Goal-directed Planning and Goal Understanding by Active Inference: Evaluation Through Simulated and Physical Robot Experiments
∗Corresponding author: [email protected])
Abstract
We show that goal-directed action planning and generation in a teleological framework can be formulated using the free energy principle. The proposed model, which is built on a variational recurrent neural network model, is characterized by three essential features. These are that (1) goals can be specified for both static sensory states, e.g., for goal images to be reached and dynamic processes, e.g., for moving around an object, (2) the model can not only generate goal-directed action plans, but can also understand goals by sensory observation, and (3) the model generates future action plans for given goals based on the best estimate of the current state, inferred using past sensory observations. The proposed model is evaluated by conducting experiments on a simulated mobile agent as well as on a real humanoid robot performing object manipulation.
Keywords: active inference; teleology; goal-directed action planning
1 Introduction
In studying contemporary models of goal-directed actions of biological and artificial agents, it is worthwhile to consider these models from the perspective of a teleological framework. Teleology is a philosophical idea that originated in the days of Plato and Aristotle. It holds that phenomena appear not by their causes, but by their end results. While teleology is controversial and largely abandoned as a means of explaining physical phenomena, the idea has been extended for modeling action generation. A teleological account explains actions by specifying the state of affairs or the event toward which the actions are directed [1, 2]. More simply, actions are generated to achieve purposes or goals. In psychology, Csibra et al. [3] proposes that a goal-directed action can be explained by a well-formed teleological representation consisting of 3 elements: (1) a goal, (2) actions intended to achieve the goal, and (3) constraints, which are physical conditions that impose limits on possible actions. In a well-formed teleological representation of an action, the action should be seen as an effective means to achieve the goal within the constraint of reality. This account predicts that agents who represent goal-directed actions in this way should be able to infer unseen goals or unseen reality constraints, given the two remaining elements. Csibra et al. [3] verified this hypothesis by showing that even year-old infants can perform such inferences in their experiments.
Brain-inspired models for goal-directed action have been developed in various forms. Most brain-inspired models are based on forward models [4, 5, 6] for predicting sensory outcomes of an action to be executed. For goals given in terms of a preferred sensory state at the distal (terminal) step, optimal action sequences leading to the goal under assumed constraints, such as a minimal torque change criterion, can be obtained inversely using the forward model. Recently, Friston and colleagues [7, 8] advanced the idea of goal-directed action using a forward model by incorporating a Bayesian perspective. Goal-directed planning for achieving the preferred sensory states is formulated under the framework of active inference [9, 10, 11] based on the free energy principle [12].
The aforementioned studies on goal-directed action can be expanded in various ways. One such possibility concerns the goal representation. Although goals in the aforementioned models are represented by a particular sensory state at each time step or at the distal step, some classes of on-going processes can also be goals for generating actions. For example, one can say ”I got up early this morning to run.” In this case, the goal is not a particular destination, but the process of running. In the teleological framework, goals or the purpose of actions could be states, events, or processes which could be either specific or abstract and conceptual. What sorts of models could incorporate such diverse forms of goal representations? Another possibility for exploration is to incorporate the capability for inferring unseen goals or unseen reality constraints provided with the remaining two elements among actions, constraints and goals, as described by Csibra et al. [3].
For the purpose of examining these possibilities, the current study proposes a novel model by extending our prior goal-directed planning model, GLean [13]. GLean was developed following the free energy principle [12] and it operates in the continuous domain using PV-RNN, a variational recurrent neural network model [14]. The newly proposed model, T-GLean, has three new key features compared to GLean. First, goals can be specified either by temporal processes (such as the earlier example of ”going out for a run”) or static sensory states, for example, ”going to the corner store.” Second, the model can infer goals by sensory observation, as well as by generating goal-directed action plans. This allows agents using the T-GLean model to anticipate goals and future actions by observing the actions of another agent. Third, the model generates future action plans for given goals based on the best estimate of the current hidden state using the past sensory observation. While this feature is not necessarily novel, given that functions of sensory reflection or postdiction [15] have been examined using deterministic generative RNN models [16] and Bayesian probabilistic generative models [8], this feature is added to the model so that robots utilizing T-GLean can generate goal-directed plans online while actions are being executed, whereas GLean can only generate plans offline.
Our proposed model is evaluated in Section 4 by conducting two experiments using two robot setups. The first experiment uses a simple simulated mobile robot that can navigate an environment with an obstacle, and the second experiment uses a physical humanoid robot with a larger degree of freedom that tracks and manipulates objects. In both experiments, the robots are trained to achieve two different types of goals. For the mobile robot, one type of goal is to reach a specified position while avoiding collisions with obstacles, and the other type of goal is to move around a specific object repeatedly. For the humanoid robot, one type of goal is to grasp an object and then to place it at a specified position and the other type of goal is to lift an object up and down repeatedly. In both experiments, the trained robots are evaluated in generating goal-directed actions for specified goals, as well as to infer corresponding unseen goals for given sensory sequences. We also touch on generating action plans based on the rationality principle [3]. The following section describes related studies in more detail so that readers can understand easily how the proposed model has been developed by extending and modifying those prior proposed models.
2 Related studies
First we look in detail at how a goal-directed action can be generated using the forward model. Kawato et al. [4] proposed that multiple future steps of proprioception (joint angles) as well as the distal position in task coordinate space of an arm robot can be predicted, given the motor torque at each time step, by training the forward dynamics model and the kinematic model that are implemented in a feed-forward network cascaded in time. After training, optimal motor commands to achieve the desired positions at the distal step following the minimal torque change criterion can be computed by using the prediction error information generated in the distal step. In order to deal with the hidden state problem encountered by real robots navigating with limited sensors, Tani [17] extended this model by implementing the forward dynamics model in a recurrent neural network (RNN) with deterministic latent variables. It was shown that a physical mobile robot can generate optimal, goal-directed navigation plans with the minimum travel distance criterion in a hidden state environment using that proposed model. Figure 1(a) depicts the scheme of goal-directed planning using a forward dynamics model implemented in an RNN.



