Global Rhythm Style Transfer Without Text Transcriptions
Abstract
Prosody plays an important role in characterizing the style of a speaker or an emotion, but most non-parallel voice or emotion style transfer algorithms do not convert any prosody information. Two major components of prosody are pitch and rhythm. Disentangling the prosody information, particularly the rhythm component, from the speech is challenging because it involves breaking the synchrony between the input speech and the disentangled speech representation. As a result, most existing prosody style transfer algorithms would need to rely on some form of text transcriptions to identify the content information, which confines their application to high-resource languages only. Recently, SpeechSplit (Qian et al., 2020b) has made sizeable progress towards unsupervised prosody style transfer, but it is unable to extract high-level global prosody style in an unsupervised manner. In this paper, we propose AutoPST, which can disentangle global prosody style from speech without relying on any text transcriptions. AutoPST is an Autoencoder-based Prosody Style Transfer framework with a thorough rhythm removal module guided by self-expressive representation learning. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.
1 Introduction
Speech contains many layers of information. Besides the speech content, which can roughly be transcribed to text for many languages, prosody also conveys rich information about the personal, conversational, and world context within which the speaker expresses the content. There are two major constituents of prosody. The first is rhythm, which summarizes the sequence of phone durations, and expresses phrasing, speech rate, pausing, and some aspects of prominence. The second is pitch, which reflects intonation.
Recently, non-parallel speech style transfer tasks have achieved rapid progress thanks to the advancement of non-parallel deep style transfer algorithms. Speech style transfer refers to the tasks of transferring the source speech into the style of the target domain, while keeping the content unchanged. For example, in voice style transfer, the domains correspond to the speaker identities. In emotion style transfer, the domains correspond to the emotion categories. In both of these tasks, prosody is supposed to be an important part of the domain style — different speakers or emotions have distinctive prosody patterns. However, few of the state-of-the-art algorithms in these two applications can convert the prosody aspect at all. Typically, the converted speech would almost always maintain the same pace and pitch contour shape as the source speech, even if the target speaker or emotion has a completely different prosody style.
The fundamental cause of not converting prosody is that disentangling the prosody information, particularly the rhythm aspect, is very challenging. Since the rhythm information corresponds to how long the speaker utters each phoneme, deriving a speech representation with the rhythm information removed implies breaking the temporal synchrony between the speech utterance and the representation, which has been shown difficult (Watanabe et al., 2017; Kim et al., 2017) even for supervised tasks (e.g. automatic speech recognition (ASR)), using state-of-the-art asynchronous sequence-to-sequence architectures such as Transformers (Vaswani et al., 2017).
Due to this challenge, most existing prosody style transfer algorithms are forced to use text transcriptions to identify the content information in speech, and thereby separate out the remaining information as style (Biadsy et al., 2019). However, such methods are language-dependent and cannot be applied to low-resource languages with few text transcriptions. Although there are some sporadic attempts to disentangle prosody in an unsupervised manner (Polyak & Wolf, 2019), their performance is limited. These algorithms typically consist of an auto-encoder pipeline with a resampling module at the input to corrupt the rhythm information. However, the corruption is often so mild that most rhythm information can still get through. SpeechSplit (Qian et al., 2020b) can achieve a more thorough prosody disentanglement, but it needs access to a set of ground-truth fine-grained local prosody information in the target domain, such as the exact timing of each phone and exact pitch contour, which is unavailable in the aforementioned style transfer tasks that can only provide high-level global prosody information. In short, global prosody style transfer without relying on text transcriptions or local prosody ground truth largely remains unresolved in the research community.
Motivated by this, we propose AutoPST, an unsupervised speech decomposition algorithm that 1) does not require text annotations, and 2) can effectively convert prosody style given domain summaries (e.g. speaker identities and emotion categories) that only provide high-level global information. As its name indicates, AutoPST is an Autoencoder-based Prosody Style Transfer framework. AutoPST introduces a much more thorough rhythm removal module guided by the self-expressive representation learning proposed by Bhati et al. (2020), and adopts a two-stage training strategy to guarantee passing full content information without leaking rhythm. Experiments on different style transfer tasks show that AutoPST can effectively convert prosody that correctly reflects the styles of the target domains.
2 Related Work
Prosody Disentanglement Several prosody disentanglement techniques are found in expressive text-to-speech (TTS) systems. Skerry-Ryan et al. (2018) introduced a Tacotron based speech synthesizer that can disentangle prosody from speech content by an auto-encoder based representation. Wang et al. (2018) further extracts global styles by quantization. Mellotron (Valle et al., 2020) is a speech synthesizer that captures and disentangles different aspects of the prosody information. CHiVE (Kenter et al., 2019) explicitly extracts and utilize prosodic features and linguistic features for expressive TTS. However, these TTS systems all require text transcriptions, which, as discussed, makes the task easier but limits their applications to high-resource language. Besides TTS systems, Parrotron (Biadsy et al., 2019) disentangles prosody by encouraging the latent codes to be the same as the corresponding phone representation of the input speech. Liu et al. (2020) proposed to disentangle phoneme repetitions by vector quantization. However, these systems still require text transcriptions. Polyak & Wolf (2019) proposed a prosody disentanglement algorithm that does not rely on text transcriptions, which attempts to remove the rhythm information by randomly resampling the input speech. However, the effect of their prosody conversion is not very pronounced. SpeechSplit (Qian et al., 2020b) can disentangle prosody with better performance, but it relies on fine-grained prosody ground-truth in the target domain.
Voice Style Transfer Many style transfer approaches have been proposed for voice conversion. VAE-VC (Hsu et al., 2016) and VAE-GAN (Hsu et al., 2017) directly learns speaker-independent content representations using a VAE. ACVAE-VC (Kameoka et al., 2019) encourages the converted speech to be correctly classified as the target speaker by classifying the output. In contrast, Chou et al. (2018) discourages the latent code from being correctly classified as the source speaker by classifying the latent code. Inspired by image style transfer, Gao et al. (2018) and Kameoka et al. (2018) adapted CycleGan (Kaneko & Kameoka, 2017) and StarGan (Choi et al., 2018) respectively for voice conversion. Later, CDVAE-VC was extended by directly applying GAN (Huang et al., 2020) to improve the degree of disentanglement. Chou & Lee (2019) uses instance normalization to further disentangle timbre from content. StarGan-VC2 (Kaneko et al., 2019) refines the adversarial network by conditioning the generator and discriminator on both the source and the target speaker. AutoVC (Qian et al., 2019) disentangles the timbre and content by tuning the information-constraining bottleneck of a simple autoencoder. Later, Qian et al. (2020a) fixed the pitch jump problem of AutoVC by F0 conditioning. Besides, the time-domain deep generative model is also gaining popularity (Niwa et al., 2018; Nachmani & Wolf, 2019; Serrà et al., 2019). However, these methods only focus on converting timbre, which is only one of the speech components.
