Graph Attention Retrospective
Abstract
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular models is graph attention networks. They were introduced to allow a node to aggregate information from features of neighbor nodes in a non-uniform way, in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we theoretically study the behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here, the node features are obtained from a mixture of Gaussians and the edges from a stochastic block model. We show that in an “easy” regime, where the distance between the means of the Gaussians is large enough, graph attention is able to distinguish inter-class from intra-class edges. Thus it maintains the weights of important edges and significantly reduces the weights of unimportant edges. Consequently, we show that this implies perfect node classification. In the “hard” regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. In addition, we show that graph attention convolution cannot (almost) perfectly classify the nodes even if intra-class edges could be separated from inter-class edges. Beyond perfect node classification, we provide a positive result on graph attention’s robustness against structural noise in the graph. In particular, our robustness result implies that graph attention can be strictly better than both the simple graph convolution and the best linear classifier of node features. We evaluate our theoretical results on synthetic and real-world data.
[email protected], [email protected]
1 Introduction
Graph learning has received a lot of attention recently due to breakthrough learning models [21, 42, 13, 18, 23, 5, 16, 22, 28] that are able to exploit multi-modal data that consist of nodes and their edges as well as the features of the nodes. One of the most important problems in graph learning is the problem of classification, where the goal is to classify the nodes or edges of a graph given the graph and the features of the nodes. Two of the most fundamental mechanisms for classification, and graph learning in general, are graph convolution and graph attention. Graph convolution, usually defined using its spatial version, corresponds to averaging the features of a node with the features of its neighbors [28].111Although the model in [28] is related to spectral convolutions, it is mainly a spatial convolution since messages are propagated along graph edges. More broadly, graph convolution can refer to different variants arising from different (approximations of) graph spectral filters. We provide details in Section 2. Graph attention [44] mechanisms augment this convolution by appropriately weighting the edges of a graph before spatially convolving the data. Graph attention is able to do this by using information from the given features for each node. Despite its wide adoption by practitioners [19, 46, 25] and its large academic impact as well, the number of works that rigorously study its effectiveness is quite limited.
One of the motivations for using a graph attention mechanism as opposed to a simple convolution is the expectation that the attention mechanism is able to distinguish inter-class edges from intra-class edges and consequently weights inter-class edges and intra-class edges differently before performing the convolution step. This ability essentially maintains the weights of important edges and significantly reduces the weights of unimportant edges, and thus it allows graph convolution to aggregate features from a subset of neighbor nodes that would help node classification tasks. In this work, we explore the regimes in which this heuristic picture holds in simple node classification tasks, namely classifying the nodes in a contextual stochastic block model (CSBM) [8, 17]. The CSBM is a coupling of the stochastic block model (SBM) with a Gaussian mixture model, where the features of the nodes within a class are drawn from the same component of the mixture model. For a more precise definition, see Section 2. We focus on the case of two classes where the answer to the above question is sufficiently precise to understand the performance of graph attention and build useful intuition about it. We briefly and informally summarize our contributions as follows:
-
1.
In the “easy regime”, i.e., when the distance between the means of the Gaussian mixture model is much larger than the standard deviation, we show that there exists a choice of attention architecture that distinguishes inter-class edges from intra-class edges with high probability (Theorem 3). In particular, we show that the attention coefficients for one class of edges are much higher than the other class of edges (Corollary 4). Furthermore, we show that these attention coefficients lead to a perfect node classification result (Corollary 5). However, in the same regime, we also show that the graph is not needed to perfectly classify the data (Proposition 7).
-
2.
In the “hard regime”, i.e., when the distance between the means is small compared to the standard deviation, we show that every attention architecture is unable to distinguish inter-class from intra-class edges with high probability (Theorem 9). Moreover, we show that using the original Graph Attention Network (GAT) architecture [44], with high probability, most of the attention coefficients are going to have uniform weights, similar to those of simple graph convolution [28] (Theorem 10). We also consider a setting where graph attention is provided with independent and perfect edge information, and we show that even in this case, if the distance between the means is sufficiently small, then graph attention would fail to (almost) perfectly classify the nodes with high probability (Theorem 13).
-
3.
Beyond perfect node classification, we show that graph attention is able to assign a significantly higher weight to self-loops, irrespective of the parameters of the Gaussian mixture model that generates node features or the stochastic block model that generates the graph. Consequently, we show that with a high probability, graph attention convolution is at least as good as the best linear classifier for node features (Theorem 14). In a high structural noise regime when the graph is not helpful for node classification, i.e., when intra-class edge probability is close to inter-class edge probability , this means that graph attention is strictly better than simple graph convolution because it is able to essentially ignore the graph structural noise (Corollary 15). In addition, we obtain lower bounds on graph attention’s performance for almost perfect node classification and partial node classification (Corollary 16).
-
4.
We provide an extensive set of experiments both on synthetic data and on three popular real-world datasets that validates our theoretical results.
1.1 Limitations of our theoretical setting
In this work, to study the benefits and the limitations of the graph attention mechanism, we focus on node classification tasks using the CSBM generative model with two classes and Gaussian node features. This theoretical setting has a few limitations. First, we note that many real-world networks are much more complex and may exhibit different structures than the ones obtainable from a stochastic block model. Furthermore, real-world node attributes such as categorical features may not even follow a continuous probability distribution. Apparently, there are clear gaps between CSBM and the actual generative processes of real-world data. Nonetheless, we note that a good understanding of graph attention’s behavior over CSBM would already provide us with useful insights. For example, it has been shown empirically that synthetic graph datasets based on CSBM constitute good benchmarks for evaluating various GNN architectures [40]. To that end, in Section 6, we summarize some practical implications of our theoretical results which could be useful for practitioners working with GNNs.
Second, there are different levels of granularity for machine learning problems on graphs. Besides node-level tasks such as node classification, other important problems include edge-level tasks such as link prediction and graph-level tasks such as graph classification. While, empirically, variants of graph attention networks have been successfully applied to solve problems at all levels of granularity, our theoretical results mostly pertain to the effects of graph attention for node classification. This is a limitation on the scope of our study. On the other hand, we note that edge-level and graph-level tasks are typically solved by adding a pooling layer which combines node representations from previous graph (attention) convolution layers. Consequently, the quality of graph attention convolution’s output for a node not only affects node classification but also has a major influence on link prediction and graph classification. Therefore, our results may be extended to study the effects of graph attention on link prediction and graph classification under the CSBM generative model. For example, link prediction is closely related to edge classification which we extensively study in Section 3. For graph classification, one may consider the problem of classifying graphs generated from different parameter settings of the CSBM. In this case, our results on graph attention’s impact on node representations may be used to establish results on graph attention’s impact on graph representations after certain pooling layers. In particular, if graph attention convolution generates good node representations that are indicative of node class memberships, then one can show that the graph representation obtained from appropriately aggregating node representations would be indicative of the clustering structure of the graph, and hence the graph representation would be useful for graph classification tasks.
1.2 Relevant work
Recently the concept of attention for neural networks [6, 43] was transferred to graph neural networks [32, 10, 44, 30, 41]. A few papers have attempted to understand the attention mechanism in [44]. One work relevant to ours is [11]. In this paper, the authors show that a node may fail to assign large edge weight to its most important neighbors due to a global ranking of nodes generated by the attention mechanism in [44]. Another related work is [29], which presents an empirical study of the ability of graph attention to generalize on larger, complex, and noisy graphs. In addition, in [24] the authors propose a different metric to generate the attention coefficients and show empirically that it has an advantage over the original GAT architecture.
Other related work to ours, which does not focus on graph attention, comes from the field of statistical learning on random data models. Random graphs and the stochastic block model have been traditionally used in clustering and community detection [1, 4, 39]. Moreover, the works by [8, 17], which also rely on CSBM are focused on the fundamental limits of unsupervised learning. Of particular relevance is the work by [7], which studies the performance of graph convolution on CSBM as a semi-supervised learning problem. Within the context of random graphs, [27] studies the approximation power of graph neural networks on random graphs. In [37] the authors derive generalization error of graph neural networks for graph classification and regression tasks. In our paper we are interested in understanding graph attention’s capability for edge/node classification with respect to different parameter regimes of CSBM.
Finally, there are a few related theoretical works on understanding the generalization and representation power of graph neural networks [14, 15, 49, 47, 20, 34, 35]. For a recent survey in this direction see [26]. Our work takes a statistical perspective which allows us to characterize the precise performance of graph attention compared to graph convolution and no convolution for CSBM, with the goal of answering the particular questions that we imposed above.
2 Preliminaries
In this section, we describe the Contextual Stochastic Block Model (CSBM) [17] which serves as our data model, and the Graph Attention mechanism [44]. We also define notations and terms that are frequently used throughout the paper.
For a vector and , the norm denotes the Euclidean norm of , i.e. . We write . We use to denote the Bernoulli distribution, so means the random variable takes value 1 with probability and 0 with probability . Let , and . Define two classes as for . For each index , we set the feature vector as , where , and is the identity matrix.222The means of the mixture of Gaussians are . Our results can be easily generalized to general means. The current setting makes our analysis simpler without loss of generality. For a given pair we consider the stochastic adjacency matrix defined as follows. For in the same class (i.e., intra-class edge), we set , and if are in different classes (i.e., inter-class edge), we set . We denote by a sample obtained according to the above random process.
