Graph Continual Learning with Debiased Lossless Memory Replay
Abstract
Real-life graph data often expands continually, rendering the learning of graph neural networks (GNNs) on static graph data impractical. Graph continual learning (GCL) tackles this problem by continually adapting GNNs to the expanded graph of the current task while maintaining the performance over the graph of previous tasks. Memory replay-based methods, which aim to replay data of previous tasks when learning new tasks, have been explored as one principled approach to mitigate the forgetting of the knowledge learned from the previous tasks. In this paper we extend this methodology with a novel framework, called Debiased Lossless Memory replay (DeLoMe). Unlike existing methods that sample nodes/edges of previous graphs to construct the memory, DeLoMe learns small lossless synthetic node representations as the memory. The learned memory can not only preserve the graph data privacy but also capture the holistic graph information, for which the sampling-based methods are not viable. Further, prior methods suffer from bias toward the current task due to the data imbalance between the classes in the memory data and the current data. A debiased GCL loss function is devised in DeLoMe to effectively alleviate this bias. Extensive experiments on four graph datasets show the effectiveness of DeLoMe under both class- and task-incremental learning settings.
1 Introduction
Due to the superior capacity to represent complex relations between samples, graph is widely used in various real-world applications Xia et al. (2021); Wu et al. (2020) such as social networks, citation networks, and online shopping. For example, in the context of online shopping, consumers could be nodes and the edges between consumers could represent that they have purchased or rated the same product. In real-world applications, graph data are often expanded continually, e.g., new consumers and the associated connections would be constantly added to the online shopping network. Following the message propagation paradigm, graph neural networks (GNNs) Wu et al. (2019); Kipf and Welling (2016) have achieved remarkable success for various graph-related tasks. Despite the success, most GNNs operate on static graph data. Directly applying them to accommodate new emerging graphs would cause the GNNs to easily forget the knowledge learned from the previous data due to the large distribution difference between the historical data and the newly added data. The forgetting of the learned knowledge when learning new graphs, a.k.a. catastrophic forgetting, would result in deteriorated performance on historical graphs. A simple solution is to store all historical data and repeatedly retrain the GNNs whenever the graph is updated, but it is prohibitively expensive in terms of computational time and resources considering the large scale of the continually expanding graph. Moreover, the previous graph data would also be inaccessible in privacy-critical application scenarios when learning the newly added data.
To tackle catastrophic forgetting, many methods have been proposed and demonstrated impressive performance on Euclidean data such as images and texts Hayes and Kanan (2020); Wu et al. (2021); Wang et al. (2023). However, it is ineffective to directly adopt them for graph continual learning (GCL) as graphs are non-Euclidean data that contain complex relations among a large number of nodes.
Recently, to address the unique challenges in graph data, several GCL works He et al. (2023); Zhou and Cao (2021); Liu et al. (2021); Sun et al. (2023); Wang et al. (2022); Su et al. (2023); Rakaraddi et al. (2022); Zhang et al. (2023a); Perini et al. (2022); Zhang et al. (2022c, 2023b) have been proposed to continually adapt GNNs to the expanded graph data of the current task while maintaining the performance over the graph data of previous tasks. Generally, these methods can be roughly divided into three categories, including regularization-based methods, parameter isolation-based methods, and replay-based methods. Due to the straightforward intuitiveness and impressive effectiveness, replay-based methods Zhang et al. (2022c, 2023b); Zhou and Cao (2021) have been widely explored and achieved remarkable capacity against catastrophic forgetting in GCL. Typically, they sample and store representative data of previous tasks in a memory buffer and replay them when learning a new task. However, since only selected graph information is stored, their constructed memory for each previous task often struggles to capture the holistic graph information of the full graph, limiting the power of memory replay against catastrophic forgetting. For example, ERGNN Zhou and Cao (2021) stores only individual nodes via sampling methods for replaying, which ignores the rich relations among the nodes, severely degrading the effectiveness of memory replay in GCL. A straightforward solution to this issue is to store the complete neighbors and the associated edges of the selected nodes for graph data of previous tasks, but this would pose great challenges to memory storage and is infeasible under tight memory budgets. To preserve the topological information and alleviate the storage requirement simultaneously, recent studies propose approaches like SSM Zhang et al. (2023b) to sparsify the neighborhood of the selected nodes by filtering unimportant ones. Nevertheless, all these methods focus on constructing the memory using partial graph data, as shown in Figure 1(Left), failing to preserve the holistic graph semantics. Also, these memory construction methods would become inapplicable in privacy-critical applications where the replay of previous graph data can lead to privacy leakage, e.g., storing the original data of the previous online shopping networks would divulge the purchase/rating information of consumers.

Further, since the amount of the memory data is often limited, the current graph data often dominates the training data, leading to a data imbalance between the classes in the memory data and that in the current graph data. When updating the GCL models with those imbalanced data, the models are biased toward the current task, amplifying the deteriorated performance on the previous tasks as the graph continually expands with a fixed memory budget (i.e., increasing imbalance rates), e.g., performance of SSM in Figure 1(Right).
To tackle these three issues, in this paper, we introduce a novel memory replay-based GCL approach, called Debiased Lossless Memory replay (DeLoMe). Rather than storing the original graph data, it learns a small graph consisting of synthetic node representations as memory so that the gradient of a randomly initialized GNN on the original large graph is lossless compared to that on the learned small graph. In doing so, the learned representations are enforced to better capture the holistic graph structure and attribute information, resulting in better performance on previous graph data, as illustrated in Figure 1(Right). This node representation-based memory also helps better preserve the privacy of the graph data, compared to the original node/edge-based memory.
To handle the aforementioned bias issue, a debiased loss function is devised in our GCL objective. This is done by calibrating the prediction logits of the classes in the memory data and the current graph data in the continual updating of our DeLoMe model, which helps largely enhance its robustness w.r.t. the class imbalance.
Our main contributions can be summarized as follows:
-
•
We propose a novel learnable memory replay-based approach DeLoMe. Compared to the concurrent work CaT Liu et al. (2023) that introduces a seminal memory learning-based GCL method, DeLoMe introduces an enhanced graph memory learning method and augments it with a debiased GCL objective, resulting in the first GCL framework for debiased learnable memory-based replay.