Emotion Style Transfer Most existing emotion style transfer algorithms disentangle prosody information using parallel data. Early methods (Tao et al., 2006; Wu et al., 2009) use classification and regression tree to disentangle prosody. Later, statistical methods, such as GMM (Aihara et al., 2012) and HMM (Inanoglu & Young, 2009), and deep learning methods (Luo et al., 2016; Ming et al., 2016) are applied. However, these approaches use parallel data. Recently, non-parallel style transfer methods (Zhou et al., 2020a, b) are applied to emotion style transfer to disentangle prosody. However, these methods are unable to explicitly disentangle rhythm information.
3 The Challenges of Disentangling Rhythm
In this section, we will provide some background information on why disentangling rhythm has been difficult.

3.1 Rhythm Information
Figure 1 shows two utterances of the same word “Please call Stella”, with the phone segments marked on the -axis. As shown, although the content is almost the same across the two utterances, each phone in the second utterance is repeated for more frames than in the first utterance. In this paper, we will measure rhythm as the number of frame-aligned repetitions of each phone symbol.
Formally, denote as the spectrogram of a speech utterance, where represents the frame index. Denote as the vector of phone symbols contained in an utterance, which we also refer to as the content information. Denote as a vector of the number of repetitions of each phone symbol in , which we also refer to as the rhythm information. Then and represent two information components in . Therefore, the task of disentangling rhythm involves removing phone repetitions while retaining phone identities. Formally, we would like to derive a hidden representation from the speech , i.e. , according to the following objective
| (1) |
| (2) |
where denotes mutual information. If the text transcriptions were available, this objective could be achieved by training an asynchronous sequence-to-sequence model, such as the Transformer (Vaswani et al., 2017), to predict the phone sequence from input speech. However, without the phonetic labels, it remains an unresolved challenge to uncover the phonetic units in an unsupervised manner.
3.2 Disentangling Rhythm by Resampling
Existing unsupervised rhythm disentanglement techniques seek to obscure the rhythm information by temporally resampling the speech sequence or its hidden representation sequence. One common resampling strategy, as proposed by Polyak & Wolf (2019), involves three steps. First, the input sequence is separated into segments of random lengths. Second, for each segment, a sampling rate is randomly drawn from some distribution. Finally, the corresponding segment is resampled at this sampling rate.
To gauge how much rhythm information the random resampling can remove, consider two hypothetical speech sequences, and , with the same content information , but with different rhythm information and respectively. If random resampling is to reduce the rhythm information in each utterance, there must be a non-zero probability that the random resampling temporally aligns them (hence making them identical because their only difference is rhythm). Thus, the original rhythm information distinguishing the two utterances is removed. Formally, denote and as the resampled outputs of the two unaligned but otherwise identical sequences. Then a necessary condition for reduction in rhythm information is that
| (3) |
Higher probability removes more rhythm information. If the probability is zero, then will reach its upper bound, which is . If the probability is one, then would reach its lower bound, which is . Please refer to Appendix A for a more formal analysis.
Therefore, we argue that the above random resampling algorithm does not remove much rhythm information, because it has a low probability of aligning any utterance pairs with the same content but different rhythm patterns. Figure 1 is a counterexample, where the duration of each phone changes disproportionally. The vowel “ea” gets more stretched than the consonants. Consider the case where the entire sequence falls into one random segment in the first step of the resampling algorithm. Then, due to the disproportional stretch among the phones, it is impossible to simultaneously align all the phones by uniformly stretching or squeezing the two utterances. If the utterances are broken into multiple random segments, it is possible to achieve the alignment, but this requires the number of random segments is greater than or equal to the number of phones, with at least one segment boundary between each pair of phone boundaries, whose probability of occurring is extremely low. In short, to overcome the limitation of the existing resampling scheme, we need better ways to account for the disproportional variations in duration across different phones.
4 The AutoPST Algorithm

In this section, we will introduce AutoPST, which can effectively overcome the aforementioned limitations.
4.1 The Framework Overview
As shown in Figure 2, AutoPST adopts a similar autoencoder structure as AutoVC (Qian et al., 2019). The decoder aims to reconstruct speech based on the output of the random resampling module and the domain identifiers, e.g., the speaker identity. AutoVC has been shown effective in disentangling the speaker’s voice via its information bottleneck, but it does not disentangle pitch and rhythm.
Therefore, AutoPST introduces three changes. First, instead of spectrogram, AutoPST takes the 13-dimensional MFCC having little pitch information. Second, AutoPST introduces a novel resampling module guided by self-expressive representation learning (Bhati et al., 2020), which can overcome the challenges mentioned in the previous section. Finally, AutoPST adopts a two-stage training scheme to prevent leaking rhythm information.
Formally, denote as the speech spectrogram, as the input MFCC feature, and as the domain identifier. The reconstruction process is described as follows
| (4) | ||||
where , , stand for the encoder, the resampling module and the decoder, respectively. Sections 4.2 to 4.4 will introduce the random resampling module, and Section 4.6 will discuss the training scheme.




(a) Synchronous training. (b) Asynchronous training.
4.2 Similarity-Based Downsampling
Our resampling scheme capitalizes on the observation that the relatively steady segments in speech tend to have more flexible durations, such as the “ea” segment in Figure 1. We thus modify the self-expressive autoencoder (SEA) algorithm proposed by Bhati et al. (2020) into a similarity-based downsampling scheme. SEA derives a frame-level speech representation, which we denote as , that contrastively promotes a high cosine similarity between frames that are similar, and a low cosine similarity between dissimilar frames. We then create a Gram matrix, to record the cosine similarities between any frame pairs:
| (5) |
More details of the SEA algorithm can be found in Appendix B.1 and the original paper (Bhati et al., 2020).