An advantage of CSBM is that it allows us to control the noise by controlling the parameters of the distributions of the model. In particular, CSBM allows us to control the distance of the means and the variance of the Gaussians, which are important for controlling the separability of the Gaussians. For example, fixing the variance, then the closer the means are the more difficult the separation of the node Gaussian features becomes. Another notable advantage of CSBM is that it allows us to control the structural noise and homophily level of the graph. The level of noise in the graph is controlled by increasing or reducing the gap between the intra-class edge probability and the inter-class edge probability , and the level of homophily in the graph is controlled by the relative magnitude between and . For example, when is much larger than , then a node is more likely to be connected with a node from the same class, and hence we obtain a homophilous graph; when is much larger than , then a node is more likely to be connected with a node from a different class, and hence we obtain a heterophilous graph. There are several recent works exploring the behavior of GNNs in heterophilous graphs [33, 48, 9, 36]. Interestingly, we note that our results for graph attention’s behavior over the CSBM data model do not depend on whether the graph is homophilous or heterophilous.
Given node representations for , a (spatial) graph convolution for node has output
where is a learnable matrix. Throughout this paper, we will refer to this operation as simple graph convolution or standard graph convolution. Our definition of graph convolution is essentially the mean aggregation step in a general GNN layer [22]. The normalization constant in our definition is closely related to the symmetric normalization used in the original Graph Convolutional Network (GCN) introduced by [28]. Our definition does not affect the discussions or implications we have for GCN with symmetric normalization. More broadly, there are other forms of graph convolution in the literature [12, 16, 31], which we do not compare within this work.
A single-head graph attention applies some weight function on the edges based on their node features (or a mapping thereof). Given two representations for two nodes , the attention model/mechanism is defined as the mapping
where and is a learnable matrix. The attention coefficient for a node and its neighbor is defined as
| (1) |
where is the set of neighbors of node that also includes node itself. Let be some element-wise activation function (which is usually nonlinear), the graph attention convolution output for a node is given by
| (2) |
A multi-head graph attention [44] uses weight matrices , , and averages their individual (single-head) outputs. We consider the most simplified case of a single graph attention layer (i.e., and ) where is realized by an MLP using the LeakyRelu activation function. The LeakyRelu activation function is defined as if and for some constant if .
The CSBM model induces node features which are correlated through the graph , represented by an adjacency matrix . A natural requirement of attention architectures is to maintain important edges in the graph and ignore unimportant edges. For example, important edges could be the set of intra-class edges and unimportant edges could be the set of inter-class edges. In this case, if graph attention mains all intra-class edges and ignores all inter-class edges, then a node from a class will be connected only to nodes from its own class. More specifically, a node will be connected to neighbor nodes whose associated node features come from the same distribution as node features of . Given two sets and , we denote and .
3 Separation of edges and its implications for graph attention’s ability for perfect node classification
In this section, we study the ability of graph attention to separate important edges from unimportant edges. In addition, we study the implications of graph attention’s behavior for node classification. In particular, we are interested in whether or not the graph attention convolution is able to perfectly classify the nodes in the graph. Depending on the parameter regimes of the CSBM, we separate the results into two parts. In Section 3.1, we study graph attention’s behavior when the distance between the means of the node features is large. We construct a specific attention architecture and demonstrate its ability to separate intra-class edges from inter-class edges. Consequently, we show that the corresponding graph attention convolution is able to perfectly classify the nodes. In Section 3.2, we study graph attention’s behavior when the distance between the means of the node features is small. We show that with high probability no attention architecture is able to separate intra-class edges from inter-class edges. Consequently, we conjecture that no graph attention is able to perfectly classify the nodes. We provide evidence of this conjecture in Section 3.2.1, where we assume the existence of a strong attention mechanism that is able to perfectly classify the edges independently from node features. We show that using this “idealistic” attention mechanism still fails to (almost) perfectly classify the nodes, provided that the distance between the means of the node features is sufficiently small.
The two-parameter regimes of the CSBM that we consider in Section 3.1 and Section 3.2 are as follows. The first (“easy regime”) is where , and the second (“hard regime”) is where for some . We start by defining edge separability and node separability.
Definition 1 (Edge separability).
Given an attention model , we say that the model separates the edges, if the outputs satisfy
whenever is an intra-class edge, i.e. , and is an inter-class edge, i.e. .
Definition 2 (Node separability).
Given a classification model which outputs a scalar representation for node , we say that the model separates the nodes if whenever and whenever .
Some of our results in this section rely on a mild assumption that lower bounds the sparsity of the graph generated by the CSBM model. This assumption says that the expected degree of a node in the graph is larger than . It is required to obtain a concentration of node degrees property used in the proofs. While this assumption may limit a direct application of our results to very sparse graphs, for example, graphs whose node degrees are bounded by a constant, it is mainly an artifact of the proof techniques that we use. We expect that similar results still hold for sparser graphs, but to rigorously remove the assumption on graph density one may have to adopt a different proof technique.
Assumption 1.
.
3.1 “Easy Regime”
In this regime we show that a two-layer MLP attention is able to separate the edges with high probability. Consequently, we show that the corresponding graph attention convolution is able to separate the nodes with high probability. At a high level, we transform the problem of classifying an edge into the problem of classifying a point in , where is a unit vector that maximizes the total pairwise distances among the four means given below. When we consider the set of points for all , we can think of each point as a two-dimensional Gaussian vector whose mean is one of the following: , , , . The set of intra-class edges corresponds to the set of bivariate Gaussian vectors whose mean is either or , while the set of inter-class edges corresponds to the set of bivariate Gaussian vectors whose mean is either or . Therefore, in order to correctly classify the edges, we need to correctly classify the data corresponding to means and as 1, and classify the data corresponding to the other means as . This problem is known in the literature as the “XOR problem” [38]. To achieve this we consider a two-layer MLP architecture which separates the first and the third quadrants of the two-dimensional space from the second and the fourth quadrants. In particular, we consider the following specification of ,
| (3) |
where
| (4) |
where is an arbitrary scaling parameter. The particular function has been chosen such that it is able to classify the means of the XOR problem correctly, that is,
To see this, we can take look at the following simplified expression of , which is obtained by substituting the specifications of and from (4) to (3),
| (5) |
Then, by substituting into (5), one easily verifies that
| (6) |
On the other hand, our assumption that guarantees that the distance between the means of the XOR problem is much larger than the standard deviation of the Gaussians, and thus with high probability there is no overlap between the distributions. More specifically, one can show that with a high probability,
| (7) |
This property guarantees that with high probability,
which implies perfect separability of the edges. We state this result below in Theorem 3 and provide detailed arguments in the appendix.
Theorem 3.
Our analysis of edge separability by the attention architecture has two important implications. First, edge separability by implies a nice concentration result for the attention coefficients defined in (1). In particular, one can show that the attention coefficients have the desirable property to maintain important edges and drop unimportant edges. Second, the nice distinguishing power of the attention coefficients in turn implies the exact recoverability of the node memberships using the graph attention convolution. We state these two results below in Corollary 4 and Corollary 5, respectively. Denote
that is, if and if , where is the two-layer MLP attention architecture given in (3) and (4). As it will become clear later, the attention architecture allows attention coefficients to assign more weights to either intra-class or inter-class edges, depending on if or , and this will help us obtain a perfect separation of the nodes.
Corollary 4.
Suppose that and that Assumption 1 holds. Then with probability at least over the data , the attention architecture yields attention coefficients such that
-
1.
If , then if is an intra-class edge and otherwise;
-
2.
If , then if is an inter-class edge and otherwise.
Corollary 5.
Corollary 4 shows the desired behavior of the attention mechanism, namely it is able to assign significantly large weights to important edges while it drops unimportant edges. When , the attention mechanism maintains intra-class edges and essentially ignores all inter-class edges; when , it maintains inter-class edges and essentially ignores all intra-class edges. We now explain the high-level idea of the proof and leave detailed arguments to Appendix A.2. Corollary 4 follows from the concentration of around given by (7). Assume for a moment that so that . Then , and (7) implies that the value of when is an intra-class edge is exponentially larger than the value of when is an inter-class edge. Therefore, by the definition of the attention coefficients in (1), the denominator of is dominated by terms where is in the same class as . Moreover, using concentration of node degrees guaranteed by Assumption 1, each node is connected to many intra-class nodes. By appropriately setting the scaling parameter in (4), the values of for all intra-class edges can be made within multiplicative factor from each other. Therefore we get when is an intra-class edge. A similar reasoning applies to inter-class edges and yields the vanishing value of when is an inter-class edge. Finally, the argument for follows analogously.
The concentration result of attention coefficients in Corollary 4 implies the node classification result in Corollary 5, which holds for any satisfying Assumption 1. That is, even when the graph structure is noisy, e.g., when , it is still possible to exactly recover the node class memberships. Essentially, by applying Corollary 4 and carrying out some straightforward algebraic simplifications, one can show that with high probability for all ,
and hence the model separates the nodes with high probability. We provide details in the appendix.