In this graphical representation, , , and denote the action, deterministic latent variable, probabilistic latent variable, and sensory prediction at time step , respectively. is the sensory goal image at the distal step . Within the scheme of the forward model and active inference, the policy is a sequence of actions that is optimized such that the error between the sensory goal image and the preferred image at can be minimized (the minimization criterion such as the travel distance is omitted for brevity.)
Friston and colleagues [7, 8] formulated goal-directed actions by extending the framework of active inference [9, 10, 11] based on the free energy principle [12]. The major advantage of this approach, compared to the aforementioned conventional forward model, is that the model can cope with uncertainty that originates from the stochastic nature of the environment by incorporating a Bayesian framework. Originally, the free energy principle was developed as a theory for perception under the framework of predictive coding, wherein probabilistic distributions of past latent variables in generative models are inferred for the observed sensation by minimizing the free energy. Later, active inference was developed as a framework for action generation wherein action policies as well as the probabilistic distribution of future latent variables in generative models are inferred by minimizing the so-called expected free energy. Minimizing the expected free energy for the future maximizes both the epistemic value shown in the first and the second terms, and extrinsic value in the third term in Equation 1.
| (1) |
where is an optimal policy or a sequence of actions, is the posterior predictive distribution, and is the current time step. The extrinsic value represents how much the sensory outcomes expected in the generated future plan are consistent with the preferred outcomes. The epistemic value, on the other hand, represents the expected information gain with predicted outcomes. This means that this value indicates the expected decrease of uncertainty with regard to the hidden state provided by the sensory observation. In summary, an optimal action policy for achieving the preferred sensory outcomes and the reduction of uncertainty of the hidden states can be generated by minimizing the expected free energy. Figure 1(b) depicts this framework wherein the probabilistic latent variables , as well as an action policy, are inferred by minimizing the expected free energy.
Although Friston and colleagues [7, 8] implemented this framework mostly in discrete space, Hafner et al. [18] proposed an analogous model implemented in continuous state problems.
Matsumoto and Tani [13] proposed another type of goal-directed action plan generation model, GLean, which is based on the free energy principle using a variational RNN. The main difference of this scheme from those proposed by Friston and colleagues [7, 8] and by Hafner et al. [18] is that an optimal goal-directed plan is obtained by inferring the lower dimensional probabilistic latent space, instead of the higher dimensional action space. The graphical model of the scheme is depicted in Figure 1(c), wherein the proprioception and the exteroception at each time step are predicted by the learned generative model using the probabilistic latent variable and deterministic latent variable . For a given preferred goal represented as an exteroceptive state at the distal step as , a proprioceptive-exteroceptive sequence expected to reach this goal state is searched by inferring an optimal sequence of the posterior distribution of the latent variables by means of minimizing the expected free energy as shown in Equation 2.
| (2) |
Here, the expected free energy is represented by a sum of two terms, namely the goal error at the distal step, shown in the first term, and the complexity summed over all future steps, shown in the second term. Complexity is the divergence between the posterior predictive distribution and the prior distribution of the probabilistic latent variables, and is described in more detail later in Section 3. By minimizing this form of free energy, plans reaching the preferred goal states, but following well-habituated trajectories learned during learning, can be generated. We note that this model does not infer the policy directly. Instead, the motor command or action at each time step is computed by means of the proprioceptive error feedback by sending the prediction of the next step proprioception as the target to the motor controller when the agent generates movement.
3 The Proposed Model
Our newly proposed model, T-GLean, is an extension of GLean [13] with a novel goal representation scheme. Each goal is represented by its category, e.g., reaching or cycling, associated with optional parameters, e.g., for position or speed. The network is designed to output the expected goal at each time step based on learning, as shown in Figure 2.

