Graph Attention Tracking
Abstract
Siamese network based trackers formulate the visual tracking task as a similarity matching problem. Almost all popular Siamese trackers realize the similarity learning via convolutional feature cross-correlation between a target branch and a search branch. However, since the size of target feature region needs to be pre-fixed, these cross-correlation base methods suffer from either reserving much adverse background information or missing a great deal of foreground information. Moreover, the global matching between the target and search region also largely neglects the target structure and part-level information.
In this paper, to solve the above issues, we propose a simple target-aware Siamese graph attention network for general object tracking. We propose to establish part-to-part correspondence between the target and the search region with a complete bipartite graph, and apply the graph attention mechanism to propagate target information from the template feature to the search feature. Further, instead of using the pre-fixed region cropping for template-feature-area selection, we investigate a target-aware area selection mechanism to fit the size and aspect ratio variations of different objects. Experiments on challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance. Code is available at: https://git.io/SiamGAT
1 Introduction

General object tracking is a fundamental but challenging task in computer vision. In recent years, mainstream trackers focus on Siamese network based architectures [10, 15, 16, 33], which achieve state-of-the-art performance as well as a good balance between tracking accuracy and efficiency. These trackers first employ a Siamese network for feature extraction. Then they develop a tracking-head network for object information decoding from one or more similarity maps (or so-called response maps) obtained by information embedding between the template-branch and the search-branch. How to embed the information of the two branches to obtain informative response maps is a key issue, since information passed from the template to the search region is critical to the accurate localization of the object. Almost all current state-of-the-art Siamese trackers like SiamRPN [16], SiamRPN++ [15], SiamFC++ [33] and SiamCAR [10] utilize a cross-correlation based layer for information embedding, which takes convolution on deep features as the basic operation. Despite their great success, some important drawbacks exist with such cross-correlation based trackers: 1) The size of convolution kernel is pre-fixed. As shown in Figure 2, a common processing is cropping the central region on the template feature map to generate the target feature, which is treated as the convolution kernel. However, when solving tracking tasks with different object scales or aspect ratios, this pre-fixed feature region may suffer from either reserving lots of background information or missing a great deal of foreground information, which consequently leads to inaccurate information embedding. 2) The target feature is treated as a whole for similarity computation with the search region. However, during tracking the target often yields large rotation, pose variation and heavy occlusions, and performing such a global matching with variable target is not robust. 3) Because of 2), the information embedding between the template and search region is a global information propagating process, in which the information transmitted from the template to the search region is limited and the information compression is excessive. Our key observation is that the information embedding should be performed by learning the part-level relations (instead of global matching), as part features tend to be invariant against shape and pose variations, thus being more robust.

Aiming at solving these issues, we leverage graph attention networks [28, 34] to design an part-to-part information embedding network for object tracking. We demonstrate that the information embedding between template and search region can be modeled with a complete bipartite graph, which encodes the relations between template nodes and search nodes by applying a graph attention mechanism [28]. With learned attentive scores, each search node can effectively aggregate target information from the template. All search nodes then yield a response map with rich information for the subsequent decoding task. With such designs, we propose a graph attention module (GAM) to realize part-to-part information propagating instead of global information propagating between the template and search region. Instead of using the whole template as a convolution kernel, this part-to-part similarity matching can greatly alleviate the effect of shape-and-pose variations of targets. Further, instead of using the pre-fixed region cropping, we investigate a target-aware template computing mechanism to fit the size and aspect-ratio variations of different objects. With the introduced GAM and target-aware template computing techniques, we present a novel tracking framework, termed Siamese Graph Attention Tracking (SiamGAT) network, for general object tracking.
Since this work mainly argues that an effective information embedding algorithm can enhance the performance of the tracking head, the proposed SiamGAT simply consists of three essential blocks, without using any feature fusion, data enhancement or other strategies to enhance the performance. We evaluate our SiamGAT on several challenge benchmarks, including GOT-10k [14], OTB-100 [31], UAV123 [21] and LaSOT [7]. Without bells and whistles, the proposed tracker achieves leading performance compared with state-of-the-art trackers. Our main contributions are as follows.
-
•
We propose a graph attention module (GAM) to realize part-to-part matching for information embedding. Compared with the traditional cross-correlation based approaches, the proposed GAM can greatly eliminate their drawbacks and effectively pass target information from template to search region.
