Gradient Descent Temporal Difference-difference Learning
Abstract
Off-policy algorithms, in which a behavior policy differs from the target policy and is used to gain experience for learning, have proven to be of great practical value in reinforcement learning. However, even for simple convex problems such as linear value function approximation, these algorithms are not guaranteed to be stable. To address this, alternative algorithms that are provably convergent in such cases have been introduced, the most well known being gradient descent temporal difference (GTD) learning. This algorithm and others like it, however, tend to converge much more slowly than conventional temporal difference learning. In this paper we propose gradient descent temporal difference-difference (Gradient-DD) learning in order to improve GTD2, a GTD algorithm [1], by introducing second-order differences in successive parameter updates. We investigate this algorithm in the framework of linear value function approximation, theoretically proving its convergence by applying the theory of stochastic approximation. Studying the model empirically on the random walk task, the Boyan-chain task, and the Baird’s off-policy counterexample, we find substantial improvement over GTD2 and, in several cases, better performance even than conventional TD learning.
1 Introduction
Off-policy algorithms for value function learning enable an agent to use a behavior policy that differs from the target policy in order to gain experience for learning. However, because off-policy methods learn a value function for a target policy given data due to a different behavior policy, they are slower to converge than on-policy methods and may even diverge when applied to problems involving function approximation [2, 3].
Two general approaches have been investigated to address the challenge of developing stable and effective off-policy temporal-difference algorithms. One approach is to use importance sampling methods to warp the update distribution so that the expected value is corrected [4, 5]. This approach is useful for the convergence guarantee, but it does not address stability issues. The second main approach to addressing the challenge of off-policy learning is to develop true gradient descent-based methods that are guaranteed to be stable regardless of the update distribution. [6, 1] proposed the first off-policy gradient-descent-based temporal difference algorithms (GTD and GTD2, respectively). These algorithms are guaranteed to be stable, with computational complexity scaling linearly with the size of the function approximator. Empirically, however, their convergence is much slower than conventional temporal difference (TD) learning, limiting their practical utility [7, 8]. Building on this work, extensions to the GTD family of algorithms (see [9] for a review) have allowed for incorporating eligibility traces [10, 11], non-linear function approximation such as with a neural network [12], and reformulation of the optimization as a saddle point problem [13, 14]. However, due to their slow convergence, none of these stable off-policy methods are commonly used in practice.
In this work, we introduce a new gradient descent algorithm for temporal difference learning with linear value function approximation. This algorithm, which we call gradient descent temporal difference-difference (Gradient-DD) learning, is an acceleration technique that employs second-order differences in successive parameter updates. The basic idea of Gradient-DD is to modify the error objective function by additionally considering the prediction error obtained in the last time step, then to derive a gradient-descent algorithm based on this modified objective function. In addition to exploiting the Bellman equation to get the solution, this modified error objective function avoids drastic changes in the value function estimate by encouraging local search around the current estimate. Algorithmically, the Gradient-DD approach only adds an additional term to the update rule of the GTD2 method, and the extra computational cost is negligible. We prove its convergence by applying the theory of stochastic approximation. This result is supported by numerical experiments, which also show that Gradient-DD obtains better convergence in many cases than conventional TD learning.
1.1 Related Work
In related approaches to ours, some previous studies have attempted to improve Gradient-TD algorithms by adding regularization terms to the objective function. These approaches have used have used regularization on weights to learn sparse representations of value functions [Liu:12], or regularization on weights [Ghiassian:20]. Our work is different from these approaches in two ways. First, whereas these previous studies investigated a variant of TD learning with gradient corrections, we take the GTD2 algorithm as our starting point. Second, unlike these previous approaches, our approach modifies the error objective function by using a distance constraint rather than a penalty on weights. The distance constraint works by restricting the search to some region around the evaluation obtained in the most recent time step. With this modification, our method provides a learning rule that contains second-order differences in successive parameter updates.