When the current preferred goal is given at each time step, the posterior predictive distribution is updated in the direction of minimizing the divergence between the preferred goal and the expected goal at each time step. This generates the expected exteroceptive and proprioceptive trajectory leading to the goal. In addition, the network can infer unseen goals from the observation of on-going sensory inputs. For a given exteroceptive trajectory, the posterior distribution is updated in the direction of minimizing the divergence between the given exteroceptive trajectory and its reconstructed trajectory. This generates the expected goal in the outputs at each time step. This model utilizes the PV-RNN architecture, which leverages the idea of multiple timescale RNN [19, 13] with the expectation of development of a functional hierarchy through learning. The network is operated in three modes, each of which minimizes free energy as its loss function. In learning mode, predictive models are learned using provided training sequences by minimizing the evidence free energy. In online action generation mode, a future goal-directed plan is generated by minimizing the expected free energy while the past sensory experience is reflected by minimizing the evidence free energy. As this occurs in real time, the past sensory experience is constantly updated online. In the goal inference mode, the expected goal is inferred using the observed exteroceptive sequence by minimizing the evidence free energy. The following sub-sections describe the model in more detail.
3.1 Model architecture
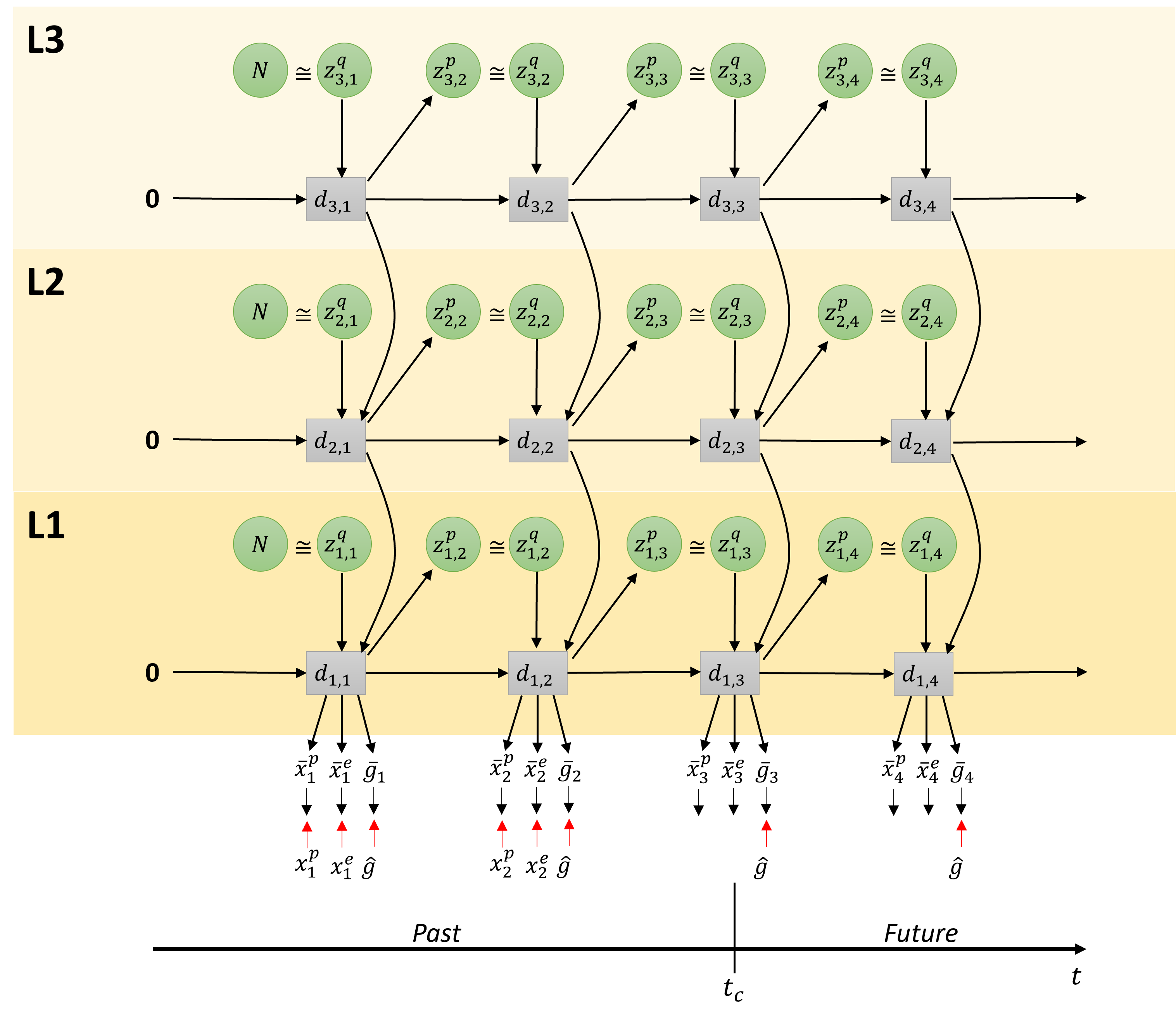
Figure 3 depicts the employed architecture as a graphical model consisting of three layers of PV-RNN. It is similar to the architecture employed in [13], with the modification introduced in [20] that has the top-down connection from higher layers to lower layers in the same time step, rather than from the previous time step. The graphical model shows the RNN unrolled into to the past as well as to the future, with the current time step at . Each layer indexed by contains the stochastic variable , from which is sampled from the prior distribution, and is the posterior distribution, as well as the deterministic latent variable , for each time step . Note that deterministic variables take as input the deterministic variable from the layer above except on the top layer. The output of the bottom layer (L1) is split into proprioception , exteroception , expected goal , and distal probability . Unless noted otherwise, the preferred goal is given at all time steps as a target. Where available, the observed proprioception and exteroception are used as targets for error minimization. The distal probability at time step (omitted from the diagram for brevity) is the probability of achieving the expected goal at . When the distal probability at a particular time step becomes the highest among those at all other time steps and it exceeds a predefined threshold value, it is assumed that the preferred goal is achieved in this time step. During training, is a one-hot vector in the time dimension with a single peak at the time step the goal is actually achieved. The output and targets are softmax encoded; however, for brevity, the output layer that decodes the network output into raw output for the agent is not shown in this figure. In subsequent subsections, we will describe in more detail the aforementioned modes on which the network can operate. We do not make a complete derivation of PV-RNN in this paper, but focus on key aspects of this model.
3.2 Learning
Based on the graph connectivity shown in Figure 3, the forward computation of PV-RNN is given in Equation 3. The internal state of each PV-RNN cell at time step and level is computed as a sum of the connectivity weight multiplication of , , and (if is not the top layer). The connectivity weight matrix is indexed from layer to layer and from unit to unit. For brevity, bias terms have been omitted.
| (3) | ||||
Where is the MTRNN time constant of layer .
The stochastic variable follows a Gaussian distribution. Each sample of the prior distribution for layer is computed as shown in in Equation 4.
| (4) | ||||
Where is a random noise sample such that . Samples of the posterior distribution are computed as shown in Equation 5. The variable is a vector for each unit and sequence. For brevity, here we assume we have a single sequence. If an output sequence is generated using the posterior adapted during training, the corresponding training sequence should be regenerated. During goal inference and plan generation, the variables are inferred by the error regression process, as will be described later.
| (5) | ||||
To compute the output at time step , there are three steps. First, the network output is computed from , as in Equation 6. This uses the output from layer 1 and treats the output layer as layer 0.
| (6) |
We then compute the predicted probability distribution output . For this purpose, we use a softmax function to represent the probability distribution of the -th dimension of the output as in Equation 7.
| (7) |
where is the predicted probability that the -th softmax element of the -th output is on.
For explaining the learning scheme following the principle of free energy minimization, we first describe the model in terms of free energy. For brevity, we will assume there is a single layer only. This is shown graphically in Figure 4.

