GPA-3D: Geometry-aware Prototype Alignment for Unsupervised Domain Adaptive 3D Object Detection from Point Clouds
Abstract
LiDAR-based 3D detection has made great progress in recent years. However, the performance of 3D detectors is considerably limited when deployed in unseen environments, owing to the severe domain gap problem. Existing domain adaptive 3D detection methods do not adequately consider the problem of the distributional discrepancy in feature space, thereby hindering generalization of detectors across domains. In this work, we propose a novel unsupervised domain adaptive 3D detection framework, namely Geometry-aware Prototype Alignment (GPA-3D), which explicitly leverages the intrinsic geometric relationship from point cloud objects to reduce the feature discrepancy, thus facilitating cross-domain transferring. Specifically, GPA-3D assigns a series of tailored and learnable prototypes to point cloud objects with distinct geometric structures. Each prototype aligns BEV (bird’s-eye-view) features derived from corresponding point cloud objects on source and target domains, reducing the distributional discrepancy and achieving better adaptation. The evaluation results obtained on various benchmarks, including Waymo, nuScenes and KITTI, demonstrate the superiority of our GPA-3D over the state-of-the-art approaches for different adaptation scenarios. The MindSpore version code will be publicly available at https://github.com/Liz66666/GPA3D.
1 Introduction
As a fundamental research in 3D scene understanding, 3D detection from point clouds has attracted increasing attention due to its essential role in intelligent robotics, augmented reality and autonomous driving [7, 22, 18, 8, 1]. Despite significant process, state-of-the-art 3D detectors still suffer from dramatic performance degradation when training data and test data are from different environments, i.e., domain shift problem [34]. Various factors, such as diverse weather conditions, object sizes, laser beams, and scanning patterns, lead to substantial discrepancies across different domains, hindering the transferability of existing LiDAR-based 3D detectors. Intuitively, fine-tuning the detectors with adequate data from the target domain could alleviate this issue. However, manually annotating a large amount of point cloud scenes is a prohibitively expensive task. Therefore, the research on unsupervised domain adaptation (UDA) for LiDAR-based 3D detection is essential.
Although many works have been proposed to deal with the UDA for image-based detection [43, 11, 25, 17, 10, 14, 13, 26, 3], directly applying these methods to 3D point cloud detection is insufficient for tackling the domain shifts. These approaches mainly concentrate on the gaps of lighting and texture variations, which could not be obtained from point clouds. While there is only a limited number of literature [34, 37, 27, 9, 40, 38, 20] dealing with the UDA on LiDAR-based 3D detection. Prior work [34] utilizes the statistics from target annotation to perform data-level normalization. MLC-Net [20] designs a mean-teacher framework to provide reliable pseudo-labels to facilitate transferring. ST3D [37] and ST3D++ [38] propose a self-training pipeline with a memory bank to collect and refine pseudo-labels. Despite their great success, these methods do not adequately consider the problem of distributional discrepancy in feature space, hampering the adaptation performance.
To reduce this discrepancy in 2D UDA task, some approaches utilize the class-wise prototypes align features from different domains [12, 32, 41, 19]. In these works, a universal prototype is employed to enforce high representational similarity among features belonging to the same category. However, in the case of 3D scenes, such as vehicles on the road, diverse locations and directions can result in distinct geometric structures, i.e., distributional patterns of point clouds, as presented in Fig. 2 (a) and (b). If a uniform prototype is applied to objects with completely different geometric structures, the efficacy of feature alignment might be hindered, as illustrated in Fig. 2 (c-d). We argue that adopting different prototypes to point cloud objects with distinct geometric structures could deal with the problem of distributional discrepancy, but more attention should also be paid to model these geometric structures during adaptation.
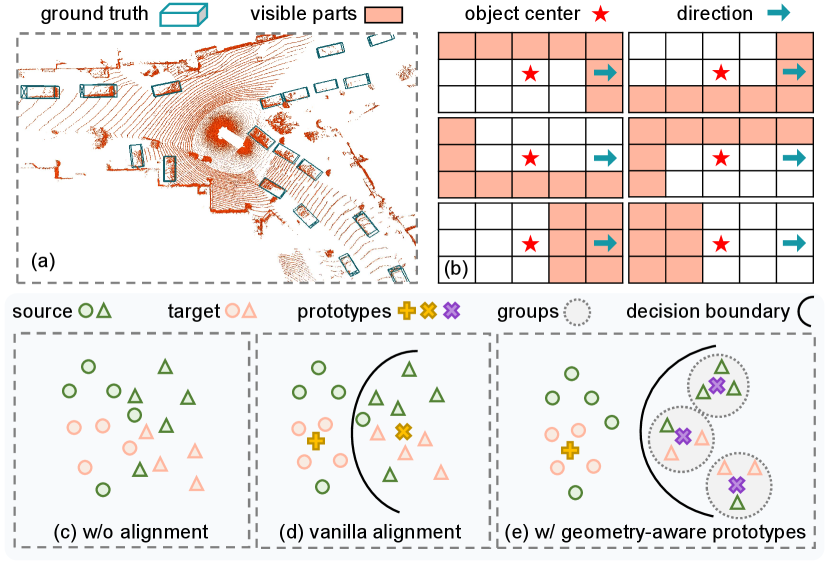
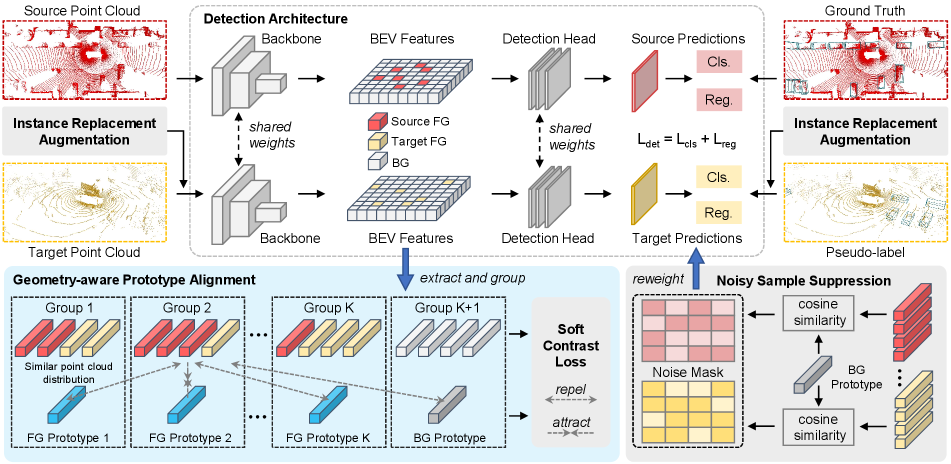
Based on the considerations, we propose a novel UDA framework for LiDAR-based 3D detectors, namely Geometry-aware Prototype Alignment (GPA-3D). Concretely, we first explore the potential relationships between the geometric structures of point cloud objects. During training, we randomly extract the BEV features of point clouds from both the source and target domains, and subsequently divide them into distinct groups based on their geometric structures. In this process, BEV features derived from point clouds with the similar geometric structures will be classified into the same group. Each group is then assigned a unique prototype, which enforces high representational similarity among the BEV features within that group, as illustrated in Fig. 2 (e). To this end, the soft contrast loss is devised to pull the intra-group feature-prototype pairs closer in the representational space and push the inter-group pairs farther away. Additionally, we develop the framework with two components, namely noise sample suppression (NSS) and instance replacement augmentation (IRA). NSS utilizes the similarities between foreground areas and the background prototype, to produce a mask for decreasing the impact of noise. IRA displaces pseudo-labels with high-quality samples that have similar geometric structures, enriching the diversity on the target domain.