Our approach is similar to trust region policy optimization [Schulman:15] or relative entropy policy search [Peters:10], which penalize large changes being learned in policy learning. In these methods, constrained optimization is used to update the policy by considering the constraint on some measure between the new policy and the old policy. Here, however, our aim is to find the optimal value function, and the regularization term uses the previous value function estimate to avoid drastic changes in the updating process.
Our approach bears similarity to the natural gradient approach widely used in reinforcement learning [Amari:98, Bh:09, Degris:12, DT:14, Thomas:16], which also features a constrained optimization form. However, Gradient-DD is distinct from the natural gradient. The essential difference is that, unlike the natural gradient, Gradient-DD is a trust region method, which defines the trust region according to the difference between the current value and the value obtained from the previous step. From the computational cost viewpoint, unlike natural TD [DT:14], which needs to update an estimate of the metric tensor, the computational cost of Gradient-DD is essentially the same as that of GTD2.
2 Gradient descent method for off-policy temporal difference learning
2.1 Problem definition and background
In this section, we formalize the problem of learning the value function for a given policy under the Markov decision process (MDP) framework. In this framework, the agent interacts with the environment over a sequence of discrete time steps, . At each time step the agent observes a state and selects an action . In response, the environment emits a reward and transitions the agent to its next state . The state and action sets are finite. State transitions are stochastic and dependent on the immediately preceding state and action. Rewards are stochastic and dependent on the preceding state and action, as well as on the next state. The process generating the agent’s actions is termed the behavior policy. In off-policy learning, this behavior policy is in general different from the target policy . The objective is to learn an approximation to the state-value function under the target policy in a particular environment:
| (1) |
where is the discount rate.
In problems for which the state space is large, it is practical to approximate the value function. In this paper we consider linear function approximation, where states are mapped to feature vectors with fewer components than the number of states. Specifically, for each state there is a corresponding feature vector , with , such that the approximate value function is given by
| (2) |
The goal is then to learn the parameters such that .
2.2 Gradient temporal difference learning
A major breakthrough for the study of the convergence properties of MDP systems came with the introduction of the GTD and GTD2 learning algorithms [SSM09, SMP09]. We begin by briefly recapitulating the GTD algorithms, which we will then extend in the following sections. To begin, we introduce the Bellman operator such that the true value function satisfies the Bellman equation:
where is the reward vector with components , and is a matrix of the state transition probabilities under the behavior policy. In temporal difference methods, an appropriate objective function should minimize the difference between the approximate value function and the solution to the Bellman equation.
Having defined the Bellman operator, we next introduce the projection operator , which takes any value function and projects it to the nearest value function within the space of approximate value functions of the form Eqn. (2). Letting be the matrix whose rows are , the approximate value function can be expressed as . The projection operator is then given by
where the matrix is diagonal, with each diagonal element corresponding to the probability of visiting state .
The natural measure of how closely the approximation satisfies the Bellman equation is the mean-squared Bellman error:
| (3) |
where the norm is weighted by , such that . However, because the Bellman operator follows the underlying state dynamics of the Markov chain, irrespective of the structure of the linear function approximator, will typically not be representable as for any . An alternative objective function, therefore, is the mean squared projected Bellman error (MSPBE), which we define as
| (4) |
Following [SMP09], our objective is to minimize this error measure. As usual in stochastic gradient descent, the weights at each time step are then updated by , where , and
| (5) |
For notational simplicity, we have denoted the feature vector associated with as . We have also introduced the temporal difference error . Let denote the estimate of at the time step . Because the factors in Eqn. (5) can be directly sampled, the resulting updates in each step are
| (6) |
These updates define the GTD2 learning algorithm, which we will build upon in the following section.