While Corollary 5 provides a positive result for graph attention, it can be shown that a simple linear classifier which does not use the graph at all achieves perfect node separability with high probability. In particular, the Bayes optimal classifier for the node features without the graph is able to separate the nodes with high probability. This means that in this regime, using the additional graph information is unnecessary, as it does not provide additional power compared to a simple linear classifier for the node classification task.
Lemma 6 (Section 6.4 in [3]).
Let . Then the optimal Bayes classifier for is realized by the linear classifier
| (8) |
Proposition 7.
Suppose . Then with probability at least over the data , the linear classifier given in (8) separates the nodes.
The proof of Proposition 7 is elementary. To see the claim one may show that the probability that the classifier in (8) misclassifies a node is . To do this, let us fix and write where . Assume for a moment . Then the probability of misclassification is
where is the cumulative distribution function of and the last equality follows from the fact that . The assumption that implies for large enough . Therefore, using standard tail bounds for normal distribution [45] we have that
This means that the probability that there exists which is misclassified is at most . A similar argument can be applied to the case where , and an application of a union bound on the events that there is which is misclassified finishes the proof of Proposition 7.
3.2 “Hard Regime”
In this regime ( for ), we show that every attention architecture fails to separate the edges if , and we conjecture that no graph attention convolution is able to separate the nodes. The conjecture is based on our node separability result in Section 3.2.1 which says that, even if we assume that there is an attention architecture which is able to separate the edges independently from node features, the corresponding graph attention convolution still fails to (almost) perfectly classify the nodes with high probability.
The goal of the attention mechanism is to decide whether an edge is an inter-class edge or an intra-class edge based on the node feature vectors and . Let denote the vector obtained from concatenating and , that is,
| (9) |
We would like to analyze every classifier which takes as input and tries to separate inter-class edges and intra-class edges. An ideal classifier would have the property
| (10) |
To understand the limitations of all such classifiers in this regime, it suffices to consider the Bayes optimal classifier for this data model, whose probability of misclassifying of an arbitrary edge lower bounds that of every attention architecture which takes as input . Consequently, by deriving a misclassification rate for the Bayes classifier, we obtain a lower bound on the misclassification rate for every attention mechanism for classifying intra-class and inter-class edges. The following Lemma 8 describes the Bayes classifier for this classification task.
Lemma 8.
Let and let be defined as in (9). The Bayes optimal classifier for is realized by the following function,
| (11) |
where and .
Using Lemma 8, we can lower bound the rate of misclassification of edges that every attention mechanism exhibits. Below we define , where is the cumulative distribution function of .
Theorem 9.
Suppose for some and let be any attention mechanism. Then,
-
1.
With probability at least , fails to correctly classify at least fraction of inter-class edges;
-
2.
For any if , then with probability at least , misclassify at least one inter-class edge.
Part 1 of Theorem 9 implies that if is linear in the standard deviation , that is if , then with overwhelming probability the attention mechanism fails to distinguish a constant fraction of inter-class edges from intra-class edges. Furthermore, part 2 of Theorem 9 characterizes a regime for the inter-class edge probability where the attention mechanism fails to distinguish at least one inter-class edge. It provides a lower bound on in terms of the scale at which the distance between the means grows compared to the standard deviation . This aligns with the intuition that as we increase the distance between the means, it gets easier for the attention mechanism to correctly distinguish inter-class and intra-class edges. However, if is also increased with the right proportion, in other words, if the noise in the graph is increased, then the attention mechanism would still fail to correctly distinguish at least one inter-class edge. For instance, for and , we get that if , then with probability at least , misclassifies at least an inter-class edge.
The proof of Theorem 9 relies on analyzing the behavior of the Bayes optimal classifier in (11). We compute an upper bound on the probability with which the optimal classifier correctly classifies an arbitrary inter-class edge. Then the proof of part 1 of Theorem 9 follows from a concentration argument for the fraction of inter-class edges that are misclassified by the optimal classifier. For part 2, we use a similar concentration argument to choose a suitable threshold for that forces the optimal classifier to fail on at least one inter-class edge. We provide formal arguments in the appendix.
As a motivating example of how the attention mechanism would fail and what exactly the attention coefficients would behave in this regime, we focus on one of the most popular attention architecture [44], where is a single-layer neural network parameterized by with activation function. Namely, the attention coefficients are defined by
| (12) |
We show that, as a consequence of the inability of the attention mechanism to distinguish intra-class and inter-class edges, with overwhelming probability most of the attention coefficients given by (12) are going to be . In particular, Theorem 10 says that for the vast majority of nodes in the graph, the attention coefficients on most edges are uniform irrespective of whether the edge is inter-class or intra-class. As a result, this means that the attention mechanism is unable to assign higher weights to important edges and lower weights to unimportant edges.
Theorem 10.
Assume that and for some absolute constants and . Moreover, assume that the parameters are bounded. Then, with probability at least over the data , there exists a subset with cardinality at least such that for all the following hold:
-
1.
There is a subset with cardinality at least , such that for all .
-
2.
There is a subset with cardinality at least , such that for all .
Theorem 10 is proved by carefully computing the numerator and the denominator in (12). In this regime, is not much larger than , that is, the signal does not dominate noise, so the numerator in (12) is not indicative of the class memberships of nodes but rather acts like Gaussian noise. On the other hand, denote the denominator in (12) by and observe that it is the same for all where . Using concentration arguments about yields and finishes up the proof. We provide details in the appendix.
Compared to the easy regime, it is difficult to obtain a separation result for the nodes without additional assumptions. In the easy regime, the distance between the means was much larger than the standard deviation, which made the “signal” (the expectation of the convolved data) dominate the “noise” (i.e., the variance of the convolved data). In the hard regime the “noise” dominates the “signal”. Thus, we conjecture the following.
Conjecture 11.
There is an absolute constant such that, whenever , every graph attention model fails to perfectly classify the nodes with high probability.
The above conjecture means that in the hard regime, the performance of the graph attention model depends on as opposed to the easy regime, where in Corollary 5 we show that it doesn’t. This property is verified by our synthetic experiments in Section 5. The quantity in the threshold comes from our conjecture that the expected maximum “noise” of the graph attention convolved data over the nodes is at least for some constant . The quantity in the threshold comes from our conjecture that the distance between the means (i.e. “signal”) of the graph attention convolved data is reduced to at most of the original distance. Proving Conjecture 11 would require delicate treatment of the correlations between the attention coefficients and the node features for .
3.2.1 Are good attention coefficients helpful in the “hard regime”?
In this subsection we are interested in understanding the implications of edge separability on node separability in the hard regime and when is restricted to a specific class of functions. In particular, we show that Conjecture 11 is true under an additional assumption that does not depend on the node features. In addition, we show that even if we were allowed to use an “extremely good” attention function which separates the edges with an arbitrarily large margin, with high probability the graph attention convolution (2) will still misclassify at least one node as long as is sufficiently small.
We consider the class of functions which can be expressed in the following form:
| (13) |
for some . The particular class of functions in (13) is motivated by the property of the ideal edge classifier in (10) and the behavior of in (6) when it is applied to the means of the Gaussians. There are a few possible ways to obtain a function which satisfies (13). For example, in the presence of good edge features which reflect the class memberships of the edges, we can make take as input the edge features. Moreover, if , one such may be easily realized from the eigenvectors of the graph adjacency matrix. By the exact spectral recovery result in Lemma 12, we know that there exists a classifier which separates the nodes. Therefore, we can set if and otherwise.
Lemma 12 (Exact recovery in [1]).
Suppose that and . Then there exists a classifier taking as input the graph and perfectly classifies the nodes with probability at least .
Theorem 13.
Suppose that satisfy Assumption 1 and that are bounded away from 1. For every , there are absolute constants such that, with probability at least over the data , using the graph attention convolution in (2) and the attention architecture in (13), the model misclassifies at least nodes for any such that , if
-
1.
and ;
-
2.
and .
Theorem 13 warrants some discussions. We start with the role of in the attention function (13). One may think of as the multiplicative margin of separation for intra-class and intra-class edges. When , the margin of separation is at most a constant. This includes the special case when for all , i.e, the margin of separation is 0. In this case, the graph attention convolution in (2) reduces to the standard graph convolution with uniform averaging among the neighbors. Therefore, part 1 of Theorem 13 also applies to the standard graph convolution. On the other hand, when , the margin of separation is not only bounded away from but also it grows with .
Next, we discuss the additional assumption that are bounded away from 1. This assumption is used to obtain a concentration result required for the proof of Theorem 13. It is also intuitive in the following sense. If both and are arbitrarily close to 1, then after the convolution the convolved node feature vectors collapse to approximately a single point, and thus this becomes a trivial case where no classifier is able to separate the nodes; on the other hand, if is arbitrarily close to 1 and is very small, then after the convolution the convolved node feature vectors collapse to approximately one of two points according to which class the node comes from, and in this case the nodes can be easily separated by a linear classifier.