During learning, the evidence free energy shown in Equation 8 is minimized by iteratively updating the posterior of as well as the RNN learning parameters at each time step for all training sequences.
| (8) |
Where and are the observed sensory states and preferred goal, respectively, while and are the deterministic and probabilistic latent states, respectively. Free energy in this work is modified by inclusion of the meta-prior , which weights the complexity term. is a hyperparameter that affects the degree of regularization, similar to in Variational Autoencoders [21]. We also note that since we are dealing with sequences of actions, the free energy is a summation over all time steps in the sequence.
The first term, complexity, is computed as the Kullback–Leibler (KL) divergence between the prior and approximate posterior distributions. This can be expressed as follows:
| (9) |
Since we have and for both prior and posterior distributions, they can be expressed as follows:
| (10) | ||||
Thus, continuing from Equation 9, complexity can be computed as:
| (11) |
For brevity, a case of a single z-unit with a pair is shown here. In practice we can have multiple z-units, each with independent , and in that case the RHS is a summation over all , ), as will be shown later in the experimental section. The second term of Equation 8, accuracy, can be computed using the probability distribution estimated in the softmax outputs. During learning, Equation 8 is used as the loss function with the Adam optimizer, as noted Section 4.
3.3 Online goal-directed action plan generation
A key difference between our newly proposed model, T-GLean, and our previous model, GLean, is the idea that the goal expectation is generated at every time step instead of expecting the goal sensory state at the distal time step. Intuitively, this means that at every time step, the agent expects a goal state that the on-going action sequence will achieve. An advantage of this model scheme is that goals can be represented not only by distal sensory states to be achieved, but also by continuously changing sensory sequences. Another key feature of T-GLean is that the model generates plans online, in real-time, while the agent is acting on the environment, whereas our prior study using GLean showed only an offline plan generation scheme. In T-GLean the network maintains the observed sensory sequence in a past window while allocating a future window for the future time steps. In the past window, evidence free energy is minimized online by updating the posterior at each time step in order to situate all the latent variables to the observed sensory sequence. In the future window, the error between the preferred goal and the expected goal output is minimized for all steps by updating the posterior predictive distribution in the window iteratively, of which computation can be performed by minimizing the expected free energy. The future plan for achieving the preferred goals can be generated once the evidence free energy in the past window is minimized, i.e., the latent variables are well situated to the past sensory observation. This scheme is referred to as online error regression [16] and analogous models can be seen also in [22, 8]. The scheme is shown graphically in Figure 5.

Within the planning window, there is the past window of length and the future window of length . In the current implementation, the length of the planning window is fixed, while the past window is allowed to grow up to half the length of the planning window. The current time step is one step ahead of the end of the past window. At the next sensorimotor time step, sensory information at becomes part of the past window, and moves forward one step, shrinking the future window. Once the past window is filled, the entire planning window slides one step to the right, discarding the oldest entry in the past window. During online planning, the network minimizes the plan free energy by optimizing the posterior at all time steps within the past and future windows. The plan free energy consists of the sum of the evidence free energy within the past window and the expected free energy within the future window. This is expressed in Equation 12.
| (12) | ||||
3.4 Goal inference
Finally, before closing the current model section, we describe how future goals can be inferred from observed sensory sequences. Figure 6 shows a graphical model accounting for the mechanism of the goal inference with observation of the exteroception, but without actually generating actions. By observing the exteroception sequence from time step to the current time step , the posterior at each step in the past window is optimized for minimizing the error between the observed and reconstructed exteroceptions. This results in inference of the expected goal for every time step , both in the past and future. The network predicts simultaneously both the exteroception and proprioception for future steps leading to the inferred goal. We note that this scheme could be applied to the problem of inferring goals of other agents through observation of their movements, provided that the coordinate transformation between the allocentric view and the egocentric view can be made. For simplicity, the current study does not delve into this view coordinate transformation problem.

Equation 13 shows the modified evidence free energy used for goal inference, where only the observation of exteroception is used.
| (13) |
4 Experiments
In order to test our proposed model, we conducted two experiments, one using a simulated agent and the other using a physical robot. In Experiment 1 (Section 4.1), we used a simulated mobile agent in 2D space in order to examine the model’s capacity in generating goal-directed actions and in understanding goals from sensory observation. Experiment 2 (Section 4.2) was carried out to test the model’s scalability in the real world setting by using a humanoid robot with higher degrees of freedom. T-GLean is implemented using LibPvrnn, a custom C++ library implementing PV-RNN that is currently under development. It is designed to be lightweight and to operate in real-time so interaction between agent and experimenter is possible. A pre-release version is available under an open source license with instructions on reproducing the simulated agent experiments.
4.1 Experiment 1: simulated mobile agent in a 2D space
We conducted a set of experiments using a simulated mobile agent that can generate goal-directed action plans based on supervised learning of sensorimotor experiences in order to evaluate the performance of T-GLean in the following four respects.
-
1.
Generalization in learning for goal-directed plan generation;
-
2.
Goal-directed plan generation for different types of goals;
-
3.
Goal understanding from sensory observation for different types of goals;
-
4.
Rational plan generation.
Following our previous work [13], we first evaluate the generalization capability of the proposed model for reaching untrained goal positions using a limited number of teaching trajectories. The second test examines how the model can generate goal-directed plans and execute them for different types of goals, in this case reaching specified goal positions and cycling around an obstacle. The third test demonstrates the capability of the model to infer different types of goals from observed sensation (exteroception). The fourth test examines the model’s capability to generate optimal travel plans to reach specified goals under the constraint of the minimal travel time.
In each test, the simulated agent is in a square workspace with coordinates in the range of for both and . The agent always starts at position . In the center of the workspace is a fixed obstacle of size . The agent does not directly sense the workspace coordinates. Instead it observes a relative bearing and distance to a fixed reference point at as exteroception. The simulated agent controller handles conversion to and from the workspace coordinates to relative bearing-distance as the robot moves. At the onset of each test trial, the experimenter sets the preferred goal as a vector . is a three dimensional one-hot vector, with each bucket representing reaching, clockwise cycling, and counter-clockwise cycling goals, respectively. is set as the goal coordinate if the reaching goal is set. Otherwise it is left as . As the network estimates the distal probability at each time step, the agent stops at the time step with the maximum estimated distal probability provided that it exceeds a threshold value, assuming that the goal is achieved at that point.
Unless stated otherwise, the experiments have different training data and separately trained networks; however, network parameters are identical between networks. Parameters used for each layer of the RNN are as shown in Table 1. Each network was trained for 100,000 epochs, using the Adam optimizer with parameters , , . During planning, the parameters are slightly modified to , 500 iterations per sensorimotor time step, and a planning window length of 70. The meta-prior remains the same in all cases.
| Layer | |||
| 1 | 2 | 3 | |
| 60 | 40 | 20 | |
| 6 | 4 | 2 | |
| 2 | 4 | 8 | |
| 0.0001 | 0.0005 | 0.001 | |
| 1.0 | 1.0 | 1.0 | |
4.1.1 Experiment 1A: Generalization in plan generation by learning
In order to evaluate how well the network can generalize goal positions in the goal area with a limited number of teaching trajectories, we prepared four teaching datasets with decreasing numbers of goal locations to be reached as shown in Figure 7. The goal locations are on a line in the range , . The agent accelerates up to speed to a branching point, and then either turns left or right to the side of the obstacle, before moving toward the goal position. As the agent approaches the goal position, it decelerates to a stop.