3 Gradient descent temporal difference-difference learning
In this section we modify the objective function by additionally considering the difference between and , which denotes the value function estimate at step of the optimization. We propose a new objective , where the notation “" in the parentheses means that the objective is defined given of the previous time step . Specifically, we modify Eqn. (4) as follows:
| (7) |
where is a parameter of the regularization. We show in Section A.1 of the appendix that minimizing Eqn. (7) is equivalent to the following optimization
| (8) |
where is a parameter which becomes large when is small, so that the MSPBE objective is recovered as , equivalent to in Eqn. (7).

Rather than simply minimizing the optimal prediction from the projected Bellman equation, the agent makes use of the most recent update to look for the solution, choosing a that minimizes the MSPBE while following the constraint that the estimated value function should not change too greatly, as illustrated in Fig. 1. In effect, the regularization term encourages searching around the estimate at previous time step, especially when the state space is large.
Eqn. (8) shows that the regularized objective is a trust region approach, which seeks a direction that attains the best improvement possible subject to the distance constraint. The trust region is defined by the value distance rather than the weight distance, meaning that Gradient-DD also makes use of the natural gradient of the objective around rather than around (see Section A.2 of the appendix for details). In this sense, our approach can be explained as a trust region method that makes use of natural gradient information to prevent the estimated value function from changing too drastically.
For comparison with related approaches using natural gradients, in Fig. 8 of the appendix we compare the empirical performance of our algorithm with natural GTD2 and natural TDC [DT:14] using the random walk task introduced below in Section 5.
With these considerations in mind, the negative gradient of is
| (9) |
Because the terms in Eqn. (3) can be directly sampled, the stochastic gradient descent updates are given by
| (10) |
These update equations define the Gradient-DD method, in which the GTD2 update equations (2.2) are generalized by including a second-order update term in the third update equation, where this term originates from the squared bias term in the objective (7). Since Gradient-DD is not sensitive to the step size of updating (see Fig. 7 in the appendix), the updates of Gradient-DD only have a single shared step size rather than two step sizes as GTD2 and TDC used. It is worth noting that the computational cost of our algorithm is essentially the same as that of GTD2. In the following sections, we shall analytically and numerically investigate the convergence and performance of Gradient-DD learning.
4 Convergence Analysis
In this section we establish the convergence of Gradient-DD learning. Denote . We rewrite the update rules in Eqn. (3) as a single iteration in a combined parameter vector with components, , and a new reward-related vector with components, , as follows:
| (11) |
Theorem 1.
Consider the update rules (11) with step-size sequences . Let the TD fixed point be , such that . Suppose that (A0) , , , (A1) is an i.i.d. sequence with uniformly bounded second moments, (A2) and are non-singular, (A3) is bounded in probability, (A4) . Then as , with probability 1.
Due to the second-order difference term in Eqn. (11), the analysis framework in [BM:00] does not directly apply to the Gradient-DD algorithm when (A0) holdes, i.e., step size is tapered. Likewise, the two-timescale convergence analysis [Bh:09] is also not directly applicable. Defining , we rewrite the iterative process in Eqn. (11) into two parallel processes which are given by
| (12) | ||||
| (13) |
We analyze the parallel processes Eqns. (12) & Eqn. (13) instead of directly analyzing Eqn. (11). Our proofs have three steps. First we show is bounded by applying the stability of the stochastic approximation [BM:00] into the recursion Eqn. (12). Second, based on this result, we shall show that goes to 0 in probability by analyzing the recursion Eqn. (13). At last, along with the result that goes to 0 in probability, by applying the convergence of the stochastic approximation [BM:00] into the recursion Eqn. (12), we show that goes to the TD fixed point which is given by the solution of . The details are provided in Section A.3 of the Appendix.
Theorem 1 shows that Gradient-DD maintains convergence as GTD2 under some mild conditions. The assumptions (A0), (A1), and (A2) are standard conditions in the convergence analysis of Gradient TD learning algorithms [SSM09, SMP09, Maei:11]. The assumption (A3) is weak since it means only that the incremental update in each step is bounded in probability. The assumption (A4) requires that is a constant, meaning . Given this assumption, the contribution of the term is controlled by as .
