
| (22) |
Let . Combining Equation 21 and Equation 22 and using Proposition 4.1 that , we have
| (23) | ||||
Appendix D Proofs of Theorem 4.6
We just need to discuss in intervals
The regret for in … can be bounded by the same method used in the proof of Theorem 4.3. We can calculate that the regret of this part has the same form as .
Recall that denote the subgraph with arms . The set of all independent dominating sets of graph is denoted as . The regret for in can be bounded as
Due to the similarity assumption, is a complete graph. Therefore,
Appendix E Proofs of Theorem 5.2
Recall that denotes the independent set at time and denotes the arm that include the optimal arm . We have . Let denote the sequences generated from with length , thus is a random variable.
Since the optimal arm may change over time, this leads to a time-varying . We denote the new gap as . Therefore, the analysis method in Theorem 4.3 is no longer applicable here. The regret can also be divided into two parts:
| (24) |
We focus on first.
| (25) | ||||
Given a fixed , is deterministic. Since the gap between optimal and suboptimal arms may be varying over time, we define
denote the minimum gap when is not the optimal selection that include the optimal arm. Then .
Following the proofs of Theorem 4.3, for any , the probability of the algorithm selecting it will be less than after it has been selected times. Therefore, the inner expectation of Equation 25 is bounded as
| (26) |
The inner expectation of Equation 25 also has a native bound .
Plugging into and using Lemma A.3, we get
| (27) | ||||
Now we consider the part .
| (28) |
Recall that Then
Since is independent of each other, the event is also mutually independent. Using Lemma A.4,
| (29) |
Given a fixed instance , we divide the rounds into parts:
This partition satisfies is stationary. The is also stationary, , let .
Let’s focus on the intervals , the analysis for other intervals is similar.
The best case is that all arms in are arrived at the beginning. In this case, the regret for this part is equivalent to the regret of using the UCB algorithm on the subgraph formed by for rounds. The independence number of the subgraph formed by is , which leads to a regret upper bound independent of the number of arms arriving. However, we are primarily concerned with the worst case. The worst case is that the algorithm cannot benefit from the graph feedback at all. That is, the algorithm spends rounds distinguishing the optimal arm from the first arriving suboptimal arm . After this process, the second suboptimal arm arrives, and again rounds are spent distinguishing the optimal arm from this arm…
Let denote the arms fall into at the rounds . If has not been arrived at round , .
Following the same argument as the proofs of Theorem 4.3, the inner expectation in Equation 28 can be bounded as
| (30) | ||||
where comes from the fact that and , follows from .
Similar to the approach of bounding , the inner expectation in Equation 28 also has a native bound .
Substituting into Equation 28, we get
| (31) | ||||
From Equation 27 and Equation 31, we get the total regret
Appendix F Proofs of Corollary 5.3
First, we calculate an that is independent of the distribution . Given as independent random variables from . Let
Denote . Then
and
where is the support set of . Since
We get
| (32) |
We need to estimate the upper and lower bounds of separately. For Gaussian distribution , We first proof
Denote the integrand function as . Let ,
| (33) |
First, we have
Now we calculate the second term.
| (36) |
We only need to bound the integral within .
| (37) | ||||
where uses Lemma A.5.
Therefore,
Then we derive a lower bound for .
Since is convex function in , we have
Then when ,
Hence,
Substituting into Equation 32,
| (38) | ||||
The function is increasing on the interval . We have
| (39) | ||||
Observe that for large ( ), . Therefore, for any ,
We have
Appendix G Proofs of Theorem 5.5
Similar to the proofs of Theorem 5.2, the regret can also be divided into two parts:
| (40) |
Part is exactly the same as the analysis in the corresponding part of Theorem 5.2. We only focus part .
Since is independent of each other, each is equally likely to be the largest one, i.e., Or we can obtain this result through Equation 32. We have
| (42) |
where is the Euler constant. Then .
Given a fixed instance , we also divide the rounds into parts:
This partition satisfies is stationary. The is also stationary, , let .
Let’s focus on the intervals , the analysis for other intervals is similar. All arms falling into at rounds are denoted by . The arms in can be divided into two parts: and . If has not been arrived at round , . Then we have
| (43) |
From the way our algorithm constructs independent sets, it can be inferred that all arms in are connected to , and the distances are all less than . Hence, both and form a clique.
Note that selecting any arm in will result in the observation of . We have
| (44) | ||||
Let . If , the event never occurs. Then
From Lemma A.1, we have
The regret incurred by in is at most
Using the same method, we can get the regret incurred by in is bounded as
Therefore, choosing , with the fixed is bounded as
| (45) |
From Equation 41 and Equation 42, we have
Therefore, we get the total regret