-
•
To obtain such memory, we introduce a lossless GCL memory learning method that utilizes gradient matching to enforce a lossless compression of large graphs of previous tasks into small synthetic graphs as the memory data. It enables DeLoMe to achieve not only a small memory budget requirement but also good privacy preservation of historical data.
-
•
To mitigate the bias toward the current graph, we devise a debiased GCL objective that effectively calibrates the GNN predictions when adapting the GCL models.
-
•
Extensive experiments on four real-world datasets show that DeLoMe learns substantially more cost-effective memory and outperforms both state-of-the-art sampling and learnable memory-based methods under both class- and task-incremental settings of GCL.
2 Related Work
2.1 Graph Continual Learning
Graph continual learning (GCL) has gained growing popularity in deep learning, and various methods have been proposed He et al. (2023); Zhou and Cao (2021); Liu et al. (2021); Sun et al. (2023); Wang et al. (2022); Su et al. (2023); Rakaraddi et al. (2022); Zhang et al. (2023a); Perini et al. (2022); Zhang et al. (2022c, 2023b), which can be divided into three categories, i.e., regularization-based, parameter isolation-based, and data replay-based methods. For example, as a regularization-based method, TWP Liu et al. (2021) preserved the important parameters in the topological aggregation and loss minimization for previous tasks via regularization terms. Among the parameter isolation methods, HPNs Zhang et al. (2022b) extracted different levels of abstract knowledge in the form of prototypes and selected different combinations of parameters for different tasks, and Zhang et al. (2023a) proposed to continually expand model parameters to learn new emerging graph patterns. Differently, ERGNN Zhou and Cao (2021) proposed to sample and store representative nodes of previous tasks in a memory buffer, and replayed them when learning new tasks. However, the graph structure, which plays a vital role in graph representation learning, is not considered in ERGNN. To cope with the topological information, Zhang et al. (2022c) and Zhang et al. (2023b) proposed the sparsification techniques to find the important neighbors of the selected nodes. Then, the important neighbors together with the edges between neighbors and representative nodes are stored in the memory buffer for replaying during the learning of new tasks. Nevertheless, all these methods focus on constructing the memory using partial graph data of previous graphs, failing to preserve the holistic graph semantics and also raising privacy concerns in privacy-critical applications. By contrast, our learned memory data helps capture the holistic graph information while effectively preserving the privacy of the previous graph data.
2.2 Graph Condensation
Graph condensation aims to compress a graph into a significantly smaller graph while preserving the holistic information of the original graph. Various graph compression methods have been proposed Jin et al. (2022a, b); Gao et al. (2023); Liu et al. (2022) that are based on gradient matching or distribution matching between the compressed graph and the original graph. In this work, we utilize gradient matching to compress the graphs with node features and structure in previous tasks into comprehensive synthetic node representations, which can serve as the memory for the subsequent replaying. Note that the concurrent work CaT Liu et al. (2023) shares a common motivation with our method. However, unlike CaT that adopts a distribution matching-based method to learn the memory, we propose to use a gradient matching method that can measure the loss of condensation in a more fine-grained manner. CaT performs the GNNs training within the learned memory bank to alleviate the class imbalance problem, but it can lead to less effective utilization of the graph data of the current task. We instead devise a debiased GCL objective to calibrate the GCL predictions while avoiding the inefficient exploitation of the current graph data.
3 Preliminaries
3.1 The GCL Problem
In this paper, we focus on the node-level GCL problem. Formally, this problem can be formulated as learning a model on a sequence of graphs (tasks) where is the number of continual learning tasks. Each is a newly emerging graph at task , where denotes the relations between nodes, represents the node features, and the labels of nodes can be denoted as . Generally, each task contains a unique set of classes, i.e., {}. When learning task , the model trained from previous tasks only has access to current data . The goal is to adapt the model to current graph while maintaining the classification performance on the previous graphs .
3.2 Class & Task Incremental Settings of GCL
Depending on whether the task indicator is provided at the testing stage, GCL can be further divided into two settings: Class-Incremental Learning (CIL) and Task-Incremental Learning (TIL). Assume that each task in has the same number of classes and we use to represent the unique set of classes in . In CIL, after learning all the tasks, the model is required to classify each test instance into one of all the learned classes. While under the TIL setting, the task indicator is also provided with the test instance. Thus, the model is only required to assign a class to the test instance from the classes set of task . Compared to TIL, CIL is more practical yet more challenging as the label prediction space contains all the learned classes so far. In this paper, we evaluate the proposed method under both settings to demonstrate its effectiveness.
3.3 Memory Replay in Graph Continual Learning
In GCL, a GNN model is sequentially trained across the task sequence . Typically, the model only has access to at task . To continually accommodate the new graph and alleviate the catastrophic forgetting, memory replay-based methods store representative data of previous tasks into a memory buffer . Then, the memory data are replayed with the data of task to fit the new graph data and maintain the knowledge of previous tasks simultaneously. Therefore, the training objective of memory replay at task can be formulated as follows:
| (1) |
where is the GNN model parameterized by , denote the labels of nodes in the memory buffer (i.e., all class labels encountered in the previous tasks), denotes a loss function, i.e., cross-entropy loss, and is a hyperparameter to control the importance of the memory loss.
The memory buffer plays an important role in maintaining previously learned knowledge and different memory construction methods have been proposed. For example, ERGNN Zhou and Cao (2021) sampled the representative nodes of the previous tasks as the memory. However, the rich topological information is neglected in ERGNN. Other approaches like SSM Zhang et al. (2023b) aim to utilize the structure information by sparsifying the neighbors of the sampled nodes based on their topological importance. Then, the important neighborhood structures together with the sampled nodes are used to construct the memory. Despite the success achieved by these methods, the memory buffer constructed with partial graph data fails to preserve the holistic semantics of the original graph and it may lead to privacy leakage issue when the sampled nodes/edges are sensitive data. Further, the memory budget is typically kept significantly smaller than the current graph data, so it can lead to class imbalance between the memory data and the current graph data. Our method DeLoMe is proposed to tackle these three issues.