5 Empirical Study
In this section, we assess the practical utility of the Gradient-DD method in numerical experiments. To validate performance of Gradient-DD learning, we compare Gradient-DD learning with GTD2 learning, TDC learning (TD with gradient correction [SMP09]), TDRC learning (TDC with regularized correction [Ghiassian:20]) and TD learning in both tabular representation and linear representation. We conducted three tasks: a simple random walk task, the Boyan-chain task, and Baird’s off-policy counterexample. In each task, we evaluate the performance of a learning algorithm by empirical root mean-squared (RMS) error: . The reason we choose the empirical RMS error rather than root projected mean-squared error or other measures as [Gh:18, Ghiassian:20] used is because it is a direct measure of concern in practical performance. We set the . We also investigate the sensitivity to in the Appendix, where we show that is a good and natural choice in our empirical studies, although tuning may be necessary for some tasks in practice.
5.1 Random walk task
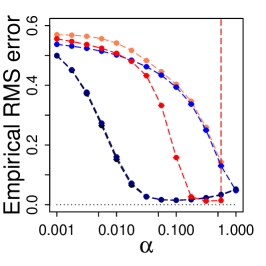
As a first test of Gradient-DD learning, we conducted a simple random walk task [Sutton:2018]. The random walk task has a linear arrangement of states plus an absorbing terminal state at each end. Thus there are sequential states, , where 10, 20, or 40. Every walk begins in the center state. At each step, the walk moves to a neighboring state, either to the right or to the left with equal probability. If either edge state ( or ) is entered, the walk terminates. A walk’s outcome is defined to be at and at . Our aim is to learn the value of each state , where the true values are . In all cases the approximate value function is initialized to the intermediate value . We first consider tabular representation of the value function. We also consider linear approximation representation and obtain the similar results, which are reported in Fig. 10 of the appendix. We consider that the learning rate is tapered according to the schedule . We tune . We also consider the constant step sizes and obtain the similar results, which are reported in Fig. 9 of the appendix. For GTD2 and TDC, we set with .
We first compare the methods by plotting the empirical RMS error from averaging the final 100 steps as a function of step size in Fig. 2, where 20,000 episodes are used. We also plot the average error of all episodes during training and report these results in Fig. 5 of the Appendix. From these figures, we can make several observations. (1) Gradient-DD clearly performs better than the GTD2 and TDC methods. This advantage is consistent in various settings, and gets bigger as the state space becomes large. (2) Gradient-DD performs similarly to TDRC and conventional TD learning, with a similar dependence on , although Gradient-DD exhibits greater sensitivity to the value of in the log domain than these other algorithms. In summary, Gradient-DD exhibits clear advantages over the GTD2 algorithm, and its performance is also as good as TDRC and conventional TD learning.






Next we look closely at the performance during training in Fig. 2. For each method, we tuned by minimizing the average error of the last 100 episodes. We also compare the performance when is tuned by minimizing the average error of the last 100 episodes and report in Fig. 5 of the appendix. From these results, we draw several observations. (1) For all conditions tested, Gradient-DD converges much more rapidly than GTD2 and TDC. The results also indicate that Gradient-DD even converges as fast as TDRC and conventional TD learning. (2) The advantage of Gradient-DD learning over GTD2 grows as the state space increases in size. (3) Gradient-DD has consistent and good performance under both the constant step size setting and under the tapered step size setting. In summary, the Gradient-DD learning curves in this task show improvements over other gradient-based methods and performance that matches conventional TD learning.