As shown in the left panel of Figure 3(3(a)), our downsampling scheme for involves two steps. First, we break into consecutive segments, such that the cosine similarity of are high within each segment, and that the cosine similarity drop across the segment boundaries. Second, each segment is merged into one code by mean-pooling.
Formally, denote the as the left boundary for the -th segment. Boundaries are sequentially determined. When all the boundaries up to are determined, the next boundary is set to if is the smallest time in where the cosine similarity between and drops below a threshold:
| (6) |
is a pre-defined threshold that can vary across . Section 4.3 will discuss how to set the threshold. After all the segments are determined, each segment is reduced to one code by mean pooling, i.e.
| (7) |
Figure 3(3(a)) shows a toy example, where the input sequence of length four. The second and the third codes are very similar. Then with a proper choice of , the downsampling would divide the input sequence into three segments, and collapse each segment into one code by mean-pooling. Note that the threshold governs how tolerant the algorithm is to dissimilarities. If , each code will be assigned to an individual segment, leading to no length reduction.
Figure 4 shows the segmentation result of the two utterances shown in Figure 1, where the vertical dashed lines denote the segment boundaries. We can see that despite their significant difference in length, the two utterances are broken into approximately equal number of segments and the segments have a high correspondence in terms of content. Since the downsampled output is obtained by mean-pooling each segment, we can expect that their downsampled output would be very similar and temporally-aligned, which implies that the necessary condition for rhythm information loss (Equation (3)) is approximately satisfied.

(a) Fast-to-slow conversion. (b) Slow-to-fast conversion.
4.3 Randomized Thresholding
For any fixed threshold in Equation (6), there is a trade-off between rhythm disentanglement and content loss. The lower the , the more rhythm information is removed, but the more content is lost as well. Ideally, during testing, we would like to set the threshold to to pass full content information to , and make the decoder ignore all the rhythm information in . This can be achieved with a randomized thresholding rule.
To see why, notice that if the decoder were to use the rhythm information in , it must know the value of , because how the decoder (partially) recovers the rhythm information depends on how the rhythm information is collapsed, which is governed by . However, the large variations in speech rate, utterance length and rhythm patterns in the training speech would overshadow the variations in , making it extremely hard to estimate the value of . Thus, the decoder will ignore whatever rhythm information remains in .
We adopt a double-randomized thresholding scheme. We first randomly draw a global variable that is shared across the entire utterance, where denotes the uniform distribution within the interval . Then to determine if time should be the next segment boundary (i.e., in Equation (6)), we draw a local variable . Then
| (8) |
denotes taking the -quantile, and b denotes the length of the sliding window within which the threshold is computed, which is set to 20 in our implementation.
The motivation for setting the two levels of randomization is that can obscure the global speech rate information and can obscure the local fine-grained rhythm patterns.
4.4 Similarity-Based Upsampling
To further obscure the rhythm information, we generalize our resampling module to accommodate upsampling. Just as downsampling aims to mostly shorten segments with higher similarity (hence decreasing the disproportionality), upsampling aims to mostly lengthen segments with higher similarity (hence increasing the disproportionality).
In the downsampling case, implies no length reduction at all. We thus seek to extrapolate the case to , where the higher the , the more the sequence gets lengthened. Our upsampling algorithm achieves this by inserting new codes in between adjacent codes. Specifically, suppose all the boundaries up to are determined. When , according to Equation (6), will definitely be set to . In addition to this, we will add yet another sentence boundary to , i.e. , if
| (9) |
In other words, we are inserting an empty segment for the -th segment (because ). During the mean-pooling stage, this empty segment will be mapped to the code at its left boundary, i.e.,
| (10) |
The non-empty segments will still be mean-pooled the same way as in Equation (7).
The left panel of Figure 3(3(b)) illustrates the upsampling process with the length-four toy example. Similar to the case of , all the codes are individually segmented. The difference is that a new empty segment is inserted after the third code, which is where the cosine similarity is very high. At the mean-pooling stage, this empty segment turns into an additional code that copies the previous code.
4.5 Summary of the Resampling Algorithm
To sum up, our resampling algorithm goes as follows.
For each frame, a random threshold is drawn from the distribution specified in Equation (8).
If , the current frame would be either merged into the previous segment, or start a new segment, depending on whether its similarity with the previous segment exceeds the , hence achieving downsampling (as elaborated in Section 4.2).
If , the current frame would form either one new segment or two new segments (by duplicating the current frame), depending on whether its similarity with the previous segment exceeds , hence achieving upsampling (as elaborated in Section 4.4).
Move onto the next frame and repeat the previous steps.
Because the threshold for each frame is random, an utterance could be downsampled at some parts, while upsampled at others. This would ensure the rhythm information is sufficiently scrambled. As a final remark, the random threshold distribution (Equation (8)) is governed by the percentile of the similarity, because the percentile has a direct correspondence to the length of the utterance after resampling. Appendix D.1 provides a visualization of how different thresholds affect the length of the utterance after resampling.
4.6 Two-Stage Training
Despite the resampling module, it is still possible for the encoder and decoder to find alternative ways to communicate the rhythm information that is robust against temporal resampling. Thus we introduce a two-stage training scheme to prevent any possible collusion.
The first stage of training, called the synchronous training, realigns with , as shown in the right panels of Figure 3. Specifically, for the downsampling case, we copy each to match the length of the original segment from which the code is mean-pooled; for the upsampling case, we delete the newly inserted . The network is then trained end-to-end to reconstruct the input with the realignment module, as shown in Figure 5(a). Since the decoder has full access to the rhythm information, the encoder will be trained to pass the content information and not the rhythm information. The second stage, called asynchronous training, removes the realignment module, freezes the encoder, and only updates the decoder, as shown in Figure 5(b).
5 Experiments
We evaluate AutoPST on speech style transfer tasks. Additional experiment results can be found in Appendix D. We encourage readers to listen to our online demo audios111https://auspicious3000.github.io/AutoPST-Demo.
5.1 Configurations
Architecture The encoder consists of eight of convolution layers with group normalization (Wu & He, 2018). The encoder output dimension is set to four. The decoder is a Transformer with four encoder layers and four decoder layers. The spectrogram is converted back to waveform using a WaveNet vocoder (Oord et al., 2016). More hyper-parameters setting details can be found in Appendix C.