We now focus on the threshold for under which the model is going to misclassify at least one node with high probability. In part 1 of Theorem 13, , i.e., the attention mechanism is either unable to separate the edges or unable to separate the edges with a large enough margin. In this case, one can show that all attention coefficients are . Consequently, the quantity appears in denominator of the threshold for in part 1 of Theorem 13. Because of that, if and are arbitrarily close, then the model is not able to separate the nodes irrespective of how large is. For example, treating as a constant since and are bounded away from 1 by assumption, we have that
This means that if and are close enough, every attention function in the form of (13) and cannot help classify all nodes correctly even if . On the contrary, recall that in the easy regime where , the attention mechanism given in (3) and (4) helps separate the nodes with high probability. This illustrates the limitation of every attention mechanism in the form of (13) which have an insignificant margin of separation. According to Theorem 10, the vast majority of attention coefficients are uniform, and thus in Conjecture 11 we expect that graph attention in general shares similar limitations in the hard regime.
In part 2 of Proposition 13, , i.e., the attention mechanism separates the edges with a large margin. In this case, one can show that the attention coefficients on important edges (e.g. intra-class edges) are exponentially larger than those on unimportant edges (e.g. inter-class edges). Consequently, the factor no longer appears in the threshold for in part 2 of Theorem 13. However, at the same time, the threshold also implies that, even when we have a perfect attention mechanism that is able to separate the edges with a large margin, as long as is small enough, then the model is going to misclassify at least one node with high probability.
Finally, notice that in Theorem 13 the parameter captures a natural tradeoff between the threshold for and the lower bound on the number of misclassified nodes. Namely, the smaller the is, the smaller the threshold for becomes, and hence the less signal there is in the node features, the more mistakes the model is going to make. This is precisely demonstrated by the scaling of and misclassification bound with respect to . We leave the proof of Theorem 13 to the appendix.
4 Robustness to structural noise and its implications beyond perfect node classification
In this section, we provide a positive result on the capacity of graph attention convolution for node classification beyond the perfect classification regime. In particular, we show that independent of the parameters of CSBM, i.e., independent of , , and , the two-layer MLP attention architecture from Section 3.1 is able to achieve the classification performance obtainable by the Bayes optimal classifier for node features. This is proved by showing that there is a parameter setting for where the attention coefficient on self-loops can be made exponentially large. Consequently, the corresponding graph attention convolution behaves like a linear function of node features. We provide two corollaries of this result. The first corollary provides a ranking of graph attention convolution, simple graph convolution, and linear function in terms of their ability to classify nodes in CSBM. More specifically, by noticing that the simple graph convolution is also realized by a specific parameter setting of the attention architecture , our result implies that the performance of graph attention convolution for node classification in CSBM is lower bounded by the best possible performance between a linear classifier and simple graph convolution. In particular, graph attention is strictly more powerful than simple graph convolution when the graph is noisy (e.g. when ), and it is strictly more powerful than a linear classifier when the graph is less noisy (e.g. when and are significantly different). The second corollary provides perfect classification, almost perfect classification, and partial classification results for graph attention convolution. It follows immediately from the reduction of graph attention convolution to a linear function under the specification of that we will discuss. In what follows we start with high-level ideas, then we present formal statements of the results, and we discuss the implications in detail.
Recall the two-layer MLP attention architecture from (3) and (4) is equivalently written in (5) as
We make the following observations. Assuming that the scaling parameter ,
-
•
If , then the function assigns more weight to an edge such that than an edge such that ;
-
•
If , then the function assigns more weight to an edge such that than an edge such that ;
-
•
If , then the function assigns uniform weight to every edge .
This means that the behavior of depends on which side of the hyperplane that comes from. In other words, for fixed , whether the attention function will up-weight or down-weight an edge depends entirely on the classification of based on the linear classifier . Moreover, note that the attention function value satisfies
Therefore, out of all unit norm vectors , our choice maximizes the range of values that can output. Recall from Lemma 6 that also happens to characterize the Bayes optimal classifier for the node features. Finally, the attention function achieves minimum/maximum at self-attention, i.e.
A consequence of these observations is that, by setting the scaling parameter sufficiently large, one can make exponentially larger than for any such that and . According to the definition of attention coefficients in (1), this means that the attention coefficients where are going to be exponentially larger than the attention coefficients where . Therefore, one could expect that in this case, if the linear classifier correctly classifies for some , e.g., for this means that , then graph attention convolution output also satisfies , due to sufficiently larger attention coefficients for which . We state the result below in Theorem 14 and leave detailed arguments in the appendix.
Theorem 14.
Theorem 14 means that there is a parameter setting for the attention architecture such that the performance of graph attention convolution matches with the performance of the Bayes optimal classifier for node features. This shows the ability of graph attention to “ignore” the graph structure, which can be beneficial when the graph is noisy. For example, if , then it is easy to see that simple graph convolution completely mixes up the node features, making it not possible to achieve any meaningful node classification result. On the other hand, as long as there is some signal from the original node features, i.e. , then graph attention will be able to pick that up and classify the nodes at least as good as the best classifier for the node features alone. It is also worth noting that by setting , the attention function has a constant value, and hence graph attention convolution reduces to the standard graph convolution, which has been shown to be useful in the regime where the original node features are not very strong but the graph has a nice structure [7]. For example, when there is a significant gap between and , , then setting could significantly improve the node separability threshold over the best linear classifier [7]. This shows the robustness of graph attention against noise in one of the two sources of information, namely node features and edge connectivities. Unlike the Bayes optimal classifier for node features which is sensitive to feature noise or the simple graph convolution which is sensitive to structural noise, one can expect graph attention to work as long as at least one of the two sources of information has a good signal. Therefore, we obtain a ranking of node classification models among graph attention convolution, simple graph convolution, and a linear classifier. We state this below in Corollary 15.
Corollary 15.
The node classification performance obtainable by graph attention convolution is lower bounded by the best possible node classification performance between a simple graph convolution and a linear classifier.
By a straightforward characterization of the performance of the linear classifier , we immediately obtain the following classification results in Corollary 16. Recall that we denoted as the cumulative distribution function of the standard normal distribution. Write
Corollary 16.
With probability at least over the data , using the two-layer MLP attention architecture given in (3) and (4) with , one has that
-
•
(Perfect classification) If then all nodes are correctly classified;
-
•
(Almost perfect classification) If then at least fraction of all nodes are correctly classified;
-
•
(Partial classification) If then at least fraction of all nodes are correctly classified.
Interestingly, we note that the perfect classification result in Corollary 16 is nearly equivalent (up to a small order in the threshold ) to the perfect classification result in Corollary 5 from Section 3.1. They are obtained from different behaviors of the attention coefficients. This shows that there could be more than one type of “good” attention coefficients that are able to deliver good node classification performance.
5 Experiments
In this section, we demonstrate empirically our results on synthetic and real data. The parameters of the models that we experiment with are set by using an ansatz based on our theorems. The particular details are given in Section 5.1. For real datasets, we use the default splits which come from PyTorch Geometric [19] and OGB [25]. In all our experiments we use MLP-GAT, where the attention mechanism is set to be the two-layer network in (3) and (4) with . For synthetic experiments using CSBM with known and , we use the variant that takes into account, . In Figure 2(b) and Figure 3(b) we additionally consider the original GAT architecture of [44] to demonstrate Theorem 10.
5.1 Ansatz for GAT, MLP-GAT and GCN
For the original GAT architecture we fix and define the first head as and ; The second head is defined as and . We now discuss the choice of such an ansatz. The parameter is picked based on the optimal Bayes classifier without a graph, and the attention is set such that the first head maintains intra-class edges in and the second head maintains intra-class edges in . Note that for the original GAT [44], due to the fact that the attention mechanism consists of just one layer (i.e. a nonlinear activation applied on a linear transformation, see (12)), it is not possible for the original GAT to keep only which correspond to intra-class edges. More specifically, one may use the same techniques in the proof of Theorem 3 and Corollaries 4 and 5 to prove the node separability results for the original GAT. In this particular case, the result will depend on in contrast to the result we get for MLP-GAT, where no dependence of was needed. For MLP-GAT we use the ansatz where is given in (3) and (4) with . This choice of two-layer network allows us to bypass the “XOR problem” [38] and separate inter-class from intra-class edges as shown in Theorem 3. Note that no single-layer architecture will be able to separate the edges due to the “XOR problem”. For GCN we used the ansatz from [7] which is also .
5.2 Synthetic data
We use the CSBM to generate the data. In a recent work [40], a simple variant of the CSBM was also chosen as the default generative model for benchmarking GNN performance for node classification tasks. We present two sets of experiments. In the first set, we fix the distance between the means and vary , and in the second set, we fix and vary the distance. We set , , and . Results are averaged over trials.
5.2.1 Fixing the distance between the means and varying
We consider the two regimes separately, where for the “easy regime” we fix the mean to be a vector where each coordinate is equal to . This guarantees that the distance between the means is . In the “hard regime” we fix the mean to a vector where each coordinate is equal to , and this guarantees that the distance is . We fix and vary from to .