Like TDRC, the updates of Gradient-DD only have a single shared step size , i.e., , rather than two independent step sizes and as in the GTD2 and TDC algorithms. A possible concern is that the performance gains in our second-order algorithm could just as easily be obtained with existing methods by adopting this two-timescale approach, where the value function weights are updated with a smaller step size than the second set of weights. Hence, in addition to investigating the effects of the learning rate, size of the state space, and magnitude of the regularization parameter, we also investigate the effect of using distinct values for the two learning rates, and , although we set with . To do this, we set for GDD, with , and report the results in Fig. 7 of the appendix. The results show that comparably good performance of Gradient-DD is obtained under these various , providing evidence that the second-order difference term in our approach provides an improvement beyond what can be obtained with previous gradient-based methods using the two time scale approach.
5.2 Boyan-chain task
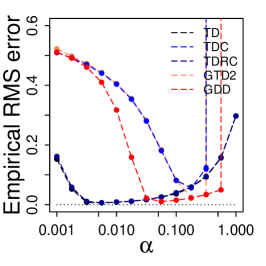
We next investigate Gradient-DD learning on the Boyan-chain problem, which is a standard task for testing linear value-function approximation [Boyan02]. In this task we allow for states, each of which is represented by a -dimensional feature vector, with or . The -dimensional representation for every fourth state from the start is for state , for , , and for the terminal state . The representations for the remaining states are obtained by linearly interpolating between these. The optimal coefficients of the feature vector are . In each state, except for the last one before the end, there are two possible actions: move forward one step or move forward two steps, where each action occurs with probability 0.5. Both actions lead to reward -0.3. The last state before the end just has one action of moving forward to the terminal with reward -0.2. We tune for each method by minimizing the average error of the final 100 episodes. The step size is tapered according to the schedule . For GTD2 and TDC, we set with . In this task, we set .
We report the performance as a function of and the performance over episodes in Fig. 3, where we tune by the performance based on the average error of the last 100 episodes. We also compare the performance based on the average error of all episodes during training and report the results in Fig. 11 of the appendix. These figures lead to conclusions similar to those already drawn in the random walk task. (1) Gradient-DD has much faster convergence than GTD2 and TDC, and generally converges to better values. (2) Gradient-DD is competitive with TDRC and conventional TD learning despite being somewhat slower at the beginning episodes. (3) The improvement over GTD2 or TDC grows as the state space becomes larger. (4) Comparing the performance with constant step size versus that with tapered step size, the Gradient-DD method performs better with tapered step size than it does with constant step size.






5.3 Baird’s off-policy counterexample
We also verify the performance of Gradient-DD on Baird’s off-policy counterexample [Baird:95, Sutton:2018], illustrated schematically in Fig. 4, for which TD learning famously diverges. We show results from Baird’s counterexample with states. The reward is always zero, and the agent learns a linear value approximation with weights : the estimated value of the -th state is for and that of the -th state is . In the task, the importance sampling ratio for the dashed action is , while the ratio for the solid action is . Thus, comparing different state sizes illustrates the impact of importance sampling ratios in these algorithms. The initial weight values are . Constant is used in this task. We set . For TDC and GTD2, thus we tune . Meanwhile we tune for TDC in a wider region. For Gradient-DD, we tune . We tune separately for each algorithm by minimizing the average error from the final 100 episodes.
Fig. 4 demonstrates that Gradient-DD works better on this counterexample than GTD2, TDC, and TDRC. It is worthwhile to observe that when the state size is 20, TDRC become unstable, meaning serious unbalance of importance sampling ratios may cause TDRC unstable. We also note that, because the linear approximation leaves a residual error in the value estimation due to the projection error, the RMS errors of GTD2, TDC, and TDRC in this task do not go to zero. In contrast to other algorithms, the errors from our Gradient-DD converge to zero.





6 Conclusion and discussion
In this work, we have proposed Gradient-DD learning, a new gradient descent-based TD learning algorithm. The algorithm is based on a modification of the projected Bellman error objective function for value function approximation by introducing a second-order difference term. The algorithm significantly improves upon existing methods for gradient-based TD learning, obtaining better convergence performance than conventional linear TD learning.