The main contributions of this paper include:
-
•
We propose a novel UDA framework for LiDAR-based 3D detectors, namely Geometry-aware Prototype Alignment (GPA-3D). It explicitly integrates geometric associations into feature alignment, effectively decreasing the distributional discrepancy and facilitating the adaptation of existing point cloud detectors.
-
•
Noise sample suppression and instance replacement augmentation are designed to enhance pseudo-labels in terms of reliability and versatility, respectively.
-
•
We conduct comprehensive experiments on Waymo, nuScenes, and KITTI. The encouraging results demonstrate the GPA-3D outperforms state-of-the-art methods in various adaptation scenarios. More importantly, thanks to the architecture-agnostic design, GPA-3D is flexible to be applied to point cloud detectors.
2 Related Work
LiDAR-based 3D Detection.
Mainstream point cloud detectors can be broadly divided into two categories: point-based and grid-based. Point-based methods mainly adopt the architectures of PointNet [23] and PointNet++ [24] to extract features from raw point clouds. PointRCNN [29] designs an encoder-decoder backbone to learn the point-wise representation. 3DSSD [39] improves the point sampling operator from the aspect of feature distance. IA-SSD [42] utilizes the instance-aware downsampling to preserve more foregrounds. On the other hand, grid-based methods first divide point clouds into fixed-size voxels, which are then processed via 2D/3D CNN. SECOND [35] adopts sparse 3D convolution for efficient feature learning. PointPillars [16] proposes a pillar encoding method and achieves a good trade-off between speed and performance. PV-RCNN [28] incorporates the voxel backbone with the keypoint branch to learn the representative scene features. Other approaches [36, 4, 31] project the point clouds into certain kinds of 2D views, and employ 2D CNN to extract the features. In this work, we conduct focused discussions with SECOND [35] and PointPillars [16] as base detectors. To demonstrate the generalization ability of our method, we also provide the comparisons with PV-RCNN [28] detector.
Domain Adaptive Object Detection.
A large amount of literature has been presented in UDA for 2D-image detection, which can be roughly classified into two groups: distribution alignment and self-training. Alignment-based methods [3, 26] leverage the adversarial training [5] to learn aligned features across domains. Self-training approaches [13, 14] utilize a multi-phase strategy to generate pseudo-labels on unlabeled data. Besides, some works [10, 17, 25, 11] adopt the CycleGAN [43] to generate training samples with styles of source and target domains.
Similarly, several recent works also aim to address the domain bias for 3D point cloud detectors. Wang et al. [34] investigate the domain bias of popular autonomous driving 3D datasets, and propose to alleviate the gaps via three techniques, i.e., output transformation, statistical normalization and few shot. SF-UDA3D [27] adopts a mature 3D tracker to find the best scaling parameter, which is further used to re-scale the target point clouds for producing high-quality pseudo-labels. MLC-Net [20] designs a mean-teacher paradigm to provide pseudo-labels for facilitating smooth learning of the student model. ST3D [37] and ST3D++ [38] build a self-training pipeline to produce pseudo-labels for fine-tuning model and update pseudo-labels via memory bank. 3D-CoCo [40] devises the domain-specific encoders with a hard sample mining strategy to learn transferable representations. Compared with previous works, our method explicitly embraces the geometric relationship to reduce the distributional discrepancy during adaptation.
3 The Proposed Method
In the following, we present GPA-3D to mitigate the domain gap for LiDAR-based detectors. Fig. 3 illustrates the whole pipeline. Sec. 3.1 formulates the UDA task for point cloud detectors. Sec. 3.2 introduces the detection architecture in our method. In Sec. 3.3, we explain the details of the geometry-aware prototype alignment, followed by the soft contrast loss, which is discussed in Sec. 3.4. Finally, we present the noise sample suppression and instance replacement augmentation in Sec. 3.5 and Sec. 3.6, respectively.
3.1 Problem Statement
In this work, we focus on the problem of unsupervised domain adaptation on 3D detection. Concretely, given the labeled source domain point clouds , as well as unlabeled target domain point clouds , our goal is to train a 3D detector based on and and maximize its performance on . Here, is the total number of scenes, and indicates the -th point cloud scene, where each point has the 3-dim spatial coordinates and an extra intensity. The corresponding label represents a series of 3D bounding boxes, each of them can be parameterized by the center location (), spatial dimension () and rotation . Note that the superscripts and stand for source and target domain respectively.
3.2 Detection Architecture
The input point cloud is first sent to a backbone network with 3D sparse convolutions or 2D convolutions to extract the point cloud representation as following:
| (1) |
where is the backbone with parameters , and indicates the BEV features. After that, a detection head with parameters produces the final output, formulated as:
| (2) |
where and represent the predicted 3D boxes and scores respectively. A co-training paradigm is applied to progressively mitigate the domain shift. In each mini-batch, both the source point clouds and target point clouds are sent to the detector, and their outputs are supervised by the corresponding ground truth and pseudo-labels, respectively.
3.3 Geometry-aware Prototype Alignment
Extract.
As mentioned in Sec. 3.2, for -th point cloud scenario from the source or target domain, LiDAR-based detector generates the BEV features , where , , and denote the height, width and channel numbers of the feature map. We first project the corresponding ground truth or pseudo-labels to the BEV feature map, and then randomly extract the equal-length sequences and . Here, is the length of the feature sequence, and represent the foreground and background features from BEV, respectively.
Group.