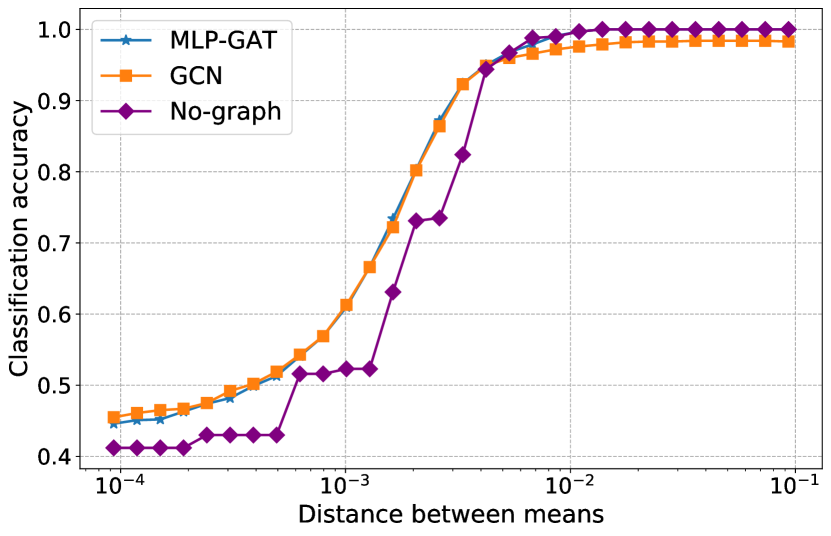
In Figure 1 we illustrate Theorem 3 and Corollaries 4, 5 for the easy regime, and in Figure 2 we illustrate Theorem 9 and Theorem 10 for the hard regime. In particular, in Figure 1(a) we show Theorem 3, MLP-GAT is able to classify intra-class and inter-class edges perfectly. In Figure 1(b) we show that in the easy regime, as claimed in Corollary 4 for MLP-GAT, when , the that correspond to intra-class edges concentrate around , while the for the inter-class edges concentrate to tiny values; when , we see the opposite, that is the that correspond to intra-class edges concentrate to tiny values, while the for the inter-class edges concentrate around . In Figure 1(c) we observe that the performance of MLP-GAT for node classification is independent of in the easy regime as claimed in Corollary 5. However, in this plot, we observe that not using the graph also achieves perfect node classification, a result which is proved in Proposition 7. In the same plot, we also show the performance of simple graph convolution, where its performance depends on (see [7]). In Figure 2(a) we show Theorem 9. MLP-GAT misclassifies a constant fraction of the intra and inter edges as proved in Theorem 9. In Figure 2(b) we show Theorem 10, where ’s in the hard regime concentrate around uniform (GCN) coefficients for both MLP-GAT and GAT. In Figure 2(c) we illustrate that node classification accuracy is a function of for MLP-GAT. This is conjectured in Conjecture 11. On the other hand, note that the performance of MLP-GAT is lower bounded by the performance of not using the graph, as proved in Theorem 14.






5.2.2 Fixing and varying the distance between the means
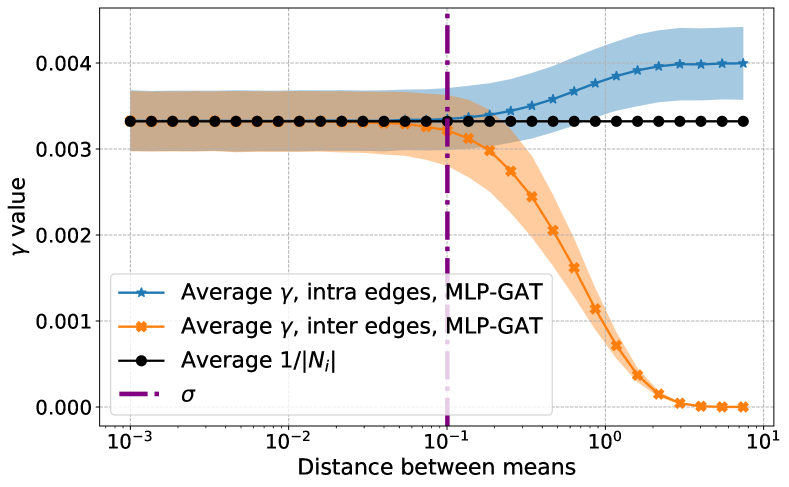
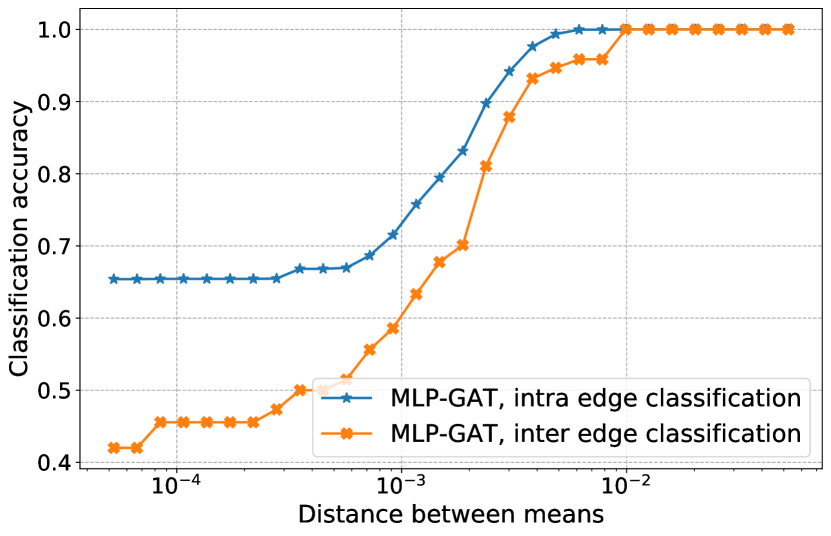
We consider the case where . In Figure 3 we show how the attention coefficients of MLP-GAT and GAT, the node and edge classification depend on the distance between the means. We also add a vertical line at to approximately separate the easy (left of ) and hard (right of ) regimes. Figure 3(c) illustrates Theorems 3 and 9 in the hard and easy regimes, respectively. In particular, we observe that in the hard regime, MLP-GAT fails to distinguish intra from inter edges, while in the easy regime, it is able to do that perfectly for a large enough distance between the means.
In Figure 3(a) we observe that in the hard regime, concentrate around the uniform (GCN) coefficients, while in the easy regime, MLP-GAT is able to maintain the for intra-class edges, while it sets the to tiny values for inter-class edges. In Figure 3(b). we observe that in the hard regime, the of GAT concentrate around the uniform coefficients (proved in Theorem 10), while in the easy regime although the concentrate, GAT is not able to distinguish intra from inter edges. This makes sense since the separation of edges can’t be done by simple linear classifiers used by GAT, see the discussion below Theorem 10. Finally, in Figure 3(d) we show node classification results for MLP-GAT. In the easy regime, we observe perfect classification as proved in Corollary 5. However, as the distance between the means decreases, we observe that MLP-GAT starts to misclassify nodes.



5.3 Real data
For the experiment on real data, we illustrate the attention coefficients, node and edge classification for MLP-GAT as a function of the distance between the means. We use popular real-world graph datasets Cora, PubMed, and CiteSeer collected by PyTorch Geometric [19] and ogbn-arxiv from Open Graph Benchmark [25]. The datasets come with multiple classes, however, for each of our experiments, we do a one-v.s.-all classification for a single class. This is a semi-supervised problem, only a fraction of the training nodes have labels. The rest of the nodes are used for measuring prediction accuracy. To control the distance between the means of the problem we use the true labels to determine the class of each node and then we compute the empirical mean for each class. We subtract the empirical means from their corresponding classes and we also add means and to each class, respectively. This modification can be thought of as translating the mean of the distribution of the data for each class.
The results of this experiment are shown in Figure 4. For Cora, PubMed, and CiteSeer we show results for class 0 since these are small datasets, each dataset contains at most 7 classes, and the classes have similar sizes. In our experiments on other classes, we observed that the results are similar. For ogbn-arxiv we show results for the largest class (i.e. class 16) since this is a larger dataset which has 40 imbalanced classes. Picking a large class makes the one-v.s.-all classification task more balanced. In our experiments on other classes having similar sizes, we obtained similar results. We note that in the real data, we also observe similar behavior of MLP-GAT in the easy and hard regimes as for the synthetic data. In particular, for all datasets as the distance of means increases, MLP-GAT is able to accurately classify intra-class and inter-class edges, see Figures 4(a), 4(d) and 4(g). Moreover, as the distance between the means increases, the average intra-class becomes much larger than the average inter-class , see Figures 4(b), 4(e), 4(h), and 4(k), and the model is able to classify the nodes accurately, see Figures 4(c), 4(f), 4(i), and 4(l). On the contrary, in the same figures, we observe that as the distance between the means decreases then MLP-GAT is not able to separate intra-class from inter-class edges, the averaged are very close to uniform coefficients and the model can’t classify the nodes accurately.










Note that Figure 4 does not show the standard deviation for the attention coefficients . We show the standard deviation of in Figure 5. We observe that the standard deviation is higher than what we observed in the synthetic data. In particular, it can be more than half of the averaged . This is to be expected since for the real data the degrees of the nodes do not concentrate as well. In Figure 5 we show that the standard deviation of the uniform coefficients is also high. For Cora, PubMed, and CiteSeer, the standard deviation for intra-class is similar to that of , while the deviation for inter-class is large for a small distance between the means, but it gets much smaller as the distance increases. For ognb-arxiv, the standard deviation of is particularly high. This implies that the degree distribution of nodes of ogbn-arxiv has a heavy tail, which could potentially result from the graph structure being noisier than other datasets and also explain GCN’s relatively much worse performance when the distance between the means is large.