-
•
We propose a target-aware Siamese Graph Attention Tracking (SiamGAT) network with GAM for general object tracking. The framework is simple yet effective. Compared with previous works using pre-fixed global feature matching, the proposed model is adaptive to the size and aspect-ratio variations of different objects.
-
•
Experiments on multiple challenging benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT demonstrate that the proposed SiamGAT outperforms many state-of-the-art trackers and achieves leading performance.
2 Related Work
In recent years, Siamese based trackers have drawn great attention for their superior performance. The main structure of these trackers can be summarized as three parts: a Siamese network for feature extraction of the template and search region, a similarity matching module for information embedding of the two Siamese branches, and a tracking head for feature decoding from the similarity maps. Many researchers devote to optimizing the Siamese model for better feature representation, or designing new tracking head for more effective bounding box regression. However, few work has been done on information embedding.
The pioneering method SiamFC [2] constructs a Siamese network model for feature extraction and utilizes a cross-correlation layer (Xcorr) to embed the two branches. It takes the template features as kernels to directly perform convolution operation on the search region and obtains a single channel response map. In essence, the correlation here can be regarded as a similarity calculation between the template and the search region, and the obtained response map is a similarity map for target location prediction. Following this similarity-learning work, many researchers try to enhance the Siamese model for feature representation but still leverage the cross-correlation for information embedding [11, 12, 30, 9]. DSiam [11] adds online learning modules to address the target appearance variation and background suppression transformation to improve feature representation. It focuses on enhancing the model updating ability, while the location of object is still computed based on the single channel response map. SA-Siam [12] utilizes a twofold Siamese network to train a semantic branch and an appearance branch. Each branch is a similarity-learning Siamese network, trained separately but combined at the testing time to complement each other. RASNet [30] introduces the spatial attention and channel attention mechanisms to enhance the discriminative capacity of the deep model. GCT [9] adopts a spatial-temporal graph convolutional network for target modeling. Since multiple scales are searched during test to handle the scale-variation of objects, these Siamese trackers are time-consuming.
Leveraging the region proposal network (RPN) [24] (proposed for object detection), Li et al.[16] propose the Siamese region proposal network SiamRPN. They add two branches for region proposal at the end of the Siamese feature extraction network: one classification branch for background-foreground classification of anchors, and one regression branch for proposal refinement. To embed the information of anchors, SiamRPN [16] conducts an up-channel cross-correlation-layer (Up-Xcorr) by cascading multiple independent cross-correlation layers to output multi-channel response maps. Based on SiamRPN [16], DaSiamRPN [37] designs a distractor-aware module to perform incremental learning and obtains much more discriminative features against semantic distractors. To tackle data imbalance, C-RPN [8] proposes to cascade a sequence of RPNs from deep high-level to shallow low-level layers in a Siamese network. Easy negative anchors can be filtered out in earlier cascade stage and hard samples are preserved across stages. Both SiamRPN++ [15] and SiamDW [35] investigate to deepen neural networks to improve the tracking performance. These RPN based trackers have achieved great success on performance as well as discarding traditional multi-scale tests. The chief drawback is that they are sensitive to hyper-parameters associated with anchors.
Apart from deepening the Siamese network, SiamRPN++ [15] also presents a depth-wise cross-correlation layer (DW-Xcorr) to embed information of the target template and the search region branches. Specifically, it performs a channel-by-channel correlation operation with the feature maps of the two branches. By replacing the up-channel cross correlation with the depth-wise cross correlation, imbalance of parameter distribution of the two branches is resolved, which makes the training procedure more stable and the information association more efficient for the prediction of bounding box. Later works in this vein devote to eliminate the negative effects of anchors. A number of anchor-free trackers, such as SiamFC++ [33], SiamCAR [10], SiamBAN [3] and Ocean [36] are proposed, which achieve state-of-the-art tracking performance. They share the general idea tackling the tracking task as a joint classification and regression problem, and take one or multiple heads to directly predict objectiveness and regress bounding boxes from response maps in a per-pixel-prediction manner. Ocean [36] further applies an online-updating module to dynamically adapt the tracker. By discarding anchors and proposals, these anchor-free trackers extricate from the tedious hyper-parameter-tuning and the requirement of providing prior information (e.g., data scale and ratio distribution) for the dataset.