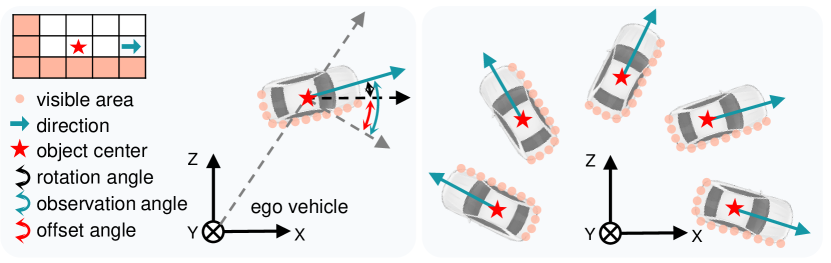
For the extracted foreground features , we further divide them into different groups according to their geometric structures on point clouds. Specifically, for -th foreground in the sequence (), we compute its offset angle as follows:
| (3) |
where is the direction, is the observation angle, as presented in Fig. 4 (left). Note that the direction is provided from the labels and , while the observation angle can be computed according to the central position of 3D bounding box. Next, all foreground features are split into groups, and the group index is formulated as:
| (4) |
where is a normalization function that converting the input angles into , and is the interval of angles between groups. In this way, the foreground features with similar offset angles are assigned into the same group, where their geometric structures are very similar, as demonstrated in Fig. 4 (right). Additionally, the extracted backgrounds are sent into an individual group, thus totally groups are built.
Prototype Construction.
At the beginning of training, we randomly initialize a series of learnable prototypes . During training, we extract the BEV features from both source and target domains, and split them into corresponding groups via Eq. 4. In -th group, the foreground features are enforced to be aligned with the foreground prototype . Similarly, the background features in the last group are aligned with the background prototype .
3.4 Soft Contrast Loss
Given a point cloud , our goal is to align its fore/background features and with the corresponding prototypes in .
Intra-group Attract.
For the foreground features , we pull them closer with the corresponding prototype in , which can be formulated as:
| (5) |
where is the cosine similarity, is an indicator function that equals to 1 if and 0 otherwise. Similarly, the background features are also required to be pulled to the background prototype , which can be calculated as:
| (6) |
Inter-group Repel.
To enhance the discriminative capacity, we need to push the features away from all prototypes belonging to other groups. For example, the distances between background features and all foreground prototypes are minimized via:
| (7) |
For foreground features within adjacent groups, their corresponding geometric structures are relatively more similar. Repelling these features away is not very necessary, and might even make the training process unstable. Hence, we adopt a more relaxed constraints as follows:
| (8) | ||||
where indicates the margin which is set to 0.5 in our experiments, is the index of the groups adjacent to , i.e., . The overall soft contrast loss can be formulated as:
| (9) |
where , and are the balance coefficients.
3.5 Noise Sample Suppression
The pseudo-labels used on the target domain are noisy and can lead to the accumulation of errors. To mitigate the impact of noise, we propose the noise sample suppression (NSS) approach, which generates a noise mask to suppress the magnitude of the gradient descent for the foreground areas that might be underlying noise. The noise mask can be represented as , where is the suppression factor to decrease the contribution of low-quality samples. In , the foreground areas that have high similarities with the background prototype, i.e., , are assigned to , while rest foreground and background areas are assigned to .
During training, the noise mask is multiplied to the co-training loss , elaborated in Sec. 3.7. With the progress of training, prototypes will be optimized with better representative capability, which enables NSS to suppress the noise more reliably and facilitate the training procedure.
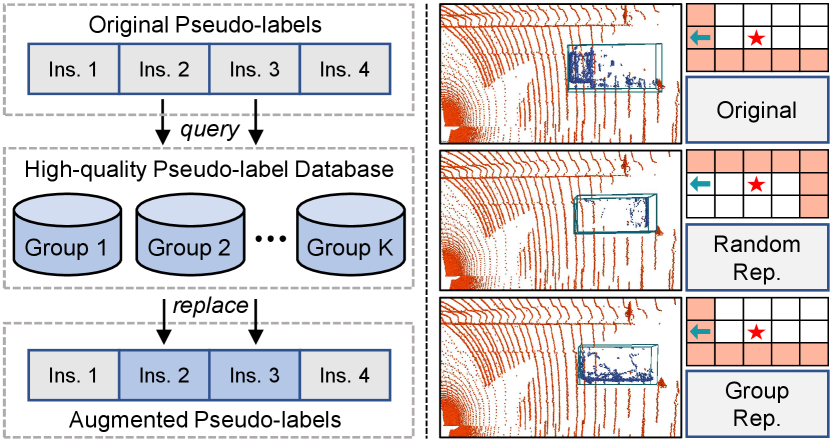
3.6 Instance Replacement Augmentation
Those uncertain pseudo-labels (with scores of 0.20.5) are usually ignored in training. Despite inaccurate, they might provide partial localization information. To this end, we devise the instance replacement augmentation (IRA) module. As shown in Fig. 5 (left), we first pick the pseudo-labels with scores over 0.5 to construct a high-quality database, which utilizes the group mechanism as Eq. 4 to divide the picked instances into groups belonging to different geometric structures. During training, we calculate the group indexes for the uncertain pseudo-labels, and replace them with instances having same group indexes from the database. In this procedure, a parameter is adopted to regulate the probability of the replacement operation.
There are two main merits of IRA. First, the quantity of target data is maintained and the diversity is also enhanced. Second, benefiting from the group mechanism, the spatial contexts around the replaced instances are unchanged and no ambiguous or unreasonable case is introduced, as devised in Fig. 5 (right).