4 Debiased Lossless Memory Replay
4.1 Lossless Memory Learning
4.1.1 Key intuition
Instead of using partial graph data as memory replay data, we propose to learn a small set of synthetic node representatives as the memory data which can holistically represent the original graph structure and attributes. Taking the task as an example, given with the label set , we aim to learn a compressed synthetic graph associated with label set as our memory data, where the fixed identity matrix represents the structure of . Note that the size of is constrained by the memory budget and is significantly smaller than .
Since the learned captures the holistic semantics of the original graph at task , we can expect that a GNN model trained on would achieve comparable performance to that trained on . Following this idea, the learning objective of can be formulated as follows:
| (2) |
where denotes the parameters of the graph neural network trained on . Due to the nested loop optimization of Eq. (2), directly solving the above objective would be prohibitively expensive. To address this challenge, one-step gradient matching Jin et al. (2022a) is proposed, which aims to match the gradient of the same model with regard to the real data and the synthetic data at the first training epoch. Inspired by this, the optimization objective Eq. (2) can be transformed into a lossless compression as follows:
| (3) |
where is a distance function to measure the difference between the two gradients. Moreover, to get more generalized without fitting to a specific model initialization, we aim to devise an objective of Eq. (3) that can be minimized under different random initializations of the . Thus, the final objective to learn is defined as follows:
| (4) |
where is a random instantiation of the parameter space .
4.1.2 The learning algorithm
To obtain the memory with of task , we need to learn the node feature and label set . Since represents the node label and is discrete, is fixed as the same classes as the original label set . Therefore, we only need to learn for task . To accelerate the learning process, let be the memory budget for each class, is initialized as the features of randomly selected nodes from each class in . To further reduce the computation cost, we sample a fixed number of neighbors for each node in at each hop, and adopt the mini-batch training strategy. In addition, the gradient matching and learning of is performed on each class separately. Specifically, for a given class in , a batch of nodes belonging to class is randomly sampled from together with the associated neighborhoods, which is denoted as . Meanwhile, we get the corresponding nodes of class from and denote it as . Then, the sampled and are fed into the same GNN model to calculate the gradient matching loss. Finally, is optimized via gradient descent to minimize the graph matching loss. Note that the graph neural network is not updated during the learning process and we adopt different initializations of to learn a generalized . By imitating the training trajectory of the original graph , is enforced to capture the holistic semantics of and the global topological information is implicitly incorporated into (see Algorithm 1 in Appendix for the detailed algorithm).
As illustrated in Figure 3 where we visualize the node embeddings of the memories constructed by two sampling methods (random node sampling and SSM) and DeLoMe, the synthetic node representations in the memory learned by DeLoMe can better preserve the distribution of the nodes of different classes in the original graph, compared to the other two methods. This indicates the better capability of DeLoMe in capturing more holistic graph semantics.

4.1.3 Time complexity analysis
We analyze the time complexity of obtaining at task . As mentioned above, the learning process is conducted for each class separately. We take a two-layer SGC Wu et al. (2019) as the GNN model for gradient matching and denote the number of nodes and edges in as and respectively. The dimension of the node features is denoted as . For the two-layer SGC, the time complexity of forward and backward propagation with regard to and are and respectively. Given the training epochs , the time complexity for class is . Then, the overall time complexity of learning is . Since we adopt the minibatch training strategy and sample a fixed number of neighbors for each node at each hop, the numbers of and are typically small and do not induce high computation. Besides, the learning process can be implemented in parallel in practice to further reduce the learning time.
4.2 Debiased Memory Replay
Although the learned memory data are lossless compared to previous graphs, there is a data imbalance between the classes in the new graph and that in the memory buffer . This is because the memory budget of each class is typically much smaller than the number of nodes belonging to new classes in . This class imbalance would increase, when the graph evolves with more current graph data or a tighter memory budget is given, amplifying the degraded performance for GCL. To tackle this problem, we propose a debiased memory replay method that adjusts the prediction logits of the classes in the memory data and the current graph data based on the class label frequencies during the memory replay. Specifically, at task , we have the memory buffer , and the vanilla objective of memory replay in Eq. (1) can be explicitly formulated as:
| (5) |
where and are the prediction logits of for the nodes in and respectively. Directly minimizing Eq. (5) would make the model biased toward the current task as the current graph data dominates the training data. We address this problem by calibrating the logits and based on their label frequencies. Given the memory budget , the calibration magnitude for each class in the memory buffer is equal and can be defined as:
| (6) |
where we assume each task contains the same classes, is a scaling hyperparameter, and returns the number of samples in . For a class in the current graph , the calibration magnitude is defined as:
| (7) |
where denotes the number of training samples of class in . By incorporating these two calibrations into Eq. (5), our debiased GCL training loss is as follows:
| (8) |
where we discard the weight parameter to simplify the parameter selection. Compared to Eq. (5), Eq. (8) augments the softmax cross-entropy with a pairwise margin based on label frequencies Menon et al. (2021). In this way, the predictions for dominant classes in the current graph do not overwhelm those for tail classes in the memory data, thus reducing the bias toward the dominant classes in . The detailed training steps of DeLoMe are presented in Algorithm 2 in Appendix.
5 Experiments
5.1 Datasets
Following the GCL benchmark Zhang et al. (2022a), four public graph datasets are employed, i.e., CoraFull McCallum et al. (2000), Arxiv Hu et al. (2020), Reddit Hamilton et al. (2017) and Products Hu et al. (2020). Specifically, CoraFull and Arxiv are citation networks, Reddit is constructed from Reddit posts, and Products is a co-purchasing network from Amazon. For all datasets, each task is set to contain only two classes Zhang et al. (2022a). Besides, for each class, the proportions of training, validation and testing are set to be 0.6, 0.2 and 0.2 respectively.