Since GTD learning was originally proposed, the Gradient-TD family of algorithms has been extended to incorporate eligibility traces and learning optimal policies [Maei:10, GS:14], as well as for application to neural networks [Maei:11]. Additionally, many variants of the vanilla Gradient-TD methods have been proposed, including HTD [Hackman12] and Proximal Gradient-TD [Liu16]. Because Gradient-DD just modifies the objective error of GTD2 by considering an additional squared-bias term, it may be extended and combined with these other methods, potentially broadening its utility for more complicated tasks.
One potential limitation of our method is that it introduces an additional hyperparameter relative to similar gradient-based algorithms, which increases the computational requirements for hyperparameter optimization. This is somewhat mitigated by our finding that the algorithm’s performance is not particularly sensitive to values of , and that was found to be a good choice for the range of environments that we considered. Another potential limitation is that we have focused on value function prediction in the two simple cases of tabular representations and linear approximation, which has enabled us to provide convergence guarantees, but not yet for the case of nonlinear function approximation. An especially interesting direction for future study will be the application of Gradient-DD learning to tasks requiring more complex representations, including neural network implementations. Such approaches are especially useful in cases where state spaces are large, and indeed we have found in our results that Gradient-DD seems to confer the greatest advantage over other methods in such cases. Intuitively, we expect that this is because the difference between the optimal update direction and that chosen by gradient descent becomes greater in higher-dimensional spaces (cf. Fig. 1). This performance benefit in large state spaces suggests that Gradient-DD may be of practical use for these more challenging cases.
Acknowledgments and Disclosure of Funding
This work was partially supported by the National Natural Science Foundation of China (No.11871459) and by the Shanghai Municipal Science and Technology Major Project (No.2018SHZDZX01). Support for this work was also provided by the National Science Foundation NeuroNex program (DBI-1707398) and the Gatsby Charitable Foundation.
References
- [1] R.S. Sutton, H.R. Maei, D. Precup, S. Bhatnagar, D. Silver, Cs. Szepesvári, and E. Wiewiora. Fast gradient-descent methods for temporal-difference learning with linear function approximation. In Proceedings of the 26th International Conference on Machine Learning, 2009.
- [2] L. C. Baird. Residual algorithms: Reinforcement learning with function approximation. In Proceedings of the 12 th International Conference on Machine Learning, pages 30–37, 1995.
- [3] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. The MIT Press, second edition edition, 2018.
- [4] D. Precup, R. S. Sutton, and S. Singh. Eligibility traces for off-policy policy evaluation. In Proceedings of the 17 th International Conference on Machine Learning, 2000.
- [5] A. R. Mahmood, H. van Hasselt, and R. S. Sutton. Weighted importance sampling for off-policy learning with linear function approximation. In Advances in Neural Information Processing Systems 27, 2014.
- [6] R. S. Sutton, Cs. Szepesvári, and H. R. Maei. A convergent O(n) algorithm for off-policy temporal difference learning with linear function approximation. In Advances in Neural Information Processing Systems 21, 2009.
- [7] S. Ghiassian, A. Patterson, S. Garg, D. Gupta, A. White, and M. White. Gradient temporal-difference learning with regularized corrections. In International Conference on Machine Learning, 2020.
- [8] A. White and M. White. Investigating practical linear temporal difference learning. In International Conference on Autonomous Agents and Multi-Agent Systems, 2016.
- [9] S. Ghiassian, A. Patterson, M. White, R.S. Sutton, and A. White. Online off-policy prediction. arXiv:1811.02597, 2018.
- [10] H.R. Maei and R.S. Sutton. : A general gradient algorithm for temporal-difference prediction learning with eligibility traces. In Proceedings of the 3rd Conference on Artificial General Intelligence, pages 91–96, 2010.
- [11] M. Geist and B. Scherrer. Off-policy learning with eligibility traces: A survey. Journal of Machine Learning Research, 15:289–333, 2014.