| Methods | SECOND-IoU | PointPillars | ||||||
|---|---|---|---|---|---|---|---|---|
| Closed Gap | Closed Gap | Closed Gap | Closed Gap | |||||
| Source Only | 67.64 | - | 27.48 | - | 47.8 | - | 11.5 | - |
| SN [34] | 78.96 | 72.33% | 59.20 | 69.00% | 27.4 | 55.14% | 6.4 | 8.49% |
| UMT [9] | 77.79 | 64.86% | 64.56 | 80.66% | - | - | - | - |
| 3D-CoCo [40] | - | - | - | - | 76.1 | 76.49% | 42.9 | 52.25% |
| ST3D [37] | 82.19 | 92.97% | 61.83 | 74.72% | 58.1 | 27.84% | 23.2 | 19.47% |
| ST3D++ [38] | 80.78 | 83.96% | 65.64 | 83.01% | - | - | - | - |
| GPA-3D (ours) | 83.79 | 103.19% | 70.88 | 94.41% | 77.29 | 79.70% | 50.84 | 65.46% |
| Improvement | 1.6 | 10.22% | 5.24 | 11.4% | 1.19 | 3.21% | 7.94 | 13.21% |
| Oracle | 83.29 | - | 73.45 | - | 84.8 | - | 71.6 | - |
| Methods | SECOND-IoU | PointPillars | ||||||
|---|---|---|---|---|---|---|---|---|
| Closed Gap | Closed Gap | Closed Gap | Closed Gap | |||||
| Source Only | 32.91 | - | 17.24 | - | 27.8 | - | 12.1 | - |
| SN [34] | 33.23 | 1.69% | 18.57 | 7.54% | 28.31 | 2.41% | 12.98 | 4.58% |
| UMT [9] | 35.10 | 11.54% | 21.05 | 21.61% | - | - | - | - |
| 3D-CoCo [40] | - | - | - | - | 33.1 | 25.00% | 20.7 | 44.79% |
| ST3D [37] | 35.92 | 15.87% | 20.19 | 16.73% | 30.6 | 13.21% | 15.6 | 18.23% |
| ST3D++ [38] | 35.73 | 14.87% | 20.90 | 20.76% | - | - | - | - |
| GPA-3D (ours) | 37.25 | 22.88% | 22.54 | 30.06% | 35.47 | 36.18% | 21.01 | 46.41% |
| Improvement | 1.33 | 7.01% | 1.49 | 8.45% | 2.37 | 11.18% | 0.31 | 1.62% |
| Oracle | 51.88 | - | 34.87 | - | 49.0 | - | 31.3 | - |
3.7 Overall Training Procedure
The overall training procedure of GPA-3D is illustrated in Alg. 1. Following previous works [37, 38], the 3D detector is first trained on the labeled source domain via minimizing the detection loss as:
| (10) |
where the and indicate the regression and classification errors respectively. Next, we use the pre-trained detector to generate pseudo-labels and the database of IRA on the unlabeled target domain . Finally, the co-training paradigm is employed to further fine-tune the model as:
| (11) |
where is the detection loss on target data, same as in Eq. 10. The overall adaptation loss is calculated via:
| (12) |
where is the total weight of the soft contrast loss, and is the noise mask of NSS. For more details of the training procedure, please refer to the supplements.
4 Experiments
4.1 Experimental Setup
Datasets.
We evaluate the GPA-3D on widely used autonomous driving benchmarks including Waymo [30], nuScenes [2], and KITTI [6]. These datasets exhibit significant diversities in foreground patterns and LiDAR beams, which can lead to severe domain bias when transferring 3D detectors from one dataset to another. Detailed information about datasets is available in the supplementary material.
Implementation Details.
We verify the GPA-3D with two popular LiDAR-based detectors, namely SECOND-IoU [37] and PointPillars [16]. All the parameter settings for network architecture are set the same with OpenPCDet [33] and ST3D [37]. We perform all experiments using 8 NVIDIA V100 GPU cards. For the pre-training step, the model is trained for 30 epochs using the ADAM [15] optimizer and the total batch size of 32 on the source domain. Next, we utilize the pre-trained model to generate pseudo-labels on the target domain with a score threshold of 0.2. Note that instances with scores over 0.5 are retained and subsequently utilized to establish the high-quality pseudo-label database for IRA. Finally, we further fine-tune the model with our proposed approach for 30 epochs. To avoid local minima, we employ the cosine annealing strategy to adjust the learning rate, which was set to 0.003 for pre-training and 0.0015 for fine-tuning. Please refer to the supplements for more implementation details.
Compared Methods.
As shown in Tab. 2, GPA-3D is first compared with the Source Only method, which trains the model on the source domain and evaluates it on the target domain without any adaptation. Next, 5 existing works are included in the comparison, namely, SN [34], UMT [9], 3D-CoCo [40], ST3D [37], and ST3D++ [38]. SN utilizes the statistics from target annotations to normalize the foreground objects on the source domain. UMT employs a mean-teacher framework to filter inaccurate pseudo-labels. 3D-CoCo learns the instance-level transferable features for better generalization. ST3D and ST3D++ adopt a memory bank to produce high-quality pseudo-labels. Additionally, we also compare GPA-3D with the Oracle method, which trains the model on the labeled target data, serving as an upper bound for performance.
4.2 Comparison with State-of-the-art Methods
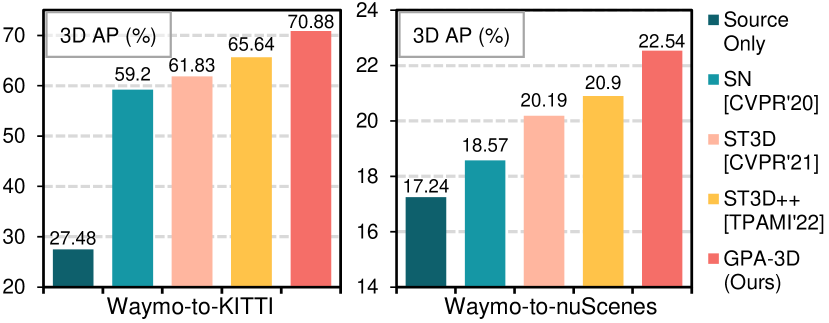
Waymo KITTI Adaptation.
To validate the effectiveness to the domain shift about object size, we conduct a comprehensive comparison on Waymo KITTI. As demonstrated in Tab. 1, with the 3D detector SECOND-IoU, our proposed GPA-3D outperforms ST3D++ [38] with a large margin, and significant performance gains are obtained compared with previous best results, i.e., 5.24% of AP and 1.6% of AP. Note that the AP of GPA-3D is also higher than Oracle method, indicating the effectiveness of incorporating the geometric structure information into UDA on 3D detection task. Even switching the base detector to PointPillars, our method still exceeds previous SOTA 3D-CoCo [40] by 7.94% and 1.19% in terms of AP and AP, respectively.
Waymo nuScenes Adaptation.
For the domain gap of LiDAR beams, we select Waymo nuScenes as representatives due to their different LiDAR sensors, i.e., 64-beam vs 32-beam. As shown in Tab. 2, GPA-3D improves the adaptation performances to 37.25% AP and 22.54% AP with the SECOND-IoU detector, surpassing previous SOTA methods. Compared with ST3D++ [38], 1.52% and 1.64% gains separately in terms of AP and AP are achieved. Based on PointPillars, our approach exceeds the best method 3D-CoCo [40] by 2.37% in AP, and outperforms ST3D [37] with 4.87% and 5.41% respectively in terms of AP and AP. These improvements demonstrate the advancement of our GPA-3D to mitigate the more challenging domain shift of cross-beam scenarios.
| Setting | Proto | Soft | NSS | IRA | ||
|---|---|---|---|---|---|---|
| (a) | 77.87 | 60.36 | ||||
| (b) | 80.49 | 66.28 | ||||
| (c) | 80.51 | 67.34 | ||||
| (d) | 83.07 | 69.45 | ||||
| (e) | 81.94 | 67.79 | ||||
| (f) | 83.79 | 70.88 |
4.3 Ablation Studies
All ablation studies are conducted on Waymo KITTI with SECOND-IoU as the base detector.