6 Summary of implications for practitioners
While this work focuses on theoretical understanding of graph attention’s capability for edge and node classification using the CSBM generative model, our findings yield a series of potential suggestions for GNN practitioners. In this section we provide some interesting practical implications of our results.
6.1 Why graph attention? Benefits of graph attention’s robustness to structural noise
When the graph is very noisy, e.g. when a node has a similar number of neighbors from the same class and from different classes, simple graph convolution will mix up node features and thus make nodes from different classes indistinguishable. In this case, simple graph convolution can do more harm than good. However, in practice, it is difficult to determine how noisy the graph is, or if the graph is even useful at all. This could pose a challenge in choosing an architecture. Our results in Theorem 14 and Corollary 15 imply that graph attention has the ability to dramatically reduce the impact of a noisy graph, in a way such that the output is at least as good as the output from the best linear classifier (on the input) which does not rely on the graph. This shows that graph attention convolution is more robust against structural noise in the graph, and hence on noisy graphs, it is strictly better than simple graph convolution.
6.2 Which attention architecture? Benefits of multi-layer attention architecture
In this work, we are able to obtain positive results for graph attention by using the two-layer MLP attention architecture in (3). This is different from the original GAT which uses a single-layer attention architecture [44]. In our analyses and empirical experiments, we found that the original single-layer attention does not have the important properties required for obtaining positive results (e.g. Theorem 3, Corollary 5, Theorem 14, Corollary 16) for graph attention convolution. Coincidentally, this aligns with the findings of [11], where the authors study limitations of the original GAT architecture from a different perspective than ours, and they propose a new architecture termed GATv2. The two-layer MLP attention architecture that we consider in (3) encompasses GATv2 as a special case. Therefore, the two-layer MLP attention architecture can be a good candidate to consider when practitioners search for a suitable graph attention architecture for their specific downstream tasks. On the other hand, our results in Section 3.2 imply that even the two-layer MLP attention architecture (and hence GATv2) has limitations when the node features are noisy. To fix that, a potential solution is to incorporate additional information such as edge features, which we discuss next.
6.3 Will additional information help? Benefits of incorporating good edge features
Even though we do not consider edge features in our analyses, our results in Theorem 13 imply that good attention functions that are able to classify the edges independently from the node features can be very helpful, as they help reduce the threshold under which graph attention convolution would fail to separate the nodes. One potential way to obtain good attention functions that behave like the one given in (13) is by incorporating good edge features. Furthermore, given our result in Theorem 9, which says that graph attention based on noisy node features cannot perfectly classify the edges, the importance of incorporating informative edge features that are more indicative of edge class memberships (if they are accessible in practice) into the attention mechanism is more pronounced.
7 Conclusion and future work
In this work, we study the impact of graph attention on edges and its implications for node classification. We show that graph attention improves robustness to noise in the graph structure. We also show that graph attention may not be very useful in a “hard” regime where the node features are noisy. Our work shows that single-layer graph attention convolution has limited power at distinguishing intra-class from inter-class edges. Given the empirical successes of graph attention and its many variants, a promising future work is to study the power of multi-layer graph attention convolutions for distinguishing intra-class and inter-class edges. Moreover, our negative results in Section 3.2 for edge/node classification pertains to perfect classification and almost perfect classification. In practice, misclassification of a small constant fraction of nodes/edges is often inevitable, but nonetheless useful. Therefore, an interesting future line of work is to characterize the threshold under which graph attention is going to misclassify a certain proportion of nodes. Finally, variants of graph attention networks have been successfully used in tasks other than node classification, such as link prediction and graph classification. These tasks are typically solved by architectures that add a final aggregation layer which combines node representations generated from graph attention convolution. It is an interesting future direction to develop a good understanding of the benefits and limitations of the graph attention mechanism for those tasks.
Acknowledgement
K. Fountoulakis would like to acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC). Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), [RGPIN-2019-04067, DGECR-2019-00147].
A. Jagannath acknowledges the support of the Natural Sciences and Engineering Research Council of Canada (NSERC). Cette recherche a été financée par le Conseil de recherches en sciences naturelles et en génie du Canada (CRSNG), [RGPIN-2020-04597, DGECR-2020-00199].
Appendix A Proofs
We define the following high-probability events which will be used in some proofs. Each of these events holds with probability at least , which follows from straightforward applications of Chernoff bound and union bound, e.g., see [7].
Definition 17.
Define the following events over the randomness of and and ,
-
•
is the event that and .
-
•
is the event that for each , .
-
•
is the event that for each , and .
-
•
is the event that for each , .
-
•
is the intersection of the above 4 events.
Lemma 18 ([7]).
With probability at least event holds.
Some of our proofs also utilize the following simple observation on the mutual independence among when are i.i.d. Gaussian random vectors.
Observation 19.
Fix in and let be i.i.d. drawn from . Then are independent.
Proof: Note that since , it suffices to prove that the covariance for all . By definition, for ,
where the last equality follows from independence between and .
A.1 Proof of Theorem 3
We restate Theorem 3 for convenience.
Theorem.
Recall from (5) that
We will condition on the event that for all , which holds with probability at least following a union bound and the Gaussian tail probability. Under this event, because , for all we have
and hence
which implies that for . Similarly, we get that
| (14) |
Therefore, we probability at least , we have that
which means perfect separability of edges, and the proof is complete.
A.2 Proof of Corollary 4
We restate Corollary 4 for convenience.
Corollary.
Suppose that and that Assumption 1 holds. Then with probability at least over the data , the attention architecture yields attention coefficients such that
-
1.
If , then if is an intra-class edge and otherwise;
-
2.
If , then if is an inter-class edge and otherwise.
The proof is straightforward by considering the cases and separately. When , we have . Using the specification of in (3) and (4), the definition of attention coefficients in (1), the high probability event in Lemma 18, the expression of in (14), and picking such that and , we obtain the claimed results. The result when is obtained in the same way.
A.3 Proof of Corollary 5
We restate Corollary 5 for convenience.
Corollary.
We prove the case and the case follows analogously. Consider the attention architecture , where is given in (3) and (4). Pick such that and ). Assume that , and denote the graph attention convolution output as
We will condition on the event , which holds with probability at least . By using Corollary 4 we have
Similarly, we have that
This means that for . Applying the same reasoning we get that for . Therefore, with probability at least , the graph attention convolution separates the nodes.
A.4 Proof of Lemma 8
We restate Lemma 8 for convenience.
Lemma.
Let and let be defined as in (9). The Bayes optimal classifier for is realized by the following function,
where and .
Proof: Note that is a mixture of -dimensional Gaussian distributions,
The optimal classifier is then given by
Note that and . Thus, by Bayes rule, we obtain that
Suppose that such that . Then if and only if . Hence, for we require that
Similarly, we obtain the reverse condition for .
A.5 Proof of Theorem 9
We restate Theorem 9 for convenience.
Theorem.
Suppose for some and let be any attention mechanism. Then,
-
1.
With probability at least , fails to correctly classify at least fraction of inter-class edges;
-
2.
For any if , then with probability at least , misclassify at least one inter-class edge.
We will write if node and node are in the same class and otherwise. From Lemma 8, we observe that for successful classification by the optimal classifier, we need
We will split the analysis into two cases. First, note that when we have for that
In the first implication, we used that , while the second implication follows from the fact that for all . Similarly, for we have for that
Therefore, for each of the above cases, we can upper bound the probability for either or that is correctly classified, by the probability of the event or equivalently . We focus on the former as the latter is equivalent and symmetric. Writing and , we have that for and ,
where we denote . In the second to last step above, we used triangle inequality to pull outside the absolute value, while in the last equation we use .
We now denote for all . Then the above probability is , where are independent random variables. Note that we have
| (15) |
To see how we obtain the last equation, observe that if then we have
| by triangle inequality | ||||
| by reverse triangle inequality | ||||
hence, . On the other hand, for , we look at each case, conditioned on the events and for each of the four cases based on the signs of and . We denote by the event that , and analyze the cases in detail. First consider the case :
The sum of the four probabilities in the above is . Similarly, we analyze the other case, :
The sum of the four probabilities above is . Therefore, we obtain that
which justifies (15).
We will now construct sets of pairs with mutually independent elements, such that the union of those sets covers all inter-class edges. This will enable us to use a concentration argument that computes the fraction of the inter-class edges that are misclassified. Since the graph operations are permutation invariant, let us assume for simplicity that and for an even number of nodes . Also, define the function
We now construct the following sequence of sets for all :
Fix and observe that the pairs in the set are mutually independent. Define a Bernoulli random variable, , to be the indicator that is misclassified. We have that . Note that the fraction of pairs in the set that are misclassified is , which is a sum of independent Bernoulli random variables. Hence, by the additive Chernoff bound, we obtain
Since , we have by the Chernoff bound and a union bound that with probability at least , for all . We now choose to obtain that on the event where , we have the following for any large :
Following a union bound over all , we conclude that for any ,
Thus, out of all the pairs with , with probability at least , we have that at least a fraction of the pairs are misclassified by the attention mechanism. This concludes part 1 of the theorem.