The maximum trajectory length is 70, although the distal step occurs at around 40 time steps. To account for randomness in training, five networks with different initial random seeds are trained for each of the four datasets, for 20 trained networks in total. Untrained test goals were drawn from a uniformly random distribution in the range . Each network was tested with ten untrained goals, with the results averaged over all test goals and networks for each dataset.
To evaluate goal generalization, we considered the difference between the final agent position reached at the end of plan execution and the preferred goal at the end for each test trial, as well as the plan free energy that remained. The difference between agent position and goal is expressed as the root-mean-square deviation, normalized to the range of (NRMSD). The result is summarized in Figure 8.

We observed that the network achieved stable goal-position generalization when at least 7 training trajectories are used. Also, it can be seen that the plan free energy was minimized in a similar manner.
4.1.2 Experiment 1B: Goal-directed plan generation for different types of goals
For this test, we used a more complex set of teaching trajectories, containing three distinct goals with significantly different patterns. The first goal, shown in Figure 9(a), is similar to the previous goal-reaching trajectories shown in Figure 7(a); however, this scenario is ill-posed. That is, the trajectories alternate between short and long paths for the same goal position. This set of teaching trajectories will also be reused in Experiment 1C and Experiment 1D. We note that while the training data themselves are not ill-posed, due to generalization, the learning outcome is ill-posed. We will revisit this issue in Section 4.1.4. The second and the third goals, consisting of the two training trajectories shown in Figure 9(b), involve the agent cycling around the central obstacle in a clockwise direction and a counter-clockwise direction, respectively. For the reaching goal, once the agent reaches the goal position, the distal step is set and the remaining steps are padded with the final value, i.e., the agent remains stationary. Unlike the reaching goal, the cycling goals have no distal step. The training sequence demonstrates a single cycle; however, it is desirable for the agent to continue the action indefinitely. There are a total of 27 teaching trajectories in this training dataset, each of which has a length of 70 time steps.
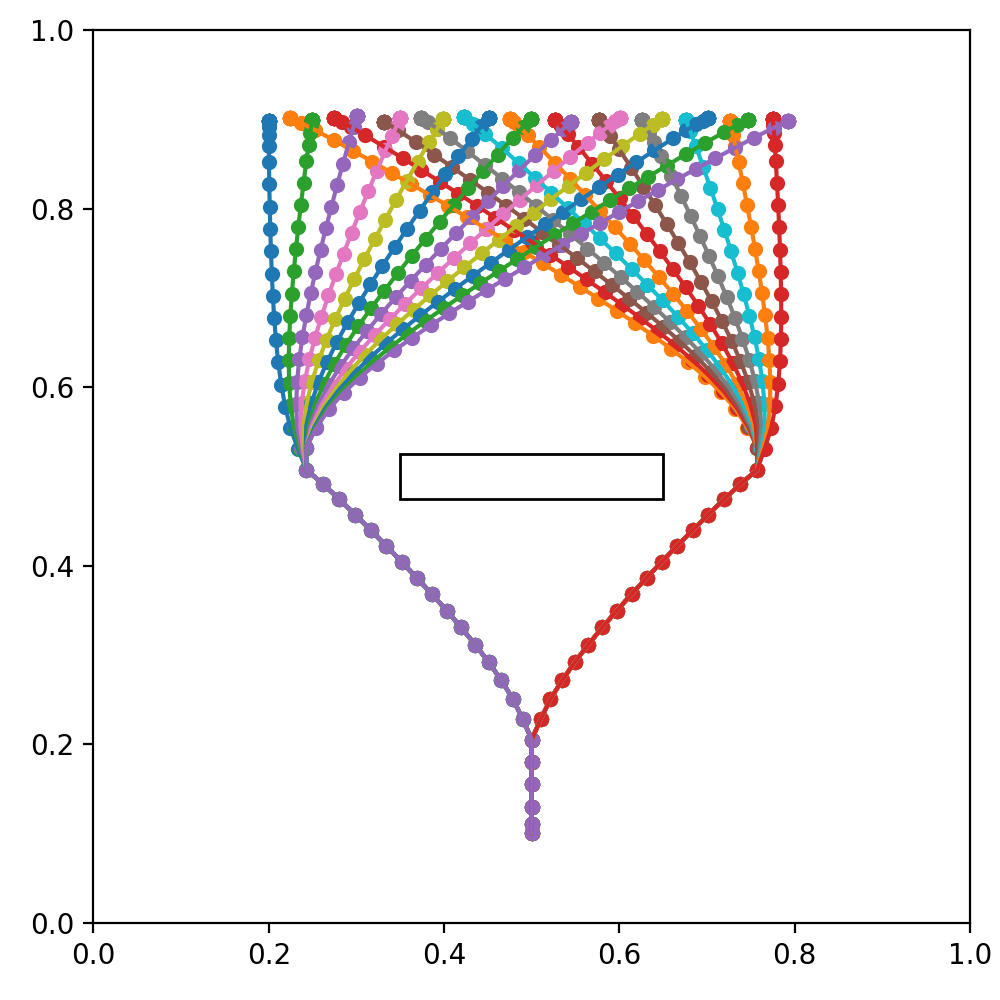

We evaluated how precisely the agent can generate movement trajectories for achieving goals specified. In Table 2 we summarize the results for the reaching and cyclic goals. For the reaching goal, as used previously, average NRMSD is given for 10 random untrained goal positions. For the cyclic goal, NRMSD between the agent’s movement and the training sequence for the entire 70 time step sequence is taken, and averaged for five clockwise and counter-clockwise orbits each. In the latter case, normalization is done over the entire dataset range rather than the goal range. Table 2 confirms that both types of goals can be achieved within minimal range of goal error.
| Reaching | Cycling | |
| NRMSD | 0.033241 | 0.028158 |
Figure 10 shows three examples of trajectories generated for three goal categories, with trajectories of motion in the left panel, the representative network values in the middle, and the expected free energy for the past window and the evidence free energy in the future window in the right panel. We observed that plan generation stabilized quickly after the onset of travel by minimizing the expected free energy, and the network was able to accurately estimate the distal step in the case of reaching the goal. Although the future plan trajectory was constantly changing due to the scheme of online plan generation and the error regression in the past, the motor plan generated was stably executed at each sensorimotor time step. It can be also observed that the evidence free energy in the past window continued to converge in all three plots, meaning that all latent variables were gradually situated to the behavioral context. Therefore, the deviation of the executed trajectory from the planned trajectory was limited. The full observed temporal processes can be seen in the recorded videos of the simulations at this link.