Component Analysis in GPA-3D.
We assess the effectiveness of each component in GPA-3D, as presented in Tab. 3. Baseline (a) represents self-training via pseudo-labels on the target domain. The application of geometry-aware prototype alignment provides 5.92% and 2.62% gains separately in terms of AP and AP, and the soft contrast loss brings an improvement of 1.06% on AP. The improvements demonstrate that incorporating the geometric relationship into domain adaptation is feasible and effective. In addition, NSS and IRA boost the performance by around 2.5% and 1.5% respectively, which indicates the efficacy of enhancing the quality of supervision on target data.
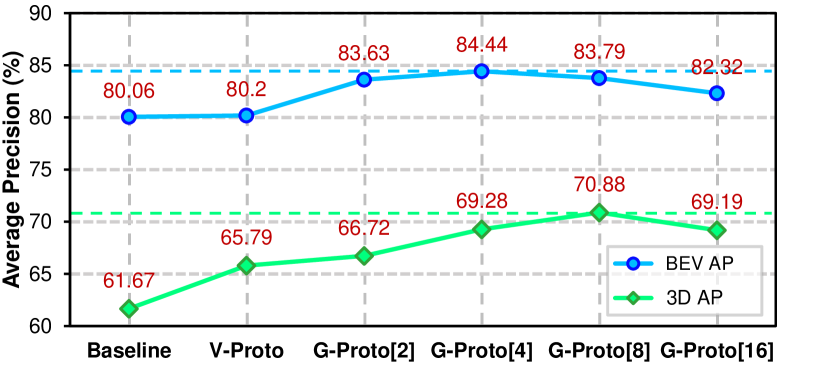
Effectiveness of Geometry-aware Prototype Alignment.
We further investigate the effects of the geometry-aware prototype alignment. As illustrated in Fig. 7, the vanilla alignment with one pair of fore/background prototypes performs better than the co-training baseline, implying that the misalignment of features distribution affects the performance. Applying two prototypes yields 3.57% and 5.05% gains of AP and AP respectively, compared to the co-training baseline. The performance reaches to the peak of 84.44% AP when 4 foreground prototypes are employed, indicating the advancement of combining geometric information with feature alignment. However, we observe minor performance degradation when too many prototypes are used, which we attribute to redundant prototypes leading to indistinguishable features in the representational space.
| Methods | Filter Domain | |||
|---|---|---|---|---|
| GPA-3D (w/o NSS) | - | - | 81.94 | 67.79 |
| GPA-3D (w/ NSS-T) | Target | 0.5 | 83.37 | 68.24 |
| GPA-3D (w/ NSS-S) | Source | 0.5 | 82.33 | 67.93 |
| GPA-3D (w/ NSS-TS) | Target + Source | 0.5 | 83.45 | 69.77 |
| GPA-3D (w/ NSS-TSH) | Target + Source | 0.0 | 83.79 | 70.88 |
Effectiveness of Noise Sample Suppression.
We conduct ablations on the noise sample filter (NSS) with various settings. As shown in Tab. 4, the detection performance drops to 67.79% AP, when we remove the NSS from GPA-3D. Only applying the NSS on target domain achieves the gains of 1.43% and 0.45% on AP and AP, respectively. We could see that using NSS on the source domain could also bring improvements. We think this is due to the fact that NSS suppresses those source samples with only a few points, which are very similar to the background noise. When the hard truncated is adopted, AP is further improved to 70.88%, indicating the effectiveness of NSS.
| Method | w/o IRA | RandRep | w/ IRA |
|---|---|---|---|
| / | 83.07 / 69.45 | 82.99 / 69.59 | 83.79 / 70.88 |
Effectiveness of Instance Replacement Augmentation.
Also, we compare different policies in instance replacement augmentation (IRA). We can see from Tab. 5 that our proposed IRA attains 0.72% and 1.43% gains in terms of and , respectively. Without the group mechanism in IRA, i.e., randomly replacing pseudo-labels with instances the database, only marginal gains are obtained in , and even degradation in . This highlights the significance of maintaining the consistency between instances and their contextual environments.
| Framework | Source | Self-T. | Co-T. | Mean T. | GPA-3D |
|---|---|---|---|---|---|
| / | 67.64 / 27.48 | 77.87 / 60.36 | 80.06 / 61.67 | 80.01 / 64.62 | 83.79 / 70.88 |
Domain Adaptation Frameworks.
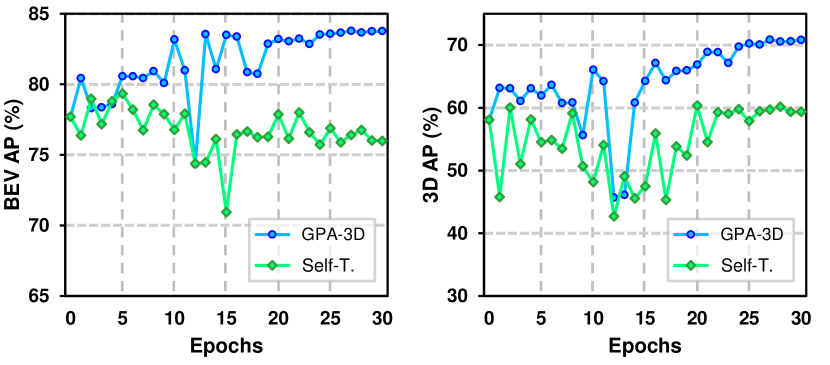
We compare our proposed GPA-3D with several adaptation frameworks, as presented in Tab. 6. The results confirm the effectiveness of GPA-3D, which leverages the geometric association to transfer 3D detectors across different domains. Fig. 8 further illustrates that, despite all models fluctuate at early epochs, our GPA-3D steadily and consistently enhances the detection performance in later training stages.