For part 2, note that by the additive Chernoff bound we have for any ,
Since with probability at least , we choose to obtain
Now note that if then we have , which implies that
Hence, in this regime of ,
and the proof is complete.
A.6 Proof of Theorem 10
We restate Theorem 10 for convenience
Theorem.
Assume that and for some absolute constants and . Moreover, assume that the parameters are bounded. Then, with probability at least over the data , there exists a subset with cardinality at least such that for all the following hold:
-
1.
There is a subset with cardinality at least , such that for all .
-
2.
There is a subset with cardinality at least , such that for all .
For let us write where , if and if . Moreover, since the parameters are bounded, we can write and such that and and are some constants. We define the following sets which will become useful later in our computation of ’s. Define
For define
where .
We start with a few claims about the sizes of these sets.
Claim 20.
With probability at least , we have that .
Proof: Because we know that is a superset of where
We give a lower bound for and hence prove the result. First of all, note that if , then and we easily get that with probability at least , for all , and thus . Therefore let us assume without loss of generality that . Consider the following sum of indicator random variables
By the multiplicative Chernoff bound, for any we have
where . Moreover, by the standard upper bound on the Gaussian tail probability (Proposition 2.1.2, [45]) we know that . Let us set
Then by the upper bound on and the assumption that we know that
It follows that
Therefore, with probability at least we have that
Apply the concentration result of node degrees, this means that with probability at least ,
Therefore we have
Claim 21.
With probability at least , we have that for all ,
Proof: We prove the result for , the result for follows analogously. First, fix . For each we have that
Denote . We have that
Apply Chernoff’s inequality (Theorem 2.3.4 in [45]) we have
Apply the union bound we get
The second inequality follows because under the event (cf. Definition 17) for all . The last equality is due to our assumption that .
Claim 22.
With probability at least , we have that for all and for all ,
Proof: We prove the result for , and the result for follows analogously. First fix and . By the additive Chernoff inequality, we have
Taking a union bound over all and we get
where the last equality follows from Assumption 1 that , and hence
for some absolute constant . Moreover, we have used degree concentration, which introduced the additional additive term in the probability upper bound. Therefore we have
We start by defining an event which is the intersection of the following events over the randomness of and and ,
-
•
is the event that for each , and .
-
•
is the event that .
-
•
is the event that and for all .
-
•
is the event that and for all and for all .
By Claims 20, 21, 22, we get that with probability at least , the event holds. We will show that under event , for all , for all where , we have . This will prove Theorem 10.
Fix and some . Let us consider
where for , we denote
and . We will show that
and hence conclude that . First of all, note that since for some absolute constant , we know that
Let us assume that and consider the following two cases regarding the magnitude of .
Case 1. If , then
where is the slope of for . Here, the second equality follows from and . The third equality follows from
-
•
We have and hence ;
-
•
We have , so , moreover, because , we get that ;
-
•
We have .
Case 2. If , then
To see the last (in)equality in the above, consider the following cases:
-
1.
If , then there are two cases depending on the sign of .
-
•
If , then we have that
-
•
If , then because and , we know that and . Therefore it follows that
where the last equality is due to the fact that so .
-
•
-
2.
If , then there are two cases depending on the sign of .
-
•
If , then we have that
-
•
If , then we have that,
where is the slope of .
-
•
Combining the two cases regarding the magnitude of and our assumption that , so far we have showed that, for any such that , for all , we have
| (16) |
By following a similar argument, one can show that Equation 16 holds for any such that .
Let us now compute
for some . Let us focus on first. We will show that .
First of all, we have that
| (17) |
where is an absolute constant (possibly negative). On the other hand, consider the following partition of :
It is easy to see that
| (18) |
where is an absolute constant. Moreover, because we have that . It follows that
| (19) |
where is an absolute constant. We can upper bound the above quantity as follows. Under the Event , we have that
where
It follows that
| (20) |
where is an absolute constant. The third inequality in the above follows from
-
•
The series converges absolutely for any constant ;
-
•
The sum because
for any . In particular, by picking we see that , and hence we get .
Combining Equations 19 and 20 we get
| (21) |
and combining Equations 18 and 21 we get
| (22) |
Now, by Equations 17 and 22 we get
| (23) |
It turns out that repeating the same argument for yields
| (24) |
Finally, Equations 23 and 24 give us
which readily implies
as required. We have showed that for all and for all , . Repeating the same argument we get that the same result holds for all and for all , too. Hence, by Claims 20 and 21 about the cardinalities of , and we have thus proved Theorem 10.
A.7 Proof of Proposition 13
We restate Proposition 13 for convenience.
Proposition 23.
Suppose that satisfy Assumption 1 and that are bounded away from 1. For every , there are absolute constants such that, with probability at least over the data , using the graph attention convolution in (2) and the attention architecture in (13), the model misclassifies at least nodes for any such that , if
-
1.
and ;
-
2.
and .
We start with part 1 of the proposition. Let us assume that . The result when follows analogously. We will condition on the events defined in Definition 17. These events are concerned with the concentration of class sizes and and the concentration of the number of intra-class and inter-class edges, i.e. and for all . By Lemma 18, the probability that these events hold simultaneously is at least . Fix any such that . Without loss of generality, assume that . Because , by the definition of in (13) and the attention coefficients in (1) we have that
| (25) |
for some positive constants and . Let us write where , if and if . Let us consider the classification of nodes in based on the model output for node . Note that, depending on whether or , the expectation of the model output is symmetric around 0, and therefore we consider the decision boundary at 0. Let and fix any partition of into a set of disjoint subsets,
such that and for every . In what follows we will consider the classification of nodes in each separately. We will show that, with probability at least , for each one of more than half of the subsets where , the model is going to misclassify at least one node, and consequently, the model is going to misclassify at least nodes, giving the required result on misclassification rate.
Fix any . Using (25) we get that, for large enough , the event that the model correctly classifies all nodes in satisfies
for some absolute constant , and hence the probability that the model correctly classifies all nodes in satisfies, for large enough ,
where the last inequality follows from our assumption on and we denote . Now we will use Sudakov’s minoration inequality [45] to obtain a lower bound on the expected maximum, and then apply Borell’s inequality to upper bound the above probability. In order to apply Sudakov’s result we will need to define a metric over the node index set . Let . For , , consider the canonical metric given by
where is the symmetric difference of the neighbors of and , is an absolute constant, and the inequality is due to (25). We lower bound as follows. For , , and a node , the probability that is a neighbor of exactly one of and is if and if . Therefore we have . It follows from the multiplicative Chernoff bound that for any ,
Choose
where the last equality follows from , which is in turn due to the assumptions that and are bounded away from 1. Apply a union bound over all , we get that with probability at least , the size of satisfies
| (26) |
Therefore it follows that, for large enough ,
We condition on the event that the inequality (26) holds for all , which happens with probability at least . Apply Sudakov’s minoration with metric , we get that for large enough , for all ,
| (27) |
for some absolute constants . The last inequality in the above follows from . In addition, note that since by assumption is independent from the node features, using (25) we have that is Gaussian with variance . We use Borell’s inequality ([2] Chapter 2) to get that for any and large enough ,
for some absolute constant . By the lower bound of the expectation (27), we get that
Now, let be any constant that also satisfies . Recall that we defined , and hence . Set
| (28) |
then combine with the events we have conditioned so far we get
Recall that the above probability is the probability of correctly classifying all nodes in . Since our choice of was arbitrary, this applies to every . Let denote the indicator variable of the event that there is at least one node in that is misclassified, then
Apply the reverse Markov inequality, we get
Therefore, with probability at least , we have . This implies the required result that the model misclassifies at least nodes.
The proof of part 2 is similar to the proof of part 1. Let us assume that since the result when can be proved analogously. We condition on the events defined in Definition 17 which simultaneous hold with probability at least by Lemma 18. Fix any such that . Because , by the definition of in (13) and the attention coefficients in (1) we have that
| (29) |
Write where , if and if . We consider the classification of nodes in based on the model output for node and the decision boundary at 0. As before, let and fix any partition of into a set of disjoint subsets such that and for every . We proceed to show that, with high probability, for each one of more than half of the subsets where , the model is going to misclassify at least one node, and consequently, the model is going to misclassify at least nodes as required. Fix any . Using (29) we get that, for large enough , the event that the model correctly classifies all nodes in satisfies
for some absolute constant , and hence the probability that the model classifies all nodes in correctly satisfies, for large enough ,
where the last inequality follows from our assumption on and we denote . The rest of the proof of part 2 proceeds as the proof of part 1.
A.8 Proof of Theorem 14
We restate Theorem 14 for convenience. Recall that we write for some .
Theorem.
We will condition on the following two events concerning the values of for . Both events hold with probability at least . First, for consider the event
Since and , each follows a normal distribution with mean and variance (recall that generates the node memberships in CSBM), we have that
Let us pick such that
This gives that
Second, consider the event that . By Lemma 18 we know that it holds with probability at least . Under these two events, we have that
Recall from (5) that
Consider an arbitrary node where . We will show that . By the definition of attention coefficients in (1), we know that
Using the above expression for , we have that
| (30) |
where the second last inequality follows from the event that for all , and , and the last inequality follows from the fact that the function
is increasing with respect to for . To see that , consider the following cases separately.