Dataset Our dataset is VCTK (Veaux et al., 2016), which consists of 44 hours of speech from 109 speakers. We use this dataset to perform the voice style transfer task, so the domain ID is the speaker ID. We use 24 speakers for training and follow the same train/test partition as in (Qian et al., 2020b). We select the two fastest speakers and two slowest speakers from the seen speakers for evaluating rhythm style transfer. For further evaluation, we select two other speaker pairs with smaller rhythm differences. The first pair consists of speakers whose speech rates are at 25% and 75% percentiles among all the test speakers; the second pair at 40% and 60%, respectively. More details can be found in Appendix C.
Baselines We introduce two baselines. The first is the F0-assisted AutoVC (Qian et al., 2020a), an autoencoder-based voice style transfer algorithm. For the second baseline, we replace the AutoPST’s random resampling module with that of the SpeechSplit (as introduced in Section 3.2). We refer to this baseline as RR (random resample).
5.2 Spectrogram Visualization
For a fast-slow speaker pair and one of their parallel sentences, “One showing mainly red and yellow”, Figure 6 shows the spectrograms of conversions from the slow speaker to the fast (left panel), and from the fast speaker to the slow (right panel). The word alignment is marked on the -axis. As shown, all the algorithms can change the voice to the target speaker, as indicated by the average F0 and formant frequencies. However, only AutoPST significantly changes the rhythm towards the desired direction. AutoVC and RR barely change the rhythm. It is also worth noting that AutoPST indeed learns the disproportionality in duration changes across phones, most duration changes occur in the steady vowel segments, e.g., “ow” in “yellow”. This verifies that our similarity-based resampling scheme can effectively obscure the relative length of each phone.




5.3 Relative Duration Difference
To objectively measure the extent to which each algorithm modifies rhythm to match the style of the target speaker, for each test sentence and each fast-slow speaker pair (the test set is a parallel dataset), we generate a fast-to-slow and a slow-to-fast conversion. If an algorithm does not change the rhythm at all, then the fast-to-slow version should have a shorter duration than its slow-to-fast counterpart; in contrast, if an algorithm can sufficiently obscure and ignore the rhythm information in the source speech, then it can flip the ordering. We compute relative duration difference as
| (11) |
where and denote the lengths of fast-to-slow and slow-to-fast conversions, respectively. If the rhythm disentanglement is sufficient, this difference should be positive.
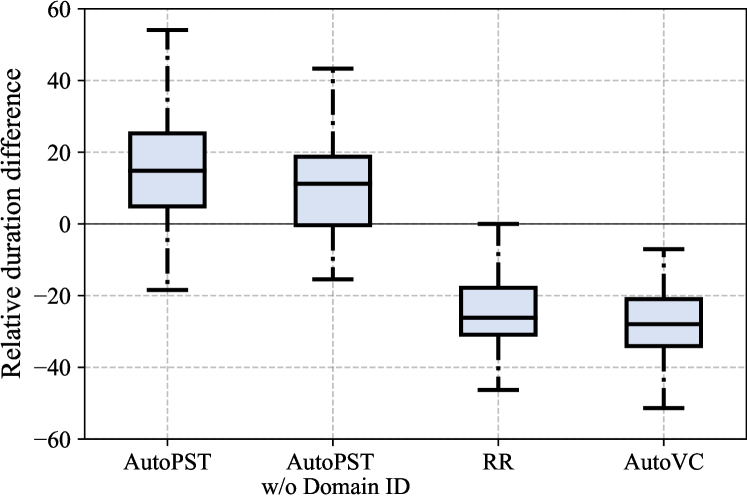
Figure 7(7(a)) shows the box plot of the relative duration differences across all test sentences and all the top four fastest-slowest speaker pairs. Figure 7(7(b)) and Figure 7(7(c)) show the results on speaker pairs with smaller rhythm differences (75% vs 25% and 60% vs 40% respectively). As shown, only AutoPST can achieve a positive average relative duration difference, which verifies its ability to disentangle rhythm. AutoVC gets the most negative relative duration differences, which is expected because it does not modify duration at all. RR achieves almost the same negative duration differences, which verifies that its rhythm disentanglement is insufficient.
| AutoPST | RR | AutoVC | |
|---|---|---|---|
| Timbre | 4.29 0.032 | 4.07 0.037 | 4.26 0.034 |
| Prosody | 3.61 0.053 | 2.97 0.063 | 2.64 0.066 |
| Overall | 3.99 0.036 | 3.63 0.045 | 3.49 0.052 |
5.4 Subjective Evaluation
To better evaluate the overall quality of prosody style transfer, and whether prosody style transfer improves the perceptual similarity to the target speaker, we performed a subjective evaluation on Amazon Mechanical Turk. Specifically, in each test unit, the subject first listens to two randomly ordered reference utterances from the source and target speaker respectively. Then the subject listens to a converted utterance from the source to the target speaker by one of the algorithms. Note that the content of the converted utterance is different from that in the reference utterances. Finally, the subject is asked to assign a score of 1-5 to describe the similarity to the target speaker in one of the three aspects: prosody similarity, timbre similarity, and overall similarity. A score of 5 means entirely like the target speaker; 1 means completely like the source speaker; 3 means somewhat between the two speakers. Each algorithm has 79 utterances, where each utterance is assigned to 5 subjects.
Table 1 shows the subjective similarity scores. As shown, AutoPST has a significant advantage in terms of prosody similarity over the baselines, which further verifies that AutoPST can generate a prosody style that is perceived as similar to the target speaker. In terms of timbre similarity, AutoPST performs on-par with AutoVC, and the gaps among the three algorithms are small because all three algorithms apply the same mechanism to disentangle timbre.
For the overall similarity, it is interesting to see how the subjects weigh the different aspects in their decisions. Specifically, although AutoVC can satisfactorily change the timbre, it is still perceived as only very slightly similar to the target speaker, because the prosody is not converted at all. In contrast, the AutoPST results, with all aspects transferred, are perceptually much more similar to the target speaker. This result shows that prosody indeed plays an important role in characterizing a speaker’s style and should be adequately accounted for in speech style transfer.