- [12] H.R. Maei. Gradient temporal-difference learning algorithms. PhD thesis, University of Alberta, Edmonton, 2011.
- [13] B. Liu, J. Liu, M. Ghavamzadeh, S. Mahadevan, and M. Petrik. Finite-sample analysis of proximal gradient TD algorithms. In Proceedings of the 31st International Conference on Uncertainty in Artificial Intelligence, pages 504–513, 2015.
- [14] S. S. Du, J. Chen, L. Li, L. Xiao, and D. Zhou. Stochastic variance reduction methods for policy evaluation. In Proceedings of the 34 th International Conference on Machine Learning, 2017.
- [15] B. Liu, S. Mahadevan, and J. Liu. Regularized off-policy TD-learning. In Advances in Neural Information Processing Systems, 2012.
- [16] John Schulman, Sergey Levine, Philipp Moritz, Michael I. Jordan, and Pieter Abbeel. Trust region policy optimization. In Proceedings of the 32nd International Conference on Machine Learning, 2015.
- [17] J. Peters, K. Mülling, and Y. Altün. Relative entropy policy search. In AAAI Conference on Artificial Intelligence, 2010.
- [18] S. Amari. Natural gradient works efficiently in learning. Neural Computation, (10):251–276, 1998.
- [19] S. Bhatnagar, R.S. Sutton, M. Ghavamzadeh, and M. Lee. Natural actor-critic algorithm. Automatic, (73):2471–2482, 2009.
- [20] T. Degris, P.M. Pilarski, and R.S. Sutton. Model-free reinforcement learning with continuous action in practice. In Proceedings of the 2012 American Control Conference, 2012.
- [21] W. Dabney and P. Thomas. Natural temporal difference learning. In Proceedings of the AAAI Conference on Artificial Intelligence, 2014.
- [22] P. Thomas, B.C. Silva, C. Dann, and E. Brunskill. Energetic natural gradient descent. In Proceedings of the 33th International Conference on Machine Learning, 2016.
- [23] V.S. Borkar and S.P. Meyn. The ODE method for convergence of stochastic approximation and reinforcement learning. SIAM Journal on Control and Optimization, 38(2):447–469, 2000.
- [24] Justin A. Boyan. Technical update: least-squares temporal difference learning. Machine Learning, 49:233–246, 2002.
- [25] L. Hackman. Faster gradient-TD algorithms. Master’s thesis, University of Alberta, Edmonton, 2012.
- [26] B. Liu, J. Liu, M. Ghavamzadeh, S. Mahadevan, and M. Petrik. Proximal gradient temporal difference learning algorithms. In The 25th International Conference on Artificial Intelligence (IJCAI-16),, 2016.
- [27] P. Thomas. GeNGA: A generalization of natural gradient ascent with positive and negative convergence results. In Proceedings of the 31st International Conference on Machine Learning, 2014.
Appendix A Appendix
A.1 On the equivalence of Eqns. (7) & (8)
The Karush-Kuhn-Tucker conditions of Eqn. (8) are the following system of equations
These equations are equivalent to
Thus, for any , there exists a such that .
A.2 The relation to natural gradients
In this section, we shall show that Gradient-DD is related to, but distinct from, the natural gradient. We thank a reviewer for pointing out the connection between Gradient-DD and the natural gradient.
Following [Amari:98] or [Thomas:14], the natural gradient of is the direction obtained by solving the following optimization:
| (A.1) |
We can note that this corresponds to the ordinary gradient in the case where the metric tensor is proportional to the identity matrix.
Now we rewrite Eqn. (8) as
Denote , where is the radius of the circle of around and is a unit vector. Thus, we have
For the MSPBE objective, we have
Minimizing Eqn. (8) is equivalent to the following optimization
| (A.2) |
In the limit as , the above optimization is equivalent to
Thus, given the metric tensor , is the direction of steepest descent, i.e. the natural gradient, of . The natural gradient of , on the other hand, is the direction of steepest descent at , rather than at .