5.2 Competing Models
Two categories of state-of-the-art (SOTA) continual learning methods are employed for comparison. The first category contains traditional continual learning methods, i.e., EWC Kirkpatrick et al. (2017), LwF Li and Hoiem (2017), GEM Lopez-Paz and Ranzato (2017) and MAS Aljundi et al. (2018). The second category includes four SOTA GCL methods: ERGNN Zhou and Cao (2021), TWP Liu et al. (2021), HPNs Zhang et al. (2022b), SSM Zhang et al. (2022c), SEM Zhang et al. (2023b) and CaT Liu et al. (2023). In addition, we include two other methods: Joint and Fine-tune. The Joint method is an oracle model that can see all graphs at all times and performs GCL on the full graphs of all tasks, while Fine-tune is a baseline that simply fine-tunes the learned model from previous tasks without continual learning techniques.
5.3 Evaluation Metrics
Average accuracy (AA) and average forgetting (AF) are adopted to evaluate the model performance. Specifically, AA and AF are calculated from the accuracy matrix , where is the number of the tasks. The entry denotes the classification accuracy on task after the model is optimized on task . After learning all the tasks, the overall AA and AF can be calculated as follows:
| (9) |
To sum up, AA evaluates the average performance of the model on all the learned tasks after learning the current task, and AF describes how the performance of previous tasks is affected by the current task. For both AA and AF, the higher value denotes the better GCL performance.
5.4 Implementation Details
To have a fair comparison, we implement the proposed method with the GCL benchmark Zhang et al. (2022a). More specifically, we adopt the two-layer SGC Wu et al. (2019) as the backbone model with the same hyper-parameters following Zhang et al. (2023b). The memory budget is also set as the same in Zhang et al. (2023b), i.e., 60 per class for the CoraFull dataset and 400 per class for the other datasets. For the lossless memory learning module, we also use a two-layer SGC as the GNN model to match the gradients of both the original graph and the synthetic graph, and the gradient divergence is calculated based on the mean square distance. For each dataset, we report the average performance with standard deviations after 5 runs with different seeds under both task incremental and class incremental settings.
| Methods | CoraFull | Arixv | Products | |||||
|---|---|---|---|---|---|---|---|---|
| AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | |
| Fine-tune | 3.50.5 | -95.20.5 | 4.90.0 | -89.70.4 | 5.91.2 | -97.93.3 | 7.60.7 | -88.70.8 |
| Joint | 81.20.4 | - | 51.30.5 | - | 97.10.1 | - | 71.50.1 | - |
| EWC | 52.68.2 | -38.512.1 | 8.51.0 | -69.58.0 | 10.311.6 | -33.226.1 | 23.83.8 | -21.77.5 |
| MAS | 6.51.5 | -92.31.5 | 4.80.4 | -72.24.1 | 9.214.5 | -23.128.2 | 16.74.8 | -57.031.9 |
| GEM | 8.41.1 | -88.41.4 | 4.90.0 | -89.80.3 | 11.55.5 | -92.45.9 | 4.51.3 | -94.70.4 |
| LwF | 33.41.6 | -59.62.2 | 9.912.1 | -43.611.9 | 86.61.1 | -9.21.1 | 48.21.6 | -18.61.6 |
| TWP | 62.62.2 | -30.64.3 | 6.71.5 | -50.613.2 | 8.05.2 | -18.89.0 | 14.14.0 | -11.42.0 |
| ERGNN | 34.54.4 | -61.64.3 | 21.55.4 | -70.05.5 | 82.70.4 | -17.30.4 | 48.31.2 | -45.71.3 |
| SSM-uniform | 73.00.3 | -14.80.5 | 47.10.5 | -11.71.5 | 94.30.1 | -1.40.1 | 62.01.6 | -9.91.3 |
| SSM-degree | 75.40.1 | -9.70.0 | 48.30.5 | -10.70.3 | 94.40.0 | -1.30.0 | 63.30.1 | -9.60.3 |
| SEM-curvature | 77.70.8 | -10.01.2 | 49.90.6 | -8.41.3 | 96.30.1 | -0.60.1 | 65.11.0 | -9.50.8 |
| CaT | 80.40.5 | -5.30.4 | 48.20.4 | -12.60.7 | 97.30.1 | -0.40.0 | 70.30.9 | -4.50.8 |
| DeLoMe (Ours) | 81.00.2 | -3.30.3 | 50.60.3 | 5.10.4 | 97.40.1 | -0.10.1 | 67.50.7 | -17.30.3 |
| Methods | CoraFull | Arixv | Products | |||||
|---|---|---|---|---|---|---|---|---|
| AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | |
| Fine-Tune | 56.04.2 | -41.04.5 | 56.22.6 | -36.22.6 | 79.524.2 | -11.74.8 | 64.43.8 | -31.14.4 |
| Joint | 95.50.2 | - | 90.30.4 | - | 99.50.0 | - | 95.30.8 | - |
| EWC | 89.81.0 | -5.10.5 | 71.50.6 | -0.90.6 | 83.915.1 | -2.01.5 | 87.01.4 | -1.71.2 |
| MAS | 92.20.9 | -3.71.3 | 72.72.6 | -18.52.5 | 61.17.1 | -0.51.0 | 80.64.3 | -13.73.7 |
| GEM | 91.50.5 | -1.90.9 | 81.11.7 | -4.01.8 | 98.90.1 | -0.50.1 | 87.71.8 | -7.02.0 |
| LwF | 93.80.1 | -0.40.1 | 71.13.2 | -1.50.8 | 98.60.1 | -0.00.0 | 86.30.2 | -0.50.1 |
| TWP | 94.30.9 | -1.60.4 | 89.40.4 | 0.00.3 | 78.018.5 | -0.20.4 | 81.83.3 | -0.30.8 |
| HPNs | - | - | 85.80.7 | 0.60.9 | - | - | 80.10.8 | 2.91.0 |
| ERGNN | 86.31.0 | -9.20.9 | 86.40.3 | 0.50.6 | 97.40.2 | 4.70.1 | 86.40.0 | 11.70.0 |
| SSM-uniform | 95.30.5 | 0.20.5 | 88.50.6 | -1.30.5 | 99.20.0 | -0.20.0 | 93.10.8 | -1.80.3 |
| SSM-degree | 95.80.3 | 0.60.2 | 88.40.3 | -1.10.1 | 99.30.0 | -0.20.0 | 93.20.7 | -1.90.0 |
| SEM-curvature | 95.90.5 | 0.70.4 | 89.90.3 | -0.10.5 | 99.30.0 | -0.20.0 | 93.20.7 | -1.80.4 |
| Cat | 95.00.2 | 1.60.7 | 90.30.3 | 0.30.4 | 99.20.0 | 0.00.0 | 94.70.1 | -0.00.1 |
| DeLoMe (Ours) | 95.40.1 | 2.00.6 | 90.40.3 | -1.10.2 | 99.40.0 | -0.10.0 | 94.80.1 | -2.20.2 |
5.5 Main Results
5.5.1 Results under class-incremental learning (CIL)