4.1.3 Experiment 1C: Goal inference by sensory observation
Next, we evaluated how precisely the network trained in Experiment 1B can infer goals as well as future movement trajectories by observing movement trajectories in terms of the exteroception sequence. In this experiment, four movement trajectories achieving different goals are prepared, which reach goals located left and right of the goal line, clockwise cycling, and counter-clockwise cycling. The four test trajectories, shown in Figure 11, were generated in the same way as the training data, but with untrained goal positions for the reaching goals and with a slight variation and extended length for the cycling goals.




Figure 12 shows the anticipated trajectories and goals at different points in time as the network observed the goal-reaching trajectories in Figures 11(a) and 11(b).






Initially, at (Figures 12(a) & 12(d)), before the agent observes any movement, the network makes a guess based on the learned prior distribution. Since the goal-reaching trajectories are most frequent in the teaching trajectory distribution, reaching a goal is inferred as a default goal when observing the movement trajectory at the starting point. Several steps later, at around (Figures 12(b) & 12(e)), the movement trajectory branches either left or right around the obstacle. We observed that in the case of the goal located on the left, the network initially anticipates a longer path going around the right side of the obstacle before observing that the movement trajectory goes around the other side of the obstacle. The observed phenomenon is due to the fact that the teaching trajectories contain two possible paths reaching the same goal position. Therefore, the network can generate two possible movement trajectory plans in the current ill-posed setting. This issue will be revisited in Section 4.1.4. The anticipated goal coordinate is refined as the movement trajectory approaches the goal area. By (Figures 12(c) & 12(f)), the goal is fully anticipated.
Figure 13 shows the trajectories and goals inferred for the observed cyclic trajectories shown in Figures 11(c) and 11(d).






Until the observed trajectories are mostly indistinguishable from the reaching trajectories, of which the occurrence probability was learned as high in the prior distribution, the network infers goal reaching as the default goal from these observations. While the observed movement trajectory begins to enter a cyclic trajectory after , it still takes some time for the network to correctly infer the ongoing goal as cyclic. During this time, free energy increases, an example of which is shown in Figure 14. This is analogous to a ‘surprising’ observation. After some time, the goals are inferred correctly as the cycling goals as shown in Figures 13(c) and 13(f) for the counter-clockwise and clockwise cases, respectively. The free energy is reduced accordingly at this moment, as also shown in Figure 14, which shows a generated plan, the plan free energy, and z information in the counter-clockwise case. We note that the activity of z units (z information) also rises and stays elevated to contribute to producing the correct inference of possible goals.

We assume that the agent can recognize consecutive switching of goals from observation; thus, we also tested a scenario wherein the agent first observes a clockwise cycling trajectory, then a counter-clockwise trajectory, and a goal-reaching trajectory, all in one continuous sequence. This is a challenging test, since the network was not trained to cope with such dynamic goal switching. A video of this experimental result is provided at this link. In the animation it can be seen that the network inferred the changing goals successfully. However, the anticipated future trajectories were quite unstable toward the end of the trial. As we observed that free energy becomes quite large, it is presumed that the goal inference from the observation may take a relatively long time for convergence of the free energy for unlearned situations. Therefore, it may be difficult for the network to catch up to the goal switching if it occurs too frequently.
4.1.4 Experiment 1D: Goal-directed planning enforcing the well-posed condition
In Experiment 1B, the network was trained using teaching trajectories that included alternative trajectories reaching similar goal positions as shown in Figure 9(a). This made the goal-directed planning ill-posed since the network cannot determine an optimal plan between two possible choices under the current definition of the expected free energy. Figure 15 shows an illustrative example as the result of the ill-posed goal-directed planning where we see that both a short and long path can be generated for the same goal.


Conventionally, it has been shown that the problem of ill-posed, goal-directed planning can be transformed into a well-posed one by adding adequate constraints, including joint torque minimization [4] and travel distance minimization [17]. The current experiment shows an examination of the case using the travel time minimization constraint by adding an additional cost term in the plan free energy shown previously in Equation 12. The modified plan free energy is shown in Equation 14.
| (14) | ||||
Where is the added cost term for minimizing the travel time. This cost can be expressed by the summation of the estimated distal probability distribution multiplied by the time step length at each time step over all time steps in the plan window. For this experiment, we set the weight of the travel time cost .
To evaluate the effect of adding the constraint for travel-time minimization, we prepared three separately trained networks and four untrained goal positions that are shown with numbers overlaid on the training trajectories in Figure 16. The goal positions are selected to avoid the edges (lack of training trajectories) and the center (no difference in trajectory length).

The generated action plans for these test goal positions were classified as ‘short’ if the shorter of the possible paths was generated. Plan generation was repeated for each test goal position with 1000 different samples. The resultant probabilities for generating the shorter plans for each goal position with and without travel time cost are shown in Figure 17.

Without introducing the travel time cost , the probability of generating the short plans was around 50%, which is consistent with the ratio in the teaching trajectory set. This probability increased to over 90% with the addition of travel time cost to the plan free energy. These results confirm that the current modified model supports goal-directed plan generation in a well-posed manner.
4.2 Experiment 2: object manipulation by a physical humanoid robot
In order to verify the performance of the proposed model in a complex physical world, we conducted experiments involving object manipulation by a humanoid robot, Torobo, manufactured by Tokyo Robotics Inc. Torobo was placed in front of an object manipulation workspace where a red cylindrical object was located for manipulation. Two types of goal-directed actions were considered. One was to grasp the object located at an arbitrary position in the workspace (36cm 31cm) with both arms and then place it at a specified goal position on the goal platform (42cm wide) fixed at one end of the workspace. The other type of goal was to grasp the object located at an arbitrary position in the workspace and to swing it up and down. The Torobo humanoid robot, red cylinder object, workspace, and goal platform are shown in Figure 18.