5.5 Restoring Abnormal Rhythm Patterns
So far, our experiments have mostly focused on the overall speech rate. One question we are interested in is whether AutoPST can recognize fine-grained rhythm patterns, or can only adjust speech rate globally. To study this question, we modify the utterance “One showing mainly red and yellow” in Figure 6(a) by stretching “yellow” by two times, creating an abnormal rhythm pattern. We then let RR and AutoPST reconstruct the utterance from this abnormal input. If these algorithms can recognize fine-grained rhythm patterns, they should be able to restore the abnormality.
Figure 8 shows the reconstructed spectrogram from the abnormal input. As shown, RR attempts to reduce the overall duration, but it seems unable to reduce the abnormally long word “yellow” more than the other words. In contrast, AutoPST not only restores the overall length, but also largely restores the word “yellow” to its normal length. This shows that AutoPST can indeed capture the fine-grained rhythm patterns instead of blindly adjusting the speech rate.
5.6 Emotion Style Transfer
Although AutoPST is designed for voice style transfer, we nevertheless also test AutoPST on the much harder non-parallel emotion style transfer to investigate the generalizability of our proposed framework. We use the EmoV-DB dataset (Adigwe et al., 2018), which contains acted expressive speech of five emotion categories (amused, sad, neutral, angry, and sleepy) from four speakers. During training, two emotion categories are randomly chosen for each speaker and held out, for the purpose of evaluating generalization to unseen emotion categories for each speaker.
Among the five emotions, neutral has the fastest speech rate and sleepy has the slowest. We thus follow the same step in Section 5.3 to compute the relative duration difference between fast-to-slow and slow-to-fast emotion conversions for each speaker. Figure 7(7(d)) shows the box plot. Consistent with the observations in Section 5.3, AutoPST can bring most of the relative duration differences to positive numbers, whereas the baselines cannot. This result shows that AutoPSTcan generalize to other domains. Additional results can be found in Appendix D.
6 Conclusion

In this paper, we propose AutoPST an autoencoder based prosody style transfer algorithm that does not rely on text transcriptions or fine-grained local prosody style information. We have empirically shown that AutoPST can effectively convert prosody, particularly the rhythm aspect, to match the target domain style. There are still some limitations of AutoPST. Currently, in order to disentangle the timbre information, AutoPST introduces a very harsh limitations on the dimension of the hidden representations. However, this would compromise the quality of the converted speech. How to strike a better balance between timbre disentanglement, prosody disentanglement, and audio quality remains a challenging future direction. Also, it has been shown by Deng et al. (2021) that AutoVC performs poorly when given in-the-wild audio examples. Since AutoPST inherits the basic framework of AutoVC, it is unlikely to generalize well to in-the-wild examples either. Improving the generalizability to audios recorded in different environments is a future direction.
Acknowledgment
We would like to give special thanks to Gaoyuan Zhang from MIT-IBM Watson AI Lab, who has helped us a lot with building our demo webpage.
References
- Adigwe et al. (2018) Adigwe, A., Tits, N., Haddad, K. E., Ostadabbas, S., and Dutoit, T. The emotional voices database: Towards controlling the emotion dimension in voice generation systems. arXiv preprint arXiv:1806.09514, 2018.
- Aihara et al. (2012) Aihara, R., Takashima, R., Takiguchi, T., and Ariki, Y. Gmm-based emotional voice conversion using spectrum and prosody features. American Journal of Signal Processing, 2(5):134–138, 2012.
- Bhati et al. (2020) Bhati, S., Villalba, J., Żelasko, P., and Dehak, N. Self-Expressing Autoencoders for Unsupervised Spoken Term Discovery. In Proc. Interspeech 2020, pp. 4876–4880, 2020. doi: 10.21437/Interspeech.2020-3000. URL http://dx.doi.org/10.21437/Interspeech.2020-3000.
- Biadsy et al. (2019) Biadsy, F., Weiss, R. J., Moreno, P. J., Kanvesky, D., and Jia, Y. Parrotron: An end-to-end speech-to-speech conversion model and its applications to hearing-impaired speech and speech separation. Proc. Interspeech 2019, pp. 4115–4119, 2019.
- Choi et al. (2018) Choi, Y., Choi, M., Kim, M., Ha, J.-W., Kim, S., and Choo, J. StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8789–8797, 2018.
- Chou & Lee (2019) Chou, J.-C. and Lee, H.-Y. One-shot voice conversion by separating speaker and content representations with instance normalization. Proc. Interspeech 2019, pp. 664–668, 2019.
- Chou et al. (2018) Chou, J.-C., Yeh, C.-C., Lee, H.-Y., and Lee, L.-S. Multi-target voice conversion without parallel data by adversarially learning disentangled audio representations. Interspeech, pp. 501–505, 2018.
- Deng et al. (2021) Deng, K., Bansal, A., and Ramanan, D. Unsupervised audiovisual synthesis via exemplar autoencoders. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=43VKWxg_Sqr.
- Gao et al. (2018) Gao, Y., Singh, R., and Raj, B. Voice impersonation using generative adversarial networks. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2506–2510. IEEE, 2018.
- Hsu et al. (2016) Hsu, C.-C., Hwang, H.-T., Wu, Y.-C., Tsao, Y., and Wang, H.-M. Voice conversion from non-parallel corpora using variational auto-encoder. In Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), pp. 1–6. IEEE, 2016.
- Hsu et al. (2017) Hsu, C.-C., Hwang, H.-T., Wu, Y.-C., Tsao, Y., and Wang, H.-M. Voice conversion from unaligned corpora using variational autoencoding Wasserstein generative adversarial networks. In Interspeech, pp. 3364–3368, 2017.
- Huang et al. (2020) Huang, W.-C., Luo, H., Hwang, H.-T., Lo, C.-C., Peng, Y.-H., Tsao, Y., and Wang, H.-M. Unsupervised representation disentanglement using cross domain features and adversarial learning in variational autoencoder based voice conversion. IEEE Transactions on Emerging Topics in Computational Intelligence, 2020.
- Inanoglu & Young (2009) Inanoglu, Z. and Young, S. Data-driven emotion conversion in spoken english. Speech Communication, 51(3):268–283, 2009.
- Kameoka et al. (2018) Kameoka, H., Kaneko, T., Tanaka, K., and Hojo, N. StarGAN-VC: Non-parallel many-to-many voice conversion using star generative adversarial networks. In IEEE Spoken Language Technology Workshop (SLT), pp. 266–273. IEEE, 2018.