Therefore, our Gradient-DD approach makes use of the natural gradient of the objective around rather than around in Eqn. (A.1). This explains the distinction of the updates of our Gradient-DD approach from the updates of directly applying the natural gradient of the objective .
A.3 Proof of Theorem 1
We introduce an ODE result on stochastic approximation in the following lemma, then show the convergence of our GDD approach in Theorem 1 by applying this result.
Lemma 1.
(Theorems 2.1 & 2.2 of [BM:00]) Consider the stochastic approximation algorithm described by the -dimensional recursion
Suppose the following conditions hold: (c1) The sequence satisfies , , . (c2) The function is Lipschitz, and there exists a function such that , where the scaled function is given by . (c3) The sequence , with , is a martingale difference sequence. (c4) For some and any initial condition , . (c5) The ODE has the origin as a globally asymptotically stable equilibrium. (c6) The ODE has a unique globally asymptotically stable equilibrium . Then (1) under the assumptions (c1-c5), in probability. (2) under the assumptions (c1-c6), as , converges to with probability 1 .
Now we investigate the stochastic gradient descent updates in Eqn. (11), which is recalled as follows:
| (A.3) |
The iterative process in Eqn. (A.3) can be rewritten as
| (A.4) |
Defining
Eqn. (A.4) becomes
Thus, the iterative process in Eqn. (A.3) is rewritten as two parallel processes that are given by
| (A.5) | ||||
| (A.6) |
Our proofs have three steps. First we shall show is bounded by applying the ordinary differential equation approach of the stochastic approximation (the 1st result of Lemma 1) into the recursion Eqn. (A.5). Second, based on this result, we shall show that goes to 0 in probability by analyzing the recursion Eqn. (A.6). At last, along with the result that goes to 0 in probability, by applying the 2nd result of Lemma 1 into the recursion Eqn. (A.5), we show that goes to the TD fixed point, which is given by the solution of .
First, we shall show is bounded. Eqn. (A.5) is rewritten as
| (A.7) |
where and . Let be -fields generated by the quantities , .
Now we verify the conditions (c1-c5) of Lemma 1. Condition (c1) is satisfied under the assumption of the step sizes. Clearly, is Lipschitz and , meaning Condition (c2) is satisfied. Condition (c3) is satisfied by noting that is a martingale difference sequence, i.e., .
We next investigate . From the triangle inequality, we have that
| (A.8) |
From Assumption A3 in Theorem 1 that is bounded and the Assumption A1 that () is an i.i.d. sequence with uniformly bounded second moments, there exists some constant such that
Thus, Condition (c4) is satisfied.
Note that is defined here with opposite sign relative to in [Maei:11]. From [SSM09] and [Maei:11], the eigenvalues of the matrix are strictly negative under the Assumption A2. Therefore, Condition (c5) is satisfied. Thus, applying the 1st part of Lemma 1 shows that is bounded in probability.
Second, we investigate the recursion Eqn. (A.6). Let . Then
| (A.9) |
Note that due to and that there exists a constant such that due to the above result that in probability. Without loss of generality, we assume that . Eqn. (A.3) implies that
| (A.10) |
Under Assumption A0, as . Based on this, Lemma 2 (given in the following section) tells us that as . Thus, Eqn. (A.10) implies that in probability.
A.4 A Lemma
Lemma 2.
Denote . If as , then as .
Proof.
Because as , there exists and some integer such that when . Define a sequence such that
Obviously,
| (A.11) |
Now we investigate the sequence .
Thus, we have that
| (A.12) |
From Eqns. (A.11) & (A.12), we have
| (A.13) |
From the definition of , we have that . It follows that
From the assumption as and Eqn. (A.13), we have as . ∎
A.5 Additional empirical results