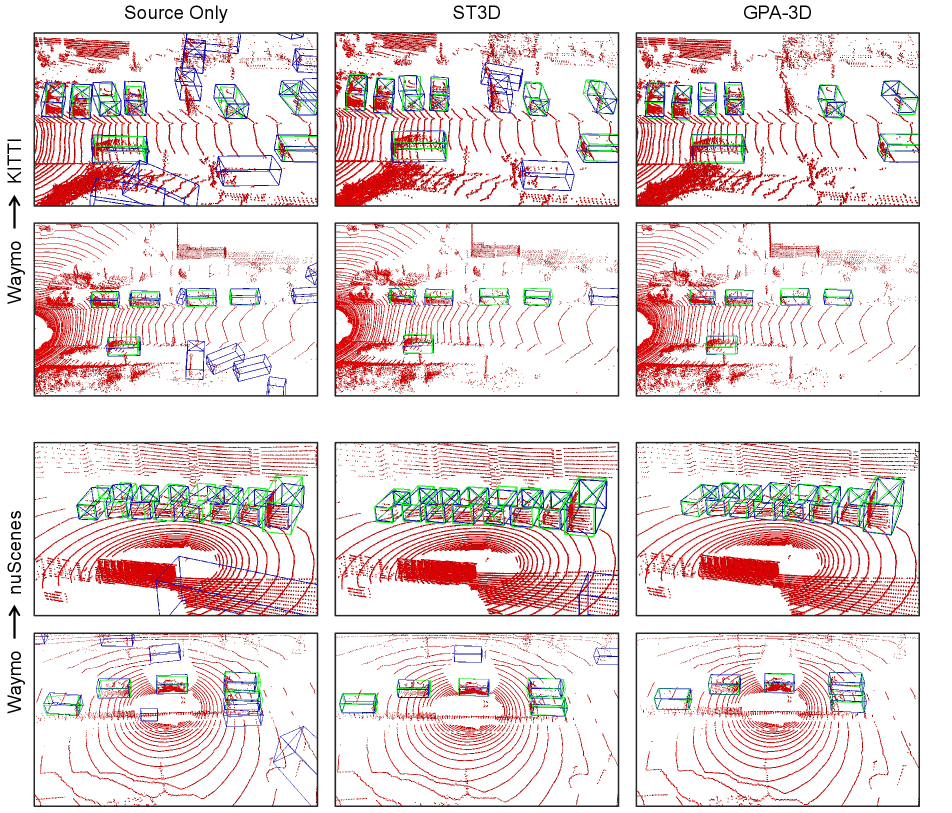
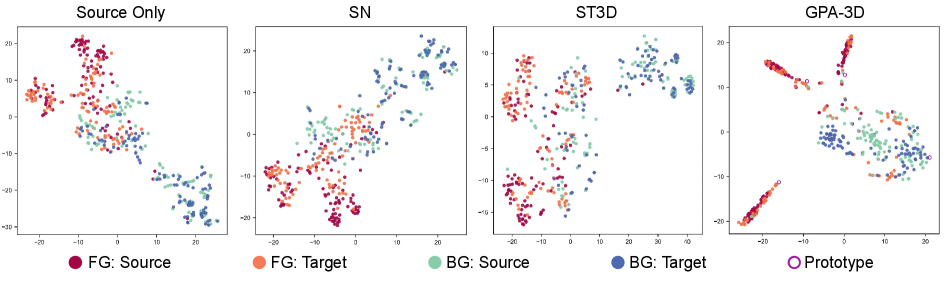
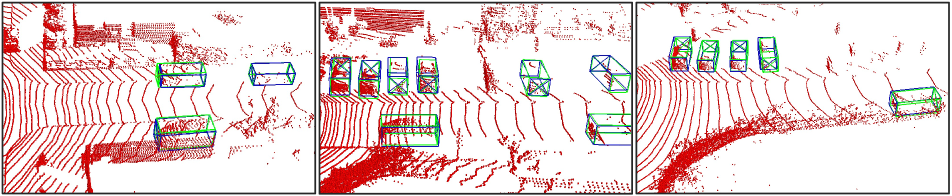
Visualization.
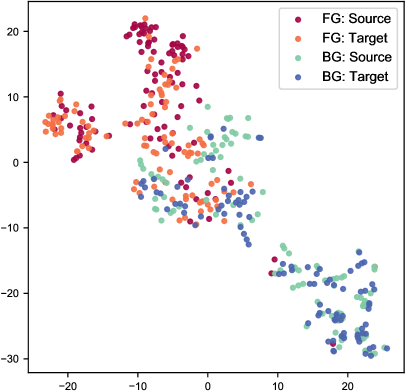
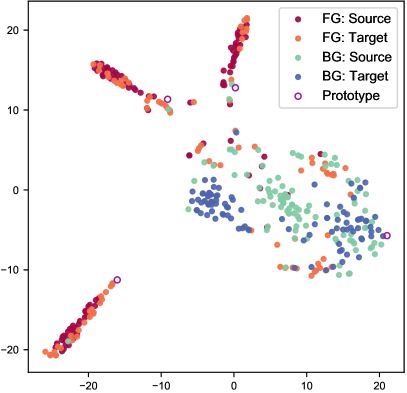
We exhibit some qualitative results of cross-domain adaptation in Fig. 6. Additionally, in Fig. 9, we visualize the distribution of BEV features. It is obvious that GPA-3D aggregates foreground samples into different prototypes, and separates them from the backgrounds. Further visualizations can be found in in the supplements.
5 Conclusion
This paper presents a novel framework for unsupervised domain adaptive 3D detection. Our proposed GPA-3D leverages the underlying geometric relationship to reduce the distributional discrepancy in the feature space, thus mitigating the domain shift problems. Comprehensive experiments demonstrate that our method is effective and can be easily incorporated into mainstream LiDAR-based 3D detectors. For future work, we plan to extend GPA-3D to support multi-modal 3D detectors. This requires a more efficient alignment mechanism to process feature streams from both point clouds and images.
Acknowledgement
This work was supported by the National Natural Science Foundation of China under No.62276061 and 62006041.
References
- [1] Eduardo Arnold, Omar Y Al-Jarrah, Mehrdad Dianati, Saber Fallah, David Oxtoby, and Alex Mouzakitis. A survey on 3D object detection methods for autonomous driving applications. TITS, 20(10):3782–3795, 2019.
- [2] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In CVPR, pages 11621–11631, 2020.
- [3] Yuhua Chen, Wen Li, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Domain adaptive faster r-cnn for object detection in the wild. In CVPR, pages 3339–3348, 2018.
- [4] Lue Fan, Xuan Xiong, Feng Wang, Naiyan Wang, and Zhaoxiang Zhang. Rangedet: In defense of range view for lidar-based 3D object detection. In ICCV, pages 2918–2927, 2021.
- [5] Yaroslav Ganin, Evgeniya Ustinova, Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, and Victor Lempitsky. Domain-adversarial training of neural networks. JMLR, 17(1):2096–2030, 2016.
- [6] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In CVPR, pages 3354–3361, 2012.
- [7] Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3D point clouds: A survey. TPAMI, 43(12):4338–4364, 2020.
- [8] Yulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3D point clouds: A survey. TPAMI, 2020.
- [9] Deepti Hegde, Vishwanath Sindagi, Velat Kilic, A Brinton Cooper, Mark Foster, and Vishal Patel. Uncertainty-aware mean teacher for source-free unsupervised domain adaptive 3D object detection. arXiv preprint arXiv:2109.14651, 2021.