Liao et al.[18] observed that traditional cross-correlation operation brings much background information, which may overwhelm the target feature and results in sensitivity to similar distracters. To solve this issue, they propose a pixel-to-global matching method to suppress the interference of background. However, similar to cross-correlation, this PG-correlation still takes a fixed-scale cropped region as the template feature.
3 Method

In this section, we present a detailed description for the proposed SiamGAT framework. The most important investigation of this work is that the performance of the Siamese trackers can be significantly improved with much effective information propagating from the target template to search region. In the following, we first introduce our Graph Attention Module which establishes the part-to-part correspondence between the Siamese branches. Then we present the target-aware graph attention tracker. An overview of our framework is illustrated in Figure 3.
3.1 Graph Attention Information Embedding
Existing correlation based information embedding methods [2, 16, 15] take the whole target feature as a unity to match with the search features. As this operation neglects the part-level correspondence between the target and the search regions, the matching is inaccurate under shape-and-pose variances of targets. Besides, this global matching manner may greatly compress the target information propagating to the search feature. In order to address these problems, we establish the part-to-part correspondence between the target template and the search region with a complete bipartite graph.
Given two images of a template patch and a search region , we first employ a Siamese feature extraction network to obtain two feature maps and . To generate a graph, we consider each grid of the feature map as a node (part), where represents the number of feature channels. Let be a node set including all nodes of , and let be another node set of . Inspired by the graph attention networks [28], we use a complete bipartite graph to model the part-level relations between the target and search region, where and . We further define two sub-graphs of by and .
For each , let denote the correlation score of node and node :
| (1) |
where and are feature vectors of node and node . Since the more similar is a location in the search region to the local features of the template, the more likely it is the foreground, and more target information should be passed to there. For this reason, we hope that the score is proportional to the similarity of the two node features. We can simply use the inner product between features as the similarity measurement. In order to adaptively learn a better representation between the nodes, we first apply linear transformations to the node features and then take the inner product between transformed feature vectors to calculate the correlation score. Formally,
| (2) |
where and are the linear transformation matrices.
In order to balance the amount of information sent to the search region, we normalize with the softmax function:
| (3) |
Intuitively, measures how much attention the tracker should pay to part , according to the viewpoint of part .
Leveraging the attentions that passed from all nodes in to the -th node in , we compute the aggregated representation for node with
| (4) |
where is a matrix for linear transformation.
Finally, we can fuse the aggregated feature with the node feature to obtain a more powerful feature representation empowered by target information:
| (5) |
where represents vector concatenation.
We compute all in parallel, which yields a response map for subsequent task.
3.2 Target-Aware Graph Attention Tracking
We have presented the graph attention module (GAM) to realize the part-to-part information propagating. Before achieving target-aware visual tracking, we need to tackle another challenge. That is, how to produce a variable template which adaptively fits different object scales and aspect-ratios.
Traditional cross-correlation based methods simply crop the center region of template as the target feature to match with the search region , which delivers much background information to the response map, especially when the template target is given in extreme aspect ratios. To address the problem, we investigate a target-aware template-feature-area selection mechanism under the supervision of labeled bounding box in the template patch. By projecting onto the feature map , we can attain a region of interest . Only the pixels in are taken as the template feature:
| (6) |
Through this simple operation, the obtained feature map is a tensor of dimensions , where and correspond to the width and height of the template bounding box , and is the number of channels of .
Each element is considered as a node in the template subgraph . Meanwhile, each element is considered as a node in the search subgraph . These two subgraphs serve as inputs to the Graph Attention Module for information embedding. As elements in are arranged in a grid pattern on the feature map , we can implement the linear transformations in Section 3.1 with convolutions. Then all correlation scores could be calculated by matrix multiplication, which is expected to greatly improve the efficiency.
In experiments, we observe that applying a batch normalization after each convolution can effectively improve the performance. However, the dimensions and corresponding to different tracking objects cannot be pre-determined, thus we cannot directly apply the batch normalization operation with the scale variable . To solve the problem, we recompute as follows:
| (7) |
Besides keeping the scale invariant, this target-aware idea renders the proposed method extendable to tasks which require non-rectangular ROIs (e.g., instance-segmentation in videos) .