- Kameoka et al. (2019) Kameoka, H., Kaneko, T., Tanaka, K., and Hojo, N. ACVAE-VC: Non-parallel voice conversion with auxiliary classifier variational autoencoder. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(9):1432–1443, 2019.
- Kaneko & Kameoka (2017) Kaneko, T. and Kameoka, H. Parallel-data-free voice conversion using cycle-consistent adversarial networks. arXiv preprint arXiv:1711.11293, 2017.
- Kaneko et al. (2019) Kaneko, T., Kameoka, H., Tanaka, K., and Hojo, N. StarGAN-VC2: Rethinking conditional methods for StarGAN-based voice conversion. Proc. Interspeech 2019, pp. 679–683, 2019.
- Kenter et al. (2019) Kenter, T., Wan, V., Chan, C.-A., Clark, R., and Vit, J. CHiVE: Varying prosody in speech synthesis with a linguistically driven dynamic hierarchical conditional variational network. In International Conference on Machine Learning, pp. 3331–3340, 2019.
- Kim et al. (2017) Kim, S., Hori, T., and Watanabe, S. Joint ctc-attention based end-to-end speech recognition using multi-task learning. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 4835–4839. IEEE, 2017.
- Liu et al. (2020) Liu, A. H., Tu, T., Lee, H.-y., and Lee, L.-s. Towards unsupervised speech recognition and synthesis with quantized speech representation learning. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7259–7263. IEEE, 2020.
- Luo et al. (2016) Luo, Z., Takiguchi, T., and Ariki, Y. Emotional voice conversion using deep neural networks with mcc and f0 features. In 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), pp. 1–5. IEEE, 2016.
- Ming et al. (2016) Ming, H., Huang, D., Xie, L., Wu, J., Dong, M., and Li, H. Deep bidirectional lstm modeling of timbre and prosody for emotional voice conversion. In Interspeech 2016, pp. 2453–2457, 2016. doi: 10.21437/Interspeech.2016-1053. URL http://dx.doi.org/10.21437/Interspeech.2016-1053.
- Nachmani & Wolf (2019) Nachmani, E. and Wolf, L. Unsupervised singing voice conversion. Proc. Interspeech 2019, pp. 2583–2587, 2019.
- Niwa et al. (2018) Niwa, J., Yoshimura, T., Hashimoto, K., Oura, K., Nankaku, Y., and Tokuda, K. Statistical voice conversion based on WaveNet. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5289–5293. IEEE, 2018.
- Oord et al. (2016) Oord, A. v. d., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., and Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499, 2016.
- Polyak & Wolf (2019) Polyak, A. and Wolf, L. Attention-based wavenet autoencoder for universal voice conversion. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6800–6804. IEEE, 2019.
- Qian et al. (2019) Qian, K., Zhang, Y., Chang, S., Yang, X., and Hasegawa-Johnson, M. Autovc: Zero-shot voice style transfer with only autoencoder loss. In International Conference on Machine Learning, pp. 5210–5219. PMLR, 2019.
- Qian et al. (2020a) Qian, K., Jin, Z., Hasegawa-Johnson, M., and Mysore, G. J. F0-consistent many-to-many non-parallel voice conversion via conditional autoencoder. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6284–6288. IEEE, 2020a.
- Qian et al. (2020b) Qian, K., Zhang, Y., Chang, S., Hasegawa-Johnson, M., and Cox, D. Unsupervised speech decomposition via triple information bottleneck. In International Conference on Machine Learning, pp. 7836–7846. PMLR, 2020b.
- Serrà et al. (2019) Serrà, J., Pascual, S., and Perales, C. S. Blow: A single-scale hyperconditioned flow for non-parallel raw-audio voice conversion. In Advances in Neural Information Processing Systems, pp. 6790–6800, 2019.
- Skerry-Ryan et al. (2018) Skerry-Ryan, R., Battenberg, E., Xiao, Y., Wang, Y., Stanton, D., Shor, J., Weiss, R., Clark, R., and Saurous, R. A. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron. In International Conference on Machine Learning, pp. 4693–4702, 2018.
- Tao et al. (2006) Tao, J., Kang, Y., and Li, A. Prosody conversion from neutral speech to emotional speech. IEEE transactions on Audio, Speech, and Language processing, 14(4):1145–1154, 2006.
- Valle et al. (2020) Valle, R., Li, J., Prenger, R., and Catanzaro, B. Mellotron: Multispeaker expressive voice synthesis by conditioning on rhythm, pitch and global style tokens. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6189–6193. IEEE, 2020.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. arXiv preprint arXiv:1706.03762, 2017.
- Veaux et al. (2016) Veaux, C., Yamagishi, J., MacDonald, K., et al. Superseded-CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit, 2016.
- Wang et al. (2018) Wang, Y., Stanton, D., Zhang, Y., Ryan, R.-S., Battenberg, E., Shor, J., Xiao, Y., Jia, Y., Ren, F., and Saurous, R. A. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. In International Conference on Machine Learning, pp. 5180–5189. PMLR, 2018.
- Watanabe et al. (2017) Watanabe, S., Hori, T., Kim, S., Hershey, J. R., and Hayashi, T. Hybrid ctc/attention architecture for end-to-end speech recognition. IEEE Journal of Selected Topics in Signal Processing, 11(8):1240–1253, 2017.
- Wu et al. (2009) Wu, C.-H., Hsia, C.-C., Lee, C.-H., and Lin, M.-C. Hierarchical prosody conversion using regression-based clustering for emotional speech synthesis. IEEE Transactions on Audio, Speech, and Language Processing, 18(6):1394–1405, 2009.
- Wu & He (2018) Wu, Y. and He, K. Group normalization. In Proceedings of the European conference on computer vision (ECCV), pp. 3–19, 2018.
- Xiong et al. (2020) Xiong, R., Yang, Y., He, D., Zheng, K., Zheng, S., Xing, C., Zhang, H., Lan, Y., Wang, L., and Liu, T. On layer normalization in the transformer architecture. In International Conference on Machine Learning, pp. 10524–10533. PMLR, 2020.
- Zhou et al. (2020a) Zhou, K., Sisman, B., and Li, H. Transforming spectrum and prosody for emotional voice conversion with non-parallel training data. arXiv preprint arXiv:2002.00198, 2020a.
- Zhou et al. (2020b) Zhou, K., Sisman, B., and Li, H. Vaw-gan for disentanglement and recomposition of emotional elements in speech. arXiv preprint arXiv:2011.02314, 2020b.