The results of all methods under the CIL setting are shown in Table 1. Note that the results of baselines are taken from the paper Zhang et al. (2023b) since we adopt the same GCL benchmark Zhang et al. (2022a)111https://github.com/QueuQ/CGLB/tree/master. From the table, we can draw the following observations: (1) Directly fine-tuning the learned model from previous tasks on the current task data leads to serious performance degradation because the knowledge of previous tasks could be easily overwritten by the new tasks. (2) Continual learning methods proposed for Euclidean data generally do not achieve satisfactory performance for GCL, which verifies the fact that the unique graph properties should be taken into consideration for GCL. (3) Replay-based graph continual learning methods achieve much better performance than other baselines. Among them, SSM and SEM outperform ERGNN on all datasets. The reason could be attributed to that SSM and SEM preserve the topological information for the historical graph data in the memory while ERGNN only stores the individual nodes. (4) Differently, CaT and DeLoMe propose to learn the memory and capture the semantics of the original graph. The performance gain of CaT and DeLoMe over SSM and SEM demonstrates that the learned memory buffer is more informative (e.g., in capturing holistic graph information) and enhances the power of replaying memory. (5) Our method DeLoMe achieves new SOTA performance in nearly all cases. Its performance can even match or outperform the ideal method Joint on the CoraFull and Reddit datasets. Note that on Products DeLoMe outperforms all methods except CaT. This may be attributed to that the node class frequency information in Products does not help accurately capture the imbalance bias due to the possible presence of less informative nodes in this largest dataset, rendering our debiased component less effective.
5.5.2 Results under task-incremental learning (TIL)
In Table 2, we report the results under the TIL setting, in which a SOTA TIL method HPNs is also included for comparison. From the table, we can first see that all the methods achieve much better performance under the TIL setting. This is because the availability of the task indicator during inference makes TIL much easier than CIL. Despite the performance of our proposed method DeLoMe being slightly inferior to SEM Zhang et al. (2023b) on the CoraFull dataset, DeLoMe achieves comparable performance with the oracle model, Joint. For the other three datasets, DeLoMe achieves the best performance, and even outperforms Joint on Arxiv dataset, which verifies the advantages of our two components in overcoming the forgetting and class imbalance problems.

5.6 Cost-effective Learning of Expressive Memory
5.6.1 Expressiveness of sampling- vs. learning-based memory
In this subsection, we evaluate the expressiveness of the memory constructed by our learning-based method against two SOTA sampling-based methods, ERGNN and SSM. To evaluate the memory expressiveness, for each task, we train a GNN model with the memory data constructed by these methods and calculate the node classification accuracy on the test set of the original graph. We follow the same experimental setting in the above GCL experiments and report the average classification accuracy of all tasks in Figure 4. It is clear that the our learning-based method achieve much better performance than both sampling-based methods, achieving improvement by up to 3% in AA. This demonstrates the superiority of capturing the semantics of the original graph when constructing memory and explains the performance gain over the sampling-based methods in the GCL experiments.
5.6.2 Memory budget efficiency
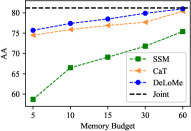
The requirement of the memory budget is crucial to replay-based methods. Here we evaluate the performance of the proposed method with different memory budgets, with two best competing methods – SSM and CaT – and the oracle model Joint as the baselines. Due to the page limits, we report the results on CoraFull and Arxiv under class-incremental settings. The memory budgets vary in the range of for CoraFull and for Arxiv. The results are shown in Figure 5. The figure demonstrates that the learning-based methods (DeLoMe and CaT) are more effective than the sampling-based method with tight memory budgets. Compared to SSM and CaT, our DeLoMe performs much more stably with varying budgets and achieves consistently better performance with different memory budgets, especially on the Arxiv dataset. These results reinforce our empirical evidence on the effectiveness of DeLoMe in constructing memory and handling the class imbalance problem.

5.6.3 Computational efficiency
We further investigate the memory construction time and inference time of DeLoMe and employ SSM and CaT for comparison. Specifically, we report the average memory construction time per task and the overall inference time of each method on the largest dataset, Products. From the results in Table 3, we can see that CaT and DeLoMe require almost the same time for memory construction while SSM is much faster than the two learning-based methods. This is attributed to that CaT and DeLoMe involve model optimization to enhance the memory to capture the holistic semantics of the original graph while SSM employs the parameter-free sampling strategy. This also explains the superiority of CaT and DeLoMe over SSM in AA and AF in Tables 1 and 2. In terms of the inference time, the three methods are nearly the same since the memory construction only happens in the training stage and the test setting remains the same for all methods.
| Stage | SSM | CaT | DeloMe |
|---|---|---|---|
| Memory Construction | 0.53 | 28.94 | 28.37 |
| Inference | 1.73 | 1.75 | 1.71 |
5.7 Ablation Study
We evaluate the contribution of two key components in DeLoMe, i.e., lossless memory learning and debiased GCL learning. Specifically, we derive four variants of DeLoMe. When the lossless memory learning is not exploited, we employ the sampling strategy to construct the memory as in ERGNN. Without loss of generality, we conduct the experiments on the CoraFull and Arxiv datasets under the CIL setting. The results of different variants are shown in the Table 4. From the table, we can see that adding either of the two components contributes to a significant improvement compard to the variant that does not use both components. These showcase the importance of both components, as well as their effectiveness in respectively addressing the memory expressiveness and data imbalance problems. In general, having a more expressive memory helps achieve larger improvement than tackling the data imbalance problem. Nevertheless, with our biased GCL objective, DeLoMe can achieve further large improvement over using our expressive memory learning component alone.