Now we can construct our tracking network with the proposed GAM for effective information embedding. As shown in Figure 3(a), our SiamGAT simply consists of three blocks: a Siamese network for feature extraction, a tracking head for target bounding box prediction and a GAM block to bridge them.
Numerous works demonstrated that trackers can greatly benefit from better feature extraction method [20, 15]. By replacing the classical HOG features and color features with deep CNN features, tracking accuracy has seen significant improvement [20]. Later, deepening the backbone networks and fusing features of multiple layers have further improved the tracking performance [15]. Since GoogLeNet [26] is able to learn multi-scale feature representations with much fewer parameter and faster reasonging speed, here we adopt GoogLeNet as our backbone (an ablation is performed as well to study the performance of SiamGAT using different backbones).
Encouraged by the success of anchor-free trackers, we leverage the classification-regression head network from SiamCAR [10] to be the tracking head. It contains two branches: a classification branch predicting the category information for each location, and a regression branch computing the target bounding box at this location. The two branches share the same response map output by GAM.
| Dataset | Backbone | Target-aware | Embedding Type | Success | Precision | FPS |
|---|---|---|---|---|---|---|
| UAV123 | AlexNet | GAM | 0.592 | 0.779 | 165 | |
| GoogLeNet | GAM | 0.646 | 0.843 | 70 | ||
| GoogLeNet | GAM | 0.626 | 0.822 | 71 | ||
| GoogLeNet | DW-Xcorr | 0.615 | 0.815 | 74 |

4 Experiment
4.1 Implementation Details
The proposed SiamGAT is implemented in Pytorch on 4 RTX-2080Ti cards. Unless specified, the modified GoogLeNet( Inception v3) [26] is adopted as the backbone network for feature extraction. The backbone is initialized with the weights that pretrained on ImageNet [25]. The training batch size is set as 76 and totally 20 epochs are trained with stochastic gradient descent (SGD). We use a learning rate that linearly increased from 0.005 to 0.01 for the first 5 warmup epoches and then exponentially decayed to 0.0005 for the rest 15 epoches. For the first 10 epoches, we freeze the parameters in the backbone to train the graph attention network and the head network. For the rest 10 epoches, we freeze stage 1 and 2 of GoogLeNet, and fine-tune stage 3 and 4.
We adopt COCO [19], ImageNet DET [25], ImageNet VID [25], YouTube-BB [23] and GOT-10k [14] as the training set for experiments on OTB100 [31] and UAV123 [21]. Specifically, for experiments on GOT-10k [14] and LaSOT [7], the model is respectively trained with only the specified training set provided by their official websites for fair comparison. In both training and testing processes, we use pre-fixed scales with pixels for the template patch and pixels for search regions. During testing, only the object in the initial frame of a sequence is adopted as the template patch and fixed for the whole tracking period of this sequence. The search region in the current frame is adopted as the input of the search branch.
4.2 Ablation Study
Backbone architecture. We evaluate our network with both shallow and deep backbone architectures for visual tracking. Table 1 shows the tracking performance with AlexNet and GoogLeNet as backbones. Different backbones greatly affect the speed and performance of the tracker. By replacing AlexNet with GoogLeNet, the success is improved by from to , the precision is increased by from to . While the tracking speed decreases from 165 FPS to 70 FPS, which still meets the real-time requirement. It is worth pointing out that, the SiamGAT using AlexNet as the backbone also achieves a competitive performance while its precision and success are and higher than SiamRPN [16], whose results are shown in Figure 4. Clearly, the proposed approach can achieve a trade-off between accuracy and efficiency with different backbones.
Target-aware vs. pre-fixed template area selection. To investigate the impact of template area selection, we train two models with GAM on GoogLeNet. One is trained with the traditional fixed-region cropping target features, and another is trained with the target-aware selected features. As shown in Table 1, the proposed target-aware feature area selecting mechanism brings and performance gains respectively on success and precision. The main reason is that the target-aware mechanism is able to effectively eliminate the background information and enhance the foreground representation, which helps to obtain more accurate target feature area than fixed-region cropping.