Appendix A Rhythm Disentanglement from an Information-Theoretic Perspective
In this appendix, we will provide further explanation on why Equation (3) is necessary for rhythm disentanglement, i.e. reducing . Before the formal analysis, we state the following assumption:
| (12) |
which means that the phonetic symbol and the rhythm information is completely determined given the speech utterance. In the following, we will show two theorems, which serve as an elaboration of the brief discussion below Equation (3).
Theorem 1.
Proof.
According to (13), when given, there forms an injective mapping from to , and thus
| (15) |
On the other hand, according to Equation (2)
| (16) |
where the last equality is due to Equation (12), and thus
| (17) |
Plug Equation (17) into Equation (15), we have
| (18) |
Therefore
| (19) | ||||
where the second line is given by Equation (18); the third line is given by Equation (12). ∎
Theorem 2.
Appendix B Additional Algorithm Details
In this appendix, we will cover the additional algorithm details of AutoPST. Our implementation is available very soon.
B.1 Self-Expressive Autoencoder (SEA)
SEA aims to derive an representation , which is very similar among similar frames, and very disimilar among disimilar frames. SEA consists of one encoder, which derives from input speech, and two decoders. One decoder reconstructs the input based on . The other decoder reconstructs the input based on another representation , which is computed as follows
| (25) |
The entire pipeline is trained jointly to minimize the reconstruction loss of both decoders. The intuition behind this self-expressive mechanism is that in order to achieve good reconstructions at both decoders, should be similar to . According to Equation (25), is essentially a linear combination of the representation of all the other frames, and the combination weight is the cosine similarity. If frame is dissimilar to the current frame to be expressed, the weight has to be close to zero, otherwise would be made dissimilar to ; if frame is similar to the current frame to be expressed, the weight has to be close to one to ensure it is contributing sufficiently to .
B.2 F0 and UV Conditioning
One of the biggest challenges of AutoPST is to infer the F0 contour and voiced/unvoiced (UV) states of the utterances based solely on the input MFCC features, because it is very hard for the system to elicit lexical, semantic and syntactic information without text transcriptions. To mitigate this problem, we introduce two optional conditioning, one on the input F0 contour and one on UV states. The sequence being conditioned upon is concatenated with the encoder output along the channel dimension before being sent to the similarity-based resampling module. The concatenation is valid because the conditioning sequence has the same temporal length as the encoder output, which are both equal to the temporal length of the input.
Although the F0 conditioning will largely resolve the ambiguity of reconstructing the F0 contour, it will make the algorithm unable to convert the F0 aspect of prosody, which is undesirable in many applications. On the other hand, UV conditioning can still resolve the ambiguity of reconstructing the F0 information to some extent, while maintaining AutoPST’s ability to disentangle the pitch aspect. In practice, we can choose F0 conditioning, UV conditioning, or neither depending on different applications.
B.3 Domain Identity Conditioning
According to Equation (4), the decoder takes the domain identity, , as a second input. This is achieved by first feeding to a feedforward layer. Then, the feedforward layer is appended to the first time step of the encoder output sequence, , as well as to the first time step of the memory of the decoder (Our decoder is a Transformer; the memory is the output of the Transformer encoder). In other words, the total length of the encoder output and the memory will increase by one after the appending, with the first time step being the appended domain identity. Since the decoder is a Transformer, it can elicit the domain identity information by attending to the first time step.
B.4 Output and Losses
In addition to outputting the reconstructed spectrogram, , the AutoPST decoder also outputs a stop token prediction. Stop token, denoted as , guides when the sequential spectrogram generation should stop. It is a scalar sequence that equals zero at time steps within the lengths of the ground truth spectrogram, and equals one at time steps after the ground truth spectrogram has ended. Denote the predicted stop token as . Then the total loss function consists of the loss for spectrogram prediction and the cross-entropy loss for stop token prediction:
| (26) | ||||
The expectation is taken over the training set. denotes the total length of the spectrogram. Notice that in the second summation, runs to from 1 to , which time steps longer than the spectrogram. This is because the ground truth stop token is always zero for . It is only equal to one for . So we set steps for the positive samples.
Nevertheless, the negative examples still occur much more often than the positive examples. To fix the unbalanced label problem, we add a positive weight, , to the positive class.
Appendix C Experiment Details
In this appendix, we will cover the additional details of our experiments.
C.1 Architecture
The AutoPST encoder is a simple 8-layer 1D convolutional network, where each layer uses filters with stride, SAME padding and ReLU activation. GroupNorm (Wu & He, 2018) is applied to every layer. The number of filters is 512 for the first five layers, and the last three layers have 128, 32, and 4 filters respectively. The AutoPST decoder is a Transformer (Vaswani et al., 2017), which has four encoder layers and four decoder layers. The model dimension is 256 and the number of heads is eight.
C.2 Training
We implement our model using Pytorch 1.6.0, and we train our model on a single Tesla V100 GPU using Adam optimizer. Synchronous training takes steps with a batch size of 4. Asynchronous training takes steps with a batch size of 4. We use Pre-LN (Xiong et al., 2020) without the warm-up stage.
C.3 Datasets
For the VCTK dataset, our test set consists of parallel utterances from 24 speakers. In order to identify speakers with the fastest and slowest speech rates, we take the average of the log duration of the test utterances. Since all the utterances are spoken in parallel by all of the speakers, the speaker with the smallest log duration can be considered as the fastest speaker, and the speaker with the largest log duration can be considered as the slowest speaker. We use the log duration instead of duration because the differences between the average log duration can be nicely interpreted as the average percentage difference in duration of the same sentence uttered by the two speakers. We then select the two fastest speakers (P231 and P239), and the two slowest speakers (P270 and P245) for our main evaluation. For further evaluation, we select two speaker pairs with smaller rhythm differences, one with speakers ranking 25% and 75% (P244 and P226) in speech rate; the other with ranking 40% and 60% (P240 and P256) in speech rate. For the Emo-VDB dataset, we follow a similar protocol of finding the fastest emotion, which is neutral, and the slowest emotion, which is sleepy, for our evaluation.