The neural network controlled Torobo’s two arms (6 degrees of freedom for each arm) and hip joints (2 degrees of freedom) to perform these goal-directed actions (total of 14 joint angles). The reading of these joint angles represents the proprioception of Torobo. Torobo can track the position of the red cylinder located in the workspace using a camera mounted in its head. The object position is constantly tracked by controlling the pitch and yaw of the camera head to keep the target object centered in the camera’s field of view. The red cylinder is visually located using YOLOv3 [23]. Therefore, the pitch and yaw of the head indicates the position of the object, and are considered to represent the exteroception of Torobo. Thus, exteroception can be represented by only a two-dimensional vector instead of a high-dimensional camera image. This simplification in visual image processing was necessary in order to generate goal-directed actions in real-time.
We conducted two experiments with Torobo. In Experiment 2A, we evaluated the performance in generating goal-directed planning and its execution in a similar fashion to Experiment 1B in Section 4.1.2, and in Experiment 2B we evaluated the capability of the network for goal inference by observation. The parameters used for each layer of the RNN are as shown in Table 3. As in Experiment 1, the network was trained for 100,000 epochs, using the Adam optimizer with a learning rate , , . In order to maintain real-time operation with the robot, planning uses different parameters of and 100 error regression iterations per sensorimotor time step.
| Layer | |||
| 1 | 2 | 3 | |
| 60 | 40 | 20 | |
| 6 | 4 | 2 | |
| 2 | 10 | 20 | |
| 0.0001 | 0.0005 | 0.001 | |
| 1.0 | 1.0 | 1.0 | |
The training dataset consists of 120 trajectories for one of the goal-directed actions, grasping then placing, and 80 trajectories for the other type of goal-directed action, grasping then swinging. The object is located at a random position within the workspace for each sample of the teaching trajectories. The goal position for placing is also randomly selected along the goal platform’s width. At each sensorimotor time step, we recorded 12 joint angles for both arms and 2 joint angles for the hip joints representing the proprioception and 2 head joint angles representing the exteroception along with a 3D vector representing the preferred goal and 1D scalar for the distal step marker. The preferred goal is represented in a similar manner to Experiment 1 wherein is a 2D one-hot vector representing either goal of grasping-placing or grasping-swinging, and is a scalar representing the preferred goal position in the width direction of the goal platform in the case of the grasping-placing goal.
4.2.1 Experiment 2A: Goal-directed plan generation and execution
To evaluate the performance of goal-directed plan generation and execution with the physical robot, we measured the RMS deviation to the ground truth, normalized to the data range, as shown in Experiment 1B. To examine the performance for achieving the grasping and placing goal, the experimenter placed the object at an arbitrary goal position on the goal platform, allowing Torobo to recognize the goal position by visual tracking. This position was marked as the ground truth. The object was then placed at a random position in the workspace, and the network started to generate action plans to achieve this specified goal while Torobo executed the generated motor plan simultaneously, in real-time. The difference between the final position of the placed object and the ground truth was then measured for 10 random goal positions. In the case of examining the grasping and swinging goal, the object was placed in three different positions in the workspace, and then the resulting robot trajectory in the swinging phase was compared to the closest teaching trajectory in the swinging phase. The result is shown in Table 4.
| Grasping-placing | Grasping-swinging | |
| NRMSD | 0.10053 | 0.01514 |
Compared to the results obtained in Section 4.1.2, the network generated a similar low deviation for achieving the grasping and swinging goal, while the deviation was higher for the grasping and placing goal. This is likely due to the relatively low precision in tracking the object, especially when placing the object on the goal platform, which was located at the far edge of the workspace. Figure 19 presents two plots showing an example of the plans generated when given the two types of goals. Example videos showing these experimental results can be seen at this link.