| Lossless Memory | Debiased Learning | CoraFull | Arixv | ||
|---|---|---|---|---|---|
| AA | AF | AA | AF | ||
| 36.9 | -59.0 | 24.6 | -66.1 | ||
| 50.2 | -40.6 | 33.9 | -31.1 | ||
| 78.5 | -9.3 | 47.9 | -15.8 | ||
| 81.0 | -3.3 | 50.6 | 5.1 | ||
6 Conclusion
In this paper, we propose a novel memory replay-based GCL method DeLoMe. Traditional replay-based graph continual learning methods typically construct the memory of the previous task using partial graph data, failing to preserve the holistic semantics of the original graph at each task. To tackle this issue, we learn compressed synthetic node representations as the memory by a gradient matching approach. In this way, the learned representations capture the holistic graph structure and attribute information. Besides, the learned representations help preserve the privacy of the graph data when replaying. To overcome the class imbalance problem between the learned memory and the new-coming graph, we further proposed a debiased memory replay objective by calibrating the prediction logits of the classes in both memory data and the current task based on the label frequencies. Extensive experiments on four datasets demonstrate the effectiveness of the proposed method under both class- and task-incremental learning settings of GCL.
References
- Aljundi et al. [2018] Rahaf Aljundi, Francesca Babiloni, Mohamed Elhoseiny, Marcus Rohrbach, and Tinne Tuytelaars. Memory aware synapses: Learning what (not) to forget. In Proceedings of the European conference on computer vision (ECCV), pages 139–154, 2018.
- Gao et al. [2023] Xinyi Gao, Tong Chen, Yilong Zang, Wentao Zhang, Quoc Viet Hung Nguyen, Kai Zheng, and Hongzhi Yin. Graph condensation for inductive node representation learning. arXiv preprint arXiv:2307.15967, 2023.
- Hamilton et al. [2017] William L Hamilton, Rex Ying, and Jure Leskovec. Representation learning on graphs: Methods and applications. arXiv preprint arXiv:1709.05584, 2017.
- Hayes and Kanan [2020] Tyler L Hayes and Christopher Kanan. Lifelong machine learning with deep streaming linear discriminant analysis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 220–221, 2020.
- He et al. [2023] Bowei He, Xu He, Yingxue Zhang, Ruiming Tang, and Chen Ma. Dynamically expandable graph convolution for streaming recommendation. In Proceedings of the ACM Web Conference 2023, pages 1457–1467, 2023.
- Hu et al. [2020] Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020.
- Jin et al. [2022a] Wei Jin, Xianfeng Tang, Haoming Jiang, Zheng Li, Danqing Zhang, Jiliang Tang, and Bing Yin. Condensing graphs via one-step gradient matching. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 720–730, 2022.
- Jin et al. [2022b] Wei Jin, Lingxiao Zhao, Shichang Zhang, Yozen Liu, Jiliang Tang, and Neil Shah. Graph condensation for graph neural networks. In International Conference on Learning Representations, 2022.
- Kipf and Welling [2016] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2016.
- Kirkpatrick et al. [2017] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- Li and Hoiem [2017] Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017.
- Liu et al. [2021] Huihui Liu, Yiding Yang, and Xinchao Wang. Overcoming catastrophic forgetting in graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 8653–8661, 2021.
- Liu et al. [2022] Mengyang Liu, Shanchuan Li, Xinshi Chen, and Le Song. Graph condensation via receptive field distribution matching. arXiv preprint arXiv:2206.13697, 2022.
- Liu et al. [2023] Yilun Liu, Ruihong Qiu, and Zi Huang. Cat: Balanced continual graph learning with graph condensation. arXiv preprint arXiv:2309.09455, 2023.
- Lopez-Paz and Ranzato [2017] David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. Advances in neural information processing systems, 30, 2017.
- McCallum et al. [2000] Andrew Kachites McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. Automating the construction of internet portals with machine learning. Information Retrieval, 3:127–163, 2000.
- Menon et al. [2021] Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. In International Conference on Learning Representations, 2021.
- Perini et al. [2022] Massimo Perini, Giorgia Ramponi, Paris Carbone, and Vasiliki Kalavri. Learning on streaming graphs with experience replay. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, pages 470–478, 2022.
- Rakaraddi et al. [2022] Appan Rakaraddi, Lam Siew Kei, Mahardhika Pratama, and Marcus De Carvalho. Reinforced continual learning for graphs. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 1666–1674, 2022.
- Sinha et al. [2015] Arnab Sinha, Zhihong Shen, Yang Song, Hao Ma, Darrin Eide, Bo-June Hsu, and Kuansan Wang. An overview of microsoft academic service (mas) and applications. In Proceedings of the 24th international conference on world wide web, pages 243–246, 2015.
- Su et al. [2023] Junwei Su, Difan Zou, Zijun Zhang, and Chuan Wu. Towards robust graph incremental learning on evolving graphs. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 32728–32748. PMLR, 23–29 Jul 2023.
- Sun et al. [2023] Li Sun, Junda Ye, Hao Peng, Feiyang Wang, and S Yu Philip. Self-supervised continual graph learning in adaptive riemannian spaces. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 4633–4642, 2023.
- Wang et al. [2022] Chen Wang, Yuheng Qiu, Dasong Gao, and Sebastian Scherer. Lifelong graph learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13719–13728, 2022.
- Wang et al. [2023] Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application. arXiv preprint arXiv:2302.00487, 2023.
- Wu et al. [2019] Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. In International conference on machine learning, pages 6861–6871. PMLR, 2019.
- Wu et al. [2020] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems, 32(1):4–24, 2020.