C.4 Subjective Evaluation
For the subjective evaluation, 18 sentences are generated for each fast-slow speaker pair (9 for fast-to-slow conversions and 9 for slow-to-fast conversions), and there are four fast-slow speaker pairs, summing to 72 utterances for each algorithm. Each utterance is assigned to five subjects. When evaluating voice similarity, the subjects are explicitly asked to focus only on voice but not on prosody; when evaluating prosody similarity, the subjects are asked to focus only on prosody but not on voice; when evaluating the overall speaker similarity, the subjects are asked to pay attention to all the aspects of speech, including voice and prosody.
For each test, the reference utterances (one from the source speaker and one from the target speaker) are randomized and named speaker 1 and speaker 2. The reference utterances are different from the test utterance in terms of content. The subjects are asked to assign a score of 1-5 on whether the aforementioned aspects sound more similar to speaker 1 or speaker 2, with 1 meaning completely like speaker 1 and 5 meaning completely like speaker 2. These scores are then converted to the similarity between the source and target speakers, with 1 meaning completely like the source speaker and 5 meaning completely like the target speaker.
Appendix D Additional Experiment Results
In this section, we will present some additional visualization and ablation study results.
D.1 Similarity-based Resampling Visualization
In order to intuitive show the effect of our similarity-based resampling module, we design the following experiment. We first train a variant of AutoPST without the random resampling module, so that it can generate a spectrogram that is synchronous with the hidden representations. Then, we performed the similarity-based random resampling on the hidden representation, and generate a time-synchronous spectrogram from the resampled representations. In this way, we can intuitively see how much each segment is being shortened/lengthened by observing the time-synchronous spectrogram.
Figure 13 shows the reconstructed spectrograms from the resampled code of the utterance “Please call Stella”. The left figures corresponds to the downsampling case, with dropping from down to . The right figures corresponds to the upsampling case, with increasing from up to . The top figure (Figure 13(13(a))) is the reference spectrogram without resampling. There are two observations. First, the total length of the code decreases as decreases, and increases as increases. Second, the relatively steady segments get stretched or shortened most, such as the “a” segment in the second word.
D.2 Upsampling v.s. Downsampling
AutoPST adopts both similarity-based upsampling (Section 4.2) and similarity-based downsampling (Section 4.4). This section shows why both are necessary. In particular, we trained two variants of AutoPST, one without upsampling, and one without downsampling. All the other settings remain the same. We then perform fast-to-slow and slow-to-fast conversions the same way as in Section 5.3. For each conversion, we compute the relative duration difference with respect to the original source speech, i.e.
| (27) | ||||
Note that this is different from the relative duration difference computed in Equation (11). If an algorithm truly converts rhythm to the correct direction, it should have a positive F2S relative duration difference and a negative S2F relative duration difference.
Table 2 shows the relative duration differences. As can be seen, AutoPST can correctly change the rhythm to the desired direction. However, without either of the resampling module, the rhythm conversion becomes incorrect. If upsampling is removed, both fast-to-slow and slow-to-fast will increase the duration. If downsampling is removed, both fast-to-slow and slow-to-fast will decrease the duration. One possible explanation for this is that random resampling is only enforced during training. During testing, the random resampling will be removed (equivalent to the case). If either downsampling or upsampling is removed, the test case, , becomes a corner case, undesirably passing a duration bias. By having both upsampling and downsampling, we can ensure is a well-represented mode among the training instances.
| AutoPST | No Up | No Down | |
|---|---|---|---|
| F2S | 26.53 (23.05) | 32.79 (12.68) | -13.65 (6.46) |
| S2F | -16.95 (23.70) | 13.47 (21.96) | -27.46 (5.00) |
D.3 Removing Two-Stage Training

As discussed, there are two mechanisms that promote prosody disentanglement. The first is similarity-based resampling; the second is two-stage training. In this section, we will explore how much each mechanism contributes to the performance advantage of AutoPST. In particular, we implement two variants of the algorithms. The first variant, called AutoPST 1-Stage, removes the two-stage training of AutoPST, while all the other settings remain the same as AutoPST. The second variant, called RR 2-Stage, supplements the RR baseline with two-stage training. We then create the same box plot of relative duration difference as discussed Section 5.3.
Figure 9 shows the results. As can be seen, without either two-stage training or similarity-based random resampling, the performance drops significantly, which implies that both mechanisms are essential for a successful rhythm disentanglement.
D.4 Generalization to Unseen Emotions

As mentioned in Section 5.6, for the emotion conversion experiment, we deliberately remove certain emotion categories for each speaker from the training set. As a result, some speakers do not have training examples of either neutral or sleepy, or both. To examine whether AutoPST generalize to unseen speakers, we break the AutoPST samples in Figure 7(7(d)) into three groups. The first group consists of the speaker who has training examples of both neutral and sleepy. The second group consists of speakers who have training examples of only sleepy. The third group consists of the speaker who has training examples of only neutral.
Figure 10 shows the box plot of the relative duration difference (same as Figure 7(7(d))) for these three groups. As can be seen, there is a slight performance advantage if both emotion categories are seen. However, even if there is one unseen emotion, the performance is still pretty competitive, demonstrating good generalizability to unseen emotions.
D.5 Training Domain Embedding
The domain ID is to assumed to present during testing, but we would like to explore the possibility of doing zero-shot conversion. Thus, we trained a variant of AutoPST where a domain encoder replaces the one-hot domain embedding. During testing, we only need to feed the domain encoder with a target speaker’s utterance without needing the domain ID. Figure 11 shows the relative duration difference of this variant, which performs slightly worse than the original AutoPST due to the increased difficulty, but still significantly better than the baselines.
D.6 SpeechSplit Baseline
Although SpeechSplit can also perform prosody style transfer, it requires ground truth target rhythm, i.e. the target speaker speaking the source utterance. On the other hand, AutoPST seeks to perform prosody style transfer without the ground truth, which is a much harder task. Nevertheless, we show the relative duration difference of SpeechSplit in Figure 12. Note since the converted rhythm is very close to the ground truth, SpeechSplit is the performance upper-bound of any prosody conversion, including AutoPST. However, when there is no ground truth available, SpeechSplit becomes vulnerable. To show this, Figure 12 also shows the result of SpeechSplit with a random target speaker utterance, instead of the ground truth target utterance, fed into its rhythm encoder. As can be observed, the relative duration difference almost completely concentrate around zero, which indicates that SpeechSplit completely fails in this case.