- •
- •
This shows that whenever . Similarly, one easily gets that whenever . Therefore the proof is complete.
A.9 Proof of Corollary 16
We restate Corollary 16 for convenience. Recall that we write for some .
Corollary.
With probability at least over the data , using the two-layer MLP attention architecture given in (3) and (4) with , one has that
-
•
(Perfect classification) If then all nodes are correctly classified;
-
•
(Almost perfect classification) If then at least fraction of all nodes are correctly classified;
-
•
(Partial classification) If then at least fraction of all nodes are correctly classified.
Fix and write where , where we recall that defines the class membership of node . We have that follows a normal distribution with mean and standard deviation . Part 1 of the corollary is exactly Proposition 7 whose proof is given in the main text. We consider the other cases for . For both classes and , the probability of correct classification is (using 0 as the decision boundary). Therefore, by applying additive Chernoff bound, we have that
The proof is complete by noticing that when and when .
References
- [1] E. Abbe. Community detection and stochastic block models: Recent developments. Journal of Machine Learning Research, 18:1–86, 2018.
- [2] Robert J Adler, Jonathan E Taylor, et al. Random fields and geometry, volume 80. Springer, 2007.
- [3] T.W. Anderson. An introduction to multivariate statistical analysis. John Wiley & Sons, 2003.
- [4] A. Athreya, D. E. Fishkind, M. Tang, C. E. Priebe, Y. Park, J. T. Vogelstein, K. Levin, V. Lyzinski, Y. Qin, and D. L. Sussman. Statistical inference on random dot product graphs: A survey. Journal of Machine Learning Research, 18(226):1–92, 2018.
- [5] J. Atwood and D. Towsley. Diffusion-convolutional neural networks. In Advances in Neural Information Processing Systems (NeurIPS), page 2001–2009, 2016.
- [6] D. Bahdanau, K. H. Cho, , and Y. Bengio. Neural machine translation by jointly learning to align and translate. In International Conference on Learning Representations (ICLR), 2015.
- [7] A. Baranwal, K. Fountoulakis, and A. Jagannath. Graph convolution for semi-supervised classification: Improved linear separability and out-of-distribution generalization. In Proceedings of the 38th International Conference on Machine Learning (ICML), volume 139, pages 684–693, 2021.
- [8] N. Binkiewicz, J. T. Vogelstein, and K. Rohe. Covariate-assisted spectral clustering. Biometrika, 104:361–377, 2017.
- [9] Cristian Bodnar, Francesco Di Giovanni, Benjamin Chamberlain, Pietro Lio, and Michael Bronstein. Neural sheaf diffusion: A topological perspective on heterophily and oversmoothing in gnns. Advances in Neural Information Processing Systems (NeurIPS), 35:18527–18541, 2022.
- [10] X. Bresson and T. Laurent. Residual gated graph convnets. In arXiv:1711.07553, 2018.
- [11] S. Brody, U. Alon, and E. Yahav. How attentive are graph attention networks. In International Conference on Learning Representations (ICLR), 2022.
- [12] Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- [13] J. Bruna, W. Zaremba, A. Szlam, and Y. LeCun. Spectral networks and locally connected networks on graphs. In International Conference on Learning Representations (ICLR), 2014.
- [14] Z. Chen, L. Li, and J. Bruna. Supervised community detection with line graph neural networks. In International Conference on Learning Representations (ICLR), 2019.
- [15] E. Chien, J. Peng, P. Li, and O. Milenkovic. Adaptive universal generalized pagerank graph neural network. In International Conference on Learning Representations (ICLR), 2021.
- [16] M. Defferrard, X. Bresson, and P. Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems (NeurIPS), page 3844–3852, 2016.
- [17] Y. Deshpande, A. Montanari S. Sen, and E. Mossel. Contextual stochastic block models. In Advances in Neural Information Processing Systems (NeurIPS), 2018.
- [18] D. Duvenaud, D. Maclaurin, J. Aguilera-Iparraguirre, R. Gómez-Bombarelli, T. Hirzel, A. Aspuru-Guzik, and R. P. Adams. Convolutional networks on graphs for learning molecular fingerprints. In Advances in Neural Information Processing Systems (NeurIPS), volume 45, page 2224–2232, 2015.
- [19] M. Fey and J. E. Lenssen. Fast graph representation learning with PyTorch Geometric. In ICLR Workshop on Representation Learning on Graphs and Manifolds, 2019.
- [20] V. Garg, S. Jegelka, and T. Jaakkola. Generalization and representational limits of graph neural networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 119, pages 3419–3430, 2020.
- [21] M. Gori, G. Monfardini, and F. Scarselli. A new model for learning in graph domains. In IEEE International Joint Conference on Neural Networks (IJCNN), 2005.
- [22] W. L. Hamilton, R. Ying, and J. Leskovec. Inductive representation learning on large graphs. In Advances in Neural Information Processing Systems (NeurIPS), pages 1025–1035, 2017.
- [23] M. Henaff, J. Bruna, and Y. LeCun. Deep convolutional networks on graph-structured data. In arXiv:1506.05163, 2015.
- [24] Y. Hou, J. Zhang, J. Cheng, K. Ma, R. T. B. Ma, H. Chen, and M.-C. Yang. Measuring and improving the use of graph information in graph neural networks. In International Conference on Learning Representations (ICLR), 2019.
- [25] W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec. Open graph benchmark: datasets for machine learning on graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [26] S. Jegelka. Theory of graph neural networks: Representation and learning. In arXiv:2204.07697, 2022.
- [27] N. Keriven, A. Bietti, and S. Vaiter. On the universality of graph neural networks on large random graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [28] T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations (ICLR), 2017.
- [29] B. Knyazev, G. W. Taylor, and M. Amer. Understanding attention and generalization in graph neural networks. In Advances in Neural Information Processing Systems (NeurIPS), pages 4202–4212, 2019.
- [30] B. J. Lee, R. A. Rossi, S. Kim, K. N. Ahmed, and E. Koh. Attention models in graphs: A survey. ACM Transactions on Knowledge Discovery from Data (TKDD), 2019.
- [31] Ron Levie, Federico Monti, Xavier Bresson, and Michael M Bronstein. Cayleynets: Graph convolutional neural networks with complex rational spectral filters. IEEE Transactions on Signal Processing, 67(1):97–109, 2018.
- [32] Y. Li, R. Zemel, M. Brockschmidt, and D. Tarlow. Gated graph sequence neural networks. In International Conference on Learning Representations (ICLR), 2016.
- [33] Derek Lim, Felix Hohne, Xiuyu Li, Sijia Linda Huang, Vaishnavi Gupta, Omkar Bhalerao, and Ser Nam Lim. Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, pages 20887–20902, 2021.
- [34] A. Loukas. How hard is to distinguish graphs with graph neural networks? In Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [35] A. Loukas. What graph neural networks cannot learn: Depth vs width. In International Conference on Learning Representations (ICLR), 2020.
- [36] Sitao Luan, Chenqing Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. Revisiting heterophily for graph neural networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 1362–1375, 2022.
- [37] S. Maskey, R. Levie, Y. Lee, and G. Kutyniok. Generalization analysis of message passing neural networks on large random graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2022.
- [38] M. Minsky and S. Papert. Perceptron: an introduction to computational geometry, 1969.
- [39] C. Moore. The computer science and physics of community detection: Landscapes, phase transitions, and hardness. Bulletin of The European Association for Theoretical Computer Science, 1(121), 2017.
- [40] John Palowitch, Anton Tsitsulin, Brandon Mayer, and Bryan Perozzi. Graphworld: Fake graphs bring real insights for gnns. In ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), pages 3691–3701, 2022.
- [41] O. Puny, H. Ben-Hamu, and Y. Lipman. Global attention improves graph networks generalization. In arXiv:2006.07846, 2020.
- [42] F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. IEEE Transactions on Neural Networks, 20(1), 2009.
- [43] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), page 6000–6010, 2017.
- [44] P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Liò, and Y. Bengio. Graph attention networks. In International Conference on Learning Representations (ICLR), 2018.
- [45] R. Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018.
- [46] M. Wang, D. Zheng, Z. Ye, Q. Gan, M. Li, X. Song, J. Zhou, C. Ma, L. Yu, Y. Gai, T. Xiao, T. He, G. Karypis, J. Li, and Z. Zhang. Deep graph library: A graph-centric, highly-performant package for graph neural networks. arXiv preprint arXiv:1909.01315, 2019.
- [47] K. Xu, W. Hu, J. Leskovec, and S. Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations (ICLR), 2019.
- [48] Yujun Yan, Milad Hashemi, Kevin Swersky, Yaoqing Yang, and Danai Koutra. Two sides of the same coin: Heterophily and oversmoothing in graph convolutional neural networks. In IEEE International Conference on Data Mining (ICDM), pages 1287–1292. IEEE, 2022.
- [49] J. Zhu, Y. Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra. Beyond homophily in graph neural networks: Current limitations and effective designs. In Advances in Neural Information Processing Systems (NeurIPS), 2020.