- Wu et al. [2021] Guile Wu, Shaogang Gong, and Pan Li. Striking a balance between stability and plasticity for class-incremental learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1124–1133, 2021.
- Xia et al. [2021] Feng Xia, Ke Sun, Shuo Yu, Abdul Aziz, Liangtian Wan, Shirui Pan, and Huan Liu. Graph learning: A survey. IEEE Transactions on Artificial Intelligence, 2(2):109–127, 2021.
- Zhang et al. [2022a] Xikun Zhang, Dongjin Song, and Dacheng Tao. Cglb: Benchmark tasks for continual graph learning. Advances in Neural Information Processing Systems, 35:13006–13021, 2022.
- Zhang et al. [2022b] Xikun Zhang, Dongjin Song, and Dacheng Tao. Hierarchical prototype networks for continual graph representation learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(4):4622–4636, 2022.
- Zhang et al. [2022c] Xikun Zhang, Dongjin Song, and Dacheng Tao. Sparsified subgraph memory for continual graph representation learning. In 2022 IEEE International Conference on Data Mining (ICDM), pages 1335–1340. IEEE, 2022.
- Zhang et al. [2023a] Peiyan Zhang, Yuchen Yan, Chaozhuo Li, Senzhang Wang, Xing Xie, Guojie Song, and Sunghun Kim. Continual learning on dynamic graphs via parameter isolation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, page 601–611, New York, NY, USA, 2023. Association for Computing Machinery.
- Zhang et al. [2023b] Xikun Zhang, Dongjin Song, and Dacheng Tao. Ricci curvature-based graph sparsification for continual graph representation learning. IEEE Transactions on Neural Networks and Learning Systems, 2023.
- Zhou and Cao [2021] Fan Zhou and Chengtai Cao. Overcoming catastrophic forgetting in graph neural networks with experience replay. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 4714–4722, 2021.
Appendix A Appendix
A.1 Algorithms
We present the algorithm of lossless memory learning at the task in Algorithm 1, and the algorithm of the proposed method DeLoMe is shown in Algorithm 2.
A.2 Details on Datasets
-
•
CoraFull222https://docs.dgl.ai/en/1.1.x/generated/dgl.data.CoraFullDataset.html: It is a citation network containing 70 classes, where nodes represent papers and edges represent citation links between papers.
-
•
Arxiv333https://ogb.stanford.edu/docs/nodeprop/#ogbn-arxiv: It is also a citation network between all Computer Science (CS) ARXIV papers indexed by MAG Sinha et al. [2015]. Each node in Arxiv denotes a CS paper and the edge between nodes represents a citation between them. The nodes are classified into 40 subject areas. The node features are computed as the average word-embedding of all words in the title and abstract.
-
•
Reddit444https://docs.dgl.ai/en/1.1.x/generated/dgl.data.RedditDataset.html#dgl.data.RedditDataset: It encompasses Reddit posts generated in September 2014, with each post classified into distinct communities or subreddits. Specifically, nodes represent individual posts, and the edges between posts exist if a user has commented on both posts. Node features are derived from various attributes, including post title, content, comments, post score, and the number of comments.
-
•
Products555https://ogb.stanford.edu/docs/nodeprop/#ogbn-products: It is an Amazon product co-purchasing network, where nodes represent products sold in Amazon and the edges between nodes indicate that the products are purchased together. The node features are constructed with the dimensionality-reduced bag-of-words of the product descriptions.
The statistics of these datasets are summarized in the Table 5.
| Datasets | CoraFull | Arxiv | Products | |
|---|---|---|---|---|
| # nodes | 19,793 | 169,343 | 227,853 | 2,449,028 |
| # edges | 130,622 | 1,166,243 | 114,615,892 | 61,859,036 |
| # classes | 70 | 40 | 40 | 46 |
| # tasks | 35 | 20 | 20 | 23 |
| # Avg. nodes per task | 660 | 8,467 | 11,393 | 122,451 |
| # Avg. edges per task | 4,354 | 58,312 | 5,730,794 | 2,689,523 |
A.3 More Implementation Details
All the continual learning methods including the proposed method are implemented based on the graph continual learning benchmark Zhang et al. [2022a]. For ERGNN Zhou and Cao [2021], the memory budget is set to be up to 800 per class to demonstrate the advantage of the proposed method. For SSM Zhang et al. [2022c] and Zhang et al. [2023b], we conduct experiments with the same memory budgets. However, to preserve the topological information, SSM and SEM need to store the neighbors of selected nodes. The number of neighbors for each node to store is set to 5 at each hop for both SSM and SEM.
Different GNN backbones, such as GCN Kipf and Welling [2016] and SGC Wu et al. [2019], can be applied to these continual learning methods. In the main paper, to have a fair comparison to the baselines Zhang et al. [2023b], we employ a two-layer SGC model as the backbone. Specifically, the hidden dimension is set to 256 for all methods. The number of training epochs of each graph learning task is 200 with Adam as the optimizer and the learning rate is set to 0.005.
For the lossless memory learning in the proposed method, we employ the same two-layer SGC model as the GNN model to calculate the gradient-matching loss. The synthetic node representations are set as learnable parameters and are initialized with the original node attributes. The labels of the synthetic nodes are fixed during the learning process. Adam is used as the optimizer to learn the synthetic representations. The learning epochs and learning rate are set to 800 and 0.0001 for all tasks and datasets respectively. The scaling parameter in the debiased loss function is set to 1 for all experiments for simplicity.
The code is implemented with Pytorch (version: 1.10.0), DGL (version: 0.9.1), OGB (version: 1.3.6), and Python 3.8.5. Moreover, all experiments are conducted on a Linux server with an Intel CPU (Intel Xeon E-2288G 3.7GHz) and a Nvidia GPU (Quadro RTX 6000).