Comparison with DW-Xcorr. To conduct a comparison with cross-correlation based methods, here we replace the target-aware GAM with the popular DW-Xcorr layer [15], which achieves the best performance among cross-correlation based methods. As shown in Table 1, compared with DW-Xcorr, the GAM with target-aware mechanism brings and performance gains respectively on success and precision, while the GAM with pre-fixed region only brings and performance gains. The results further demonstrate that the pre-fixed region of target features has become the bottleneck for accurate target-information-passing. Benefiting from the GAM architecture, our method enables the target-aware region, which is adaptive to different aspect ratios of objects.
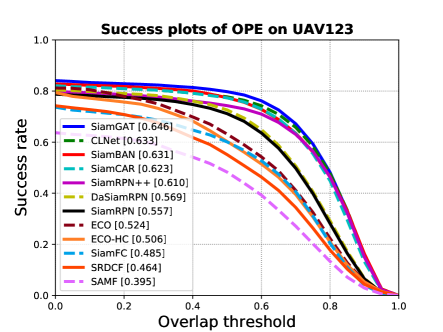
4.3 Evaluation on UAV123
The UAV123 dataset contains a total of 123 video sequences and all sequences are fully annotated with upright bounding boxes. Objects in the dataset suffer from occlusions, fast motion, illumination and large scale variations, which pose challenges to the trackers. A comparison with state-of-the-art trackers is shown in Figure 4 in terms of the precision and success plots of OPE. Our tracker outperforms all other trackers for both metrics. Compared with the baseline SiamCAR, our tracker improves the performance by in precision and in success.
4.4 Evaluation on GOT-10k
| Tracker | AO | SR0.5 | SR0.75 |
|---|---|---|---|
| CFNet [27] | 29.3 | 26.5 | 8.7 |
| MDNet [22] | 29.9 | 30.3 | 9.9 |
| ECO [4] | 31.6 | 30.9 | 11.1 |
| CCOT [6] | 32.5 | 32.8 | 10.7 |
| GOTURN [13] | 34.7 | 37.5 | 12.4 |
| SiamFC [2] | 34.8 | 35.3 | 9.8 |
| SiamRPN_R18 [16] | 48.3 | 58.1 | 27.0 |
| SPM [29] | 51.3 | 59.3 | 35.9 |
| SiamRPN++ [15] | 51.7 | 61.5 | 32.9 |
| ATOM [5] | 55.6 | 63.4 | 40.2 |
| SiamCAR [10] | 57.9 | 67.7 | 43.7 |
| SiamFC++ [33] | 59.5 | 69.5 | 47.9 |
| D3S [1] | 59.7 | 67.6 | 46.2 |
| Ocean-offline [36] | 59.2 | 69.5 | 47.3 |
| Ocean-online [36] | 61.1 | 72.1 | 47.3 |
| SiamGAT (ours) | 62.7 | 74.3 | 48.8 |






To evaluate the generalization of our tracker, we test it on the GOT-10k (Generic Object Tracking Benchmark) and compare it with state-of-the-art trackers. GOT-10k is a challenging large-scale dataset which contains more than 10,000 videos of moving objects in real-world. It is also challenging in terms of zero-class-overlap between the provided training subset and testing subset. For fair comparison, we follow the the protocol of GOT-10k that only training our model with its training subset. We evaluate SiamGAT on GOT-10k and compare it with state-of-the-art trackers including SiamCAR [10], Ocean [36], SiamFC++ [33], D3S [1], SiamRPN++ [15], SPM [29], SiamRPN [16] and other baselines. As shown in Table 2, the proposed SiamGAT performs best in term of all metrics. Compared with the baseline SiamCAR, our tracker improves by , and respectively in terms of , and . Impressively, it even outperforms the online update tracker ‘Ocean’ and improves the scores respectively by , and with a much simple network architecture, which validates the generalization ability of our tracker on unseen classes. Figure 5 shows a comparison on success plots. Some qualitative results and comparisons are provided by Figure 1, which demonstrates that our SiamGAT is able to predict more accurate bounding boxes of targets.