- [10] Han-Kai Hsu, Chun-Han Yao, Yi-Hsuan Tsai, Wei-Chih Hung, Hung-Yu Tseng, Maneesh Singh, and Ming-Hsuan Yang. Progressive domain adaptation for object detection. In WCCV, pages 749–757, 2020.
- [11] Sheng-Wei Huang, Che-Tsung Lin, Shu-Ping Chen, Yen-Yi Wu, Po-Hao Hsu, and Shang-Hong Lai. Auggan: Cross domain adaptation with gan-based data augmentation. In ECCV, pages 718–731, 2018.
- [12] Zhengkai Jiang, Yuxi Li, Ceyuan Yang, Peng Gao, Yabiao Wang, Ying Tai, and Chengjie Wang. Prototypical contrast adaptation for domain adaptive semantic segmentation. In ECCV, pages 36–54. Springer, 2022.
- [13] Mehran Khodabandeh, Arash Vahdat, Mani Ranjbar, and William G Macready. A robust learning approach to domain adaptive object detection. In ICCV, pages 480–490, 2019.
- [14] Seunghyeon Kim, Jaehoon Choi, Taekyung Kim, and Changick Kim. Self-training and adversarial background regularization for unsupervised domain adaptive one-stage object detection. In ICCV, pages 6092–6101, 2019.
- [15] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [16] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. In CVPR, pages 12697–12705, 2019.
- [17] Guofa Li, Zefeng Ji, and Xingda Qu. Stepwise domain adaptation (sda) for object detection in autonomous vehicles using an adaptive centernet. TITS, 2022.
- [18] Ying Li, Lingfei Ma, Zilong Zhong, Fei Liu, Michael A Chapman, Dongpu Cao, and Jonathan Li. Deep learning for lidar point clouds in autonomous driving: a review. TNLLS, 2020.
- [19] Hongbin Lin, Yifan Zhang, Zhen Qiu, Shuaicheng Niu, Chuang Gan, Yanxia Liu, and Mingkui Tan. Prototype-guided continual adaptation for class-incremental unsupervised domain adaptation. In ECCV, pages 351–368. Springer, 2022.
- [20] Zhipeng Luo, Zhongang Cai, Changqing Zhou, Gongjie Zhang, Haiyu Zhao, Shuai Yi, Shijian Lu, Hongsheng Li, Shanghang Zhang, and Ziwei Liu. Unsupervised domain adaptive 3D detection with multi-level consistency. In ICCV, pages 8866–8875, 2021.
- [21] Jiageng Mao, Minzhe Niu, Chenhan Jiang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, Jie Yu, et al. One million scenes for autonomous driving: Once dataset. In NIPS, 2021.
- [22] Jiageng Mao, Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. 3D object detection for autonomous driving: a review and new outlooks. arXiv preprint arXiv:2206.09474, 2022.
- [23] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3D classification and segmentation. In CVPR, pages 652–660, 2017.
- [24] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, pages 5099–5108, 2017.
- [25] Adrian Lopez Rodriguez and Krystian Mikolajczyk. Domain adaptation for object detection via style consistency. arXiv preprint arXiv:1911.10033, 2019.
- [26] Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, and Kate Saenko. Strong-weak distribution alignment for adaptive object detection. In CVPR, pages 6956–6965, 2019.
- [27] Cristiano Saltori, Stéphane Lathuilière, Nicu Sebe, Elisa Ricci, and Fabio Galasso. Sf-uda 3D: Source-free unsupervised domain adaptation for lidar-based 3D object detection. In 3DV, pages 771–780, 2020.
- [28] Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In CVPR, pages 10529–10538, 2020.
- [29] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3D object proposal generation and detection from point cloud. In CVPR, pages 770–779, 2019.
- [30] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, pages 2446–2454, 2020.
- [31] Pei Sun, Weiyue Wang, Yuning Chai, Gamaleldin Elsayed, Alex Bewley, Xiao Zhang, Cristian Sminchisescu, and Dragomir Anguelov. Rsn: Range sparse net for efficient, accurate lidar 3D object detection. In CVPR, pages 5725–5734, 2021.
- [32] Korawat Tanwisuth, Xinjie Fan, Huangjie Zheng, Shujian Zhang, Hao Zhang, Bo Chen, and Mingyuan Zhou. A prototype-oriented framework for unsupervised domain adaptation. Advances in Neural Information Processing Systems, 34:17194–17208, 2021.
- [33] OpenPCDet Development Team. Openpcdet: An open-source toolbox for 3D object detection from point clouds. https://github.com/open-mmlab/OpenPCDet, 2020.
- [34] Yan Wang, Xiangyu Chen, Yurong You, Li Erran Li, Bharath Hariharan, Mark Campbell, Kilian Q Weinberger, and Wei-Lun Chao. Train in germany, test in the usa: Making 3D object detectors generalize. In CVPR, pages 11713–11723, 2020.
- [35] Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. Sensors, 18(10):3337, 2018.
- [36] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Real-time 3D object detection from point clouds. In CVPR, pages 7652–7660, 2018.
- [37] Jihan Yang, Shaoshuai Shi, Zhe Wang, Hongsheng Li, and Xiaojuan Qi. St3d: Self-training for unsupervised domain adaptation on 3D object detection. In CVPR, pages 10368–10378, 2021.
- [38] Jihan Yang, Shaoshuai Shi, Zhe Wang, Hongsheng Li, and Xiaojuan Qi. St3d++: Denoised self-training for unsupervised domain adaptation on 3D object detection. TPAMI, 2022.
- [39] Zetong Yang, Yanan Sun, Shu Liu, and Jiaya Jia. 3dssd: Point-based 3D single stage object detector. In CVPR, pages 11040–11048, 2020.
- [40] Zeng Yihan, Chunwei Wang, Yunbo Wang, Hang Xu, Chaoqiang Ye, Zhen Yang, and Chao Ma. Learning transferable features for point cloud detection via 3D contrastive co-training. NIPS, 34:21493–21504, 2021.
- [41] Jinze Yu, Jiaming Liu, Xiaobao Wei, Haoyi Zhou, Yohei Nakata, Denis Gudovskiy, Tomoyuki Okuno, Jianxin Li, Kurt Keutzer, and Shanghang Zhang. Cross-domain object detection with mean-teacher transformer. In ECCV, 2022.
- [42] Yifan Zhang, Qingyong Hu, Guoquan Xu, Yanxin Ma, Jianwei Wan, and Yulan Guo. Not all points are equal: Learning highly efficient point-based detectors for 3D lidar point clouds. In CVPR, pages 18953–18962, 2022.
- [43] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. In ICCV, pages 2223–2232, 2017.