A.4 Full Results with Standard Deviation
In the main paper, we only report the average performance of different methods. The full results with standard deviation under both class- and task-incremental settings are shown in Table 1 and Table 2 respectively.
| Methods | CoraFull | Arixv | Products | |||||
|---|---|---|---|---|---|---|---|---|
| AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | |
| Fine-tune | 2.90.0 | -94.70.1 | 4.90.0 | -87.01.5 | 5.10.3 | -94.52.5 | 3.40.8 | -82.50.8 |
| Joint | 80.60.3 | - | 46.41.4 | - | 99.30.2 | - | 71.50.7 | - |
| EWC | 15.20.7 | -81.11.0 | 4.90.0 | -88.90.3 | 10.61.5 | -92.91.6 | 3.31.2 | -89.62.0 |
| MAS | 12.33.8 | -83.74.1 | 4.90.0 | -86.80.6 | 13.12.6 | -35.23.5 | 15.02.1 | -66.31.5 |
| GEM | 7.92.7 | -84.82.7 | 4.80.5 | -87.80.2 | 28.43.5 | -71.94.2 | 5.50.7 | -84.30.9 |
| LwF | 2.00.2 | -95.00.2 | 4.90.0 | -87.91.0 | 4.50.5 | -82.11.0 | 3.10.8 | -85.91.4 |
| TWP | 20.93.8 | -73.34.1 | 4.90.0 | -89.00.4 | 13.52.6 | -89.72.7 | 3.00.7 | -89.71.0 |
| ERGNN | 3.00.1 | -93.80.5 | 30.31.5 | -54.01.3 | 88.52.3 | -10.82.4 | 24.51.9 | -67.41.9 |
| SSM-uniform | 72.30.8 | -15.51.5 | 45.11.1 | -12.21.4 | 93.80.4 | -2.00.3 | 61.81.2 | -10.71.1 |
| SSM-degree | 74.40.2 | -9.90.1 | 46.00.4 | -11.30.8 | 94.00.2 | -1.90.2 | 62.90.4 | -10.30.5 |
| SEM-curvature | 79.60.3 | -2.70.1 | 51.00.3 | -6.70.6 | 95.10.6 | -1.50.7 | 64.01.6 | -11.21.8 |
| CaT | 79.50.4 | -5.50.2 | 47.10.4 | -13.70.2 | 98.00.1 | -0.10.1 | 70.61.0 | -4.00.9 |
| DeLoMe (Ours) | 81.80.3 | 1.90.4 | 52.80.3 | 0.20.6 | 98.10.1 | 0.60.2 | 67.00.8 | -18.30.4 |
| Methods | CoraFull | Arixv | Products | |||||
|---|---|---|---|---|---|---|---|---|
| AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | AA/% | AF/% | |
| Fine-Tune | 58.01.7 | -38.41.8 | 61.73.8 | -28.23.3 | 73.63.5 | -26.93.5 | 67.61.6 | -25.41.6 |
| Joint | 95.20.2 | - | 90.30.2 | - | 99.40.1 | - | 91.80.2 | - |
| EWC | 78.92.4 | -15.52.3 | 78.82.7 | -5.03.1 | 91.54.2 | -8.14.6 | 90.10.3 | -0.70.3 |
| MAS | 93.00.5 | -0.60.2 | 88.40.2 | -0.00.0 | 98.60.5 | -0.10.1 | 91.20.6 | -0.50.2 |
| GEM | 91.60.6 | -1.80.6 | 87.30.6 | 2.80.3 | 91.65.6 | -8.15.8 | 87.80.5 | -2.90.5 |
| LwF | 56.12.0 | -37.51.8 | 84.20.5 | -3.70.6 | 80.94.3 | -19.14.6 | 66.52.2 | -26.32.3 |
| TWP | 92.20.5 | -0.90.3 | 86.00.8 | -2.80.8 | 87.43.8 | -12.64.0 | 90.30.1 | -0.50.1 |
| ERGNN | 90.60.1 | -3.70.1 | 86.70.1 | 11.40.9 | 98.90.0 | -0.10.1 | 89.00.4 | -2.50.3 |
| SSM-uniform | 94.50.8 | -0.10.9 | 88.81.2 | -2.10.7 | 98.80.3 | -0.90.6 | 90.92.8 | -2.21.0 |
| SSM-degree | 94.31.1 | 0.90.5 | 88.11.3 | -1.00.4 | 99.00.2 | -0.40.2 | 91.10.9 | -1.80.8 |
| SEM-curvature | 95.00.5 | -0.20.8 | 88.80.1 | -1.00.2 | 99.20.1 | -0.10.3 | 91.60.5 | -1.50.8 |
| CaT | 94.30.2 | 0.50.5 | 90.20.2 | 0.20.1 | 99.20.0 | 0.10.1 | 94.30.6 | 0.10.2 |
| DeLoMe (Ours) | 95.20.3 | 1.30.1 | 90.60.3 | 2.31.1 | 99.30.1 | -0.20.1 | 94.20.1 | -1.40.1 |
A.5 Memory budget efficiency
In the main paper, we report the results of the proposed method with different memory budgets under class-incremental learning. Here, we present the results under task-incremental learning in Figure 6. From the figure, we can see that all methods exhibit significantly improved performance under task-incremental learning compared to class-incremental learning. However, the learning-based methods (DeLoMe and CaT) are still more effective than the sampling-based method with tight memory budgets, indicating the importance of capturing the holistic semantics of the original graph into the memory buffer. Note that the performance gain of DeLoMe over CaT is not as significant as observed in class-incremental learning, which is attributed to the fact that task-incremental learning is less challenging than class-incremental learning.


A.6 Results with GCN as Backbone
As stated above, different GNNs can be used as the backbone of DeLoMe. In the main paper, we report the results with SGC Wu et al. [2019] as the backbone. In this subsection, we further present the results with GCN Kipf and Welling [2016] as the backbone. Specifically, we employ the same baselines as in the main paper for comparison, and the results under the class- and task-incremental learning are shown in Table 6 and Table 7 respectively. From the results, we can draw similar observations as in the main paper, i.e., the proposed DeLoMe can effectively overcome the catastrophic forgetting problem in graph continual learning by utilizing lossless memory and debiased memory replay. The results also verify the effectiveness of DeLoMe with different backbones.