4.5 Evaluation on OTB-100
OTB-100 is one of the most classical benchmarks that provides a fair test-bed on robustness. All sequences in the dataset are labeled with 11 interference attributes, including illumination variation (IV), scale variation (SV), occlusion (OCC), deformation (DEF), motion blur (MB), fast motion (FM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), low resolution (LR) and background clutter (BC). A comparison with state-of-the-art trackers is shown in Figure 6 in terms of success plots of OPE. Our SiamGAT reaches a success score of that surpasses all other trackers. An evaluation on different attributes is shown by Figure 7. Our tracker can better handle the challenges like deformation (DEF), out-of-plane rotation (OPR), occlusion (OCC), illumination variation (IV), in-plane rotation (IPR) and scale variation (SV), which may cause large shape and pose variations of the object. Regarding to fast motion (FM), out-of-view (OV), low resolution (LR) which may cause extreme appearance variations, the proposed tracker obtains a lower score than the baseline SiamCAR. The results demonstrate that the proposed tracker can achieve robust performance against shape and pose variations.
4.6 Evaluation on LaSOT
To further evaluate the proposed approach on a more challenging dataset, we conduct experiments on LaSOT [7], which is a large-scale, high-quality, and densely annotated dataset for long-term tracking. To mitigate potential class bias, it provides the same number of sequences for each category. The results on LaSOT are shown in Figure 8. Our SiamGAT is the second best only behind the online tracker Ocean-online [36] but surpasses the long-term tracker GlobalTrack [17] by in normalized precision, in precision and in success. Compared with Ocean-offline [36] which is much more complex than SiamGAT in terms of network architecture, SiamGAT performs points better in normalized precision, in precision and in success. The results indicate that the proposed tracker is competitive for long-term tracking tasks. Moreover, up to our investigation, both attentive and target-aware properties of the proposed tracker allow more efficient online tracking without model updating. Online tracking modules can be easily integrated in future.
5 Conclusion
In this paper, we have presented a novel target-aware Siamese Graph Attention network, termed SiamGAT, for general object tracking. We provide theoretical and empirical evidences that how GAM establishes part-to-part correspondence and enables each part of the search region to aggregate information from the target. Instead of using the traditional cross-correlation based information embedding method, our GAM realizes part-level information propagating between the two Siamese branches and yields a much effective information embedding map. By recomputing a target-aware template area that can adaptively fit with different object scales and aspect ratios, the proposed approach enables more generalizable visual tracking. Without bells and whistles, our SiamGAT outperforms state-of-the-art trackers by clear margins on multiple main-stream benchmarks including GOT-10k, UAV123, OTB-100 and LaSOT.
References
- [1] L. Alan, M. Jiri, and K. Matej. D3s - a discriminative single shot segmentation tracker. In IEEE Conf. Comput. Vis. Pattern Recog., 2020.
- [2] L. Bertinetto, J. Valmadre, J.F. Henriques, A. Vedaldi, and P.H. Torr. Fully-convolutional siamese networks for object tracking. In Eur. Conf. Comput. Vis., 2016.
- [3] Z.D. Chen, B.N. Zhong, G.R. Li, S.P. Zhang, and R.R. Ji. Siamese box adaptive network for visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2020.
- [4] M. Danelljan, G. Bhat, F.S. Khan, and M. Felsberg. Eco: Efficient convolution operators for tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2017.
- [5] M. Danelljan, G. Bhat, F.S. Khan, and M. Felsberg. Accurate tracking by overlap maximization. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [6] M. Danelljan, A. Robinson, F.S. Khan, and M. Felsberg. Beyond correlation filters:learning continuous convolution operators for visual tracking. In Eur. Conf. Comput. Vis., 2016.
- [7] H. Fan, L.T. Lin, F. Yang, P. Chu, G. Deng, S.J. Yu, H.X. Bai, Y. Xu, C.Y. Liao, and H.B. Ling. Lasot: A high-quality benchmark for large-scale single object tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [8] H. Fan and H.B. Ling. Siamese cascaded region proposal networks for real-time visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [9] J.Y. Gao, T.Z. Zhang, and C.S. Xu. Graph convolutional tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [10] D.Y. Guo, J. Wang, Y. Cui, Z. H. Wang, and S.Y. Chen. Siamcar: Siamese fully convolutional classification and regression for visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2020.
- [11] Q. Guo, W. Feng, C. Zhou, R. Huang, L. Wan, and S. Wang. Learning dynamic siamese network for visual object tracking. In Int. Conf. Comput. Vis., 2017.