Appendix A Overview
This document presents additional technical details, and provides both quantitative and qualitative results to support the submitted paper. In Sec. B, we discuss the large-scale datasets used in the experiments, and analyze their intrinsic characteristics that cause severe domain shifts. In Sec. C, we elaborate on the network architectures of the 3D detectors employed for comparisons, and describe the implementation details of GPA-3D. In Sec. D, we offer more comprehensive quantitative results and visualizations of our approach.
Appendix B Datasets
We conduct comprehensive experiments on the prevalent autonomous driving datasets, namely Waymo [30], nuScenes [2], and KITTI [6]. These datasets have diverse weather conditions, sensor configurations, foreground styles, and annotation quantities, thereby causing serious domain shifts when adapting a LiDAR-based 3D detector from one dataset to another. Fig. 10 presents randomly selected examples from the aforementioned datasets. Subsequently, we will introduce each dataset in detail.
Waymo.
For recent 3D detection task, Waymo [30] is the most large-scale and challenge benchmark, which includes 798 sequences (more than 150,000 frames) for training and 202 sequences (approximately 40,000 frames) for validation. Waymo provides the point clouds captured by a 64-beam LiDAR and 4 200-beam blind LiDAR for each frame. In our experiments, we use the 1.2 version of Waymo and subsample only 50% of the training samples, consistent with ST3D [37] and ST3D++ [38].
nuScenes.
The nuScenes [2] dataset comprises of 28,130 samples in the training set and 6,019 samples in the validation set. Point clouds within nuScenes are captured by a 32-beam LiDAR in Boston and Singapore, under diverse weather conditions. To ensure consistency with previous works, we access the performance of transferring 3D detectors across different LiDAR beams by treating all 28,130 training scenes as the target domain.

KITTI.
As a popular autonomous driving dataset, KITTI [6] contains 7,481 labeled frames for training and 7,518 unlabeled frames for testing. The point clouds of KITTI are captured by a 64-beam Velodyne LiDAR in Karlsruhe, Germany. Following previous approaches, we partition the training frames into two distinct sets: the train split, comprising 3,712 samples, and the val split, consisting of 3,769 samples.
Appendix C More Implementation Details
Co-training Framework.
We follow the default settings of ONCE [21], an open-source 3D detection codebase, to construct the co-training framework in GPA-3D. Specifically, this co-training framework feeds an equal number of point clouds from both source and target domains into the 3D detector in each mini-batch. The outputs generated by the detector are then used for loss computation, with the supervision of ground truth and pseudo-labels, respectively. The calculated losses are subsequently summed together to update the detector parameters and prototypes via the back-propagation method.
Detection Architecture.
To ensure fair comparisons, we adopt the default configurations of ST3D [37] and ST3D++ [38] to set the voxel size in SECOND-IoU [35] and PointPillars [16] to (0.1, 0.1, 0.15) and (0.2, 0.2), respectively. Furthermore, for all datasets utilized in our experiments, we shift the coordinate origins to the ground plane, and separately set the detection ranges of , , axes to [-75.2, 75.2], [-75.2, 75.2], and [-2, 4].
Hyper-parameters in GPA-3D.
For the geometry-aware prototype alignment, we set the length of the feature sequences to be equal to the number of foreground areas in the -th BEV feature map. Additionally, we set the prototype numbers to 8 and 4 for the adaptation scenarios of Waymo KITTI and Waymo nuScenes, respectively. For the soft contrast loss, we determine the balance coefficients , , and to be 5, 1, and 5, respectively. In our implementation, we perform the instance replacement augmentation with the probability of 0.25.
Appendix D Exploration Studies
Extend GPA-3D to Multiple Categories.
For autonomous driving vehicles, the detection of pedestrians on the road is also a crucial aspect. In fact, it is easy and effective to extend GPA-3D to other classes. Compared to cars, the geometric variations of pedestrians are smaller, thus we reduce the prototype numbers to 3 for pedestrian. As shown in Tab. 7, GPA-3D improves the pedestrian detection performances to 48.17% and 45.20% , surpassing previous state-of-the-art methods. Compared to ST3D++ [38], our approach achieves 0.97% and 1.3% gains in terms of and , respectively. These improvements demonstrate that GPA-3D has consistent effectiveness on the pedestrian detection.
Why Could Adaptation Method Outperforms the Oracle.
In the adaptation scenario of Waymo KITTI, the of GPA-3D has surpassed that of the Oracle method, which is fully supervised by the ground truth of KITTI dataset. We attribute the reason into two aspects. 1) Label-insufficient target domain: Compared to Waymo, KITTI is a relatively label-insufficient dataset (7,000 vs. 150,000). The limited annotations affect the performance of Oracle. 2) Stronger generalization ability: Our method reduces the feature discrepancy across domains, bringing stronger generalization ability. This makes it easier for model to apply the knowledge learned from source domain to the target domain, thereby improving the final performance.
| Method | w/o align | Conv. | Pre. | BEV |
|---|---|---|---|---|
| / | 35.34 / 20.13 | 35.92 / 22.37 | 35.72 / 22.13 | 37.25 / 22.54 |
| Method | SF-UDA | Dreaming | MLC-Net | ST3D++ | GPA-3D |
|---|---|---|---|---|---|
| Reference | [3DV’20] | [ICRA’22] | [ICCV’21] | [TPAMI’22] | (ours) |
| 0.7 IoU | 54.5 | - | 55.42 | 67.51 | 67.77 |
| 0.5 IoU | - | 70.3 | - | 79.93 | 81.06 |
Analysis of Different Alignment Schemes.
We investigate the effects of different alignment schemes in GPA-3D, as shown in Tab. 8. Without alignment, the adaptation performance degrades due to the distributional discrepancy in the feature space. Compared with the policies of Conv. and Pre., our BEV-level alignment achieves superior results, indicating the effectiveness of our approach in directly dealing with the distributional discrepancy problem at BEV features.
Extend GPA-3D to Point-based Architecture.
We also try to extend GPA-3D to a point-based 3D detector, PointRCNN [29]. For the point-wise features, we assign prototypes to them based on the geometric information of the objects to which they belong. The results on nuScensKITTI demonstrate that GPA-3D has the potential to be applied to point-based detectors with minor adjustments.
Qualitative Results.
We present more visualizations on the adaptation scenarios of Waymo KITTI and Waymo nuScenes in Fig. 11. These qualitative results demonstrate the effectiveness of GPA-3D in improving adaptation performance via reducing the false positive predictions and enhancing the regression accuracy. To further validate the efficacy of our GPA-3D, we employ the t-SNE method to visualize the feature distributions of different approaches, as illustrated in Fig. 12. The results clearly show that GPA-3D clusters the features of the same category in different domains, while also separates the features of different categories. This indicates that GPA-3D provides better alignment of features and facilitates the transferring across domains.