4.2.2 Experiment 2B: Goal understanding
Finally, the experimental results for goal understanding are briefly described. In this experiment, the object was moved by the experimenter emulating the manipulation of the object by Torobo for each goal type. Torobo observed this object movement using object tracking while Torobo remained in the initial posture, except for its head joints, used for object tracking. The network in Torobo inferred the expected goal and predicted the future movement trajectory in terms of the sensory sequence, as shown in Experiment 1B. This experiment was repeated 5 times for each of the goal-directed grasping actions, placing and swinging. The network was judged to have correctly inferred the goal if the anticipated goal stably matched the experimenter’s actions, before plan execution or the experimenter’s actions ended. A video showing this experiment can be seen at this link.
The result of this experiment was that the network inferred the goal correctly with 60% probability while observing the placing actions with 100% probability while observing the swinging actions. However, we note that the capability of the network to correctly infer the goal and future actions requires the actions of the human grasping the cylindrical object to closely match the robot’s own learned movement image, which is not easy for humans to consistently reproduce. Particularly in the case of grasping-placing, precise timing and position in grasping and placing become critical and the loss of precision in the visual tracking of the object at longer distances posed additional challenges. When the demonstrated actions deviated from those learned by the network, we observed that the free energy increased instead of decreasing over time, which produced unreliable results. A future study should investigate methods of making the network more robust in order to better tolerate unreliable human factors, which would be encountered in real world settings.
5 Discussion
The current study proposed a novel model for goal-directed action, planning, and execution under a teleological framework using the free energy principle. The proposed model, T-GLean, is characterized by three features. First, goals can be specified either by a specific sensory state expected at a distal step or dynamically changing sensory sequences. Second, goals can be inferred by observed sensory sequences. Third, the goal-directed plan is generated by situating the latent state to the observed sensation by means of the online inference.
The proposed model was evaluated by conducting two experiments, the first using a simulated mobile agent for navigation and the second using a physical humanoid for object manipulation. The results of experiments using a simulated mobile agent showed that generalization in generation of reaching movements to unlearned goal positions is sufficient with a relatively small number of training samples, with modest improvement as the number of teaching trajectories is increased. It was also shown that both types of goal-directed plan generation and their execution, i.e., reaching a specified position and cycling could be performed precisely. Furthermore, it was demonstrated that goals could be inferred adequately from the observed sensation, even in the case of dynamically changing goals. Finally, it was shown that the network could generate goal-directed reaching plans with the shortest path when an additional cost for travel time minimization was added to the original plan free energy formula. This confirms that the current model using this modified plan free energy can generate optimal goal-directed plans under well-posed conditions.
In the results of the experiments scaled up to using a real humanoid robot, it was shown that goal-directed plan generation and execution, as well as goal inference by observation could be performed with reasonable performance for two different goal-directed actions, grasping-placing and grasping-swinging, although their performance was slightly worse compared to the simulated mobile agent case. This could be due to various real world constraints, including limited precision in the visual tracking system and in motor control, as well as unreliable human behavioral factors in demonstrating emulated goal-directed actions to the robot. There is still plenty of room for improving performance in such real-world situations by making technical efforts in various regards.
Various research topics can be considered for extending the current study in the future. One interesting topic would be to examine how robots can deal with unexpected environmental changes, using the current model. For example, if Torobo fails to grasp the object or drops it, can it recover from the failure by generating a new recovery action plan? It would be interesting to examine how much such an unexpected situation can be recognized by inferring the latent state by means of minimization of the evidence free energy applied to the past window. This may require additional learning of various failure situations so that novel situations can be adequately handled through generalization, while maintaining well-posed solutions for normal situations.
Another direction for future study would be further scaling up in action and goal complexity by introducing a language modality. By using the power of rich linguistic expressions, it is expected that various complex goals can be represented in a compositional manner. It is, however, very likely that it will be quite difficult to learn an adequate amount of language relevant to goal-directed actions with different levels of complexity at once. With regard to this problem, one plausible but challenging approach may be the introduction of developmental pathways in learning. It would be natural to start by learning a set of simple goal representations that could be achieved by some primitive behaviors. When learning proceeds further, more complex goal-directed actions could be learned by means of compositions of the prior-learned action primitives associated with corresponding compositional linguistic expressions. This might lead to acquisition of a more abstract goal representation at the conceptual level.
References
- Sehon [2007] Scott R Sehon. Goal-directed action and teleological explanation. Causation and Explanation, pages 155–170, 2007.
- Löhrer [2016] Guido Löhrer. Actions, reason explanations, and values. Tutti i diritti riservati, page 17, 2016.
- Csibra et al. [2003] Gergely Csibra, Szilvia Bíró, Orsolya Koós, and György Gergely. One-year-old infants use teleological representations of actions productively. Cognitive Science, 27(1):111–133, 2003.
- Kawato et al. [1990] Maeda Kawato, Y Maeda, Y Uno, and R Suzuki. Trajectory formation of arm movement by cascade neural network model based on minimum torque-change criterion. Biological cybernetics, 62(4):275–288, 1990.
- Miall and Wolpert [1996] R Chris Miall and Daniel M Wolpert. Forward models for physiological motor control. Neural networks, 9(8):1265–1279, 1996.
- Kawato [1999] Mitsuo Kawato. Internal models for motor control and trajectory planning. Current opinion in neurobiology, 9(6):718–727, 1999.
- Friston et al. [2015] Karl Friston, Francesco Rigoli, Dimitri Ognibene, Christoph Mathys, Thomas Fitzgerald, and Giovanni Pezzulo. Active inference and epistemic value. Cognitive neuroscience, 6(4):187–214, 2015.
- Parr and Friston [2019] Thomas Parr and Karl J Friston. Generalised free energy and active inference. Biological cybernetics, 113(5):495–513, 2019.
- Friston et al. [2011] Karl Friston, Jérémie Mattout, and James Kilner. Action understanding and active inference. Biological cybernetics, 104(1):137–160, 2011.
- Friston et al. [2012] Karl Friston, Spyridon Samothrakis, and Read Montague. Active inference and agency: optimal control without cost functions. Biological cybernetics, 106(8):523–541, 2012.
- Baltieri and Buckley [2017] Manuel Baltieri and Christopher L Buckley. An active inference implementation of phototaxis. In Artificial Life Conference Proceedings 14, pages 36–43. MIT Press, 2017.
- Friston [2005] Karl Friston. A theory of cortical responses. Philosophical transactions of the Royal Society B: Biological sciences, 360(1456):815–836, 2005.
- Matsumoto and Tani [2020] Takazumi Matsumoto and Jun Tani. Goal-directed planning for habituated agents by active inference using a variational recurrent neural network. Entropy, 22(5):564, May 2020. ISSN 1099-4300. doi: 10.3390/e22050564. URL http://dx.doi.org/10.3390/e22050564.
- Ahmadi and Tani [2019] Ahmadreza Ahmadi and Jun Tani. A novel predictive-coding-inspired variational rnn model for online prediction and recognition. Neural computation, 31(11):2025–2074, 2019.
- Shimojo [2014] Shinsuke Shimojo. Postdiction: its implications on visual awareness, hindsight, and sense of agency. Frontiers in psychology, 5:196, 2014.
- Tani [2003] Jun Tani. Learning to generate articulated behavior through the bottom-up and the top-down interaction processes. Neural networks, 16(1):11–23, 2003.
- Tani [1996] Jun Tani. Model-based learning for mobile robot navigation from the dynamical systems perspective. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 26(3):421–436, 1996.
- Hafner et al. [2019] Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. arXiv preprint arXiv:1912.01603, 2019.
- Yamashita and Tani [2008] Yuichi Yamashita and Jun Tani. Emergence of functional hierarchy in a multiple timescale neural network model: a humanoid robot experiment. PLoS computational biology, 4(11):e1000220, 2008.
- Ohata and Tani [2020] Wataru Ohata and Jun Tani. Investigation of the sense of agency in social cognition, based on frameworks of predictive coding and active inference: A simulation study on multimodal imitative interaction. Frontiers in Neurorobotics, 14:61, 2020. ISSN 1662-5218. doi: 10.3389/fnbot.2020.00061. URL https://www.frontiersin.org/article/10.3389/fnbot.2020.00061.
- Kingma and Welling [2014] Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors, 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6114.
- Butz et al. [2019] Martin V Butz, David Bilkey, Dania Humaidan, Alistair Knott, and Sebastian Otte. Learning, planning, and control in a monolithic neural event inference architecture. Neural Networks, 117:135–144, 2019.
- Redmon and Farhadi [2018] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement, 2018.