- [12] A. F. He, C. Luo, X.M. Tian, and W.J. Zeng. A twofold siamese network for real-time object tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2018.
- [13] D. Held, S. Thrun, and S. Savarese. Learning to track at 100 fps with deep regression networks. In Eur. Conf. Comput. Vis., 2016.
- [14] L.H. Huang, X. Zhao, and K.Q. Huang. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell., 2018.
- [15] B. Li, W. Wu, Q. Wang, F.Y. Zhang, J.L. Xing, and J.J. Yan. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [16] B. Li, J.J. Yan, W. Wu, Z. Zhu, and X.L. Hu. High performance visual tracking with siamese region proposal network. In IEEE Conf. Comput. Vis. Pattern Recog., 2018.
- [17] Kaiqi Huang Lianghua Huang, Xin Zhao. Globaltrack: A simple and strong baseline for long-term tracking. In AAAI Conf. Artificial Intelligence, 2020.
- [18] B.Y. Liao, C.Y. Wang, Y.Y. Wang, Y.N. Wang, and J. Yin. Pg-net: Pixel to global matching network for visual tracking. In Eur. Conf. Comput. Vis., 2020.
- [19] T.Y. Lin, M. Michael, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C.L. Zitnick. Microsoft coco: Common objects in context. In Eur. Conf. Comput. Vis., 2014.
- [20] B. Luca, V. Jack, G. Stuart, M. Ondrej, and T. Philip HS. Staple: Complementary learners for real-time tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2016.
- [21] M. Muller, N. Smith, and B. Ghanem. A benchmark and simulator for uav tracking. In Eur. Conf. Comput. Vis., 2016.
- [22] H. Nam and B. Han. Learning multi-domain convolutional neural networks for visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2016.
- [23] E. Real, J. Shlens, S. Mazzocchi, X. Pan, and V. Vanhoucke. Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video. In IEEE Conf. Comput. Vis. Pattern Recog., 2017.
- [24] S.Q. Ren, K.M. He, R. Girshick, and J. Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., (6):1137–1149, 2017.
- [25] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, and M. Bernstein. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis., 2015.
- [26] Szegedy, Christian, Vanhoucke, Vincent, Ioffe, Sergey, Shlens, Jonathon, Wojna, and Zbigniew. Rethinking the inception architecture for computer vision. In IEEE Conf. Comput. Vis. Pattern Recog., 2016.
- [27] J. Valmadre, L. Bertinetto, J.F. Henriques, A. Vedaldi, and P.H. Torr. End-to-end representation learning for correlation filter based tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2017.
- [28] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph attention networks. In Int. Conf. Learn. Represent., 2018.
- [29] G.T. Wang, C. Luo, Z.W. Xiong, and W.J. Zeng. Spm-tracker: Series-parallel matching for real-time visual object tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [30] Q. Wang, T. Zhu, J. Xing, J. Gao, W. Hu, and S. Maybank. Learning attentions: residual attentional siamese network for high performance online visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2018.
- [31] Y. Wu, J.W. Lim, and M.H. Yang. Online object tracking: A benchmark. In IEEE Conf. Comput. Vis. Pattern Recog., 2013.
- [32] Y. Wu, J. Lim, and M.H. Yang. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell., 37(9):1834, 2015.
- [33] Y.D. Xu, Z.Y. Wang, Z.X. Li, Y. Yuan, and G. Yu. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In AAAI Conf. Artificial Intelligence, 2020.
- [34] C. Zhang, G.S. Lin, F.Y. Liu, J.S. Guo, Q.Y. Wu, and R. Yao. Pyramid graph networks with connection attention for region-based one-shot semantic segmentation. In Int. Conf. Comput. Vis., 2019.
- [35] Z.P. Zhang and H.W. Peng. Deeper and wider siamese networks for real-time visual tracking. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
- [36] Z.P. Zhang, H.W. Peng, J.L. Fu, B. Li, and W.M. Hu. Ocean: Object-aware anchor-free tracking. In Eur. Conf. Comput. Vis., 2020.
- [37] Z. Zhu, Q. Wang, B. Li, W. Wu, J.J. Yan, and W.M. Hu. Distractor-aware siamese networks for visual object tracking. In Eur. Conf. Comput. Vis., 2018.